HyukjinKwon commented on code in PR #36509: URL: https://github.com/apache/spark/pull/36509#discussion_r881585500
########## python/pyspark/pandas/supported_api_gen.py: ########## @@ -0,0 +1,377 @@ +# +# Licensed to the Apache Software Foundation (ASF) under one or more +# contributor license agreements. See the NOTICE file distributed with +# this work for additional information regarding copyright ownership. +# The ASF licenses this file to You under the Apache License, Version 2.0 +# (the "License"); you may not use this file except in compliance with +# the License. You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# + +""" +Generate 'Supported pandas APIs' documentation file +""" +import warnings +from distutils.version import LooseVersion +from enum import Enum, unique +from inspect import getmembers, isclass, isfunction, signature +from typing import Any, Callable, Dict, List, NamedTuple, Set, TextIO, Tuple + +import pyspark.pandas as ps +import pyspark.pandas.groupby as psg +import pyspark.pandas.window as psw + +import pandas as pd +import pandas.core.groupby as pdg +import pandas.core.window as pdw + +MAX_MISSING_PARAMS_SIZE = 5 +COMMON_PARAMETER_SET = { + "kwargs", + "args", + "cls", +} # These are not counted as missing parameters. +MODULE_GROUP_MATCH = [(pd, ps), (pdw, psw), (pdg, psg)] + +RST_HEADER = """ +===================== +Supported pandas APIs +===================== + +.. currentmodule:: pyspark.pandas + +The following table shows the pandas APIs that implemented or non-implemented from pandas API on +Spark. + +Some pandas APIs do not implement full parameters, so the third column shows missing parameters for +each API. + +'Y' in the second column means it's implemented including its whole parameter. +'N' means it's not implemented yet. +'P' means it's partially implemented with the missing of some parameters. + +If there is non-implemented pandas API or parameter you want, you can create an `Apache Spark +JIRA <https://issues.apache.org/jira/projects/SPARK/summary>`__ to request or to contribute by your +own. + +The API list is updated based on the `latest pandas official API +reference <https://pandas.pydata.org/docs/reference/index.html#>`__. + +All implemented APIs listed here are distributed except the ones that requires the local +computation by design. For example, `DataFrame.to_numpy() <https://spark.apache.org +/docs/latest/api/python/reference/pyspark.pandas/api/pyspark.pandas.DataFrame. +to_numpy.html>`__ requires to collect the data to the driver side. + +""" + + +@unique +class Implemented(Enum): + IMPLEMENTED = "Y" + NOT_IMPLEMENTED = "N" + PARTIALLY_IMPLEMENTED = "P" + + +class SupportedStatus(NamedTuple): + """ + Defines a supported status for a specific pandas API + """ + + implemented: str + missing: str + + +def generate_supported_api(output_rst_file_path: str) -> None: + """ + Generate supported APIs status dictionary. + Parameters + ---------- + output_rst_file_path : str + The path to the document file in RST format. + + Write supported APIs documentation. + """ + if LooseVersion(pd.__version__) < LooseVersion("1.4.0"): + warnings.warn( + "Warning: Latest version of pandas(>=1.4.0) is required to generate the documentation; " + + "however, your version was %s" % pd.__version__, + UserWarning, + ) + + all_supported_status: Dict[Tuple[str, str], Dict[str, SupportedStatus]] = {} + for pd_module_group, ps_module_group in MODULE_GROUP_MATCH: + pd_modules = _get_pd_modules(pd_module_group) + _update_all_supported_status( + all_supported_status, pd_modules, pd_module_group, ps_module_group + ) + _write_rst(output_rst_file_path, all_supported_status) + + +def _create_supported_by_module( + module_name: str, pd_module_group: Any, ps_module_group: Any +) -> Dict[str, SupportedStatus]: + """ + Retrieves supported status of pandas module + + Parameters + ---------- + module_name : str + Class name that exists in the path of the module. + pd_module_group : Any + Specific path of importable pandas module. + ps_module_group: Any + Specific path of importable pyspark.pandas module. + """ + pd_module = getattr(pd_module_group, module_name) if module_name else pd_module_group + try: + ps_module = getattr(ps_module_group, module_name) if module_name else ps_module_group + except AttributeError: + # module not implemented + return {} + + pd_funcs = dict([m for m in getmembers(pd_module, isfunction) if not m[0].startswith("_")]) + if not pd_funcs: + return {} + + ps_funcs = dict([m for m in getmembers(ps_module, isfunction) if not m[0].startswith("_")]) + + return _organize_by_implementation_status( + module_name, pd_funcs, ps_funcs, pd_module_group, ps_module_group + ) + + +def _organize_by_implementation_status( + module_name: str, + pd_funcs: Dict[str, Callable], + ps_funcs: Dict[str, Callable], + pd_module_group: Any, + ps_module_group: Any, +) -> Dict[str, SupportedStatus]: + """ + Check the implementation status and parameters of both modules. + + Parmeters + --------- + module_name : str + Class name that exists in the path of the module. + pd_funcs: Dict[str, Callable] + function name and function object mapping of pandas module. + ps_funcs: Dict[str, Callable] + function name and function object mapping of pyspark.pandas module. + pd_module_group : Any + Specific path of importable pandas module. + ps_module_group: Any + Specific path of importable pyspark.pandas module. + """ + pd_dict = {} + for pd_func_name, pd_func in pd_funcs.items(): + ps_func = ps_funcs.get(pd_func_name) + if ps_func: + missing_set = ( + set(signature(pd_func).parameters) + - set(signature(ps_func).parameters) + - COMMON_PARAMETER_SET + ) + if missing_set: + # partially implemented + pd_dict[pd_func_name] = SupportedStatus( + implemented=Implemented.PARTIALLY_IMPLEMENTED.value, + missing=_transform_missing( + module_name, + pd_func_name, + missing_set, + pd_module_group.__name__, + ps_module_group.__name__, + ), + ) + else: + # implemented including it's whole parameter + pd_dict[pd_func_name] = SupportedStatus( + implemented=Implemented.IMPLEMENTED.value, missing="" + ) + else: + # not implemented yet + pd_dict[pd_func_name] = SupportedStatus( + implemented=Implemented.NOT_IMPLEMENTED.value, missing="" + ) + return pd_dict + + +def _transform_missing( + module_name: str, + pd_func_name: str, + missing_set: Set[str], + pd_module_path: str, + ps_module_path: str, +) -> str: + """ + Transform missing parameters into table information string. + + Parameters + ---------- + module_name : str + Class name that exists in the path of the module. + pd_func_name : str + Name of pandas API. + missing_set : Set[str] + A set of parameters not yet implemented. + pd_module_path : str + Path string of pandas module. + ps_module_path : str + Path string of pyspark.pandas module. + + Examples + -------- + >>> _transform_missing("DataFrame", "add", {"axis", "fill_value", "level"}, + ... "pandas.DataFrame", "pyspark.pandas.DataFrame") + '``axis`` , ``fill_value`` , ``level``' + """ + missing_str = " , ".join("``%s``" % x for x in sorted(missing_set)[:MAX_MISSING_PARAMS_SIZE]) + if len(missing_set) > MAX_MISSING_PARAMS_SIZE: + module_dot_func = "%s.%s" % (module_name, pd_func_name) if module_name else pd_func_name + additional_str = ( + " and more. See the " + + "`%s.%s " % (pd_module_path, module_dot_func) + + "<https://pandas.pydata.org/docs/reference/api/"; + + "%s.%s.html>`__ and " % (pd_module_path, module_dot_func) + + "`%s.%s " % (ps_module_path, module_dot_func) + + "<https://spark.apache.org/docs/latest/api/python/reference/pyspark.pandas/api/"; + + "%s.%s.html>`__ for detail." % (ps_module_path, module_dot_func) + ) + missing_str += additional_str + return missing_str + + +def _get_pd_modules(pd_module_group: Any) -> List[str]: + """ + Returns sorted pandas memeber list from pandas module path. + + Parameters + ---------- + pd_module_group : Any + Specific path of importable pandas module. + """ + return sorted([m[0] for m in getmembers(pd_module_group, isclass) if not m[0].startswith("_")]) + + +def _update_all_supported_status( + all_supported_status: Dict[Tuple[str, str], Dict[str, SupportedStatus]], + pd_modules: List[str], + pd_module_group: Any, + ps_module_group: Any, +) -> None: + """ + Updates supported status across multiple module paths. + + Parmeters + --------- + all_supported_status: Dict[Tuple[str, str], Dict[str, SupportedStatus]] + Data that stores the supported status across multiple module paths. + pd_modles: List[str] + Name list of pandas modules. + pd_module_group : Any + Specific path of importable pandas module. + ps_module_group: Any + Specific path of importable pyspark.pandas module. + """ + pd_modules += [""] # for General Function APIs + for module_name in pd_modules: + supported_status = _create_supported_by_module( + module_name, pd_module_group, ps_module_group + ) + if supported_status: + all_supported_status[(module_name, ps_module_group.__name__)] = supported_status + + +def _write_table( + module_name: str, + module_path: str, + supported_status: Dict[str, SupportedStatus], + w_fd: TextIO, +) -> None: + """ + Write table by using Sphinx list-table directive. + """ + lines = [] + lines.append("Supported ") + if module_name: + lines.append(module_name) + else: + lines.append("General Function") + lines.append(" APIs\n") + lines.append("-" * 100) + lines.append("\n") + lines.append(".. currentmodule:: %s" % module_path) + if module_name: + lines.append(".%s\n" % module_name) + else: + lines.append("\n") + lines.append("\n") + lines.append(".. list-table::\n") + lines.append(" :header-rows: 1\n") + lines.append("\n") + lines.append(" * - API\n") + lines.append(" - Implemented\n") + lines.append(" - Missing parameters\n") + for func_str, status in supported_status.items(): + func_str = _escape_func_str(func_str) + if status.implemented == Implemented.NOT_IMPLEMENTED.value: + lines.append(" * - %s\n" % func_str) + else: + lines.append(" * - :func:`%s`\n" % func_str) Review Comment: another example: 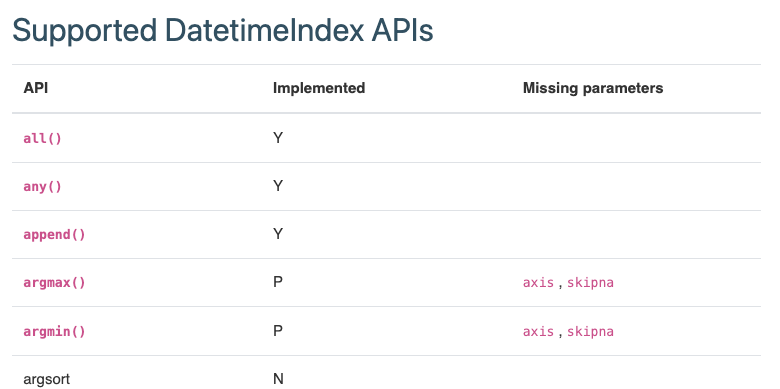 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org --------------------------------------------------------------------- To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
{kind=link}