[
https://issues.apache.org/jira/browse/SPARK-4672?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Lijie Xu updated SPARK-4672:
----------------------------
Description:
While running iterative algorithms in GraphX, a StackOverflow error will stably
occur in the serialization phase at about 300th iteration. In general, these
kinds of algorithms have two things in common:
# They have a long computing chain.
{code:borderStyle=solid}
(e.g., “degreeGraph=>subGraph=>degreeGraph=>subGraph=>…=>”)
{code}
# They will iterate many times to converge. An example:
{code:borderStyle=solid}
//K-Core Algorithm
val kNum = 5
var degreeGraph = graph.outerJoinVertices(graph.degrees) {
(vid, vd, degree) => degree.getOrElse(0)
}.cache()
do {
val subGraph = degreeGraph.subgraph(
vpred = (vid, degree) => degree >= KNum
).cache()
val newDegreeGraph = subGraph.degrees
degreeGraph = subGraph.outerJoinVertices(newDegreeGraph) {
(vid, vd, degree) => degree.getOrElse(0)
}.cache()
isConverged = check(degreeGraph)
} while(isConverged == false)
{code}
After about 300 iterations, StackOverflow will definitely occur with the
following stack trace:
{code:borderStyle=solid}
Exception in thread "main" org.apache.spark.SparkException: Job aborted due to
stage failure: Task serialization failed: java.lang.StackOverflowError
java.io.ObjectOutputStream.writeNonProxyDesc(ObjectOutputStream.java:1275)
java.io.ObjectOutputStream.writeClassDesc(ObjectOutputStream.java:1230)
java.io.ObjectOutputStream.writeOrdinaryObject(ObjectOutputStream.java:1426)
java.io.ObjectOutputStream.writeObject0(ObjectOutputStream.java:1177)
{code}
It is a very tricky bug, which only occurs with enough iterations. Since it
took us a long time to find out its causes, we will detail the causes in the
following 3 paragraphs.
h3. Phase 1: Try using checkpoint() to shorten the lineage
It's easy to come to the thought that the long lineage may be the cause. For
some RDDs, their lineages may grow with the iterations. Also, for some magical
references, their lineage lengths never decrease and finally become very long.
As a result, the call stack of task's serialization()/deserialization() method
will be very long too, which finally exhausts the whole JVM stack.
In deed, the lineage of some RDDs (e.g., EdgeRDD.partitionsRDD) increases 3
OneToOne dependencies in each iteration in the above example. Lineage length
refers to the maximum length of OneToOne dependencies (e.g., from the finalRDD
to the ShuffledRDD) in each stage.
To shorten the lineage, a checkpoint() is performed every N (e.g., 10)
iterations. Then, the lineage will drop down when it reaches a certain length
(e.g., 33).
However, StackOverflow error still occurs after 300+ iterations!
h3. Phase 2: Abnormal f closure function leads to a unbreakable serialization
chain
After a long-time debug, we found that an abnormal _*f*_ function closure and a
potential bug in GraphX (will be detailed in Phase 3) are the "Suspect Zero".
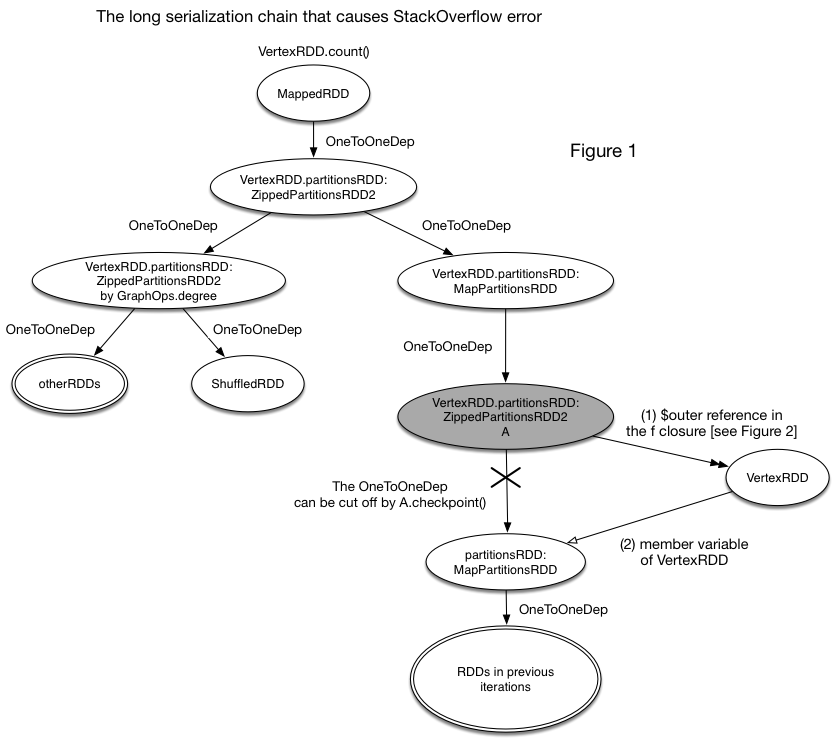
They together build another serialization chain that can bypass the broken
lineage cut by checkpoint() (as shown in Figure 1). In other words, the
serialization chain can be as long as the original lineage before checkpoint().
Figure 1 shows how the unbreakable serialization chain is generated. Yes, the
OneToOneDep can be cut off by checkpoint(). However, the serialization chain
can still access the previous RDDs through the (1)->(2) reference chain. As a
result, the checkpoint() action is meaningless and the lineage is as long as
that before.
!https://raw.githubusercontent.com/JerryLead/Misc/master/SparkPRFigures/g1.png!
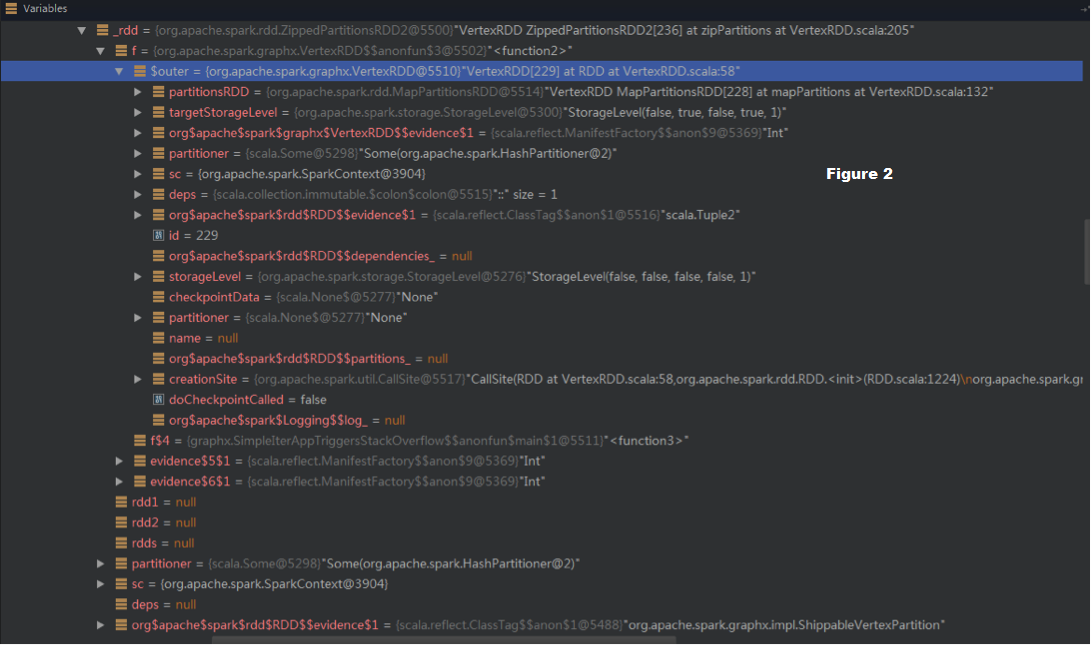
The (1)->(2) chain can be observed in the debug view (in Figure 2).
{code:borderStyle=solid}
_rdd (i.e., A in Figure 1, checkpointed) -> f -> $outer (VertexRDD) ->
partitionsRDD:MapPartitionsRDD -> RDDs in the previous iterations
{code}
!https://raw.githubusercontent.com/JerryLead/Misc/master/SparkPRFigures/g2.png|width=80%!
More description: While a RDD is being serialized, its f function
{code:borderStyle=solid}
e.g., f: (Iterator[A], Iterator[B]) => Iterator[V]) in ZippedPartitionsRDD2
{code}
will be serialized too. This action will be very dangerous if the f closure has
a member “$outer” that references its outer class (as shown in Figure 1). This
reference will be another way (except the OneToOneDependency) that a RDD (e.g.,
PartitionsRDD) can reference the other RDDs (e.g., VertexRDD). Note that
checkpoint() only cuts off the direct lineage, while the function reference is
still kept. So, serialization() can still access the other RDDs along the f
references.
h3. Phase 3: Non-transient member variable of VertexRDD makes things worse
Reference (1) in Figure 1 is caused by the abnormal f clousre, while Reference
(2) is caused by the potential bug in GraphX: *PartitionsRDD is a non-transient
member variable of VertexRDD*.
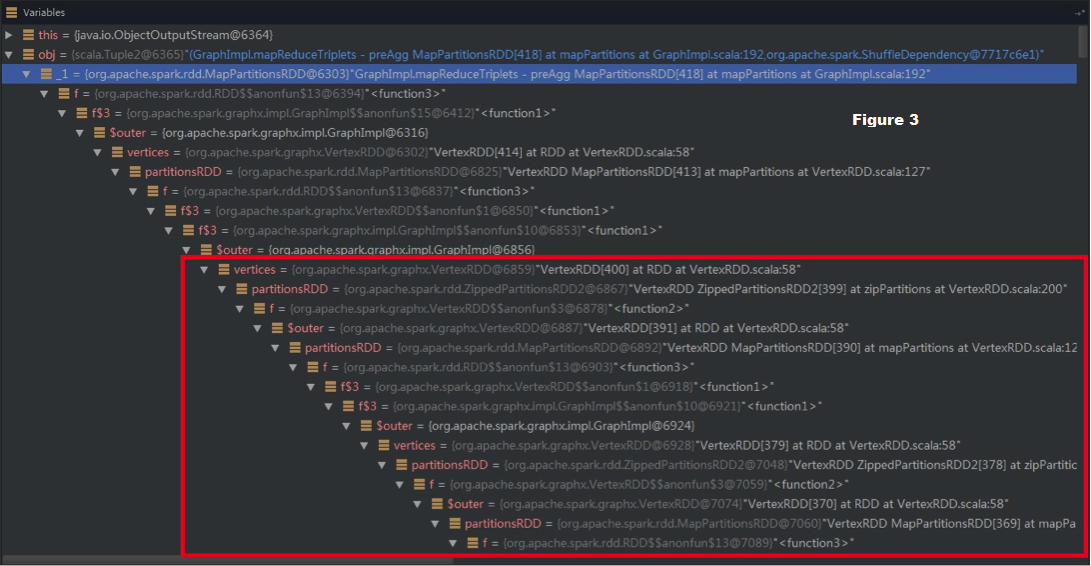
With this _small_ bug, the f closure itself (without OneToOne dependency) can
cause StackOverflow error, as shown in the red box in Figure 3:
# While _vertices:VertexRDD_ is being serialized, its member _PartitionsRDD_
will be serialized too.
# Next, while serializing this _partitionsRDD_, serialization() will
simultaneously serialize its f’s referenced $outer. Here, it is another
_partitionsRDD_.
# Finally, the chain
{code:borderStyle=solid}
"f => f$3 => f$3 => $outer => vertices: VertexRDD => partitionsRDD => … =>
ShuffledRDD"
{code}
comes into shape. As a result, the serialization chain can be as long as the
original lineage and finally triggers StackOverflow error.
!https://raw.githubusercontent.com/JerryLead/Misc/master/SparkPRFigures/g3.png|width=80%!
h2. Conclusions
In conclusion, the root cause of StackOverflow error is the long serialization
chain, which cannot be cut off by _checkpoint()_. This long chain is caused by
the multiple factors, including:
# long lineage
# $outer reference in the f closure
# non-transient member variable
As a result, we will need about three pull requests (will be added later) to
solve this problem thoroughly.
was:
While running iterative algorithms in GraphX, a StackOverflow error will stably
occur in the serialization phase at about 300th iteration. In general, these
kinds of algorithms have two things in common:
# They have a long computing chain.
{code:borderStyle=solid}
(e.g., “degreeGraph=>subGraph=>degreeGraph=>subGraph=>…=>”)
{code}
# They will iterate many times to converge. An example:
{code:borderStyle=solid}
//K-Core Algorithm
val kNum = 5
var degreeGraph = graph.outerJoinVertices(graph.degrees) {
(vid, vd, degree) => degree.getOrElse(0)
}.cache()
do {
val subGraph = degreeGraph.subgraph(
vpred = (vid, degree) => degree >= KNum
).cache()
val newDegreeGraph = subGraph.degrees
degreeGraph = subGraph.outerJoinVertices(newDegreeGraph) {
(vid, vd, degree) => degree.getOrElse(0)
}.cache()
isConverged = check(degreeGraph)
} while(isConverged == false)
{code}
After about 300 iterations, StackOverflow will definitely occur with the
following stack trace:
{code:borderStyle=solid}
Exception in thread "main" org.apache.spark.SparkException: Job aborted due to
stage failure: Task serialization failed: java.lang.StackOverflowError
java.io.ObjectOutputStream.writeNonProxyDesc(ObjectOutputStream.java:1275)
java.io.ObjectOutputStream.writeClassDesc(ObjectOutputStream.java:1230)
java.io.ObjectOutputStream.writeOrdinaryObject(ObjectOutputStream.java:1426)
java.io.ObjectOutputStream.writeObject0(ObjectOutputStream.java:1177)
{code}
It is a very tricky bug, which only occurs with enough iterations. Since it
took us a long time to find out its causes, we will detail the causes in the
following 3 paragraphs.
h3. Phase 1: Try using checkpoint() to shorten the lineage
It's easy to come to the thought that the long lineage may be the cause. For
some RDDs, their lineages may grow with the iterations. Also, for some magical
references, their lineage lengths never decrease and finally become very long.
As a result, the call stack of task's serialization()/deserialization() method
will be very long too, which finally exhausts the whole JVM stack.
In deed, the lineage of some RDDs (e.g., EdgeRDD.partitionsRDD) increases 3
OneToOne dependencies in each iteration in the above example. Lineage length
refers to the maximum length of OneToOne dependencies (e.g., from the finalRDD
to the ShuffledRDD) in each stage.
To shorten the lineage, a checkpoint() is performed every N (e.g., 10)
iterations. Then, the lineage will drop down when it reaches a certain length
(e.g., 33).
However, StackOverflow error still occurs after 300+ iterations!
h3. Phase 2: Abnormal f closure function leads to a unbreakable serialization
chain
After a long-time debug, we found that an abnormal _*f*_ function closure and a
potential bug in GraphX (will be detailed in Phase 3) are the "Suspect Zero".
They together build another serialization chain that can bypass the broken
lineage cut by checkpoint() (as shown in Figure 1). In other words, the
serialization chain can be as long as the original lineage before checkpoint().
Figure 1 shows how the unbreakable serialization chain is generated. Yes, the
OneToOneDep can be cut off by checkpoint(). However, the serialization chain
can still access the previous RDDs through the (1)->(2) reference chain. As a
result, the checkpoint() action is meaningless and the lineage is as long as
that before.
!https://raw.githubusercontent.com/JerryLead/Misc/master/SparkPRFigures/g1.png!
The (1)->(2) chain can be observed in the debug view (in Figure 2).
{code:borderStyle=solid}
_rdd (i.e., A in Figure 1, checkpointed) -> f -> $outer (VertexRDD) ->
partitionsRDD:MapPartitionsRDD -> RDDs in the previous iterations
{code}
!https://raw.githubusercontent.com/JerryLead/Misc/master/SparkPRFigures/g2.png!
More description: While a RDD is being serialized, its f function
{code:borderStyle=solid}
e.g., f: (Iterator[A], Iterator[B]) => Iterator[V]) in ZippedPartitionsRDD2
{code}
will be serialized too. This action will be very dangerous if the f closure has
a member “$outer” that references its outer class (as shown in Figure 1). This
reference will be another way (except the OneToOneDependency) that a RDD (e.g.,
PartitionsRDD) can reference the other RDDs (e.g., VertexRDD). Note that
checkpoint() only cuts off the direct lineage, while the function reference is
still kept. So, serialization() can still access the other RDDs along the f
references.
h3. Phase 3: Non-transient member variable of VertexRDD makes things worse
Reference (1) in Figure 1 is caused by the abnormal f clousre, while Reference
(2) is caused by the potential bug in GraphX: *PartitionsRDD is a non-transient
member variable of VertexRDD*.
With this _small_ bug, the f closure itself (without OneToOne dependency) can
cause StackOverflow error, as shown in the red box in Figure 3:
# While _vertices:VertexRDD_ is being serialized, its member _PartitionsRDD_
will be serialized too.
# Next, while serializing this _partitionsRDD_, serialization() will
simultaneously serialize its f’s referenced $outer. Here, it is another
_partitionsRDD_.
# Finally, the chain
{code:borderStyle=solid}
"f => f$3 => f$3 => $outer => vertices: VertexRDD => partitionsRDD => … =>
ShuffledRDD"
{code}
comes into shape. As a result, the serialization chain can be as long as the
original lineage and finally triggers StackOverflow error.
!https://raw.githubusercontent.com/JerryLead/Misc/master/SparkPRFigures/g3.png!
h2. Conclusions
In conclusion, the root cause of StackOverflow error is the long serialization
chain, which cannot be cut off by _checkpoint()_. This long chain is caused by
the multiple factors, including:
# long lineage
# $outer reference in the f closure
# non-transient member variable
As a result, we will need about three pull requests (will be added later) to
solve this problem thoroughly.
> Cut off the super long serialization chain in GraphX to avoid the
> StackOverflow error
> -------------------------------------------------------------------------------------
>
> Key: SPARK-4672
> URL: https://issues.apache.org/jira/browse/SPARK-4672
> Project: Spark
> Issue Type: Bug
> Components: GraphX, Spark Core
> Affects Versions: 1.1.0
> Reporter: Lijie Xu
> Priority: Critical
>
> While running iterative algorithms in GraphX, a StackOverflow error will
> stably occur in the serialization phase at about 300th iteration. In general,
> these kinds of algorithms have two things in common:
> # They have a long computing chain.
> {code:borderStyle=solid}
> (e.g., “degreeGraph=>subGraph=>degreeGraph=>subGraph=>…=>”)
> {code}
> # They will iterate many times to converge. An example:
> {code:borderStyle=solid}
> //K-Core Algorithm
> val kNum = 5
> var degreeGraph = graph.outerJoinVertices(graph.degrees) {
> (vid, vd, degree) => degree.getOrElse(0)
> }.cache()
>
> do {
> val subGraph = degreeGraph.subgraph(
> vpred = (vid, degree) => degree >= KNum
> ).cache()
> val newDegreeGraph = subGraph.degrees
> degreeGraph = subGraph.outerJoinVertices(newDegreeGraph) {
> (vid, vd, degree) => degree.getOrElse(0)
> }.cache()
> isConverged = check(degreeGraph)
> } while(isConverged == false)
> {code}
> After about 300 iterations, StackOverflow will definitely occur with the
> following stack trace:
> {code:borderStyle=solid}
> Exception in thread "main" org.apache.spark.SparkException: Job aborted due
> to stage failure: Task serialization failed: java.lang.StackOverflowError
> java.io.ObjectOutputStream.writeNonProxyDesc(ObjectOutputStream.java:1275)
> java.io.ObjectOutputStream.writeClassDesc(ObjectOutputStream.java:1230)
> java.io.ObjectOutputStream.writeOrdinaryObject(ObjectOutputStream.java:1426)
> java.io.ObjectOutputStream.writeObject0(ObjectOutputStream.java:1177)
> {code}
> It is a very tricky bug, which only occurs with enough iterations. Since it
> took us a long time to find out its causes, we will detail the causes in the
> following 3 paragraphs.
>
> h3. Phase 1: Try using checkpoint() to shorten the lineage
> It's easy to come to the thought that the long lineage may be the cause. For
> some RDDs, their lineages may grow with the iterations. Also, for some
> magical references, their lineage lengths never decrease and finally become
> very long. As a result, the call stack of task's
> serialization()/deserialization() method will be very long too, which finally
> exhausts the whole JVM stack.
> In deed, the lineage of some RDDs (e.g., EdgeRDD.partitionsRDD) increases 3
> OneToOne dependencies in each iteration in the above example. Lineage length
> refers to the maximum length of OneToOne dependencies (e.g., from the
> finalRDD to the ShuffledRDD) in each stage.
> To shorten the lineage, a checkpoint() is performed every N (e.g., 10)
> iterations. Then, the lineage will drop down when it reaches a certain length
> (e.g., 33).
> However, StackOverflow error still occurs after 300+ iterations!
> h3. Phase 2: Abnormal f closure function leads to a unbreakable
> serialization chain
> After a long-time debug, we found that an abnormal _*f*_ function closure and
> a potential bug in GraphX (will be detailed in Phase 3) are the "Suspect
> Zero". They together build another serialization chain that can bypass the
> broken lineage cut by checkpoint() (as shown in Figure 1). In other words,
> the serialization chain can be as long as the original lineage before
> checkpoint().
> Figure 1 shows how the unbreakable serialization chain is generated. Yes, the
> OneToOneDep can be cut off by checkpoint(). However, the serialization chain
> can still access the previous RDDs through the (1)->(2) reference chain. As a
> result, the checkpoint() action is meaningless and the lineage is as long as
> that before.
> !https://raw.githubusercontent.com/JerryLead/Misc/master/SparkPRFigures/g1.png!
> The (1)->(2) chain can be observed in the debug view (in Figure 2).
> {code:borderStyle=solid}
> _rdd (i.e., A in Figure 1, checkpointed) -> f -> $outer (VertexRDD) ->
> partitionsRDD:MapPartitionsRDD -> RDDs in the previous iterations
> {code}
> !https://raw.githubusercontent.com/JerryLead/Misc/master/SparkPRFigures/g2.png|width=80%!
> More description: While a RDD is being serialized, its f function
> {code:borderStyle=solid}
> e.g., f: (Iterator[A], Iterator[B]) => Iterator[V]) in ZippedPartitionsRDD2
> {code}
> will be serialized too. This action will be very dangerous if the f closure
> has a member “$outer” that references its outer class (as shown in Figure 1).
> This reference will be another way (except the OneToOneDependency) that a RDD
> (e.g., PartitionsRDD) can reference the other RDDs (e.g., VertexRDD). Note
> that checkpoint() only cuts off the direct lineage, while the function
> reference is still kept. So, serialization() can still access the other RDDs
> along the f references.
> h3. Phase 3: Non-transient member variable of VertexRDD makes things worse
> Reference (1) in Figure 1 is caused by the abnormal f clousre, while
> Reference (2) is caused by the potential bug in GraphX: *PartitionsRDD is a
> non-transient member variable of VertexRDD*.
> With this _small_ bug, the f closure itself (without OneToOne dependency) can
> cause StackOverflow error, as shown in the red box in Figure 3:
> # While _vertices:VertexRDD_ is being serialized, its member _PartitionsRDD_
> will be serialized too.
> # Next, while serializing this _partitionsRDD_, serialization() will
> simultaneously serialize its f’s referenced $outer. Here, it is another
> _partitionsRDD_.
> # Finally, the chain
> {code:borderStyle=solid}
> "f => f$3 => f$3 => $outer => vertices: VertexRDD => partitionsRDD => … =>
> ShuffledRDD"
> {code}
> comes into shape. As a result, the serialization chain can be as long as the
> original lineage and finally triggers StackOverflow error.
>
> !https://raw.githubusercontent.com/JerryLead/Misc/master/SparkPRFigures/g3.png|width=80%!
> h2. Conclusions
> In conclusion, the root cause of StackOverflow error is the long
> serialization chain, which cannot be cut off by _checkpoint()_. This long
> chain is caused by the multiple factors, including:
> # long lineage
> # $outer reference in the f closure
> # non-transient member variable
> As a result, we will need about three pull requests (will be added later) to
> solve this problem thoroughly.
--
This message was sent by Atlassian JIRA
(v6.3.4#6332)
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscr...@spark.apache.org
For additional commands, e-mail: issues-h...@spark.apache.org
{kind=link}
{kind=link}
{kind=link}