This is an automated email from the ASF dual-hosted git repository.
azexin pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/shardingsphere.git
The following commit(s) were added to refs/heads/master by this push:
new 62eaa02b063 Fix 2 articles and upload 2 more articles to
Shardingsphere's Blogs (#24518)
62eaa02b063 is described below
commit 62eaa02b0636de35ddfa6344fe9a26e3d0b088aa
Author: FPokerFace <[email protected]>
AuthorDate: Thu Mar 9 13:59:13 2023 +0800
Fix 2 articles and upload 2 more articles to Shardingsphere's Blogs (#24518)
* Upload 2 articles to Shardingsphere Blogs
* Update
2022_11_15_Alibaba_Cloud’s_OpenSergo_&_ShardingSphere_release_database_governance_standard_for_microservices_—_combining_Database_Plus_and_Database_Mesh_concepts.en.md
* Fix 2 articles and upload 2 more articles to Shardingsphere's Blogs
---
...Database_Plus_and_Database_Mesh_concepts.en.md" | 211 +++++++++++++++
...and_SAML_single_sign-on_thanks_to_Casdoor.en.md | 8 +-
...idecar_for_a_true_cloud-native_experience.en.md | 96 +++++++
...is_released_new_features_and_improvements.en.md | 291 +++++++++++++++++++++
...Sidecar_for_a_true_cloud-native_experience1.png | Bin 0 -> 62138 bytes
..._is_released_new_features_and_improvements1.png | Bin 0 -> 244050 bytes
..._is_released_new_features_and_improvements2.png | Bin 0 -> 225157 bytes
7 files changed, 602 insertions(+), 4 deletions(-)
diff --git
"a/docs/blog/content/material/2022_11_15_Alibaba_Cloud\342\200\231s_OpenSergo_&_ShardingSphere_release_database_governance_standard_for_microservices_-_combining_Database_Plus_and_Database_Mesh_concepts.en.md"
"b/docs/blog/content/material/2022_11_15_Alibaba_Cloud\342\200\231s_OpenSergo_&_ShardingSphere_release_database_governance_standard_for_microservices_-_combining_Database_Plus_and_Database_Mesh_concepts.en.md"
new file mode 100644
index 00000000000..1ef67b980d2
--- /dev/null
+++
"b/docs/blog/content/material/2022_11_15_Alibaba_Cloud\342\200\231s_OpenSergo_&_ShardingSphere_release_database_governance_standard_for_microservices_-_combining_Database_Plus_and_Database_Mesh_concepts.en.md"
@@ -0,0 +1,211 @@
++++
+title = "Alibaba Cloud's OpenSergo & ShardingSphere release database
governance standard for microservices - combining Database Plus and Database
Mesh concepts"
+weight = 79
+chapter = true
+
++++
+
+# Background
+
+Recently, [Alibaba
Cloud](https://us.alibabacloud.com/?utm_key=se_1007722888&utm_content=se_1007722888&gclid=Cj0KCQiAyMKbBhD1ARIsANs7rEE71bHtu1aPbMS_E5-awHyWwTtyRn8CfmMU0qD1eH2hKSVEIDxcxaIaAuAVEALw_wcB)'s
[OpenSergo](https://opensergo.io/) and
[ShardingSphere](https://shardingsphere.apache.org/) jointly released the
database governance standard for microservices. By combining the [Database
Plus](https://medium.com/faun/whats-the-database-plus-concepand-what-challenges-can-it-solve-715920
[...]
+
+
+
+***The founders of both communities expressed their opinions concerning the
collaboration between the ShardingSphere community and the OpenSergo
community:***
+
+**Zhang Liang, the PMC Chair of the Apache ShardingSphere community:**
+
+In the microservices field, the interaction and collaboration between services
have been gradually perfected, but there is still no effective standard for
services to access the database. Being, ShardingSphere has been continuously
following the **"connect, enhance, and pluggable"** design philosophy.
"Connect" refers to providing standardized protocols and interfaces, breaking
the barriers for development languages to access heterogeneous databases. It's
forward-looking for OpenSergo to [...]
+
+**Zhao Yihao, the founder of the OpenSergo community:**
+
+In microservice governance, in addition to the governance of the microservices
itself, it is also a critical step to ensure business reliability and
continuity to deal with microservices' access to databases. As a Top-Level
project in the database governance field, ShardingSphere has integrated a
wealth of best practices and technical experience, which complements OpenSergo.
In this context, we work with the ShardingSphere community to jointly build a
database governance standard from th [...]
+
+**Note:** database governance in this article includes all aspects of database
governance in microservice systems. All business information and key data need
a robust and stable database system as it is the most important state terminal.
+
+# The database is increasingly vital in the microservice system
+
+To meet flexible business requirements, the application architecture can be
transformed from monolithic to service-oriented and then to
microservice-oriented. In this case, the database used to store the core data
becomes the focus of the distributed system.
+
+Enterprises take advantage of microservices to separate services and adopt a
distributed architecture to achieve loose coupling among multiple services,
flexible adjustment and combination of services, and high availability of
systems. In particular, microservices indeed have delivered enormous benefits
in the face of rapidly changing businesses.
+
+However, after services are separated, their corresponding underlying
databases should also be separated to ensure the independent deployment of each
service. In this way, each service can be an independent unit, finally
achieving the microservices. In this context, the database is becoming
increasingly complicated:
+
+- The transformation from monolithic to microservice-oriented architecture
models leads to increasingly complicated services, diversified requirements,
larger scale infrastructure, complex call relations between services, and
higher requirements on the underlying database performance.
+- Different transactions usually involve multiple services - but it is a
challenge to ensure data consistency between services.
+- It is also challenging to query data across multiple services.
+
+With most backend applications, their system performance improvement is mainly
limited to databases. Particularly in a microservice environment, it is a
team's top priority to deal with database performance governance. Database
governance naturally becomes an indispensable part of microservice governance.
+
+In database governance, we now mainly focus on **read/write splitting,
sharding, shadow databases, database discovery, and distributed transactions**.
At the same time, how to use databases and the actual database storage nodes
rely on **the virtual database and database endpoint**.
+
+In response to the above-mentioned problems, OpenSergo and ShardingSphere have
assimilated the latter's database governance experience and released the
**database governance standard under microservices**. By doing so, they can
standardize the database governance method, lower the entry barriers of this
field, and improve the business applicability of microservices.
+
+# ShardingSphere's strategies on database traffic governance
+
+**1. VirtualDatabase**
+
+In database governance, whether it is read/write splitting, sharding, shadow
database or encryption, audit, and access control, they all have to act on a
specific database. Here such a logical database is called a virtual database,
namely VirtualDatabase.
+
+From the application's viewpoint, VirtualDatabase refers to a set of specific
database access information, which can achieve governance capability by binding
corresponding governance strategies.
+
+**2. DatabaseEndpoint**
+
+In database governance, VirtualDatabase declares the logical database
available to applications, but actually, data storage depends on a physical
database. Here it is called database access endpoint, namely DatabaseEndpoint.
+
+DatabaseEndpoint is imperceptible to applications. It can only be bound to
VirtualDatabase by a specific governance strategy and then be connected and
used.
+
+**3. ReadWriteSplitting**
+
+Read/write splitting is a commonly used database extension method. The primary
database is used for transactional read/write operations, while the secondary
database is mainly used for queries.
+
+**4. Sharding**
+
+Data sharding is an extension strategy based on data attributes. Once data
attributes are calculated, requests are sent to a specific data backend.
Currently, sharding consists of sharding with shard keys and automatic
sharding. Sharding with shard keys needs to specify which table or column is to
be sharded and the algorithms used for sharding.
+
+**5. Encryption**
+
+To meet the requirements of audit security and compliance, enterprises need to
provide strict security measures for data storage, such as data encryption.
+
+Data encryption parses the SQL entered by users and rewrites SQL according to
the encryption rules provided by users.
+
+By doing so, the plaintext data can be encrypted, and plaintext data
(optional) and ciphertext data can be both stored in the underlying database.
+
+When the user queries the data, Encryption only takes the ciphertext data from
the database, decrypts it, and finally returns the decrypted original data to
the user.
+
+**6. Shadow**
+
+Shadow database can receive grayscale traffic or data test requests in a
grayscale environment or test environment, and flexibly configure multiple
routing methods combined with shadow algorithms.
+
+**7. DatabaseDiscovery**
+
+Database auto-discovery can detect the change of data source status according
to the high availability configuration of the database and then make
adjustments to traffic strategy accordingly.
+
+For example, if the backend data source is [MySQL](https://www.mysql.com/)
MGR, you can set the database discovery type as MYSQL.MGR, specify `group-name`
and configure corresponding heartbeat intervals.
+
+**8. DistributedTransaction**
+
+It can declare configurations related to distributed transactions. Users can
declare the transaction types without additional configuration.
+
+# Database Governance Example
+
+```sql
+# Virtual database configuration
+apiVersion: database.opensergo.io/v1alpha1
+kind: VirtualDatabase
+metadata:
+ name: sharding_db
+spec:
+ services:
+ - name: sharding_db
+ databaseMySQL:
+ db: sharding_db
+ host: localhost
+ port: 3306
+ user: root
+ password: root
+ sharding: "sharding_db" # Declare the desired sharding strategy.
+---
+# The database endpoint configuration of the first data source
+apiVersion: database.opensergo.io/v1alpha1
+kind: DatabaseEndpoint
+metadata:
+ name: ds_0
+spec:
+ database:
+ MySQL: # Declare the backend data source type and other
related information.
+ url:
jdbc:mysql://192.168.1.110:3306/demo_ds_0?serverTimezone=UTC&useSSL=false
+ username: root
+ password: root
+ connectionTimeout: 30000
+ idleTimeoutMilliseconds: 60000
+ maxLifetimeMilliseconds: 1800000
+ maxPoolSize: 50
+ minPoolSize: 1
+---
+# The database endpoint configuration of the second data source
+apiVersion: database.opensergo.io/v1alpha1
+kind: DatabaseEndpoint
+metadata:
+ name: ds_1
+spec:
+ database:
+ MySQL: # Declare the backend data source type
and other related information.
+ url:
jdbc:mysql://192.168.1.110:3306/demo_ds_1?serverTimezone=UTC&useSSL=false
+ username: root
+ password: root
+ connectionTimeout: 30000
+ idleTimeoutMilliseconds: 60000
+ maxLifetimeMilliseconds: 1800000
+ maxPoolSize: 50
+ minPoolSize: 1
+---
+# Sharding configuration
+apiVersion: database.opensergo.io/v1alpha1
+kind: Sharding
+metadata:
+ name: sharding_db
+spec:
+ tables: # map[string]object type
+ t_order:
+ actualDataNodes: "ds_${0..1}.t_order_${0..1}"
+ tableStrategy:
+ standard:
+ shardingColumn: "order_id"
+ shardingAlgorithmName: "t_order_inline"
+ keyGenerateStrategy:
+ column: "order_id"
+ keyGeneratorName: "snowflake"
+ t_order_item:
+ actualDataNodes: "ds_${0..1}.t_order_item_${0..1}"
+ tableStrategy:
+ standard:
+ shardingColumn: "order_id"
+ shardingAlgorithmName: "t_order_item_inline"
+ keyGenerateStrategy:
+ column: order_item_id
+ keyGeneratorName: snowflake
+ bindingTables:
+ - "t_order,t_order_item"
+ defaultDatabaseStrategy:
+ standard:
+ shardingColumn: "user_id"
+ shardingAlgorithmName: "database_inline"
+ # defaultTableStrategy: # Null means none
+ shardingAlgorithms: # map[string]object type
+ database_inline:
+ type: INLINE
+ props: # map[string]string type
+ algorithm-expression: "ds_${user_id % 2}"
+ t_order_inline:
+ type: INLINE
+ props:
+ algorithm-expression: "d_order_${order_id % 2}"
+ t_order_item_inline:
+ type: INLINE
+ props:
+ algorithm-expression: "d_order_item_${order_id % 2}"
+ keyGenerators: # map[string]object type
+ snowflake:
+ type: SNOWFLAKE
+```
+
+# About Apache ShardingSphere
+
+[Apache ShardingSphere](https://shardingsphere.apache.org/) is a distributed
database ecosystem that can transform any database into a distributed database
and enhance it with sharding, elastic scaling, encryption features & more.
+
+Apache ShardingSphere follows the Database Plus concept, designed to build an
ecosystem on top of fragmented heterogeneous databases. It focuses on how to
fully use the computing and storage capabilities of databases rather than
creating a brand-new database. It attaches greater importance to the
collaboration between multiple databases instead of the database itself.
+
+🔗 [**Apache ShardingSphere Useful
Links**](https://linktr.ee/ApacheShardingSphere)
+
+# About OpenSergo
+
+[OpenSergo](https://opensergo.io/) is an open and universal service governance
specification that is oriented toward distributed service architecture and
covers a full-link heterogeneous ecosystem.
+
+It is formed based on the industry's service governance scenarios and
practices. The biggest characteristic of OpenSergo is defining service
governance rules with a unified set of configuration/DSL/protocol and is
oriented towards multi-language heterogeneous architecture, achieving full-link
ecosystem coverage.
+
+No matter if the microservice language is Java, Go, Node.js, or some other
language, or whether it's a standard microservice or Mesh-based access,
developers can use the same set of OpenSergo CRD standard configurations.
+
+This allows developers to implement unified governance and control for each
layer, ranging from the gateway to microservices, from database to cache, and
from registration and discovery to the configuration of services.
+
+🔗 [**OpenSergo GitHub**](https://github.com/opensergo/opensergo-specification)
\ No newline at end of file
diff --git
a/docs/blog/content/material/2022_11_22_ElasticJob_UI_now_supports_Auth_2.0,_OIDC_and_SAML_single_sign-on_thanks_to_Casdoor.en.md
b/docs/blog/content/material/2022_11_22_ElasticJob_UI_now_supports_Auth_2.0,_OIDC_and_SAML_single_sign-on_thanks_to_Casdoor.en.md
index cca3dc4c9f6..e2ef65163ed 100644
---
a/docs/blog/content/material/2022_11_22_ElasticJob_UI_now_supports_Auth_2.0,_OIDC_and_SAML_single_sign-on_thanks_to_Casdoor.en.md
+++
b/docs/blog/content/material/2022_11_22_ElasticJob_UI_now_supports_Auth_2.0,_OIDC_and_SAML_single_sign-on_thanks_to_Casdoor.en.md
@@ -6,7 +6,7 @@ chapter = true

-> If you‘re looking to add SSO to the administration console when using
ElasticJob UI, this article will help you tackle this user management problem
using ElasticJob UI’s built-in Casdoor.
+> If you're looking to add SSO to the administration console when using
ElasticJob UI, this article will help you tackle this user management problem
using ElasticJob UI's built-in Casdoor.
# Background
@@ -44,7 +44,7 @@ yarn start
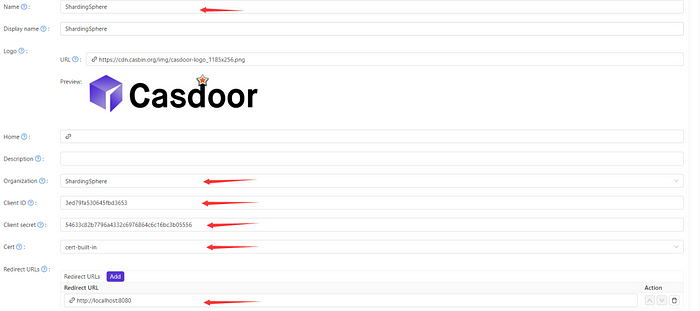
-The red arrows indicate what the backend configuration requires, with
“Redirect URLs” referring to the address where you perform a callback.
+The red arrows indicate what the backend configuration requires, with
"Redirect URLs" referring to the address where you perform a callback.
We also need to find the corresponding cert we selected in the cert option,
such as `cert-build-in` here. A certificate is also needed.
@@ -64,7 +64,7 @@ Paste the data we obtained from Casdoor into the
corresponding position as follo
Now, we can use Casdoor in ElasticJob UI.
-Once the ElasticJob’s admin console connects to Casdoor, it will support
UI-first centralized identity access/single sign-on based on [OAuth
2.0](https://oauth.net/2/), [OIDC](https://openid.net/connect/) and
[SAML](https://auth0.com/blog/how-saml-authentication-works/).
+Once the ElasticJob's admin console connects to Casdoor, it will support
UI-first centralized identity access/single sign-on based on [OAuth
2.0](https://oauth.net/2/), [OIDC](https://openid.net/connect/) and
[SAML](https://auth0.com/blog/how-saml-authentication-works/).
Thanks to developers from the Casdoor and Apache ShardingSphere community, our
collaboration has been going on in a smooth and friendly way. At first,
[jakiuncle](https://github.com/jakiuncle) from Casdoor proposed an issue and
committed a PR, and then our Committer [TeslaCN](https://github.com/TeslaCN)
and PMC [tristaZero](https://github.com/tristaZero) reviewed the PR. This
cross-community collaboration stands as a testament to the Beaty of open source.
@@ -80,6 +80,6 @@ It provides elastic scheduling, resource management, and job
governance combined
# About Casdoor
-[Casdoor](https://casdoor.org/) is a UI-first identity access management (IAM)
/ single-sign-on (SSO) platform based on OAuth 2.0 / OIDC. Casdoor can help you
solve user management problems. There’s no need to develop a series of
authentication features such as user login and registration. It can manage the
user module entirely in a few simple steps in conjunction with the host
application. It’s convenient, easy-to-use and powerful.
+[Casdoor](https://casdoor.org/) is a UI-first identity access management (IAM)
/ single-sign-on (SSO) platform based on OAuth 2.0 / OIDC. Casdoor can help you
solve user management problems. There's no need to develop a series of
authentication features such as user login and registration. It can manage the
user module entirely in a few simple steps in conjunction with the host
application. It's convenient, easy-to-use and powerful.
🔗 [**GitHub**](https://github.com/casdoor/casdoor)
\ No newline at end of file
diff --git
a/docs/blog/content/material/2022_11_24_ShardingSphere-on-Cloud_&_Pisanix_replace_Sidecar_for_a_true_cloud-native_experience.en.md
b/docs/blog/content/material/2022_11_24_ShardingSphere-on-Cloud_&_Pisanix_replace_Sidecar_for_a_true_cloud-native_experience.en.md
new file mode 100644
index 00000000000..44be1af11f7
--- /dev/null
+++
b/docs/blog/content/material/2022_11_24_ShardingSphere-on-Cloud_&_Pisanix_replace_Sidecar_for_a_true_cloud-native_experience.en.md
@@ -0,0 +1,96 @@
++++
+title = "ShardingSphere-on-Cloud & Pisanix replace Sidecar for a true
cloud-native experience"
+weight = 81
+chapter = true
++++
+
+# Background
+
+For a while, many of our blog posts have shown that
[**ShardingSphere**](https://shardingsphere.apache.org/) **consists of three
independent products:**
[**ShardingSphere-JDBC**](https://shardingsphere.apache.org/document/current/en/overview/#shardingsphere-jdbc)**,**
[**ShardingSphere-Proxy**](https://shardingsphere.apache.org/document/current/en/quick-start/shardingsphere-proxy-quick-start/)**,
and ShardingSphere-Sidecar.**
+
+As ShardingSphere has become increasingly popular, JDBC and Proxy have been
used in numerous production environments, but Sidecar's status has remaining as
"**under planning"**. you may have noticed this on our GitHub `READ ME` or our
website.
+
+With cloud-native gaining momentum, many enterprises are choosing to use
databases on the cloud or cloud native databases. This represents an excellent
opportunity for ShardingSphere-Sidecar, which is positioned as a **cloud-native
database proxy in** [**Kubernetes**](https://kubernetes.io/).
+
+However, some of you may have noticed that any mention of Sidecar has
disappeared from ShardingSphere's latest documentation. Has
ShardingSphere-Sidecar been canceled? What will ShardingSphere's cloud native
future look like? Here's what's coming.
+
+# What's ShardingSphere's plan for the cloud?
+
+## Stop the R&D of ShardingSphere-Sidecar
+
+As far as ShardingSphere users are concerned, ShardingSphere-JDBC and
ShardingSphere-Proxy can already meet most requirements.
ShardingSphere-Sidecar's only difference from them is in the deployment form.
JDBC and Proxy are functionally identical, but each has unique advantages.
+
+ShardingSphere-JDBC is positioned as a lightweight Java framework that
provides additional services at theJava JDBC layer. With the client connecting
directly to the database, it provides services in the form of `jar` and
requires no extra deployment and dependence. It can be viewed as an enhanced
JDBC driver, fully compatible with JDBC and all kinds of
[ORM](https://stackoverflow.com/questions/1279613/what-is-an-orm-how-does-it-work-and-how-should-i-use-one)
frameworks. It's targeted at [...]
+
+ShardingSphere-Proxy is a transparent database proxy, supporting heterogeneous
languages through the implementation of database binary protocol. Currently,
[MySQL](https://www.mysql.com/) and [PostgreSQL](https://www.postgresql.org/)
protocols are provided. Nevertheless, Proxy adds a gateway between the database
and the front-end application layer, which will partially lower the performance.
+
+**Our community recommends users to adopt a hybrid deployment mode allowing
JDBC and Proxy to complement each other, maximizing ShardingSphere's advantages
in terms of performance, availability and heterogeneous support.**
+
+
+
+As you can see, it's a bit awkward for ShardingSphere-Sidecar: JDBC and Proxy
are applicable to most scenarios, environments and businesses, and can
complement each other, leaving little room for Sidecar to innovate. From the
viewpoint of the community and its users, Sidecar is more like an extension in
deployment mode, and it is not capable of enhancing ShardingSphere as a whole.
+
+**Taking the above factors into consideration, it is more efficient to develop
a patch tool for ShardingSphere that can be easily used and run in a Kubernetes
environment. This way, users can deploy and use ShardingSphere in cloud native
environments, while saving R&D time for the ShardingSphere community.**
+
+## ShardingSphere's cloud solution:
[ShardingSphere-On-Cloud](https://github.com/apache/shardingsphere-on-cloud)
+
+> ShardingSphere-on-Cloud is a comprehensive system upgrade based on
ShardingSphere.
+
+ShardingSphere-Sidecar was born when Kubernetes thrived. Back then, more and
more enterprises were trying to adopt cloud-native concepts. The ShardingSphere
community is not an exception.
+
+We proposed ShardingSphere-Sidecar to promote cloud-native transformation in
the data field. However, since JDBC and Proxy are mature enough to deal with
data governance in most scenarios, it's unnecessary to make ShardingSphere
entirely cloud native.
+
+Sidecar can indeed play a big role in certain scenarios, but it doesn't mean
that we have to create a Sidecar version for each component. ShardingSphere is
working on how to come up with a solution based on real cloud-native scenarios
after fully integrating the cloud computing concept. That's how
ShardingSphere-on-Cloud was born.
+
+[ShardingSphere-on-Cloud](https://github.com/apache/shardingsphere-on-cloud)
is capable of deploying and migrating ShardingSphere in a Kubernetes
environment. With the help of [AWS
CloudFormation](https://aws.amazon.com/cloudformation/),
[Helm](https://helm.sh/), Operator, and Terraform (coming soon) and other
tools, it provides best practices with quick deployment, higher observability,
security and migration, and high availability deployment in a cloud native
environment.
+
+> Please refer to [***Database Plus Embracing the Cloud:
ShardingSphere-on-Cloud Solution
Released***](https://medium.com/codex/database-plus-embracing-the-cloud-shardingsphere-on-cloud-solution-released-29916290ad06?source=your_stories_page-------------------------------------)
for details.
+
+## Achieving the vision of ShardingSphere-Sidecar through
[Pisanix](https://www.pisanix.io/)
+
+**Why did we develop a new open source project oriented towards data
governance in cloud native scenarios?**
+
+Our community has been contemplating the position of ShardingSphere and
[Database
Mesh](https://medium.com/faun/database-mesh-2-0-database-governance-in-a-cloud-native-environment-ac24080349eb?source=your_stories_page-------------------------------------)
concept.
+
+Within the community we hold different viewpoints on Sidecar at different
stages. In the beginning, the community wanted to use Sidecar to manage cloud
data issues. As the community gained a deeper understanding of cloud native and
cloud data management processes, the limitations of ShardingSphere-Sidecar have
been gradually exposed.
+
+ShardingSphere-Sidecar is only a deployment mode of ShardingSphere in cloud
native environments, so it can only solve a single problem. It is incapable of
helping ShardingSphere develop a mature and cloud-native solution for
enterprises.
+
+**Therefore, we needed to redesign an open source product with higher
adaptability, availability and agility in a cloud native system - in order to
make up for ShardingSphere's limitations on cloud data governance.**
+
+That is why some of our community members at
[SphereEx](https://www.sphere-ex.com/en/) developed [Pisanix, a cloud-native
data governance tool](https://www.sphere-ex.com/news/43/), based on the
Database Mesh concept. It can provide capabilities such as SQL-aware traffic
governance, runtime resource-oriented management and DBRE.
+
+## Is Pisanix the same with ShardingSphere-Sidecar?
+
+ShardingSphere-Sidecar and Pisanix convey different understandings of Database
Mesh. They are different in the following aspects.
+
+- **Different design concepts:** the design philosophy of JDBC & Proxy is
Database Plus, which adds an interface on top of multiple data sources for
unified governance and enhancement. Pisanix represents the specific practice of
Database Mesh concept, leading to efficient and smooth DevOps of databases for
applications in cloud native scenarios.
+- **Different language ecosystems:** JDBC is developed solely in Java. As Java
is popular with numerous enterprise-grade community users and developers, JDBC
can be easily applied to Java-developed applications. In comparison, Pisanix is
developed in [Rust](https://www.rust-lang.org/) to improve the reliability and
efficiency of the access layer.
+
+Despite small differences, both of them are oriented towards cloud-native data
infrastructure. That is also what Database Mesh expects in the long term by
implementing cloud native DBRE.
+
+In terms of deployment mode, Pisanix and ShardingSphere-Sidecar can both be
deployed with business applications in the form of Sidecar, providing standard
protocol access for developers. **Moreover, Pisanix is highly compatible with
the ShardingSphere ecosystem. You can connect Pisanix to ShardingSphere-Proxy
in the same way that ShardingSphere-Proxy connects to MySQL.**
+
+In short, ShardingSphere presents a complete database form for developers and
applications under the Database Plus concept. Pisanix is designed for the same
purpose. Through Pisanix, the entrance to cloud data traffic, users can use
ShardingSphere-Proxy as a database and explore the collaboration mode in a
cloud native environment.
+
+However, they belong to independent product lines. Pisanix followed the
Database Mesh concept from the very beginning and achieved high-performance
expansion through four aspects, including **local database, unified
configuration and management, multi-protocol support and cloud native
architecture**.
+
+Pisanix is only the first step towards unifying database types on the cloud,
and Sidecar is only a deployment form.
+
+> The protocols and DevOps features of different databases vary, and the point
lies in abstracting the standard governance behavior.
+
+Unlike Pisanix, the ShardingSphere ecosystem is not only accessible through
protocols, and ShardingSphere-JDBC can be used more conveniently by Java
applications.
+
+Its natural compatibility maintains functional integrity, optimizes resource
utilization and provides ultimate performance, with which developers can
configure data governance at their will from the perspective of businesses.
Meanwhile, by combining ShardingSphere and the underlying databases, users can
deploy strong computing capability on the application side and transform the
original monolithic database into a distributed database with high performance,
optimizing resource allocation [...]
+
+In conclusion, ShardingSphere and Pisanix together offer two solutions for
community users. **For users who'd like to deploy ShardingSphere in a
Kubernetes environment, ShardingSphere-on-Cloud is enough, and ShardingSphere's
other features are exactly the same as when used locally.**
+
+**For users looking to achieve unified traffic governance on the upper-layer
database in cloud native scenarios, Pisanix is a better choice.**
+
+Compared with ShardingSphere-Sidecar, ShardingSphere-on-Cloud combined with
Pisanix is more effective and convenient.
+
+[**ShardingSphere Official Website**](https://shardingsphere.apache.org/)
+
+[**Database Mesh Official Website**](https://www.database-mesh.io/)
+
+[**Pisanix Official Website**](https://www.pisanix.io/)
diff --git
a/docs/blog/content/material/2022_12_08_ShardingSphere_5.3.0_is_released_new_features_and_improvements.en.md
b/docs/blog/content/material/2022_12_08_ShardingSphere_5.3.0_is_released_new_features_and_improvements.en.md
new file mode 100644
index 00000000000..e303dc59e04
--- /dev/null
+++
b/docs/blog/content/material/2022_12_08_ShardingSphere_5.3.0_is_released_new_features_and_improvements.en.md
@@ -0,0 +1,291 @@
++++
+title = "ShardingSphere 5.3.0 is released: new features and improvements"
+weight = 82
+chapter = true
++++
+
+
+
+After 1.5 months in development, [Apache ShardingSphere
5.3.0](https://shardingsphere.apache.org/document/current/en/downloads/) is
released. Our community merged [687
PRs](https://github.com/apache/shardingsphere/pulls?q=is%3Amerged+is%3Apr+milestone%3A5.3.0)
from contributors around the world.
+
+The new release has been improved in terms of features, performance, testing,
documentation, examples, etc.
+
+The 5.3.0 release brings the following highlights:
+
+- Support fuzzy query for CipherColumn.
+- Support Datasource-level heterogeneous database.
+- Support checkpoint resume for data consistency check.
+- Automatically start a distributed transaction, while executing DML
statements across multiple shards.
+
+Additionally, release 5.3.0 also brings the following adjustments:
+
+- Remove the Spring configuration.
+- Systematically refactor the DistSQL syntax.
+- Refactor the configuration format of ShardingSphere-Proxy.
+
+# Highlights
+
+## **1. Support fuzzy query for CipherColumn**
+
+In previous versions, ShardingSphere's Encrypt feature didn't support the use
of the `LIKE` operator in SQL.
+
+For a while users strongly requested adding the `LIKE` operator to the Encrypt
feature. Usually, encrypted fields are mainly of the string type, and it is a
common practice for the string to execute `LIKE`.
+
+To minimize friction in accessing the Encrypt feature, our community has
initiated a discussion about the implementation of encrypted `LIKE`.
+
+Since then, we've received a lot of feedback.
+
+Some community members even contributed their original encryption algorithm
implementation supporting fuzzy queries after fully investigating conventional
solutions.
+
+🔗 **The relevant issue can be found**
[**here**](https://github.com/apache/shardingsphere/issues/20435)**.**
+
+🔗 **For the algorithm design, please refer to the**
[**attachment**](https://github.com/apache/shardingsphere/files/9684570/default.pdf)
**within the**
[**issue**](https://github.com/apache/shardingsphere/files/9684570/default.pdf)**.**
+
+The [single-character abstract algorithm] contributed by the community members
is implemented as `CHAR_DIGEST_LIKE` in the ShardingSphere encryption algorithm
SPI.
+
+## 2. Support datasource-level heterogeneous database
+
+[ShardingSphere](https://shardingsphere.apache.org/) supports a database
gateway, but its heterogeneous capability is limited to the logical database in
previous versions. This means that all the data sources under a logical
database must be of the same database type.
+
+This new release supports datasource-level heterogeneous databases at the
kernel level. This means the datasources under a logical database can be
different database types, allowing you to use different databases to store data.
+
+Combined with ShardingSphere's SQL dialect conversion capability, this new
feature significantly enhances ShardingSphere's heterogeneous data gateway
capability.
+
+## 3. Data migration: support checkpoint resume for data consistency check
+
+Data consistency checks happen at the later stage of data migration.
+
+Previously, the data consistency check was triggered and stopped by
[DistSQL](https://shardingsphere.apache.org/document/5.1.0/en/concepts/distsql/).
If a large amount of data was migrated and the data consistency check was
stopped for any reason, the check would've had to be started again — which is
sub-optimal and affects user experience.
+
+ShardingSphere 5.3.0 now supports checkpoint storage, which means data
consistency checks can be resumed from the checkpoint.
+
+For example, if data is being verified during data migration and the user
stops the verification for some reason, with the verification progress
`(finished_percentage)` being 5%, then:
+
+```
+mysql> STOP MIGRATION CHECK 'j0101395cd93b2cfc189f29958b8a0342e882';
+Query OK, 0 rows affected (0.12 sec)
+mysql> SHOW MIGRATION CHECK STATUS 'j0101395cd93b2cfc189f29958b8a0342e882';
++--------+--------+---------------------+-------------------+-------------------------+-------------------------+------------------+---------------+
+| tables | result | finished_percentage | remaining_seconds | check_begin_time
| check_end_time | duration_seconds | error_message |
++--------+--------+---------------------+-------------------+-------------------------+-------------------------+------------------+---------------+
+| sbtest | false | 5 | 324 | 2022-11-10
19:27:15.919 | 2022-11-10 19:27:35.358 | 19 | |
++--------+--------+---------------------+-------------------+-------------------------+-------------------------+------------------+---------------+
+1 row in set (0.02 sec)
+```
+
+In this case, the user restarts the data verification. But the work does not
have to restart from the beginning. The verification progress
`(finished_percentage)` remains at 5%.
+
+```
+mysql> START MIGRATION CHECK 'j0101395cd93b2cfc189f29958b8a0342e882';
+Query OK, 0 rows affected (0.35 sec)
+mysql> SHOW MIGRATION CHECK STATUS 'j0101395cd93b2cfc189f29958b8a0342e882';
++--------+--------+---------------------+-------------------+-------------------------+----------------+------------------+---------------+
+| tables | result | finished_percentage | remaining_seconds | check_begin_time
| check_end_time | duration_seconds | error_message |
++--------+--------+---------------------+-------------------+-------------------------+----------------+------------------+---------------+
+| sbtest | false | 5 | 20 | 2022-11-10
19:28:49.422 | | 1 | |
++--------+--------+---------------------+-------------------+-------------------------+----------------+------------------+---------------+
+1 row in set (0.02 sec)
+```
+
+**Limitation:** this new feature is unavailable with the `CRC32_MATCH`
algorithm because the algorithm calculates all data at once.
+
+## 4. Automatically start a distributed transaction while executing DML
statements across multiple shards
+
+Previously, even with XA and other distributed transactions configured,
ShardingSphere could not guarantee the atomicity of DML statements that are
routed to multiple shards — if users didn't manually enable the transaction.
+
+Take the following SQL as an example:
+
+```
+insert into account(id, balance, transaction_id) values
+(1, 1, 1),(2, 2, 2),(3, 3, 3),(4, 4, 4),
+(5, 5, 5),(6, 6, 6),(7, 7, 7),(8, 8, 8);
+```
+
+When this SQL is sharded according to `id mod 2`, the ShardingSphere kernel
layer will automatically split it into the following two SQLs and route them to
different shards respectively for execution:
+
+```
+insert into account(id, balance, transaction_id) values
+(1, 1, 1),(3, 3, 3),(5, 5, 5),(7, 7, 7);
+insert into account(id, balance, transaction_id) values
+(2, 2, 2),(4, 4, 4),(6, 6, 6),(8, 8, 8);
+```
+
+If the user does not manually start the transaction, and one of the sharded
SQL fails to execute, the atomicity cannot be guaranteed because the successful
operation cannot be rolled back.
+
+ShardingSphere 5.3.0 is optimized in terms of distributed transactions. If
distributed transactions are configured in ShardingSphere, they can be
automatically started when DML statements are routed to multiple shards. This
way, we can ensure atomicity when executing DML statements.
+
+# Significant Adjustments
+
+**1. Remove Spring configuration**
+
+In earlier versions,
[ShardingSphere-JDBC](https://shardingsphere.apache.org/document/current/en/overview/#shardingsphere-jdbc)
provided services in the format of DataSource. If you wanted to introduce
ShardingSphere-JDBC without modifying the code in the
[Spring](https://spring.io/)/[Spring
Boot](https://spring.io/projects/spring-boot) project, you needed to use
modules such as Spring/[Spring Boot
Starter](https://www.javatpoint.com/spring-boot-starters) provided by
ShardingSphere.
+
+Although ShardingSphere supports multiple configuration formats, it also has
the following problems:
+
+1. When API changes, many config files need to be adjusted, which is a heavy
workload.
+2. The community has to maintain multiple config files.
+3. The lifecycle management of [Spring
bean](https://www.baeldung.com/spring-bean) is susceptible to other
dependencies of the project such as PostProcessor failure.
+4. Spring Boot Starter and Spring NameSpace are affected by Spring, and their
configuration styles are different from YAML.
+5. Spring Boot Starter and Spring NameSpace are affected by the version of
Spring. When users access them, the configuration may not be identified and
dependency conflicts may occur. For example, Spring Boot versions 1.x and 2.x
have different configuration styles.
+
+[ShardingSphere 5.1.2 first supported the introduction of ShardingSphere-JDBC
in the form of JDBC
Driver](https://medium.com/codex/shardingsphere-jdbc-driver-released-a-jdbc-driver-that-requires-no-code-modifications-5464c30bcd64?source=your_stories_page-------------------------------------).
That means applications only need to configure the Driver provided by
ShardingSphere at the JDBC URL before accessing to ShardingSphere-JDBC.
+
+Removing the Spring configuration simplifies and unifies the configuration
mode of ShardingSphere. This adjustment not only simplifies the configuraiton
of ShardingSphere when using different configuration modes, but also reduces
maintenance work for the ShardingSphere community.
+
+**2. Systematically refactor the DistSQL syntax**
+
+One of the characteristics of Apache ShardingSphere is its flexible rule
configuration and resource control capability.
+
+[DistSQL (Distributed
SQL)](https://shardingsphere.apache.org/document/5.1.0/en/concepts/distsql/) is
ShardingSphere's SQL-like operating language. It's used the same way as
standard SQL, and is designed to provide incremental SQL operation capability.
+
+ShardingSphere 5.3.0 systematically refactors DistSQL. The community
redesigned the syntax, semantics and operating procedure of DistSQL. The new
version is more consistent with ShardingSphere's design philosophy and focuses
on a better user experience.
+
+Please refer to the [latest ShardingSphere
documentation](https://shardingsphere.apache.org/) for details. A DistSQL
roadmap will be available soon, and you're welcome to leave your feedback.
+
+**3. Refactor the configuration format of**
[**ShardingSphere-Proxy**](https://shardingsphere.apache.org/document/current/en/quick-start/shardingsphere-proxy-quick-start/)
+
+In this update, ShardingSphere-Proxy has adjusted the configuration format and
reduced config files required for startup.
+
+`server.yaml` before refactoring:
+
+```yaml
+rules:
+ - !AUTHORITY
+ users:
+ - root@%:root
+ - sharding@:sharding
+ provider:
+ type: ALL_PERMITTED
+ - !TRANSACTION
+ defaultType: XA
+ providerType: Atomikos
+ - !SQL_PARSER
+ sqlCommentParseEnabled: true
+ sqlStatementCache:
+ initialCapacity: 2000
+ maximumSize: 65535
+ parseTreeCache:
+ initialCapacity: 128
+ maximumSize: 1024
+```
+
+`server.yaml` after refactoring:
+
+```yaml
+authority:
+ users:
+ - user: root@%
+ password: root
+ - user: sharding
+ password: sharding
+ privilege:
+ type: ALL_PERMITTED
+transaction:
+ defaultType: XA
+ providerType: AtomikossqlParser:
+ sqlCommentParseEnabled: true
+ sqlStatementCache:
+ initialCapacity: 2000
+ maximumSize: 65535
+ parseTreeCache:
+ initialCapacity: 128
+ maximumSize: 1024
+```
+
+In ShardingSphere 5.3.0, `server.yaml` is no longer required to start Proxy.
If no config file is provided by default, Proxy provides the default account
root/root.
+
+ShardingSphere is completely committed to becoming cloud native. Thanks to
DistSQL, ShardingSphere-Proxy's config files can be further simplified, which
is more friendly to container deployment.
+
+# Release Notes
+
+## API Changes
+
+1. DistSQL: refactor syntax API, please refer to the user manual
+2. Proxy: change the configuration style of global rule, remove the
exclamation mark
+3. Proxy: allow zero-configuration startup, enable the default account
root/root when there is no Authority configuration
+4. Proxy: remove the default `logback.xml `and use API initialization
+5. JDBC: remove the Spring configuration and use Driver + YAML configuration
instead
+
+## Enhancements
+
+1. DistSQL: new syntax `REFRESH DATABASE METADATA`, refresh logic database
metadata
+2. Kernel: support DistSQL `REFRESH DATABASE METADATA` to load configuration
from the governance center and rebuild `MetaDataContext`
+3. Support PostgreSQL/openGauss setting transaction isolation level
+4. Scaling: increase inventory task progress update frequence
+5. Scaling: `DATA_MATCH` consistency check support checkpoint resume
+6. Scaling: support drop consistency check job via DistSQL
+7. Scaling: rename column from `sharding_total_count` to `job_item_count` in
job list DistSQL response
+8. Scaling: add sharding column in incremental task SQL to avoid broadcast
routing
+9. Scaling: sharding column could be updated when generating SQL
+10. Scaling: improve column value reader for `DATA_MATCH` consistency check
+11. DistSQL: encrypt DistSQL syntax optimization, support like query algorithm
+12. DistSQL: add properties value check when `REGISTER STORAGE UNIT`
+13. DistSQL: remove useless algorithms at the same time when `DROP RULE`
+14. DistSQL: `EXPORT DATABASE CONFIGURATION` supports broadcast tables
+15. DistSQL: `REGISTER STORAGE UNIT` supports heterogeneous data sources
+16. Encrypt: support `Encrypt` LIKE feature
+17. Automatically start distributed transactions when executing DML statements
across multiple shards
+18. Kernel: support `client \d` for PostgreSQL and openGauss
+19. Kernel: support select group by, order by statement when column contains
null values
+20. Kernel: support parse `RETURNING` clause of PostgreSQL/openGauss Insert
+21. Kernel: SQL `HINT` performance improvement
+22. Kernel: support mysql case when then statement parse
+23. Kernel: support data source level heterogeneous database gateway
+24. (Experimental) Sharding: add sharding cache plugin
+25. Proxy: support more PostgreSQL datetime formats
+26. Proxy: support MySQL `COM_RESET_CONNECTION`
+27. Scaling: improve `MySQLBinlogEventType.valueOf` to support unknown event
type
+28. Kernel: support case when for federation
+
+## Bug Fix
+
+1. Scaling: fix barrier node created at job deletion
+2. Scaling: fix part of columns value might be ignored in `DATA_MATCH`
consistency check
+3. Scaling: fix jdbc url parameters are not updated in consistency check
+4. Scaling: fix tables sharding algorithm type `INLINE` is case-sensitive
+5. Scaling: fix incremental task on MySQL require mysql system database
permission
+6. Proxy: fix the NPE when executing select SQL without storage node
+7. Proxy: support `DATABASE_PERMITTED` permission verification in unicast
scenarios
+8. Kernel: fix the wrong value of `worker-id` in show compute nodes
+9. Kernel: fix route error when the number of readable data sources and weight
configurations of the Weight algorithm are not equal
+10. Kernel: fix multiple groups of readwrite-splitting refer to the same load
balancer name, and the load balancer fails problem
+11. Kernel: fix can not disable and enable compute node problem
+12. JDBC: fix data source is closed in ShardingSphereDriver cluster mode when
startup problem
+13. Kernel: fix wrong rewrite result when part of logical table name of the
binding table is consistent with the actual table name, and some are
inconsistent
+14. Kernel: fix startup exception when use SpringBoot without configuring rules
+15. Encrypt: fix null pointer exception when Encrypt value is null
+16. Kernel: fix oracle parsing does not support varchar2 specified type
+17. Kernel: fix serial flag judgment error within the transaction
+18. Kernel: fix cursor fetch error caused by `wasNull` change
+19. Kernel: fix alter transaction rule error when refresh metadata
+20. Encrypt: fix `EncryptRule` cast to `TransparentRule` exception that occurs
when the call procedure statement is executed in the `Encrypt` scenario
+21. Encrypt: fix exception which caused by `ExpressionProjection` in shorthand
projection
+22. Proxy: fix PostgreSQL Proxy int2 negative value decoding incorrect
+23. Proxy: PostgreSQL/openGauss support describe insert returning clause
+24. Proxy: fix gsql 3.0 may be stuck when connecting Proxy
+25. Proxy: fix parameters are missed when checking SQL in Proxy backend
+26. Proxy: enable MySQL Proxy to encode large packets
+27. Kernel: fix oracle parse comment without whitespace error
+28. DistSQL: fix show create table for encrypt table
+
+## Refactor
+
+1. Scaling: reverse table name and column name when generating SQL if it's SQL
keyword
+2. Scaling: improve incremental task failure handling
+3. Kernel: governance center node adjustment, unified hump to underscore
+
+# Links
+
+🔗 [Download
Link](https://shardingsphere.apache.org/document/current/en/downloads/)
+
+🔗 [Release Notes](https://github.com/apache/shardingsphere/discussions/22564)
+
+🔗 [Project Address](https://shardingsphere.apache.org/)
+
+🔗 [ShardingSphere-on-Cloud](https://github.com/apache/shardingsphere-on-cloud)
+
+# Community Contribution
+
+This Apache ShardingSphere 5.3.0 release is the result of 687 merged PRs,
committed by 49 contributors. Thank you for your efforts.
+
+
diff --git
a/docs/blog/static/img/2022_11_24_ShardingSphere-on-Cloud_&_Pisanix_replace_Sidecar_for_a_true_cloud-native_experience1.png
b/docs/blog/static/img/2022_11_24_ShardingSphere-on-Cloud_&_Pisanix_replace_Sidecar_for_a_true_cloud-native_experience1.png
new file mode 100644
index 00000000000..58e2fb52cce
Binary files /dev/null and
b/docs/blog/static/img/2022_11_24_ShardingSphere-on-Cloud_&_Pisanix_replace_Sidecar_for_a_true_cloud-native_experience1.png
differ
diff --git
a/docs/blog/static/img/2022_12_08_ShardingSphere_5.3.0_is_released_new_features_and_improvements1.png
b/docs/blog/static/img/2022_12_08_ShardingSphere_5.3.0_is_released_new_features_and_improvements1.png
new file mode 100644
index 00000000000..f43ecbbad79
Binary files /dev/null and
b/docs/blog/static/img/2022_12_08_ShardingSphere_5.3.0_is_released_new_features_and_improvements1.png
differ
diff --git
a/docs/blog/static/img/2022_12_08_ShardingSphere_5.3.0_is_released_new_features_and_improvements2.png
b/docs/blog/static/img/2022_12_08_ShardingSphere_5.3.0_is_released_new_features_and_improvements2.png
new file mode 100644
index 00000000000..b0dfdaa3033
Binary files /dev/null and
b/docs/blog/static/img/2022_12_08_ShardingSphere_5.3.0_is_released_new_features_and_improvements2.png
differ
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}