[GitHub] [hudi] qingyuan18 opened a new issue #3737: how can we migrate a legacy COW table into MOR table
qingyuan18 opened a new issue #3737: URL: https://github.com/apache/hudi/issues/3737 we have a customer which using COW table before, however ,their sourcing data become more and more huge in Kafka, and also there are couple of upsert into Hudi table sink in spark streaming , so to turning the performance of writing, we plan to convert the COW table into MOR table the problem is : how can we migrate their former COW table, which their live system has already consuming it. does it need to re-bootstrap , or it can directly change sink mechanism in Spark streaming and write into the MOR table on top of the COW table? please help to guide a best practise , have you met this requirement before ? **Environment Description** * Hudi version : 0.8 * Spark version : 3.1 * Hive version :2.4 * Hadoop version : 3.1 * Storage (HDFS/S3/GCS..) : AWS S3 * Running on Docker? (yes/no) : no -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] yanghua commented on pull request #3674: [HUDI-2440] Add dependency change diff script for dependency governace
yanghua commented on pull request #3674: URL: https://github.com/apache/hudi/pull/3674#issuecomment-930860695 @xushiyan I have addresses some suggestions. Any new inputs? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Created] (HUDI-2504) Add configuration to make HoodieBootstrap support ignoring file suffix
liujinhui created HUDI-2504: --- Summary: Add configuration to make HoodieBootstrap support ignoring file suffix Key: HUDI-2504 URL: https://issues.apache.org/jira/browse/HUDI-2504 Project: Apache Hudi Issue Type: Improvement Components: bootstrap Reporter: liujinhui Fix For: 0.10.0 -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [hudi] hudi-bot edited a comment on pull request #3674: [HUDI-2440] Add dependency change diff script for dependency governace
hudi-bot edited a comment on pull request #3674: URL: https://github.com/apache/hudi/pull/3674#issuecomment-920690239 ## CI report: * cf1f2dba2dd9ca560cd33ca012dbe5613e42a733 Azure: [SUCCESS](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=2469) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run travis` re-run the last Travis build - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] leesf commented on a change in pull request #3736: Add jfs support doc for hudi
leesf commented on a change in pull request #3736:
URL: https://github.com/apache/hudi/pull/3736#discussion_r719085443
##
File path: website/docs/jfs_hoodie.md
##
@@ -0,0 +1,90 @@
+---
+title: JuiceFS keywords: [ hudi, hive, jfs, spark, flink]
+summary: On this page, we go over how to configure Hudi with JuiceFS.
+last_modified_at: 2021-09-30T10:42:24-10:00
+---
+On this page, we explain how to use Hudi with JuiceFS.
+
+## JuiceFS Preparing
+
+JuiceFS is a high-performance distributed file system. Any data stored into
JuiceFS, the data itself will be persisted in object storage (e.g. Amazon S3),
and the metadata corresponding to the data can be persisted in various database
engines such as Redis, MySQL, and TiKV according to the needs of the scene.
+
+There are three configurations required for Hudi-JuiceFS compatibility:
+
+- Creating JuiceFS
+- Adding JuiceFS configuration for Hudi
+- Adding required jar to `classpath`
+
+### Creating JuiceFS
+
+JuiceFS supports multiple engines such as Redis, MySQL, SQLite, and TiKV.
+
+This example uses Redis as Meta Engine and AWS S3 as Data Storage in Linux env.
+
+- Download
+```shell
+JFS_LATEST_TAG=$(curl -s
https://api.github.com/repos/juicedata/juicefs/releases/latest | grep
'tag_name' | cut -d '"' -f 4 | tr -d 'v')
+wget
"https://github.com/juicedata/juicefs/releases/download/v${JFS_LATEST_TAG}/juicefs-${JFS_LATEST_TAG}-linux-amd64.tar.gz";
+```
+
+- Install
+```shell
+mkdir juice && tar -zxvf "juicefs-${JFS_LATEST_TAG}-linux-amd64.tar.gz" -C
juice
+sudo install juice/juicefs /usr/local/bin
+```
+
+- Format a filesystem
+```shell
+juicefs format \
+--storage s3 \
+--bucket https:// \
+--access-key \
+--secret-key \
+redis://:@:6379/1 \
+myjfs
+```
+
+### JuiceFS configuration
+
+Add the required configurations in your core-site.xml from where Hudi can
fetch them.
+
+```xml
+
+fs.defaultFS
+jfs://myfs
+Optional, you can also specify full path
"jfs://myfs/path-to-dir" with location to use JuiceFS
+
+
+fs.jfs.impl
+io.juicefs.JuiceFileSystem
+
+
+fs.AbstractFileSystem.jfs.impl
+io.juicefs.JuiceFS
+
+
+juicefs.meta
+redis://:@:6379/1
Review comment:
thanks for the clarification, have you tested the docs manually to see
if it works?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[jira] [Closed] (HUDI-2451) HoodieTableMetaClient The file separator from Window to HDFS is faulty
[ https://issues.apache.org/jira/browse/HUDI-2451?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] yao.zhou closed HUDI-2451. -- > HoodieTableMetaClient The file separator from Window to HDFS is faulty > -- > > Key: HUDI-2451 > URL: https://issues.apache.org/jira/browse/HUDI-2451 > Project: Apache Hudi > Issue Type: Bug > Components: Common Core >Affects Versions: 0.9.0 >Reporter: yao.zhou >Assignee: yao.zhou >Priority: Major > Labels: pull-request-available > Fix For: 0.9.0 > > Attachments: image-2021-09-18-15-05-30-324.png > > > This issue was fixed in HUD-1420, but seems to have been accidentally > overwritten by hud-1486 and is still happening > path:/apps/hive/warehouse/dw_t1.db/test_hudi_table/.hoodie\.temp/20210918131318 > !image-2021-09-18-15-05-30-324.png! -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Assigned] (HUDI-2451) HoodieTableMetaClient The file separator from Window to HDFS is faulty
[ https://issues.apache.org/jira/browse/HUDI-2451?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] yao.zhou reassigned HUDI-2451: -- Assignee: yao.zhou > HoodieTableMetaClient The file separator from Window to HDFS is faulty > -- > > Key: HUDI-2451 > URL: https://issues.apache.org/jira/browse/HUDI-2451 > Project: Apache Hudi > Issue Type: Bug > Components: Common Core >Affects Versions: 0.9.0 >Reporter: yao.zhou >Assignee: yao.zhou >Priority: Major > Labels: pull-request-available > Fix For: 0.9.0 > > Attachments: image-2021-09-18-15-05-30-324.png > > > This issue was fixed in HUD-1420, but seems to have been accidentally > overwritten by hud-1486 and is still happening > path:/apps/hive/warehouse/dw_t1.db/test_hudi_table/.hoodie\.temp/20210918131318 > !image-2021-09-18-15-05-30-324.png! -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [hudi] hudi-bot edited a comment on pull request #3674: [HUDI-2440] Add dependency change diff script for dependency governace
hudi-bot edited a comment on pull request #3674: URL: https://github.com/apache/hudi/pull/3674#issuecomment-920690239 ## CI report: * 7c634fd5d815d4643732d0c26144171c9dd8e64c Azure: [SUCCESS](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=2333) * cf1f2dba2dd9ca560cd33ca012dbe5613e42a733 Azure: [PENDING](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=2469) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run travis` re-run the last Travis build - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot edited a comment on pull request #3674: [HUDI-2440] Add dependency change diff script for dependency governace
hudi-bot edited a comment on pull request #3674: URL: https://github.com/apache/hudi/pull/3674#issuecomment-920690239 ## CI report: * 7c634fd5d815d4643732d0c26144171c9dd8e64c Azure: [SUCCESS](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=2333) * cf1f2dba2dd9ca560cd33ca012dbe5613e42a733 UNKNOWN Bot commands @hudi-bot supports the following commands: - `@hudi-bot run travis` re-run the last Travis build - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] tangyoupeng commented on a change in pull request #3736: Add jfs support doc for hudi
tangyoupeng commented on a change in pull request #3736:
URL: https://github.com/apache/hudi/pull/3736#discussion_r719061631
##
File path: website/docs/jfs_hoodie.md
##
@@ -0,0 +1,90 @@
+---
+title: JuiceFS keywords: [ hudi, hive, jfs, spark, flink]
+summary: On this page, we go over how to configure Hudi with JuiceFS.
+last_modified_at: 2021-09-30T10:42:24-10:00
+---
+On this page, we explain how to use Hudi with JuiceFS.
+
+## JuiceFS Preparing
+
+JuiceFS is a high-performance distributed file system. Any data stored into
JuiceFS, the data itself will be persisted in object storage (e.g. Amazon S3),
and the metadata corresponding to the data can be persisted in various database
engines such as Redis, MySQL, and TiKV according to the needs of the scene.
+
+There are three configurations required for Hudi-JuiceFS compatibility:
+
+- Creating JuiceFS
+- Adding JuiceFS configuration for Hudi
+- Adding required jar to `classpath`
+
+### Creating JuiceFS
+
+JuiceFS supports multiple engines such as Redis, MySQL, SQLite, and TiKV.
+
+This example uses Redis as Meta Engine and AWS S3 as Data Storage in Linux env.
+
+- Download
+```shell
+JFS_LATEST_TAG=$(curl -s
https://api.github.com/repos/juicedata/juicefs/releases/latest | grep
'tag_name' | cut -d '"' -f 4 | tr -d 'v')
+wget
"https://github.com/juicedata/juicefs/releases/download/v${JFS_LATEST_TAG}/juicefs-${JFS_LATEST_TAG}-linux-amd64.tar.gz";
+```
+
+- Install
+```shell
+mkdir juice && tar -zxvf "juicefs-${JFS_LATEST_TAG}-linux-amd64.tar.gz" -C
juice
+sudo install juice/juicefs /usr/local/bin
+```
+
+- Format a filesystem
+```shell
+juicefs format \
+--storage s3 \
+--bucket https:// \
+--access-key \
+--secret-key \
+redis://:@:6379/1 \
+myjfs
+```
+
+### JuiceFS configuration
+
+Add the required configurations in your core-site.xml from where Hudi can
fetch them.
+
+```xml
+
+fs.defaultFS
+jfs://myfs
+Optional, you can also specify full path
"jfs://myfs/path-to-dir" with location to use JuiceFS
+
+
+fs.jfs.impl
+io.juicefs.JuiceFileSystem
+
+
+fs.AbstractFileSystem.jfs.impl
+io.juicefs.JuiceFS
+
+
+juicefs.meta
+redis://:@:6379/1
Review comment:
it's a redis database index. If you use database 1 formatted as jfs meta
database, you need specify database 1 as juicefs.meta
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] tangyoupeng commented on a change in pull request #3736: Add jfs support doc for hudi
tangyoupeng commented on a change in pull request #3736:
URL: https://github.com/apache/hudi/pull/3736#discussion_r719061631
##
File path: website/docs/jfs_hoodie.md
##
@@ -0,0 +1,90 @@
+---
+title: JuiceFS keywords: [ hudi, hive, jfs, spark, flink]
+summary: On this page, we go over how to configure Hudi with JuiceFS.
+last_modified_at: 2021-09-30T10:42:24-10:00
+---
+On this page, we explain how to use Hudi with JuiceFS.
+
+## JuiceFS Preparing
+
+JuiceFS is a high-performance distributed file system. Any data stored into
JuiceFS, the data itself will be persisted in object storage (e.g. Amazon S3),
and the metadata corresponding to the data can be persisted in various database
engines such as Redis, MySQL, and TiKV according to the needs of the scene.
+
+There are three configurations required for Hudi-JuiceFS compatibility:
+
+- Creating JuiceFS
+- Adding JuiceFS configuration for Hudi
+- Adding required jar to `classpath`
+
+### Creating JuiceFS
+
+JuiceFS supports multiple engines such as Redis, MySQL, SQLite, and TiKV.
+
+This example uses Redis as Meta Engine and AWS S3 as Data Storage in Linux env.
+
+- Download
+```shell
+JFS_LATEST_TAG=$(curl -s
https://api.github.com/repos/juicedata/juicefs/releases/latest | grep
'tag_name' | cut -d '"' -f 4 | tr -d 'v')
+wget
"https://github.com/juicedata/juicefs/releases/download/v${JFS_LATEST_TAG}/juicefs-${JFS_LATEST_TAG}-linux-amd64.tar.gz";
+```
+
+- Install
+```shell
+mkdir juice && tar -zxvf "juicefs-${JFS_LATEST_TAG}-linux-amd64.tar.gz" -C
juice
+sudo install juice/juicefs /usr/local/bin
+```
+
+- Format a filesystem
+```shell
+juicefs format \
+--storage s3 \
+--bucket https:// \
+--access-key \
+--secret-key \
+redis://:@:6379/1 \
+myjfs
+```
+
+### JuiceFS configuration
+
+Add the required configurations in your core-site.xml from where Hudi can
fetch them.
+
+```xml
+
+fs.defaultFS
+jfs://myfs
+Optional, you can also specify full path
"jfs://myfs/path-to-dir" with location to use JuiceFS
+
+
+fs.jfs.impl
+io.juicefs.JuiceFileSystem
+
+
+fs.AbstractFileSystem.jfs.impl
+io.juicefs.JuiceFS
+
+
+juicefs.meta
+redis://:@:6379/1
Review comment:
it's a redis database index
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] leesf commented on a change in pull request #3736: Add jfs support doc for hudi
leesf commented on a change in pull request #3736:
URL: https://github.com/apache/hudi/pull/3736#discussion_r719056860
##
File path: website/docs/jfs_hoodie.md
##
@@ -0,0 +1,90 @@
+---
+title: JuiceFS keywords: [ hudi, hive, jfs, spark, flink]
+summary: On this page, we go over how to configure Hudi with JuiceFS.
+last_modified_at: 2021-09-30T10:42:24-10:00
+---
+On this page, we explain how to use Hudi with JuiceFS.
+
+## JuiceFS Preparing
+
+JuiceFS is a high-performance distributed file system. Any data stored into
JuiceFS, the data itself will be persisted in object storage (e.g. Amazon S3),
and the metadata corresponding to the data can be persisted in various database
engines such as Redis, MySQL, and TiKV according to the needs of the scene.
+
+There are three configurations required for Hudi-JuiceFS compatibility:
+
+- Creating JuiceFS
+- Adding JuiceFS configuration for Hudi
+- Adding required jar to `classpath`
+
+### Creating JuiceFS
+
+JuiceFS supports multiple engines such as Redis, MySQL, SQLite, and TiKV.
+
+This example uses Redis as Meta Engine and AWS S3 as Data Storage in Linux env.
+
+- Download
+```shell
+JFS_LATEST_TAG=$(curl -s
https://api.github.com/repos/juicedata/juicefs/releases/latest | grep
'tag_name' | cut -d '"' -f 4 | tr -d 'v')
+wget
"https://github.com/juicedata/juicefs/releases/download/v${JFS_LATEST_TAG}/juicefs-${JFS_LATEST_TAG}-linux-amd64.tar.gz";
+```
+
+- Install
+```shell
+mkdir juice && tar -zxvf "juicefs-${JFS_LATEST_TAG}-linux-amd64.tar.gz" -C
juice
+sudo install juice/juicefs /usr/local/bin
+```
+
+- Format a filesystem
+```shell
+juicefs format \
+--storage s3 \
+--bucket https:// \
+--access-key \
+--secret-key \
+redis://:@:6379/1 \
+myjfs
+```
+
+### JuiceFS configuration
+
+Add the required configurations in your core-site.xml from where Hudi can
fetch them.
+
+```xml
+
+fs.defaultFS
+jfs://myfs
+Optional, you can also specify full path
"jfs://myfs/path-to-dir" with location to use JuiceFS
+
+
+fs.jfs.impl
+io.juicefs.JuiceFileSystem
+
+
+fs.AbstractFileSystem.jfs.impl
+io.juicefs.JuiceFS
+
+
+juicefs.meta
+redis://:@:6379/1
Review comment:
a native question, here what's the meaning of `/1`?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[hudi] branch master updated (2f07e12 -> def08d7)
This is an automated email from the ASF dual-hosted git repository. leesf pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/hudi.git. from 2f07e12 [MINOR] Fix typo Hooodie corrected to Hoodie & reuqired corrected to required (#3730) add def08d7 [MINOR] Support JuiceFileSystem (#3729) No new revisions were added by this update. Summary of changes: hudi-common/src/main/java/org/apache/hudi/common/fs/StorageSchemes.java | 2 ++ .../src/test/java/org/apache/hudi/common/fs/TestStorageSchemes.java | 1 + 2 files changed, 3 insertions(+)
[GitHub] [hudi] leesf merged pull request #3729: Support JuiceFileSystem
leesf merged pull request #3729: URL: https://github.com/apache/hudi/pull/3729 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] mauropelucchi commented on issue #2564: Hoodie clean is not deleting old files
mauropelucchi commented on issue #2564: URL: https://github.com/apache/hudi/issues/2564#issuecomment-930774206 > @mauropelucchi : curious as to your table type choice. I see you are setting max delta commits to compact to 1. So, you might as well choose COW to easier operability. wondering if you are doing some POC or something, but intend to bump this number up later. Hi @nsivabalan, we changed the configuration 'hoodie.cleaner.commits.retained': 4 from 1 during our test. As @rswagatika mentioned: > UPDATE => Today morning when I ran the above query I could see the cleaning triggered and it did delete the files. So for production use I changed my config 'hoodie.cleaner.commits.retained': 4 from 1 and ran the test and it did work. Following your suggestion, I will open today a new issue about this behaviour -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Assigned] (HUDI-2482) Support drop partitions SQL
[ https://issues.apache.org/jira/browse/HUDI-2482?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Yann Byron reassigned HUDI-2482: Assignee: Yann Byron > Support drop partitions SQL > --- > > Key: HUDI-2482 > URL: https://issues.apache.org/jira/browse/HUDI-2482 > Project: Apache Hudi > Issue Type: Sub-task > Components: Spark Integration >Reporter: Yann Byron >Assignee: Yann Byron >Priority: Major > Labels: features, pull-request-available > Fix For: 0.10.0 > > -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Created] (HUDI-2503) HoodieFlinkWriteClient supports to allow parallel writing to tables using Locking service
Nicholas Jiang created HUDI-2503: Summary: HoodieFlinkWriteClient supports to allow parallel writing to tables using Locking service Key: HUDI-2503 URL: https://issues.apache.org/jira/browse/HUDI-2503 Project: Apache Hudi Issue Type: Improvement Components: Flink Integration Reporter: Nicholas Jiang The strategy interface for conflict resolution with multiple writers is introduced and the SparkRDDWriteClient has integrated with the ConflictResolutionStrategy. HoodieFlinkWriteClient should also support to allow parallel writing to tables using Locking service based on ConflictResolutionStrategy. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [hudi] tangyoupeng commented on pull request #3736: Add jfs support doc for hudi
tangyoupeng commented on pull request #3736: URL: https://github.com/apache/hudi/pull/3736#issuecomment-930715835 #3729 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] tangyoupeng commented on a change in pull request #3729: Support JuiceFileSystem
tangyoupeng commented on a change in pull request #3729:
URL: https://github.com/apache/hudi/pull/3729#discussion_r719021678
##
File path:
hudi-common/src/main/java/org/apache/hudi/common/fs/StorageSchemes.java
##
@@ -62,6 +62,8 @@
OBS("obs", false),
// Kingsoft Standard Storage ks3
KS3("ks3", false),
+ // JuiceFileSystem
+ JFS("jfs", true),
Review comment:
#3736
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] tangyoupeng opened a new pull request #3736: Add jfs support doc for hudi
tangyoupeng opened a new pull request #3736: URL: https://github.com/apache/hudi/pull/3736 ## *Tips* - *Thank you very much for contributing to Apache Hudi.* - *Please review https://hudi.apache.org/contribute/how-to-contribute before opening a pull request.* ## What is the purpose of the pull request *(For example: This pull request adds quick-start document.)* ## Brief change log *(for example:)* - *Modify AnnotationLocation checkstyle rule in checkstyle.xml* ## Verify this pull request *(Please pick either of the following options)* This pull request is a trivial rework / code cleanup without any test coverage. *(or)* This pull request is already covered by existing tests, such as *(please describe tests)*. (or) This change added tests and can be verified as follows: *(example:)* - *Added integration tests for end-to-end.* - *Added HoodieClientWriteTest to verify the change.* - *Manually verified the change by running a job locally.* ## Committer checklist - [ ] Has a corresponding JIRA in PR title & commit - [ ] Commit message is descriptive of the change - [ ] CI is green - [ ] Necessary doc changes done or have another open PR - [ ] For large changes, please consider breaking it into sub-tasks under an umbrella JIRA. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] peanut-chenzhong commented on issue #3735: [SUPPORT] OverwriteNonDefaultsWithLatestAvroPayload doesn`t work when upsert data with some null value column
peanut-chenzhong commented on issue #3735: URL: https://github.com/apache/hudi/issues/3735#issuecomment-930703026 @n3nash could you kindly help check this is an issue? If yes I can rise an PR to solve it soom. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] peanut-chenzhong opened a new issue #3735: [SUPPORT] OverwriteNonDefaultsWithLatestAvroPayload doesn`t work when upsert data with some null value column
peanut-chenzhong opened a new issue #3735:
URL: https://github.com/apache/hudi/issues/3735
For my understanding, if we using OverwriteNonDefaultsWithLatestAvroPayload,
Hudi will update column by comlun. If the upsert data has some column which is
null, Hudi will ignore these columns and only update the other columns. But the
behavior now seems not correct.
Steps to reproduce the behavior:
1.use spark-sql to init test data
create table test_payload (par1 int,par2 int,key int,col0 string,col1
double,col2 date,col3 timestamp);
insert into test_payload select
1,20,100,'bb',220.22,'2011-02-10','2011-01-10 01:11:20';
insert into test_payload select 1,10,100,'cc',null,null,'2011-01-10
01:11:00';
2.insert the first line data to Hudi using
OverwriteNonDefaultsWithLatestAvroPayload
val base_data = sql("select * from test_payload where col0='aa' or col0='bb'
;")
base_data.write.format("hudi").
option("hoodie.datasource.write.table.type", COW_TABLE_TYPE_OPT_VAL).
option("hoodie.datasource.write.precombine.field", "col3").
option("hoodie.datasource.write.recordkey.field", "key").
option("hoodie.datasource.write.partitionpath.field", "").
option("hoodie.datasource.write.keygenerator.class",
"org.apache.hudi.keygen.NonpartitionedKeyGenerator").
option("hoodie.datasource.write.operation", "upsert").
option("hoodie.datasource.write.payload.class",
"org.apache.hudi.common.model.OverwriteNonDefaultsWithLatestAvroPayload").
option("hoodie.upsert.shuffle.parallelism", 4).
option("hoodie.datasource.write.hive_style_partitioning", "true").
option("hoodie.table.name",
"tb_test_payload").mode(Overwrite).save(s"/tmp/huditest/tb_test_payload")
3.upsert the second line data to Hudi using
OverwriteNonDefaultsWithLatestAvroPayload
upsert_data.write.format("hudi").
option("hoodie.datasource.write.table.type", COW_TABLE_TYPE_OPT_VAL).
option("hoodie.datasource.write.precombine.field", "col3").
option("hoodie.datasource.write.recordkey.field", "key").
option("hoodie.datasource.write.partitionpath.field", "").
option("hoodie.datasource.write.keygenerator.class",
"org.apache.hudi.keygen.NonpartitionedKeyGenerator").
option("hoodie.datasource.write.payload.class",
"org.apache.hudi.common.model.OverwriteNonDefaultsWithLatestAvroPayload").
option("hoodie.datasource.write.operation", "upsert").
option("hoodie.upsert.shuffle.parallelism", 4).
option("hoodie.datasource.write.hive_style_partitioning", "true").
option("hoodie.table.name",
"tb_test_payload").mode(Append).save(s"/tmp/huditest/tb_test_payload")
4.query table
spark.read.format("org.apache.hudi").load("/tmp/huditest/tb_test_payload/*").createOrReplaceTempView("hudi_ro_table")
spark.sql("select * from hudi_ro_table").show(30,false)
+---++--+--+---+++---++++---+
|_hoodie_commit_time|_hoodie_commit_seqno|_hoodie_record_key|_hoodie_partition_path|_hoodie_file_name
|par1|par2|key|col0|col1|col2|col3 |
+---++--+--+---+++---++++---+
|20210930083222 |20210930083222_0_6 |100 |
|191bf655-bc6c-4944-b7bb-1f00304c033e-0_0-190-316_20210930083222.parquet|1
|10 |100|cc |null|null|2011-01-10 01:11:00|
+---++--+--+---+++---++++---+
You can see the hole row has been update even col1 and col2 is null.
**Expected behavior**
expected behavior is the col1 and col2 shouldn`t been updated.
A clear and concise description of what you expected to happen.
**Environment Description**
* Hudi version :0.9
* Spark version :3.1.1
* Hive version :3.1
* Hadoop version :3.1.1
* Storage (HDFS/S3/GCS..) :hdfs
* Running on Docker? (yes/no) :no
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] hudi-bot edited a comment on pull request #3668: [RFC-33] [HUDI-2429][WIP] Full schema evolution
hudi-bot edited a comment on pull request #3668: URL: https://github.com/apache/hudi/pull/3668#issuecomment-919855741 ## CI report: * a423a63a9a530365b531a4199a5010dd52708d86 Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=2461) Azure: [SUCCESS](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=2466) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run travis` re-run the last Travis build - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[hudi] branch master updated (dd1bd62 -> 2f07e12)
This is an automated email from the ASF dual-hosted git repository. vinoyang pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/hudi.git. from dd1bd62 [HUDI-2277] HoodieDeltaStreamer reading ORC files directly using ORCDFSSource (#3413) add 2f07e12 [MINOR] Fix typo Hooodie corrected to Hoodie & reuqired corrected to required (#3730) No new revisions were added by this update. Summary of changes: .../src/main/java/org/apache/hudi/internal/DefaultSource.java | 2 +- .../src/main/java/org/apache/hudi/spark3/internal/DefaultSource.java| 2 +- 2 files changed, 2 insertions(+), 2 deletions(-)
[GitHub] [hudi] yanghua merged pull request #3730: [MINOR] Fix typo Hooodie corrected to Hoodie & reuqired corrected to required
yanghua merged pull request #3730: URL: https://github.com/apache/hudi/pull/3730 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot edited a comment on pull request #3734: [HUDI-2497] Refactor clean and restore actions in hudi-client module
hudi-bot edited a comment on pull request #3734: URL: https://github.com/apache/hudi/pull/3734#issuecomment-930618920 ## CI report: * 3cec644131a4fda77510a97d548d3633b4731e78 Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=2464) Azure: [SUCCESS](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=2465) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run travis` re-run the last Travis build - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot edited a comment on pull request #3668: [RFC-33] [HUDI-2429][WIP] Full schema evolution
hudi-bot edited a comment on pull request #3668: URL: https://github.com/apache/hudi/pull/3668#issuecomment-919855741 ## CI report: * a423a63a9a530365b531a4199a5010dd52708d86 Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=2461) Azure: [PENDING](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=2466) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run travis` re-run the last Travis build - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] xiarixiaoyao commented on pull request #3668: [RFC-33] [HUDI-2429][WIP] Full schema evolution
xiarixiaoyao commented on pull request #3668: URL: https://github.com/apache/hudi/pull/3668#issuecomment-930677502 @hudi-bot run azure -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot edited a comment on pull request #3734: [HUDI-2497] Refactor clean and restore actions in hudi-client module
hudi-bot edited a comment on pull request #3734: URL: https://github.com/apache/hudi/pull/3734#issuecomment-930618920 ## CI report: * 3cec644131a4fda77510a97d548d3633b4731e78 Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=2464) Azure: [PENDING](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=2465) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run travis` re-run the last Travis build - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] yihua commented on pull request #3734: [HUDI-2497] Refactor clean and restore actions in hudi-client module
yihua commented on pull request #3734: URL: https://github.com/apache/hudi/pull/3734#issuecomment-930657396 @hudi-bot run azure -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot edited a comment on pull request #3734: [HUDI-2497] Refactor clean and restore actions in hudi-client module
hudi-bot edited a comment on pull request #3734: URL: https://github.com/apache/hudi/pull/3734#issuecomment-930618920 ## CI report: * 3cec644131a4fda77510a97d548d3633b4731e78 Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=2464) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run travis` re-run the last Travis build - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] nsivabalan commented on a change in pull request #3727: [HUDI-2497] Refactor clean, restore, and compaction actions in hudi-client module
nsivabalan commented on a change in pull request #3727:
URL: https://github.com/apache/hudi/pull/3727#discussion_r718849052
##
File path:
hudi-client/hudi-client-common/src/main/java/org/apache/hudi/table/action/compact/CompactHelpers.java
##
@@ -0,0 +1,178 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.table.action.compact;
+
+import org.apache.hudi.avro.model.HoodieCompactionPlan;
+import org.apache.hudi.client.AbstractHoodieWriteClient;
+import org.apache.hudi.client.WriteStatus;
+import org.apache.hudi.common.data.HoodieData;
+import org.apache.hudi.common.engine.HoodieEngineContext;
+import org.apache.hudi.common.engine.TaskContextSupplier;
+import org.apache.hudi.common.model.CompactionOperation;
+import org.apache.hudi.common.model.HoodieCommitMetadata;
+import org.apache.hudi.common.model.HoodieRecordPayload;
+import org.apache.hudi.common.model.HoodieWriteStat;
+import org.apache.hudi.common.table.HoodieTableMetaClient;
+import org.apache.hudi.common.table.TableSchemaResolver;
+import org.apache.hudi.common.table.timeline.HoodieActiveTimeline;
+import org.apache.hudi.common.table.timeline.HoodieInstant;
+import org.apache.hudi.common.table.timeline.HoodieTimeline;
+import org.apache.hudi.common.table.timeline.TimelineMetadataUtils;
+import org.apache.hudi.common.util.CompactionUtils;
+import org.apache.hudi.common.util.Option;
+import org.apache.hudi.config.HoodieWriteConfig;
+import org.apache.hudi.exception.HoodieCompactionException;
+import org.apache.hudi.table.HoodieCopyOnWriteTableOperation;
+import org.apache.hudi.table.HoodieTable;
+import org.apache.hudi.table.action.HoodieWriteMetadata;
+
+import org.apache.avro.Schema;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+import java.io.IOException;
+import java.nio.charset.StandardCharsets;
+import java.util.List;
+
+import static java.util.stream.Collectors.toList;
+
+/**
+ * Base class helps to perform compact.
+ *
+ * @param Type of payload in {@link
org.apache.hudi.common.model.HoodieRecord}
+ */
+public class CompactHelpers {
+
+ private static final Logger LOG =
LoggerFactory.getLogger(CompactHelpers.class);
+
+ private CompactHelpers() {
+ }
+
+ private static class CompactHelperHolder {
+private static final CompactHelpers COMPACT_HELPERS = new CompactHelpers();
+ }
+
+ public static CompactHelpers newInstance() {
+return CompactHelperHolder.COMPACT_HELPERS;
+ }
+
+ public HoodieWriteMetadata> compact(
+ HoodieEngineContext context, HoodieTable table,
+ HoodieCopyOnWriteTableOperation copyOnWriteTableOperation,
HoodieWriteConfig config,
+ String compactionInstantTime, AbstractHoodieWriteClient writeClient,
+ TaskContextSupplier taskContextSupplier) {
+HoodieTimeline pendingCompactionTimeline =
table.getActiveTimeline().filterPendingCompactionTimeline();
+HoodieInstant inflightInstant =
HoodieTimeline.getCompactionInflightInstant(compactionInstantTime);
+if (pendingCompactionTimeline.containsInstant(inflightInstant)) {
+ writeClient.rollbackInflightCompaction(inflightInstant, table);
+ table.getMetaClient().reloadActiveTimeline();
+}
+
+HoodieWriteMetadata> compactionMetadata = new
HoodieWriteMetadata<>();
+compactionMetadata.setWriteStatuses(context.createEmptyHoodieData());
+try {
+ // generate compaction plan
+ // should support configurable commit metadata
+ HoodieCompactionPlan compactionPlan = CompactionUtils.getCompactionPlan(
+ table.getMetaClient(), compactionInstantTime);
+
+ if (compactionPlan == null || (compactionPlan.getOperations() == null)
+ || (compactionPlan.getOperations().isEmpty())) {
+// do nothing.
+LOG.info("No compaction plan for instant " + compactionInstantTime);
+return compactionMetadata;
+ }
+
+ HoodieInstant instant =
HoodieTimeline.getCompactionRequestedInstant(compactionInstantTime);
+ // Mark instant as compaction inflight
+
table.getActiveTimeline().transitionCompactionRequestedToInflight(instant);
+ table.getMetaClient().reloadActiveTimeline();
+
+ HoodieTableMetaClient metaClient = table.getMetaClien
[GitHub] [hudi] yanghua commented on pull request #3671: [HUDI-2418] add HiveSchemaProvider
yanghua commented on pull request #3671: URL: https://github.com/apache/hudi/pull/3671#issuecomment-929787041 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot edited a comment on pull request #3729: Support JuiceFileSystem
hudi-bot edited a comment on pull request #3729: URL: https://github.com/apache/hudi/pull/3729#issuecomment-929788240 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #3729: Support JuiceFileSystem
hudi-bot commented on pull request #3729: URL: https://github.com/apache/hudi/pull/3729#issuecomment-929788240 ## CI report: * c66e724bfa44a5147c8965bb585d07ac3b36 UNKNOWN Bot commands @hudi-bot supports the following commands: - `@hudi-bot run travis` re-run the last Travis build - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] xushiyan merged pull request #3413: [HUDI-2277] HoodieDeltaStreamer reading ORC files directly using ORCDFSSource
xushiyan merged pull request #3413: URL: https://github.com/apache/hudi/pull/3413 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] codope commented on issue #3242: Hive sync error by using run_sync_tool.sh JDODataStoreException: Error executing SQL query "select "DB_ID" from "DBS""
codope commented on issue #3242: URL: https://github.com/apache/hudi/issues/3242#issuecomment-930129481 > @moranyuwen can you solve this problem? I have this problem, but I can not solve it. I don't know how set mysql database instead derby, in Hudi config in spark code. @niloo-sh Ensure that the following configs are set properly in hive-site.xml ``` "javax.jdo.option.ConnectionURL": "jdbc:mysql://hostname:3306/hive?createDatabaseIfNotExist=true", "javax.jdo.option.ConnectionDriverName": "org.mariadb.jdbc.Driver", "javax.jdo.option.ConnectionUserName": "username", "javax.jdo.option.ConnectionPassword": "password" ``` Then, you need to specify the following Hudi configs to run hive sync: ``` "hoodie.datasource.meta.sync.enable": "true", "hoodie.datasource.hive_sync.use_jdbc": "true", "hoodie.datasource.hive_sync.jdbcurl": "jdbc:mysql://hostname:3306/hive?createDatabaseIfNotExist=true", "hoodie.datasource.hive_sync.username": "username", "hoodie.datasource.hive_sync.password": "password", "hoodie.datasource.hive_sync.table": "my_hudi_table_name" ``` -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] xiarixiaoyao commented on pull request #3668: [RFC-33] [HUDI-2429][WIP] Full schema evolution
xiarixiaoyao commented on pull request #3668:
URL: https://github.com/apache/hudi/pull/3668#issuecomment-930001505
@bvaradar @codope @leesf . could you pls help me review this pr again,
thanks
code changes
1) support mor(incremental/realtime/optimize) read/write
2) support cow (incremental/realtime) read/write
3) support spark3 DDL. include:
alter statement:
* ALTER TABLE table1 ALTER COLUMN a.b.c TYPE bigint
* ALTER TABLE table1 ALTER COLUMN a.b.c SET NOT NULL
* ALTER TABLE table1 ALTER COLUMN a.b.c DROP NOT NULL
* ALTER TABLE table1 ALTER COLUMN a.b.c COMMENT 'new comment'
* ALTER TABLE table1 ALTER COLUMN a.b.c FIRST
* ALTER TABLE table1 ALTER COLUMN a.b.c AFTER x
add statement:
* ALTER TABLE table1 ADD COLUMNS (col_name data_type [COMMENT
col_comment], ...);
rename:
* ALTER TABLE table1 RENAME COLUMN a.b.c TO x
drop:
* ALTER TABLE table1 DROP COLUMN a.b.c
* ALTER TABLE table1 DROP COLUMNS a.b.c, x, y
set/unset Properties:
* ALTER TABLE table SET TBLPROPERTIES ('table_property' =
'property_value');
* ALTER TABLE table UNSET TBLPROPERTIES [IF EXISTS] ('comment', 'key');
4) support spark2 DDL.
5) add FileBaseInternalSchemasManager to manger history schemas, and save
historySchemas in "./hoodie/.schema" . now we no need to save historySchemas
into commit file.
6) add segment lock to TableInternalSchemaUtils to support concurrent read
and write cache.
7) rename mergeSchemaAction to SchemaMerger; remove helper methods from
TableChanges to a helper class, now TableChanges is ok; use visitor mode to
produce nameToId for internalSchema; and other samll fixed.
Remaining problem: add more UT for this pr, add support for bootstrap table.
@bvaradar forgive me this change is too large, i still use squahsing.
Subsequent modifications will be in the form of add commit.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] stym06 commented on issue #2688: [SUPPORT] Sync to Hive using Metastore
stym06 commented on issue #2688: URL: https://github.com/apache/hudi/issues/2688#issuecomment-929828308 hi, i made it to work with Hive 3.1.2 after importing some jars into the classpath after finding out the classes not found (majorly calcite, datanucleus) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] xushiyan closed issue #3641: [SUPPORT] Retrieving latest completed commit timestamp via HoodieTableMetaClient in PySpark
xushiyan closed issue #3641: URL: https://github.com/apache/hudi/issues/3641 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] davehagman commented on issue #3733: [SUPPORT] Periodic and sustained latency spikes during index lookup
davehagman commented on issue #3733: URL: https://github.com/apache/hudi/issues/3733#issuecomment-930488974 I would also like to show some graphs comparing the baseline and what they look like during these latency spikes. This is a graph of the number of files Created vs. Updated per batch (`commit.totalFilesInsert` and `commit.totalFilesUpdate` respectively). The number of updated files explodes: 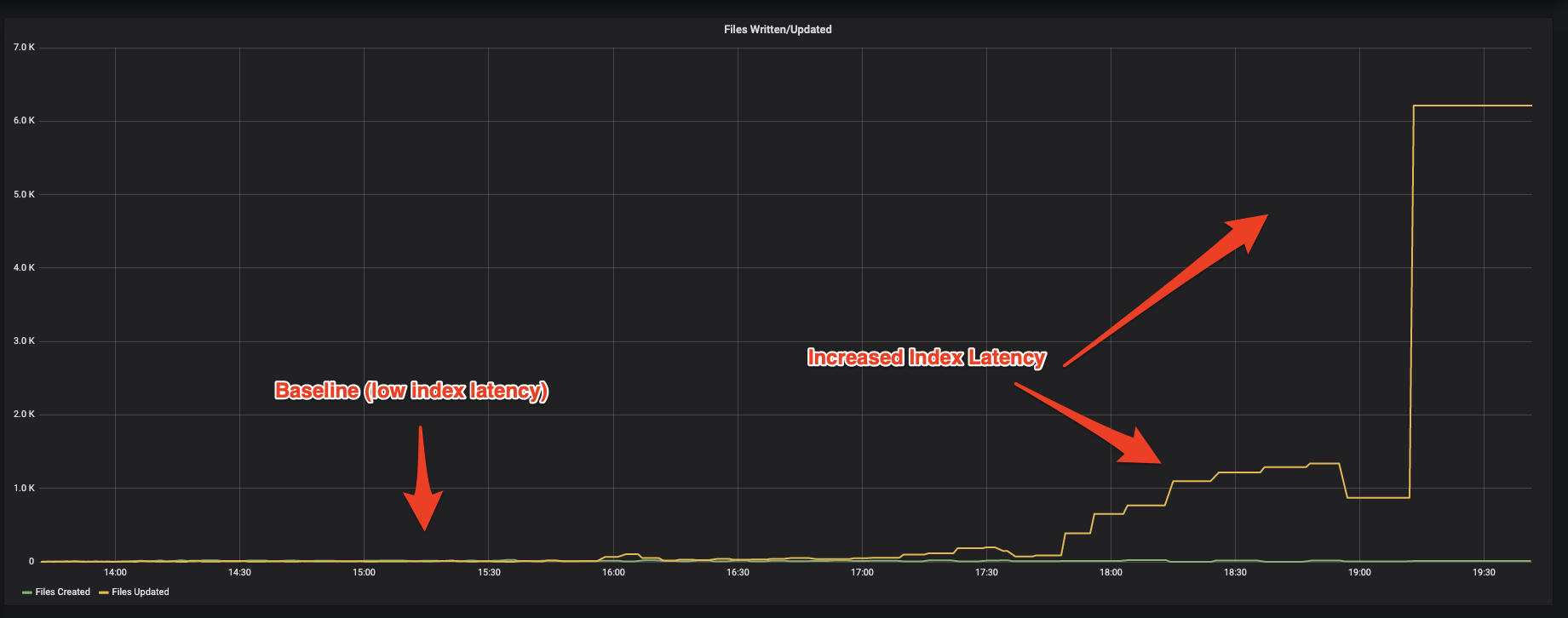 The next graph shows that the number of bytes being written is magnitudes higher than baseline, according to Hudi metrics (`commit.totalBytesWritten`): 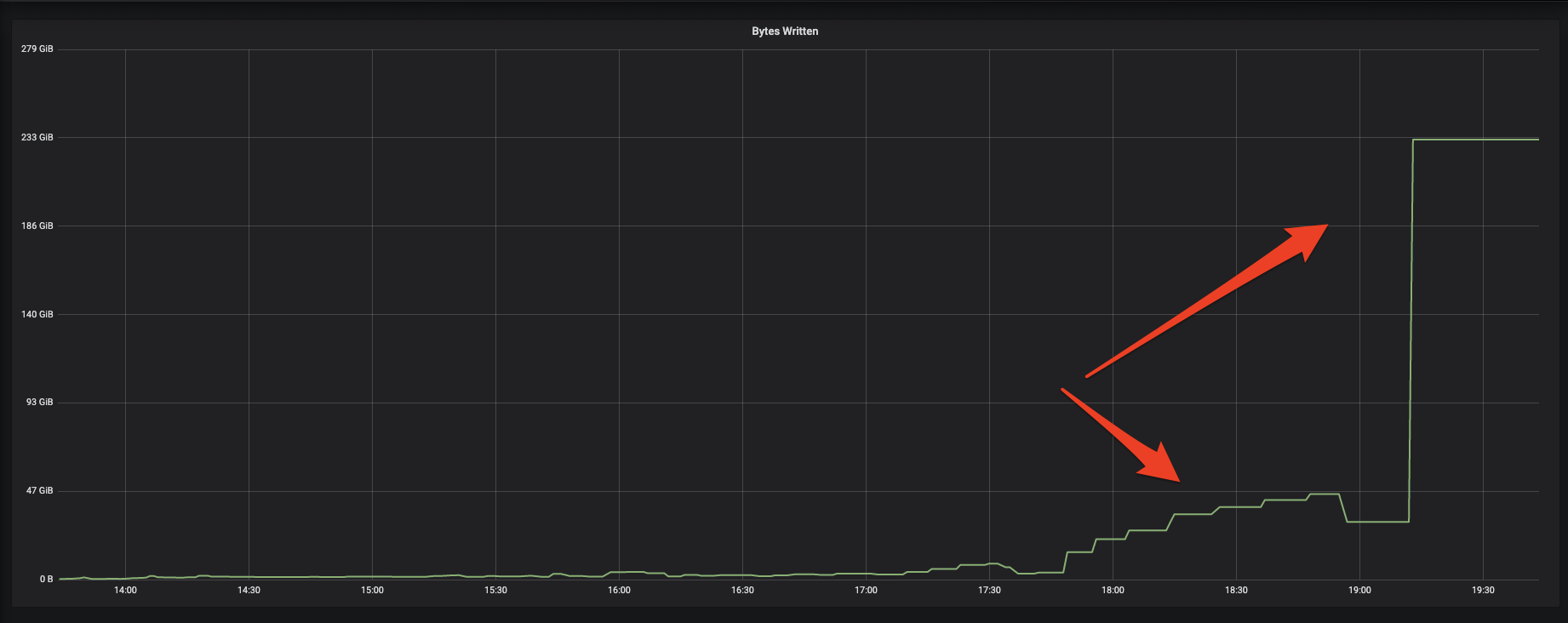 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] xushiyan commented on issue #3641: [SUPPORT] Retrieving latest completed commit timestamp via HoodieTableMetaClient in PySpark
xushiyan commented on issue #3641:
URL: https://github.com/apache/hudi/issues/3641#issuecomment-929916500
Ok @bryanburke i think your approach is valid. metaclient APIs should be
quite stable and even if in case of change, there should be a deprecation
period to allow transition. You may also consider this example to get the
latest commit
https://hudi.apache.org/docs/quick-start-guide#incremental-query
```python
commits = list(map(lambda row: row[0], spark.sql("select
distinct(_hoodie_commit_time) as commitTime from hudi_trips_snapshot order by
commitTime").limit(50).collect()))
```
As for more python API support, we don't have this ranked up high in the
roadmap. If you're keen, please feel free to drive this feature. You could
start by sending a [DISCUSS] email in the dev email list to gather more inputs.
Thanks for illustrating your ideas. Closing this now. Feel free to follow up
here or through email list.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] nsivabalan commented on issue #2564: Hoodie clean is not deleting old files
nsivabalan commented on issue #2564: URL: https://github.com/apache/hudi/issues/2564#issuecomment-930088089 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] xushiyan commented on a change in pull request #3413: [HUDI-2277] HoodieDeltaStreamer reading ORC files directly using ORCDFSSource
xushiyan commented on a change in pull request #3413: URL: https://github.com/apache/hudi/pull/3413#discussion_r718245885 ## File path: hudi-common/src/test/java/org/apache/hudi/common/testutils/HoodieTestDataGenerator.java ## @@ -129,10 +129,12 @@ public static final Schema AVRO_SCHEMA = new Schema.Parser().parse(TRIP_EXAMPLE_SCHEMA); + public static final Schema ORC_SCHEMA = new Schema.Parser().parse(TRIP_EXAMPLE_SCHEMA); Review comment: ditto ```suggestion public static final TypeDescription ORC_SCHEMA = AvroOrcUtils.createOrcSchema(new Schema.Parser().parse(TRIP_EXAMPLE_SCHEMA)); ``` ## File path: hudi-common/src/test/java/org/apache/hudi/common/testutils/HoodieTestDataGenerator.java ## @@ -129,10 +129,12 @@ public static final Schema AVRO_SCHEMA = new Schema.Parser().parse(TRIP_EXAMPLE_SCHEMA); + public static final Schema ORC_SCHEMA = new Schema.Parser().parse(TRIP_EXAMPLE_SCHEMA); public static final Schema AVRO_SCHEMA_WITH_METADATA_FIELDS = HoodieAvroUtils.addMetadataFields(AVRO_SCHEMA); public static final Schema AVRO_SHORT_TRIP_SCHEMA = new Schema.Parser().parse(SHORT_TRIP_SCHEMA); public static final Schema AVRO_TRIP_SCHEMA = new Schema.Parser().parse(TRIP_SCHEMA); + public static final Schema ORC_TRIP_SCHEMA = new Schema.Parser().parse(TRIP_SCHEMA); Review comment: @zhangyue19921010 I think I wasn't clear about the suggestion. What i meant is, here in HoodieTestDataGenerator, ```suggestion public static final TypeDescription ORC_TRIP_SCHEMA = AvroOrcUtils.createOrcSchema(new Schema.Parser().parse(TRIP_SCHEMA)); ``` This constant is named as `ORC_XXX_SCHEMA` but its type still an avro schema, causing confusion. That's why i suggest do conversion here, and make the constant less confusing and easier to use. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] xiarixiaoyao commented on pull request #3203: [HUDI-2086] Redo the logical of mor_incremental_view for hive
xiarixiaoyao commented on pull request #3203: URL: https://github.com/apache/hudi/pull/3203#issuecomment-929873306 @danny0405 @leesf thanks for your review, i will update the code。 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] nsivabalan edited a comment on issue #3499: [SUPPORT] Inline Clustering fails with Hudi
nsivabalan edited a comment on issue #3499: URL: https://github.com/apache/hudi/issues/3499#issuecomment-930269121 @codejoyan : whats the key generator you are using? Can you confirm you are setting those params (key gen, record key, partition path) while setting these clustering configs as well. because, from stack trace this is what I see. Since you don't set any value for "hoodie.clustering.plan.strategy.sort.columns", we resot to using built in BulkInsertSort mode. by default we do global sorting here depending on (partition path, record key) pair. We can try out one thing here. We can try to set no sorting mode and see what happens. "hoodie.bulkinsert.sort.mode" = "NONE" Alternatively, can you give it a shot by setting "hoodie.clustering.plan.strategy.sort.columns" to record key field may be. We can also see how that pans out. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #3732: [HUDI-2499] Make jdbc-url, user and pass as non-required for other sync-modes
hudi-bot commented on pull request #3732: URL: https://github.com/apache/hudi/pull/3732#issuecomment-930199853 ## CI report: * 546b457005237b5f7c2c51b9e1aef4b121110dc1 UNKNOWN Bot commands @hudi-bot supports the following commands: - `@hudi-bot run travis` re-run the last Travis build - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot edited a comment on pull request #3668: [RFC-33] [HUDI-2429][WIP] Full schema evolution
hudi-bot edited a comment on pull request #3668: URL: https://github.com/apache/hudi/pull/3668#issuecomment-919855741 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #3730: [MINOR] Fix typo,'Hooodie' corrected to 'Hoodie' & 'reuqired' corrected to 'required'
hudi-bot commented on pull request #3730: URL: https://github.com/apache/hudi/pull/3730#issuecomment-929947925 ## CI report: * f7f969d842ed6181f8c4cf1094ed9fff383d7d60 UNKNOWN Bot commands @hudi-bot supports the following commands: - `@hudi-bot run travis` re-run the last Travis build - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] codope edited a comment on issue #3713: [SUPPORT] Cannot read from Hudi table created by same Spark job
codope edited a comment on issue #3713: URL: https://github.com/apache/hudi/issues/3713#issuecomment-930112068 > The end-goal is to have a docker image which can be used to run tests locally on a dev machine. For this I would suggest to give our readymade [docker setup](https://hudi.apache.org/docs/docker_demo/) a try. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] zhangyue19921010 commented on pull request #3413: [HUDI-2277] HoodieDeltaStreamer reading ORC files directly using ORCDFSSource
zhangyue19921010 commented on pull request #3413: URL: https://github.com/apache/hudi/pull/3413#issuecomment-929987870 Hi @xushiyan Thanks a lot for your attention and review. My bad for misunderstanding :) code changed and waiting for ci/cd green. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] tangyoupeng commented on a change in pull request #3729: Support JuiceFileSystem
tangyoupeng commented on a change in pull request #3729:
URL: https://github.com/apache/hudi/pull/3729#discussion_r718202955
##
File path:
hudi-common/src/main/java/org/apache/hudi/common/fs/StorageSchemes.java
##
@@ -62,6 +62,8 @@
OBS("obs", false),
// Kingsoft Standard Storage ks3
KS3("ks3", false),
+ // JuiceFileSystem
+ JFS("jfs", true),
Review comment:
ok, i will do it
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] codope commented on issue #3607: [SUPPORT]Presto query hudi data with metadata table enable un-successfully.
codope commented on issue #3607: URL: https://github.com/apache/hudi/issues/3607#issuecomment-930110816 @zhangyue19921010 You're right. I think you're talking about #3623 Just left a small comment there. If that works let's merge it. I can also help in testing the dependency changes. FYI, there is an [open PR](https://github.com/prestodb/presto/pull/15866) for Presto to integrate with Hudi's metadata listing. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] codope commented on a change in pull request #3623: [WIP][HUDI-2409] Using HBase shaded jars in Hudi presto bundle
codope commented on a change in pull request #3623:
URL: https://github.com/apache/hudi/pull/3623#discussion_r718434282
##
File path: packaging/hudi-presto-bundle/pom.xml
##
@@ -158,11 +158,66 @@
org.apache.hudi
hudi-common
${project.version}
+
+
+ org.apache.hbase
+ hbase-server
+
+
+ org.apache.hbase
+ hbase-client
+
+
+
org.apache.hudi
hudi-hadoop-mr-bundle
${project.version}
+
+
+ org.apache.hbase
+ hbase-server
+
+
+ org.apache.hbase
+ hbase-client
+
+
+
+
+
+
+ org.apache.hbase
+ hbase-shaded-client
+ ${hbase.version}
+ test
+
+
+
+ org.apache.hbase
+ hbase-shaded-server
Review comment:
+1
@zhangyue19921010 If we add to hudi-common then it should be sufficient.
hudi-common is a dependency in hudi-presto-bundle. It also makes sense from the
perpective of integrating with Presto. That way we will only need to add
hudi-common dependency in presto-hive module (which should be lighter than
adding hudi-presto-bundle).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] nsivabalan commented on issue #3297: HoodieMetadataException throwed when execute merge and hoodie.metadata.enable='true'
nsivabalan commented on issue #3297: URL: https://github.com/apache/hudi/issues/3297#issuecomment-930255663 @zxding : can you respond to Sagar's question above. I am going to try reproducing this issue. would appreciate if you can give more specifics. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] yihua commented on pull request #3727: [HUDI-2497] Refactor clean, restore, and compaction actions in hudi-client module
yihua commented on pull request #3727: URL: https://github.com/apache/hudi/pull/3727#issuecomment-930614238 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] zhangyue19921010 commented on a change in pull request #3719: [HUDI-2489]Tuning HoodieROTablePathFilter by caching hoodieTableFileSystemView, aiming to reduce unnecessary list/get requ
zhangyue19921010 commented on a change in pull request #3719:
URL: https://github.com/apache/hudi/pull/3719#discussion_r718205032
##
File path:
hudi-hadoop-mr/src/main/java/org/apache/hudi/hadoop/HoodieROTablePathFilter.java
##
@@ -175,8 +181,12 @@ public boolean accept(Path path) {
metaClientCache.put(baseDir.toString(), metaClient);
}
- fsView =
FileSystemViewManager.createInMemoryFileSystemView(engineContext,
- metaClient,
HoodieInputFormatUtils.buildMetadataConfig(getConf()));
+ fsView = hoodieTableFileSystemViewCache.get(baseDir.toString());
Review comment:
Thanks for your review.
As we can see HoodieROTablePathFilter already **create and cache**
`HoodieTableMetaClient` at baseDir level, also
`setLoadActiveTimelineOnLoad(true)` which will create an active timeline in
singleton mode.
So that IMO no matter we cache the fsView or not, any new created files will
not appear in current hoodieROTablePathFilter.
Now we cached the fsView using above cached meta client and cached active
timeline. Maybe can have no bad effect but can reduce unnecessary init action.
##
File path:
hudi-hadoop-mr/src/main/java/org/apache/hudi/hadoop/HoodieROTablePathFilter.java
##
@@ -202,10 +212,6 @@ public boolean accept(Path path) {
}
nonHoodiePathCache.add(folder.toString());
return true;
-} finally {
- if (fsView != null) {
-fsView.close();
- }
Review comment:
`fsView.close()` will do
```
@Override
public void close() {
closed = true;
super.reset();
partitionToFileGroupsMap = null;
fgIdToPendingCompaction = null;
fgIdToBootstrapBaseFile = null;
fgIdToReplaceInstants = null;
}
because of we recycling fsView, we can't close it. Although we create fsView
for each baseDir. And will cause no memory leak maybe.
```
##
File path:
hudi-hadoop-mr/src/main/java/org/apache/hudi/hadoop/HoodieROTablePathFilter.java
##
@@ -202,10 +212,6 @@ public boolean accept(Path path) {
}
nonHoodiePathCache.add(folder.toString());
return true;
-} finally {
- if (fsView != null) {
-fsView.close();
- }
Review comment:
`fsView.close()` will do
```
@Override
public void close() {
closed = true;
super.reset();
partitionToFileGroupsMap = null;
fgIdToPendingCompaction = null;
fgIdToBootstrapBaseFile = null;
fgIdToReplaceInstants = null;
}
```
Because of we recycling fsView, we can't close it. Although we only create
one fsView for each baseDir. And will cause no memory leak maybe.
##
File path:
hudi-hadoop-mr/src/main/java/org/apache/hudi/hadoop/HoodieROTablePathFilter.java
##
@@ -175,8 +181,12 @@ public boolean accept(Path path) {
metaClientCache.put(baseDir.toString(), metaClient);
}
- fsView =
FileSystemViewManager.createInMemoryFileSystemView(engineContext,
- metaClient,
HoodieInputFormatUtils.buildMetadataConfig(getConf()));
+ fsView = hoodieTableFileSystemViewCache.get(baseDir.toString());
Review comment:
Feel free to correct me if I am wrong :)
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] hudi-bot edited a comment on pull request #3732: [HUDI-2499] Make jdbc-url, user and pass as non-required for other sync-modes
hudi-bot edited a comment on pull request #3732: URL: https://github.com/apache/hudi/pull/3732#issuecomment-930199853 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] xushiyan edited a comment on issue #3670: [SUPPORT] SQL stmt managed table, not update/delete with datasource API
xushiyan edited a comment on issue #3670: URL: https://github.com/apache/hudi/issues/3670#issuecomment-930335250 i can replicate the issue in local env, even by setting `ComplexKeyGenerator`, datasource delete not working, while delete via spark sql worked. Filing a JIRA to have detailed scripts https://issues.apache.org/jira/browse/HUDI-2500 Thanks @parisni for raising this. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #3734: [HUDI-2497] Refactor clean and restore actions in hudi-client module
hudi-bot commented on pull request #3734: URL: https://github.com/apache/hudi/pull/3734#issuecomment-930618920 ## CI report: * 3cec644131a4fda77510a97d548d3633b4731e78 UNKNOWN Bot commands @hudi-bot supports the following commands: - `@hudi-bot run travis` re-run the last Travis build - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] danny0405 commented on pull request #3203: [HUDI-2086] Redo the logical of mor_incremental_view for hive
danny0405 commented on pull request #3203: URL: https://github.com/apache/hudi/pull/3203#issuecomment-929775609 Changes the title and commit message to "[HUDI-2086] Redo the logic of mor incremental view for hive" -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] codope commented on issue #2544: [SUPPORT]failed to read timestamp column in version 0.7.0 even when HIVE_SUPPORT_TIMESTAMP is enabled
codope commented on issue #2544: URL: https://github.com/apache/hudi/issues/2544#issuecomment-930078959 This issue has been fixed and is no longer reproducible. Here's the gist with the latest master code: https://gist.github.com/codope/fea4455d84d37496e8f518afdc803795 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] leesf commented on a change in pull request #3719: [HUDI-2489]Tuning HoodieROTablePathFilter by caching hoodieTableFileSystemView, aiming to reduce unnecessary list/get requests
leesf commented on a change in pull request #3719:
URL: https://github.com/apache/hudi/pull/3719#discussion_r718137137
##
File path:
hudi-hadoop-mr/src/main/java/org/apache/hudi/hadoop/HoodieROTablePathFilter.java
##
@@ -175,8 +181,12 @@ public boolean accept(Path path) {
metaClientCache.put(baseDir.toString(), metaClient);
}
- fsView =
FileSystemViewManager.createInMemoryFileSystemView(engineContext,
- metaClient,
HoodieInputFormatUtils.buildMetadataConfig(getConf()));
+ fsView = hoodieTableFileSystemViewCache.get(baseDir.toString());
Review comment:
it is in flink incremental read code path. still a problem?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] hudi-bot edited a comment on pull request #3730: [MINOR] Fix typo,'Hooodie' corrected to 'Hoodie' & 'reuqired' corrected to 'required'
hudi-bot edited a comment on pull request #3730: URL: https://github.com/apache/hudi/pull/3730#issuecomment-929947925 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] xiarixiaoyao commented on pull request #3330: [HUDI-2101][RFC-28]support z-order for hudi
xiarixiaoyao commented on pull request #3330: URL: https://github.com/apache/hudi/pull/3330#issuecomment-930004681 kindly ping @vinothchandar . already rebase the code. could you help me review this code again, thanks. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] nsivabalan commented on issue #2992: [SUPPORT] Insert_Override Api not working as expected in Hudi 0.7.0
nsivabalan commented on issue #2992: URL: https://github.com/apache/hudi/issues/2992#issuecomment-930092640 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] ibuda commented on issue #3728: [SUPPORT] Hudi Flink S3 Java Example
ibuda commented on issue #3728:
URL: https://github.com/apache/hudi/issues/3728#issuecomment-929883637
Thank you @danny0405 for the link.
I am trying to set up an AWS Kinesis Application project, and as a start, I
used the code provided by you in the link.
Although I used the code below, Kinesis complains about the hudi connector,
error is supplied below. Is it because the Flink version conflict? Kinesis uses
Apache Flink 1.11, and a follow-up question is whether because of this version
conflict, I wont be able to use Hudi on AWS within Kinesis Application?
Kinesis Application Error log:
```
org.apache.flink.table.api.internal.TableEnvironmentImpl.executeOperation(TableEnvironmentImpl.java:787)
org.apache.flink.table.api.internal.TableEnvironmentImpl.executeSql(TableEnvironmentImpl.java:690)
com.amazonaws.services.kinesisanalytics.S3StreamingSinkJob.execInsertSql(S3StreamingSinkJob.java:63)
com.amazonaws.services.kinesisanalytics.S3StreamingSinkJob.main(S3StreamingSinkJob.java:59)
java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke0(Native
Method)
java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
java.base/jdk.internal.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
java.base/java.lang.reflect.Method.invoke(Method.java:566)
org.apache.flink.client.program.PackagedProgram.callMainMethod(PackagedProgram.java:294)
... 12 more\nCaused by: org.apache.flink.table.api.ValidationException:
Cannot discover a connector using option ''connector'='hudi''.
```
Here is the code I use (you will find below the pom.xml file as well):
```
static TableEnvironment streamTableEnv;
public static void main(String[] args) throws Exception {
EnvironmentSettings settings =
EnvironmentSettings.newInstance().build();
streamTableEnv = TableEnvironmentImpl.create(settings);
streamTableEnv.getConfig().getConfiguration()
.setInteger(ExecutionConfigOptions.TABLE_EXEC_RESOURCE_DEFAULT_PARALLELISM, 1);
streamTableEnv.getConfig().getConfiguration().setString("execution.checkpointing.interval",
"2s");
String hoodieTableDDL = "create table t1(\n"
+ " uuid varchar(20),\n"
+ " name varchar(10),\n"
+ " age int,\n"
+ " `partition` varchar(20),\n" // test streaming read with
partition field in the middle
+ " ts timestamp(3),\n"
+ " PRIMARY KEY(uuid) NOT ENFORCED\n"
+ ")\n"
+ "PARTITIONED BY (`partition`)\n"
+ "with (\n"
+ " 'connector' = 'hudi',\n"
+ " 'path' = 's3://bucket-name/hudi/sql-api/',\n"
+ " 'read.streaming.enabled' = 'true'\n"
+ ")";
streamTableEnv.executeSql(hoodieTableDDL);
String insertInto = "insert into t1 values\n"
+ "('id1','Danny',23,'par1',TIMESTAMP '1970-01-01
00:00:01'),\n"
+ "('id2','Stephen',33,'par1',TIMESTAMP '1970-01-01
00:00:02'),\n"
+ "('id3','Julian',53,'par2',TIMESTAMP '1970-01-01
00:00:03'),\n"
+ "('id4','Fabian',31,'par2',TIMESTAMP '1970-01-01
00:00:04'),\n"
+ "('id5','Sophia',18,'par3',TIMESTAMP '1970-01-01
00:00:05'),\n"
+ "('id6','Emma',20,'par3',TIMESTAMP '1970-01-01
00:00:06'),\n"
+ "('id7','Bob',44,'par4',TIMESTAMP '1970-01-01
00:00:07'),\n"
+ "('id8','Han',56,'par4',TIMESTAMP '1970-01-01 00:00:08')";
execInsertSql(streamTableEnv, insertInto);
}
static void execInsertSql(TableEnvironment tEnv, String insert) {
TableResult tableResult = tEnv.executeSql(insert);
// wait to finish
try {
tableResult.getJobClient().get().getJobExecutionResult().get();
} catch (InterruptedException | ExecutionException ex) {
throw new RuntimeException(ex);
}
}
```
Here is the pom I used to build the project with maven:
```
http://maven.apache.org/POM/4.0.0";
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance";
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0
http://maven.apache.org/xsd/maven-4.0.0.xsd";>
4.0.0
com.amazonaws
aws-kinesis-analytics-java-apps
1.0
jar
1.11
2.11
1.12.2
0.9.0
2.0.0
1.2.0
com.amazonaws
aws-java-sdk-bom
1.11.903
pom
import
[GitHub] [hudi] fengjian428 commented on pull request #3671: [HUDI-2418] add HiveSchemaProvider
fengjian428 commented on pull request #3671: URL: https://github.com/apache/hudi/pull/3671#issuecomment-929816532 > @fengjian428 Check CI again? what you mean? the checks below all passed -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] nsivabalan commented on issue #3499: [SUPPORT] Inline Clustering fails with Hudi
nsivabalan commented on issue #3499: URL: https://github.com/apache/hudi/issues/3499#issuecomment-930269121 @codejoyan : whats the key generator you are using? Can you confirm you are setting those params (key gen, record key, partition path) while setting these clustering configs as well. because, from stack trace this is what I see. Since you don't set any value for "hoodie.clustering.plan.strategy.sort.columns", we resot to using built in BulkInsertSort mode. by default we do global sorting here depending on (partition path, record key) pair. Alternatively, can you give it a shot by setting "hoodie.clustering.plan.strategy.sort.columns" to record key field may be. We can see how that pans out. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] xushiyan commented on issue #3670: [SUPPORT] SQL stmt managed table, not update/delete with datasource API
xushiyan commented on issue #3670: URL: https://github.com/apache/hudi/issues/3670#issuecomment-930335250 i can replicate the issue in local env, even by setting `ComplexKeyGenerator`, datasource delete not working, while delete via spark sql delete. Filing a JIRA to have detailed scripts https://issues.apache.org/jira/browse/HUDI-2500 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] parisni commented on issue #3731: [SUPPORT] Concurrent write (OCC) on distinct partitions random errors
parisni commented on issue #3731: URL: https://github.com/apache/hudi/issues/3731#issuecomment-930043315 tried to dig the source code, there is nothing about partition level lock. Apparently the lock mecanism is on the database+table level only. https://github.com/apache/hudi/blob/f52cb32f5f0c9e31b5addf29adbb886ca6d167dd/hudi-client/hudi-client-common/src/main/java/org/apache/hudi/client/transaction/TransactionManager.java#L52 https://github.com/apache/hudi/blob/f52cb32f5f0c9e31b5addf29adbb886ca6d167dd/hudi-client/hudi-client-common/src/main/java/org/apache/hudi/client/transaction/lock/LockManager.java https://github.com/apache/hudi/blob/f52cb32f5f0c9e31b5addf29adbb886ca6d167dd/hudi-sync/hudi-hive-sync/src/main/java/org/apache/hudi/hive/HiveMetastoreBasedLockProvider.java#L104 Also according to the hivemestastore implementation SHALL have a zookeeper. This is not mentionned in the documentation https://github.com/apache/hudi/blob/f52cb32f5f0c9e31b5addf29adbb886ca6d167dd/hudi-sync/hudi-hive-sync/src/main/java/org/apache/hudi/hive/HiveMetastoreBasedLockProvider.java#L68 > This feature is currently experimental and requires either Zookeeper or HiveMetastore to acquire locks. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] danny0405 commented on a change in pull request #3203: [HUDI-2086] Redo the logical of mor_incremental_view for hive
danny0405 commented on a change in pull request #3203:
URL: https://github.com/apache/hudi/pull/3203#discussion_r718116742
##
File path:
hudi-hadoop-mr/src/main/java/org/apache/hudi/hadoop/realtime/HoodieMergedLogReader.java
##
@@ -0,0 +1,145 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.hadoop.realtime;
+
+import java.io.IOException;
+import java.text.MessageFormat;
+import java.util.Iterator;
+
+import org.apache.avro.generic.GenericRecord;
+import org.apache.hadoop.io.ArrayWritable;
+import org.apache.hadoop.io.NullWritable;
+import org.apache.hadoop.io.Writable;
+import org.apache.hadoop.mapred.JobConf;
+import org.apache.hadoop.mapred.RecordReader;
+import org.apache.hudi.avro.HoodieAvroUtils;
+import org.apache.hudi.common.model.HoodieRecord;
+import org.apache.hudi.common.model.HoodieRecordPayload;
+import org.apache.hudi.common.table.log.HoodieMergedLogRecordScanner;
+import org.apache.hudi.common.util.Option;
+import org.apache.hudi.hadoop.utils.HoodieRealtimeRecordReaderUtils;
+import org.apache.log4j.LogManager;
+import org.apache.log4j.Logger;
+
+/**
+ * Record Reader implementation to read avro data, to support inc queries.
+ */
+public class HoodieMergedLogReader extends AbstractRealtimeRecordReader
+implements RecordReader {
+ private static final Logger LOG =
LogManager.getLogger(AbstractRealtimeRecordReader.class);
+ private final HoodieMergedLogRecordScanner logRecordScanner;
+ private final Iterator>
logRecordsKeyIterator;
+ private ArrayWritable valueObj;
+ private boolean supportTimeStamp = false;
+
+ private int end;
+ private int offset;
+
+ public HoodieMergedLogReader(RealtimeSplit split, JobConf job,
HoodieMergedLogRecordScanner logRecordScanner) {
+super(split, job);
+this.logRecordScanner = logRecordScanner;
+this.end = logRecordScanner.getRecords().size();
+this.logRecordsKeyIterator = logRecordScanner.iterator();
+this.valueObj = new ArrayWritable(Writable.class, new
Writable[getHiveSchema().getFields().size()]);
+ }
+
+ private Option buildGenericRecordwithCustomPayload(HoodieRecord record)
throws IOException {
+if (usesCustomPayload) {
+ return record.getData().getInsertValue(getWriterSchema());
+} else {
+ return record.getData().getInsertValue(getReaderSchema());
+}
+ }
+
+ @Override
+ public boolean next(NullWritable key, ArrayWritable arrayWritable) throws
IOException {
+if (!logRecordsKeyIterator.hasNext()) {
+ return false;
+}
+Option rec;
+HoodieRecord currentRecord = logRecordsKeyIterator.next();
+
+rec = buildGenericRecordwithCustomPayload(currentRecord);
+// try to skip delete record
+while (!rec.isPresent() && logRecordsKeyIterator.hasNext()) {
+ offset++;
+ rec = buildGenericRecordwithCustomPayload(logRecordsKeyIterator.next());
+}
+if (!rec.isPresent()) {
+ return false;
+}
+
+GenericRecord recordToReturn = rec.get();
+if (usesCustomPayload) {
+ // If using a custom payload, return only the projection fields. The
readerSchema is a schema derived from
+ // the writerSchema with only the projection fields
+ recordToReturn = HoodieAvroUtils.rewriteRecord(rec.get(),
getReaderSchema());
+}
+ArrayWritable curWritable = (ArrayWritable)
HoodieRealtimeRecordReaderUtils.avroToArrayWritable(recordToReturn,
getHiveSchema());
+
+if (arrayWritable != curWritable) {
+ final Writable[] arrValue = arrayWritable.get();
+ final Writable[] arrCurrent = curWritable.get();
+ if (arrayWritable != null && arrValue.length == arrCurrent.length) {
+System.arraycopy(arrCurrent, 0, arrValue, 0, arrCurrent.length);
Review comment:
`arrayWritable != null` should never reach because `arrayWritable.get()`
is invoked.
##
File path:
hudi-hadoop-mr/src/main/java/org/apache/hudi/hadoop/realtime/HoodieMergedLogReader.java
##
@@ -0,0 +1,145 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF lic
[GitHub] [hudi] leesf commented on a change in pull request #3729: Support JuiceFileSystem
leesf commented on a change in pull request #3729:
URL: https://github.com/apache/hudi/pull/3729#discussion_r718152109
##
File path:
hudi-common/src/main/java/org/apache/hudi/common/fs/StorageSchemes.java
##
@@ -62,6 +62,8 @@
OBS("obs", false),
// Kingsoft Standard Storage ks3
KS3("ks3", false),
+ // JuiceFileSystem
+ JFS("jfs", true),
Review comment:
can we also add some docs on how to use jfs like this
http://hudi.apache.org/docs/cloud in another PR(on asf-site branch rather than
master branch)
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] hudi-bot edited a comment on pull request #3413: [HUDI-2277] HoodieDeltaStreamer reading ORC files directly using ORCDFSSource
hudi-bot edited a comment on pull request #3413: URL: https://github.com/apache/hudi/pull/3413#issuecomment-893311636 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] sebastiantruj commented on issue #2688: [SUPPORT] Sync to Hive using Metastore
sebastiantruj commented on issue #2688: URL: https://github.com/apache/hudi/issues/2688#issuecomment-929891629 Hi @stym06, could you post a spark-submit/spark-shell example of your workaround? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] xiarixiaoyao commented on a change in pull request #3203: [HUDI-2086] Redo the logical of mor_incremental_view for hive
xiarixiaoyao commented on a change in pull request #3203:
URL: https://github.com/apache/hudi/pull/3203#discussion_r718189151
##
File path:
hudi-hadoop-mr/src/main/java/org/apache/hudi/hadoop/realtime/HoodieParquetRealtimeInputFormat.java
##
@@ -66,6 +90,138 @@
return HoodieRealtimeInputFormatUtils.getRealtimeSplits(job, fileSplits);
}
+ /**
+ * keep the logical of mor_incr_view as same as spark datasource.
+ * to do: unify the incremental view code between hive/spark-sql and spark
datasource
Review comment:
the logic has already be unified,now the logic of hive incremental and
spark incremental is same。 but to do unify the code has a little
difficult。 may be can do it in another pr。
##
File path:
hudi-hadoop-mr/src/main/java/org/apache/hudi/hadoop/realtime/HoodieMergedLogReader.java
##
@@ -0,0 +1,145 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.hadoop.realtime;
+
+import java.io.IOException;
+import java.text.MessageFormat;
+import java.util.Iterator;
+
+import org.apache.avro.generic.GenericRecord;
+import org.apache.hadoop.io.ArrayWritable;
+import org.apache.hadoop.io.NullWritable;
+import org.apache.hadoop.io.Writable;
+import org.apache.hadoop.mapred.JobConf;
+import org.apache.hadoop.mapred.RecordReader;
+import org.apache.hudi.avro.HoodieAvroUtils;
+import org.apache.hudi.common.model.HoodieRecord;
+import org.apache.hudi.common.model.HoodieRecordPayload;
+import org.apache.hudi.common.table.log.HoodieMergedLogRecordScanner;
+import org.apache.hudi.common.util.Option;
+import org.apache.hudi.hadoop.utils.HoodieRealtimeRecordReaderUtils;
+import org.apache.log4j.LogManager;
+import org.apache.log4j.Logger;
+
+/**
+ * Record Reader implementation to read avro data, to support inc queries.
+ */
+public class HoodieMergedLogReader extends AbstractRealtimeRecordReader
+implements RecordReader {
+ private static final Logger LOG =
LogManager.getLogger(AbstractRealtimeRecordReader.class);
+ private final HoodieMergedLogRecordScanner logRecordScanner;
+ private final Iterator>
logRecordsKeyIterator;
+ private ArrayWritable valueObj;
+ private boolean supportTimeStamp = false;
+
+ private int end;
+ private int offset;
+
+ public HoodieMergedLogReader(RealtimeSplit split, JobConf job,
HoodieMergedLogRecordScanner logRecordScanner) {
+super(split, job);
+this.logRecordScanner = logRecordScanner;
+this.end = logRecordScanner.getRecords().size();
+this.logRecordsKeyIterator = logRecordScanner.iterator();
+this.valueObj = new ArrayWritable(Writable.class, new
Writable[getHiveSchema().getFields().size()]);
+ }
+
+ private Option buildGenericRecordwithCustomPayload(HoodieRecord record)
throws IOException {
+if (usesCustomPayload) {
+ return record.getData().getInsertValue(getWriterSchema());
+} else {
+ return record.getData().getInsertValue(getReaderSchema());
+}
+ }
+
+ @Override
+ public boolean next(NullWritable key, ArrayWritable arrayWritable) throws
IOException {
+if (!logRecordsKeyIterator.hasNext()) {
+ return false;
+}
+Option rec;
+HoodieRecord currentRecord = logRecordsKeyIterator.next();
+
+rec = buildGenericRecordwithCustomPayload(currentRecord);
+// try to skip delete record
+while (!rec.isPresent() && logRecordsKeyIterator.hasNext()) {
+ offset++;
+ rec = buildGenericRecordwithCustomPayload(logRecordsKeyIterator.next());
+}
+if (!rec.isPresent()) {
+ return false;
+}
+
+GenericRecord recordToReturn = rec.get();
+if (usesCustomPayload) {
+ // If using a custom payload, return only the projection fields. The
readerSchema is a schema derived from
+ // the writerSchema with only the projection fields
+ recordToReturn = HoodieAvroUtils.rewriteRecord(rec.get(),
getReaderSchema());
+}
+ArrayWritable curWritable = (ArrayWritable)
HoodieRealtimeRecordReaderUtils.avroToArrayWritable(recordToReturn,
getHiveSchema());
+
+if (arrayWritable != curWritable) {
+ final Writable[] arrValue = arrayWritable.get();
+ final Writable[] arrCurrent = curWritable.get();
+ if (arra
[GitHub] [hudi] yihua closed pull request #3727: [HUDI-2497] Refactor clean, restore, and compaction actions in hudi-client module
yihua closed pull request #3727: URL: https://github.com/apache/hudi/pull/3727 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] danny0405 commented on a change in pull request #3637: [HUDI-2301] Support Flink async compaction scheduling
danny0405 commented on a change in pull request #3637:
URL: https://github.com/apache/hudi/pull/3637#discussion_r718091146
##
File path:
hudi-flink/src/main/java/org/apache/hudi/configuration/FlinkOptions.java
##
@@ -430,14 +430,14 @@ private FlinkOptions() {
public static final ConfigOption COMPACTION_SCHEDULE_ENABLED =
ConfigOptions
.key("compaction.schedule.enabled")
.booleanType()
- .defaultValue(true) // default true for MOR write
- .withDescription("Schedule the compaction plan, enabled by default for
MOR");
+ .defaultValue(false) // default false for MOR write
Review comment:
Fine with the change.
##
File path:
hudi-flink/src/main/java/org/apache/hudi/configuration/FlinkOptions.java
##
@@ -486,8 +486,8 @@ private FlinkOptions() {
public static final ConfigOption CLEAN_ASYNC_ENABLED = ConfigOptions
.key("clean.async.enabled")
.booleanType()
- .defaultValue(true)
- .withDescription("Whether to cleanup the old commits immediately on new
commits, enabled by default");
+ .defaultValue(false)
+ .withDescription("Whether to cleanup the old commits immediately on new
commits, disabled by default");
Review comment:
We should keep it true, the cleaning logic also works for COW table.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] zhangyue19921010 commented on issue #3607: [SUPPORT]Presto query hudi data with metadata table enable un-successfully.
zhangyue19921010 commented on issue #3607: URL: https://github.com/apache/hudi/issues/3607#issuecomment-930028288 Are you able to query normal Hudi data tables using Presto? => Yes, normal hudi table works. Are you getting the NoClassDefFoundError only when you query Hudi metadata table? => Yes Seems there is dependency conflicts between hudi metadata table(HBase) and presto, I am trying to fix it. Thanks for your attention :) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot edited a comment on pull request #3734: [HUDI-2497] Refactor clean and restore actions in hudi-client module
hudi-bot edited a comment on pull request #3734: URL: https://github.com/apache/hudi/pull/3734#issuecomment-930618920 ## CI report: * 3cec644131a4fda77510a97d548d3633b4731e78 Azure: [PENDING](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=2464) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run travis` re-run the last Travis build - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] codope commented on issue #3713: [SUPPORT] Cannot read from Hudi table created by same Spark job
codope commented on issue #3713: URL: https://github.com/apache/hudi/issues/3713#issuecomment-930112068 > The end-goal is to have a docker image which can be used to run tests locally on a dev machine. For this I would suggest to give our readymade [docker setup](https://hudi.apache.org/docs/docker_demo/) a try. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] codope commented on issue #2439: [SUPPORT] Unable to sync with external hive metastore via metastore uris in the thrift protocol
codope commented on issue #2439:
URL: https://github.com/apache/hudi/issues/2439#issuecomment-930059601
@rakeshramakrishnan For hive sync to work inline through Hudi, the
hive-site.xml at /conf should also be placed under
/conf and it should have the correct metastore uri. Can you
check the hive metastore uri in hive-site.xml inside /conf?
I tried to reproduce with a remote MySQL database as metastore. My jdbc
specific configs in hive-site.xml look like as follows:
```
"javax.jdo.option.ConnectionURL":
"jdbc:mysql://hostname:3306/hive?createDatabaseIfNotExist=true",
"javax.jdo.option.ConnectionDriverName": "org.mariadb.jdbc.Driver",
"javax.jdo.option.ConnectionUserName": "username",
"javax.jdo.option.ConnectionPassword": "password"
```
Then the following pyspark script works:
```
pyspark \
> --conf "spark.serializer=org.apache.spark.serializer.KryoSerializer" \
> --conf "spark.sql.hive.convertMetastoreParquet=false" \
> --jars
/home/hadoop/hudi-spark3-bundle_2.12-0.10.0-SNAPSHOT.jar,/usr/lib/spark/external/lib/spark-avro.jar
...
...
Using Python version 3.7.9 (default, Aug 27 2020 21:59:41)
SparkSession available as 'spark'.
>>> from pyspark.sql import functions as F
>>>
>>> inputDF = spark.createDataFrame([
... ("100", "2015/01/01", "2015-01-01T13:51:39.340396Z"),
... ("101", "2015/01/01", "2015-01-01T12:14:58.597216Z"),
... ("102", "2015/01/01", "2015-01-01T13:51:40.417052Z"),
... ("103", "2015/01/01", "2015-01-01T13:51:40.519832Z"),
... ("104", "2015/01/02", "2015-01-01T12:15:00.512679Z"),
... ("105", "2015/01/02", "2015-01-01T13:51:42.248818Z")],
... ["id", "creation_date", "last_update_time"])
>>>
>>> hudiOptions = {
... "hoodie.table.name" : "hudi_hive_table",
... "hoodie.datasource.write.table.type" : "COPY_ON_WRITE",
... "hoodie.datasource.write.operation" : "insert",
... "hoodie.datasource.write.recordkey.field" : "id",
... "hoodie.datasource.write.partitionpath.field" : "creation_date",
... "hoodie.datasource.write.precombine.field" : "last_update_time",
... "hoodie.datasource.hive_sync.enable" : "true",
... "hoodie.datasource.hive_sync.table" : "hudi_hive_table",
... "hoodie.datasource.hive_sync.partition_fields" : "creation_date"
... }
>>>
>>>
inputDF.write.format("org.apache.hudi").options(**hudiOptions).mode("overwrite").save("s3://huditestbkt/hive_sync/")
21/09/29 10:22:08 WARN HoodieSparkSqlWriter$: hoodie table at
s3://huditestbkt/hive_sync already exists. Deleting existing data & overwriting
with new data.
21/09/29 10:22:34 WARN HiveConf: HiveConf of name hive.server2.thrift.url
does not exist
>>>
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] danny0405 commented on a change in pull request #3719: [HUDI-2489]Tuning HoodieROTablePathFilter by caching hoodieTableFileSystemView, aiming to reduce unnecessary list/get requests
danny0405 commented on a change in pull request #3719:
URL: https://github.com/apache/hudi/pull/3719#discussion_r718104393
##
File path:
hudi-hadoop-mr/src/main/java/org/apache/hudi/hadoop/HoodieROTablePathFilter.java
##
@@ -175,8 +181,12 @@ public boolean accept(Path path) {
metaClientCache.put(baseDir.toString(), metaClient);
}
- fsView =
FileSystemViewManager.createInMemoryFileSystemView(engineContext,
- metaClient,
HoodieInputFormatUtils.buildMetadataConfig(getConf()));
+ fsView = hoodieTableFileSystemViewCache.get(baseDir.toString());
Review comment:
Flink streaming reader does not use this code path.
##
File path:
hudi-hadoop-mr/src/main/java/org/apache/hudi/hadoop/HoodieROTablePathFilter.java
##
@@ -175,8 +181,12 @@ public boolean accept(Path path) {
metaClientCache.put(baseDir.toString(), metaClient);
}
- fsView =
FileSystemViewManager.createInMemoryFileSystemView(engineContext,
- metaClient,
HoodieInputFormatUtils.buildMetadataConfig(getConf()));
+ fsView = hoodieTableFileSystemViewCache.get(baseDir.toString());
+ if (null == fsView) {
+fsView =
FileSystemViewManager.createInMemoryFileSystemView(engineContext, metaClient,
HoodieInputFormatUtils.buildMetadataConfig(getConf()));
+hoodieTableFileSystemViewCache.put(baseDir.toString(), fsView);
Review comment:
Use `computeIfAbsent` to simplify the logic.
##
File path:
hudi-hadoop-mr/src/main/java/org/apache/hudi/hadoop/HoodieROTablePathFilter.java
##
@@ -202,10 +212,6 @@ public boolean accept(Path path) {
}
nonHoodiePathCache.add(folder.toString());
return true;
-} finally {
- if (fsView != null) {
-fsView.close();
- }
Review comment:
How should the cached views been closed ?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] danny0405 commented on issue #3728: [SUPPORT] Hudi Flink S3 Java Example
danny0405 commented on issue #3728: URL: https://github.com/apache/hudi/issues/3728#issuecomment-929754237 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Created] (HUDI-2502) Refactor index in hudi-client module
Ethan Guo created HUDI-2502: --- Summary: Refactor index in hudi-client module Key: HUDI-2502 URL: https://issues.apache.org/jira/browse/HUDI-2502 Project: Apache Hudi Issue Type: Task Components: Code Cleanup Reporter: Ethan Guo Assignee: Ethan Guo Fix For: 0.10.0 -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Created] (HUDI-2501) Refactor compaction actions in hudi-client module
Ethan Guo created HUDI-2501: --- Summary: Refactor compaction actions in hudi-client module Key: HUDI-2501 URL: https://issues.apache.org/jira/browse/HUDI-2501 Project: Apache Hudi Issue Type: Task Components: Code Cleanup Reporter: Ethan Guo Assignee: Ethan Guo Fix For: 0.10.0 -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Updated] (HUDI-2497) Refactor clean and restore actions in hudi-client module
[ https://issues.apache.org/jira/browse/HUDI-2497?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Ethan Guo updated HUDI-2497: Summary: Refactor clean and restore actions in hudi-client module (was: Refactor clean, restore, and compaction actions in hudi-client module) > Refactor clean and restore actions in hudi-client module > - > > Key: HUDI-2497 > URL: https://issues.apache.org/jira/browse/HUDI-2497 > Project: Apache Hudi > Issue Type: Task > Components: Code Cleanup >Reporter: Ethan Guo >Assignee: Ethan Guo >Priority: Major > Labels: pull-request-available > Fix For: 0.10.0 > > -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Closed] (HUDI-2433) Refactor table.action.rollback package in hudi-client module
[ https://issues.apache.org/jira/browse/HUDI-2433?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Ethan Guo closed HUDI-2433. --- Resolution: Done > Refactor table.action.rollback package in hudi-client module > > > Key: HUDI-2433 > URL: https://issues.apache.org/jira/browse/HUDI-2433 > Project: Apache Hudi > Issue Type: Improvement > Components: Code Cleanup >Reporter: Ethan Guo >Assignee: Ethan Guo >Priority: Major > Labels: pull-request-available > Fix For: 0.10.0 > > -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [hudi] hudi-bot edited a comment on pull request #3734: [HUDI-2497] Refactor clean and restore actions in hudi-client module
hudi-bot edited a comment on pull request #3734: URL: https://github.com/apache/hudi/pull/3734#issuecomment-930618920 ## CI report: * 3cec644131a4fda77510a97d548d3633b4731e78 Azure: [PENDING](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=2464) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run travis` re-run the last Travis build - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #3734: [HUDI-2497] Refactor clean and restore actions in hudi-client module
hudi-bot commented on pull request #3734: URL: https://github.com/apache/hudi/pull/3734#issuecomment-930618920 ## CI report: * 3cec644131a4fda77510a97d548d3633b4731e78 UNKNOWN Bot commands @hudi-bot supports the following commands: - `@hudi-bot run travis` re-run the last Travis build - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] yihua opened a new pull request #3734: [HUDI-2497] Refactor clean and restore actions in hudi-client module
yihua opened a new pull request #3734: URL: https://github.com/apache/hudi/pull/3734 ## What is the purpose of the pull request This PR refactors the clean and restore actions in hudi-client module to extract common logic into hudi-client-common module and reduce LoC. ## Brief change log ## Verify this pull request This pull request is already covered by existing tests around clean and restore actions. ## Committer checklist - [ ] Has a corresponding JIRA in PR title & commit - [ ] Commit message is descriptive of the change - [ ] CI is green - [ ] Necessary doc changes done or have another open PR - [ ] For large changes, please consider breaking it into sub-tasks under an umbrella JIRA. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] yihua commented on pull request #3727: [HUDI-2497] Refactor clean, restore, and compaction actions in hudi-client module
yihua commented on pull request #3727: URL: https://github.com/apache/hudi/pull/3727#issuecomment-930614516 @nsivabalan I'll address your comments in the PR of refactoring compaction. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] yihua closed pull request #3727: [HUDI-2497] Refactor clean, restore, and compaction actions in hudi-client module
yihua closed pull request #3727: URL: https://github.com/apache/hudi/pull/3727 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] yihua commented on pull request #3727: [HUDI-2497] Refactor clean, restore, and compaction actions in hudi-client module
yihua commented on pull request #3727: URL: https://github.com/apache/hudi/pull/3727#issuecomment-930614238 I'm going to split this PR into two given the complexity of the compaction. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] nsivabalan commented on a change in pull request #3727: [HUDI-2497] Refactor clean, restore, and compaction actions in hudi-client module
nsivabalan commented on a change in pull request #3727:
URL: https://github.com/apache/hudi/pull/3727#discussion_r718849052
##
File path:
hudi-client/hudi-client-common/src/main/java/org/apache/hudi/table/action/compact/CompactHelpers.java
##
@@ -0,0 +1,178 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.table.action.compact;
+
+import org.apache.hudi.avro.model.HoodieCompactionPlan;
+import org.apache.hudi.client.AbstractHoodieWriteClient;
+import org.apache.hudi.client.WriteStatus;
+import org.apache.hudi.common.data.HoodieData;
+import org.apache.hudi.common.engine.HoodieEngineContext;
+import org.apache.hudi.common.engine.TaskContextSupplier;
+import org.apache.hudi.common.model.CompactionOperation;
+import org.apache.hudi.common.model.HoodieCommitMetadata;
+import org.apache.hudi.common.model.HoodieRecordPayload;
+import org.apache.hudi.common.model.HoodieWriteStat;
+import org.apache.hudi.common.table.HoodieTableMetaClient;
+import org.apache.hudi.common.table.TableSchemaResolver;
+import org.apache.hudi.common.table.timeline.HoodieActiveTimeline;
+import org.apache.hudi.common.table.timeline.HoodieInstant;
+import org.apache.hudi.common.table.timeline.HoodieTimeline;
+import org.apache.hudi.common.table.timeline.TimelineMetadataUtils;
+import org.apache.hudi.common.util.CompactionUtils;
+import org.apache.hudi.common.util.Option;
+import org.apache.hudi.config.HoodieWriteConfig;
+import org.apache.hudi.exception.HoodieCompactionException;
+import org.apache.hudi.table.HoodieCopyOnWriteTableOperation;
+import org.apache.hudi.table.HoodieTable;
+import org.apache.hudi.table.action.HoodieWriteMetadata;
+
+import org.apache.avro.Schema;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+import java.io.IOException;
+import java.nio.charset.StandardCharsets;
+import java.util.List;
+
+import static java.util.stream.Collectors.toList;
+
+/**
+ * Base class helps to perform compact.
+ *
+ * @param Type of payload in {@link
org.apache.hudi.common.model.HoodieRecord}
+ */
+public class CompactHelpers {
+
+ private static final Logger LOG =
LoggerFactory.getLogger(CompactHelpers.class);
+
+ private CompactHelpers() {
+ }
+
+ private static class CompactHelperHolder {
+private static final CompactHelpers COMPACT_HELPERS = new CompactHelpers();
+ }
+
+ public static CompactHelpers newInstance() {
+return CompactHelperHolder.COMPACT_HELPERS;
+ }
+
+ public HoodieWriteMetadata> compact(
+ HoodieEngineContext context, HoodieTable table,
+ HoodieCopyOnWriteTableOperation copyOnWriteTableOperation,
HoodieWriteConfig config,
+ String compactionInstantTime, AbstractHoodieWriteClient writeClient,
+ TaskContextSupplier taskContextSupplier) {
+HoodieTimeline pendingCompactionTimeline =
table.getActiveTimeline().filterPendingCompactionTimeline();
+HoodieInstant inflightInstant =
HoodieTimeline.getCompactionInflightInstant(compactionInstantTime);
+if (pendingCompactionTimeline.containsInstant(inflightInstant)) {
+ writeClient.rollbackInflightCompaction(inflightInstant, table);
+ table.getMetaClient().reloadActiveTimeline();
+}
+
+HoodieWriteMetadata> compactionMetadata = new
HoodieWriteMetadata<>();
+compactionMetadata.setWriteStatuses(context.createEmptyHoodieData());
+try {
+ // generate compaction plan
+ // should support configurable commit metadata
+ HoodieCompactionPlan compactionPlan = CompactionUtils.getCompactionPlan(
+ table.getMetaClient(), compactionInstantTime);
+
+ if (compactionPlan == null || (compactionPlan.getOperations() == null)
+ || (compactionPlan.getOperations().isEmpty())) {
+// do nothing.
+LOG.info("No compaction plan for instant " + compactionInstantTime);
+return compactionMetadata;
+ }
+
+ HoodieInstant instant =
HoodieTimeline.getCompactionRequestedInstant(compactionInstantTime);
+ // Mark instant as compaction inflight
+
table.getActiveTimeline().transitionCompactionRequestedToInflight(instant);
+ table.getMetaClient().reloadActiveTimeline();
+
+ HoodieTableMetaClient metaClient = table.getMetaClien
[GitHub] [hudi] davehagman commented on issue #3733: [SUPPORT] Periodic and sustained latency spikes during index lookup
davehagman commented on issue #3733: URL: https://github.com/apache/hudi/issues/3733#issuecomment-930488974 I would also like to show some graphs comparing the baseline and what they look like during these latency spikes. This is a graph of the number of files Created vs. Updated per batch (`commit.totalFilesInsert` and `commit.totalFilesUpdate` respectively). The number of updated files explodes:  The next graph shows that the number of bytes being written is magnitudes higher than baseline, according to Hudi metrics (`commit.totalBytesWritten`):  -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] davehagman opened a new issue #3733: [SUPPORT] Periodic and sustained latency spikes during index lookup
davehagman opened a new issue #3733: URL: https://github.com/apache/hudi/issues/3733 **Describe the problem you faced** We're running Hudi 0.9 in production and we are seeing intermittent issues where the latency introduced by index operations spiked to 8-10x longer than usual which causes us to have a much higher write latency into our datalake. I have put some information about our setup below as well as screenshots of the spark UI. You can see in the screenshots that the time it takes to perform the index lookup starts increasing for each batch. I'd like to figure out what could be causing this as it manifests as a large increase in write latency into our production datalake. **To Reproduce** I am unsure of the root-cause of this issue so I do not currently have concrete reproduction steps. **Expected behavior** The time to perform index lookup should not spike 8-10x it's normal latency. **Environment Description** * Hudi version : 0.9.0 * Spark version : 3.1.2 (AWS EMR 6.3.0) * Hadoop version : 3.2.1 * Storage (HDFS/S3/GCS..) : S3 * Running on Docker? (yes/no) : no **Additional context** Ingestion Config: * Compute: 150 nodes, m5.4xlarge * Using the Deltastreamer (source = Kafka) * INSERT mode * Drop dupes enabled * Index type: Bloom Dynamic * No changes to default bloom settings * Data is partitioned by: year / month / day / hour   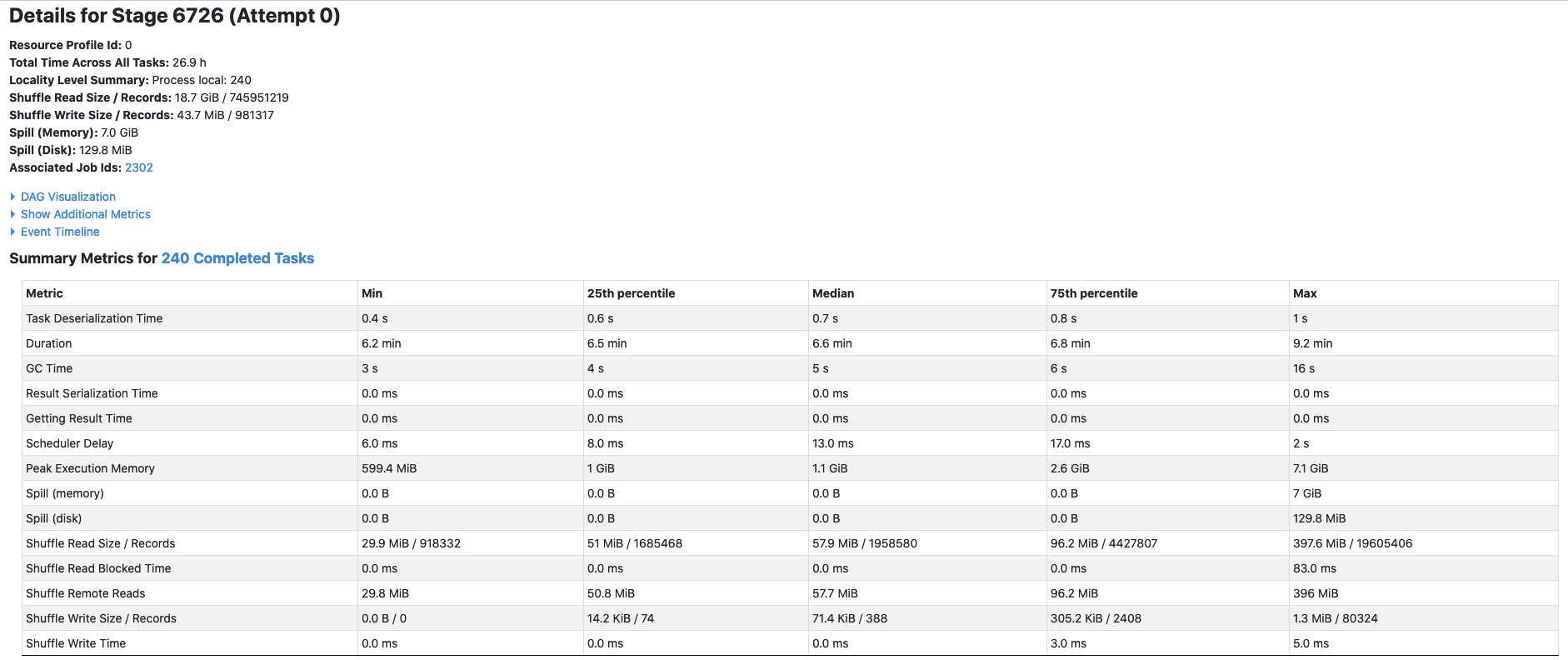 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] xushiyan edited a comment on issue #3670: [SUPPORT] SQL stmt managed table, not update/delete with datasource API
xushiyan edited a comment on issue #3670: URL: https://github.com/apache/hudi/issues/3670#issuecomment-930335250 i can replicate the issue in local env, even by setting `ComplexKeyGenerator`, datasource delete not working, while delete via spark sql worked. Filing a JIRA to have detailed scripts https://issues.apache.org/jira/browse/HUDI-2500 Thanks @parisni for raising this. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] xushiyan commented on issue #3670: [SUPPORT] SQL stmt managed table, not update/delete with datasource API
xushiyan commented on issue #3670: URL: https://github.com/apache/hudi/issues/3670#issuecomment-930335250 i can replicate the issue in local env, even by setting `ComplexKeyGenerator`, datasource delete not working, while delete via spark sql delete. Filing a JIRA to have detailed scripts https://issues.apache.org/jira/browse/HUDI-2500 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Created] (HUDI-2500) Spark datasource delete not working on Spark SQL created table
Raymond Xu created HUDI-2500: Summary: Spark datasource delete not working on Spark SQL created table Key: HUDI-2500 URL: https://issues.apache.org/jira/browse/HUDI-2500 Project: Apache Hudi Issue Type: Bug Components: Spark Integration Reporter: Raymond Xu Fix For: 0.10.0 Original issue https://github.com/apache/hudi/issues/3670 -- This message was sent by Atlassian Jira (v8.3.4#803005)