js2xml is based on slimit (https://github.com/rspivak/slimit), so it does parse Javascript code (but does not compile it) It's on PyPI (https://pypi.python.org/pypi/js2xml), so you can pip install js2xml
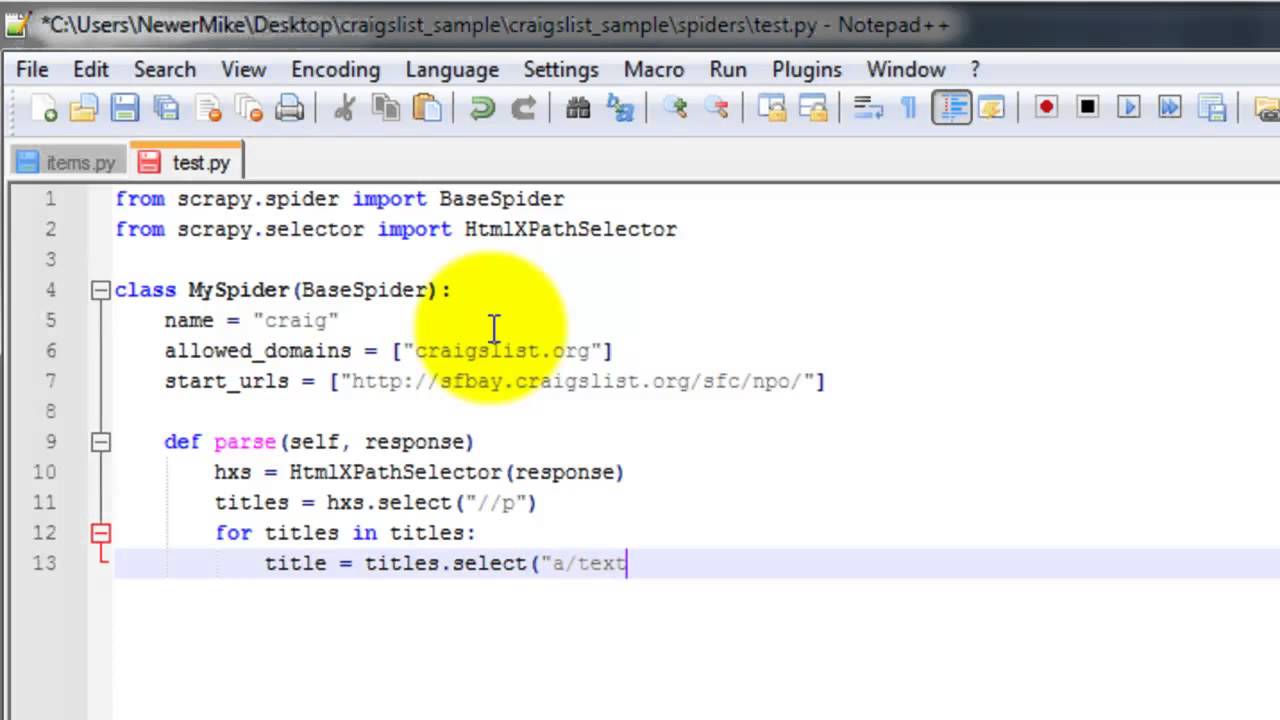
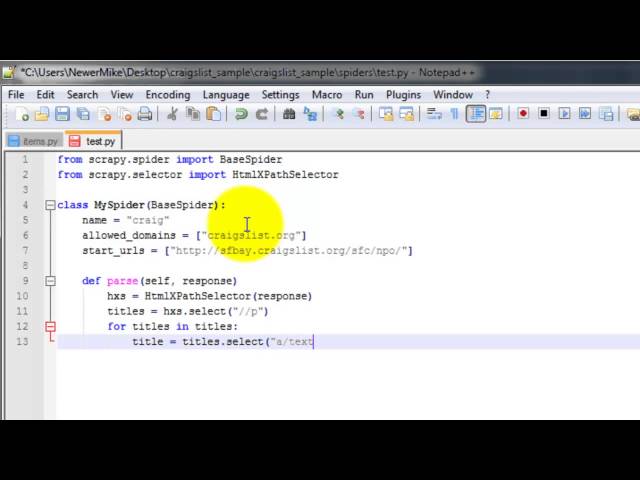
js2xml.jsonlike module contains methods that proved useful to quickly get things that can be represented as dicts in Python (arrays, strings etc), that are used as init values for variables, or function arguments. But in fact js2xml.parse() does build an (lxml) parse tree of the code, so you can use XPath to dig into Javascript source. So you can for example get arguments for a specific function by it's name Here are a few example of what you get: https://github.com/redapple/js2xml/blob/master/SCHEMA.rst I find it so much easier than regexp (but the performance can be improved) I should really publish docs to readthedocs On Tue, Dec 30, 2014 at 8:17 PM, bruce <[email protected]> wrote: > Hey Paul, > > Good catch, I totally missed/forgot to ask if the source displayed the > "video" element, or just how he got the "source" he listed.. > > By the way, the app you mentioned, for the js xml, I'm assuming it only > works where it can really rip apart exiting dicts to exract certain data. > > It's not really a "jscript parser/compiler" for python is it??!! > > That would be wishful thinking!! > > I'm looking at different dynamic sites that require combination of > straight static parsing, as well as dynamic casperjs parsing. > > Thanks > > > On Tue, Dec 30, 2014 at 9:30 AM, Paul Tremberth <[email protected]> > wrote: > >> YouTube pages rely on Javascript to create the <video> element, >> and your browser's XPath tool works because it operates on the rendered >> page, after Javascript has done its work. >> >> Scrapy itself does not interpret Javascript instructions, it's not a >> browser, >> so it can only work on what's inside the HTML source code when the web >> page is fetched. >> >> You can see for example that the elements with ID "player-api", which >> contains "movie-player" in your screenshot, >> is empty in the source code >> >> <div id="player-api" class="player-width player-height >> off-screen-target player-api"></div> >> >> What you can see also is that this #player-api element is followed by >> <script> elements. >> And while is not straighforward to read what this Javascript code is >> about, >> you can use js2xml (disclaimer: I wrote and maintain js2xml) >> >> Below is an example usage for js2xml using scrapy shell: >> >> it parses Javascript statements from <script> elements in #player, and >> then extracts dicts. >> There's an "args" key in the main script, that itself contains an >> url_encoded_fmt_stream_map >> key with some URLs for the video you may be after: >> >> I'm using urlparse to decode what looks like a query string >> >> (the full scrapy shell session is >> https://gist.github.com/redapple/8269818915cc2c337dc2) >> >> $ scrapy shell "https://www.youtube.com/watch?v=1EFnX1UkXVU"; >> 2014-12-30 15:18:09+0100 [default] DEBUG: Crawled (200) <GET >> https://www.youtube.com/watch?v=1EFnX1UkXVU> (referer: None) >> >> In [1]: import js2xml >> In [2]: import urlparse >> In [3]: import pprint >> >> In [4]: for script in response.css('#player >> script').xpath('string()').extract(): >> jstree = js2xml.parse(script) >> data = js2xml.jsonlike.getall(jstree) >> for d in data: >> pprint.pprint(d) >> ...: >> {} >> {'args': {'account_playback_token': >> 'QUFFLUhqa0sweExRZno5OHZEaGcwWVVQaXAxVWh0NUNFZ3xBQ3Jtc0tseE9DRUw3cFVRbkFGN1hub2VmQlNERGl3WjFIQV84aTI0b0lxZnhwdDZKRl96N1g5eWN3dkZER1pFbVM4dS1FeWJoc1FJeTBXdS0tbU5LY1NsWngtSHY1R0hoTl9xdy1iWUNoam1nRFM2czEweVdMNA==', >> 'adaptive_fmts': >> 'size=1280x720&clen=51269588&fps=15&itag=136&init=0-709...bitrate=80798', >> 'allow_embed': '1', >> 'allow_ratings': '1', >> 'atc': >> 'a=3&b=nhjwMM7ySu8wj8OhutnokFK8Dvs&c=1419949090&d=1&e=1EFnX1UkXVU&c3a=28&c1a=1&hh=hKbH2J9f2WwblpFs2hvo0H17oZo', >> 'author': 'Michael Herman', >> 'avg_rating': '4.948387146', >> 'c': 'WEB', >> 'cc3_module': '1', >> 'cc_asr': '1', >> 'cc_font': 'Arial Unicode MS, arial, verdana, _sans', >> 'cc_fonts_url': ' >> https://s.ytimg.com/yts/swfbin/player-vfly1u_c5/fonts708.swf', >> 'cc_load_policy': '2', >> 'cc_module': ' >> https://s.ytimg.com/yts/swfbin/player-vfly1u_c5/subtitle_module.swf', >> 'cl': '82697338', >> 'cr': 'FR', >> 'csi_page_type': 'watch,watch7', >> 'dash': '1', >> 'dashmpd': 'http://manifest.googlevideo.com/api/...', >> 'enablecsi': '1', >> 'enablejsapi': 1, >> 'eventid': 'IrSiVP-kC4v4cKrwgRg', >> 'fexp': >> '900718,927622,931342,932404,938809,9405699,9406022,940927,940940,941004,943917,947209,947218,948124,952302,952605,952901,955110,955301,957103,957105,957201', >> 'fmt_list': >> '22/1280x720/9/0/115,43/640x360/99/0/0,18/640x360/9/0/115,5/426x240/7/0/0,36/426x240/99/1/0,17/256x144/99/1/0', >> 'hl': 'en_US', >> 'host_language': 'en', >> 'idpj': '-6', >> 'iurl': 'https://i.ytimg.com/vi/1EFnX1UkXVU/hqdefault.jpg', >> 'iurlhq': 'https://i.ytimg.com/vi/1EFnX1UkXVU/hqdefault.jpg', >> 'iurlmaxres': ' >> https://i.ytimg.com/vi/1EFnX1UkXVU/maxresdefault.jpg', >> 'iurlmq': 'https://i.ytimg.com/vi/1EFnX1UkXVU/mqdefault.jpg', >> 'iurlsd': 'https://i.ytimg.com/vi/1EFnX1UkXVU/sddefault.jpg', >> 'iv3_module': '1', >> 'iv_invideo_url': ' >> https://www.youtube.com/annotations_invideo?cta=2&video_id=1EFnX1UkXVU', >> 'iv_load_policy': '1', >> 'iv_module': ' >> https://s.ytimg.com/yts/swfbin/player-vfly1u_c5/iv_module.swf', >> 'keywords': 'Scrapy,Python,scraping,python scrapy,web scraping', >> 'ldpj': '-25', >> 'length_seconds': '717', >> 'loaderUrl': 'https://www.youtube.com/watch?v=1EFnX1UkXVU', >> 'no_get_video_log': '1', >> 'of': 'lNeUuIm8BRrYa4UFYW3Vbw', >> 'plid': 'AAULb6kfjbEHoNwt', >> 'pltype': 'contentugc', >> 'probe_url': ' >> http://r5---sn-5hn7ym7z.googlevideo.com/videogoodput?id=o-ACe-sIXL0cLvgJC4v5mIahOxT1PHw4zDPr8ZGMCgqwQI&source=goodput&range=0-99999&expire=1419952690&ip=89.84.122.217&ms=pm&mm=35&nh=EAk&sparams=id,source,range,expire,ip,ms,mm,nh&signature=3B4094AEE2FC1C0142BCEDB115F785607DEC0CF1.04988A5889C0348F50D45D76A7D6831155C91407&key=cms1 >> ', >> 'ptk': 'youtube_none', >> 'ssl': '1', >> 'storyboard_spec': ' >> https://i.ytimg.com/sb/1EFnX1UkXVU/storyboard3_L$L/$N.jpg|48#27#100#10#10#0#default#28F7DFM7_rVji4ZXj1Inr3KDPBE|80#45#145#10#10#5000#M$M#oy8NWkx8UFfdFYJoDyKoK-F6EUo|160#90#145#5#5#5000#M$M#RPAH69FExaDD6f0lYwoCjc64vI8 >> ', >> 't': '1', >> 'thumbnail_url': ' >> https://i.ytimg.com/vi/1EFnX1UkXVU/default.jpg', >> 'timestamp': '1419949090', >> 'title': 'Scraping Web Pages with Scrapy', >> 'tmi': '1', >> 'token': '1', >> 'ttsurl': 'https://www.youtube.com/api/timedtext?...', >> 'ucid': 'UCt7yOnL7bI7yCa1Xe_GTjJQ', >> 'url_encoded_fmt_stream_map': 'fallback_host= >> tc.v18.cache4.googlevideo.com&quality=hd720...', >> 'video_id': '1EFnX1UkXVU', >> 'view_count': '52035', >> 'vq': 'auto', >> 'watermark': ', >> https://s.ytimg.com/yts/img/watermark/youtube_watermark-vflHX6b6E.png,https://s.ytimg.com/yts/img/watermark/youtube_hd_watermark-vflAzLcD6.png' >> }, >> 'assets': {'css': '//s.ytimg.com/yts/cssbin/www-player-vflPfi1TF.css', >> 'html': '/html5_player_template', >> 'js': '// >> s.ytimg.com/yts/jsbin/html5player-en_US-vflw4H1P-/html5player.js'}, >> 'attrs': {'id': 'movie_player'}, >> 'html5': False, >> 'messages': {'player_fallback': ['Adobe Flash Player or an HTML5 >> supported browser is required for video playback.<br><a href=" >> http://get.adobe.com/flashplayer/";>Get the latest Flash Player >> </a><br><a href="/html5">Learn more about upgrading to an HTML5 >> browser</a>']}, >> 'min_version': '8.0.0', >> 'params': {'allowfullscreen': 'true', >> 'allowscriptaccess': 'always', >> 'bgcolor': '#000000'}, >> 'sts': 16427, >> 'url': 'https://s.ytimg.com/yts/swfbin/player-vfly1u_c5/watch_as3.swf', >> 'url_v8': 'https://s.ytimg.com/yts/swfbin/player-vfly1u_c5/cps.swf', >> 'url_v9as2': 'https://s.ytimg.com/yts/swfbin/player-vfly1u_c5/cps.swf'} >> [] >> >> In [5]: for script in response.css('#player >> script').xpath('string()').extract(): >> ...: jstree = js2xml.parse(script) >> ...: data = js2xml.jsonlike.getall(jstree) >> ...: for d in data: >> ...: try: >> ...: if d: >> ...: pprint.pprint(urlparse.parse_qsl(d.get("args", >> {}).get("url_encoded_fmt_stream_map", ""))) >> ...: except: >> ...: pass >> ...: >> [('fallback_host', 'tc.v18.cache4.googlevideo.com'), >> ('quality', 'hd720'), >> ('itag', '22'), >> ('type', 'video/mp4; codecs="avc1.64001F, mp4a.40.2"'), >> ('url', >> ' >> http://r3---sn-25ge7n7d.googlevideo.com/videoplayback?dur=716.985&id=o-AMERlvuyknt71bMvL2Sjki6y2WsGz0TDKn11unO3_SQy&mm=31&ip=89.84.122.217&key=yt5&itag=22&mime=video%2Fmp4&source=youtube&ms=au&fexp=900718%2C927622%2C931342%2C932404%2C938809%2C9405699%2C9406022%2C940927%2C940940%2C941004%2C943917%2C947209%2C947218%2C948124%2C952302%2C952605%2C952901%2C955110%2C955301%2C957103%2C957105%2C957201&mv=m&mt=1419949043&sver=3&initcwndbps=872500&sparams=dur%2Cid%2Cinitcwndbps%2Cip%2Cipbits%2Citag%2Cmime%2Cmm%2Cms%2Cmv%2Cratebypass%2Csource%2Cupn%2Cexpire&ratebypass=yes&signature=75A8510F49A9C73C72BC4F4A8759320481305D26.EA7ABB7DD01D7B4BA5228ABD8DF8DD47AB73A3A1&expire=1419970690&upn=5QFvFRIqKzs&ipbits=0,fallback_host=tc.v20.cache6.googlevideo.com' >> ), >> ('quality', 'medium'), >> ('itag', '43'), >> ('type', 'video/webm; codecs="vp8.0, vorbis"'), >> ('url', >> ' >> http://r3---sn-25ge7n7d.googlevideo.com/videoplayback?dur=0.000&id=o-AMERlvuyknt71bMvL2Sjki6y2WsGz0TDKn11unO3_SQy&mm=31&ip=89.84.122.217&key=yt5&itag=43&mime=video%2Fwebm&source=youtube&ms=au&fexp=900718%2C927622%2C931342%2C932404%2C938809%2C9405699%2C9406022%2C940927%2C940940%2C941004%2C943917%2C947209%2C947218%2C948124%2C952302%2C952605%2C952901%2C955110%2C955301%2C957103%2C957105%2C957201&mv=m&mt=1419949043&sver=3&initcwndbps=872500&sparams=dur%2Cid%2Cinitcwndbps%2Cip%2Cipbits%2Citag%2Cmime%2Cmm%2Cms%2Cmv%2Cratebypass%2Csource%2Cupn%2Cexpire&ratebypass=yes&signature=E17363F74C7068BEB4DB31FC90AEF2EA70A3C233.F634AC2BD1B5A6B27E1DDFB4FB09DE7C04D1DF0E&expire=1419970690&upn=5QFvFRIqKzs&ipbits=0,fallback_host=tc.v13.cache4.googlevideo.com' >> ), >> ('quality', 'medium'), >> ('itag', '18'), >> ('type', 'video/mp4; codecs="avc1.42001E, mp4a.40.2"'), >> ('url', >> ' >> http://r3---sn-25ge7n7d.googlevideo.com/videoplayback?dur=716.985&id=o-AMERlvuyknt71bMvL2Sjki6y2WsGz0TDKn11unO3_SQy&mm=31&ip=89.84.122.217&key=yt5&itag=18&mime=video%2Fmp4&source=youtube&ms=au&fexp=900718%2C927622%2C931342%2C932404%2C938809%2C9405699%2C9406022%2C940927%2C940940%2C941004%2C943917%2C947209%2C947218%2C948124%2C952302%2C952605%2C952901%2C955110%2C955301%2C957103%2C957105%2C957201&mv=m&mt=1419949043&sver=3&initcwndbps=872500&sparams=dur%2Cid%2Cinitcwndbps%2Cip%2Cipbits%2Citag%2Cmime%2Cmm%2Cms%2Cmv%2Cratebypass%2Csource%2Cupn%2Cexpire&ratebypass=yes&signature=78201511AECE7F328D67AA08EC40E22777C62616.6B0C1787F391F30F1D28D8C2BCD6E67C71F1BB5F&expire=1419970690&upn=5QFvFRIqKzs&ipbits=0,fallback_host=tc.v4.cache4.googlevideo.com' >> ), >> ('quality', 'small'), >> ('itag', '5'), >> ('type', 'video/x-flv'), >> ('url', >> ' >> http://r3---sn-25ge7n7d.googlevideo.com/videoplayback?dur=716.983&id=o-AMERlvuyknt71bMvL2Sjki6y2WsGz0TDKn11unO3_SQy&mm=31&ip=89.84.122.217&key=yt5&itag=5&mime=video%2Fx-flv&source=youtube&ms=au&fexp=900718%2C927622%2C931342%2C932404%2C938809%2C9405699%2C9406022%2C940927%2C940940%2C941004%2C943917%2C947209%2C947218%2C948124%2C952302%2C952605%2C952901%2C955110%2C955301%2C957103%2C957105%2C957201&mv=m&mt=1419949043&sver=3&initcwndbps=872500&sparams=dur%2Cid%2Cinitcwndbps%2Cip%2Cipbits%2Citag%2Cmime%2Cmm%2Cms%2Cmv%2Csource%2Cupn%2Cexpire&signature=DE27A5283FB425F79CC1ACBB67D0B20FF07D5BD5.DBACE3E830A573BF4092AC442C99278D4CFF549F&expire=1419970690&upn=5QFvFRIqKzs&ipbits=0,fallback_host=tc.v4.cache5.googlevideo.com' >> ), >> ('quality', 'small'), >> ('itag', '36'), >> ('type', 'video/3gpp; codecs="mp4v.20.3, mp4a.40.2"'), >> ('url', >> ' >> http://r3---sn-25ge7n7d.googlevideo.com/videoplayback?dur=717.125&id=o-AMERlvuyknt71bMvL2Sjki6y2WsGz0TDKn11unO3_SQy&mm=31&ip=89.84.122.217&key=yt5&itag=36&mime=video%2F3gpp&source=youtube&ms=au&fexp=900718%2C927622%2C931342%2C932404%2C938809%2C9405699%2C9406022%2C940927%2C940940%2C941004%2C943917%2C947209%2C947218%2C948124%2C952302%2C952605%2C952901%2C955110%2C955301%2C957103%2C957105%2C957201&mv=m&mt=1419949043&sver=3&initcwndbps=872500&sparams=dur%2Cid%2Cinitcwndbps%2Cip%2Cipbits%2Citag%2Cmime%2Cmm%2Cms%2Cmv%2Csource%2Cupn%2Cexpire&signature=E9DD3B41DDA5B39F12D7311682DEB24A376F04C9.0C3EEEFED598AF77E877D361B57385CE5941303F&expire=1419970690&upn=5QFvFRIqKzs&ipbits=0,fallback_host=tc.v9.cache5.googlevideo.com' >> ), >> ('quality', 'small'), >> ('itag', '17'), >> ('type', 'video/3gpp; codecs="mp4v.20.3, mp4a.40.2"'), >> ('url', >> ' >> http://r3---sn-25ge7n7d.googlevideo.com/videoplayback?dur=717.217&id=o-AMERlvuyknt71bMvL2Sjki6y2WsGz0TDKn11unO3_SQy&mm=31&ip=89.84.122.217&key=yt5&itag=17&mime=video%2F3gpp&source=youtube&ms=au&fexp=900718%2C927622%2C931342%2C932404%2C938809%2C9405699%2C9406022%2C940927%2C940940%2C941004%2C943917%2C947209%2C947218%2C948124%2C952302%2C952605%2C952901%2C955110%2C955301%2C957103%2C957105%2C957201&mv=m&mt=1419949043&sver=3&initcwndbps=872500&sparams=dur%2Cid%2Cinitcwndbps%2Cip%2Cipbits%2Citag%2Cmime%2Cmm%2Cms%2Cmv%2Csource%2Cupn%2Cexpire&signature=E4199F944FC4A5A1DFBAD4562EB628E62B53FD27.FA0A2D69378E3AB8B4E50FD55A2F64CA7A048EA1&expire=1419970690&upn=5QFvFRIqKzs&ipbits=0' >> )] >> >> >> >> >> On Tuesday, December 30, 2014 6:49:51 AM UTC+1, Gaurang shah wrote: >>> >>> Following is the details. >>> Os: Windows 7 64 bit >>> Python 2.7 >>> Scrapy 0.25.1 >>> >>> I don't understand the last question. I am using selector provided by >>> scrapy to get the node using xpath. Following is the code. >>> >>> selector = Selector(response) >>> view_count = selector.xpath("//div[@class=' >>> watch-view-count']/text()")[0].extract().strip() >>> video_url = selector.xpath("//video[contains(@class,'html5-main- >>> video')]/@src").extract() >>> >>> >>> Gaurang Shah >>> Blog: qtp-help.blogspot.com >>> Mobile: +91 738756556 >>> >>> On Tue, Dec 30, 2014 at 1:24 AM, bruce <[email protected]> wrote: >>> >>>> Hey Gaurang, >>>> >>>> What's the OS, version of python, version of scrapy you're using? >>>> >>>> Does scrapy use urlib? or better, if you know, what lib does scrapy use >>>> for the url/xpath processing? >>>> >>>> >>>> >>>> On Mon, Dec 29, 2014 at 11:32 AM, Gaurang shah <[email protected]> >>>> wrote: >>>> >>>>> Sorry guys, Forgot to mentioned. All these xpath is able to identify >>>>> the elemenet using firepath add-on of firefox. >>>>> >>>>> *//video * >>>>> *//video[contains(@class,'html5-main-video')]/@src* >>>>> >>>>> *//div[@class='html5-video-container']/video/@src* >>>>> >>>>> *//div[@id='movie_player']/div[1]/video/@src* >>>>> >>>>> *//div[@id='player-api']/div[1]/div[1]/video/@src* >>>>> >>>>> *However none of them is working in scrapy ???* >>>>> >>>>> Gaurang Shah >>>>> Blog: qtp-help.blogspot.com >>>>> Mobile: +91 738756556 >>>>> >>>>> On Mon, Dec 29, 2014 at 9:41 PM, bruce <[email protected]> wrote: >>>>> >>>>>> Are you able to effectively create an xpath using your browser's >>>>>> xpath/dev tools? >>>>>> >>>>>> in firefox, you can use dom inspector, there are others as well, not >>>>>> sure of your browser.. >>>>>> >>>>>> In other words, is the issue with the "video" element, or something >>>>>> else in your xpath? >>>>>> >>>>>> If you can resolve the xpath with a separate tool, that should give >>>>>> you direction to solve the issue. >>>>>> >>>>>> >>>>>> >>>>>> On Mon, Dec 29, 2014 at 7:38 AM, Gaurang shah <[email protected]> >>>>>> wrote: >>>>>> >>>>>>> Hi Guys, >>>>>>> >>>>>>> I am trying to scrap the youtube site. And somehow the xpath which >>>>>>> fetches the video src is not working in scrapy. >>>>>>> >>>>>>> Url: https://www.youtube.com/watch?v=1EFnX1UkXVU >>>>>>> >>>>>>> >>>>>>> following xpaths is not working >>>>>>> *//video * >>>>>>> *//video[contains(@class,'html5-main-video')]/@src* >>>>>>> >>>>>>> >>>>>>> <https://lh3.googleusercontent.com/--_vqbGQxgWg/VKFLFyraflI/AAAAAAAACLY/2352f1VU0ds/s1600/Image%2B004.jpg> >>>>>>> I am able to retrive xpath till,* //div[@id='player-api']*, after >>>>>>> that it's dead end. scrapy is not able to find any more node in this. >>>>>>> However there are nodes inside that as well. >>>>>>> >>>>>>> -- >>>>>>> You received this message because you are subscribed to the Google >>>>>>> Groups "scrapy-users" group. >>>>>>> To unsubscribe from this group and stop receiving emails from it, >>>>>>> send an email to [email protected]. >>>>>>> To post to this group, send email to [email protected]. >>>>>>> Visit this group at http://groups.google.com/group/scrapy-users. >>>>>>> For more options, visit https://groups.google.com/d/optout. >>>>>>> >>>>>> >>>>>> -- >>>>>> You received this message because you are subscribed to a topic in >>>>>> the Google Groups "scrapy-users" group. >>>>>> To unsubscribe from this topic, visit https://groups.google.com/d/ >>>>>> topic/scrapy-users/nGisMymqofU/unsubscribe. >>>>>> To unsubscribe from this group and all its topics, send an email to >>>>>> [email protected]. >>>>>> To post to this group, send email to [email protected]. >>>>>> Visit this group at http://groups.google.com/group/scrapy-users. >>>>>> For more options, visit https://groups.google.com/d/optout. >>>>>> >>>>> >>>>> -- >>>>> You received this message because you are subscribed to the Google >>>>> Groups "scrapy-users" group. >>>>> To unsubscribe from this group and stop receiving emails from it, send >>>>> an email to [email protected]. >>>>> To post to this group, send email to [email protected]. >>>>> Visit this group at http://groups.google.com/group/scrapy-users. >>>>> For more options, visit https://groups.google.com/d/optout. >>>>> >>>> >>>> -- >>>> You received this message because you are subscribed to a topic in the >>>> Google Groups "scrapy-users" group. >>>> To unsubscribe from this topic, visit https://groups.google.com/d/ >>>> topic/scrapy-users/nGisMymqofU/unsubscribe. >>>> To unsubscribe from this group and all its topics, send an email to >>>> [email protected]. >>>> To post to this group, send email to [email protected]. >>>> Visit this group at http://groups.google.com/group/scrapy-users. >>>> For more options, visit https://groups.google.com/d/optout. >>>> >>> >>> -- >> You received this message because you are subscribed to the Google Groups >> "scrapy-users" group. >> To unsubscribe from this group and stop receiving emails from it, send an >> email to [email protected]. >> To post to this group, send email to [email protected]. >> Visit this group at http://groups.google.com/group/scrapy-users. >> For more options, visit https://groups.google.com/d/optout. >> > > -- > You received this message because you are subscribed to the Google Groups > "scrapy-users" group. > To unsubscribe from this group and stop receiving emails from it, send an > email to [email protected]. > To post to this group, send email to [email protected]. > Visit this group at http://groups.google.com/group/scrapy-users. > For more options, visit https://groups.google.com/d/optout. > -- You received this message because you are subscribed to the Google Groups "scrapy-users" group. To unsubscribe from this group and stop receiving emails from it, send an email to [email protected]. To post to this group, send email to [email protected]. Visit this group at http://groups.google.com/group/scrapy-users. For more options, visit https://groups.google.com/d/optout.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}