zhongyu09 commented on a change in pull request #31167:
URL: https://github.com/apache/spark/pull/31167#discussion_r560052568
##########
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/adaptive/AdaptiveSparkPlanExec.scala
##########
@@ -190,7 +191,36 @@ case class AdaptiveSparkPlanExec(
executionId.foreach(onUpdatePlan(_, result.newStages.map(_.plan)))
// Start materialization of all new stages and fail fast if any
stages failed eagerly
- result.newStages.foreach { stage =>
+
+ // SPARK-33933: we should materialize broadcast stages first and
wait the
+ // materialization finish before materialize other stages, to avoid
waiting
+ // for broadcast tasks to be scheduled and leading to broadcast
timeout.
+ val broadcastMaterializationFutures = result.newStages
+ .filter(_.isInstanceOf[BroadcastQueryStageExec])
+ .map { stage =>
+ var future: Future[Any] = null
+ try {
+ future = stage.materialize()
+ future.onComplete { res =>
+ if (res.isSuccess) {
+ events.offer(StageSuccess(stage, res.get))
+ } else {
+ events.offer(StageFailure(stage, res.failed.get))
+ }
+ }(AdaptiveSparkPlanExec.executionContext)
+ } catch {
+ case e: Throwable =>
+ cleanUpAndThrowException(Seq(e), Some(stage.id))
+ }
+ future
+ }
+
+ // Wait for the materialization of all broadcast stages finish
Review comment:
> No, it maybe true for your run. In your case, maybe all resources are
occupied by the broadcast. So no other job can be really scheduled to
executors. But logically we don't set this limitation. I repeat, if there are
enough resources, broadcast job and shuffle stage can be run in parallel.
I can ensure there's enough resources to run broadcast and shuffle in
parallel. Actually, there haven't come to TaskScheduler, "sc.runJob" is called
after the broadcast finished.
>
1. During preparing the SparkPlan, broadcast job is submitted to run, right?
And we don't stop and wait here.
2. Now Spark continues the execution of the query. If there is shuffle stage
independent to the broadcast, it can be scheduled to run in parallel if there
are enough resources in the cluster.
3. Only if Spark calls executeBroadcast of the broadcast's query plan, we
really stop and wait for the broadcast result.
I agree with you for 1 and 3, but cannot agree with you for 2. In non-AQE,
break a job into stages is happened in DAGScheduler, it is after physical plan
has been transformed to RDD. I don't think DAGScheduler can call the
executeBroadcast, which is part of spark-sql.
Below is the physical plan.
== Physical Plan ==
* Project (13)
+- * BroadcastHashJoin Inner BuildRight (12)
:- * HashAggregate (6)
: +- Exchange (5)
: +- * HashAggregate (4)
: +- * Project (3)
: +- * SerializeFromObject (2)
: +- Scan (1)
+- BroadcastExchange (11)
+- Coalesce (10)
+- * Project (9)
+- * SerializeFromObject (8)
+- Scan (7)
You can see the submission time in the screenshot.
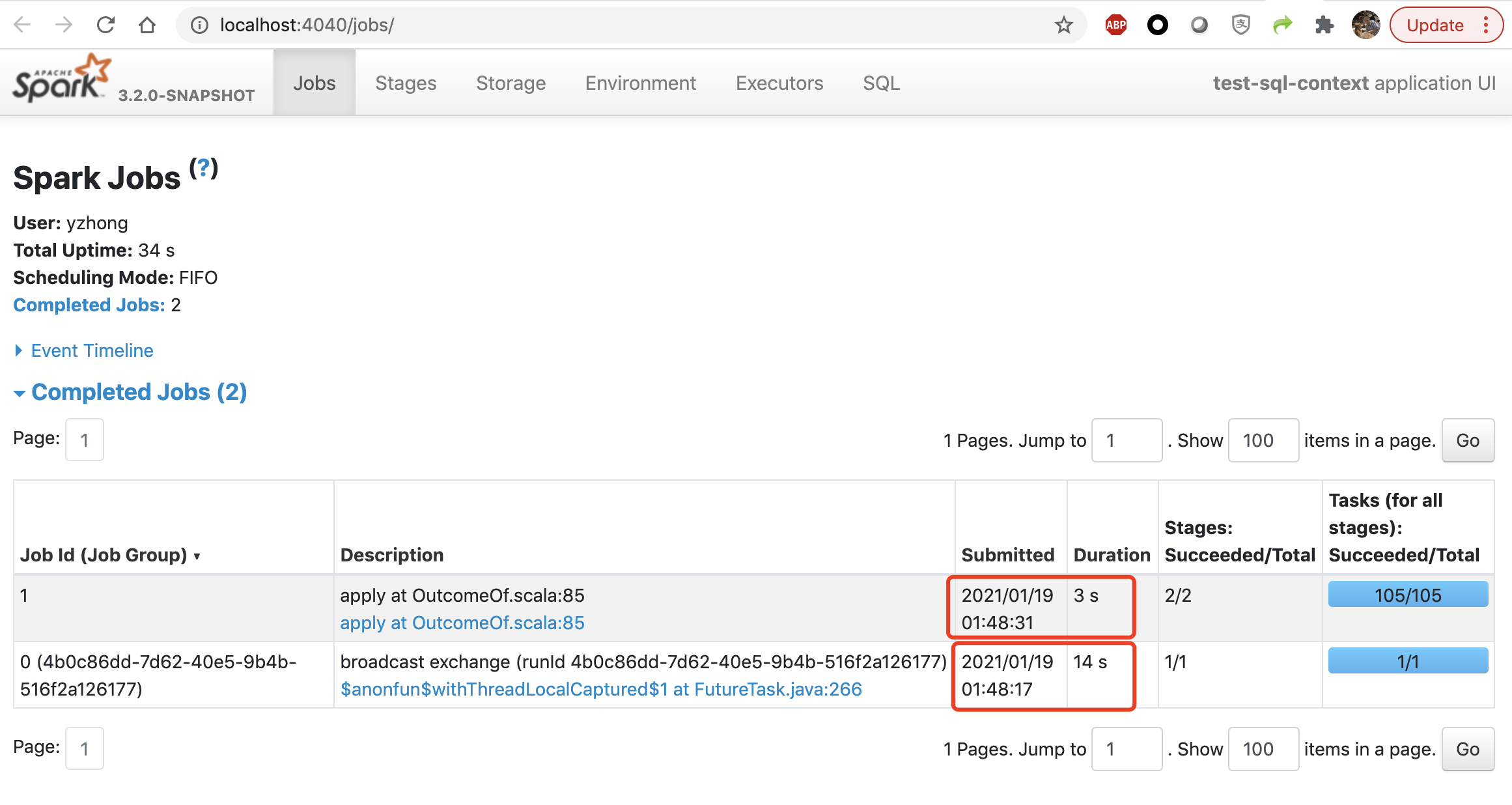
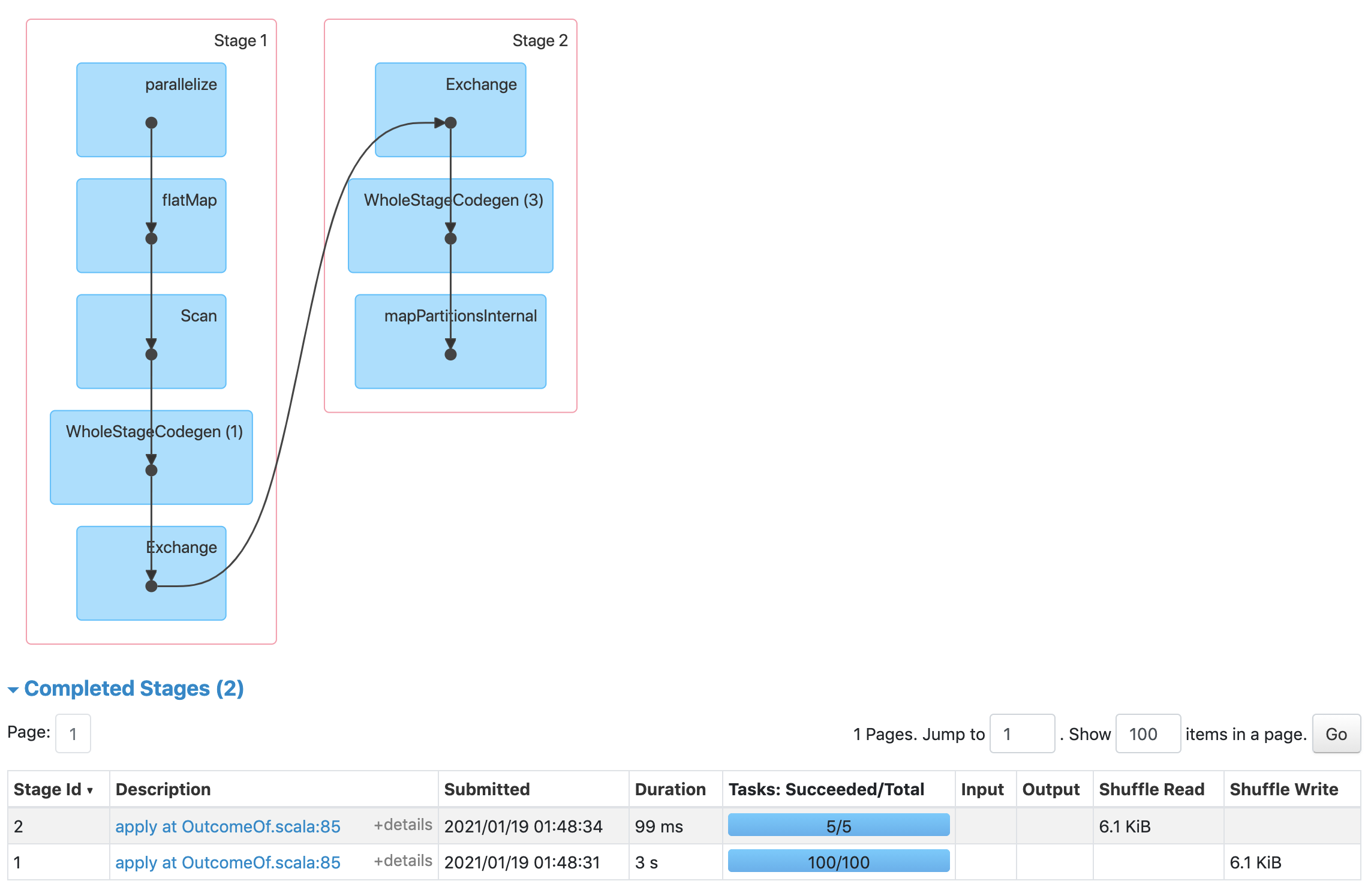
There are 4 cores and only 1 task for broadcast job:
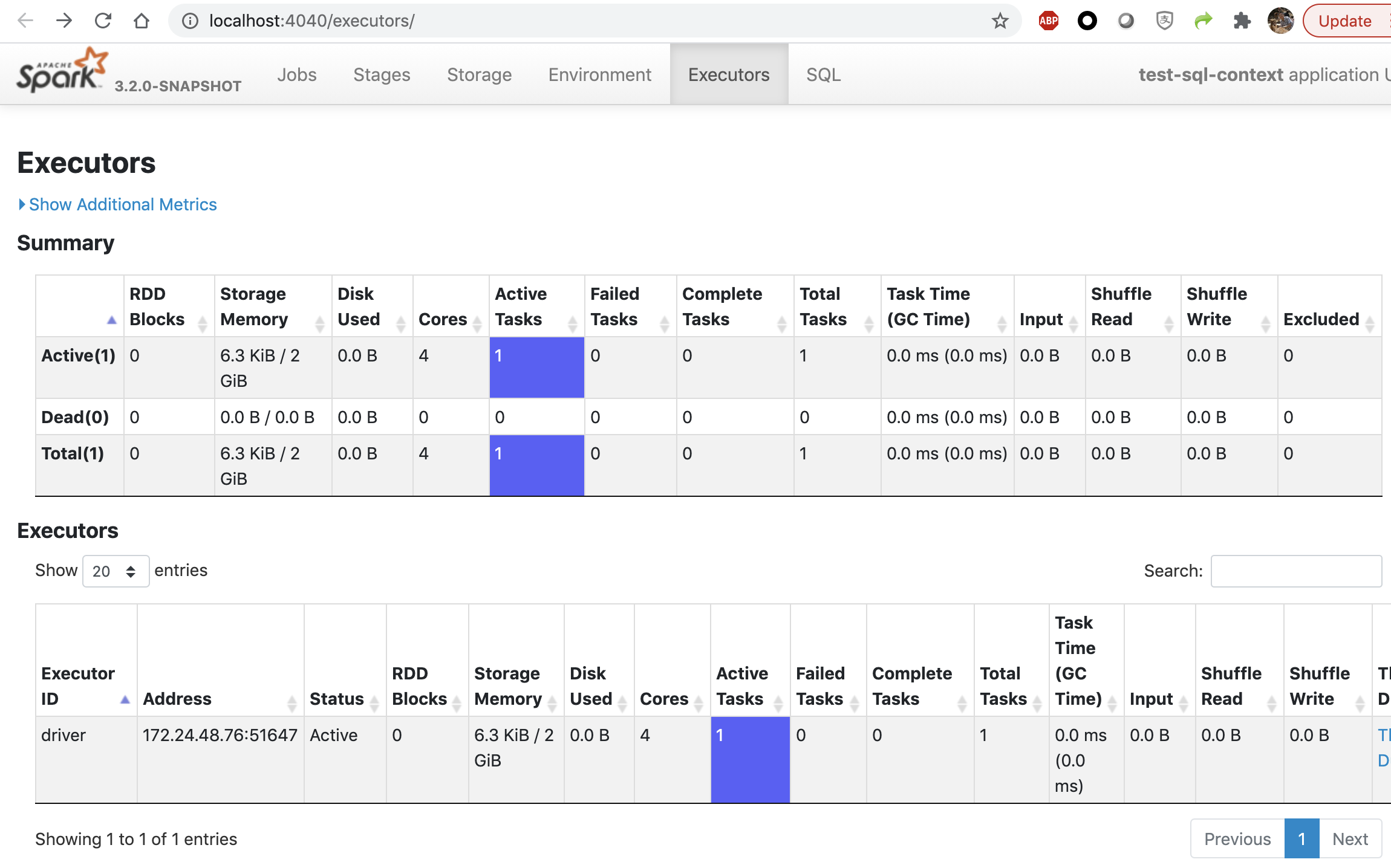
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
{kind=link}
{kind=link}
{kind=link}