[GitHub] spark pull request #21537: [SPARK-24505][SQL] Convert strings in codegen to ...
Github user viirya commented on a diff in the pull request:
https://github.com/apache/spark/pull/21537#discussion_r195626960
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/codegen/javaCode.scala
---
@@ -155,6 +170,17 @@ object Block {
val CODE_BLOCK_BUFFER_LENGTH: Int = 512
+ /**
+ * A custom string interpolator which inlines all types of input
arguments into a string without
--- End diff --
I think part of this comment can be moved to `InlineBlock`.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21477: [SPARK-24396] [SS] [PYSPARK] Add Structured Strea...
Github user HeartSaVioR commented on a diff in the pull request:
https://github.com/apache/spark/pull/21477#discussion_r195625921
--- Diff: python/pyspark/sql/streaming.py ---
@@ -843,6 +843,170 @@ def trigger(self, processingTime=None, once=None,
continuous=None):
self._jwrite = self._jwrite.trigger(jTrigger)
return self
+@since(2.4)
+def foreach(self, f):
+"""
+Sets the output of the streaming query to be processed using the
provided writer ``f``.
+This is often used to write the output of a streaming query to
arbitrary storage systems.
+The processing logic can be specified in two ways.
+
+#. A **function** that takes a row as input.
+This is a simple way to express your processing logic. Note
that this does
+not allow you to deduplicate generated data when failures
cause reprocessing of
+some input data. That would require you to specify the
processing logic in the next
+way.
+
+#. An **object** with a ``process`` method and optional ``open``
and ``close`` methods.
+The object can have the following methods.
+
+* ``open(partition_id, epoch_id)``: *Optional* method that
initializes the processing
+(for example, open a connection, start a transaction,
etc). Additionally, you can
+use the `partition_id` and `epoch_id` to deduplicate
regenerated data
+(discussed later).
+
+* ``process(row)``: *Non-optional* method that processes each
:class:`Row`.
+
+* ``close(error)``: *Optional* method that finalizes and
cleans up (for example,
+close connection, commit transaction, etc.) after all rows
have been processed.
+
+The object will be used by Spark in the following way.
+
+* A single copy of this object is responsible of all the data
generated by a
+single task in a query. In other words, one instance is
responsible for
+processing one partition of the data generated in a
distributed manner.
+
+* This object must be serializable because each task will get
a fresh
+serialized-deserialized copy of the provided object.
Hence, it is strongly
+recommended that any initialization for writing data (e.g.
opening a
+connection or starting a transaction) is done after the
`open(...)`
+method has been called, which signifies that the task is
ready to generate data.
+
+* The lifecycle of the methods are as follows.
+
+For each partition with ``partition_id``:
+
+... For each batch/epoch of streaming data with
``epoch_id``:
+
+... Method ``open(partitionId, epochId)`` is called.
+
+... If ``open(...)`` returns true, for each row in the
partition and
+batch/epoch, method ``process(row)`` is called.
+
+... Method ``close(errorOrNull)`` is called with error
(if any) seen while
+processing rows.
+
+Important points to note:
+
+* The `partitionId` and `epochId` can be used to deduplicate
generated data when
+failures cause reprocessing of some input data. This
depends on the execution
+mode of the query. If the streaming query is being
executed in the micro-batch
+mode, then every partition represented by a unique tuple
(partition_id, epoch_id)
+is guaranteed to have the same data. Hence, (partition_id,
epoch_id) can be used
+to deduplicate and/or transactionally commit data and
achieve exactly-once
+guarantees. However, if the streaming query is being
executed in the continuous
+mode, then this guarantee does not hold and therefore
should not be used for
+deduplication.
+
+* The ``close()`` method (if exists) will be called if
`open()` method exists and
+returns successfully (irrespective of the return value),
except if the Python
+crashes in the middle.
+
+.. note:: Evolving.
+
+>>> # Print every row using a function
+>>> def print_row(row):
+... print(row)
+...
+>>> writer = sdf.writeStream.foreach(print_row)
+>>> # Print every row using a object with process() method
+>>> class RowPrinter:
+... def open(self, partition_id, epoch_id):
+... print("Opened %d,
[GitHub] spark issue #21560: [SPARK-24386][SS] coalesce(1) aggregates in continuous p...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/21560 **[Test build #91882 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/91882/testReport)** for PR 21560 at commit [`252f5c9`](https://github.com/apache/spark/commit/252f5c9d0e4a5b6d1a456e847a53cf4f0e84dcfb). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21560: [SPARK-24386][SS] coalesce(1) aggregates in continuous p...
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/21560 restest this please --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21560: [SPARK-24386][SS] coalesce(1) aggregates in conti...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21560#discussion_r195420149
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/v2/DataSourceV2Strategy.scala
---
@@ -36,6 +37,17 @@ object DataSourceV2Strategy extends Strategy {
case WriteToContinuousDataSource(writer, query) =>
WriteToContinuousDataSourceExec(writer, planLater(query)) :: Nil
+case Repartition(1, false, child) =>
+ val isContinuous = child.collectFirst {
+case StreamingDataSourceV2Relation(_, _, _, r: ContinuousReader)
=> r
+ }.isDefined
--- End diff --
The judgement of whether the plan is continuous or not can be a sperated
method and other place can use it?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21560: [SPARK-24386][SS] coalesce(1) aggregates in conti...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21560#discussion_r195415777
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/continuous/ContinuousCoalesceRDD.scala
---
@@ -0,0 +1,93 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.streaming.continuous
+
+import org.apache.spark._
+import org.apache.spark.rdd.{CoalescedRDDPartition, RDD}
+import org.apache.spark.sql.catalyst.InternalRow
+import org.apache.spark.sql.catalyst.expressions.UnsafeRow
+import org.apache.spark.sql.execution.streaming.continuous.shuffle._
+
+case class ContinuousCoalesceRDDPartition(index: Int) extends Partition {
+ private[continuous] var writersInitialized: Boolean = false
+}
+
+/**
+ * RDD for continuous coalescing. Asynchronously writes all partitions of
`prev` into a local
+ * continuous shuffle, and then reads them in the task thread using
`reader`.
+ */
+class ContinuousCoalesceRDD(var reader: ContinuousShuffleReadRDD, var
prev: RDD[InternalRow])
--- End diff --
why the `reader` and `prev` both is var here?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21556: [SPARK-24549][SQL] 32BitDecimalType and 64BitDecimalType...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/21556 **[Test build #91881 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/91881/testReport)** for PR 21556 at commit [`51d8540`](https://github.com/apache/spark/commit/51d854000186dcef1385e4b8bcd84c2b9fd763c6). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21556: [SPARK-24549][SQL] 32BitDecimalType and 64BitDecimalType...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21556 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution/4056/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21556: [SPARK-24549][SQL] 32BitDecimalType and 64BitDecimalType...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21556 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21556: [SPARK-24549][SQL] 32BitDecimalType and 64BitDecimalType...
Github user wangyum commented on the issue: https://github.com/apache/spark/pull/21556 Another performance test: https://user-images.githubusercontent.com/5399861/41448622-437d029a-708e-11e8-9c18-5d9f17cd1edf.png";> --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21556: [SPARK-24549][SQL] 32BitDecimalType and 64BitDecimalType...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21556 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/165/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20636: [SPARK-23415][SQL][TEST] Make behavior of BufferHolderSp...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/20636 Merged build finished. Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21556: [SPARK-24549][SQL] 32BitDecimalType and 64BitDecimalType...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21556 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20636: [SPARK-23415][SQL][TEST] Make behavior of BufferHolderSp...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/20636 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/91880/ Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20636: [SPARK-23415][SQL][TEST] Make behavior of BufferHolderSp...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/20636 **[Test build #91880 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/91880/testReport)** for PR 20636 at commit [`2995a9c`](https://github.com/apache/spark/commit/2995a9ca6bf2d3e5ebafabe2c512ea46b50a5621). * This patch **fails to build**. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21570: [SPARK-24564][TEST] Add test suite for RecordBinaryCompa...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21570 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/91872/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20636: [SPARK-23415][SQL][TEST] Make behavior of BufferHolderSp...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/20636 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/164/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20636: [SPARK-23415][SQL][TEST] Make behavior of BufferHolderSp...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/20636 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution/4055/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20636: [SPARK-23415][SQL][TEST] Make behavior of BufferHolderSp...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/20636 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21570: [SPARK-24564][TEST] Add test suite for RecordBinaryCompa...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21570 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20636: [SPARK-23415][SQL][TEST] Make behavior of BufferHolderSp...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/20636 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21570: [SPARK-24564][TEST] Add test suite for RecordBinaryCompa...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/21570 **[Test build #91872 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/91872/testReport)** for PR 21570 at commit [`79508ec`](https://github.com/apache/spark/commit/79508ec7a33735690b0d5f0c74168efbf804866c). * This patch passes all tests. * This patch merges cleanly. * This patch adds the following public classes _(experimental)_: * `public class RecordBinaryComparatorSuite ` --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20636: [SPARK-23415][SQL][TEST] Make behavior of BufferHolderSp...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/20636 **[Test build #91880 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/91880/testReport)** for PR 20636 at commit [`2995a9c`](https://github.com/apache/spark/commit/2995a9ca6bf2d3e5ebafabe2c512ea46b50a5621). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21477: [SPARK-24396] [SS] [PYSPARK] Add Structured Streaming Fo...
Github user HyukjinKwon commented on the issue: https://github.com/apache/spark/pull/21477 (Please ignore nits. They are ignorable but I just left them in case you might want to address them) --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21439: [SPARK-24391][SQL] Support arrays of any types by from_j...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21439 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21439: [SPARK-24391][SQL] Support arrays of any types by from_j...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21439 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/91874/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21477: [SPARK-24396] [SS] [PYSPARK] Add Structured Strea...
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/21477#discussion_r195623128
--- Diff: python/pyspark/sql/tests.py ---
@@ -1885,6 +1885,263 @@ def test_query_manager_await_termination(self):
q.stop()
shutil.rmtree(tmpPath)
+class ForeachWriterTester:
+
+def __init__(self, spark):
+self.spark = spark
+
+def write_open_event(self, partitionId, epochId):
+self._write_event(
+self.open_events_dir,
+{'partition': partitionId, 'epoch': epochId})
+
+def write_process_event(self, row):
+self._write_event(self.process_events_dir, {'value': 'text'})
+
+def write_close_event(self, error):
+self._write_event(self.close_events_dir, {'error': str(error)})
+
+def write_input_file(self):
+self._write_event(self.input_dir, "text")
+
+def open_events(self):
+return self._read_events(self.open_events_dir, 'partition INT,
epoch INT')
+
+def process_events(self):
+return self._read_events(self.process_events_dir, 'value
STRING')
+
+def close_events(self):
+return self._read_events(self.close_events_dir, 'error STRING')
+
+def run_streaming_query_on_writer(self, writer, num_files):
+self._reset()
+try:
+sdf =
self.spark.readStream.format('text').load(self.input_dir)
+sq = sdf.writeStream.foreach(writer).start()
+for i in range(num_files):
+self.write_input_file()
+sq.processAllAvailable()
+finally:
+self.stop_all()
+
+def assert_invalid_writer(self, writer, msg=None):
+self._reset()
+try:
+sdf =
self.spark.readStream.format('text').load(self.input_dir)
+sq = sdf.writeStream.foreach(writer).start()
+self.write_input_file()
+sq.processAllAvailable()
+self.fail("invalid writer %s did not fail the query" %
str(writer)) # not expected
+except Exception as e:
+if msg:
+assert(msg in str(e), "%s not in %s" % (msg, str(e)))
+
+finally:
+self.stop_all()
+
+def stop_all(self):
+for q in self.spark._wrapped.streams.active:
+q.stop()
+
+def _reset(self):
+self.input_dir = tempfile.mkdtemp()
+self.open_events_dir = tempfile.mkdtemp()
+self.process_events_dir = tempfile.mkdtemp()
+self.close_events_dir = tempfile.mkdtemp()
+
+def _read_events(self, dir, json):
+rows = self.spark.read.schema(json).json(dir).collect()
+dicts = [row.asDict() for row in rows]
+return dicts
+
+def _write_event(self, dir, event):
+import uuid
+with open(os.path.join(dir, str(uuid.uuid4())), 'w') as f:
+f.write("%s\n" % str(event))
+
+def __getstate__(self):
+return (self.open_events_dir, self.process_events_dir,
self.close_events_dir)
+
+def __setstate__(self, state):
+self.open_events_dir, self.process_events_dir,
self.close_events_dir = state
+
+def test_streaming_foreach_with_simple_function(self):
+tester = self.ForeachWriterTester(self.spark)
+
+def foreach_func(row):
+tester.write_process_event(row)
+
+tester.run_streaming_query_on_writer(foreach_func, 2)
+self.assertEqual(len(tester.process_events()), 2)
+
+def test_streaming_foreach_with_basic_open_process_close(self):
+tester = self.ForeachWriterTester(self.spark)
+
+class ForeachWriter:
+def open(self, partitionId, epochId):
+tester.write_open_event(partitionId, epochId)
+return True
+
+def process(self, row):
+tester.write_process_event(row)
+
+def close(self, error):
+tester.write_close_event(error)
+
+tester.run_streaming_query_on_writer(ForeachWriter(), 2)
+
+open_events = tester.open_events()
+self.assertEqual(len(open_events), 2)
+self.assertSetEqual(set([e['epoch'] for e in open_events]), {0, 1})
+
+self.assertEqual(len(tester.process_events()), 2)
+
+close_events = tester.close_events()
[GitHub] spark pull request #21477: [SPARK-24396] [SS] [PYSPARK] Add Structured Strea...
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/21477#discussion_r195623149
--- Diff: python/pyspark/sql/tests.py ---
@@ -1885,6 +1885,263 @@ def test_query_manager_await_termination(self):
q.stop()
shutil.rmtree(tmpPath)
+class ForeachWriterTester:
+
+def __init__(self, spark):
+self.spark = spark
+
+def write_open_event(self, partitionId, epochId):
+self._write_event(
+self.open_events_dir,
+{'partition': partitionId, 'epoch': epochId})
+
+def write_process_event(self, row):
+self._write_event(self.process_events_dir, {'value': 'text'})
+
+def write_close_event(self, error):
+self._write_event(self.close_events_dir, {'error': str(error)})
+
+def write_input_file(self):
+self._write_event(self.input_dir, "text")
+
+def open_events(self):
+return self._read_events(self.open_events_dir, 'partition INT,
epoch INT')
+
+def process_events(self):
+return self._read_events(self.process_events_dir, 'value
STRING')
+
+def close_events(self):
+return self._read_events(self.close_events_dir, 'error STRING')
+
+def run_streaming_query_on_writer(self, writer, num_files):
+self._reset()
+try:
+sdf =
self.spark.readStream.format('text').load(self.input_dir)
+sq = sdf.writeStream.foreach(writer).start()
+for i in range(num_files):
+self.write_input_file()
+sq.processAllAvailable()
+finally:
+self.stop_all()
+
+def assert_invalid_writer(self, writer, msg=None):
+self._reset()
+try:
+sdf =
self.spark.readStream.format('text').load(self.input_dir)
+sq = sdf.writeStream.foreach(writer).start()
+self.write_input_file()
+sq.processAllAvailable()
+self.fail("invalid writer %s did not fail the query" %
str(writer)) # not expected
+except Exception as e:
+if msg:
+assert(msg in str(e), "%s not in %s" % (msg, str(e)))
+
+finally:
+self.stop_all()
+
+def stop_all(self):
+for q in self.spark._wrapped.streams.active:
+q.stop()
+
+def _reset(self):
+self.input_dir = tempfile.mkdtemp()
+self.open_events_dir = tempfile.mkdtemp()
+self.process_events_dir = tempfile.mkdtemp()
+self.close_events_dir = tempfile.mkdtemp()
+
+def _read_events(self, dir, json):
+rows = self.spark.read.schema(json).json(dir).collect()
+dicts = [row.asDict() for row in rows]
+return dicts
+
+def _write_event(self, dir, event):
+import uuid
+with open(os.path.join(dir, str(uuid.uuid4())), 'w') as f:
+f.write("%s\n" % str(event))
+
+def __getstate__(self):
+return (self.open_events_dir, self.process_events_dir,
self.close_events_dir)
+
+def __setstate__(self, state):
+self.open_events_dir, self.process_events_dir,
self.close_events_dir = state
+
+def test_streaming_foreach_with_simple_function(self):
+tester = self.ForeachWriterTester(self.spark)
+
+def foreach_func(row):
+tester.write_process_event(row)
+
+tester.run_streaming_query_on_writer(foreach_func, 2)
+self.assertEqual(len(tester.process_events()), 2)
+
+def test_streaming_foreach_with_basic_open_process_close(self):
+tester = self.ForeachWriterTester(self.spark)
+
+class ForeachWriter:
+def open(self, partitionId, epochId):
+tester.write_open_event(partitionId, epochId)
+return True
+
+def process(self, row):
+tester.write_process_event(row)
+
+def close(self, error):
+tester.write_close_event(error)
+
+tester.run_streaming_query_on_writer(ForeachWriter(), 2)
+
+open_events = tester.open_events()
+self.assertEqual(len(open_events), 2)
+self.assertSetEqual(set([e['epoch'] for e in open_events]), {0, 1})
+
+self.assertEqual(len(tester.process_events()), 2)
+
+close_events = tester.close_events()
[GitHub] spark issue #21439: [SPARK-24391][SQL] Support arrays of any types by from_j...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/21439 **[Test build #91874 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/91874/testReport)** for PR 21439 at commit [`ce9918b`](https://github.com/apache/spark/commit/ce9918b2598a4d70a95d2e8269a32afe2db2ec26). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21477: [SPARK-24396] [SS] [PYSPARK] Add Structured Strea...
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/21477#discussion_r195622979
--- Diff: python/pyspark/sql/streaming.py ---
@@ -843,6 +843,170 @@ def trigger(self, processingTime=None, once=None,
continuous=None):
self._jwrite = self._jwrite.trigger(jTrigger)
return self
+@since(2.4)
+def foreach(self, f):
+"""
+Sets the output of the streaming query to be processed using the
provided writer ``f``.
+This is often used to write the output of a streaming query to
arbitrary storage systems.
+The processing logic can be specified in two ways.
+
+#. A **function** that takes a row as input.
+This is a simple way to express your processing logic. Note
that this does
+not allow you to deduplicate generated data when failures
cause reprocessing of
+some input data. That would require you to specify the
processing logic in the next
+way.
+
+#. An **object** with a ``process`` method and optional ``open``
and ``close`` methods.
+The object can have the following methods.
+
+* ``open(partition_id, epoch_id)``: *Optional* method that
initializes the processing
+(for example, open a connection, start a transaction,
etc). Additionally, you can
+use the `partition_id` and `epoch_id` to deduplicate
regenerated data
+(discussed later).
+
+* ``process(row)``: *Non-optional* method that processes each
:class:`Row`.
+
+* ``close(error)``: *Optional* method that finalizes and
cleans up (for example,
+close connection, commit transaction, etc.) after all rows
have been processed.
+
+The object will be used by Spark in the following way.
+
+* A single copy of this object is responsible of all the data
generated by a
+single task in a query. In other words, one instance is
responsible for
+processing one partition of the data generated in a
distributed manner.
+
+* This object must be serializable because each task will get
a fresh
+serialized-deserialized copy of the provided object.
Hence, it is strongly
+recommended that any initialization for writing data (e.g.
opening a
+connection or starting a transaction) is done after the
`open(...)`
+method has been called, which signifies that the task is
ready to generate data.
+
+* The lifecycle of the methods are as follows.
+
+For each partition with ``partition_id``:
+
+... For each batch/epoch of streaming data with
``epoch_id``:
+
+... Method ``open(partitionId, epochId)`` is called.
+
+... If ``open(...)`` returns true, for each row in the
partition and
+batch/epoch, method ``process(row)`` is called.
+
+... Method ``close(errorOrNull)`` is called with error
(if any) seen while
+processing rows.
+
+Important points to note:
+
+* The `partitionId` and `epochId` can be used to deduplicate
generated data when
+failures cause reprocessing of some input data. This
depends on the execution
+mode of the query. If the streaming query is being
executed in the micro-batch
+mode, then every partition represented by a unique tuple
(partition_id, epoch_id)
+is guaranteed to have the same data. Hence, (partition_id,
epoch_id) can be used
+to deduplicate and/or transactionally commit data and
achieve exactly-once
+guarantees. However, if the streaming query is being
executed in the continuous
+mode, then this guarantee does not hold and therefore
should not be used for
+deduplication.
+
+* The ``close()`` method (if exists) will be called if
`open()` method exists and
+returns successfully (irrespective of the return value),
except if the Python
+crashes in the middle.
+
+.. note:: Evolving.
+
+>>> # Print every row using a function
+>>> def print_row(row):
+... print(row)
+...
+>>> writer = sdf.writeStream.foreach(print_row)
+>>> # Print every row using a object with process() method
+>>> class RowPrinter:
+... def open(self, partition_id, epoch_id):
+... print("Opened %d,
[GitHub] spark issue #21566: [Python] Fix typo in serializer exception
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/21566 **[Test build #91878 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/91878/testReport)** for PR 21566 at commit [`370265f`](https://github.com/apache/spark/commit/370265fca63ac992399f1d0eb115daa1bea1af7b). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21566: [Python] Fix typo in serializer exception
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21566 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/91878/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21566: [Python] Fix typo in serializer exception
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21566 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21477: [SPARK-24396] [SS] [PYSPARK] Add Structured Strea...
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/21477#discussion_r195622516
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/python/PythonForeachWriter.scala
---
@@ -0,0 +1,161 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.python
+
+import java.io.File
+import java.util.concurrent.TimeUnit
+import java.util.concurrent.locks.ReentrantLock
+
+import org.apache.spark.{SparkEnv, TaskContext}
+import org.apache.spark.api.python._
+import org.apache.spark.internal.Logging
+import org.apache.spark.memory.TaskMemoryManager
+import org.apache.spark.sql.ForeachWriter
+import org.apache.spark.sql.catalyst.expressions.UnsafeRow
+import org.apache.spark.sql.types.StructType
+import org.apache.spark.util.{NextIterator, Utils}
+
+class PythonForeachWriter(func: PythonFunction, schema: StructType)
+ extends ForeachWriter[UnsafeRow] {
+
+ private lazy val context = TaskContext.get()
+ private lazy val buffer = new PythonForeachWriter.UnsafeRowBuffer(
+context.taskMemoryManager, new
File(Utils.getLocalDir(SparkEnv.get.conf)), schema.fields.length)
+ private lazy val inputRowIterator = buffer.iterator
+
+ private lazy val inputByteIterator = {
+EvaluatePython.registerPicklers()
+val objIterator = inputRowIterator.map { row =>
EvaluatePython.toJava(row, schema) }
+new SerDeUtil.AutoBatchedPickler(objIterator)
+ }
+
+ private lazy val pythonRunner = {
+val conf = SparkEnv.get.conf
+val bufferSize = conf.getInt("spark.buffer.size", 65536)
+val reuseWorker = conf.getBoolean("spark.python.worker.reuse", true)
+PythonRunner(func, bufferSize, reuseWorker)
+ }
+
+ private lazy val outputIterator =
+pythonRunner.compute(inputByteIterator, context.partitionId(), context)
+
+ override def open(partitionId: Long, version: Long): Boolean = {
+outputIterator // initialize everything
+TaskContext.get.addTaskCompletionListener { _ => buffer.close() }
+true
+ }
+
+ override def process(value: UnsafeRow): Unit = {
+buffer.add(value)
+ }
+
+ override def close(errorOrNull: Throwable): Unit = {
+buffer.allRowsAdded()
+if (outputIterator.hasNext) outputIterator.next() // to throw python
exception if there was one
+ }
+}
+
+object PythonForeachWriter {
+
+ /**
+ * A buffer that is designed for the sole purpose of buffering
UnsafeRows in PythonForeachWriter.
+ * It is designed to be used with only 1 writer thread (i.e. JVM task
thread) and only 1 reader
+ * thread (i.e. PythonRunner writing thread that reads from the buffer
and writes to the Python
+ * worker stdin). Adds to the buffer are non-blocking, and reads through
the buffer's iterator
+ * are blocking, that is, it blocks until new data is available or all
data has been added.
+ *
+ * Internally, it uses a [[HybridRowQueue]] to buffer the rows in a
practically unlimited queue
+ * across memory and local disk. However, HybridRowQueue is designed to
be used only with
+ * EvalPythonExec where the reader is always behind the the writer, that
is, the reader does not
+ * try to read n+1 rows if the writer has only written n rows at any
point of time. This
+ * assumption is not true for PythonForeachWriter where rows may be
added at a different rate as
+ * they are consumed by the python worker. Hence, to maintain the
invariant of the reader being
+ * behind the writer while using HybridRowQueue, the buffer does the
following
+ * - Keeps a count of the rows in the HybridRowQueue
+ * - Blocks the buffer's consuming iterator when the count is 0 so that
the reader does not
+ * try to read more rows than what has been written.
+ *
+ * The implementation of the blocking iterator (ReentrantLock,
Condition, etc.) has been b
[GitHub] spark issue #20636: [SPARK-23415][SQL][TEST] Make behavior of BufferHolderSp...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/20636 Merged build finished. Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20636: [SPARK-23415][SQL][TEST] Make behavior of BufferHolderSp...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/20636 **[Test build #91879 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/91879/testReport)** for PR 20636 at commit [`9a96475`](https://github.com/apache/spark/commit/9a9647576b6e3d0e26b2f254f15775241814fad3). * This patch **fails to build**. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20636: [SPARK-23415][SQL][TEST] Make behavior of BufferHolderSp...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/20636 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/91879/ Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21552: [SPARK-24544][SQL] Print actual failure cause when look ...
Github user caneGuy commented on the issue: https://github.com/apache/spark/pull/21552 cc @cloud-fan Could help review this?Thanks --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20636: [SPARK-23415][SQL][TEST] Make behavior of BufferHolderSp...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/20636 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution/4054/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20636: [SPARK-23415][SQL][TEST] Make behavior of BufferHolderSp...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/20636 **[Test build #91879 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/91879/testReport)** for PR 20636 at commit [`9a96475`](https://github.com/apache/spark/commit/9a9647576b6e3d0e26b2f254f15775241814fad3). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20636: [SPARK-23415][SQL][TEST] Make behavior of BufferHolderSp...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/20636 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20636: [SPARK-23415][SQL][TEST] Make behavior of BufferHolderSp...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/20636 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20636: [SPARK-23415][SQL][TEST] Make behavior of BufferHolderSp...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/20636 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/163/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21573: revert [SPARK-21743][SQL] top-most limit should not caus...
Github user viirya commented on the issue: https://github.com/apache/spark/pull/21573 I take a look at `LocalLimit` again, seems it won't consume rows once it reaches limit number? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21566: [Python] Fix typo in serializer exception
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/21566 **[Test build #91878 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/91878/testReport)** for PR 21566 at commit [`370265f`](https://github.com/apache/spark/commit/370265fca63ac992399f1d0eb115daa1bea1af7b). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21566: [Python] Fix typo in serializer exception
Github user HyukjinKwon commented on the issue: https://github.com/apache/spark/pull/21566 ok to test --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21566: [Python] Fix typo in serializer exception
Github user HyukjinKwon commented on the issue: https://github.com/apache/spark/pull/21566 ok to test --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21366: [SPARK-24248][K8S] Use level triggering and state reconc...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21366 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/91870/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21366: [SPARK-24248][K8S] Use level triggering and state reconc...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21366 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21515: [SPARK-24372][build] Add scripts to help with preparing ...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21515 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21515: [SPARK-24372][build] Add scripts to help with preparing ...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21515 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/91869/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21366: [SPARK-24248][K8S] Use level triggering and state reconc...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/21366 **[Test build #91870 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/91870/testReport)** for PR 21366 at commit [`1a99dce`](https://github.com/apache/spark/commit/1a99dceeb9dfbfc58e26885c290461cbf37a5428). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21515: [SPARK-24372][build] Add scripts to help with preparing ...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/21515 **[Test build #91869 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/91869/testReport)** for PR 21515 at commit [`48eda71`](https://github.com/apache/spark/commit/48eda71029bb414f404312fbdecf7a35d883660c). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21563: [SPARK-24557][ML] ClusteringEvaluator support arr...
Github user zhengruifeng commented on a diff in the pull request:
https://github.com/apache/spark/pull/21563#discussion_r195618344
--- Diff:
mllib/src/main/scala/org/apache/spark/ml/evaluation/ClusteringEvaluator.scala
---
@@ -107,15 +106,18 @@ class ClusteringEvaluator @Since("2.3.0")
(@Since("2.3.0") override val uid: Str
@Since("2.3.0")
override def evaluate(dataset: Dataset[_]): Double = {
-SchemaUtils.checkColumnType(dataset.schema, $(featuresCol), new
VectorUDT)
+SchemaUtils.validateVectorCompatibleColumn(dataset.schema,
$(featuresCol))
SchemaUtils.checkNumericType(dataset.schema, $(predictionCol))
+val vectorCol = DatasetUtils.columnToVector(dataset, $(featuresCol))
+val df = dataset.select(col($(predictionCol)),
--- End diff --
@mgaido91 Thanks for your reviewing!
I have considered this, however there exists a problem:
if we want to append metadata into the transformed column (like using
method `.as(alias: String, metadata: Metadata)`) in
`DatasetUtils.columnToVector`, how can we get the name of transformed column?
The only way to do this I know is:
```
val metadata = ...
val vectorCol = ..
val vectorName = dataset.select(vectorCol) .schema.head.name
vectorCol.as(vectorName, metadata)
```
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21573: revert [SPARK-21743][SQL] top-most limit should not caus...
Github user viirya commented on the issue: https://github.com/apache/spark/pull/21573 Hmm, this LGTM, however it didn't catch up 2.3.1 release. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21573: revert [SPARK-21743][SQL] top-most limit should not caus...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/21573 **[Test build #91877 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/91877/testReport)** for PR 21573 at commit [`2b20b3c`](https://github.com/apache/spark/commit/2b20b3c2ac5e7312097ba23e4c3b130317d56f26). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21573: revert [SPARK-21743][SQL] top-most limit should not caus...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21573 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/162/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21573: revert [SPARK-21743][SQL] top-most limit should not caus...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21573 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21573: revert [SPARK-21743][SQL] top-most limit should not caus...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21573 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution/4053/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21477: [SPARK-24396] [SS] [PYSPARK] Add Structured Streaming Fo...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21477 Merged build finished. Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21573: revert [SPARK-21743][SQL] top-most limit should not caus...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21573 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21477: [SPARK-24396] [SS] [PYSPARK] Add Structured Streaming Fo...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21477 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/91871/ Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21477: [SPARK-24396] [SS] [PYSPARK] Add Structured Streaming Fo...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/21477 **[Test build #91871 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/91871/testReport)** for PR 21477 at commit [`d081110`](https://github.com/apache/spark/commit/d081110210c4c883a82169c1c6687369469189af). * This patch **fails Spark unit tests**. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21379: [SPARK-24327][SQL] Verify and normalize a partition colu...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21379 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21379: [SPARK-24327][SQL] Verify and normalize a partition colu...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21379 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/91867/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21573: revert [SPARK-21743][SQL] top-most limit should not caus...
Github user cloud-fan commented on the issue: https://github.com/apache/spark/pull/21573 cc @hvanhovell @rednaxelafx @viirya @gatorsmile --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21573: revert [SPARK-21743][SQL] top-most limit should n...
GitHub user cloud-fan opened a pull request:
https://github.com/apache/spark/pull/21573
revert [SPARK-21743][SQL] top-most limit should not cause memory leak
## What changes were proposed in this pull request?
There is a performance regression in Spark 2.3. When we read a big
compressed text file which is un-splittable(e.g. gz), and then take the first
record, Spark will scan all the data in the text file which is very slow. For
example, `spark.read.text("/tmp/test.csv.gz").head(1)`, we can check out the
SQL UI and see that the file is fully scanned.
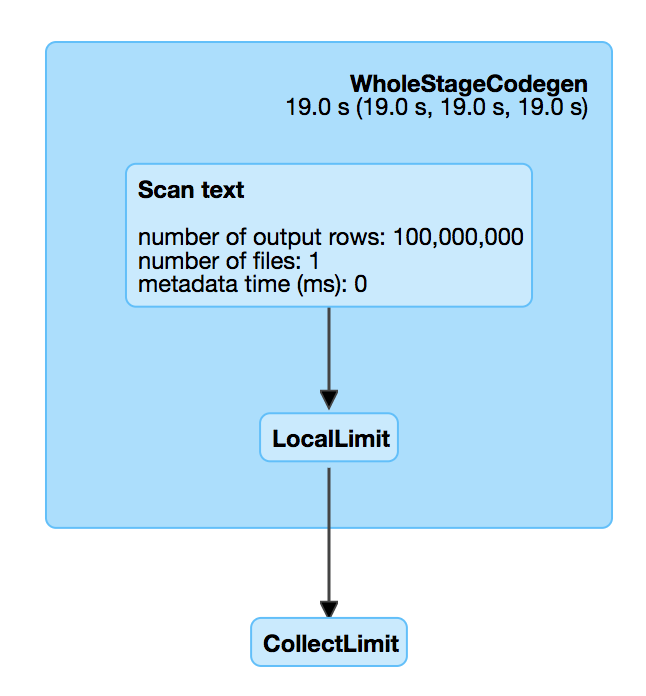
This is introduced by #18955 , which adds a LocalLimit to the query when
executing `Dataset.head`. The foundamental problem is, `Limit` is not well
whole-stage-codegened. It keeps consuming the input even if we have already hit
the limitation.
However, if we just fix LIMIT whole-stage-codegen, the memory leak test
will fail, as we don't fully consume the inputs to trigger the resource cleanup.
To fix it completely, we should do the following
1. fix LIMIT whole-stage-codegen, stop consuming inputs after hitting the
limitation.
2. in whole-stage-codegen, provide a way to release resource of the parant
operator, and apply it in LIMIT
3. automatically release resource when task ends.
Howere this is a non-trivial change, and is risky to backport to Spark 2.3.
This PR proposes to revert #18955 in Spark 2.3. The memory leak is not a
big issue. When task ends, Spark will release all the pages allocated by this
task, which is kind of releasing most of the resources.
I'll submit a exhaustive fix to master later.
## How was this patch tested?
N/A
You can merge this pull request into a Git repository by running:
$ git pull https://github.com/cloud-fan/spark limit
Alternatively you can review and apply these changes as the patch at:
https://github.com/apache/spark/pull/21573.patch
To close this pull request, make a commit to your master/trunk branch
with (at least) the following in the commit message:
This closes #21573
commit 2b20b3c2ac5e7312097ba23e4c3b130317d56f26
Author: Wenchen Fan
Date: 2018-06-15T00:51:00Z
revert [SPARK-21743][SQL] top-most limit should not cause memory leak
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21379: [SPARK-24327][SQL] Verify and normalize a partition colu...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/21379 **[Test build #91867 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/91867/testReport)** for PR 21379 at commit [`614c87a`](https://github.com/apache/spark/commit/614c87aada943c16faa3f7a718837de0e4dcaeab). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20636: [SPARK-23415][SQL][TEST] Make behavior of BufferHolderSp...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/20636 **[Test build #91876 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/91876/testReport)** for PR 20636 at commit [`b0d13bf`](https://github.com/apache/spark/commit/b0d13bfd3311ca80960cb7649b1b6a3ed3dfa681). * This patch **fails to build**. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20636: [SPARK-23415][SQL][TEST] Make behavior of BufferHolderSp...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/20636 Merged build finished. Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20636: [SPARK-23415][SQL][TEST] Make behavior of BufferHolderSp...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/20636 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/91876/ Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20636: [SPARK-23415][SQL][TEST] Make behavior of BufferHolderSp...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/20636 **[Test build #91876 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/91876/testReport)** for PR 20636 at commit [`b0d13bf`](https://github.com/apache/spark/commit/b0d13bfd3311ca80960cb7649b1b6a3ed3dfa681). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20636: [SPARK-23415][SQL][TEST] Make behavior of BufferHolderSp...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/20636 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20636: [SPARK-23415][SQL][TEST] Make behavior of BufferHolderSp...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/20636 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution/4052/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20636: [SPARK-23415][SQL][TEST] Make behavior of BufferHolderSp...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/20636 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20636: [SPARK-23415][SQL][TEST] Make behavior of BufferHolderSp...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/20636 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/161/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21366: [SPARK-24248][K8S] Use level triggering and state reconc...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21366 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21366: [SPARK-24248][K8S] Use level triggering and state reconc...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21366 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/91866/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21366: [SPARK-24248][K8S] Use level triggering and state reconc...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/21366 **[Test build #91866 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/91866/testReport)** for PR 21366 at commit [`1a99dce`](https://github.com/apache/spark/commit/1a99dceeb9dfbfc58e26885c290461cbf37a5428). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21559: [SPARK-24525][SS] Provide an option to limit number of r...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21559 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21559: [SPARK-24525][SS] Provide an option to limit number of r...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21559 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/91868/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21559: [SPARK-24525][SS] Provide an option to limit number of r...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/21559 **[Test build #91868 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/91868/testReport)** for PR 21559 at commit [`e5b6175`](https://github.com/apache/spark/commit/e5b6175f0b638dc7235e4d3b610284a761e01480). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21571: [WIP][SPARK-24565][SS] Add API for in Structured Streami...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21571 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/91875/ Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21571: [WIP][SPARK-24565][SS] Add API for in Structured Streami...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/21571 **[Test build #91875 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/91875/testReport)** for PR 21571 at commit [`985a4fe`](https://github.com/apache/spark/commit/985a4fe017623137b09dee8b84e568514e07e70d). * This patch **fails Python style tests**. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21571: [WIP][SPARK-24565][SS] Add API for in Structured Streami...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21571 Merged build finished. Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21571: [WIP][SPARK-24565][SS] Add API for in Structured Streami...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21571 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution/4051/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21571: [WIP][SPARK-24565][SS] Add API for in Structured Streami...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/21571 **[Test build #91875 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/91875/testReport)** for PR 21571 at commit [`985a4fe`](https://github.com/apache/spark/commit/985a4fe017623137b09dee8b84e568514e07e70d). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21571: [WIP][SPARK-24565][SS] Add API for in Structured Streami...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21571 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/160/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21571: [WIP][SPARK-24565][SS] Add API for in Structured Streami...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21571 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21571: [WIP][SPARK-24565][SS] Add API for in Structured Streami...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21571 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21346: [SPARK-6237][NETWORK] Network-layer changes to al...
Github user witgo commented on a diff in the pull request:
https://github.com/apache/spark/pull/21346#discussion_r195287202
--- Diff:
common/network-common/src/main/java/org/apache/spark/network/protocol/UploadStream.java
---
@@ -0,0 +1,107 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.network.protocol;
+
+import java.io.IOException;
+import java.nio.ByteBuffer;
+
+import com.google.common.base.Objects;
+import io.netty.buffer.ByteBuf;
+
+import org.apache.spark.network.buffer.ManagedBuffer;
+import org.apache.spark.network.buffer.NettyManagedBuffer;
+
+/**
+ * An RPC with data that is sent outside of the frame, so it can be read
as a stream.
+ */
+public final class UploadStream extends AbstractMessage implements
RequestMessage {
--- End diff --
Is it possible to merge UploadStream and RpcRequest into a class?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21572: Bypass non spark-on-k8s commands
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21572 Can one of the admins verify this patch? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21572: Bypass non spark-on-k8s commands
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21572 Can one of the admins verify this patch? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21572: Bypass non spark-on-k8s commands
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21572 Can one of the admins verify this patch? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21572: Bypass non spark-on-k8s commands
GitHub user rimolive opened a pull request: https://github.com/apache/spark/pull/21572 Bypass non spark-on-k8s commands ## What changes were proposed in this pull request? This PR changes the entrypoint.sh to provide an option to run non spark-on-k8s commands (init, driver, executor) in order to let the user keep with the normal workflow without hacking the image to bypass the entrypoint ## How was this patch tested? This patch was built manually in my local machine and I ran some tests with a combination of ```docker run``` commands. You can merge this pull request into a Git repository by running: $ git pull https://github.com/rimolive/spark rimolive-spark-24534 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/21572.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #21572 commit 787b9047852c35f7bc8cc58cc8278c311468fa34 Author: rimolive Date: 2018-06-14T23:55:51Z Bypass non spark-on-k8s commands --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21477: [SPARK-24396] [SS] [PYSPARK] Add Structured Streaming Fo...
Github user zsxwing commented on the issue: https://github.com/apache/spark/pull/21477 LGTM --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21439: [SPARK-24391][SQL] Support arrays of any types by from_j...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/21439 **[Test build #91874 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/91874/testReport)** for PR 21439 at commit [`ce9918b`](https://github.com/apache/spark/commit/ce9918b2598a4d70a95d2e8269a32afe2db2ec26). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21439: [SPARK-24391][SQL] Support arrays of any types by from_j...
Github user MaxGekk commented on the issue: https://github.com/apache/spark/pull/21439 @maropu @gengliangwang I added SQL tests. Please, take a look at the PR again, please. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21571: [WIP][SPARK-24565][SS] Add API for in Structured Streami...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21571 Merged build finished. Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21571: [WIP][SPARK-24565][SS] Add API for in Structured Streami...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/21571 **[Test build #91873 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/91873/testReport)** for PR 21571 at commit [`3b7b20d`](https://github.com/apache/spark/commit/3b7b20d5c1b662abd935c0a812d9e54f8ab01b24). * This patch **fails Python style tests**. * This patch merges cleanly. * This patch adds the following public classes _(experimental)_: * `class GBTClassificationModel(TreeEnsembleModel, JavaClassificationModel, JavaMLWritable,` * `class PrefixSpan(JavaParams):` * `public class MaskExpressionsUtils ` * `case class ArrayRemove(left: Expression, right: Expression)` * `trait MaskLike ` * `trait MaskLikeWithN extends MaskLike ` * `case class Mask(child: Expression, upper: String, lower: String, digit: String)` * `case class MaskFirstN(` * `case class MaskLastN(` * `case class MaskShowFirstN(` * `case class MaskShowLastN(` * `case class MaskHash(child: Expression)` * `abstract class FileFormatDataWriter(` * `class EmptyDirectoryDataWriter(` * `class SingleDirectoryDataWriter(` * `class DynamicPartitionDataWriter(` * `class WriteJobDescription(` * `case class WriteTaskResult(commitMsg: TaskCommitMessage, summary: ExecutedWriteSummary)` * `case class ExecutedWriteSummary(` --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org