southernriver opened a new pull request #23490: [SPARK-26543][SQL] Support the coordinator to determine post-shuffle partitions more reasonably URL: https://github.com/apache/spark/pull/23490 ## What changes were proposed in this pull request? For SparkSQL ,when we open AE by 'set spark.sql.adapative.enable=true',the ExchangeCoordinator will introduced to determine the number of post-shuffle partitions. But in some certain conditions,the coordinator performed not very well, there are always some tasks retained and they worked with Shuffle Read Size / Records 0.0B/0 ,We could increase the spark.sql.adaptive.shuffle.targetPostShuffleInputSize to solve this,but this action is unreasonable as targetPostShuffleInputSize Should not be set too large. As follow: 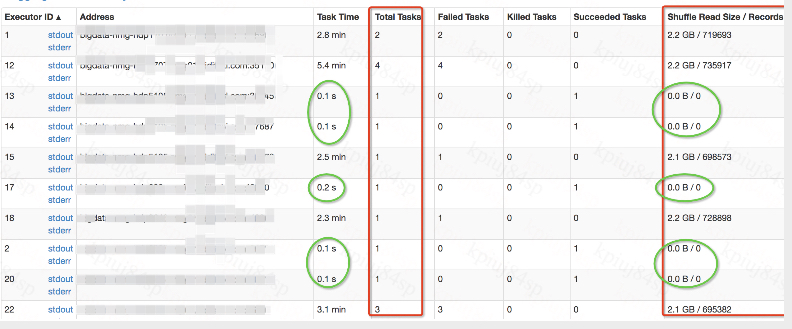 We could reproduce this problem easily with the SQL: `set spark.sql.adaptive.enabled=true;` ` spark.sql.shuffle.partitions 100;` ` spark.sql.adaptive.shuffle.targetPostShuffleInputSize 33554432 ;` ` SELECT a,COUNT(1) FROM TABLE GROUP BY a DISTRIBUTE BY cast(rand()* 10 as bigint)` before fix: 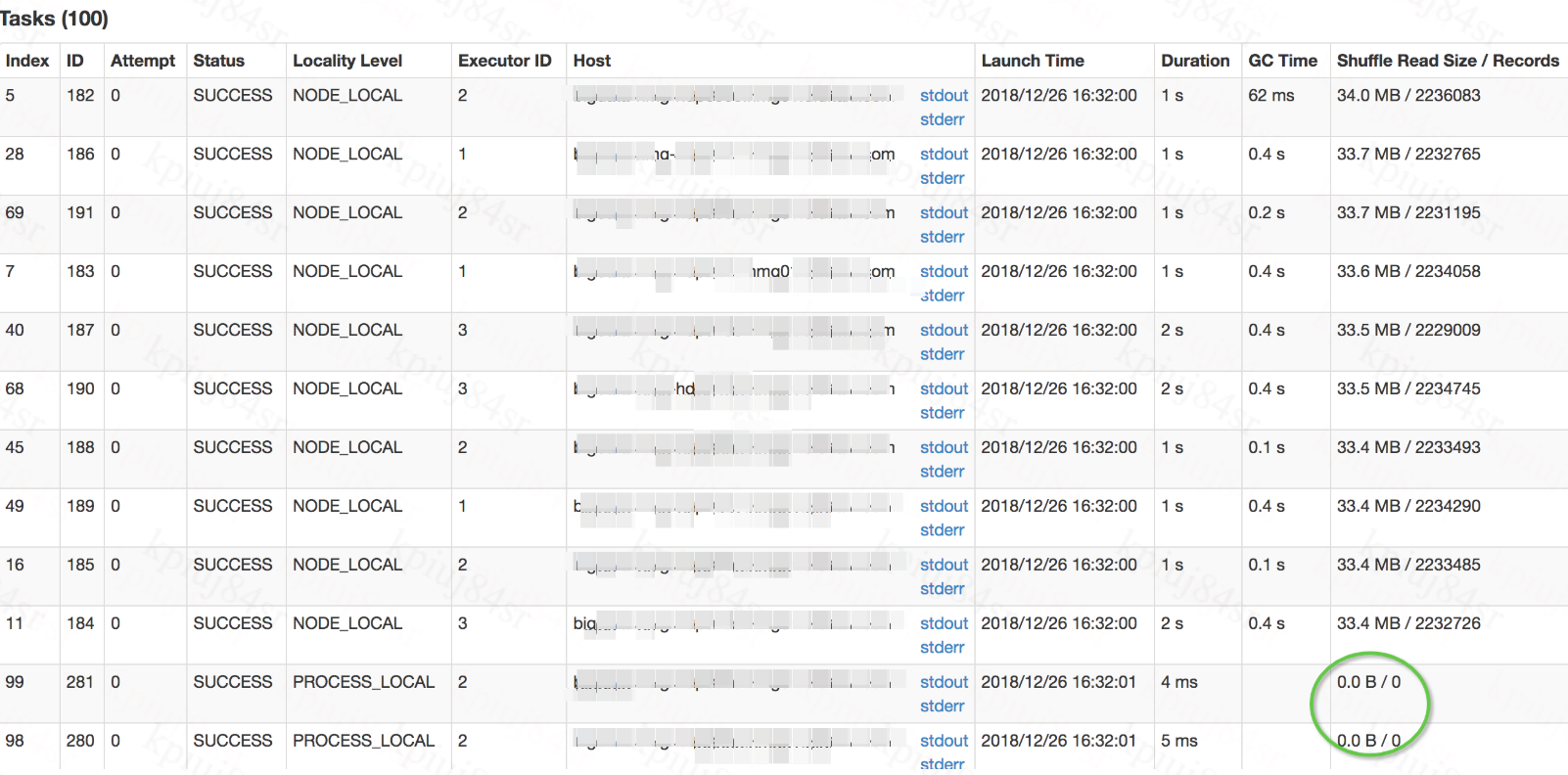 after fix: 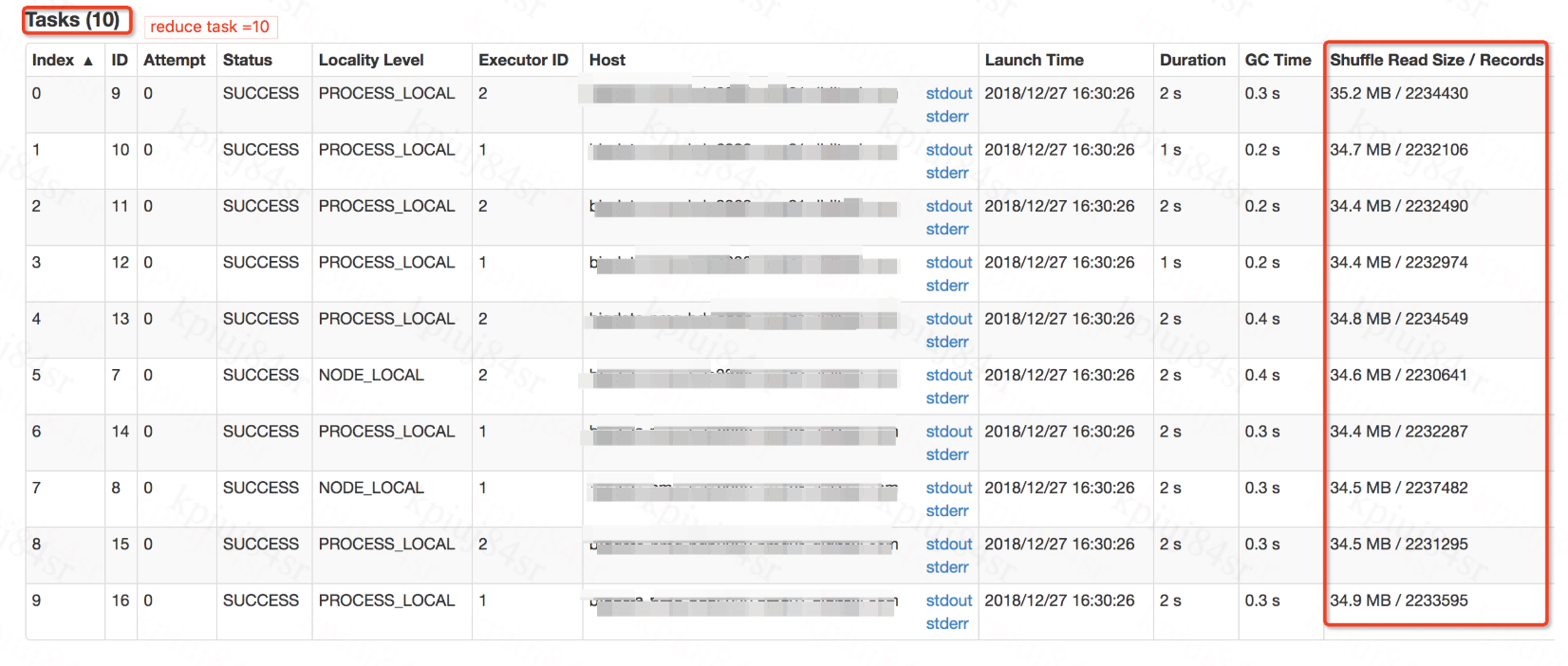 ## How was this patch tested? manual and unit tests
{kind=link}
{kind=link}
{kind=link}
---------------------------------------------------------------- This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services --------------------------------------------------------------------- To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org