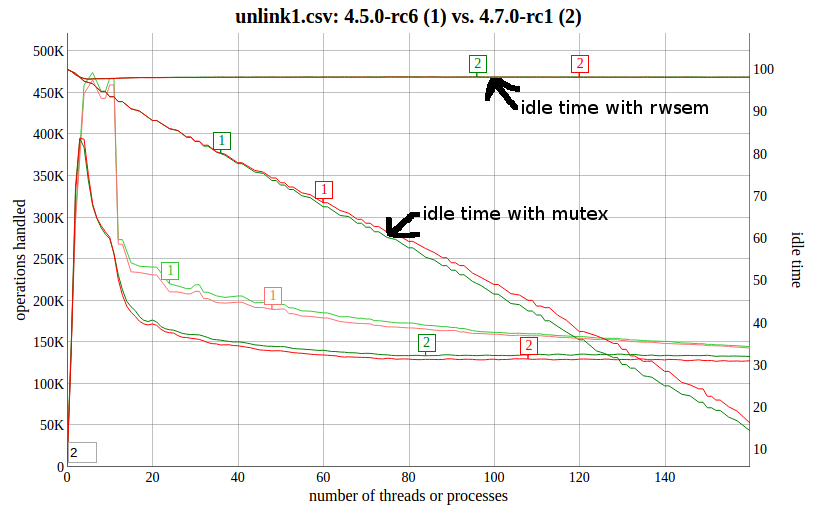
>> Ok, these enhancements are now in the locking tree and are queued up for >v4.8: >> >> git pull git://git.kernel.org/pub/scm/linux/kernel/git/tip/tip.git >> locking/core >> >> Dave, you might want to check your numbers with these changes: is >> rwsem performance still significantly worse than mutex performance? > >It's substantially closer than it was, but there's probably a little work >still to do. >The rwsem still looks to be sleeping a lot more than the mutex. Here's where >we started: > > https://www.sr71.net/~dave/intel/rwsem-vs-mutex.png > >The rwsem peaked lower and earlier than the mutex code. Now, if we compare >the old (4.7-rc1) rwsem code to the newly-patched rwsem code (from >tip/locking): > >> https://www.sr71.net/~dave/intel/bb.html?1=4.7.0-rc1&2=4.7.0-rc1-00127 >> -gd4c3be7 > >We can see the peak is a bit higher and more importantly, it's more of a >plateau >than a sharp peak. We can also compare the new rwsem code to the 4.5 code >that had the mutex in place: > >> https://www.sr71.net/~dave/intel/bb.html?1=4.5.0-rc6&2=4.7.0-rc1-00127 >> -gd4c3be7 > >rwsems are still a _bit_ below the mutex code at the peak, and they also seem >to be substantially lower during the tail from 20 cpus on up. The rwsems are >sleeping less than they were before the tip/locking updates, but they are still >idling the CPUs 90% of the time while the mutexes end up idle 15-20% of the >time when all the cpus are contending on the lock.
{kind=link}
In Al Viro's conversion, he introduced inode_lock_shared which uses read lock in lookup_slow. The rwsem does bail out of optimistic spin when readers acquire the lock, thus causing us to see a lot less optimistic spinning attempts for the unlink test case. Whereas earlier for mutex, we will keep spinning. A simple test may be to see if we get similar performance when changing inode_lock_shared to the writer version. That said, hopefully we should have a lot more read locking than write locking (i.e. more path look up than changes to the path) so the switch to rwsem is still a win. I guess the lesson here is when there is an equal mix of writers and readers, rwsem could be a bit worse in performance than mutex as we don't spin as hard. Tim