[GitHub] [hudi] zherenyu831 commented on issue #2837: [SUPPORT]How to measure the performance of upsert
zherenyu831 commented on issue #2837: URL: https://github.com/apache/hudi/issues/2837#issuecomment-820956020 It dependent on count of cores, configuration, ratio of insert/update, storage type IMO, it is not slow -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] liijiankang opened a new issue #2837: [SUPPORT]How to measure the performance of upsert
liijiankang opened a new issue #2837: URL: https://github.com/apache/hudi/issues/2837 **Describe the problem you faced** I am a novice and would appreciate your help. We use Structured Streaming to consume the data in Kafka, and then write the data to the cow table of hudi.I want to know whether the performance of this program is high or low 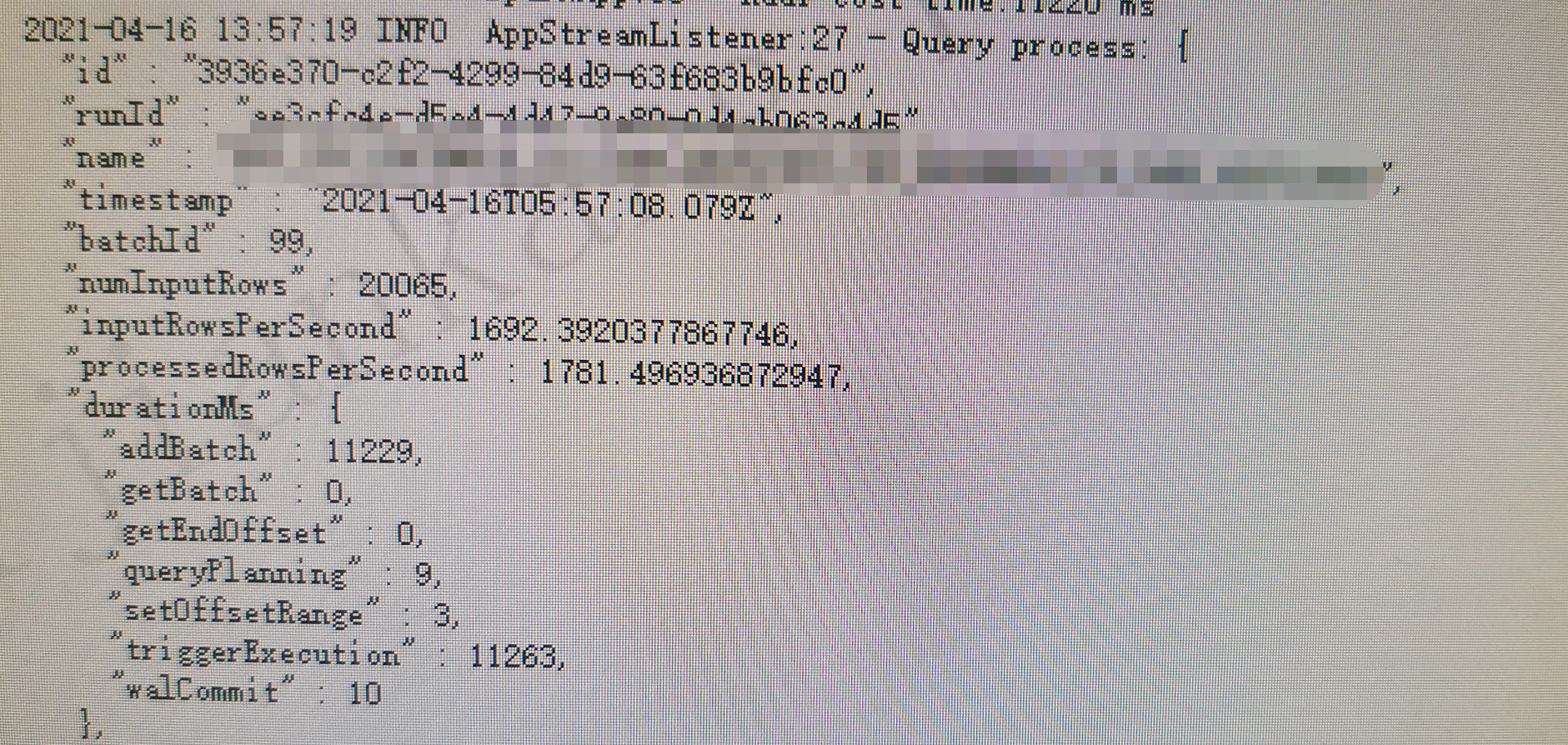  -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (HUDI-1803) Hopefully Hudi will officially support BAIDU AFS storage format
[ https://issues.apache.org/jira/browse/HUDI-1803?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] ASF GitHub Bot updated HUDI-1803: - Labels: pull-request-available (was: ) > Hopefully Hudi will officially support BAIDU AFS storage format > --- > > Key: HUDI-1803 > URL: https://issues.apache.org/jira/browse/HUDI-1803 > Project: Apache Hudi > Issue Type: Improvement >Reporter: Xu Guang Lv >Assignee: Xu Guang Lv >Priority: Minor > Labels: pull-request-available > > The storage format of BAIDU Advanced File System(AFS) can naturally be > supported by Hudi each time after I checkout hudi source code and modify the > related code. Hopefully Hudi will officially support it, for convenience -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [hudi] xglv1985 opened a new pull request #2836: [MINOR] support BAIDU afs. jira id: HUDI-1803
xglv1985 opened a new pull request #2836: URL: https://github.com/apache/hudi/pull/2836 ## *Tips* - *Thank you very much for contributing to Apache Hudi.* - *Please review https://hudi.apache.org/contributing.html before opening a pull request.* ## What is the purpose of the pull request *The storage format of BAIDU Advanced File System(AFS) can naturally be supported by Hudi. Each time after I checkout hudi source code, I have to add it in "StorageSchemes". Hopefully Hudi will officially integrate it, for convenience* ## Brief change log - *Modify org.apache.hudi.common.fs.StorageSchemes to add afs format to the class* ## Verify this pull request This pull request is a trivial rework / code cleanup without any test coverage. ## Committer checklist - [Yes ] Has a corresponding JIRA in PR title & commit - [Yes] Commit message is descriptive of the change - [Yes] CI is green - [ ] Necessary doc changes done or have another open PR - [ ] For large changes, please consider breaking it into sub-tasks under an umbrella JIRA. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] liujinhui1994 commented on pull request #2666: [HUDI-1160] Support update partial fields for CoW table
liujinhui1994 commented on pull request #2666: URL: https://github.com/apache/hudi/pull/2666#issuecomment-820931906 > > sorry for late turn around on reviewing this. We should definitely get this before next release. > > I am yet to review tests. but few high level thoughts on reviewing source code. > > > > * Shouldn't we check schema compatibility? what incase new incoming batch is not compatible w/ table schema w/ partial updates set to true? did we cover this scenario. > > * I see we have added support only for COW. should we throw exception if the config is set for MOR? > > * I don't have a good idea of adding sql DML support to hoodie table. But if feasible, once such support is added, do you think we can leverage this w/o duplicating the work for sql DML. for eg, "update col1 = 'new_york' where col2= '123'" Such partial updates should translate from sql layer to this right. > > * In tests, do verify that schema in commit metadata refers to table schema and not incoming partial schema. > > I have the same feeling, we should still use the old schema with full fields there, for new records with partial values, we can patch them up with a builtin placeholder values, and when we pre_combine the old and new, if we encounter the placeholder values, use the value from the existing record. > > In any case, to be consistent with SQL, please do not modify the schema which mess the thing up. Okay, I think of a way to support such a situation -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (HUDI-1792) flink-client query error when processing files larger than 128mb
[
https://issues.apache.org/jira/browse/HUDI-1792?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
vinoyang updated HUDI-1792:
---
Fix Version/s: 0.9.0
> flink-client query error when processing files larger than 128mb
> -
>
> Key: HUDI-1792
> URL: https://issues.apache.org/jira/browse/HUDI-1792
> Project: Apache Hudi
> Issue Type: Bug
> Components: Flink Integration
>Reporter: jing
>Assignee: jing
>Priority: Major
> Labels: pull-request-available
> Fix For: 0.9.0
>
>
> Use the flink client to query the cow table and report an error. The error
> message is as follows:
> {code:java}
> Caused by: org.apache.flink.runtime.JobException: Creating the input splits
> caused an error: org.apache.hadoop.fs.HdfsBlockLocation cannot be cast to
> java.lang.ComparableCaused by: org.apache.flink.runtime.JobException:
> Creating the input splits caused an error:
> org.apache.hadoop.fs.HdfsBlockLocation cannot be cast to java.lang.Comparable
> at
> org.apache.flink.runtime.executiongraph.ExecutionJobVertex.(ExecutionJobVertex.java:260)
> at
> org.apache.flink.runtime.executiongraph.ExecutionGraph.attachJobGraph(ExecutionGraph.java:866)
> at
> org.apache.flink.runtime.executiongraph.ExecutionGraphBuilder.buildGraph(ExecutionGraphBuilder.java:257)
> at
> org.apache.flink.runtime.scheduler.SchedulerBase.createExecutionGraph(SchedulerBase.java:322)
> at
> org.apache.flink.runtime.scheduler.SchedulerBase.createAndRestoreExecutionGraph(SchedulerBase.java:276)
> at
> org.apache.flink.runtime.scheduler.SchedulerBase.(SchedulerBase.java:249)
> at
> org.apache.flink.runtime.scheduler.DefaultScheduler.(DefaultScheduler.java:133)
> at
> org.apache.flink.runtime.scheduler.DefaultSchedulerFactory.createInstance(DefaultSchedulerFactory.java:111)
> at
> org.apache.flink.runtime.jobmaster.JobMaster.createScheduler(JobMaster.java:345)
> at org.apache.flink.runtime.jobmaster.JobMaster.(JobMaster.java:330)
> at
> org.apache.flink.runtime.jobmaster.factories.DefaultJobMasterServiceFactory.createJobMasterService(DefaultJobMasterServiceFactory.java:95)
> at
> org.apache.flink.runtime.jobmaster.factories.DefaultJobMasterServiceFactory.createJobMasterService(DefaultJobMasterServiceFactory.java:39)
> at
> org.apache.flink.runtime.jobmaster.JobManagerRunnerImpl.(JobManagerRunnerImpl.java:162)
> at
> org.apache.flink.runtime.dispatcher.DefaultJobManagerRunnerFactory.createJobManagerRunner(DefaultJobManagerRunnerFactory.java:86)
> at
> org.apache.flink.runtime.dispatcher.Dispatcher.lambda$createJobManagerRunner$5(Dispatcher.java:478)
> ... 4 more
> {code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Closed] (HUDI-1792) flink-client query error when processing files larger than 128mb
[
https://issues.apache.org/jira/browse/HUDI-1792?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
vinoyang closed HUDI-1792.
--
Resolution: Fixed
62b8a341ddae0ab80195c41c7a44b84c1fe23d31
> flink-client query error when processing files larger than 128mb
> -
>
> Key: HUDI-1792
> URL: https://issues.apache.org/jira/browse/HUDI-1792
> Project: Apache Hudi
> Issue Type: Bug
> Components: Flink Integration
>Reporter: jing
>Assignee: jing
>Priority: Major
> Labels: pull-request-available
> Fix For: 0.9.0
>
>
> Use the flink client to query the cow table and report an error. The error
> message is as follows:
> {code:java}
> Caused by: org.apache.flink.runtime.JobException: Creating the input splits
> caused an error: org.apache.hadoop.fs.HdfsBlockLocation cannot be cast to
> java.lang.ComparableCaused by: org.apache.flink.runtime.JobException:
> Creating the input splits caused an error:
> org.apache.hadoop.fs.HdfsBlockLocation cannot be cast to java.lang.Comparable
> at
> org.apache.flink.runtime.executiongraph.ExecutionJobVertex.(ExecutionJobVertex.java:260)
> at
> org.apache.flink.runtime.executiongraph.ExecutionGraph.attachJobGraph(ExecutionGraph.java:866)
> at
> org.apache.flink.runtime.executiongraph.ExecutionGraphBuilder.buildGraph(ExecutionGraphBuilder.java:257)
> at
> org.apache.flink.runtime.scheduler.SchedulerBase.createExecutionGraph(SchedulerBase.java:322)
> at
> org.apache.flink.runtime.scheduler.SchedulerBase.createAndRestoreExecutionGraph(SchedulerBase.java:276)
> at
> org.apache.flink.runtime.scheduler.SchedulerBase.(SchedulerBase.java:249)
> at
> org.apache.flink.runtime.scheduler.DefaultScheduler.(DefaultScheduler.java:133)
> at
> org.apache.flink.runtime.scheduler.DefaultSchedulerFactory.createInstance(DefaultSchedulerFactory.java:111)
> at
> org.apache.flink.runtime.jobmaster.JobMaster.createScheduler(JobMaster.java:345)
> at org.apache.flink.runtime.jobmaster.JobMaster.(JobMaster.java:330)
> at
> org.apache.flink.runtime.jobmaster.factories.DefaultJobMasterServiceFactory.createJobMasterService(DefaultJobMasterServiceFactory.java:95)
> at
> org.apache.flink.runtime.jobmaster.factories.DefaultJobMasterServiceFactory.createJobMasterService(DefaultJobMasterServiceFactory.java:39)
> at
> org.apache.flink.runtime.jobmaster.JobManagerRunnerImpl.(JobManagerRunnerImpl.java:162)
> at
> org.apache.flink.runtime.dispatcher.DefaultJobManagerRunnerFactory.createJobManagerRunner(DefaultJobManagerRunnerFactory.java:86)
> at
> org.apache.flink.runtime.dispatcher.Dispatcher.lambda$createJobManagerRunner$5(Dispatcher.java:478)
> ... 4 more
> {code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[hudi] branch master updated: [HUDI-1792] flink-client query error when processing files larger than 128mb (#2814)
This is an automated email from the ASF dual-hosted git repository.
vinoyang pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/hudi.git
The following commit(s) were added to refs/heads/master by this push:
new 62b8a34 [HUDI-1792] flink-client query error when processing files
larger than 128mb (#2814)
62b8a34 is described below
commit 62b8a341ddae0ab80195c41c7a44b84c1fe23d31
Author: hj2016
AuthorDate: Fri Apr 16 13:59:19 2021 +0800
[HUDI-1792] flink-client query error when processing files larger than
128mb (#2814)
Co-authored-by: huangjing
---
.../org/apache/hudi/table/format/cow/CopyOnWriteInputFormat.java | 9 -
1 file changed, 8 insertions(+), 1 deletion(-)
diff --git
a/hudi-flink/src/main/java/org/apache/hudi/table/format/cow/CopyOnWriteInputFormat.java
b/hudi-flink/src/main/java/org/apache/hudi/table/format/cow/CopyOnWriteInputFormat.java
index 77f3e2a..477f54b 100644
---
a/hudi-flink/src/main/java/org/apache/hudi/table/format/cow/CopyOnWriteInputFormat.java
+++
b/hudi-flink/src/main/java/org/apache/hudi/table/format/cow/CopyOnWriteInputFormat.java
@@ -40,6 +40,7 @@ import org.slf4j.LoggerFactory;
import java.io.IOException;
import java.util.ArrayList;
import java.util.Arrays;
+import java.util.Comparator;
import java.util.HashSet;
import java.util.LinkedHashMap;
import java.util.List;
@@ -209,7 +210,13 @@ public class CopyOnWriteInputFormat extends
FileInputFormat {
// get the block locations and make sure they are in order with
respect to their offset
final BlockLocation[] blocks = fs.getFileBlockLocations(file, 0, len);
-Arrays.sort(blocks);
+Arrays.sort(blocks, new Comparator() {
+ @Override
+ public int compare(BlockLocation o1, BlockLocation o2) {
+long diff = o1.getLength() - o2.getOffset();
+return diff < 0L ? -1 : (diff > 0L ? 1 : 0);
+ }
+});
long bytesUnassigned = len;
long position = 0;
[GitHub] [hudi] yanghua merged pull request #2814: [HUDI-1792] Fix flink-client query error when processing files larger than 128mb
yanghua merged pull request #2814: URL: https://github.com/apache/hudi/pull/2814 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Created] (HUDI-1803) Hopefully Hudi will officially support BAIDU AFS storage format
Xu Guang Lv created HUDI-1803: - Summary: Hopefully Hudi will officially support BAIDU AFS storage format Key: HUDI-1803 URL: https://issues.apache.org/jira/browse/HUDI-1803 Project: Apache Hudi Issue Type: Improvement Reporter: Xu Guang Lv Assignee: Xu Guang Lv The storage format of BAIDU Advanced File System(AFS) can naturally be supported by Hudi each time after I checkout hudi source code and modify the related code. Hopefully Hudi will officially support it, for convenience -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [hudi] ssdong commented on pull request #2784: [HUDI-1740] Fix insert-overwrite API archival
ssdong commented on pull request #2784: URL: https://github.com/apache/hudi/pull/2784#issuecomment-820928674 @satishkotha @lw309637554 Just to share some updates, this PR fixed the following 2 issues during archival 1. `Positive number of partitions required` 2. `java.util.NoSuchElementException: No value present in Option` However, the aforementioned ``` // Initialize with new Hoodie timeline. init(metaClient, getTimeline()); ``` does cause `java.io.FileNotFoundException: File file:/Users/susu.dong/Dev/clustering-insert-overwrite-test/.hoodie/20210415220131.replacecommit does not exist` which is a 3rd issue during archival if we turn _off_ `"hoodie.clean.automatic"`, the cleaner option, which is `true` by default. Turning off cleaner is making the internally maintained timeline to be out-of-sync with the physical commit file status. The archival removes the commit files while the `init` call still references those commit files that are being removed/archived when it propagates to the `readDataFromPath` method call and throws the exception ultimately. Full stacktrace: ``` org.apache.hudi.exception.HoodieIOException: Could not read commit details from /Users/susu.dong/Dev/clustering-insert-overwrite-test/.hoodie/20210415220131.replacecommit at org.apache.hudi.common.table.timeline.HoodieActiveTimeline.readDataFromPath(HoodieActiveTimeline.java:561) at org.apache.hudi.common.table.timeline.HoodieActiveTimeline.getInstantDetails(HoodieActiveTimeline.java:225) at org.apache.hudi.common.table.view.AbstractTableFileSystemView.lambda$resetFileGroupsReplaced$8(AbstractTableFileSystemView.java:217) at java.base/java.util.stream.ReferencePipeline$7$1.accept(ReferencePipeline.java:271) at java.base/java.util.ArrayList$ArrayListSpliterator.forEachRemaining(ArrayList.java:1654) at java.base/java.util.stream.AbstractPipeline.copyInto(AbstractPipeline.java:484) at java.base/java.util.stream.AbstractPipeline.wrapAndCopyInto(AbstractPipeline.java:474) at java.base/java.util.stream.ReduceOps$ReduceOp.evaluateSequential(ReduceOps.java:913) at java.base/java.util.stream.AbstractPipeline.evaluate(AbstractPipeline.java:234) at java.base/java.util.stream.ReferencePipeline.collect(ReferencePipeline.java:578) at org.apache.hudi.common.table.view.AbstractTableFileSystemView.resetFileGroupsReplaced(AbstractTableFileSystemView.java:228) at org.apache.hudi.common.table.view.AbstractTableFileSystemView.init(AbstractTableFileSystemView.java:106) at org.apache.hudi.common.table.view.HoodieTableFileSystemView.init(HoodieTableFileSystemView.java:106) at org.apache.hudi.common.table.view.AbstractTableFileSystemView.reset(AbstractTableFileSystemView.java:248) at org.apache.hudi.common.table.view.HoodieTableFileSystemView.close(HoodieTableFileSystemView.java:353) at java.base/java.util.concurrent.ConcurrentHashMap$ValuesView.forEach(ConcurrentHashMap.java:4772) at org.apache.hudi.common.table.view.FileSystemViewManager.close(FileSystemViewManager.java:118) at org.apache.hudi.timeline.service.TimelineService.close(TimelineService.java:207) at org.apache.hudi.client.embedded.EmbeddedTimelineService.stop(EmbeddedTimelineService.java:119) at org.apache.hudi.client.AbstractHoodieClient.stopEmbeddedServerView(AbstractHoodieClient.java:94) at org.apache.hudi.client.AbstractHoodieClient.close(AbstractHoodieClient.java:86) at org.apache.hudi.client.AbstractHoodieWriteClient.close(AbstractHoodieWriteClient.java:1047) at org.apache.hudi.HoodieSparkSqlWriter$.commitAndPerformPostOperations(HoodieSparkSqlWriter.scala:505) at org.apache.hudi.HoodieSparkSqlWriter$.write(HoodieSparkSqlWriter.scala:225) at org.apache.hudi.DefaultSource.createRelation(DefaultSource.scala:161) at org.apache.spark.sql.execution.datasources.SaveIntoDataSourceCommand.run(SaveIntoDataSourceCommand.scala:46) at org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult$lzycompute(commands.scala:70) at org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult(commands.scala:68) at org.apache.spark.sql.execution.command.ExecutedCommandExec.doExecute(commands.scala:90) at org.apache.spark.sql.execution.SparkPlan.$anonfun$execute$1(SparkPlan.scala:175) at org.apache.spark.sql.execution.SparkPlan.$anonfun$executeQuery$1(SparkPlan.scala:213) at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151) at org.apache.spark.sql.execution.SparkPlan.executeQuery(SparkPlan.scala:210) at org.apache.spark.sql.execution.SparkPlan.execute(SparkPlan.scala:171) at org.apache.spark.sql.execution.QueryExecution.toRdd$lzycompute(QueryExecution.scala:122) at org.apache.spark.sql.execution.QueryExecution.toRdd(QueryExecution.scala:121) at org.apache.spark.sql.Data
[GitHub] [hudi] yanghua commented on pull request #2814: [HUDI-1792] Fix flink-client query error when processing files larger than 128mb
yanghua commented on pull request #2814: URL: https://github.com/apache/hudi/pull/2814#issuecomment-820928266 > of course. > Before fixing the problem: >  >  > After fixing the problem: >  >  Great! -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hj2016 commented on pull request #2814: [HUDI-1792] Fix flink-client query error when processing files larger than 128mb
hj2016 commented on pull request #2814: URL: https://github.com/apache/hudi/pull/2814#issuecomment-820927569 of course. Before fixing the problem:   After fixing the problem:   -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] xglv1985 commented on issue #2812: [SUPPORT]Got a parquet related error when incremental querying MOR table, using Spark 2.4
xglv1985 commented on issue #2812: URL: https://github.com/apache/hudi/issues/2812#issuecomment-820914205 > Okay, do you mind re-opening that Spark ticket and asking a question there ? Other options are to try a different Spark build to confirm that this is a spark issue and should probably go away with a different build (may be 2.4) OK, I've left a message there. And I will try a different Spark version. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] codecov-io commented on pull request #2835: [HUDI-1802] Timeline Server Bundle need to include com.esotericsoftware package
codecov-io commented on pull request #2835: URL: https://github.com/apache/hudi/pull/2835#issuecomment-820896412 # [Codecov](https://codecov.io/gh/apache/hudi/pull/2835?src=pr&el=h1&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=The+Apache+Software+Foundation) Report > Merging [#2835](https://codecov.io/gh/apache/hudi/pull/2835?src=pr&el=desc&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=The+Apache+Software+Foundation) (ccdac0e) into [master](https://codecov.io/gh/apache/hudi/commit/191470d1fc9b3596eb4da2413e8bef286ccc7135?el=desc&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=The+Apache+Software+Foundation) (191470d) will **decrease** coverage by `43.22%`. > The diff coverage is `n/a`. [](https://codecov.io/gh/apache/hudi/pull/2835?src=pr&el=tree&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=The+Apache+Software+Foundation) ```diff @@ Coverage Diff @@ ## master #2835 +/- ## - Coverage 52.60% 9.38% -43.23% + Complexity 3709 48 -3661 Files 485 54 -431 Lines 232241993-21231 Branches 2465 235 -2230 - Hits 12218 187-12031 + Misses 99281793 -8135 + Partials 1078 13 -1065 ``` | Flag | Coverage Δ | Complexity Δ | | |---|---|---|---| | hudicli | `?` | `?` | | | hudiclient | `?` | `?` | | | hudicommon | `?` | `?` | | | hudiflink | `?` | `?` | | | hudihadoopmr | `?` | `?` | | | hudisparkdatasource | `?` | `?` | | | hudisync | `?` | `?` | | | huditimelineservice | `?` | `?` | | | hudiutilities | `9.38% <ø> (-60.42%)` | `48.00 <ø> (-325.00)` | | Flags with carried forward coverage won't be shown. [Click here](https://docs.codecov.io/docs/carryforward-flags?utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=The+Apache+Software+Foundation#carryforward-flags-in-the-pull-request-comment) to find out more. | [Impacted Files](https://codecov.io/gh/apache/hudi/pull/2835?src=pr&el=tree&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=The+Apache+Software+Foundation) | Coverage Δ | Complexity Δ | | |---|---|---|---| | [...va/org/apache/hudi/utilities/IdentitySplitter.java](https://codecov.io/gh/apache/hudi/pull/2835/diff?src=pr&el=tree&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=The+Apache+Software+Foundation#diff-aHVkaS11dGlsaXRpZXMvc3JjL21haW4vamF2YS9vcmcvYXBhY2hlL2h1ZGkvdXRpbGl0aWVzL0lkZW50aXR5U3BsaXR0ZXIuamF2YQ==) | `0.00% <0.00%> (-100.00%)` | `0.00% <0.00%> (-2.00%)` | | | [...va/org/apache/hudi/utilities/schema/SchemaSet.java](https://codecov.io/gh/apache/hudi/pull/2835/diff?src=pr&el=tree&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=The+Apache+Software+Foundation#diff-aHVkaS11dGlsaXRpZXMvc3JjL21haW4vamF2YS9vcmcvYXBhY2hlL2h1ZGkvdXRpbGl0aWVzL3NjaGVtYS9TY2hlbWFTZXQuamF2YQ==) | `0.00% <0.00%> (-100.00%)` | `0.00% <0.00%> (-3.00%)` | | | [...a/org/apache/hudi/utilities/sources/RowSource.java](https://codecov.io/gh/apache/hudi/pull/2835/diff?src=pr&el=tree&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=The+Apache+Software+Foundation#diff-aHVkaS11dGlsaXRpZXMvc3JjL21haW4vamF2YS9vcmcvYXBhY2hlL2h1ZGkvdXRpbGl0aWVzL3NvdXJjZXMvUm93U291cmNlLmphdmE=) | `0.00% <0.00%> (-100.00%)` | `0.00% <0.00%> (-4.00%)` | | | [.../org/apache/hudi/utilities/sources/AvroSource.java](https://codecov.io/gh/apache/hudi/pull/2835/diff?src=pr&el=tree&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=The+Apache+Software+Foundation#diff-aHVkaS11dGlsaXRpZXMvc3JjL21haW4vamF2YS9vcmcvYXBhY2hlL2h1ZGkvdXRpbGl0aWVzL3NvdXJjZXMvQXZyb1NvdXJjZS5qYXZh) | `0.00% <0.00%> (-100.00%)` | `0.00% <0.00%> (-1.00%)` | | | [.../org/apache/hudi/utilities/sources/JsonSource.java](https://codecov.io/gh/apache/hudi/pull/2835/diff?src=pr&el=tree&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=The+Apache+Software+Foundation#diff-aHVkaS11dGlsaXRpZXMvc3JjL21haW4vamF2YS9vcmcvYXBhY2hlL2h1ZGkvdXRpbGl0aWVzL3NvdXJjZXMvSnNvblNvdXJjZS5qYXZh) | `0.00% <0.00%> (-100.0
[jira] [Assigned] (HUDI-1802) Timeline Server Bundle need to include com.esotericsoftware package
[
https://issues.apache.org/jira/browse/HUDI-1802?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
vinoyang reassigned HUDI-1802:
--
Assignee: cdmikechen
> Timeline Server Bundle need to include com.esotericsoftware package
> ---
>
> Key: HUDI-1802
> URL: https://issues.apache.org/jira/browse/HUDI-1802
> Project: Apache Hudi
> Issue Type: Bug
> Components: Common Core
>Reporter: cdmikechen
>Assignee: cdmikechen
>Priority: Major
> Labels: pull-request-available
> Fix For: 0.9.0
>
>
> When using Timeline Server Bundle to be a timeline remote server, it will not
> work fine sometimes when getting files.
> {code}
> 21/04/16 02:32:16 INFO service.FileSystemViewHandler:
> TimeTakenMillis[Total=1, Refresh=0, handle=1, Check=0], Success=true,
> Query=basepath=%2Fhive%2Fwarehouse%2Fbigdata.db%2Fetl_datasource&lastinstantts=20210413051307&timelinehash=f3173e19a150f2c50e2a0f3c724351683edbf526bcbde67774f9e34981130b6b,
> Host=hudi-timeline-server.bigdata.svc.cluster.local:26754, synced=false
> 21/04/16 02:32:17 INFO view.AbstractTableFileSystemView: Building file system
> view for partition ()
> 21/04/16 02:32:17 INFO view.AbstractTableFileSystemView: #files found in
> partition () =3, Time taken =8
> 21/04/16 02:32:17 INFO view.RocksDbBasedFileSystemView: Resetting and adding
> new partition () to ROCKSDB based file-system view at
> /home/hdfs/software/hudi/hudi-timeline-server/hoodie_timeline_rocksdb, Total
> file-groups=1
> 21/04/16 02:32:17 INFO collection.RocksDBDAO: Prefix DELETE
> (query=type=slice,part=,id=) on
> hudi_view__hive_warehouse_bigdata.db_etl_datasource
> 21/04/16 02:32:17 INFO collection.RocksDBDAO: Prefix DELETE
> (query=type=df,part=,id=) on
> hudi_view__hive_warehouse_bigdata.db_etl_datasource
> 21/04/16 02:32:17 INFO service.FileSystemViewHandler:
> TimeTakenMillis[Total=154, Refresh=5, handle=0, Check=0], Success=true,
> Query=partition=&maxinstant=20210413051307&basepath=%2Fhive%2Fwarehouse%2Fbigdata.db%2Fetl_datasource&lastinstantts=20210413051307&timelinehash=f3173e19a150f2c50e2a0f3c724351683edbf526bcbde67774f9e34981130b6b,
> Host=hudi-timeline-server.bigdata.svc.cluster.local:26754, synced=false
> 21/04/16 02:32:17 ERROR javalin.Javalin: Exception occurred while servicing
> http-request
> java.lang.NoClassDefFoundError: com/esotericsoftware/kryo/Kryo
> at
> org.apache.hudi.common.util.SerializationUtils$KryoInstantiator.newKryo(SerializationUtils.java:116)
> at
> org.apache.hudi.common.util.SerializationUtils$KryoSerializerInstance.(SerializationUtils.java:89)
> at
> java.lang.ThreadLocal$SuppliedThreadLocal.initialValue(ThreadLocal.java:284)
> at java.lang.ThreadLocal.setInitialValue(ThreadLocal.java:180)
> at java.lang.ThreadLocal.get(ThreadLocal.java:170)
> at
> org.apache.hudi.common.util.SerializationUtils.serialize(SerializationUtils.java:52)
> at
> org.apache.hudi.common.util.collection.RocksDBDAO.putInBatch(RocksDBDAO.java:172)
> at
> org.apache.hudi.common.table.view.RocksDbBasedFileSystemView.lambda$null$12(RocksDbBasedFileSystemView.java:237)
> at
> java.util.stream.ForEachOps$ForEachOp$OfRef.accept(ForEachOps.java:184)
> at
> java.util.stream.ReferencePipeline$3$1.accept(ReferencePipeline.java:193)
> at
> java.util.TreeMap$EntrySpliterator.forEachRemaining(TreeMap.java:2969)
> at java.util.stream.AbstractPipeline.copyInto(AbstractPipeline.java:482)
> at
> java.util.stream.AbstractPipeline.wrapAndCopyInto(AbstractPipeline.java:472)
> at
> java.util.stream.ForEachOps$ForEachOp.evaluateSequential(ForEachOps.java:151)
> at
> java.util.stream.ForEachOps$ForEachOp$OfRef.evaluateSequential(ForEachOps.java:174)
> at java.util.stream.AbstractPipeline.evaluate(AbstractPipeline.java:234)
> at
> java.util.stream.ReferencePipeline.forEach(ReferencePipeline.java:418)
> at
> org.apache.hudi.common.table.view.RocksDbBasedFileSystemView.lambda$null$13(RocksDbBasedFileSystemView.java:236)
> at
> org.apache.hudi.common.util.collection.RocksDBDAO.writeBatch(RocksDBDAO.java:154)
> at
> org.apache.hudi.common.table.view.RocksDbBasedFileSystemView.lambda$storePartitionView$14(RocksDbBasedFileSystemView.java:235)
> at java.util.ArrayList.forEach(ArrayList.java:1257)
> at
> org.apache.hudi.common.table.view.RocksDbBasedFileSystemView.storePartitionView(RocksDbBasedFileSystemView.java:234)
> at
> org.apache.hudi.common.table.view.AbstractTableFileSystemView.lambda$addFilesToView$2(AbstractTableFileSystemView.java:145)
> at java.util.HashMap.forEach(HashMap.java:1289)
> at
> org.apache.hudi.common.table.view.AbstractTableFileSystemView.addFilesToView(AbstractTableFileSystemView
[jira] [Closed] (HUDI-1801) FlinkMergeHandle rolling over may miss to rename the latest file handle
[
https://issues.apache.org/jira/browse/HUDI-1801?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
vinoyang closed HUDI-1801.
--
Resolution: Fixed
b6d949b48a649acac27d5d9b91677bf2e25e9342
> FlinkMergeHandle rolling over may miss to rename the latest file handle
> ---
>
> Key: HUDI-1801
> URL: https://issues.apache.org/jira/browse/HUDI-1801
> Project: Apache Hudi
> Issue Type: Bug
> Components: Flink Integration
>Affects Versions: 0.8.0
>Reporter: Danny Chen
>Assignee: Danny Chen
>Priority: Major
> Labels: pull-request-available
> Fix For: 0.9.0
>
>
> The {{FlinkMergeHandle}} may rename the N-1 th file handle instead of the
> latest one, thus to cause data duplication.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[hudi] branch master updated (191470d -> b6d949b)
This is an automated email from the ASF dual-hosted git repository. vinoyang pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/hudi.git. from 191470d [HUDI-1797] Remove the com.google.guave jar from hudi-flink-bundle to avoid conflicts. (#2828) add b6d949b [HUDI-1801] FlinkMergeHandle rolling over may miss to rename the latest file handle (#2831) No new revisions were added by this update. Summary of changes: .../java/org/apache/hudi/io/FlinkMergeHandle.java | 39 +- .../commit/BaseFlinkCommitActionExecutor.java | 2 +- .../hudi/table/action/commit/FlinkMergeHelper.java | 8 ++--- .../apache/hudi/table/HoodieDataSourceITCase.java | 28 4 files changed, 48 insertions(+), 29 deletions(-)
[GitHub] [hudi] yanghua merged pull request #2831: [HUDI-1801] FlinkMergeHandle rolling over may miss to rename the late…
yanghua merged pull request #2831: URL: https://github.com/apache/hudi/pull/2831 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (HUDI-1802) Timeline Server Bundle need to include com.esotericsoftware package
[
https://issues.apache.org/jira/browse/HUDI-1802?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
ASF GitHub Bot updated HUDI-1802:
-
Labels: pull-request-available (was: )
> Timeline Server Bundle need to include com.esotericsoftware package
> ---
>
> Key: HUDI-1802
> URL: https://issues.apache.org/jira/browse/HUDI-1802
> Project: Apache Hudi
> Issue Type: Bug
> Components: Common Core
>Reporter: cdmikechen
>Priority: Major
> Labels: pull-request-available
> Fix For: 0.9.0
>
>
> When using Timeline Server Bundle to be a timeline remote server, it will not
> work fine sometimes when getting files.
> {code}
> 21/04/16 02:32:16 INFO service.FileSystemViewHandler:
> TimeTakenMillis[Total=1, Refresh=0, handle=1, Check=0], Success=true,
> Query=basepath=%2Fhive%2Fwarehouse%2Fbigdata.db%2Fetl_datasource&lastinstantts=20210413051307&timelinehash=f3173e19a150f2c50e2a0f3c724351683edbf526bcbde67774f9e34981130b6b,
> Host=hudi-timeline-server.bigdata.svc.cluster.local:26754, synced=false
> 21/04/16 02:32:17 INFO view.AbstractTableFileSystemView: Building file system
> view for partition ()
> 21/04/16 02:32:17 INFO view.AbstractTableFileSystemView: #files found in
> partition () =3, Time taken =8
> 21/04/16 02:32:17 INFO view.RocksDbBasedFileSystemView: Resetting and adding
> new partition () to ROCKSDB based file-system view at
> /home/hdfs/software/hudi/hudi-timeline-server/hoodie_timeline_rocksdb, Total
> file-groups=1
> 21/04/16 02:32:17 INFO collection.RocksDBDAO: Prefix DELETE
> (query=type=slice,part=,id=) on
> hudi_view__hive_warehouse_bigdata.db_etl_datasource
> 21/04/16 02:32:17 INFO collection.RocksDBDAO: Prefix DELETE
> (query=type=df,part=,id=) on
> hudi_view__hive_warehouse_bigdata.db_etl_datasource
> 21/04/16 02:32:17 INFO service.FileSystemViewHandler:
> TimeTakenMillis[Total=154, Refresh=5, handle=0, Check=0], Success=true,
> Query=partition=&maxinstant=20210413051307&basepath=%2Fhive%2Fwarehouse%2Fbigdata.db%2Fetl_datasource&lastinstantts=20210413051307&timelinehash=f3173e19a150f2c50e2a0f3c724351683edbf526bcbde67774f9e34981130b6b,
> Host=hudi-timeline-server.bigdata.svc.cluster.local:26754, synced=false
> 21/04/16 02:32:17 ERROR javalin.Javalin: Exception occurred while servicing
> http-request
> java.lang.NoClassDefFoundError: com/esotericsoftware/kryo/Kryo
> at
> org.apache.hudi.common.util.SerializationUtils$KryoInstantiator.newKryo(SerializationUtils.java:116)
> at
> org.apache.hudi.common.util.SerializationUtils$KryoSerializerInstance.(SerializationUtils.java:89)
> at
> java.lang.ThreadLocal$SuppliedThreadLocal.initialValue(ThreadLocal.java:284)
> at java.lang.ThreadLocal.setInitialValue(ThreadLocal.java:180)
> at java.lang.ThreadLocal.get(ThreadLocal.java:170)
> at
> org.apache.hudi.common.util.SerializationUtils.serialize(SerializationUtils.java:52)
> at
> org.apache.hudi.common.util.collection.RocksDBDAO.putInBatch(RocksDBDAO.java:172)
> at
> org.apache.hudi.common.table.view.RocksDbBasedFileSystemView.lambda$null$12(RocksDbBasedFileSystemView.java:237)
> at
> java.util.stream.ForEachOps$ForEachOp$OfRef.accept(ForEachOps.java:184)
> at
> java.util.stream.ReferencePipeline$3$1.accept(ReferencePipeline.java:193)
> at
> java.util.TreeMap$EntrySpliterator.forEachRemaining(TreeMap.java:2969)
> at java.util.stream.AbstractPipeline.copyInto(AbstractPipeline.java:482)
> at
> java.util.stream.AbstractPipeline.wrapAndCopyInto(AbstractPipeline.java:472)
> at
> java.util.stream.ForEachOps$ForEachOp.evaluateSequential(ForEachOps.java:151)
> at
> java.util.stream.ForEachOps$ForEachOp$OfRef.evaluateSequential(ForEachOps.java:174)
> at java.util.stream.AbstractPipeline.evaluate(AbstractPipeline.java:234)
> at
> java.util.stream.ReferencePipeline.forEach(ReferencePipeline.java:418)
> at
> org.apache.hudi.common.table.view.RocksDbBasedFileSystemView.lambda$null$13(RocksDbBasedFileSystemView.java:236)
> at
> org.apache.hudi.common.util.collection.RocksDBDAO.writeBatch(RocksDBDAO.java:154)
> at
> org.apache.hudi.common.table.view.RocksDbBasedFileSystemView.lambda$storePartitionView$14(RocksDbBasedFileSystemView.java:235)
> at java.util.ArrayList.forEach(ArrayList.java:1257)
> at
> org.apache.hudi.common.table.view.RocksDbBasedFileSystemView.storePartitionView(RocksDbBasedFileSystemView.java:234)
> at
> org.apache.hudi.common.table.view.AbstractTableFileSystemView.lambda$addFilesToView$2(AbstractTableFileSystemView.java:145)
> at java.util.HashMap.forEach(HashMap.java:1289)
> at
> org.apache.hudi.common.table.view.AbstractTableFileSystemView.addFilesToView(AbstractTableFileSystemView.java:133)
[GitHub] [hudi] cdmikechen opened a new pull request #2835: [HUDI-1802] Timeline Server Bundle need to include com.esotericsoftware package
cdmikechen opened a new pull request #2835: URL: https://github.com/apache/hudi/pull/2835 ## *Tips* - *Thank you very much for contributing to Apache Hudi.* - *Please review https://hudi.apache.org/contributing.html before opening a pull request.* ## What is the purpose of the pull request Fix https://issues.apache.org/jira/browse/HUDI-1802 ## Brief change log Add `com.esotericsoftware` package to `hudi-timeline-server-bundle` pom.xml ## Verify this pull request Have tested in a standalone hudi timeline server. ## Committer checklist - [x] Has a corresponding JIRA in PR title & commit - [ ] Commit message is descriptive of the change - [ ] CI is green - [ ] Necessary doc changes done or have another open PR - [ ] For large changes, please consider breaking it into sub-tasks under an umbrella JIRA. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] njalan commented on issue #2609: [SUPPORT] Presto hudi query slow when compared to parquet
njalan commented on issue #2609: URL: https://github.com/apache/hudi/issues/2609#issuecomment-820876527 @tooptoop4 So is there any plan to merge it in prestosql? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Created] (HUDI-1802) Timeline Server Bundle need to include com.esotericsoftware package
cdmikechen created HUDI-1802:
Summary: Timeline Server Bundle need to include
com.esotericsoftware package
Key: HUDI-1802
URL: https://issues.apache.org/jira/browse/HUDI-1802
Project: Apache Hudi
Issue Type: Bug
Components: Common Core
Reporter: cdmikechen
Fix For: 0.9.0
When using Timeline Server Bundle to be a timeline remote server, it will not
work fine sometimes when getting files.
{code}
21/04/16 02:32:16 INFO service.FileSystemViewHandler: TimeTakenMillis[Total=1,
Refresh=0, handle=1, Check=0], Success=true,
Query=basepath=%2Fhive%2Fwarehouse%2Fbigdata.db%2Fetl_datasource&lastinstantts=20210413051307&timelinehash=f3173e19a150f2c50e2a0f3c724351683edbf526bcbde67774f9e34981130b6b,
Host=hudi-timeline-server.bigdata.svc.cluster.local:26754, synced=false
21/04/16 02:32:17 INFO view.AbstractTableFileSystemView: Building file system
view for partition ()
21/04/16 02:32:17 INFO view.AbstractTableFileSystemView: #files found in
partition () =3, Time taken =8
21/04/16 02:32:17 INFO view.RocksDbBasedFileSystemView: Resetting and adding
new partition () to ROCKSDB based file-system view at
/home/hdfs/software/hudi/hudi-timeline-server/hoodie_timeline_rocksdb, Total
file-groups=1
21/04/16 02:32:17 INFO collection.RocksDBDAO: Prefix DELETE
(query=type=slice,part=,id=) on
hudi_view__hive_warehouse_bigdata.db_etl_datasource
21/04/16 02:32:17 INFO collection.RocksDBDAO: Prefix DELETE
(query=type=df,part=,id=) on hudi_view__hive_warehouse_bigdata.db_etl_datasource
21/04/16 02:32:17 INFO service.FileSystemViewHandler:
TimeTakenMillis[Total=154, Refresh=5, handle=0, Check=0], Success=true,
Query=partition=&maxinstant=20210413051307&basepath=%2Fhive%2Fwarehouse%2Fbigdata.db%2Fetl_datasource&lastinstantts=20210413051307&timelinehash=f3173e19a150f2c50e2a0f3c724351683edbf526bcbde67774f9e34981130b6b,
Host=hudi-timeline-server.bigdata.svc.cluster.local:26754, synced=false
21/04/16 02:32:17 ERROR javalin.Javalin: Exception occurred while servicing
http-request
java.lang.NoClassDefFoundError: com/esotericsoftware/kryo/Kryo
at
org.apache.hudi.common.util.SerializationUtils$KryoInstantiator.newKryo(SerializationUtils.java:116)
at
org.apache.hudi.common.util.SerializationUtils$KryoSerializerInstance.(SerializationUtils.java:89)
at
java.lang.ThreadLocal$SuppliedThreadLocal.initialValue(ThreadLocal.java:284)
at java.lang.ThreadLocal.setInitialValue(ThreadLocal.java:180)
at java.lang.ThreadLocal.get(ThreadLocal.java:170)
at
org.apache.hudi.common.util.SerializationUtils.serialize(SerializationUtils.java:52)
at
org.apache.hudi.common.util.collection.RocksDBDAO.putInBatch(RocksDBDAO.java:172)
at
org.apache.hudi.common.table.view.RocksDbBasedFileSystemView.lambda$null$12(RocksDbBasedFileSystemView.java:237)
at
java.util.stream.ForEachOps$ForEachOp$OfRef.accept(ForEachOps.java:184)
at
java.util.stream.ReferencePipeline$3$1.accept(ReferencePipeline.java:193)
at
java.util.TreeMap$EntrySpliterator.forEachRemaining(TreeMap.java:2969)
at java.util.stream.AbstractPipeline.copyInto(AbstractPipeline.java:482)
at
java.util.stream.AbstractPipeline.wrapAndCopyInto(AbstractPipeline.java:472)
at
java.util.stream.ForEachOps$ForEachOp.evaluateSequential(ForEachOps.java:151)
at
java.util.stream.ForEachOps$ForEachOp$OfRef.evaluateSequential(ForEachOps.java:174)
at java.util.stream.AbstractPipeline.evaluate(AbstractPipeline.java:234)
at
java.util.stream.ReferencePipeline.forEach(ReferencePipeline.java:418)
at
org.apache.hudi.common.table.view.RocksDbBasedFileSystemView.lambda$null$13(RocksDbBasedFileSystemView.java:236)
at
org.apache.hudi.common.util.collection.RocksDBDAO.writeBatch(RocksDBDAO.java:154)
at
org.apache.hudi.common.table.view.RocksDbBasedFileSystemView.lambda$storePartitionView$14(RocksDbBasedFileSystemView.java:235)
at java.util.ArrayList.forEach(ArrayList.java:1257)
at
org.apache.hudi.common.table.view.RocksDbBasedFileSystemView.storePartitionView(RocksDbBasedFileSystemView.java:234)
at
org.apache.hudi.common.table.view.AbstractTableFileSystemView.lambda$addFilesToView$2(AbstractTableFileSystemView.java:145)
at java.util.HashMap.forEach(HashMap.java:1289)
at
org.apache.hudi.common.table.view.AbstractTableFileSystemView.addFilesToView(AbstractTableFileSystemView.java:133)
at
org.apache.hudi.common.table.view.AbstractTableFileSystemView.lambda$ensurePartitionLoadedCorrectly$9(AbstractTableFileSystemView.java:284)
at
java.util.concurrent.ConcurrentHashMap.computeIfAbsent(ConcurrentHashMap.java:1660)
at
org.apache.hudi.common.table.view.AbstractTableFileSystemView.ensurePartitionLoadedCorrectly(AbstractTableFileSystemView.java:269)
at
or
[GitHub] [hudi] garyli1019 commented on issue #2818: [SUPPORT] Exception thrown in incremental query(MOR) and potential change data loss after archiving
garyli1019 commented on issue #2818: URL: https://github.com/apache/hudi/issues/2818#issuecomment-820874107 @ssdong Thanks for report the issue. For the `NoSuchElementException`, please feel free to submit a fix. For the incremental pulling form archived commits, do you think we should get the commits from the archive folder? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] danny0405 commented on a change in pull request #2831: [HUDI-1801] FlinkMergeHandle rolling over may miss to rename the late…
danny0405 commented on a change in pull request #2831:
URL: https://github.com/apache/hudi/pull/2831#discussion_r614527384
##
File path:
hudi-client/hudi-flink-client/src/main/java/org/apache/hudi/io/FlinkMergeHandle.java
##
@@ -138,12 +128,12 @@ public void rollOver(Iterator>
newRecordsItr) {
this.writeStatus.setTotalErrorRecords(0);
this.timer = new HoodieTimer().startTimer();
-rollNumber++;
+rollNumber += 1;
Review comment:
No difference, just make the logic more clear ~
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] yanghua commented on a change in pull request #2831: [HUDI-1801] FlinkMergeHandle rolling over may miss to rename the late…
yanghua commented on a change in pull request #2831:
URL: https://github.com/apache/hudi/pull/2831#discussion_r614520445
##
File path:
hudi-client/hudi-flink-client/src/main/java/org/apache/hudi/io/FlinkMergeHandle.java
##
@@ -138,12 +128,12 @@ public void rollOver(Iterator>
newRecordsItr) {
this.writeStatus.setTotalErrorRecords(0);
this.timer = new HoodieTimer().startTimer();
-rollNumber++;
+rollNumber += 1;
Review comment:
What's the difference between these changes?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] wk888 opened a new issue #2834: [SUPPORT]org.apache.hudi.exception.TableNotFoundException
wk888 opened a new issue #2834: URL: https://github.com/apache/hudi/issues/2834 **_Tips before filing an issue_** - Have you gone through our [FAQs](https://cwiki.apache.org/confluence/display/HUDI/FAQ)? - Join the mailing list to engage in conversations and get faster support at dev-subscr...@hudi.apache.org. - If you have triaged this as a bug, then file an [issue](https://issues.apache.org/jira/projects/HUDI/issues) directly. hive> set hive.input.format=org.apache.hudi.hadoop.hive.HoodieCombineHiveInputFormat; hive> select * from test.hudu_test_1_rt where dt=2021-04-15; WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases. Query ID = root_20210416094020_2f0117b1-4007-4390-ab58-be9ca46a1915 Total jobs = 1 Launching Job 1 out of 1 Number of reduce tasks is set to 0 since there's no reduce operator org.apache.hudi.exception.TableNotFoundException: Hoodie table not found in path ofs://qqq.myqcloud.com/tmp/hive/root/1c7ec12e-4953-4913-bf9f-a09372b51609/.hoodie at org.apache.hudi.exception.TableNotFoundException.checkTableValidity(TableNotFoundException.java:53) at org.apache.hudi.common.table.HoodieTableMetaClient.(HoodieTableMetaClient.java:110) at org.apache.hudi.common.table.HoodieTableMetaClient.(HoodieTableMetaClient.java:71) at org.apache.hudi.common.table.HoodieTableMetaClient$Builder.build(HoodieTableMetaClient.java:581) at org.apache.hudi.hadoop.utils.HoodieInputFormatUtils.getTableMetaClientForBasePath(HoodieInputFormatUtils.java:327) at org.apache.hudi.hadoop.utils.HoodieInputFormatUtils.lambda$getTableMetaClientByBasePath$3(HoodieInputFormatUtils.java:302) at java.util.stream.Collectors.lambda$toMap$58(Collectors.java:1321) at java.util.stream.ReduceOps$3ReducingSink.accept(ReduceOps.java:169) at java.util.HashMap$KeySpliterator.forEachRemaining(HashMap.java:1548) at java.util.stream.AbstractPipeline.copyInto(AbstractPipeline.java:481) at java.util.stream.AbstractPipeline.wrapAndCopyInto(AbstractPipeline.java:471) at java.util.stream.ReduceOps$ReduceOp.evaluateSequential(ReduceOps.java:708) at java.util.stream.AbstractPipeline.evaluate(AbstractPipeline.java:234) at java.util.stream.ReferencePipeline.collect(ReferencePipeline.java:499) at org.apache.hudi.hadoop.utils.HoodieInputFormatUtils.getTableMetaClientByBasePath(HoodieInputFormatUtils.java:293) at org.apache.hudi.hadoop.utils.HoodieRealtimeInputFormatUtils.getRealtimeSplits(HoodieRealtimeInputFormatUtils.java:66) at org.apache.hudi.hadoop.realtime.HoodieParquetRealtimeInputFormat.getSplits(HoodieParquetRealtimeInputFormat.java:66) at org.apache.hudi.hadoop.hive.HoodieCombineHiveInputFormat$HoodieCombineFileInputFormatShim.getSplits(HoodieCombineHiveInputFormat.java:922) at org.apache.hudi.hadoop.hive.HoodieCombineHiveInputFormat.getCombineSplits(HoodieCombineHiveInputFormat.java:241) at org.apache.hudi.hadoop.hive.HoodieCombineHiveInputFormat.getSplits(HoodieCombineHiveInputFormat.java:363) at org.apache.hadoop.mapreduce.JobSubmitter.writeOldSplits(JobSubmitter.java:333) at org.apache.hadoop.mapreduce.JobSubmitter.writeSplits(JobSubmitter.java:324) at org.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal(JobSubmitter.java:200) at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1307) at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1304) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:422) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1924) at org.apache.hadoop.mapreduce.Job.submit(Job.java:1304) at org.apache.hadoop.mapred.JobClient$1.run(JobClient.java:578) at org.apache.hadoop.mapred.JobClient$1.run(JobClient.java:573) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:422) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1924) at org.apache.hadoop.mapred.JobClient.submitJobInternal(JobClient.java:573) at org.apache.hadoop.mapred.JobClient.submitJob(JobClient.java:564) at org.apache.hadoop.hive.ql.exec.mr.ExecDriver.execute(ExecDriver.java:414) at org.apache.hadoop.hive.ql.exec.mr.MapRedTask.execute(MapRedTask.java:151) at org.apache.hadoop.hive.ql.exec.Task.executeTask(Task.java:199) at org.apache.hadoop.hive.ql.exec.TaskRunner.runSequential(TaskRunner.java:100) at org.apache.hadoop.h
[GitHub] [hudi] yanghua commented on pull request #2814: [HUDI-1792] Fix flink-client query error when processing files larger than 128mb
yanghua commented on pull request #2814: URL: https://github.com/apache/hudi/pull/2814#issuecomment-820843182 @hj2016 Since this fix is hard to write test. Did you test it in your local env? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] zhedoubushishi commented on pull request #2833: [WIP][HUDI-89] Add configOption & refactor HoodieBootstrapConfig for a demo
zhedoubushishi commented on pull request #2833: URL: https://github.com/apache/hudi/pull/2833#issuecomment-820836368 @vinothchandar can you take a look when you have time to see if this is something you want to go with? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (HUDI-89) Clean up placement, naming, defaults of HoodieWriteConfig
[ https://issues.apache.org/jira/browse/HUDI-89?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] ASF GitHub Bot updated HUDI-89: --- Labels: pull-request-available (was: ) > Clean up placement, naming, defaults of HoodieWriteConfig > - > > Key: HUDI-89 > URL: https://issues.apache.org/jira/browse/HUDI-89 > Project: Apache Hudi > Issue Type: Improvement > Components: Code Cleanup, Usability, Writer Core >Reporter: Vinoth Chandar >Assignee: Vinoth Chandar >Priority: Major > Labels: pull-request-available > > # Rename HoodieWriteConfig to HoodieClientConfig > # Move bunch of configs from CompactionConfig to StorageConfig > # Introduce new HoodieCleanConfig > # Should we consider lombok or something to automate the > defaults/getters/setters > # Consistent name of properties/defaults > # Enforce bounds more strictly -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [hudi] zhedoubushishi opened a new pull request #2833: [WIP][HUDI-89] Add configOption & refactor HoodieBootstrapConfig for a demo
zhedoubushishi opened a new pull request #2833: URL: https://github.com/apache/hudi/pull/2833 ## *Tips* - *Thank you very much for contributing to Apache Hudi.* - *Please review https://hudi.apache.org/contributing.html before opening a pull request.* ## What is the purpose of the pull request This is just a immature demo for discussion. Similar to flink [ConfigOption](https://github.com/apache/flink/blob/master/flink-core/src/main/java/org/apache/flink/configuration/ConfigOption.java), and based on the changes in this [pr](https://github.com/apache/hudi/pull/1094/files), I wrote a demo for using configOption for HoodieBootstrapConfig. The advantage of pr is that it binds property key, property defaultValue, property description, property deprecated names together which is straightforward for developers to use. And for the next step, we could also do something similar to Flink to automatically add/update property description on the website: https://github.com/apache/flink/blob/master/flink-core/src/main/java/org/apache/flink/configuration/description/Description.java. Also this is extensible, we can bind more features if needed. The disadvantage is for users who are now using e.g. ```HoodieBootstrapConfig.BOOTSTRAP_BASE_PATH_PROP``` in their client code, they need to either replace it with ```HoodieBootstrapConfig.BOOTSTRAP_BASE_PATH_PROP``` or ```hoodie.bootstrap.base.path```. ## Brief change log - Add configOption & refactor HoodieBootstrapConfig ## Verify this pull request This pull request is already covered by existing tests, such as *(please describe tests)*. ## Committer checklist - [x] Has a corresponding JIRA in PR title & commit - [x] Commit message is descriptive of the change - [x] CI is green - [ ] Necessary doc changes done or have another open PR - [ ] For large changes, please consider breaking it into sub-tasks under an umbrella JIRA. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] umehrot2 commented on a change in pull request #2283: [HUDI-1415] Read Hoodie Table As Spark DataSource Table
umehrot2 commented on a change in pull request #2283:
URL: https://github.com/apache/hudi/pull/2283#discussion_r614431975
##
File path:
hudi-spark-datasource/hudi-spark/src/main/scala/org/apache/hudi/HoodieSparkSqlWriter.scala
##
@@ -388,7 +399,8 @@ private[hudi] object HoodieSparkSqlWriter {
}
}
- private def syncHive(basePath: Path, fs: FileSystem, parameters: Map[String,
String]): Boolean = {
+ private def syncHive(basePath: Path, fs: FileSystem, parameters: Map[String,
String],
+ hadoopConf: Configuration): Boolean = {
Review comment:
This modification seems unnecessary, as `hadoopConf` is not being used.
##
File path:
hudi-spark-datasource/hudi-spark/src/main/scala/org/apache/hudi/HoodieSparkSqlWriter.scala
##
@@ -306,7 +311,10 @@ private[hudi] object HoodieSparkSqlWriter {
} finally {
writeClient.close()
}
-val metaSyncSuccess = metaSync(parameters, basePath,
jsc.hadoopConfiguration)
+val newParameters =
+ addSqlTableProperties(sqlContext.sparkSession.sessionState.conf,
df.schema, parameters)
Review comment:
Can be moved to `metaSync` or `syncHive` method.
##
File path:
hudi-sync/hudi-hive-sync/src/main/java/org/apache/hudi/hive/HiveSyncConfig.java
##
@@ -88,6 +88,12 @@
@Parameter(names = {"--verify-metadata-file-listing"}, description = "Verify
file listing from Hudi's metadata against file system")
public Boolean verifyMetadataFileListing =
HoodieMetadataConfig.DEFAULT_METADATA_VALIDATE;
+ @Parameter(names = {"--table-properties"}, description = "Table properties
to hive table")
+ public String tableProperties;
+
+ @Parameter(names = {"--serde-properties"}, description = "Serde properties
to hive table")
+ public String serdeProperties;
+
Review comment:
Can you update the `toString()` in this class ?
##
File path:
hudi-sync/hudi-hive-sync/src/main/java/org/apache/hudi/hive/HoodieHiveClient.java
##
@@ -138,6 +138,27 @@ public void updatePartitionsToTable(String tableName,
List changedPartit
}
}
+ /**
+ * Update the table properties to the table.
+ * @param tableProperties
+ */
+ @Override
+ public void updateTableProperties(String tableName, Map
tableProperties) {
+if (tableProperties == null || tableProperties.size() == 0) {
Review comment:
nit: `tableProperties.isEmpty()` ?
##
File path:
hudi-sync/hudi-hive-sync/src/main/java/org/apache/hudi/hive/HiveSyncTool.java
##
@@ -164,7 +165,13 @@ private void syncHoodieTable(String tableName, boolean
useRealtimeInputFormat) {
LOG.info("Storage partitions scan complete. Found " +
writtenPartitionsSince.size());
// Sync the partitions if needed
syncPartitions(tableName, writtenPartitionsSince);
-
+// Sync the table properties if need
+if (cfg.tableProperties != null) {
+ Map tableProperties =
ConfigUtils.toMap(cfg.tableProperties);
+ hoodieHiveClient.updateTableProperties(tableName, tableProperties);
+ LOG.info("Sync table properties for " + tableName + ", table properties
is: "
+ + cfg.tableProperties);
+}
Review comment:
Can't we sync this while creating the table itself, like you are doing
for serde properties ?
##
File path:
hudi-spark-datasource/hudi-spark-common/src/main/scala/org/apache/hudi/DataSourceOptions.scala
##
@@ -353,6 +353,8 @@ object DataSourceWriteOptions {
val HIVE_IGNORE_EXCEPTIONS_OPT_KEY =
"hoodie.datasource.hive_sync.ignore_exceptions"
val HIVE_SKIP_RO_SUFFIX = "hoodie.datasource.hive_sync.skip_ro_suffix"
val HIVE_SUPPORT_TIMESTAMP = "hoodie.datasource.hive_sync.support_timestamp"
+ val HIVE_TABLE_PROPERTIES = "hoodie.datasource.hive_sync.table_properties"
Review comment:
Lets introduce another additional boolean property
`hoodie.datasource.hive_sync.sync_as_datasource` and put the feature behind it.
We can use `true` by default, but atleast there would be a way to turn it off.
This is going to change the way spark sql queries currently run with Hudi, and
is a huge change.
##
File path:
hudi-sync/hudi-hive-sync/src/main/java/org/apache/hudi/hive/HoodieHiveClient.java
##
@@ -138,6 +138,27 @@ public void updatePartitionsToTable(String tableName,
List changedPartit
}
}
+ /**
+ * Update the table properties to the table.
+ * @param tableProperties
+ */
Review comment:
Can you improve the javadoc ? It has missing properties and descriptions.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] nevgin opened a new issue #2832: [SUPPORT]
nevgin opened a new issue #2832: URL: https://github.com/apache/hudi/issues/2832 I have installed vanilla versions of hive and spark. Put the jar hoodie spark bundle in the spark. Put hudi-hadoop-mr-bundle-x.y.z-SNAPSHOT.jar in aux hive dir and to classpath hadoop on all datanodes. When a query is executed in hive with the MP engine, the queries are executed. Requests also be executed from spark. However, when running a query to Hive with Engine Spark, an error is thrown Error: org.apache.hive.service.cli.HiveSQLException: Error while processing statement: FAILED: Execution Error, return code 3 from org.apache.hadoop.hive.ql.exec.spark.SparkTask. java.l ang.NoClassDefFoundError: org / apache / hadoop / hive / ql / io / parquet / MapredParquetInputFormat **Expected behavior** Executed query **Environment Description** * Hudi version : 0.7.0 * Spark version : 2.4.7 * Hive version : 2.3.8 * Hadoop version : 2.7.3 * Storage (HDFS/S3/GCS..) : HDFS * Running on Docker? (yes/no) : NO **Additional context** Add any other context about the problem here. **Stacktrace** java.lang.ClassNotFoundException: org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat ```Add the stacktrace of the error.``` -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (HUDI-57) [UMBRELLA] Support ORC Storage
[ https://issues.apache.org/jira/browse/HUDI-57?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17322470#comment-17322470 ] Nishith Agarwal commented on HUDI-57: - [~Teresa] Please create the tickets for the remaining work around fixing test cases as well as the HoodieORCInputFormat under this ticket. We will use that to collaborate and source help from other members of the community. > [UMBRELLA] Support ORC Storage > -- > > Key: HUDI-57 > URL: https://issues.apache.org/jira/browse/HUDI-57 > Project: Apache Hudi > Issue Type: Improvement > Components: Hive Integration, Writer Core >Affects Versions: 0.9.0 >Reporter: Vinoth Chandar >Assignee: Teresa Kang >Priority: Major > Labels: hudi-umbrellas, pull-request-available > Fix For: 0.9.0 > > Time Spent: 20m > Remaining Estimate: 0h > > [https://github.com/uber/hudi/issues/68] > https://github.com/uber/hudi/issues/155 -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Assigned] (HUDI-765) Implement OrcReaderIterator
[ https://issues.apache.org/jira/browse/HUDI-765?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Nishith Agarwal reassigned HUDI-765: Assignee: Teresa Kang (was: Yanjia Gary Li) > Implement OrcReaderIterator > --- > > Key: HUDI-765 > URL: https://issues.apache.org/jira/browse/HUDI-765 > Project: Apache Hudi > Issue Type: Sub-task >Reporter: lamber-ken >Assignee: Teresa Kang >Priority: Major > -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Assigned] (HUDI-57) [UMBRELLA] Support ORC Storage
[ https://issues.apache.org/jira/browse/HUDI-57?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Nishith Agarwal reassigned HUDI-57: --- Assignee: Teresa Kang (was: Mani Jindal) > [UMBRELLA] Support ORC Storage > -- > > Key: HUDI-57 > URL: https://issues.apache.org/jira/browse/HUDI-57 > Project: Apache Hudi > Issue Type: Improvement > Components: Hive Integration, Writer Core >Affects Versions: 0.9.0 >Reporter: Vinoth Chandar >Assignee: Teresa Kang >Priority: Major > Labels: hudi-umbrellas, pull-request-available > Fix For: 0.9.0 > > Time Spent: 20m > Remaining Estimate: 0h > > [https://github.com/uber/hudi/issues/68] > https://github.com/uber/hudi/issues/155 -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Assigned] (HUDI-764) Implement HoodieOrcWriter
[ https://issues.apache.org/jira/browse/HUDI-764?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Nishith Agarwal reassigned HUDI-764: Assignee: Teresa Kang > Implement HoodieOrcWriter > - > > Key: HUDI-764 > URL: https://issues.apache.org/jira/browse/HUDI-764 > Project: Apache Hudi > Issue Type: Sub-task > Components: Storage Management >Reporter: lamber-ken >Assignee: Teresa Kang >Priority: Critical > > Implement HoodieOrcWriter > * Avro to ORC schema > * Write record in row -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Assigned] (HUDI-764) Implement HoodieOrcWriter
[ https://issues.apache.org/jira/browse/HUDI-764?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Nishith Agarwal reassigned HUDI-764: Assignee: (was: lamber-ken) > Implement HoodieOrcWriter > - > > Key: HUDI-764 > URL: https://issues.apache.org/jira/browse/HUDI-764 > Project: Apache Hudi > Issue Type: Sub-task > Components: Storage Management >Reporter: lamber-ken >Priority: Critical > > Implement HoodieOrcWriter > * Avro to ORC schema > * Write record in row -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Assigned] (HUDI-764) Implement HoodieOrcWriter
[ https://issues.apache.org/jira/browse/HUDI-764?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Nishith Agarwal reassigned HUDI-764: Assignee: (was: lamber-ken) > Implement HoodieOrcWriter > - > > Key: HUDI-764 > URL: https://issues.apache.org/jira/browse/HUDI-764 > Project: Apache Hudi > Issue Type: Sub-task > Components: Storage Management >Reporter: lamber-ken >Priority: Critical > > Implement HoodieOrcWriter > * Avro to ORC schema > * Write record in row -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Updated] (HUDI-1796) allow ExternalSpillMap use accurate payload size rather than estimated
[ https://issues.apache.org/jira/browse/HUDI-1796?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] ZiyueGuan updated HUDI-1796: Description: Situation: In ExternalSpillMap, we need to control the amount of data in memory map to avoid OOM. Currently, we evaluate this by estimate the average size of each payload twice. And get total memory use by multiplying average payload size with payload number. The first time we get the size is when first payload is inserted while the second time is when there are 100 payloads stored in memory. Problem: If the size is underestimated in the second estimation, an OOM will happen. Plan: Could we have a flag to control if we want an evaluation in accurate? Currently, I have several ideas but not sure which one could be the best or if there are any better one. # Estimate each payload, store the length of payload with its value. Once update or remove happen, use diff old length and add new length if needed so that we keep the sum of all payload size precisely. This is the method I currently use in prod. # Do not store the length but evaluate old payload again when it is popped. It trades off space against time comparing to method one. A better performance may be reached when updating and removing are rare. I didn't adopt this because I had profile ingestion process by arthas and found size estimating in that may be time consuming in flame graph. But I'm not sure whether it is true in compaction. In my intuition,HoodieRecordPayload has a quite simple structure. # I also have a more accurate estimate method that is evaluate the whole map when size is 1,100,1 and one million. Less underestimate will happen in such large amount of data. Look forward to any advice or suggestion or discussion. was: Situation: In ExternalSpillMap, we need to control the amount of data in memory map to avoid OOM. Currently, we evaluate this by estimate the average size of each payload twice. And get total memory use by multiple average payload size with payload number. The first time we get the size is when first payload is inserted while the second time is when there are 100 payloads stored in memory. Problem: If the size is underestimated in the second estimation, an OOM will happen. Plan: Could we have a flag to control if we want an evaluation in accurate? Currently, I have several ideas but not sure which one could be the best or if there are any better one. # Estimate each payload, store the length of payload with its value. Once update or remove happen, use diff old length and add new length if needed so that we keep the sum of all payload size precisely. This is the method I currently use in prod. # Do not store the length but evaluate old payload again when it is popped. It trades off space against time comparing to method one. A better performance may be reached when updating and removing are rare. I didn't adopt this because I had profile ingestion process by arthas and found size estimating in that may be time consuming in flame graph. But I'm not sure whether it is true in compaction. In my intuition,HoodieRecordPayload has a quite simple structure. # I also have a more accurate estimate method that is evaluate the whole map when size is 1,100,1 and one million. Less underestimate will happen in such large amount of data. Look forward to any advice or suggestion or discussion. > allow ExternalSpillMap use accurate payload size rather than estimated > -- > > Key: HUDI-1796 > URL: https://issues.apache.org/jira/browse/HUDI-1796 > Project: Apache Hudi > Issue Type: Improvement > Components: Compaction >Reporter: ZiyueGuan >Priority: Major > > Situation: In ExternalSpillMap, we need to control the amount of data in > memory map to avoid OOM. Currently, we evaluate this by estimate the average > size of each payload twice. And get total memory use by multiplying average > payload size with payload number. The first time we get the size is when > first payload is inserted while the second time is when there are 100 > payloads stored in memory. > Problem: If the size is underestimated in the second estimation, an OOM will > happen. > Plan: Could we have a flag to control if we want an evaluation in accurate? > Currently, I have several ideas but not sure which one could be the best or > if there are any better one. > # Estimate each payload, store the length of payload with its value. Once > update or remove happen, use diff old length and add new length if needed so > that we keep the sum of all payload size precisely. This is the method I > currently use in prod. > # Do not store the length but evaluate old payload again when it is popped. > It trades off space against time comparing to method one. A b
[GitHub] [hudi] vburenin commented on issue #2811: [SUPPORT] How to run hudi on dataproc and write to gcs bucket
vburenin commented on issue #2811: URL: https://github.com/apache/hudi/issues/2811#issuecomment-820530141 It looks like core-site.xml is not visible since it didn't trigger gs:// schema handler. One more thing though, I would recommend to upgrade google GCS connector to the latest version 2.1.x. Don't use 2.2, it won't work. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] leesf commented on a change in pull request #2645: [HUDI-1659] Basic Implementation Of Spark Sql Support
leesf commented on a change in pull request #2645:
URL: https://github.com/apache/hudi/pull/2645#discussion_r614153933
##
File path:
hudi-spark-datasource/hudi-spark/src/test/scala/org/apache/spark/sql/hudi/TestDelete.scala
##
@@ -0,0 +1,67 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.hudi
+
+class TestDelete extends TestHoodieSqlBase {
+
+ test("Test Delete Table") {
+withTempDir { tmp =>
+ Seq("cow", "mor").foreach {tableType =>
+val tableName = generateTableName
+// create table
+spark.sql(
+ s"""
+ |create table $tableName (
+ | id int,
+ | name string,
+ | price double,
+ | ts long
+ |) using hudi
+ | location '${tmp.getCanonicalPath}/$tableName'
+ | options (
+ | type = '$tableType',
+ | primaryKey = 'id',
+ | versionColumn = 'ts'
+ | )
+ """.stripMargin)
+// insert data to table
+spark.sql(s"insert into $tableName select 1, 'a1', 10, 1000")
+checkAnswer(s"select id, name, price, ts from $tableName")(
+ Seq(1, "a1", 10.0, 1000)
+)
+
+// delete table
Review comment:
delete data from table?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] leesf commented on a change in pull request #2645: [HUDI-1659] Basic Implementation Of Spark Sql Support
leesf commented on a change in pull request #2645:
URL: https://github.com/apache/hudi/pull/2645#discussion_r614152609
##
File path:
hudi-spark-datasource/hudi-spark/src/test/scala/org/apache/spark/sql/hudi/TestDelete.scala
##
@@ -0,0 +1,67 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.hudi
+
+class TestDelete extends TestHoodieSqlBase {
+
+ test("Test Delete Table") {
+withTempDir { tmp =>
+ Seq("cow", "mor").foreach {tableType =>
+val tableName = generateTableName
+// create table
+spark.sql(
+ s"""
+ |create table $tableName (
+ | id int,
+ | name string,
+ | price double,
+ | ts long
+ |) using hudi
+ | location '${tmp.getCanonicalPath}/$tableName'
+ | options (
+ | type = '$tableType',
+ | primaryKey = 'id',
+ | versionColumn = 'ts'
+ | )
+ """.stripMargin)
+// insert data to table
+spark.sql(s"insert into $tableName select 1, 'a1', 10, 1000")
+checkAnswer(s"select id, name, price, ts from $tableName")(
+ Seq(1, "a1", 10.0, 1000)
+)
+
+// delete table
Review comment:
delete records from table?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] leesf commented on a change in pull request #2645: [HUDI-1659] Basic Implementation Of Spark Sql Support
leesf commented on a change in pull request #2645:
URL: https://github.com/apache/hudi/pull/2645#discussion_r614150697
##
File path:
hudi-spark-datasource/hudi-spark/src/test/scala/org/apache/spark/sql/hudi/TestCreateTable.scala
##
@@ -0,0 +1,230 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.hudi
+
+import scala.collection.JavaConverters._
+import org.apache.hudi.common.model.HoodieRecord
+import org.apache.hudi.hadoop.realtime.HoodieParquetRealtimeInputFormat
+import org.apache.spark.sql.catalyst.TableIdentifier
+import org.apache.spark.sql.catalyst.catalog.CatalogTableType
+import org.apache.spark.sql.types.{DoubleType, IntegerType, LongType,
StringType, StructField}
+
+class TestCreateTable extends TestHoodieSqlBase {
+
+ test("Test Create Managed Hoodie Table") {
+val tableName = generateTableName
+// Create a managed table
+spark.sql(
+ s"""
+ | create table $tableName (
+ | id int,
+ | name string,
+ | price double,
+ | ts long
+ | ) using hudi
+ | options (
+ | primaryKey = 'id',
+ | versionColumn = 'ts'
Review comment:
possible to resolve `ts` as default versionColumn?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] leesf commented on a change in pull request #2645: [HUDI-1659] Basic Implementation Of Spark Sql Support
leesf commented on a change in pull request #2645:
URL: https://github.com/apache/hudi/pull/2645#discussion_r614142342
##
File path:
hudi-spark-datasource/hudi-spark/src/main/scala/org/apache/spark/sql/hudi/command/CreateHoodieTableAsSelectCommand.scala
##
@@ -0,0 +1,69 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.hudi.command
+
+import org.apache.spark.sql.{Row, SaveMode, SparkSession}
+import org.apache.spark.sql.catalyst.catalog.{CatalogTable, CatalogTableType}
+import org.apache.spark.sql.catalyst.plans.logical.LogicalPlan
+import org.apache.spark.sql.execution.SparkPlan
+import org.apache.spark.sql.execution.command.DataWritingCommand
+
+/**
+ * Command for create table as query statement.
+ */
+case class CreateHoodieTableAsSelectCommand(
+ table: CatalogTable,
+ mode: SaveMode,
+ query: LogicalPlan) extends DataWritingCommand {
+
+ override def run(sparkSession: SparkSession, child: SparkPlan): Seq[Row] = {
+assert(table.tableType != CatalogTableType.VIEW)
+assert(table.provider.isDefined)
+
+val sessionState = sparkSession.sessionState
+val db =
table.identifier.database.getOrElse(sessionState.catalog.getCurrentDatabase)
+val tableIdentWithDB = table.identifier.copy(database = Some(db))
+val tableName = tableIdentWithDB.unquotedString
+
+if (sessionState.catalog.tableExists(tableIdentWithDB)) {
+ assert(mode != SaveMode.Overwrite,
+s"Expect the table $tableName has been dropped when the save mode is
Overwrite")
+
+ if (mode == SaveMode.ErrorIfExists) {
+throw new RuntimeException(s"Table $tableName already exists. You need
to drop it first.")
+ }
+ if (mode == SaveMode.Ignore) {
+// Since the table already exists and the save mode is Ignore, we will
just return.
+// scalastyle:off
+return Seq.empty
+// scalastyle:on
Review comment:
ditto
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] leesf commented on a change in pull request #2645: [HUDI-1659] Basic Implementation Of Spark Sql Support
leesf commented on a change in pull request #2645:
URL: https://github.com/apache/hudi/pull/2645#discussion_r614142192
##
File path:
hudi-spark-datasource/hudi-spark/src/main/scala/org/apache/spark/sql/hudi/command/CreateHoodieTableAsSelectCommand.scala
##
@@ -0,0 +1,69 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.hudi.command
+
+import org.apache.spark.sql.{Row, SaveMode, SparkSession}
+import org.apache.spark.sql.catalyst.catalog.{CatalogTable, CatalogTableType}
+import org.apache.spark.sql.catalyst.plans.logical.LogicalPlan
+import org.apache.spark.sql.execution.SparkPlan
+import org.apache.spark.sql.execution.command.DataWritingCommand
+
+/**
+ * Command for create table as query statement.
+ */
+case class CreateHoodieTableAsSelectCommand(
+ table: CatalogTable,
+ mode: SaveMode,
+ query: LogicalPlan) extends DataWritingCommand {
+
+ override def run(sparkSession: SparkSession, child: SparkPlan): Seq[Row] = {
+assert(table.tableType != CatalogTableType.VIEW)
+assert(table.provider.isDefined)
+
+val sessionState = sparkSession.sessionState
+val db =
table.identifier.database.getOrElse(sessionState.catalog.getCurrentDatabase)
+val tableIdentWithDB = table.identifier.copy(database = Some(db))
+val tableName = tableIdentWithDB.unquotedString
+
+if (sessionState.catalog.tableExists(tableIdentWithDB)) {
+ assert(mode != SaveMode.Overwrite,
+s"Expect the table $tableName has been dropped when the save mode is
Overwrite")
+
+ if (mode == SaveMode.ErrorIfExists) {
+throw new RuntimeException(s"Table $tableName already exists. You need
to drop it first.")
+ }
+ if (mode == SaveMode.Ignore) {
+// Since the table already exists and the save mode is Ignore, we will
just return.
+// scalastyle:off
Review comment:
useless?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] leesf commented on a change in pull request #2645: [HUDI-1659] Basic Implementation Of Spark Sql Support
leesf commented on a change in pull request #2645:
URL: https://github.com/apache/hudi/pull/2645#discussion_r614141295
##
File path:
hudi-spark-datasource/hudi-spark/src/main/scala/org/apache/spark/sql/hudi/analysis/HoodieAnalysis.scala
##
@@ -0,0 +1,318 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.hudi.analysis
+
+import org.apache.hudi.SparkSqlAdapterSupport
+
+import scala.collection.JavaConverters._
+import org.apache.hudi.common.model.HoodieRecord
+import org.apache.spark.SPARK_VERSION
+import org.apache.spark.sql.{AnalysisException, SparkSession}
+import org.apache.spark.sql.catalyst.analysis.UnresolvedStar
+import org.apache.spark.sql.catalyst.expressions.AttributeReference
+import org.apache.spark.sql.catalyst.analysis.UnresolvedAttribute
+import org.apache.spark.sql.catalyst.expressions.{Alias, Expression, Literal,
NamedExpression}
+import org.apache.spark.sql.catalyst.plans.Inner
+import org.apache.spark.sql.catalyst.plans.logical.{Assignment, DeleteAction,
DeleteFromTable, InsertAction, LogicalPlan, MergeIntoTable, Project,
UpdateAction, UpdateTable}
+import org.apache.spark.sql.catalyst.rules.Rule
+import org.apache.spark.sql.execution.command.CreateDataSourceTableCommand
+import org.apache.spark.sql.execution.datasources.{CreateTable,
LogicalRelation}
+import org.apache.spark.sql.hudi.HoodieSqlUtils._
+import org.apache.spark.sql.hudi.command.{CreateHoodieTableAsSelectCommand,
CreateHoodieTableCommand, DeleteHoodieTableCommand,
InsertIntoHoodieTableCommand, MergeIntoHoodieTableCommand,
UpdateHoodieTableCommand}
+import org.apache.spark.sql.types.StringType
+
+object HoodieAnalysis {
+ def customResolutionRules(): Seq[SparkSession => Rule[LogicalPlan]] =
+Seq(
+ session => HoodieResolveReferences(session),
+ session => HoodieAnalysis(session)
+)
+
+ def customPostHocResolutionRules(): Seq[SparkSession => Rule[LogicalPlan]] =
+Seq(
+ session => HoodiePostAnalysisRule(session)
+)
+}
+
+/**
+ * Rule for convert the logical plan to command.
+ * @param sparkSession
+ */
+case class HoodieAnalysis(sparkSession: SparkSession) extends Rule[LogicalPlan]
+ with SparkSqlAdapterSupport {
+
+ override def apply(plan: LogicalPlan): LogicalPlan = {
+plan match {
+ // Convert to MergeIntoHoodieTableCommand
+ case m @ MergeIntoTable(target, _, _, _, _)
+if m.resolved && isHoodieTable(target, sparkSession) =>
+ MergeIntoHoodieTableCommand(m)
+
+ // Convert to UpdateHoodieTableCommand
+ case u @ UpdateTable(table, _, _)
+if u.resolved && isHoodieTable(table, sparkSession) =>
+ UpdateHoodieTableCommand(u)
+
+ // Convert to DeleteHoodieTableCommand
+ case d @ DeleteFromTable(table, _)
+if d.resolved && isHoodieTable(table, sparkSession) =>
+ DeleteHoodieTableCommand(d)
+
+ // Convert to InsertIntoHoodieTableCommand
+ case l if sparkSqlAdapter.isInsertInto(l) =>
+val (table, partition, query, overwrite, _) =
sparkSqlAdapter.getInsertIntoChildren(l).get
+table match {
+ case relation: LogicalRelation if isHoodieTable(relation,
sparkSession) =>
+new InsertIntoHoodieTableCommand(relation, query, partition,
overwrite)
+ case _ =>
+l
+}
+ // Convert to CreateHoodieTableAsSelectCommand
+ case CreateTable(table, mode, Some(query))
+if query.resolved && isHoodieTable(table) =>
+ CreateHoodieTableAsSelectCommand(table, mode, query)
+ case _=> plan
+}
+ }
+}
+
+/**
+ * Rule for resolve hoodie's extended syntax or rewrite some logical plan.
+ * @param sparkSession
+ */
+case class HoodieResolveReferences(sparkSession: SparkSession) extends
Rule[LogicalPlan]
+ with SparkSqlAdapterSupport {
+ private lazy val analyzer = sparkSession.sessionState.analyzer
+
+ def apply(plan: LogicalPlan): LogicalPlan = {
+plan match {
+ // Resolve merge into
+ case MergeIntoTable(target, source, mergeCondition, matchedActions,
notMatchedActions)
+if isHoodieTable(target, sparkSession) && target.resolved &&
source.resolved =>
+
+def isEmptyAssignments(ass
[GitHub] [hudi] leesf commented on a change in pull request #2645: [HUDI-1659] Basic Implementation Of Spark Sql Support
leesf commented on a change in pull request #2645:
URL: https://github.com/apache/hudi/pull/2645#discussion_r614135849
##
File path:
hudi-spark-datasource/hudi-spark/src/main/scala/org/apache/hudi/SparkSqlAdapterSupport.scala
##
@@ -0,0 +1,34 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi
+
+import org.apache.spark.SPARK_VERSION
+import org.apache.spark.sql.hudi.SparkSqlAdapter
+
+trait SparkSqlAdapterSupport {
+
+ lazy val sparkSqlAdapter: SparkSqlAdapter = {
+val adapterClass = if (SPARK_VERSION.startsWith("2.")) {
+ "org.apache.spark.sql.adapter.Spark2SqlAdapter"
Review comment:
here must define adapter path using string instead of class?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] leesf commented on a change in pull request #2645: [HUDI-1659] Basic Implementation Of Spark Sql Support
leesf commented on a change in pull request #2645:
URL: https://github.com/apache/hudi/pull/2645#discussion_r614133690
##
File path:
hudi-spark-datasource/hudi-spark/src/main/scala/org/apache/hudi/MergeOnReadSnapshotRelation.scala
##
@@ -61,8 +62,17 @@ class MergeOnReadSnapshotRelation(val sqlContext: SQLContext,
private val jobConf = new JobConf(conf)
// use schema from latest metadata, if not present, read schema from the
data file
private val schemaUtil = new TableSchemaResolver(metaClient)
- private val tableAvroSchema = schemaUtil.getTableAvroSchema
- private val tableStructSchema =
AvroConversionUtils.convertAvroSchemaToStructType(tableAvroSchema)
+ private lazy val tableAvroSchema = {
+try {
+ schemaUtil.getTableAvroSchema
+} catch {
+ case _: Throwable => // If this is no commit in the table, we cann't get
the schema
Review comment:
this -> there
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] leesf commented on a change in pull request #2645: [HUDI-1659] Basic Implementation Of Spark Sql Support
leesf commented on a change in pull request #2645: URL: https://github.com/apache/hudi/pull/2645#discussion_r614125884 ## File path: hudi-common/src/main/java/org/apache/hudi/common/model/HoodiePayloadProps.java ## @@ -40,4 +40,12 @@ */ public static final String PAYLOAD_EVENT_TIME_FIELD_PROP = "hoodie.payload.event.time.field"; public static String DEFAULT_PAYLOAD_EVENT_TIME_FIELD_VAL = "ts"; + + public static final String PAYLOAD_DELETE_CONDITION = "hoodie.payload.delete.condition"; Review comment: would you please add some docs about the added fields? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] leesf commented on a change in pull request #2645: [HUDI-1659] Basic Implementation Of Spark Sql Support
leesf commented on a change in pull request #2645:
URL: https://github.com/apache/hudi/pull/2645#discussion_r614125206
##
File path:
hudi-common/src/main/java/org/apache/hudi/common/model/DefaultHoodieRecordPayload.java
##
@@ -97,4 +86,20 @@ public DefaultHoodieRecordPayload(Option
record) {
}
return metadata.isEmpty() ? Option.empty() : Option.of(metadata);
}
+
+ protected boolean noNeedUpdatePersistedRecord(IndexedRecord currentValue,
+ IndexedRecord incomingRecord,
Properties properties) {
+/*
+ * Combining strategy here returns currentValue on disk if incoming record
is older.
+ * The incoming record can be either a delete (sent as an upsert with
_hoodie_is_deleted set to true)
+ * or an insert/update record. In any case, if it is older than the record
in disk, the currentValue
+ * in disk is returned (to be rewritten with new commit time).
+ *
+ * NOTE: Deletes sent via EmptyHoodieRecordPayload and/or Delete operation
type do not hit this code path
+ * and need to be dealt with separately.
+ */
+Object persistedOrderingVal = getNestedFieldVal((GenericRecord)
currentValue,
properties.getProperty(HoodiePayloadProps.PAYLOAD_ORDERING_FIELD_PROP), true);
+Comparable incomingOrderingVal = (Comparable)
getNestedFieldVal((GenericRecord) incomingRecord,
properties.getProperty(HoodiePayloadProps.PAYLOAD_ORDERING_FIELD_PROP), false);
Review comment:
pls split into two lines for better readability.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] leesf commented on a change in pull request #2645: [HUDI-1659] Basic Implementation Of Spark Sql Support
leesf commented on a change in pull request #2645:
URL: https://github.com/apache/hudi/pull/2645#discussion_r614124751
##
File path:
hudi-common/src/main/java/org/apache/hudi/common/model/DefaultHoodieRecordPayload.java
##
@@ -97,4 +86,20 @@ public DefaultHoodieRecordPayload(Option
record) {
}
return metadata.isEmpty() ? Option.empty() : Option.of(metadata);
}
+
+ protected boolean noNeedUpdatePersistedRecord(IndexedRecord currentValue,
Review comment:
would rename the method name to needUpdatePersistedRecord?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] rubenssoto commented on issue #2787: [SUPPORT] Error upserting bucketType UPDATE for partition
rubenssoto commented on issue #2787: URL: https://github.com/apache/hudi/issues/2787#issuecomment-820462928 Its a new Hudi table. It happens intermittently, probably some schema mismatch I think...is there any way to know where exactly the problem or I will have to inspect the new when the problem starts to happen? thank you. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] codecov-io commented on pull request #2831: [HUDI-1801] FlinkMergeHandle rolling over may miss to rename the late…
codecov-io commented on pull request #2831: URL: https://github.com/apache/hudi/pull/2831#issuecomment-820383022 # [Codecov](https://codecov.io/gh/apache/hudi/pull/2831?src=pr&el=h1&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=The+Apache+Software+Foundation) Report > Merging [#2831](https://codecov.io/gh/apache/hudi/pull/2831?src=pr&el=desc&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=The+Apache+Software+Foundation) (908425d) into [master](https://codecov.io/gh/apache/hudi/commit/191470d1fc9b3596eb4da2413e8bef286ccc7135?el=desc&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=The+Apache+Software+Foundation) (191470d) will **decrease** coverage by `43.22%`. > The diff coverage is `n/a`. [](https://codecov.io/gh/apache/hudi/pull/2831?src=pr&el=tree&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=The+Apache+Software+Foundation) ```diff @@ Coverage Diff @@ ## master #2831 +/- ## - Coverage 52.60% 9.38% -43.23% + Complexity 3709 48 -3661 Files 485 54 -431 Lines 232241993-21231 Branches 2465 235 -2230 - Hits 12218 187-12031 + Misses 99281793 -8135 + Partials 1078 13 -1065 ``` | Flag | Coverage Δ | Complexity Δ | | |---|---|---|---| | hudicli | `?` | `?` | | | hudiclient | `?` | `?` | | | hudicommon | `?` | `?` | | | hudiflink | `?` | `?` | | | hudihadoopmr | `?` | `?` | | | hudisparkdatasource | `?` | `?` | | | hudisync | `?` | `?` | | | huditimelineservice | `?` | `?` | | | hudiutilities | `9.38% <ø> (-60.42%)` | `48.00 <ø> (-325.00)` | | Flags with carried forward coverage won't be shown. [Click here](https://docs.codecov.io/docs/carryforward-flags?utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=The+Apache+Software+Foundation#carryforward-flags-in-the-pull-request-comment) to find out more. | [Impacted Files](https://codecov.io/gh/apache/hudi/pull/2831?src=pr&el=tree&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=The+Apache+Software+Foundation) | Coverage Δ | Complexity Δ | | |---|---|---|---| | [...va/org/apache/hudi/utilities/IdentitySplitter.java](https://codecov.io/gh/apache/hudi/pull/2831/diff?src=pr&el=tree&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=The+Apache+Software+Foundation#diff-aHVkaS11dGlsaXRpZXMvc3JjL21haW4vamF2YS9vcmcvYXBhY2hlL2h1ZGkvdXRpbGl0aWVzL0lkZW50aXR5U3BsaXR0ZXIuamF2YQ==) | `0.00% <0.00%> (-100.00%)` | `0.00% <0.00%> (-2.00%)` | | | [...va/org/apache/hudi/utilities/schema/SchemaSet.java](https://codecov.io/gh/apache/hudi/pull/2831/diff?src=pr&el=tree&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=The+Apache+Software+Foundation#diff-aHVkaS11dGlsaXRpZXMvc3JjL21haW4vamF2YS9vcmcvYXBhY2hlL2h1ZGkvdXRpbGl0aWVzL3NjaGVtYS9TY2hlbWFTZXQuamF2YQ==) | `0.00% <0.00%> (-100.00%)` | `0.00% <0.00%> (-3.00%)` | | | [...a/org/apache/hudi/utilities/sources/RowSource.java](https://codecov.io/gh/apache/hudi/pull/2831/diff?src=pr&el=tree&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=The+Apache+Software+Foundation#diff-aHVkaS11dGlsaXRpZXMvc3JjL21haW4vamF2YS9vcmcvYXBhY2hlL2h1ZGkvdXRpbGl0aWVzL3NvdXJjZXMvUm93U291cmNlLmphdmE=) | `0.00% <0.00%> (-100.00%)` | `0.00% <0.00%> (-4.00%)` | | | [.../org/apache/hudi/utilities/sources/AvroSource.java](https://codecov.io/gh/apache/hudi/pull/2831/diff?src=pr&el=tree&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=The+Apache+Software+Foundation#diff-aHVkaS11dGlsaXRpZXMvc3JjL21haW4vamF2YS9vcmcvYXBhY2hlL2h1ZGkvdXRpbGl0aWVzL3NvdXJjZXMvQXZyb1NvdXJjZS5qYXZh) | `0.00% <0.00%> (-100.00%)` | `0.00% <0.00%> (-1.00%)` | | | [.../org/apache/hudi/utilities/sources/JsonSource.java](https://codecov.io/gh/apache/hudi/pull/2831/diff?src=pr&el=tree&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=The+Apache+Software+Foundation#diff-aHVkaS11dGlsaXRpZXMvc3JjL21haW4vamF2YS9vcmcvYXBhY2hlL2h1ZGkvdXRpbGl0aWVzL3NvdXJjZXMvSnNvblNvdXJjZS5qYXZh) | `0.00% <0.00%> (-100.0
[GitHub] [hudi] tmac2100 commented on issue #2806: Spark upsert Hudi performance degrades significantly
tmac2100 commented on issue #2806: URL: https://github.com/apache/hudi/issues/2806#issuecomment-820367824 @n3nash Thank you for your help.I can't transfer pictures because of company information security restrictions. 1)BloomIndex is more efficient when the number of fields is smaller than when the number of fields is higher; 2)The data is written to hudi by partition. Thank you. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] dszakallas edited a comment on issue #1751: [SUPPORT] Hudi not working with Spark 3.0.0
dszakallas edited a comment on issue #1751: URL: https://github.com/apache/hudi/issues/1751#issuecomment-820315925 I resolved the issue by deleting these two exclusions from Spark: https://github.com/apache/spark/blob/v3.0.1/pom.xml#L1692-L1699. After that calcite-core becomes part of the distribution. After that I get the following error: ``` SemanticException Cannot find class 'org.apache.hudi.hadoop.HoodieParquetInputFormat' org.apache.hadoop.hive.ql.parse.SemanticException: Cannot find class 'org.apache.hudi.hadoop.HoodieParquetInputFormat' at org.apache.hadoop.hive.ql.parse.ParseUtils.ensureClassExists(ParseUtils.java:263) ``` -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] dszakallas edited a comment on issue #1751: [SUPPORT] Hudi not working with Spark 3.0.0
dszakallas edited a comment on issue #1751: URL: https://github.com/apache/hudi/issues/1751#issuecomment-820315925 I resolved the issue by deleting these two exclusions from Spark: https://github.com/apache/spark/blob/v3.0.1/pom.xml#L1692-L1699. After that calcite-core becomes part of the distribution. After that I get the following error: ``` 21/04/15 10:22:30 ERROR Driver: FAILED: SemanticException Cannot find class 'org.apache.hudi.hadoop.HoodieParquetInputFormat' org.apache.hadoop.hive.ql.parse.SemanticException: Cannot find class 'org.apache.hudi.hadoop.HoodieParquetInputFormat' at org.apache.hadoop.hive.ql.parse.ParseUtils.ensureClassExists(ParseUtils.java:263) ``` -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (HUDI-1801) FlinkMergeHandle rolling over may miss to rename the latest file handle
[
https://issues.apache.org/jira/browse/HUDI-1801?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
ASF GitHub Bot updated HUDI-1801:
-
Labels: pull-request-available (was: )
> FlinkMergeHandle rolling over may miss to rename the latest file handle
> ---
>
> Key: HUDI-1801
> URL: https://issues.apache.org/jira/browse/HUDI-1801
> Project: Apache Hudi
> Issue Type: Bug
> Components: Flink Integration
>Affects Versions: 0.8.0
>Reporter: Danny Chen
>Assignee: Danny Chen
>Priority: Major
> Labels: pull-request-available
> Fix For: 0.9.0
>
>
> The {{FlinkMergeHandle}} may rename the N-1 th file handle instead of the
> latest one, thus to cause data duplication.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [hudi] danny0405 opened a new pull request #2831: [HUDI-1801] FlinkMergeHandle rolling over may miss to rename the late…
danny0405 opened a new pull request #2831: URL: https://github.com/apache/hudi/pull/2831 …st file handle The FlinkMergeHandle may rename the N-1 th file handle instead of the latest one, thus to cause data duplication. ## *Tips* - *Thank you very much for contributing to Apache Hudi.* - *Please review https://hudi.apache.org/contributing.html before opening a pull request.* ## What is the purpose of the pull request *(For example: This pull request adds quick-start document.)* ## Brief change log *(for example:)* - *Modify AnnotationLocation checkstyle rule in checkstyle.xml* ## Verify this pull request *(Please pick either of the following options)* This pull request is a trivial rework / code cleanup without any test coverage. *(or)* This pull request is already covered by existing tests, such as *(please describe tests)*. (or) This change added tests and can be verified as follows: *(example:)* - *Added integration tests for end-to-end.* - *Added HoodieClientWriteTest to verify the change.* - *Manually verified the change by running a job locally.* ## Committer checklist - [ ] Has a corresponding JIRA in PR title & commit - [ ] Commit message is descriptive of the change - [ ] CI is green - [ ] Necessary doc changes done or have another open PR - [ ] For large changes, please consider breaking it into sub-tasks under an umbrella JIRA. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Created] (HUDI-1801) FlinkMergeHandle rolling over may miss to rename the latest file handle
Danny Chen created HUDI-1801:
Summary: FlinkMergeHandle rolling over may miss to rename the
latest file handle
Key: HUDI-1801
URL: https://issues.apache.org/jira/browse/HUDI-1801
Project: Apache Hudi
Issue Type: Bug
Components: Flink Integration
Affects Versions: 0.8.0
Reporter: Danny Chen
Assignee: Danny Chen
Fix For: 0.9.0
The {{FlinkMergeHandle}} may rename the N-1 th file handle instead of the
latest one, thus to cause data duplication.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [hudi] dszakallas edited a comment on issue #1751: [SUPPORT] Hudi not working with Spark 3.0.0
dszakallas edited a comment on issue #1751: URL: https://github.com/apache/hudi/issues/1751#issuecomment-820315925 I resolved the issue by deleting these two exclusions from Spark: https://github.com/apache/spark/blob/v3.0.1/pom.xml#L1692-L1699. After that calcite-core becomes part of the distribution. I am not sure if calcite-avatica is needed though. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] dszakallas commented on issue #1751: [SUPPORT] Hudi not working with Spark 3.0.0
dszakallas commented on issue #1751: URL: https://github.com/apache/hudi/issues/1751#issuecomment-820315925 I resolved the issue by deleting these two exclusions from Spark: https://github.com/apache/spark/blob/v3.0.1/pom.xml#L1692-L1699 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] huzekang commented on issue #2656: HUDI insert operation is working same as upsert
huzekang commented on issue #2656:
URL: https://github.com/apache/hudi/issues/2656#issuecomment-820287948
I have the same problem.
when i set insert operation to hudi, I expect the result has 10 records,but
there is 8 records .
It just like upsert opt.
```
val spark = SparkSession.builder()
.master("local[*]")
.config("spark.serializer",
"org.apache.spark.serializer.KryoSerializer")
// Uses Hive SerDe, this is mandatory for MoR tables
.config("spark.sql.hive.convertMetastoreParquet", "false")
.config("spark.hadoop.fs.defaultFS", "hdfs://hadoop-master:8020")
.getOrCreate()
val tableName = "hudi_archive_insert"
val basePath = "/tmp/hudi/"+tableName
val inserts = List(
"""{"id" : 1, "name": "iteblog1", "age" : 101, "ts" : 1, "dt" :
"20191212"}""",
"""{"id" : 1, "name": "iteblog2", "age" : 101, "ts" : 2, "dt" :
"20191212"}""",
"""{"id" : 1, "name": "iteblog3", "age" : 101, "ts" : 3, "dt" :
"20191212"}""",
"""{"id" : 3, "name": "hudi2", "age" : 103, "ts" : 1, "dt" :
"20191212"}""",
"""{"id" : 2, "name": "iteblog_hadoop2", "age" : 102, "ts" : 3, "dt" :
"20191213"}""",
"""{"id" : 1, "name": "flink2", "age" : 102, "ts" : 1, "dt" :
"20191213"}"""
)
insert(spark, inserts, tableName, basePath)
val inserts2 = List(
"""{"id" : 4, "name": "Dingding", "age" : 101, "ts" : 1, "dt" :
"20191212"}""",
"""{"id" : 5, "name": "Kugou", "age" : 101, "ts" : 2, "dt" :
"20191212"}""",
"""{"id" : 2, "name": "Mumu", "age" : 102, "ts" : 1, "dt" :
"20191213"}""",
"""{"id" : 2, "name": "Mumu2", "age" : 102, "ts" : 2, "dt" :
"20191213"}"""
)
insert(spark, inserts2, tableName, basePath)
val df = spark.read.format("org.apache.hudi").load(basePath + "/*")
df.show()
//
+---++--+--++---++---++---+
//
|_hoodie_commit_time|_hoodie_commit_seqno|_hoodie_record_key|_hoodie_partition_path|
_hoodie_file_name|age| dt| id|name| ts|
//
+---++--+--++---++---++---+
//| 20210415173137| 20210415173137_1_1| 1|
20191212|87062f4a-1de0-416...|101|20191212| 1|iteblog3| 3|
//| 20210415173137| 20210415173137_1_3| 1|
20191212|87062f4a-1de0-416...|101|20191212| 1|iteblog3| 3|
//| 20210415173137| 20210415173137_1_5| 1|
20191212|87062f4a-1de0-416...|101|20191212| 1|iteblog3| 3|
//| 20210415173137| 20210415173137_1_6| 3|
20191212|87062f4a-1de0-416...|103|20191212| 3| hudi2| 1|
//| 20210415173144| 20210415173144_1_8| 4|
20191212|87062f4a-1de0-416...|101|20191212| 4|Dingding| 1|
//| 20210415173144| 20210415173144_1_9| 5|
20191212|87062f4a-1de0-416...|101|20191212| 5| Kugou| 2|
//| 20210415173144| 20210415173144_0_7| 2|
20191213|f93a2c86-8eda-4cc...|102|20191213| 2| Mumu2| 2|
//| 20210415173137| 20210415173137_0_4| 1|
20191213|f93a2c86-8eda-4cc...|102|20191213| 1| flink2| 1|
//
+---++--+--++---++---++---+
spark.stop()
}
def insert(spark: SparkSession, inserts: List[String], tableName: String,
basePath: String) = {
val df = spark.read.json(spark.sparkContext.parallelize(inserts, 2))
df.write.format("org.apache.hudi")
.option(DataSourceWriteOptions.PRECOMBINE_FIELD_OPT_KEY, "ts")
.option(DataSourceWriteOptions.RECORDKEY_FIELD_OPT_KEY, "id")
.option(DataSourceWriteOptions.PARTITIONPATH_FIELD_OPT_KEY, "dt")
.option(DataSourceWriteOptions.OPERATION_OPT_KEY,
DataSourceWriteOptions.INSERT_OPERATION_OPT_VAL)
.option(HoodieWriteConfig.TABLE_NAME, tableName)
// Set this to a lower value to improve performance.
.option("hoodie.insert.shuffle.parallelism", "2")
.mode("append")
.save(basePath)
}
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] wsxGit opened a new issue #2830: [SUPPORT]same _hoodie_record_key has duplicates data
wsxGit opened a new issue #2830:
URL: https://github.com/apache/hudi/issues/2830
config is :
`props.put("hoodie.datasource.write.table.type", "COPY_ON_WRITE")
props.put(RECORDKEY_FIELD_OPT_KEY, "hudi_uuid")
props.put(PRECOMBINE_FIELD_OPT_KEY, "opttime")
props.put(PARTITIONPATH_FIELD_OPT_KEY, partitionColumn)
props.put("hoodie.insert.shuffle.parallelism", "10")
props.put("hoodie.upsert.shuffle.parallelism", "10")
props.put("hoodie.datasource.hive_sync.database", "fdm")
props.put("hoodie.datasource.hive_sync.table", tableName)
props.put("hoodie.datasource.hive_sync.enable", "true")
props.put("hoodie.datasource.hive_sync.partition_fields",
partitionColumn)
props.put("hoodie.datasource.hive_sync.jdbcurl", HIVE_URL)
props.put("hoodie.datasource.hive_sync.partition_extractor_class",
"org.apache.hudi.hive.MultiPartKeysValueExtractor")
props.put("hoodie.datasource.hive_sync.username", HIVE_USERNAME)
props.put(HoodieWriteConfig.TABLE_NAME, config.tableName)
props.put(DataSourceWriteOptions.HIVE_DATABASE_OPT_KEY, "fdm")
props.put(HoodieIndexConfig.BLOOM_INDEX_UPDATE_PARTITION_PATH, "true")
props.put(HoodieIndexConfig.INDEX_TYPE_PROP,
HoodieIndex.IndexType.GLOBAL_BLOOM.name())
mode(SaveMode.Append)
`
data is
++--+--++-+-+
|_hoodie_commit_seqno|_hoodie_record_key|_hoodie_partition_path|
_hoodie_file_name| opttime|hudi_uuid|
++--+--++-+-+
|20210407160004_26...| 100102_1366831027|
100102|0c00e34d-0d20-427...|1617782081000|100102_1366831027|
|20210407160004_26...| 100102_1366831027|
100102|0c00e34d-0d20-427...|1617782081000|100102_1366831027|
|20210407160004_26...| 100102_1366831027|
100102|0c00e34d-0d20-427...|1617782081000|100102_1366831027|
++--+--++-+-+
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] manishbol opened a new issue #2829: Getting an Exception Property hoodie.deltastreamer.schemaprovider.registry.baseUrl not found
manishbol opened a new issue #2829: URL: https://github.com/apache/hudi/issues/2829 What do the below two properties mean? What can be the possible values of these properties? hoodie.deltastreamer.schemaprovider.registry.baseUrl hoodie.deltastreamer.schemaprovider.registry.urlSuffix EMR Version: emr-5.32.0 Hudi Version: 0.6.0 Spark Version: Spark 2.4.7 Spark submit command: `spark-submit --class org.apache.hudi.utilities.deltastreamer.HoodieMultiTableDeltaStreamer --packages org.apache.spark:spark-avro_2.11:2.4.7 /usr/lib/hudi/hudi-utilities-bundle.jar --props s3://config-private-qa/datalake/hudi-properties/kafka-source.properties --config-folder s3://config-private-qa/datalake/hudi-properties/table_ingestion/ --schemaprovider-class org.apache.hudi.utilities.schema.SchemaRegistryProvider --source-class org.apache.hudi.utilities.sources.AvroKafkaSource --source-ordering-field impresssiontime --base-path-prefix s3://aws-dms-qa/s3-raw-data-dms/icici/ --target-table icici --op BULK_INSERT --table-type COPY_ON_WRITE` Exception Raised: ``` Exception in thread "main" java.lang.IllegalArgumentException: Property hoodie.deltastreamer.schemaprovider.registry.baseUrl not found at org.apache.hudi.common.config.TypedProperties.checkKey(TypedProperties.java:42) at org.apache.hudi.common.config.TypedProperties.getString(TypedProperties.java:47) at org.apache.hudi.utilities.deltastreamer.HoodieMultiTableDeltaStreamer.populateSchemaProviderProps(HoodieMultiTableDeltaStreamer.java:149) at org.apache.hudi.utilities.deltastreamer.HoodieMultiTableDeltaStreamer.populateTableExecutionContextList(HoodieMultiTableDeltaStreamer.java:128) at org.apache.hudi.utilities.deltastreamer.HoodieMultiTableDeltaStreamer.(HoodieMultiTableDeltaStreamer.java:78) at org.apache.hudi.utilities.deltastreamer.HoodieMultiTableDeltaStreamer.main(HoodieMultiTableDeltaStreamer.java:201) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at org.apache.spark.deploy.JavaMainApplication.start(SparkApplication.scala:52) at org.apache.spark.deploy.SparkSubmit.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:853) at org.apache.spark.deploy.SparkSubmit.doRunMain$1(SparkSubmit.scala:161) at org.apache.spark.deploy.SparkSubmit.submit(SparkSubmit.scala:184) at org.apache.spark.deploy.SparkSubmit.doSubmit(SparkSubmit.scala:86) at org.apache.spark.deploy.SparkSubmit$$anon$2.doSubmit(SparkSubmit.scala:928) at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:937) at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala) ``` -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (HUDI-1797) Shade google guava for hudi-flink-bundle jar
[ https://issues.apache.org/jira/browse/HUDI-1797?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17321961#comment-17321961 ] vinoyang commented on HUDI-1797: [~wangminchao] Welcome to Hudi community! I have given you jira contributor permission. > Shade google guava for hudi-flink-bundle jar > > > Key: HUDI-1797 > URL: https://issues.apache.org/jira/browse/HUDI-1797 > Project: Apache Hudi > Issue Type: Task > Components: Flink Integration >Reporter: Danny Chen >Assignee: WangMinChao >Priority: Major > Labels: pull-request-available > Fix For: 0.9.0 > > Attachments: screenshot-1.png > > > Shade the guava to avoid conflicts. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Closed] (HUDI-1797) Shade google guava for hudi-flink-bundle jar
[ https://issues.apache.org/jira/browse/HUDI-1797?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] vinoyang closed HUDI-1797. -- Resolution: Done 191470d1fc9b3596eb4da2413e8bef286ccc7135 > Shade google guava for hudi-flink-bundle jar > > > Key: HUDI-1797 > URL: https://issues.apache.org/jira/browse/HUDI-1797 > Project: Apache Hudi > Issue Type: Task > Components: Flink Integration >Reporter: Danny Chen >Assignee: WangMinChao >Priority: Major > Labels: pull-request-available > Fix For: 0.9.0 > > Attachments: screenshot-1.png > > > Shade the guava to avoid conflicts. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Assigned] (HUDI-1797) Shade google guava for hudi-flink-bundle jar
[ https://issues.apache.org/jira/browse/HUDI-1797?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] vinoyang reassigned HUDI-1797: -- Assignee: WangMinChao > Shade google guava for hudi-flink-bundle jar > > > Key: HUDI-1797 > URL: https://issues.apache.org/jira/browse/HUDI-1797 > Project: Apache Hudi > Issue Type: Task > Components: Flink Integration >Reporter: Danny Chen >Assignee: WangMinChao >Priority: Major > Labels: pull-request-available > Fix For: 0.9.0 > > Attachments: screenshot-1.png > > > Shade the guava to avoid conflicts. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [hudi] ssdong commented on issue #2818: [SUPPORT] Exception thrown in incremental query(MOR) and potential change data loss after archiving
ssdong commented on issue #2818: URL: https://github.com/apache/hudi/issues/2818#issuecomment-820180331 @n3nash Thank you for getting back to me. Let me know if you need extra manpower to help fix `MergeOnReadIncrementalRelation`. :) As for the second issue, thank you for providing extra insights into this, and I understand your point that if the checkpoint has not changed; once there is another "latest" change, it will surely pull that out for me incrementally given it will be on the active timeline again. However, what if the "intermediate" changes are supposed to the "last" changes to the records, and the archival puts them in an _invisible_ state? 🤔And will the checkpoint stay the same all the time? Right now, it seems like the relationship between archived/active timeline and incremental pull _requires_ the user to have a carefully controlled incremental pull interval to get all updates before it gets archived, and I wonder if that's easy to achieve? Just throwing a bunch of my thoughts and concerns, and please do let me know what you find regarding commit time provided is way in the past and not in the hudi timeline. 😅 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (HUDI-1797) Shade google guava for hudi-flink-bundle jar
[ https://issues.apache.org/jira/browse/HUDI-1797?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] ASF GitHub Bot updated HUDI-1797: - Labels: pull-request-available (was: ) > Shade google guava for hudi-flink-bundle jar > > > Key: HUDI-1797 > URL: https://issues.apache.org/jira/browse/HUDI-1797 > Project: Apache Hudi > Issue Type: Task > Components: Flink Integration >Reporter: Danny Chen >Priority: Major > Labels: pull-request-available > Fix For: 0.9.0 > > Attachments: screenshot-1.png > > > Shade the guava to avoid conflicts. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[hudi] branch master updated (6d1aec6 -> 191470d)
This is an automated email from the ASF dual-hosted git repository. vinoyang pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/hudi.git. from 6d1aec6 [HUDI-1798] Flink streaming reader should always monitor the delta commits files (#2825) add 191470d [HUDI-1797] Remove the com.google.guave jar from hudi-flink-bundle to avoid conflicts. (#2828) No new revisions were added by this update. Summary of changes: packaging/hudi-flink-bundle/pom.xml | 36 1 file changed, 36 insertions(+)
[GitHub] [hudi] yanghua merged pull request #2828: [HUDI-1797] Remove the com.google.guave jar from hudi-flink-bundle to avoid conflicts.
yanghua merged pull request #2828: URL: https://github.com/apache/hudi/pull/2828 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] xiarixiaoyao commented on a change in pull request #2796: [HUDI-1783] Support Huawei Cloud Object Storage
xiarixiaoyao commented on a change in pull request #2796:
URL: https://github.com/apache/hudi/pull/2796#discussion_r613814357
##
File path:
hudi-common/src/main/java/org/apache/hudi/common/fs/StorageSchemes.java
##
@@ -53,7 +53,9 @@
// Databricks file system
DBFS("dbfs", false),
// IBM Cloud Object Storage
- COS("cos", false);
+ COS("cos", false),
+ // Huawei Cloud Object Storage
+ OBS("obs", false);
Review comment:
sorry for later, i will try today。 thanks @leesf
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] hudi-bot edited a comment on pull request #2643: DO NOT MERGE (Azure CI) test branch ci
hudi-bot edited a comment on pull request #2643: URL: https://github.com/apache/hudi/pull/2643#issuecomment-792368481 ## CI report: * 9831a6c50e9f49f8a71c02fc6ac50ae1446f7c1f UNKNOWN * a569dbe9409910fbb83b3764b300574c0e52612e Azure: [FAILURE](https://dev.azure.com/XUSH0012/0ef433cc-d4b4-47cc-b6a1-03d032ef546c/_build/results?buildId=142) * e6e9f1f1554a1474dd6c20338215030cad23a2e0 UNKNOWN * 2a6690a256c8cd8efe9ed2b1984b896fb27ef077 UNKNOWN * d8b7cca55e057a52a2e229d81e8cb52b60dc275f UNKNOWN * 3bce301333cc78194d13a702598b46e04fe9f85f UNKNOWN Bot commands @hudi-bot supports the following commands: - `@hudi-bot run travis` re-run the last Travis build - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Assigned] (HUDI-1696) artifactSet of maven-shade-plugin has not commons-codec
[ https://issues.apache.org/jira/browse/HUDI-1696?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Harshit Mittal reassigned HUDI-1696: Assignee: Harshit Mittal > artifactSet of maven-shade-plugin has not commons-codec > --- > > Key: HUDI-1696 > URL: https://issues.apache.org/jira/browse/HUDI-1696 > Project: Apache Hudi > Issue Type: Bug > Components: Spark Integration >Affects Versions: 0.7.0 > Environment: spark2.4.4 > scala2.11.8 > centos7 >Reporter: peng-xin >Assignee: Harshit Mittal >Priority: Critical > Labels: pull-request-available, sev:high, user-support-issues > Fix For: 0.8.0 > > Attachments: image-2021-03-16-18-20-16-477.png > > Original Estimate: 24h > Remaining Estimate: 24h > > when i use hbase index,it cause some error like below > !image-2021-03-16-18-20-16-477.png! -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Resolved] (HUDI-1696) artifactSet of maven-shade-plugin has not commons-codec
[ https://issues.apache.org/jira/browse/HUDI-1696?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Harshit Mittal resolved HUDI-1696. -- Resolution: Fixed > artifactSet of maven-shade-plugin has not commons-codec > --- > > Key: HUDI-1696 > URL: https://issues.apache.org/jira/browse/HUDI-1696 > Project: Apache Hudi > Issue Type: Bug > Components: Spark Integration >Affects Versions: 0.7.0 > Environment: spark2.4.4 > scala2.11.8 > centos7 >Reporter: peng-xin >Assignee: Harshit Mittal >Priority: Critical > Labels: pull-request-available, sev:high, user-support-issues > Fix For: 0.8.0 > > Attachments: image-2021-03-16-18-20-16-477.png > > Original Estimate: 24h > Remaining Estimate: 24h > > when i use hbase index,it cause some error like below > !image-2021-03-16-18-20-16-477.png! -- This message was sent by Atlassian Jira (v8.3.4#803005)