Github user xuanyuanking commented on the issue:
https://github.com/apache/spark/pull/21370
```
Can we also do something a bit more generic that works for non-Jupyter
notebooks as well?
```
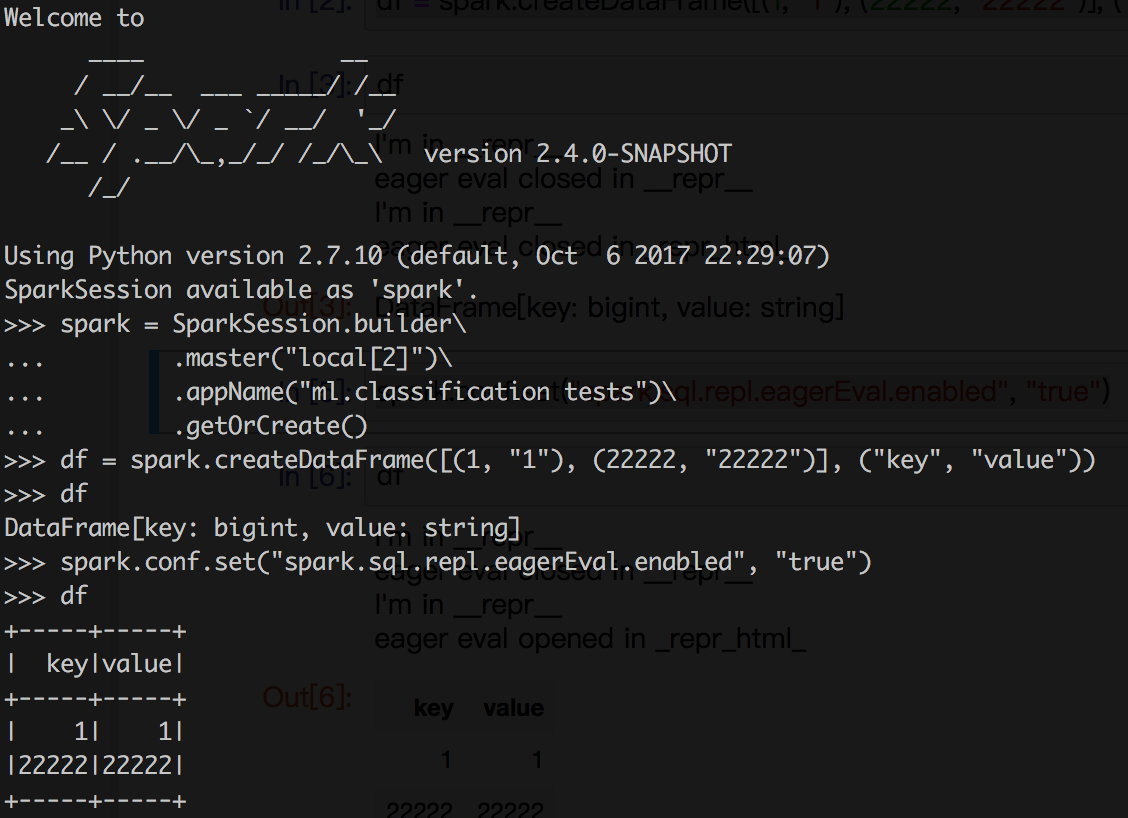
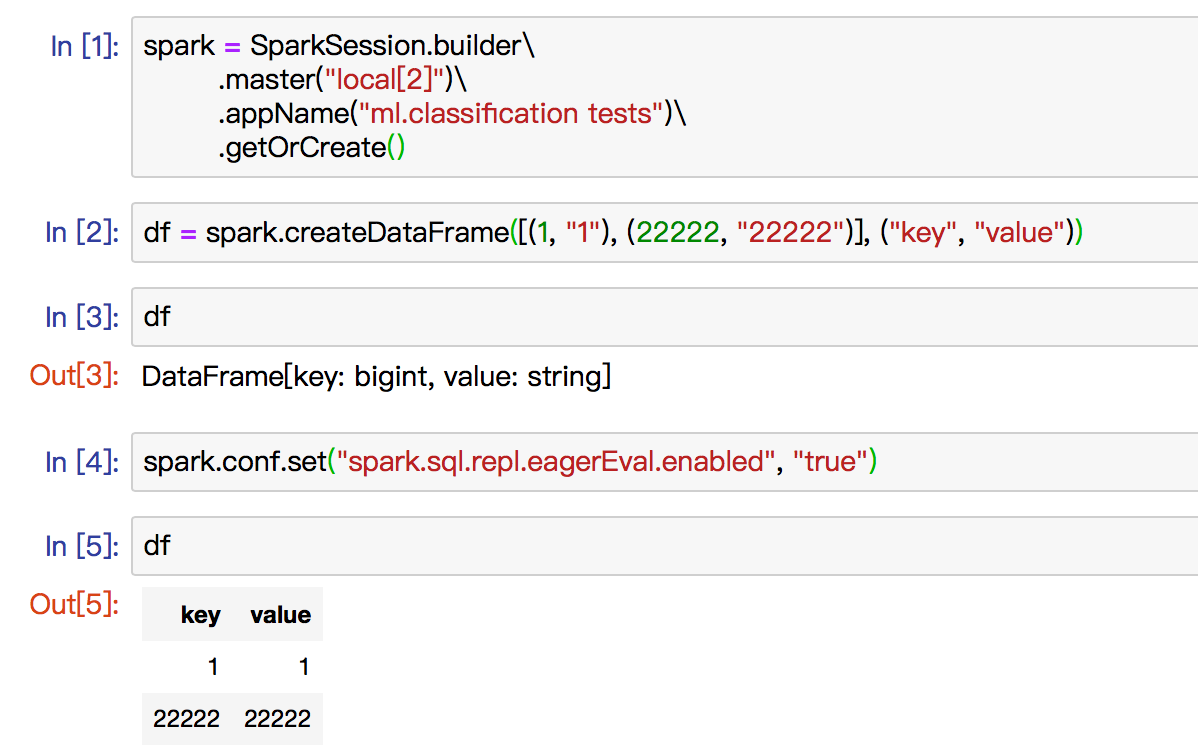
Can we accept `spark.sql.repl.eagerEval.enabled` to control both
\_\_repr\_\_ and \_repr\_html\_ ?
The behavior like below:
1. If not support _repr_html_ and open eagerEval.enable, just call
something like `show` and trigger `take` inside.
2. If support _repr_html_, use the html output. (Here need a small trick,
we should add a var in python dataframe to check whether _repr_html_ called or
not, otherwise in this mode _repr_html and __repr__ will both call showString).
I test offline an it can work both python shell and Jupyter, if we agree
this way, I'll add this support in next commit together will the refactor of
showString in scala Dataset.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
{kind=link}
{kind=link}