[GitHub] [airflow] feluelle commented on a change in pull request #8895: Add Delete/Create S3 bucket operators
feluelle commented on a change in pull request #8895:
URL: https://github.com/apache/airflow/pull/8895#discussion_r428473778
##
File path: airflow/providers/amazon/aws/operators/s3_bucket.py
##
@@ -0,0 +1,119 @@
+#
+# Licensed to the Apache Software Foundation (ASF) under one
+# or more contributor license agreements. See the NOTICE file
+# distributed with this work for additional information
+# regarding copyright ownership. The ASF licenses this file
+# to you under the Apache License, Version 2.0 (the
+# "License"); you may not use this file except in compliance
+# with the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing,
+# software distributed under the License is distributed on an
+# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+# KIND, either express or implied. See the License for the
+# specific language governing permissions and limitations
+# under the License.
+"""
+This module contains AWS S3 operators.
+"""
+from typing import Optional
+
+from airflow.exceptions import AirflowException
+from airflow.models import BaseOperator
+from airflow.providers.amazon.aws.hooks.s3 import S3Hook
+
+
+class S3CreateBucketOperator(BaseOperator):
+"""
+This operator creates an S3 bucket
+
+:param bucket_name: This is bucket name you want to create
+:type bucket_name: Optional[str]
+:param aws_conn_id: The Airflow connection used for AWS credentials.
+If this is None or empty then the default boto3 behaviour is used. If
+running Airflow in a distributed manner and aws_conn_id is None or
+empty, then default boto3 configuration would be used (and must be
+maintained on each worker node).
+:type aws_conn_id: Optional[str]
+:param region_name: AWS region_name. If not specified fetched from
connection.
+:type region_name: Optional[str]
+"""
+def __init__(self,
+ bucket_name,
+ aws_conn_id: Optional[str] = "aws_default",
+ region_name: Optional[str] = None,
+ *args,
+ **kwargs) -> None:
+super().__init__(*args, **kwargs)
+self.bucket_name = bucket_name
+self.region_name = region_name
+self.s3_hook = S3Hook(aws_conn_id=aws_conn_id, region_name=region_name)
+
+def execute(self, context):
+S3CreateBucketOperator.check_for_bucket(self.s3_hook, self.bucket_name)
+self.s3_hook.create_bucket(bucket_name=self.bucket_name,
region_name=self.region_name)
+self.log.info("Created bucket with name: %s", self.bucket_name)
+
+@staticmethod
+def check_for_bucket(s3_hook: S3Hook, bucket_name: str) -> None:
+"""
+Override this method if you don't want to raise excaption if bucket
already exists.
+
+:param s3_hook: Hook to interact with aws s3 services
+:type s3_hook: S3Hook
+:param bucket_name: Bucket name
+:type bucket_name: str
+:return: None
+:rtype: None
+"""
+if s3_hook.check_for_bucket(bucket_name):
+raise AirflowException(f"The bucket name {bucket_name} already
exists")
Review comment:
Actually, sorry but I think it is not even necessary to put behind a
flag like `check_if_...`. Can you revert it and also not have a method to
override? The check should always happen in my opinion and raising an exception
is the correct behavior.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [airflow] feluelle commented on a change in pull request #8895: Add Delete/Create S3 bucket operators
feluelle commented on a change in pull request #8895:
URL: https://github.com/apache/airflow/pull/8895#discussion_r428473778
##
File path: airflow/providers/amazon/aws/operators/s3_bucket.py
##
@@ -0,0 +1,119 @@
+#
+# Licensed to the Apache Software Foundation (ASF) under one
+# or more contributor license agreements. See the NOTICE file
+# distributed with this work for additional information
+# regarding copyright ownership. The ASF licenses this file
+# to you under the Apache License, Version 2.0 (the
+# "License"); you may not use this file except in compliance
+# with the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing,
+# software distributed under the License is distributed on an
+# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+# KIND, either express or implied. See the License for the
+# specific language governing permissions and limitations
+# under the License.
+"""
+This module contains AWS S3 operators.
+"""
+from typing import Optional
+
+from airflow.exceptions import AirflowException
+from airflow.models import BaseOperator
+from airflow.providers.amazon.aws.hooks.s3 import S3Hook
+
+
+class S3CreateBucketOperator(BaseOperator):
+"""
+This operator creates an S3 bucket
+
+:param bucket_name: This is bucket name you want to create
+:type bucket_name: Optional[str]
+:param aws_conn_id: The Airflow connection used for AWS credentials.
+If this is None or empty then the default boto3 behaviour is used. If
+running Airflow in a distributed manner and aws_conn_id is None or
+empty, then default boto3 configuration would be used (and must be
+maintained on each worker node).
+:type aws_conn_id: Optional[str]
+:param region_name: AWS region_name. If not specified fetched from
connection.
+:type region_name: Optional[str]
+"""
+def __init__(self,
+ bucket_name,
+ aws_conn_id: Optional[str] = "aws_default",
+ region_name: Optional[str] = None,
+ *args,
+ **kwargs) -> None:
+super().__init__(*args, **kwargs)
+self.bucket_name = bucket_name
+self.region_name = region_name
+self.s3_hook = S3Hook(aws_conn_id=aws_conn_id, region_name=region_name)
+
+def execute(self, context):
+S3CreateBucketOperator.check_for_bucket(self.s3_hook, self.bucket_name)
+self.s3_hook.create_bucket(bucket_name=self.bucket_name,
region_name=self.region_name)
+self.log.info("Created bucket with name: %s", self.bucket_name)
+
+@staticmethod
+def check_for_bucket(s3_hook: S3Hook, bucket_name: str) -> None:
+"""
+Override this method if you don't want to raise excaption if bucket
already exists.
+
+:param s3_hook: Hook to interact with aws s3 services
+:type s3_hook: S3Hook
+:param bucket_name: Bucket name
+:type bucket_name: str
+:return: None
+:rtype: None
+"""
+if s3_hook.check_for_bucket(bucket_name):
+raise AirflowException(f"The bucket name {bucket_name} already
exists")
Review comment:
Actually, sorry but I think it is not even necessary to put behind a
flag like `check_if_...`. Can you revert it but also not have a method to
override? The check should always happen in my opinion and raising an exception
is the correct behavior.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [airflow] potiuk opened a new pull request #8943: Python base images are stored in cache
potiuk opened a new pull request #8943: URL: https://github.com/apache/airflow/pull/8943 All PRs will used cached "latest good" version of the python base images from our GitHub registry. The python versions in the Github Registry will only get updated after a master build (which pulls latest Python image from DockerHub) builds and passes test correctly. This is to avoid problems that we had recently with Python patchlevel releases breaking our Docker builds. --- Make sure to mark the boxes below before creating PR: [x] - [x] Description above provides context of the change - [x] Unit tests coverage for changes (not needed for documentation changes) - [x] Target Github ISSUE in description if exists - [x] Commits follow "[How to write a good git commit message](http://chris.beams.io/posts/git-commit/)" - [x] Relevant documentation is updated including usage instructions. - [x] I will engage committers as explained in [Contribution Workflow Example](https://github.com/apache/airflow/blob/master/CONTRIBUTING.rst#contribution-workflow-example). --- In case of fundamental code change, Airflow Improvement Proposal ([AIP](https://cwiki.apache.org/confluence/display/AIRFLOW/Airflow+Improvements+Proposals)) is needed. In case of a new dependency, check compliance with the [ASF 3rd Party License Policy](https://www.apache.org/legal/resolved.html#category-x). In case of backwards incompatible changes please leave a note in [UPDATING.md](https://github.com/apache/airflow/blob/master/UPDATING.md). Read the [Pull Request Guidelines](https://github.com/apache/airflow/blob/master/CONTRIBUTING.rst#pull-request-guidelines) for more information. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [airflow] randr97 commented on a change in pull request #8895: Add Delete/Create S3 bucket operators
randr97 commented on a change in pull request #8895:
URL: https://github.com/apache/airflow/pull/8895#discussion_r428471046
##
File path: airflow/providers/amazon/aws/example_dags/example_s3_bucket.py
##
@@ -0,0 +1,70 @@
+# Licensed to the Apache Software Foundation (ASF) under one
+# or more contributor license agreements. See the NOTICE file
+# distributed with this work for additional information
+# regarding copyright ownership. The ASF licenses this file
+# to you under the Apache License, Version 2.0 (the
+# "License"); you may not use this file except in compliance
+# with the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing,
+# software distributed under the License is distributed on an
+# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+# KIND, either express or implied. See the License for the
+# specific language governing permissions and limitations
+# under the License.
+import io
+
+import boto3
+
+from airflow.models.dag import DAG
+from airflow.operators.python import PythonOperator
+from airflow.providers.amazon.aws.operators.s3_bucket import
S3CreateBucketOperator, S3DeleteBucketOperator
+from airflow.utils.dates import days_ago
+
+DAG_NAME = 's3_bucket_dag'
+default_args = {
+'owner': 'airflow',
+'depends_on_past': True,
+'start_date': days_ago(2)
+}
+BUCKET_NAME = 'test-airflow-12345'
+
+
+def upload_keys():
+# add keys to bucket
+conn = boto3.client('s3')
+key_pattern = "path/data"
+n_keys = 3
+keys = [key_pattern + str(i) for i in range(n_keys)]
+for k in keys:
+conn.upload_fileobj(Bucket=BUCKET_NAME,
+Key=k,
+Fileobj=io.BytesIO(b"input"))
Review comment:
Ohh right got it! :)
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [airflow] feluelle commented on a change in pull request #8895: Add Delete/Create S3 bucket operators
feluelle commented on a change in pull request #8895:
URL: https://github.com/apache/airflow/pull/8895#discussion_r428468425
##
File path: airflow/providers/amazon/aws/example_dags/example_s3_bucket.py
##
@@ -0,0 +1,70 @@
+# Licensed to the Apache Software Foundation (ASF) under one
+# or more contributor license agreements. See the NOTICE file
+# distributed with this work for additional information
+# regarding copyright ownership. The ASF licenses this file
+# to you under the Apache License, Version 2.0 (the
+# "License"); you may not use this file except in compliance
+# with the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing,
+# software distributed under the License is distributed on an
+# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+# KIND, either express or implied. See the License for the
+# specific language governing permissions and limitations
+# under the License.
+import io
+
+import boto3
+
+from airflow.models.dag import DAG
+from airflow.operators.python import PythonOperator
+from airflow.providers.amazon.aws.operators.s3_bucket import
S3CreateBucketOperator, S3DeleteBucketOperator
+from airflow.utils.dates import days_ago
+
+DAG_NAME = 's3_bucket_dag'
+default_args = {
+'owner': 'airflow',
+'depends_on_past': True,
+'start_date': days_ago(2)
+}
+BUCKET_NAME = 'test-airflow-12345'
+
+
+def upload_keys():
+# add keys to bucket
+conn = boto3.client('s3')
+key_pattern = "path/data"
+n_keys = 3
+keys = [key_pattern + str(i) for i in range(n_keys)]
+for k in keys:
+conn.upload_fileobj(Bucket=BUCKET_NAME,
+Key=k,
+Fileobj=io.BytesIO(b"input"))
Review comment:
Sorry, I meant `load_string` instead of `lod_file_obj`. So you do not
need to do byte conversion. :)
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [airflow] Khrol commented on pull request #7622: [AIRFLOW-6983] Use SingletonThreadPool for database communication
Khrol commented on pull request #7622: URL: https://github.com/apache/airflow/pull/7622#issuecomment-631898187 https://docs.sqlalchemy.org/en/13/core/pooling.html#sqlalchemy.pool.SingletonThreadPool ``` SingletonThreadPool may be improved in a future release, however in its current status it is generally used only for test scenarios using a SQLite :memory: database and is not recommended for production use. ``` I'm a bit worried about this warning. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (AIRFLOW-6983) Disabled connection pool in CLI might be harmful
[ https://issues.apache.org/jira/browse/AIRFLOW-6983?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17112822#comment-17112822 ] ASF GitHub Bot commented on AIRFLOW-6983: - Khrol commented on pull request #7622: URL: https://github.com/apache/airflow/pull/7622#issuecomment-631898187 https://docs.sqlalchemy.org/en/13/core/pooling.html#sqlalchemy.pool.SingletonThreadPool ``` SingletonThreadPool may be improved in a future release, however in its current status it is generally used only for test scenarios using a SQLite :memory: database and is not recommended for production use. ``` I'm a bit worried about this warning. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > Disabled connection pool in CLI might be harmful > > > Key: AIRFLOW-6983 > URL: https://issues.apache.org/jira/browse/AIRFLOW-6983 > Project: Apache Airflow > Issue Type: Improvement > Components: database >Affects Versions: 1.10.9 >Reporter: Igor Khrol >Assignee: Igor Khrol >Priority: Trivial > > Tasks are executed in CLI mode when connection pool to the database is > disabled. > `settings.configure_orm(disable_connection_pool=True)` > > While one task is run, multiple DB communications are happening while a > separate connection is allocated for each of them. > > It results in DB failures. > > Default behavior might be ok but it worth making it configurable. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (AIRFLOW-6983) Disabled connection pool in CLI might be harmful
[
https://issues.apache.org/jira/browse/AIRFLOW-6983?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17112821#comment-17112821
]
ASF GitHub Bot commented on AIRFLOW-6983:
-
Khrol commented on a change in pull request #7622:
URL: https://github.com/apache/airflow/pull/7622#discussion_r428460044
##
File path: airflow/settings.py
##
@@ -148,18 +148,6 @@ def configure_orm(disable_connection_pool=False):
# 0 means no limit, which could lead to exceeding the Database
connection limit.
pool_size = conf.getint('core', 'SQL_ALCHEMY_POOL_SIZE', fallback=5)
Review comment:
https://docs.sqlalchemy.org/en/13/core/pooling.html#sqlalchemy.pool.SingletonThreadPool
`SingletonThreadPool` has `pool_size` parameter.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> Disabled connection pool in CLI might be harmful
>
>
> Key: AIRFLOW-6983
> URL: https://issues.apache.org/jira/browse/AIRFLOW-6983
> Project: Apache Airflow
> Issue Type: Improvement
> Components: database
>Affects Versions: 1.10.9
>Reporter: Igor Khrol
>Assignee: Igor Khrol
>Priority: Trivial
>
> Tasks are executed in CLI mode when connection pool to the database is
> disabled.
> `settings.configure_orm(disable_connection_pool=True)`
>
> While one task is run, multiple DB communications are happening while a
> separate connection is allocated for each of them.
>
> It results in DB failures.
>
> Default behavior might be ok but it worth making it configurable.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [airflow] Khrol commented on a change in pull request #7622: [AIRFLOW-6983] Use SingletonThreadPool for database communication
Khrol commented on a change in pull request #7622:
URL: https://github.com/apache/airflow/pull/7622#discussion_r428460044
##
File path: airflow/settings.py
##
@@ -148,18 +148,6 @@ def configure_orm(disable_connection_pool=False):
# 0 means no limit, which could lead to exceeding the Database
connection limit.
pool_size = conf.getint('core', 'SQL_ALCHEMY_POOL_SIZE', fallback=5)
Review comment:
https://docs.sqlalchemy.org/en/13/core/pooling.html#sqlalchemy.pool.SingletonThreadPool
`SingletonThreadPool` has `pool_size` parameter.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [airflow] yuqian90 commented on pull request #8867: Fixed BaseSensorOperator to make respect the trigger_rule in downstream tasks, when setting soft_fail="True"
yuqian90 commented on pull request #8867: URL: https://github.com/apache/airflow/pull/8867#issuecomment-631890833 > On a side note... > If you know of a documentation file that needs to be modified, please let me know. I think the document you need to update is UPDATING.md. It should mention something about the removal of `_do_skip_downstream_tasks()` and suggest how people can preserve/achieve the original behaviour (by setting every downstream task to `all_success`). Also pls ping a committer on slack to get them to review/merge. Or try posting in the #development channel. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [airflow] potiuk edited a comment on pull request #8938: Hive/Hadoop minicluster needs JDK8 and JAVA_HOME to work
potiuk edited a comment on pull request #8938: URL: https://github.com/apache/airflow/pull/8938#issuecomment-631888486 Thanks @ashb ! I merged it now - even though one of the tests failed (but It looked like a transient error). Once the master build for this one succeeds, the case in the github registry will get updated. Again Python buster image change with some dependency update made us suffer. I am rebasing and adding my python caching change shortly to avoid this in the future. Looking at it now. And yes - ripping out hive and minicluster is quite high on the priority list. There are event those issues grouped under #8783 #8784 and #8785 to do that ... This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [airflow] potiuk edited a comment on pull request #8938: Hive/Hadoop minicluster needs JDK8 and JAVA_HOME to work
potiuk edited a comment on pull request #8938: URL: https://github.com/apache/airflow/pull/8938#issuecomment-631888486 Thanks @ashb ! I merged it now - even though one of the tests failed (but It looked like a transient error). Once the master build for this one succeeds, the case in the github registry will get updated. Again Python buster image change with some dependency update made us suffer. I am reading and adding my python caching change shortly to avoid this in the future. Looking at it now. And yes - ripping out hive and minicluster is quite high on the priority list. There are event those issues grouped under #8783 #8784 and #8785 to do that ... This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [airflow] potiuk commented on pull request #8938: Hive/Hadoop minicluster needs JDK8 and JAVA_HOME to work
potiuk commented on pull request #8938: URL: https://github.com/apache/airflow/pull/8938#issuecomment-631888486 Thanks @ashb ! I merged it now - even though one of the tests failed (but It looked like a transient error). Once the master build for this one succeeds, the case in the github registry will get updated. Again Python buster image change with some dependency update mad us suffer. I am reading and adding my python caching change shortly to avoid this in the future. Looking at it now. And yes - ripping out hive and minicluster is quite high on the priority list. There are event those issues grouped under #8783 #8784 and #8785 to do that ... This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[airflow] branch master updated (12c22e0 -> 8476c1e)
This is an automated email from the ASF dual-hosted git repository. potiuk pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/airflow.git. from 12c22e0 Added Greytip to Airflow Users list (#8887) add 8476c1e Hive/Hadoop minicluster needs JDK8 and JAVA_HOME to work (#8938) No new revisions were added by this update. Summary of changes: Dockerfile.ci | 7 ++- 1 file changed, 6 insertions(+), 1 deletion(-)
[GitHub] [airflow] potiuk merged pull request #8938: Hive/Hadoop minicluster needs JDK8 and JAVA_HOME to work
potiuk merged pull request #8938: URL: https://github.com/apache/airflow/pull/8938 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [airflow] potiuk edited a comment on pull request #8889: Support custom Variable implementation
potiuk edited a comment on pull request #8889: URL: https://github.com/apache/airflow/pull/8889#issuecomment-631885153 I think maybe it's the right time to raise that as a separate thread on the devlist so that other people can state their opinion as well? I agree with @ashb and @kaxil that creating a custom variable implementation in this form might be super confusing and in the form proposed it's -1 from me. Regarding the case you mentioned - using variables for sharing data between tasks - I believe that's not what it is intended for and it should be strongly discouraged. Variables should be relatively static, changeable externally. Using variables for sharing data between tasks breaks the idempotency mechanism built-in Airflow via Xcom (separate value stored for each dag run). If you want to use variable and maintain idempotency you have to reproduce the xcom apprach - and make your variable key contain the dag_run_id which I think many people would not do that or even think about if they use a convenient variable mechanism. It would have to create multiple variables with a similar name + dag_run_id. That would result in the number of variables growing continuously over time - I think this is a very, very bad use of variables in this case - and having variables effectively read-only with secrets is actually a nice way to avoid this behavior. In the example from (a bit related but not the same as mentioned by @ashb ) the discussion about hooks (https://lists.apache.org/thread.html/re2bd54b0682e14fac6c767895311baf411ea10b18685474f7683a2f5%40%3Cdev.airflow.apache.org%3E). I created a similar example where Secret backend could be used for sharing data between tasks. But then it would be custom implementation, and we can encourage using pattern where dag_run is part of the secret key name, or even better - you can generate and keep the name of the secret in the XCOM. This is the "standard" Airflow pattern for sharing data between tasks and once we have separate hooks for all secret backend, it is something that should be used rather than variables if you would like to keep the shared data "secret". This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [airflow] potiuk commented on pull request #8889: Support custom Variable implementation
potiuk commented on pull request #8889: URL: https://github.com/apache/airflow/pull/8889#issuecomment-631885153 I think maybe it's the right time to raise that as a separate thread on the devlist so that other people can state their opinion as well? I agree with @ashb and @kaxil that creating a custom variable implementation in this form might be super confusing and in the form proposed it's -1 from me. Regarding the case you mentioned - using variables for sharing data between tasks - I believe that's not what it is intended for and it should be strongly discouraged. Variables should be relatively static, changeable externally. Using variables for sharing data between tasks breaks the idempotency mechanism built-in Airflow via Xcom (separate value stored for each dag run). If you want to use variable and maintain idempotency you have to reproduce it and make your variable key contain the dag_run_id which I think many people would not do that or even think about if they use a convenient variable mechanism. It would have to create multiple variables with a similar name + dag_run_id. That would result in the number of variables growing continuously over time - I think this is a very, very bad use of variables in this case - and having variables effectively read-only with secrets is actually a nice way to avoid this behavior. In the example from (a bit related but not the same as mentioned by @ashb ) the discussion about hooks (https://lists.apache.org/thread.html/re2bd54b0682e14fac6c767895311baf411ea10b18685474f7683a2f5%40%3Cdev.airflow.apache.org%3E). I created a similar example where Secret backend could be used for sharing data between tasks. But then it would be custom implementation, and we can encourage using pattern where dag_run is part of the secret key name, or even better - you can generate and keep the name of the secret in the XCOM. This is the "standard" Airflow pattern for sharing data between tasks and once we have separate hooks for all secret backend, it is something that should be used rather than variables if you would like to keep the shared data "secret". This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [airflow] boring-cyborg[bot] commented on pull request #8942: Add SQL Branch Operator #8525
boring-cyborg[bot] commented on pull request #8942: URL: https://github.com/apache/airflow/pull/8942#issuecomment-631884466 Congratulations on your first Pull Request and welcome to the Apache Airflow community! If you have any issues or are unsure about any anything please check our Contribution Guide (https://github.com/apache/airflow/blob/master/CONTRIBUTING.rst) Here are some useful points: - Pay attention to the quality of your code (flake8, pylint and type annotations). Our [pre-commits]( https://github.com/apache/airflow/blob/master/STATIC_CODE_CHECKS.rst#prerequisites-for-pre-commit-hooks) will help you with that. - In case of a new feature add useful documentation (in docstrings or in `docs/` directory). Adding a new operator? Check this short [guide](https://github.com/apache/airflow/blob/master/docs/howto/custom-operator.rst) Consider adding an example DAG that shows how users should use it. - Consider using [Breeze environment](https://github.com/apache/airflow/blob/master/BREEZE.rst) for testing locally, it’s a heavy docker but it ships with a working Airflow and a lot of integrations. - Be patient and persistent. It might take some time to get a review or get the final approval from Committers. - Be sure to read the [Airflow Coding style]( https://github.com/apache/airflow/blob/master/CONTRIBUTING.rst#coding-style-and-best-practices). Apache Airflow is a community-driven project and together we are making it better 🚀. In case of doubts contact the developers at: Mailing List: d...@airflow.apache.org Slack: https://apache-airflow-slack.herokuapp.com/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [airflow] samuelkhtu opened a new pull request #8942: Add SQL Branch Operator #8525
samuelkhtu opened a new pull request #8942: URL: https://github.com/apache/airflow/pull/8942 SQL Branch Operator allow user to execute a SQL query in any supported backend to decide which branch of the DAG to follow. The SQL branch operator expects SQL query to return any of the following: - Boolean: True/False - Integer: 0/1 - String: true/y/yes/1/on/false/n/no/0/off --- Make sure to mark the boxes below before creating PR: [x] - [x] Description above provides context of the change - [x] Unit tests coverage for changes (not needed for documentation changes) - [x] Target Github ISSUE in description if exists - [x] Commits follow "[How to write a good git commit message](http://chris.beams.io/posts/git-commit/)" - [x] Relevant documentation is updated including usage instructions. - [x] I will engage committers as explained in [Contribution Workflow Example](https://github.com/apache/airflow/blob/master/CONTRIBUTING.rst#contribution-workflow-example). --- In case of fundamental code change, Airflow Improvement Proposal ([AIP](https://cwiki.apache.org/confluence/display/AIRFLOW/Airflow+Improvements+Proposals)) is needed. In case of a new dependency, check compliance with the [ASF 3rd Party License Policy](https://www.apache.org/legal/resolved.html#category-x). In case of backwards incompatible changes please leave a note in [UPDATING.md](https://github.com/apache/airflow/blob/master/UPDATING.md). Read the [Pull Request Guidelines](https://github.com/apache/airflow/blob/master/CONTRIBUTING.rst#pull-request-guidelines) for more information. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [airflow] samuelkhtu commented on issue #8525: SQLBranchOperator
samuelkhtu commented on issue #8525: URL: https://github.com/apache/airflow/issues/8525#issuecomment-631871536 Code and test completed for this item. I am working on the PR. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [airflow] ryanyuan commented on a change in pull request #8575: [AIRFLOW-6981] Move Google Cloud Build from Discovery API to Python Library
ryanyuan commented on a change in pull request #8575:
URL: https://github.com/apache/airflow/pull/8575#discussion_r428403561
##
File path: airflow/providers/google/cloud/operators/cloud_build.py
##
@@ -15,186 +15,678 @@
# KIND, either express or implied. See the License for the
# specific language governing permissions and limitations
# under the License.
-"""Operators that integrat with Google Cloud Build service."""
-import re
-from copy import deepcopy
-from typing import Any, Dict, Iterable, Optional
-from urllib.parse import unquote, urlparse
-from airflow.exceptions import AirflowException
-from airflow.models import BaseOperator
-from airflow.providers.google.cloud.hooks.cloud_build import CloudBuildHook
-from airflow.utils.decorators import apply_defaults
-
-REGEX_REPO_PATH =
re.compile(r"^/p/(?P[^/]+)/r/(?P[^/]+)")
+"""Operators that integrates with Google Cloud Build service."""
+from typing import Dict, Optional, Sequence, Tuple, Union
-class BuildProcessor:
-"""
-Processes build configurations to add additional functionality to support
the use of operators.
+from google.api_core.retry import Retry
+from google.cloud.devtools.cloudbuild_v1.types import Build, BuildTrigger,
RepoSource
+from google.protobuf.json_format import MessageToDict
-The following improvements are made:
+from airflow.models import BaseOperator
+from airflow.providers.google.cloud.hooks.cloud_build import CloudBuildHook #
noqa
+from airflow.utils.decorators import apply_defaults
-* It is required to provide the source and only one type can be given,
-* It is possible to provide the source as the URL address instead dict.
-:param body: The request body.
-See:
https://cloud.google.com/cloud-build/docs/api/reference/rest/Shared.Types/Build
-:type body: dict
+class CloudBuildCancelBuildOperator(BaseOperator):
+"""
+Cancels a build in progress.
+
+:param id_: The ID of the build.
+:type id_: str
+:param project_id: Optional, Google Cloud Project project_id where the
function belongs.
+If set to None or missing, the default project_id from the GCP
connection is used.
+:type project_id: Optional[str]
+:param retry: Optional, a retry object used to retry requests. If `None`
is specified, requests
+will not be retried.
+:type retry: Optional[Retry]
+:param timeout: Optional, the amount of time, in seconds, to wait for the
request to complete.
+Note that if `retry` is specified, the timeout applies to each
individual attempt.
+:type timeout: Optional[float]
+:param metadata: Optional, additional metadata that is provided to the
method.
+:type metadata: Optional[Sequence[Tuple[str, str]]]
+:param gcp_conn_id: Optional, the connection ID used to connect to Google
Cloud Platform.
+:type gcp_conn_id: Optional[str]
+
+:rtype: dict
"""
-def __init__(self, body: Dict) -> None:
-self.body = deepcopy(body)
-
-def _verify_source(self):
-is_storage = "storageSource" in self.body["source"]
-is_repo = "repoSource" in self.body["source"]
-
-sources_count = sum([is_storage, is_repo])
-if sources_count != 1:
-raise AirflowException(
-"The source could not be determined. Please choose one data
source from: "
-"storageSource and repoSource."
-)
+template_fields = ("project_id", "id_", "gcp_conn_id")
-def _reformat_source(self):
-self._reformat_repo_source()
-self._reformat_storage_source()
+@apply_defaults
+def __init__(
+self,
+id_: str,
+project_id: Optional[str] = None,
+retry: Optional[Retry] = None,
+timeout: Optional[float] = None,
+metadata: Optional[Sequence[Tuple[str, str]]] = None,
+gcp_conn_id: str = "google_cloud_default",
+*args,
+**kwargs
+) -> None:
+super().__init__(*args, **kwargs)
+self.id_ = id_
+self.project_id = project_id
+self.retry = retry
+self.timeout = timeout
+self.metadata = metadata
+self.gcp_conn_id = gcp_conn_id
-def _reformat_repo_source(self):
-if "repoSource" not in self.body["source"]:
-return
+def execute(self, context):
+hook = CloudBuildHook(gcp_conn_id=self.gcp_conn_id)
+result = hook.cancel_build(
+id_=self.id_,
+project_id=self.project_id,
+retry=self.retry,
+timeout=self.timeout,
+metadata=self.metadata,
+)
+return MessageToDict(result)
+
+
+class CloudBuildCreateBuildOperator(BaseOperator):
+"""
+Starts a build with the specified configuration.
-source = self.body["source"]["repoSource"]
+:param build: The build resource to create. If a dict is provided, it must
be of the same form
+as the protobuf message
`google.clo
[jira] [Commented] (AIRFLOW-6981) Move Google Cloud Build from Discovery API to Python Library
[
https://issues.apache.org/jira/browse/AIRFLOW-6981?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17112717#comment-17112717
]
ASF GitHub Bot commented on AIRFLOW-6981:
-
ryanyuan commented on a change in pull request #8575:
URL: https://github.com/apache/airflow/pull/8575#discussion_r428403561
##
File path: airflow/providers/google/cloud/operators/cloud_build.py
##
@@ -15,186 +15,678 @@
# KIND, either express or implied. See the License for the
# specific language governing permissions and limitations
# under the License.
-"""Operators that integrat with Google Cloud Build service."""
-import re
-from copy import deepcopy
-from typing import Any, Dict, Iterable, Optional
-from urllib.parse import unquote, urlparse
-from airflow.exceptions import AirflowException
-from airflow.models import BaseOperator
-from airflow.providers.google.cloud.hooks.cloud_build import CloudBuildHook
-from airflow.utils.decorators import apply_defaults
-
-REGEX_REPO_PATH =
re.compile(r"^/p/(?P[^/]+)/r/(?P[^/]+)")
+"""Operators that integrates with Google Cloud Build service."""
+from typing import Dict, Optional, Sequence, Tuple, Union
-class BuildProcessor:
-"""
-Processes build configurations to add additional functionality to support
the use of operators.
+from google.api_core.retry import Retry
+from google.cloud.devtools.cloudbuild_v1.types import Build, BuildTrigger,
RepoSource
+from google.protobuf.json_format import MessageToDict
-The following improvements are made:
+from airflow.models import BaseOperator
+from airflow.providers.google.cloud.hooks.cloud_build import CloudBuildHook #
noqa
+from airflow.utils.decorators import apply_defaults
-* It is required to provide the source and only one type can be given,
-* It is possible to provide the source as the URL address instead dict.
-:param body: The request body.
-See:
https://cloud.google.com/cloud-build/docs/api/reference/rest/Shared.Types/Build
-:type body: dict
+class CloudBuildCancelBuildOperator(BaseOperator):
+"""
+Cancels a build in progress.
+
+:param id_: The ID of the build.
+:type id_: str
+:param project_id: Optional, Google Cloud Project project_id where the
function belongs.
+If set to None or missing, the default project_id from the GCP
connection is used.
+:type project_id: Optional[str]
+:param retry: Optional, a retry object used to retry requests. If `None`
is specified, requests
+will not be retried.
+:type retry: Optional[Retry]
+:param timeout: Optional, the amount of time, in seconds, to wait for the
request to complete.
+Note that if `retry` is specified, the timeout applies to each
individual attempt.
+:type timeout: Optional[float]
+:param metadata: Optional, additional metadata that is provided to the
method.
+:type metadata: Optional[Sequence[Tuple[str, str]]]
+:param gcp_conn_id: Optional, the connection ID used to connect to Google
Cloud Platform.
+:type gcp_conn_id: Optional[str]
+
+:rtype: dict
"""
-def __init__(self, body: Dict) -> None:
-self.body = deepcopy(body)
-
-def _verify_source(self):
-is_storage = "storageSource" in self.body["source"]
-is_repo = "repoSource" in self.body["source"]
-
-sources_count = sum([is_storage, is_repo])
-if sources_count != 1:
-raise AirflowException(
-"The source could not be determined. Please choose one data
source from: "
-"storageSource and repoSource."
-)
+template_fields = ("project_id", "id_", "gcp_conn_id")
-def _reformat_source(self):
-self._reformat_repo_source()
-self._reformat_storage_source()
+@apply_defaults
+def __init__(
+self,
+id_: str,
+project_id: Optional[str] = None,
+retry: Optional[Retry] = None,
+timeout: Optional[float] = None,
+metadata: Optional[Sequence[Tuple[str, str]]] = None,
+gcp_conn_id: str = "google_cloud_default",
+*args,
+**kwargs
+) -> None:
+super().__init__(*args, **kwargs)
+self.id_ = id_
+self.project_id = project_id
+self.retry = retry
+self.timeout = timeout
+self.metadata = metadata
+self.gcp_conn_id = gcp_conn_id
-def _reformat_repo_source(self):
-if "repoSource" not in self.body["source"]:
-return
+def execute(self, context):
+hook = CloudBuildHook(gcp_conn_id=self.gcp_conn_id)
+result = hook.cancel_build(
+id_=self.id_,
+project_id=self.project_id,
+retry=self.retry,
+timeout=self.timeout,
+metadata=self.metadata,
+)
+return MessageToDict(result)
+
+
+class CloudBuildCreateBuildOperator(BaseOperator):
+
[GitHub] [airflow] chrismclennon opened a new pull request #8941: Tree view tooltip to show next execution date
chrismclennon opened a new pull request #8941: URL: https://github.com/apache/airflow/pull/8941 This proposed change modifies the tooltip on the Tree View to include "Next Execution Date". I've found that Airflow scheduling work at the end of a schedule interval is a common source of confusion for my users. When they see on the tree view that the "last run" was one schedule interval away from the current time, they often raise questions about why the latest run hasn't kicked off yet. I believe that showing both execution date and next execution date in this tooltip better illustrates the window of time that their Airflow task is operating on. 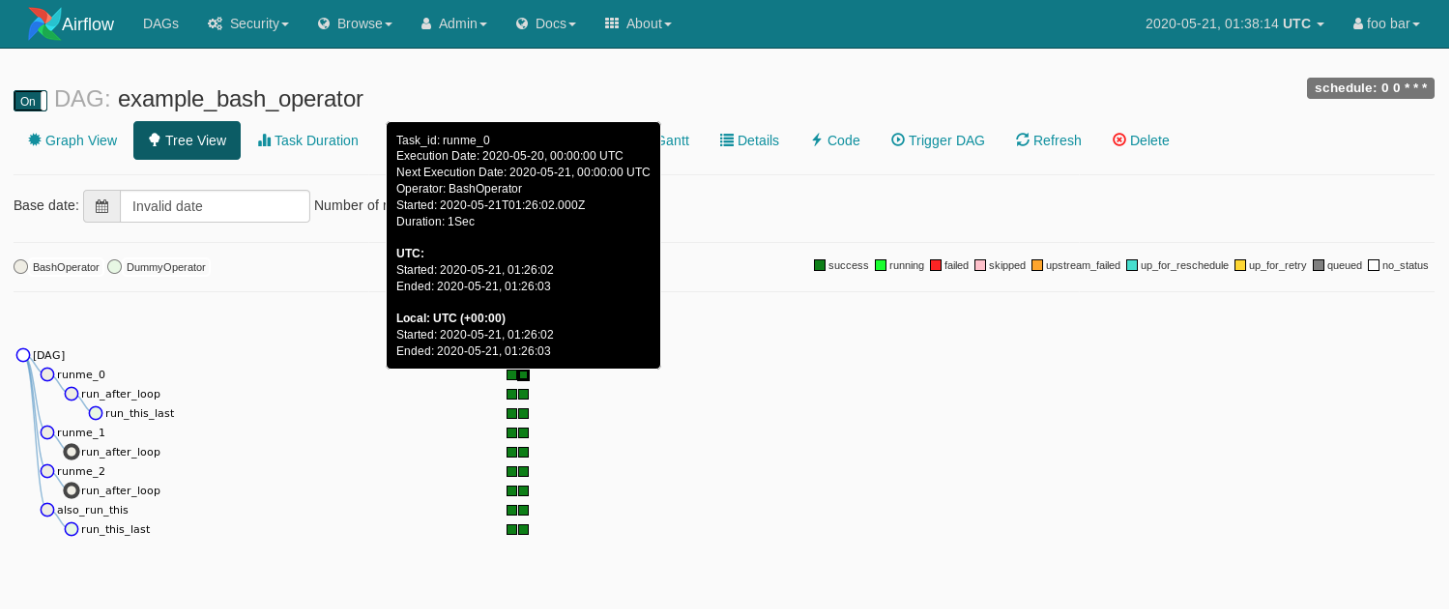 --- Make sure to mark the boxes below before creating PR: [x] - [x] Description above provides context of the change - [x] Unit tests coverage for changes (not needed for documentation changes) - [x] Target Github ISSUE in description if exists -- No issue - [x] Commits follow "[How to write a good git commit message](http://chris.beams.io/posts/git-commit/)" - [x] Relevant documentation is updated including usage instructions. - [x] I will engage committers as explained in [Contribution Workflow Example](https://github.com/apache/airflow/blob/master/CONTRIBUTING.rst#contribution-workflow-example). --- In case of fundamental code change, Airflow Improvement Proposal ([AIP](https://cwiki.apache.org/confluence/display/AIRFLOW/Airflow+Improvements+Proposals)) is needed. In case of a new dependency, check compliance with the [ASF 3rd Party License Policy](https://www.apache.org/legal/resolved.html#category-x). In case of backwards incompatible changes please leave a note in [UPDATING.md](https://github.com/apache/airflow/blob/master/UPDATING.md). Read the [Pull Request Guidelines](https://github.com/apache/airflow/blob/master/CONTRIBUTING.rst#pull-request-guidelines) for more information. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [airflow] thesuperzapper commented on pull request #8777: Add Production Helm chart support
thesuperzapper commented on pull request #8777: URL: https://github.com/apache/airflow/pull/8777#issuecomment-631823022 @schnie I have released v7.0.0 of the `stable/airflow` chart, [see here](https://github.com/helm/charts/tree/master/stable/airflow). There definitely are a few changes from your chart which would improve things in `stable/airflow` (like how you do health checks), but there are features in the `stable/airflow` chart which users need for production/enterprise environments, so we should either aim to include them in a new official chart, or start from the `stable/airflow` one. Regardless, I think we should decouple the release of airflow from its Helm chart (and potentially keep it in a seperate repo). Also note, the official `helm/charts` repo is being depreciated at the end of the year, so the community will need an upgrade path. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (AIRFLOW-249) Refactor the SLA mechanism
[
https://issues.apache.org/jira/browse/AIRFLOW-249?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17112691#comment-17112691
]
ASF GitHub Bot commented on AIRFLOW-249:
houqp commented on a change in pull request #8545:
URL: https://github.com/apache/airflow/pull/8545#discussion_r428389970
##
File path: airflow/models/dagrun.py
##
@@ -491,6 +491,25 @@ def is_backfill(self):
self.run_id.startswith(f"{DagRunType.BACKFILL_JOB.value}")
)
+@classmethod
+@provide_session
+def get_latest_run(cls, dag_id, session):
+"""Returns the latest DagRun for a given dag_id"""
+subquery = (
+session
+.query(func.max(cls.execution_date).label('execution_date'))
+.filter(cls.dag_id == dag_id)
+.subquery()
+)
+dagrun = (
Review comment:
ha, ok, i didn't know execution_date column is not indexed, that's
surprising. in that case, subquery is better.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> Refactor the SLA mechanism
> --
>
> Key: AIRFLOW-249
> URL: https://issues.apache.org/jira/browse/AIRFLOW-249
> Project: Apache Airflow
> Issue Type: Improvement
>Reporter: dud
>Priority: Major
>
> Hello
> I've noticed the SLA feature is currently behaving as follow :
> - it doesn't work on DAG scheduled @once or None because they have no
> dag.followwing_schedule property
> - it keeps endlessly checking for SLA misses without ever worrying about any
> end_date. Worse I noticed that emails are still being sent for runs that are
> never happening because of end_date
> - it keeps checking for recent TIs even if SLA notification has been already
> been sent for them
> - the SLA logic is only being fired after following_schedule + sla has
> elapsed, in other words one has to wait for the next TI before having a
> chance of getting any email. Also the email reports dag.following_schedule
> time (I guess because it is close of TI.start_date), but unfortunately that
> doesn't match what the task instances shows nor the log filename
> - the SLA logic is based on max(TI.execution_date) for the starting point of
> its checks, that means that for a DAG whose SLA is longer than its schedule
> period if half of the TIs are running longer than expected it will go
> unnoticed. This could be demonstrated with a DAG like this one :
> {code}
> from airflow import DAG
> from airflow.operators import *
> from datetime import datetime, timedelta
> from time import sleep
> default_args = {
> 'owner': 'airflow',
> 'depends_on_past': False,
> 'start_date': datetime(2016, 6, 16, 12, 20),
> 'email': my_email
> 'sla': timedelta(minutes=2),
> }
> dag = DAG('unnoticed_sla', default_args=default_args,
> schedule_interval=timedelta(minutes=1))
> def alternating_sleep(**kwargs):
> minute = kwargs['execution_date'].strftime("%M")
> is_odd = int(minute) % 2
> if is_odd:
> sleep(300)
> else:
> sleep(10)
> return True
> PythonOperator(
> task_id='sla_miss',
> python_callable=alternating_sleep,
> provide_context=True,
> dag=dag)
> {code}
> I've tried to rework the SLA triggering mechanism by addressing the above
> points., please [have a look on
> it|https://github.com/dud225/incubator-airflow/commit/972260354075683a8d55a1c960d839c37e629e7d]
> I made some tests with this patch :
> - the fluctuent DAG shown above no longer make Airflow skip any SLA event :
> {code}
> task_id |dag_id | execution_date| email_sent |
> timestamp | description | notification_sent
> --+---+-+++-+---
> sla_miss | dag_sla_miss1 | 2016-06-16 15:05:00 | t | 2016-06-16
> 15:08:26.058631 | | t
> sla_miss | dag_sla_miss1 | 2016-06-16 15:07:00 | t | 2016-06-16
> 15:10:06.093253 | | t
> sla_miss | dag_sla_miss1 | 2016-06-16 15:09:00 | t | 2016-06-16
> 15:12:06.241773 | | t
> {code}
> - on a normal DAG, the SLA is being triggred more quickly :
> {code}
> // start_date = 2016-06-16 15:55:00
> // end_date = 2016-06-16 16:00:00
> // schedule_interval = timedelta(minutes=1)
> // sla = timedelta(minutes=2)
> task_id |dag_id | execution_date| email_sent |
> timestamp | description | notification_sent
> --+---+-++-
[GitHub] [airflow] houqp commented on a change in pull request #8545: [AIRFLOW-249] Refactor the SLA mechanism (Continuation from #3584 )
houqp commented on a change in pull request #8545:
URL: https://github.com/apache/airflow/pull/8545#discussion_r428389970
##
File path: airflow/models/dagrun.py
##
@@ -491,6 +491,25 @@ def is_backfill(self):
self.run_id.startswith(f"{DagRunType.BACKFILL_JOB.value}")
)
+@classmethod
+@provide_session
+def get_latest_run(cls, dag_id, session):
+"""Returns the latest DagRun for a given dag_id"""
+subquery = (
+session
+.query(func.max(cls.execution_date).label('execution_date'))
+.filter(cls.dag_id == dag_id)
+.subquery()
+)
+dagrun = (
Review comment:
ha, ok, i didn't know execution_date column is not indexed, that's
surprising. in that case, subquery is better.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [airflow] mik-laj commented on pull request #8940: Remove side-effect of session in FAB
mik-laj commented on pull request #8940: URL: https://github.com/apache/airflow/pull/8940#issuecomment-631815639 I need this change to integrate connexion with Airflow. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[airflow] branch master updated: Added Greytip to Airflow Users list (#8887)
This is an automated email from the ASF dual-hosted git repository. kaxilnaik pushed a commit to branch master in repository https://gitbox.apache.org/repos/asf/airflow.git The following commit(s) were added to refs/heads/master by this push: new 12c22e0 Added Greytip to Airflow Users list (#8887) 12c22e0 is described below commit 12c22e0fe0d8f254b8bb3ca36b7f7679f6cc8205 Author: Saran AuthorDate: Thu May 21 06:05:04 2020 +0530 Added Greytip to Airflow Users list (#8887) --- README.md | 1 + 1 file changed, 1 insertion(+) diff --git a/README.md b/README.md index 424a432..22da6d7 100644 --- a/README.md +++ b/README.md @@ -344,6 +344,7 @@ Currently **officially** using Airflow: 1. [Grab](https://www.grab.com/sg/) [[@calvintran](https://github.com/canhtran)] 1. [Gradeup](https://gradeup.co) [[@gradeup](https://github.com/gradeup)] 1. [Grand Rounds](https://www.grandrounds.com/) [[@richddr](https://github.com/richddr), [@timz1290](https://github.com/timz1290), [@wenever](https://github.com/@wenever), & [@runongirlrunon](https://github.com/runongirlrunon)] +1. [Greytip](https://www.greytip.com) [[@greytip](https://github.com/greytip)] 1. [Groupalia](http://es.groupalia.com) [[@jesusfcr](https://github.com/jesusfcr)] 1. [Groupon](https://groupon.com) [[@stevencasey](https://github.com/stevencasey)] 1. [Growbots](https://www.growbots.com/)[[@exploy](https://github.com/exploy)]
[GitHub] [airflow] kaxil merged pull request #8887: added greytip to official company list
kaxil merged pull request #8887: URL: https://github.com/apache/airflow/pull/8887 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [airflow] boring-cyborg[bot] commented on pull request #8887: added greytip to official company list
boring-cyborg[bot] commented on pull request #8887: URL: https://github.com/apache/airflow/pull/8887#issuecomment-631809699 Awesome work, congrats on your first merged pull request! This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[airflow] branch master updated (51d9557 -> c6224e2)
This is an automated email from the ASF dual-hosted git repository. kaxilnaik pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/airflow.git. from 51d9557 Re-run all tests when Dockerfile or Github worflow change (#8924) add c6224e2 Remove unused self.max_threads argument in SchedulerJob (#8935) No new revisions were added by this update. Summary of changes: airflow/jobs/scheduler_job.py | 2 -- 1 file changed, 2 deletions(-)
[GitHub] [airflow] kaxil merged pull request #8935: Remove unused SchedulerJob.max_threads argument
kaxil merged pull request #8935: URL: https://github.com/apache/airflow/pull/8935 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (AIRFLOW-249) Refactor the SLA mechanism
[
https://issues.apache.org/jira/browse/AIRFLOW-249?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17112677#comment-17112677
]
ASF GitHub Bot commented on AIRFLOW-249:
seanxwzhang commented on a change in pull request #8545:
URL: https://github.com/apache/airflow/pull/8545#discussion_r428375456
##
File path: airflow/models/dagrun.py
##
@@ -491,6 +491,25 @@ def is_backfill(self):
self.run_id.startswith(f"{DagRunType.BACKFILL_JOB.value}")
)
+@classmethod
+@provide_session
+def get_latest_run(cls, dag_id, session):
+"""Returns the latest DagRun for a given dag_id"""
+subquery = (
+session
+.query(func.max(cls.execution_date).label('execution_date'))
+.filter(cls.dag_id == dag_id)
+.subquery()
+)
+dagrun = (
Review comment:
they can, but since we don't have index on execution_date, order_by will
translate to sort on postgres, and thus it may be more expensive (at least on
postgres),
```
airflow=# explain select max(execution_date) from dag_run;
QUERY PLAN
---
Aggregate (cost=10.75..10.76 rows=1 width=8)
-> Seq Scan on dag_run (cost=0.00..10.60 rows=60 width=8)
(2 rows)
airflow=# explain select execution_date from dag_run order by execution_date
desc limit 1;
QUERY PLAN
-
Limit (cost=10.90..10.90 rows=1 width=8)
-> Sort (cost=10.90..11.05 rows=60 width=8)
Sort Key: execution_date DESC
-> Seq Scan on dag_run (cost=0.00..10.60 rows=60 width=8)
(4 rows)
```
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> Refactor the SLA mechanism
> --
>
> Key: AIRFLOW-249
> URL: https://issues.apache.org/jira/browse/AIRFLOW-249
> Project: Apache Airflow
> Issue Type: Improvement
>Reporter: dud
>Priority: Major
>
> Hello
> I've noticed the SLA feature is currently behaving as follow :
> - it doesn't work on DAG scheduled @once or None because they have no
> dag.followwing_schedule property
> - it keeps endlessly checking for SLA misses without ever worrying about any
> end_date. Worse I noticed that emails are still being sent for runs that are
> never happening because of end_date
> - it keeps checking for recent TIs even if SLA notification has been already
> been sent for them
> - the SLA logic is only being fired after following_schedule + sla has
> elapsed, in other words one has to wait for the next TI before having a
> chance of getting any email. Also the email reports dag.following_schedule
> time (I guess because it is close of TI.start_date), but unfortunately that
> doesn't match what the task instances shows nor the log filename
> - the SLA logic is based on max(TI.execution_date) for the starting point of
> its checks, that means that for a DAG whose SLA is longer than its schedule
> period if half of the TIs are running longer than expected it will go
> unnoticed. This could be demonstrated with a DAG like this one :
> {code}
> from airflow import DAG
> from airflow.operators import *
> from datetime import datetime, timedelta
> from time import sleep
> default_args = {
> 'owner': 'airflow',
> 'depends_on_past': False,
> 'start_date': datetime(2016, 6, 16, 12, 20),
> 'email': my_email
> 'sla': timedelta(minutes=2),
> }
> dag = DAG('unnoticed_sla', default_args=default_args,
> schedule_interval=timedelta(minutes=1))
> def alternating_sleep(**kwargs):
> minute = kwargs['execution_date'].strftime("%M")
> is_odd = int(minute) % 2
> if is_odd:
> sleep(300)
> else:
> sleep(10)
> return True
> PythonOperator(
> task_id='sla_miss',
> python_callable=alternating_sleep,
> provide_context=True,
> dag=dag)
> {code}
> I've tried to rework the SLA triggering mechanism by addressing the above
> points., please [have a look on
> it|https://github.com/dud225/incubator-airflow/commit/972260354075683a8d55a1c960d839c37e629e7d]
> I made some tests with this patch :
> - the fluctuent DAG shown above no longer make Airflow skip any SLA event :
> {code}
> task_id |dag_id | execution_date| email_sent |
> timestamp | description | notification_sent
> --+---+-
[GitHub] [airflow] seanxwzhang commented on a change in pull request #8545: [AIRFLOW-249] Refactor the SLA mechanism (Continuation from #3584 )
seanxwzhang commented on a change in pull request #8545:
URL: https://github.com/apache/airflow/pull/8545#discussion_r428375456
##
File path: airflow/models/dagrun.py
##
@@ -491,6 +491,25 @@ def is_backfill(self):
self.run_id.startswith(f"{DagRunType.BACKFILL_JOB.value}")
)
+@classmethod
+@provide_session
+def get_latest_run(cls, dag_id, session):
+"""Returns the latest DagRun for a given dag_id"""
+subquery = (
+session
+.query(func.max(cls.execution_date).label('execution_date'))
+.filter(cls.dag_id == dag_id)
+.subquery()
+)
+dagrun = (
Review comment:
they can, but since we don't have index on execution_date, order_by will
translate to sort on postgres, and thus it may be more expensive (at least on
postgres),
```
airflow=# explain select max(execution_date) from dag_run;
QUERY PLAN
---
Aggregate (cost=10.75..10.76 rows=1 width=8)
-> Seq Scan on dag_run (cost=0.00..10.60 rows=60 width=8)
(2 rows)
airflow=# explain select execution_date from dag_run order by execution_date
desc limit 1;
QUERY PLAN
-
Limit (cost=10.90..10.90 rows=1 width=8)
-> Sort (cost=10.90..11.05 rows=60 width=8)
Sort Key: execution_date DESC
-> Seq Scan on dag_run (cost=0.00..10.60 rows=60 width=8)
(4 rows)
```
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [airflow] mik-laj commented on a change in pull request #8940: Remove side-effect of session in FAB
mik-laj commented on a change in pull request #8940: URL: https://github.com/apache/airflow/pull/8940#discussion_r428373704 ## File path: tests/www/test_views.py ## @@ -428,7 +428,7 @@ def prepare_dagruns(self): state=State.RUNNING) def test_index(self): -with assert_queries_count(5): +with assert_queries_count(37): Review comment: Queries from FAB Security are also now included. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [airflow] mik-laj commented on a change in pull request #8940: Remove side-effect of session in FAB
mik-laj commented on a change in pull request #8940: URL: https://github.com/apache/airflow/pull/8940#discussion_r428373315 ## File path: airflow/www/app.py ## @@ -46,7 +46,7 @@ log = logging.getLogger(__name__) -def create_app(config=None, session=None, testing=False, app_name="Airflow"): Review comment: session parameter is not used anymore. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [airflow] mik-laj commented on a change in pull request #8940: Remove side-effect of session in FAB
mik-laj commented on a change in pull request #8940: URL: https://github.com/apache/airflow/pull/8940#discussion_r428372980 ## File path: airflow/www/app.py ## @@ -272,10 +282,6 @@ def apply_caching(response): response.headers["X-Frame-Options"] = "DENY" return response -@app.teardown_appcontext Review comment: This is now handled correctly by the flask-sqlalchemy library. https://github.com/pallets/flask-sqlalchemy/blob/master/flask_sqlalchemy/__init__.py#L840-L847 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [airflow] mik-laj commented on a change in pull request #8940: Remove side-effect of session in FAB
mik-laj commented on a change in pull request #8940: URL: https://github.com/apache/airflow/pull/8940#discussion_r428372980 ## File path: airflow/www/app.py ## @@ -272,10 +282,6 @@ def apply_caching(response): response.headers["X-Frame-Options"] = "DENY" return response -@app.teardown_appcontext Review comment: This is now handled correctly by the flask-sqlalchemy library. https://github.com/pallets/flask-sqlalchemy/blob/706982bb8a096220d29e5cef156950237753d89f/flask_sqlalchemy/__init__.py#L840-L847 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [airflow] mik-laj commented on a change in pull request #8940: Remove side-effect of session in FAB
mik-laj commented on a change in pull request #8940: URL: https://github.com/apache/airflow/pull/8940#discussion_r428372645 ## File path: airflow/www/app.py ## @@ -95,9 +96,18 @@ def create_app(config=None, session=None, testing=False, app_name="Airflow"): """Your CUSTOM_SECURITY_MANAGER must now extend AirflowSecurityManager, not FAB's security manager.""") -appbuilder = AppBuilder( -app, -db.session if not session else session, +class AirflowAppBuilder(AppBuilder): + +def add_view(self, baseview, *args, **kwargs): +if hasattr(baseview, 'datamodel'): +# Delete sessions if initiated previously to limit side effects. We want to use +# the current session in the current application. +baseview.datamodel.session = None Review comment: The session is saved to the object, which is an attribute of the class (not instance), so we have a huge side effect. https://github.com/dpgaspar/Flask-AppBuilder/blob/master/flask_appbuilder/base.py#L339-L347 https://github.com/apache/airflow/blob/df159826d61a934862e9fe6a62b535eb443e5710/airflow/www/views.py#L2309 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [airflow] mik-laj commented on a change in pull request #8940: Remove side-effect of session in FAB
mik-laj commented on a change in pull request #8940: URL: https://github.com/apache/airflow/pull/8940#discussion_r428370876 ## File path: airflow/www/app.py ## @@ -70,8 +70,9 @@ def create_app(config=None, session=None, testing=False, app_name="Airflow"): app.json_encoder = AirflowJsonEncoder csrf.init_app(app) - -db = SQLA(app) +db = SQLA() Review comment: This creates a new session, but we want to use your global session instead of creating another session. https://github.com/pallets/flask-sqlalchemy/blob/706982bb8a096220d29e5cef156950237753d89f/flask_sqlalchemy/__init__.py#L714 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [airflow] mik-laj opened a new pull request #8940: Remove side-effect of session in FAB
mik-laj opened a new pull request #8940: URL: https://github.com/apache/airflow/pull/8940 --- Make sure to mark the boxes below before creating PR: [x] - [X] Description above provides context of the change - [X] Unit tests coverage for changes (not needed for documentation changes) - [X] Target Github ISSUE in description if exists - [X] Commits follow "[How to write a good git commit message](http://chris.beams.io/posts/git-commit/)" - [X] Relevant documentation is updated including usage instructions. - [X] I will engage committers as explained in [Contribution Workflow Example](https://github.com/apache/airflow/blob/master/CONTRIBUTING.rst#contribution-workflow-example). --- In case of fundamental code change, Airflow Improvement Proposal ([AIP](https://cwiki.apache.org/confluence/display/AIRFLOW/Airflow+Improvements+Proposals)) is needed. In case of a new dependency, check compliance with the [ASF 3rd Party License Policy](https://www.apache.org/legal/resolved.html#category-x). In case of backwards incompatible changes please leave a note in [UPDATING.md](https://github.com/apache/airflow/blob/master/UPDATING.md). Read the [Pull Request Guidelines](https://github.com/apache/airflow/blob/master/CONTRIBUTING.rst#pull-request-guidelines) for more information. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [airflow] boring-cyborg[bot] commented on issue #8939: next_execution_date is not a pendulum instance
boring-cyborg[bot] commented on issue #8939: URL: https://github.com/apache/airflow/issues/8939#issuecomment-631787061 Thanks for opening your first issue here! Be sure to follow the issue template! This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [airflow] danly opened a new issue #8939: next_execution_date is not a pendulum instance
danly opened a new issue #8939:
URL: https://github.com/apache/airflow/issues/8939
**Apache Airflow version**: 1.10.2
**What happened**:
[According to the
docs](https://airflow.apache.org/docs/stable/macros-ref.html)
`next_execution_date` is a pendulum instance:
> the next execution date (pendulum.Pendulum)
However, when trying to call `start_of` method of `next_execution_date` it
is a `datetime.datetime` instance.
Code:
```python
def execute(**kwargs):
next_execution_date = kwargs.get('next_execution_date')
stop = next_execution_date.start_of('day')
#...
```
Error Log:
```
Subtask my_task stop = next_execution_date.start_of('day')
Subtask my_task AttributeError: 'datetime.datetime' object has no attribute
'start_of'
```
**How to reproduce it**:
Try calling pendulum methods from `next_execution_date`
**Stop-gap**:
As a temporary fix, I am creating a pendulum instance from the
`datetime.datetime` object.
```
def execute(**kwargs):
next_execution_date = kwargs.get('next_execution_date')
stop = pendulum.instance(next_execution_date).start_of('day')
#...
```
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [airflow] snazzyfox commented on issue #8933: pyhive is installed without Hive dependencies
snazzyfox commented on issue #8933: URL: https://github.com/apache/airflow/issues/8933#issuecomment-631786295 Yep, pyhive supports both hive and presto, so depending on the user's needs either `pyhive[hive]` or `pyhive[presto]` is installed. Since airflow is just installing `pyhive` itself, it doesn't include the underlying libs for either. Maybe just change the dependency to `pyhive[hive]` for now works? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [airflow] zachliu commented on issue #8915: CSRF configuration is missing the WTF_ prefix
zachliu commented on issue #8915: URL: https://github.com/apache/airflow/issues/8915#issuecomment-63137 > I'm not quite sure what you are asking us to do here -- the `webserver_config.py` that airflow generates does not set a time limit, `CSRF_TIME_LIMIT` or `WTF_CSRF_TIME_LIMIT`. > > Once airflow has generated that file _you_ are in control of what you put in it -- it lives in your Airflow install, not the airflow code base. > > Unless I've misunderstood here, there's nothing for us to do, and you've already found the correct setting to set. my bad, i should describe it more clearly the `CSRF_ENABLED = True` in this file in airflow's code base https://github.com/apache/airflow/blob/51d955787b009b9e3a88f3e9b4ca1a3933a061f0/airflow/config_templates/default_webserver_config.py#L37 should be ``` WTF_CSRF_ENABLED = True ``` without `WTF_` that line is useless This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [airflow] ashb commented on issue #8717: DagRuns page renders the state column with artifacts
ashb commented on issue #8717: URL: https://github.com/apache/airflow/issues/8717#issuecomment-631770256 This appears to a bug in our (soon to be remove) old UI. The easy fix for now is to switch to the RBAC UI by enabling it in your config files. We are only doing bug fixes against the old UI now (so this should get fixed) but you won't get any new features, such as the ability to show datetimes in your local TZ if you stick on this UI. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [airflow] ashb commented on issue #8484: Airflow 1.10.7+ suppresses Operator logs
ashb commented on issue #8484: URL: https://github.com/apache/airflow/issues/8484#issuecomment-631768825 Is anyone able to make a clean, stand-along reproduction case that shows this please? (Ideally in the form of a docker image I can pull, or a git repo we can clone) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [airflow] dimberman edited a comment on pull request #8932: K8s tests on GitHub actions
dimberman edited a comment on pull request #8932: URL: https://github.com/apache/airflow/pull/8932#issuecomment-631768481 @potiuk @ashb I'm starting to wonder if our image has gotten so big KinD can't even load it ``` ERROR: command "docker save -o /tmp/image-tar606047533/image.tar apache/airflow:master-python3.6-ci-kubernetes" failed with error: exit status 1 Loaded the apache/airflow:master-python3.6-ci-kubernetes to cluster airflow-python-3.6-v1.15.3 ``` This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [airflow] dimberman commented on pull request #8932: K8s tests on GitHub actions
dimberman commented on pull request #8932: URL: https://github.com/apache/airflow/pull/8932#issuecomment-631768481 @potiuk @ashb I'm starting to wonder if our image has gotten so big KinD can't even load it ``` ERROR: command "docker save -o /tmp/image-tar606047533/image.tar apache/airflow:master-python3.6-ci-kubernetes" failed with error: exit status 1 Loaded the apache/airflow:master-python3.6-ci-kubernetes to cluster airflow-python-3.6-v1.15.3 ``` This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [airflow] ashb closed issue #8753: Airflow suddenly died in all the instances
ashb closed issue #8753: URL: https://github.com/apache/airflow/issues/8753 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [airflow] ashb commented on issue #8753: Airflow suddenly died in all the instances
ashb commented on issue #8753: URL: https://github.com/apache/airflow/issues/8753#issuecomment-631768132 There is nothing we can do to debug this with so little information, sorry. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [airflow] ashb commented on issue #8779: Webserver OOM killed by Kubernetes when using KubernetesExecutor
ashb commented on issue #8779: URL: https://github.com/apache/airflow/issues/8779#issuecomment-631767373 Are you using the "Run" button in the webserver by any chance? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [airflow] ashb closed issue #8861: HttpHook.run method doesn't convert dict in 'data' parameter to json object
ashb closed issue #8861: URL: https://github.com/apache/airflow/issues/8861 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [airflow] ashb commented on issue #8861: HttpHook.run method doesn't convert dict in 'data' parameter to json object
ashb commented on issue #8861:
URL: https://github.com/apache/airflow/issues/8861#issuecomment-631766490
I don't think anything needs doing, the hook already supports extra
arguments
https://github.com/apache/airflow/blob/96697180d79bfc90f6964a8e99f9dd441789177c/airflow/hooks/http_hook.py#L100-L101
The request docs you linked to:
> :param data: the body to attach to the request. If a dictionary or
>list of tuples ``[(key, value)]`` is provided, form-encoding will
>take place.
Passing data is doing what is says -- _form_ encoding, as if this was a
`` submitted by a browser.
If you want to submit json as the body, do `hook.run(json={'a': [1,2,3]})'
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [airflow] ashb closed issue #8915: CSRF configuration is missing the WTF_ prefix
ashb closed issue #8915: URL: https://github.com/apache/airflow/issues/8915 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [airflow] ashb commented on issue #8915: CSRF configuration is missing the WTF_ prefix
ashb commented on issue #8915: URL: https://github.com/apache/airflow/issues/8915#issuecomment-631764412 I'm not quite sure what you are asking us to do here -- the `webserver_config.py` that airflow generates does not set a time limit, `CSRF_TIME_LIMIT` or `WTF_CSRF_TIME_LIMIT`. Once airflow has generated that file _you_ are in control of what you put in it -- it lives in your Airflow install, not the airflow code base. Unless I've misunderstood here, there's nothing for us to do, and you've already found the correct setting to set. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [airflow] ashb commented on issue #8907: Airflow web UI is slow
ashb commented on issue #8907: URL: https://github.com/apache/airflow/issues/8907#issuecomment-631763397 @sylr A flat 5s latency sounds odd, and isn't something Airflow itself is doing, so there's something environmental going on here. Things to check: if you run it locally, do you see this? Is there anything of note in the webserver logs? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [airflow] ashb commented on issue #8933: pyhive is installed without Hive dependencies
ashb commented on issue #8933: URL: https://github.com/apache/airflow/issues/8933#issuecomment-631762509 Wait, pyhive has an extra called hive? :exploding_head: > I know this will be a much bigger conversation, but maybe it's worth it to consider testing operators only with the dependencies they're supposed to rely on? That would be amazing, yes, but would make our test suite take days to run to completion. Still, might be something to think about. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [airflow] ashb closed pull request #8929: Add JAVA_HOME env var back to CI Docker image
ashb closed pull request #8929: URL: https://github.com/apache/airflow/pull/8929 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [airflow] ashb commented on pull request #8929: Add JAVA_HOME env var back to CI Docker image
ashb commented on pull request #8929: URL: https://github.com/apache/airflow/pull/8929#issuecomment-631753751 Closing in favour of #8938 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [airflow] ashb opened a new pull request #8938: Hive/Hadoop minicluster needs JDK8 and JAVA_HOME to work
ashb opened a new pull request #8938: URL: https://github.com/apache/airflow/pull/8938 Debian Buster only ships with a JDK11, and Hive/Hadoop fails in odd, hard to debug ways (complains about metastore not being initalized, possibly related to the class loader issues.) Until we rip Hive out from the CI (replacing it with Hadoop in a seprate integration, only on for some builds) we'll have to stick with JRE8 Our previous approach of installing openjdk-8 from Sid/Unstable started failing as Debian Sid has a new (and conflicting) version of GCC/libc. The adoptopenjdk package archive is designed for Buster so should be more resilient --- Make sure to mark the boxes below before creating PR: [x] - [x] Description above provides context of the change - [x] Unit tests coverage for changes (not needed for documentation changes) - [x] Target Github ISSUE in description if exists - [x] Commits follow "[How to write a good git commit message](http://chris.beams.io/posts/git-commit/)" - [x] Relevant documentation is updated including usage instructions. - [x] I will engage committers as explained in [Contribution Workflow Example](https://github.com/apache/airflow/blob/master/CONTRIBUTING.rst#contribution-workflow-example). --- In case of fundamental code change, Airflow Improvement Proposal ([AIP](https://cwiki.apache.org/confluence/display/AIRFLOW/Airflow+Improvements+Proposals)) is needed. In case of a new dependency, check compliance with the [ASF 3rd Party License Policy](https://www.apache.org/legal/resolved.html#category-x). In case of backwards incompatible changes please leave a note in [UPDATING.md](https://github.com/apache/airflow/blob/master/UPDATING.md). Read the [Pull Request Guidelines](https://github.com/apache/airflow/blob/master/CONTRIBUTING.rst#pull-request-guidelines) for more information. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [airflow] ashb commented on pull request #8929: Add JAVA_HOME env var back to CI Docker image
ashb commented on pull request #8929: URL: https://github.com/apache/airflow/pull/8929#issuecomment-631751289 Think I've got a fix -- using https://adoptopenjdk.net/index.html instead. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (AIRFLOW-249) Refactor the SLA mechanism
[
https://issues.apache.org/jira/browse/AIRFLOW-249?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17112631#comment-17112631
]
ASF GitHub Bot commented on AIRFLOW-249:
houqp commented on a change in pull request #8545:
URL: https://github.com/apache/airflow/pull/8545#discussion_r428324933
##
File path: airflow/models/dagrun.py
##
@@ -491,6 +491,25 @@ def is_backfill(self):
self.run_id.startswith(f"{DagRunType.BACKFILL_JOB.value}")
)
+@classmethod
+@provide_session
+def get_latest_run(cls, dag_id, session):
+"""Returns the latest DagRun for a given dag_id"""
+subquery = (
+session
+.query(func.max(cls.execution_date).label('execution_date'))
+.filter(cls.dag_id == dag_id)
+.subquery()
+)
+dagrun = (
Review comment:
can these two queries be combined into one using order by and limit?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> Refactor the SLA mechanism
> --
>
> Key: AIRFLOW-249
> URL: https://issues.apache.org/jira/browse/AIRFLOW-249
> Project: Apache Airflow
> Issue Type: Improvement
>Reporter: dud
>Priority: Major
>
> Hello
> I've noticed the SLA feature is currently behaving as follow :
> - it doesn't work on DAG scheduled @once or None because they have no
> dag.followwing_schedule property
> - it keeps endlessly checking for SLA misses without ever worrying about any
> end_date. Worse I noticed that emails are still being sent for runs that are
> never happening because of end_date
> - it keeps checking for recent TIs even if SLA notification has been already
> been sent for them
> - the SLA logic is only being fired after following_schedule + sla has
> elapsed, in other words one has to wait for the next TI before having a
> chance of getting any email. Also the email reports dag.following_schedule
> time (I guess because it is close of TI.start_date), but unfortunately that
> doesn't match what the task instances shows nor the log filename
> - the SLA logic is based on max(TI.execution_date) for the starting point of
> its checks, that means that for a DAG whose SLA is longer than its schedule
> period if half of the TIs are running longer than expected it will go
> unnoticed. This could be demonstrated with a DAG like this one :
> {code}
> from airflow import DAG
> from airflow.operators import *
> from datetime import datetime, timedelta
> from time import sleep
> default_args = {
> 'owner': 'airflow',
> 'depends_on_past': False,
> 'start_date': datetime(2016, 6, 16, 12, 20),
> 'email': my_email
> 'sla': timedelta(minutes=2),
> }
> dag = DAG('unnoticed_sla', default_args=default_args,
> schedule_interval=timedelta(minutes=1))
> def alternating_sleep(**kwargs):
> minute = kwargs['execution_date'].strftime("%M")
> is_odd = int(minute) % 2
> if is_odd:
> sleep(300)
> else:
> sleep(10)
> return True
> PythonOperator(
> task_id='sla_miss',
> python_callable=alternating_sleep,
> provide_context=True,
> dag=dag)
> {code}
> I've tried to rework the SLA triggering mechanism by addressing the above
> points., please [have a look on
> it|https://github.com/dud225/incubator-airflow/commit/972260354075683a8d55a1c960d839c37e629e7d]
> I made some tests with this patch :
> - the fluctuent DAG shown above no longer make Airflow skip any SLA event :
> {code}
> task_id |dag_id | execution_date| email_sent |
> timestamp | description | notification_sent
> --+---+-+++-+---
> sla_miss | dag_sla_miss1 | 2016-06-16 15:05:00 | t | 2016-06-16
> 15:08:26.058631 | | t
> sla_miss | dag_sla_miss1 | 2016-06-16 15:07:00 | t | 2016-06-16
> 15:10:06.093253 | | t
> sla_miss | dag_sla_miss1 | 2016-06-16 15:09:00 | t | 2016-06-16
> 15:12:06.241773 | | t
> {code}
> - on a normal DAG, the SLA is being triggred more quickly :
> {code}
> // start_date = 2016-06-16 15:55:00
> // end_date = 2016-06-16 16:00:00
> // schedule_interval = timedelta(minutes=1)
> // sla = timedelta(minutes=2)
> task_id |dag_id | execution_date| email_sent |
> timestamp | description | notification_sent
> --+---+-+++-+---
>
[GitHub] [airflow] houqp commented on a change in pull request #8545: [AIRFLOW-249] Refactor the SLA mechanism (Continuation from #3584 )
houqp commented on a change in pull request #8545:
URL: https://github.com/apache/airflow/pull/8545#discussion_r428324933
##
File path: airflow/models/dagrun.py
##
@@ -491,6 +491,25 @@ def is_backfill(self):
self.run_id.startswith(f"{DagRunType.BACKFILL_JOB.value}")
)
+@classmethod
+@provide_session
+def get_latest_run(cls, dag_id, session):
+"""Returns the latest DagRun for a given dag_id"""
+subquery = (
+session
+.query(func.max(cls.execution_date).label('execution_date'))
+.filter(cls.dag_id == dag_id)
+.subquery()
+)
+dagrun = (
Review comment:
can these two queries be combined into one using order by and limit?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [airflow] RosterIn opened a new issue #8937: change from zdesk to zenpy in ZendeskHook
RosterIn opened a new issue #8937: URL: https://github.com/apache/airflow/issues/8937 **Description** [zdesk ](https://github.com/fprimex/zdesk) hasn't been updated in two years. there is a better maintained package [zenpy](https://github.com/facetoe/zenpy) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [airflow] ashb commented on pull request #8929: Add JAVA_HOME env var back to CI Docker image
ashb commented on pull request #8929: URL: https://github.com/apache/airflow/pull/8929#issuecomment-631733162 This is failing now because Hive isn't creating (or has corrupt) meta store. But that doesn't _seem_ to be related to JDK vs JRE. Confused This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [airflow] Acehaidrey closed pull request #8680: Add metric for start/end task run
Acehaidrey closed pull request #8680: URL: https://github.com/apache/airflow/pull/8680 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [airflow] szczeles opened a new pull request #8936: Fixed S3FileTransformOperator to support S3 Select transformation only
szczeles opened a new pull request #8936: URL: https://github.com/apache/airflow/pull/8936 Documentation for S3FileTransformOperator states that users can skip transformation script if S3 Select experession is specified, but in this case the created file is always zero bytes long. This fix changes the behaviour, so in case of no transformation given, the source file (a result of S3Select) is uploaded. --- Make sure to mark the boxes below before creating PR: [x] - [x] Description above provides context of the change - [x] Unit tests coverage for changes (not needed for documentation changes) - [ ] Target Github ISSUE in description if exists - [x] Commits follow "[How to write a good git commit message](http://chris.beams.io/posts/git-commit/)" - [ ] Relevant documentation is updated including usage instructions. - [x] I will engage committers as explained in [Contribution Workflow Example](https://github.com/apache/airflow/blob/master/CONTRIBUTING.rst#contribution-workflow-example). --- In case of fundamental code change, Airflow Improvement Proposal ([AIP](https://cwiki.apache.org/confluence/display/AIRFLOW/Airflow+Improvements+Proposals)) is needed. In case of a new dependency, check compliance with the [ASF 3rd Party License Policy](https://www.apache.org/legal/resolved.html#category-x). In case of backwards incompatible changes please leave a note in [UPDATING.md](https://github.com/apache/airflow/blob/master/UPDATING.md). Read the [Pull Request Guidelines](https://github.com/apache/airflow/blob/master/CONTRIBUTING.rst#pull-request-guidelines) for more information. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [airflow] kaxil opened a new pull request #8935: Remove unused SchedulerJob.max_threads argument
kaxil opened a new pull request #8935: URL: https://github.com/apache/airflow/pull/8935 SchedulerJob.max_threads is not used anywhere. --- Make sure to mark the boxes below before creating PR: [x] - [x] Description above provides context of the change - [x] Unit tests coverage for changes (not needed for documentation changes) - [x] Target Github ISSUE in description if exists - [x] Commits follow "[How to write a good git commit message](http://chris.beams.io/posts/git-commit/)" - [x] Relevant documentation is updated including usage instructions. - [x] I will engage committers as explained in [Contribution Workflow Example](https://github.com/apache/airflow/blob/master/CONTRIBUTING.rst#contribution-workflow-example). --- In case of fundamental code change, Airflow Improvement Proposal ([AIP](https://cwiki.apache.org/confluence/display/AIRFLOW/Airflow+Improvements+Proposals)) is needed. In case of a new dependency, check compliance with the [ASF 3rd Party License Policy](https://www.apache.org/legal/resolved.html#category-x). In case of backwards incompatible changes please leave a note in [UPDATING.md](https://github.com/apache/airflow/blob/master/UPDATING.md). Read the [Pull Request Guidelines](https://github.com/apache/airflow/blob/master/CONTRIBUTING.rst#pull-request-guidelines) for more information. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [airflow] kaxil opened a new pull request #8934: Fix DagRun Prefix for Performance script
kaxil opened a new pull request #8934: URL: https://github.com/apache/airflow/pull/8934 `DagRun.ID_PREFIX` no longer exists and is moved to `airflow.utils.types.DagRunType` enum. I have hardcoded `scheduled__` so that I can use it for 1.10.* too --- Make sure to mark the boxes below before creating PR: [x] - [x] Description above provides context of the change - [x] Unit tests coverage for changes (not needed for documentation changes) - [x] Target Github ISSUE in description if exists - [x] Commits follow "[How to write a good git commit message](http://chris.beams.io/posts/git-commit/)" - [x] Relevant documentation is updated including usage instructions. - [x] I will engage committers as explained in [Contribution Workflow Example](https://github.com/apache/airflow/blob/master/CONTRIBUTING.rst#contribution-workflow-example). --- In case of fundamental code change, Airflow Improvement Proposal ([AIP](https://cwiki.apache.org/confluence/display/AIRFLOW/Airflow+Improvements+Proposals)) is needed. In case of a new dependency, check compliance with the [ASF 3rd Party License Policy](https://www.apache.org/legal/resolved.html#category-x). In case of backwards incompatible changes please leave a note in [UPDATING.md](https://github.com/apache/airflow/blob/master/UPDATING.md). Read the [Pull Request Guidelines](https://github.com/apache/airflow/blob/master/CONTRIBUTING.rst#pull-request-guidelines) for more information. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [airflow] snazzyfox opened a new issue #8933: pyhive is installed without Hive dependencies
snazzyfox opened a new issue #8933: URL: https://github.com/apache/airflow/issues/8933 **Apache Airflow version**: 1.10.10 (appears to also affect master) **What happened**: When airflow is installed with Hive support using `apache-airflow[hive]`, using HiveServer2Hook to run a query throws the following exception: ``` ... File "/usr/local/lib/python3.7/site-packages/airflow/hooks/hive_hooks.py", line 828, in get_conn database=schema or db.schema or 'default') File "/usr/local/lib/python3.7/site-packages/pyhive/hive.py", line 94, in connect return Connection(*args, **kwargs) File "/usr/local/lib/python3.7/site-packages/pyhive/hive.py", line 152, in __init__ import sasl ModuleNotFoundError: No module named 'sasl' ``` **What you expected to happen**: The error should not appear. **How to reproduce it**: Any minimal dag that uses HiveServer2Hook generates the error. Connection to a working Hive cluster is not required since the required dependencies are not installed **Probable Reason**: For `pyhive` to work with Hive, it should be installed as `pyhive[hive]`. The hive extra brings in the `sasl` package. This is not caught testing since tests run with all the dependencies, and the packages required by [`pyhive[hive]`](https://github.com/dropbox/PyHive/blob/master/setup.py#L47) happen to be also used for [`kerberos`](https://github.com/apache/airflow/blob/master/setup.py#L313). I know this will be a much bigger conversation, but maybe it's worth it to consider testing operators _only_ with the dependencies they're supposed to rely on? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [airflow] kaxil commented on a change in pull request #8852: Add task instance mutation hook
kaxil commented on a change in pull request #8852:
URL: https://github.com/apache/airflow/pull/8852#discussion_r428282991
##
File path: tests/models/test_dagrun.py
##
@@ -564,6 +565,27 @@ def with_all_tasks_removed(dag):
flaky_ti.refresh_from_db()
self.assertEqual(State.NONE, flaky_ti.state)
+@mock.patch('airflow.models.dagrun.task_instance_mutation_hook')
Review comment:
Can you add a test for TI where it is UP_FOR_RETRY
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [airflow] kaxil commented on a change in pull request #8852: Add task instance mutation hook
kaxil commented on a change in pull request #8852: URL: https://github.com/apache/airflow/pull/8852#discussion_r428282635 ## File path: airflow/models/dagrun.py ## @@ -431,6 +432,7 @@ def verify_integrity(self, session=None): # check for removed or restored tasks task_ids = [] for ti in tis: +task_instance_mutation_hook(ti) Review comment: aah yes if you want to have a different queue for TI's that are up for retry this does makes sense This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [airflow] ashb commented on pull request #8929: Add JAVA_HOME env var back to CI Docker image
ashb commented on pull request #8929: URL: https://github.com/apache/airflow/pull/8929#issuecomment-631693292 Not sure I can fix it, maybe we change default-jre-headless to default-jdk-headless in Dockerfile.ci Could you try that @dimberman ? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (AIRFLOW-249) Refactor the SLA mechanism
[
https://issues.apache.org/jira/browse/AIRFLOW-249?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17112569#comment-17112569
]
ASF GitHub Bot commented on AIRFLOW-249:
seanxwzhang commented on pull request #8545:
URL: https://github.com/apache/airflow/pull/8545#issuecomment-631691752
Made requested changes, please take a look again :) @houqp @BasPH thanks
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> Refactor the SLA mechanism
> --
>
> Key: AIRFLOW-249
> URL: https://issues.apache.org/jira/browse/AIRFLOW-249
> Project: Apache Airflow
> Issue Type: Improvement
>Reporter: dud
>Priority: Major
>
> Hello
> I've noticed the SLA feature is currently behaving as follow :
> - it doesn't work on DAG scheduled @once or None because they have no
> dag.followwing_schedule property
> - it keeps endlessly checking for SLA misses without ever worrying about any
> end_date. Worse I noticed that emails are still being sent for runs that are
> never happening because of end_date
> - it keeps checking for recent TIs even if SLA notification has been already
> been sent for them
> - the SLA logic is only being fired after following_schedule + sla has
> elapsed, in other words one has to wait for the next TI before having a
> chance of getting any email. Also the email reports dag.following_schedule
> time (I guess because it is close of TI.start_date), but unfortunately that
> doesn't match what the task instances shows nor the log filename
> - the SLA logic is based on max(TI.execution_date) for the starting point of
> its checks, that means that for a DAG whose SLA is longer than its schedule
> period if half of the TIs are running longer than expected it will go
> unnoticed. This could be demonstrated with a DAG like this one :
> {code}
> from airflow import DAG
> from airflow.operators import *
> from datetime import datetime, timedelta
> from time import sleep
> default_args = {
> 'owner': 'airflow',
> 'depends_on_past': False,
> 'start_date': datetime(2016, 6, 16, 12, 20),
> 'email': my_email
> 'sla': timedelta(minutes=2),
> }
> dag = DAG('unnoticed_sla', default_args=default_args,
> schedule_interval=timedelta(minutes=1))
> def alternating_sleep(**kwargs):
> minute = kwargs['execution_date'].strftime("%M")
> is_odd = int(minute) % 2
> if is_odd:
> sleep(300)
> else:
> sleep(10)
> return True
> PythonOperator(
> task_id='sla_miss',
> python_callable=alternating_sleep,
> provide_context=True,
> dag=dag)
> {code}
> I've tried to rework the SLA triggering mechanism by addressing the above
> points., please [have a look on
> it|https://github.com/dud225/incubator-airflow/commit/972260354075683a8d55a1c960d839c37e629e7d]
> I made some tests with this patch :
> - the fluctuent DAG shown above no longer make Airflow skip any SLA event :
> {code}
> task_id |dag_id | execution_date| email_sent |
> timestamp | description | notification_sent
> --+---+-+++-+---
> sla_miss | dag_sla_miss1 | 2016-06-16 15:05:00 | t | 2016-06-16
> 15:08:26.058631 | | t
> sla_miss | dag_sla_miss1 | 2016-06-16 15:07:00 | t | 2016-06-16
> 15:10:06.093253 | | t
> sla_miss | dag_sla_miss1 | 2016-06-16 15:09:00 | t | 2016-06-16
> 15:12:06.241773 | | t
> {code}
> - on a normal DAG, the SLA is being triggred more quickly :
> {code}
> // start_date = 2016-06-16 15:55:00
> // end_date = 2016-06-16 16:00:00
> // schedule_interval = timedelta(minutes=1)
> // sla = timedelta(minutes=2)
> task_id |dag_id | execution_date| email_sent |
> timestamp | description | notification_sent
> --+---+-+++-+---
> sla_miss | dag_sla_miss1 | 2016-06-16 15:55:00 | t | 2016-06-16
> 15:58:11.832299 | | t
> sla_miss | dag_sla_miss1 | 2016-06-16 15:56:00 | t | 2016-06-16
> 15:59:09.663778 | | t
> sla_miss | dag_sla_miss1 | 2016-06-16 15:57:00 | t | 2016-06-16
> 16:00:13.651422 | | t
> sla_miss | dag_sla_miss1 | 2016-06-16 15:58:00 | t | 2016-06-16
> 16:01:08.576399 | | t
> sla_miss | dag_sla_miss1 | 2016-06-16 15:59:00 | t | 2016-06-16
> 16:02:08.523486 | | t
> sla_miss |
[GitHub] [airflow] seanxwzhang commented on pull request #8545: [AIRFLOW-249] Refactor the SLA mechanism (Continuation from #3584 )
seanxwzhang commented on pull request #8545: URL: https://github.com/apache/airflow/pull/8545#issuecomment-631691752 Made requested changes, please take a look again :) @houqp @BasPH thanks This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [airflow] chrismclennon edited a comment on issue #7935: scheduler gets stuck without a trace
chrismclennon edited a comment on issue #7935: URL: https://github.com/apache/airflow/issues/7935#issuecomment-631684732 I see a similar issue on 1.10.9 where the scheduler runs fine on start but typically after 10 to 15 days the CPU utilization actually drops to near 0%. The scheduler health check in the webserver does still pass, but no jobs get scheduled. A restart fixes this. Seeing as I observe a CPU drop instead of a CPU spike, I'm not sure if these are the same issues, but they share symptoms. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [airflow] milton0825 edited a comment on pull request #8889: Support custom Variable implementation
milton0825 edited a comment on pull request #8889: URL: https://github.com/apache/airflow/pull/8889#issuecomment-631680187 Other use cases might be that we can replace the variable backend with other non-vault storage like S3 and support both read/write. It seems like `Variable` is now tightly coupled with `SecretBackend` for DAGs to retrieve secrets from Vault. However, I have seen Airflow users that use `Variable` to share data between tasks/DAGs (yes they can also use xcom but they still can choose to use `Variable` as long as it exists) so it's usage is not limited to retrieving secrets. As long as `Variable` support a set method, it can be confusing to the users that they thought they can set a variable backed by Vault, which they actually can't. Should we separate the secret management out from the Variable? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [airflow] chrismclennon commented on issue #7935: scheduler gets stuck without a trace
chrismclennon commented on issue #7935: URL: https://github.com/apache/airflow/issues/7935#issuecomment-631684732 I see a similar issue on 1.10.9 where the scheduler runs fine on start but typically after ~10~15 days the CPU utilization actually drops to near 0%. The scheduler health check in the webserver does still pass, but no jobs get scheduled. A restart fixes this. Seeing as I observe a CPU drop instead of a CPU spike, I'm not sure if these are the same issues, but they share symptoms. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [airflow] milton0825 commented on a change in pull request #8852: Add task instance mutation hook
milton0825 commented on a change in pull request #8852: URL: https://github.com/apache/airflow/pull/8852#discussion_r428262018 ## File path: airflow/models/dagrun.py ## @@ -431,6 +432,7 @@ def verify_integrity(self, session=None): # check for removed or restored tasks task_ids = [] for ti in tis: +task_instance_mutation_hook(ti) Review comment: L468 is reached when the task instance does not exist thus you create the task instance. However, during retries, the task instance already exists so it won't reach L468 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [airflow] milton0825 edited a comment on pull request #8889: Support custom Variable implementation
milton0825 edited a comment on pull request #8889: URL: https://github.com/apache/airflow/pull/8889#issuecomment-631680187 Other use cases might be that we can replace the variable backend with other storage like S3 and support both read/write. It seems like `Variable` is now tightly coupled with `SecretBackend` for DAGs to retrieve secrets from Vault. However, I have seen Airflow users that use `Variable` to share data between tasks/DAGs (yes they can also use xcom but they still can choose to use `Variable` as long as it exists) so it's usage is not limited to retrieving secrets. As long as `Variable` support a set method, it can be confusing to the users that they thought they can set a variable backed by Vault, which they actually can't. Should we separate the secret management out from the Variable? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [airflow] milton0825 edited a comment on pull request #8889: Support custom Variable implementation
milton0825 edited a comment on pull request #8889: URL: https://github.com/apache/airflow/pull/8889#issuecomment-631680187 Other use cases might be that we can replace the variable backend with other storage like S3 and support both read/write. It seems like `Variable` is now tightly coupled with `SecretBackend` for DAGs to retrieve secrets from Vault. However, I have seen Airflow users that use `Variable` to share data between tasks/DAGs (yes they can also use xcom but they still can choose to use `Variable` as long as it exists) so it's usage is not limited to retrieving secrets. As long as `Variable` support a set method, it can be confusing to the users that they thought they can set a variable backed by Vault, which they actually can't. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [airflow] dimberman commented on pull request #8929: Add JAVA_HOME env var back to CI Docker image
dimberman commented on pull request #8929: URL: https://github.com/apache/airflow/pull/8929#issuecomment-631680458 @ashb yup, was gonna mention it tonight (didn't want to bother you if you were off for the day) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [airflow] milton0825 commented on pull request #8889: Support custom Variable implementation
milton0825 commented on pull request #8889: URL: https://github.com/apache/airflow/pull/8889#issuecomment-631680187 Other use cases might be that we can replace the variable backend with other storage like S3 and support both read/write. It seems like `Variable` is now tightly coupled with `SecretBackend` for DAGs to retrieve secrets from Vault. However, I have seen Airflow users that use `Variable` to share data between tasks/DAGs (yes they can also use xcom but they still can choose to use `Variable`) so it's usage is not limited to retrieving secrets. As long as `Variable` support a set method, it can be confusing to the users that they thought they can set a variable backed by Vault, which they actually can't. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [airflow] ashb commented on pull request #8929: Add JAVA_HOME env var back to CI Docker image
ashb commented on pull request #8929: URL: https://github.com/apache/airflow/pull/8929#issuecomment-631679851 Damn This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [airflow] dimberman opened a new pull request #8932: K8s tests on GitHub actions
dimberman opened a new pull request #8932: URL: https://github.com/apache/airflow/pull/8932 --- Make sure to mark the boxes below before creating PR: [x] - [ ] Description above provides context of the change - [ ] Unit tests coverage for changes (not needed for documentation changes) - [ ] Target Github ISSUE in description if exists - [ ] Commits follow "[How to write a good git commit message](http://chris.beams.io/posts/git-commit/)" - [ ] Relevant documentation is updated including usage instructions. - [ ] I will engage committers as explained in [Contribution Workflow Example](https://github.com/apache/airflow/blob/master/CONTRIBUTING.rst#contribution-workflow-example). --- In case of fundamental code change, Airflow Improvement Proposal ([AIP](https://cwiki.apache.org/confluence/display/AIRFLOW/Airflow+Improvements+Proposals)) is needed. In case of a new dependency, check compliance with the [ASF 3rd Party License Policy](https://www.apache.org/legal/resolved.html#category-x). In case of backwards incompatible changes please leave a note in [UPDATING.md](https://github.com/apache/airflow/blob/master/UPDATING.md). Read the [Pull Request Guidelines](https://github.com/apache/airflow/blob/master/CONTRIBUTING.rst#pull-request-guidelines) for more information. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [airflow] JeffryMAC opened a new issue #8931: Graph to see DAG run duration metric
JeffryMAC opened a new issue #8931: URL: https://github.com/apache/airflow/issues/8931 **Description** airflow has many graph showing insights on task level (task duration, task tries, landing times, gantt) yet there are no graphs that show metrics on graph level I have a simple question that I want to see in a graph. Did the overall time the dag runs has increased or not? it can be simple graph just calculating the dag start time and stop time and putting all durations on one graph. something like:  would be extra cool if it will allow to play with the duration units (seconds, minutes, hours, days) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [airflow] kaxil commented on a change in pull request #8852: Add task instance mutation hook
kaxil commented on a change in pull request #8852: URL: https://github.com/apache/airflow/pull/8852#discussion_r428251168 ## File path: airflow/models/dagrun.py ## @@ -431,6 +432,7 @@ def verify_integrity(self, session=None): # check for removed or restored tasks task_ids = [] for ti in tis: +task_instance_mutation_hook(ti) Review comment: But you are already adding it before saving it to DB on L468, so is it needed here too is my question? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [airflow] milton0825 commented on a change in pull request #8852: Add task instance mutation hook
milton0825 commented on a change in pull request #8852: URL: https://github.com/apache/airflow/pull/8852#discussion_r428248777 ## File path: airflow/models/dagrun.py ## @@ -431,6 +432,7 @@ def verify_integrity(self, session=None): # check for removed or restored tasks task_ids = [] for ti in tis: +task_instance_mutation_hook(ti) Review comment: For cases that we want to mutate task instances before each executions. For example, re-routing to different queue for retries. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (AIRFLOW-5615) BaseJob subclasses shouldn't implement own heartbeat logic
[ https://issues.apache.org/jira/browse/AIRFLOW-5615?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17112532#comment-17112532 ] ASF GitHub Bot commented on AIRFLOW-5615: - houqp commented on a change in pull request #6311: URL: https://github.com/apache/airflow/pull/6311#discussion_r428236112 ## File path: airflow/jobs/base_job.py ## @@ -147,7 +147,7 @@ def heartbeat_callback(self, session=None): Callback that is called during heartbeat. This method should be overwritten. """ -def heartbeat(self): +def heartbeat(self, only_if_necessary=False): Review comment: yes, having type hint prevents caller from passing in with a variable of wrong type by accident. it will also help with type checking within this method anywhere `only_if_necessary` is used. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > BaseJob subclasses shouldn't implement own heartbeat logic > -- > > Key: AIRFLOW-5615 > URL: https://issues.apache.org/jira/browse/AIRFLOW-5615 > Project: Apache Airflow > Issue Type: Improvement > Components: core >Affects Versions: 1.10.5 >Reporter: Ash Berlin-Taylor >Assignee: Ash Berlin-Taylor >Priority: Trivial > Fix For: 2.0.0 > > > Both SchedulerJob and LocalTaskJob have their own timers and decide when to > call heartbeat based upon that. > That logic should be removed and live in BaseJob to simplify the code. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [airflow] houqp commented on a change in pull request #6311: [AIRFLOW-5615] Reduce duplicated logic around job heartbeating
houqp commented on a change in pull request #6311: URL: https://github.com/apache/airflow/pull/6311#discussion_r428236112 ## File path: airflow/jobs/base_job.py ## @@ -147,7 +147,7 @@ def heartbeat_callback(self, session=None): Callback that is called during heartbeat. This method should be overwritten. """ -def heartbeat(self): +def heartbeat(self, only_if_necessary=False): Review comment: yes, having type hint prevents caller from passing in with a variable of wrong type by accident. it will also help with type checking within this method anywhere `only_if_necessary` is used. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [airflow] randr97 commented on a change in pull request #8895: Add Delete/Create S3 bucket operators
randr97 commented on a change in pull request #8895:
URL: https://github.com/apache/airflow/pull/8895#discussion_r428229819
##
File path: airflow/providers/amazon/aws/operators/s3_bucket.py
##
@@ -0,0 +1,119 @@
+#
+# Licensed to the Apache Software Foundation (ASF) under one
+# or more contributor license agreements. See the NOTICE file
+# distributed with this work for additional information
+# regarding copyright ownership. The ASF licenses this file
+# to you under the Apache License, Version 2.0 (the
+# "License"); you may not use this file except in compliance
+# with the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing,
+# software distributed under the License is distributed on an
+# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+# KIND, either express or implied. See the License for the
+# specific language governing permissions and limitations
+# under the License.
+"""
+This module contains AWS S3 operators.
+"""
+from typing import Optional
+
+from airflow.exceptions import AirflowException
+from airflow.models import BaseOperator
+from airflow.providers.amazon.aws.hooks.s3 import S3Hook
+
+
+class S3CreateBucketOperator(BaseOperator):
+"""
+This operator creates an S3 bucket
+
+:param bucket_name: This is bucket name you want to create
+:type bucket_name: Optional[str]
+:param aws_conn_id: The Airflow connection used for AWS credentials.
+If this is None or empty then the default boto3 behaviour is used. If
+running Airflow in a distributed manner and aws_conn_id is None or
+empty, then default boto3 configuration would be used (and must be
+maintained on each worker node).
+:type aws_conn_id: Optional[str]
+:param region_name: AWS region_name. If not specified fetched from
connection.
+:type region_name: Optional[str]
+"""
+def __init__(self,
+ bucket_name,
+ aws_conn_id: Optional[str] = "aws_default",
+ region_name: Optional[str] = None,
+ *args,
+ **kwargs) -> None:
+super().__init__(*args, **kwargs)
+self.bucket_name = bucket_name
+self.region_name = region_name
+self.s3_hook = S3Hook(aws_conn_id=aws_conn_id, region_name=region_name)
+
+def execute(self, context):
+S3CreateBucketOperator.check_for_bucket(self.s3_hook, self.bucket_name)
+self.s3_hook.create_bucket(bucket_name=self.bucket_name,
region_name=self.region_name)
+self.log.info("Created bucket with name: %s", self.bucket_name)
+
+@staticmethod
+def check_for_bucket(s3_hook: S3Hook, bucket_name: str) -> None:
+"""
+Override this method if you don't want to raise excaption if bucket
already exists.
+
+:param s3_hook: Hook to interact with aws s3 services
+:type s3_hook: S3Hook
+:param bucket_name: Bucket name
+:type bucket_name: str
+:return: None
+:rtype: None
+"""
+if s3_hook.check_for_bucket(bucket_name):
+raise AirflowException(f"The bucket name {bucket_name} already
exists")
Review comment:
Makes sense!
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [airflow] maxcountryman commented on issue #8243: Sentry tags appear to be missing
maxcountryman commented on issue #8243: URL: https://github.com/apache/airflow/issues/8243#issuecomment-631651715 This is addressed by #7232. We were able to apply the above patch and observe it resolving this issue for us. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (AIRFLOW-6983) Disabled connection pool in CLI might be harmful
[ https://issues.apache.org/jira/browse/AIRFLOW-6983?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17112507#comment-17112507 ] ASF GitHub Bot commented on AIRFLOW-6983: - ashb commented on pull request #7622: URL: https://github.com/apache/airflow/pull/7622#issuecomment-631641575 @Khrol ci having some general issues today , should be fixed in an hour hopefully This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > Disabled connection pool in CLI might be harmful > > > Key: AIRFLOW-6983 > URL: https://issues.apache.org/jira/browse/AIRFLOW-6983 > Project: Apache Airflow > Issue Type: Improvement > Components: database >Affects Versions: 1.10.9 >Reporter: Igor Khrol >Assignee: Igor Khrol >Priority: Trivial > > Tasks are executed in CLI mode when connection pool to the database is > disabled. > `settings.configure_orm(disable_connection_pool=True)` > > While one task is run, multiple DB communications are happening while a > separate connection is allocated for each of them. > > It results in DB failures. > > Default behavior might be ok but it worth making it configurable. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (AIRFLOW-6983) Disabled connection pool in CLI might be harmful
[
https://issues.apache.org/jira/browse/AIRFLOW-6983?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17112506#comment-17112506
]
ASF GitHub Bot commented on AIRFLOW-6983:
-
ashb commented on a change in pull request #7622:
URL: https://github.com/apache/airflow/pull/7622#discussion_r428213605
##
File path: airflow/settings.py
##
@@ -148,18 +148,6 @@ def configure_orm(disable_connection_pool=False):
# 0 means no limit, which could lead to exceeding the Database
connection limit.
pool_size = conf.getint('core', 'SQL_ALCHEMY_POOL_SIZE', fallback=5)
Review comment:
Shouldn't we remove this too?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> Disabled connection pool in CLI might be harmful
>
>
> Key: AIRFLOW-6983
> URL: https://issues.apache.org/jira/browse/AIRFLOW-6983
> Project: Apache Airflow
> Issue Type: Improvement
> Components: database
>Affects Versions: 1.10.9
>Reporter: Igor Khrol
>Assignee: Igor Khrol
>Priority: Trivial
>
> Tasks are executed in CLI mode when connection pool to the database is
> disabled.
> `settings.configure_orm(disable_connection_pool=True)`
>
> While one task is run, multiple DB communications are happening while a
> separate connection is allocated for each of them.
>
> It results in DB failures.
>
> Default behavior might be ok but it worth making it configurable.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [airflow] ashb commented on pull request #7622: [AIRFLOW-6983] Use SingletonThreadPool for database communication
ashb commented on pull request #7622: URL: https://github.com/apache/airflow/pull/7622#issuecomment-631641575 @Khrol ci having some general issues today , should be fixed in an hour hopefully This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [airflow] ashb commented on a change in pull request #7622: [AIRFLOW-6983] Use SingletonThreadPool for database communication
ashb commented on a change in pull request #7622:
URL: https://github.com/apache/airflow/pull/7622#discussion_r428213605
##
File path: airflow/settings.py
##
@@ -148,18 +148,6 @@ def configure_orm(disable_connection_pool=False):
# 0 means no limit, which could lead to exceeding the Database
connection limit.
pool_size = conf.getint('core', 'SQL_ALCHEMY_POOL_SIZE', fallback=5)
Review comment:
Shouldn't we remove this too?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [airflow] feluelle commented on a change in pull request #8895: Add Delete/Create S3 bucket operators
feluelle commented on a change in pull request #8895:
URL: https://github.com/apache/airflow/pull/8895#discussion_r428206674
##
File path: airflow/providers/amazon/aws/operators/s3_bucket.py
##
@@ -0,0 +1,119 @@
+#
+# Licensed to the Apache Software Foundation (ASF) under one
+# or more contributor license agreements. See the NOTICE file
+# distributed with this work for additional information
+# regarding copyright ownership. The ASF licenses this file
+# to you under the Apache License, Version 2.0 (the
+# "License"); you may not use this file except in compliance
+# with the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing,
+# software distributed under the License is distributed on an
+# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+# KIND, either express or implied. See the License for the
+# specific language governing permissions and limitations
+# under the License.
+"""
+This module contains AWS S3 operators.
+"""
+from typing import Optional
+
+from airflow.exceptions import AirflowException
+from airflow.models import BaseOperator
+from airflow.providers.amazon.aws.hooks.s3 import S3Hook
+
+
+class S3CreateBucketOperator(BaseOperator):
+"""
+This operator creates an S3 bucket
+
+:param bucket_name: This is bucket name you want to create
+:type bucket_name: Optional[str]
+:param aws_conn_id: The Airflow connection used for AWS credentials.
+If this is None or empty then the default boto3 behaviour is used. If
+running Airflow in a distributed manner and aws_conn_id is None or
+empty, then default boto3 configuration would be used (and must be
+maintained on each worker node).
+:type aws_conn_id: Optional[str]
+:param region_name: AWS region_name. If not specified fetched from
connection.
+:type region_name: Optional[str]
+"""
+def __init__(self,
+ bucket_name,
+ aws_conn_id: Optional[str] = "aws_default",
+ region_name: Optional[str] = None,
+ *args,
+ **kwargs) -> None:
+super().__init__(*args, **kwargs)
+self.bucket_name = bucket_name
+self.region_name = region_name
+self.s3_hook = S3Hook(aws_conn_id=aws_conn_id, region_name=region_name)
+
+def execute(self, context):
+S3CreateBucketOperator.check_for_bucket(self.s3_hook, self.bucket_name)
+self.s3_hook.create_bucket(bucket_name=self.bucket_name,
region_name=self.region_name)
+self.log.info("Created bucket with name: %s", self.bucket_name)
+
+@staticmethod
+def check_for_bucket(s3_hook: S3Hook, bucket_name: str) -> None:
+"""
+Override this method if you don't want to raise excaption if bucket
already exists.
+
+:param s3_hook: Hook to interact with aws s3 services
+:type s3_hook: S3Hook
+:param bucket_name: Bucket name
+:type bucket_name: str
+:return: None
+:rtype: None
+"""
+if s3_hook.check_for_bucket(bucket_name):
+raise AirflowException(f"The bucket name {bucket_name} already
exists")
Review comment:
If someone wants to do extra operations he/she can do so by having a
task (operator) calling before or after this one, don't you think?
Why do you think it is necessary to call this function / the extra
operations right there i.e. in this context instead of outside of this context
in another task/operator?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[jira] [Commented] (AIRFLOW-6569) Broken sentry integration
[ https://issues.apache.org/jira/browse/AIRFLOW-6569?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17112497#comment-17112497 ] ASF GitHub Bot commented on AIRFLOW-6569: - mikeclarke commented on pull request #7232: URL: https://github.com/apache/airflow/pull/7232#issuecomment-631635519 Rebased master just now - last time the tests were failing for unrelated reasons, but we'll see. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > Broken sentry integration > - > > Key: AIRFLOW-6569 > URL: https://issues.apache.org/jira/browse/AIRFLOW-6569 > Project: Apache Airflow > Issue Type: Bug > Components: configuration, hooks >Affects Versions: 2.0.0, 1.10.7 >Reporter: Robin Edwards >Priority: Minor > > I believe the new forking mechanism AIRFLOW-5931 has unintentionally broken > the sentry integration. > Sentry relies on the atexit > http://man7.org/linux/man-pages/man3/atexit.3.html signal to flush collected > errors to their servers. Previously as the task was executed in a new process > as opposed to forked this got invoked. However now os._exit() is called > (which is semantically correct with child processes) > https://docs.python.org/3/library/os.html#os._exit > Point os._exit is called in airflow: > https://github.com/apache/airflow/pull/6627/files#diff-736081a3535ff0b9e60ada2f51154ca4R84 > Also related on sentry bug tracker: > https://github.com/getsentry/sentry-python/issues/291 > Unfortunately sentry doesn't provide (from what i can find) a public > interface for flushing errors to their system. The return value of their > init() functions returns an object containg a client but the property is > `_client` so it would be wrong to rely on it. > I've side stepped this in two ways, you can disable the forking feature > through patching CAN_FORK to False. But after seeing the performance > improvement on my workers I opted to monkey patch the whole _exec_by_fork() > and naughtily call sys.exit instead as a temporary fix. > I personally dont find the actual sentry integration in airflow useful as it > doesn't collect errors from the rest of the system only tasks. I've been > wiring it in through my log config module since before the integration was > added however its still effected by the above change. > My personal vote (unless anyone has a better idea) would be to remove the > integration completely document the way of setting it up through the logging > class and providing a 'post_execute' hook of some form on the > StandardTaskRunner where people can flush errors using what not. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [airflow] feluelle commented on a change in pull request #8895: Add Delete/Create S3 bucket operators
feluelle commented on a change in pull request #8895:
URL: https://github.com/apache/airflow/pull/8895#discussion_r428206674
##
File path: airflow/providers/amazon/aws/operators/s3_bucket.py
##
@@ -0,0 +1,119 @@
+#
+# Licensed to the Apache Software Foundation (ASF) under one
+# or more contributor license agreements. See the NOTICE file
+# distributed with this work for additional information
+# regarding copyright ownership. The ASF licenses this file
+# to you under the Apache License, Version 2.0 (the
+# "License"); you may not use this file except in compliance
+# with the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing,
+# software distributed under the License is distributed on an
+# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+# KIND, either express or implied. See the License for the
+# specific language governing permissions and limitations
+# under the License.
+"""
+This module contains AWS S3 operators.
+"""
+from typing import Optional
+
+from airflow.exceptions import AirflowException
+from airflow.models import BaseOperator
+from airflow.providers.amazon.aws.hooks.s3 import S3Hook
+
+
+class S3CreateBucketOperator(BaseOperator):
+"""
+This operator creates an S3 bucket
+
+:param bucket_name: This is bucket name you want to create
+:type bucket_name: Optional[str]
+:param aws_conn_id: The Airflow connection used for AWS credentials.
+If this is None or empty then the default boto3 behaviour is used. If
+running Airflow in a distributed manner and aws_conn_id is None or
+empty, then default boto3 configuration would be used (and must be
+maintained on each worker node).
+:type aws_conn_id: Optional[str]
+:param region_name: AWS region_name. If not specified fetched from
connection.
+:type region_name: Optional[str]
+"""
+def __init__(self,
+ bucket_name,
+ aws_conn_id: Optional[str] = "aws_default",
+ region_name: Optional[str] = None,
+ *args,
+ **kwargs) -> None:
+super().__init__(*args, **kwargs)
+self.bucket_name = bucket_name
+self.region_name = region_name
+self.s3_hook = S3Hook(aws_conn_id=aws_conn_id, region_name=region_name)
+
+def execute(self, context):
+S3CreateBucketOperator.check_for_bucket(self.s3_hook, self.bucket_name)
+self.s3_hook.create_bucket(bucket_name=self.bucket_name,
region_name=self.region_name)
+self.log.info("Created bucket with name: %s", self.bucket_name)
+
+@staticmethod
+def check_for_bucket(s3_hook: S3Hook, bucket_name: str) -> None:
+"""
+Override this method if you don't want to raise excaption if bucket
already exists.
+
+:param s3_hook: Hook to interact with aws s3 services
+:type s3_hook: S3Hook
+:param bucket_name: Bucket name
+:type bucket_name: str
+:return: None
+:rtype: None
+"""
+if s3_hook.check_for_bucket(bucket_name):
+raise AirflowException(f"The bucket name {bucket_name} already
exists")
Review comment:
If someone wants to do extra operation he/she can do so by having a task
(operator) calling before or after this one, don't you think?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org