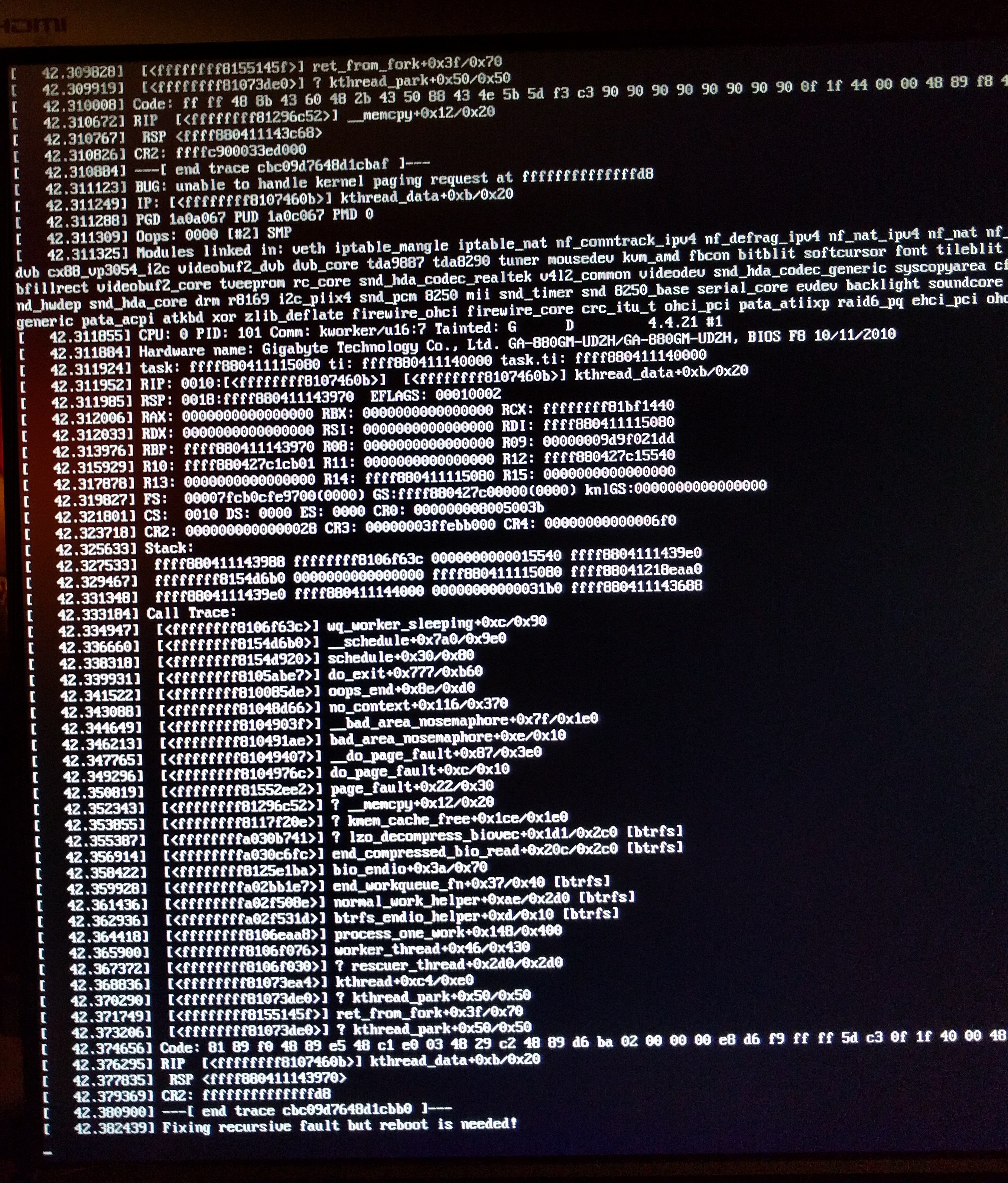
On 9/30/16 2:54 PM, Rich Freeman wrote: > On Thu, Sep 22, 2016 at 1:41 PM, Jeff Mahoney <je...@suse.com> wrote: >> On 9/22/16 8:18 AM, Rich Freeman wrote: >>> I have been getting panics consistently after doing a btrfs replace >>> operation on a raid1 and rebooting. I linked a photo of the panic; I >>> haven't been able to get a text capture of it. >>> >>> https://ibin.co/2vx0HhDeViu3.jpg >>> >>> I'm getting this error on the latest 4.4, 4.1, and even on an old >>> 3.18.26 kernel I had lying around. >>> >>> I tried the remove root_log_ctx from ctx list before btrfs_sync_log >>> returns patch on 4.1 and that did not solve my problem either. >>> >>> I'm able to boot into single-user mode and if I don't start any >>> processes the system seems fairly stable. I am also able to start a >>> btrfs balance and run that for several hours without issue. If I >>> start launching services the system will tend to panic, though how >>> many processes I can launch will vary. I don't think that it is a >>> particular file being accessed that is triggering the issue since the >>> point where it fails varies. I suspect it may be load-related. >>> >>> Mounting with compress=no doesn't seem to help either. Granted, I see >>> lzo_decompress in the backtrace and that is probably a read operation. >>> >>> Any suggestions? Google hasn't been helpful on this one... >> >> Can you boot with panic_on_oops=1, reproduce it, and capture that Oops? >> The trace in your photo is a secondary Oops (tainted D), which means >> that something else went wrong before that and now the system is >> tripping over it. Secondary Oopses don't really help the debugging >> process because the system was already in a broken, undefined, state. >> > > Ok, the system has been up for a week without issue, but just paniced > and rebooted right towards the end of a balance (it literally had > about 30 of 2500 chunks left). > > After it came up (and waiting for it to fully mount as there were a > bunch of free space warnings/etc) I managed to capture an initial oops > when it happened again: > > https://ibin.co/2wt0n2IaCOA3.jpg > > This is on a system without swap, though my understanding is that the > paging system is used for other things.
{kind=link}
{kind=link}
It's not paging in the way Microsoft uses the term. In this context, it just means that the kernel tried to resolve a virtual address and failed. When the address is < PAGE_SIZE, it prints the NULL pointer dereference message instead. It's literally the same code otherwise. Short version: it's the same thing as a segfault in userspace code. This looks like a use-after-free on one of the pages used for compression. Can you post the output of objdump -Dr /lib/modules/$(uname -r)/kernel/fs/btrfs/btrfs.ko somewhere? -Jeff -- Jeff Mahoney SUSE Labs
![]() signature.asc
signature.asc
Description: OpenPGP digital signature