HHoflittlefish777 commented on code in PR #302: URL: https://github.com/apache/skywalking-banyandb/pull/302#discussion_r1266251482
########## docs/concept/clustering.md: ########## @@ -0,0 +1,158 @@ +# BanyanDB Clustering + +BanyanDB Clustering introduces a robust and scalable architecture that comprises "Query Nodes", "Liaison Nodes", "Data Nodes", and "Meta Nodes". This structure allows for effectively distributing and managing time-series data within the system. + +## 1. Architectural Overview + +A BanyanDB installation includes four distinct types of nodes: Data Nodes, Meta Nodes, Query Nodes, and Liaison Nodes. + +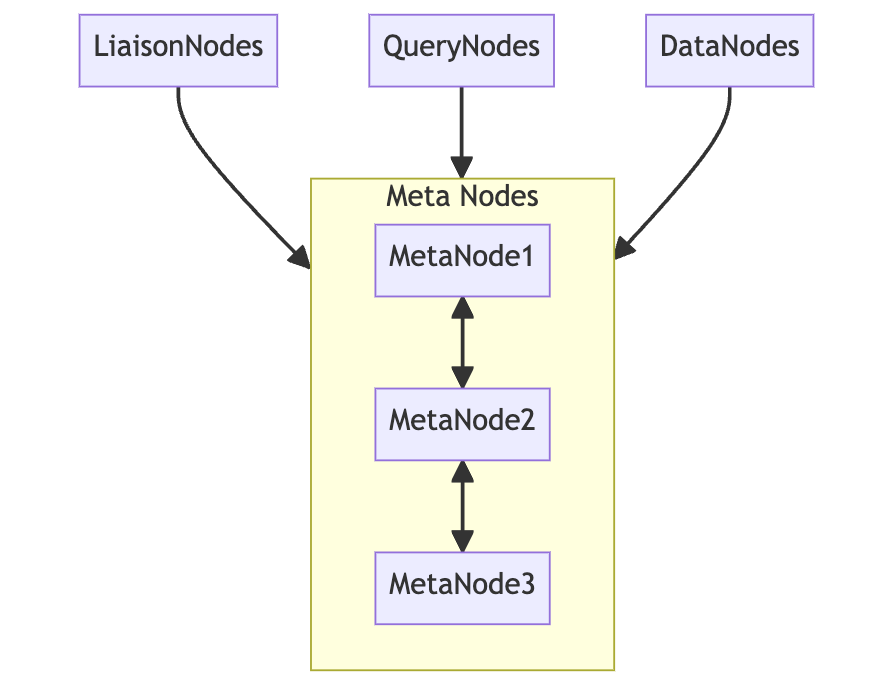 + +### 1.1 Data Nodes + +Data Nodes hold all the raw time series data, metadata, and indexed data. They handle the storage and management of data, including streams and measures, tag keys and values, as well as field keys and values. + +In addition to persistent raw data, Data Nodes also handle TopN aggregation calculation or other computational tasks. + +### 1.2 Meta Nodes + +Meta Nodes are responsible for maintaining high-level metadata of the cluster, which includes: + +- All nodes in the cluster +- All database schemas + +### 1.3 Query Nodes + +Query Nodes are responsible for handling computational tasks associated with querying the database. They build query tasks and search for data from Data Nodes. + +### 1.4 Liaison Nodes + +Liaison Nodes serve as gateways, routing traffic to Query Nodes and Data Nodes. In addition to routing, they also provide authentication, TTL, and other security services to ensure secure and effective communication without the cluster. + +### 1.5 Standalone Mode + +BanyanDB integrates multiple roles into a single process in the standalone mode, making it simpler and faster to deploy. This mode is especially useful for scenarios with a limited number of data points or for testing and development purposes. + +In this mode, the single process performs the roles of the Liaison Node, Query Node, Data Node, and Meta Node. It receives requests, maintains metadata, processes queries, and handles data, all within a unified setup. + +## 2. Communication within a Cluster + +All nodes within a BanyanDB cluster communicate with other nodes according to their roles: + +- Meta Nodes share high-level metadata about the cluster. +- Data Nodes store and manage the raw time series data and communicate with Meta Nodes. +- Query Nodes interact with Data Nodes to execute queries and return results to the Liaison Nodes. +- Liaison Nodes distribute incoming requests to the appropriate Query Nodes or Data Nodes. + +## 3. **Data Organization** + +Different nodes in BanyanDB are responsible for different parts of the database, while Query and Liaison Nodes manage the routing and processing of queries. + +### 3.1 Meta Nodes + +Meta Nodes store all high-level metadata that describes the cluster. This data is kept in an etcd-backed database on disk, including information about the shard allocation of each Data Node. This information is used by the Liaison Nodes to route data to the appropriate Data Nodes, based on the sharding key of the data. + +By storing shard allocation information, Meta Nodes help ensure that data is routed efficiently and accurately across the cluster. This information is constantly updated as the cluster changes, allowing for dynamic allocation of resources and efficient use of available capacity. + +### 3.2 Data Nodes + +Data Nodes store all raw time series data, metadata, and indexed data. On disk, the data is organized by `<group>/shard-<shard_id>/<segment_id>/`. The segment is designed to support retention policy. + +### 3.3 Query Nodes + +Query Nodes do not store data. They handle the computational tasks associated with data queries, interacting directly with Data Nodes to execute queries and return results. + +### 3.4 Liaison Nodes + +Liaison Nodes do not store data but manage the routing of incoming requests to the appropriate Query or Data Nodes. They also provide authentication, TTL, and other security services. + +## 4. **Determining Optimal Node Counts** + +When creating a BanyanDB cluster, choosing the appropriate number of each node type to configure and connect is crucial. The number of Meta Nodes should always be odd, for instance, “3”. The number of Data Nodes scales based on your storage and query needs. The number of Query Nodes and Liaison Nodes depends on the expected query load and routing complexity. + +The BanyanDB architecture allows for efficient clustering, scaling, and high availability, making it a robust choice for time series data management. + +## 5. Writes in a Cluster + +In BanyanDB, writing data in a cluster is designed to take advantage of the robust capabilities of underlying storage systems, such as Google Compute Persistent Disk or Amazon S3(TBD). These platforms ensure high levels of data durability, making them an optimal choice for storing raw time series data. + +Unlike some other systems, BanyanDB does not support application-level replication. Instead, it delegates the task of replication to these underlying storage systems. This approach simplifies the BanyanDB architecture and reduces the complexity of managing replication at the application level. + +Data distribution across the cluster is determined based on the `shard_num` setting for a group and the specified `entity` in each resource, be it a stream or measure. The resource’s `name` with its `entity` is the sharding key, guiding data distribution to the appropriate Data Node during write operations. + +Liaison Nodes retrieve shard mapping information from Meta Nodes to achieve efficient data routing. This information is used to route data to the appropriate Data Nodes based on the sharding key of the data. + +This sharding strategy ensures the write load is evenly distributed across the cluster, enhancing write performance and overall system efficiency. BanyanDB uses a hash algorithm for sharding. The hash function maps the sharding key (resource name and entity) to a node in the cluster. Each shard is assigned to the node returned by the hash function. + +Here's a text-based diagram illustrating the data write path in BanyanDB: + +``` +User + | + | API Request (Write) + | + v +------------------------------------ +| Liaison Node | <--- Stateless Node, Routes Request +| (Identifies relevant Data Nodes | +| and dispatches write request) | +------------------------------------ + | + v +----------------- ----------------- ----------------- +| Data Node 1 | | Data Node 2 | | Data Node 3 | +| (Shard 1) | | (Shard 2) | | (Shard 3) | +----------------- ----------------- ----------------- + Review Comment: ```suggestion User | | API Request (Write) | v ------------------------------------ | Liaison Node | <--- Stateless Node, Routes Request | (Identifies relevant Data Nodes | | and dispatches write request) | ------------------------------------ | v ----------------- ----------------- ----------------- | Data Node 1 | | Data Node 2 | | Data Node 3 | | (Shard 1) | | (Shard 2) | | (Shard 3) | ----------------- ----------------- ----------------- User | | API Request (Write) | v ------------------------------------ | Liaison Node | <--- Stateless Node, Routes Request | (Identifies relevant Data Nodes | | and dispatches write request) | ------------------------------------ | v ----------------- ----------------- ----------------- | Data Node 1 | | Data Node 2 | | Data Node 3 | | (Shard 1) | | (Shard 2) | | (Shard 3) | ----------------- ----------------- ----------------- | | | v v v ------------------------------------------------------ shared storage ------------------------------------------------------ ``` -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: [email protected] For queries about this service, please contact Infrastructure at: [email protected]
{kind=link}