kuwii commented on PR #39190:
URL: https://github.com/apache/spark/pull/39190#issuecomment-1398579998
I'm not familiar with how Spark creates and runs jobs and stages for a
query, but I think it may be related to this case. I can reproduce this locally
using Spark on Yarn mode with this code:
```python
from pyspark import SparkConf, SparkContext
from pyspark.sql import SQLContext
from pyspark.sql.functions import countDistinct, col, count, when
import time
conf = SparkConf().setAppName('test')
sc = SparkContext(conf = conf)
spark = SQLContext(sc).sparkSession
spark.range(1, 100).count()
```
The execution for `count` creates 2 jobs: job 0 with stage 0 and job 1 with
stage 1, 2.
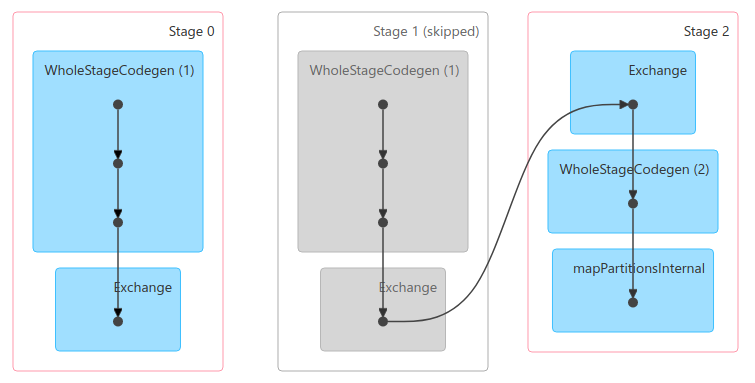
Because of some logic, stage 1 will always be skipped, not even submitted.
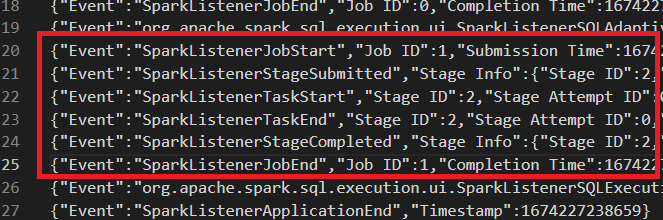
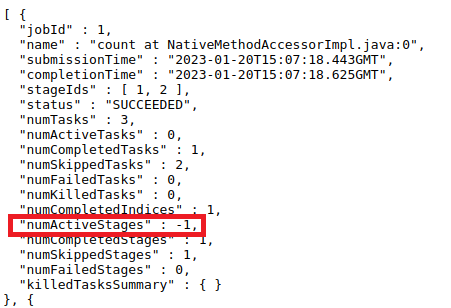
This is the case that is mentioned in the PR's description. And because the
incorrect logic of updating `numActiveStages`, it will be `-1` in jobs API.
This PR can fix it.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
{kind=link}
{kind=link}
{kind=link}