[spark] branch master updated: [SPARK-37727][SQL] Show ignored confs & hide warnings for conf already set in SparkSession.builder.getOrCreate
This is an automated email from the ASF dual-hosted git repository.
gurwls223 pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 472629a [SPARK-37727][SQL] Show ignored confs & hide warnings for
conf already set in SparkSession.builder.getOrCreate
472629a is described below
commit 472629afcc0518ad5b9f5042bf4d9a791822d378
Author: Hyukjin Kwon
AuthorDate: Fri Dec 24 12:51:45 2021 +0900
[SPARK-37727][SQL] Show ignored confs & hide warnings for conf already set
in SparkSession.builder.getOrCreate
### What changes were proposed in this pull request?
This PR proposes to show ignored configurations and hide the warnings for
configurations that are already set when invoking
`SparkSession.builder.getOrCreate`.
### Why are the changes needed?
Currently, `SparkSession.builder.getOrCreate()` is too noisy even when
duplicate configurations are set. Users cannot easily tell which configurations
are to fix. See the example below:
```bash
./bin/spark-shell --conf spark.abc=abc
```
```scala
import org.apache.spark.sql.SparkSession
spark.sparkContext.setLogLevel("DEBUG")
SparkSession.builder.config("spark.abc", "abc").getOrCreate
```
```
21:04:01.670 [main] WARN org.apache.spark.sql.SparkSession - Using an
existing SparkSession; some spark core configurations may not take effect.
```
It is straitforward when there are few configurations but it is difficult
for users to figure out when there are too many configurations especially when
these configurations are defined in a property file like 'spark-default.conf'
maintained separately by system admins in production.
See also https://github.com/apache/spark/pull/34757#discussion_r769248275.
### Does this PR introduce _any_ user-facing change?
Yes.
1. Show ignored configurations in debug level logs:
```bash
./bin/spark-shell --conf spark.abc=abc
```
```scala
import org.apache.spark.sql.SparkSession
spark.sparkContext.setLogLevel("DEBUG")
SparkSession.builder
.config("spark.sql.warehouse.dir", "2")
.config("spark.abc", "abcb")
.config("spark.abcd", "abcb4")
.getOrCreate
```
**Before:**
```
21:13:28.360 [main] WARN org.apache.spark.sql.SparkSession - Using an
existing SparkSession; the static sql configurations will not take effect.
21:13:28.360 [main] WARN org.apache.spark.sql.SparkSession - Using an
existing SparkSession; some spark core configurations may not take effect.
```
**After**:
```
20:34:30.619 [main] WARN org.apache.spark.sql.SparkSession - Using an
existing Spark session; only runtime SQL configurations will take effect.
20:34:30.622 [main] DEBUG org.apache.spark.sql.SparkSession - Ignored
static SQL configurations:
spark.sql.warehouse.dir=2
20:34:30.623 [main] DEBUG org.apache.spark.sql.SparkSession -
Configurations that might not take effect:
spark.abcd=abcb4
spark.abc=abcb
```
2. Do not issue a warning and hide a configuration already explicitly set
(with the same value) before.
```bash
./bin/spark-shell --conf spark.abc=abc
```
```scala
import org.apache.spark.sql.SparkSession
spark.sparkContext.setLogLevel("DEBUG")
SparkSession.builder.config("spark.abc", "abc").getOrCreate //
**Ignore** warnings because it's already set in --conf
SparkSession.builder.config("spark.abc.new", "abc").getOrCreate //
**Show** warnings for only configuration newly set.
SparkSession.builder.config("spark.abc.new", "abc").getOrCreate //
**Ignore** warnings because it's set ^.
```
**Before**:
```
21:13:56.183 [main] WARN org.apache.spark.sql.SparkSession - Using an
existing SparkSession; some spark core configurations may not take effect.
21:13:56.356 [main] WARN org.apache.spark.sql.SparkSession - Using an
existing SparkSession; some spark core configurations may not take effect.
21:13:56.476 [main] WARN org.apache.spark.sql.SparkSession - Using an
existing SparkSession; some spark core configurations may not take effect.
```
**After:**
```
20:36:36.251 [main] WARN org.apache.spark.sql.SparkSession - Using an
existing Spark session; only runtime SQL configurations will take effect.
20:36:36.253 [main] DEBUG org.apache.spark.sql.SparkSession -
Configurations that might not take effect:
spark.abc.new=abc
```
3. Do not issue a warning and hide runtime SQL configurations in debug log:
```bash
[spark] branch master updated: [SPARK-6305][CORE][TEST][FOLLOWUP] Add LoggingSuite and some improvements
This is an automated email from the ASF dual-hosted git repository.
viirya pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 7fd3619 [SPARK-6305][CORE][TEST][FOLLOWUP] Add LoggingSuite and some
improvements
7fd3619 is described below
commit 7fd361973d22c4e98a008989f81cfcb2f9a41443
Author: Liang-Chi Hsieh
AuthorDate: Thu Dec 23 19:41:02 2021 -0800
[SPARK-6305][CORE][TEST][FOLLOWUP] Add LoggingSuite and some improvements
### What changes were proposed in this pull request?
This patch proposes to add `LoggingSuite` back and also does some other
improvements. In summary:
1. Add `LoggingSuite` back
2. Refactor logging related change based on community suggestion, e.g. let
`SparkShellLoggingFilter` inherit from `AbstractFilter` instead of `Filter`.
3. Fix maven test failures for hive-thriftserver module
4. Fix K8S decommision integration tests which check log output
5. A few places in code/doc which refer/mention log4j.properties
### Why are the changes needed?
`LoggingSuite` was wrongly removed in previous PR. We should add it back.
There are a few places we can also simplify the code. A few places in code
which programmingly write out log4j properties files are also changed to log4j2
here.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Pass all tests.
Closes #34965 from viirya/log4j2_improvement.
Authored-by: Liang-Chi Hsieh
Signed-off-by: Liang-Chi Hsieh
---
R/{log4j.properties => log4j2.properties} | 19 +-
R/run-tests.sh | 4 +-
.../org/apache/spark/log4j-defaults.properties | 43 ---
.../scala/org/apache/spark/deploy/Client.scala | 5 +-
.../org/apache/spark/deploy/ClientArguments.scala | 2 +-
.../scala/org/apache/spark/internal/Logging.scala | 85 +
.../apache/spark/util/logging/DriverLogger.scala | 1 -
.../scala/org/apache/spark/SparkFunSuite.scala | 25 +-
.../org/apache/spark/internal/LoggingSuite.scala | 64
docs/configuration.md | 8 +-
.../dev/dev-run-integration-tests.sh | 1 -
.../src/test/resources/log4j2.properties | 2 +-
.../k8s/integrationtest/DecommissionSuite.scala| 355 -
.../org/apache/spark/deploy/yarn/Client.scala | 12 +-
.../src/test/resources/log4j2.properties | 2 +-
.../thriftserver/HiveThriftServer2Suites.scala | 8 +-
.../sql/hive/thriftserver/UISeleniumSuite.scala| 16 +-
17 files changed, 324 insertions(+), 328 deletions(-)
diff --git a/R/log4j.properties b/R/log4j2.properties
similarity index 71%
rename from R/log4j.properties
rename to R/log4j2.properties
index cce8d91..8ed7b9f 100644
--- a/R/log4j.properties
+++ b/R/log4j2.properties
@@ -16,13 +16,16 @@
#
# Set everything to be logged to the file target/unit-tests.log
-log4j.rootCategory=INFO, file
-log4j.appender.file=org.apache.log4j.FileAppender
-log4j.appender.file.append=true
-log4j.appender.file.file=R/target/unit-tests.log
-log4j.appender.file.layout=org.apache.log4j.PatternLayout
-log4j.appender.file.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss.SSS} %t %p
%c{1}: %m%n
+rootLogger.level = info
+rootLogger.appenderRef.file.ref = File
+
+appender.file.type = File
+appender.file.name = File
+appender.file.fileName = target/unit-tests.log
+appender.file.append = true
+appender.file.layout.type = PatternLayout
+appender.file.layout.pattern = %d{yy/MM/dd HH:mm:ss.SSS} %t %p %c{1}: %m%n
# Ignore messages below warning level from Jetty, because it's a bit verbose
-log4j.logger.org.eclipse.jetty=WARN
-org.eclipse.jetty.LEVEL=WARN
+logger.jetty.name = org.eclipse.jetty
+logger.jetty.level = warn
diff --git a/R/run-tests.sh b/R/run-tests.sh
index edc2b2b..99b7438 100755
--- a/R/run-tests.sh
+++ b/R/run-tests.sh
@@ -30,9 +30,9 @@ if [[ $(echo $SPARK_AVRO_JAR_PATH | wc -l) -eq 1 ]]; then
fi
if [ -z "$SPARK_JARS" ]; then
- SPARK_TESTING=1 NOT_CRAN=true $FWDIR/../bin/spark-submit
--driver-java-options "-Dlog4j.configuration=file:$FWDIR/log4j.properties"
--conf spark.hadoop.fs.defaultFS="file:///" --conf
spark.driver.extraJavaOptions="-Dio.netty.tryReflectionSetAccessible=true"
--conf
spark.executor.extraJavaOptions="-Dio.netty.tryReflectionSetAccessible=true"
$FWDIR/pkg/tests/run-all.R 2>&1 | tee -a $LOGFILE
+ SPARK_TESTING=1 NOT_CRAN=true $FWDIR/../bin/spark-submit
--driver-java-options "-Dlog4j.configurationFile=file:$FWDIR/log4j2.properties"
--conf spark.hadoop.fs.defaultFS="file:///" --conf
spark.driver.extraJavaOptions="-Dio.netty.tryReflectionSetAccessible=true"
--conf
spark.executor.extraJavaOptions="-Dio.netty.tryReflectionSetAccessible=true"
$FWDIR/pkg/tests/run-all.R 2>&1 | tee -a $LOGFILE
else
-
[spark] branch branch-3.2 updated: [SPARK-37302][BUILD][FOLLOWUP] Extract the versions of dependencies accurately
This is an automated email from the ASF dual-hosted git repository.
sarutak pushed a commit to branch branch-3.2
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.2 by this push:
new 0888622 [SPARK-37302][BUILD][FOLLOWUP] Extract the versions of
dependencies accurately
0888622 is described below
commit 08886223c6373cc7c7e132bfb58f1536e70286ef
Author: Kousuke Saruta
AuthorDate: Fri Dec 24 11:29:37 2021 +0900
[SPARK-37302][BUILD][FOLLOWUP] Extract the versions of dependencies
accurately
### What changes were proposed in this pull request?
This PR changes `dev/test-dependencies.sh` to extract the versions of
dependencies accurately.
In the current implementation, the versions are extracted like as follows.
```
GUAVA_VERSION=`build/mvn help:evaluate -Dexpression=guava.version -q
-DforceStdout`
```
But, if the output of the `mvn` command includes not only the version but
also other messages like warnings, a following command referring the version
will fail.
```
build/mvn dependency:get -Dartifact=com.google.guava:guava:${GUAVA_VERSION}
-q
...
[ERROR] Failed to execute goal
org.apache.maven.plugins:maven-dependency-plugin:3.1.1:get (default-cli) on
project spark-parent_2.12: Couldn't download artifact:
org.eclipse.aether.resolution.DependencyResolutionException:
com.google.guava:guava:jar:Falling was not found in
https://maven-central.storage-download.googleapis.com/maven2/ during a previous
attempt. This failure was cached in the local repository and resolution is not
reattempted until the update interval of gcs-maven-cent [...]
```
Actually, this causes the recent linter failure.
https://github.com/apache/spark/runs/4623297663?check_suite_focus=true
### Why are the changes needed?
To recover the CI.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Manually run `dev/test-dependencies.sh`.
Closes #35006 from sarutak/followup-SPARK-37302.
Authored-by: Kousuke Saruta
Signed-off-by: Kousuke Saruta
(cherry picked from commit dd0decff5f1e95cedd8fe83de7e4449be57cb31c)
Signed-off-by: Kousuke Saruta
---
dev/test-dependencies.sh | 4 ++--
1 file changed, 2 insertions(+), 2 deletions(-)
diff --git a/dev/test-dependencies.sh b/dev/test-dependencies.sh
index 363ba1a..39a11e7 100755
--- a/dev/test-dependencies.sh
+++ b/dev/test-dependencies.sh
@@ -48,9 +48,9 @@ OLD_VERSION=$($MVN -q \
--non-recursive \
org.codehaus.mojo:exec-maven-plugin:1.6.0:exec | grep -E
'[0-9]+\.[0-9]+\.[0-9]+')
# dependency:get for guava and jetty-io are workaround for SPARK-37302.
-GUAVA_VERSION=`build/mvn help:evaluate -Dexpression=guava.version -q
-DforceStdout`
+GUAVA_VERSION=$(build/mvn help:evaluate -Dexpression=guava.version -q
-DforceStdout | grep -E "^[0-9.]+$")
build/mvn dependency:get -Dartifact=com.google.guava:guava:${GUAVA_VERSION} -q
-JETTY_VERSION=`build/mvn help:evaluate -Dexpression=jetty.version -q
-DforceStdout`
+JETTY_VERSION=$(build/mvn help:evaluate -Dexpression=jetty.version -q
-DforceStdout | grep -E "^[0-9.]+v[0-9]+")
build/mvn dependency:get
-Dartifact=org.eclipse.jetty:jetty-io:${JETTY_VERSION} -q
if [ $? != 0 ]; then
echo -e "Error while getting version string from Maven:\n$OLD_VERSION"
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-37302][BUILD][FOLLOWUP] Extract the versions of dependencies accurately
This is an automated email from the ASF dual-hosted git repository.
sarutak pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new dd0decf [SPARK-37302][BUILD][FOLLOWUP] Extract the versions of
dependencies accurately
dd0decf is described below
commit dd0decff5f1e95cedd8fe83de7e4449be57cb31c
Author: Kousuke Saruta
AuthorDate: Fri Dec 24 11:29:37 2021 +0900
[SPARK-37302][BUILD][FOLLOWUP] Extract the versions of dependencies
accurately
### What changes were proposed in this pull request?
This PR changes `dev/test-dependencies.sh` to extract the versions of
dependencies accurately.
In the current implementation, the versions are extracted like as follows.
```
GUAVA_VERSION=`build/mvn help:evaluate -Dexpression=guava.version -q
-DforceStdout`
```
But, if the output of the `mvn` command includes not only the version but
also other messages like warnings, a following command referring the version
will fail.
```
build/mvn dependency:get -Dartifact=com.google.guava:guava:${GUAVA_VERSION}
-q
...
[ERROR] Failed to execute goal
org.apache.maven.plugins:maven-dependency-plugin:3.1.1:get (default-cli) on
project spark-parent_2.12: Couldn't download artifact:
org.eclipse.aether.resolution.DependencyResolutionException:
com.google.guava:guava:jar:Falling was not found in
https://maven-central.storage-download.googleapis.com/maven2/ during a previous
attempt. This failure was cached in the local repository and resolution is not
reattempted until the update interval of gcs-maven-cent [...]
```
Actually, this causes the recent linter failure.
https://github.com/apache/spark/runs/4623297663?check_suite_focus=true
### Why are the changes needed?
To recover the CI.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Manually run `dev/test-dependencies.sh`.
Closes #35006 from sarutak/followup-SPARK-37302.
Authored-by: Kousuke Saruta
Signed-off-by: Kousuke Saruta
---
dev/test-dependencies.sh | 4 ++--
1 file changed, 2 insertions(+), 2 deletions(-)
diff --git a/dev/test-dependencies.sh b/dev/test-dependencies.sh
index cf05126..2268a26 100755
--- a/dev/test-dependencies.sh
+++ b/dev/test-dependencies.sh
@@ -50,9 +50,9 @@ OLD_VERSION=$($MVN -q \
--non-recursive \
org.codehaus.mojo:exec-maven-plugin:1.6.0:exec | grep -E
'[0-9]+\.[0-9]+\.[0-9]+')
# dependency:get for guava and jetty-io are workaround for SPARK-37302.
-GUAVA_VERSION=`build/mvn help:evaluate -Dexpression=guava.version -q
-DforceStdout`
+GUAVA_VERSION=$(build/mvn help:evaluate -Dexpression=guava.version -q
-DforceStdout | grep -E "^[0-9.]+$")
build/mvn dependency:get -Dartifact=com.google.guava:guava:${GUAVA_VERSION} -q
-JETTY_VERSION=`build/mvn help:evaluate -Dexpression=jetty.version -q
-DforceStdout`
+JETTY_VERSION=$(build/mvn help:evaluate -Dexpression=jetty.version -q
-DforceStdout | grep -E "^[0-9.]+v[0-9]+")
build/mvn dependency:get
-Dartifact=org.eclipse.jetty:jetty-io:${JETTY_VERSION} -q
if [ $? != 0 ]; then
echo -e "Error while getting version string from Maven:\n$OLD_VERSION"
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.1 updated: [SPARK-37391][SQL] JdbcConnectionProvider tells if it modifies security context
This is an automated email from the ASF dual-hosted git repository.
gurwls223 pushed a commit to branch branch-3.1
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.1 by this push:
new 5e0f0da [SPARK-37391][SQL] JdbcConnectionProvider tells if it
modifies security context
5e0f0da is described below
commit 5e0f0da58edc5ce60fa972515fba73655400543d
Author: Danny Guinther
AuthorDate: Fri Dec 24 10:48:04 2021 +0900
[SPARK-37391][SQL] JdbcConnectionProvider tells if it modifies security
context
# branch-3.1 version!
For master version see : https://github.com/apache/spark/pull/34745
Augments the JdbcConnectionProvider API such that a provider can indicate
that it will need to modify the global security configuration when establishing
a connection, and as such, if access to the global security configuration
should be synchronized to prevent races.
### What changes were proposed in this pull request?
As suggested by gaborgsomogyi
[here](https://github.com/apache/spark/pull/29024/files#r755788709), augments
the `JdbcConnectionProvider` API to include a `modifiesSecurityContext` method
that can be used by `ConnectionProvider` to determine when
`SecurityConfigurationLock.synchronized` is required to avoid race conditions
when establishing a JDBC connection.
### Why are the changes needed?
Provides a path forward for working around a significant bottleneck
introduced by synchronizing `SecurityConfigurationLock` every time a connection
is established. The synchronization isn't always needed and it should be at the
discretion of the `JdbcConnectionProvider` to determine when locking is
necessary. See [SPARK-37391](https://issues.apache.org/jira/browse/SPARK-37391)
or [this thread](https://github.com/apache/spark/pull/29024/files#r754441783).
### Does this PR introduce _any_ user-facing change?
Any existing implementations of `JdbcConnectionProvider` will need to add a
definition of `modifiesSecurityContext`. I'm also open to adding a default
implementation, but it seemed to me that requiring an explicit implementation
of the method was preferable.
A drop-in implementation that would continue the existing behavior is:
```scala
override def modifiesSecurityContext(
driver: Driver,
options: Map[String, String]
): Boolean = true
```
### How was this patch tested?
Unit tests. Also ran a real workflow by swapping in a locally published
version of `spark-sql` into my local spark 3.1.2 installation's jars.
Closes #34988 from
tdg5/SPARK-37391-opt-in-security-configuration-sync-branch-3.1.
Authored-by: Danny Guinther
Signed-off-by: Hyukjin Kwon
---
project/MimaExcludes.scala | 5 -
.../jdbc/connection/BasicConnectionProvider.scala | 8
.../jdbc/connection/ConnectionProvider.scala | 23 +-
.../spark/sql/jdbc/JdbcConnectionProvider.scala| 19 --
.../IntentionallyFaultyConnectionProvider.scala| 4
5 files changed, 47 insertions(+), 12 deletions(-)
diff --git a/project/MimaExcludes.scala b/project/MimaExcludes.scala
index c29dd9e..c95c3815 100644
--- a/project/MimaExcludes.scala
+++ b/project/MimaExcludes.scala
@@ -105,7 +105,10 @@ object MimaExcludes {
ProblemFilters.exclude[InheritedNewAbstractMethodProblem]("org.apache.spark.ml.classification.BinaryLogisticRegressionSummary.weightCol"),
// [SPARK-32879] Pass SparkSession.Builder options explicitly to
SparkSession
-
ProblemFilters.exclude[DirectMissingMethodProblem]("org.apache.spark.sql.SparkSession.this")
+
ProblemFilters.exclude[DirectMissingMethodProblem]("org.apache.spark.sql.SparkSession.this"),
+
+// [SPARK-37391][SQL] JdbcConnectionProvider tells if it modifies security
context
+
ProblemFilters.exclude[ReversedMissingMethodProblem]("org.apache.spark.sql.jdbc.JdbcConnectionProvider.modifiesSecurityContext")
)
// Exclude rules for 3.0.x
diff --git
a/sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/jdbc/connection/BasicConnectionProvider.scala
b/sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/jdbc/connection/BasicConnectionProvider.scala
index 890205f..84b1ab9 100644
---
a/sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/jdbc/connection/BasicConnectionProvider.scala
+++
b/sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/jdbc/connection/BasicConnectionProvider.scala
@@ -48,4 +48,12 @@ private[jdbc] class BasicConnectionProvider extends
JdbcConnectionProvider with
logDebug(s"JDBC connection initiated with URL: ${jdbcOptions.url} and
properties: $properties")
driver.connect(jdbcOptions.url, properties)
}
+
+ override def modifiesSecurityContext(
+driver: Driver,
+options: Map[String, String]
+ ): Boolean = {
[spark] branch branch-3.2 updated (d1cd110 -> 662c6e8)
This is an automated email from the ASF dual-hosted git repository. gurwls223 pushed a change to branch branch-3.2 in repository https://gitbox.apache.org/repos/asf/spark.git. from d1cd110 [SPARK-37695][CORE][SHUFFLE] Skip diagnosis ob merged blocks from push-based shuffle add 662c6e8 [SPARK-37391][SQL] JdbcConnectionProvider tells if it modifies security context No new revisions were added by this update. Summary of changes: .../sql/jdbc/ExampleJdbcConnectionProvider.scala | 5 + project/MimaExcludes.scala | 5 - .../jdbc/connection/BasicConnectionProvider.scala | 8 .../jdbc/connection/ConnectionProvider.scala | 23 +- .../spark/sql/jdbc/JdbcConnectionProvider.scala| 19 -- .../main/scala/org/apache/spark/sql/jdbc/README.md | 5 +++-- .../IntentionallyFaultyConnectionProvider.scala| 4 7 files changed, 55 insertions(+), 14 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-37391][SQL] JdbcConnectionProvider tells if it modifies security context
This is an automated email from the ASF dual-hosted git repository.
sarutak pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 6cc4c90 [SPARK-37391][SQL] JdbcConnectionProvider tells if it
modifies security context
6cc4c90 is described below
commit 6cc4c90cbc09a7729f9c40f440fcdda83e3d8648
Author: Danny Guinther
AuthorDate: Fri Dec 24 10:07:16 2021 +0900
[SPARK-37391][SQL] JdbcConnectionProvider tells if it modifies security
context
Augments the JdbcConnectionProvider API such that a provider can indicate
that it will need to modify the global security configuration when establishing
a connection, and as such, if access to the global security configuration
should be synchronized to prevent races.
### What changes were proposed in this pull request?
As suggested by gaborgsomogyi
[here](https://github.com/apache/spark/pull/29024/files#r755788709), augments
the `JdbcConnectionProvider` API to include a `modifiesSecurityContext` method
that can be used by `ConnectionProvider` to determine when
`SecurityConfigurationLock.synchronized` is required to avoid race conditions
when establishing a JDBC connection.
### Why are the changes needed?
Provides a path forward for working around a significant bottleneck
introduced by synchronizing `SecurityConfigurationLock` every time a connection
is established. The synchronization isn't always needed and it should be at the
discretion of the `JdbcConnectionProvider` to determine when locking is
necessary. See [SPARK-37391](https://issues.apache.org/jira/browse/SPARK-37391)
or [this thread](https://github.com/apache/spark/pull/29024/files#r754441783).
### Does this PR introduce _any_ user-facing change?
Any existing implementations of `JdbcConnectionProvider` will need to add a
definition of `modifiesSecurityContext`. I'm also open to adding a default
implementation, but it seemed to me that requiring an explicit implementation
of the method was preferable.
A drop-in implementation that would continue the existing behavior is:
```scala
override def modifiesSecurityContext(
driver: Driver,
options: Map[String, String]
): Boolean = true
```
### How was this patch tested?
Unit tests, but I also plan to run a real workflow once I get the initial
thumbs up on this implementation.
Closes #34745 from tdg5/SPARK-37391-opt-in-security-configuration-sync.
Authored-by: Danny Guinther
Signed-off-by: Kousuke Saruta
---
.../sql/jdbc/ExampleJdbcConnectionProvider.scala | 5 ++
project/MimaExcludes.scala | 5 +-
.../jdbc/connection/BasicConnectionProvider.scala | 8
.../jdbc/connection/ConnectionProvider.scala | 22 +
.../spark/sql/jdbc/JdbcConnectionProvider.scala| 19 +++-
.../main/scala/org/apache/spark/sql/jdbc/README.md | 5 +-
.../jdbc/connection/ConnectionProviderSuite.scala | 55 ++
.../IntentionallyFaultyConnectionProvider.scala| 4 ++
8 files changed, 109 insertions(+), 14 deletions(-)
diff --git
a/examples/src/main/scala/org/apache/spark/examples/sql/jdbc/ExampleJdbcConnectionProvider.scala
b/examples/src/main/scala/org/apache/spark/examples/sql/jdbc/ExampleJdbcConnectionProvider.scala
index 6d275d4..c63467d 100644
---
a/examples/src/main/scala/org/apache/spark/examples/sql/jdbc/ExampleJdbcConnectionProvider.scala
+++
b/examples/src/main/scala/org/apache/spark/examples/sql/jdbc/ExampleJdbcConnectionProvider.scala
@@ -30,4 +30,9 @@ class ExampleJdbcConnectionProvider extends
JdbcConnectionProvider with Logging
override def canHandle(driver: Driver, options: Map[String, String]):
Boolean = false
override def getConnection(driver: Driver, options: Map[String, String]):
Connection = null
+
+ override def modifiesSecurityContext(
+driver: Driver,
+options: Map[String, String]
+ ): Boolean = false
}
diff --git a/project/MimaExcludes.scala b/project/MimaExcludes.scala
index 75fa001..6cf639f 100644
--- a/project/MimaExcludes.scala
+++ b/project/MimaExcludes.scala
@@ -40,7 +40,10 @@ object MimaExcludes {
// The followings are necessary for Scala 2.13.
ProblemFilters.exclude[DirectMissingMethodProblem]("org.apache.spark.executor.CoarseGrainedExecutorBackend#Arguments.*"),
ProblemFilters.exclude[IncompatibleResultTypeProblem]("org.apache.spark.executor.CoarseGrainedExecutorBackend#Arguments.*"),
-
ProblemFilters.exclude[MissingTypesProblem]("org.apache.spark.executor.CoarseGrainedExecutorBackend$Arguments$")
+
ProblemFilters.exclude[MissingTypesProblem]("org.apache.spark.executor.CoarseGrainedExecutorBackend$Arguments$"),
+
+// [SPARK-37391][SQL] JdbcConnectionProvider tells if it modifies security
context
+
[spark] branch master updated (66c2d1f -> 656127d)
This is an automated email from the ASF dual-hosted git repository. gurwls223 pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 66c2d1f [SPARK-37193][SQL] DynamicJoinSelection.shouldDemoteBroadcastHashJoin should not apply to outer joins add 656127d [SPARK-37657][PYTHON] Support str and timestamp for (Series|DataFrame).describe() No new revisions were added by this update. Summary of changes: python/pyspark/pandas/frame.py| 183 + python/pyspark/pandas/tests/test_dataframe.py | 188 +- 2 files changed, 345 insertions(+), 26 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (d9e3d9b -> 66c2d1f)
This is an automated email from the ASF dual-hosted git repository. wenchen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from d9e3d9b [SPARK-37644][SQL] Support datasource v2 complete aggregate pushdown add 66c2d1f [SPARK-37193][SQL] DynamicJoinSelection.shouldDemoteBroadcastHashJoin should not apply to outer joins No new revisions were added by this update. Summary of changes: python/pyspark/pandas/tests/test_ops_on_diff_frames.py | 2 +- .../sql/execution/adaptive/DynamicJoinSelection.scala | 18 +- .../execution/adaptive/AdaptiveQueryExecSuite.scala| 17 + 3 files changed, 31 insertions(+), 6 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-37644][SQL] Support datasource v2 complete aggregate pushdown
This is an automated email from the ASF dual-hosted git repository.
wenchen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new d9e3d9b [SPARK-37644][SQL] Support datasource v2 complete aggregate
pushdown
d9e3d9b is described below
commit d9e3d9b9d97e7a238062060675913e29b9184cfb
Author: Jiaan Geng
AuthorDate: Thu Dec 23 23:05:20 2021 +0800
[SPARK-37644][SQL] Support datasource v2 complete aggregate pushdown
### What changes were proposed in this pull request?
Currently , Spark supports push down aggregate with partial-agg and
final-agg . For some data source (e.g. JDBC ) , we can avoid partial-agg and
final-agg by running completely on database.
### Why are the changes needed?
Improve performance for aggregate pushdown.
### Does this PR introduce _any_ user-facing change?
'No'. Just change the inner implement.
### How was this patch tested?
New tests.
Closes #34904 from beliefer/SPARK-37644.
Authored-by: Jiaan Geng
Signed-off-by: Wenchen Fan
---
.../connector/read/SupportsPushDownAggregates.java | 8 ++
.../datasources/v2/V2ScanRelationPushDown.scala| 101 +
.../datasources/v2/jdbc/JDBCScanBuilder.scala | 3 +
.../org/apache/spark/sql/jdbc/JDBCV2Suite.scala| 101 -
4 files changed, 173 insertions(+), 40 deletions(-)
diff --git
a/sql/catalyst/src/main/java/org/apache/spark/sql/connector/read/SupportsPushDownAggregates.java
b/sql/catalyst/src/main/java/org/apache/spark/sql/connector/read/SupportsPushDownAggregates.java
index 3e643b5..4e6c59e 100644
---
a/sql/catalyst/src/main/java/org/apache/spark/sql/connector/read/SupportsPushDownAggregates.java
+++
b/sql/catalyst/src/main/java/org/apache/spark/sql/connector/read/SupportsPushDownAggregates.java
@@ -46,6 +46,14 @@ import
org.apache.spark.sql.connector.expressions.aggregate.Aggregation;
public interface SupportsPushDownAggregates extends ScanBuilder {
/**
+ * Whether the datasource support complete aggregation push-down. Spark
could avoid partial-agg
+ * and final-agg when the aggregation operation can be pushed down to the
datasource completely.
+ *
+ * @return true if the aggregation can be pushed down to datasource
completely, false otherwise.
+ */
+ default boolean supportCompletePushDown() { return false; }
+
+ /**
* Pushes down Aggregation to datasource. The order of the datasource scan
output columns should
* be: grouping columns, aggregate columns (in the same order as the
aggregate functions in
* the given Aggregation).
diff --git
a/sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/v2/V2ScanRelationPushDown.scala
b/sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/v2/V2ScanRelationPushDown.scala
index e7c06d0..3a792f4 100644
---
a/sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/v2/V2ScanRelationPushDown.scala
+++
b/sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/v2/V2ScanRelationPushDown.scala
@@ -19,7 +19,7 @@ package org.apache.spark.sql.execution.datasources.v2
import scala.collection.mutable
-import org.apache.spark.sql.catalyst.expressions.{And, Attribute,
AttributeReference, Expression, IntegerLiteral, NamedExpression,
PredicateHelper, ProjectionOverSchema, SubqueryExpression}
+import org.apache.spark.sql.catalyst.expressions.{Alias, And, Attribute,
AttributeReference, Cast, Expression, IntegerLiteral, NamedExpression,
PredicateHelper, ProjectionOverSchema, SubqueryExpression}
import org.apache.spark.sql.catalyst.expressions.aggregate
import org.apache.spark.sql.catalyst.expressions.aggregate.AggregateExpression
import org.apache.spark.sql.catalyst.planning.ScanOperation
@@ -30,7 +30,7 @@ import
org.apache.spark.sql.connector.expressions.aggregate.Aggregation
import org.apache.spark.sql.connector.read.{Scan, ScanBuilder,
SupportsPushDownAggregates, SupportsPushDownFilters, V1Scan}
import org.apache.spark.sql.execution.datasources.DataSourceStrategy
import org.apache.spark.sql.sources
-import org.apache.spark.sql.types.StructType
+import org.apache.spark.sql.types.{DataType, LongType, StructType}
import org.apache.spark.sql.util.SchemaUtils._
object V2ScanRelationPushDown extends Rule[LogicalPlan] with PredicateHelper {
@@ -131,7 +131,8 @@ object V2ScanRelationPushDown extends Rule[LogicalPlan]
with PredicateHelper {
case (a: Attribute, b: Attribute) => b.withExprId(a.exprId)
case (_, b) => b
}
-val output = groupAttrs ++ newOutput.drop(groupAttrs.length)
+val aggOutput = newOutput.drop(groupAttrs.length)
+val output = groupAttrs ++ aggOutput
logInfo(
s"""
@@ -147,40 +148,59 @@ object
[spark] branch master updated (805e3fb -> 64c79a7)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 805e3fb [SPARK-37462][CORE] Avoid unnecessary calculating the number of outstanding fetch requests and RPCS add 64c79a7 [SPARK-37718][MINOR][DOCS] Demo sql is incorrect No new revisions were added by this update. Summary of changes: docs/sql-ref-null-semantics.md | 2 +- 1 file changed, 1 insertion(+), 1 deletion(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (f6be769 -> 805e3fb)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from f6be769 [SPARK-37668][PYTHON] 'Index' object has no attribute 'levels' in pyspark.pandas.frame.DataFrame.insert add 805e3fb [SPARK-37462][CORE] Avoid unnecessary calculating the number of outstanding fetch requests and RPCS No new revisions were added by this update. Summary of changes: .../java/org/apache/spark/network/server/TransportChannelHandler.java | 2 +- 1 file changed, 1 insertion(+), 1 deletion(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-37668][PYTHON] 'Index' object has no attribute 'levels' in pyspark.pandas.frame.DataFrame.insert
This is an automated email from the ASF dual-hosted git repository.
gurwls223 pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new f6be769 [SPARK-37668][PYTHON] 'Index' object has no attribute
'levels' in pyspark.pandas.frame.DataFrame.insert
f6be769 is described below
commit f6be7693ba66c81fda8ee97ec7c6346e34495235
Author: itholic
AuthorDate: Thu Dec 23 22:15:07 2021 +0900
[SPARK-37668][PYTHON] 'Index' object has no attribute 'levels' in
pyspark.pandas.frame.DataFrame.insert
### What changes were proposed in this pull request?
This PR proposes to address the unexpected error in
`pyspark.pandas.frame.DataFrame.insert`.
Assigning tuple as column name is only supported for MultiIndex Columns for
now in pandas API on Spark:
```python
# MultiIndex column
>>> psdf
x
y
0 1
1 2
2 3
>>> psdf[('a', 'b')] = [4, 5, 6]
>>> psdf
x a
y b
0 1 4
1 2 5
2 3 6
# However, not supported for non-MultiIndex column
>>> psdf
A
0 1
1 2
2 3
>>> psdf[('a', 'b')] = [4, 5, 6]
Traceback (most recent call last):
...
KeyError: 'Key length (2) exceeds index depth (1)'
```
So, we should show proper error message rather than `AttributeError:
'Index' object has no attribute 'levels'` when users try to insert the tuple
named column.
**Before**
```python
>>> psdf.insert(0, ("a", "b"), 10)
Traceback (most recent call last):
...
AttributeError: 'Index' object has no attribute 'levels'
```
**After**
```python
>>> psdf.insert(0, ("a", "b"), 10)
Traceback (most recent call last):
...
NotImplementedError: Assigning column name as tuple is only supported for
MultiIndex columns for now.
```
### Why are the changes needed?
Let users know proper usage.
### Does this PR introduce _any_ user-facing change?
Yes, the exception message is changed as described in the **After**.
### How was this patch tested?
Unittests.
Closes #34957 from itholic/SPARK-37668.
Authored-by: itholic
Signed-off-by: Hyukjin Kwon
---
python/pyspark/pandas/frame.py| 14 ++
python/pyspark/pandas/tests/test_dataframe.py | 11 +++
2 files changed, 21 insertions(+), 4 deletions(-)
diff --git a/python/pyspark/pandas/frame.py b/python/pyspark/pandas/frame.py
index c2a7385..985bd9b 100644
--- a/python/pyspark/pandas/frame.py
+++ b/python/pyspark/pandas/frame.py
@@ -3988,13 +3988,19 @@ defaultdict(, {'col..., 'col...})]
'"column" should be a scalar value or tuple that contains
scalar values'
)
+# TODO(SPARK-37723): Support tuple for non-MultiIndex column name.
if is_name_like_tuple(column):
-if len(column) != len(self.columns.levels): # type:
ignore[attr-defined] # SPARK-37668
-# To be consistent with pandas
-raise ValueError('"column" must have length equal to number of
column levels.')
+if self._internal.column_labels_level > 1:
+if len(column) != len(self.columns.levels): # type:
ignore[attr-defined]
+# To be consistent with pandas
+raise ValueError('"column" must have length equal to
number of column levels.')
+else:
+raise NotImplementedError(
+"Assigning column name as tuple is only supported for
MultiIndex columns for now."
+)
if column in self.columns:
-raise ValueError("cannot insert %s, already exists" % column)
+raise ValueError("cannot insert %s, already exists" % str(column))
psdf = self.copy()
psdf[column] = value
diff --git a/python/pyspark/pandas/tests/test_dataframe.py
b/python/pyspark/pandas/tests/test_dataframe.py
index 84a53c0..88416d3 100644
--- a/python/pyspark/pandas/tests/test_dataframe.py
+++ b/python/pyspark/pandas/tests/test_dataframe.py
@@ -223,6 +223,12 @@ class DataFrameTest(PandasOnSparkTestCase, SQLTestUtils):
"loc must be int",
lambda: psdf.insert((1,), "b", 10),
)
+self.assertRaisesRegex(
+NotImplementedError,
+"Assigning column name as tuple is only supported for MultiIndex
columns for now.",
+lambda: psdf.insert(0, ("e",), 10),
+)
+
self.assertRaises(ValueError, lambda: psdf.insert(0, "e", [7, 8, 9,
10]))
self.assertRaises(ValueError, lambda: psdf.insert(0, "f",
ps.Series([7, 8])))
self.assertRaises(AssertionError, lambda: psdf.insert(100, "y", psser))
@@ -249,6 +255,11 @@ class DataFrameTest(PandasOnSparkTestCase, SQLTestUtils):
)
[spark] branch master updated: [SPARK-37714][SQL] ANSI mode: allow casting between numeric type and timestamp type
This is an automated email from the ASF dual-hosted git repository. gengliang pushed a commit to branch master in repository https://gitbox.apache.org/repos/asf/spark.git The following commit(s) were added to refs/heads/master by this push: new 198b90c [SPARK-37714][SQL] ANSI mode: allow casting between numeric type and timestamp type 198b90c is described below commit 198b90c3bf5c3cbc90ba1bb4460e92c72695b50c Author: Gengliang Wang AuthorDate: Thu Dec 23 20:13:10 2021 +0800 [SPARK-37714][SQL] ANSI mode: allow casting between numeric type and timestamp type ### What changes were proposed in this pull request? * Allow casting between numeric type and timestamp type under ANSI mode * Remove the user-facing configuration `spark.sql.ansi.allowCastBetweenDatetimeAndNumeric` ### Why are the changes needed? Same reason as mentioned in https://github.com/apache/spark/pull/34459. It is for better adoption of ANSI SQL mode since users are relying on it: - As we did some data science, we found that many Spark SQL users are actually using `Cast(Timestamp as Numeric)` and `Cast(Numeric as Timestamp)`. - The Spark SQL connector for Tableau is using this feature for DateTime math. e.g. `CAST(FROM_UNIXTIME(CAST(CAST(%1 AS BIGINT) + (%2 * 86400) AS BIGINT)) AS TIMESTAMP)` ### Does this PR introduce _any_ user-facing change? Yes, casting between numeric type and timestamp type is allowed by default under ANSI SQL mode ### How was this patch tested? Unit tests. Here is the screenshot of the document change: 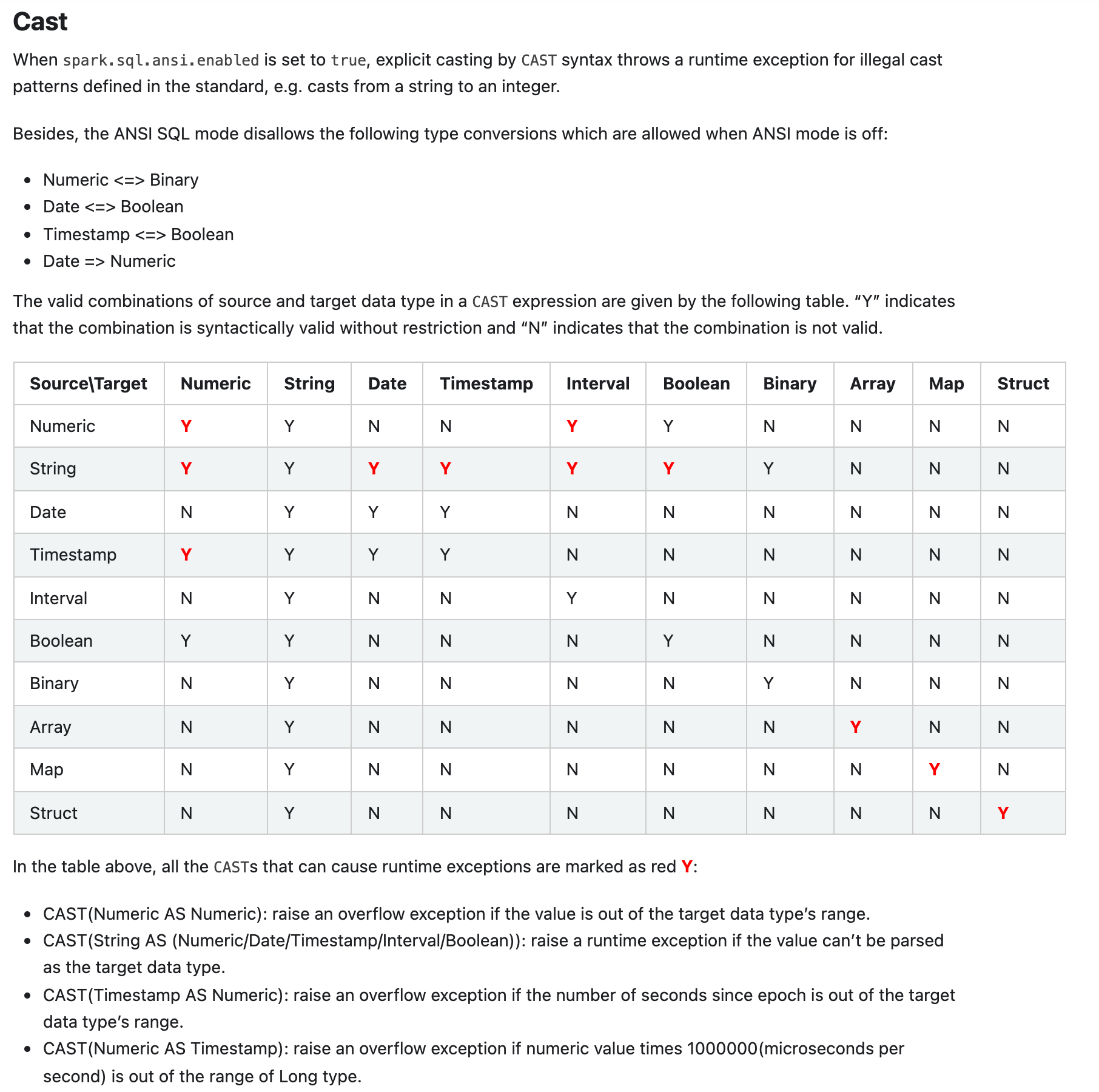 Closes #34985 from gengliangwang/changeSubConf. Authored-by: Gengliang Wang Signed-off-by: Gengliang Wang --- docs/sql-ref-ansi-compliance.md| 18 ++-- .../spark/sql/catalyst/expressions/Cast.scala | 5 +- .../org/apache/spark/sql/internal/SQLConf.scala| 12 --- .../catalyst/expressions/AnsiCastSuiteBase.scala | 120 + .../spark/sql/catalyst/expressions/CastSuite.scala | 32 +- .../sql/catalyst/expressions/CastSuiteBase.scala | 31 ++ 6 files changed, 67 insertions(+), 151 deletions(-) diff --git a/docs/sql-ref-ansi-compliance.md b/docs/sql-ref-ansi-compliance.md index d8d5a24..03b8db1 100644 --- a/docs/sql-ref-ansi-compliance.md +++ b/docs/sql-ref-ansi-compliance.md @@ -70,23 +70,21 @@ SELECT abs(-2147483648); When `spark.sql.ansi.enabled` is set to `true`, explicit casting by `CAST` syntax throws a runtime exception for illegal cast patterns defined in the standard, e.g. casts from a string to an integer. -The `CAST` clause of Spark ANSI mode follows the syntax rules of section 6.13 "cast specification" in [ISO/IEC 9075-2:2011 Information technology — Database languages - SQL — Part 2: Foundation (SQL/Foundation)](https://www.iso.org/standard/53682.html), except it specially allows the following - straightforward type conversions which are disallowed as per the ANSI standard: -* NumericType <=> BooleanType -* StringType <=> BinaryType -* ArrayType => String -* MapType => String -* StructType => String +Besides, the ANSI SQL mode disallows the following type conversions which are allowed when ANSI mode is off: +* Numeric <=> Binary +* Date <=> Boolean +* Timestamp <=> Boolean +* Date => Numeric The valid combinations of source and target data type in a `CAST` expression are given by the following table. “Y” indicates that the combination is syntactically valid without restriction and “N” indicates that the combination is not valid. | Source\Target | Numeric | String | Date | Timestamp | Interval | Boolean | Binary | Array | Map | Struct | |---|-||--|---|--|-||---|-|| -| Numeric | **Y** | Y | N| N | N| Y | N | N | N | N | +| Numeric | **Y** | Y | N| N | **Y** | Y | N | N | N | N | | String| **Y** | Y | **Y** | **Y** | **Y** | **Y** | Y | N | N | N | | Date | N | Y | Y| Y | N| N | N | N | N | N | -| Timestamp | N | Y | Y| Y | N| N | N | N | N | N | +| Timestamp | **Y** | Y | Y| Y | N| N | N | N | N | N | | Interval | N | Y | N| N | Y| N | N | N | N | N | | Boolean | Y | Y | N| N | N| Y | N | N | N | N | | Binary| N | Y | N| N | N| N | Y | N | N | N | @@ -97,6 +95,8 @@ The `CAST` clause of Spark ANSI mode follows the syntax rules of section 6.13 "c In the table above,
[spark] branch master updated (29e3e8d -> e76ae9a)
This is an automated email from the ASF dual-hosted git repository. gurwls223 pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 29e3e8d [SPARK-37659][UI] Fix FsHistoryProvider race condition between list and delet log info add e76ae9a [SPARK-37721][PYTHON] Fix SPARK_HOME key error when running PySpark test No new revisions were added by this update. Summary of changes: python/pyspark/sql/utils.py| 8 ++-- python/pyspark/testing/utils.py| 5 +++-- python/pyspark/tests/test_appsubmit.py | 4 +++- 3 files changed, 8 insertions(+), 9 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org