wangyum edited a comment on pull request #29726:
URL: https://github.com/apache/spark/pull/29726#issuecomment-780266596
```scala
sql("set spark.sql.adaptive.enabled=false")
sql("CREATE TABLE t1 using parquet partitioned by (b) AS SELECT id AS a, id
% 1000 AS b FROM range(200000000L) distribute by b")
sql("CREATE TABLE t2 using parquet AS SELECT id as c,id AS d FROM
range(2000)")
sql("SELECT count(*) FROM t2 left join t1 on t1.b=t2.c where t2.d < 10").show
```
Before this pr | After this pr
-- | --
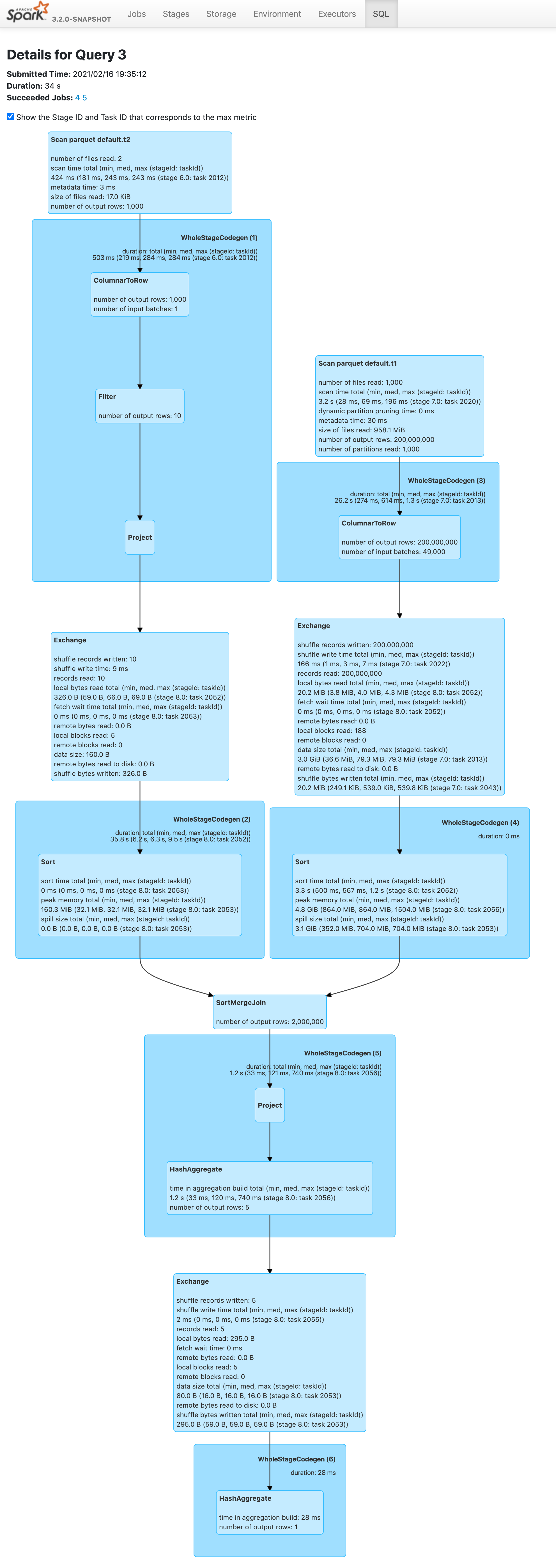
|
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
{kind=link}
{kind=link}