EasonFeng5870 commented on a change in pull request #6193: URL: https://github.com/apache/shardingsphere/pull/6193#discussion_r448301275
########## File path: docs/blog/content/material/database.en.md ########## @@ -4,4 +4,296 @@ weight = 6 chapter = true +++ -## TODO +## How we build a distributed database + +Author | Liang Zhang + + In the past few decades, relational database continuously occupy an absolute dominant position in the field of databases. The advantages of relational database, like stability, safety, ease of use that are the cornerstone of a modern system. With the rapid development of the Internet, databases built on stand-alone systems are no longer able to meet higher and higher concurrent requests and larger and larger data storage requirements. Therefore, distributed databases are more and more widely adopted. + + All along, the database field has been dominated by Western technology companies and communities. Nowadays, more and more domestic database solutions take distributed as the fulcrum, and gradually make achievements in this field. Apache ShardingSphere is one of the distributed database solutions and the only database middleware in the Apache Software Foundation so far. + +### 1 Background + + Fully compatible with SQL and transactions for traditional relational databases, and naturally friendly to distribution, is the design goal of distributed database solutions. Its core functions are mainly concentrated in the following points: + +- Distributed storage: Data storage is not limited by the disk capacity of a single machine, and the storage capacity can be improved by increasing the number of data servers; + +- Separation of computing and storage: Computing nodes are stateless and can increase computing power through horizontal expansion. Storage nodes and computing nodes can be optimized hierarchically; + +- Distributed transaction: A high-performance, distributed transaction processing engine that fully supports the original meaning of local transactions ACID; + +- Elastic scaling: You can dynamically expand and shrink data storage nodes anytime, anywhere without affecting existing applications; + +- Multiple data copies: Automatically copy the data to multiple copies across datacenters in a strong and consistent manner to ensure the absolute security of the data; + +- HTAP: The same set of products is used to mix transactional operations of OLTP and analytical operations of OLAP. + + +The implementation solutions of distributed database can be divided into aggressive and stable. The aggressive implementation solution refers to the development of a new architecture of NewSQL. Such products are in pursuit of higher performance in exchange for the lack of stability and the lack of experience in operation and maintenance; the stable implementation solution refers to the middleware that provides incremental capabilities based on the existing database. Such products sacrifice some performance to ensure the stability of the database and reuse of operation and maintenance experience. + +### 2 Architecture + +Apache ShardingSphere is an ecosystem of open source distributed database middleware solutions, It consists of three independent products, Sharding-JDBC, Sharding-Proxy, and Sharding-Sidecar (planned). They all provide functions such as standardized data sharding, distributed transactions, and distributed governance, and can be applied to various diverse application scenarios such as Java isomorphism, heterogeneous languages, and cloud native. With the continuous exploration of Apache ShardingSphere in query optimizer and distributed transaction engine, it has gradually broken the product boundary of the implementation solution and evolved into an aggressive and stable platform-level solution. + +**Sharding-JDBC** + +Positioned as a lightweight Java framework, additional services provided in Java's JDBC layer. It uses the client to connect directly to the database and provides services in the form of jar packages without additional deployment and dependencies. It can be understood as an enhanced version of the JDBC driver and is fully compatible with JDBC and various ORM frameworks. + +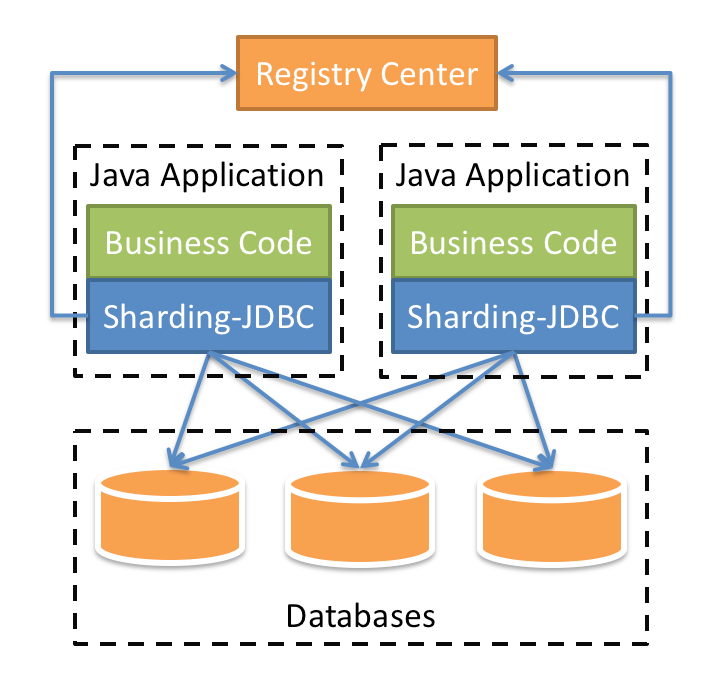 + +**Sharding-Proxy** + +Positioned as a transparent database agent, it provides a server-side version that encapsulates the database binary protocol to complete support for heterogeneous languages. Currently, MySQL and PostgreSQL versions are available. It can use any access client compatible with MySQL and PostgreSQL protocol (such as: MySQL Command Client, MySQL Workbench, Navicat, etc.) to operate data, which is more friendly to DBA. + +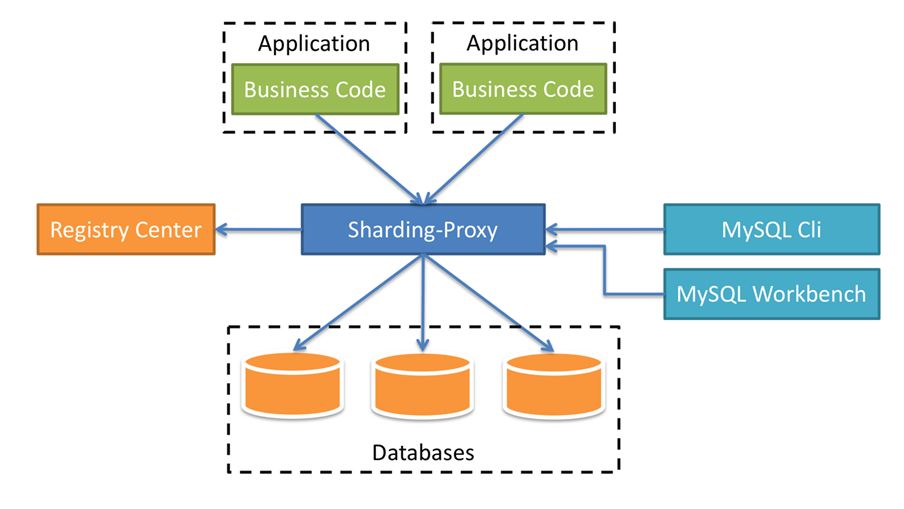 + +**Sharding-Sidecar(Planned)** + +Positioned as a cloud-native database agent for Kubernetes, it will proxy all access to the database in the form of Sidecar. Through a non-central, zero-intrusion solution, it provides the meshing layer that interacts with the database, called as Database Mesh, which can also be called a database grid. + +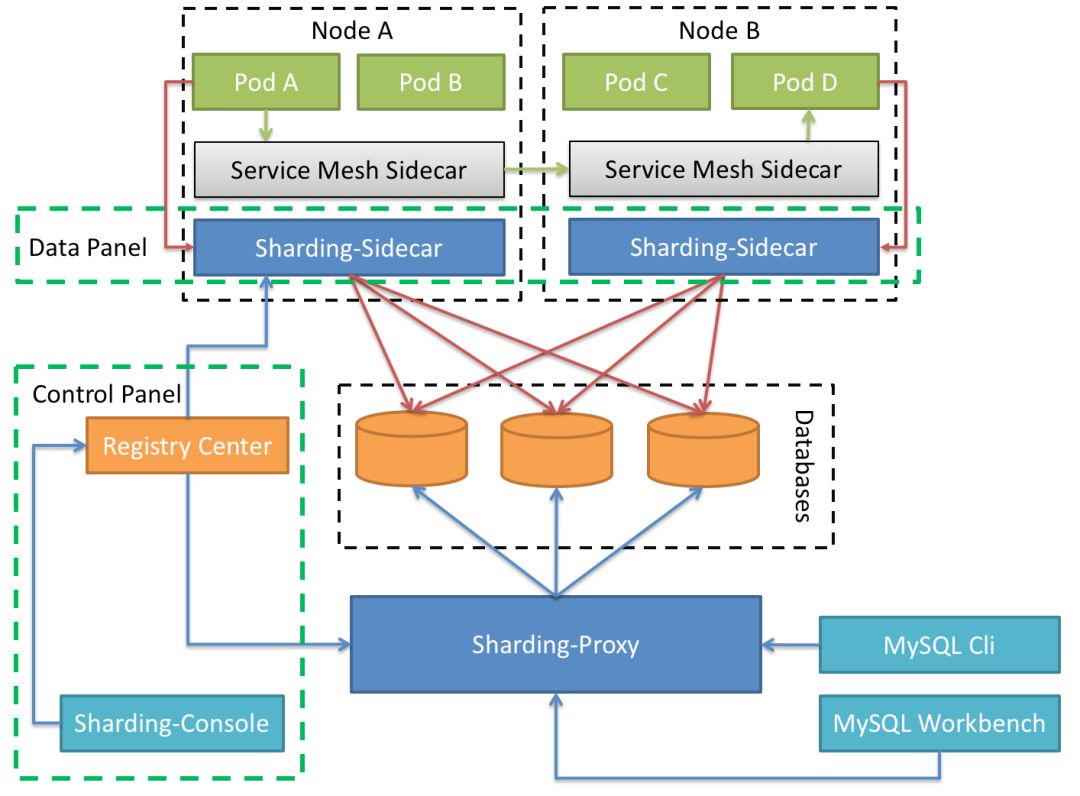 + +**Hybrid architecture with separate computing and storage** + +Sharding-JDBC adopts a decentralized architecture, suitable for high-performance lightweight OLTP applications developed in Java; Sharding-Proxy provides static entry and heterogeneous language support, suitable for OLAP applications and management and operation and maintenance of sharded databases scene. + +Each architecture solution has its own advantages and disadvantages. The following table compares the advantages and disadvantages of various architecture models in different scenarios: + +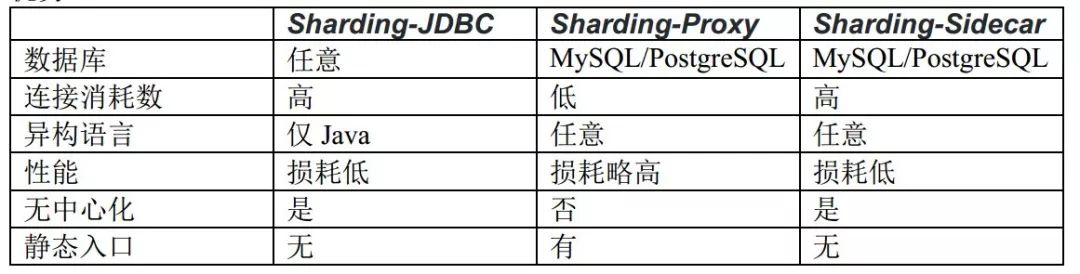 + +Apache ShardingSphere is an ecosystem composed of multiple access points. By mixing Sharding-JDBC and Sharding-Proxy, and using the same configuration center to configure the sharding strategy uniformly, it is possible to flexibly build application systems suitable for various scenarios, allowing architects to freely adjust the best system suitable for the current business Architecture. + +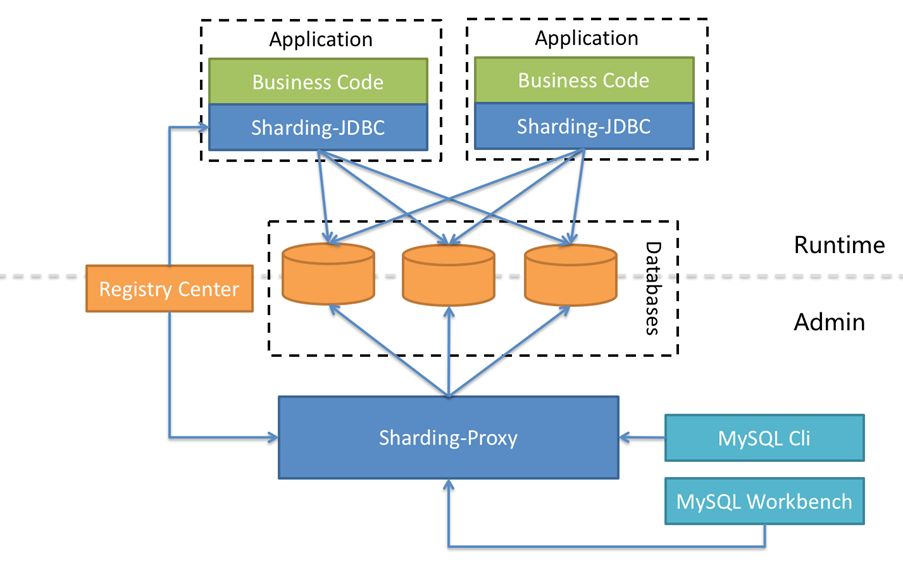 + +Apache ShardingSphere adopts Share Nothing architecture, and its JDBC and Proxy access endpoints both adopt a stateless design. As a computing node, Apache ShardingSphere is responsible for the final calculation and summary of the acquired data. Since it does not store data itself, Apache ShardingSphere can push the calculation down to the data node to take full advantage of the database's own computing power. Apache ShardingSphere can increase the computing power by increasing the number of deployed nodes; increase the storage capacity by increasing the number of database nodes. + +### 3 Core functions + +Data sharding, distributed transactions, elastic scaling, and distributed governance are the four core functions of Apache ShardingSphere at the current stage. + +#### Data sharding + +Divide and conquer is the solution used by Apache ShardingSphere to process massive data. Apache ShardingSphere enables distributed storage capabilities in databases through data sharding solutions. + +It can automatically route SQL to the corresponding data node according to the user's preset sharding algorithm to achieve the purpose of operating multiple databases. Users can use multiple databases managed by Apache ShardingSphere like a stand-alone database. Currently supports MySQL, PostgreSQL, Oracle, SQLServer and any database that supports SQL92 standard and JDBC standard protocol. The core flow of data sharding is shown in the figure below: + +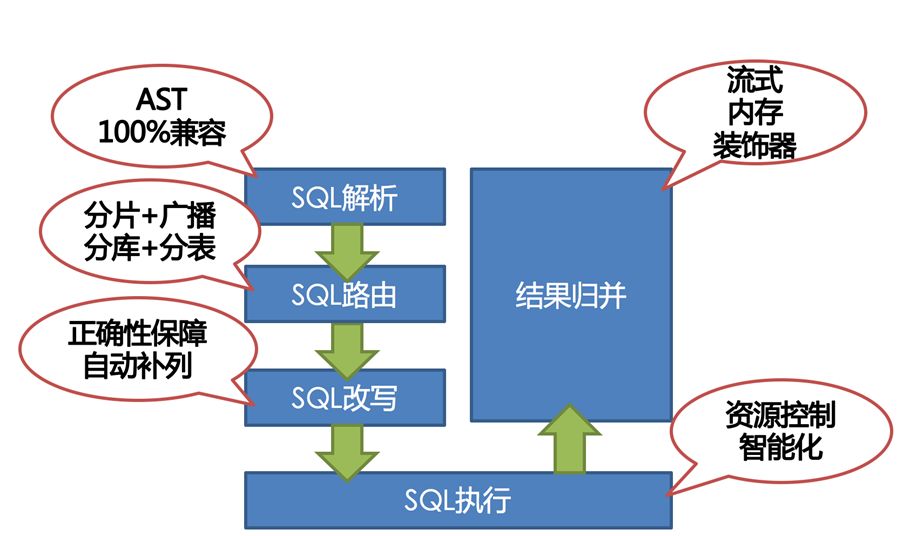 + +The main process is as follows: + +1. Obtain the SQL and parameters input by the user by parsing the database protocol package or JDBC driver; + +2. Parse SQL into AST (Abstract Syntax Tree) according to lexical analyzer and grammar analyzer, and extract the information required for fragmentation; + +3. Match the shard key according to the user preset algorithm and calculate the routing path; Review comment: releated also changed. ---------------------------------------------------------------- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}