[GitHub] spark issue #20850: [SPARK-23713][SQL] Cleanup UnsafeWriter and BufferHolder...
Github user kiszk commented on the issue: https://github.com/apache/spark/pull/20850 retest this please --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20850: [SPARK-23713][SQL] Cleanup UnsafeWriter and BufferHolder...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/20850 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20850: [SPARK-23713][SQL] Cleanup UnsafeWriter and BufferHolder...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/20850 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution/1886/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20850: [SPARK-23713][SQL] Cleanup UnsafeWriter and BufferHolder...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/20850 **[Test build #88789 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/88789/testReport)** for PR 20850 at commit [`6caf11c`](https://github.com/apache/spark/commit/6caf11cc0244a43e1b01c3b76942eea67a7318f5). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20955: [SPARK-23838][WEBUI] Running SQL query is display...
GitHub user gengliangwang opened a pull request: https://github.com/apache/spark/pull/20955 [SPARK-23838][WEBUI] Running SQL query is displayed as "completed" in SQL tab ## What changes were proposed in this pull request? A running SQL query would appear as completed in the Spark UI:  We can see the query in "Completed queries", while in in the job page we see it's still running Job 132. 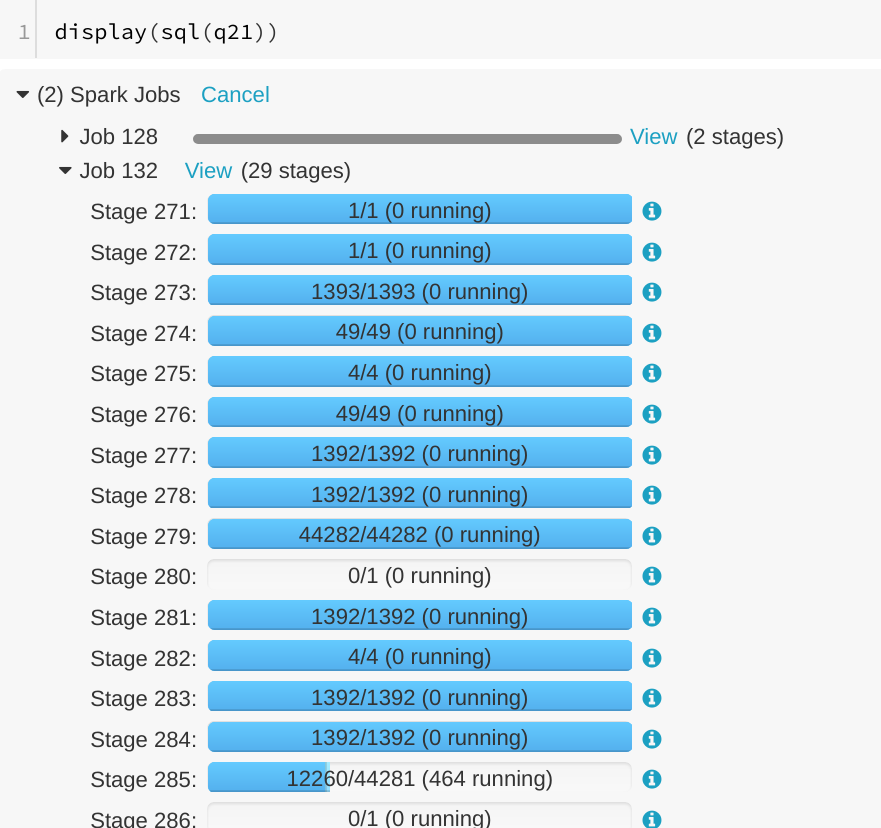 After some time in the query still appears in "Completed queries" (while it's still running), but the "Duration" gets increased.  To reproduce, we can run a query with multiple jobs. E.g. Run TPCDS q6. The reason is that updates from executions are written into kvstore periodically, and the job start event may be missing. ## How was this patch tested? Manually run the job again and check the SQL Tab. The fix is pretty simple. You can merge this pull request into a Git repository by running: $ git pull https://github.com/gengliangwang/spark jobCompleted Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/20955.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #20955 commit b418feb6ac4bb7523c50ea27f74d3b02c310956a Author: Wang Gengliang Date: 2018-04-01T07:08:06Z Fix sql tab --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20909: [SPARK-23776][python][test] Check for needed components/...
Github user HyukjinKwon commented on the issue: https://github.com/apache/spark/pull/20909 > I modeled this after pyspark/streaming/tests.py, which checks for prereqs and raises exceptions with a useful message so one can get past the error (although pyspark/streaming/tests.py only checks for its own prereqs, not those required by streaming docstring tests). I actually have been thinking about skipping and proceeding the tests in `pyspark/streaming/tests.py` with an explicit message as well. Can we skip and continue the tests? I think we basically should just skip the tests. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20955: [SPARK-23838][WEBUI] Running SQL query is displayed as "...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/20955 **[Test build #88790 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/88790/testReport)** for PR 20955 at commit [`b418feb`](https://github.com/apache/spark/commit/b418feb6ac4bb7523c50ea27f74d3b02c310956a). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20909: [SPARK-23776][python][test] Check for needed comp...
Github user HyukjinKwon commented on a diff in the pull request: https://github.com/apache/spark/pull/20909#discussion_r178450100 --- Diff: python/pyspark/sql/tests.py --- @@ -2977,6 +2977,20 @@ def test_create_dateframe_from_pandas_with_dst(self): class HiveSparkSubmitTests(SparkSubmitTests): +@classmethod +def setUpClass(cls): --- End diff -- I think this way is more correct, as @felixcheung pointed out. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20955: [SPARK-23838][WEBUI] Running SQL query is displayed as "...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/20955 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution/1887/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20955: [SPARK-23838][WEBUI] Running SQL query is displayed as "...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/20955 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20894: [SPARK-23786][SQL] Checking column names of csv headers
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/20894 **[Test build #88791 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/88791/testReport)** for PR 20894 at commit [`0904daf`](https://github.com/apache/spark/commit/0904daf52b1d94467f75bc6703d3d81747208e77). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20894: [SPARK-23786][SQL] Checking column names of csv headers
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/20894 Merged build finished. Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20894: [SPARK-23786][SQL] Checking column names of csv headers
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/20894 **[Test build #88791 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/88791/testReport)** for PR 20894 at commit [`0904daf`](https://github.com/apache/spark/commit/0904daf52b1d94467f75bc6703d3d81747208e77). * This patch **fails to build**. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20894: [SPARK-23786][SQL] Checking column names of csv headers
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/20894 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/88791/ Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20894: [SPARK-23786][SQL] Checking column names of csv headers
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/20894 **[Test build #88792 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/88792/testReport)** for PR 20894 at commit [`191b415`](https://github.com/apache/spark/commit/191b415e77bbc8fe662c19faae627e40787c5e23). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20953: [SPARK-23822][SQL] Improve error message for Parquet sch...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/20953 **[Test build #88793 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/88793/testReport)** for PR 20953 at commit [`c65a8a6`](https://github.com/apache/spark/commit/c65a8a6465e234debab8ba4e50645e56c22025e1). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20955: [SPARK-23838][WEBUI] Running SQL query is displayed as "...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/20955 **[Test build #88790 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/88790/testReport)** for PR 20955 at commit [`b418feb`](https://github.com/apache/spark/commit/b418feb6ac4bb7523c50ea27f74d3b02c310956a). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20955: [SPARK-23838][WEBUI] Running SQL query is displayed as "...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/20955 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20955: [SPARK-23838][WEBUI] Running SQL query is displayed as "...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/20955 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/88790/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20850: [SPARK-23713][SQL] Cleanup UnsafeWriter and BufferHolder...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/20850 **[Test build #88789 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/88789/testReport)** for PR 20850 at commit [`6caf11c`](https://github.com/apache/spark/commit/6caf11cc0244a43e1b01c3b76942eea67a7318f5). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20850: [SPARK-23713][SQL] Cleanup UnsafeWriter and BufferHolder...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/20850 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20850: [SPARK-23713][SQL] Cleanup UnsafeWriter and BufferHolder...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/20850 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/88789/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20945: [SPARK-23790][Mesos] fix metastore connection issue
Github user skonto commented on the issue: https://github.com/apache/spark/pull/20945 Failed unit test: org.apache.spark.launcher.LauncherServerSuite.testAppHandleDisconnect Will re-test this is not from this patch. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20945: [SPARK-23790][Mesos] fix metastore connection issue
Github user skonto commented on the issue: https://github.com/apache/spark/pull/20945 retest this please --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20945: [SPARK-23790][Mesos] fix metastore connection issue
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/20945 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution/1888/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20945: [SPARK-23790][Mesos] fix metastore connection issue
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/20945 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20945: [SPARK-23790][Mesos] fix metastore connection issue
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/20945 **[Test build #88794 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/88794/testReport)** for PR 20945 at commit [`1060405`](https://github.com/apache/spark/commit/1060405b11cc4da88e1a65b5d694fb7f9e7e18b5). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20955: [SPARK-23838][WEBUI] Running SQL query is displayed as "...
Github user gengliangwang commented on the issue: https://github.com/apache/spark/pull/20955 @vanzin --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20894: [SPARK-23786][SQL] Checking column names of csv headers
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/20894 **[Test build #88792 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/88792/testReport)** for PR 20894 at commit [`191b415`](https://github.com/apache/spark/commit/191b415e77bbc8fe662c19faae627e40787c5e23). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20894: [SPARK-23786][SQL] Checking column names of csv headers
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/20894 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20894: [SPARK-23786][SQL] Checking column names of csv headers
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/20894 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/88792/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20953: [SPARK-23822][SQL] Improve error message for Parquet sch...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/20953 **[Test build #88793 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/88793/testReport)** for PR 20953 at commit [`c65a8a6`](https://github.com/apache/spark/commit/c65a8a6465e234debab8ba4e50645e56c22025e1). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20953: [SPARK-23822][SQL] Improve error message for Parquet sch...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/20953 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20953: [SPARK-23822][SQL] Improve error message for Parquet sch...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/20953 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/88793/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20955: [SPARK-23838][WEBUI] Running SQL query is displayed as "...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/20955 **[Test build #88795 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/88795/testReport)** for PR 20955 at commit [`2357f59`](https://github.com/apache/spark/commit/2357f59a8f0b1cbea2ac1431bb3669cb1a26f687). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20955: [SPARK-23838][WEBUI] Running SQL query is displayed as "...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/20955 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20955: [SPARK-23838][WEBUI] Running SQL query is displayed as "...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/20955 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution/1889/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20886: [SPARK-19724][SQL]create a managed table with an existed...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/20886 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20886: [SPARK-19724][SQL]create a managed table with an existed...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/20886 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution/1890/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20886: [SPARK-19724][SQL]create a managed table with an existed...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/20886 **[Test build #88796 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/88796/testReport)** for PR 20886 at commit [`f1de70c`](https://github.com/apache/spark/commit/f1de70c5284df3b3980d509e2ef7d7e77e020c1c). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20954: [BACKPORT][SPARK-23040][CORE] Returns interruptible iter...
Github user cloud-fan commented on the issue: https://github.com/apache/spark/pull/20954 thanks, merging to 2.3! --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20850: [SPARK-23713][SQL] Cleanup UnsafeWriter and Buffe...
Github user cloud-fan commented on a diff in the pull request:
https://github.com/apache/spark/pull/20850#discussion_r178460515
--- Diff:
sql/catalyst/src/main/java/org/apache/spark/sql/catalyst/expressions/codegen/BufferHolder.java
---
@@ -86,11 +82,23 @@ public void grow(int neededSize) {
}
}
- public void reset() {
+ byte[] buffer() {
--- End diff --
nit: `getBuffer` is more java-style
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20945: [SPARK-23790][Mesos] fix metastore connection issue
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/20945 **[Test build #88794 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/88794/testReport)** for PR 20945 at commit [`1060405`](https://github.com/apache/spark/commit/1060405b11cc4da88e1a65b5d694fb7f9e7e18b5). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20945: [SPARK-23790][Mesos] fix metastore connection issue
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/20945 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/88794/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20945: [SPARK-23790][Mesos] fix metastore connection issue
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/20945 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20850: [SPARK-23713][SQL] Cleanup UnsafeWriter and Buffe...
Github user cloud-fan commented on a diff in the pull request:
https://github.com/apache/spark/pull/20850#discussion_r178460747
--- Diff:
sql/catalyst/src/main/java/org/apache/spark/sql/catalyst/expressions/codegen/UnsafeArrayWriter.java
---
@@ -32,141 +30,123 @@
*/
public final class UnsafeArrayWriter extends UnsafeWriter {
- private BufferHolder holder;
-
- // The offset of the global buffer where we start to write this array.
- private int startingOffset;
-
// The number of elements in this array
private int numElements;
+ // The element size in this array
+ private int elementSize;
+
private int headerInBytes;
private void assertIndexIsValid(int index) {
assert index >= 0 : "index (" + index + ") should >= 0";
assert index < numElements : "index (" + index + ") should < " +
numElements;
}
- public void initialize(BufferHolder holder, int numElements, int
elementSize) {
+ public UnsafeArrayWriter(UnsafeWriter writer, int elementSize) {
+super(writer.getBufferHolder());
+this.elementSize = elementSize;
+ }
+
+ public void initialize(int numElements) {
// We need 8 bytes to store numElements in header
this.numElements = numElements;
this.headerInBytes = calculateHeaderPortionInBytes(numElements);
-this.holder = holder;
-this.startingOffset = holder.cursor;
+this.startingOffset = cursor();
// Grows the global buffer ahead for header and fixed size data.
int fixedPartInBytes =
ByteArrayMethods.roundNumberOfBytesToNearestWord(elementSize *
numElements);
holder.grow(headerInBytes + fixedPartInBytes);
// Write numElements and clear out null bits to header
-Platform.putLong(holder.buffer, startingOffset, numElements);
+Platform.putLong(buffer(), startingOffset, numElements);
for (int i = 8; i < headerInBytes; i += 8) {
- Platform.putLong(holder.buffer, startingOffset + i, 0L);
+ Platform.putLong(buffer(), startingOffset + i, 0L);
}
// fill 0 into reminder part of 8-bytes alignment in unsafe array
for (int i = elementSize * numElements; i < fixedPartInBytes; i++) {
- Platform.putByte(holder.buffer, startingOffset + headerInBytes + i,
(byte) 0);
+ Platform.putByte(buffer(), startingOffset + headerInBytes + i,
(byte) 0);
}
-holder.cursor += (headerInBytes + fixedPartInBytes);
+increaseCursor(headerInBytes + fixedPartInBytes);
}
- private void zeroOutPaddingBytes(int numBytes) {
-if ((numBytes & 0x07) > 0) {
- Platform.putLong(holder.buffer, holder.cursor + ((numBytes >> 3) <<
3), 0L);
-}
- }
-
- private long getElementOffset(int ordinal, int elementSize) {
+ private long getElementOffset(int ordinal) {
return startingOffset + headerInBytes + ordinal * elementSize;
}
- public void setOffsetAndSize(int ordinal, int currentCursor, int size) {
-assertIndexIsValid(ordinal);
-final long relativeOffset = currentCursor - startingOffset;
-final long offsetAndSize = (relativeOffset << 32) | (long)size;
-
-write(ordinal, offsetAndSize);
- }
-
private void setNullBit(int ordinal) {
assertIndexIsValid(ordinal);
-BitSetMethods.set(holder.buffer, startingOffset + 8, ordinal);
+BitSetMethods.set(buffer(), startingOffset + 8, ordinal);
}
public void setNull1Bytes(int ordinal) {
--- End diff --
seems now we only need a single `setNullAt` method.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20935: [SPARK-23819][SQL] Fix InMemoryTableScanExec comp...
Github user pwoody commented on a diff in the pull request:
https://github.com/apache/spark/pull/20935#discussion_r178460763
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/columnar/ColumnStats.scala
---
@@ -322,19 +324,76 @@ private[columnar] final class
DecimalColumnStats(precision: Int, scale: Int) ext
Array[Any](lower, upper, nullCount, count, sizeInBytes)
}
-private[columnar] final class ObjectColumnStats(dataType: DataType)
extends ColumnStats {
- val columnType = ColumnType(dataType)
+private abstract class OrderableSafeColumnStats[T](dataType: DataType)
extends ColumnStats {
+ protected var upper: T = _
+ protected var lower: T = _
+
+ private val columnType = ColumnType(dataType)
+ private val ordering = dataType match {
+case x if RowOrdering.isOrderable(dataType) =>
+ Option(TypeUtils.getInterpretedOrdering(x))
+case _ => None
+ }
override def gatherStats(row: InternalRow, ordinal: Int): Unit = {
if (!row.isNullAt(ordinal)) {
- val size = columnType.actualSize(row, ordinal)
- sizeInBytes += size
+ sizeInBytes += columnType.actualSize(row, ordinal)
count += 1
+ ordering.foreach { order =>
+val value = getValue(row, ordinal)
+if (upper == null || order.gt(value, upper)) upper = copy(value)
+if (lower == null || order.lt(value, lower)) lower = copy(value)
+ }
} else {
- gatherNullStats
+ gatherNullStats()
}
}
+ def getValue(row: InternalRow, ordinal: Int): T
+
+ def copy(value: T): T
+
+ override def collectedStatistics: Array[Any] =
+Array[Any](lower, upper, nullCount, count, sizeInBytes)
+}
+
+private[columnar] final class ArrayColumnStats(dataType: DataType)
+ extends OrderableSafeColumnStats[UnsafeArrayData](dataType) {
+ override def getValue(row: InternalRow, ordinal: Int): UnsafeArrayData =
+row.getArray(ordinal).asInstanceOf[UnsafeArrayData]
+
+ override def copy(value: UnsafeArrayData): UnsafeArrayData = value.copy()
+}
+
+private[columnar] final class StructColumnStats(dataType: DataType)
+ extends OrderableSafeColumnStats[UnsafeRow](dataType) {
+ private val numFields = dataType.asInstanceOf[StructType].fields.length
+
+ override def getValue(row: InternalRow, ordinal: Int): UnsafeRow =
+row.getStruct(ordinal, numFields).asInstanceOf[UnsafeRow]
+
+ override def copy(value: UnsafeRow): UnsafeRow = value.copy()
+}
+
+private[columnar] final class MapColumnStats(dataType: DataType) extends
ColumnStats {
--- End diff --
Now that you mention it - we can just have it use it now since it will
always fall through to the unorderable case. Everything will just work when we
make it orderable w/o code change here.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20850: [SPARK-23713][SQL] Cleanup UnsafeWriter and Buffe...
Github user cloud-fan commented on a diff in the pull request:
https://github.com/apache/spark/pull/20850#discussion_r178460820
--- Diff:
sql/catalyst/src/main/java/org/apache/spark/sql/catalyst/expressions/codegen/UnsafeRowWriter.java
---
@@ -117,150 +138,81 @@ public long getFieldOffset(int ordinal) {
return startingOffset + nullBitsSize + 8 * ordinal;
}
- public void setOffsetAndSize(int ordinal, int size) {
-setOffsetAndSize(ordinal, holder.cursor, size);
- }
-
- public void setOffsetAndSize(int ordinal, int currentCursor, int size) {
-final long relativeOffset = currentCursor - startingOffset;
-final long fieldOffset = getFieldOffset(ordinal);
-final long offsetAndSize = (relativeOffset << 32) | (long) size;
-
-Platform.putLong(holder.buffer, fieldOffset, offsetAndSize);
- }
-
public void write(int ordinal, boolean value) {
final long offset = getFieldOffset(ordinal);
-Platform.putLong(holder.buffer, offset, 0L);
-Platform.putBoolean(holder.buffer, offset, value);
+Platform.putLong(buffer(), offset, 0L);
--- End diff --
`writeLong(0)`?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20850: [SPARK-23713][SQL] Cleanup UnsafeWriter and Buffe...
Github user cloud-fan commented on a diff in the pull request:
https://github.com/apache/spark/pull/20850#discussion_r178460833
--- Diff:
sql/catalyst/src/main/java/org/apache/spark/sql/catalyst/expressions/codegen/UnsafeRowWriter.java
---
@@ -117,150 +138,81 @@ public long getFieldOffset(int ordinal) {
return startingOffset + nullBitsSize + 8 * ordinal;
}
- public void setOffsetAndSize(int ordinal, int size) {
-setOffsetAndSize(ordinal, holder.cursor, size);
- }
-
- public void setOffsetAndSize(int ordinal, int currentCursor, int size) {
-final long relativeOffset = currentCursor - startingOffset;
-final long fieldOffset = getFieldOffset(ordinal);
-final long offsetAndSize = (relativeOffset << 32) | (long) size;
-
-Platform.putLong(holder.buffer, fieldOffset, offsetAndSize);
- }
-
public void write(int ordinal, boolean value) {
final long offset = getFieldOffset(ordinal);
-Platform.putLong(holder.buffer, offset, 0L);
-Platform.putBoolean(holder.buffer, offset, value);
+Platform.putLong(buffer(), offset, 0L);
--- End diff --
`writeLong(offset, 0L)`?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20850: [SPARK-23713][SQL] Cleanup UnsafeWriter and Buffe...
Github user cloud-fan commented on a diff in the pull request:
https://github.com/apache/spark/pull/20850#discussion_r178460868
--- Diff:
sql/catalyst/src/main/java/org/apache/spark/sql/catalyst/expressions/codegen/UnsafeRowWriter.java
---
@@ -117,150 +138,81 @@ public long getFieldOffset(int ordinal) {
return startingOffset + nullBitsSize + 8 * ordinal;
}
- public void setOffsetAndSize(int ordinal, int size) {
-setOffsetAndSize(ordinal, holder.cursor, size);
- }
-
- public void setOffsetAndSize(int ordinal, int currentCursor, int size) {
-final long relativeOffset = currentCursor - startingOffset;
-final long fieldOffset = getFieldOffset(ordinal);
-final long offsetAndSize = (relativeOffset << 32) | (long) size;
-
-Platform.putLong(holder.buffer, fieldOffset, offsetAndSize);
- }
-
public void write(int ordinal, boolean value) {
final long offset = getFieldOffset(ordinal);
-Platform.putLong(holder.buffer, offset, 0L);
-Platform.putBoolean(holder.buffer, offset, value);
+Platform.putLong(buffer(), offset, 0L);
+writeBoolean(offset, value);
}
public void write(int ordinal, byte value) {
final long offset = getFieldOffset(ordinal);
-Platform.putLong(holder.buffer, offset, 0L);
-Platform.putByte(holder.buffer, offset, value);
+Platform.putLong(buffer(), offset, 0L);
+writeByte(offset, value);
}
public void write(int ordinal, short value) {
final long offset = getFieldOffset(ordinal);
-Platform.putLong(holder.buffer, offset, 0L);
-Platform.putShort(holder.buffer, offset, value);
+Platform.putLong(buffer(), offset, 0L);
+writeShort(offset, value);
}
public void write(int ordinal, int value) {
final long offset = getFieldOffset(ordinal);
-Platform.putLong(holder.buffer, offset, 0L);
-Platform.putInt(holder.buffer, offset, value);
+Platform.putLong(buffer(), offset, 0L);
+writeInt(offset, value);
}
public void write(int ordinal, long value) {
-Platform.putLong(holder.buffer, getFieldOffset(ordinal), value);
+writeLong(getFieldOffset(ordinal), value);
}
public void write(int ordinal, float value) {
-if (Float.isNaN(value)) {
- value = Float.NaN;
-}
final long offset = getFieldOffset(ordinal);
-Platform.putLong(holder.buffer, offset, 0L);
-Platform.putFloat(holder.buffer, offset, value);
+Platform.putLong(buffer(), offset, 0L);
+writeFloat(offset, value);
}
public void write(int ordinal, double value) {
-if (Double.isNaN(value)) {
- value = Double.NaN;
-}
-Platform.putDouble(holder.buffer, getFieldOffset(ordinal), value);
+writeDouble(getFieldOffset(ordinal), value);
}
public void write(int ordinal, Decimal input, int precision, int scale) {
if (precision <= Decimal.MAX_LONG_DIGITS()) {
// make sure Decimal object has the same scale as DecimalType
if (input.changePrecision(precision, scale)) {
--- End diff --
do we need `input != null` here like
https://github.com/apache/spark/pull/20850/files#diff-85658ffc242280699a331c90530f54baR149
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20935: [SPARK-23819][SQL] Fix InMemoryTableScanExec complex typ...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/20935 **[Test build #88797 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/88797/testReport)** for PR 20935 at commit [`6ea0919`](https://github.com/apache/spark/commit/6ea0919ec0a9dfc6b121c88790fac79aa072bc60). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20850: [SPARK-23713][SQL] Cleanup UnsafeWriter and Buffe...
Github user kiszk commented on a diff in the pull request:
https://github.com/apache/spark/pull/20850#discussion_r178463388
--- Diff:
sql/catalyst/src/main/java/org/apache/spark/sql/catalyst/expressions/codegen/UnsafeRowWriter.java
---
@@ -117,150 +138,81 @@ public long getFieldOffset(int ordinal) {
return startingOffset + nullBitsSize + 8 * ordinal;
}
- public void setOffsetAndSize(int ordinal, int size) {
-setOffsetAndSize(ordinal, holder.cursor, size);
- }
-
- public void setOffsetAndSize(int ordinal, int currentCursor, int size) {
-final long relativeOffset = currentCursor - startingOffset;
-final long fieldOffset = getFieldOffset(ordinal);
-final long offsetAndSize = (relativeOffset << 32) | (long) size;
-
-Platform.putLong(holder.buffer, fieldOffset, offsetAndSize);
- }
-
public void write(int ordinal, boolean value) {
final long offset = getFieldOffset(ordinal);
-Platform.putLong(holder.buffer, offset, 0L);
-Platform.putBoolean(holder.buffer, offset, value);
+Platform.putLong(buffer(), offset, 0L);
+writeBoolean(offset, value);
}
public void write(int ordinal, byte value) {
final long offset = getFieldOffset(ordinal);
-Platform.putLong(holder.buffer, offset, 0L);
-Platform.putByte(holder.buffer, offset, value);
+Platform.putLong(buffer(), offset, 0L);
+writeByte(offset, value);
}
public void write(int ordinal, short value) {
final long offset = getFieldOffset(ordinal);
-Platform.putLong(holder.buffer, offset, 0L);
-Platform.putShort(holder.buffer, offset, value);
+Platform.putLong(buffer(), offset, 0L);
+writeShort(offset, value);
}
public void write(int ordinal, int value) {
final long offset = getFieldOffset(ordinal);
-Platform.putLong(holder.buffer, offset, 0L);
-Platform.putInt(holder.buffer, offset, value);
+Platform.putLong(buffer(), offset, 0L);
+writeInt(offset, value);
}
public void write(int ordinal, long value) {
-Platform.putLong(holder.buffer, getFieldOffset(ordinal), value);
+writeLong(getFieldOffset(ordinal), value);
}
public void write(int ordinal, float value) {
-if (Float.isNaN(value)) {
- value = Float.NaN;
-}
final long offset = getFieldOffset(ordinal);
-Platform.putLong(holder.buffer, offset, 0L);
-Platform.putFloat(holder.buffer, offset, value);
+Platform.putLong(buffer(), offset, 0L);
+writeFloat(offset, value);
}
public void write(int ordinal, double value) {
-if (Double.isNaN(value)) {
- value = Double.NaN;
-}
-Platform.putDouble(holder.buffer, getFieldOffset(ordinal), value);
+writeDouble(getFieldOffset(ordinal), value);
}
public void write(int ordinal, Decimal input, int precision, int scale) {
if (precision <= Decimal.MAX_LONG_DIGITS()) {
// make sure Decimal object has the same scale as DecimalType
if (input.changePrecision(precision, scale)) {
--- End diff --
Good point. I will add `input != null`.
I am also curious about the differences between these two methods.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #15614: [SPARK-18079] [SQL] CollectLimitExec.executeToIte...
Github user pwoody closed the pull request at: https://github.com/apache/spark/pull/15614 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20955: [SPARK-23838][WEBUI] Running SQL query is displayed as "...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/20955 **[Test build #88795 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/88795/testReport)** for PR 20955 at commit [`2357f59`](https://github.com/apache/spark/commit/2357f59a8f0b1cbea2ac1431bb3669cb1a26f687). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20955: [SPARK-23838][WEBUI] Running SQL query is displayed as "...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/20955 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/88795/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20955: [SPARK-23838][WEBUI] Running SQL query is displayed as "...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/20955 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20886: [SPARK-19724][SQL]create a managed table with an existed...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/20886 **[Test build #88796 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/88796/testReport)** for PR 20886 at commit [`f1de70c`](https://github.com/apache/spark/commit/f1de70c5284df3b3980d509e2ef7d7e77e020c1c). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20886: [SPARK-19724][SQL]create a managed table with an existed...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/20886 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20886: [SPARK-19724][SQL]create a managed table with an existed...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/20886 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/88796/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20935: [SPARK-23819][SQL] Fix InMemoryTableScanExec complex typ...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/20935 **[Test build #88797 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/88797/testReport)** for PR 20935 at commit [`6ea0919`](https://github.com/apache/spark/commit/6ea0919ec0a9dfc6b121c88790fac79aa072bc60). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20935: [SPARK-23819][SQL] Fix InMemoryTableScanExec complex typ...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/20935 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/88797/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20697: [SPARK-23010][k8s] Initial checkin of k8s integration te...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/20697 **[Test build #88798 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/88798/testReport)** for PR 20697 at commit [`84a7779`](https://github.com/apache/spark/commit/84a7779f50a0e4d4ca3ef01f5c3e430c681e569c). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20935: [SPARK-23819][SQL] Fix InMemoryTableScanExec complex typ...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/20935 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20697: [SPARK-23010][k8s] Initial checkin of k8s integration te...
Github user felixcheung commented on the issue: https://github.com/apache/spark/pull/20697 Jenkins, retest this please --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20697: [SPARK-23010][k8s] Initial checkin of k8s integration te...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/20697 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution/1891/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20954: [BACKPORT][SPARK-23040][CORE] Returns interruptible iter...
Github user dongjoon-hyun commented on the issue: https://github.com/apache/spark/pull/20954 Hi, @cloud-fan and @jiangxb1987 . It seems that the newly added test case starts to fail at `sbt-hadoop2.7`. Could you take a look at the failure? - https://amplab.cs.berkeley.edu/jenkins/view/Spark%20QA%20Test%20(Dashboard)/job/spark-branch-2.3-test-sbt-hadoop-2.7/lastCompletedBuild/testReport/org.apache.spark/JobCancellationSuite/interruptible_iterator_of_shuffle_reader/ --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20697: [SPARK-23010][k8s] Initial checkin of k8s integration te...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/20697 Kubernetes integration test starting URL: https://amplab.cs.berkeley.edu/jenkins/job/testing-k8s-prb-spark-integration/1867/ --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20697: [SPARK-23010][k8s] Initial checkin of k8s integration te...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/20697 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20697: [SPARK-23010][k8s] Initial checkin of k8s integration te...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/20697 Kubernetes integration test status success URL: https://amplab.cs.berkeley.edu/jenkins/job/testing-k8s-prb-spark-integration/1867/ --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20640: [SPARK-19755][Mesos] Blacklist is always active for Meso...
Github user felixcheung commented on the issue: https://github.com/apache/spark/pull/20640 @skonto, @squito , @kayousterhout ? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20722: [SPARK-23571][K8S] Delete auxiliary Kubernetes resources...
Github user felixcheung commented on the issue: https://github.com/apache/spark/pull/20722 so where are we on this? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20850: [SPARK-23713][SQL] Cleanup UnsafeWriter and Buffe...
Github user kiszk commented on a diff in the pull request:
https://github.com/apache/spark/pull/20850#discussion_r178466997
--- Diff:
sql/catalyst/src/main/java/org/apache/spark/sql/catalyst/expressions/codegen/UnsafeArrayWriter.java
---
@@ -32,141 +30,123 @@
*/
public final class UnsafeArrayWriter extends UnsafeWriter {
- private BufferHolder holder;
-
- // The offset of the global buffer where we start to write this array.
- private int startingOffset;
-
// The number of elements in this array
private int numElements;
+ // The element size in this array
+ private int elementSize;
+
private int headerInBytes;
private void assertIndexIsValid(int index) {
assert index >= 0 : "index (" + index + ") should >= 0";
assert index < numElements : "index (" + index + ") should < " +
numElements;
}
- public void initialize(BufferHolder holder, int numElements, int
elementSize) {
+ public UnsafeArrayWriter(UnsafeWriter writer, int elementSize) {
+super(writer.getBufferHolder());
+this.elementSize = elementSize;
+ }
+
+ public void initialize(int numElements) {
// We need 8 bytes to store numElements in header
this.numElements = numElements;
this.headerInBytes = calculateHeaderPortionInBytes(numElements);
-this.holder = holder;
-this.startingOffset = holder.cursor;
+this.startingOffset = cursor();
// Grows the global buffer ahead for header and fixed size data.
int fixedPartInBytes =
ByteArrayMethods.roundNumberOfBytesToNearestWord(elementSize *
numElements);
holder.grow(headerInBytes + fixedPartInBytes);
// Write numElements and clear out null bits to header
-Platform.putLong(holder.buffer, startingOffset, numElements);
+Platform.putLong(buffer(), startingOffset, numElements);
for (int i = 8; i < headerInBytes; i += 8) {
- Platform.putLong(holder.buffer, startingOffset + i, 0L);
+ Platform.putLong(buffer(), startingOffset + i, 0L);
}
// fill 0 into reminder part of 8-bytes alignment in unsafe array
for (int i = elementSize * numElements; i < fixedPartInBytes; i++) {
- Platform.putByte(holder.buffer, startingOffset + headerInBytes + i,
(byte) 0);
+ Platform.putByte(buffer(), startingOffset + headerInBytes + i,
(byte) 0);
}
-holder.cursor += (headerInBytes + fixedPartInBytes);
+increaseCursor(headerInBytes + fixedPartInBytes);
}
- private void zeroOutPaddingBytes(int numBytes) {
-if ((numBytes & 0x07) > 0) {
- Platform.putLong(holder.buffer, holder.cursor + ((numBytes >> 3) <<
3), 0L);
-}
- }
-
- private long getElementOffset(int ordinal, int elementSize) {
+ private long getElementOffset(int ordinal) {
return startingOffset + headerInBytes + ordinal * elementSize;
}
- public void setOffsetAndSize(int ordinal, int currentCursor, int size) {
-assertIndexIsValid(ordinal);
-final long relativeOffset = currentCursor - startingOffset;
-final long offsetAndSize = (relativeOffset << 32) | (long)size;
-
-write(ordinal, offsetAndSize);
- }
-
private void setNullBit(int ordinal) {
assertIndexIsValid(ordinal);
-BitSetMethods.set(holder.buffer, startingOffset + 8, ordinal);
+BitSetMethods.set(buffer(), startingOffset + 8, ordinal);
}
public void setNull1Bytes(int ordinal) {
--- End diff --
IIUC, `UnsafeRowWriter` need a single `setNullAt` method for 8-byte width
field.
On the other hand, `UnsafeArrayWriter` needs multiple `setNull?Bytes()` for
different element size. Generated code also uses `setNull?Bytes`.
Could you elaborate your thought?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20850: [SPARK-23713][SQL] Cleanup UnsafeWriter and Buffe...
Github user hvanhovell commented on a diff in the pull request:
https://github.com/apache/spark/pull/20850#discussion_r178469079
--- Diff:
sql/catalyst/src/main/java/org/apache/spark/sql/catalyst/expressions/codegen/UnsafeArrayWriter.java
---
@@ -32,141 +30,123 @@
*/
public final class UnsafeArrayWriter extends UnsafeWriter {
- private BufferHolder holder;
-
- // The offset of the global buffer where we start to write this array.
- private int startingOffset;
-
// The number of elements in this array
private int numElements;
+ // The element size in this array
+ private int elementSize;
+
private int headerInBytes;
private void assertIndexIsValid(int index) {
assert index >= 0 : "index (" + index + ") should >= 0";
assert index < numElements : "index (" + index + ") should < " +
numElements;
}
- public void initialize(BufferHolder holder, int numElements, int
elementSize) {
+ public UnsafeArrayWriter(UnsafeWriter writer, int elementSize) {
+super(writer.getBufferHolder());
+this.elementSize = elementSize;
+ }
+
+ public void initialize(int numElements) {
// We need 8 bytes to store numElements in header
this.numElements = numElements;
this.headerInBytes = calculateHeaderPortionInBytes(numElements);
-this.holder = holder;
-this.startingOffset = holder.cursor;
+this.startingOffset = cursor();
// Grows the global buffer ahead for header and fixed size data.
int fixedPartInBytes =
ByteArrayMethods.roundNumberOfBytesToNearestWord(elementSize *
numElements);
holder.grow(headerInBytes + fixedPartInBytes);
// Write numElements and clear out null bits to header
-Platform.putLong(holder.buffer, startingOffset, numElements);
+Platform.putLong(buffer(), startingOffset, numElements);
for (int i = 8; i < headerInBytes; i += 8) {
- Platform.putLong(holder.buffer, startingOffset + i, 0L);
+ Platform.putLong(buffer(), startingOffset + i, 0L);
}
// fill 0 into reminder part of 8-bytes alignment in unsafe array
for (int i = elementSize * numElements; i < fixedPartInBytes; i++) {
- Platform.putByte(holder.buffer, startingOffset + headerInBytes + i,
(byte) 0);
+ Platform.putByte(buffer(), startingOffset + headerInBytes + i,
(byte) 0);
}
-holder.cursor += (headerInBytes + fixedPartInBytes);
+increaseCursor(headerInBytes + fixedPartInBytes);
}
- private void zeroOutPaddingBytes(int numBytes) {
-if ((numBytes & 0x07) > 0) {
- Platform.putLong(holder.buffer, holder.cursor + ((numBytes >> 3) <<
3), 0L);
-}
- }
-
- private long getElementOffset(int ordinal, int elementSize) {
+ private long getElementOffset(int ordinal) {
return startingOffset + headerInBytes + ordinal * elementSize;
}
- public void setOffsetAndSize(int ordinal, int currentCursor, int size) {
-assertIndexIsValid(ordinal);
-final long relativeOffset = currentCursor - startingOffset;
-final long offsetAndSize = (relativeOffset << 32) | (long)size;
-
-write(ordinal, offsetAndSize);
- }
-
private void setNullBit(int ordinal) {
assertIndexIsValid(ordinal);
-BitSetMethods.set(holder.buffer, startingOffset + 8, ordinal);
+BitSetMethods.set(buffer(), startingOffset + 8, ordinal);
}
public void setNull1Bytes(int ordinal) {
--- End diff --
We still need the various `setNull*` methods because of arrays.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20345: [SPARK-23172][SQL] Expand the ReorderJoin rule to handle...
Github user maropu commented on the issue: https://github.com/apache/spark/pull/20345 ping --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20850: [SPARK-23713][SQL] Cleanup UnsafeWriter and Buffe...
Github user hvanhovell commented on a diff in the pull request:
https://github.com/apache/spark/pull/20850#discussion_r178469520
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/columnar/GenerateColumnAccessor.scala
---
@@ -212,11 +210,11 @@ object GenerateColumnAccessor extends
CodeGenerator[Seq[DataType], ColumnarItera
public InternalRow next() {
currentRow += 1;
- bufferHolder.reset();
+ rowWriter.reset();
rowWriter.zeroOutNullBytes();
${extractorCalls}
- unsafeRow.setTotalSize(bufferHolder.totalSize());
- return unsafeRow;
+ rowWriter.setTotalSize();
+ return rowWriter.getRow();
--- End diff --
Is there any place where we call `getRow()` without calling
`setTotalSize()` before that? If there aren't then I'd combine the two.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20886: [SPARK-19724][SQL]create a managed table with an ...
Github user gatorsmile commented on a diff in the pull request:
https://github.com/apache/spark/pull/20886#discussion_r178470143
--- Diff:
sql/core/src/test/scala/org/apache/spark/sql/execution/command/DDLSuite.scala
---
@@ -103,6 +103,60 @@ class InMemoryCatalogedDDLSuite extends DDLSuite with
SharedSQLContext with Befo
}
}
+ test("CTAS a managed table with the existing empty directory") {
+val tableLoc = new
File(spark.sessionState.catalog.defaultTablePath(TableIdentifier("tab1")))
+try {
+ tableLoc.mkdir()
+ withTable("tab1") {
+sql("CREATE TABLE tab1 USING PARQUET AS SELECT 1, 'a'")
--- End diff --
Move them to `DDLSuite`? Change the format based on `isUsingHiveMetastore`?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20886: [SPARK-19724][SQL]create a managed table with an ...
Github user gatorsmile commented on a diff in the pull request:
https://github.com/apache/spark/pull/20886#discussion_r178470268
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/catalog/SessionCatalog.scala
---
@@ -298,15 +302,28 @@ class SessionCatalog(
makeQualifiedPath(tableDefinition.storage.locationUri.get)
tableDefinition.copy(
storage = tableDefinition.storage.copy(locationUri =
Some(qualifiedTableLocation)),
-identifier = TableIdentifier(table, Some(db)))
+identifier = tableIdentifier)
} else {
- tableDefinition.copy(identifier = TableIdentifier(table, Some(db)))
+ tableDefinition.copy(identifier = tableIdentifier)
}
requireDbExists(db)
externalCatalog.createTable(newTableDefinition, ignoreIfExists)
}
+ def validateTableLocation(table: CatalogTable, tableIdentifier:
TableIdentifier): Unit = {
--- End diff --
`CatalogTable ` already contains `TableIdentifier `. What is the reason you
do not use the one directly?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20886: [SPARK-19724][SQL]create a managed table with an ...
Github user gatorsmile commented on a diff in the pull request:
https://github.com/apache/spark/pull/20886#discussion_r178470264
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/catalog/SessionCatalog.scala
---
@@ -298,15 +302,28 @@ class SessionCatalog(
makeQualifiedPath(tableDefinition.storage.locationUri.get)
tableDefinition.copy(
storage = tableDefinition.storage.copy(locationUri =
Some(qualifiedTableLocation)),
-identifier = TableIdentifier(table, Some(db)))
+identifier = tableIdentifier)
} else {
- tableDefinition.copy(identifier = TableIdentifier(table, Some(db)))
+ tableDefinition.copy(identifier = tableIdentifier)
}
requireDbExists(db)
externalCatalog.createTable(newTableDefinition, ignoreIfExists)
}
+ def validateTableLocation(table: CatalogTable, tableIdentifier:
TableIdentifier): Unit = {
+// SPARK-19724: the default location of a managed table should be
non-existent or empty.
+ if (table.tableType == CatalogTableType.MANAGED) {
+ val tableLocation = new Path(defaultTablePath(tableIdentifier))
--- End diff --
We always check `defaultTablePath `? Is that possible, the table location
points to the different location?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20886: [SPARK-19724][SQL]create a managed table with an existed...
Github user gatorsmile commented on the issue: https://github.com/apache/spark/pull/20886 This is a behavior change, we need to make it configurable and also document it in the migration guide. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20697: [SPARK-23010][k8s] Initial checkin of k8s integration te...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/20697 **[Test build #88798 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/88798/testReport)** for PR 20697 at commit [`84a7779`](https://github.com/apache/spark/commit/84a7779f50a0e4d4ca3ef01f5c3e430c681e569c). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20697: [SPARK-23010][k8s] Initial checkin of k8s integration te...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/20697 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/88798/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20697: [SPARK-23010][k8s] Initial checkin of k8s integration te...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/20697 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20930: [SPARK-23811][Core] FetchFailed comes before Succ...
Github user cloud-fan commented on a diff in the pull request:
https://github.com/apache/spark/pull/20930#discussion_r178470893
--- Diff:
core/src/main/scala/org/apache/spark/scheduler/TaskSetManager.scala ---
@@ -794,6 +794,19 @@ private[spark] class TaskSetManager(
fetchFailed.bmAddress.host, fetchFailed.bmAddress.executorId))
}
+// Kill any other attempts for this FetchFailed task
+for (attemptInfo <- taskAttempts(index) if attemptInfo.running) {
+ logInfo(s"Killing attempt ${attemptInfo.attemptNumber} for task
${attemptInfo.id} " +
+s"in stage ${taskSet.id} (TID ${attemptInfo.taskId}) on
${attemptInfo.host} " +
+s"as the attempt ${info.attemptNumber} failed because
FetchFailed")
+ killedByOtherAttempt(index) = true
+ sched.backend.killTask(
--- End diff --
if this is async, we can't guarantee to not have task success events after
marking staging as failed, right?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20850: [SPARK-23713][SQL] Cleanup UnsafeWriter and Buffe...
Github user cloud-fan commented on a diff in the pull request:
https://github.com/apache/spark/pull/20850#discussion_r178470952
--- Diff:
sql/catalyst/src/main/java/org/apache/spark/sql/catalyst/expressions/codegen/UnsafeArrayWriter.java
---
@@ -32,141 +30,123 @@
*/
public final class UnsafeArrayWriter extends UnsafeWriter {
- private BufferHolder holder;
-
- // The offset of the global buffer where we start to write this array.
- private int startingOffset;
-
// The number of elements in this array
private int numElements;
+ // The element size in this array
+ private int elementSize;
+
private int headerInBytes;
private void assertIndexIsValid(int index) {
assert index >= 0 : "index (" + index + ") should >= 0";
assert index < numElements : "index (" + index + ") should < " +
numElements;
}
- public void initialize(BufferHolder holder, int numElements, int
elementSize) {
+ public UnsafeArrayWriter(UnsafeWriter writer, int elementSize) {
+super(writer.getBufferHolder());
+this.elementSize = elementSize;
+ }
+
+ public void initialize(int numElements) {
// We need 8 bytes to store numElements in header
this.numElements = numElements;
this.headerInBytes = calculateHeaderPortionInBytes(numElements);
-this.holder = holder;
-this.startingOffset = holder.cursor;
+this.startingOffset = cursor();
// Grows the global buffer ahead for header and fixed size data.
int fixedPartInBytes =
ByteArrayMethods.roundNumberOfBytesToNearestWord(elementSize *
numElements);
holder.grow(headerInBytes + fixedPartInBytes);
// Write numElements and clear out null bits to header
-Platform.putLong(holder.buffer, startingOffset, numElements);
+Platform.putLong(buffer(), startingOffset, numElements);
for (int i = 8; i < headerInBytes; i += 8) {
- Platform.putLong(holder.buffer, startingOffset + i, 0L);
+ Platform.putLong(buffer(), startingOffset + i, 0L);
}
// fill 0 into reminder part of 8-bytes alignment in unsafe array
for (int i = elementSize * numElements; i < fixedPartInBytes; i++) {
- Platform.putByte(holder.buffer, startingOffset + headerInBytes + i,
(byte) 0);
+ Platform.putByte(buffer(), startingOffset + headerInBytes + i,
(byte) 0);
}
-holder.cursor += (headerInBytes + fixedPartInBytes);
+increaseCursor(headerInBytes + fixedPartInBytes);
}
- private void zeroOutPaddingBytes(int numBytes) {
-if ((numBytes & 0x07) > 0) {
- Platform.putLong(holder.buffer, holder.cursor + ((numBytes >> 3) <<
3), 0L);
-}
- }
-
- private long getElementOffset(int ordinal, int elementSize) {
+ private long getElementOffset(int ordinal) {
return startingOffset + headerInBytes + ordinal * elementSize;
}
- public void setOffsetAndSize(int ordinal, int currentCursor, int size) {
-assertIndexIsValid(ordinal);
-final long relativeOffset = currentCursor - startingOffset;
-final long offsetAndSize = (relativeOffset << 32) | (long)size;
-
-write(ordinal, offsetAndSize);
- }
-
private void setNullBit(int ordinal) {
assertIndexIsValid(ordinal);
-BitSetMethods.set(holder.buffer, startingOffset + 8, ordinal);
+BitSetMethods.set(buffer(), startingOffset + 8, ordinal);
}
public void setNull1Bytes(int ordinal) {
--- End diff --
nvm, I thought we can pattern match the `elementSize`, but that may hurt
performance a lot.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20795: [SPARK-23486]cache the function name from the cat...
Github user gatorsmile commented on a diff in the pull request:
https://github.com/apache/spark/pull/20795#discussion_r178471806
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/catalog/SessionCatalog.scala
---
@@ -1072,8 +1072,17 @@ class SessionCatalog(
def functionExists(name: FunctionIdentifier): Boolean = {
val db =
formatDatabaseName(name.database.getOrElse(getCurrentDatabase))
requireDbExists(db)
-functionRegistry.functionExists(name) ||
- externalCatalog.functionExists(db, name.funcName)
+builtinFunctionExists(name) || externalFunctionExists(name)
+ }
+
+ def builtinFunctionExists(name: FunctionIdentifier): Boolean = {
--- End diff --
```Scala
/**
* Returns whether this function has been registered in the function
registry of the current
* session. If not existed, returns false.
*/
def isRegisteredFunction(name: FunctionIdentifier): Boolean = {
functionRegistry.functionExists(name)
}
/**
* Returns whether it is a persistent function. If not existed, returns
false.
*/
def isPersistentFunction(name: FunctionIdentifier): Boolean = {
val db = formatDatabaseName(name.database.getOrElse(getCurrentDatabase))
databaseExists(db) && externalCatalog.functionExists(db, name.funcName)
}
```
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20795: [SPARK-23486]cache the function name from the cat...
Github user gatorsmile commented on a diff in the pull request:
https://github.com/apache/spark/pull/20795#discussion_r178471822
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/catalog/SessionCatalog.scala
---
@@ -1072,8 +1072,17 @@ class SessionCatalog(
def functionExists(name: FunctionIdentifier): Boolean = {
val db =
formatDatabaseName(name.database.getOrElse(getCurrentDatabase))
requireDbExists(db)
-functionRegistry.functionExists(name) ||
- externalCatalog.functionExists(db, name.funcName)
+builtinFunctionExists(name) || externalFunctionExists(name)
+ }
+
+ def builtinFunctionExists(name: FunctionIdentifier): Boolean = {
--- End diff --
Please also add the unit test cases to `SessionCatalogSuite`
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20795: [SPARK-23486]cache the function name from the cat...
Github user gatorsmile commented on a diff in the pull request:
https://github.com/apache/spark/pull/20795#discussion_r178471847
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/catalog/SessionCatalog.scala
---
@@ -1072,8 +1072,17 @@ class SessionCatalog(
def functionExists(name: FunctionIdentifier): Boolean = {
val db =
formatDatabaseName(name.database.getOrElse(getCurrentDatabase))
requireDbExists(db)
-functionRegistry.functionExists(name) ||
- externalCatalog.functionExists(db, name.funcName)
+builtinFunctionExists(name) || externalFunctionExists(name)
+ }
+
+ def builtinFunctionExists(name: FunctionIdentifier): Boolean = {
--- End diff --
Move them after `def isTemporaryFunction(name: FunctionIdentifier): Boolean
`
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20886: [SPARK-19724][SQL]create a managed table with an ...
Github user gengliangwang commented on a diff in the pull request:
https://github.com/apache/spark/pull/20886#discussion_r178472405
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/catalog/SessionCatalog.scala
---
@@ -298,15 +302,28 @@ class SessionCatalog(
makeQualifiedPath(tableDefinition.storage.locationUri.get)
tableDefinition.copy(
storage = tableDefinition.storage.copy(locationUri =
Some(qualifiedTableLocation)),
-identifier = TableIdentifier(table, Some(db)))
+identifier = tableIdentifier)
} else {
- tableDefinition.copy(identifier = TableIdentifier(table, Some(db)))
+ tableDefinition.copy(identifier = tableIdentifier)
}
requireDbExists(db)
externalCatalog.createTable(newTableDefinition, ignoreIfExists)
}
+ def validateTableLocation(table: CatalogTable, tableIdentifier:
TableIdentifier): Unit = {
+// SPARK-19724: the default location of a managed table should be
non-existent or empty.
+ if (table.tableType == CatalogTableType.MANAGED) {
+ val tableLocation = new Path(defaultTablePath(tableIdentifier))
--- End diff --
I think managed tables are always created on default path. So the check
here should be correct.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20886: [SPARK-19724][SQL]create a managed table with an existed...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/20886 **[Test build #88799 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/88799/testReport)** for PR 20886 at commit [`f26c08c`](https://github.com/apache/spark/commit/f26c08c1638e2e0caef6283c20cab8364109f0e0). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20886: [SPARK-19724][SQL]create a managed table with an existed...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/20886 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20886: [SPARK-19724][SQL]create a managed table with an existed...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/20886 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution/1892/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20940: [SPARK-23429][CORE] Add executor memory metrics to heart...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/20940 **[Test build #88800 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/88800/testReport)** for PR 20940 at commit [`5e24fc6`](https://github.com/apache/spark/commit/5e24fc6d7e06d9b836fe759407c270ca004637fe). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20850: [SPARK-23713][SQL] Cleanup UnsafeWriter and Buffe...
Github user kiszk commented on a diff in the pull request:
https://github.com/apache/spark/pull/20850#discussion_r178477937
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/columnar/GenerateColumnAccessor.scala
---
@@ -212,11 +210,11 @@ object GenerateColumnAccessor extends
CodeGenerator[Seq[DataType], ColumnarItera
public InternalRow next() {
currentRow += 1;
- bufferHolder.reset();
+ rowWriter.reset();
rowWriter.zeroOutNullBytes();
${extractorCalls}
- unsafeRow.setTotalSize(bufferHolder.totalSize());
- return unsafeRow;
+ rowWriter.setTotalSize();
+ return rowWriter.getRow();
--- End diff --
I think that
[here](https://github.com/apache/spark/pull/20850/files#diff-90b107e5c61791e17d5b4b25021b89fdR349)
is only a place where we call `getRow()` without calling `setTotalSize()` if
`numVarLenFields == 0`.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20850: [SPARK-23713][SQL] Cleanup UnsafeWriter and Buffe...
Github user kiszk commented on a diff in the pull request:
https://github.com/apache/spark/pull/20850#discussion_r178478113
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/columnar/GenerateColumnAccessor.scala
---
@@ -212,11 +210,11 @@ object GenerateColumnAccessor extends
CodeGenerator[Seq[DataType], ColumnarItera
public InternalRow next() {
currentRow += 1;
- bufferHolder.reset();
+ rowWriter.reset();
rowWriter.zeroOutNullBytes();
${extractorCalls}
- unsafeRow.setTotalSize(bufferHolder.totalSize());
- return unsafeRow;
+ rowWriter.setTotalSize();
+ return rowWriter.getRow();
--- End diff --
Should we call `reset()` and `setTotalSize()` as the interpreted version
does?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20886: [SPARK-19724][SQL]create a managed table with an existed...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/20886 **[Test build #88799 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/88799/testReport)** for PR 20886 at commit [`f26c08c`](https://github.com/apache/spark/commit/f26c08c1638e2e0caef6283c20cab8364109f0e0). * This patch **fails Spark unit tests**. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20886: [SPARK-19724][SQL]create a managed table with an existed...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/20886 Merged build finished. Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20886: [SPARK-19724][SQL]create a managed table with an existed...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/20886 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/88799/ Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20937: [SPARK-23723][SPARK-23724][SQL] Support custom en...
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/20937#discussion_r178476075
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/json/CreateJacksonParser.scala
---
@@ -39,11 +40,36 @@ private[sql] object CreateJacksonParser extends
Serializable {
jsonFactory.createParser(new InputStreamReader(bain, "UTF-8"))
}
- def text(jsonFactory: JsonFactory, record: Text): JsonParser = {
-jsonFactory.createParser(record.getBytes, 0, record.getLength)
+ def text(jsonFactory: JsonFactory, record: Text, encoding:
Option[String] = None): JsonParser = {
+encoding match {
--- End diff --
Looks we create a partial function and then use it and therefore it's going
to do the type dispatch for every record. Can we avoid this?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20937: [SPARK-23723][SPARK-23724][SQL] Support custom en...
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/20937#discussion_r178476931
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/json/JsonDataSource.scala
---
@@ -92,32 +93,34 @@ object TextInputJsonDataSource extends JsonDataSource {
sparkSession: SparkSession,
inputPaths: Seq[FileStatus],
parsedOptions: JSONOptions): StructType = {
-val json: Dataset[String] = createBaseDataset(
- sparkSession, inputPaths, parsedOptions.lineSeparator)
+val json: Dataset[String] = createBaseDataset(sparkSession,
inputPaths, parsedOptions)
+
inferFromDataset(json, parsedOptions)
}
def inferFromDataset(json: Dataset[String], parsedOptions: JSONOptions):
StructType = {
val sampled: Dataset[String] = JsonUtils.sample(json, parsedOptions)
-val rdd: RDD[UTF8String] =
sampled.queryExecution.toRdd.map(_.getUTF8String(0))
-JsonInferSchema.infer(rdd, parsedOptions,
CreateJacksonParser.utf8String)
+val rdd: RDD[InternalRow] = sampled.queryExecution.toRdd
+
+JsonInferSchema.infer[InternalRow](
+ rdd,
+ parsedOptions,
+ CreateJacksonParser.internalRow(_, _, 0, parsedOptions.encoding)
+)
}
private def createBaseDataset(
sparkSession: SparkSession,
inputPaths: Seq[FileStatus],
- lineSeparator: Option[String]): Dataset[String] = {
-val textOptions = lineSeparator.map { lineSep =>
- Map(TextOptions.LINE_SEPARATOR -> lineSep)
-}.getOrElse(Map.empty[String, String])
-
+ parsedOptions: JSONOptions
+ ): Dataset[String] = {
--- End diff --
Let's move this line up too. I think it should be either
```
...
parsedOptions: JSONOptions)
: Dataset[String] = {
```
or
```
parsedOptions: JSONOptions) : Dataset[String] = {
```
https://github.com/databricks/scala-style-guide#spacing-and-indentation
but somehow I believe we usually do the latter style.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20937: [SPARK-23723][SPARK-23724][SQL] Support custom en...
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/20937#discussion_r178478519
--- Diff:
sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/json/JsonSuite.scala
---
@@ -2070,9 +2070,9 @@ class JsonSuite extends QueryTest with
SharedSQLContext with TestJsonData {
// Read
val data =
s"""
- | {"f":
- |"a", "f0": 1}$lineSep{"f":
- |
+ | {"f":
+ |"a", "f0": 1}$lineSep{"f":
+ |
--- End diff --
Seems a mistake ?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org