Well it's not hard to add something like UncenteredCosineSimilarity for sure, I don't mind. It's actually a matter of configuring the superclass to center or not.
But it's also easy to center the data in the M/R. I agree it makes little difference in your case, and the effect is subtle. I can add centering, to at least have it in the code for consistency -- in addition to adding the implementation above for completeness. While I'm at it I think we might be able to simplify this item-item computation. A straightforward alternative is something like this: 1. Compute item vectors (using Vector output, ideally) in one M/R 2M. For each item-item pair output both vectors 2R. With both Vectors in hand easily compute the cosine measure It's quite simple, and lends itself to dropping in a different reducer stage to implement different similarities, which is great. The question is performance. Say I have P prefs, U users and I items. Assume P/I prefs per item. The bottleneck of this stage is outputting I^2 vectors of size P/I, or about P*I output. What you're doing now bottlenecks in the last bit where you output for each user some data for every pair of items. That's coarsely U * (P/U)^2 = U*P^2 output. I think that P^2 is killer. Double-check my thinking but if you like it I think I can significantly simplify this job. I can maybe make a patch for you to try. On Wed, Apr 28, 2010 at 9:05 AM, Sebastian Schelter <[email protected]> wrote: > However, I'm a little bit confused now, let me explain why I thought > that this additional similarity implementation would be necessary: Three > weeks ago, I submitted a patch computing the cosine item similarities > via map-reduce (MAHOUT-362), which is how I currently fill my database > table of precomputed item-item-similarities. Some days ago I needed to > precompute lots of recommendations offline via > org.apache.mahout.cf.taste.hadoop.pseudo.RecommenderJob and didn't want > to connect my map-reduce code to the database. So I was in need of a > similarity implementation that would give me the same results on the fly > from a FileDataModel, which is how I came to create the > CosineItemSimilarity implementation. So my point here would be that if > the code in org.apache.mahout.cf.taste.hadoop.similarity.item does not > center the data, a non-distributed implementation of that way of > computing the similarity should be available too, or the code in > org.apache.mahout.cf.taste.hadoop.similarity.item should be changed to > center the data. > > You stated that centering the data "adjusts for a user's tendency to > rate high or low on average" which is certainly necessary when you > collect explicit ratings from your users. However in my usecase (a big > online-shopping platform) I unfortunately do not have explicit ratings > from the users, so I chose to interpret certain actions as ratings (I > recall this is called implicit ratings in the literature), e.g. a user > putting an item into their shopping basket as a rating of 3 or a user > purchasing an item as a rating of 5, like suggested in the "Making > Recommendations" chapter" of "Programming Collective Intelligence" by T. > Searagan. As far as I can judge (to be honest my mathematical knowledge > is kinda limited) there are no different interpretations of the rating > scala here as the values are fixed, so I thought that a centering of the > data would not be necessary. > > Regards, > Sebastian > > Sean Owen (JIRA) schrieb: >> [ >> https://issues.apache.org/jira/browse/MAHOUT-387?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel >> ] >> >> Sean Owen updated MAHOUT-387: >> ----------------------------- >> >> Status: Resolved (was: Patch Available) >> Assignee: Sean Owen >> Fix Version/s: 0.3 >> Resolution: Won't Fix >> >> Yes like Jeff said, this actually exists as PearsonCorrelationSimilarity. In >> the case where the mean of each series is 0, the result is the same. The >> fastest way I know to see this is to just look at this form of the sample >> correlation: >> http://upload.wikimedia.org/math/c/a/6/ca68fbe94060a2591924b380c9bc4e27.png >> ... and note that sum(xi) = sum (yi) = 0 when the mean of xi and yi are 0. >> You're left with sum(xi*yi) in the numerator, which is the dot product, and >> sqrt(sum(xi^2)) * sqrt(sum(yi^2)) in the denominator, which are the vector >> sizes. This is just the cosine of the angle between x and y. >> >> One can argue whether forcing the data to be centered is right. I think it's >> a good thing in all cases. It adjusts for a user's tendency to rate high or >> low on average. It also makes the computation simpler, and more consistent >> with Pearson (well, it makes it identical!). This has a good treatment: >> http://en.wikipedia.org/wiki/Pearson_product-moment_correlation_coefficient#Geometric_interpretation >> >> Only for this reason I'd mark this as won't-fix for the moment; the patch is >> otherwise nice. I'd personally like to hear more about why to not center if >> there's an argument for it. >> >> >>> Cosine item similarity implementation >>> ------------------------------------- >>> >>> Key: MAHOUT-387 >>> URL: https://issues.apache.org/jira/browse/MAHOUT-387 >>> Project: Mahout >>> Issue Type: New Feature >>> Components: Collaborative Filtering >>> Reporter: Sebastian Schelter >>> Assignee: Sean Owen >>> Fix For: 0.3 >>> >>> Attachments: MAHOUT-387.patch >>> >>> >>> I needed to compute the cosine similarity between two items when running >>> org.apache.mahout.cf.taste.hadoop.pseudo.RecommenderJob, I couldn't find an >>> implementation (did I overlook it maybe?) so I created my own. I want to >>> share it here, in case you find it useful. >>> >> >> > >
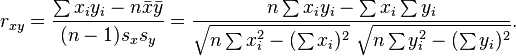{kind=link}