[GitHub] [airflow] mik-laj commented on a change in pull request #6792: [AIRFLOW-5930] Use cached-SQL query building for hot-path queries
mik-laj commented on a change in pull request #6792: [AIRFLOW-5930] Use
cached-SQL query building for hot-path queries
URL: https://github.com/apache/airflow/pull/6792#discussion_r357000170
##
File path: airflow/jobs/scheduler_job.py
##
@@ -1006,8 +978,7 @@ def _change_state_for_tis_without_dagrun(self,
)
Stats.gauge('scheduler.tasks.without_dagrun', tis_changed)
-@provide_session
-def __get_concurrency_maps(self, states, session=None):
+def __get_concurrency_maps(self, states, session):
Review comment:
This method has an invalid rtype. Returns two dictionaries in a tuple, not
just one dictionary. Can you correct that?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [airflow] mik-laj commented on a change in pull request #6792: [AIRFLOW-5930] Use cached-SQL query building for hot-path queries
mik-laj commented on a change in pull request #6792: [AIRFLOW-5930] Use
cached-SQL query building for hot-path queries
URL: https://github.com/apache/airflow/pull/6792#discussion_r357000170
##
File path: airflow/jobs/scheduler_job.py
##
@@ -1006,8 +978,7 @@ def _change_state_for_tis_without_dagrun(self,
)
Stats.gauge('scheduler.tasks.without_dagrun', tis_changed)
-@provide_session
-def __get_concurrency_maps(self, states, session=None):
+def __get_concurrency_maps(self, states, session):
Review comment:
This method has an invalid rtype. Returns two dictionaries in a tuple, not
just one. Can you correct that?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [airflow] mik-laj commented on a change in pull request #6792: [AIRFLOW-5930] Use cached-SQL query building for hot-path queries
mik-laj commented on a change in pull request #6792: [AIRFLOW-5930] Use
cached-SQL query building for hot-path queries
URL: https://github.com/apache/airflow/pull/6792#discussion_r357000170
##
File path: airflow/jobs/scheduler_job.py
##
@@ -1006,8 +978,7 @@ def _change_state_for_tis_without_dagrun(self,
)
Stats.gauge('scheduler.tasks.without_dagrun', tis_changed)
-@provide_session
-def __get_concurrency_maps(self, states, session=None):
+def __get_concurrency_maps(self, states, session):
Review comment:
This method has an invalid rtype. Returns two dictionaries in a tuple, not
just one.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [airflow] mik-laj commented on a change in pull request #6792: [AIRFLOW-5930] Use cached-SQL query building for hot-path queries
mik-laj commented on a change in pull request #6792: [AIRFLOW-5930] Use cached-SQL query building for hot-path queries URL: https://github.com/apache/airflow/pull/6792#discussion_r356997115 ## File path: airflow/models/dagrun.py ## @@ -286,25 +321,27 @@ def update_state(self, session=None): session=session Review comment: Can you check if double calling get_task_instances is faster than filtering the list in Python? Line 319 and 306 contains calls to the get_task_instances method, and this method invokes a database query. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [airflow] RosterIn commented on issue #2460: [AIRFLOW-1424] make the next execution date of DAGs visible
RosterIn commented on issue #2460: [AIRFLOW-1424] make the next execution date of DAGs visible URL: https://github.com/apache/airflow/pull/2460#issuecomment-564890113 Would it be possible for this column to be configured from airflow.cfg with default `False`? Something like: `show_next_execution_column_in_ui = False` I do think this feature is valuable but not all users may require it. This new column doesn't bring new information to the UI (as it can be understood from the last run + interval) so I think it should be hidden by default and shown for users who needs it. **OR (and maybe even better)** If not from airflow.cfg then maybe the UI itself can have hide/show feature something similar to the hide paused DAGs button? This will allow every user to decide for himself if he wants to see it. This way no need to define standard that effects all users but it's more a personalised UI. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [airflow] mik-laj commented on a change in pull request #6792: [AIRFLOW-5930] Use cached-SQL query building for hot-path queries
mik-laj commented on a change in pull request #6792: [AIRFLOW-5930] Use
cached-SQL query building for hot-path queries
URL: https://github.com/apache/airflow/pull/6792#discussion_r356995764
##
File path: airflow/models/dagrun.py
##
@@ -263,10 +294,14 @@ def update_state(self, session=None):
Determines the overall state of the DagRun based on the state
of its TaskInstances.
-:return: State
+:return: state, schedulable_task_instances
+:rtype: (State, list[TaskInstance])
"""
+from airflow.ti_deps.deps.ready_to_reschedule import
ReadyToRescheduleDep
+from airflow.ti_deps.deps.not_in_retry_period_dep import
NotInRetryPeriodDep
dag = self.get_dag()
+tis_to_schedule = []
tis = self.get_task_instances(session=session)
self.log.debug("Updating state for %s considering %s task(s)", self,
len(tis))
Review comment:
Do you think it is worth dividing the loop from line 272 into two loops? One
loop will filters the elements and the second loop will set tasks on task
instances. This does not affect performance, but will make it easier to
understand the code.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [airflow] mik-laj commented on a change in pull request #6792: [AIRFLOW-5930] Use cached-SQL query building for hot-path queries
mik-laj commented on a change in pull request #6792: [AIRFLOW-5930] Use cached-SQL query building for hot-path queries URL: https://github.com/apache/airflow/pull/6792#discussion_r356994088 ## File path: airflow/models/dagrun.py ## @@ -263,10 +294,14 @@ def update_state(self, session=None): Determines the overall state of the DagRun based on the state Review comment: Is it not necessary to change the method name? Now does not contain information about tasks. This may not be clear in the future. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [airflow] albertusk95 commented on a change in pull request #6795: Adjust the MASTER_URL of spark-submit in SparkSubmitHook
albertusk95 commented on a change in pull request #6795: Adjust the MASTER_URL
of spark-submit in SparkSubmitHook
URL: https://github.com/apache/airflow/pull/6795#discussion_r356992460
##
File path: airflow/contrib/hooks/spark_submit_hook.py
##
@@ -185,6 +185,8 @@ def _resolve_connection(self):
conn_data['master'] = "{}:{}".format(conn.host, conn.port)
else:
conn_data['master'] = conn.host
+if conn.uri:
+conn_data['master'] = conn.uri
Review comment:
since the specified URI might consist of other attributes other than scheme,
host, and port (ex: query & schema), I think we couldn't directly assign the
master address to `conn.uri`
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [airflow] mik-laj commented on a change in pull request #6792: [AIRFLOW-5930] Use cached-SQL query building for hot-path queries
mik-laj commented on a change in pull request #6792: [AIRFLOW-5930] Use cached-SQL query building for hot-path queries URL: https://github.com/apache/airflow/pull/6792#discussion_r356991452 ## File path: airflow/jobs/scheduler_job.py ## @@ -1057,30 +1027,34 @@ def _find_executable_task_instances(self, simple_dag_bag, states, session=None): TI = models.TaskInstance DR = models.DagRun DM = models.DagModel -ti_query = ( -session -.query(TI) -.filter(TI.dag_id.in_(simple_dag_bag.dag_ids)) +ti_query = BAKED_QUERIES( +lambda session: session.query(TI).filter( +TI.dag_id.in_(simple_dag_bag.dag_ids) +) .outerjoin( DR, and_(DR.dag_id == TI.dag_id, DR.execution_date == TI.execution_date) ) -.filter(or_(DR.run_id == None, # noqa: E711 pylint: disable=singleton-comparison -not_(DR.run_id.like(BackfillJob.ID_PREFIX + '%' +.filter(or_(DR.run_id.is_(None), +not_(DR.run_id.like(BackfillJob.ID_PREFIX + '%' Review comment: I really don't like filtering with the like expression. This makes the query very difficult to optimize. It is not possible to store it in a simple data structure. We have to have a very complex binary tree, but which takes more memory than a simple structure with 3 values. Which causes other problems, e.g. unbalanced tree, and thus performance degradation. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [airflow] mik-laj commented on a change in pull request #6792: [AIRFLOW-5930] Use cached-SQL query building for hot-path queries
mik-laj commented on a change in pull request #6792: [AIRFLOW-5930] Use
cached-SQL query building for hot-path queries
URL: https://github.com/apache/airflow/pull/6792#discussion_r356988665
##
File path: airflow/jobs/scheduler_job.py
##
@@ -1006,8 +978,7 @@ def _change_state_for_tis_without_dagrun(self,
)
Stats.gauge('scheduler.tasks.without_dagrun', tis_changed)
-@provide_session
-def __get_concurrency_maps(self, states, session=None):
+def __get_concurrency_maps(self, states, session):
Review comment:
Why did you delete this decorator? It has no effect on performance because
it is very simple logic.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [airflow] mik-laj commented on a change in pull request #6792: [AIRFLOW-5930] Use cached-SQL query building for hot-path queries
mik-laj commented on a change in pull request #6792: [AIRFLOW-5930] Use cached-SQL query building for hot-path queries URL: https://github.com/apache/airflow/pull/6792#discussion_r356988211 ## File path: airflow/jobs/scheduler_job.py ## @@ -686,10 +664,10 @@ def _process_dags(self, dagbag, dags, tis_out): :type dagbag: airflow.models.DagBag :param dags: the DAGs from the DagBag to process :type dags: airflow.models.DAG -:param tis_out: A list to add generated TaskInstance objects -:type tis_out: list[TaskInstance] -:rtype: None +:return: A list of TaskInstance objects +:rtype: list[TaskInstance] Review comment: Can you also add rtype for _process_task_instances also? Now it is difficult to check if this is true. Especially since this method previously use TaskInstanceKeyType. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [airflow] mik-laj commented on a change in pull request #6792: [AIRFLOW-5930] Use cached-SQL query building for hot-path queries
mik-laj commented on a change in pull request #6792: [AIRFLOW-5930] Use cached-SQL query building for hot-path queries URL: https://github.com/apache/airflow/pull/6792#discussion_r356986778 ## File path: airflow/__init__.py ## @@ -48,3 +48,8 @@ login: Optional[Callable] = None integrate_plugins() + + +# Ensure that this query is build in the master process, before we fork of a sub-process to parse the DAGs +from . import ti_deps Review comment: I don't know if this should be done here or when starting SchedulerJob. In my opinion, adding additional logic to init is not the best solution and we can probably avoid it in this situation. We don't need this query to be loaded in many cases, e.g. on workers. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [airflow] mik-laj commented on a change in pull request #6792: [AIRFLOW-5930] Use cached-SQL query building for hot-path queries
mik-laj commented on a change in pull request #6792: [AIRFLOW-5930] Use cached-SQL query building for hot-path queries URL: https://github.com/apache/airflow/pull/6792#discussion_r356986173 ## File path: airflow/ti_deps/deps/trigger_rule_dep.py ## @@ -34,9 +35,38 @@ class TriggerRuleDep(BaseTIDep): IGNOREABLE = True IS_TASK_DEP = True +@staticmethod +def bake_dep_status_query(): +TI = airflow.models.TaskInstance +# TODO(unknown): this query becomes quite expensive with dags that have many +# tasks. It should be refactored to let the task report to the dag run and get the +# aggregates from there. +q = BAKED_QUERIES(lambda session: session.query( +func.coalesce(func.sum(case([(TI.state == State.SUCCESS, 1)], else_=0)), 0), Review comment: Can you provide me this query in SQL format? I think it can be optimized for PostgresQL by using COUNT...FILTER syntax. However, this also requires checking if this syntax has an effect on performance, or is it just syntactic sugar. But for logic this additional information can be used by the planner to make a more efficient query. https://www.postgresql.org/docs/9.4/sql-expressions.html#SYNTAX-AGGREGATES This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [airflow] mik-laj commented on a change in pull request #6792: [AIRFLOW-5930] Use cached-SQL query building for hot-path queries
mik-laj commented on a change in pull request #6792: [AIRFLOW-5930] Use cached-SQL query building for hot-path queries URL: https://github.com/apache/airflow/pull/6792#discussion_r356986173 ## File path: airflow/ti_deps/deps/trigger_rule_dep.py ## @@ -34,9 +35,38 @@ class TriggerRuleDep(BaseTIDep): IGNOREABLE = True IS_TASK_DEP = True +@staticmethod +def bake_dep_status_query(): +TI = airflow.models.TaskInstance +# TODO(unknown): this query becomes quite expensive with dags that have many +# tasks. It should be refactored to let the task report to the dag run and get the +# aggregates from there. +q = BAKED_QUERIES(lambda session: session.query( +func.coalesce(func.sum(case([(TI.state == State.SUCCESS, 1)], else_=0)), 0), Review comment: Can you provide me this query in SQL format? I think it can be optimized for PostgresQL by using COUNT...FILTER syntax. However, this also requires checking if this syntax has an effect on performance, or is it just syntactic sugar. https://www.postgresql.org/docs/9.4/sql-expressions.html#SYNTAX-AGGREGATES This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [airflow] mik-laj commented on issue #6791: [AIRFLOW-XXX] Add link to XCom section in concepts.rst
mik-laj commented on issue #6791: [AIRFLOW-XXX] Add link to XCom section in concepts.rst URL: https://github.com/apache/airflow/pull/6791#issuecomment-564874675 @dimberman This is just a change in the documentation. Does this require a ticket? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Comment Edited] (AIRFLOW-6214) Spark driver status tracking for standalone, YARN, Mesos and K8s with cluster deploy mode
[
https://issues.apache.org/jira/browse/AIRFLOW-6214?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16994276#comment-16994276
]
xifeng edited comment on AIRFLOW-6214 at 12/12/19 6:32 AM:
---
Hi Albertus,
yes, I agree, I think it the conn.host should be only hostname, without
scheme.
I'm not sure why in testcase it is written as
host='spark://spark-standalone-master:6066'.
I just issued a PR: https://github.com/apache/airflow/pull/6795
was (Author: dennisli):
yes, I agree, I think the conn.host should be only hostname, without scheme.
But I'm not sure why in testcase it is written as
host='spark://spark-standalone-master:6066'.
I just issued a PR: https://github.com/apache/airflow/pull/6795
> Spark driver status tracking for standalone, YARN, Mesos and K8s with cluster
> deploy mode
> -
>
> Key: AIRFLOW-6214
> URL: https://issues.apache.org/jira/browse/AIRFLOW-6214
> Project: Apache Airflow
> Issue Type: Improvement
> Components: hooks, operators
>Affects Versions: 1.10.6
>Reporter: Albertus Kelvin
>Assignee: xifeng
>Priority: Minor
>
> Based on the following code snippet:
> {code:python}
> def _resolve_should_track_driver_status(self):
> return ('spark://' in self._connection['master'] and
> self._connection['deploy_mode'] == 'cluster')
> {code}
>
> It seems that the above code will always return *False* because the master
> address for standalone cluster doesn't contain *spark://* as shown from the
> below code snippet.
> {code:python}
> conn = self.get_connection(self._conn_id)
> if conn.port:
> conn_data['master'] = "{}:{}".format(conn.host, conn.port)
> else:
> conn_data['master'] = conn.host
> {code}
> Additionally, I think this driver status tracker should also be enabled for
> mesos and kubernetes with cluster mode since the *--status* argument supports
> all of these cluster managers. Refer to
> [this|https://github.com/apache/spark/blob/be867e8a9ee8fc5e4831521770f51793e9265550/core/src/main/scala/org/apache/spark/deploy/SparkSubmitArguments.scala#L543].
> For YARN cluster mode, I think we can use built-in commands from yarn itself,
> such as *yarn application -status *.
> Therefore, the *_build_track_driver_status_command* method should be updated
> accordingly to accommodate such a need, such as the following.
> {code:python}
> def _build_track_driver_status_command(self):
> # The driver id so we can poll for its status
> if not self._driver_id:
> raise AirflowException(
> "Invalid status: attempted to poll driver " +
> "status but no driver id is known. Giving up.")
> if self._connection['master'].startswith("spark://") or
>self._connection['master'].startswith("mesos://") or
>self._connection['master'].startswith("k8s://"):
> # standalone, mesos, kubernetes
> connection_cmd = self._get_spark_binary_path()
> connection_cmd += ["--master", self._connection['master']]
> connection_cmd += ["--status", self._driver_id]
> else:
> # yarn
> connection_cmd = ["yarn application -status"]
> connection_cmd += [self._driver_id]
> self.log.debug("Poll driver status cmd: %s", connection_cmd)
> return connection_cmd
> {code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Commented] (AIRFLOW-6214) Spark driver status tracking for standalone, YARN, Mesos and K8s with cluster deploy mode
[
https://issues.apache.org/jira/browse/AIRFLOW-6214?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16994276#comment-16994276
]
xifeng commented on AIRFLOW-6214:
-
yes, I agree, I think the conn.host should be only hostname, without scheme.
But I'm not sure why in testcase it is written as
host='spark://spark-standalone-master:6066'.
I just issued a PR: https://github.com/apache/airflow/pull/6795
> Spark driver status tracking for standalone, YARN, Mesos and K8s with cluster
> deploy mode
> -
>
> Key: AIRFLOW-6214
> URL: https://issues.apache.org/jira/browse/AIRFLOW-6214
> Project: Apache Airflow
> Issue Type: Improvement
> Components: hooks, operators
>Affects Versions: 1.10.6
>Reporter: Albertus Kelvin
>Assignee: xifeng
>Priority: Minor
>
> Based on the following code snippet:
> {code:python}
> def _resolve_should_track_driver_status(self):
> return ('spark://' in self._connection['master'] and
> self._connection['deploy_mode'] == 'cluster')
> {code}
>
> It seems that the above code will always return *False* because the master
> address for standalone cluster doesn't contain *spark://* as shown from the
> below code snippet.
> {code:python}
> conn = self.get_connection(self._conn_id)
> if conn.port:
> conn_data['master'] = "{}:{}".format(conn.host, conn.port)
> else:
> conn_data['master'] = conn.host
> {code}
> Additionally, I think this driver status tracker should also be enabled for
> mesos and kubernetes with cluster mode since the *--status* argument supports
> all of these cluster managers. Refer to
> [this|https://github.com/apache/spark/blob/be867e8a9ee8fc5e4831521770f51793e9265550/core/src/main/scala/org/apache/spark/deploy/SparkSubmitArguments.scala#L543].
> For YARN cluster mode, I think we can use built-in commands from yarn itself,
> such as *yarn application -status *.
> Therefore, the *_build_track_driver_status_command* method should be updated
> accordingly to accommodate such a need, such as the following.
> {code:python}
> def _build_track_driver_status_command(self):
> # The driver id so we can poll for its status
> if not self._driver_id:
> raise AirflowException(
> "Invalid status: attempted to poll driver " +
> "status but no driver id is known. Giving up.")
> if self._connection['master'].startswith("spark://") or
>self._connection['master'].startswith("mesos://") or
>self._connection['master'].startswith("k8s://"):
> # standalone, mesos, kubernetes
> connection_cmd = self._get_spark_binary_path()
> connection_cmd += ["--master", self._connection['master']]
> connection_cmd += ["--status", self._driver_id]
> else:
> # yarn
> connection_cmd = ["yarn application -status"]
> connection_cmd += [self._driver_id]
> self.log.debug("Poll driver status cmd: %s", connection_cmd)
> return connection_cmd
> {code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Commented] (AIRFLOW-6212) SparkSubmitHook failed to execute spark-submit to standalone cluster
[
https://issues.apache.org/jira/browse/AIRFLOW-6212?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16994260#comment-16994260
]
xifeng commented on AIRFLOW-6212:
-
Fix it with: https://github.com/apache/airflow/pull/6795
> SparkSubmitHook failed to execute spark-submit to standalone cluster
>
>
> Key: AIRFLOW-6212
> URL: https://issues.apache.org/jira/browse/AIRFLOW-6212
> Project: Apache Airflow
> Issue Type: Bug
> Components: hooks, operators
>Affects Versions: 1.10.6
>Reporter: Albertus Kelvin
>Assignee: xifeng
>Priority: Trivial
>
> I was trying to submit a pyspark job with spark-submit using
> SparkSubmitOperator. I already set up the master appropriately via
> environment variable (AIRFLOW_CONN_SPARK_DEFAULT). The value was something
> like *spark://host:port*.
> However, an exception occurred:
> {noformat}
> airflow.exceptions.AirflowException: Cannot execute: ['path/to/spark-submit',
> '--master', 'host:port', 'job.py']
> {noformat}
> Turns out that the master should have *spark://* preceding the host:port. I
> checked the code and found that this wasn't handled.
> {code:python}
> conn = self.get_connection(self._conn_id)
> if conn.port:
> conn_data['master'] = "{}:{}".format(conn.host, conn.port)
> else:
> conn_data['master'] = conn.host
> {code}
> I think the protocol should be added like the following.
> {code:python}
> conn_data['master'] = "spark://{}:{}".format(conn.host, conn.port)
> {code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [airflow] baolsen commented on a change in pull request #6773: [AIRFLOW-6038] AWS DataSync example_dags added
baolsen commented on a change in pull request #6773: [AIRFLOW-6038] AWS DataSync example_dags added URL: https://github.com/apache/airflow/pull/6773#discussion_r356971393 ## File path: airflow/providers/amazon/aws/operators/datasync.py ## @@ -27,25 +25,45 @@ from airflow.utils.decorators import apply_defaults -class AWSDataSyncCreateTaskOperator(BaseOperator): -r"""Create an AWS DataSync Task. +# pylint: disable=too-many-instance-attributes, too-many-arguments +class AWSDataSyncOperator(BaseOperator): +r"""Find, Create, Update, Execute and Delete AWS DataSync Tasks. + +If ``do_xcom_push`` is True, then the TaskArn and TaskExecutionArn which +were executed will be pushed to an XCom. -If there are existing Locations which match the specified -source and destination URIs then these will be used for the Task. -Otherwise, new Locations can be created automatically, -depending on input parameters. +.. seealso:: +For more information on how to use this operator, take a look at the guide: +:ref:`howto/operator:AWSDataSyncOperator` -If ``do_xcom_push`` is True, the TaskArn which is created -will be pushed to an XCom. +.. note:: There may be 0, 1, or many existing DataSync Tasks. The default +behavior is to create a new Task if there are 0, or execute the Task +if there was 1 Task, or fail if there were many Tasks. :param str aws_conn_id: AWS connection to use. -:param str source_location_uri: Source location URI. +:param int wait_for_task_execution: Time to wait between two +consecutive calls to check TaskExecution status. +:param str task_arn: AWS DataSync TaskArn to use. If None, then this operator will +attempt to either search for an existing Task or create a new Task. +:param str source_location_uri: Source location URI to search for. All DataSync +Tasks with a LocationArn with this URI will be considered. Example: ``smb://server/subdir`` -:param str destination_location_uri: Destination location URI. +:param str destination_location_uri: Destination location URI to search for. +All DataSync Tasks with a LocationArn with this URI will be considered. Example: ``s3://airflow_bucket/stuff`` -:param bool case_sensitive_location_search: Whether or not to do a +:param bool location_search_case_sensitive: Whether or not to do a Review comment: Happy with that suggestion, I will make it default as it is more intuitive. I will leave the option in the datasync_hook constructor, in case the user wants to change this default behavior. They can inherit and override the Operator methods if they want. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [airflow] baolsen commented on a change in pull request #6773: [AIRFLOW-6038] AWS DataSync example_dags added
baolsen commented on a change in pull request #6773: [AIRFLOW-6038] AWS
DataSync example_dags added
URL: https://github.com/apache/airflow/pull/6773#discussion_r356969219
##
File path:
airflow/providers/amazon/aws/example_dags/example_datasync_complex.py
##
@@ -0,0 +1,101 @@
+# Licensed to the Apache Software Foundation (ASF) under one
+# or more contributor license agreements. See the NOTICE file
+# distributed with this work for additional information
+# regarding copyright ownership. The ASF licenses this file
+# to you under the Apache License, Version 2.0 (the
+# "License"); you may not use this file except in compliance
+# with the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing,
+# software distributed under the License is distributed on an
+# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+# KIND, either express or implied. See the License for the
+# specific language governing permissions and limitations
+# under the License.
+"""
+This is an example dag for using `AWSDataSyncOperator` in a more complex
manner.
+
+- Try to get a TaskArn. If one exists, update it.
+- If no tasks exist, try to create a new DataSync Task.
+- If source and destination locations dont exist for the new task, create
them first
+- If many tasks exist, raise an Exception
+- After getting or creating a DataSync Task, run it
+
+This DAG relies on the following environment variables:
+
+* SOURCE_LOCATION_URI - Source location URI, usually on premisis SMB or NFS
+* DESTINATION_LOCATION_URI - Destination location URI, usually S3
+* CREATE_TASK_KWARGS - Passed to boto3.create_task(**kwargs)
+* CREATE_SOURCE_LOCATION_KWARGS - Passed to boto3.create_location(**kwargs)
+* CREATE_DESTINATION_LOCATION_KWARGS - Passed to
boto3.create_location(**kwargs)
+* UPDATE_TASK_KWARGS - Passed to boto3.update_task(**kwargs)
+"""
+
+import json
+from os import getenv
+
+from airflow import models, utils
+from airflow.providers.amazon.aws.operators.datasync import AWSDataSyncOperator
+
+# [START howto_operator_datasync_complex_args]
+SOURCE_LOCATION_URI = getenv(
+"SOURCE_LOCATION_URI", "smb://hostname/directory/")
+
+DESTINATION_LOCATION_URI = getenv(
+"DESTINATION_LOCATION_URI", "s3://mybucket/prefix")
+
+default_create_task_kwargs = '{"Name": "Created by Airflow"}'
+CREATE_TASK_KWARGS = json.loads(
+getenv("CREATE_TASK_KWARGS", default_create_task_kwargs)
+)
+
+default_create_source_location_kwargs = "{}"
+CREATE_SOURCE_LOCATION_KWARGS = json.loads(
+getenv("CREATE_SOURCE_LOCATION_KWARGS",
+ default_create_source_location_kwargs)
+)
+
+bucket_access_role_arn = (
+"arn:aws:iam::2223344:role/r-2223344-my-bucket-access-role"
+)
+default_destination_location_kwargs = """\
+{"S3BucketArn": "arn:aws:s3:::mybucket",
+"S3Config": {"BucketAccessRoleArn": bucket_access_role_arn}
+}"""
+CREATE_DESTINATION_LOCATION_KWARGS = json.loads(
+getenv("CREATE_DESTINATION_LOCATION_KWARGS",
+ default_destination_location_kwargs)
+)
+
+default_update_task_kwargs = '{"Name": "Updated by Airflow"}'
+UPDATE_TASK_KWARGS = json.loads(
+getenv("UPDATE_TASK_KWARGS", default_update_task_kwargs)
+)
+
+default_args = {"start_date": utils.dates.days_ago(1)}
+# [END howto_operator_datasync_complex_args]
+
+with models.DAG(
+"example_datasync_complex",
Review comment:
Agreed :) I'll change them to "example_1" and "example_2" to make it clearer.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[jira] [Comment Edited] (AIRFLOW-6214) Spark driver status tracking for standalone, YARN, Mesos and K8s with cluster deploy mode
[
https://issues.apache.org/jira/browse/AIRFLOW-6214?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16994238#comment-16994238
]
Albertus Kelvin edited comment on AIRFLOW-6214 at 12/12/19 5:44 AM:
hi [~dennisli], thanks for your comment. Really appreciate.
Just fyi, I set up the connection via environment variables and provided the
URI. But I think it should apply to db as well.
I investigated the *Connection* module (airflow.models.connection) further and
found that if we provide the URI (ex: spark://host:port), then the attributes
will be derived by parsing the URI.
When parsing the host
([code|https://github.com/apache/airflow/blob/master/airflow/models/connection.py#L137]),
the resulting value was only the hostname without the scheme.
Therefore, the *conn.host* in the following code will only contain the hostname.
{code:python}
conn = self.get_connection(self._conn_id)
if conn.port:
conn_data['master'] = "{}:{}".format(conn.host, conn.port)
else:
conn_data['master'] = conn.host
{code}
Since *conn* consists of several attributes, including scheme (conn_type), host
(host), and port (_port_), I think the *conn_data['master']* should be resolved
like:
{code:python}
conn = self.get_connection(self._conn_id)
if conn.port:
conn_data['master'] = "{}://{}:{}".format(conn.conn_type, conn.host,
conn.port)
else:
conn_data['master'] = "{}://{}".format(conn.conn_type, conn.host)
{code}
In addition to your note about the scheme should be put in the *host* (like in
the unit test), I think it is somewhat not relevant to how the *Connection*
module works. It also might result in some kinds of exception since the
*Connection* table has a dedicated column for *scheme* and *host*. Moreover, I
didn't find any method that parse the scheme from the host.
What do you think?
was (Author: albertus-kelvin):
hi [~dennisli], thanks for your comment. Really appreciate.
Just fyi, I set up the connection via environment variables and provided the
URI. But I think it should apply to db as well.
I investigated the *Connection* module (airflow.models.connection) further and
found that if we provide the URI (ex: spark://host:port), then the attributes
will be derived by parsing the URI.
When parsing the host
([code|https://github.com/apache/airflow/blob/master/airflow/models/connection.py#L137]),
the resulting value was only the hostname without the scheme.
Therefore, the *conn.host* in the following code will only contain the hostname.
{code:python}
conn = self.get_connection(self._conn_id)
if conn.port:
conn_data['master'] = "{}:{}".format(conn.host, conn.port)
else:
conn_data['master'] = conn.host
{code}
Since *conn* consists of several attributes, including scheme, host, and port,
I think the *conn_data['master']* should be resolved like:
{code:python}
conn = self.get_connection(self._conn_id)
if conn.port:
conn_data['master'] = "{}://{}:{}".format(conn.conn_type, conn.host,
conn.port)
else:
conn_data['master'] = "{}://{}".format(conn.conn_type, conn.host)
{code}
In addition to your note about the scheme should be put in the *host* (like in
the unit test), I think it is somewhat not relevant to how the *Connection*
module works. It also might result in some kinds of exception since the
*Connection* table has a dedicated column for *scheme* and *host*. Moreover, I
didn't find any method that parse the scheme from the host.
What do you think?
> Spark driver status tracking for standalone, YARN, Mesos and K8s with cluster
> deploy mode
> -
>
> Key: AIRFLOW-6214
> URL: https://issues.apache.org/jira/browse/AIRFLOW-6214
> Project: Apache Airflow
> Issue Type: Improvement
> Components: hooks, operators
>Affects Versions: 1.10.6
>Reporter: Albertus Kelvin
>Assignee: xifeng
>Priority: Minor
>
> Based on the following code snippet:
> {code:python}
> def _resolve_should_track_driver_status(self):
> return ('spark://' in self._connection['master'] and
> self._connection['deploy_mode'] == 'cluster')
> {code}
>
> It seems that the above code will always return *False* because the master
> address for standalone cluster doesn't contain *spark://* as shown from the
> below code snippet.
> {code:python}
> conn = self.get_connection(self._conn_id)
> if conn.port:
> conn_data['master'] = "{}:{}".format(conn.host, conn.port)
> else:
> conn_data['master'] = conn.host
> {code}
> Additionally, I think this driver status tracker should also be enabled for
> mesos and kubernetes with cluster mode since the *--status* argument supports
> all of these cluster managers. Refer to
>
[jira] [Commented] (AIRFLOW-6214) Spark driver status tracking for standalone, YARN, Mesos and K8s with cluster deploy mode
[
https://issues.apache.org/jira/browse/AIRFLOW-6214?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16994238#comment-16994238
]
Albertus Kelvin commented on AIRFLOW-6214:
--
hi [~dennisli], thanks for your comment. Really appreciate.
Just fyi, I set up the connection via environment variables and provided the
URI. But I think it should apply to db as well.
I investigated the *Connection* module (airflow.models.connection) further and
found that if we provide the URI (ex: spark://host:port), then the attributes
will be derived by parsing the URI.
When parsing the host
([code|https://github.com/apache/airflow/blob/master/airflow/models/connection.py#L137]),
the resulting value was only the hostname without the scheme.
Therefore, the *conn.host* in the following code will only contain the hostname.
{code:python}
conn = self.get_connection(self._conn_id)
if conn.port:
conn_data['master'] = "{}:{}".format(conn.host, conn.port)
else:
conn_data['master'] = conn.host
{code}
Since *conn* consists of several attributes, including scheme, host, and port,
I think the *conn_data['master']* should be resolved like:
{code:python}
conn = self.get_connection(self._conn_id)
if conn.port:
conn_data['master'] = "{}://{}:{}".format(conn.conn_type, conn.host,
conn.port)
else:
conn_data['master'] = "{}://{}".format(conn.conn_type, conn.host)
{code}
In addition to your note about the scheme should be put in the *host* (like in
the unit test), I think it is somewhat not relevant to how the *Connection*
module works. It also might result in some kinds of exception since the
*Connection* table has a dedicated column for *scheme* and *host*. Moreover, I
didn't find any method that parse the scheme from the host.
What do you think?
> Spark driver status tracking for standalone, YARN, Mesos and K8s with cluster
> deploy mode
> -
>
> Key: AIRFLOW-6214
> URL: https://issues.apache.org/jira/browse/AIRFLOW-6214
> Project: Apache Airflow
> Issue Type: Improvement
> Components: hooks, operators
>Affects Versions: 1.10.6
>Reporter: Albertus Kelvin
>Assignee: xifeng
>Priority: Minor
>
> Based on the following code snippet:
> {code:python}
> def _resolve_should_track_driver_status(self):
> return ('spark://' in self._connection['master'] and
> self._connection['deploy_mode'] == 'cluster')
> {code}
>
> It seems that the above code will always return *False* because the master
> address for standalone cluster doesn't contain *spark://* as shown from the
> below code snippet.
> {code:python}
> conn = self.get_connection(self._conn_id)
> if conn.port:
> conn_data['master'] = "{}:{}".format(conn.host, conn.port)
> else:
> conn_data['master'] = conn.host
> {code}
> Additionally, I think this driver status tracker should also be enabled for
> mesos and kubernetes with cluster mode since the *--status* argument supports
> all of these cluster managers. Refer to
> [this|https://github.com/apache/spark/blob/be867e8a9ee8fc5e4831521770f51793e9265550/core/src/main/scala/org/apache/spark/deploy/SparkSubmitArguments.scala#L543].
> For YARN cluster mode, I think we can use built-in commands from yarn itself,
> such as *yarn application -status *.
> Therefore, the *_build_track_driver_status_command* method should be updated
> accordingly to accommodate such a need, such as the following.
> {code:python}
> def _build_track_driver_status_command(self):
> # The driver id so we can poll for its status
> if not self._driver_id:
> raise AirflowException(
> "Invalid status: attempted to poll driver " +
> "status but no driver id is known. Giving up.")
> if self._connection['master'].startswith("spark://") or
>self._connection['master'].startswith("mesos://") or
>self._connection['master'].startswith("k8s://"):
> # standalone, mesos, kubernetes
> connection_cmd = self._get_spark_binary_path()
> connection_cmd += ["--master", self._connection['master']]
> connection_cmd += ["--status", self._driver_id]
> else:
> # yarn
> connection_cmd = ["yarn application -status"]
> connection_cmd += [self._driver_id]
> self.log.debug("Poll driver status cmd: %s", connection_cmd)
> return connection_cmd
> {code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [airflow] baolsen commented on issue #6773: [AIRFLOW-6038] AWS DataSync example_dags added
baolsen commented on issue #6773: [AIRFLOW-6038] AWS DataSync example_dags added URL: https://github.com/apache/airflow/pull/6773#issuecomment-564857060 Thanks for the great feedback @potiuk and @dimberman , I'll work through them now. A good opportunity for me to try some of the Git features suggested by @potiuk before :) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [airflow] vsoch commented on issue #4846: [AIRFLOW-4030] adding start to singularity for airflow
vsoch commented on issue #4846: [AIRFLOW-4030] adding start to singularity for airflow URL: https://github.com/apache/airflow/pull/4846#issuecomment-564847214 I thought so too! This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [airflow] pbranson commented on issue #4846: [AIRFLOW-4030] adding start to singularity for airflow
pbranson commented on issue #4846: [AIRFLOW-4030] adding start to singularity for airflow URL: https://github.com/apache/airflow/pull/4846#issuecomment-564846284 I would like to add some community support for this to be merged please We would make use of this for using airflow in the HPC context This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [airflow] codecov-io edited a comment on issue #6765: [AIRFLOW-5889] Fix polling for AWS Batch job status
codecov-io edited a comment on issue #6765: [AIRFLOW-5889] Fix polling for AWS Batch job status URL: https://github.com/apache/airflow/pull/6765#issuecomment-563889078 # [Codecov](https://codecov.io/gh/apache/airflow/pull/6765?src=pr=h1) Report > Merging [#6765](https://codecov.io/gh/apache/airflow/pull/6765?src=pr=desc) into [master](https://codecov.io/gh/apache/airflow/commit/0863d41254f9eea0bd66fd096dccf574fa041960?src=pr=desc) will **decrease** coverage by `0.01%`. > The diff coverage is `98.61%`. [](https://codecov.io/gh/apache/airflow/pull/6765?src=pr=tree) ```diff @@Coverage Diff@@ ## master #6765 +/- ## = - Coverage 84.32% 84.3% -0.02% = Files 672 672 Lines 38179 38210 +31 = + Hits32195 32214 +19 - Misses 59845996 +12 ``` | [Impacted Files](https://codecov.io/gh/apache/airflow/pull/6765?src=pr=tree) | Coverage Δ | | |---|---|---| | [airflow/contrib/operators/awsbatch\_operator.py](https://codecov.io/gh/apache/airflow/pull/6765/diff?src=pr=tree#diff-YWlyZmxvdy9jb250cmliL29wZXJhdG9ycy9hd3NiYXRjaF9vcGVyYXRvci5weQ==) | `95.83% <98.61%> (+17.18%)` | :arrow_up: | | [airflow/kubernetes/volume\_mount.py](https://codecov.io/gh/apache/airflow/pull/6765/diff?src=pr=tree#diff-YWlyZmxvdy9rdWJlcm5ldGVzL3ZvbHVtZV9tb3VudC5weQ==) | `44.44% <0%> (-55.56%)` | :arrow_down: | | [airflow/kubernetes/volume.py](https://codecov.io/gh/apache/airflow/pull/6765/diff?src=pr=tree#diff-YWlyZmxvdy9rdWJlcm5ldGVzL3ZvbHVtZS5weQ==) | `52.94% <0%> (-47.06%)` | :arrow_down: | | [airflow/kubernetes/pod\_launcher.py](https://codecov.io/gh/apache/airflow/pull/6765/diff?src=pr=tree#diff-YWlyZmxvdy9rdWJlcm5ldGVzL3BvZF9sYXVuY2hlci5weQ==) | `45.25% <0%> (-46.72%)` | :arrow_down: | | [airflow/kubernetes/refresh\_config.py](https://codecov.io/gh/apache/airflow/pull/6765/diff?src=pr=tree#diff-YWlyZmxvdy9rdWJlcm5ldGVzL3JlZnJlc2hfY29uZmlnLnB5) | `50.98% <0%> (-23.53%)` | :arrow_down: | | [...rflow/contrib/operators/kubernetes\_pod\_operator.py](https://codecov.io/gh/apache/airflow/pull/6765/diff?src=pr=tree#diff-YWlyZmxvdy9jb250cmliL29wZXJhdG9ycy9rdWJlcm5ldGVzX3BvZF9vcGVyYXRvci5weQ==) | `78.2% <0%> (-20.52%)` | :arrow_down: | | [airflow/utils/dag\_processing.py](https://codecov.io/gh/apache/airflow/pull/6765/diff?src=pr=tree#diff-YWlyZmxvdy91dGlscy9kYWdfcHJvY2Vzc2luZy5weQ==) | `87.42% <0%> (-0.39%)` | :arrow_down: | | [airflow/hooks/dbapi\_hook.py](https://codecov.io/gh/apache/airflow/pull/6765/diff?src=pr=tree#diff-YWlyZmxvdy9ob29rcy9kYmFwaV9ob29rLnB5) | `91.52% <0%> (+0.84%)` | :arrow_up: | | [airflow/models/connection.py](https://codecov.io/gh/apache/airflow/pull/6765/diff?src=pr=tree#diff-YWlyZmxvdy9tb2RlbHMvY29ubmVjdGlvbi5weQ==) | `68.96% <0%> (+0.98%)` | :arrow_up: | | [airflow/hooks/hive\_hooks.py](https://codecov.io/gh/apache/airflow/pull/6765/diff?src=pr=tree#diff-YWlyZmxvdy9ob29rcy9oaXZlX2hvb2tzLnB5) | `77.6% <0%> (+1.52%)` | :arrow_up: | | ... and [3 more](https://codecov.io/gh/apache/airflow/pull/6765/diff?src=pr=tree-more) | | -- [Continue to review full report at Codecov](https://codecov.io/gh/apache/airflow/pull/6765?src=pr=continue). > **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta) > `Δ = absolute (impact)`, `ø = not affected`, `? = missing data` > Powered by [Codecov](https://codecov.io/gh/apache/airflow/pull/6765?src=pr=footer). Last update [0863d41...c52463e](https://codecov.io/gh/apache/airflow/pull/6765?src=pr=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [airflow] codecov-io edited a comment on issue #6765: [AIRFLOW-5889] Fix polling for AWS Batch job status
codecov-io edited a comment on issue #6765: [AIRFLOW-5889] Fix polling for AWS Batch job status URL: https://github.com/apache/airflow/pull/6765#issuecomment-563889078 # [Codecov](https://codecov.io/gh/apache/airflow/pull/6765?src=pr=h1) Report > Merging [#6765](https://codecov.io/gh/apache/airflow/pull/6765?src=pr=desc) into [master](https://codecov.io/gh/apache/airflow/commit/0863d41254f9eea0bd66fd096dccf574fa041960?src=pr=desc) will **decrease** coverage by `0.01%`. > The diff coverage is `98.61%`. [](https://codecov.io/gh/apache/airflow/pull/6765?src=pr=tree) ```diff @@Coverage Diff@@ ## master #6765 +/- ## = - Coverage 84.32% 84.3% -0.02% = Files 672 672 Lines 38179 38210 +31 = + Hits32195 32214 +19 - Misses 59845996 +12 ``` | [Impacted Files](https://codecov.io/gh/apache/airflow/pull/6765?src=pr=tree) | Coverage Δ | | |---|---|---| | [airflow/contrib/operators/awsbatch\_operator.py](https://codecov.io/gh/apache/airflow/pull/6765/diff?src=pr=tree#diff-YWlyZmxvdy9jb250cmliL29wZXJhdG9ycy9hd3NiYXRjaF9vcGVyYXRvci5weQ==) | `95.83% <98.61%> (+17.18%)` | :arrow_up: | | [airflow/kubernetes/volume\_mount.py](https://codecov.io/gh/apache/airflow/pull/6765/diff?src=pr=tree#diff-YWlyZmxvdy9rdWJlcm5ldGVzL3ZvbHVtZV9tb3VudC5weQ==) | `44.44% <0%> (-55.56%)` | :arrow_down: | | [airflow/kubernetes/volume.py](https://codecov.io/gh/apache/airflow/pull/6765/diff?src=pr=tree#diff-YWlyZmxvdy9rdWJlcm5ldGVzL3ZvbHVtZS5weQ==) | `52.94% <0%> (-47.06%)` | :arrow_down: | | [airflow/kubernetes/pod\_launcher.py](https://codecov.io/gh/apache/airflow/pull/6765/diff?src=pr=tree#diff-YWlyZmxvdy9rdWJlcm5ldGVzL3BvZF9sYXVuY2hlci5weQ==) | `45.25% <0%> (-46.72%)` | :arrow_down: | | [airflow/kubernetes/refresh\_config.py](https://codecov.io/gh/apache/airflow/pull/6765/diff?src=pr=tree#diff-YWlyZmxvdy9rdWJlcm5ldGVzL3JlZnJlc2hfY29uZmlnLnB5) | `50.98% <0%> (-23.53%)` | :arrow_down: | | [...rflow/contrib/operators/kubernetes\_pod\_operator.py](https://codecov.io/gh/apache/airflow/pull/6765/diff?src=pr=tree#diff-YWlyZmxvdy9jb250cmliL29wZXJhdG9ycy9rdWJlcm5ldGVzX3BvZF9vcGVyYXRvci5weQ==) | `78.2% <0%> (-20.52%)` | :arrow_down: | | [airflow/utils/dag\_processing.py](https://codecov.io/gh/apache/airflow/pull/6765/diff?src=pr=tree#diff-YWlyZmxvdy91dGlscy9kYWdfcHJvY2Vzc2luZy5weQ==) | `87.42% <0%> (-0.39%)` | :arrow_down: | | [airflow/hooks/dbapi\_hook.py](https://codecov.io/gh/apache/airflow/pull/6765/diff?src=pr=tree#diff-YWlyZmxvdy9ob29rcy9kYmFwaV9ob29rLnB5) | `91.52% <0%> (+0.84%)` | :arrow_up: | | [airflow/models/connection.py](https://codecov.io/gh/apache/airflow/pull/6765/diff?src=pr=tree#diff-YWlyZmxvdy9tb2RlbHMvY29ubmVjdGlvbi5weQ==) | `68.96% <0%> (+0.98%)` | :arrow_up: | | [airflow/hooks/hive\_hooks.py](https://codecov.io/gh/apache/airflow/pull/6765/diff?src=pr=tree#diff-YWlyZmxvdy9ob29rcy9oaXZlX2hvb2tzLnB5) | `77.6% <0%> (+1.52%)` | :arrow_up: | | ... and [3 more](https://codecov.io/gh/apache/airflow/pull/6765/diff?src=pr=tree-more) | | -- [Continue to review full report at Codecov](https://codecov.io/gh/apache/airflow/pull/6765?src=pr=continue). > **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta) > `Δ = absolute (impact)`, `ø = not affected`, `? = missing data` > Powered by [Codecov](https://codecov.io/gh/apache/airflow/pull/6765?src=pr=footer). Last update [0863d41...c52463e](https://codecov.io/gh/apache/airflow/pull/6765?src=pr=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [airflow] codecov-io edited a comment on issue #6765: [AIRFLOW-5889] Fix polling for AWS Batch job status
codecov-io edited a comment on issue #6765: [AIRFLOW-5889] Fix polling for AWS Batch job status URL: https://github.com/apache/airflow/pull/6765#issuecomment-563889078 # [Codecov](https://codecov.io/gh/apache/airflow/pull/6765?src=pr=h1) Report > Merging [#6765](https://codecov.io/gh/apache/airflow/pull/6765?src=pr=desc) into [master](https://codecov.io/gh/apache/airflow/commit/0863d41254f9eea0bd66fd096dccf574fa041960?src=pr=desc) will **decrease** coverage by `0.01%`. > The diff coverage is `98.61%`. [](https://codecov.io/gh/apache/airflow/pull/6765?src=pr=tree) ```diff @@Coverage Diff@@ ## master #6765 +/- ## = - Coverage 84.32% 84.3% -0.02% = Files 672 672 Lines 38179 38210 +31 = + Hits32195 32214 +19 - Misses 59845996 +12 ``` | [Impacted Files](https://codecov.io/gh/apache/airflow/pull/6765?src=pr=tree) | Coverage Δ | | |---|---|---| | [airflow/contrib/operators/awsbatch\_operator.py](https://codecov.io/gh/apache/airflow/pull/6765/diff?src=pr=tree#diff-YWlyZmxvdy9jb250cmliL29wZXJhdG9ycy9hd3NiYXRjaF9vcGVyYXRvci5weQ==) | `95.83% <98.61%> (+17.18%)` | :arrow_up: | | [airflow/kubernetes/volume\_mount.py](https://codecov.io/gh/apache/airflow/pull/6765/diff?src=pr=tree#diff-YWlyZmxvdy9rdWJlcm5ldGVzL3ZvbHVtZV9tb3VudC5weQ==) | `44.44% <0%> (-55.56%)` | :arrow_down: | | [airflow/kubernetes/volume.py](https://codecov.io/gh/apache/airflow/pull/6765/diff?src=pr=tree#diff-YWlyZmxvdy9rdWJlcm5ldGVzL3ZvbHVtZS5weQ==) | `52.94% <0%> (-47.06%)` | :arrow_down: | | [airflow/kubernetes/pod\_launcher.py](https://codecov.io/gh/apache/airflow/pull/6765/diff?src=pr=tree#diff-YWlyZmxvdy9rdWJlcm5ldGVzL3BvZF9sYXVuY2hlci5weQ==) | `45.25% <0%> (-46.72%)` | :arrow_down: | | [airflow/kubernetes/refresh\_config.py](https://codecov.io/gh/apache/airflow/pull/6765/diff?src=pr=tree#diff-YWlyZmxvdy9rdWJlcm5ldGVzL3JlZnJlc2hfY29uZmlnLnB5) | `50.98% <0%> (-23.53%)` | :arrow_down: | | [...rflow/contrib/operators/kubernetes\_pod\_operator.py](https://codecov.io/gh/apache/airflow/pull/6765/diff?src=pr=tree#diff-YWlyZmxvdy9jb250cmliL29wZXJhdG9ycy9rdWJlcm5ldGVzX3BvZF9vcGVyYXRvci5weQ==) | `78.2% <0%> (-20.52%)` | :arrow_down: | | [airflow/utils/dag\_processing.py](https://codecov.io/gh/apache/airflow/pull/6765/diff?src=pr=tree#diff-YWlyZmxvdy91dGlscy9kYWdfcHJvY2Vzc2luZy5weQ==) | `87.42% <0%> (-0.39%)` | :arrow_down: | | [airflow/hooks/dbapi\_hook.py](https://codecov.io/gh/apache/airflow/pull/6765/diff?src=pr=tree#diff-YWlyZmxvdy9ob29rcy9kYmFwaV9ob29rLnB5) | `91.52% <0%> (+0.84%)` | :arrow_up: | | [airflow/models/connection.py](https://codecov.io/gh/apache/airflow/pull/6765/diff?src=pr=tree#diff-YWlyZmxvdy9tb2RlbHMvY29ubmVjdGlvbi5weQ==) | `68.96% <0%> (+0.98%)` | :arrow_up: | | [airflow/hooks/hive\_hooks.py](https://codecov.io/gh/apache/airflow/pull/6765/diff?src=pr=tree#diff-YWlyZmxvdy9ob29rcy9oaXZlX2hvb2tzLnB5) | `77.6% <0%> (+1.52%)` | :arrow_up: | | ... and [3 more](https://codecov.io/gh/apache/airflow/pull/6765/diff?src=pr=tree-more) | | -- [Continue to review full report at Codecov](https://codecov.io/gh/apache/airflow/pull/6765?src=pr=continue). > **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta) > `Δ = absolute (impact)`, `ø = not affected`, `? = missing data` > Powered by [Codecov](https://codecov.io/gh/apache/airflow/pull/6765?src=pr=footer). Last update [0863d41...c52463e](https://codecov.io/gh/apache/airflow/pull/6765?src=pr=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Commented] (AIRFLOW-4184) Add an AWS Athena Helper to insert into table
[
https://issues.apache.org/jira/browse/AIRFLOW-4184?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16994113#comment-16994113
]
Junyoung Park commented on AIRFLOW-4184:
Now Athena support INSERT INTO clause.
[https://docs.aws.amazon.com/athena/latest/ug/insert-into.html]
> Add an AWS Athena Helper to insert into table
> -
>
> Key: AIRFLOW-4184
> URL: https://issues.apache.org/jira/browse/AIRFLOW-4184
> Project: Apache Airflow
> Issue Type: New Feature
>Reporter: Bryan Yang
>Assignee: Bryan Yang
>Priority: Major
>
> AWS Athena does not support {{inert into table}} clause now, but this
> function is really critical for ETL.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [airflow] codecov-io edited a comment on issue #6794: [AIRFLOW-6231] Display DAG run conf in the graph view
codecov-io edited a comment on issue #6794: [AIRFLOW-6231] Display DAG run conf in the graph view URL: https://github.com/apache/airflow/pull/6794#issuecomment-564805241 # [Codecov](https://codecov.io/gh/apache/airflow/pull/6794?src=pr=h1) Report > Merging [#6794](https://codecov.io/gh/apache/airflow/pull/6794?src=pr=desc) into [master](https://codecov.io/gh/apache/airflow/commit/3bf5195e9e32cc9bfff4e0c1b3f958740225f444?src=pr=desc) will **decrease** coverage by `75.06%`. > The diff coverage is `0%`. [](https://codecov.io/gh/apache/airflow/pull/6794?src=pr=tree) ```diff @@Coverage Diff @@ ## master #6794 +/- ## == - Coverage 84.54% 9.48% -75.07% == Files 672 671-1 Lines 38175 38169-6 == - Hits322753619-28656 - Misses 5900 34550+28650 ``` | [Impacted Files](https://codecov.io/gh/apache/airflow/pull/6794?src=pr=tree) | Coverage Δ | | |---|---|---| | [airflow/www/views.py](https://codecov.io/gh/apache/airflow/pull/6794/diff?src=pr=tree#diff-YWlyZmxvdy93d3cvdmlld3MucHk=) | `0% <0%> (-75.94%)` | :arrow_down: | | [...low/contrib/operators/wasb\_delete\_blob\_operator.py](https://codecov.io/gh/apache/airflow/pull/6794/diff?src=pr=tree#diff-YWlyZmxvdy9jb250cmliL29wZXJhdG9ycy93YXNiX2RlbGV0ZV9ibG9iX29wZXJhdG9yLnB5) | `0% <0%> (-100%)` | :arrow_down: | | [...flow/contrib/example\_dags/example\_qubole\_sensor.py](https://codecov.io/gh/apache/airflow/pull/6794/diff?src=pr=tree#diff-YWlyZmxvdy9jb250cmliL2V4YW1wbGVfZGFncy9leGFtcGxlX3F1Ym9sZV9zZW5zb3IucHk=) | `0% <0%> (-100%)` | :arrow_down: | | [airflow/example\_dags/subdags/subdag.py](https://codecov.io/gh/apache/airflow/pull/6794/diff?src=pr=tree#diff-YWlyZmxvdy9leGFtcGxlX2RhZ3Mvc3ViZGFncy9zdWJkYWcucHk=) | `0% <0%> (-100%)` | :arrow_down: | | [airflow/gcp/sensors/bigquery\_dts.py](https://codecov.io/gh/apache/airflow/pull/6794/diff?src=pr=tree#diff-YWlyZmxvdy9nY3Avc2Vuc29ycy9iaWdxdWVyeV9kdHMucHk=) | `0% <0%> (-100%)` | :arrow_down: | | [airflow/operators/dummy\_operator.py](https://codecov.io/gh/apache/airflow/pull/6794/diff?src=pr=tree#diff-YWlyZmxvdy9vcGVyYXRvcnMvZHVtbXlfb3BlcmF0b3IucHk=) | `0% <0%> (-100%)` | :arrow_down: | | [airflow/gcp/operators/text\_to\_speech.py](https://codecov.io/gh/apache/airflow/pull/6794/diff?src=pr=tree#diff-YWlyZmxvdy9nY3Avb3BlcmF0b3JzL3RleHRfdG9fc3BlZWNoLnB5) | `0% <0%> (-100%)` | :arrow_down: | | [...ample\_dags/example\_emr\_job\_flow\_automatic\_steps.py](https://codecov.io/gh/apache/airflow/pull/6794/diff?src=pr=tree#diff-YWlyZmxvdy9jb250cmliL2V4YW1wbGVfZGFncy9leGFtcGxlX2Vtcl9qb2JfZmxvd19hdXRvbWF0aWNfc3RlcHMucHk=) | `0% <0%> (-100%)` | :arrow_down: | | [...irflow/providers/apache/cassandra/sensors/table.py](https://codecov.io/gh/apache/airflow/pull/6794/diff?src=pr=tree#diff-YWlyZmxvdy9wcm92aWRlcnMvYXBhY2hlL2Nhc3NhbmRyYS9zZW5zb3JzL3RhYmxlLnB5) | `0% <0%> (-100%)` | :arrow_down: | | [...contrib/example\_dags/example\_papermill\_operator.py](https://codecov.io/gh/apache/airflow/pull/6794/diff?src=pr=tree#diff-YWlyZmxvdy9jb250cmliL2V4YW1wbGVfZGFncy9leGFtcGxlX3BhcGVybWlsbF9vcGVyYXRvci5weQ==) | `0% <0%> (-100%)` | :arrow_down: | | ... and [596 more](https://codecov.io/gh/apache/airflow/pull/6794/diff?src=pr=tree-more) | | -- [Continue to review full report at Codecov](https://codecov.io/gh/apache/airflow/pull/6794?src=pr=continue). > **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta) > `Δ = absolute (impact)`, `ø = not affected`, `? = missing data` > Powered by [Codecov](https://codecov.io/gh/apache/airflow/pull/6794?src=pr=footer). Last update [3bf5195...8e856e2](https://codecov.io/gh/apache/airflow/pull/6794?src=pr=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [airflow] codecov-io commented on issue #6794: [AIRFLOW-6231] Display DAG run conf in the graph view
codecov-io commented on issue #6794: [AIRFLOW-6231] Display DAG run conf in the graph view URL: https://github.com/apache/airflow/pull/6794#issuecomment-564805241 # [Codecov](https://codecov.io/gh/apache/airflow/pull/6794?src=pr=h1) Report > Merging [#6794](https://codecov.io/gh/apache/airflow/pull/6794?src=pr=desc) into [master](https://codecov.io/gh/apache/airflow/commit/3bf5195e9e32cc9bfff4e0c1b3f958740225f444?src=pr=desc) will **decrease** coverage by `75.06%`. > The diff coverage is `0%`. [](https://codecov.io/gh/apache/airflow/pull/6794?src=pr=tree) ```diff @@Coverage Diff @@ ## master #6794 +/- ## == - Coverage 84.54% 9.48% -75.07% == Files 672 671-1 Lines 38175 38169-6 == - Hits322753619-28656 - Misses 5900 34550+28650 ``` | [Impacted Files](https://codecov.io/gh/apache/airflow/pull/6794?src=pr=tree) | Coverage Δ | | |---|---|---| | [airflow/www/views.py](https://codecov.io/gh/apache/airflow/pull/6794/diff?src=pr=tree#diff-YWlyZmxvdy93d3cvdmlld3MucHk=) | `0% <0%> (-75.94%)` | :arrow_down: | | [...low/contrib/operators/wasb\_delete\_blob\_operator.py](https://codecov.io/gh/apache/airflow/pull/6794/diff?src=pr=tree#diff-YWlyZmxvdy9jb250cmliL29wZXJhdG9ycy93YXNiX2RlbGV0ZV9ibG9iX29wZXJhdG9yLnB5) | `0% <0%> (-100%)` | :arrow_down: | | [...flow/contrib/example\_dags/example\_qubole\_sensor.py](https://codecov.io/gh/apache/airflow/pull/6794/diff?src=pr=tree#diff-YWlyZmxvdy9jb250cmliL2V4YW1wbGVfZGFncy9leGFtcGxlX3F1Ym9sZV9zZW5zb3IucHk=) | `0% <0%> (-100%)` | :arrow_down: | | [airflow/example\_dags/subdags/subdag.py](https://codecov.io/gh/apache/airflow/pull/6794/diff?src=pr=tree#diff-YWlyZmxvdy9leGFtcGxlX2RhZ3Mvc3ViZGFncy9zdWJkYWcucHk=) | `0% <0%> (-100%)` | :arrow_down: | | [airflow/gcp/sensors/bigquery\_dts.py](https://codecov.io/gh/apache/airflow/pull/6794/diff?src=pr=tree#diff-YWlyZmxvdy9nY3Avc2Vuc29ycy9iaWdxdWVyeV9kdHMucHk=) | `0% <0%> (-100%)` | :arrow_down: | | [airflow/operators/dummy\_operator.py](https://codecov.io/gh/apache/airflow/pull/6794/diff?src=pr=tree#diff-YWlyZmxvdy9vcGVyYXRvcnMvZHVtbXlfb3BlcmF0b3IucHk=) | `0% <0%> (-100%)` | :arrow_down: | | [airflow/gcp/operators/text\_to\_speech.py](https://codecov.io/gh/apache/airflow/pull/6794/diff?src=pr=tree#diff-YWlyZmxvdy9nY3Avb3BlcmF0b3JzL3RleHRfdG9fc3BlZWNoLnB5) | `0% <0%> (-100%)` | :arrow_down: | | [...ample\_dags/example\_emr\_job\_flow\_automatic\_steps.py](https://codecov.io/gh/apache/airflow/pull/6794/diff?src=pr=tree#diff-YWlyZmxvdy9jb250cmliL2V4YW1wbGVfZGFncy9leGFtcGxlX2Vtcl9qb2JfZmxvd19hdXRvbWF0aWNfc3RlcHMucHk=) | `0% <0%> (-100%)` | :arrow_down: | | [...irflow/providers/apache/cassandra/sensors/table.py](https://codecov.io/gh/apache/airflow/pull/6794/diff?src=pr=tree#diff-YWlyZmxvdy9wcm92aWRlcnMvYXBhY2hlL2Nhc3NhbmRyYS9zZW5zb3JzL3RhYmxlLnB5) | `0% <0%> (-100%)` | :arrow_down: | | [...contrib/example\_dags/example\_papermill\_operator.py](https://codecov.io/gh/apache/airflow/pull/6794/diff?src=pr=tree#diff-YWlyZmxvdy9jb250cmliL2V4YW1wbGVfZGFncy9leGFtcGxlX3BhcGVybWlsbF9vcGVyYXRvci5weQ==) | `0% <0%> (-100%)` | :arrow_down: | | ... and [596 more](https://codecov.io/gh/apache/airflow/pull/6794/diff?src=pr=tree-more) | | -- [Continue to review full report at Codecov](https://codecov.io/gh/apache/airflow/pull/6794?src=pr=continue). > **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta) > `Δ = absolute (impact)`, `ø = not affected`, `? = missing data` > Powered by [Codecov](https://codecov.io/gh/apache/airflow/pull/6794?src=pr=footer). Last update [3bf5195...8e856e2](https://codecov.io/gh/apache/airflow/pull/6794?src=pr=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [airflow] darrenleeweber commented on a change in pull request #6765: [AIRFLOW-5889] Fix polling for AWS Batch job status
darrenleeweber commented on a change in pull request #6765: [AIRFLOW-5889] Fix
polling for AWS Batch job status
URL: https://github.com/apache/airflow/pull/6765#discussion_r356908610
##
File path: airflow/contrib/operators/awsbatch_operator.py
##
@@ -156,32 +179,68 @@ def _wait_for_task_ended(self):
waiter.config.max_attempts = sys.maxsize # timeout is managed by
airflow
waiter.wait(jobs=[self.jobId])
except ValueError:
-# If waiter not available use expo
+self._poll_for_task_ended()
-# Allow a batch job some time to spin up. A random interval
-# decreases the chances of exceeding an AWS API throttle
-# limit when there are many concurrent tasks.
-pause = randint(5, 30)
+def _poll_for_task_ended(self):
+"""
+Poll for task status using a exponential backoff
-retries = 1
-while retries <= self.max_retries:
-self.log.info('AWS Batch job (%s) status check (%d of %d) in
the next %.2f seconds',
- self.jobId, retries, self.max_retries, pause)
-sleep(pause)
+* docs.aws.amazon.com/general/latest/gr/api-retries.html
+"""
+# Allow a batch job some time to spin up. A random interval
+# decreases the chances of exceeding an AWS API throttle
+# limit when there are many concurrent tasks.
+pause = randint(5, 30)
Review comment:
The details on how quickly a batch job can possibly start are complex and
captured in some JIRA tickets related to that change (see commit message for
JIRA ticket). That was all reviewed in a prior PR, so I'd prefer not to
revisit that every time. Details are to be found in:
- https://issues.apache.org/jira/browse/AIRFLOW-5218
- https://github.com/apache/airflow/pull/5825
If it should be configured, please open a new JIRA issue for that
enhancement and propose how to handle/allow the configuration options. My best
guess is that it might be a callable, but I don't want to confuse the focus of
this PR with that enhancement.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [airflow] darrenleeweber commented on a change in pull request #6765: [WIP][AIRFLOW-5889] Fix polling for AWS Batch job status
darrenleeweber commented on a change in pull request #6765: [WIP][AIRFLOW-5889]
Fix polling for AWS Batch job status
URL: https://github.com/apache/airflow/pull/6765#discussion_r356908842
##
File path: airflow/contrib/operators/awsbatch_operator.py
##
@@ -156,32 +179,68 @@ def _wait_for_task_ended(self):
waiter.config.max_attempts = sys.maxsize # timeout is managed by
airflow
waiter.wait(jobs=[self.jobId])
except ValueError:
-# If waiter not available use expo
+self._poll_for_task_ended()
-# Allow a batch job some time to spin up. A random interval
-# decreases the chances of exceeding an AWS API throttle
-# limit when there are many concurrent tasks.
-pause = randint(5, 30)
+def _poll_for_task_ended(self):
+"""
+Poll for task status using a exponential backoff
-retries = 1
-while retries <= self.max_retries:
-self.log.info('AWS Batch job (%s) status check (%d of %d) in
the next %.2f seconds',
- self.jobId, retries, self.max_retries, pause)
-sleep(pause)
+* docs.aws.amazon.com/general/latest/gr/api-retries.html
+"""
+# Allow a batch job some time to spin up. A random interval
+# decreases the chances of exceeding an AWS API throttle
+# limit when there are many concurrent tasks.
+pause = randint(5, 30)
+
+retries = 1
+while retries <= self.max_retries:
+self.log.info(
+'AWS Batch job (%s) status check (%d of %d) in the next %.2f
seconds',
+self.jobId,
+retries,
+self.max_retries,
+pause,
+)
+sleep(pause)
+
+response = self._get_job_status()
+status = response['jobs'][-1]['status'] # check last job status
+self.log.info('AWS Batch job (%s) status: %s', self.jobId, status)
+
+# jobStatus:
'SUBMITTED'|'PENDING'|'RUNNABLE'|'STARTING'|'RUNNING'|'SUCCEEDED'|'FAILED'
+if status in ['SUCCEEDED', 'FAILED']:
+break
+
+retries += 1
+pause = 1 + pow(retries * 0.3, 2)
+
+def _get_job_status(self) -> Optional[dict]:
+"""
+Get job description
+*
https://docs.aws.amazon.com/batch/latest/APIReference/API_DescribeJobs.html
+"""
+tries = 0
+while tries <= 10:
+tries += 1
+try:
response = self.client.describe_jobs(jobs=[self.jobId])
-status = response['jobs'][-1]['status']
-self.log.info('AWS Batch job (%s) status: %s', self.jobId,
status)
-if status in ['SUCCEEDED', 'FAILED']:
-break
-
-retries += 1
-pause = 1 + pow(retries * 0.3, 2)
+if response and response.get('jobs'):
+return response
+except botocore.exceptions.ClientError as err:
+response = err.response
+self.log.info('Failed to get job status: ', response)
+if response:
+if response.get('Error', {}).get('Code') ==
'TooManyRequestsException':
+self.log.info('Continue for TooManyRequestsException')
+sleep(randint(1, 10)) # avoid excess requests with a
random pause
+continue
+
+self.log.error('Failed to get job status: ', self.jobId)
Review comment:
The latest commits should resolve this.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [airflow] darrenleeweber commented on a change in pull request #6765: [WIP][AIRFLOW-5889] Fix polling for AWS Batch job status
darrenleeweber commented on a change in pull request #6765: [WIP][AIRFLOW-5889]
Fix polling for AWS Batch job status
URL: https://github.com/apache/airflow/pull/6765#discussion_r356908610
##
File path: airflow/contrib/operators/awsbatch_operator.py
##
@@ -156,32 +179,68 @@ def _wait_for_task_ended(self):
waiter.config.max_attempts = sys.maxsize # timeout is managed by
airflow
waiter.wait(jobs=[self.jobId])
except ValueError:
-# If waiter not available use expo
+self._poll_for_task_ended()
-# Allow a batch job some time to spin up. A random interval
-# decreases the chances of exceeding an AWS API throttle
-# limit when there are many concurrent tasks.
-pause = randint(5, 30)
+def _poll_for_task_ended(self):
+"""
+Poll for task status using a exponential backoff
-retries = 1
-while retries <= self.max_retries:
-self.log.info('AWS Batch job (%s) status check (%d of %d) in
the next %.2f seconds',
- self.jobId, retries, self.max_retries, pause)
-sleep(pause)
+* docs.aws.amazon.com/general/latest/gr/api-retries.html
+"""
+# Allow a batch job some time to spin up. A random interval
+# decreases the chances of exceeding an AWS API throttle
+# limit when there are many concurrent tasks.
+pause = randint(5, 30)
Review comment:
The details on how quickly a batch job can possibly start are complex and
captured in some JIRA tickets related to that change (see commit message for
JIRA ticket). That was all reviewed in a prior PR, so I'd prefer not to
revisit that every time. If it must be configured, please open a new JIRA
issue for it and propose how to handle/allow the configuration options.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [airflow] konqui0 commented on a change in pull request #6767: [AIRFLOW-6208] Implement fileno in StreamLogWriter
konqui0 commented on a change in pull request #6767: [AIRFLOW-6208] Implement fileno in StreamLogWriter URL: https://github.com/apache/airflow/pull/6767#discussion_r356894253 ## File path: airflow/utils/log/logging_mixin.py ## @@ -116,6 +116,13 @@ def isatty(self): """ return False +def fileno(self): +""" +Returns the stdout file descriptor 1. +For compatibility reasons e.g python subprocess module stdout redirection. +""" +return 1 Review comment: Is there a way to identify if the stream is stderr within the StreamLogWriter? That's true, the only alternative I can think of would be creating a pipe, returning its fd and writing everything written to that pipe. I'm not sure if this would be an acceptable solution / workaround. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [airflow] dimberman commented on issue #6643: [AIRFLOW-6040] Fix KubernetesJobWatcher Read time out error
dimberman commented on issue #6643: [AIRFLOW-6040] Fix KubernetesJobWatcher Read time out error URL: https://github.com/apache/airflow/pull/6643#issuecomment-564787657 @ashb @davlum bumping this ticket as I would like to get this merged. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Commented] (AIRFLOW-6084) Add info endpoint to experimental api
[ https://issues.apache.org/jira/browse/AIRFLOW-6084?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16994007#comment-16994007 ] ASF GitHub Bot commented on AIRFLOW-6084: - dimberman commented on pull request #6651: [AIRFLOW-6084] Add info endpoint to experimental api URL: https://github.com/apache/airflow/pull/6651 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > Add info endpoint to experimental api > - > > Key: AIRFLOW-6084 > URL: https://issues.apache.org/jira/browse/AIRFLOW-6084 > Project: Apache Airflow > Issue Type: Improvement > Components: api >Affects Versions: 1.10.6 >Reporter: Alexandre YANG >Assignee: Alexandre YANG >Priority: Minor > > Add version info endpoint to experimental api. > Use case: version info is useful for audit/monitoring purpose. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (AIRFLOW-6084) Add info endpoint to experimental api
[ https://issues.apache.org/jira/browse/AIRFLOW-6084?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16994008#comment-16994008 ] ASF subversion and git services commented on AIRFLOW-6084: -- Commit 0863d41254f9eea0bd66fd096dccf574fa041960 in airflow's branch refs/heads/master from Alexandre Yang [ https://gitbox.apache.org/repos/asf?p=airflow.git;h=0863d41 ] [AIRFLOW-6084] Add info endpoint to experimental api (#6651) > Add info endpoint to experimental api > - > > Key: AIRFLOW-6084 > URL: https://issues.apache.org/jira/browse/AIRFLOW-6084 > Project: Apache Airflow > Issue Type: Improvement > Components: api >Affects Versions: 1.10.6 >Reporter: Alexandre YANG >Assignee: Alexandre YANG >Priority: Minor > > Add version info endpoint to experimental api. > Use case: version info is useful for audit/monitoring purpose. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [airflow] dimberman merged pull request #6651: [AIRFLOW-6084] Add info endpoint to experimental api
dimberman merged pull request #6651: [AIRFLOW-6084] Add info endpoint to experimental api URL: https://github.com/apache/airflow/pull/6651 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [airflow] dimberman commented on issue #6791: [AIRFLOW-XXX] Add link to XCom section in concepts.rst
dimberman commented on issue #6791: [AIRFLOW-XXX] Add link to XCom section in concepts.rst URL: https://github.com/apache/airflow/pull/6791#issuecomment-564786532 @pradeepbhadani please create a JIRA and add to the title of this PR This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Work started] (AIRFLOW-6231) Show DAG Run conf in graph view
[ https://issues.apache.org/jira/browse/AIRFLOW-6231?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Work on AIRFLOW-6231 started by Daniel Huang. - > Show DAG Run conf in graph view > --- > > Key: AIRFLOW-6231 > URL: https://issues.apache.org/jira/browse/AIRFLOW-6231 > Project: Apache Airflow > Issue Type: Improvement > Components: webserver >Affects Versions: 1.10.6 >Reporter: Daniel Huang >Assignee: Daniel Huang >Priority: Trivial > > A DAG run's conf (from triggered DAGs) isn't surfaced anywhere other than in > the database itself. Would be handy to show it when one exists. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (AIRFLOW-6231) Show DAG Run conf in graph view
[
https://issues.apache.org/jira/browse/AIRFLOW-6231?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16993998#comment-16993998
]
ASF GitHub Bot commented on AIRFLOW-6231:
-
dhuang commented on pull request #6794: [AIRFLOW-6231] Display DAG run conf in
the graph view
URL: https://github.com/apache/airflow/pull/6794
Make sure you have checked _all_ steps below.
### Jira
- [x] My PR addresses the following [Airflow
Jira](https://issues.apache.org/jira/browse/AIRFLOW/) issues and references
them in the PR title. For example, "\[AIRFLOW-XXX\] My Airflow PR"
- https://issues.apache.org/jira/browse/AIRFLOW-6231
### Description
- [x] Here are some details about my PR, including screenshots of any UI
changes:
- Show DAG run conf in the UI since it's not surfaced anywhere else. Text
box won't show unless a conf is specified.
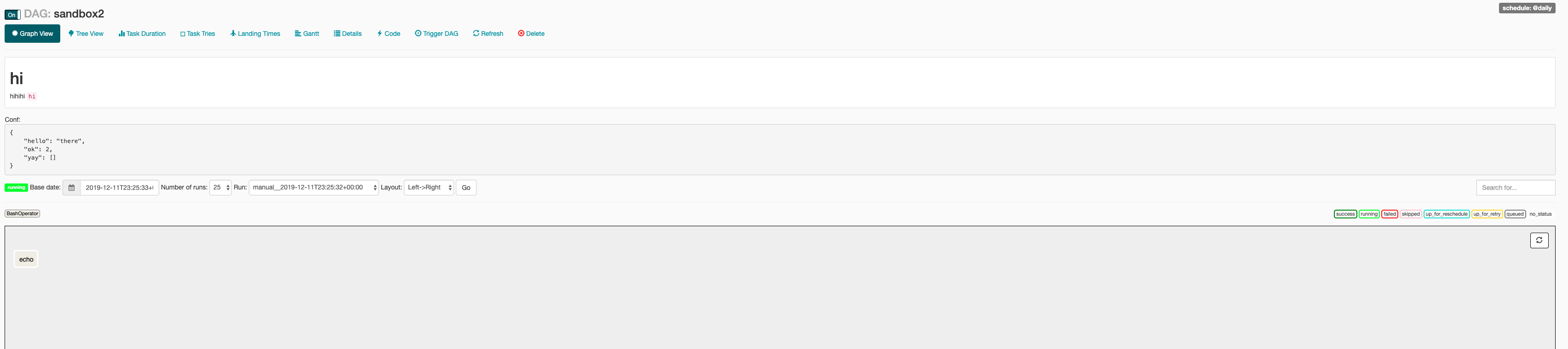
### Tests
- [ ] My PR adds the following unit tests __OR__ does not need testing for
this extremely good reason:
### Commits
- [x] My commits all reference Jira issues in their subject lines, and I
have squashed multiple commits if they address the same issue. In addition, my
commits follow the guidelines from "[How to write a good git commit
message](http://chris.beams.io/posts/git-commit/)":
1. Subject is separated from body by a blank line
1. Subject is limited to 50 characters (not including Jira issue reference)
1. Subject does not end with a period
1. Subject uses the imperative mood ("add", not "adding")
1. Body wraps at 72 characters
1. Body explains "what" and "why", not "how"
### Documentation
- [ ] In case of new functionality, my PR adds documentation that describes
how to use it.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> Show DAG Run conf in graph view
> ---
>
> Key: AIRFLOW-6231
> URL: https://issues.apache.org/jira/browse/AIRFLOW-6231
> Project: Apache Airflow
> Issue Type: Improvement
> Components: webserver
>Affects Versions: 1.10.6
>Reporter: Daniel Huang
>Assignee: Daniel Huang
>Priority: Trivial
>
> A DAG run's conf (from triggered DAGs) isn't surfaced anywhere other than in
> the database itself. Would be handy to show it when one exists.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [airflow] dhuang opened a new pull request #6794: [AIRFLOW-6231] Display DAG run conf in the graph view
dhuang opened a new pull request #6794: [AIRFLOW-6231] Display DAG run conf in
the graph view
URL: https://github.com/apache/airflow/pull/6794
Make sure you have checked _all_ steps below.
### Jira
- [x] My PR addresses the following [Airflow
Jira](https://issues.apache.org/jira/browse/AIRFLOW/) issues and references
them in the PR title. For example, "\[AIRFLOW-XXX\] My Airflow PR"
- https://issues.apache.org/jira/browse/AIRFLOW-6231
### Description
- [x] Here are some details about my PR, including screenshots of any UI
changes:
- Show DAG run conf in the UI since it's not surfaced anywhere else. Text
box won't show unless a conf is specified.

### Tests
- [ ] My PR adds the following unit tests __OR__ does not need testing for
this extremely good reason:
### Commits
- [x] My commits all reference Jira issues in their subject lines, and I
have squashed multiple commits if they address the same issue. In addition, my
commits follow the guidelines from "[How to write a good git commit
message](http://chris.beams.io/posts/git-commit/)":
1. Subject is separated from body by a blank line
1. Subject is limited to 50 characters (not including Jira issue reference)
1. Subject does not end with a period
1. Subject uses the imperative mood ("add", not "adding")
1. Body wraps at 72 characters
1. Body explains "what" and "why", not "how"
### Documentation
- [ ] In case of new functionality, my PR adds documentation that describes
how to use it.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [airflow] konqui0 commented on a change in pull request #6767: [AIRFLOW-6208] Implement fileno in StreamLogWriter
konqui0 commented on a change in pull request #6767: [AIRFLOW-6208] Implement fileno in StreamLogWriter URL: https://github.com/apache/airflow/pull/6767#discussion_r356894253 ## File path: airflow/utils/log/logging_mixin.py ## @@ -116,6 +116,13 @@ def isatty(self): """ return False +def fileno(self): +""" +Returns the stdout file descriptor 1. +For compatibility reasons e.g python subprocess module stdout redirection. +""" +return 1 Review comment: Is there a way to identify if the stream is stderr? That's true, the only alternative I can think of would be creating a pipe, returning its fd and writing everything written to that pipe. I'm not sure if this would be an acceptable solution / workaround. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Created] (AIRFLOW-6231) Show DAG Run conf in graph view
Daniel Huang created AIRFLOW-6231: - Summary: Show DAG Run conf in graph view Key: AIRFLOW-6231 URL: https://issues.apache.org/jira/browse/AIRFLOW-6231 Project: Apache Airflow Issue Type: Improvement Components: webserver Affects Versions: 1.10.6 Reporter: Daniel Huang Assignee: Daniel Huang A DAG run's conf (from triggered DAGs) isn't surfaced anywhere other than in the database itself. Would be handy to show it when one exists. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (AIRFLOW-6211) Document using conda virtualenv for development
[ https://issues.apache.org/jira/browse/AIRFLOW-6211?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16993988#comment-16993988 ] ASF subversion and git services commented on AIRFLOW-6211: -- Commit 51bfc302dea863967effca9eda8e565df189f689 in airflow's branch refs/heads/v1-10-test from Darren Weber [ https://gitbox.apache.org/repos/asf?p=airflow.git;h=51bfc30 ] [AIRFLOW-6211] Use conda for local virtualenv (#6766) (cherry picked from commit 0f21e9b5a7914c859490de7a54b3daf382d6675d) > Document using conda virtualenv for development > --- > > Key: AIRFLOW-6211 > URL: https://issues.apache.org/jira/browse/AIRFLOW-6211 > Project: Apache Airflow > Issue Type: Improvement > Components: documentation >Affects Versions: 1.10.6 >Reporter: Darren Weber >Assignee: Darren Weber >Priority: Minor > > Add documentation on how to use a conda virtual environment for developing > airflow. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (AIRFLOW-6226) warning.catch_warning should not be used in our code
[ https://issues.apache.org/jira/browse/AIRFLOW-6226?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16993989#comment-16993989 ] ASF subversion and git services commented on AIRFLOW-6226: -- Commit 01f163cbc2fc47e41391f0ce611d53be96423059 in airflow's branch refs/heads/v1-10-test from Jarek Potiuk [ https://gitbox.apache.org/repos/asf?p=airflow.git;h=01f163c ] [AIRFLOW-6226] Always reset warnings in tests > warning.catch_warning should not be used in our code > - > > Key: AIRFLOW-6226 > URL: https://issues.apache.org/jira/browse/AIRFLOW-6226 > Project: Apache Airflow > Issue Type: Bug > Components: ci >Affects Versions: 2.0.0, 1.10.6 >Reporter: Jarek Potiuk >Priority: Major > > Sometime we use warning.catch_warnings in our code directly. > As explained in [https://blog.ionelmc.ro/2013/06/26/testing-python-warnings/] > warnings are cached in "__warningregistry__" and if warning is emitted, it is > not emited for the second time. > > Therefore warning.catch_warnings should never be used directly in our test > code. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (AIRFLOW-6018) Display task instance in table during backfilling
[ https://issues.apache.org/jira/browse/AIRFLOW-6018?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16993984#comment-16993984 ] ASF subversion and git services commented on AIRFLOW-6018: -- Commit f9ed9b36e089a7822c3b3691b63dc534625bd37b in airflow's branch refs/heads/v1-10-test from Kamil Breguła [ https://gitbox.apache.org/repos/asf?p=airflow.git;h=f9ed9b3 ] [AIRFLOW-6018] Display task instance in table during backfilling (#6612) * [AIRFLOW-6018] Display task instance in table during backfilling (cherry picked from commit da088b3b9f7e54397c4e4242f1933e20151ae47b) > Display task instance in table during backfilling > - > > Key: AIRFLOW-6018 > URL: https://issues.apache.org/jira/browse/AIRFLOW-6018 > Project: Apache Airflow > Issue Type: Bug > Components: core >Affects Versions: 1.10.6 >Reporter: Kamil Bregula >Priority: Major > Fix For: 1.10.7 > > -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (AIRFLOW-6191) Adjust pytest verbosity in CI and local environment
[ https://issues.apache.org/jira/browse/AIRFLOW-6191?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16993986#comment-16993986 ] ASF subversion and git services commented on AIRFLOW-6191: -- Commit 6a56973bb537d3f62d6c8f8dcedab5838c4a999d in airflow's branch refs/heads/v1-10-test from Tomek [ https://gitbox.apache.org/repos/asf?p=airflow.git;h=6a56973 ] [AIRFLOW-6191] Adjust pytest verbosity in CI and local environment (#6746) (cherry picked from commit d0879257d02a06738093045717e1c711443a94b2) > Adjust pytest verbosity in CI and local environment > --- > > Key: AIRFLOW-6191 > URL: https://issues.apache.org/jira/browse/AIRFLOW-6191 > Project: Apache Airflow > Issue Type: Improvement > Components: tests >Affects Versions: 2.0.0 >Reporter: Tomasz Urbaszek >Priority: Major > Fix For: 2.0.0 > > -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (AIRFLOW-6189) Reduce the maximum test duration to 8 minutes
[ https://issues.apache.org/jira/browse/AIRFLOW-6189?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16993983#comment-16993983 ] ASF subversion and git services commented on AIRFLOW-6189: -- Commit de46d862d4675e15822520aa4a82dd5483a4b07f in airflow's branch refs/heads/v1-10-test from Kamil Breguła [ https://gitbox.apache.org/repos/asf?p=airflow.git;h=de46d86 ] [AIRFLOW-6189] Reduce the maximum test duration to 8 minutes (#6744) (cherry picked from commit a873de4366e43dee9d1d5b3ef019ab3234545fbf) > Reduce the maximum test duration to 8 minutes > - > > Key: AIRFLOW-6189 > URL: https://issues.apache.org/jira/browse/AIRFLOW-6189 > Project: Apache Airflow > Issue Type: Bug > Components: tests >Affects Versions: 1.10.6 >Reporter: Kamil Bregula >Priority: Major > Fix For: 1.10.7 > > -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (AIRFLOW-6018) Display task instance in table during backfilling
[ https://issues.apache.org/jira/browse/AIRFLOW-6018?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16993985#comment-16993985 ] ASF subversion and git services commented on AIRFLOW-6018: -- Commit f9ed9b36e089a7822c3b3691b63dc534625bd37b in airflow's branch refs/heads/v1-10-test from Kamil Breguła [ https://gitbox.apache.org/repos/asf?p=airflow.git;h=f9ed9b3 ] [AIRFLOW-6018] Display task instance in table during backfilling (#6612) * [AIRFLOW-6018] Display task instance in table during backfilling (cherry picked from commit da088b3b9f7e54397c4e4242f1933e20151ae47b) > Display task instance in table during backfilling > - > > Key: AIRFLOW-6018 > URL: https://issues.apache.org/jira/browse/AIRFLOW-6018 > Project: Apache Airflow > Issue Type: Bug > Components: core >Affects Versions: 1.10.6 >Reporter: Kamil Bregula >Priority: Major > Fix For: 1.10.7 > > -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (AIRFLOW-6216) Allow pytests to be run without "tests"
[ https://issues.apache.org/jira/browse/AIRFLOW-6216?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16993987#comment-16993987 ] ASF subversion and git services commented on AIRFLOW-6216: -- Commit 83c9b4efbb614d330be731fa0c22571063e0e8ae in airflow's branch refs/heads/v1-10-test from Jarek Potiuk [ https://gitbox.apache.org/repos/asf?p=airflow.git;h=83c9b4e ] [AIRFLOW-6216] Allow pytests to be run without "tests" (#6770) With this change you should be able to simply run `pytest` to run all the tests in the main airflow directory. This consist of two changes: * moving pytest.ini to the main airflow directory * skipping collecting kubernetes tests when ENV != kubernetes (cherry picked from commit 239d51ed31f9607e192d1e1c5a997dd03304b870) > Allow pytests to be run without "tests" > --- > > Key: AIRFLOW-6216 > URL: https://issues.apache.org/jira/browse/AIRFLOW-6216 > Project: Apache Airflow > Issue Type: Improvement > Components: ci >Affects Versions: 2.0.0, 1.10.7 >Reporter: Jarek Potiuk >Priority: Major > Fix For: 1.10.7 > > > With this change you should be able to simply run `pytest` to run all the > tests in the main airflow directory. > This consist of two changes: > * moving pytest.ini to the main airflow directory > * skipping collecting kubernetes tests when ENV != kubernetes -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (AIRFLOW-1076) Support getting variable by string in templates
[
https://issues.apache.org/jira/browse/AIRFLOW-1076?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16993968#comment-16993968
]
ASF GitHub Bot commented on AIRFLOW-1076:
-
dhuang commented on pull request #6793: [AIRFLOW-1076] Add get method for
template variable accessor
URL: https://github.com/apache/airflow/pull/6793
Support getting variables in templates by string. This is necessary when
fetching variables with characters not allowed in a class attribute
name. We can then also support returning default values when a variable does
not exist.
Original PR went stale, https://github.com/apache/airflow/pull/2223.
Make sure you have checked _all_ steps below.
### Jira
- [x] My PR addresses the following [Airflow
Jira](https://issues.apache.org/jira/browse/AIRFLOW/) issues and references
them in the PR title. For example, "\[AIRFLOW-XXX\] My Airflow PR"
- https://issues.apache.org/jira/browse/AIRFLOW-1076
### Description
- [x] Here are some details about my PR, including screenshots of any UI
changes:
- See above.
### Tests
- [x] My PR adds the following unit tests __OR__ does not need testing for
this extremely good reason:
- Added unit tests for calling `var.value.get()` and `var.json.get()`,
with or without default
### Commits
- [x] My commits all reference Jira issues in their subject lines, and I
have squashed multiple commits if they address the same issue. In addition, my
commits follow the guidelines from "[How to write a good git commit
message](http://chris.beams.io/posts/git-commit/)":
1. Subject is separated from body by a blank line
1. Subject is limited to 50 characters (not including Jira issue reference)
1. Subject does not end with a period
1. Subject uses the imperative mood ("add", not "adding")
1. Body wraps at 72 characters
1. Body explains "what" and "why", not "how"
### Documentation
- [x] In case of new functionality, my PR adds documentation that describes
how to use it.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> Support getting variable by string in templates
> ---
>
> Key: AIRFLOW-1076
> URL: https://issues.apache.org/jira/browse/AIRFLOW-1076
> Project: Apache Airflow
> Issue Type: Improvement
>Reporter: Daniel Huang
>Assignee: Daniel Huang
>Priority: Minor
>
> Currently, one can fetch variables in templates with {{ var.value.foo }}. But
> that doesn't work if the variable key has a character you can't use as an
> attribute, like ":" or "-".
> Should provide alternative method of {{ var.value.get('foo:bar') }}. Can then
> also supply a default value if the variable is not found. This also allows
> you to fetch the variable specified in another jinja variable (probably not
> common use case).
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [airflow] dhuang commented on issue #2223: [AIRFLOW-1076] Add get method for template variable accessor
dhuang commented on issue #2223: [AIRFLOW-1076] Add get method for template variable accessor URL: https://github.com/apache/airflow/pull/2223#issuecomment-564772309 Re-opened a PR in https://github.com/apache/airflow/pull/6793. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [airflow] dhuang opened a new pull request #6793: [AIRFLOW-1076] Add get method for template variable accessor
dhuang opened a new pull request #6793: [AIRFLOW-1076] Add get method for
template variable accessor
URL: https://github.com/apache/airflow/pull/6793
Support getting variables in templates by string. This is necessary when
fetching variables with characters not allowed in a class attribute
name. We can then also support returning default values when a variable does
not exist.
Original PR went stale, https://github.com/apache/airflow/pull/2223.
Make sure you have checked _all_ steps below.
### Jira
- [x] My PR addresses the following [Airflow
Jira](https://issues.apache.org/jira/browse/AIRFLOW/) issues and references
them in the PR title. For example, "\[AIRFLOW-XXX\] My Airflow PR"
- https://issues.apache.org/jira/browse/AIRFLOW-1076
### Description
- [x] Here are some details about my PR, including screenshots of any UI
changes:
- See above.
### Tests
- [x] My PR adds the following unit tests __OR__ does not need testing for
this extremely good reason:
- Added unit tests for calling `var.value.get()` and `var.json.get()`,
with or without default
### Commits
- [x] My commits all reference Jira issues in their subject lines, and I
have squashed multiple commits if they address the same issue. In addition, my
commits follow the guidelines from "[How to write a good git commit
message](http://chris.beams.io/posts/git-commit/)":
1. Subject is separated from body by a blank line
1. Subject is limited to 50 characters (not including Jira issue reference)
1. Subject does not end with a period
1. Subject uses the imperative mood ("add", not "adding")
1. Body wraps at 72 characters
1. Body explains "what" and "why", not "how"
### Documentation
- [x] In case of new functionality, my PR adds documentation that describes
how to use it.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[jira] [Comment Edited] (AIRFLOW-6207) Dag run twice in airflow
[ https://issues.apache.org/jira/browse/AIRFLOW-6207?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16993931#comment-16993931 ] anilkumar edited comment on AIRFLOW-6207 at 12/11/19 10:07 PM: --- I have attached my production dags images i hope it will help. Also Please do check the cron expression. was (Author: anilkumar13): I have attached my production dags images i hope it will help. > Dag run twice in airflow > > > Key: AIRFLOW-6207 > URL: https://issues.apache.org/jira/browse/AIRFLOW-6207 > Project: Apache Airflow > Issue Type: Bug > Components: DagRun >Affects Versions: 1.10.6 >Reporter: anilkumar >Priority: Critical > Attachments: airflow1.PNG, airflow10.png, airflow11.PNG, > airflow2.PNG, airflow3.PNG, airflow4.PNG, airflow5.PNG, airflow6.PNG, > airflow7.PNG, airflow8.PNG, airflow9.PNG > > > [!https://user-images.githubusercontent.com/26398961/70459068-67356780-1ad9-11ea-86a8-44d1bbfb574d.png!|https://user-images.githubusercontent.com/26398961/70459068-67356780-1ad9-11ea-86a8-44d1bbfb574d.png] > As you can see the dag xyz_dag run twice a day and XYZ dag is the scheduled > dag, not manual trigger for the first run it runs at 5:10:16 and the second > run it ran at 5:10:58 similarly this behavior has been observed for my all > 400 dags. I don't know why this behavior has occurred and I don't know how > this can be solved any help will be appreciated. below I have shared > xyx_dag.py file. > [!https://user-images.githubusercontent.com/26398961/70460387-30ad1c00-1adc-11ea-8241-ce3dd6d7556c.png!|https://user-images.githubusercontent.com/26398961/70460387-30ad1c00-1adc-11ea-8241-ce3dd6d7556c.png] -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (AIRFLOW-6207) Dag run twice in airflow
[ https://issues.apache.org/jira/browse/AIRFLOW-6207?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16993931#comment-16993931 ] anilkumar commented on AIRFLOW-6207: I have attached my production dags images i hope it will help. > Dag run twice in airflow > > > Key: AIRFLOW-6207 > URL: https://issues.apache.org/jira/browse/AIRFLOW-6207 > Project: Apache Airflow > Issue Type: Bug > Components: DagRun >Affects Versions: 1.10.6 >Reporter: anilkumar >Priority: Critical > Attachments: airflow1.PNG, airflow10.png, airflow11.PNG, > airflow2.PNG, airflow3.PNG, airflow4.PNG, airflow5.PNG, airflow6.PNG, > airflow7.PNG, airflow8.PNG, airflow9.PNG > > > [!https://user-images.githubusercontent.com/26398961/70459068-67356780-1ad9-11ea-86a8-44d1bbfb574d.png!|https://user-images.githubusercontent.com/26398961/70459068-67356780-1ad9-11ea-86a8-44d1bbfb574d.png] > As you can see the dag xyz_dag run twice a day and XYZ dag is the scheduled > dag, not manual trigger for the first run it runs at 5:10:16 and the second > run it ran at 5:10:58 similarly this behavior has been observed for my all > 400 dags. I don't know why this behavior has occurred and I don't know how > this can be solved any help will be appreciated. below I have shared > xyx_dag.py file. > [!https://user-images.githubusercontent.com/26398961/70460387-30ad1c00-1adc-11ea-8241-ce3dd6d7556c.png!|https://user-images.githubusercontent.com/26398961/70460387-30ad1c00-1adc-11ea-8241-ce3dd6d7556c.png] -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Updated] (AIRFLOW-6207) Dag run twice in airflow
[ https://issues.apache.org/jira/browse/AIRFLOW-6207?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] anilkumar updated AIRFLOW-6207: --- Attachment: airflow11.PNG airflow10.png airflow9.PNG airflow8.PNG airflow7.PNG airflow6.PNG airflow5.PNG airflow4.PNG airflow3.PNG airflow2.PNG airflow1.PNG > Dag run twice in airflow > > > Key: AIRFLOW-6207 > URL: https://issues.apache.org/jira/browse/AIRFLOW-6207 > Project: Apache Airflow > Issue Type: Bug > Components: DagRun >Affects Versions: 1.10.6 >Reporter: anilkumar >Priority: Critical > Attachments: airflow1.PNG, airflow10.png, airflow11.PNG, > airflow2.PNG, airflow3.PNG, airflow4.PNG, airflow5.PNG, airflow6.PNG, > airflow7.PNG, airflow8.PNG, airflow9.PNG > > > [!https://user-images.githubusercontent.com/26398961/70459068-67356780-1ad9-11ea-86a8-44d1bbfb574d.png!|https://user-images.githubusercontent.com/26398961/70459068-67356780-1ad9-11ea-86a8-44d1bbfb574d.png] > As you can see the dag xyz_dag run twice a day and XYZ dag is the scheduled > dag, not manual trigger for the first run it runs at 5:10:16 and the second > run it ran at 5:10:58 similarly this behavior has been observed for my all > 400 dags. I don't know why this behavior has occurred and I don't know how > this can be solved any help will be appreciated. below I have shared > xyx_dag.py file. > [!https://user-images.githubusercontent.com/26398961/70460387-30ad1c00-1adc-11ea-8241-ce3dd6d7556c.png!|https://user-images.githubusercontent.com/26398961/70460387-30ad1c00-1adc-11ea-8241-ce3dd6d7556c.png] -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Updated] (AIRFLOW-6207) Dag run twice in airflow
[ https://issues.apache.org/jira/browse/AIRFLOW-6207?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] anilkumar updated AIRFLOW-6207: --- Attachment: airflow1.PNG > Dag run twice in airflow > > > Key: AIRFLOW-6207 > URL: https://issues.apache.org/jira/browse/AIRFLOW-6207 > Project: Apache Airflow > Issue Type: Bug > Components: DagRun >Affects Versions: 1.10.6 >Reporter: anilkumar >Priority: Critical > > [!https://user-images.githubusercontent.com/26398961/70459068-67356780-1ad9-11ea-86a8-44d1bbfb574d.png!|https://user-images.githubusercontent.com/26398961/70459068-67356780-1ad9-11ea-86a8-44d1bbfb574d.png] > As you can see the dag xyz_dag run twice a day and XYZ dag is the scheduled > dag, not manual trigger for the first run it runs at 5:10:16 and the second > run it ran at 5:10:58 similarly this behavior has been observed for my all > 400 dags. I don't know why this behavior has occurred and I don't know how > this can be solved any help will be appreciated. below I have shared > xyx_dag.py file. > [!https://user-images.githubusercontent.com/26398961/70460387-30ad1c00-1adc-11ea-8241-ce3dd6d7556c.png!|https://user-images.githubusercontent.com/26398961/70460387-30ad1c00-1adc-11ea-8241-ce3dd6d7556c.png] -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Updated] (AIRFLOW-6207) Dag run twice in airflow
[ https://issues.apache.org/jira/browse/AIRFLOW-6207?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] anilkumar updated AIRFLOW-6207: --- Attachment: (was: airflow1.PNG) > Dag run twice in airflow > > > Key: AIRFLOW-6207 > URL: https://issues.apache.org/jira/browse/AIRFLOW-6207 > Project: Apache Airflow > Issue Type: Bug > Components: DagRun >Affects Versions: 1.10.6 >Reporter: anilkumar >Priority: Critical > > [!https://user-images.githubusercontent.com/26398961/70459068-67356780-1ad9-11ea-86a8-44d1bbfb574d.png!|https://user-images.githubusercontent.com/26398961/70459068-67356780-1ad9-11ea-86a8-44d1bbfb574d.png] > As you can see the dag xyz_dag run twice a day and XYZ dag is the scheduled > dag, not manual trigger for the first run it runs at 5:10:16 and the second > run it ran at 5:10:58 similarly this behavior has been observed for my all > 400 dags. I don't know why this behavior has occurred and I don't know how > this can be solved any help will be appreciated. below I have shared > xyx_dag.py file. > [!https://user-images.githubusercontent.com/26398961/70460387-30ad1c00-1adc-11ea-8241-ce3dd6d7556c.png!|https://user-images.githubusercontent.com/26398961/70460387-30ad1c00-1adc-11ea-8241-ce3dd6d7556c.png] -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [airflow] antonymayi commented on issue #6088: [AIRFLOW-5349] Add schedulername option for KubernetesPodOperator
antonymayi commented on issue #6088: [AIRFLOW-5349] Add schedulername option for KubernetesPodOperator URL: https://github.com/apache/airflow/pull/6088#issuecomment-564752633 > @antonymayi I don't think you meant to change 1043 files for this PR. ah, sorry, bad rebase... fixed This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Commented] (AIRFLOW-203) Scheduler fails to reliably schedule tasks when many dag runs are triggered
[
https://issues.apache.org/jira/browse/AIRFLOW-203?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16993910#comment-16993910
]
Nidhi commented on AIRFLOW-203:
---
I am facing the same issue as I have around 60,000 tasks inside one DAG. When I
trigger the dag it is not scheduling my tasks and DAG is staying into Running
state. Please let me know if you know how to solve it. I am working with Celery
Executor and tried to change "dagbag_import_timeout" and "max_threads" but
nothing is working for my case.
Any help to solve this issue will be appreciated.
> Scheduler fails to reliably schedule tasks when many dag runs are triggered
> ---
>
> Key: AIRFLOW-203
> URL: https://issues.apache.org/jira/browse/AIRFLOW-203
> Project: Apache Airflow
> Issue Type: Bug
> Components: scheduler
>Affects Versions: 1.7.1.2
>Reporter: Sergei Iakhnin
>Priority: Major
> Attachments: airflow.cfg, airflow_scheduler_non_working.log,
> airflow_scheduler_working.log
>
>
> Using Airflow with Celery, Rabbitmq, and Postgres backend. Running 1 master
> node and 115 worker nodes, each with 8 cores. The workflow consists of series
> of 27 tasks, some of which are nearly instantaneous and some take hours to
> complete. Dag runs are manually triggered, about 3000 at a time, resulting in
> roughly 75 000 tasks.
> My observations are that the scheduling behaviour is extremely inconsistent,
> i.e. about 1000 tasks get scheduled and executed and then no new tasks get
> scheduled after that. Sometimes it is enough to restart the scheduler for new
> tasks to get scheduled, sometimes the scheduler and worker services need to
> be restarted multiple times to get any progress. When I look at the scheduler
> output it seems to be chugging away at trying to schedule tasks with messages
> like:
> "2016-06-01 11:28:25,908] {base_executor.py:34} INFO - Adding to queue:
> airflow run ..."
> However, these tasks do not show up in queued status on the UI and don't
> actually get scheduled out to the workers (nor make it into the rabbitmq
> queue, or the task_instance table).
> It is unclear what may be causing this behaviour as no errors are produced
> anywhere. The impact is especially high when short-running tasks are
> concerned because the cluster should be able to blow through them within a
> couple of minutes, but instead it takes hours of manual restarts to get
> through them.
> I'm happy to share logs or any other useful debug output as desired.
> Thanks in advance.
> Sergei.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Commented] (AIRFLOW-3909) cant read log file for previous tries with multiply celery workers
[
https://issues.apache.org/jira/browse/AIRFLOW-3909?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16993909#comment-16993909
]
Nidhi commented on AIRFLOW-3909:
I faced the same issues. This issue is solved , you can try following links to
resolve this issue:
[https://github.com/puckel/docker-airflow/issues/44]
[https://github.com/apache/airflow/pull/3036/commits/127d21f1078063b8f13d23074a48c026106e0028#diff-d496b62128eacd68ed88d779ebd2f0d9]
> cant read log file for previous tries with multiply celery workers
> --
>
> Key: AIRFLOW-3909
> URL: https://issues.apache.org/jira/browse/AIRFLOW-3909
> Project: Apache Airflow
> Issue Type: Bug
> Components: logging
>Affects Versions: 1.10.2
>Reporter: Vitaliy Okulov
>Priority: Major
>
> With 1.10.2 version i have a error when try to read log via web interface for
> job that have multiply tries, and some of this tries executed on different
> celery worker than the first one.
> As example:
>
> {code:java}
> *** Log file does not exist:
> /usr/local/airflow/logs/php_firebot_log_2/php_firebot_log_task/2019-02-13T20:55:00+00:00/2.log
> *** Fetching from:
> http://airdafworker2:8793/log/php_firebot_log_2/php_firebot_log_task/2019-02-13T20:55:00+00:00/2.log
> *** Failed to fetch log file from worker. 404 Client Error: NOT FOUND for
> url:
> http://airdafworker2:8793/log/php_firebot_log_2/php_firebot_log_task/2019-02-13T20:55:00+00:00/2.log
> {code}
> But this task was executed on airdafworker1 worker, and log file exist on
> this host.
>
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Comment Edited] (AIRFLOW-5506) Airflow scheduler stuck
[
https://issues.apache.org/jira/browse/AIRFLOW-5506?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16993899#comment-16993899
]
Nidhi edited comment on AIRFLOW-5506 at 12/11/19 9:11 PM:
--
I am facing the same issue as I have around 60,000 tasks inside one DAG. When I
trigger the dag it is not scheduling my tasks and DAG is staying into Running
state. The DAG stays into Running state for 2 or 3 days without scheduling the
tasks without even going into queued state and in case of Celery workers , they
are not even receiving the task which I have triggered.
Please let me know if you know how to solve it. I am working with Celery
Executor and tried to change "dagbag_import_timeout" and "max_threads" but
nothing is working for my case.
was (Author: trivedi):
I am facing the same issue as I have around 60,000 tasks inside one DAG. When I
trigger the dag it is not scheduling my tasks and DAG is staying into Running
state. The DAG stays into Running state for 2 or 3 days without scheduling the
tasks amd in case of Celery workers , they are not even receiving the task
which I have triggered.
Please let me know if you know how to solve it. I am working with Celery
Executor and tried to change "dagbag_import_timeout" and "max_threads" but
nothing is working for my case.
> Airflow scheduler stuck
> ---
>
> Key: AIRFLOW-5506
> URL: https://issues.apache.org/jira/browse/AIRFLOW-5506
> Project: Apache Airflow
> Issue Type: Bug
> Components: scheduler
>Affects Versions: 1.10.4, 1.10.5
>Reporter: t oo
>Priority: Major
>
> re-post of
> [https://stackoverflow.com/questions/57713394/airflow-scheduler-stuck] and
> slack discussion
>
>
> I'm testing the use of Airflow, and after triggering a (seemingly) large
> number of DAGs at the same time, it seems to just fail to schedule anything
> and starts killing processes. These are the logs the scheduler prints:
> {{[2019-08-29 11:17:13,542] \{scheduler_job.py:214} WARNING - Killing PID
> 199809
> [2019-08-29 11:17:13,544] \{scheduler_job.py:214} WARNING - Killing PID 199809
> [2019-08-29 11:17:44,614] \{scheduler_job.py:214} WARNING - Killing PID 2992
> [2019-08-29 11:17:44,614] \{scheduler_job.py:214} WARNING - Killing PID 2992
> [2019-08-29 11:18:15,692] \{scheduler_job.py:214} WARNING - Killing PID 5174
> [2019-08-29 11:18:15,693] \{scheduler_job.py:214} WARNING - Killing PID 5174
> [2019-08-29 11:18:46,765] \{scheduler_job.py:214} WARNING - Killing PID 22410
> [2019-08-29 11:18:46,766] \{scheduler_job.py:214} WARNING - Killing PID 22410
> [2019-08-29 11:19:17,845] \{scheduler_job.py:214} WARNING - Killing PID 42177
> [2019-08-29 11:19:17,846] \{scheduler_job.py:214} WARNING - Killing PID 42177
> ...}}
> I'm using a LocalExecutor with a PostgreSQL backend DB. It seems to be
> happening only after I'm triggering a large number (>100) of DAGs at about
> the same time using external triggering. As in:
> {{airflow trigger_dag DAG_NAME}}
> After waiting for it to finish killing whatever processes he is killing, he
> starts executing all of the tasks properly. I don't even know what these
> processes were, as I can't really see them after they are killed...
> Did anyone encounter this kind of behavior? Any idea why would that happen?
>
>
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Commented] (AIRFLOW-5881) Dag gets stuck in "Scheduled" State when scheduling a large number of tasks
[ https://issues.apache.org/jira/browse/AIRFLOW-5881?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16993898#comment-16993898 ] Nidhi commented on AIRFLOW-5881: I am facing the same issue as I have around 60,000 tasks inside one DAG. When I trigger the dag it is not scheduling my tasks and DAG is staying into Running state. The DAG stays into Running state for 2 or 3 days without scheduling the tasks amd in case of Celery workers , they are not even receiving the task which I have triggered. Please let me know if you know how to solve it. I am working with Celery Executor and tried to change "dagbag_import_timeout" and "max_threads" but nothing is working for my case. > Dag gets stuck in "Scheduled" State when scheduling a large number of tasks > --- > > Key: AIRFLOW-5881 > URL: https://issues.apache.org/jira/browse/AIRFLOW-5881 > Project: Apache Airflow > Issue Type: Bug > Components: scheduler >Affects Versions: 1.10.6 >Reporter: David Hartig >Priority: Critical > Attachments: 2 (1).log, airflow.cnf > > > Running with the KubernetesExecutor in and AKS cluster, when we upgraded to > version 1.10.6 we noticed that the all the Dags stop making progress but > start running and immediate exiting with the following message: > "Instance State' FAILED: Task is in the 'scheduled' state which is not a > valid state for execution. The task must be cleared in order to be run." > See attached log file for the worker. Nothing seems out of the ordinary in > the Scheduler log. > Reverting to 1.10.5 clears the problem. > Note that at the time of the failure maybe 100 or so tasks are in this state, > with 70 coming from one highly parallelized dag. Clearing the scheduled tasks > just makes them reappear shortly thereafter. Marking them "up_for_retry" > results in one being executed but then the system is stuck in the original > zombie state. > Attached is the also a redacted airflow config flag. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (AIRFLOW-5506) Airflow scheduler stuck
[
https://issues.apache.org/jira/browse/AIRFLOW-5506?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16993899#comment-16993899
]
Nidhi commented on AIRFLOW-5506:
I am facing the same issue as I have around 60,000 tasks inside one DAG. When I
trigger the dag it is not scheduling my tasks and DAG is staying into Running
state. The DAG stays into Running state for 2 or 3 days without scheduling the
tasks amd in case of Celery workers , they are not even receiving the task
which I have triggered.
Please let me know if you know how to solve it. I am working with Celery
Executor and tried to change "dagbag_import_timeout" and "max_threads" but
nothing is working for my case.
> Airflow scheduler stuck
> ---
>
> Key: AIRFLOW-5506
> URL: https://issues.apache.org/jira/browse/AIRFLOW-5506
> Project: Apache Airflow
> Issue Type: Bug
> Components: scheduler
>Affects Versions: 1.10.4, 1.10.5
>Reporter: t oo
>Priority: Major
>
> re-post of
> [https://stackoverflow.com/questions/57713394/airflow-scheduler-stuck] and
> slack discussion
>
>
> I'm testing the use of Airflow, and after triggering a (seemingly) large
> number of DAGs at the same time, it seems to just fail to schedule anything
> and starts killing processes. These are the logs the scheduler prints:
> {{[2019-08-29 11:17:13,542] \{scheduler_job.py:214} WARNING - Killing PID
> 199809
> [2019-08-29 11:17:13,544] \{scheduler_job.py:214} WARNING - Killing PID 199809
> [2019-08-29 11:17:44,614] \{scheduler_job.py:214} WARNING - Killing PID 2992
> [2019-08-29 11:17:44,614] \{scheduler_job.py:214} WARNING - Killing PID 2992
> [2019-08-29 11:18:15,692] \{scheduler_job.py:214} WARNING - Killing PID 5174
> [2019-08-29 11:18:15,693] \{scheduler_job.py:214} WARNING - Killing PID 5174
> [2019-08-29 11:18:46,765] \{scheduler_job.py:214} WARNING - Killing PID 22410
> [2019-08-29 11:18:46,766] \{scheduler_job.py:214} WARNING - Killing PID 22410
> [2019-08-29 11:19:17,845] \{scheduler_job.py:214} WARNING - Killing PID 42177
> [2019-08-29 11:19:17,846] \{scheduler_job.py:214} WARNING - Killing PID 42177
> ...}}
> I'm using a LocalExecutor with a PostgreSQL backend DB. It seems to be
> happening only after I'm triggering a large number (>100) of DAGs at about
> the same time using external triggering. As in:
> {{airflow trigger_dag DAG_NAME}}
> After waiting for it to finish killing whatever processes he is killing, he
> starts executing all of the tasks properly. I don't even know what these
> processes were, as I can't really see them after they are killed...
> Did anyone encounter this kind of behavior? Any idea why would that happen?
>
>
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [airflow] ultrabug commented on a change in pull request #2460: [AIRFLOW-1424] make the next execution date of DAGs visible
ultrabug commented on a change in pull request #2460: [AIRFLOW-1424] make the next execution date of DAGs visible URL: https://github.com/apache/airflow/pull/2460#discussion_r356832756 ## File path: airflow/jobs.py ## @@ -892,6 +891,11 @@ def create_dag_run(self, dag, session=None): if next_run_date and min_task_end_date and next_run_date > min_task_end_date: return +# Don't really schedule the job, we are interested in its next run date +# as calculated by the scheduler +if dry_run is True: +return next_run_date Review comment: ok @ashb I guess we can work on something to make it better indeed. Your point is not depending on the concurrency limit if I'm correct and display the *theorically due schedule in time". Am I right? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [airflow] ultrabug commented on a change in pull request #2460: [AIRFLOW-1424] make the next execution date of DAGs visible
ultrabug commented on a change in pull request #2460: [AIRFLOW-1424] make the next execution date of DAGs visible URL: https://github.com/apache/airflow/pull/2460#discussion_r356832756 ## File path: airflow/jobs.py ## @@ -892,6 +891,11 @@ def create_dag_run(self, dag, session=None): if next_run_date and min_task_end_date and next_run_date > min_task_end_date: return +# Don't really schedule the job, we are interested in its next run date +# as calculated by the scheduler +if dry_run is True: +return next_run_date Review comment: ok @ashb I guess we can work on something to make it better indeed. Your point is not depending on the concurrency limit if I'm correct and display the *theorically due schedule in time*. Am I right? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Commented] (AIRFLOW-6225) Better Logging for the K8sPodOperator
[
https://issues.apache.org/jira/browse/AIRFLOW-6225?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16993879#comment-16993879
]
Daniel Imberman commented on AIRFLOW-6225:
--
Hi [~xbhuang],
We just created this ticket yesterday and have not started working on it. If
you would like to take on this ticket I would be glad to offer help wherever
you need it :).
> Better Logging for the K8sPodOperator
> -
>
> Key: AIRFLOW-6225
> URL: https://issues.apache.org/jira/browse/AIRFLOW-6225
> Project: Apache Airflow
> Issue Type: Improvement
> Components: operators
>Affects Versions: 1.10.6
>Reporter: Daniel Imberman
>Assignee: Daniel Imberman
>Priority: Minor
> Fix For: 1.10.7
>
>
> If a user uses the k8sPodOperator and a pod dies, there's valuable info in
> the {{kubectl describe pod}} that is NOT being reported in either airflow or
> ES. We should determine if there is a better way to track that information in
> airflow to bubble up to users who do not have direct k8s access.
>
> Possible additions:
> * getting all events for the pod
> kubectl get events --field-selector involvedObject.name=\{pod_name}]
> * having a delete mode such as "only_on_success"
> * Adding a prestop hook to propagate exception information in cases of
> failures
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Commented] (AIRFLOW-6225) Better Logging for the K8sPodOperator
[
https://issues.apache.org/jira/browse/AIRFLOW-6225?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16993877#comment-16993877
]
Xinbin Huang commented on AIRFLOW-6225:
---
Hi [~dimberman], what is the progress on this ticket right now? I wonder if I
can help or contribute on working this ticket.
> Better Logging for the K8sPodOperator
> -
>
> Key: AIRFLOW-6225
> URL: https://issues.apache.org/jira/browse/AIRFLOW-6225
> Project: Apache Airflow
> Issue Type: Improvement
> Components: operators
>Affects Versions: 1.10.6
>Reporter: Daniel Imberman
>Assignee: Daniel Imberman
>Priority: Minor
> Fix For: 1.10.7
>
>
> If a user uses the k8sPodOperator and a pod dies, there's valuable info in
> the {{kubectl describe pod}} that is NOT being reported in either airflow or
> ES. We should determine if there is a better way to track that information in
> airflow to bubble up to users who do not have direct k8s access.
>
> Possible additions:
> * getting all events for the pod
> kubectl get events --field-selector involvedObject.name=\{pod_name}]
> * having a delete mode such as "only_on_success"
> * Adding a prestop hook to propagate exception information in cases of
> failures
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Comment Edited] (AIRFLOW-5616) PrestoHook to use prestodb
[ https://issues.apache.org/jira/browse/AIRFLOW-5616?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16993875#comment-16993875 ] Gaurav Sehgal edited comment on AIRFLOW-5616 at 12/11/19 8:25 PM: -- [~jackjack10] [~brilhana] Hi, if no one working on this. I could pick this up. This would be my first contribution to airflow. I've been working on it for the past one year. was (Author: gaurav123): Hi, if no one working on this. I could pick this up. This would be my first contribution to airflow. I've been working on it for the past one year. > PrestoHook to use prestodb > -- > > Key: AIRFLOW-5616 > URL: https://issues.apache.org/jira/browse/AIRFLOW-5616 > Project: Apache Airflow > Issue Type: Improvement > Components: hooks >Affects Versions: 1.10.5 >Reporter: Alexandre Brilhante >Priority: Minor > > PrestoHook currently uses PyHive which doesn't support transactions whereas > prestodb > ([https://github.com/prestodb/presto-python-client)|https://github.com/prestodb/presto-python-client] > does. I think it would more flexible to use prestodb as client. I can work > on a PR. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (AIRFLOW-5616) PrestoHook to use prestodb
[ https://issues.apache.org/jira/browse/AIRFLOW-5616?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16993875#comment-16993875 ] Gaurav Sehgal commented on AIRFLOW-5616: Hi, if no one working on this. I could pick this up. This would be my first contribution to airflow. I've been working on it for the past one year. > PrestoHook to use prestodb > -- > > Key: AIRFLOW-5616 > URL: https://issues.apache.org/jira/browse/AIRFLOW-5616 > Project: Apache Airflow > Issue Type: Improvement > Components: hooks >Affects Versions: 1.10.5 >Reporter: Alexandre Brilhante >Priority: Minor > > PrestoHook currently uses PyHive which doesn't support transactions whereas > prestodb > ([https://github.com/prestodb/presto-python-client)|https://github.com/prestodb/presto-python-client] > does. I think it would more flexible to use prestodb as client. I can work > on a PR. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (AIRFLOW-5744) Environment variables not correctly set in Spark submit operator
[ https://issues.apache.org/jira/browse/AIRFLOW-5744?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16993869#comment-16993869 ] Joseph McCartin commented on AIRFLOW-5744: -- The fix is somewhat simple, but it is unclear for what cases the '_env_vars' variable should be handed down to the Popen process. *yarn:* [from the docs|https://spark.apache.org/docs/latest/running-on-yarn.html] _"Unlike other cluster managers supported by Spark in which the master’s address is specified in the --master parameter, in YARN mode the ResourceManager’s address is picked up from the Hadoop configuration."_ This configuration is pointed by one or more of the env vars. *k8s:* the master is set in the spark-submit arguments of the form _k8s://https://:_, and not in the hadoop configuration [link to documentation|https://spark.apache.org/docs/latest/running-on-kubernetes.html]. To minimise disruption or having unwanted environment variables present at runtime, it's probably best that this is only added for the yarn case, but it should be trivial to add it to the k8s case in the future. > Environment variables not correctly set in Spark submit operator > > > Key: AIRFLOW-5744 > URL: https://issues.apache.org/jira/browse/AIRFLOW-5744 > Project: Apache Airflow > Issue Type: Bug > Components: contrib, operators >Affects Versions: 1.10.5 >Reporter: Joseph McCartin >Priority: Trivial > > AIRFLOW-2380 added support for setting environment variables at runtime for > the SparkSubmitOperator. The intention was to allow for dynamic configuration > paths (such as HADOOP_CONF_DIR). The pull request, however, only made it so > that these env vars would only be set at runtime if a standalone cluster and > a client deploy mode was chosen. For kubernetes and yarn modes, the env vars > would be sent to the driver via the spark arguments _spark.yarn.appMasterEnv_ > (and equivalent for k8s). > If one wishes to dynamically set the yarn master address (via a > _yarn-site.xml_ file), then one or more environment variables __ need to be > present at runtime, and this is not currently done. > The SparkSubmitHook class var `_env` is assigned the `_env_vars` variable > from the SparkSubmitOperator, in the `_build_spark_submit_command` method. If > running in YARN mode however, this is not set as it should be, and therefore > `_env` is not passed to the Popen process. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (AIRFLOW-5930) Reduce time spent building SQL strings
[
https://issues.apache.org/jira/browse/AIRFLOW-5930?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16993866#comment-16993866
]
ASF GitHub Bot commented on AIRFLOW-5930:
-
ashb commented on pull request #6792: [AIRFLOW-5930] Use cached-SQL query
building for hot-path queries
URL: https://github.com/apache/airflow/pull/6792
Make sure you have checked _all_ steps below.
### Jira
- [x] https://issues.apache.org/jira/browse/AIRFLOW-5930
### Description
- [ ] Building the SQL string for this query takes up about 25% of the time
that the DAG parsing process spends, so replacing this one query should help
speed up the rate at which the scheduler can queue tasks.
See https://docs.sqlalchemy.org/en/13/orm/extensions/baked.html for more
info. The docs explain a lot of how/why this works, so rather than rebuilding
them from string 10s of times (once per task per active dag run) we cache the
build SQL string!
I will collect up-to-date performance numbers against master, but this
makes the "dag parsing" process of the scheduler (which creates and updates dag
runs, and creates Task Instances) about 2x quicker:
Concurrent DagRuns | Tasks | Before | After | Speedup
-- | -- | -- | -- | --
2 | 12 | 0.146s (±0.0163s) | 0.074s (±0.0037s) | x1.97
10 | 12 | 1.11s (±0.0171s) | 0.266s (±0.0229s) | x4.17
40 | 12 | 4.28s (±0.101s) | 0.852s (±0.0113s) | x5.02
40 | 40 | 6.72s (±0.067s) | 2.659s (±0.0283s) | x2.53
### Tests
- [x] No new tests, no change in behaviour.
### Commits
- [ ] My commits all reference Jira issues in their subject lines, and I
have squashed multiple commits if they address the same issue. In addition, my
commits follow the guidelines from "[How to write a good git commit
message](http://chris.beams.io/posts/git-commit/)":
1. Subject is separated from body by a blank line
1. Subject is limited to 50 characters (not including Jira issue reference)
1. Subject does not end with a period
1. Subject uses the imperative mood ("add", not "adding")
1. Body wraps at 72 characters
1. Body explains "what" and "why", not "how"
### Documentation
- [ ] In case of new functionality, my PR adds documentation that describes
how to use it.
- All the public functions and the classes in the PR contain docstrings
that explain what it does
- If you implement backwards incompatible changes, please leave a note in
the [Updating.md](https://github.com/apache/airflow/blob/master/UPDATING.md) so
we can assign it to a appropriate release
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> Reduce time spent building SQL strings
> --
>
> Key: AIRFLOW-5930
> URL: https://issues.apache.org/jira/browse/AIRFLOW-5930
> Project: Apache Airflow
> Issue Type: Improvement
> Components: scheduler
>Affects Versions: 2.0.0
>Reporter: Ash Berlin-Taylor
>Assignee: Ash Berlin-Taylor
>Priority: Major
>
> My profling of the scheduler work turned up a lot of cases where the
> scheduler_job/dag parser process was spending a lot of time building (not
> executing!) the SQL string.
> This can be improved with
> https://docs.sqlalchemy.org/en/13/orm/extensions/baked.html
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [airflow] ashb opened a new pull request #6792: [AIRFLOW-5930] Use cached-SQL query building for hot-path queries
ashb opened a new pull request #6792: [AIRFLOW-5930] Use cached-SQL query
building for hot-path queries
URL: https://github.com/apache/airflow/pull/6792
Make sure you have checked _all_ steps below.
### Jira
- [x] https://issues.apache.org/jira/browse/AIRFLOW-5930
### Description
- [ ] Building the SQL string for this query takes up about 25% of the time
that the DAG parsing process spends, so replacing this one query should help
speed up the rate at which the scheduler can queue tasks.
See https://docs.sqlalchemy.org/en/13/orm/extensions/baked.html for more
info. The docs explain a lot of how/why this works, so rather than rebuilding
them from string 10s of times (once per task per active dag run) we cache the
build SQL string!
I will collect up-to-date performance numbers against master, but this
makes the "dag parsing" process of the scheduler (which creates and updates dag
runs, and creates Task Instances) about 2x quicker:
Concurrent DagRuns | Tasks | Before | After | Speedup
-- | -- | -- | -- | --
2 | 12 | 0.146s (±0.0163s) | 0.074s (±0.0037s) | x1.97
10 | 12 | 1.11s (±0.0171s) | 0.266s (±0.0229s) | x4.17
40 | 12 | 4.28s (±0.101s) | 0.852s (±0.0113s) | x5.02
40 | 40 | 6.72s (±0.067s) | 2.659s (±0.0283s) | x2.53
### Tests
- [x] No new tests, no change in behaviour.
### Commits
- [ ] My commits all reference Jira issues in their subject lines, and I
have squashed multiple commits if they address the same issue. In addition, my
commits follow the guidelines from "[How to write a good git commit
message](http://chris.beams.io/posts/git-commit/)":
1. Subject is separated from body by a blank line
1. Subject is limited to 50 characters (not including Jira issue reference)
1. Subject does not end with a period
1. Subject uses the imperative mood ("add", not "adding")
1. Body wraps at 72 characters
1. Body explains "what" and "why", not "how"
### Documentation
- [ ] In case of new functionality, my PR adds documentation that describes
how to use it.
- All the public functions and the classes in the PR contain docstrings
that explain what it does
- If you implement backwards incompatible changes, please leave a note in
the [Updating.md](https://github.com/apache/airflow/blob/master/UPDATING.md) so
we can assign it to a appropriate release
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [airflow] nuclearpinguin commented on a change in pull request #6740: [AIRFLOW-6181] Add InProcessExecutor
nuclearpinguin commented on a change in pull request #6740: [AIRFLOW-6181] Add InProcessExecutor URL: https://github.com/apache/airflow/pull/6740#discussion_r356806438 ## File path: tests/executors/test_inprocess_executor.py ## @@ -0,0 +1,116 @@ +# Licensed to the Apache Software Foundation (ASF) under one +# or more contributor license agreements. See the NOTICE file +# distributed with this work for additional information +# regarding copyright ownership. The ASF licenses this file +# to you under the Apache License, Version 2.0 (the +# "License"); you may not use this file except in compliance +# with the License. You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, +# software distributed under the License is distributed on an +# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY +# KIND, either express or implied. See the License for the +# specific language governing permissions and limitations +# under the License. + +from unittest import mock +from unittest.mock import MagicMock + +from airflow.executors.debug_executor import DebugExecutor +from airflow.utils.state import State + + +class TestDebugExecutor: Review comment: Thanks! This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [airflow] dimberman commented on a change in pull request #6740: [AIRFLOW-6181] Add InProcessExecutor
dimberman commented on a change in pull request #6740: [AIRFLOW-6181] Add InProcessExecutor URL: https://github.com/apache/airflow/pull/6740#discussion_r356802770 ## File path: tests/executors/test_inprocess_executor.py ## @@ -0,0 +1,116 @@ +# Licensed to the Apache Software Foundation (ASF) under one +# or more contributor license agreements. See the NOTICE file +# distributed with this work for additional information +# regarding copyright ownership. The ASF licenses this file +# to you under the Apache License, Version 2.0 (the +# "License"); you may not use this file except in compliance +# with the License. You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, +# software distributed under the License is distributed on an +# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY +# KIND, either express or implied. See the License for the +# specific language governing permissions and limitations +# under the License. + +from unittest import mock +from unittest.mock import MagicMock + +from airflow.executors.debug_executor import DebugExecutor +from airflow.utils.state import State + + +class TestDebugExecutor: Review comment: please change the name of this file This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [airflow] dimberman commented on a change in pull request #6740: [AIRFLOW-6181] Add InProcessExecutor
dimberman commented on a change in pull request #6740: [AIRFLOW-6181] Add
InProcessExecutor
URL: https://github.com/apache/airflow/pull/6740#discussion_r356802582
##
File path: airflow/executors/executor_loader.py
##
@@ -57,21 +59,20 @@ def _get_executor(executor_name: str) -> BaseExecutor:
In case the executor name is unknown in airflow,
look for it in the plugins
"""
-if executor_name == ExecutorLoader.LOCAL_EXECUTOR:
-from airflow.executors.local_executor import LocalExecutor
-return LocalExecutor()
-elif executor_name == ExecutorLoader.SEQUENTIAL_EXECUTOR:
-from airflow.executors.sequential_executor import
SequentialExecutor
-return SequentialExecutor()
-elif executor_name == ExecutorLoader.CELERY_EXECUTOR:
-from airflow.executors.celery_executor import CeleryExecutor
-return CeleryExecutor()
-elif executor_name == ExecutorLoader.DASK_EXECUTOR:
-from airflow.executors.dask_executor import DaskExecutor
-return DaskExecutor()
-elif executor_name == ExecutorLoader.KUBERNETES_EXECUTOR:
-from airflow.executors.kubernetes_executor import
KubernetesExecutor
-return KubernetesExecutor()
+
+executors = {
+ExecutorLoader.LOCAL_EXECUTOR: 'airflow.executors.local_executor',
+ExecutorLoader.SEQUENTIAL_EXECUTOR:
'airflow.executors.sequential_executor',
+ExecutorLoader.CELERY_EXECUTOR:
'airflow.executors.celery_executor',
+ExecutorLoader.DASK_EXECUTOR: 'airflow.executors.dask_executor',
+ExecutorLoader.KUBERNETES_EXECUTOR:
'airflow.executors.kubernetes_executor',
+ExecutorLoader.INPROCESS_EXECUTOR:
'airflow.executors.inprocess_executor'
+
+}
+if executor_name in executors:
+executor_module = importlib.import_module(executors[executor_name])
+executor = getattr(executor_module, executor_name)
+return executor()
Review comment:
I agree. this is muuuch cleaner.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[jira] [Updated] (AIRFLOW-5744) Environment variables not correctly set in Spark submit operator
[
https://issues.apache.org/jira/browse/AIRFLOW-5744?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Joseph McCartin updated AIRFLOW-5744:
-
Description:
AIRFLOW-2380 added support for setting environment variables at runtime for the
SparkSubmitOperator. The intention was to allow for dynamic configuration paths
(such as HADOOP_CONF_DIR). The pull request, however, only made it so that
these env vars would only be set at runtime if a standalone cluster and a
client deploy mode was chosen. For kubernetes and yarn modes, the env vars
would be sent to the driver via the spark arguments _spark.yarn.appMasterEnv_
(and equivalent for k8s).
If one wishes to dynamically set the yarn master address (via a _yarn-site.xml_
file), then one or more environment variables __ need to be present at runtime,
and this is not currently done.
The SparkSubmitHook class var `_env` is assigned the `_env_vars` variable from
the SparkSubmitOperator, in the `_build_spark_submit_command` method. If
running in YARN mode however, this is not set as it should be, and therefore
`_env` is not passed to the Popen process.
was:
AIRFLOW-2380 added support for setting environment variables at runtime for the
SparkSubmitOperator. This allows one to dynamically set the Hadoop
configuration paths (such as YARN_CONF_DIR), in cases where the previous step
was creating a Spark cluster.
Normal behaviour should ensure that the SparkSubmitHook class var `_env` is
assigned the `_env_vars` variable from the SparkSubmitOperator, in the
`_build_spark_submit_command` method. If running in YARN mode however, this is
not set as it should be, and therefore `_env` is not passed to the Popen
process. This currently only occurs when the deploy_mode is 'cluster' (yarn and
cluster deploy modes are possible).
One can replicate this by setting a bash script which subsequently prints the
environment variables as the spark-submit executable instead of the real one.
I have confirmed that adding the line: {{self._env = self._env_vars }}after
line 244 in spark_submit_hook.py correctly propagates these environment
variables.
> Environment variables not correctly set in Spark submit operator
>
>
> Key: AIRFLOW-5744
> URL: https://issues.apache.org/jira/browse/AIRFLOW-5744
> Project: Apache Airflow
> Issue Type: Bug
> Components: contrib, operators
>Affects Versions: 1.10.5
>Reporter: Joseph McCartin
>Priority: Trivial
>
> AIRFLOW-2380 added support for setting environment variables at runtime for
> the SparkSubmitOperator. The intention was to allow for dynamic configuration
> paths (such as HADOOP_CONF_DIR). The pull request, however, only made it so
> that these env vars would only be set at runtime if a standalone cluster and
> a client deploy mode was chosen. For kubernetes and yarn modes, the env vars
> would be sent to the driver via the spark arguments _spark.yarn.appMasterEnv_
> (and equivalent for k8s).
> If one wishes to dynamically set the yarn master address (via a
> _yarn-site.xml_ file), then one or more environment variables __ need to be
> present at runtime, and this is not currently done.
> The SparkSubmitHook class var `_env` is assigned the `_env_vars` variable
> from the SparkSubmitOperator, in the `_build_spark_submit_command` method. If
> running in YARN mode however, this is not set as it should be, and therefore
> `_env` is not passed to the Popen process.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [airflow] dimberman commented on a change in pull request #6740: [AIRFLOW-6181] Add InProcessExecutor
dimberman commented on a change in pull request #6740: [AIRFLOW-6181] Add InProcessExecutor URL: https://github.com/apache/airflow/pull/6740#discussion_r356801542 ## File path: airflow/config_templates/default_airflow.cfg ## @@ -232,6 +232,11 @@ api_client = airflow.api.client.local_client # So api will look like: http://localhost:8080/myroot/api/experimental/... endpoint_url = http://localhost:8080 +[debug] +# Used only with DebugExecutor. If set to True DAG will fail with first +# failed task. Helpful for debugging purposes. +fail_fast = False Review comment: +1 on this This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [airflow] digger commented on a change in pull request #6784: [AIRFLOW-6171] Apply .airflowignore to correct subdirectories
digger commented on a change in pull request #6784: [AIRFLOW-6171] Apply
.airflowignore to correct subdirectories
URL: https://github.com/apache/airflow/pull/6784#discussion_r356791260
##
File path: tests/dags/subdir1/test_ignore_this.py
##
@@ -0,0 +1,40 @@
+# -*- coding: utf-8 -*-
+#
+# Licensed to the Apache Software Foundation (ASF) under one
+# or more contributor license agreements. See the NOTICE file
+# distributed with this work for additional information
+# regarding copyright ownership. The ASF licenses this file
+# to you under the Apache License, Version 2.0 (the
+# "License"); you may not use this file except in compliance
+# with the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing,
+# software distributed under the License is distributed on an
+# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+# KIND, either express or implied. See the License for the
+# specific language governing permissions and limitations
+# under the License.
+from datetime import datetime
+
+from airflow.models import DAG
+from airflow.operators.python_operator import PythonOperator
+
+
+def raise_error():
+raise Exception("This dag shouldn't have been executed")
Review comment:
Agreed, I'm changing this to the code you gave above.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [airflow] digger commented on a change in pull request #6784: [AIRFLOW-6171] Apply .airflowignore to correct subdirectories
digger commented on a change in pull request #6784: [AIRFLOW-6171] Apply
.airflowignore to correct subdirectories
URL: https://github.com/apache/airflow/pull/6784#discussion_r356790841
##
File path: tests/dags/subdir2/test_dont_ignore_this.py
##
@@ -0,0 +1,35 @@
+# -*- coding: utf-8 -*-
+#
+# Licensed to the Apache Software Foundation (ASF) under one
+# or more contributor license agreements. See the NOTICE file
+# distributed with this work for additional information
+# regarding copyright ownership. The ASF licenses this file
+# to you under the Apache License, Version 2.0 (the
+# "License"); you may not use this file except in compliance
+# with the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing,
+# software distributed under the License is distributed on an
+# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+# KIND, either express or implied. See the License for the
+# specific language governing permissions and limitations
+# under the License.
+from datetime import datetime
+
+from airflow.models import DAG
+from airflow.operators.bash_operator import BashOperator
+
+DEFAULT_DATE = datetime(2019, 12, 1)
+
+args = {
+'owner': 'airflow',
+'start_date': DEFAULT_DATE,
+}
+
+dag = DAG(dag_id='test_dag_under_subdir2', default_args=args)
Review comment:
It can be almost empty but this is under the dags folder and we're making
this file look like a dag to Airflow so it seems to make sense to place an
actual test dag here.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[airflow-site] branch aijamalnk-patch-1 updated (9d62ea2 -> 5347c87)
This is an automated email from the ASF dual-hosted git repository. aizhamal pushed a change to branch aijamalnk-patch-1 in repository https://gitbox.apache.org/repos/asf/airflow-site.git. from 9d62ea2 A blog post announcing the new website add 5347c87 adding the links to new and old websites No new revisions were added by this update. Summary of changes: landing-pages/site/content/en/blog/announcing-new-website.md | 3 +-- 1 file changed, 1 insertion(+), 2 deletions(-)
[GitHub] [airflow-site] aijamalnk opened a new pull request #218: A blog post announcing the new website
aijamalnk opened a new pull request #218: A blog post announcing the new website URL: https://github.com/apache/airflow-site/pull/218 @mik-laj could you take a look? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[airflow-site] branch aijamalnk-patch-1 created (now 9d62ea2)
This is an automated email from the ASF dual-hosted git repository. aizhamal pushed a change to branch aijamalnk-patch-1 in repository https://gitbox.apache.org/repos/asf/airflow-site.git. at 9d62ea2 A blog post announcing the new website This branch includes the following new commits: new 9d62ea2 A blog post announcing the new website The 1 revisions listed above as "new" are entirely new to this repository and will be described in separate emails. The revisions listed as "add" were already present in the repository and have only been added to this reference.
[airflow-site] 01/01: A blog post announcing the new website
This is an automated email from the ASF dual-hosted git repository. aizhamal pushed a commit to branch aijamalnk-patch-1 in repository https://gitbox.apache.org/repos/asf/airflow-site.git commit 9d62ea27a675deb17be7dc45fe6d8cd042be0fd1 Author: Aizhamal Nurmamat kyzy AuthorDate: Wed Dec 11 11:10:46 2019 -0800 A blog post announcing the new website --- .../site/content/en/blog/announcing-new-website.md | 35 ++ 1 file changed, 35 insertions(+) diff --git a/landing-pages/site/content/en/blog/announcing-new-website.md b/landing-pages/site/content/en/blog/announcing-new-website.md new file mode 100644 index 000..de77b7f --- /dev/null +++ b/landing-pages/site/content/en/blog/announcing-new-website.md @@ -0,0 +1,35 @@ +--- +title: "New Airflow website" +linkTitle: "New Airflow website" +author: "Aizhamal Nurmamat kyzy" +description: "We are thrilled about our new website!" +tags: ["Community"] +date: "2019-12-11" +--- + +The brand new Airflow website has arrived! Those who have been following the process know that the journey +to update the old Airflow website started at the beginning of the year. +Thanks to sponsorship from the Cloud Composer team at Google that allowed to +collaborate with Polidea and deliver an awesome website. + +Documentation of open source projects is key to engaging new contributors in the maintenance, +development, and adoption of software. We want the Apache Airflow community to have +the best possible experience to contribute and use the project. We also took this opportunity to make the project +more accessible, and in doing so, increase its reach. + +In the past three and a half months, we have updated everything: created a more efficient landing page, +enhanced information architecture, and improved UX & UI. Most importantly, the website now has capabilities +to be translated into many languages. This is our effort to foster a more inclusive community around +Apache Airflow, and we look forward to seeing contributions in Spanish, Chinese, Russian, and other languages as well! + +We built our website on Docsy, a platform that is easy to use and contribute to. Follow +[these steps](https://github.com/apache/airflow-site/blob/aip-11/README.md) to set up your environment and +to create your first pull request. You may also use +the new website for your own open source project as a template. +All of our [code is open and hosted on Github](https://github.com/apache/airflow-site/tree/aip-11). + +Share your questions, comments, and suggestions with us, to help us improve the website. +We hope that this new design makes finding documentation about Airflow easier, +and that its improved accessibility increases adoption and use of Apache Airflow around the world. + +Happy browsing!
[jira] [Commented] (AIRFLOW-6058) Run tests with pytest
[ https://issues.apache.org/jira/browse/AIRFLOW-6058?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16993824#comment-16993824 ] ASF subversion and git services commented on AIRFLOW-6058: -- Commit 24f1e7f26a5e423402e07d98fc3d5522c8a2afca in airflow's branch refs/heads/v1-10-test from Jarek Potiuk [ https://gitbox.apache.org/repos/asf?p=airflow.git;h=24f1e7f ] fixup! fixup! fixup! [AIRFLOW-6058] Running tests with pytest (#6472) > Run tests with pytest > - > > Key: AIRFLOW-6058 > URL: https://issues.apache.org/jira/browse/AIRFLOW-6058 > Project: Apache Airflow > Issue Type: Improvement > Components: tests >Affects Versions: 2.0.0 >Reporter: Tomasz Urbaszek >Assignee: Tomasz Urbaszek >Priority: Major > Fix For: 1.10.7 > > -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [airflow] dimberman commented on a change in pull request #6765: [WIP][AIRFLOW-5889] Fix polling for AWS Batch job status
dimberman commented on a change in pull request #6765: [WIP][AIRFLOW-5889] Fix
polling for AWS Batch job status
URL: https://github.com/apache/airflow/pull/6765#discussion_r356768774
##
File path: airflow/contrib/operators/awsbatch_operator.py
##
@@ -156,32 +179,68 @@ def _wait_for_task_ended(self):
waiter.config.max_attempts = sys.maxsize # timeout is managed by
airflow
waiter.wait(jobs=[self.jobId])
except ValueError:
-# If waiter not available use expo
+self._poll_for_task_ended()
-# Allow a batch job some time to spin up. A random interval
-# decreases the chances of exceeding an AWS API throttle
-# limit when there are many concurrent tasks.
-pause = randint(5, 30)
+def _poll_for_task_ended(self):
+"""
+Poll for task status using a exponential backoff
-retries = 1
-while retries <= self.max_retries:
-self.log.info('AWS Batch job (%s) status check (%d of %d) in
the next %.2f seconds',
- self.jobId, retries, self.max_retries, pause)
-sleep(pause)
+* docs.aws.amazon.com/general/latest/gr/api-retries.html
+"""
+# Allow a batch job some time to spin up. A random interval
+# decreases the chances of exceeding an AWS API throttle
+# limit when there are many concurrent tasks.
+pause = randint(5, 30)
Review comment:
should this be configurable?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [airflow] dimberman commented on a change in pull request #6773: [AIRFLOW-6038] AWS DataSync example_dags added
dimberman commented on a change in pull request #6773: [AIRFLOW-6038] AWS
DataSync example_dags added
URL: https://github.com/apache/airflow/pull/6773#discussion_r356767772
##
File path: airflow/providers/amazon/aws/hooks/datasync.py
##
@@ -76,44 +80,52 @@ def create_location(self, location_uri,
**create_location_kwargs):
:return str: LocationArn of the created Location.
:raises AirflowException: If location type (prefix from
``location_uri``) is invalid.
"""
-typ = location_uri.split(':')[0]
-if typ == 'smb':
+typ = location_uri.split(":")[0]
+if typ == "smb":
location =
self.get_conn().create_location_smb(**create_location_kwargs)
-elif typ == 's3':
+elif typ == "s3":
location =
self.get_conn().create_location_s3(**create_location_kwargs)
-elif typ == 'nfs':
+elif typ == "nfs":
location =
self.get_conn().create_loction_nfs(**create_location_kwargs)
-elif typ == 'efs':
+elif typ == "efs":
location =
self.get_conn().create_loction_efs(**create_location_kwargs)
else:
-raise AirflowException('Invalid location type: {0}'.format(typ))
+raise AirflowException("Invalid location type: {0}".format(typ))
self._refresh_locations()
-return location['LocationArn']
+return location["LocationArn"]
-def get_location_arns(self, location_uri, case_sensitive=True):
+def get_location_arns(
+self, location_uri, case_sensitive=True, ignore_trailing_slash=True
+):
"""
Return all LocationArns which match a LocationUri.
:param str location_uri: Location URI to search for, eg
``s3://mybucket/mypath``
:param bool case_sensitive: Do a case sensitive search for location
URI.
+:param bool ignore_trailing_slash: Ignore / at the end of URI when
matching.
:return: List of LocationArns.
:rtype: list(str)
:raises AirflowBadRequest: if ``location_uri`` is empty
"""
if not location_uri:
-raise AirflowBadRequest('location_uri not specified')
+raise AirflowBadRequest("location_uri not specified")
if not self.locations:
self._refresh_locations()
result = []
+if not case_sensitive:
+location_uri = location_uri.lower()
+if ignore_trailing_slash and location_uri.endswith("/"):
+location_uri = location_uri[:-1]
+
for location in self.locations:
-match = False
-if case_sensitive:
-match = location['LocationUri'] == location_uri
-else:
-match = location['LocationUri'].lower() == location_uri.lower()
-if match:
-result.append(location['LocationArn'])
+location_uri2 = location["LocationUri"]
Review comment:
location_uri2 is kind o f vague. Can you give this a more descriptive name?
Why do we need need this second location_uri etc.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [airflow] KKcorps commented on issue #6762: [AIRFLOW-XXX] Add task lifecycle image to documentation
KKcorps commented on issue #6762: [AIRFLOW-XXX] Add task lifecycle image to documentation URL: https://github.com/apache/airflow/pull/6762#issuecomment-564660703 Looks great! This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Closed] (AIRFLOW-6217) KubernetesPodOperator XCom pushes not working
[
https://issues.apache.org/jira/browse/AIRFLOW-6217?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Eugene Serdyuk closed AIRFLOW-6217.
---
Resolution: Not A Bug
This issue relates to the versions incompatibility.
Seems like it was needed just to upgrade PostgreSQL to the newer version.
> KubernetesPodOperator XCom pushes not working
> -
>
> Key: AIRFLOW-6217
> URL: https://issues.apache.org/jira/browse/AIRFLOW-6217
> Project: Apache Airflow
> Issue Type: Bug
> Components: contrib, xcom
>Affects Versions: 1.10.6
> Environment: Kubernetes version: 1.11.10
> Minikube version: 1.5.2
> Airflow version: 1.10.6
>Reporter: Eugene Serdyuk
>Priority: Major
>
>
> XCom pushes don’t work with KubernetesPodOperator both when I’m using
> LocalExecutor and KubernetesExecutor.
> I do write a return information to the /airflow/xcom/return.json, but despite
> this fact it’s still an error:
>
> {code:java}
> [2019-12-06 15:12:40,116] {logging_mixin.py:112} INFO - [2019-12-06
> 15:12:40,116] {pod_launcher.py:217} INFO - Running command... cat
> /airflow/xcom/return.json
> [2019-12-06 15:12:40,201] {logging_mixin.py:112} INFO - [2019-12-06
> 15:12:40,201] {pod_launcher.py:224} INFO - cat: can't open
> '/airflow/xcom/return.json': No such file or directory{code}
>
> I've also implemented the same code that is written
> [here|https://github.com/apache/airflow/blob/36f3bfb0619cc78698280f6ec3bc985f84e58343/tests/contrib/minikube/test_kubernetes_pod_operator.py#L315].
> But this error still persists. In other words, this test doest not pass.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Comment Edited] (AIRFLOW-6217) KubernetesPodOperator XCom pushes not working
[
https://issues.apache.org/jira/browse/AIRFLOW-6217?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16993742#comment-16993742
]
Eugene Serdyuk edited comment on AIRFLOW-6217 at 12/11/19 5:36 PM:
---
Finally got it working even on 1.11.10. I've just reinstalled minikube cluster
and changed postgresql helm chart dependency to the newer version (also
postgres updated from 9.6.* to 11.7.0).
Unit tests made for xcom pushing are now working fine.
It also turned out for me that to xcom_push a KubernetesPodOperator (KPO)
results, you have to do it manually via cmds/arguments parameters.
In our project we are using factory pattern to create KPO's, and to xcom_push
correctly it became needed to decorate this operator's arguments attribute by
adding the following line:
{code:java}
' | python -c "import json, sys, os; os.makedirs(\'/airflow/xcom\',
exist_ok=True); f = open(\'/airflow/xcom/return.json\', \'w\');
json.dump({\'result\': sys.stdin.read()}, f); f.close()"'{code}
For me it looks VERY inconvenient.
was (Author: eserdk):
Finally got it working even on 1.11.10. I've just reinstalled minikube cluster
and changed postgresql helm chart dependency to the newer version (also
postgres updated from 9.6.* to 11.7.0).
Unit tests made for xcom pushing are now working fine.
It also turned out for me that to xcom_push a KubernetesPodOperator (KPO)
results, you have to do it manually via cmds/arguments parameters.
In our project we are using factory pattern for creating KPO's and to xcom_push
correctly it became needed to decorate this operator's arguments attribute by
adding the following line:
{code:java}
' | python -c "import json, sys, os; os.makedirs(\'/airflow/xcom\',
exist_ok=True); f = open(\'/airflow/xcom/return.json\', \'w\');
json.dump({\'result\': sys.stdin.read()}, f); f.close()"'{code}
For me it looks VERY inconvenient.
> KubernetesPodOperator XCom pushes not working
> -
>
> Key: AIRFLOW-6217
> URL: https://issues.apache.org/jira/browse/AIRFLOW-6217
> Project: Apache Airflow
> Issue Type: Bug
> Components: contrib, xcom
>Affects Versions: 1.10.6
> Environment: Kubernetes version: 1.11.10
> Minikube version: 1.5.2
> Airflow version: 1.10.6
>Reporter: Eugene Serdyuk
>Priority: Major
>
>
> XCom pushes don’t work with KubernetesPodOperator both when I’m using
> LocalExecutor and KubernetesExecutor.
> I do write a return information to the /airflow/xcom/return.json, but despite
> this fact it’s still an error:
>
> {code:java}
> [2019-12-06 15:12:40,116] {logging_mixin.py:112} INFO - [2019-12-06
> 15:12:40,116] {pod_launcher.py:217} INFO - Running command... cat
> /airflow/xcom/return.json
> [2019-12-06 15:12:40,201] {logging_mixin.py:112} INFO - [2019-12-06
> 15:12:40,201] {pod_launcher.py:224} INFO - cat: can't open
> '/airflow/xcom/return.json': No such file or directory{code}
>
> I've also implemented the same code that is written
> [here|https://github.com/apache/airflow/blob/36f3bfb0619cc78698280f6ec3bc985f84e58343/tests/contrib/minikube/test_kubernetes_pod_operator.py#L315].
> But this error still persists. In other words, this test doest not pass.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Commented] (AIRFLOW-6217) KubernetesPodOperator XCom pushes not working
[
https://issues.apache.org/jira/browse/AIRFLOW-6217?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16993742#comment-16993742
]
Eugene Serdyuk commented on AIRFLOW-6217:
-
Finally got it working even on 1.11.10. I've just reinstalled minikube cluster
and changed postgresql helm chart dependency to the newer version (also
postgres updated from 9.6.* to 11.7.0).
Unit tests made for xcom pushing are now working fine.
It also turned out for me that to xcom_push a KubernetesPodOperator (KPO)
results, you have to do it manually via cmds/arguments parameters.
In our project we are using factory pattern for creating KPO's and to xcom_push
correctly it became needed to decorate this operator's arguments attribute by
adding the following line:
{code:java}
' | python -c "import json, sys, os; os.makedirs(\'/airflow/xcom\',
exist_ok=True); f = open(\'/airflow/xcom/return.json\', \'w\');
json.dump({\'result\': sys.stdin.read()}, f); f.close()"'{code}
For me it looks VERY inconvenient.
> KubernetesPodOperator XCom pushes not working
> -
>
> Key: AIRFLOW-6217
> URL: https://issues.apache.org/jira/browse/AIRFLOW-6217
> Project: Apache Airflow
> Issue Type: Bug
> Components: contrib, xcom
>Affects Versions: 1.10.6
> Environment: Kubernetes version: 1.11.10
> Minikube version: 1.5.2
> Airflow version: 1.10.6
>Reporter: Eugene Serdyuk
>Priority: Major
>
>
> XCom pushes don’t work with KubernetesPodOperator both when I’m using
> LocalExecutor and KubernetesExecutor.
> I do write a return information to the /airflow/xcom/return.json, but despite
> this fact it’s still an error:
>
> {code:java}
> [2019-12-06 15:12:40,116] {logging_mixin.py:112} INFO - [2019-12-06
> 15:12:40,116] {pod_launcher.py:217} INFO - Running command... cat
> /airflow/xcom/return.json
> [2019-12-06 15:12:40,201] {logging_mixin.py:112} INFO - [2019-12-06
> 15:12:40,201] {pod_launcher.py:224} INFO - cat: can't open
> '/airflow/xcom/return.json': No such file or directory{code}
>
> I've also implemented the same code that is written
> [here|https://github.com/apache/airflow/blob/36f3bfb0619cc78698280f6ec3bc985f84e58343/tests/contrib/minikube/test_kubernetes_pod_operator.py#L315].
> But this error still persists. In other words, this test doest not pass.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Commented] (AIRFLOW-6230) Improve mocking in GCP tests
[ https://issues.apache.org/jira/browse/AIRFLOW-6230?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16993701#comment-16993701 ] ASF subversion and git services commented on AIRFLOW-6230: -- Commit 3bf5195e9e32cc9bfff4e0c1b3f958740225f444 in airflow's branch refs/heads/master from Tomek [ https://gitbox.apache.org/repos/asf?p=airflow.git;h=3bf5195 ] [AIRFLOW-6230] Improve mocking in GCP tests (#6789) > Improve mocking in GCP tests > > > Key: AIRFLOW-6230 > URL: https://issues.apache.org/jira/browse/AIRFLOW-6230 > Project: Apache Airflow > Issue Type: Improvement > Components: gcp, tests >Affects Versions: 2.0.0 >Reporter: Tomasz Urbaszek >Priority: Major > -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Resolved] (AIRFLOW-6230) Improve mocking in GCP tests
[ https://issues.apache.org/jira/browse/AIRFLOW-6230?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Jarek Potiuk resolved AIRFLOW-6230. --- Fix Version/s: 1.10.7 Resolution: Fixed > Improve mocking in GCP tests > > > Key: AIRFLOW-6230 > URL: https://issues.apache.org/jira/browse/AIRFLOW-6230 > Project: Apache Airflow > Issue Type: Improvement > Components: gcp, tests >Affects Versions: 2.0.0 >Reporter: Tomasz Urbaszek >Priority: Major > Fix For: 1.10.7 > > -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [airflow] potiuk merged pull request #6789: [Airflow-6230] Improve mocking in GCP tests
potiuk merged pull request #6789: [Airflow-6230] Improve mocking in GCP tests URL: https://github.com/apache/airflow/pull/6789 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [airflow] codecov-io edited a comment on issue #6771: [AIRFLOW-6121] [API-21] Rename CloudBuildCreateBuildOperator
codecov-io edited a comment on issue #6771: [AIRFLOW-6121] [API-21] Rename CloudBuildCreateBuildOperator URL: https://github.com/apache/airflow/pull/6771#issuecomment-564572271 # [Codecov](https://codecov.io/gh/apache/airflow/pull/6771?src=pr=h1) Report > Merging [#6771](https://codecov.io/gh/apache/airflow/pull/6771?src=pr=desc) into [master](https://codecov.io/gh/apache/airflow/commit/999d704d64dfd5898275c8b86d081431f7887692?src=pr=desc) will **decrease** coverage by `0.28%`. > The diff coverage is `100%`. [](https://codecov.io/gh/apache/airflow/pull/6771?src=pr=tree) ```diff @@Coverage Diff @@ ## master#6771 +/- ## == - Coverage 84.54% 84.25% -0.29% == Files 672 672 Lines 3817538179 +4 == - Hits3227532168 -107 - Misses 5900 6011 +111 ``` | [Impacted Files](https://codecov.io/gh/apache/airflow/pull/6771?src=pr=tree) | Coverage Δ | | |---|---|---| | [airflow/gcp/operators/cloud\_build.py](https://codecov.io/gh/apache/airflow/pull/6771/diff?src=pr=tree#diff-YWlyZmxvdy9nY3Avb3BlcmF0b3JzL2Nsb3VkX2J1aWxkLnB5) | `100% <100%> (ø)` | :arrow_up: | | [...flow/contrib/operators/gcp\_cloud\_build\_operator.py](https://codecov.io/gh/apache/airflow/pull/6771/diff?src=pr=tree#diff-YWlyZmxvdy9jb250cmliL29wZXJhdG9ycy9nY3BfY2xvdWRfYnVpbGRfb3BlcmF0b3IucHk=) | `100% <100%> (ø)` | :arrow_up: | | [airflow/gcp/example\_dags/example\_cloud\_build.py](https://codecov.io/gh/apache/airflow/pull/6771/diff?src=pr=tree#diff-YWlyZmxvdy9nY3AvZXhhbXBsZV9kYWdzL2V4YW1wbGVfY2xvdWRfYnVpbGQucHk=) | `100% <100%> (ø)` | :arrow_up: | | [airflow/kubernetes/volume\_mount.py](https://codecov.io/gh/apache/airflow/pull/6771/diff?src=pr=tree#diff-YWlyZmxvdy9rdWJlcm5ldGVzL3ZvbHVtZV9tb3VudC5weQ==) | `44.44% <0%> (-55.56%)` | :arrow_down: | | [airflow/kubernetes/volume.py](https://codecov.io/gh/apache/airflow/pull/6771/diff?src=pr=tree#diff-YWlyZmxvdy9rdWJlcm5ldGVzL3ZvbHVtZS5weQ==) | `52.94% <0%> (-47.06%)` | :arrow_down: | | [airflow/kubernetes/pod\_launcher.py](https://codecov.io/gh/apache/airflow/pull/6771/diff?src=pr=tree#diff-YWlyZmxvdy9rdWJlcm5ldGVzL3BvZF9sYXVuY2hlci5weQ==) | `45.25% <0%> (-46.72%)` | :arrow_down: | | [airflow/kubernetes/refresh\_config.py](https://codecov.io/gh/apache/airflow/pull/6771/diff?src=pr=tree#diff-YWlyZmxvdy9rdWJlcm5ldGVzL3JlZnJlc2hfY29uZmlnLnB5) | `50.98% <0%> (-23.53%)` | :arrow_down: | | [...rflow/contrib/operators/kubernetes\_pod\_operator.py](https://codecov.io/gh/apache/airflow/pull/6771/diff?src=pr=tree#diff-YWlyZmxvdy9jb250cmliL29wZXJhdG9ycy9rdWJlcm5ldGVzX3BvZF9vcGVyYXRvci5weQ==) | `78.2% <0%> (-20.52%)` | :arrow_down: | | [airflow/jobs/backfill\_job.py](https://codecov.io/gh/apache/airflow/pull/6771/diff?src=pr=tree#diff-YWlyZmxvdy9qb2JzL2JhY2tmaWxsX2pvYi5weQ==) | `91.59% <0%> (-0.29%)` | :arrow_down: | -- [Continue to review full report at Codecov](https://codecov.io/gh/apache/airflow/pull/6771?src=pr=continue). > **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta) > `Δ = absolute (impact)`, `ø = not affected`, `? = missing data` > Powered by [Codecov](https://codecov.io/gh/apache/airflow/pull/6771?src=pr=footer). Last update [999d704...3c7cdfe](https://codecov.io/gh/apache/airflow/pull/6771?src=pr=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [airflow] codecov-io edited a comment on issue #6771: [AIRFLOW-6121] [API-21] Rename CloudBuildCreateBuildOperator
codecov-io edited a comment on issue #6771: [AIRFLOW-6121] [API-21] Rename CloudBuildCreateBuildOperator URL: https://github.com/apache/airflow/pull/6771#issuecomment-564572271 # [Codecov](https://codecov.io/gh/apache/airflow/pull/6771?src=pr=h1) Report > Merging [#6771](https://codecov.io/gh/apache/airflow/pull/6771?src=pr=desc) into [master](https://codecov.io/gh/apache/airflow/commit/999d704d64dfd5898275c8b86d081431f7887692?src=pr=desc) will **decrease** coverage by `0.28%`. > The diff coverage is `100%`. [](https://codecov.io/gh/apache/airflow/pull/6771?src=pr=tree) ```diff @@Coverage Diff @@ ## master#6771 +/- ## == - Coverage 84.54% 84.25% -0.29% == Files 672 672 Lines 3817538179 +4 == - Hits3227532168 -107 - Misses 5900 6011 +111 ``` | [Impacted Files](https://codecov.io/gh/apache/airflow/pull/6771?src=pr=tree) | Coverage Δ | | |---|---|---| | [airflow/gcp/operators/cloud\_build.py](https://codecov.io/gh/apache/airflow/pull/6771/diff?src=pr=tree#diff-YWlyZmxvdy9nY3Avb3BlcmF0b3JzL2Nsb3VkX2J1aWxkLnB5) | `100% <100%> (ø)` | :arrow_up: | | [...flow/contrib/operators/gcp\_cloud\_build\_operator.py](https://codecov.io/gh/apache/airflow/pull/6771/diff?src=pr=tree#diff-YWlyZmxvdy9jb250cmliL29wZXJhdG9ycy9nY3BfY2xvdWRfYnVpbGRfb3BlcmF0b3IucHk=) | `100% <100%> (ø)` | :arrow_up: | | [airflow/gcp/example\_dags/example\_cloud\_build.py](https://codecov.io/gh/apache/airflow/pull/6771/diff?src=pr=tree#diff-YWlyZmxvdy9nY3AvZXhhbXBsZV9kYWdzL2V4YW1wbGVfY2xvdWRfYnVpbGQucHk=) | `100% <100%> (ø)` | :arrow_up: | | [airflow/kubernetes/volume\_mount.py](https://codecov.io/gh/apache/airflow/pull/6771/diff?src=pr=tree#diff-YWlyZmxvdy9rdWJlcm5ldGVzL3ZvbHVtZV9tb3VudC5weQ==) | `44.44% <0%> (-55.56%)` | :arrow_down: | | [airflow/kubernetes/volume.py](https://codecov.io/gh/apache/airflow/pull/6771/diff?src=pr=tree#diff-YWlyZmxvdy9rdWJlcm5ldGVzL3ZvbHVtZS5weQ==) | `52.94% <0%> (-47.06%)` | :arrow_down: | | [airflow/kubernetes/pod\_launcher.py](https://codecov.io/gh/apache/airflow/pull/6771/diff?src=pr=tree#diff-YWlyZmxvdy9rdWJlcm5ldGVzL3BvZF9sYXVuY2hlci5weQ==) | `45.25% <0%> (-46.72%)` | :arrow_down: | | [airflow/kubernetes/refresh\_config.py](https://codecov.io/gh/apache/airflow/pull/6771/diff?src=pr=tree#diff-YWlyZmxvdy9rdWJlcm5ldGVzL3JlZnJlc2hfY29uZmlnLnB5) | `50.98% <0%> (-23.53%)` | :arrow_down: | | [...rflow/contrib/operators/kubernetes\_pod\_operator.py](https://codecov.io/gh/apache/airflow/pull/6771/diff?src=pr=tree#diff-YWlyZmxvdy9jb250cmliL29wZXJhdG9ycy9rdWJlcm5ldGVzX3BvZF9vcGVyYXRvci5weQ==) | `78.2% <0%> (-20.52%)` | :arrow_down: | | [airflow/jobs/backfill\_job.py](https://codecov.io/gh/apache/airflow/pull/6771/diff?src=pr=tree#diff-YWlyZmxvdy9qb2JzL2JhY2tmaWxsX2pvYi5weQ==) | `91.59% <0%> (-0.29%)` | :arrow_down: | -- [Continue to review full report at Codecov](https://codecov.io/gh/apache/airflow/pull/6771?src=pr=continue). > **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta) > `Δ = absolute (impact)`, `ø = not affected`, `? = missing data` > Powered by [Codecov](https://codecov.io/gh/apache/airflow/pull/6771?src=pr=footer). Last update [999d704...3c7cdfe](https://codecov.io/gh/apache/airflow/pull/6771?src=pr=lastupdated). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Commented] (AIRFLOW-6058) Run tests with pytest
[ https://issues.apache.org/jira/browse/AIRFLOW-6058?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16993683#comment-16993683 ] ASF subversion and git services commented on AIRFLOW-6058: -- Commit 71805bfe3d01dd68c3cfd8d97070c7e1ab257972 in airflow's branch refs/heads/v1-10-test from Jarek Potiuk [ https://gitbox.apache.org/repos/asf?p=airflow.git;h=71805bf ] fixup! fixup! [AIRFLOW-6058] Running tests with pytest (#6472) > Run tests with pytest > - > > Key: AIRFLOW-6058 > URL: https://issues.apache.org/jira/browse/AIRFLOW-6058 > Project: Apache Airflow > Issue Type: Improvement > Components: tests >Affects Versions: 2.0.0 >Reporter: Tomasz Urbaszek >Assignee: Tomasz Urbaszek >Priority: Major > Fix For: 1.10.7 > > -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Work started] (AIRFLOW-6084) Add info endpoint to experimental api
[ https://issues.apache.org/jira/browse/AIRFLOW-6084?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Work on AIRFLOW-6084 started by Alexandre YANG. --- > Add info endpoint to experimental api > - > > Key: AIRFLOW-6084 > URL: https://issues.apache.org/jira/browse/AIRFLOW-6084 > Project: Apache Airflow > Issue Type: Improvement > Components: api >Affects Versions: 1.10.6 >Reporter: Alexandre YANG >Assignee: Alexandre YANG >Priority: Minor > > Add version info endpoint to experimental api. > Use case: version info is useful for audit/monitoring purpose. -- This message was sent by Atlassian Jira (v8.3.4#803005)