> > Problem already solved http://dl.acm.org/citation.cfm?id=2145863 :-) >
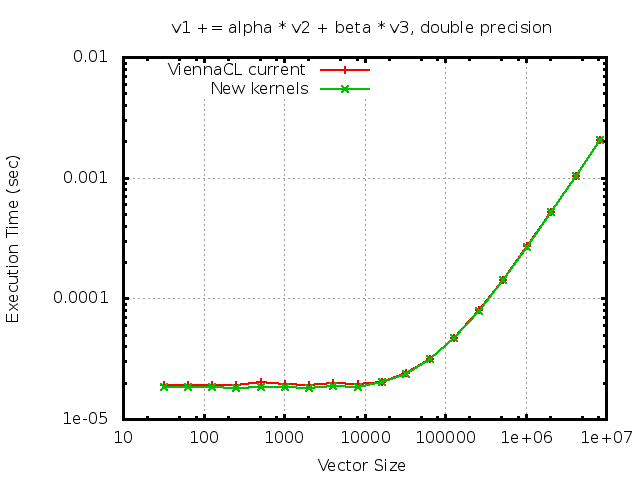
Oh, yes, these are the SnuCL guys, cf. http://aces.snu.ac.kr/~jlee/Jaejin_Lees_Home/Pact11_tutorial.html Their approach is to collect all devices across the cluster and make it available as if it were all local on the same machine, cf. http://www.acrc.a-star.edu.sg/astaratipreg_2012/Proceedings/Presentation%20-%20Jaejin%20Lee.pdf, Slide 6. As they are presenting results for the standard matrix-matrix multiplication benchmark, memory transfer is not the bottleneck. However, I doubt that the same works well with BLAS level 1 and 2 operations. By the way, I've attached benchmark results for a simple BLAS 1 kernel using double precision on an NVIDIA GPU using OpenCL (CUDA is qualitatively the same, yet may have slightly lower latency). You usually won't see this kind of benchmark result in publications on GPUs, as they are considering BLAS 3 only, or hide this unpleasant fact in diagrams starting at higher data sizes. For vector sizes below about 50k (!!), one can clearly see that one is in the kernel launch overhead regime, even if data transfer to the GPU is ignored. We are taking about latencies of 10us here, which is in the range of 1us when running the same benchmark on the CPU (I have to rerun benchmarks on latest SDKs, maybe the situation has improved). For this reason, I suggest to refrain from unconditionally submitting all types of jobs to an OpenCL scheduler and rather preserve the option of starting a small job right away using e.g. threadcomm (with the cost of an indirect function call, as Jed noted). Best regards, Karli -------------- next part -------------- A non-text attachment was scrubbed... Name: v1_peq_alpha_v2_p_beta_v3_double.png Type: image/png Size: 7402 bytes Desc: not available URL: <http://lists.mcs.anl.gov/pipermail/petsc-dev/attachments/20121007/1844c25f/attachment.png>
{kind=link}