[GitHub] [incubator-druid] clintropolis opened a new pull request #8797: serve web-console even if router management proxy is not enabled
clintropolis opened a new pull request #8797: serve web-console even if router management proxy is not enabled URL: https://github.com/apache/incubator-druid/pull/8797 This PR modifies the router to always serve the web-console, regardless of whether or not the management proxy is enabled (@vogievetsky is planning on adding a graceful degradation mode to the Druid web-console). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] alexwangx commented on issue #8289: druid 0.15.0 with cdh 5.9.2 index-hadoop happend java.lang.NoSuchFieldError:org.apache.hadoop.mapreduce.TypeConverter.fromYarn error
alexwangx commented on issue #8289: druid 0.15.0 with cdh 5.9.2 index-hadoop happend java.lang.NoSuchFieldError:org.apache.hadoop.mapreduce.TypeConverter.fromYarn error URL: https://github.com/apache/incubator-druid/issues/8289#issuecomment-548224002 I also encountered this problem, have you solved it? @shuaidonga This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[incubator-druid] branch master updated (bca649e -> edb3b00)
This is an automated email from the ASF dual-hosted git repository. cwylie pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/incubator-druid.git. from bca649e Case sensitive comparison of nonbinary string in MySQL metadata storage (#8758) add edb3b00 Startup scripts: verify Java 8 (exactly), improve port/java verification messages. (#8794) No new revisions were added by this update. Summary of changes: examples/bin/verify-default-ports | 26 +++--- examples/bin/verify-java | 32 +++- 2 files changed, 50 insertions(+), 8 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] clintropolis merged pull request #8794: Startup scripts: verify Java 8 (exactly), improve port/java verification messages.
clintropolis merged pull request #8794: Startup scripts: verify Java 8 (exactly), improve port/java verification messages. URL: https://github.com/apache/incubator-druid/pull/8794 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] koupeng closed issue #8787: how to connect kakfa by zookeeper
koupeng closed issue #8787: how to connect kakfa by zookeeper URL: https://github.com/apache/incubator-druid/issues/8787 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] vogievetsky opened a new pull request #8796: Web console: use SQL for the supervisor
vogievetsky opened a new pull request #8796: Web console: use SQL for the supervisor URL: https://github.com/apache/incubator-druid/pull/8796 Use the new supervisor system table for the web console 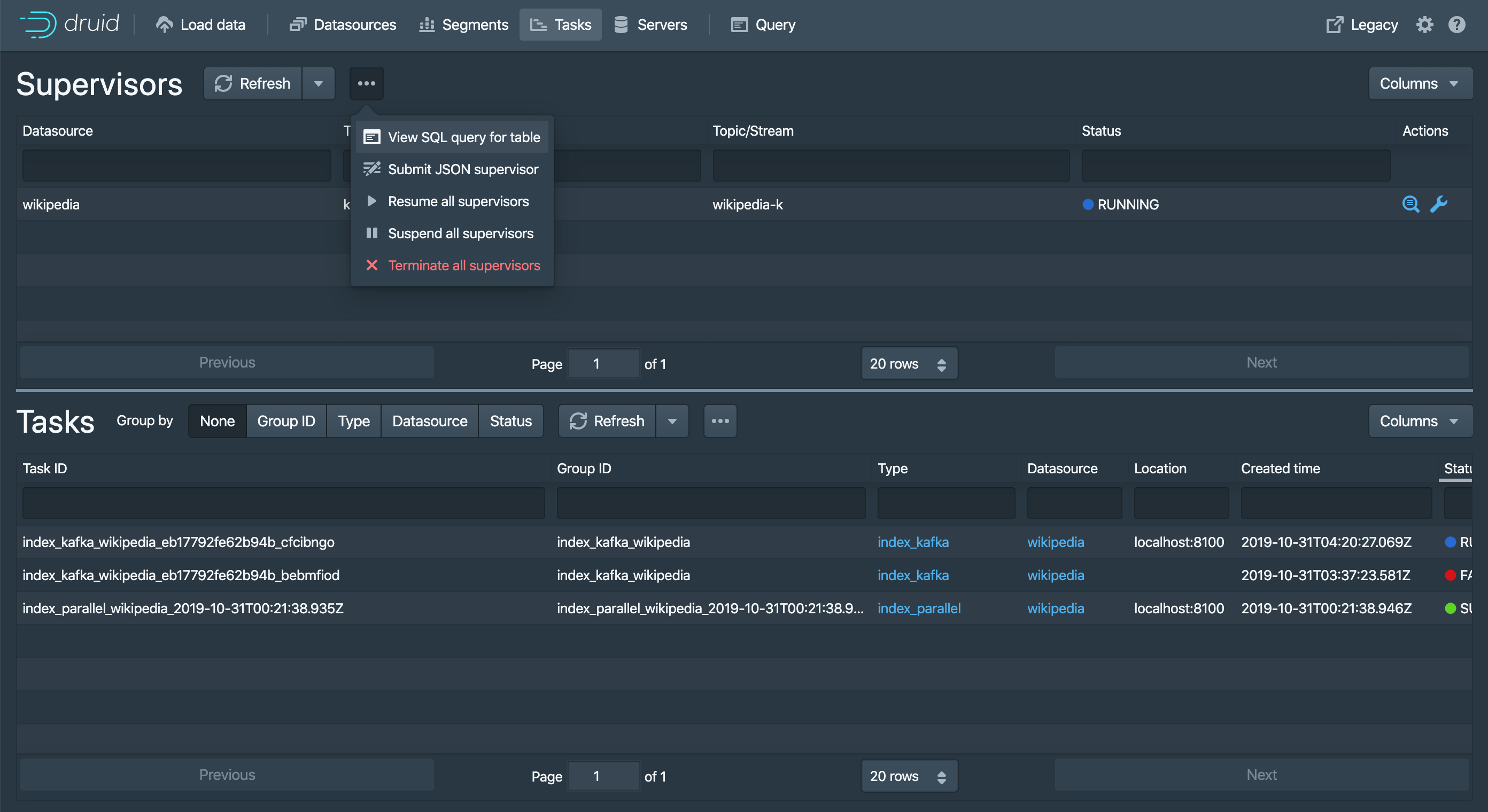 Also the home card! This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] suneet-amp commented on issue #8794: Startup scripts: verify Java 8 (exactly), improve port/java verification messages.
suneet-amp commented on issue #8794: Startup scripts: verify Java 8 (exactly), improve port/java verification messages. URL: https://github.com/apache/incubator-druid/pull/8794#issuecomment-548207239 Thanks for this fix! This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] suneet-amp commented on a change in pull request #8794: Startup scripts: verify Java 8 (exactly), improve port/java verification messages.
suneet-amp commented on a change in pull request #8794: Startup scripts: verify
Java 8 (exactly), improve port/java verification messages.
URL: https://github.com/apache/incubator-druid/pull/8794#discussion_r340951524
##
File path: examples/bin/verify-default-ports
##
@@ -21,12 +21,28 @@ use strict;
use warnings;
use Socket;
-my @ports = (1527, 2181, 8081, 8082, 8083, 8090, 8091, 8200, 9095);
+my $skip_var = $ENV{'DRUID_SKIP_PORT_CHECK'};
+if ($skip_var && $skip_var ne "0" && $skip_var ne "false" && $skip_var ne "f")
{
+ exit 0;
+}
+
+my @ports = (1527, 2181, 8081, 8082, 8083, 8090, 8091, 8200, );
my $tcp = getprotobyname("tcp");
for my $port (@ports) {
socket(my $sock, PF_INET, SOCK_STREAM, $tcp) or die "socket: $!";
setsockopt($sock, SOL_SOCKET, SO_REUSEADDR, pack("l", 1)) or die
"setsockopt: $!";
- bind($sock, sockaddr_in($port, INADDR_ANY)) or die "Cannot start up because
port[$port] is already in use.\n";
- close $sock;
+ if (!bind($sock, sockaddr_in($port, INADDR_ANY))) {
+print STDERR <<"EOT";
+Cannot start up because port $port is already in use.
+
+If you believe this check is in error, you can skip it using an
+environment variable:
+
+ export DRUID_SKIP_PORT_CHECK=1
+
+Otherwise, free up port $port and try again.
Review comment:
Looks good!
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org
For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] gianm merged pull request #8758: Case sensitive comparison of nonbinary string in MySQL metadata storage
gianm merged pull request #8758: Case sensitive comparison of nonbinary string in MySQL metadata storage URL: https://github.com/apache/incubator-druid/pull/8758 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[incubator-druid] branch master updated (ed6be81 -> bca649e)
This is an automated email from the ASF dual-hosted git repository. gian pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/incubator-druid.git. from ed6be81 Web console: fix error when querying with grand totals (#8795) add bca649e Case sensitive comparison of nonbinary string in MySQL metadata storage (#8758) No new revisions were added by this update. Summary of changes: .../metadata/storage/mysql/MySQLConnector.java | 7 + .../druid/metadata/SQLMetadataConnector.java | 31 +++--- 2 files changed, 28 insertions(+), 10 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] gianm commented on a change in pull request #8775: Fix NPE for subquery with limit
gianm commented on a change in pull request #8775: Fix NPE for subquery with
limit
URL: https://github.com/apache/incubator-druid/pull/8775#discussion_r340945547
##
File path:
sql/src/main/java/org/apache/druid/sql/calcite/rel/DruidOuterQueryRel.java
##
@@ -129,8 +131,10 @@ public DruidQuery toDruidQuery(final boolean
finalizeAggregations)
}
final RowSignature sourceRowSignature = subQuery.getOutputRowSignature();
+final GroupByQuery groupByQuery = subQuery.toGroupByQuery();
+final DataSource dataSource = groupByQuery == null ?
subQuery.getDataSource() : new QueryDataSource(groupByQuery);
Review comment:
I don't think this is correct. It is ignoring everything about `subQuery`
except the underlying dataSource. It means that if the underlying query is
doing something "interesting", like a limit, or expression, etc, then it will
be ignored.
I'd suggest doing this instead, to at least return a "nice" null instead of
throwing NPE. Then that will get understood by the planner as an unplannable
query.
```java
if (groupByQuery == null) {
return null;
}
```
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org
For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] gianm commented on a change in pull request #8775: Fix NPE for subquery with limit
gianm commented on a change in pull request #8775: Fix NPE for subquery with
limit
URL: https://github.com/apache/incubator-druid/pull/8775#discussion_r340945489
##
File path:
sql/src/test/java/org/apache/druid/sql/calcite/http/SqlResourceTest.java
##
@@ -671,6 +671,48 @@ public void testResourceLimitExceeded() throws Exception
checkSqlRequestLog(false);
}
+ @Test
+ public void testSubQueryWithLimit() throws Exception
+ {
+final List> rows = doPost(
+new SqlQuery(
+"SELECT COUNT(*) AS cnt FROM ( SELECT * FROM ( SELECT * FROM
druid.foo LIMIT 10 ) tmpA ) tmpB",
Review comment:
I think a query like this is actually legitimately unplannable in Druid
today. It is an aggregation query on top of a non-aggregating subquery.
Currently, groupBy subqueries must also be groupBys.
I think that to really fix this bug, we need to really support groupBys with
something other than a groupBy as a subquery. To make this work, we could
potentially build on point (3) in "native queries" of the join proposal
https://github.com/apache/incubator-druid/issues/8728:
> Allow joining on to "query" datasources as well. To make this work, we’ll
need to add a sense of a ‘standard translation’ of results from certain query
types into flat schemas that we can offer column selectors on top of. There may
be more than one way to do this, since certain query types (notably, topN and
scan) return nested results in some cases. We could do this by adding a new
QueryToolChest method.
The "standard translation" could also be used to support running a groupBy
on top of a non-aggregating subquery.
Something to think about for the future.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org
For additional commands, e-mail: commits-h...@druid.apache.org
[incubator-druid] branch master updated (3ff5e02 -> ed6be81)
This is an automated email from the ASF dual-hosted git repository.
fjy pushed a change to branch master
in repository https://gitbox.apache.org/repos/asf/incubator-druid.git.
from 3ff5e02 remove select query (#8739)
add ed6be81 Web console: fix error when querying with grand totals (#8795)
No new revisions were added by this update.
Summary of changes:
.../table-cell-unparseable.spec.tsx.snap | 17 +
.../table-cell-unparseable.scss} |4 +-
.../table-cell-unparseable.spec.tsx} | 20 +-
.../table-cell-unparseable.tsx}| 18 +-
.../__snapshots__/table-cell.spec.tsx.snap | 28 +-
.../src/components/table-cell/table-cell.scss |4 -
.../src/components/table-cell/table-cell.spec.tsx | 44 +-
.../src/components/table-cell/table-cell.tsx | 40 +-
.../load-data-view/filter-table/filter-table.tsx |2 +-
.../parse-data-table/parse-data-table.tsx |3 +-
.../parse-time-table/parse-time-table.tsx |5 +-
.../load-data-view/schema-table/schema-table.tsx |2 +-
.../transform-table/transform-table.tsx|2 +-
.../__snapshots__/query-output.spec.tsx.snap | 1089 ++--
.../query-view/query-output/query-output.spec.tsx | 35 +-
.../views/query-view/query-output/query-output.tsx |4 +-
16 files changed, 456 insertions(+), 861 deletions(-)
create mode 100644
web-console/src/components/table-cell-unparseable/__snapshots__/table-cell-unparseable.spec.tsx.snap
copy
web-console/src/{views/load-data-view/parse-time-table/parse-time-table.scss =>
components/table-cell-unparseable/table-cell-unparseable.scss} (94%)
copy web-console/src/{visualization/visualization.spec.tsx =>
components/table-cell-unparseable/table-cell-unparseable.spec.tsx} (69%)
copy web-console/src/{views/load-data-view/learn-more/learn-more.tsx =>
components/table-cell-unparseable/table-cell-unparseable.tsx} (69%)
-
To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org
For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] fjy merged pull request #8795: Web console: fix error when querying with grand totals
fjy merged pull request #8795: Web console: fix error when querying with grand totals URL: https://github.com/apache/incubator-druid/pull/8795 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] fjy closed issue #8791: Druid Console SQL query page crashes for a timeseries query issued with grandTotal query
fjy closed issue #8791: Druid Console SQL query page crashes for a timeseries query issued with grandTotal query URL: https://github.com/apache/incubator-druid/issues/8791 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[incubator-druid] branch master updated (2363b61 -> 3ff5e02)
This is an automated email from the ASF dual-hosted git repository. gian pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/incubator-druid.git. from 2363b61 Asynchronous file copy in the shuffle of parallel indexing task (#8783) add 3ff5e02 remove select query (#8739) No new revisions were added by this update. Summary of changes: .../druid/benchmark/query/SelectBenchmark.java | 385 --- .../druid/data/input/impl/TimestampSpec.java |2 +- docs/configuration/index.md|8 +- docs/querying/scan-query.md|5 +- docs/querying/select-query.md | 235 + .../TimestampAggregationSelectTest.java| 157 --- .../time-min-max/src/test/resources/select.json| 11 - .../druid/segment/MapVirtualColumnSelectTest.java | 204 .../theta/SketchAggregationWithSimpleDataTest.java | 25 - .../src/test/resources/select_query.json | 11 - .../src/test/resources/indexer/select.query| 19 - .../test/resources/indexer/select_reindex.query| 19 - .../test/resources/indexer/union_select_query.json | 121 --- .../main/java/org/apache/druid/query/Druids.java | 169 --- .../java/org/apache/druid/query/QueryConfig.java |1 - .../java/org/apache/druid/query/QueryMetrics.java |3 +- .../query/dimension/DefaultDimensionSpec.java | 23 +- .../query/select/DefaultSelectQueryMetrics.java| 263 - .../select/DefaultSelectQueryMetricsFactory.java | 51 - .../org/apache/druid/query/select/EventHolder.java | 128 --- .../apache/druid/query/select/PagingOffset.java| 117 --- .../org/apache/druid/query/select/PagingSpec.java | 194 .../apache/druid/query/select/SelectBinaryFn.java | 105 -- .../org/apache/druid/query/select/SelectQuery.java | 191 ++-- .../druid/query/select/SelectQueryConfig.java | 51 - .../druid/query/select/SelectQueryEngine.java | 321 -- .../druid/query/select/SelectQueryMetrics.java | 34 - .../query/select/SelectQueryMetricsFactory.java| 36 - .../query/select/SelectQueryQueryToolChest.java| 403 --- .../query/select/SelectQueryRunnerFactory.java | 105 -- .../druid/query/select/SelectResultValue.java | 136 --- .../query/select/SelectResultValueBuilder.java | 153 --- .../main/java/org/apache/druid/segment/Cursor.java |1 - .../QueryableIndexCursorSequenceBuilder.java | 10 - .../IncrementalIndexStorageAdapter.java| 10 - .../query/aggregation/AggregationTestHelper.java | 60 -- .../query/scan/MultiSegmentScanQueryTest.java |8 +- .../select/DefaultSelectQueryMetricsTest.java | 99 -- .../query/select/MultiSegmentSelectQueryTest.java | 356 --- .../druid/query/select/PagingOffsetTest.java | 71 -- .../druid/query/select/SelectBinaryFnTest.java | 277 - .../druid/query/select/SelectQueryConfigTest.java | 58 -- .../select/SelectQueryQueryToolChestTest.java | 72 -- .../druid/query/select/SelectQueryRunnerTest.java | 1095 .../druid/query/select/SelectQuerySpecTest.java| 155 --- .../apache/druid/query/select/SelectQueryTest.java | 63 ++ .../org/apache/druid/client/cache/CacheConfig.java |2 +- .../druid/guice/QueryRunnerFactoryModule.java |3 - .../apache/druid/guice/QueryToolChestModule.java | 19 - .../realtime/firehose/IngestSegmentFirehose.java |4 +- .../CachingClusteredClientFunctionalityTest.java |8 +- .../druid/client/CachingClusteredClientTest.java | 266 + .../client/CachingClusteredClientTestUtils.java| 14 +- .../apache/druid/sql/calcite/rel/DruidQuery.java |3 +- .../druid/sql/calcite/BaseCalciteQueryTest.java|2 - .../druid/sql/calcite/util/CalciteTests.java | 15 - 56 files changed, 155 insertions(+), 6202 deletions(-) delete mode 100644 benchmarks/src/main/java/org/apache/druid/benchmark/query/SelectBenchmark.java delete mode 100644 extensions-contrib/time-min-max/src/test/java/org/apache/druid/query/aggregation/TimestampAggregationSelectTest.java delete mode 100644 extensions-contrib/time-min-max/src/test/resources/select.json delete mode 100644 extensions-contrib/virtual-columns/src/test/java/org/apache/druid/segment/MapVirtualColumnSelectTest.java delete mode 100644 extensions-core/datasketches/src/test/resources/select_query.json delete mode 100644 integration-tests/src/test/resources/indexer/select.query delete mode 100644 integration-tests/src/test/resources/indexer/select_reindex.query delete mode 100644 integration-tests/src/test/resources/indexer/union_select_query.json delete mode 100644 processing/src/main/java/org/apache/druid/query/select/DefaultSelectQueryMetrics.java delete mode 100644 processing/src/main/java/org/apache/druid/query/select/DefaultSelectQueryMetricsFactory.java delete mode 100644
[GitHub] [incubator-druid] gianm merged pull request #8739: remove select query
gianm merged pull request #8739: remove select query URL: https://github.com/apache/incubator-druid/pull/8739 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] gianm commented on a change in pull request #8794: Startup scripts: verify Java 8 (exactly), improve port/java verification messages.
gianm commented on a change in pull request #8794: Startup scripts: verify Java
8 (exactly), improve port/java verification messages.
URL: https://github.com/apache/incubator-druid/pull/8794#discussion_r340934210
##
File path: examples/bin/verify-default-ports
##
@@ -21,12 +21,28 @@ use strict;
use warnings;
use Socket;
-my @ports = (1527, 2181, 8081, 8082, 8083, 8090, 8091, 8200, 9095);
+my $skip_var = $ENV{'DRUID_SKIP_PORT_CHECK'};
+if ($skip_var && $skip_var ne "0" && $skip_var ne "false" && $skip_var ne "f")
{
+ exit 0;
+}
+
+my @ports = (1527, 2181, 8081, 8082, 8083, 8090, 8091, 8200, );
my $tcp = getprotobyname("tcp");
for my $port (@ports) {
socket(my $sock, PF_INET, SOCK_STREAM, $tcp) or die "socket: $!";
setsockopt($sock, SOL_SOCKET, SO_REUSEADDR, pack("l", 1)) or die
"setsockopt: $!";
- bind($sock, sockaddr_in($port, INADDR_ANY)) or die "Cannot start up because
port[$port] is already in use.\n";
- close $sock;
+ if (!bind($sock, sockaddr_in($port, INADDR_ANY))) {
+print STDERR <<"EOT";
+Cannot start up because port $port is already in use.
+
+If you believe this check is in error, you can skip it using an
+environment variable:
+
+ export DRUID_SKIP_PORT_CHECK=1
+
+Otherwise, free up port $port and try again.
Review comment:
I made some adjustments, let me know what you think.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org
For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] gianm commented on a change in pull request #8794: Startup scripts: verify Java 8 (exactly), improve port/java verification messages.
gianm commented on a change in pull request #8794: Startup scripts: verify Java
8 (exactly), improve port/java verification messages.
URL: https://github.com/apache/incubator-druid/pull/8794#discussion_r340923713
##
File path: examples/bin/verify-java
##
@@ -20,14 +20,35 @@
use strict;
use warnings;
+sub fail_check {
+ my ($current_version) = @_;
+ my $current_version_text =
+$current_version ? " Your current version is: $current_version." : "";
Review comment:
Good idea, I added `Make sure that "java" is installed and on your PATH.`
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org
For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] jihoonson merged pull request #8783: Asynchronous file copy in the shuffle of parallel indexing task
jihoonson merged pull request #8783: Asynchronous file copy in the shuffle of parallel indexing task URL: https://github.com/apache/incubator-druid/pull/8783 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] koupeng removed a comment on issue #7099: broker metadata refresh failing
koupeng removed a comment on issue #7099: broker metadata refresh failing URL: https://github.com/apache/incubator-druid/issues/7099#issuecomment-547933538 me too! This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] koupeng commented on issue #8786: web-console failed to compiled
koupeng commented on issue #8786: web-console failed to compiled URL: https://github.com/apache/incubator-druid/issues/8786#issuecomment-548173368 @vogievetsky thanks,but,my pc is win10? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[incubator-druid] branch master updated (7605c23 -> 2363b61)
This is an automated email from the ASF dual-hosted git repository. jihoonson pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/incubator-druid.git. from 7605c23 Remove Tranquility configs and certain doc references. (#8793) add 2363b61 Asynchronous file copy in the shuffle of parallel indexing task (#8783) No new revisions were added by this update. Summary of changes: .../indexing/common/task/batch/parallel/PartialSegmentMergeTask.java | 4 ++-- 1 file changed, 2 insertions(+), 2 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] jihoonson commented on issue #3435: Consider including hadoop-aws in the lib folder
jihoonson commented on issue #3435: Consider including hadoop-aws in the lib folder URL: https://github.com/apache/incubator-druid/issues/3435#issuecomment-548170033 I think it makes more sense to add to docs as for GCS (https://druid.apache.org/docs/latest/development/extensions-core/hdfs.html). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] suneet-amp commented on a change in pull request #8794: Startup scripts: verify Java 8 (exactly), improve port/java verification messages.
suneet-amp commented on a change in pull request #8794: Startup scripts: verify
Java 8 (exactly), improve port/java verification messages.
URL: https://github.com/apache/incubator-druid/pull/8794#discussion_r340912915
##
File path: examples/bin/verify-default-ports
##
@@ -21,12 +21,28 @@ use strict;
use warnings;
use Socket;
-my @ports = (1527, 2181, 8081, 8082, 8083, 8090, 8091, 8200, 9095);
+my $skip_var = $ENV{'DRUID_SKIP_PORT_CHECK'};
+if ($skip_var && $skip_var ne "0" && $skip_var ne "false" && $skip_var ne "f")
{
+ exit 0;
+}
+
+my @ports = (1527, 2181, 8081, 8082, 8083, 8090, 8091, 8200, );
my $tcp = getprotobyname("tcp");
for my $port (@ports) {
socket(my $sock, PF_INET, SOCK_STREAM, $tcp) or die "socket: $!";
setsockopt($sock, SOL_SOCKET, SO_REUSEADDR, pack("l", 1)) or die
"setsockopt: $!";
- bind($sock, sockaddr_in($port, INADDR_ANY)) or die "Cannot start up because
port[$port] is already in use.\n";
- close $sock;
+ if (!bind($sock, sockaddr_in($port, INADDR_ANY))) {
+print STDERR <<"EOT";
+Cannot start up because port $port is already in use.
+
+If you believe this check is in error, you can skip it using an
+environment variable:
+
+ export DRUID_SKIP_PORT_CHECK=1
+
+Otherwise, free up port $port and try again.
Review comment:
nit: Would be nice to link to
https://druid.apache.org/docs/latest/configuration/index.html for more details
on changing the ports / what the different ports are used for.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org
For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] suneet-amp commented on a change in pull request #8794: Startup scripts: verify Java 8 (exactly), improve port/java verification messages.
suneet-amp commented on a change in pull request #8794: Startup scripts: verify
Java 8 (exactly), improve port/java verification messages.
URL: https://github.com/apache/incubator-druid/pull/8794#discussion_r340911345
##
File path: examples/bin/verify-java
##
@@ -20,14 +20,35 @@
use strict;
use warnings;
+sub fail_check {
+ my ($current_version) = @_;
+ my $current_version_text =
+$current_version ? " Your current version is: $current_version." : "";
Review comment:
nit: would be nice to have the error message say something along the lines
of `java isn't on the PATH` for the else case
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org
For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] gianm commented on issue #3435: Consider including hadoop-aws in the lib folder
gianm commented on issue #3435: Consider including hadoop-aws in the lib folder URL: https://github.com/apache/incubator-druid/issues/3435#issuecomment-548160990 > I think the packaged jars should be minimized and so include only mandatory ones. `hadoop-aws` is only useful when they want to deal with s3 via hdfs. It seems a sort of an extension of an extension to me. Hmm, well, personally I think including it is nice, since it makes the app easier to use out of the box for AWS people and doesn't bloat the distribution too much. However, I would be ok not including it if we add something to the docs that says exactly what command to run to get `hadoop-aws` working properly. (These things are hard for users to figure out from first principles) I'm ok with whatever y'all think is best (@jihoonson and @nishantmonu51) if you agree with each other. If not my vote goes to including the jar. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] jihoonson commented on issue #3435: Consider including hadoop-aws in the lib folder
jihoonson commented on issue #3435: Consider including hadoop-aws in the lib folder URL: https://github.com/apache/incubator-druid/issues/3435#issuecomment-548155894 > Hmm, why not include it? We include the aws sdk in the s3 extensions bundled with Druid, it seems nice to include the hadoop version too. I think the packaged jars should be minimized and so include only mandatory ones. `hadoop-aws` is only useful when they want to deal with s3 via hdfs. It seems a sort of an extension of an extension to me. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] clintropolis commented on issue #8578: parallel broker merges on fork join pool
clintropolis commented on issue #8578: parallel broker merges on fork join pool URL: https://github.com/apache/incubator-druid/pull/8578#issuecomment-548155872 ### my conclusions I think the performance degradation under load spikes falls within what I consider acceptable range. Particularly important, I find the degradation to be relatively predictable so that we can update the cluster tuning guide (in a future PR) to best advise how to tune your brokers for a given cluster size and load pattern. I also believe there is quite a lot of room for further improvement, so maybe we could get to place where this approach nears the same overloaded characteristics of the http thread pool based merges we currently perform. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[incubator-druid] branch master updated (c922d2c -> 7605c23)
This is an automated email from the ASF dual-hosted git repository. fjy pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/incubator-druid.git. from c922d2c Use bundled ZooKeeper in tutorials. (#8792) add 7605c23 Remove Tranquility configs and certain doc references. (#8793) No new revisions were added by this update. Summary of changes: docs/configuration/index.md| 5 +- docs/development/extensions-contrib/thrift.md | 42 +-- .../development/extensions-core/kafka-ingestion.md | 5 +- .../extensions-core/kinesis-ingestion.md | 5 +- docs/development/extensions-core/protobuf.md | 2 +- docs/ingestion/tasks.md| 2 +- docs/querying/multitenancy.md | 9 +-- docs/tutorials/cluster.md | 21 -- examples/conf/supervise/cluster/data.conf | 3 - examples/conf/supervise/single-server/large.conf | 3 - examples/conf/supervise/single-server/medium.conf | 3 - .../supervise/single-server/micro-quickstart.conf | 3 - .../supervise/single-server/nano-quickstart.conf | 3 - examples/conf/supervise/single-server/small.conf | 3 - examples/conf/supervise/single-server/xlarge.conf | 3 - examples/conf/tranquility/kafka.json | 76 examples/conf/tranquility/server.json | 73 --- examples/conf/tranquility/wikipedia-server.json| 84 -- 18 files changed, 10 insertions(+), 335 deletions(-) delete mode 100644 examples/conf/tranquility/kafka.json delete mode 100644 examples/conf/tranquility/server.json delete mode 100644 examples/conf/tranquility/wikipedia-server.json - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] fjy merged pull request #8793: Remove Tranquility configs and certain doc references.
fjy merged pull request #8793: Remove Tranquility configs and certain doc references. URL: https://github.com/apache/incubator-druid/pull/8793 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] clintropolis commented on issue #8578: parallel broker merges on fork join pool
clintropolis commented on issue #8578: parallel broker merges on fork join pool
URL: https://github.com/apache/incubator-druid/pull/8578#issuecomment-548152735
### worst case
The other really important part to highlight, is to determine how this
approach degrades under increasing concurrency by looking at the absolute worst
case scenario with the current approach, the concurrent load spike. I consider
this the nemesis of the current parallelism chooser, since it will potentially
dramatically under-estimate the available CPU capacity.
For reference, I included a measurement when the
`ParallelMergeCombiningSequence` level of parallelism was limited to 1. This is
what the computed level of parallelism will trend towards when load is
gradually increased and sustained, and so is how continued overloading is
expected to behave.
From the left of the following line plots, the vertical dotted lines
represent the number of physical cores and number of hyper-threads of the
benchmark machine.

This looks pretty bad for parallelism under huge load spikes, but also keep
in mind that this measurement is looking at the time to complete all threads,
not the average per thread timing (so at the far right of the plot, the time to
simultaneously complete 4 times as many threads as we have processors).
Using an offset of 10ms before each concurrent thread to help even out the
load shrinks the gap of performance degradation significantly:

and helps tie the greedy parallelism chooser to the poor load spike
performance.
blocking
Looking at the `ParallelMergeCombiningSequenceJmhThreadsBenchmark` output
shows similar observations, but the apparent degradation doesn't seem as bad
because it is not entirely driven by the slowest thread.

This is due to many of the concurrent threads not seeing particularly worse
performance, but having the worst performing threads averaged into the overall
time. It also produces a plot that grows in the same linear fashion as the same
threaded approach currently in use.
Introducing blocking input sequences caused some unexpected erratic behavior
in the 10ms target task run time that I found surprising, but was repeatable.
As far as I have been able to determine, the increased overall number of tasks
that need to run on the `ForkJoinPool` and additional contention since there
are more operations adding to and taking from a `BlockingQueue`.

The larger task run time results in the least amount of both tasks and
cooperative blocking operations, which is why it was ultimately chosen as the
default.
Longer delays and smaller result sets also shrink the apparent difference
between the approach in this PR and the current approach, even without delays
between threads:

This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org
For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] vogievetsky commented on issue #7884: Single server Druid quickstart should not need Zookeeper
vogievetsky commented on issue #7884: Single server Druid quickstart should not need Zookeeper URL: https://github.com/apache/incubator-druid/issues/7884#issuecomment-548152477 This is fixed by #8792 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] vogievetsky closed issue #7884: Single server Druid quickstart should not need Zookeeper
vogievetsky closed issue #7884: Single server Druid quickstart should not need Zookeeper URL: https://github.com/apache/incubator-druid/issues/7884 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[incubator-druid] branch master updated (929a8b6 -> c922d2c)
This is an automated email from the ASF dual-hosted git repository.
vogievetsky pushed a change to branch master
in repository https://gitbox.apache.org/repos/asf/incubator-druid.git.
from 929a8b6 Web console: Support all possible metric types in the data
loader (#8785)
add c922d2c Use bundled ZooKeeper in tutorials. (#8792)
No new revisions were added by this update.
Summary of changes:
docs/tutorials/cluster.md | 11 ++-
docs/tutorials/index.md | 20 ++--
examples/bin/run-zk | 3 ++-
examples/conf/zk/log4j.xml | 17 -
.../single-server/medium/_common => zk}/log4j2.xml | 21 ++---
5 files changed, 16 insertions(+), 56 deletions(-)
delete mode 100644 examples/conf/zk/log4j.xml
copy examples/conf/{druid/single-server/medium/_common => zk}/log4j2.xml (75%)
-
To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org
For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] vogievetsky merged pull request #8792: Use bundled ZooKeeper in tutorials.
vogievetsky merged pull request #8792: Use bundled ZooKeeper in tutorials. URL: https://github.com/apache/incubator-druid/pull/8792 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] vogievetsky commented on issue #8792: Use bundled ZooKeeper in tutorials.
vogievetsky commented on issue #8792: Use bundled ZooKeeper in tutorials. URL: https://github.com/apache/incubator-druid/pull/8792#issuecomment-548152141 Just tried it out and it totes works!  This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] clintropolis commented on issue #8578: parallel broker merges on fork join pool
clintropolis commented on issue #8578: parallel broker merges on fork join pool URL: https://github.com/apache/incubator-druid/pull/8578#issuecomment-548142920 ### best case All benchmarks for this phase were done on an AWS `m5.8xl` which has 16 physical cores, 32 hyper-threads. The currently chosen default configuration is `parallelism-16-100ms-4096-16384` in all of the following charts. As mentioned in an earlier comment, the first area I wanted to benchmark is looking at the best case scenario to illustrate the raw performance increase of performing sequence and result merging in parallel when no other work is concurrently happening. Relatively quickly the benchmarks made it apparent that the parallelism chooser (`computeNumTasks`) was far too greedy, which in hind-sight seems obvious. Prior to running this benchmark, `computeNumTasks` did a check to ensure that _at least 2 sequences would be in every partition_ since that is the minimum number required to do meaningful work in parallel. However, this leads to a potentially very unbalanced amount of work between the layer 1 and layer 2 tasks, where layer 1 tasks would do very little work but the final merge layer 2 task would have a lot more to do from the increased number of input sequences. See this chart, which is plotting out artificially limited parallelism to compare to 'max' parallelism with different configurations, how the more parallelism used results in slower overall times.  By moving to balance the number of partitions to the size of each partition by limiting parallelism to the square root of total number of input sequences, this has been improved to the point that I consider 'good enough' for now.  These performance improvements should be most apparent in * large clusters (high number of sequences to merge) with most result set sizes * moderate sized clusters with large result sets and high combinability This performance improvement applies across all result set sizes as well (here from 1k per input sequence up to 10m per input sequence)  Of note, in the best case the configuration parameters other than maximum parallelism seemed to provide a relatively insignificant amount of variation in these tests, leading me to believe that they didn't really matter so much. For small result sets, the default value I have chosen does tend to do worse than the smaller sized tasks, but performs better with larger result sets which I believe is what we should tune for. However, the worst case, heavy concurrency benchmarks did end up changing my stance on this, where the larger sized unit of work per task seems to perform a lot better, particularly when blocking is involved. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] clintropolis commented on issue #8578: parallel broker merges on fork join pool
clintropolis commented on issue #8578: parallel broker merges on fork join pool URL: https://github.com/apache/incubator-druid/pull/8578#issuecomment-548141222 ### Hyper-threading and default ForkJoinPool parallelism and per query parallelism configuration values Another side-note before I dig into benchmark results, I wanted to call out that I modified the default values for `druid.processing.merge.pool.parallelism` and `druid.processing.merge.pool.defaultMaxQueryParallelism` to be 0.75 and 0.5 times `Runtime.getRuntime().availableProcessors()` instead of 1.5 and 1.0 respectively, to make an assumption that there are 2 hyper-threads per physical core. This run of `ParallelMergeCombiningSequenceBenchmark` on an `m5.4xl`, which has 8 physical cores but reports 16 cores through `Runtime.getRuntime.availableProcessors()` since that is the 'vCPU' count, illustrates the reason for this. ``` Benchmark (concurrentSequenceConsumers) (inputSequenceType) (numSequences) (rowsPerSequence) (strategy) Mode Cnt ScoreError Units ParallelMergeCombiningSequenceBenchmark.exec 1 non-blocking 128 75000 combiningMergeSequence-same-thread avgt 20 2975.944 ± 3.406 ms/op ParallelMergeCombiningSequenceBenchmark.exec 1 non-blocking 128 75000 parallelism-1-10ms-256-1024 avgt 20 2903.598 ± 7.425 ms/op ParallelMergeCombiningSequenceBenchmark.exec 1 non-blocking 128 75000 parallelism-4-10ms-256-1024 avgt 20 918.689 ± 7.172 ms/op ParallelMergeCombiningSequenceBenchmark.exec 1 non-blocking 128 75000 parallelism-6-10ms-256-1024 avgt 20 549.228 ± 1.545 ms/op ParallelMergeCombiningSequenceBenchmark.exec 1 non-blocking 128 75000 parallelism-8-10ms-256-1024 avgt 20 394.795 ± 1.110 ms/op ParallelMergeCombiningSequenceBenchmark.exec 1 non-blocking 128 75000 parallelism-12-10ms-256-1024 avgt 20 707.393 ± 2.392 ms/op ParallelMergeCombiningSequenceBenchmark.exec 1 non-blocking 128 75000 parallelism-16-10ms-256-1024 avgt 20 2069.897 ± 35.939 ms/op ``` This is of course because hyper-threads are not _real_ cores, so when actually fully utilizing a CPU to do work, counting them as such results in slower overall throughput. This is in line with the fine print on hyper-threads I think. This assumption for the default value might be wrong, but it held true for both my laptop and AWS, so maybe isn't unreasonable. I updated the user facing documentation on these settings to include this assumption, so that if an operators hardware differs and has more or no hyper-threading the value should be adjusted accordingly. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] clintropolis commented on issue #8578: parallel broker merges on fork join pool
clintropolis commented on issue #8578: parallel broker merges on fork join pool
URL: https://github.com/apache/incubator-druid/pull/8578#issuecomment-548140327
### ParallelMergeCombiningSequenceBenchmark and
ParallelMergeCombiningSequenceJmhThreadsBenchmark
These are the new benchmarks I have added which I have been using to try and
illustrate some things so that we can feel confident about merging this PR and
making it the default behavior.
**My primary goal with this PR and approach to doing broker merges in
parallel is to:**
* be better when we can (low concurrency/under utilized processors)
* be not much worse when we can't (high concurrency/over utilized
processors)
so I have been mainly focusing on the performance increase to be had in the
best case, and on trying to trace out the behavior in the worst case so we can
see that it is not _dramatically_ worse than what is currently in master.
For each of these sets of observations, I decided to try different
configurations in order to determine the best set of defaults based on the
earlier questions about whether 10ms or 100ms task run time would be better,
wall-time or CPU time, etc.
The `strategy` parameter of the benchmark encodes these configuration
options, with parallel merges in the form of
`parallelism-{number of parallel tasks}-{target task time}ms-{batch
size}-{initial task yield size}`
and `combiningMergeSequence-same-thread` to be the reference that is the
same threaded analog of what `ParallelMergeCombiningSequence` is doing.
Additionally, `inputSequenceType` specifies the behavior of the input sequences
being fed into the `strategy`, covering behavior when the sequences are totally
non-blocking, non-blocking after some amount of delay, and occasionally
blocking after some delay.
The benchmarks are split into two because I wanted to look at two slightly
different measurements of the worst case. The first is provided by
`ParallelMergeCombiningSequenceBenchmark` which is measuring the time to
complete a concurrently executed group of queries which uses an executor thread
pool to run some number of concurrent sequences and collect the average time
for the entire group of threads to complete. The second is to focus more on
invididual thread experience and uses the JMH `@Thread` annotation, and is
provided by `ParallelMergeCombiningSequenceJmhThreadsBenchmark`. This
measurement is expected to be lower than the concurrency performance
measurement provided by `ParallelMergeCombiningSequenceBenchmark` because it is
not driven entirely by the _slowest_ thread, rather the slower threads will be
averaged across all of the threads.
If you would like to run these yourself:
```
java -server -cp benchmarks/target/benchmarks.jar
org.apache.druid.benchmark.sequences.ParallelMergeCombiningSequenceBenchmark
```
and
```
java -server -cp benchmarks/target/benchmarks.jar
org.apache.druid.benchmark.sequences.ParallelMergeCombiningSequenceJmhThreadsBenchmark
```
Just be sure to adjust the configuration to **not include all of the
available parameters** unless you have multiple days of patience for them to
complete.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org
For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] gianm commented on issue #3435: Consider including hadoop-aws in the lib folder
gianm commented on issue #3435: Consider including hadoop-aws in the lib folder URL: https://github.com/apache/incubator-druid/issues/3435#issuecomment-548138772 > Is this a good idea? I think users should download the valid version of hadoop-aws.jar by themselves. They can use the pull-deps tool for it. Hmm, why not include it? We include the aws sdk in the s3 extensions bundled with Druid, it seems nice to include the hadoop version too. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] clintropolis commented on issue #8578: parallel broker merges on fork join pool
clintropolis commented on issue #8578: parallel broker merges on fork join pool URL: https://github.com/apache/incubator-druid/pull/8578#issuecomment-548137628 Ok, apologies for going dark while I was running benchmarks and making minor adjustments over the last couple weeks; I have some good findings and I'll try to capture everything here across a few comments to follow. **tl;dr** though is that I have changed the defaults to `100ms` run time (using CPU time as the basis of measurement), batch sizes of `4096` results, and `16384` as the number of results to process (4 batches) for the initial task. Based on my observations, this configuration seems to perform the best across different result set sizes, blocking patterns, and concurrency loads. I've also gained more confidence that this will be an acceptable default for most workloads where the broker is not expected to be constantly overloaded with significantly more active requests than the number of cores it has, though this approach can even be tuned to run reasonably well in this case. Next we can see if all of you will come to the same conclusion :+1: This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] vogievetsky opened a new pull request #8795: Web console: fix error when querying with grand totals
vogievetsky opened a new pull request #8795: Web console: fix error when querying with grand totals URL: https://github.com/apache/incubator-druid/pull/8795 Fixes #8791. The issue was that the console was rendering unchecked JS objects and that can make react sad. Generalized and wrapped everything in `TableCell` Side bonus: the `null`s are not in pretty italics  This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] gianm opened a new pull request #8794: Startup scripts: verify Java 8 (exactly), improve port/java verification messages.
gianm opened a new pull request #8794: Startup scripts: verify Java 8 (exactly), improve port/java verification messages. URL: https://github.com/apache/incubator-druid/pull/8794 Java 11 compatibility isn't fully baked yet (users have reported various issues on Java 11), so block startup with an error message unless Java 8 is found. Allow overriding this decision with an environment variable. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] gianm opened a new pull request #8793: Remove Tranquility configs and certain doc references.
gianm opened a new pull request #8793: Remove Tranquility configs and certain doc references. URL: https://github.com/apache/incubator-druid/pull/8793 Since it hasn't received updates or community interest in a while, it makes sense to de-emphasize it in the distribution and most documentation (outside of simple mentions of its existence). With this change, Tranquility is gone from the distribution. It will remain mentioned in the documentation in two places: - The landing page at https://druid.apache.org/docs/latest/ingestion/tranquility.html - The table at https://druid.apache.org/docs/latest/ingestion/index.html#streaming This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] jihoonson commented on issue #8718: Fix graceful shutdown for tasks
jihoonson commented on issue #8718: Fix graceful shutdown for tasks URL: https://github.com/apache/incubator-druid/issues/8718#issuecomment-548112999 I think tasks can be categorized into two groups, i.e., restorable tasks and non-restorable tasks. Restorable tasks should store their last status on disk when graceful shutdown is called, but can stop without it if force shutdown is called. Non-restorable tasks just clean up their resources on both graceful shutdown and force shutdown. Realtime tasks are restorable while batch tasks are not currently. You can tell a given task is restorable or not by calling `Task.canRestore()`. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] jihoonson commented on a change in pull request #8564: Fix ambiguity about IndexerSQLMetadataStorageCoordinator.getUsedSegmentsForInterval() returning only non-overshadowed
jihoonson commented on a change in pull request #8564: Fix ambiguity about
IndexerSQLMetadataStorageCoordinator.getUsedSegmentsForInterval() returning
only non-overshadowed or all used segments
URL: https://github.com/apache/incubator-druid/pull/8564#discussion_r340854094
##
File path:
server/src/main/java/org/apache/druid/indexing/overlord/IndexerMetadataStorageCoordinator.java
##
@@ -36,41 +37,63 @@
public interface IndexerMetadataStorageCoordinator
{
/**
- * Get all segments which may include any data in the interval and are
flagged as used.
+ * Get all segments which may include any data in the interval and are
marked as used.
*
- * @param dataSource The datasource to query
- * @param interval The interval for which all applicable and used
datasources are requested. Start is inclusive, end is exclusive
- *
- * @return The DataSegments which include data in the requested interval.
These segments may contain data outside the requested interval.
+ * The order of segments within the returned collection is unspecified, but
each segment is guaranteed to appear in
+ * the collection only once.
*
- * @throws IOException
+ * @param dataSource The datasource to query
+ * @param interval The interval for which all applicable and used
datasources are requested. Start is inclusive,
+ * end is exclusive
+ * @param visibility Whether only visible or visible as well as overshadowed
segments should be returned. The
+ * visibility is considered within the specified interval:
that is, a segment which is globally
Review comment:
It's still unclear to me what "visible outside of an interval" means. Does
this imply that a segment can be overshadowed only when we want to find the
most recent one among segments in the same interval?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org
For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] gianm opened a new pull request #8792: Use bundled ZooKeeper in tutorials.
gianm opened a new pull request #8792: Use bundled ZooKeeper in tutorials. URL: https://github.com/apache/incubator-druid/pull/8792 It turns out we have enough stuff bundled with Druid already to launch a ZooKeeper server. This patch modifies Druid's start scripts and tutorials to use the bundled jar rather than a downloaded jar, simplifying initial setup. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] vogievetsky commented on issue #8791: Druid Console SQL query page crashes for a timeseries query issued with grandTotal query
vogievetsky commented on issue #8791: Druid Console SQL query page crashes for a timeseries query issued with grandTotal query URL: https://github.com/apache/incubator-druid/issues/8791#issuecomment-548090750 Can repro. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] abhishekrb19 opened a new issue #8791: Druid Console SQL query page crashes for a timeseries query issued with grandTotal query
abhishekrb19 opened a new issue #8791: Druid Console SQL query page crashes for
a timeseries query issued with grandTotal query
URL: https://github.com/apache/incubator-druid/issues/8791
The Druid Console SQL query page crashes for a timeseries query issued with
`grandTotal` query param set to `true` in the query param.
### Affected Version
0.16.0
### Description
- MicroQuickStart setup running locally on OSX
- Issue a `timeseries` query, with `"grandTotal" : true` set in the query
context param in the UI
The same query issued directly to the Druid Broker via a `curl` command with
the same query params set works:
```json
[
{
"EXPR$0": "2019-10-29T21:30:00.000Z",
"EXPR$1": 112
},
{
"EXPR$0": "2019-10-29T21:33:00.000Z",
"EXPR$1": 106
},
{
"EXPR$0": "2019-10-29T21:36:00.000Z",
"EXPR$1": 106
},
{
"EXPR$0": "2019-10-29T21:39:00.000Z",
"EXPR$1": 123
},
{
"EXPR$0": "2019-10-29T21:42:00.000Z",
"EXPR$1": 115
},
{
"EXPR$0": "2019-10-29T21:45:00.000Z",
"EXPR$1": 9
},
{}
]
```
**I suspect that the last row returned (empty in this case) is not handled
correctly causing the UI screen to crash/blank out.**
Further, setting `"grandTotal" : false` doesn't cause the page to crash.
Please see screenshots attached:
_Setting query param:_
https://user-images.githubusercontent.com/8687261/67894231-5de9d000-fb15-11e9-9ad0-ad82bf9eb87d.png;>
_Network/console tab for inspection:_
https://user-images.githubusercontent.com/8687261/67894230-5de9d000-fb15-11e9-8d64-d19467ae9027.png;>
_BOOM - page crashes:_
https://user-images.githubusercontent.com/8687261/67894229-5de9d000-fb15-11e9-9aba-ea247fedf7b4.png;>
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org
For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] gianm commented on issue #8739: remove select query
gianm commented on issue #8739: remove select query URL: https://github.com/apache/incubator-druid/pull/8739#issuecomment-548087635 > I'm wondering whether we really need this. Should we remove `SelectQuery` at some point anyway because we cannot keep all legacy classes forever? A nice error message is always good for Druid users, but I guess this may not be needed since we will call out in the release notes and keep the doc for removed select query. I would suggest keeping the error message for at least a few releases. The Select query, even though flawed, was somewhat popular and I think this message will reduce confusion in the user base. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] gianm commented on issue #7394: A central place explaining and linking to different types of segments and tasks
gianm commented on issue #7394: A central place explaining and linking to different types of segments and tasks URL: https://github.com/apache/incubator-druid/issues/7394#issuecomment-548087364 > Seems to contradict the naming of `IndexerMetadataStorageCoordinator.announceHistoricalSegments()`. IMO, this method is misnamed. Most other usages of "announce" refer to announcing availability (most notably, DataSegmentAnnouncer). > If you are going to copy these descriptions somewhere to docs, there is a small problem with this description: looks like "available" segments are _always_ "published", not "in most cases". It's the opposite which is _in most cases_: "published" are in most cases "available". This also uses your prior definition of "published", which I suggest to keep "published used" or simply "used" above. Available segments can also be non-published in two situations. 1. Realtime segments, while they're being created. They are available and queryable but not published yet. 2. Previously-published segments, for a few minutes after being marked unused. They immediately become non-published, but stay available until the Coordinator asks Historicals to drop them, and they actually do so. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] clintropolis commented on issue #8739: remove select query
clintropolis commented on issue #8739: remove select query URL: https://github.com/apache/incubator-druid/pull/8739#issuecomment-548085601 >I'm wondering whether we really need this. Should we remove SelectQuery at some point anyway because we cannot keep all legacy classes forever? A nice error message is always good for Druid users, but I guess this may not be needed since we will call out in the release notes and keep the doc for removed select query. I am in this camp as well, originally the PR just removed it all, but I guess this is a nicer user experience. I do think we could remove this placeholder in a release or two after the next one. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] clintropolis commented on a change in pull request #8739: remove select query
clintropolis commented on a change in pull request #8739: remove select query
URL: https://github.com/apache/incubator-druid/pull/8739#discussion_r340827515
##
File path:
processing/src/main/java/org/apache/druid/query/select/SelectQuery.java
##
@@ -20,212 +20,150 @@
package org.apache.druid.query.select;
import com.fasterxml.jackson.annotation.JsonCreator;
-import com.fasterxml.jackson.annotation.JsonProperty;
-import com.fasterxml.jackson.annotation.JsonTypeName;
-import com.google.common.base.Preconditions;
-import org.apache.druid.java.util.common.granularity.Granularities;
+import com.google.common.collect.Ordering;
import org.apache.druid.java.util.common.granularity.Granularity;
-import org.apache.druid.query.BaseQuery;
import org.apache.druid.query.DataSource;
-import org.apache.druid.query.Druids;
import org.apache.druid.query.Query;
-import org.apache.druid.query.Result;
-import org.apache.druid.query.dimension.DimensionSpec;
+import org.apache.druid.query.QueryRunner;
+import org.apache.druid.query.QuerySegmentWalker;
import org.apache.druid.query.filter.DimFilter;
import org.apache.druid.query.spec.QuerySegmentSpec;
-import org.apache.druid.segment.VirtualColumns;
+import org.joda.time.DateTimeZone;
+import org.joda.time.Duration;
+import org.joda.time.Interval;
import java.util.List;
import java.util.Map;
-import java.util.Objects;
-/**
- */
-@JsonTypeName("select")
-public class SelectQuery extends BaseQuery>
+public class SelectQuery implements Query
Review comment:
added
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org
For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] leventov commented on issue #8788: OvershadowableManager.isComplete() looks buggy
leventov commented on issue #8788: OvershadowableManager.isComplete() looks buggy URL: https://github.com/apache/incubator-druid/issues/8788#issuecomment-548083319 Thanks. I relabel this issue to `Improvement` to indicate that comments should be added. Also, it may be related to #8168. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] leventov commented on issue #7394: A central place explaining and linking to different types of segments and tasks
leventov commented on issue #7394: A central place explaining and linking to different types of segments and tasks URL: https://github.com/apache/incubator-druid/issues/7394#issuecomment-548081333 > published segment → a segment which has a record in the metadata store with used = 1. There is a long project to call such segments _used_ segments: https://github.com/apache/incubator-druid/pull/7306. I suggest to call them _published used_ or _published unused_, or simply _used_ or _unused_ for short. > announce → what Historicals do when they start serving a segment for querying. Seems to contradict the naming of `IndexerMetadataStorageCoordinator.announceHistoricalSegments()`. > available segment → a segment that is currently available for querying. In most cases, these are also published, but it isn't perfectly analogous (for example, a new segment is published immediately, but may take a few minutes to become available). If you are going to copy these descriptions somewhere to docs, there is a small problem with this description: looks like "available" segments are _always_ "published", not "in most cases". It's the opposite which is _in most cases_: "published" are in most cases "available". This also uses your prior definition of "published", which I suggest to keep "published used" or simply "used" above. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] MrMoronIV opened a new issue #8790: Parse/ Flatten Json Field inside TSV source event?
MrMoronIV opened a new issue #8790: Parse/ Flatten Json Field inside TSV source
event?
URL: https://github.com/apache/incubator-druid/issues/8790
I have a Kafka Event in TSV which has a field that contains JSON. it
possible to flatten this json field for ingestion, and so, how?
I now have something like this for the parser, which works great:
```
"parser": {
"type": "string",
"parseSpec": {
"format": "tsv",
"timestampSpec": {
"column": "derived_tstamp",
"format": "auto"
},
"hasHeaderRow": false,
"columns": [
"column1",
"column2",
"jsonColumn"
]
```
How would I flatten `jsonColumn`? Do I need to include multiple parseSpecs,
is that even possible? Or can the column have a specific `flattenSpec` defined
in the columns array?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org
For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] jihoonson commented on issue #8788: OvershadowableManager.isComplete() looks buggy
jihoonson commented on issue #8788: OvershadowableManager.isComplete() looks buggy URL: https://github.com/apache/incubator-druid/issues/8788#issuecomment-548069961 I understand this may be confusing. This is not a bug, but may be a missing comment on `visibleGroups`. The value type of`visibleGroup` is `SingleEntryShort2ObjectSortedMap` which can hold at most a single entry. This was to use the same interface with other groups such as `standbyGroups` and `overshadowedGroups` so that I can reuse the same help methods across all groups. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] jihoonson commented on a change in pull request #8739: remove select query
jihoonson commented on a change in pull request #8739: remove select query
URL: https://github.com/apache/incubator-druid/pull/8739#discussion_r340800931
##
File path:
processing/src/main/java/org/apache/druid/query/select/SelectQuery.java
##
@@ -20,212 +20,150 @@
package org.apache.druid.query.select;
import com.fasterxml.jackson.annotation.JsonCreator;
-import com.fasterxml.jackson.annotation.JsonProperty;
-import com.fasterxml.jackson.annotation.JsonTypeName;
-import com.google.common.base.Preconditions;
-import org.apache.druid.java.util.common.granularity.Granularities;
+import com.google.common.collect.Ordering;
import org.apache.druid.java.util.common.granularity.Granularity;
-import org.apache.druid.query.BaseQuery;
import org.apache.druid.query.DataSource;
-import org.apache.druid.query.Druids;
import org.apache.druid.query.Query;
-import org.apache.druid.query.Result;
-import org.apache.druid.query.dimension.DimensionSpec;
+import org.apache.druid.query.QueryRunner;
+import org.apache.druid.query.QuerySegmentWalker;
import org.apache.druid.query.filter.DimFilter;
import org.apache.druid.query.spec.QuerySegmentSpec;
-import org.apache.druid.segment.VirtualColumns;
+import org.joda.time.DateTimeZone;
+import org.joda.time.Duration;
+import org.joda.time.Interval;
import java.util.List;
import java.util.Map;
-import java.util.Objects;
-/**
- */
-@JsonTypeName("select")
-public class SelectQuery extends BaseQuery>
+public class SelectQuery implements Query
Review comment:
Please add `@Deprecated`.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org
For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] vogievetsky commented on issue #8786: web-console failed to compiled
vogievetsky commented on issue #8786: web-console failed to compiled URL: https://github.com/apache/incubator-druid/issues/8786#issuecomment-548067820 Try running `npm run compile` in the console dir. It will run `./script/build` which will make the file you are missing. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] gianm commented on issue #8661: Druid SQL - natively support mathematical functions ROUND(), RADIANS(), EXP(), LN(), POWER(), RAND()
gianm commented on issue #8661: Druid SQL - natively support mathematical functions ROUND(), RADIANS(), EXP(), LN(), POWER(), RAND() URL: https://github.com/apache/incubator-druid/issues/8661#issuecomment-548066861 Hi @ntkawasaki, Druid does support all of those functions today except `RAND`. Most of them were added in version 0.15. (You can access old Druid docs at e.g. https://druid.apache.org/docs/0.14.0-incubating/querying/sql; note that the 0.14 docs don't include most of these functions.) I raised an issue specifically for `RAND`: https://github.com/apache/incubator-druid/issues/8789, which is still missing today. Btw, we deprecated and removed `useFallback` because it led to unscalable query plans in many cases. We found that often, queries with `useFallback` would pull all raw data into the Druid Broker and process it there, which was a bad approach for big datasets. This risk outweighed the benefits, and so we decided to implement more functionality in Druid's native query system instead of relying on SQL interpreter fallback. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] gianm opened a new issue #8789: SQL RAND function
gianm opened a new issue #8789: SQL RAND function URL: https://github.com/apache/incubator-druid/issues/8789 ### Description Add a `RAND()` function to Druid SQL. ### Motivation It could be used for random sampling (e.g. `WHERE RAND() < 0.2`). See also https://github.com/apache/incubator-druid/issues/8661. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] fjy commented on issue #8777: Web console: Interval input component
fjy commented on issue #8777: Web console: Interval input component URL: https://github.com/apache/incubator-druid/pull/8777#issuecomment-548059710 Can we clearly label which boxes are for HH, mm, and ss? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] gianm edited a comment on issue #7394: A central place explaining and linking to different types of segments and tasks
gianm edited a comment on issue #7394: A central place explaining and linking to different types of segments and tasks URL: https://github.com/apache/incubator-druid/issues/7394#issuecomment-548058373 The definitions I have been using recently when writing docs and method names are: - _pending segment_ → a segment that is currently being built by an indexer, but hasn't had its metadata inserted into the metadata store yet. - _pushed segment_ → a segment that has been written to deep storage. This happens before publishing (see next term). - _published segment_ → a segment which has a record in the metadata store with `used = 1`. All published segments should also be pushed. None of them are pending. - _publish_ → the act of inserting segment records into the metadata store (what the Overlord does when SegmentInsertAction is called). - _insert_ → a synonym for _publish_. I prefer _publish_ over _insert_. - _announce_ → what Historicals do when they start serving a segment for querying. - _available segment_ → a segment that is currently available for querying. In most cases, these are also published, but it isn't perfectly analogous (for example, a new segment is published immediately, but may take a few minutes to become available). - _announced segment_ → a synonym for _available segment_. I prefer _available segment_ to _announced segment_. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] gianm commented on issue #7394: A central place explaining and linking to different types of segments and tasks
gianm commented on issue #7394: A central place explaining and linking to different types of segments and tasks URL: https://github.com/apache/incubator-druid/issues/7394#issuecomment-548058373 The definitions I have been using recently when writing docs and method names are: - _pending segment_ → a segment that is currently being built by an indexer, but hasn't had its metadata inserted into the metadata store yet. - _pushed segment_ → a segment that has been written to deep storage. This happens before publishing (see next term). - _published segment_ → a segment which has a record in the metadata store with `used = 1`. All published segments should also be pushed. None of them are pending. - _publish_ → the act of inserting segment records into the metadata store (what the Overlord does when SegmentInsertAction is called). - _insert_ → a synonym for _publish_. _publish_ is preferred over _insert_. - _announce_ → what Historicals do when they start serving a segment for querying. - _available segment_ → a segment that is currently available for querying. In most cases, these are also published, but it isn't perfectly analogous (for example, a new segment is published immediately, but may take a few minutes to become available). - _available segment_ → a synonym for _announced segment_. - _announced segment_ → a synonym for _available segment_. I prefer _available segment_ to _announced segment_. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] gianm edited a comment on issue #7394: A central place explaining and linking to different types of segments and tasks
gianm edited a comment on issue #7394: A central place explaining and linking to different types of segments and tasks URL: https://github.com/apache/incubator-druid/issues/7394#issuecomment-548058373 The definitions I have been using recently when writing docs and method names are: - _pending segment_ → a segment that is currently being built by an indexer, but hasn't had its metadata inserted into the metadata store yet. - _pushed segment_ → a segment that has been written to deep storage. This happens before publishing (see next term). - _published segment_ → a segment which has a record in the metadata store with `used = 1`. All published segments should also be pushed. None of them are pending. - _publish_ → the act of inserting segment records into the metadata store (what the Overlord does when SegmentInsertAction is called). - _insert_ → a synonym for _publish_. I prefer _publish_ over _insert_. - _announce_ → what Historicals do when they start serving a segment for querying. - _available segment_ → a segment that is currently available for querying. In most cases, these are also published, but it isn't perfectly analogous (for example, a new segment is published immediately, but may take a few minutes to become available). - _available segment_ → a synonym for _announced segment_. - _announced segment_ → a synonym for _available segment_. I prefer _available segment_ to _announced segment_. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] ccaominh commented on a change in pull request #8748: Use earliest offset on kafka newly discovered partitions
ccaominh commented on a change in pull request #8748: Use earliest offset on
kafka newly discovered partitions
URL: https://github.com/apache/incubator-druid/pull/8748#discussion_r340758704
##
File path:
indexing-service/src/main/java/org/apache/druid/indexing/seekablestream/supervisor/SeekableStreamSupervisor.java
##
@@ -3130,6 +3130,18 @@ public void checkpoint(int taskGroupId,
DataSourceMetadata checkpointMetadata)
return partitionGroups;
}
+ @VisibleForTesting
+ public boolean removePartitionId(PartitionIdType partitionId)
+ {
+return this.partitionIds.remove(partitionId);
+ }
+
+ @VisibleForTesting
+ public List getParitionIds()
+ {
+return this.partitionIds;
+ }
Review comment:
Ideally, we should not have to add new public methods that are only used by
tests. For example, is it possible to do some refactoring so that a mock object
can be supplied to the constructor, thereby providing you with more control
over the internal behavior for the tests?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org
For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] ccaominh commented on a change in pull request #8748: Use earliest offset on kafka newly discovered partitions
ccaominh commented on a change in pull request #8748: Use earliest offset on
kafka newly discovered partitions
URL: https://github.com/apache/incubator-druid/pull/8748#discussion_r340756328
##
File path:
extensions-core/kafka-indexing-service/src/test/java/org/apache/druid/indexing/kafka/supervisor/KafkaSupervisorTest.java
##
@@ -585,6 +585,109 @@ public void testLatestOffset() throws Exception
);
}
+ /**
+ * Test if always use earliest offset on newly discovered partitions
+ */
+ @Test
+ public void testLatestOffsetOnDiscovery() throws Exception
+ {
+supervisor = getTestableSupervisor(2, 2, false, "PT1H", null, null);
+addSomeEvents(1);
+
+Capture captured = Capture.newInstance(CaptureType.ALL);
+
EasyMock.expect(taskMaster.getTaskQueue()).andReturn(Optional.of(taskQueue)).anyTimes();
+
EasyMock.expect(taskMaster.getTaskRunner()).andReturn(Optional.of(taskRunner)).anyTimes();
+
EasyMock.expect(taskRunner.getRunningTasks()).andReturn(Collections.EMPTY_LIST).anyTimes();
+
EasyMock.expect(taskStorage.getActiveTasksByDatasource(DATASOURCE)).andReturn(ImmutableList.of()).anyTimes();
+EasyMock.expect(taskClient.getStatusAsync(EasyMock.anyString()))
+.andReturn(Futures.immediateFuture(Status.NOT_STARTED))
+.anyTimes();
+EasyMock.expect(taskClient.getStartTimeAsync(EasyMock.anyString()))
+.andReturn(Futures.immediateFuture(DateTimes.nowUtc()))
+.anyTimes();
+
EasyMock.expect(indexerMetadataStorageCoordinator.getDataSourceMetadata(DATASOURCE)).andReturn(
+new KafkaDataSourceMetadata(
+null
+)
+).anyTimes();
+
EasyMock.expect(taskQueue.add(EasyMock.capture(captured))).andReturn(true).times(4);
+taskRunner.registerListener(EasyMock.anyObject(TaskRunnerListener.class),
EasyMock.anyObject(Executor.class));
+
+replayAll();
+
+supervisor.start();
+supervisor.runInternal();
+verifyAll();
+
+List tasks = captured.getValues();
+
+EasyMock.reset(taskStorage, taskClient);
+
+EasyMock.expect(taskClient.getStatusAsync(EasyMock.anyString()))
+.andReturn(Futures.immediateFuture(Status.NOT_STARTED))
+.anyTimes();
+EasyMock.expect(taskClient.getStartTimeAsync(EasyMock.anyString()))
+.andReturn(Futures.immediateFuture(DateTimes.nowUtc()))
+.anyTimes();
+TreeMap> checkpoints1 = new TreeMap<>();
+checkpoints1.put(0, ImmutableMap.of(0, 0L, 2, 0L));
+TreeMap> checkpoints2 = new TreeMap<>();
+checkpoints2.put(0, ImmutableMap.of(1, 0L));
+// there would be 4 tasks, 2 for each task group
+
EasyMock.expect(taskClient.getCheckpointsAsync(EasyMock.contains("sequenceName-0"),
EasyMock.anyBoolean()))
+.andReturn(Futures.immediateFuture(checkpoints1))
+.times(2);
+
EasyMock.expect(taskClient.getCheckpointsAsync(EasyMock.contains("sequenceName-1"),
EasyMock.anyBoolean()))
+.andReturn(Futures.immediateFuture(checkpoints2))
+.times(2);
+
+
EasyMock.expect(taskStorage.getActiveTasksByDatasource(DATASOURCE)).andReturn(tasks).anyTimes();
+for (Task task : tasks) {
+ EasyMock.expect(taskStorage.getStatus(task.getId()))
+ .andReturn(Optional.of(TaskStatus.running(task.getId(
+ .anyTimes();
+
EasyMock.expect(taskStorage.getTask(task.getId())).andReturn(Optional.of(task)).anyTimes();
+}
+EasyMock.replay(taskStorage);
+EasyMock.replay(taskClient);
Review comment:
Why is the middle section of the test needed?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org
For additional commands, e-mail: commits-h...@druid.apache.org
[incubator-druid] branch master updated (a95e3d4 -> 929a8b6)
This is an automated email from the ASF dual-hosted git repository. fjy pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/incubator-druid.git. from a95e3d4 Web console: Data loader user feedback changes (#8770) add 929a8b6 Web console: Support all possible metric types in the data loader (#8785) No new revisions were added by this update. Summary of changes: .../__snapshots__/retention-dialog.spec.tsx.snap | 1 + .../dialogs/retention-dialog/retention-dialog.tsx | 7 +- web-console/src/utils/ingestion-spec.tsx | 225 ++--- .../src/views/load-data-view/load-data-view.scss | 4 +- .../src/views/load-data-view/load-data-view.tsx| 65 -- 5 files changed, 244 insertions(+), 58 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] fjy merged pull request #8785: Web console: Support all possible metric types in the data loader
fjy merged pull request #8785: Web console: Support all possible metric types in the data loader URL: https://github.com/apache/incubator-druid/pull/8785 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] leventov commented on a change in pull request #8272: Support incremental load in Druid lookups
leventov commented on a change in pull request #8272: Support incremental load
in Druid lookups
URL: https://github.com/apache/incubator-druid/pull/8272#discussion_r340717483
##
File path:
extensions-core/lookups-cached-global/src/main/java/org/apache/druid/server/lookup/namespace/cache/CacheScheduler.java
##
@@ -421,9 +443,16 @@ public String getVersion()
@Override
public void close()
{
- cacheHandler.close();
- // Log statement after cacheHandler.close(), because logging may fail
(e. g. in shutdown hooks)
- log.debug("Closed version [%s] of %s", version, entryId);
+ // ideally, close shouldn't be called by users of VersionedCache in case
of a incremental load,
+ // we do not close cacheHandler for such case.
+ if (this.incremental) {
+log.debug("VersionedCache is of type incremental load, thus not
closing cacheHandler " +
Review comment:
I don't see why an `if` is still needed with `VersionedCacheBuilder`: in
`VersionedCacheBuilder.close()`, you always close `CacheHandler`. In
`JdbcCacheGenerator`, `doIncrementalLoad` branch you don't deal with
`VersionedCacheBuilder` because you obtain `VersionedCache` object directly
from `createFromExistingCache()` method. `VersionedCache` doesn't have
`close()` method at all.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org
For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] leventov commented on a change in pull request #8564: Fix ambiguity about IndexerSQLMetadataStorageCoordinator.getUsedSegmentsForInterval() returning only non-overshadowed o
leventov commented on a change in pull request #8564: Fix ambiguity about
IndexerSQLMetadataStorageCoordinator.getUsedSegmentsForInterval() returning
only non-overshadowed or all used segments
URL: https://github.com/apache/incubator-druid/pull/8564#discussion_r340660374
##
File path:
server/src/main/java/org/apache/druid/indexing/overlord/IndexerMetadataStorageCoordinator.java
##
@@ -36,41 +37,63 @@
public interface IndexerMetadataStorageCoordinator
{
/**
- * Get all segments which may include any data in the interval and are
flagged as used.
+ * Get all segments which may include any data in the interval and are
marked as used.
*
- * @param dataSource The datasource to query
- * @param interval The interval for which all applicable and used
datasources are requested. Start is inclusive, end is exclusive
- *
- * @return The DataSegments which include data in the requested interval.
These segments may contain data outside the requested interval.
+ * The order of segments within the returned collection is unspecified, but
each segment is guaranteed to appear in
+ * the collection only once.
*
- * @throws IOException
+ * @param dataSource The datasource to query
+ * @param interval The interval for which all applicable and used
datasources are requested. Start is inclusive,
+ * end is exclusive
+ * @param visibility Whether only visible or visible as well as overshadowed
segments should be returned. The
+ * visibility is considered within the specified interval:
that is, a segment which is globally
Review comment:
Reworded to "visible outside of the specified interval(s)"
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org
For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] leventov commented on a change in pull request #8564: Fix ambiguity about IndexerSQLMetadataStorageCoordinator.getUsedSegmentsForInterval() returning only non-overshadowed o
leventov commented on a change in pull request #8564: Fix ambiguity about IndexerSQLMetadataStorageCoordinator.getUsedSegmentsForInterval() returning only non-overshadowed or all used segments URL: https://github.com/apache/incubator-druid/pull/8564#discussion_r340660112 ## File path: indexing-service/src/test/java/org/apache/druid/indexing/seekablestream/SeekableStreamIndexTaskTestBase.java ## @@ -0,0 +1,404 @@ +/* + * Licensed to the Apache Software Foundation (ASF) under one + * or more contributor license agreements. See the NOTICE file + * distributed with this work for additional information + * regarding copyright ownership. The ASF licenses this file + * to you under the Apache License, Version 2.0 (the + * "License"); you may not use this file except in compliance + * with the License. You may obtain a copy of the License at + * + * http://www.apache.org/licenses/LICENSE-2.0 + * + * Unless required by applicable law or agreed to in writing, + * software distributed under the License is distributed on an + * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY + * KIND, either express or implied. See the License for the + * specific language governing permissions and limitations + * under the License. + */ + +package org.apache.druid.indexing.seekablestream; + +import com.fasterxml.jackson.core.type.TypeReference; +import com.fasterxml.jackson.databind.ObjectMapper; +import com.google.common.base.Predicates; +import com.google.common.base.Throwables; +import com.google.common.collect.ImmutableList; +import com.google.common.collect.ImmutableMap; +import com.google.common.collect.ImmutableSet; +import com.google.common.io.Files; +import com.google.common.util.concurrent.ListenableFuture; +import com.google.common.util.concurrent.ListeningExecutorService; +import org.apache.druid.data.input.impl.DimensionsSpec; +import org.apache.druid.data.input.impl.FloatDimensionSchema; +import org.apache.druid.data.input.impl.JSONParseSpec; +import org.apache.druid.data.input.impl.LongDimensionSchema; +import org.apache.druid.data.input.impl.StringDimensionSchema; +import org.apache.druid.data.input.impl.StringInputRowParser; +import org.apache.druid.data.input.impl.TimestampSpec; +import org.apache.druid.indexer.TaskStatus; +import org.apache.druid.indexing.common.IngestionStatsAndErrorsTaskReportData; +import org.apache.druid.indexing.common.LockGranularity; +import org.apache.druid.indexing.common.TaskReport; +import org.apache.druid.indexing.common.TaskToolbox; +import org.apache.druid.indexing.common.TaskToolboxFactory; +import org.apache.druid.indexing.common.TestUtils; +import org.apache.druid.indexing.common.task.Task; +import org.apache.druid.indexing.common.task.Tasks; +import org.apache.druid.indexing.overlord.IndexerMetadataStorageCoordinator; +import org.apache.druid.indexing.overlord.Segments; +import org.apache.druid.indexing.overlord.TaskLockbox; +import org.apache.druid.indexing.overlord.TaskStorage; +import org.apache.druid.java.util.common.ISE; +import org.apache.druid.java.util.common.Intervals; +import org.apache.druid.java.util.common.StringUtils; +import org.apache.druid.java.util.common.granularity.Granularities; +import org.apache.druid.java.util.common.guava.Comparators; +import org.apache.druid.java.util.common.logger.Logger; +import org.apache.druid.java.util.common.parsers.JSONPathSpec; +import org.apache.druid.metadata.EntryExistsException; +import org.apache.druid.query.Druids; +import org.apache.druid.query.QueryPlus; +import org.apache.druid.query.Result; +import org.apache.druid.query.SegmentDescriptor; +import org.apache.druid.query.aggregation.AggregatorFactory; +import org.apache.druid.query.aggregation.CountAggregatorFactory; +import org.apache.druid.query.aggregation.DoubleSumAggregatorFactory; +import org.apache.druid.query.aggregation.LongSumAggregatorFactory; +import org.apache.druid.query.timeseries.TimeseriesQuery; +import org.apache.druid.query.timeseries.TimeseriesResultValue; +import org.apache.druid.segment.DimensionHandlerUtils; +import org.apache.druid.segment.IndexIO; +import org.apache.druid.segment.QueryableIndex; +import org.apache.druid.segment.column.DictionaryEncodedColumn; +import org.apache.druid.segment.indexing.DataSchema; +import org.apache.druid.segment.indexing.granularity.UniformGranularitySpec; +import org.apache.druid.segment.realtime.appenderator.AppenderatorImpl; +import org.apache.druid.timeline.DataSegment; +import org.apache.druid.utils.CompressionUtils; +import org.assertj.core.api.Assertions; +import org.easymock.EasyMockSupport; +import org.joda.time.Interval; +import org.junit.Assert; + +import java.io.File; +import java.io.IOException; +import java.lang.reflect.InvocationTargetException; +import java.lang.reflect.Method; +import java.nio.charset.StandardCharsets; +import java.util.ArrayList; +import java.util.Arrays; +import java.util.Collections; +import java.util.Comparator; +import java.util.List;
[GitHub] [incubator-druid] leventov commented on a change in pull request #8564: Fix ambiguity about IndexerSQLMetadataStorageCoordinator.getUsedSegmentsForInterval() returning only non-overshadowed o
leventov commented on a change in pull request #8564: Fix ambiguity about
IndexerSQLMetadataStorageCoordinator.getUsedSegmentsForInterval() returning
only non-overshadowed or all used segments
URL: https://github.com/apache/incubator-druid/pull/8564#discussion_r340659783
##
File path:
server/src/main/java/org/apache/druid/indexing/overlord/Segments.java
##
@@ -0,0 +1,32 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.druid.indexing.overlord;
+
+/**
+ * This enum is used as a parameter for several methods in {@link
IndexerMetadataStorageCoordinator}, specifying whether
+ * only visible segments, or visible as well as overshadowed segments should
be included in results.
Review comment:
I think this would be overspecification for the enum. Instead, I've added
"published" adjective to descriptions of all related methods in
`IndexerMetadataStorageCoordinator`.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org
For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] leventov commented on a change in pull request #8564: Fix ambiguity about IndexerSQLMetadataStorageCoordinator.getUsedSegmentsForInterval() returning only non-overshadowed o
leventov commented on a change in pull request #8564: Fix ambiguity about IndexerSQLMetadataStorageCoordinator.getUsedSegmentsForInterval() returning only non-overshadowed or all used segments URL: https://github.com/apache/incubator-druid/pull/8564#discussion_r340659984 ## File path: indexing-service/src/test/java/org/apache/druid/indexing/common/actions/SegmentListActionsTest.java ## @@ -94,21 +95,18 @@ private DataSegment createSegment(Interval interval, String version) } @Test - public void testSegmentListUsedAction() + public void testRetrieveUsedSegmentsAction() Review comment: Thanks, changed This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] leventov commented on a change in pull request #8564: Fix ambiguity about IndexerSQLMetadataStorageCoordinator.getUsedSegmentsForInterval() returning only non-overshadowed o
leventov commented on a change in pull request #8564: Fix ambiguity about
IndexerSQLMetadataStorageCoordinator.getUsedSegmentsForInterval() returning
only non-overshadowed or all used segments
URL: https://github.com/apache/incubator-druid/pull/8564#discussion_r340658231
##
File path: core/src/main/java/org/apache/druid/timeline/Partitions.java
##
@@ -17,28 +17,16 @@
* under the License.
*/
-package org.apache.druid.indexer.path;
-
-import org.apache.druid.timeline.DataSegment;
-import org.joda.time.Interval;
-
-import java.io.IOException;
-import java.util.List;
+package org.apache.druid.timeline;
/**
+ * This enum is used a parameter for several methods in {@link
VersionedIntervalTimeline}, specifying whether only
+ * complete partitions should be considered, or incomplete partitions as well.
Review comment:
Since `VersionedIntervalTimeline` treats completion status mechanically
rather than semantically (that is, the implementation of
`VersionedIntervalTimeline` would be the same regardless of what `isComplete()`
semantically means), I just added reference to the method. I think Javadoc
should be added to `isComplete()` method to explain illustratively what does it
mean, but I don't feel confident about it. I've also opened issue #8788 which
is related.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org
For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] leventov commented on a change in pull request #8564: Fix ambiguity about IndexerSQLMetadataStorageCoordinator.getUsedSegmentsForInterval() returning only non-overshadowed o
leventov commented on a change in pull request #8564: Fix ambiguity about
IndexerSQLMetadataStorageCoordinator.getUsedSegmentsForInterval() returning
only non-overshadowed or all used segments
URL: https://github.com/apache/incubator-druid/pull/8564#discussion_r340658583
##
File path:
server/src/main/java/org/apache/druid/metadata/IndexerSQLMetadataStorageCoordinator.java
##
@@ -177,6 +175,32 @@ public void start()
final String dataSource,
final List intervals
)
+ {
+Query> sql =
createUsedSegmentsSqlQueryForIntervals(handle, dataSource, intervals);
+
+try (final ResultIterator dbSegments =
sql.map(ByteArrayMapper.FIRST).iterator()) {
+ return VersionedIntervalTimeline.forSegments(
+ Iterators.transform(dbSegments, payload ->
JacksonUtils.readValue(jsonMapper, payload, DataSegment.class))
+ );
+}
+ }
+
+ private Collection getAllUsedSegmentsForIntervalsWithHandle(
+ final Handle handle,
+ final String dataSource,
+ final List intervals
+ )
+ {
+return createUsedSegmentsSqlQueryForIntervals(handle, dataSource,
intervals)
+.map((index, r, ctx) -> JacksonUtils.readValue(jsonMapper,
r.getBytes("payload"), DataSegment.class))
+.list();
+ }
+
+ private Query> createUsedSegmentsSqlQueryForIntervals(
Review comment:
Added
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org
For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] leventov commented on a change in pull request #8564: Fix ambiguity about IndexerSQLMetadataStorageCoordinator.getUsedSegmentsForInterval() returning only non-overshadowed o
leventov commented on a change in pull request #8564: Fix ambiguity about
IndexerSQLMetadataStorageCoordinator.getUsedSegmentsForInterval() returning
only non-overshadowed or all used segments
URL: https://github.com/apache/incubator-druid/pull/8564#discussion_r340658231
##
File path: core/src/main/java/org/apache/druid/timeline/Partitions.java
##
@@ -17,28 +17,16 @@
* under the License.
*/
-package org.apache.druid.indexer.path;
-
-import org.apache.druid.timeline.DataSegment;
-import org.joda.time.Interval;
-
-import java.io.IOException;
-import java.util.List;
+package org.apache.druid.timeline;
/**
+ * This enum is used a parameter for several methods in {@link
VersionedIntervalTimeline}, specifying whether only
+ * complete partitions should be considered, or incomplete partitions as well.
Review comment:
Since `VersionedIntervalTimeline` treats completion status mechanically
rather than semantically (that is, the implementation of
`VersionedIntervalTimeline` would be the same regardless of what `isComplete()`
semantically means), I just reference the method. I think Javadoc should be
added to `isComplete()` method to explain illustratively what does it mean, but
I don't feel confident about it. I've also opened issue #8788 which is related.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org
For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] koupeng commented on issue #7099: broker metadata refresh failing
koupeng commented on issue #7099: broker metadata refresh failing URL: https://github.com/apache/incubator-druid/issues/7099#issuecomment-547933538 me too! This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] leventov commented on issue #7394: A central place explaining and linking to different types of segments and tasks
leventov commented on issue #7394: A central place explaining and linking to different types of segments and tasks URL: https://github.com/apache/incubator-druid/issues/7394#issuecomment-547931927 > It's also not clear to me whether "published" segment is an antonym to "pending" (that is, any segment could be either "pending" or "published", exclusively, and not anything else), and that "announcement" is the process which transitions a segment from "pending" to "published" state. BTW, if this is true, then "publish" and "announce" verbs are synonyms. The third verb phrase which is used in the codebase (at least; maybe somewhere in docs, too) to describe this process is "insert (a set of) segment(s) (in)to (the) metadata store/storage" (see `SegmentInsertAction`, for instance). The central doc place about segment states and transitions (in both codebase and documentation) should also mention that these verbs/verb phrases are synonyms. If they are actually not synonyms, the central doc place should highlight the difference. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] leventov commented on issue #7394: A central place explaining and linking to different types of segments and tasks
leventov commented on issue #7394: A central place explaining and linking to different types of segments and tasks URL: https://github.com/apache/incubator-druid/issues/7394#issuecomment-547927836 Another dimension is "historical" (vs. "indexing"?) segments. Of course, "visible" (which is a synonym to "non-overshadowed") and "overshadowed" should be explained, too. The following questions should also be covered: - Whether "historical" or "indexing" segments could overshadow other segments? (I think, the answer is both.) - Whether "pending" or "published" segments could overshadow other segments? (I think, the answer is "published".) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] leventov commented on issue #7394: A central place explaining and linking to different types of segments and tasks
leventov commented on issue #7394: A central place explaining and linking to different types of segments and tasks URL: https://github.com/apache/incubator-druid/issues/7394#issuecomment-547924239 It's also not clear to me whether "published" segment is an antonym to "pending" (that is, any segment could be either "pending" or "published", exclusively, and not anything else), and that "announcement" is the process which transitions a segment from "pending" to "published" state. @jihoonson is this true? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] leventov opened a new issue #8788: OvershadowableManager.isComplete() looks buggy
leventov opened a new issue #8788: OvershadowableManager.isComplete() looks buggy URL: https://github.com/apache/incubator-druid/issues/8788 The current implementation of `OvershadowableManager.isComplete()`: https://github.com/apache/incubator-druid/blob/a95e3d438e676310522a68c74a43d99f5f0492d5/core/src/main/java/org/apache/druid/timeline/partition/OvershadowableManager.java#L891-L894 looks buggy because it might throw an exception when any value in `visibleGroup` is a map with more than one element. If there are never more than one element in this map, why this is a map, not just a single value? It might be this this is not a bug because there are some invisible contract between callers to `OvershadowableManager.isComplete()` and `OvershadowableManager` which guarantee that when `isComplete()` is called all values in `visibleGroup` are maps of at most one value. But such a contract would need to be expressed explicitly in comments, at least. (Not to say that it is very fragile design and should preferably be avoided). FYI @jihoonson This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] koupeng opened a new issue #8787: how to connect kakfa by zookeeper
koupeng opened a new issue #8787: how to connect kakfa by zookeeper URL: https://github.com/apache/incubator-druid/issues/8787 ### Affected Version 0.16.0 ### Description how to connect kakfa by zookeeper? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] koupeng opened a new issue #8786: web-console failed to compiled
koupeng opened a new issue #8786: web-console failed to compiled URL: https://github.com/apache/incubator-druid/issues/8786 Please provide a detailed title (e.g. "Broker crashes when using TopN query with Bound filter" instead of just "Broker crashes"). ### Affected Version The Druid version 0.16.0 ### Description ERROR in ./src/entry.scss (./node_modules/css-loader/dist/cjs.js!./node_modules/postcss-loader/src??postcss!./node_modules/sass-loader/dist/cjs.js!./src/entry.scss) Module build failed (from ./node_modules/sass-loader/dist/cjs.js): SassError: File to import not found or unreadable: ../lib/react-table. on line 21 of F:\gitsource\incubator-druid-master\web-console\src\entry.scss >> @import '../lib/react-table'; ^ @ ./src/entry.scss 1:14-171 20:4-31:5 23:25-182 @ ./src/entry.ts ERROR in ./src/views/query-view/query-input/query-input.tsx Module not found: Error: Can't resolve '../../../../lib/sql-docs' in 'F:\gitsource\incubator-druid-master\web-console\src\views\query-view\query-input' @ ./src/views/query-view/query-input/query-input.tsx 10:17-52 @ ./src/views/query-view/query-view.tsx @ ./src/views/index.ts @ ./src/console-application.tsx @ ./src/entry.ts ERROR in ./src/views/query-view/query-view.tsx Module not found: Error: Can't resolve '../../../lib/sql-docs' in 'F:\gitsource\incubator-druid-master\web-console\src\views\query-view' @ ./src/views/query-view/query-view.tsx 12:17-49 @ ./src/views/index.ts @ ./src/console-application.tsx @ ./src/entry.ts ERROR in ./src/ace-modes/dsql.js Module not found: Error: Can't resolve '../../lib/sql-docs' in 'F:\gitsource\incubator-druid-master\web-console\src\ace-modes' @ ./src/ace-modes/dsql.js 25:21-50 @ ./src/entry.ts This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org