[
https://issues.apache.org/jira/browse/SPARK-43504?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Fei Wang updated SPARK-43504:
-----------------------------
Summary: [K8S] Mounts the hadoop config map on the executor pod (was:
[K8S] Mount hadoop config map in executor side)
> [K8S] Mounts the hadoop config map on the executor pod
> ------------------------------------------------------
>
> Key: SPARK-43504
> URL: https://issues.apache.org/jira/browse/SPARK-43504
> Project: Spark
> Issue Type: Improvement
> Components: Kubernetes
> Affects Versions: 3.4.0
> Reporter: Fei Wang
> Priority: Major
>
> Since SPARK-25815 [,|https://github.com/apache/spark/pull/22911,] the hadoop
> config map is not in executor side.
> Per the [https://github.com/apache/spark/pull/22911] description:
> {code:java}
> The main two things that don't need to happen in executors anymore are:
> 1. adding the Hadoop config to the executor pods: this is not needed
> since the Spark driver will serialize the Hadoop config and send
> it to executors when running tasks. {code}
> But in fact, the executor still need the hadoop configuration.
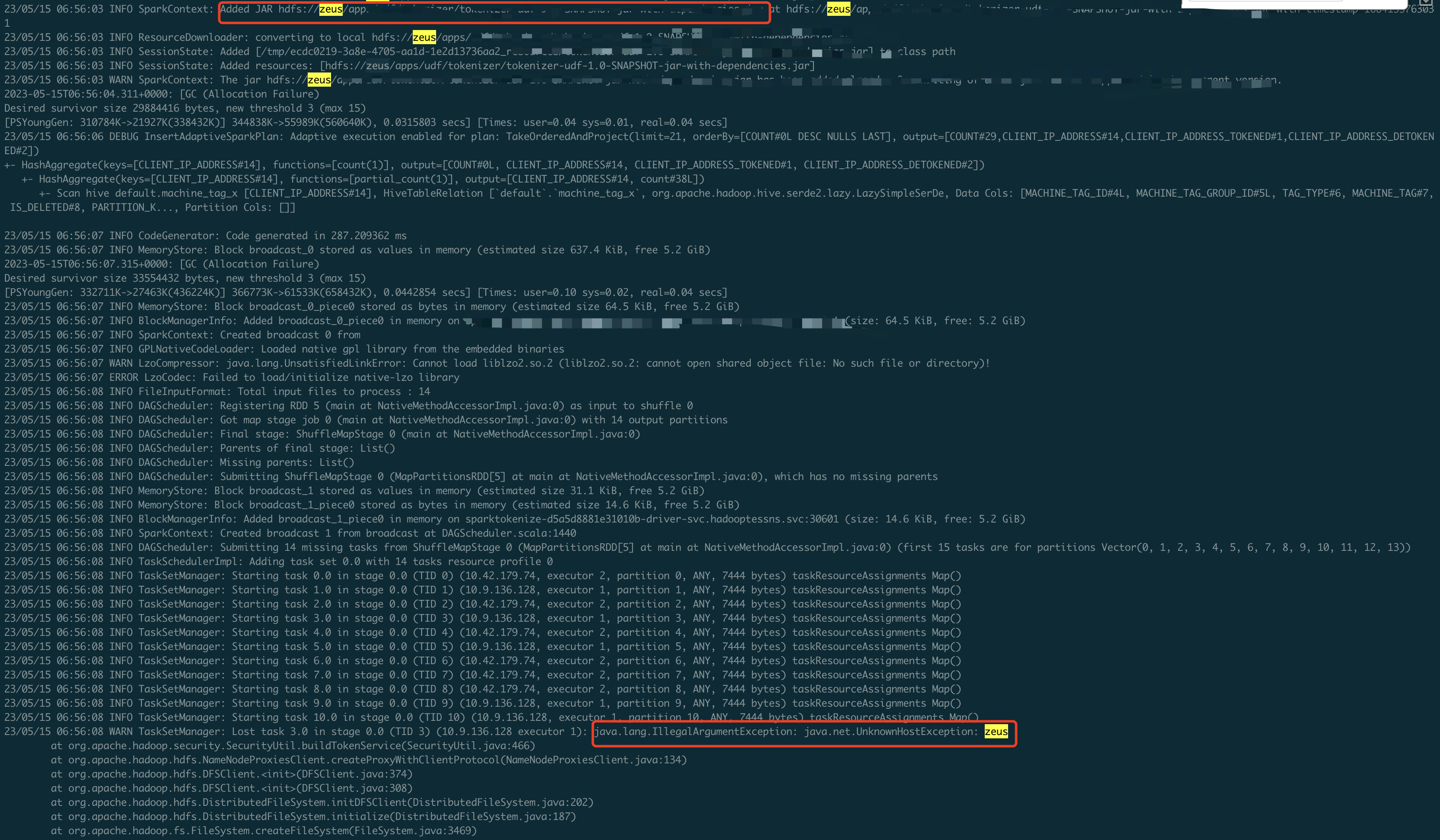
>
> !https://user-images.githubusercontent.com/6757692/238268640-8ff41144-5812-4232-b572-2de2408348ed.png!
>
> As shown in above picture, the driver can resolve `hdfs://zeus`, but the
> executor can not.
> so we still need to mount the hadoop config map in executor side.
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscr...@spark.apache.org
For additional commands, e-mail: issues-h...@spark.apache.org
{kind=link}