Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/22326#discussion_r220418201
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/Optimizer.scala
---
@@ -1304,10 +1307,27 @@ object CheckCartesianProducts extends
Rule[LogicalPlan] with PredicateHelper {
}
}
+ /**
+ * Check if a join contains PythonUDF in join condition.
+ */
+ def hasPythonUDFInJoinCondition(join: Join): Boolean = {
+ val conditions =
join.condition.map(splitConjunctivePredicates).getOrElse(Nil)
+ conditions.exists(HandlePythonUDFInJoinCondition.hasPythonUDF)
+ }
+
def apply(plan: LogicalPlan): LogicalPlan =
if (SQLConf.get.crossJoinEnabled) {
plan
} else plan transform {
+ case j @ Join(_, _, _, _) if hasPythonUDFInJoinCondition(j) =>
--- End diff --
Maybe not, we should keep the current logic, as the test below:
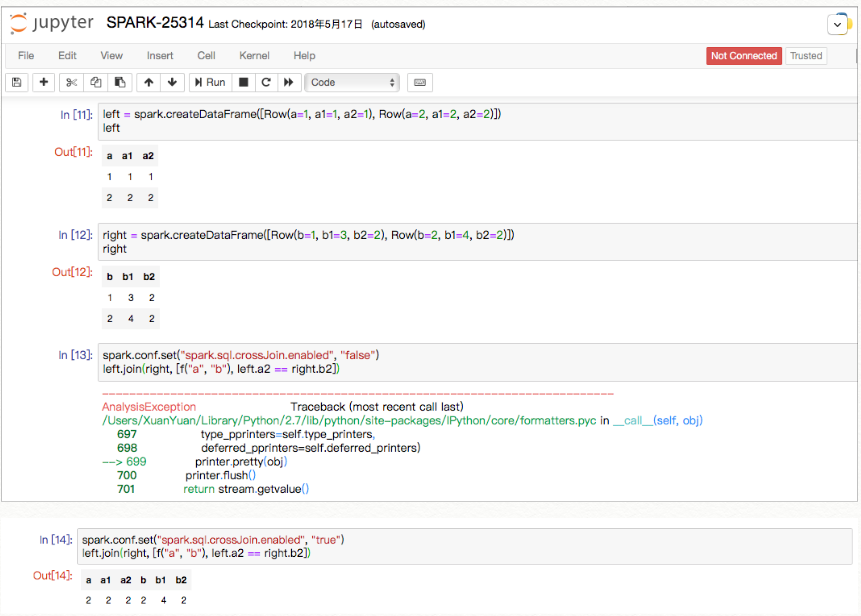
In the join condition, only one python udf but we still need this
AnalysisException. If the logic here change to `havePythonUDFInAllConditions`,
you'll get a runtime exception of `requires attributes from more than one
child.` like:
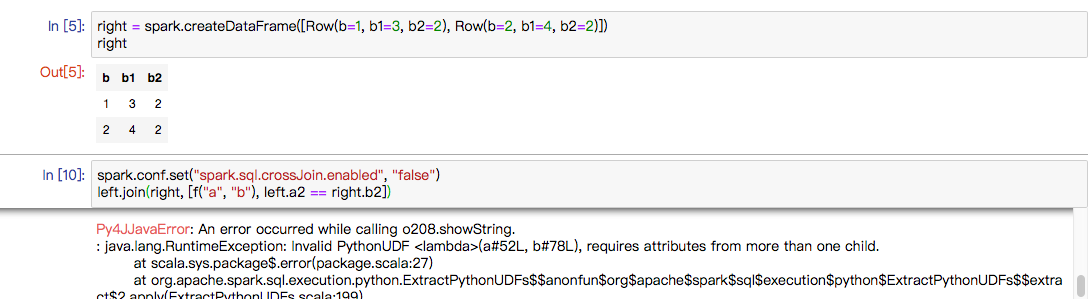
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
{kind=link}
{kind=link}