GitHub user jaceklaskowski opened a pull request:
https://github.com/apache/spark/pull/20855
[SPARK-23731][SQL] FileSourceScanExec throws NullPointerException in
subexpression elimination
## What changes were proposed in this pull request?
Avoids (not necessarily fixes) a NullPointerException in subexpression
elimination for subqueries with FileSourceScanExec.
## How was this patch tested?
Local build. No new tests as I could not reproduce it other than using the
query and data under NDA. Waiting for Jenkins.
You can merge this pull request into a Git repository by running:
$ git pull https://github.com/jaceklaskowski/spark
SPARK-23731-FileSourceScanExec-throws-NPE
Alternatively you can review and apply these changes as the patch at:
https://github.com/apache/spark/pull/20855.patch
To close this pull request, make a commit to your master/trunk branch
with (at least) the following in the commit message:
This closes #20855
----
commit 8ef323c572cee181e3bdbddeeb7119eda03d78f4
Author: Dongjoon Hyun <dongjoon@...>
Date: 2018-01-17T06:32:18Z
[SPARK-23072][SQL][TEST] Add a Unicode schema test for file-based data
sources
## What changes were proposed in this pull request?
After [SPARK-20682](https://github.com/apache/spark/pull/19651), Apache
Spark 2.3 is able to read ORC files with Unicode schema. Previously, it raises
`org.apache.spark.sql.catalyst.parser.ParseException`.
This PR adds a Unicode schema test for CSV/JSON/ORC/Parquet file-based data
sources. Note that TEXT data source only has [a single column with a fixed name
'value'](https://github.com/apache/spark/blob/master/sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/text/TextFileFormat.scala#L71).
## How was this patch tested?
Pass the newly added test case.
Author: Dongjoon Hyun <dongj...@apache.org>
Closes #20266 from dongjoon-hyun/SPARK-23072.
(cherry picked from commit a0aedb0ded4183cc33b27e369df1cbf862779e26)
Signed-off-by: Wenchen Fan <wenc...@databricks.com>
commit bfbc2d41b8a9278b347b6df2d516fe4679b41076
Author: Henry Robinson <henry@...>
Date: 2018-01-17T08:01:41Z
[SPARK-23062][SQL] Improve EXCEPT documentation
## What changes were proposed in this pull request?
Make the default behavior of EXCEPT (i.e. EXCEPT DISTINCT) more
explicit in the documentation, and call out the change in behavior
from 1.x.
Author: Henry Robinson <he...@cloudera.com>
Closes #20254 from henryr/spark-23062.
(cherry picked from commit 1f3d933e0bd2b1e934a233ed699ad39295376e71)
Signed-off-by: gatorsmile <gatorsm...@gmail.com>
commit cbb6bda437b0d2832496b5c45f8264e5527f1cce
Author: Dongjoon Hyun <dongjoon@...>
Date: 2018-01-17T13:53:36Z
[SPARK-21783][SQL] Turn on ORC filter push-down by default
## What changes were proposed in this pull request?
ORC filter push-down is disabled by default from the beginning,
[SPARK-2883](https://github.com/apache/spark/commit/aa31e431fc09f0477f1c2351c6275769a31aca90#diff-41ef65b9ef5b518f77e2a03559893f4dR149
).
Now, Apache Spark starts to depend on Apache ORC 1.4.1. For Apache Spark
2.3, this PR turns on ORC filter push-down by default like Parquet
([SPARK-9207](https://issues.apache.org/jira/browse/SPARK-21783)) as a part of
[SPARK-20901](https://issues.apache.org/jira/browse/SPARK-20901), "Feature
parity for ORC with Parquet".
## How was this patch tested?
Pass the existing tests.
Author: Dongjoon Hyun <dongj...@apache.org>
Closes #20265 from dongjoon-hyun/SPARK-21783.
(cherry picked from commit 0f8a28617a0742d5a99debfbae91222c2e3b5cec)
Signed-off-by: Wenchen Fan <wenc...@databricks.com>
commit aae73a21a42fa366a09c2be1a4b91308ef211beb
Author: Wang Gengliang <ltnwgl@...>
Date: 2018-01-17T16:05:26Z
[SPARK-23079][SQL] Fix query constraints propagation with aliases
## What changes were proposed in this pull request?
Previously, PR #19201 fix the problem of non-converging constraints.
After that PR #19149 improve the loop and constraints is inferred only once.
So the problem of non-converging constraints is gone.
However, the case below will fail.
```
spark.range(5).write.saveAsTable("t")
val t = spark.read.table("t")
val left = t.withColumn("xid", $"id" + lit(1)).as("x")
val right = t.withColumnRenamed("id", "xid").as("y")
val df = left.join(right, "xid").filter("id = 3").toDF()
checkAnswer(df, Row(4, 3))
```
Because `aliasMap` replace all the aliased child. See the test case in PR
for details.
This PR is to fix this bug by removing useless code for preventing
non-converging constraints.
It can be also fixed with #20270, but this is much simpler and clean up the
code.
## How was this patch tested?
Unit test
Author: Wang Gengliang <ltn...@gmail.com>
Closes #20278 from gengliangwang/FixConstraintSimple.
(cherry picked from commit 8598a982b4147abe5f1aae005fea0fd5ae395ac4)
Signed-off-by: Wenchen Fan <wenc...@databricks.com>
commit 1a6dfaf25f507545debdf4cb1d427b9cc78c3cc8
Author: Sameer Agarwal <sameerag@...>
Date: 2018-01-17T17:27:49Z
[SPARK-23020] Ignore Flaky Test: SparkLauncherSuite.testInProcessLauncher
## What changes were proposed in this pull request?
Temporarily ignoring flaky test `SparkLauncherSuite.testInProcessLauncher`
to de-flake the builds. This should be re-enabled when SPARK-23020 is merged.
## How was this patch tested?
N/A (Test Only Change)
Author: Sameer Agarwal <samee...@apache.org>
Closes #20291 from sameeragarwal/disable-test-2.
(cherry picked from commit c132538a164cd8b55dbd7e8ffdc0c0782a0b588c)
Signed-off-by: Sameer Agarwal <samee...@apache.org>
commit dbd2a5566d8924ab340c3c840d31e83e5af92242
Author: Jose Torres <jose@...>
Date: 2018-01-17T21:52:51Z
[SPARK-23033][SS] Don't use task level retry for continuous processing
## What changes were proposed in this pull request?
Continuous processing tasks will fail on any attempt number greater than 0.
ContinuousExecution will catch these failures and restart globally from the
last recorded checkpoints.
## How was this patch tested?
unit test
Author: Jose Torres <j...@databricks.com>
Closes #20225 from jose-torres/no-retry.
(cherry picked from commit 86a845031824a5334db6a5299c6f5dcc982bc5b8)
Signed-off-by: Tathagata Das <tathagata.das1...@gmail.com>
commit 79ccd0cadf09c41c0f4b5853a54798be17a20584
Author: Jose Torres <jose@...>
Date: 2018-01-17T21:58:44Z
[SPARK-23093][SS] Don't change run id when reconfiguring a continuous
processing query.
## What changes were proposed in this pull request?
Keep the run ID static, using a different ID for the epoch coordinator to
avoid cross-execution message contamination.
## How was this patch tested?
new and existing unit tests
Author: Jose Torres <j...@databricks.com>
Closes #20282 from jose-torres/fix-runid.
(cherry picked from commit e946c63dd56d121cf898084ed7e9b5b0868b226e)
Signed-off-by: Shixiong Zhu <zsxw...@gmail.com>
commit 6e509fde3f056316f46c71b672a7d69adb1b4f8e
Author: Li Jin <ice.xelloss@...>
Date: 2018-01-17T22:26:43Z
[SPARK-23047][PYTHON][SQL] Change MapVector to NullableMapVector in
ArrowColumnVector
## What changes were proposed in this pull request?
This PR changes usage of `MapVector` in Spark codebase to use
`NullableMapVector`.
`MapVector` is an internal Arrow class that is not supposed to be used
directly. We should use `NullableMapVector` instead.
## How was this patch tested?
Existing test.
Author: Li Jin <ice.xell...@gmail.com>
Closes #20239 from icexelloss/arrow-map-vector.
(cherry picked from commit 4e6f8fb150ae09c7d1de6beecb2b98e5afa5da19)
Signed-off-by: hyukjinkwon <gurwls...@gmail.com>
commit b84c2a30665ebbd65feb7418826501f6c959eb96
Author: hyukjinkwon <gurwls223@...>
Date: 2018-01-17T22:30:54Z
[SPARK-23132][PYTHON][ML] Run doctests in ml.image when testing
## What changes were proposed in this pull request?
This PR proposes to actually run the doctests in `ml/image.py`.
## How was this patch tested?
doctests in `python/pyspark/ml/image.py`.
Author: hyukjinkwon <gurwls...@gmail.com>
Closes #20294 from HyukjinKwon/trigger-image.
(cherry picked from commit 45ad97df87c89cb94ce9564e5773897b6d9326f5)
Signed-off-by: hyukjinkwon <gurwls...@gmail.com>
commit 9783aea2c75700e7ce9551ccfd33e43765de8981
Author: Tathagata Das <tathagata.das1565@...>
Date: 2018-01-18T00:40:02Z
[SPARK-23119][SS] Minor fixes to V2 streaming APIs
## What changes were proposed in this pull request?
- Added `InterfaceStability.Evolving` annotations
- Improved docs.
## How was this patch tested?
Existing tests.
Author: Tathagata Das <tathagata.das1...@gmail.com>
Closes #20286 from tdas/SPARK-23119.
(cherry picked from commit bac0d661af6092dd26638223156827aceb901229)
Signed-off-by: Shixiong Zhu <zsxw...@gmail.com>
commit 050c1e24e506ff224bcf4e3e458e57fbd216765c
Author: Tathagata Das <tathagata.das1565@...>
Date: 2018-01-18T00:41:43Z
[SPARK-23064][DOCS][SS] Added documentation for stream-stream joins
## What changes were proposed in this pull request?
Added documentation for stream-stream joins




## How was this patch tested?
N/a
Author: Tathagata Das <tathagata.das1...@gmail.com>
Closes #20255 from tdas/join-docs.
(cherry picked from commit 1002bd6b23ff78a010ca259ea76988ef4c478c6e)
Signed-off-by: Shixiong Zhu <zsxw...@gmail.com>
commit f2688ef0fbd9d355d13ce4056d35e99970f4cd47
Author: Xiayun Sun <xiayunsun@...>
Date: 2018-01-18T00:42:38Z
[SPARK-21996][SQL] read files with space in name for streaming
## What changes were proposed in this pull request?
Structured streaming is now able to read files with space in file name
(previously it would skip the file and output a warning)
## How was this patch tested?
Added new unit test.
Author: Xiayun Sun <xiayun...@gmail.com>
Closes #19247 from xysun/SPARK-21996.
(cherry picked from commit 02194702068291b3af77486d01029fb848c36d7b)
Signed-off-by: Shixiong Zhu <zsxw...@gmail.com>
commit 3a80cc59b54bb8e92df507777e836f167a4db14e
Author: hyukjinkwon <gurwls223@...>
Date: 2018-01-18T05:51:05Z
[SPARK-23122][PYTHON][SQL] Deprecate register* for UDFs in SQLContext and
Catalog in PySpark
## What changes were proposed in this pull request?
This PR proposes to deprecate `register*` for UDFs in `SQLContext` and
`Catalog` in Spark 2.3.0.
These are inconsistent with Scala / Java APIs and also these basically do
the same things with `spark.udf.register*`.
Also, this PR moves the logcis from `[sqlContext|spark.catalog].register*`
to `spark.udf.register*` and reuse the docstring.
This PR also handles minor doc corrections. It also includes
https://github.com/apache/spark/pull/20158
## How was this patch tested?
Manually tested, manually checked the API documentation and tests added to
check if deprecated APIs call the aliases correctly.
Author: hyukjinkwon <gurwls...@gmail.com>
Closes #20288 from HyukjinKwon/deprecate-udf.
(cherry picked from commit 39d244d921d8d2d3ed741e8e8f1175515a74bdbd)
Signed-off-by: Takuya UESHIN <ues...@databricks.com>
commit 2a87c3a77cbe40cbe5a8bdef41e3c37a660e2308
Author: Jose Torres <jose@...>
Date: 2018-01-18T06:36:29Z
[SPARK-23052][SS] Migrate ConsoleSink to data source V2 api.
## What changes were proposed in this pull request?
Migrate ConsoleSink to data source V2 api.
Note that this includes a missing piece in DataStreamWriter required to
specify a data source V2 writer.
Note also that I've removed the "Rerun batch" part of the sink, because as
far as I can tell this would never have actually happened. A
MicroBatchExecution object will only commit each batch once for its lifetime,
and a new MicroBatchExecution object would have a new ConsoleSink object which
doesn't know it's retrying a batch. So I think this represents an anti-feature
rather than a weakness in the V2 API.
## How was this patch tested?
new unit test
Author: Jose Torres <j...@databricks.com>
Closes #20243 from jose-torres/console-sink.
(cherry picked from commit 1c76a91e5fae11dcb66c453889e587b48039fdc9)
Signed-off-by: Tathagata Das <tathagata.das1...@gmail.com>
commit f801ac417ba13a975887ba83904ee771bc3a003e
Author: jerryshao <sshao@...>
Date: 2018-01-18T11:18:55Z
[SPARK-23140][SQL] Add DataSourceV2Strategy to Hive Session state's planner
## What changes were proposed in this pull request?
`DataSourceV2Strategy` is missing in `HiveSessionStateBuilder`'s planner,
which will throw exception as described in
[SPARK-23140](https://issues.apache.org/jira/browse/SPARK-23140).
## How was this patch tested?
Manual test.
Author: jerryshao <ss...@hortonworks.com>
Closes #20305 from jerryshao/SPARK-23140.
(cherry picked from commit 7a2248341396840628eef398aa512cac3e3bd55f)
Signed-off-by: Wenchen Fan <wenc...@databricks.com>
commit 8a98274823a4671cee85081dd19f40146e736325
Author: Marco Gaido <marcogaido91@...>
Date: 2018-01-18T13:24:39Z
[SPARK-22036][SQL] Decimal multiplication with high precision/scale often
returns NULL
## What changes were proposed in this pull request?
When there is an operation between Decimals and the result is a number
which is not representable exactly with the result's precision and scale, Spark
is returning `NULL`. This was done to reflect Hive's behavior, but it is
against SQL ANSI 2011, which states that "If the result cannot be represented
exactly in the result type, then whether it is rounded or truncated is
implementation-defined". Moreover, Hive now changed its behavior in order to
respect the standard, thanks to HIVE-15331.
Therefore, the PR propose to:
- update the rules to determine the result precision and scale according
to the new Hive's ones introduces in HIVE-15331;
- round the result of the operations, when it is not representable exactly
with the result's precision and scale, instead of returning `NULL`
- introduce a new config `spark.sql.decimalOperations.allowPrecisionLoss`
which default to `true` (ie. the new behavior) in order to allow users to
switch back to the previous one.
Hive behavior reflects SQLServer's one. The only difference is that the
precision and scale are adjusted for all the arithmetic operations in Hive,
while SQL Server is said to do so only for multiplications and divisions in the
documentation. This PR follows Hive's behavior.
A more detailed explanation is available here:
https://mail-archives.apache.org/mod_mbox/spark-dev/201712.mbox/%3CCAEorWNAJ4TxJR9NBcgSFMD_VxTg8qVxusjP%2BAJP-x%2BJV9zH-yA%40mail.gmail.com%3E.
## How was this patch tested?
modified and added UTs. Comparisons with results of Hive and SQLServer.
Author: Marco Gaido <marcogaid...@gmail.com>
Closes #20023 from mgaido91/SPARK-22036.
(cherry picked from commit e28eb431146bcdcaf02a6f6c406ca30920592a6a)
Signed-off-by: Wenchen Fan <wenc...@databricks.com>
commit e0421c65093f66b365539358dd9be38d2006fa47
Author: Takuya UESHIN <ueshin@...>
Date: 2018-01-18T13:33:04Z
[SPARK-23141][SQL][PYSPARK] Support data type string as a returnType for
registerJavaFunction.
## What changes were proposed in this pull request?
Currently `UDFRegistration.registerJavaFunction` doesn't support data type
string as a `returnType` whereas `UDFRegistration.register`, `udf`, or
`pandas_udf` does.
We can support it for `UDFRegistration.registerJavaFunction` as well.
## How was this patch tested?
Added a doctest and existing tests.
Author: Takuya UESHIN <ues...@databricks.com>
Closes #20307 from ueshin/issues/SPARK-23141.
(cherry picked from commit 5063b7481173ad72bd0dc941b5cf3c9b26a591e4)
Signed-off-by: hyukjinkwon <gurwls...@gmail.com>
commit bd0a1627b9396c69dbe3554e6ca6c700eeb08f74
Author: jerryshao <sshao@...>
Date: 2018-01-18T18:19:36Z
[SPARK-23147][UI] Fix task page table IndexOutOfBound Exception
## What changes were proposed in this pull request?
Stage's task page table will throw an exception when there's no complete
tasks. Furthermore, because the `dataSize` doesn't take running tasks into
account, so sometimes UI cannot show the running tasks. Besides table will only
be displayed when first task is finished according to the default
sortColumn("index").
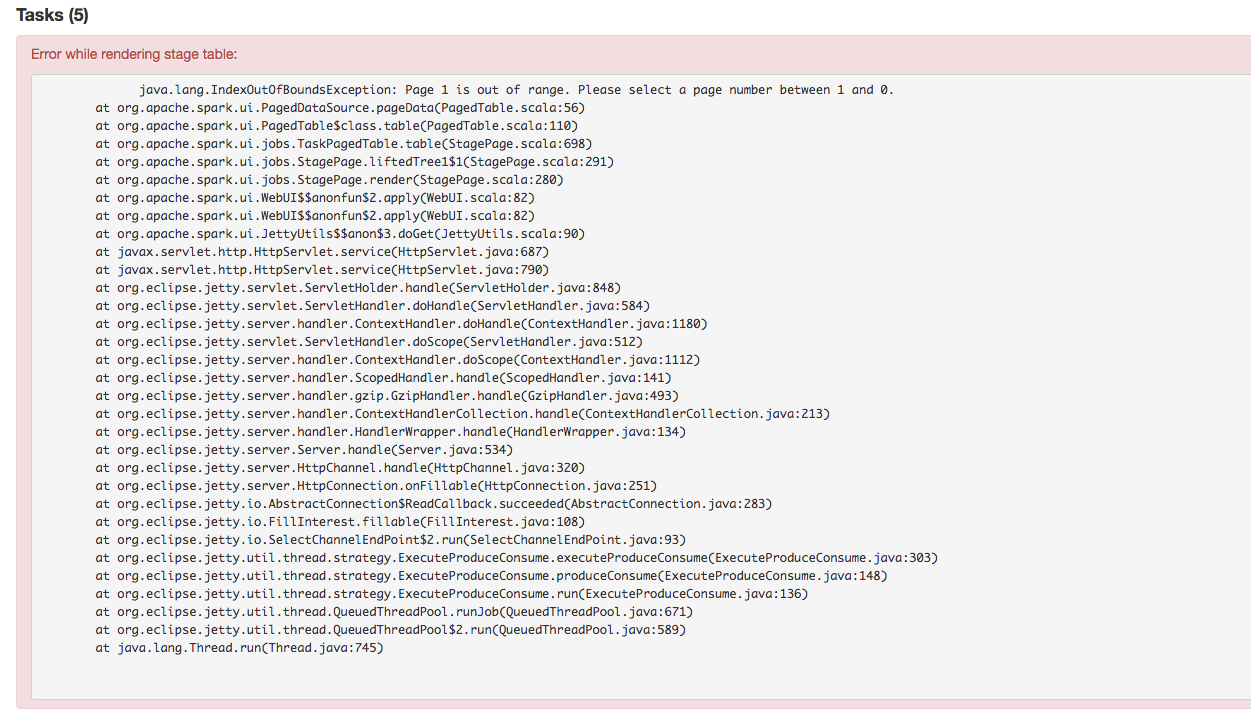
To reproduce this issue, user could try `sc.parallelize(1 to 20, 20).map {
i => Thread.sleep(10000); i }.collect()` or `sc.parallelize(1 to 20, 20).map {
i => Thread.sleep((20 - i) * 1000); i }.collect` to reproduce the above issue.
Here propose a solution to fix it. Not sure if it is a right fix, please
help to review.
## How was this patch tested?
Manual test.
Author: jerryshao <ss...@hortonworks.com>
Closes #20315 from jerryshao/SPARK-23147.
(cherry picked from commit cf7ee1767ddadce08dce050fc3b40c77cdd187da)
Signed-off-by: Marcelo Vanzin <van...@cloudera.com>
commit bfdbdd37951a872676a22b0524cbde12a1df418d
Author: Fernando Pereira <fernando.pereira@...>
Date: 2018-01-18T19:02:03Z
[SPARK-23029][DOCS] Specifying default units of configuration entries
## What changes were proposed in this pull request?
This PR completes the docs, specifying the default units assumed in
configuration entries of type size.
This is crucial since unit-less values are accepted and the user might
assume the base unit is bytes, which in most cases it is not, leading to
hard-to-debug problems.
## How was this patch tested?
This patch updates only documentation only.
Author: Fernando Pereira <fernando.pere...@epfl.ch>
Closes #20269 from ferdonline/docs_units.
(cherry picked from commit 9678941f54ebc5db935ed8d694e502086e2a31c0)
Signed-off-by: Sean Owen <so...@cloudera.com>
commit e6e8bbe84625861f3a4834a2d71cb2f0fe7f6b5a
Author: Tathagata Das <tathagata.das1565@...>
Date: 2018-01-18T20:25:52Z
[SPARK-23143][SS][PYTHON] Added python API for setting continuous trigger
## What changes were proposed in this pull request?
Self-explanatory.
## How was this patch tested?
New python tests.
Author: Tathagata Das <tathagata.das1...@gmail.com>
Closes #20309 from tdas/SPARK-23143.
(cherry picked from commit 2d41f040a34d6483919fd5d491cf90eee5429290)
Signed-off-by: Tathagata Das <tathagata.das1...@gmail.com>
commit 1f88fcd41c6c5521d732b25e83d6c9d150d7f24a
Author: Tathagata Das <tathagata.das1565@...>
Date: 2018-01-18T20:33:39Z
[SPARK-23144][SS] Added console sink for continuous processing
## What changes were proposed in this pull request?
Refactored ConsoleWriter into ConsoleMicrobatchWriter and
ConsoleContinuousWriter.
## How was this patch tested?
new unit test
Author: Tathagata Das <tathagata.das1...@gmail.com>
Closes #20311 from tdas/SPARK-23144.
(cherry picked from commit bf34d665b9c865e00fac7001500bf6d521c2dff9)
Signed-off-by: Tathagata Das <tathagata.das1...@gmail.com>
commit b8c6d9303d029f6bf8ee43bae3f159112eb0fb79
Author: Andrew Korzhuev <korzhuev@...>
Date: 2018-01-18T22:00:12Z
[SPARK-23133][K8S] Fix passing java options to Executor
Pass through spark java options to the executor in context of docker image.
Closes #20296
andrusha: Deployed two version of containers to local k8s, checked that
java options were present in the updated image on the running executor.
Manual test
Author: Andrew Korzhuev <korzh...@andrusha.me>
Closes #20322 from foxish/patch-1.
(cherry picked from commit f568e9cf76f657d094f1d036ab5a95f2531f5761)
Signed-off-by: Marcelo Vanzin <van...@cloudera.com>
commit a295034da6178f8654c3977903435384b3765b5e
Author: Burak Yavuz <brkyvz@...>
Date: 2018-01-18T22:36:06Z
[SPARK-23094] Fix invalid character handling in JsonDataSource
## What changes were proposed in this pull request?
There were two related fixes regarding `from_json`, `get_json_object` and
`json_tuple` ([Fix
#1](https://github.com/apache/spark/commit/c8803c06854683c8761fdb3c0e4c55d5a9e22a95),
[Fix
#2](https://github.com/apache/spark/commit/86174ea89b39a300caaba6baffac70f3dc702788)),
but they weren't comprehensive it seems. I wanted to extend those fixes to all
the parsers, and add tests for each case.
## How was this patch tested?
Regression tests
Author: Burak Yavuz <brk...@gmail.com>
Closes #20302 from brkyvz/json-invfix.
(cherry picked from commit e01919e834d301e13adc8919932796ebae900576)
Signed-off-by: hyukjinkwon <gurwls...@gmail.com>
commit 7057e310ab3756c83c13586137e8390fe9ef7e9a
Author: Yinan Li <liyinan926@...>
Date: 2018-01-18T22:44:22Z
[SPARK-22962][K8S] Fail fast if submission client local files are used
## What changes were proposed in this pull request?
In the Kubernetes mode, fails fast in the submission process if any
submission client local dependencies are used as the use case is not supported
yet.
## How was this patch tested?
Unit tests, integration tests, and manual tests.
vanzin foxish
Author: Yinan Li <liyinan...@gmail.com>
Closes #20320 from liyinan926/master.
(cherry picked from commit 5d7c4ba4d73a72f26d591108db3c20b4a6c84f3f)
Signed-off-by: Marcelo Vanzin <van...@cloudera.com>
commit acf3b70d16cc4d2416b4ce3f42b3cf95836170ed
Author: Tathagata Das <tathagata.das1565@...>
Date: 2018-01-19T00:29:45Z
[SPARK-23142][SS][DOCS] Added docs for continuous processing
## What changes were proposed in this pull request?
Added documentation for continuous processing. Modified two locations.
- Modified the overview to have a mention of Continuous Processing.
- Added a new section on Continuous Processing at the end.


## How was this patch tested?
N/A
Author: Tathagata Das <tathagata.das1...@gmail.com>
Closes #20308 from tdas/SPARK-23142.
(cherry picked from commit 4cd2ecc0c7222fef1337e04f1948333296c3be86)
Signed-off-by: Tathagata Das <tathagata.das1...@gmail.com>
commit 225b1afdd1582cd4087e7cb98834505eaf16743e
Author: brandonJY <brandonjy@...>
Date: 2018-01-19T00:57:49Z
[DOCS] change to dataset for java code in
structured-streaming-kafka-integration document
## What changes were proposed in this pull request?
In latest structured-streaming-kafka-integration document, Java code
example for Kafka integration is using `DataFrame<Row>`, shouldn't it be
changed to `DataSet<Row>`?
## How was this patch tested?
manual test has been performed to test the updated example Java code in
Spark 2.2.1 with Kafka 1.0
Author: brandonJY <brando...@users.noreply.github.com>
Closes #20312 from brandonJY/patch-2.
(cherry picked from commit 6121e91b7f5c9513d68674e4d5edbc3a4a5fd5fd)
Signed-off-by: Sean Owen <so...@cloudera.com>
commit 541dbc00b24f17d83ea2531970f2e9fe57fe3718
Author: Takuya UESHIN <ueshin@...>
Date: 2018-01-19T03:37:08Z
[SPARK-23054][SQL][PYSPARK][FOLLOWUP] Use sqlType casting when casting
PythonUserDefinedType to String.
## What changes were proposed in this pull request?
This is a follow-up of #20246.
If a UDT in Python doesn't have its corresponding Scala UDT, cast to string
will be the raw string of the internal value, e.g.
`"org.apache.spark.sql.catalyst.expressions.UnsafeArrayDataxxxxxxxx"` if the
internal type is `ArrayType`.
This pr fixes it by using its `sqlType` casting.
## How was this patch tested?
Added a test and existing tests.
Author: Takuya UESHIN <ues...@databricks.com>
Closes #20306 from ueshin/issues/SPARK-23054/fup1.
(cherry picked from commit 568055da93049c207bb830f244ff9b60c638837c)
Signed-off-by: Wenchen Fan <wenc...@databricks.com>
commit 54c1fae12df654c7713ac5e7eb4da7bb2f785401
Author: Sameer Agarwal <sameerag@...>
Date: 2018-01-19T09:38:08Z
[BUILD][MINOR] Fix java style check issues
## What changes were proposed in this pull request?
This patch fixes a few recently introduced java style check errors in
master and release branch.
As an aside, given that [java linting currently
fails](https://github.com/apache/spark/pull/10763
) on machines with a clean maven cache, it'd be great to find another
workaround to [re-enable the java style
checks](https://github.com/apache/spark/blob/3a07eff5af601511e97a05e6fea0e3d48f74c4f0/dev/run-tests.py#L577)
as part of Spark PRB.
/cc zsxwing JoshRosen srowen for any suggestions
## How was this patch tested?
Manual Check
Author: Sameer Agarwal <samee...@apache.org>
Closes #20323 from sameeragarwal/java.
(cherry picked from commit 9c4b99861cda3f9ec44ca8c1adc81a293508190c)
Signed-off-by: Sameer Agarwal <samee...@apache.org>
commit e58223171ecae6450482aadf4e7994c3b8d8a58d
Author: Nick Pentreath <nickp@...>
Date: 2018-01-19T10:43:23Z
[SPARK-23127][DOC] Update FeatureHasher guide for categoricalCols parameter
Update user guide entry for `FeatureHasher` to match the Scala / Python
doc, to describe the `categoricalCols` parameter.
## How was this patch tested?
Doc only
Author: Nick Pentreath <ni...@za.ibm.com>
Closes #20293 from MLnick/SPARK-23127-catCol-userguide.
(cherry picked from commit 60203fca6a605ad158184e1e0ce5187e144a3ea7)
Signed-off-by: Nick Pentreath <ni...@za.ibm.com>
commit ef7989d55b65f386ed1ab87535a44e9367029a52
Author: Liang-Chi Hsieh <viirya@...>
Date: 2018-01-19T10:48:42Z
[SPARK-23048][ML] Add OneHotEncoderEstimator document and examples
## What changes were proposed in this pull request?
We have `OneHotEncoderEstimator` now and `OneHotEncoder` will be deprecated
since 2.3.0. We should add `OneHotEncoderEstimator` into mllib document.
We also need to provide corresponding examples for `OneHotEncoderEstimator`
which are used in the document too.
## How was this patch tested?
Existing tests.
Author: Liang-Chi Hsieh <vii...@gmail.com>
Closes #20257 from viirya/SPARK-23048.
(cherry picked from commit b74366481cc87490adf4e69d26389ec737548c15)
Signed-off-by: Nick Pentreath <ni...@za.ibm.com>
----
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}