Any updates or further inputs on this. On Wed, 2 Dec 2020 at 09:27, Krunal Bauskar <[email protected]> wrote:
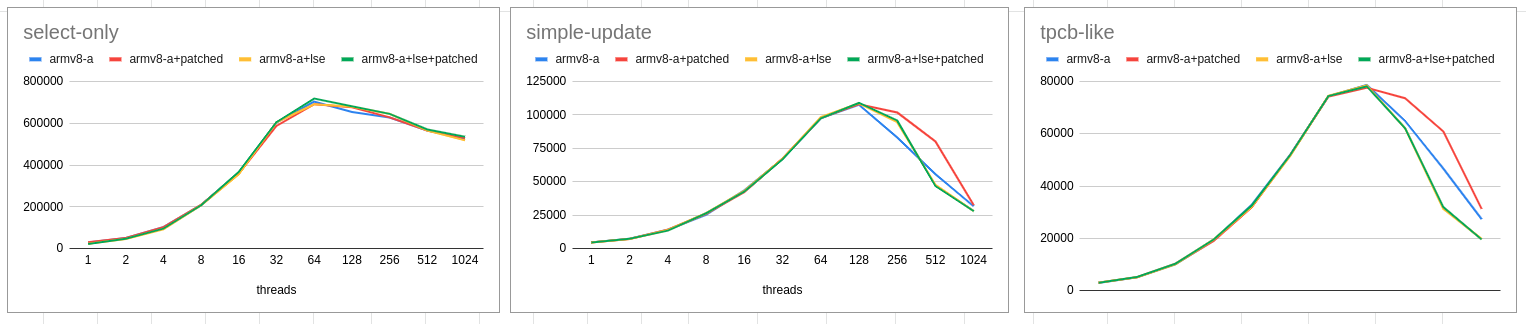
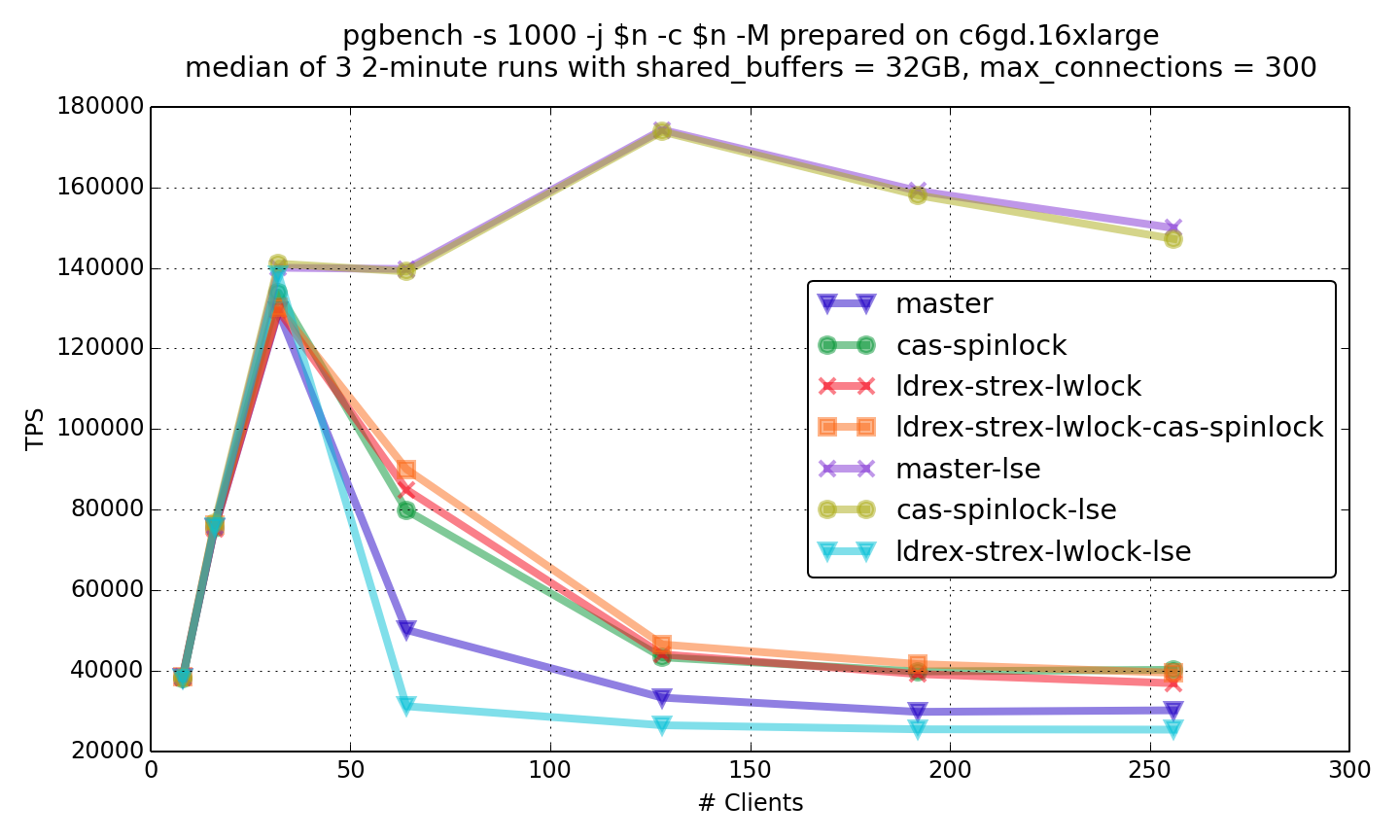
> > > On Tue, 1 Dec 2020 at 22:19, Tom Lane <[email protected]> wrote: > >> Alexander Korotkov <[email protected]> writes: >> > On Tue, Dec 1, 2020 at 6:19 PM Krunal Bauskar <[email protected]> >> wrote: >> >> I would request you guys to re-think it from this perspective to help >> ensure that PGSQL can scale well on ARM. >> >> s_lock becomes a top-most function and LSE is not a universal solution >> but CAS surely helps ease the main bottleneck. >> >> > CAS patch isn't proven to be a universal solution as well. We have >> > tested the patch on just a few processors, and Tom has seen the >> > regression [1]. The benchmark used by Tom was artificial, but the >> > results may be relevant for some real-life workload. >> >> Yeah. I think that the main conclusion from what we've seen here is >> that on smaller machines like M1, a standard pgbench benchmark just >> isn't capable of driving PG into serious spinlock contention. (That >> reflects very well on the work various people have done over the years >> to get rid of spinlock contention, because ten or so years ago it was >> a huge problem on this size of machine. But evidently, not any more.) >> Per the results others have posted, nowadays you need dozens of cores >> and hundreds of client threads to measure any such issue with pgbench. >> >> So that is why I experimented with a special test that does nothing >> except pound on one spinlock. Sure it's artificial, but if you want >> to see the effects of different spinlock implementations then it's >> just too hard to get any results with pgbench's regular scripts. >> >> And that's why it disturbs me that the CAS-spinlock patch showed up >> worse in that environment. The fact that it's not visible in the >> regular pgbench test just means that the effect is too small to >> measure in that test. But in a test where we *can* measure an effect, >> it's not looking good. >> >> It would be interesting to see some results from the same test I did >> on other processors. I suspect the results would look a lot different >> from mine ... but we won't know unless someone does it. Or, if someone >> wants to propose some other test case, let's have a look. >> >> > I'm expressing just my personal opinion, other committers can have >> > different opinions. I don't particularly think this topic is >> > necessarily a non-starter. But I do think that given ambiguity we've >> > observed in the benchmark, much more research is needed to push this >> > topic forward. >> >> Yeah. I'm not here to say "do nothing". But I think we need results >> from more machines and more test cases to convince ourselves whether >> there's a consistent, worthwhile win from any specific patch. >> > > I think there is > *an ambiguity with lse and that has been the* > *source of some confusion* so let's make another attempt to > understand all the observations and then define the next steps. > > ----------------------------------------------------------------- > > > *1. CAS patch (applied on the baseline)* - Kunpeng: 10-45% improvement > observed [1] > - Graviton2: 30-50% improvement observed [2] > - M1: Only select results are available cas continue to maintain a > marginal gain but not significant. [3] > [inline with what we observed with Kunpeng and Graviton2 for select > results too]. > > > *2. Let's ignore CAS for a sec and just think of LSE independently* - > Kunpeng: regression observed > - Graviton2: gain observed > - M1: regression observed > [while lse probably is default explicitly enabling it with +lse > causes regression on the head itself [4]. > client=2/4: 1816/714 ---- vs ---- 892/610] > > There is enough reason not to immediately consider enabling LSE given > its unable to perform consistently on all hardware. > ----------------------------------------------------------------- > > With those 2 aspects clear let's evaluate what options we have in hand > > > *1. Enable CAS approach* *- What we gain:* pgsql scale on > Kunpeng/Graviton2 > (m1 awaiting read-write result but may marginally scale [[5]: "but > the patched numbers are only about a few percent better"]) > *- What we lose:* Nothing for now. > > > *2. LSE:* *- What we gain: *Scaled workload with Graviton2 > * - What we lose:* regression on M1 and Kunpeng. > > Let's think of both approaches independently. > > - Enabling CAS would help us scale on all hardware (Kunpeng/Graviton2/M1) > - Enabling LSE would help us scale only on some but regress on others. > [LSE could be considered in the future once it stabilizes and all > hardware adapts to it] > > ------------------------------------------------------------------- > > *Let me know what do you think about this analysis and any specific > direction that we should consider to help move forward.* > > ------------------------------------------------------------------- > > Links: > [1]: > https://www.postgresql.org/message-id/attachment/116612/Screenshot%20from%202020-12-01%2017-55-21.png > [2]: https://www.postgresql.org/message-id/attachment/116521/arm-rw.png > [3]: > https://www.postgresql.org/message-id/1367116.1606802480%40sss.pgh.pa.us > [4]: > https://www.postgresql.org/message-id/1158478.1606716507%40sss.pgh.pa.us > [5]: > https://www.postgresql.org/message-id/51e2f75b-3742-7f28-4438-0425b11cf410%40enterprisedb.com > > >> regards, tom lane >> > > > -- > Regards, > Krunal Bauskar > -- Regards, Krunal Bauskar
{kind=link}
{kind=link}