hanahmily commented on code in PR #302: URL: https://github.com/apache/skywalking-banyandb/pull/302#discussion_r1266185878
########## docs/concept/clustering.md: ########## @@ -0,0 +1,158 @@ +# BanyanDB Clustering + +BanyanDB Clustering introduces a robust and scalable architecture that comprises "Query Nodes", "Liaison Nodes", "Data Nodes", and "Meta Nodes". This structure allows for effectively distributing and managing time-series data within the system. + +## 1. Architectural Overview + +A BanyanDB installation includes four distinct types of nodes: Data Nodes, Meta Nodes, Query Nodes, and Liaison Nodes. + +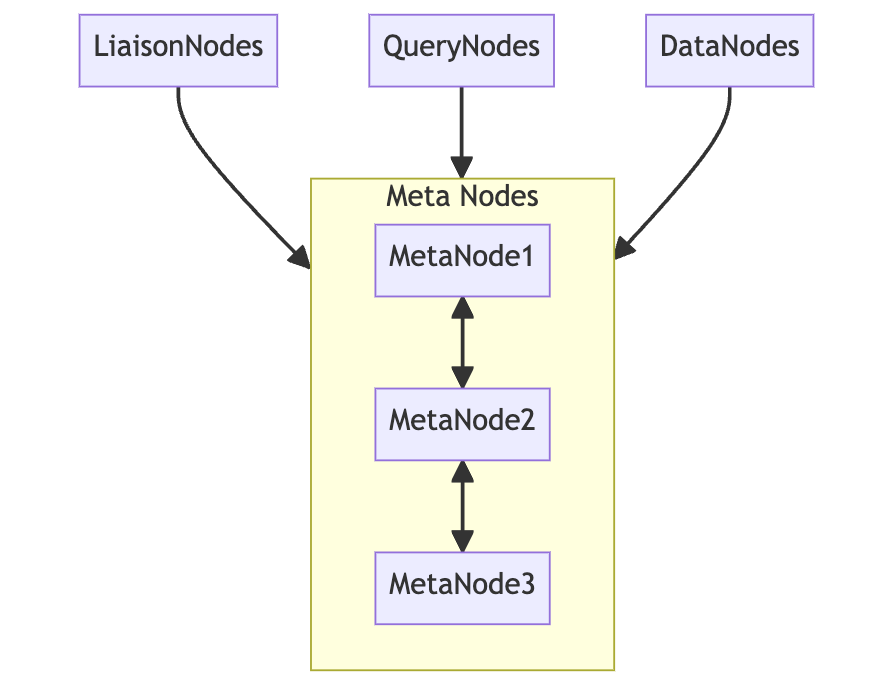) + +### 1.1 Data Nodes + +Data Nodes hold all the raw time series data, metadata, and indexed data. They handle the storage and management of data, including streams and measures, tag keys and values, as well as field keys and values. + +In addition to persistent raw data, Data Nodes also handle TopN aggregation calculation or other computational tasks. Review Comment: The streaming pipeline could store the result in the local data nodes. As I mentioned in the query nodes part, the query task will retrieve data from all shards to retrieve the result. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: [email protected] For queries about this service, please contact Infrastructure at: [email protected]
{kind=link}