zhengruifeng edited a comment on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-978884601
@wangyum
this PR was updated to support `rank` and `dense_rank`
```
scala> spark.conf.set("spark.sql.rankLimit.enabled", "true")
scala> spark.sql("""SELECT a, b, rank() OVER (PARTITION BY a ORDER BY b) as
rk FROM VALUES ('A1', 1), ('A1', 1), ('A2', 3), ('A1', 1) tab(a,
b);""").where("rk = 1").queryExecution.optimizedPlan
res1: org.apache.spark.sql.catalyst.plans.logical.LogicalPlan =
Filter (rk#0 = 1)
+- Window [rank(b#4) windowspecdefinition(a#3, b#4 ASC NULLS FIRST,
specifiedwindowframe(RowFrame, unboundedpreceding$(), currentrow$())) AS rk#0],
[a#3], [b#4 ASC NULLS FIRST]
+- RankLimit [a#3], [b#4 ASC NULLS FIRST], rank(b#4), 1
+- LocalRelation [a#3, b#4]
scala> spark.sql("""SELECT a, b, rank() OVER (PARTITION BY a ORDER BY b) as
rk FROM VALUES ('A1', 1), ('A1', 1), ('A2', 3), ('A1', 1) tab(a,
b);""").where("rk = 1").show
+---+---+---+
| a| b| rk|
+---+---+---+
| A1| 1| 1|
| A1| 1| 1|
| A1| 1| 1|
| A2| 3| 1|
+---+---+---+
```
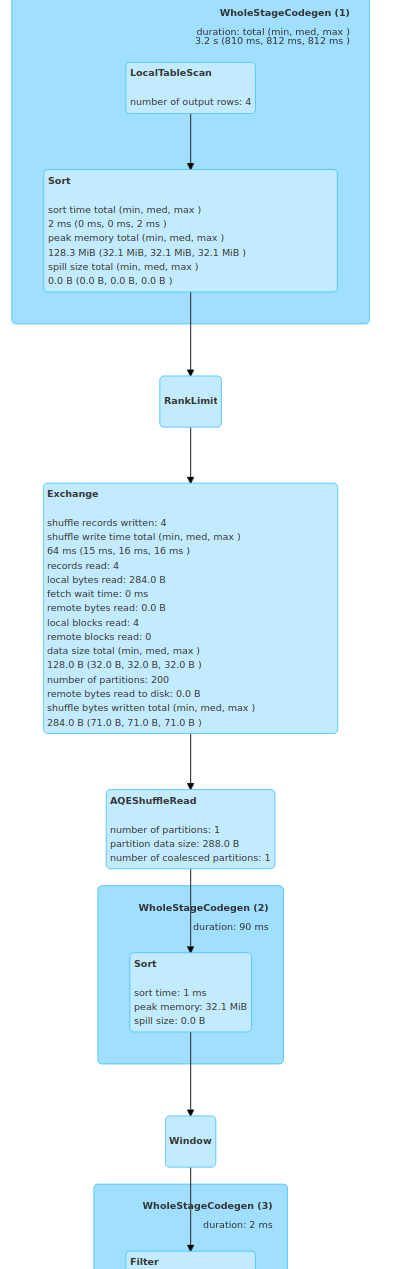
```
== Physical Plan ==
AdaptiveSparkPlan (17)
+- == Final Plan ==
* Project (10)
+- * Filter (9)
+- Window (8)
+- * Sort (7)
+- AQEShuffleRead (6)
+- ShuffleQueryStage (5)
+- Exchange (4)
+- RankLimit (3)
+- * Sort (2)
+- * LocalTableScan (1)
+- == Initial Plan ==
Project (16)
+- Filter (15)
+- Window (14)
+- Sort (13)
+- Exchange (12)
+- RankLimit (11)
+- Sort (2)
+- LocalTableScan (1)
(1) LocalTableScan [codegen id : 1]
Output [2]: [a#17, b#18]
Arguments: [a#17, b#18]
(2) Sort [codegen id : 1]
Input [2]: [a#17, b#18]
Arguments: [a#17 ASC NULLS FIRST, b#18 ASC NULLS FIRST], false, 0
(3) RankLimit
Input [2]: [a#17, b#18]
Arguments: [a#17], [b#18 ASC NULLS FIRST], rank(b#18), 1
(4) Exchange
Input [2]: [a#17, b#18]
Arguments: hashpartitioning(a#17, 200), ENSURE_REQUIREMENTS, [id=#37]
(5) ShuffleQueryStage
Output [2]: [a#17, b#18]
Arguments: 0
(6) AQEShuffleRead
Input [2]: [a#17, b#18]
Arguments: coalesced
(7) Sort [codegen id : 2]
Input [2]: [a#17, b#18]
Arguments: [a#17 ASC NULLS FIRST, b#18 ASC NULLS FIRST], false, 0
(8) Window
Input [2]: [a#17, b#18]
Arguments: [rank(b#18) windowspecdefinition(a#17, b#18 ASC NULLS FIRST,
specifiedwindowframe(RowFrame, unboundedpreceding$(), currentrow$())) AS
rk#14], [a#17], [b#18 ASC NULLS FIRST]
(9) Filter [codegen id : 3]
Input [3]: [a#17, b#18, rk#14]
Condition : (rk#14 = 1)
(10) Project [codegen id : 3]
Output [3]: [a#17, cast(b#18 as string) AS b#32, cast(rk#14 as string) AS
rk#33]
Input [3]: [a#17, b#18, rk#14]
(11) RankLimit
Input [2]: [a#17, b#18]
Arguments: [a#17], [b#18 ASC NULLS FIRST], rank(b#18), 1
(12) Exchange
Input [2]: [a#17, b#18]
Arguments: hashpartitioning(a#17, 200), ENSURE_REQUIREMENTS, [id=#23]
(13) Sort
Input [2]: [a#17, b#18]
Arguments: [a#17 ASC NULLS FIRST, b#18 ASC NULLS FIRST], false, 0
(14) Window
Input [2]: [a#17, b#18]
Arguments: [rank(b#18) windowspecdefinition(a#17, b#18 ASC NULLS FIRST,
specifiedwindowframe(RowFrame, unboundedpreceding$(), currentrow$())) AS
rk#14], [a#17], [b#18 ASC NULLS FIRST]
(15) Filter
Input [3]: [a#17, b#18, rk#14]
Condition : (rk#14 = 1)
(16) Project
Output [3]: [a#17, cast(b#18 as string) AS b#32, cast(rk#14 as string) AS
rk#33]
Input [3]: [a#17, b#18, rk#14]
(17) AdaptiveSparkPlan
Output [3]: [a#17, b#32, rk#33]
Arguments: isFinalPlan=true
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
{kind=link}