On 04/02/2023 16.24, Thomas Passin wrote:
On 2/3/2023 5:14 PM, [email protected] wrote:
Keep It Simple: Put all four modules at the top level, and run with it
until you falsify it. Yes, I would give you that same advice no matter
what language you're using.
In my recent message I supported DESIGN 1. But I really don't care much
about the directory organization. It's designing modules whose business
is to handle various kinds of operations that counts, not so much the
actual directory organization.
+1 (and to comments made in preceding post)
With ETL the 'reasons to change' (SRP) come from different 'actors'. For
example, the data-source may be altered either in format or by changing
the tool you'll utilise to access. Accordingly, the virtue of keeping it
separate from other parts. If you have multiple data-sources, then each
should be separate for the same reason.
The transform is likely dictated by your client's specification. So,
another separation. Hence Design 1.
There is a strong argument for suggesting that we're going out of our
way to imagine problems or future-changes (which may never happen). If
this is (definitely?) a one-off, then why-bother? If permanence is
likely, (so many 'temporary' solutions end-up lasting years!) then
re-use can?should be considered.
Thus, when it comes to loading the data into your own DB; perhaps this
should be separate, because it is highly likely that the mechanisms you
build for loading will be matched by at least one 'someone else' wanting
to access the same data for the desired end-purposes. Accordingly, a
shareable module and/or class for that.
We can't see the code-structure, so some of the other parts of your
question(s) are too broad. Here's hoping you and Liskov have a good time
together...
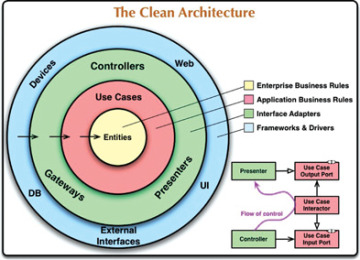
My preference is for (what I term) the 'circles' diagram (see copy at
https://mahu.rangi.cloud/CraftingSoftware/CleanArchitecture.jpg). This
illustrates the 'rule' that code handling the inner functionality not
know what happens at the more detailed/lower-level functional level of
the outer rings.
With ETL, there's precious little to embody various circles, but the
content of the outer ring is obvious. The "T" rules comprise the inner
"Use Case", even if you eschew "Entities" insofar as OOP-avoidance is
concerned. This 'inversion', where the inner controls don't need to care
about the details of outer-ring implementation (is it an RDBMS, MySQL or
Postgres; or is it some NoSQL system?) brings to life the "D" of SOLID,
ie Dependency Inversion.
You may pick-up some ideas or reassurance from "Making a Simple Data
Pipeline Part 1: The ETL Pattern"
(https://www.codeproject.com/Articles/5324207/Making-a-Simple-Data-Pipeline-Part-1-The-ETL-Patte).
Let us know how it turns-out...
--
Regards,
=dn
--
https://mail.python.org/mailman/listinfo/python-list
{kind=link}