abhishekd0907 opened a new pull request #91: [Bahir 213] Faster S3 file Source for Structured Streaming with SQS URL: https://github.com/apache/bahir/pull/91 ## What changes were proposed in this pull request? Using FileStreamSource to read files from a S3 bucket has problems both in terms of costs and latency: - **Latency**: Listing all the files in S3 buckets every microbatch can be both slow and resource intensive. - **Costs**: Making List API requests to S3 every microbatch can be costly. The solution is to use Amazon Simple Queue Service (SQS) which lets you find new files written to S3 bucket without the need to list all the files every microbatch. S3 buckets can be configured to send notification to an Amazon SQS Queue on Object Create / Object Delete events. For details see AWS documentation here [Configuring S3 Event Notifications](https://docs.aws.amazon.com/AmazonS3/latest/dev/NotificationHowTo.html) Spark can leverage this to find new files written to S3 bucket by reading notifications from SQS queue instead of listing files every microbatch. This PR adds a new SQSSource which uses Amazon SQS queue to find new files every microbatch. ## Usage `val inputDf = spark .readStream .format("s3-sqs") .schema(schema) .option("fileFormat", "json") .option("sqsUrl", "https://QUEUE_URL";) .option("region", "us-east-1") .load()` ## Implementation Details We create a scheduled thread which runs asynchronously with the streaming query thread and periodically fetches messages from the SQS Queue. Key information related to file path & timestamp is extracted from the SQS messages and the new files are stored in a thread safe SQS file cache. Streaming Query thread gets the files from SQS File Cache and filters out the new files. Based on the maxFilesPerTrigger condition, all or a part of the new files are added to the offset log and marked as processed in the SQS File Cache. The corresponding SQS messages for the processed files are deleted from the Amazon SQS Queue and the offset value is incremented and returned. 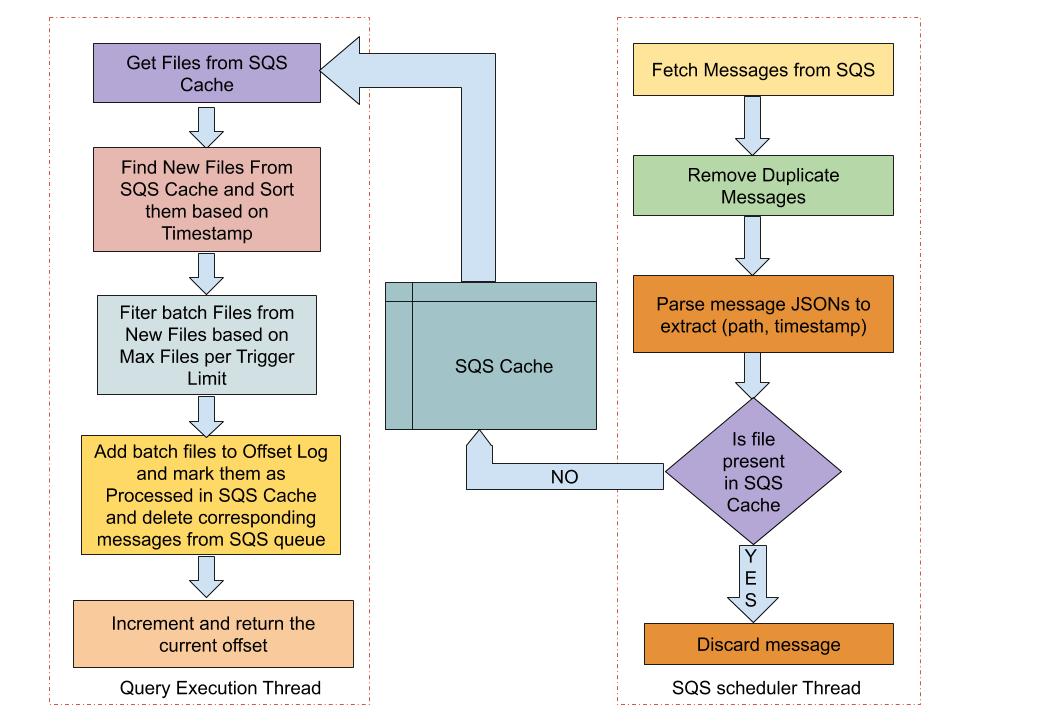 ## How was this patch tested? Added new unit tests in SqsSourceOptionsSuite which test various SqsSourceOptions. Will add more tests after some initial feedback on design approach and functionality.
{kind=link}
---------------------------------------------------------------- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services