praveenkumarb1207 opened a new issue, #4102: URL: https://github.com/apache/kyuubi/issues/4102
### Code of Conduct - [X] I agree to follow this project's [Code of Conduct](https://www.apache.org/foundation/policies/conduct) ### Search before asking - [X] I have searched in the [issues](https://github.com/apache/kyuubi/issues?q=is%3Aissue) and found no similar issues. ### Describe the bug I have followed the instructions in https://github.com/apache/kyuubi/blob/master/docs/security/authorization/spark/build.md and build the Apache Kyuubi for **Spark 3.2.3 with Hadoop 3.3.4** and **Ranger 2.3.0** versions for the Kyuubi master branch using the below command. ``` mvn clean package -pl :kyuubi-spark-authz_2.12 DskipTests -Dspark.version=3.2.3 -Dranger.version=2.3.0 ``` After the above step , following the instructions in https://github.com/apache/kyuubi/blob/master/docs/security/authorization/spark/install.md , I have installed Kyuubi plugin by copying all the jars and required configuration files as mentioned in the link to $SPARK_HOME . **Kyuubi Jar copied :**  **Transitive Dependency jars Copied :** 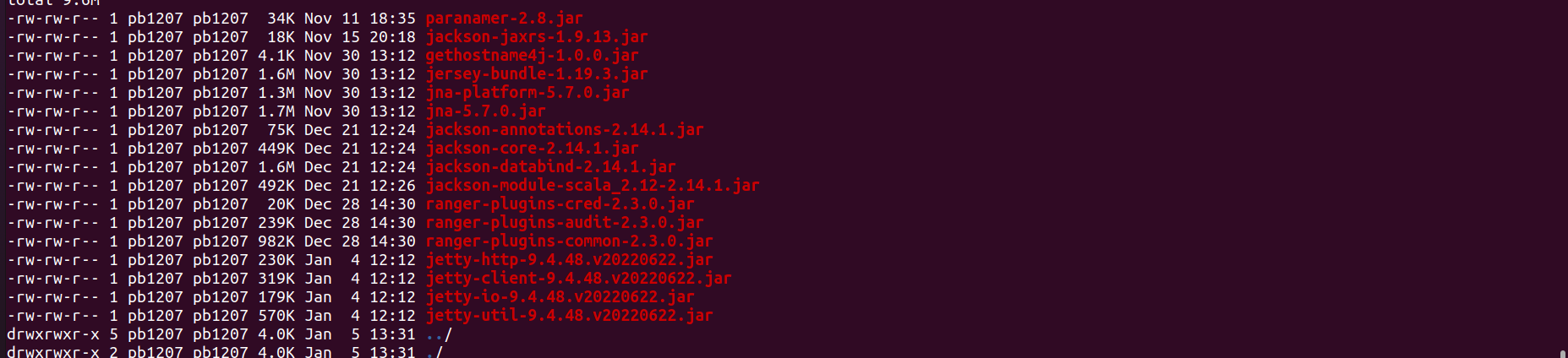 **Jars in my $SPARK_HOME/jars folder :** 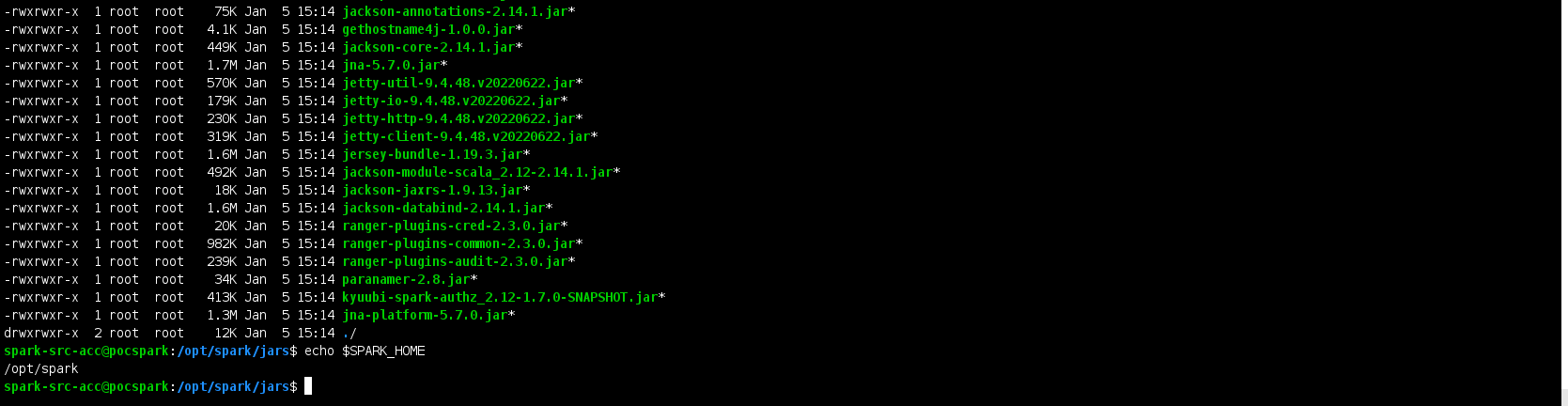 When I open the spark-shell and run the below code , I am facing error . **Spark-shell command :** `spark-shell --packages "org.apache.spark:spark-hive_2.12:3.2.3,org.apache.hadoop:hadoop-aws:3.3.4"` **Code :** spark.sql("show databases").show(false) **Error :** ``` com.fasterxml.jackson.databind.JsonMappingException: Scala module 2.12.3 requires Jackson Databind version >= 2.12.0 and < 2.13.0 at com.fasterxml.jackson.module.scala.JacksonModule.setupModule(JacksonModule.scala:61) at com.fasterxml.jackson.module.scala.JacksonModule.setupModule$(JacksonModule.scala:46) at com.fasterxml.jackson.module.scala.DefaultScalaModule.setupModule(DefaultScalaModule.scala:17) at com.fasterxml.jackson.databind.ObjectMapper.registerModule(ObjectMapper.java:879) at org.apache.spark.rdd.RDDOperationScope$.<init>(RDDOperationScope.scala:82) at org.apache.spark.rdd.RDDOperationScope$.<clinit>(RDDOperationScope.scala) at org.apache.spark.sql.execution.SparkPlan.executeQuery(SparkPlan.scala:220) at org.apache.spark.sql.execution.SparkPlan.execute(SparkPlan.scala:181) at org.apache.spark.sql.execution.SparkPlan.getByteArrayRdd(SparkPlan.scala:326) at org.apache.spark.sql.execution.SparkPlan.executeTake(SparkPlan.scala:459) at org.apache.spark.sql.execution.SparkPlan.executeTake(SparkPlan.scala:445) at org.apache.spark.sql.execution.CollectLimitExec.executeCollect(limit.scala:48) at org.apache.spark.sql.Dataset.collectFromPlan(Dataset.scala:3715) at org.apache.spark.sql.Dataset.$anonfun$head$1(Dataset.scala:2728) at org.apache.spark.sql.Dataset.$anonfun$withAction$1(Dataset.scala:3706) at org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$5(SQLExecution.scala:103) at org.apache.spark.sql.execution.SQLExecution$.withSQLConfPropagated(SQLExecution.scala:163) at org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$1(SQLExecution.scala:90) at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:775) at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:64) at org.apache.spark.sql.Dataset.withAction(Dataset.scala:3704) at org.apache.spark.sql.Dataset.head(Dataset.scala:2728) at org.apache.spark.sql.Dataset.take(Dataset.scala:2935) at org.apache.spark.sql.Dataset.getRows(Dataset.scala:287) at org.apache.spark.sql.Dataset.showString(Dataset.scala:326) at org.apache.spark.sql.Dataset.show(Dataset.scala:808) at org.apache.spark.sql.Dataset.show(Dataset.scala:785) ``` **Screenshot :** 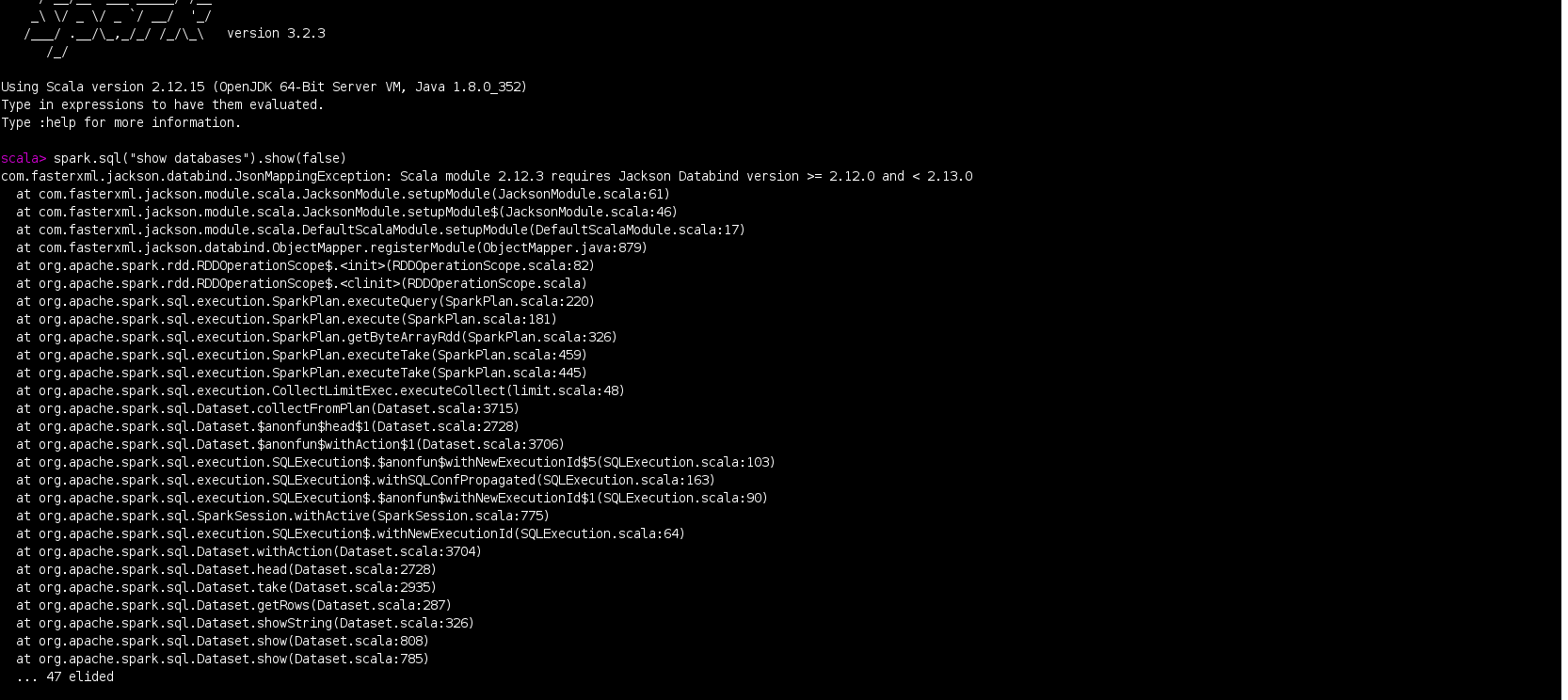 Because of the above issue , I have removed below jackson related dependencies which are added as part of Kyuubi intall.md to $SPARK_HOME/jars folder and executed the the same code which solved the issue. ``` jackson-annotations-2.14.1.jar jackson-core-2.14.1.jar jackson-databind-2.14.1.jar ``` **Result :**  Then I have executed the below code `spark.sql("show tables from test").show(false)` **ERROR :** ``` java.lang.NoSuchMethodError: com.fasterxml.jackson.module.scala.ClassTagExtensions$.$colon$colon(Lcom/fasterxml/jackson/databind/json/JsonMapper;)Lcom/fasterxml/jackson/databind/json/JsonMapper; at org.apache.kyuubi.plugin.spark.authz.serde.package$.<init>(package.scala:30) at org.apache.kyuubi.plugin.spark.authz.serde.package$.<clinit>(package.scala) at org.apache.kyuubi.plugin.spark.authz.PrivilegesBuilder$.buildCommand(PrivilegesBuilder.scala:244) at org.apache.kyuubi.plugin.spark.authz.PrivilegesBuilder$.build(PrivilegesBuilder.scala:322) at org.apache.kyuubi.plugin.spark.authz.ranger.RuleAuthorization$.checkPrivileges(RuleAuthorization.scala:50) at org.apache.kyuubi.plugin.spark.authz.ranger.RuleAuthorization.apply(RuleAuthorization.scala:36) at org.apache.kyuubi.plugin.spark.authz.ranger.RuleAuthorization.apply(RuleAuthorization.scala:33) at org.apache.spark.sql.catalyst.rules.RuleExecutor.$anonfun$execute$2(RuleExecutor.scala:211) at scala.collection.LinearSeqOptimized.foldLeft(LinearSeqOptimized.scala:126) at scala.collection.LinearSeqOptimized.foldLeft$(LinearSeqOptimized.scala:122) at scala.collection.immutable.List.foldLeft(List.scala:91) at org.apache.spark.sql.catalyst.rules.RuleExecutor.$anonfun$execute$1(RuleExecutor.scala:208) at org.apache.spark.sql.catalyst.rules.RuleExecutor.$anonfun$execute$1$adapted(RuleExecutor.scala:200) at scala.collection.immutable.List.foreach(List.scala:431) at org.apache.spark.sql.catalyst.rules.RuleExecutor.execute(RuleExecutor.scala:200) at org.apache.spark.sql.catalyst.rules.RuleExecutor.$anonfun$executeAndTrack$1(RuleExecutor.scala:179) at org.apache.spark.sql.catalyst.QueryPlanningTracker$.withTracker(QueryPlanningTracker.scala:88) at org.apache.spark.sql.catalyst.rules.RuleExecutor.executeAndTrack(RuleExecutor.scala:179) at org.apache.spark.sql.execution.QueryExecution.$anonfun$optimizedPlan$1(QueryExecution.scala:125) at org.apache.spark.sql.catalyst.QueryPlanningTracker.measurePhase(QueryPlanningTracker.scala:111) at org.apache.spark.sql.execution.QueryExecution.$anonfun$executePhase$1(QueryExecution.scala:183) at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:775) at org.apache.spark.sql.execution.QueryExecution.executePhase(QueryExecution.scala:183) at org.apache.spark.sql.execution.QueryExecution.optimizedPlan$lzycompute(QueryExecution.scala:121) at org.apache.spark.sql.execution.QueryExecution.optimizedPlan(QueryExecution.scala:117) at org.apache.spark.sql.execution.QueryExecution.assertOptimized(QueryExecution.scala:135) at org.apache.spark.sql.execution.QueryExecution.executedPlan$lzycompute(QueryExecution.scala:153) at org.apache.spark.sql.execution.QueryExecution.executedPlan(QueryExecution.scala:150) at org.apache.spark.sql.execution.QueryExecution.simpleString(QueryExecution.scala:201) at org.apache.spark.sql.execution.QueryExecution.org$apache$spark$sql$execution$QueryExecution$$explainString(QueryExecution.scala:246) at org.apache.spark.sql.execution.QueryExecution.explainString(QueryExecution.scala:215) at org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$5(SQLExecution.scala:98) at org.apache.spark.sql.execution.SQLExecution$.withSQLConfPropagated(SQLExecution.scala:163) at org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$1(SQLExecution.scala:90) at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:775) at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:64) at org.apache.spark.sql.execution.QueryExecution$$anonfun$eagerlyExecuteCommands$1.applyOrElse(QueryExecution.scala:97) at org.apache.spark.sql.execution.QueryExecution$$anonfun$eagerlyExecuteCommands$1.applyOrElse(QueryExecution.scala:93) at org.apache.spark.sql.catalyst.trees.TreeNode.$anonfun$transformDownWithPruning$1(TreeNode.scala:481) at org.apache.spark.sql.catalyst.trees.CurrentOrigin$.withOrigin(TreeNode.scala:82) at org.apache.spark.sql.catalyst.trees.TreeNode.transformDownWithPruning(TreeNode.scala:481) at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.org$apache$spark$sql$catalyst$plans$logical$AnalysisHelper$$super$transformDownWithPruning(LogicalPlan.scala:30) at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper.transformDownWithPruning(AnalysisHelper.scala:267) at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper.transformDownWithPruning$(AnalysisHelper.scala:263) at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.transformDownWithPruning(LogicalPlan.scala:30) at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.transformDownWithPruning(LogicalPlan.scala:30) at org.apache.spark.sql.catalyst.trees.TreeNode.transformDown(TreeNode.scala:457) at org.apache.spark.sql.execution.QueryExecution.eagerlyExecuteCommands(QueryExecution.scala:93) at org.apache.spark.sql.execution.QueryExecution.commandExecuted$lzycompute(QueryExecution.scala:80) at org.apache.spark.sql.execution.QueryExecution.commandExecuted(QueryExecution.scala:78) at org.apache.spark.sql.Dataset.<init>(Dataset.scala:219) at org.apache.spark.sql.Dataset$.$anonfun$ofRows$2(Dataset.scala:99) at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:775) at org.apache.spark.sql.Dataset$.ofRows(Dataset.scala:96) at org.apache.spark.sql.SparkSession.$anonfun$sql$1(SparkSession.scala:618) at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:775) at org.apache.spark.sql.SparkSession.sql(SparkSession.scala:613) ... 47 elided ``` **Screenshot :** 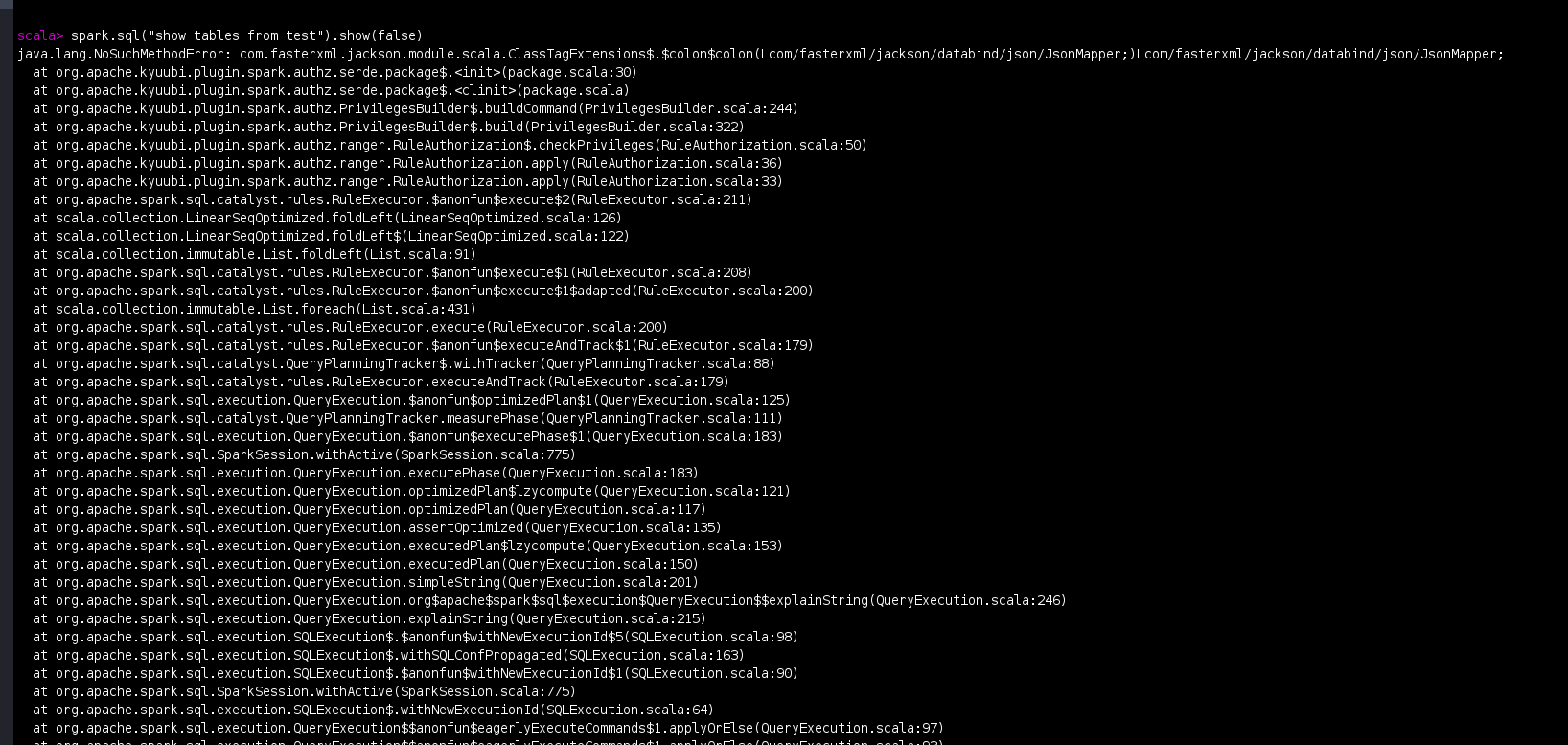 Can you please help us in solving the above issue for the master version . **NOTE :** I have followed the same above steps for the below commit of Kyuubi and everything was working as expected without any issues . I am facing issues with master version. https://github.com/apache/kyuubi/tree/d2463e2a81cf2c695638ba717b39db7d54f0941b ### Affects Version(s) master ### Kyuubi Server Log Output _No response_ ### Kyuubi Engine Log Output _No response_ ### Kyuubi Server Configurations _No response_ ### Kyuubi Engine Configurations _No response_ ### Additional context _No response_ ### Are you willing to submit PR? - [ ] Yes. I would be willing to submit a PR with guidance from the Kyuubi community to fix. - [ ] No. I cannot submit a PR at this time. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: [email protected] For queries about this service, please contact Infrastructure at: [email protected] --------------------------------------------------------------------- To unsubscribe, e-mail: [email protected] For additional commands, e-mail: [email protected]
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}