i'm sorry this is so confusing, let me try to re-state the problem in as clear
a way as i can.
I have a C++ program, with very well tested unicode support. All logging is
done in utf8. I have conversion routines that work flawlessly, so i can assure
you there is nothing wrong with logging and unicode support in the underlying
program.
I am embedding python 2.7 into the program, and extending python with routines
in my C++ program.
I have a script, encoded in utf8, and *marked* as utf8 with this line:
# -*- coding: utf-8 -*-
In that script, i have inline unicode text. When I pass that text to my C++
program, the Python interpreter decides that these bytes are macRoman, and
handily "converts" them to unicode. To compensate, i must "convert" these
"macRoman" characters encoded as utf8, back to macRoman, then "interpret" them
as utf8. In this way i can recover the original unicode.
When i return a unicode string back to python, i must do the reverse so that
Python gets back what it expects.
This is not related to printing, or sys.stdout, it does happen with that too
but focusing on that is a red-herring. Let's focus on just passing a string
into C++ then back out.
This would all actually make sense IF my script was marked as being "macRoman"
even tho i entered UTF8 Characters, but that is not the case.
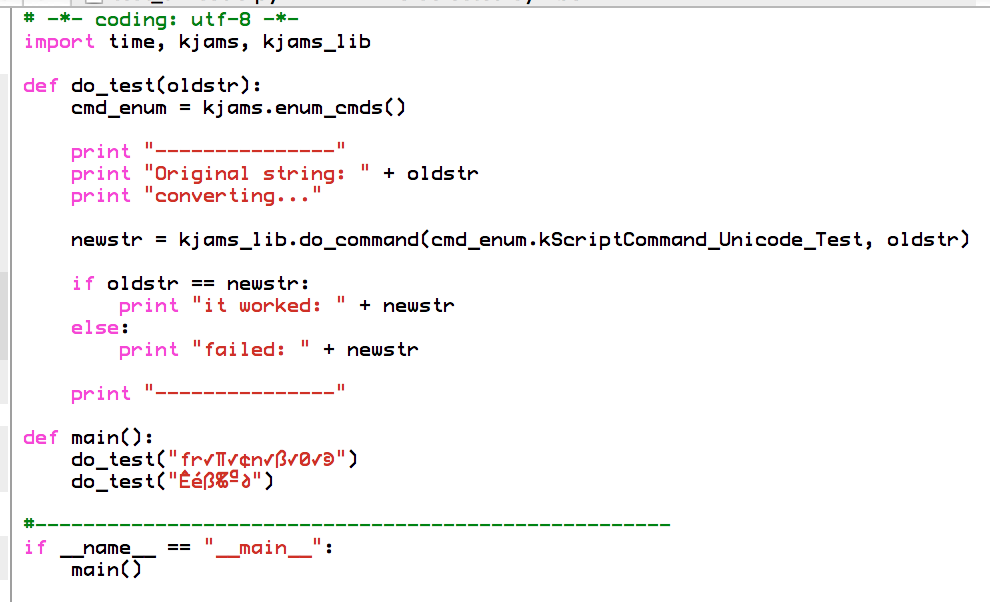
Let's prove my statements. Here is the script, *interpreted* as MacRoman:
http://karaoke.kjams.com/screenshots/bugs/python_unicode/script_as_macroman.png
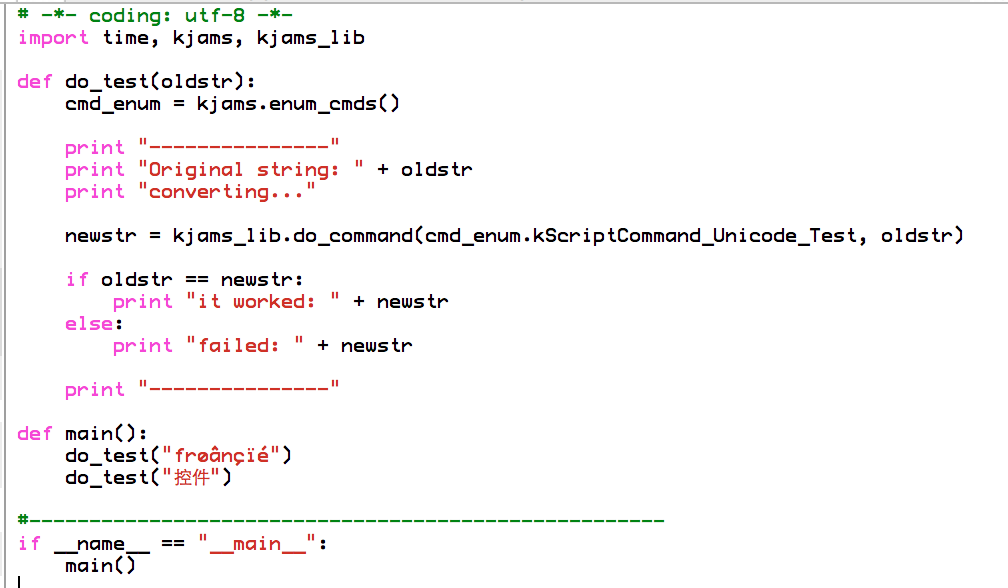
and here it is again *interpreted* as utf8:
http://karaoke.kjams.com/screenshots/bugs/python_unicode/script_as_utf8.png
here is the string conversion code:
SuperString ScPyObject::GetAs_String()
{
SuperString str; // underlying format of
SuperString is unicode
if (PyUnicode_Check(i_objP)) {
ScPyObject utf8Str(PyUnicode_AsUTF8String(i_objP));
str = utf8Str.GetAs_String();
} else {
const UTF8Char *bytes_to_interpetZ =
uc(PyString_AsString(i_objP));
// the "Set" call *interprets*, does not *convert*
str.Set(bytes_to_interpetZ, kCFStringEncodingUTF8);
// str is now unicode characters which *represent*
macRoman characters
// so *convert* these to actual macRoman
// fyi: Update_utf8 means "convert to this encoding and
// store the resulting bytes in the variable named "utf8"
str.Update_utf8(kCFStringEncodingMacRoman);
// str is now unicode characters converted from macRoman
// so *reinterpret* them as UTF8
// FYI, we're just taking the pure bytes that are stored
in the utf8 variable
// and *interpreting* them to this encoding
bytes_to_interpetZ = str.utf8().c_str();
str.Set(bytes_to_interpetZ, kCFStringEncodingUTF8);
}
return str;
}
PyObject* PyString_FromString(const SuperString& str)
{
SuperString localStr(str);
// localStr is the real, actual unicode string
// but we must *interpret* it as macRoman, then take these
"macRoman" characters
// and "convert" them to unicode for Python to "get it"
const UTF8Char *bytes_to_interpetZ = localStr.utf8().c_str();
// take the utf8 bytes (actual utf8 prepresentation of string)
// and say "no, these bytes are macRoman"
localStr.Set(bytes_to_interpetZ, kCFStringEncodingMacRoman);
// okay so now we have unicode of MacRoman characters (!?)
// return the underlying utf8 bytes of THAT as our string
return PyString_FromString(localStr.utf8Z());
}
And here is the results from running the script:
18: ---------------
18: Original string: frøânçïé
18: converting...
18: it worked: frøânçïé
18: ---------------
18: ---------------
18: Original string: 控件
18: converting...
18: it worked: 控件
18: ---------------
Now the thing that absolutely utterly baffles me (if i'm not baffled enough) is
that i get the EXACT same results on both Mac and Windows. Why do they both
insist on interpreting my script's bytes as MacRoman?
--
http://mail.python.org/mailman/listinfo/python-list
{kind=link}
{kind=link}