zhengruifeng edited a comment on pull request #27473:
URL: https://github.com/apache/spark/pull/27473#issuecomment-624531334
test on the first 1M rows in HIGGS:
test code:
```scala
import org.apache.spark.ml.clustering._
import org.apache.spark.storage.StorageLevel
import org.apache.spark.ml.linalg._
val df =
spark.read.format("libsvm").load("/data1/Datasets/higgs/HIGGS.1m").repartition(1)
df.persist(StorageLevel.MEMORY_AND_DISK)
df.count
val gmm = new
GaussianMixture().setSeed(0).setK(4).setMaxIter(2).setBlockSize(64)
gmm.fit(df)
val results = Seq(1, 4, 16, 64, 256, 1024, 4096).map { size => val start =
System.currentTimeMillis; val model =
gmm.setK(4).setMaxIter(20).setBlockSize(size).fit(df); val end =
System.currentTimeMillis; (size, model, end - start) }
results.map(_._2.summary.numIter)
results.map(_._2.summary.logLikelihood)
results.map(_._3)
```
Results **WITHOUT** native BLAS:
```
scala> results.map(_._2.summary.numIter)
res3: Seq[Int] = List(20, 20, 20, 20, 20, 20, 20)
scala> results.map(_._2.summary.logLikelihood)
res4: Seq[Double] = List(-2.3353357834421366E7, -2.3353357834421184E7,
-2.3353357834421184E7, -2.3353357834421184E7, -2.3353357834421184E7,
-2.3353357834421184E7, -2.3353357834421184E7)
scala> results.map(_._3)
res5: Seq[Long] = List(105777, 113261, 110608, 106573, 108141, 109825,
113094)
```
It is surprising that there is a small performance regression on dense
input: 105777 -> 106573
**blockSize==1**
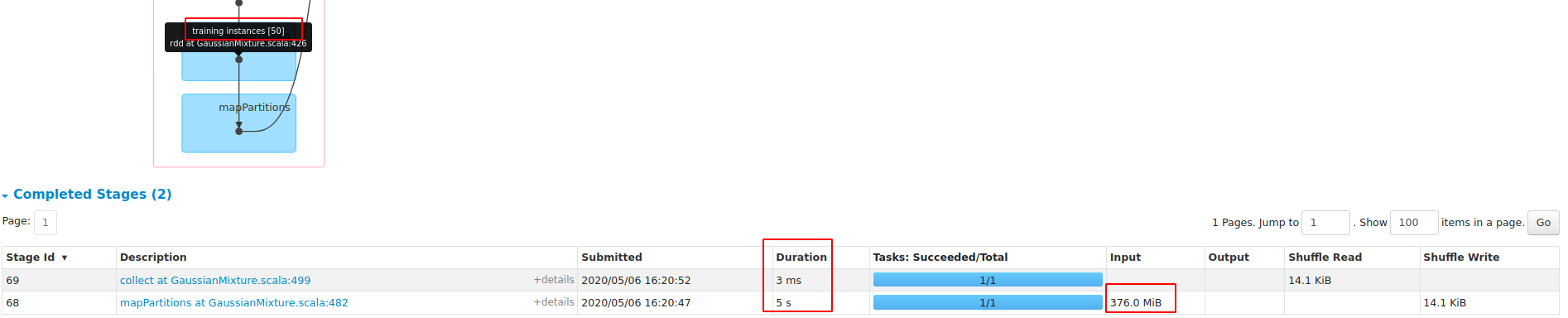
**blockSize==1024**
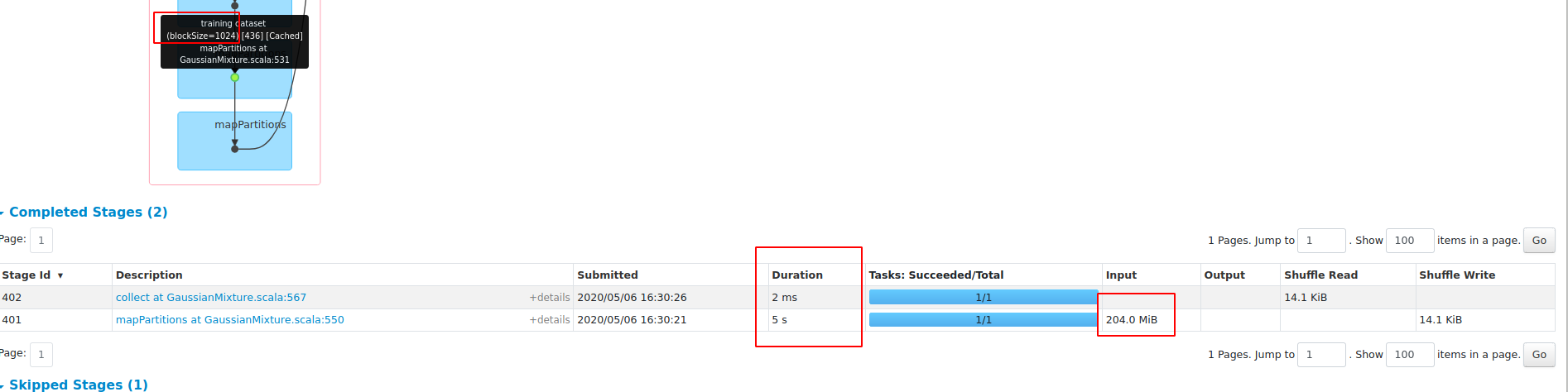
Results **WITH** native BLAS (OPENBLAS_NUM_THREADS=1):
```
scala> results.map(_._2.summary.numIter)
res3: Seq[Int] = List(20, 20, 20, 20, 20, 20, 20)
scala> results.map(_._2.summary.logLikelihood)
res4: Seq[Double] = List(-2.3353357834421374E7, -2.3353357834422573E7,
-2.3353357834422797E7, -2.335335783442225E7, -2.3353357834422205E7,
-2.3353357834422156E7, -2.335335783442218E7)
scala> results.map(_._3)
res5: Seq[Long] = List(108005, 54975, 39802, 35807, 35027, 36369, 38717)
```
When OpenBLAS is used, it obtain about 3x speedup.
**blockSize==1** with OpenBLAS
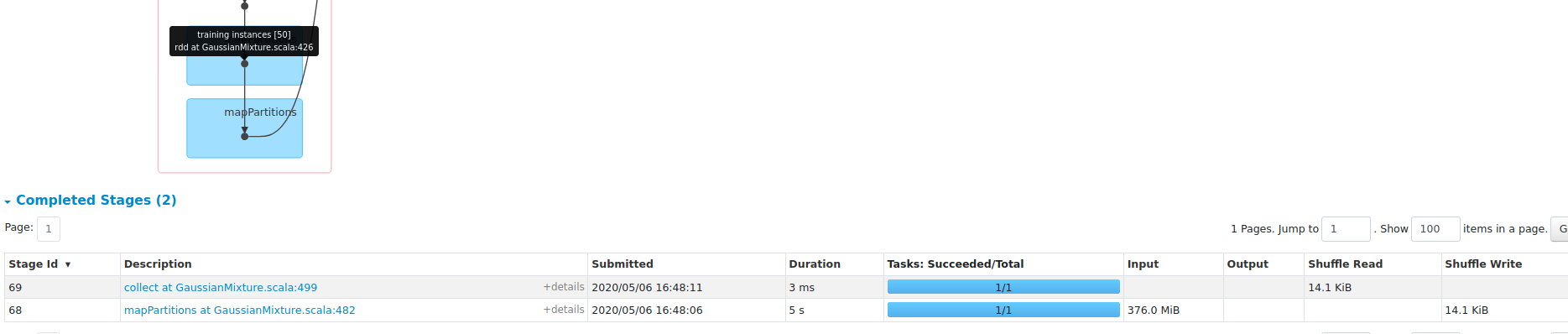
**blockSize==1024** with OpenBLAS
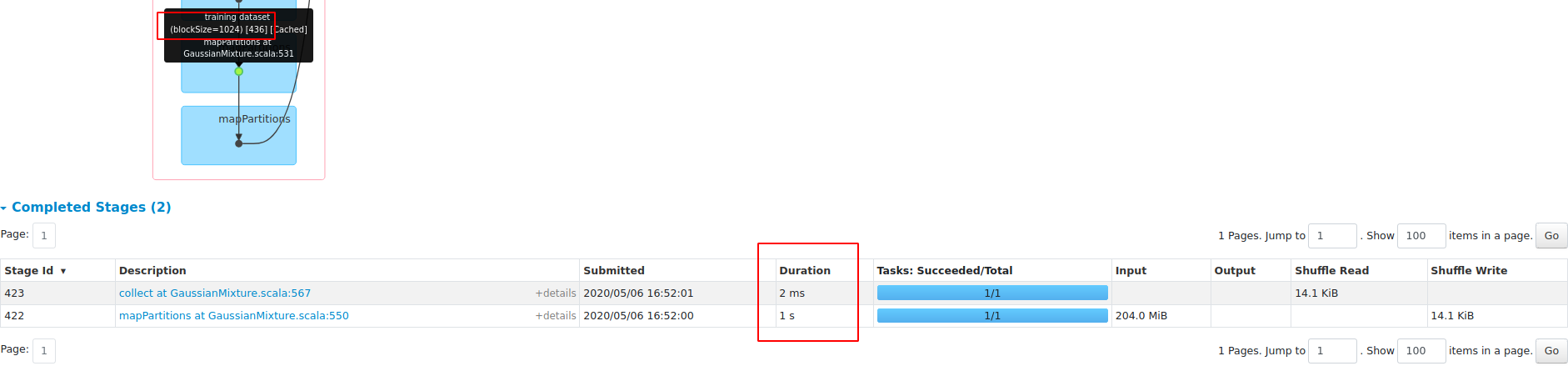
Comparsion to Master (**WITHOUT** native BLAS):
```
scala> val start = System.currentTimeMillis; val model =
gmm.setK(4).setMaxIter(20).fit(df); val end = System.currentTimeMillis; end -
start
start: Long = 1587976220511
model: org.apache.spark.ml.clustering.GaussianMixtureModel =
GaussianMixtureModel: uid=GaussianMixture_753da885644b, k=4, numFeatures=28
end: Long = 1587976324361
res4: Long = 103850
```
This PR keeps original behavior and performance if `BlockSize==1`
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
{kind=link}
{kind=link}
{kind=link}
{kind=link}