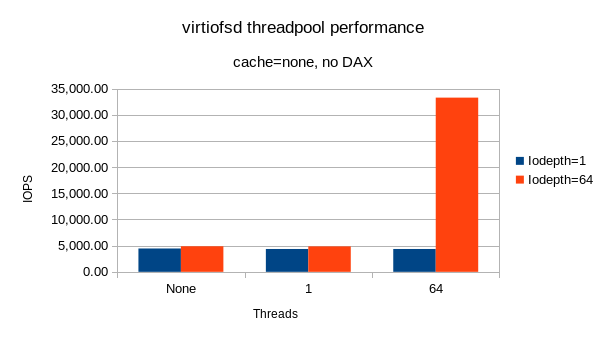
On Wed, Aug 07, 2019 at 07:03:55PM +0100, Stefan Hajnoczi wrote: > On Thu, Aug 01, 2019 at 05:54:05PM +0100, Stefan Hajnoczi wrote: > > Performance > > ----------- > > Please try these patches out and share your results. > > Here are the performance numbers: > > Threadpool | iodepth | iodepth > size | 1 | 64 > -----------+---------+-------- > None | 4451 | 4876 > 1 | 4360 | 4858 > 64 | 4359 | 33,266 > > A graph is available here: > https://vmsplice.net/~stefan/virtiofsd-threadpool-performance.png > > Summary: > > * iodepth=64 performance is increased by 6.8 times. > * iodepth=1 performance degrades by 2%. > * DAX is bottlenecked by QEMU's single-threaded > VHOST_USER_SLAVE_FS_MAP/UNMAP handler. > > Threadpool size "none" is virtiofsd commit 813a824b707 ("virtiofsd: use > fuse_lowlevel_is_virtio() in fuse_session_destroy()") without any of the > multithreading preparation patches. I benchmarked this to check whether > the patches introduce a regression for iodepth=1. They do, but it's > only around 2%. > > I also ran with DAX but found there was not much difference between > iodepth=1 and iodepth=64. This might be because the host mmap(2) > syscall becomes the bottleneck and a serialization point. QEMU only > processes one VHOST_USER_SLAVE_FS_MAP/UNMAP at a time. If we want to > accelerate DAX it may be necessary to parallelize mmap, assuming the > host kernel can do them in parallel on a single file. This performance > optimization is future work and not directly related to this patch > series.
{kind=link}
Good to see nice improvement with higher queue depth. Kernel also serializes MAP/UNMAP on one inode. So you will need to run multiple jobs operating on different inodes to see parallel MAP/UNMAP (atleast from kernel's point of view). Thanks Vivek