[GitHub] [hudi] codecov-io edited a comment on pull request #2640: [HUDI-1663] Streaming read for Flink MOR table
codecov-io edited a comment on pull request #2640: URL: https://github.com/apache/hudi/pull/2640#issuecomment-791887408 # [Codecov](https://codecov.io/gh/apache/hudi/pull/2640?src=pr=h1) Report > Merging [#2640](https://codecov.io/gh/apache/hudi/pull/2640?src=pr=desc) (16b2d89) into [master](https://codecov.io/gh/apache/hudi/commit/7cc75e0be25b7c3345efd890b1a353d49db5bace?el=desc) (7cc75e0) will **increase** coverage by `10.07%`. > The diff coverage is `n/a`. [](https://codecov.io/gh/apache/hudi/pull/2640?src=pr=tree) ```diff @@ Coverage Diff @@ ## master#2640 +/- ## = + Coverage 51.46% 61.53% +10.07% + Complexity 3486 325 -3161 = Files 462 53 -409 Lines 21782 1963-19819 Branches 2315 235 -2080 = - Hits 11210 1208-10002 + Misses 9601 632 -8969 + Partials971 123 -848 ``` | Flag | Coverage Δ | Complexity Δ | | |---|---|---|---| | hudicli | `?` | `?` | | | hudiclient | `100.00% <ø> (ø)` | `0.00 <ø> (ø)` | | | hudicommon | `?` | `?` | | | hudiflink | `?` | `?` | | | hudihadoopmr | `?` | `?` | | | hudisparkdatasource | `?` | `?` | | | hudisync | `?` | `?` | | | huditimelineservice | `?` | `?` | | | hudiutilities | `61.53% <ø> (-8.07%)` | `0.00 <ø> (ø)` | | Flags with carried forward coverage won't be shown. [Click here](https://docs.codecov.io/docs/carryforward-flags#carryforward-flags-in-the-pull-request-comment) to find out more. | [Impacted Files](https://codecov.io/gh/apache/hudi/pull/2640?src=pr=tree) | Coverage Δ | Complexity Δ | | |---|---|---|---| | [...ies/exception/HoodieSnapshotExporterException.java](https://codecov.io/gh/apache/hudi/pull/2640/diff?src=pr=tree#diff-aHVkaS11dGlsaXRpZXMvc3JjL21haW4vamF2YS9vcmcvYXBhY2hlL2h1ZGkvdXRpbGl0aWVzL2V4Y2VwdGlvbi9Ib29kaWVTbmFwc2hvdEV4cG9ydGVyRXhjZXB0aW9uLmphdmE=) | `0.00% <0.00%> (-100.00%)` | `0.00% <0.00%> (-1.00%)` | | | [.../apache/hudi/utilities/HoodieSnapshotExporter.java](https://codecov.io/gh/apache/hudi/pull/2640/diff?src=pr=tree#diff-aHVkaS11dGlsaXRpZXMvc3JjL21haW4vamF2YS9vcmcvYXBhY2hlL2h1ZGkvdXRpbGl0aWVzL0hvb2RpZVNuYXBzaG90RXhwb3J0ZXIuamF2YQ==) | `5.17% <0.00%> (-83.63%)` | `0.00% <0.00%> (-28.00%)` | | | [...hudi/utilities/schema/JdbcbasedSchemaProvider.java](https://codecov.io/gh/apache/hudi/pull/2640/diff?src=pr=tree#diff-aHVkaS11dGlsaXRpZXMvc3JjL21haW4vamF2YS9vcmcvYXBhY2hlL2h1ZGkvdXRpbGl0aWVzL3NjaGVtYS9KZGJjYmFzZWRTY2hlbWFQcm92aWRlci5qYXZh) | `0.00% <0.00%> (-72.23%)` | `0.00% <0.00%> (-2.00%)` | | | [...he/hudi/utilities/transform/AWSDmsTransformer.java](https://codecov.io/gh/apache/hudi/pull/2640/diff?src=pr=tree#diff-aHVkaS11dGlsaXRpZXMvc3JjL21haW4vamF2YS9vcmcvYXBhY2hlL2h1ZGkvdXRpbGl0aWVzL3RyYW5zZm9ybS9BV1NEbXNUcmFuc2Zvcm1lci5qYXZh) | `0.00% <0.00%> (-66.67%)` | `0.00% <0.00%> (-2.00%)` | | | [...in/java/org/apache/hudi/utilities/UtilHelpers.java](https://codecov.io/gh/apache/hudi/pull/2640/diff?src=pr=tree#diff-aHVkaS11dGlsaXRpZXMvc3JjL21haW4vamF2YS9vcmcvYXBhY2hlL2h1ZGkvdXRpbGl0aWVzL1V0aWxIZWxwZXJzLmphdmE=) | `40.69% <0.00%> (-25.00%)` | `27.00% <0.00%> (-6.00%)` | | | [...apache/hudi/utilities/deltastreamer/DeltaSync.java](https://codecov.io/gh/apache/hudi/pull/2640/diff?src=pr=tree#diff-aHVkaS11dGlsaXRpZXMvc3JjL21haW4vamF2YS9vcmcvYXBhY2hlL2h1ZGkvdXRpbGl0aWVzL2RlbHRhc3RyZWFtZXIvRGVsdGFTeW5jLmphdmE=) | `70.34% <0.00%> (-0.73%)` | `53.00% <0.00%> (ø%)` | | | [...src/main/java/org/apache/hudi/cli/TableHeader.java](https://codecov.io/gh/apache/hudi/pull/2640/diff?src=pr=tree#diff-aHVkaS1jbGkvc3JjL21haW4vamF2YS9vcmcvYXBhY2hlL2h1ZGkvY2xpL1RhYmxlSGVhZGVyLmphdmE=) | | | | | [...e/hudi/common/table/log/HoodieLogFormatWriter.java](https://codecov.io/gh/apache/hudi/pull/2640/diff?src=pr=tree#diff-aHVkaS1jb21tb24vc3JjL21haW4vamF2YS9vcmcvYXBhY2hlL2h1ZGkvY29tbW9uL3RhYmxlL2xvZy9Ib29kaWVMb2dGb3JtYXRXcml0ZXIuamF2YQ==) | | | | | [.../hudi/common/bloom/InternalDynamicBloomFilter.java](https://codecov.io/gh/apache/hudi/pull/2640/diff?src=pr=tree#diff-aHVkaS1jb21tb24vc3JjL21haW4vamF2YS9vcmcvYXBhY2hlL2h1ZGkvY29tbW9uL2Jsb29tL0ludGVybmFsRHluYW1pY0Jsb29tRmlsdGVyLmphdmE=) | | | | | [...n/java/org/apache/hudi/common/model/FileSlice.java](https://codecov.io/gh/apache/hudi/pull/2640/diff?src=pr=tree#diff-aHVkaS1jb21tb24vc3JjL21haW4vamF2YS9vcmcvYXBhY2hlL2h1ZGkvY29tbW9uL21vZGVsL0ZpbGVTbGljZS5qYXZh) | | | | | ... and [400 more](https://codecov.io/gh/apache/hudi/pull/2640/diff?src=pr=tree-more) | |
[GitHub] [hudi] codecov-io commented on pull request #2640: [HUDI-1663] Streaming read for Flink MOR table
codecov-io commented on pull request #2640: URL: https://github.com/apache/hudi/pull/2640#issuecomment-791887408 # [Codecov](https://codecov.io/gh/apache/hudi/pull/2640?src=pr=h1) Report > Merging [#2640](https://codecov.io/gh/apache/hudi/pull/2640?src=pr=desc) (16b2d89) into [master](https://codecov.io/gh/apache/hudi/commit/7cc75e0be25b7c3345efd890b1a353d49db5bace?el=desc) (7cc75e0) will **increase** coverage by `10.07%`. > The diff coverage is `n/a`. [](https://codecov.io/gh/apache/hudi/pull/2640?src=pr=tree) ```diff @@ Coverage Diff @@ ## master#2640 +/- ## = + Coverage 51.46% 61.53% +10.07% + Complexity 3486 325 -3161 = Files 462 53 -409 Lines 21782 1963-19819 Branches 2315 235 -2080 = - Hits 11210 1208-10002 + Misses 9601 632 -8969 + Partials971 123 -848 ``` | Flag | Coverage Δ | Complexity Δ | | |---|---|---|---| | hudicli | `?` | `?` | | | hudiclient | `?` | `?` | | | hudicommon | `?` | `?` | | | hudiflink | `?` | `?` | | | hudihadoopmr | `?` | `?` | | | hudisparkdatasource | `?` | `?` | | | hudisync | `?` | `?` | | | huditimelineservice | `?` | `?` | | | hudiutilities | `61.53% <ø> (-8.07%)` | `0.00 <ø> (ø)` | | Flags with carried forward coverage won't be shown. [Click here](https://docs.codecov.io/docs/carryforward-flags#carryforward-flags-in-the-pull-request-comment) to find out more. | [Impacted Files](https://codecov.io/gh/apache/hudi/pull/2640?src=pr=tree) | Coverage Δ | Complexity Δ | | |---|---|---|---| | [...ies/exception/HoodieSnapshotExporterException.java](https://codecov.io/gh/apache/hudi/pull/2640/diff?src=pr=tree#diff-aHVkaS11dGlsaXRpZXMvc3JjL21haW4vamF2YS9vcmcvYXBhY2hlL2h1ZGkvdXRpbGl0aWVzL2V4Y2VwdGlvbi9Ib29kaWVTbmFwc2hvdEV4cG9ydGVyRXhjZXB0aW9uLmphdmE=) | `0.00% <0.00%> (-100.00%)` | `0.00% <0.00%> (-1.00%)` | | | [.../apache/hudi/utilities/HoodieSnapshotExporter.java](https://codecov.io/gh/apache/hudi/pull/2640/diff?src=pr=tree#diff-aHVkaS11dGlsaXRpZXMvc3JjL21haW4vamF2YS9vcmcvYXBhY2hlL2h1ZGkvdXRpbGl0aWVzL0hvb2RpZVNuYXBzaG90RXhwb3J0ZXIuamF2YQ==) | `5.17% <0.00%> (-83.63%)` | `0.00% <0.00%> (-28.00%)` | | | [...hudi/utilities/schema/JdbcbasedSchemaProvider.java](https://codecov.io/gh/apache/hudi/pull/2640/diff?src=pr=tree#diff-aHVkaS11dGlsaXRpZXMvc3JjL21haW4vamF2YS9vcmcvYXBhY2hlL2h1ZGkvdXRpbGl0aWVzL3NjaGVtYS9KZGJjYmFzZWRTY2hlbWFQcm92aWRlci5qYXZh) | `0.00% <0.00%> (-72.23%)` | `0.00% <0.00%> (-2.00%)` | | | [...he/hudi/utilities/transform/AWSDmsTransformer.java](https://codecov.io/gh/apache/hudi/pull/2640/diff?src=pr=tree#diff-aHVkaS11dGlsaXRpZXMvc3JjL21haW4vamF2YS9vcmcvYXBhY2hlL2h1ZGkvdXRpbGl0aWVzL3RyYW5zZm9ybS9BV1NEbXNUcmFuc2Zvcm1lci5qYXZh) | `0.00% <0.00%> (-66.67%)` | `0.00% <0.00%> (-2.00%)` | | | [...in/java/org/apache/hudi/utilities/UtilHelpers.java](https://codecov.io/gh/apache/hudi/pull/2640/diff?src=pr=tree#diff-aHVkaS11dGlsaXRpZXMvc3JjL21haW4vamF2YS9vcmcvYXBhY2hlL2h1ZGkvdXRpbGl0aWVzL1V0aWxIZWxwZXJzLmphdmE=) | `40.69% <0.00%> (-25.00%)` | `27.00% <0.00%> (-6.00%)` | | | [...apache/hudi/utilities/deltastreamer/DeltaSync.java](https://codecov.io/gh/apache/hudi/pull/2640/diff?src=pr=tree#diff-aHVkaS11dGlsaXRpZXMvc3JjL21haW4vamF2YS9vcmcvYXBhY2hlL2h1ZGkvdXRpbGl0aWVzL2RlbHRhc3RyZWFtZXIvRGVsdGFTeW5jLmphdmE=) | `70.34% <0.00%> (-0.73%)` | `53.00% <0.00%> (ø%)` | | | [...he/hudi/metadata/HoodieMetadataFileSystemView.java](https://codecov.io/gh/apache/hudi/pull/2640/diff?src=pr=tree#diff-aHVkaS1jb21tb24vc3JjL21haW4vamF2YS9vcmcvYXBhY2hlL2h1ZGkvbWV0YWRhdGEvSG9vZGllTWV0YWRhdGFGaWxlU3lzdGVtVmlldy5qYXZh) | | | | | [...java/org/apache/hudi/common/util/NumericUtils.java](https://codecov.io/gh/apache/hudi/pull/2640/diff?src=pr=tree#diff-aHVkaS1jb21tb24vc3JjL21haW4vamF2YS9vcmcvYXBhY2hlL2h1ZGkvY29tbW9uL3V0aWwvTnVtZXJpY1V0aWxzLmphdmE=) | | | | | [...src/main/java/org/apache/hudi/sink/CommitSink.java](https://codecov.io/gh/apache/hudi/pull/2640/diff?src=pr=tree#diff-aHVkaS1mbGluay9zcmMvbWFpbi9qYXZhL29yZy9hcGFjaGUvaHVkaS9zaW5rL0NvbW1pdFNpbmsuamF2YQ==) | | | | | [.../org/apache/hudi/exception/HoodieKeyException.java](https://codecov.io/gh/apache/hudi/pull/2640/diff?src=pr=tree#diff-aHVkaS1jb21tb24vc3JjL21haW4vamF2YS9vcmcvYXBhY2hlL2h1ZGkvZXhjZXB0aW9uL0hvb2RpZUtleUV4Y2VwdGlvbi5qYXZh) | | | | | ... and [400 more](https://codecov.io/gh/apache/hudi/pull/2640/diff?src=pr=tree-more) | | This
[jira] [Updated] (HUDI-1663) Streaming read for Flink MOR table
[ https://issues.apache.org/jira/browse/HUDI-1663?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] ASF GitHub Bot updated HUDI-1663: - Labels: pull-request-available (was: ) > Streaming read for Flink MOR table > -- > > Key: HUDI-1663 > URL: https://issues.apache.org/jira/browse/HUDI-1663 > Project: Apache Hudi > Issue Type: Sub-task > Components: Flink Integration >Reporter: Danny Chen >Assignee: Danny Chen >Priority: Major > Labels: pull-request-available > Fix For: 0.8.0 > > > Supports reading as streaming for Flink MOR table. The writer writes avro > logs and reader monitor the latest commits in the timeline the assign the > split reading task for the incremental logs. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [hudi] danny0405 opened a new pull request #2640: [HUDI-1663] Streaming read for Flink MOR table
danny0405 opened a new pull request #2640: URL: https://github.com/apache/hudi/pull/2640 ## What is the purpose of the pull request Support streaming read for HUDI Flink MOR table. ## Brief change log *(for example:)* - *Modify AnnotationLocation checkstyle rule in checkstyle.xml* ## Verify this pull request *(Please pick either of the following options)* This pull request is a trivial rework / code cleanup without any test coverage. *(or)* This pull request is already covered by existing tests, such as *(please describe tests)*. (or) This change added tests and can be verified as follows: *(example:)* - *Added integration tests for end-to-end.* - *Added HoodieClientWriteTest to verify the change.* - *Manually verified the change by running a job locally.* ## Committer checklist - [ ] Has a corresponding JIRA in PR title & commit - [ ] Commit message is descriptive of the change - [ ] CI is green - [ ] Necessary doc changes done or have another open PR - [ ] For large changes, please consider breaking it into sub-tasks under an umbrella JIRA. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] codecov-io edited a comment on pull request #2628: [HUDI-1635] Improvements to Hudi Test Suite
codecov-io edited a comment on pull request #2628: URL: https://github.com/apache/hudi/pull/2628#issuecomment-790378502 # [Codecov](https://codecov.io/gh/apache/hudi/pull/2628?src=pr=h1) Report > Merging [#2628](https://codecov.io/gh/apache/hudi/pull/2628?src=pr=desc) (71b53bd) into [master](https://codecov.io/gh/apache/hudi/commit/11ad4ed26b6046201945f0e14449e1cbc5b6f1f2?el=desc) (11ad4ed) will **not change** coverage. > The diff coverage is `n/a`. [](https://codecov.io/gh/apache/hudi/pull/2628?src=pr=tree) ```diff @@Coverage Diff@@ ## master#2628 +/- ## = Coverage 61.48% 61.48% Complexity 324 324 = Files53 53 Lines 1963 1963 Branches235 235 = Hits 1207 1207 Misses 632 632 Partials124 124 ``` | Flag | Coverage Δ | Complexity Δ | | |---|---|---|---| | hudiclient | `100.00% <ø> (ø)` | `0.00 <ø> (ø)` | | | hudiutilities | `61.48% <ø> (ø)` | `0.00 <ø> (ø)` | | Flags with carried forward coverage won't be shown. [Click here](https://docs.codecov.io/docs/carryforward-flags#carryforward-flags-in-the-pull-request-comment) to find out more. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] afeldman1 opened a new issue #2639: [SUPPORT] Spark upgrade cause severe increase in Hudi write time
afeldman1 opened a new issue #2639: URL: https://github.com/apache/hudi/issues/2639 Using Hudi 0.6.0, updated from Spark 2.4.7 on EMR 5.32.0 to Spark 3.0.1 on EMR 6.2.0, there is a significant slowdown on writing into Hudi tables. With Spark 2.4.7 the process writing into the Hudi table takes about 6 minutes, while with Spark 3.0.1, the same code takes about 3.4 hours. The table has 60073874 records. The source Spark is reading the data from is a single un-partitioned parquet file. Using AWS Glue as the metastore and S3 as the table file store location. Originally it was writing into a Hudi table with a single partition, but I also attempted to break it up partitioned into groups as see below, with no significant change in performance: 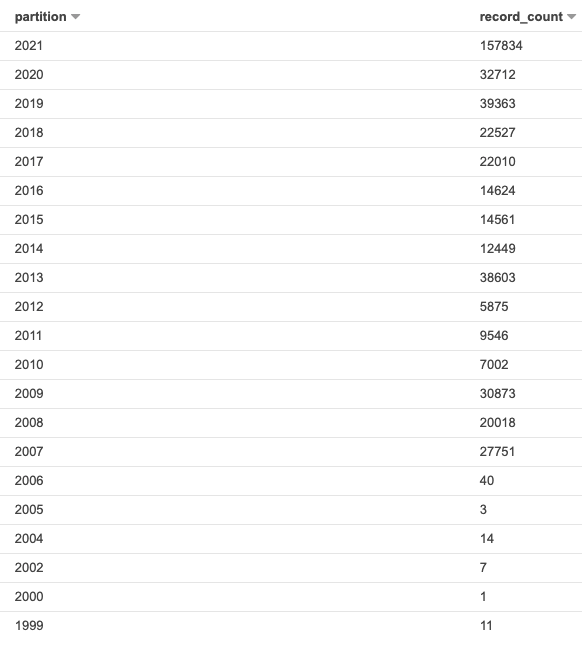 The Hudi write config is the same with both Spark 2.4.7 and Spark 3.0.1: `DataSourceWriteOptions.HIVE_DATABASE_OPT_KEY -> datalakeDbName, HoodieWriteConfig.TABLE_NAME -> table.tableName, DataSourceWriteOptions.TABLE_TYPE_OPT_KEY -> DataSourceWriteOptions.COW_TABLE_TYPE_OPT_VAL, DataSourceWriteOptions.OPERATION_OPT_KEY -> DataSourceWriteOptions.BULK_INSERT_OPERATION_OPT_VAL, DataSourceWriteOptions.KEYGENERATOR_CLASS_OPT_KEY -> classOf[ComplexKeyGenerator].getName, DataSourceWriteOptions.RECORDKEY_FIELD_OPT_KEY -> table.keyCols.reduce(_ + "," + _), DataSourceWriteOptions.PARTITIONPATH_FIELD_OPT_KEY -> table.partitionCols, DataSourceWriteOptions.PRECOMBINE_FIELD_OPT_KEY -> "ts", DataSourceWriteOptions.HIVE_SYNC_ENABLED_OPT_KEY -> "true", DataSourceWriteOptions.HIVE_TABLE_OPT_KEY -> table.tableName, DataSourceWriteOptions.HIVE_PARTITION_EXTRACTOR_CLASS_OPT_KEY -> classOf[MultiPartKeysValueExtractor].getCanonicalName, DataSourceWriteOptions.HIVE_PARTITION_FIELDS_OPT_KEY -> partitionCols DataSourceWriteOptions.HIVE_URL_OPT_KEY -> getHiveMetastoreJdbcUrl` (also attempted to switch to `DataSourceWriteOptions.INSERT_OPERATION_OPT_VAL` for `DataSourceWriteOptions.OPERATION_OPT_KEY`, but this does not help) It’s spending most time time on the piece “UpsertPartitioner”, “Getting small files from partitions” with spark job “sortBy at GlobalSortPartitioner.java” and “count at HoodieSparkSqlWriter.scala" Is there something wrong with the config, that's causing this extreme increase in hudi processing time? With Spark 3.0.1 Using single partition: 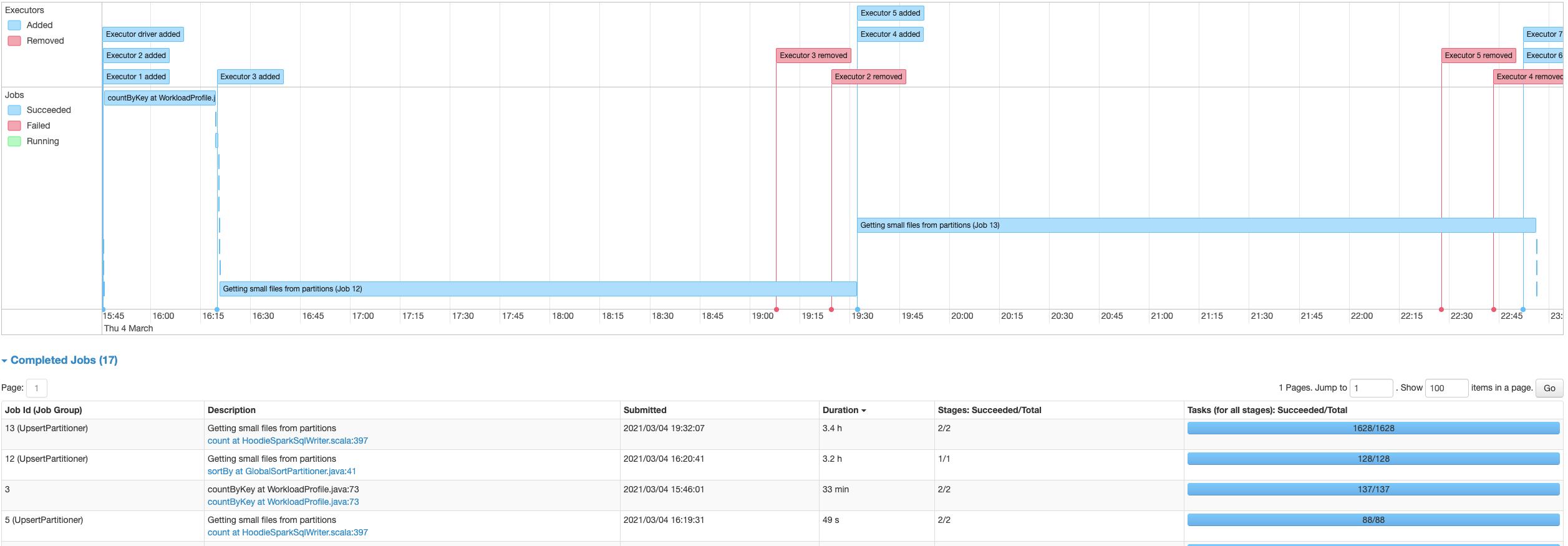 With Spark 3.0.1 Using multiple partitions: 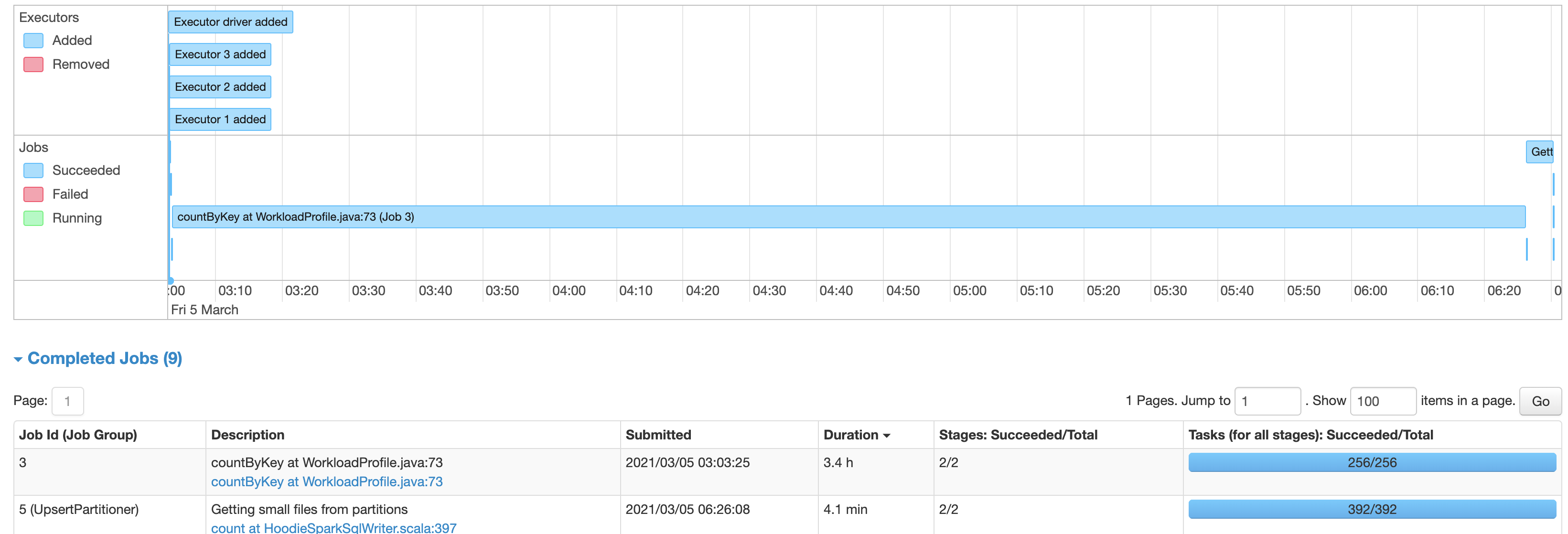 With Spark 2.4.7: 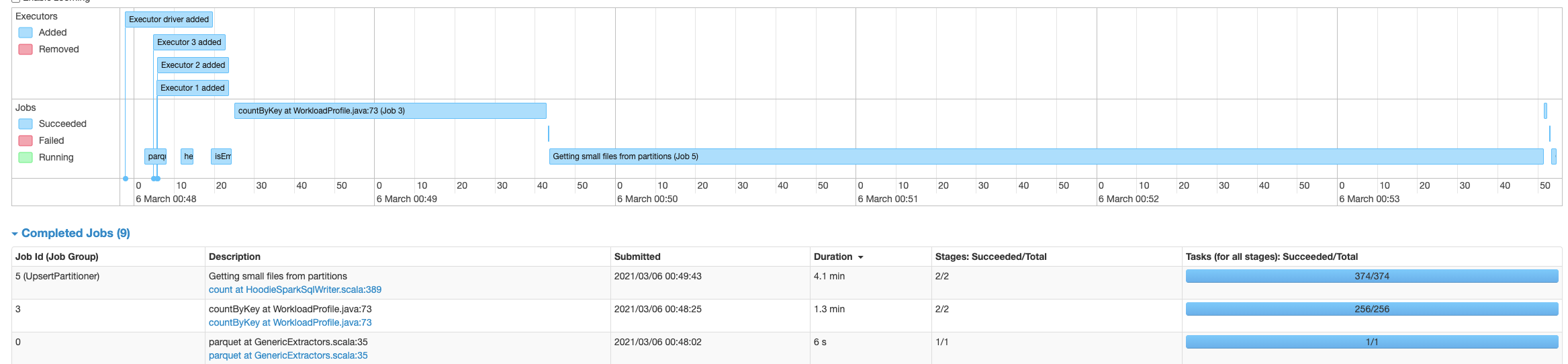 **Problematic Environment Description** Hudi version : 0.6.0 Spark version : 3.0.1 Storage: AWS S3 Running on EMR This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] yanghua commented on a change in pull request #2638: [MINOR] Fix import in StreamerUtil.java
yanghua commented on a change in pull request #2638: URL: https://github.com/apache/hudi/pull/2638#discussion_r588828682 ## File path: hudi-flink/src/main/java/org/apache/hudi/util/StreamerUtil.java ## @@ -19,6 +19,7 @@ package org.apache.hudi.util; import org.apache.hudi.common.model.HoodieRecordLocation; +import org.apache.hudi.common.model.HoodieTableType; Review comment: Strange. Why the CI did not find the compile error before we merge relevant changes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] yanghua commented on a change in pull request #2638: [MINOR] Fix import in StreamerUtil.java
yanghua commented on a change in pull request #2638: URL: https://github.com/apache/hudi/pull/2638#discussion_r588828682 ## File path: hudi-flink/src/main/java/org/apache/hudi/util/StreamerUtil.java ## @@ -19,6 +19,7 @@ package org.apache.hudi.util; import org.apache.hudi.common.model.HoodieRecordLocation; +import org.apache.hudi.common.model.HoodieTableType; Review comment: Do we meet a compile error? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Created] (HUDI-1671) Update docker demo with an example of how to do concurrent writes
Nishith Agarwal created HUDI-1671: - Summary: Update docker demo with an example of how to do concurrent writes Key: HUDI-1671 URL: https://issues.apache.org/jira/browse/HUDI-1671 Project: Apache Hudi Issue Type: New Feature Components: Docs Reporter: Nishith Agarwal Assignee: Nishith Agarwal -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Created] (HUDI-1670) Documentation of configs and use of Optimistic Locks
Nishith Agarwal created HUDI-1670: - Summary: Documentation of configs and use of Optimistic Locks Key: HUDI-1670 URL: https://issues.apache.org/jira/browse/HUDI-1670 Project: Apache Hudi Issue Type: New Feature Components: Docs Reporter: Nishith Agarwal Assignee: Nishith Agarwal -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [hudi] vinothchandar commented on a change in pull request #2374: [HUDI-845] Added locking capability to allow multiple writers
vinothchandar commented on a change in pull request #2374:
URL: https://github.com/apache/hudi/pull/2374#discussion_r588775163
##
File path:
hudi-common/src/main/java/org/apache/hudi/common/lock/LockProvider.java
##
@@ -0,0 +1,86 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.common.lock;
+
+import org.apache.hudi.common.config.LockConfiguration;
+import org.apache.hudi.common.util.StringUtils;
+import org.apache.hudi.exception.HoodieLockException;
+import org.apache.log4j.LogManager;
+import org.apache.log4j.Logger;
+
+import java.util.concurrent.TimeUnit;
+import java.util.concurrent.locks.Condition;
+import java.util.concurrent.locks.Lock;
+
+/**
+ * Pluggable lock implementations using this provider class.
+ */
+public abstract class LockProvider implements Lock, AutoCloseable {
+
+ private static final Logger LOG = LogManager.getLogger(LockProvider.class);
+
+ protected LockConfiguration lockConfiguration;
+
+ @Override
+ public final void lockInterruptibly() {
+throw new UnsupportedOperationException();
+ }
+
+ @Override
+ public final void lock() {
+throw new UnsupportedOperationException();
+ }
+
+ @Override
+ public final boolean tryLock() {
+throw new UnsupportedOperationException();
+ }
+
+ @Override
+ public boolean tryLock(long time, TimeUnit unit) {
+try {
+ return tryLock(time, unit);
+} catch (Exception e) {
+ throw new HoodieLockException(e);
+}
+ }
+
+ public T getLock() {
+throw new UnsupportedOperationException();
+ }
+
+ @Override
+ public final Condition newCondition() {
+throw new UnsupportedOperationException();
+ }
+
+ @Override
+ public void close() {
+try {
+ close();
Review comment:
is this a recursive call? won't it recurse infinitely?
##
File path:
hudi-common/src/main/java/org/apache/hudi/common/lock/LockProvider.java
##
@@ -0,0 +1,86 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.common.lock;
+
+import org.apache.hudi.common.config.LockConfiguration;
+import org.apache.hudi.common.util.StringUtils;
+import org.apache.hudi.exception.HoodieLockException;
+import org.apache.log4j.LogManager;
+import org.apache.log4j.Logger;
+
+import java.util.concurrent.TimeUnit;
+import java.util.concurrent.locks.Condition;
+import java.util.concurrent.locks.Lock;
+
+/**
+ * Pluggable lock implementations using this provider class.
+ */
+public abstract class LockProvider implements Lock, AutoCloseable {
Review comment:
We can always to interface and default methods, right?
##
File path:
hudi-common/src/main/java/org/apache/hudi/common/lock/LockProvider.java
##
@@ -0,0 +1,86 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express
[GitHub] [hudi] vinothchandar commented on a change in pull request #2374: [HUDI-845] Added locking capability to allow multiple writers
vinothchandar commented on a change in pull request #2374:
URL: https://github.com/apache/hudi/pull/2374#discussion_r588774464
##
File path:
hudi-common/src/main/java/org/apache/hudi/common/model/WriteConcurrencyMode.java
##
@@ -0,0 +1,66 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.common.model;
+
+import org.apache.hudi.exception.HoodieException;
+
+import java.util.Locale;
+
+/**
+ * Different concurrency modes for write operations.
+ */
+public enum WriteConcurrencyMode {
+ // Only a single writer can perform write ops
+ SINGLE_WRITER("single_writer"),
+ // Multiple writer can perform write ops with lazy conflict resolution using
locks
+ OPTIMISTIC_CONCURRENCY_CONTROL("optimistic_concurrency_control");
+
+ private final String value;
+
+ WriteConcurrencyMode(String value) {
+this.value = value;
+ }
+
+ /**
+ * Getter for write concurrency mode.
+ * @return
+ */
+ public String value() {
+return value;
+ }
+
+ /**
+ * Convert string value to WriteConcurrencyMode.
+ */
+ public static WriteConcurrencyMode fromValue(String value) {
+switch (value.toLowerCase(Locale.ROOT)) {
+ case "single_writer":
+return SINGLE_WRITER;
+ case "optimistic_concurrency_control":
+return OPTIMISTIC_CONCURRENCY_CONTROL;
+ default:
+throw new HoodieException("Invalid value of Type.");
+}
+ }
+
+ public boolean supportsOptimisticConcurrencyControl() {
Review comment:
I was thinking from perspective of, you are just doing a direct
comparison. thus hte `isXXX` naming. but I see your view. lets keep it as is
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] vinothchandar commented on a change in pull request #2374: [HUDI-845] Added locking capability to allow multiple writers
vinothchandar commented on a change in pull request #2374:
URL: https://github.com/apache/hudi/pull/2374#discussion_r588771691
##
File path:
hudi-client/hudi-spark-client/src/main/java/org/apache/hudi/table/action/bootstrap/SparkBootstrapCommitActionExecutor.java
##
@@ -222,6 +225,17 @@ protected void commit(Option>
extraMetadata, HoodieWriteMeta
LOG.info("Committing metadata bootstrap !!");
}
+ @Override
+ protected void syncTableMetadata() {
Review comment:
can we please file a ticket for removing this auto commit stuff. it's
kind of messy.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] xushiyan commented on pull request #2638: [MINOR] Fix import in StreamerUtil.java
xushiyan commented on pull request #2638: URL: https://github.com/apache/hudi/pull/2638#issuecomment-791744407 @vinothchandar how would this bypass CI 樂 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] codecov-io commented on pull request #2638: [MINOR] Fix import in StreamerUtil.java
codecov-io commented on pull request #2638: URL: https://github.com/apache/hudi/pull/2638#issuecomment-791741011 # [Codecov](https://codecov.io/gh/apache/hudi/pull/2638?src=pr=h1) Report > Merging [#2638](https://codecov.io/gh/apache/hudi/pull/2638?src=pr=desc) (1c476b7) into [master](https://codecov.io/gh/apache/hudi/commit/f53bca404f1482e0e99ad683dd29bfaff8bfb8ab?el=desc) (f53bca4) will **decrease** coverage by `41.96%`. > The diff coverage is `0.00%`. [](https://codecov.io/gh/apache/hudi/pull/2638?src=pr=tree) ```diff @@ Coverage Diff @@ ## master #2638 +/- ## - Coverage 51.48% 9.52% -41.97% + Complexity 3486 48 -3438 Files 462 53 -409 Lines 217841963-19821 Branches 2315 235 -2080 - Hits 11216 187-11029 + Misses 95971763 -7834 + Partials971 13 -958 ``` | Flag | Coverage Δ | Complexity Δ | | |---|---|---|---| | hudicli | `?` | `?` | | | hudiclient | `?` | `?` | | | hudicommon | `?` | `?` | | | hudiflink | `?` | `?` | | | hudihadoopmr | `?` | `?` | | | hudisparkdatasource | `?` | `?` | | | hudisync | `?` | `?` | | | huditimelineservice | `?` | `?` | | | hudiutilities | `9.52% <0.00%> (-60.06%)` | `0.00 <0.00> (ø)` | | Flags with carried forward coverage won't be shown. [Click here](https://docs.codecov.io/docs/carryforward-flags#carryforward-flags-in-the-pull-request-comment) to find out more. | [Impacted Files](https://codecov.io/gh/apache/hudi/pull/2638?src=pr=tree) | Coverage Δ | Complexity Δ | | |---|---|---|---| | [...udi/utilities/deltastreamer/BootstrapExecutor.java](https://codecov.io/gh/apache/hudi/pull/2638/diff?src=pr=tree#diff-aHVkaS11dGlsaXRpZXMvc3JjL21haW4vamF2YS9vcmcvYXBhY2hlL2h1ZGkvdXRpbGl0aWVzL2RlbHRhc3RyZWFtZXIvQm9vdHN0cmFwRXhlY3V0b3IuamF2YQ==) | `0.00% <0.00%> (-79.55%)` | `0.00 <0.00> (-6.00)` | | | [...apache/hudi/utilities/deltastreamer/DeltaSync.java](https://codecov.io/gh/apache/hudi/pull/2638/diff?src=pr=tree#diff-aHVkaS11dGlsaXRpZXMvc3JjL21haW4vamF2YS9vcmcvYXBhY2hlL2h1ZGkvdXRpbGl0aWVzL2RlbHRhc3RyZWFtZXIvRGVsdGFTeW5jLmphdmE=) | `0.00% <0.00%> (-70.72%)` | `0.00 <0.00> (-52.00)` | | | [...va/org/apache/hudi/utilities/IdentitySplitter.java](https://codecov.io/gh/apache/hudi/pull/2638/diff?src=pr=tree#diff-aHVkaS11dGlsaXRpZXMvc3JjL21haW4vamF2YS9vcmcvYXBhY2hlL2h1ZGkvdXRpbGl0aWVzL0lkZW50aXR5U3BsaXR0ZXIuamF2YQ==) | `0.00% <0.00%> (-100.00%)` | `0.00% <0.00%> (-2.00%)` | | | [...va/org/apache/hudi/utilities/schema/SchemaSet.java](https://codecov.io/gh/apache/hudi/pull/2638/diff?src=pr=tree#diff-aHVkaS11dGlsaXRpZXMvc3JjL21haW4vamF2YS9vcmcvYXBhY2hlL2h1ZGkvdXRpbGl0aWVzL3NjaGVtYS9TY2hlbWFTZXQuamF2YQ==) | `0.00% <0.00%> (-100.00%)` | `0.00% <0.00%> (-3.00%)` | | | [...a/org/apache/hudi/utilities/sources/RowSource.java](https://codecov.io/gh/apache/hudi/pull/2638/diff?src=pr=tree#diff-aHVkaS11dGlsaXRpZXMvc3JjL21haW4vamF2YS9vcmcvYXBhY2hlL2h1ZGkvdXRpbGl0aWVzL3NvdXJjZXMvUm93U291cmNlLmphdmE=) | `0.00% <0.00%> (-100.00%)` | `0.00% <0.00%> (-4.00%)` | | | [.../org/apache/hudi/utilities/sources/AvroSource.java](https://codecov.io/gh/apache/hudi/pull/2638/diff?src=pr=tree#diff-aHVkaS11dGlsaXRpZXMvc3JjL21haW4vamF2YS9vcmcvYXBhY2hlL2h1ZGkvdXRpbGl0aWVzL3NvdXJjZXMvQXZyb1NvdXJjZS5qYXZh) | `0.00% <0.00%> (-100.00%)` | `0.00% <0.00%> (-1.00%)` | | | [.../org/apache/hudi/utilities/sources/JsonSource.java](https://codecov.io/gh/apache/hudi/pull/2638/diff?src=pr=tree#diff-aHVkaS11dGlsaXRpZXMvc3JjL21haW4vamF2YS9vcmcvYXBhY2hlL2h1ZGkvdXRpbGl0aWVzL3NvdXJjZXMvSnNvblNvdXJjZS5qYXZh) | `0.00% <0.00%> (-100.00%)` | `0.00% <0.00%> (-1.00%)` | | | [...rg/apache/hudi/utilities/sources/CsvDFSSource.java](https://codecov.io/gh/apache/hudi/pull/2638/diff?src=pr=tree#diff-aHVkaS11dGlsaXRpZXMvc3JjL21haW4vamF2YS9vcmcvYXBhY2hlL2h1ZGkvdXRpbGl0aWVzL3NvdXJjZXMvQ3N2REZTU291cmNlLmphdmE=) | `0.00% <0.00%> (-100.00%)` | `0.00% <0.00%> (-10.00%)` | | | [...g/apache/hudi/utilities/sources/JsonDFSSource.java](https://codecov.io/gh/apache/hudi/pull/2638/diff?src=pr=tree#diff-aHVkaS11dGlsaXRpZXMvc3JjL21haW4vamF2YS9vcmcvYXBhY2hlL2h1ZGkvdXRpbGl0aWVzL3NvdXJjZXMvSnNvbkRGU1NvdXJjZS5qYXZh) | `0.00% <0.00%> (-100.00%)` | `0.00% <0.00%> (-4.00%)` | | | [...apache/hudi/utilities/sources/JsonKafkaSource.java](https://codecov.io/gh/apache/hudi/pull/2638/diff?src=pr=tree#diff-aHVkaS11dGlsaXRpZXMvc3JjL21haW4vamF2YS9vcmcvYXBhY2hlL2h1ZGkvdXRpbGl0aWVzL3NvdXJjZXMvSnNvbkthZmthU291cmNlLmphdmE=) | `0.00% <0.00%> (-100.00%)` |
[GitHub] [hudi] xushiyan opened a new pull request #2638: [MINOR] Fix import in StreamerUtil.java
xushiyan opened a new pull request #2638: URL: https://github.com/apache/hudi/pull/2638 ## Committer checklist - [ ] Has a corresponding JIRA in PR title & commit - [ ] Commit message is descriptive of the change - [ ] CI is green - [ ] Necessary doc changes done or have another open PR - [ ] For large changes, please consider breaking it into sub-tasks under an umbrella JIRA. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[hudi] branch master updated: [HUDI-1661] Exclude clustering commits from getExtraMetadataFromLatest API (#2632)
This is an automated email from the ASF dual-hosted git repository.
nagarwal pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/hudi.git
The following commit(s) were added to refs/heads/master by this push:
new 11ad4ed [HUDI-1661] Exclude clustering commits from
getExtraMetadataFromLatest API (#2632)
11ad4ed is described below
commit 11ad4ed26b6046201945f0e14449e1cbc5b6f1f2
Author: satishkotha
AuthorDate: Fri Mar 5 13:42:19 2021 -0800
[HUDI-1661] Exclude clustering commits from getExtraMetadataFromLatest API
(#2632)
---
.../hudi/common/table/timeline/TimelineUtils.java | 39 ++-
.../hudi/common/table/TestTimelineUtils.java | 45 ++
2 files changed, 75 insertions(+), 9 deletions(-)
diff --git
a/hudi-common/src/main/java/org/apache/hudi/common/table/timeline/TimelineUtils.java
b/hudi-common/src/main/java/org/apache/hudi/common/table/timeline/TimelineUtils.java
index f9dacf0..de8c582 100644
---
a/hudi-common/src/main/java/org/apache/hudi/common/table/timeline/TimelineUtils.java
+++
b/hudi-common/src/main/java/org/apache/hudi/common/table/timeline/TimelineUtils.java
@@ -22,9 +22,12 @@ import org.apache.hudi.avro.model.HoodieCleanMetadata;
import org.apache.hudi.avro.model.HoodieRestoreMetadata;
import org.apache.hudi.common.model.HoodieCommitMetadata;
import org.apache.hudi.common.model.HoodieReplaceCommitMetadata;
+import org.apache.hudi.common.model.WriteOperationType;
import org.apache.hudi.common.table.HoodieTableMetaClient;
import org.apache.hudi.common.util.Option;
import org.apache.hudi.exception.HoodieIOException;
+import org.apache.log4j.LogManager;
+import org.apache.log4j.Logger;
import java.io.IOException;
import java.util.Collection;
@@ -43,6 +46,7 @@ import java.util.stream.Stream;
* 2) Incremental reads - InputFormats can use this API to query
*/
public class TimelineUtils {
+ private static final Logger LOG = LogManager.getLogger(TimelineUtils.class);
/**
* Returns partitions that have new data strictly after commitTime.
@@ -117,13 +121,27 @@ public class TimelineUtils {
}
/**
- * Get extra metadata for specified key from latest commit/deltacommit
instant.
+ * Get extra metadata for specified key from latest
commit/deltacommit/replacecommit(eg. insert_overwrite) instant.
*/
public static Option
getExtraMetadataFromLatest(HoodieTableMetaClient metaClient, String
extraMetadataKey) {
-return
metaClient.getCommitsTimeline().filterCompletedInstants().getReverseOrderedInstants().findFirst().map(instant
->
+return
metaClient.getCommitsTimeline().filterCompletedInstants().getReverseOrderedInstants()
+// exclude clustering commits for returning user stored extra metadata
+.filter(instant -> !isClusteringCommit(metaClient, instant))
+.findFirst().map(instant ->
getMetadataValue(metaClient, extraMetadataKey,
instant)).orElse(Option.empty());
}
+
+ /**
+ * Get extra metadata for specified key from latest
commit/deltacommit/replacecommit instant including internal commits
+ * such as clustering.
+ */
+ public static Option
getExtraMetadataFromLatestIncludeClustering(HoodieTableMetaClient metaClient,
String extraMetadataKey) {
+return
metaClient.getCommitsTimeline().filterCompletedInstants().getReverseOrderedInstants()
+.findFirst().map(instant ->
+getMetadataValue(metaClient, extraMetadataKey,
instant)).orElse(Option.empty());
+ }
+
/**
* Get extra metadata for specified key from all active commit/deltacommit
instants.
*/
@@ -134,6 +152,7 @@ public class TimelineUtils {
private static Option getMetadataValue(HoodieTableMetaClient
metaClient, String extraMetadataKey, HoodieInstant instant) {
try {
+ LOG.info("reading checkpoint info for:" + instant + " key: " +
extraMetadataKey);
HoodieCommitMetadata commitMetadata = HoodieCommitMetadata.fromBytes(
metaClient.getCommitsTimeline().getInstantDetails(instant).get(),
HoodieCommitMetadata.class);
@@ -142,4 +161,20 @@ public class TimelineUtils {
throw new HoodieIOException("Unable to parse instant metadata " +
instant, e);
}
}
+
+ private static boolean isClusteringCommit(HoodieTableMetaClient metaClient,
HoodieInstant instant) {
+try {
+ if (HoodieTimeline.REPLACE_COMMIT_ACTION.equals(instant.getAction())) {
+// replacecommit is used for multiple operations:
insert_overwrite/cluster etc.
+// Check operation type to see if this instant is related to
clustering.
+HoodieReplaceCommitMetadata replaceMetadata =
HoodieReplaceCommitMetadata.fromBytes(
+metaClient.getActiveTimeline().getInstantDetails(instant).get(),
HoodieReplaceCommitMetadata.class);
+return
WriteOperationType.CLUSTER.equals(replaceMetadata.getOperationType());
+ }
+
+ return false;
+} catch (IOException e) {
+
[GitHub] [hudi] n3nash merged pull request #2632: [HUDI-1661] Exclude clustering commits from TimelineUtils API
n3nash merged pull request #2632: URL: https://github.com/apache/hudi/pull/2632 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Created] (HUDI-1669) Add tests for checking candidate instants to rollback
Nishith Agarwal created HUDI-1669: - Summary: Add tests for checking candidate instants to rollback Key: HUDI-1669 URL: https://issues.apache.org/jira/browse/HUDI-1669 Project: Apache Hudi Issue Type: Improvement Components: Writer Core Reporter: Nishith Agarwal Assignee: Nishith Agarwal -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [hudi] vinothchandar commented on a change in pull request #2374: [HUDI-845] Added locking capability to allow multiple writers
vinothchandar commented on a change in pull request #2374: URL: https://github.com/apache/hudi/pull/2374#discussion_r588685863 ## File path: hudi-client/hudi-client-common/src/main/java/org/apache/hudi/config/HoodieLockConfig.java ## @@ -0,0 +1,191 @@ +/* + * Licensed to the Apache Software Foundation (ASF) under one or more + * contributor license agreements. See the NOTICE file distributed with + * this work for additional information regarding copyright ownership. + * The ASF licenses this file to You under the Apache License, Version 2.0 + * (the "License"); you may not use this file except in compliance with + * the License. You may obtain a copy of the License at + * + *http://www.apache.org/licenses/LICENSE-2.0 + * + * Unless required by applicable law or agreed to in writing, software + * distributed under the License is distributed on an "AS IS" BASIS, + * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. + * See the License for the specific language governing permissions and + * limitations under the License. + */ + +package org.apache.hudi.config; + +import org.apache.hudi.client.lock.SimpleConcurrentFileWritesConflictResolutionStrategy; +import org.apache.hudi.client.lock.ConflictResolutionStrategy; +import org.apache.hudi.client.lock.ZookeeperBasedLockProvider; +import org.apache.hudi.common.config.DefaultHoodieConfig; +import org.apache.hudi.common.lock.LockProvider; + +import java.io.File; +import java.io.FileReader; +import java.io.IOException; +import java.util.Properties; + +import static org.apache.hudi.common.config.LockConfiguration.DEFAULT_ACQUIRE_LOCK_WAIT_TIMEOUT_MS; Review comment: But, could you explain why even `HiveMetastoreLockProvider` that has to be in hudi-common? That was my main point. We will be needlessly increasing the weight of hudi-common, which is picked up by hudi-hadoop-mr for e.g. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] vinothchandar commented on a change in pull request #2374: [HUDI-845] Added locking capability to allow multiple writers
vinothchandar commented on a change in pull request #2374: URL: https://github.com/apache/hudi/pull/2374#discussion_r588684413 ## File path: hudi-client/hudi-client-common/src/main/java/org/apache/hudi/config/HoodieCompactionConfig.java ## @@ -43,7 +43,8 @@ public static final String CLEANER_POLICY_PROP = "hoodie.cleaner.policy"; public static final String AUTO_CLEAN_PROP = "hoodie.clean.automatic"; public static final String ASYNC_CLEAN_PROP = "hoodie.clean.async"; - + // Turn on inline cleaning + public static final String INLINE_CLEAN_PROP = "hoodie.clean.inline"; Review comment: sure. the idea is to not proliferate, since it then becomes one more config to take care of. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] vinothchandar commented on a change in pull request #2374: [HUDI-845] Added locking capability to allow multiple writers
vinothchandar commented on a change in pull request #2374:
URL: https://github.com/apache/hudi/pull/2374#discussion_r588682179
##
File path:
hudi-client/hudi-client-common/src/main/java/org/apache/hudi/client/transaction/lock/ZookeeperBasedLockProvider.java
##
@@ -0,0 +1,161 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.client.transaction.lock;
+
+import org.apache.curator.framework.CuratorFramework;
+import org.apache.curator.framework.CuratorFrameworkFactory;
+import org.apache.curator.framework.imps.CuratorFrameworkState;
+import org.apache.curator.framework.recipes.locks.InterProcessMutex;
+import org.apache.curator.retry.BoundedExponentialBackoffRetry;
+import org.apache.hadoop.conf.Configuration;
+import org.apache.hudi.common.config.LockConfiguration;
+import org.apache.hudi.common.lock.LockProvider;
+import org.apache.hudi.common.lock.LockState;
+import org.apache.hudi.common.util.StringUtils;
+import org.apache.hudi.common.util.ValidationUtils;
+import org.apache.hudi.exception.HoodieLockException;
+import org.apache.log4j.LogManager;
+import org.apache.log4j.Logger;
+
+import javax.annotation.concurrent.NotThreadSafe;
+import java.util.concurrent.TimeUnit;
+
+import static
org.apache.hudi.common.config.LockConfiguration.DEFAULT_ZK_CONNECTION_TIMEOUT_MS;
+import static
org.apache.hudi.common.config.LockConfiguration.DEFAULT_ZK_SESSION_TIMEOUT_MS;
+import static
org.apache.hudi.common.config.LockConfiguration.LOCK_ACQUIRE_NUM_RETRIES_PROP;
+import static
org.apache.hudi.common.config.LockConfiguration.LOCK_ACQUIRE_RETRY_WAIT_TIME_IN_MILLIS_PROP;
+import static
org.apache.hudi.common.config.LockConfiguration.ZK_BASE_PATH_PROP;
+import static
org.apache.hudi.common.config.LockConfiguration.ZK_CONNECTION_TIMEOUT_MS_PROP;
+import static
org.apache.hudi.common.config.LockConfiguration.ZK_CONNECT_URL_PROP;
+import static org.apache.hudi.common.config.LockConfiguration.ZK_LOCK_KEY_PROP;
+import static
org.apache.hudi.common.config.LockConfiguration.ZK_SESSION_TIMEOUT_MS_PROP;
+
+/**
+ * A zookeeper based lock. This {@link LockProvider} implementation allows to
lock table operations
+ * using zookeeper. Users need to have a Zookeeper cluster deployed to be able
to use this lock.
+ */
+@NotThreadSafe
+public class ZookeeperBasedLockProvider extends LockProvider {
+
+ private static final Logger LOG =
LogManager.getLogger(ZookeeperBasedLockProvider.class);
+
+ private final CuratorFramework curatorFrameworkClient;
+ private volatile InterProcessMutex lock = null;
+
+ public ZookeeperBasedLockProvider(final LockConfiguration lockConfiguration,
final Configuration conf) {
+checkRequiredProps(lockConfiguration);
+this.lockConfiguration = lockConfiguration;
+this.curatorFrameworkClient = CuratorFrameworkFactory.builder()
+
.connectString(lockConfiguration.getConfig().getString(ZK_CONNECT_URL_PROP))
+.retryPolicy(new
BoundedExponentialBackoffRetry(lockConfiguration.getConfig().getInteger(LOCK_ACQUIRE_RETRY_WAIT_TIME_IN_MILLIS_PROP),
+5000,
lockConfiguration.getConfig().getInteger(LOCK_ACQUIRE_NUM_RETRIES_PROP)))
+
.sessionTimeoutMs(lockConfiguration.getConfig().getInteger(ZK_SESSION_TIMEOUT_MS_PROP,
DEFAULT_ZK_SESSION_TIMEOUT_MS))
+
.connectionTimeoutMs(lockConfiguration.getConfig().getInteger(ZK_CONNECTION_TIMEOUT_MS_PROP,
DEFAULT_ZK_CONNECTION_TIMEOUT_MS))
+.build();
+this.curatorFrameworkClient.start();
+ }
+
+ // Only used for testing
+ public ZookeeperBasedLockProvider(
+ final LockConfiguration lockConfiguration, final CuratorFramework
curatorFrameworkClient) {
+checkRequiredProps(lockConfiguration);
+this.lockConfiguration = lockConfiguration;
+this.curatorFrameworkClient = curatorFrameworkClient;
+synchronized (this.curatorFrameworkClient) {
+ if (this.curatorFrameworkClient.getState() !=
CuratorFrameworkState.STARTED) {
+this.curatorFrameworkClient.start();
+ }
+}
+ }
+
+ @Override
+ public boolean tryLock(long time, TimeUnit unit) {
+LOG.info(generateLogStatement(LockState.ACQUIRING,
generateLogSuffixString()));
+try {
+ acquireLock(time,
[GitHub] [hudi] vinothchandar commented on a change in pull request #2374: [HUDI-845] Added locking capability to allow multiple writers
vinothchandar commented on a change in pull request #2374:
URL: https://github.com/apache/hudi/pull/2374#discussion_r588672526
##
File path:
hudi-client/hudi-client-common/src/main/java/org/apache/hudi/client/transaction/SimpleConcurrentFileWritesConflictResolutionStrategy.java
##
@@ -0,0 +1,105 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.client.transaction;
+
+import org.apache.hudi.common.model.HoodieCommitMetadata;
+import org.apache.hudi.common.model.WriteOperationType;
+import org.apache.hudi.common.table.timeline.HoodieActiveTimeline;
+import org.apache.hudi.common.table.timeline.HoodieInstant;
+import org.apache.hudi.common.table.timeline.HoodieTimeline;
+import org.apache.hudi.common.util.CollectionUtils;
+import org.apache.hudi.common.util.Option;
+import org.apache.hudi.exception.HoodieWriteConflictException;
+import org.apache.hudi.table.HoodieTable;
+import org.apache.log4j.LogManager;
+import org.apache.log4j.Logger;
+
+import java.util.ConcurrentModificationException;
+import java.util.HashSet;
+import java.util.Set;
+import java.util.stream.Stream;
+
+import static
org.apache.hudi.common.table.timeline.HoodieTimeline.COMPACTION_ACTION;
+import static
org.apache.hudi.common.table.timeline.HoodieTimeline.REPLACE_COMMIT_ACTION;
+
+/**
+ * This class is a basic implementation of a conflict resolution strategy for
concurrent writes {@link ConflictResolutionStrategy}.
+ */
+public class SimpleConcurrentFileWritesConflictResolutionStrategy
+implements ConflictResolutionStrategy {
+
+ private static final Logger LOG =
LogManager.getLogger(SimpleConcurrentFileWritesConflictResolutionStrategy.class);
+
+ @Override
+ public Stream getCandidateInstants(HoodieActiveTimeline
activeTimeline, HoodieInstant currentInstant,
+ Option
lastSuccessfulInstant) {
+
+// To find which instants are conflicting, we apply the following logic
+// 1. Get completed instants timeline only for commits that have happened
since the last successful write.
+// 2. Get any scheduled or completed compaction or clustering operations
that have started and/or finished
+// after the current instant. We need to check for write conflicts since
they may have mutated the same files
+// that are being newly created by the current write.
+// NOTE that any commits from table services such as compaction,
clustering or cleaning since the
+// overlapping of files is handled using MVCC.
+Stream completedCommitsInstantStream = activeTimeline
+.getCommitsTimeline()
+.filterCompletedInstants()
+.findInstantsAfter(lastSuccessfulInstant.isPresent() ?
lastSuccessfulInstant.get().getTimestamp() : HoodieTimeline.INIT_INSTANT_TS)
+.getInstants();
+
+Stream compactionAndClusteringTimeline = activeTimeline
+.getTimelineOfActions(CollectionUtils.createSet(REPLACE_COMMIT_ACTION,
COMPACTION_ACTION))
+.findInstantsAfter(currentInstant.getTimestamp())
+.getInstants();
+return Stream.concat(completedCommitsInstantStream,
compactionAndClusteringTimeline);
+ }
+
+ @Override
+ public boolean hasConflict(HoodieCommitOperation thisOperation,
HoodieCommitOperation otherOperation) {
+// TODO : UUID's can clash even for insert/insert, handle that case.
+Set fileIdsSetForFirstInstant = thisOperation.getMutatedFileIds();
+Set fileIdsSetForSecondInstant =
otherOperation.getMutatedFileIds();
+Set intersection = new HashSet<>(fileIdsSetForFirstInstant);
+intersection.retainAll(fileIdsSetForSecondInstant);
+if (!intersection.isEmpty()) {
+ LOG.warn("Found conflicting writes between first operation = " +
thisOperation
+ + ", second operation = " + otherOperation + " , intersecting file
ids " + intersection);
+ return true;
+}
+return false;
+ }
+
+ @Override
+ public Option resolveConflict(HoodieTable table,
+ HoodieCommitOperation thisOperation, HoodieCommitOperation
otherOperation) {
+// Since compaction is eventually written as commit, we need to ensure
+// we handle this during conflict resolution and not treat the commit
[GitHub] [hudi] vinothchandar commented on a change in pull request #2374: [HUDI-845] Added locking capability to allow multiple writers
vinothchandar commented on a change in pull request #2374:
URL: https://github.com/apache/hudi/pull/2374#discussion_r588662387
##
File path:
hudi-client/hudi-client-common/src/main/java/org/apache/hudi/client/transaction/SimpleConcurrentFileWritesConflictResolutionStrategy.java
##
@@ -0,0 +1,105 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.client.transaction;
+
+import org.apache.hudi.common.model.HoodieCommitMetadata;
+import org.apache.hudi.common.model.WriteOperationType;
+import org.apache.hudi.common.table.timeline.HoodieActiveTimeline;
+import org.apache.hudi.common.table.timeline.HoodieInstant;
+import org.apache.hudi.common.table.timeline.HoodieTimeline;
+import org.apache.hudi.common.util.CollectionUtils;
+import org.apache.hudi.common.util.Option;
+import org.apache.hudi.exception.HoodieWriteConflictException;
+import org.apache.hudi.table.HoodieTable;
+import org.apache.log4j.LogManager;
+import org.apache.log4j.Logger;
+
+import java.util.ConcurrentModificationException;
+import java.util.HashSet;
+import java.util.Set;
+import java.util.stream.Stream;
+
+import static
org.apache.hudi.common.table.timeline.HoodieTimeline.COMPACTION_ACTION;
+import static
org.apache.hudi.common.table.timeline.HoodieTimeline.REPLACE_COMMIT_ACTION;
+
+/**
+ * This class is a basic implementation of a conflict resolution strategy for
concurrent writes {@link ConflictResolutionStrategy}.
+ */
+public class SimpleConcurrentFileWritesConflictResolutionStrategy
+implements ConflictResolutionStrategy {
+
+ private static final Logger LOG =
LogManager.getLogger(SimpleConcurrentFileWritesConflictResolutionStrategy.class);
+
+ @Override
+ public Stream getCandidateInstants(HoodieActiveTimeline
activeTimeline, HoodieInstant currentInstant,
+ Option
lastSuccessfulInstant) {
+
+// To find which instants are conflicting, we apply the following logic
+// 1. Get completed instants timeline only for commits that have happened
since the last successful write.
+// 2. Get any scheduled or completed compaction or clustering operations
that have started and/or finished
+// after the current instant. We need to check for write conflicts since
they may have mutated the same files
+// that are being newly created by the current write.
+// NOTE that any commits from table services such as compaction,
clustering or cleaning since the
+// overlapping of files is handled using MVCC.
+Stream completedCommitsInstantStream = activeTimeline
+.getCommitsTimeline()
+.filterCompletedInstants()
+.findInstantsAfter(lastSuccessfulInstant.isPresent() ?
lastSuccessfulInstant.get().getTimestamp() : HoodieTimeline.INIT_INSTANT_TS)
+.getInstants();
+
+Stream compactionAndClusteringTimeline = activeTimeline
+.getTimelineOfActions(CollectionUtils.createSet(REPLACE_COMMIT_ACTION,
COMPACTION_ACTION))
+.findInstantsAfter(currentInstant.getTimestamp())
+.getInstants();
+return Stream.concat(completedCommitsInstantStream,
compactionAndClusteringTimeline);
+ }
+
+ @Override
+ public boolean hasConflict(HoodieCommitOperation thisOperation,
HoodieCommitOperation otherOperation) {
+// TODO : UUID's can clash even for insert/insert, handle that case.
+Set fileIdsSetForFirstInstant = thisOperation.getMutatedFileIds();
+Set fileIdsSetForSecondInstant =
otherOperation.getMutatedFileIds();
+Set intersection = new HashSet<>(fileIdsSetForFirstInstant);
+intersection.retainAll(fileIdsSetForSecondInstant);
+if (!intersection.isEmpty()) {
+ LOG.warn("Found conflicting writes between first operation = " +
thisOperation
+ + ", second operation = " + otherOperation + " , intersecting file
ids " + intersection);
+ return true;
+}
+return false;
+ }
+
+ @Override
+ public Option resolveConflict(HoodieTable table,
+ HoodieCommitOperation thisOperation, HoodieCommitOperation
otherOperation) {
+// Since compaction is eventually written as commit, we need to ensure
+// we handle this during conflict resolution and not treat the commit
[GitHub] [hudi] vinothchandar commented on a change in pull request #2374: [HUDI-845] Added locking capability to allow multiple writers
vinothchandar commented on a change in pull request #2374: URL: https://github.com/apache/hudi/pull/2374#discussion_r588660702 ## File path: hudi-client/hudi-client-common/src/main/java/org/apache/hudi/client/lock/ZookeeperBasedLockProvider.java ## @@ -0,0 +1,157 @@ +/* + * Licensed to the Apache Software Foundation (ASF) under one + * or more contributor license agreements. See the NOTICE file + * distributed with this work for additional information + * regarding copyright ownership. The ASF licenses this file + * to you under the Apache License, Version 2.0 (the + * "License"); you may not use this file except in compliance + * with the License. You may obtain a copy of the License at + * + * http://www.apache.org/licenses/LICENSE-2.0 + * + * Unless required by applicable law or agreed to in writing, software + * distributed under the License is distributed on an "AS IS" BASIS, + * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. + * See the License for the specific language governing permissions and + * limitations under the License. + */ + +package org.apache.hudi.client.lock; + +import org.apache.curator.framework.CuratorFramework; Review comment: In the bundles, we explicitly white list dependencies. So not sure how transitive dependencies would have been picked up. How are you testing all this - not using the utilities/spark bundles? Standard practice for dependencies that are actually used in the projects code, is to explicitly deal with the dependency. We should not depend on hbase-server transitiively bringing it in. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] vinothchandar commented on a change in pull request #2374: [HUDI-845] Added locking capability to allow multiple writers
vinothchandar commented on a change in pull request #2374:
URL: https://github.com/apache/hudi/pull/2374#discussion_r588656248
##
File path:
hudi-client/hudi-client-common/src/main/java/org/apache/hudi/client/lock/SimpleConcurrentFileWritesConflictResolutionStrategy.java
##
@@ -0,0 +1,102 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.client.lock;
+
+import org.apache.hudi.common.model.HoodieCommitMetadata;
+import org.apache.hudi.common.model.WriteOperationType;
+import org.apache.hudi.common.table.timeline.HoodieActiveTimeline;
+import org.apache.hudi.common.table.timeline.HoodieInstant;
+import org.apache.hudi.common.table.timeline.HoodieTimeline;
+import org.apache.hudi.common.util.CollectionUtils;
+import org.apache.hudi.common.util.Option;
+import org.apache.hudi.exception.HoodieWriteConflictException;
+import org.apache.hudi.metadata.HoodieBackedTableMetadataWriter;
+import org.apache.hudi.table.HoodieTable;
+import org.apache.log4j.LogManager;
+import org.apache.log4j.Logger;
+
+import java.util.ConcurrentModificationException;
+import java.util.HashSet;
+import java.util.Set;
+import java.util.stream.Stream;
+
+import static
org.apache.hudi.common.table.timeline.HoodieTimeline.COMPACTION_ACTION;
+import static
org.apache.hudi.common.table.timeline.HoodieTimeline.REPLACE_COMMIT_ACTION;
+
+/**
+ * This class is a basic implementation of a conflict resolution strategy for
concurrent writes {@link ConflictResolutionStrategy}.
+ */
+public class SimpleConcurrentFileWritesConflictResolutionStrategy
+implements ConflictResolutionStrategy {
+
+ private static final Logger LOG =
LogManager.getLogger(SimpleConcurrentFileWritesConflictResolutionStrategy.class);
+
+ @Override
+ public Stream getInstantsStream(HoodieActiveTimeline
activeTimeline, HoodieInstant currentInstant,
+ Option
lastSuccessfulInstant) {
+
+// To find which instants are conflicting, we apply the following logic
+// 1. Get completed instants timeline only for commits that have happened
since the last successful write.
+// 2. Get any scheduled or completed compaction or clustering operations
that have started and/or finished
+// after the current instant. We need to check for write conflicts since
they may have mutated the same files
+// that are being newly created by the current write.
+Stream completedCommitsInstantStream = activeTimeline
+.getCommitsTimeline()
+// TODO : getWriteTimeline to ensure we include replace commits as well
+.filterCompletedInstants()
+.findInstantsAfter(lastSuccessfulInstant.isPresent() ?
lastSuccessfulInstant.get().getTimestamp() : "0")
+.getInstants();
+
+Stream compactionAndClusteringTimeline = activeTimeline
+.getTimelineOfActions(CollectionUtils.createSet(REPLACE_COMMIT_ACTION,
COMPACTION_ACTION))
+.findInstantsAfter(currentInstant.getTimestamp())
+.getInstants();
+return Stream.concat(completedCommitsInstantStream,
compactionAndClusteringTimeline);
+ }
+
+ @Override
+ public boolean hasConflict(HoodieCommitOperation thisOperation,
HoodieCommitOperation otherOperation) {
+// TODO : UUID's can clash even for insert/insert, handle that case.
+Set fileIdsSetForFirstInstant = thisOperation.getMutatedFileIds();
+Set fileIdsSetForSecondInstant =
otherOperation.getMutatedFileIds();
+Set intersection = new HashSet<>(fileIdsSetForFirstInstant);
+intersection.retainAll(fileIdsSetForSecondInstant);
+if (!intersection.isEmpty()) {
+ LOG.error("Found conflicting writes between first operation = " +
thisOperation
Review comment:
`WARN` should indicate abnormal execution. So may be or may be not. I
still think INFO is the cleanest, since this code is supposed to handle the
conflcting case. For debugging, users can always turn it on.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please
[GitHub] [hudi] vinothchandar commented on a change in pull request #2374: [HUDI-845] Added locking capability to allow multiple writers
vinothchandar commented on a change in pull request #2374:
URL: https://github.com/apache/hudi/pull/2374#discussion_r588655275
##
File path:
hudi-client/hudi-client-common/src/main/java/org/apache/hudi/client/lock/LockManager.java
##
@@ -0,0 +1,125 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.client.lock;
+
+import static
org.apache.hudi.common.config.LockConfiguration.LOCK_ACQUIRE_CLIENT_NUM_RETRIES_PROP;
+import static
org.apache.hudi.common.config.LockConfiguration.LOCK_ACQUIRE_CLIENT_RETRY_WAIT_TIME_IN_MILLIS_PROP;
+
+import org.apache.hadoop.fs.FileSystem;
+import org.apache.hudi.common.config.LockConfiguration;
+import org.apache.hudi.common.config.SerializableConfiguration;
+import org.apache.hudi.common.lock.LockProvider;
+import org.apache.hudi.common.table.timeline.HoodieInstant;
+import org.apache.hudi.common.util.Option;
+import org.apache.hudi.common.util.ReflectionUtils;
+import org.apache.hudi.config.HoodieWriteConfig;
+import org.apache.hudi.exception.HoodieLockException;
+import org.apache.log4j.LogManager;
+import org.apache.log4j.Logger;
+
+import java.io.Serializable;
+import java.util.concurrent.TimeUnit;
+import java.util.concurrent.atomic.AtomicReference;
+
+/**
+ * This class wraps implementations of {@link LockProvider} and provides an
easy way to manage the lifecycle of a lock.
+ */
+public class LockManager implements Serializable {
+
+ private static final Logger LOG = LogManager.getLogger(LockManager.class);
+ private final HoodieWriteConfig writeConfig;
+ private final LockConfiguration lockConfiguration;
+ private final SerializableConfiguration hadoopConf;
+ private volatile LockProvider lockProvider;
+ // Holds the latest completed write instant to know which ones to check
conflict against
+ private final AtomicReference>
latestCompletedWriteInstant;
+
+ public LockManager(HoodieWriteConfig writeConfig, FileSystem fs) {
+this.latestCompletedWriteInstant = new AtomicReference<>(Option.empty());
+this.writeConfig = writeConfig;
+this.hadoopConf = new SerializableConfiguration(fs.getConf());
+this.lockConfiguration = new LockConfiguration(writeConfig.getProps());
+ }
+
+ public void lock() {
+if
(writeConfig.getWriteConcurrencyMode().supportsOptimisticConcurrencyControl()) {
+ LockProvider lockProvider = getLockProvider();
+ boolean acquired = false;
+ try {
+int retries =
lockConfiguration.getConfig().getInteger(LOCK_ACQUIRE_CLIENT_NUM_RETRIES_PROP);
+long waitTimeInMs =
lockConfiguration.getConfig().getInteger(LOCK_ACQUIRE_CLIENT_RETRY_WAIT_TIME_IN_MILLIS_PROP);
+int retryCount = 0;
+while (retryCount <= retries) {
+ acquired =
lockProvider.tryLock(writeConfig.getLockAcquireWaitTimeoutInMs(),
TimeUnit.MILLISECONDS);
+ if (acquired) {
+break;
+ }
+ LOG.info("Retrying...");
+ Thread.sleep(waitTimeInMs);
+ retryCount++;
+}
+ } catch (Exception e) {
Review comment:
I think. for the retries, we should handle interrupted exception and
continue retrying. Thats what I was getting at.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] vinothchandar commented on a change in pull request #2374: [HUDI-845] Added locking capability to allow multiple writers
vinothchandar commented on a change in pull request #2374:
URL: https://github.com/apache/hudi/pull/2374#discussion_r588654337
##
File path:
hudi-client/hudi-client-common/src/main/java/org/apache/hudi/client/lock/HoodieCommitOperation.java
##
@@ -0,0 +1,142 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.client.lock;
+
+import org.apache.hudi.common.model.HoodieCommitMetadata;
+import org.apache.hudi.common.model.HoodieCommonMetadata;
+import org.apache.hudi.common.model.WriteOperationType;
+import org.apache.hudi.common.table.timeline.HoodieInstant;
+import org.apache.hudi.common.util.CommitUtils;
+import org.apache.hudi.common.util.Option;
+import java.util.Collections;
+import java.util.Set;
+import java.util.stream.Collectors;
+import static
org.apache.hudi.common.table.timeline.HoodieTimeline.COMMIT_ACTION;
+import static
org.apache.hudi.common.table.timeline.HoodieTimeline.COMPACTION_ACTION;
+import static
org.apache.hudi.common.table.timeline.HoodieTimeline.DELTA_COMMIT_ACTION;
+import static
org.apache.hudi.common.table.timeline.HoodieTimeline.REPLACE_COMMIT_ACTION;
+
+/**
+ * This class is used to hold all information used to identify how to resolve
conflicts between instants.
+ * Since we interchange payload types between AVRO specific records and
POJO's, this object serves as
+ * a common payload to manage these conversions.
+ */
+public class HoodieCommitOperation {
Review comment:
So the thing is , this has the common metadata, overloading "commit" is
always confusing in our code base, since `commit` often refers to a specific
action type. Given its used specifically, in the conflict resolution scenario,
I think somethihg like `ConcurrentOperation` captures the intent. Its just
concurrent to the current operation, the conflict resolution will determine if
its actually a conflict like you mentioned.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] vinothchandar commented on a change in pull request #2374: [HUDI-845] Added locking capability to allow multiple writers
vinothchandar commented on a change in pull request #2374:
URL: https://github.com/apache/hudi/pull/2374#discussion_r588651406
##
File path:
hudi-client/hudi-client-common/src/main/java/org/apache/hudi/client/lock/ConflictResolutionStrategy.java
##
@@ -0,0 +1,64 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.client.lock;
+
+import org.apache.hudi.ApiMaturityLevel;
+import org.apache.hudi.PublicAPIMethod;
+import org.apache.hudi.common.model.HoodieCommitMetadata;
+import org.apache.hudi.common.table.timeline.HoodieActiveTimeline;
+import org.apache.hudi.common.table.timeline.HoodieInstant;
+import org.apache.hudi.common.util.Option;
+import org.apache.hudi.metadata.HoodieBackedTableMetadataWriter;
+import org.apache.hudi.table.HoodieTable;
+
+import java.util.stream.Stream;
+
+/**
+ * Strategy interface for conflict resolution with multiple writers.
+ * Users can provide pluggable implementations for different kinds of
strategies to resolve conflicts when multiple
+ * writers are mutating the hoodie table.
+ */
+public interface ConflictResolutionStrategy {
+
+ /**
+ * Stream of instants to check conflicts against.
+ * @return
+ */
+ Stream getInstantsStream(HoodieActiveTimeline activeTimeline,
HoodieInstant currentInstant, Option lastSuccessfulInstant);
+
+ /**
+ * Implementations of this method will determine whether a conflict exists
between 2 commits.
+ * @param thisOperation
+ * @param otherOperation
+ * @return
+ */
+ @PublicAPIMethod(maturity = ApiMaturityLevel.EVOLVING)
+ boolean hasConflict(HoodieCommitOperation thisOperation,
HoodieCommitOperation otherOperation);
+
+ /**
+ * Implementations of this method will determine how to resolve a conflict
between 2 commits.
+ * @param thisOperation
+ * @param otherOperation
+ * @return
+ */
+ @PublicAPIMethod(maturity = ApiMaturityLevel.EVOLVING)
+ Option
resolveConflict(Option metadataWriter,
HoodieTable table,
Review comment:
lets remove it. we can introduce it as needed. This will simplify the
implementation, as it stands now.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] vinothchandar commented on a change in pull request #2374: [HUDI-845] Added locking capability to allow multiple writers
vinothchandar commented on a change in pull request #2374:
URL: https://github.com/apache/hudi/pull/2374#discussion_r588650200
##
File path:
hudi-client/hudi-client-common/src/main/java/org/apache/hudi/client/AbstractHoodieWriteClient.java
##
@@ -359,10 +388,21 @@ public abstract O bulkInsertPreppedRecords(I
preppedRecords, final String instan
* Common method containing steps to be performed before write
(upsert/insert/...
* @param instantTime
* @param writeOperationType
+ * @param metaClient
*/
- protected void preWrite(String instantTime, WriteOperationType
writeOperationType) {
+ protected void preWrite(String instantTime, WriteOperationType
writeOperationType,
+ HoodieTableMetaClient metaClient) {
setOperationType(writeOperationType);
-syncTableMetadata();
+
this.txnManager.setLastCompletedTransaction(metaClient.getActiveTimeline().getCommitsTimeline().filterCompletedInstants()
+.lastInstant());
+LOG.info("Last Instant Cached by writer with instant " + instantTime + "
is " + this.txnManager.getLastCompletedTransactionOwner());
+this.txnManager.setTransactionOwner(Option.of(new
HoodieInstant(State.INFLIGHT, metaClient.getCommitActionType(), instantTime)));
+this.txnManager.beginTransaction();
+try {
+ syncTableMetadata();
+} finally {
+ this.txnManager.endTransaction();
Review comment:
I was wondering about the following scenario. if the cleanup fails, I
guess it throws an error in both cases also? if so, this is okay. gtg
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] vinothchandar commented on a change in pull request #2374: [HUDI-845] Added locking capability to allow multiple writers
vinothchandar commented on a change in pull request #2374:
URL: https://github.com/apache/hudi/pull/2374#discussion_r588648870
##
File path:
hudi-client/hudi-client-common/src/main/java/org/apache/hudi/client/AbstractHoodieWriteClient.java
##
@@ -359,10 +388,21 @@ public abstract O bulkInsertPreppedRecords(I
preppedRecords, final String instan
* Common method containing steps to be performed before write
(upsert/insert/...
* @param instantTime
* @param writeOperationType
+ * @param metaClient
*/
- protected void preWrite(String instantTime, WriteOperationType
writeOperationType) {
+ protected void preWrite(String instantTime, WriteOperationType
writeOperationType,
+ HoodieTableMetaClient metaClient) {
setOperationType(writeOperationType);
-syncTableMetadata();
+
this.txnManager.setLastCompletedTransaction(metaClient.getActiveTimeline().getCommitsTimeline().filterCompletedInstants()
+.lastInstant());
+LOG.info("Last Instant Cached by writer with instant " + instantTime + "
is " + this.txnManager.getLastCompletedTransactionOwner());
+this.txnManager.setTransactionOwner(Option.of(new
HoodieInstant(State.INFLIGHT, metaClient.getCommitActionType(), instantTime)));
+this.txnManager.beginTransaction();
Review comment:
Understood. but if some calls are needed prior to this, then either the
object constructor should take them or the method should take them as
arguments. Or we have a transaction builder or sorts.
So I would say, if this is always the case, i.e the setters are needed, then
we change the beginTransaction() signature for good, not just an overload.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] vinothchandar commented on a change in pull request #2374: [HUDI-845] Added locking capability to allow multiple writers
vinothchandar commented on a change in pull request #2374: URL: https://github.com/apache/hudi/pull/2374#discussion_r588647208 ## File path: hudi-client/hudi-client-common/src/main/java/org/apache/hudi/client/AbstractHoodieWriteClient.java ## @@ -30,16 +31,19 @@ import org.apache.hudi.callback.util.HoodieCommitCallbackFactory; import org.apache.hudi.client.embedded.EmbeddedTimelineService; import org.apache.hudi.client.heartbeat.HeartbeatUtils; +import org.apache.hudi.client.lock.TransactionManager; import org.apache.hudi.common.engine.HoodieEngineContext; import org.apache.hudi.common.model.HoodieCommitMetadata; import org.apache.hudi.common.model.HoodieFailedWritesCleaningPolicy; import org.apache.hudi.common.model.HoodieKey; import org.apache.hudi.common.model.HoodieRecordPayload; import org.apache.hudi.common.model.HoodieWriteStat; +import org.apache.hudi.common.model.TableService; Review comment: If its an enum, its okay. I thought it had code. Still not a `model` per se, but we can do the moving in a different PR This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (HUDI-1660) Exclude pending compaction & clustering from rollback
[ https://issues.apache.org/jira/browse/HUDI-1660?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] ASF GitHub Bot updated HUDI-1660: - Labels: pull-request-available (was: ) > Exclude pending compaction & clustering from rollback > - > > Key: HUDI-1660 > URL: https://issues.apache.org/jira/browse/HUDI-1660 > Project: Apache Hudi > Issue Type: Bug > Components: Writer Core >Reporter: Nishith Agarwal >Assignee: Nishith Agarwal >Priority: Major > Labels: pull-request-available > -- This message was sent by Atlassian Jira (v8.3.4#803005)
[hudi] branch master updated: [HUDI-1660] Excluding compaction and clustering instants from inflight rollback (#2631)
This is an automated email from the ASF dual-hosted git repository.
satish pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/hudi.git
The following commit(s) were added to refs/heads/master by this push:
new f2159c4 [HUDI-1660] Excluding compaction and clustering instants from
inflight rollback (#2631)
f2159c4 is described below
commit f2159c4573810f922fadff640a953175a852dc43
Author: n3nash
AuthorDate: Fri Mar 5 11:18:09 2021 -0800
[HUDI-1660] Excluding compaction and clustering instants from inflight
rollback (#2631)
---
.../hudi/client/AbstractHoodieWriteClient.java | 27 +++---
1 file changed, 13 insertions(+), 14 deletions(-)
diff --git
a/hudi-client/hudi-client-common/src/main/java/org/apache/hudi/client/AbstractHoodieWriteClient.java
b/hudi-client/hudi-client-common/src/main/java/org/apache/hudi/client/AbstractHoodieWriteClient.java
index 6ce0564..a3ba008 100644
---
a/hudi-client/hudi-client-common/src/main/java/org/apache/hudi/client/AbstractHoodieWriteClient.java
+++
b/hudi-client/hudi-client-common/src/main/java/org/apache/hudi/client/AbstractHoodieWriteClient.java
@@ -19,6 +19,7 @@
package org.apache.hudi.client;
import com.codahale.metrics.Timer;
+import java.util.stream.Stream;
import org.apache.hadoop.conf.Configuration;
import org.apache.hudi.avro.model.HoodieCleanMetadata;
import org.apache.hudi.avro.model.HoodieClusteringPlan;
@@ -32,7 +33,6 @@ import
org.apache.hudi.client.embedded.EmbeddedTimelineService;
import org.apache.hudi.client.heartbeat.HeartbeatUtils;
import org.apache.hudi.common.engine.HoodieEngineContext;
import org.apache.hudi.common.model.HoodieCommitMetadata;
-import org.apache.hudi.common.model.HoodieFailedWritesCleaningPolicy;
import org.apache.hudi.common.model.HoodieKey;
import org.apache.hudi.common.model.HoodieRecordPayload;
import org.apache.hudi.common.model.HoodieWriteStat;
@@ -765,21 +765,20 @@ public abstract class AbstractHoodieWriteClient getInstantsToRollback(HoodieTable table) {
+Stream inflightInstantsStream =
getInflightTimelineExcludeCompactionAndClustering(table)
+.getReverseOrderedInstants();
if (config.getFailedWritesCleanPolicy().isEager()) {
- HoodieTimeline inflightTimeline =
table.getMetaClient().getCommitsTimeline().filterPendingExcludingCompaction();
- return
inflightTimeline.getReverseOrderedInstants().map(HoodieInstant::getTimestamp)
- .collect(Collectors.toList());
-} else if (config.getFailedWritesCleanPolicy() ==
HoodieFailedWritesCleaningPolicy.NEVER) {
- return Collections.EMPTY_LIST;
+ return
inflightInstantsStream.map(HoodieInstant::getTimestamp).collect(Collectors.toList());
} else if (config.getFailedWritesCleanPolicy().isLazy()) {
- return table.getMetaClient().getActiveTimeline()
-
.getCommitsTimeline().filterInflights().getReverseOrderedInstants().filter(instant
-> {
-try {
- return
heartbeatClient.isHeartbeatExpired(instant.getTimestamp());
-} catch (IOException io) {
- throw new HoodieException("Failed to check heartbeat for instant
" + instant, io);
-}
- }).map(HoodieInstant::getTimestamp).collect(Collectors.toList());
+ return inflightInstantsStream.filter(instant -> {
+try {
+ return heartbeatClient.isHeartbeatExpired(instant.getTimestamp());
+} catch (IOException io) {
+ throw new HoodieException("Failed to check heartbeat for instant " +
instant, io);
+}
+ }).map(HoodieInstant::getTimestamp).collect(Collectors.toList());
+} else if (config.getFailedWritesCleanPolicy().isNever()) {
+ return Collections.EMPTY_LIST;
} else {
throw new IllegalArgumentException("Invalid Failed Writes Cleaning
Policy " + config.getFailedWritesCleanPolicy());
}
[GitHub] [hudi] satishkotha merged pull request #2631: [HUDI-1660] Excluding compaction and clustering instants from inflight rollback
satishkotha merged pull request #2631: URL: https://github.com/apache/hudi/pull/2631 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] satishkotha commented on pull request #2631: [HUDI-1660] Excluding compaction and clustering instants from inflight rollback
satishkotha commented on pull request #2631: URL: https://github.com/apache/hudi/pull/2631#issuecomment-791626693 LGTM. Maybe create a ticket for adding unit test so this wont be missed (if you havent already created one) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] n3nash commented on a change in pull request #2374: [HUDI-845] Added locking capability to allow multiple writers
n3nash commented on a change in pull request #2374:
URL: https://github.com/apache/hudi/pull/2374#discussion_r588086851
##
File path:
hudi-client/hudi-client-common/src/main/java/org/apache/hudi/client/lock/SimpleConcurrentFileWritesConflictResolutionStrategy.java
##
@@ -0,0 +1,102 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.client.lock;
+
+import org.apache.hudi.common.model.HoodieCommitMetadata;
+import org.apache.hudi.common.model.WriteOperationType;
+import org.apache.hudi.common.table.timeline.HoodieActiveTimeline;
+import org.apache.hudi.common.table.timeline.HoodieInstant;
+import org.apache.hudi.common.table.timeline.HoodieTimeline;
+import org.apache.hudi.common.util.CollectionUtils;
+import org.apache.hudi.common.util.Option;
+import org.apache.hudi.exception.HoodieWriteConflictException;
+import org.apache.hudi.metadata.HoodieBackedTableMetadataWriter;
+import org.apache.hudi.table.HoodieTable;
+import org.apache.log4j.LogManager;
+import org.apache.log4j.Logger;
+
+import java.util.ConcurrentModificationException;
+import java.util.HashSet;
+import java.util.Set;
+import java.util.stream.Stream;
+
+import static
org.apache.hudi.common.table.timeline.HoodieTimeline.COMPACTION_ACTION;
+import static
org.apache.hudi.common.table.timeline.HoodieTimeline.REPLACE_COMMIT_ACTION;
+
+/**
+ * This class is a basic implementation of a conflict resolution strategy for
concurrent writes {@link ConflictResolutionStrategy}.
+ */
+public class SimpleConcurrentFileWritesConflictResolutionStrategy
+implements ConflictResolutionStrategy {
+
+ private static final Logger LOG =
LogManager.getLogger(SimpleConcurrentFileWritesConflictResolutionStrategy.class);
+
+ @Override
+ public Stream getInstantsStream(HoodieActiveTimeline
activeTimeline, HoodieInstant currentInstant,
+ Option
lastSuccessfulInstant) {
+
+// To find which instants are conflicting, we apply the following logic
+// 1. Get completed instants timeline only for commits that have happened
since the last successful write.
+// 2. Get any scheduled or completed compaction or clustering operations
that have started and/or finished
+// after the current instant. We need to check for write conflicts since
they may have mutated the same files
+// that are being newly created by the current write.
+Stream completedCommitsInstantStream = activeTimeline
+.getCommitsTimeline()
+// TODO : getWriteTimeline to ensure we include replace commits as well
+.filterCompletedInstants()
+.findInstantsAfter(lastSuccessfulInstant.isPresent() ?
lastSuccessfulInstant.get().getTimestamp() : "0")
+.getInstants();
+
+Stream compactionAndClusteringTimeline = activeTimeline
+.getTimelineOfActions(CollectionUtils.createSet(REPLACE_COMMIT_ACTION,
COMPACTION_ACTION))
+.findInstantsAfter(currentInstant.getTimestamp())
+.getInstants();
+return Stream.concat(completedCommitsInstantStream,
compactionAndClusteringTimeline);
+ }
+
+ @Override
+ public boolean hasConflict(HoodieCommitOperation thisOperation,
HoodieCommitOperation otherOperation) {
+// TODO : UUID's can clash even for insert/insert, handle that case.
+Set fileIdsSetForFirstInstant = thisOperation.getMutatedFileIds();
+Set fileIdsSetForSecondInstant =
otherOperation.getMutatedFileIds();
+Set intersection = new HashSet<>(fileIdsSetForFirstInstant);
+intersection.retainAll(fileIdsSetForSecondInstant);
+if (!intersection.isEmpty()) {
+ LOG.error("Found conflicting writes between first operation = " +
thisOperation
+ + ", second operation = " + otherOperation + " , intersecting file
ids " + intersection);
+ return true;
+}
+return false;
+ }
+
+ @Override
+ public Option
resolveConflict(Option metadataWriter,
HoodieTable table,
+ HoodieCommitOperation
thisOperation, HoodieCommitOperation otherOperation) {
+// NOTE that any commits from table services such as compaction,
clustering or cleaning since the
+// overlapping of files is handled
[jira] [Updated] (HUDI-1659) Basic Implement Of Spark Sql Support For Hoodie
[ https://issues.apache.org/jira/browse/HUDI-1659?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] pengzhiwei updated HUDI-1659: - Description: The Basic Implement include the follow things based on DataSource V1: 1、CREATE TABLE FOR HOODIE 2、CTAS 3、INSERT Hoodie Table 4、MergeInto with the RowKey constraint. was: The Basic Implement include the follow things: 1、CREATE TABLE FOR HOODIE 2、CTAS 3、INSERT Hoodie Table 4、MergeInto with the RowKey constraint. > Basic Implement Of Spark Sql Support For Hoodie > --- > > Key: HUDI-1659 > URL: https://issues.apache.org/jira/browse/HUDI-1659 > Project: Apache Hudi > Issue Type: Sub-task > Components: Spark Integration >Reporter: pengzhiwei >Assignee: pengzhiwei >Priority: Major > > The Basic Implement include the follow things based on DataSource V1: > 1、CREATE TABLE FOR HOODIE > 2、CTAS > 3、INSERT Hoodie Table > 4、MergeInto with the RowKey constraint. > -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Updated] (HUDI-1659) Basic Implement Of Spark Sql Support For Hoodie
[ https://issues.apache.org/jira/browse/HUDI-1659?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] pengzhiwei updated HUDI-1659: - Description: The Basic Implement include the follow things: 1、CREATE TABLE FOR HOODIE 2、CTAS 3、INSERT Hoodie Table 4、MergeInto with the RowKey constraint. > Basic Implement Of Spark Sql Support For Hoodie > --- > > Key: HUDI-1659 > URL: https://issues.apache.org/jira/browse/HUDI-1659 > Project: Apache Hudi > Issue Type: Sub-task > Components: Spark Integration >Reporter: pengzhiwei >Assignee: pengzhiwei >Priority: Major > > The Basic Implement include the follow things: > 1、CREATE TABLE FOR HOODIE > 2、CTAS > 3、INSERT Hoodie Table > 4、MergeInto with the RowKey constraint. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Updated] (HUDI-1659) Basic Implement Of Spark Sql Support For Hoodie
[ https://issues.apache.org/jira/browse/HUDI-1659?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] pengzhiwei updated HUDI-1659: - Summary: Basic Implement Of Spark Sql Support For Hoodie (was: Support DDL And Insert For Hudi In Spark Sql) > Basic Implement Of Spark Sql Support For Hoodie > --- > > Key: HUDI-1659 > URL: https://issues.apache.org/jira/browse/HUDI-1659 > Project: Apache Hudi > Issue Type: Sub-task > Components: Spark Integration >Reporter: pengzhiwei >Assignee: pengzhiwei >Priority: Major > -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Updated] (HUDI-1658) [UMBRELLA] Spark Sql Support For Hudi
[ https://issues.apache.org/jira/browse/HUDI-1658?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Vinoth Chandar updated HUDI-1658: - Labels: hudi-umbrellas (was: Umbrella) > [UMBRELLA] Spark Sql Support For Hudi > - > > Key: HUDI-1658 > URL: https://issues.apache.org/jira/browse/HUDI-1658 > Project: Apache Hudi > Issue Type: New Feature > Components: Spark Integration >Reporter: pengzhiwei >Assignee: pengzhiwei >Priority: Major > Labels: hudi-umbrellas > Fix For: 0.8.0 > > > This is the main task for supporting spark sql for hudi, including the > DDL、DML and Hoodie CLI command. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Updated] (HUDI-1658) [UMBRELLA] Spark Sql Support For Hudi
[ https://issues.apache.org/jira/browse/HUDI-1658?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Vinoth Chandar updated HUDI-1658: - Labels: Umbrella (was: ) Summary: [UMBRELLA] Spark Sql Support For Hudi (was: Spark Sql Support For Hudi) > [UMBRELLA] Spark Sql Support For Hudi > - > > Key: HUDI-1658 > URL: https://issues.apache.org/jira/browse/HUDI-1658 > Project: Apache Hudi > Issue Type: New Feature > Components: Spark Integration >Reporter: pengzhiwei >Assignee: pengzhiwei >Priority: Major > Labels: Umbrella > Fix For: 0.8.0 > > > This is the main task for supporting spark sql for hudi, including the > DDL、DML and Hoodie CLI command. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [hudi] Sugamber opened a new issue #2637: [SUPPORT]
Sugamber opened a new issue #2637: URL: https://github.com/apache/hudi/issues/2637 **_Tips before filing an issue_** - Have you gone through our [FAQs](https://cwiki.apache.org/confluence/display/HUDI/FAQ)? - Join the mailing list to engage in conversations and get faster support at dev-subscr...@hudi.apache.org. - If you have triaged this as a bug, then file an [issue](https://issues.apache.org/jira/projects/HUDI/issues) directly. **Describe the problem you faced** A clear and concise description of the problem. **To Reproduce** Steps to reproduce the behavior: 1. 2. 3. 4. **Expected behavior** A clear and concise description of what you expected to happen. **Environment Description** * Hudi version : * Spark version : * Hive version : * Hadoop version : * Storage (HDFS/S3/GCS..) : * Running on Docker? (yes/no) : **Additional context** Add any other context about the problem here. **Stacktrace** ```Add the stacktrace of the error.``` This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (HUDI-1668) GlobalSortPartitioner is getting called twice during bulk_insert.
[
https://issues.apache.org/jira/browse/HUDI-1668?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Sugamber updated HUDI-1668:
---
Description:
Hi Team,
I'm using bulk insert option to load close to 2 TB data. The process is taking
near by 2 hours to get completed. While looking at the job log, it is
identified that [sortBy at
GlobalSortPartitioner.java:41|https://gdlcuspc1a3-6.us-central1.us.walmart.net:18481/history/application_1614298633248_1444/1/jobs/job?id=1]
is running twice.
It is getting triggered at 1 stage. *refer this screenshot ->[^1st.png]*.
Second time it is getting trigged from *HoodieSparkSqlWriter.scala:433*
*[count at
HoodieSparkSqlWriter.scala:433|https://gdlcuspc1a3-6.us-central1.us.walmart.net:18481/history/application_1614298633248_1444/1/jobs/job?id=2]*
step.
In both cases, same number of job got triggered and running time is close to
each other. *Refer this screenshot* -> [^2nd.png]
Is there any way to run only one time so that data can be loaded faster or it
is expected behaviour.
*Spark and Hudi configurations*
{code:java}
Spark - 2.3.0
Scala- 2.11.12
Hudi - 0.7.0
{code}
Hudi Configuration
{code:java}
"hoodie.cleaner.commits.retained" = 2
"hoodie.bulkinsert.shuffle.parallelism"=2000
"hoodie.parquet.small.file.limit" = 1
"hoodie.parquet.max.file.size" = 12800
"hoodie.index.bloom.num_entries" = 180
"hoodie.bloom.index.filter.type" = "DYNAMIC_V0"
"hoodie.bloom.index.filter.dynamic.max.entries" = 250
"hoodie.bloom.index.bucketized.checking" = "false"
"hoodie.datasource.write.operation" = "bulk_insert"
"hoodie.datasource.write.table.type" = "COPY_ON_WRITE"
{code}
Spark Configuration -
{code:java}
--num-executors 180
--executor-cores 4
--executor-memory 16g
--driver-memory=24g
--conf spark.rdd.compress=true
--queue=default
--conf spark.serializer=org.apache.spark.serializer.KryoSerializer
--conf spark.executor.memoryOverhead=1600
--conf spark.driver.memoryOverhead=1200
--conf spark.driver.maxResultSize=2g
--conf spark.kryoserializer.buffer.max=512m
{code}
was:
Hi Team,
I'm using bulk insert option to load close to 2 TB data. The process is taking
near by 2 hours to get completed. While looking at the job log, it is
identified that [sortBy at
GlobalSortPartitioner.java:41|https://gdlcuspc1a3-6.us-central1.us.walmart.net:18481/history/application_1614298633248_1444/1/jobs/job?id=1]
is running twice.
It is getting triggered at 1 stage. *refer this screenshot ->[^1st.png]*.
Second time it is getting trigged from *HoodieSparkSqlWriter.scala:433*
*[count at
HoodieSparkSqlWriter.scala:433|https://gdlcuspc1a3-6.us-central1.us.walmart.net:18481/history/application_1614298633248_1444/1/jobs/job?id=2]*
step.
In both cases, same number of job got triggered and running time is close to
each other. *Refer this screenshot* -> [^2nd.png]
Is there any way to run only one time so that data can be loaded faster.
*Spark and Hudi configurations*
{code:java}
Spark - 2.3.0
Scala- 2.11.12
Hudi - 0.7.0
{code}
Hudi Configuration
{code:java}
"hoodie.cleaner.commits.retained" = 2
"hoodie.bulkinsert.shuffle.parallelism"=2000
"hoodie.parquet.small.file.limit" = 1
"hoodie.parquet.max.file.size" = 12800
"hoodie.index.bloom.num_entries" = 180
"hoodie.bloom.index.filter.type" = "DYNAMIC_V0"
"hoodie.bloom.index.filter.dynamic.max.entries" = 250
"hoodie.bloom.index.bucketized.checking" = "false"
"hoodie.datasource.write.operation" = "bulk_insert"
"hoodie.datasource.write.table.type" = "COPY_ON_WRITE"
{code}
Spark Configuration -
{code:java}
--num-executors 180
--executor-cores 4
--executor-memory 16g
--driver-memory=24g
--conf spark.rdd.compress=true
--queue=default
--conf spark.serializer=org.apache.spark.serializer.KryoSerializer
--conf spark.executor.memoryOverhead=1600
--conf spark.driver.memoryOverhead=1200
--conf spark.driver.maxResultSize=2g
--conf spark.kryoserializer.buffer.max=512m
{code}
> GlobalSortPartitioner is getting called twice during bulk_insert.
> -
>
> Key: HUDI-1668
> URL: https://issues.apache.org/jira/browse/HUDI-1668
> Project: Apache Hudi
> Issue Type: Bug
>Reporter: Sugamber
>Priority: Minor
> Attachments: 1st.png, 2nd.png
>
>
> Hi Team,
> I'm using bulk insert option to load close to 2 TB data. The process is
> taking near by 2 hours to get completed. While looking at the job log, it is
> identified that [sortBy at
> GlobalSortPartitioner.java:41|https://gdlcuspc1a3-6.us-central1.us.walmart.net:18481/history/application_1614298633248_1444/1/jobs/job?id=1]
> is running twice.
> It is getting triggered at 1 stage. *refer this screenshot ->[^1st.png]*.
> Second time it is getting trigged from *HoodieSparkSqlWriter.scala:433*
[jira] [Updated] (HUDI-1668) GlobalSortPartitioner is getting called twice during bulk_insert.
[
https://issues.apache.org/jira/browse/HUDI-1668?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Sugamber updated HUDI-1668:
---
Description:
Hi Team,
I'm using bulk insert option to load close to 2 TB data. The process is taking
near by 2 hours to get completed. While looking at the job log, it is
identified that [sortBy at
GlobalSortPartitioner.java:41|https://gdlcuspc1a3-6.us-central1.us.walmart.net:18481/history/application_1614298633248_1444/1/jobs/job?id=1]
is running twice.
It is getting triggered at 1 stage. *refer this screenshot ->[^1st.png]*.
Second time it is getting trigged from *HoodieSparkSqlWriter.scala:433*
*[count at
HoodieSparkSqlWriter.scala:433|https://gdlcuspc1a3-6.us-central1.us.walmart.net:18481/history/application_1614298633248_1444/1/jobs/job?id=2]*
step.
In both cases, same number of job got triggered and running time is close to
each other. *Refer this screenshot* -> [^2nd.png]
Is there any way to run only one time so that data can be loaded faster.
*Spark and Hudi configurations*
{code:java}
Spark - 2.3.0
Scala- 2.11.12
Hudi - 0.7.0
{code}
Hudi Configuration
{code:java}
"hoodie.cleaner.commits.retained" = 2
"hoodie.bulkinsert.shuffle.parallelism"=2000
"hoodie.parquet.small.file.limit" = 1
"hoodie.parquet.max.file.size" = 12800
"hoodie.index.bloom.num_entries" = 180
"hoodie.bloom.index.filter.type" = "DYNAMIC_V0"
"hoodie.bloom.index.filter.dynamic.max.entries" = 250
"hoodie.bloom.index.bucketized.checking" = "false"
"hoodie.datasource.write.operation" = "bulk_insert"
"hoodie.datasource.write.table.type" = "COPY_ON_WRITE"
{code}
Spark Configuration -
{code:java}
--num-executors 180
--executor-cores 4
--executor-memory 16g
--driver-memory=24g
--conf spark.rdd.compress=true
--queue=default
--conf spark.serializer=org.apache.spark.serializer.KryoSerializer
--conf spark.executor.memoryOverhead=1600
--conf spark.driver.memoryOverhead=1200
--conf spark.driver.maxResultSize=2g
--conf spark.kryoserializer.buffer.max=512m
{code}
was:
Hi Team,
I'm using bulk insert option to load close to 2 TB data. The process is taking
near by 2 hours to get completed. While looking at the job log, it is
identified that [sortBy at
GlobalSortPartitioner.java:41|https://gdlcuspc1a3-6.us-central1.us.walmart.net:18481/history/application_1614298633248_1444/1/jobs/job?id=1]
is running twice.
It is getting triggered at 1 stage. *refer this screenshot ->[^1st.png]*.
Second time it is getting trigged from *HoodieSparkSqlWriter.scala:433*
*[count at
HoodieSparkSqlWriter.scala:433|https://gdlcuspc1a3-6.us-central1.us.walmart.net:18481/history/application_1614298633248_1444/1/jobs/job?id=2]*
step.
In both cases, same number of job got triggered and running time is close to
each other. *Refer this screenshot* -> [^2nd.png]
Is there any way to run only one time so that data can be loaded faster.
*Spark and Hudi configurations*
{code:java}
Spark - 2.3.0
Scala- 2.11.12
Hudi - 0.7.0
{code}
Hudi Configuration
{code:java}
"hoodie.cleaner.commits.retained" = 2
"hoodie.bulkinsert.shuffle.parallelism"=2000
"hoodie.parquet.small.file.limit" = 1
"hoodie.parquet.max.file.size" = 12800
"hoodie.index.bloom.num_entries" = 180
"hoodie.bloom.index.filter.type" = "DYNAMIC_V0"
"hoodie.bloom.index.filter.dynamic.max.entries" = 250
"hoodie.bloom.index.bucketized.checking" = "false"
"hoodie.datasource.write.operation" = "bulk_insert"
"hoodie.datasource.write.table.type" = "COPY_ON_WRITE"
{code}
Spark Configuration -
{code:java}
--num-executors 180
--executor-cores 4
--executor-memory 16g
--driver-memory=24g
--conf spark.rdd.compress=true
--queue=default
--conf spark.serializer=org.apache.spark.serializer.KryoSerializer
--conf spark.executor.memoryOverhead=1600
--conf spark.driver.memoryOverhead=1200
--conf spark.driver.maxResultSize=2g
--conf spark.kryoserializer.buffer.max=512m
{code}
> GlobalSortPartitioner is getting called twice during bulk_insert.
> -
>
> Key: HUDI-1668
> URL: https://issues.apache.org/jira/browse/HUDI-1668
> Project: Apache Hudi
> Issue Type: Bug
>Reporter: Sugamber
>Priority: Minor
> Attachments: 1st.png, 2nd.png
>
>
> Hi Team,
> I'm using bulk insert option to load close to 2 TB data. The process is
> taking near by 2 hours to get completed. While looking at the job log, it is
> identified that [sortBy at
> GlobalSortPartitioner.java:41|https://gdlcuspc1a3-6.us-central1.us.walmart.net:18481/history/application_1614298633248_1444/1/jobs/job?id=1]
> is running twice.
> It is getting triggered at 1 stage. *refer this screenshot ->[^1st.png]*.
> Second time it is getting trigged from *HoodieSparkSqlWriter.scala:433*
> *[count at
>
[jira] [Updated] (HUDI-1668) GlobalSortPartitioner is getting called twice during bulk_insert.
[
https://issues.apache.org/jira/browse/HUDI-1668?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Sugamber updated HUDI-1668:
---
Priority: Minor (was: Major)
> GlobalSortPartitioner is getting called twice during bulk_insert.
> -
>
> Key: HUDI-1668
> URL: https://issues.apache.org/jira/browse/HUDI-1668
> Project: Apache Hudi
> Issue Type: Bug
>Reporter: Sugamber
>Priority: Minor
> Attachments: 1st.png, 2nd.png
>
>
> Hi Team,
> I'm using bulk insert option to load close to 2 TB data. The process is
> taking near by 2 hours to get completed. While looking at the job log, it is
> identified that [sortBy at
> GlobalSortPartitioner.java:41|https://gdlcuspc1a3-6.us-central1.us.walmart.net:18481/history/application_1614298633248_1444/1/jobs/job?id=1]
> is running twice.
> It is getting triggered at 1 stage. *refer this screenshot ->[^1st.png]*.
> Second time it is getting trigged from *HoodieSparkSqlWriter.scala:433*
> *[count at
> HoodieSparkSqlWriter.scala:433|https://gdlcuspc1a3-6.us-central1.us.walmart.net:18481/history/application_1614298633248_1444/1/jobs/job?id=2]*
> step.
> In both cases, same number of job got triggered and running time is close to
> each other. *Refer this screenshot* -> [^2nd.png]
> Is there any way to run only one time so that data can be loaded faster.
> *Spark and Hudi configurations*
>
> {code:java}
> Spark - 2.3.0
> Scala- 2.11.12
> Hudi - 0.7.0
>
> {code}
>
> Hudi Configuration
> {code:java}
> "hoodie.cleaner.commits.retained" = 2
> "hoodie.bulkinsert.shuffle.parallelism"=2000
> "hoodie.parquet.small.file.limit" = 1
> "hoodie.parquet.max.file.size" = 12800
> "hoodie.index.bloom.num_entries" = 180
> "hoodie.bloom.index.filter.type" = "DYNAMIC_V0"
> "hoodie.bloom.index.filter.dynamic.max.entries" = 250
> "hoodie.bloom.index.bucketized.checking" = "false"
> "hoodie.datasource.write.operation" = "bulk_insert"
> "hoodie.datasource.write.table.type" = "COPY_ON_WRITE"
> {code}
>
> Spark Configuration -
> {code:java}
> --num-executors 180
> --executor-cores 4
> --executor-memory 16g
> --driver-memory=24g
> --conf spark.rdd.compress=true
> --queue=default
> --conf spark.serializer=org.apache.spark.serializer.KryoSerializer
> --conf spark.executor.memoryOverhead=1600
> --conf spark.driver.memoryOverhead=1200
> --conf spark.driver.maxResultSize=2g
> --conf spark.kryoserializer.buffer.max=512m
> {code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Updated] (HUDI-1668) GlobalSortPartitioner is getting called twice during bulk_insert.
[
https://issues.apache.org/jira/browse/HUDI-1668?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Sugamber updated HUDI-1668:
---
Description:
Hi Team,
I'm using bulk insert option to load close to 2 TB data. The process is taking
near by 2 hours to get completed. While looking at the job log, it is
identified that [sortBy at
GlobalSortPartitioner.java:41|https://gdlcuspc1a3-6.us-central1.us.walmart.net:18481/history/application_1614298633248_1444/1/jobs/job?id=1]
is running twice.
It is getting triggered at 1 stage. *refer this screenshot ->[^1st.png]*.
Second time it is getting trigged from *HoodieSparkSqlWriter.scala:433*
*[count at
HoodieSparkSqlWriter.scala:433|https://gdlcuspc1a3-6.us-central1.us.walmart.net:18481/history/application_1614298633248_1444/1/jobs/job?id=2]*
step.
In both cases, same number of job got triggered and running time is close to
each other. *Refer this screenshot* ->
Is there any way to run only one time so that data can be loaded faster.
*Spark and Hudi configurations*
{code:java}
Spark - 2.3.0
Scala- 2.11.12
Hudi - 0.7.0
{code}
Hudi Configuration
{code:java}
"hoodie.cleaner.commits.retained" = 2
"hoodie.bulkinsert.shuffle.parallelism"=2000
"hoodie.parquet.small.file.limit" = 1
"hoodie.parquet.max.file.size" = 12800
"hoodie.index.bloom.num_entries" = 180
"hoodie.bloom.index.filter.type" = "DYNAMIC_V0"
"hoodie.bloom.index.filter.dynamic.max.entries" = 250
"hoodie.bloom.index.bucketized.checking" = "false"
"hoodie.datasource.write.operation" = "bulk_insert"
"hoodie.datasource.write.table.type" = "COPY_ON_WRITE"
{code}
Spark Configuration -
{code:java}
--num-executors 180
--executor-cores 4
--executor-memory 16g
--driver-memory=24g
--conf spark.rdd.compress=true
--queue=default
--conf spark.serializer=org.apache.spark.serializer.KryoSerializer
--conf spark.executor.memoryOverhead=1600
--conf spark.driver.memoryOverhead=1200
--conf spark.driver.maxResultSize=2g
--conf spark.kryoserializer.buffer.max=512m
{code}
was:
Hi Team,
I'm using bulk insert option to load close to 2 TB data. The process is taking
near by 2 hours to get completed. While looking at the job log, it is
identified that [sortBy at
GlobalSortPartitioner.java:41|https://gdlcuspc1a3-6.us-central1.us.walmart.net:18481/history/application_1614298633248_1444/1/jobs/job?id=1]
is running twice.
It is getting triggered at 1 stage. *refer this screenshot ->*.
Second time it is getting trigged from *HoodieSparkSqlWriter.scala:433*
*[count at
HoodieSparkSqlWriter.scala:433|https://gdlcuspc1a3-6.us-central1.us.walmart.net:18481/history/application_1614298633248_1444/1/jobs/job?id=2]*
step.
In both cases, same number of job got triggered and running time is close to
each other.
Is there any way to run only one time so that data can be loaded faster.
*Spark and Hudi configurations*
{code:java}
Spark - 2.3.0
Scala- 2.11.12
Hudi - 0.7.0
{code}
Hudi Configuration
{code:java}
"hoodie.cleaner.commits.retained" = 2
"hoodie.bulkinsert.shuffle.parallelism"=2000
"hoodie.parquet.small.file.limit" = 1
"hoodie.parquet.max.file.size" = 12800
"hoodie.index.bloom.num_entries" = 180
"hoodie.bloom.index.filter.type" = "DYNAMIC_V0"
"hoodie.bloom.index.filter.dynamic.max.entries" = 250
"hoodie.bloom.index.bucketized.checking" = "false"
"hoodie.datasource.write.operation" = "bulk_insert"
"hoodie.datasource.write.table.type" = "COPY_ON_WRITE"
{code}
Spark Configuration -
{code:java}
--num-executors 180
--executor-cores 4
--executor-memory 16g
--driver-memory=24g
--conf spark.rdd.compress=true
--queue=default
--conf spark.serializer=org.apache.spark.serializer.KryoSerializer
--conf spark.executor.memoryOverhead=1600
--conf spark.driver.memoryOverhead=1200
--conf spark.driver.maxResultSize=2g
--conf spark.kryoserializer.buffer.max=512m
{code}
> GlobalSortPartitioner is getting called twice during bulk_insert.
> -
>
> Key: HUDI-1668
> URL: https://issues.apache.org/jira/browse/HUDI-1668
> Project: Apache Hudi
> Issue Type: Bug
>Reporter: Sugamber
>Priority: Major
> Attachments: 1st.png, 2nd.png
>
>
> Hi Team,
> I'm using bulk insert option to load close to 2 TB data. The process is
> taking near by 2 hours to get completed. While looking at the job log, it is
> identified that [sortBy at
> GlobalSortPartitioner.java:41|https://gdlcuspc1a3-6.us-central1.us.walmart.net:18481/history/application_1614298633248_1444/1/jobs/job?id=1]
> is running twice.
> It is getting triggered at 1 stage. *refer this screenshot ->[^1st.png]*.
> Second time it is getting trigged from *HoodieSparkSqlWriter.scala:433*
> *[count at
>
[jira] [Updated] (HUDI-1668) GlobalSortPartitioner is getting called twice during bulk_insert.
[
https://issues.apache.org/jira/browse/HUDI-1668?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Sugamber updated HUDI-1668:
---
Description:
Hi Team,
I'm using bulk insert option to load close to 2 TB data. The process is taking
near by 2 hours to get completed. While looking at the job log, it is
identified that [sortBy at
GlobalSortPartitioner.java:41|https://gdlcuspc1a3-6.us-central1.us.walmart.net:18481/history/application_1614298633248_1444/1/jobs/job?id=1]
is running twice.
It is getting triggered at 1 stage. *refer this screenshot ->[^1st.png]*.
Second time it is getting trigged from *HoodieSparkSqlWriter.scala:433*
*[count at
HoodieSparkSqlWriter.scala:433|https://gdlcuspc1a3-6.us-central1.us.walmart.net:18481/history/application_1614298633248_1444/1/jobs/job?id=2]*
step.
In both cases, same number of job got triggered and running time is close to
each other. *Refer this screenshot* -> [^2nd.png]
Is there any way to run only one time so that data can be loaded faster.
*Spark and Hudi configurations*
{code:java}
Spark - 2.3.0
Scala- 2.11.12
Hudi - 0.7.0
{code}
Hudi Configuration
{code:java}
"hoodie.cleaner.commits.retained" = 2
"hoodie.bulkinsert.shuffle.parallelism"=2000
"hoodie.parquet.small.file.limit" = 1
"hoodie.parquet.max.file.size" = 12800
"hoodie.index.bloom.num_entries" = 180
"hoodie.bloom.index.filter.type" = "DYNAMIC_V0"
"hoodie.bloom.index.filter.dynamic.max.entries" = 250
"hoodie.bloom.index.bucketized.checking" = "false"
"hoodie.datasource.write.operation" = "bulk_insert"
"hoodie.datasource.write.table.type" = "COPY_ON_WRITE"
{code}
Spark Configuration -
{code:java}
--num-executors 180
--executor-cores 4
--executor-memory 16g
--driver-memory=24g
--conf spark.rdd.compress=true
--queue=default
--conf spark.serializer=org.apache.spark.serializer.KryoSerializer
--conf spark.executor.memoryOverhead=1600
--conf spark.driver.memoryOverhead=1200
--conf spark.driver.maxResultSize=2g
--conf spark.kryoserializer.buffer.max=512m
{code}
was:
Hi Team,
I'm using bulk insert option to load close to 2 TB data. The process is taking
near by 2 hours to get completed. While looking at the job log, it is
identified that [sortBy at
GlobalSortPartitioner.java:41|https://gdlcuspc1a3-6.us-central1.us.walmart.net:18481/history/application_1614298633248_1444/1/jobs/job?id=1]
is running twice.
It is getting triggered at 1 stage. *refer this screenshot ->[^1st.png]*.
Second time it is getting trigged from *HoodieSparkSqlWriter.scala:433*
*[count at
HoodieSparkSqlWriter.scala:433|https://gdlcuspc1a3-6.us-central1.us.walmart.net:18481/history/application_1614298633248_1444/1/jobs/job?id=2]*
step.
In both cases, same number of job got triggered and running time is close to
each other. *Refer this screenshot* ->
Is there any way to run only one time so that data can be loaded faster.
*Spark and Hudi configurations*
{code:java}
Spark - 2.3.0
Scala- 2.11.12
Hudi - 0.7.0
{code}
Hudi Configuration
{code:java}
"hoodie.cleaner.commits.retained" = 2
"hoodie.bulkinsert.shuffle.parallelism"=2000
"hoodie.parquet.small.file.limit" = 1
"hoodie.parquet.max.file.size" = 12800
"hoodie.index.bloom.num_entries" = 180
"hoodie.bloom.index.filter.type" = "DYNAMIC_V0"
"hoodie.bloom.index.filter.dynamic.max.entries" = 250
"hoodie.bloom.index.bucketized.checking" = "false"
"hoodie.datasource.write.operation" = "bulk_insert"
"hoodie.datasource.write.table.type" = "COPY_ON_WRITE"
{code}
Spark Configuration -
{code:java}
--num-executors 180
--executor-cores 4
--executor-memory 16g
--driver-memory=24g
--conf spark.rdd.compress=true
--queue=default
--conf spark.serializer=org.apache.spark.serializer.KryoSerializer
--conf spark.executor.memoryOverhead=1600
--conf spark.driver.memoryOverhead=1200
--conf spark.driver.maxResultSize=2g
--conf spark.kryoserializer.buffer.max=512m
{code}
> GlobalSortPartitioner is getting called twice during bulk_insert.
> -
>
> Key: HUDI-1668
> URL: https://issues.apache.org/jira/browse/HUDI-1668
> Project: Apache Hudi
> Issue Type: Bug
>Reporter: Sugamber
>Priority: Major
> Attachments: 1st.png, 2nd.png
>
>
> Hi Team,
> I'm using bulk insert option to load close to 2 TB data. The process is
> taking near by 2 hours to get completed. While looking at the job log, it is
> identified that [sortBy at
> GlobalSortPartitioner.java:41|https://gdlcuspc1a3-6.us-central1.us.walmart.net:18481/history/application_1614298633248_1444/1/jobs/job?id=1]
> is running twice.
> It is getting triggered at 1 stage. *refer this screenshot ->[^1st.png]*.
> Second time it is getting trigged from *HoodieSparkSqlWriter.scala:433*
> *[count at
>
[jira] [Updated] (HUDI-1668) GlobalSortPartitioner is getting called twice during bulk_insert.
[
https://issues.apache.org/jira/browse/HUDI-1668?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Sugamber updated HUDI-1668:
---
Description:
Hi Team,
I'm using bulk insert option to load close to 2 TB data. The process is taking
near by 2 hours to get completed. While looking at the job log, it is
identified that [sortBy at
GlobalSortPartitioner.java:41|https://gdlcuspc1a3-6.us-central1.us.walmart.net:18481/history/application_1614298633248_1444/1/jobs/job?id=1]
is running twice.
It is getting triggered at 1 stage. *refer this screenshot ->*.
Second time it is getting trigged from *HoodieSparkSqlWriter.scala:433*
*[count at
HoodieSparkSqlWriter.scala:433|https://gdlcuspc1a3-6.us-central1.us.walmart.net:18481/history/application_1614298633248_1444/1/jobs/job?id=2]*
step.
In both cases, same number of job got triggered and running time is close to
each other.
Is there any way to run only one time so that data can be loaded faster.
*Spark and Hudi configurations*
{code:java}
Spark - 2.3.0
Scala- 2.11.12
Hudi - 0.7.0
{code}
Hudi Configuration
{code:java}
"hoodie.cleaner.commits.retained" = 2
"hoodie.bulkinsert.shuffle.parallelism"=2000
"hoodie.parquet.small.file.limit" = 1
"hoodie.parquet.max.file.size" = 12800
"hoodie.index.bloom.num_entries" = 180
"hoodie.bloom.index.filter.type" = "DYNAMIC_V0"
"hoodie.bloom.index.filter.dynamic.max.entries" = 250
"hoodie.bloom.index.bucketized.checking" = "false"
"hoodie.datasource.write.operation" = "bulk_insert"
"hoodie.datasource.write.table.type" = "COPY_ON_WRITE"
{code}
Spark Configuration -
{code:java}
--num-executors 180
--executor-cores 4
--executor-memory 16g
--driver-memory=24g
--conf spark.rdd.compress=true
--queue=default
--conf spark.serializer=org.apache.spark.serializer.KryoSerializer
--conf spark.executor.memoryOverhead=1600
--conf spark.driver.memoryOverhead=1200
--conf spark.driver.maxResultSize=2g
--conf spark.kryoserializer.buffer.max=512m
{code}
was:
Hi Team,
I'm using bulk insert option to load close to 2 TB data. The process is taking
near by 2 hours to get completed. While looking at the job log, it is
identified that [sortBy at
GlobalSortPartitioner.java:41|https://gdlcuspc1a3-6.us-central1.us.walmart.net:18481/history/application_1614298633248_1444/1/jobs/job?id=1]
is running twice.
It is getting triggered at 1 stage. refer this screenshot.
Second time it is getting trigged from *HoodieSparkSqlWriter.scala:433*
*[count at
HoodieSparkSqlWriter.scala:433|https://gdlcuspc1a3-6.us-central1.us.walmart.net:18481/history/application_1614298633248_1444/1/jobs/job?id=2]*
step.
In both cases, same number of job got triggered and running time is close to
each other.
Is there any way to run only one time so that data can be loaded faster.
*Spark and Hudi configurations*
{code:java}
Spark - 2.3.0
Scala- 2.11.12
Hudi - 0.7.0
{code}
Hudi Configuration
{code:java}
"hoodie.cleaner.commits.retained" = 2
"hoodie.bulkinsert.shuffle.parallelism"=2000
"hoodie.parquet.small.file.limit" = 1
"hoodie.parquet.max.file.size" = 12800
"hoodie.index.bloom.num_entries" = 180
"hoodie.bloom.index.filter.type" = "DYNAMIC_V0"
"hoodie.bloom.index.filter.dynamic.max.entries" = 250
"hoodie.bloom.index.bucketized.checking" = "false"
"hoodie.datasource.write.operation" = "bulk_insert"
"hoodie.datasource.write.table.type" = "COPY_ON_WRITE"
{code}
Spark Configuration -
{code:java}
--num-executors 180
--executor-cores 4
--executor-memory 16g
--driver-memory=24g
--conf spark.rdd.compress=true
--queue=default
--conf spark.serializer=org.apache.spark.serializer.KryoSerializer
--conf spark.executor.memoryOverhead=1600
--conf spark.driver.memoryOverhead=1200
--conf spark.driver.maxResultSize=2g
--conf spark.kryoserializer.buffer.max=512m
{code}
> GlobalSortPartitioner is getting called twice during bulk_insert.
> -
>
> Key: HUDI-1668
> URL: https://issues.apache.org/jira/browse/HUDI-1668
> Project: Apache Hudi
> Issue Type: Bug
>Reporter: Sugamber
>Priority: Major
> Attachments: 1st.png, 2nd.png
>
>
> Hi Team,
> I'm using bulk insert option to load close to 2 TB data. The process is
> taking near by 2 hours to get completed. While looking at the job log, it is
> identified that [sortBy at
> GlobalSortPartitioner.java:41|https://gdlcuspc1a3-6.us-central1.us.walmart.net:18481/history/application_1614298633248_1444/1/jobs/job?id=1]
> is running twice.
> It is getting triggered at 1 stage. *refer this screenshot ->*.
> Second time it is getting trigged from *HoodieSparkSqlWriter.scala:433*
> *[count at
>
[jira] [Updated] (HUDI-1668) GlobalSortPartitioner is getting called twice during bulk_insert.
[
https://issues.apache.org/jira/browse/HUDI-1668?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Sugamber updated HUDI-1668:
---
Attachment: 2nd.png
1st.png
> GlobalSortPartitioner is getting called twice during bulk_insert.
> -
>
> Key: HUDI-1668
> URL: https://issues.apache.org/jira/browse/HUDI-1668
> Project: Apache Hudi
> Issue Type: Bug
>Reporter: Sugamber
>Priority: Major
> Attachments: 1st.png, 2nd.png
>
>
> Hi Team,
> I'm using bulk insert option to load close to 2 TB data. The process is
> taking near by 2 hours to get completed. While looking at the job log, it is
> identified that [sortBy at
> GlobalSortPartitioner.java:41|https://gdlcuspc1a3-6.us-central1.us.walmart.net:18481/history/application_1614298633248_1444/1/jobs/job?id=1]
> is running twice.
> It is getting triggered at 1 stage. refer this screenshot.
> Second time it is getting trigged from *HoodieSparkSqlWriter.scala:433*
> *[count at
> HoodieSparkSqlWriter.scala:433|https://gdlcuspc1a3-6.us-central1.us.walmart.net:18481/history/application_1614298633248_1444/1/jobs/job?id=2]*
> step.
> In both cases, same number of job got triggered and running time is close to
> each other.
> Is there any way to run only one time so that data can be loaded faster.
> *Spark and Hudi configurations*
>
> {code:java}
> Spark - 2.3.0
> Scala- 2.11.12
> Hudi - 0.7.0
>
> {code}
>
> Hudi Configuration
> {code:java}
> "hoodie.cleaner.commits.retained" = 2
> "hoodie.bulkinsert.shuffle.parallelism"=2000
> "hoodie.parquet.small.file.limit" = 1
> "hoodie.parquet.max.file.size" = 12800
> "hoodie.index.bloom.num_entries" = 180
> "hoodie.bloom.index.filter.type" = "DYNAMIC_V0"
> "hoodie.bloom.index.filter.dynamic.max.entries" = 250
> "hoodie.bloom.index.bucketized.checking" = "false"
> "hoodie.datasource.write.operation" = "bulk_insert"
> "hoodie.datasource.write.table.type" = "COPY_ON_WRITE"
> {code}
>
> Spark Configuration -
> {code:java}
> --num-executors 180
> --executor-cores 4
> --executor-memory 16g
> --driver-memory=24g
> --conf spark.rdd.compress=true
> --queue=default
> --conf spark.serializer=org.apache.spark.serializer.KryoSerializer
> --conf spark.executor.memoryOverhead=1600
> --conf spark.driver.memoryOverhead=1200
> --conf spark.driver.maxResultSize=2g
> --conf spark.kryoserializer.buffer.max=512m
> {code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Created] (HUDI-1668) GlobalSortPartitioner is getting called twice during bulk_insert.
Sugamber created HUDI-1668:
--
Summary: GlobalSortPartitioner is getting called twice during
bulk_insert.
Key: HUDI-1668
URL: https://issues.apache.org/jira/browse/HUDI-1668
Project: Apache Hudi
Issue Type: Bug
Reporter: Sugamber
Attachments: 1st.png, 2nd.png
Hi Team,
I'm using bulk insert option to load close to 2 TB data. The process is taking
near by 2 hours to get completed. While looking at the job log, it is
identified that [sortBy at
GlobalSortPartitioner.java:41|https://gdlcuspc1a3-6.us-central1.us.walmart.net:18481/history/application_1614298633248_1444/1/jobs/job?id=1]
is running twice.
It is getting triggered at 1 stage. refer this screenshot.
Second time it is getting trigged from *HoodieSparkSqlWriter.scala:433*
*[count at
HoodieSparkSqlWriter.scala:433|https://gdlcuspc1a3-6.us-central1.us.walmart.net:18481/history/application_1614298633248_1444/1/jobs/job?id=2]*
step.
In both cases, same number of job got triggered and running time is close to
each other.
Is there any way to run only one time so that data can be loaded faster.
*Spark and Hudi configurations*
{code:java}
Spark - 2.3.0
Scala- 2.11.12
Hudi - 0.7.0
{code}
Hudi Configuration
{code:java}
"hoodie.cleaner.commits.retained" = 2
"hoodie.bulkinsert.shuffle.parallelism"=2000
"hoodie.parquet.small.file.limit" = 1
"hoodie.parquet.max.file.size" = 12800
"hoodie.index.bloom.num_entries" = 180
"hoodie.bloom.index.filter.type" = "DYNAMIC_V0"
"hoodie.bloom.index.filter.dynamic.max.entries" = 250
"hoodie.bloom.index.bucketized.checking" = "false"
"hoodie.datasource.write.operation" = "bulk_insert"
"hoodie.datasource.write.table.type" = "COPY_ON_WRITE"
{code}
Spark Configuration -
{code:java}
--num-executors 180
--executor-cores 4
--executor-memory 16g
--driver-memory=24g
--conf spark.rdd.compress=true
--queue=default
--conf spark.serializer=org.apache.spark.serializer.KryoSerializer
--conf spark.executor.memoryOverhead=1600
--conf spark.driver.memoryOverhead=1200
--conf spark.driver.maxResultSize=2g
--conf spark.kryoserializer.buffer.max=512m
{code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [hudi] Liulietong commented on pull request #2636: [HUDI-1667]: Fix bug when HoodieMergeOnReadRDD read record from base …
Liulietong commented on pull request #2636: URL: https://github.com/apache/hudi/pull/2636#issuecomment-791305070 hi @garyli1019 , would you take a look? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (HUDI-1667) Fix bug when HoodieMergeOnReadRDD read record from base file, Hoodie may set non-null value in field which is null if vectorization is enabled.
[
https://issues.apache.org/jira/browse/HUDI-1667?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
ASF GitHub Bot updated HUDI-1667:
-
Labels: pull-request-available (was: )
> Fix bug when HoodieMergeOnReadRDD read record from base file, Hoodie may set
> non-null value in field which is null if vectorization is enabled.
> ---
>
> Key: HUDI-1667
> URL: https://issues.apache.org/jira/browse/HUDI-1667
> Project: Apache Hudi
> Issue Type: Bug
> Components: Common Core
>Reporter: Lietong Liu
>Priority: Major
> Labels: pull-request-available
> Fix For: 0.6.0
>
>
> When HoodieMergeOnReadRDD read record from base file, will create new
> InternalRow base on requiredStructSchema.
> {code:java}
> //代码占位符
> private def createRowWithRequiredSchema(row: InternalRow): InternalRow = {
> val rowToReturn = new SpecificInternalRow(tableState.requiredStructSchema)
> val posIterator = requiredFieldPosition.iterator
> var curIndex = 0
> tableState.requiredStructSchema.foreach(
> f => {
> val curPos = posIterator.next()
> val curField = row.get(curPos, f.dataType)
> rowToReturn.update(curIndex, curField)
> curIndex = curIndex + 1
> }
> )
> rowToReturn
> }
> {code}
> Hoodie doesn't check isNull when get value from all fields here.
> If vectorization is enabled, which means row is *ColumnarBatchRow*_*.*_
> ***ColumnarBatchRow* may return non-null value even if value of field is
> null. So, hoodie may set non-null value in field which is null.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [hudi] Liulietong opened a new pull request #2636: [HUDI-1667]: Fix bug when HoodieMergeOnReadRDD read record from base …
Liulietong opened a new pull request #2636: URL: https://github.com/apache/hudi/pull/2636 …file, Hoodie may set non-null value in field which is null if vectorization is enabled. ## *Tips* - *Thank you very much for contributing to Apache Hudi.* - *Please review https://hudi.apache.org/contributing.html before opening a pull request.* ## What is the purpose of the pull request * Fix bug when HoodieMergeOnReadRDD read record from base file, Hoodie may set non-null value in field which is null if vectorization is enabled.* ## Brief change log - When HoodieMergeOnReadRDD read record from base file, will create new InternalRow base on requiredStructSchema. - Hoodie doesn't check isNull when get value from all fields. If vectorization is enabled, which means row is ColumnarBatchRow. ColumnarBatchRow may return non-null value even if value of field is null. So, hoodie may set non-null value in field which is null. ## Verify this pull request *(Please pick either of the following options)* This pull request is a trivial rework / code cleanup without any test coverage. ## Committer checklist - [x] Has a corresponding JIRA in PR title & commit - [x] Commit message is descriptive of the change - [x] CI is green - [ ] Necessary doc changes done or have another open PR - [ ] For large changes, please consider breaking it into sub-tasks under an umbrella JIRA. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (HUDI-1667) Fix bug when HoodieMergeOnReadRDD read record from base file, Hoodie may set non-null value in field which is null if vectorization is enabled.
[
https://issues.apache.org/jira/browse/HUDI-1667?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Lietong Liu updated HUDI-1667:
--
Fix Version/s: 0.6.0
Description:
When HoodieMergeOnReadRDD read record from base file, will create new
InternalRow base on requiredStructSchema.
{code:java}
//代码占位符
private def createRowWithRequiredSchema(row: InternalRow): InternalRow = {
val rowToReturn = new SpecificInternalRow(tableState.requiredStructSchema)
val posIterator = requiredFieldPosition.iterator
var curIndex = 0
tableState.requiredStructSchema.foreach(
f => {
val curPos = posIterator.next()
val curField = row.get(curPos, f.dataType)
rowToReturn.update(curIndex, curField)
curIndex = curIndex + 1
}
)
rowToReturn
}
{code}
Hoodie doesn't check isNull when get value from all fields here.
If vectorization is enabled, which means row is *ColumnarBatchRow*_*.*_
***ColumnarBatchRow* may return non-null value even if value of field is null.
So, hoodie may set non-null value in field which is null.
was:
When HoodieMergeOnReadRDD read record from base file, will create new
InternalRow base on requiredStructSchema.
{code:java}
//代码占位符
private def createRowWithRequiredSchema(row: InternalRow): InternalRow = {
val rowToReturn = new SpecificInternalRow(tableState.requiredStructSchema)
val posIterator = requiredFieldPosition.iterator
var curIndex = 0
tableState.requiredStructSchema.foreach(
f => {
val curPos = posIterator.next()
val curField = row.get(curPos, f.dataType)
rowToReturn.update(curIndex, curField)
curIndex = curIndex + 1
}
)
rowToReturn
}
{code}
> Fix bug when HoodieMergeOnReadRDD read record from base file, Hoodie may set
> non-null value in field which is null if vectorization is enabled.
> ---
>
> Key: HUDI-1667
> URL: https://issues.apache.org/jira/browse/HUDI-1667
> Project: Apache Hudi
> Issue Type: Bug
> Components: Common Core
>Reporter: Lietong Liu
>Priority: Major
> Fix For: 0.6.0
>
>
> When HoodieMergeOnReadRDD read record from base file, will create new
> InternalRow base on requiredStructSchema.
> {code:java}
> //代码占位符
> private def createRowWithRequiredSchema(row: InternalRow): InternalRow = {
> val rowToReturn = new SpecificInternalRow(tableState.requiredStructSchema)
> val posIterator = requiredFieldPosition.iterator
> var curIndex = 0
> tableState.requiredStructSchema.foreach(
> f => {
> val curPos = posIterator.next()
> val curField = row.get(curPos, f.dataType)
> rowToReturn.update(curIndex, curField)
> curIndex = curIndex + 1
> }
> )
> rowToReturn
> }
> {code}
> Hoodie doesn't check isNull when get value from all fields here.
> If vectorization is enabled, which means row is *ColumnarBatchRow*_*.*_
> ***ColumnarBatchRow* may return non-null value even if value of field is
> null. So, hoodie may set non-null value in field which is null.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Created] (HUDI-1667) Fix bug when HoodieMergeOnReadRDD read record from base file, Hoodie may set non-null value in field which is null if vectorization is enabled.
Lietong Liu created HUDI-1667:
-
Summary: Fix bug when HoodieMergeOnReadRDD read record from base
file, Hoodie may set non-null value in field which is null if vectorization is
enabled.
Key: HUDI-1667
URL: https://issues.apache.org/jira/browse/HUDI-1667
Project: Apache Hudi
Issue Type: Bug
Components: Common Core
Reporter: Lietong Liu
When HoodieMergeOnReadRDD read record from base file, will create new
InternalRow base on requiredStructSchema.
{code:java}
//代码占位符
private def createRowWithRequiredSchema(row: InternalRow): InternalRow = {
val rowToReturn = new SpecificInternalRow(tableState.requiredStructSchema)
val posIterator = requiredFieldPosition.iterator
var curIndex = 0
tableState.requiredStructSchema.foreach(
f => {
val curPos = posIterator.next()
val curField = row.get(curPos, f.dataType)
rowToReturn.update(curIndex, curField)
curIndex = curIndex + 1
}
)
rowToReturn
}
{code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Resolved] (HUDI-1583) Hudi will skip remaining log files if there is logFile with zero size in logFileList when merge on read.
[
https://issues.apache.org/jira/browse/HUDI-1583?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Lietong Liu resolved HUDI-1583.
---
Resolution: Fixed
> Hudi will skip remaining log files if there is logFile with zero size in
> logFileList when merge on read.
> -
>
> Key: HUDI-1583
> URL: https://issues.apache.org/jira/browse/HUDI-1583
> Project: Apache Hudi
> Issue Type: Bug
> Components: Common Core
>Affects Versions: 0.6.0
>Reporter: Lietong Liu
>Priority: Major
> Fix For: 0.6.0
>
>
> When 'spark.speculation' is enabled, there may be logFile with zero size.
> *HoodieLogFormatReader.hasNext()* will return false when encounter logFile
> with zero size,which will skip remaining log files。
>
> {code:java}
> @Override
> public boolean hasNext() {
> if (currentReader == null)
> { return false; }
> else if (currentReader.hasNext())
> { return true; }
> else if (logFiles.size() > 0) {
> try {
> HoodieLogFile nextLogFile = logFiles.remove(0);
> // First close previous reader only if readBlockLazily is true
> if (!readBlocksLazily)
> { this.currentReader.close(); }
> else
> { this.prevReadersInOpenState.add(currentReader); }
> this.currentReader =
> new HoodieLogFileReader(fs, nextLogFile, readerSchema, bufferSize,
> readBlocksLazily, false);
> } catch (IOException io)
> { throw new HoodieIOException("unable to initialize read with log file ",
> io); }
> LOG.info("Moving to the next reader for logfile " +
> currentReader.getLogFile());
> return this.currentReader.hasNext() || hasNext();
> }
> return false;
> }
>
> {code}
>
>
>
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [hudi] n3nash commented on a change in pull request #2374: [HUDI-845] Added locking capability to allow multiple writers
n3nash commented on a change in pull request #2374:
URL: https://github.com/apache/hudi/pull/2374#discussion_r58089
##
File path:
hudi-client/hudi-client-common/src/main/java/org/apache/hudi/client/AbstractHoodieWriteClient.java
##
@@ -30,16 +31,19 @@
import org.apache.hudi.callback.util.HoodieCommitCallbackFactory;
import org.apache.hudi.client.embedded.EmbeddedTimelineService;
import org.apache.hudi.client.heartbeat.HeartbeatUtils;
+import org.apache.hudi.client.lock.TransactionManager;
import org.apache.hudi.common.engine.HoodieEngineContext;
import org.apache.hudi.common.model.HoodieCommitMetadata;
import org.apache.hudi.common.model.HoodieFailedWritesCleaningPolicy;
import org.apache.hudi.common.model.HoodieKey;
import org.apache.hudi.common.model.HoodieRecordPayload;
import org.apache.hudi.common.model.HoodieWriteStat;
+import org.apache.hudi.common.model.TableService;
Review comment:
I kept it here because WriteOperationType is also here.
##
File path:
hudi-client/hudi-client-common/src/main/java/org/apache/hudi/client/AbstractHoodieWriteClient.java
##
@@ -359,10 +388,21 @@ public abstract O bulkInsertPreppedRecords(I
preppedRecords, final String instan
* Common method containing steps to be performed before write
(upsert/insert/...
* @param instantTime
* @param writeOperationType
+ * @param metaClient
*/
- protected void preWrite(String instantTime, WriteOperationType
writeOperationType) {
+ protected void preWrite(String instantTime, WriteOperationType
writeOperationType,
+ HoodieTableMetaClient metaClient) {
setOperationType(writeOperationType);
-syncTableMetadata();
+
this.txnManager.setLastCompletedTransaction(metaClient.getActiveTimeline().getCommitsTimeline().filterCompletedInstants()
+.lastInstant());
+LOG.info("Last Instant Cached by writer with instant " + instantTime + "
is " + this.txnManager.getLastCompletedTransactionOwner());
+this.txnManager.setTransactionOwner(Option.of(new
HoodieInstant(State.INFLIGHT, metaClient.getCommitActionType(), instantTime)));
+this.txnManager.beginTransaction();
Review comment:
I also realized this during implementation but wanted to keep
`beginTransaction(..)` API simple. I've added a overridden method now
##
File path:
hudi-client/hudi-client-common/src/main/java/org/apache/hudi/client/lock/ConflictResolutionStrategy.java
##
@@ -0,0 +1,64 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.client.lock;
+
+import org.apache.hudi.ApiMaturityLevel;
+import org.apache.hudi.PublicAPIMethod;
+import org.apache.hudi.common.model.HoodieCommitMetadata;
+import org.apache.hudi.common.table.timeline.HoodieActiveTimeline;
+import org.apache.hudi.common.table.timeline.HoodieInstant;
+import org.apache.hudi.common.util.Option;
+import org.apache.hudi.metadata.HoodieBackedTableMetadataWriter;
+import org.apache.hudi.table.HoodieTable;
+
+import java.util.stream.Stream;
+
+/**
+ * Strategy interface for conflict resolution with multiple writers.
+ * Users can provide pluggable implementations for different kinds of
strategies to resolve conflicts when multiple
+ * writers are mutating the hoodie table.
+ */
+public interface ConflictResolutionStrategy {
+
+ /**
+ * Stream of instants to check conflicts against.
+ * @return
+ */
+ Stream getInstantsStream(HoodieActiveTimeline activeTimeline,
HoodieInstant currentInstant, Option lastSuccessfulInstant);
+
+ /**
+ * Implementations of this method will determine whether a conflict exists
between 2 commits.
+ * @param thisOperation
+ * @param otherOperation
+ * @return
+ */
+ @PublicAPIMethod(maturity = ApiMaturityLevel.EVOLVING)
+ boolean hasConflict(HoodieCommitOperation thisOperation,
HoodieCommitOperation otherOperation);
+
+ /**
+ * Implementations of this method will determine how to resolve a conflict
between 2 commits.
+ * @param thisOperation
+ * @param otherOperation
+ * @return
+ */
+ @PublicAPIMethod(maturity = ApiMaturityLevel.EVOLVING)
+ Option
resolveConflict(Option metadataWriter,
HoodieTable table,
Review comment:
So this is