[jira] [Commented] (HUDI-2576) flink do checkpoint error because parquet file is missing
[ https://issues.apache.org/jira/browse/HUDI-2576?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17430351#comment-17430351 ] liyuanzhao435 commented on HUDI-2576: - the *20211019124727* instant commit twice, why? > flink do checkpoint error because parquet file is missing > -- > > Key: HUDI-2576 > URL: https://issues.apache.org/jira/browse/HUDI-2576 > Project: Apache Hudi > Issue Type: Bug > Components: Flink Integration >Affects Versions: 0.10.0 >Reporter: liyuanzhao435 >Priority: Major > Labels: flink, hudi > Fix For: 0.10.0 > > Attachments: error.txt > > Original Estimate: 96h > Remaining Estimate: 96h > > hudi:0.10.0, flink 1.13.1 > some times when flink do checkpoint , error occurs, the error shows a hudi > parquet file is missing (says file not exists) : > *2021-10-19 09:20:03,796 INFO > org.apache.hudi.io.storage.row.HoodieRowDataCreateHandle [] - start close > hoodie row data* > *2021-10-19 09:20:03,800 WARN org.apache.hadoop.hdfs.DataStreamer [] - > DataStreamer Exception* > *java.io.FileNotFoundException: File does not exist: > /tmp/test_liyz2/aa/2ff301cc-8db2-478e-b707-e8f2327ba38f-0_0-1-4_20211019091917.parquet > (inode 32234795) Holder DFSClient_NONMAPREDUCE_633610786_99 does not have > any open files.* > *at > org.apache.hadoop.hdfs.server.namenode.FSNamesystem.checkLease(FSNamesystem.java:2815)* > > detail see appendix -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Comment Edited] (HUDI-2563) Refactor XScheduleCompactionActionExecutor and CompactionTriggerStrategy.
[ https://issues.apache.org/jira/browse/HUDI-2563?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17430028#comment-17430028 ] Yuepeng Pan edited comment on HUDI-2563 at 10/19/21, 6:41 AM: -- Hi,[~xleesf] [~xushiyan] [~danny0405] Could you help me to review this pr ? Thank you. was (Author: rocmarshal): Hi, [~danny0405] Could you help me to review this pr ? Thank you. > Refactor XScheduleCompactionActionExecutor and CompactionTriggerStrategy. > - > > Key: HUDI-2563 > URL: https://issues.apache.org/jira/browse/HUDI-2563 > Project: Apache Hudi > Issue Type: Improvement > Components: CLI, Compaction, Writer Core >Reporter: Yuepeng Pan >Assignee: Yuepeng Pan >Priority: Minor > Labels: pull-request-available > > # Pull up some common methods from XXXScheduleCompactionActionExecutor to > BaseScheduleCompactionActionExecutor. > # Replace conditional in XXXScheduleCompactionActionExecutor with > polymorphsim of CompactionTriggerStrategy class. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Comment Edited] (HUDI-2576) flink do checkpoint error because parquet file is missing
[
https://issues.apache.org/jira/browse/HUDI-2576?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17430326#comment-17430326
]
liyuanzhao435 edited comment on HUDI-2576 at 10/19/21, 6:31 AM:
Hoodie table says:
*LOG.info("Removing duplicate data files created due to spark retries before
committing. Paths=" + invalidDataPaths);*
however, the invalid path means have spececial extension: parquet, log, orc,
hfile
but my deleted file is end with the extension parquet, why the jobmanager
delete it? I can't understand it
was (Author: liyuanzhao435):
Hoodie table says:
*LOG.info("Removing duplicate data files created due to spark retries before
committing. Paths=" + invalidDataPaths);*
however, the invalid path means have spececial extension: parquet, log, orc,
hfile
bug my deleted file is end with the extension parquet, why the jobmanager
delete it? I can't understand it
> flink do checkpoint error because parquet file is missing
> --
>
> Key: HUDI-2576
> URL: https://issues.apache.org/jira/browse/HUDI-2576
> Project: Apache Hudi
> Issue Type: Bug
> Components: Flink Integration
>Affects Versions: 0.10.0
>Reporter: liyuanzhao435
>Priority: Major
> Labels: flink, hudi
> Fix For: 0.10.0
>
> Attachments: error.txt
>
> Original Estimate: 96h
> Remaining Estimate: 96h
>
> hudi:0.10.0, flink 1.13.1
> some times when flink do checkpoint , error occurs, the error shows a hudi
> parquet file is missing (says file not exists) :
> *2021-10-19 09:20:03,796 INFO
> org.apache.hudi.io.storage.row.HoodieRowDataCreateHandle [] - start close
> hoodie row data*
> *2021-10-19 09:20:03,800 WARN org.apache.hadoop.hdfs.DataStreamer [] -
> DataStreamer Exception*
> *java.io.FileNotFoundException: File does not exist:
> /tmp/test_liyz2/aa/2ff301cc-8db2-478e-b707-e8f2327ba38f-0_0-1-4_20211019091917.parquet
> (inode 32234795) Holder DFSClient_NONMAPREDUCE_633610786_99 does not have
> any open files.*
> *at
> org.apache.hadoop.hdfs.server.namenode.FSNamesystem.checkLease(FSNamesystem.java:2815)*
>
> detail see appendix
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Commented] (HUDI-2576) flink do checkpoint error because parquet file is missing
[
https://issues.apache.org/jira/browse/HUDI-2576?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17430326#comment-17430326
]
liyuanzhao435 commented on HUDI-2576:
-
Hoodie table says:
*LOG.info("Removing duplicate data files created due to spark retries before
committing. Paths=" + invalidDataPaths);*
however, the invalid path means have spececial extension: parquet, log, orc,
hfile
bug my deleted file is end with the extension parquet, why the jobmanager
delete it? I can't understand it
> flink do checkpoint error because parquet file is missing
> --
>
> Key: HUDI-2576
> URL: https://issues.apache.org/jira/browse/HUDI-2576
> Project: Apache Hudi
> Issue Type: Bug
> Components: Flink Integration
>Affects Versions: 0.10.0
>Reporter: liyuanzhao435
>Priority: Major
> Labels: flink, hudi
> Fix For: 0.10.0
>
> Attachments: error.txt
>
> Original Estimate: 96h
> Remaining Estimate: 96h
>
> hudi:0.10.0, flink 1.13.1
> some times when flink do checkpoint , error occurs, the error shows a hudi
> parquet file is missing (says file not exists) :
> *2021-10-19 09:20:03,796 INFO
> org.apache.hudi.io.storage.row.HoodieRowDataCreateHandle [] - start close
> hoodie row data*
> *2021-10-19 09:20:03,800 WARN org.apache.hadoop.hdfs.DataStreamer [] -
> DataStreamer Exception*
> *java.io.FileNotFoundException: File does not exist:
> /tmp/test_liyz2/aa/2ff301cc-8db2-478e-b707-e8f2327ba38f-0_0-1-4_20211019091917.parquet
> (inode 32234795) Holder DFSClient_NONMAPREDUCE_633610786_99 does not have
> any open files.*
> *at
> org.apache.hadoop.hdfs.server.namenode.FSNamesystem.checkLease(FSNamesystem.java:2815)*
>
> detail see appendix
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [hudi] xushiyan commented on issue #3821: [SUPPORT] Ingestion taking very long time getting small files from partitions/
xushiyan commented on issue #3821: URL: https://github.com/apache/hudi/issues/3821#issuecomment-946406362 @rohit-m-99 it depends on your business logic. you can choose any field(s) that make sense for you (year/month/day, country, city, timezone, etc anything similar to those that makes sense) or simply use `hash(run_id)%10` to partition by the hash value's mod, which guarantees the number of partitions. Hope this helps. And closing this now. if you run into further issues, feel free to follow up here. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] xushiyan closed issue #3821: [SUPPORT] Ingestion taking very long time getting small files from partitions/
xushiyan closed issue #3821: URL: https://github.com/apache/hudi/issues/3821 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] xushiyan commented on issue #3804: [SUPPORT] Error with metadata table
xushiyan commented on issue #3804: URL: https://github.com/apache/hudi/issues/3804#issuecomment-946402297 @rubenssoto On the metadata issue on EMR, please note that EMR has its own hudi built to work with other libraries bundled on each EMR release. See the version matrix here https://docs.aws.amazon.com/emr/latest/ReleaseGuide/emr-640-release.html Therefore you'd be better off to stay with EMR's Hudi / Spark / Flink versions. Otherwise, if you want to use a different Hudi version, you may also need to install your own and desired+compatible Spark version on the EMR machines. It'd take much more effort on environment setup so stay with EMR's version support is the best choice, plus this allows you to engage with AWS support if anything goes wrong, which should be the first choice of support. On your local build problem, please follow readme instructions closely. Double check java version, maven version, and purge your local maven repo if needed. Our CI build is passing so there should be no issue to build the project. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] xushiyan closed issue #3804: [SUPPORT] Error with metadata table
xushiyan closed issue #3804: URL: https://github.com/apache/hudi/issues/3804 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] rohit-m-99 commented on issue #3821: [SUPPORT] Ingestion taking very long time getting small files from partitions/
rohit-m-99 commented on issue #3821: URL: https://github.com/apache/hudi/issues/3821#issuecomment-946395852 I see, as of now the main problem is that intuitively we'd partition by each `run` but each `run` is only about 2000-4000k records, so it is not immediately obvious on what field we should be partitioning by. Any advice here would be appreciated. We chose to not partition by the `run` id for query performance (not to have too many partitions). But not sure about alternatives - our use case has pretty high variability between time periods so have moved away from time base partitioning. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] xushiyan commented on issue #3821: [SUPPORT] Ingestion taking very long time getting small files from partitions/
xushiyan commented on issue #3821:
URL: https://github.com/apache/hudi/issues/3821#issuecomment-946393073
@rohit-m-99 you'd need to partition your dataset the normal way you
partition a spark dataset. Something like
`df.repartition().write().format("hudi").partitionBy().mode().options().save()`.
You can search more on how to do Spark partitioning.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] xushiyan commented on issue #3814: [SUPPORT] Error o Trying to create a table using Spark SQL
xushiyan commented on issue #3814: URL: https://github.com/apache/hudi/issues/3814#issuecomment-946390788 @rubenssoto since you're on EMR, please use EMR pre-installed hudi jars instead of open source ones ``` --packages org.apache.hudi:hudi-spark3-bundle_2.12:0.9.0,org.apache.spark:spark-avro_2.12:3.0.1 ``` change to ``` --jars /usr/lib/hudi/hudi-spark-bundle.jar,/usr/lib/spark/external/lib/spark-avro.jar ``` See more from https://docs.aws.amazon.com/emr/latest/ReleaseGuide/emr-hudi-installation-and-configuration.html https://docs.aws.amazon.com/emr/latest/ReleaseGuide/emr-hudi-work-with-dataset.html And please engage with AWS support for EMR specific setup problems. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] xushiyan closed issue #3814: [SUPPORT] Error o Trying to create a table using Spark SQL
xushiyan closed issue #3814: URL: https://github.com/apache/hudi/issues/3814 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] rohit-m-99 commented on issue #3821: [SUPPORT] Ingestion taking very long time getting small files from partitions/
rohit-m-99 commented on issue #3821: URL: https://github.com/apache/hudi/issues/3821#issuecomment-946385171 Thank you for the advice, how do you set the number of partitions when using df.write()? Currently basing my code off of the intro guide found here: https://hudi.apache.org/docs/quick-start-guide. I am specifically using pyspark. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] xushiyan commented on issue #3821: [SUPPORT] Ingestion taking very long time getting small files from partitions/
xushiyan commented on issue #3821: URL: https://github.com/apache/hudi/issues/3821#issuecomment-946383159 @rohit-m-99 this is likely due to non-partitioned dataset https://github.com/apache/hudi/blob/dbcf60f370e93ab490cf82e677387a07ea743cda/hudi-client/hudi-spark-client/src/main/java/org/apache/hudi/table/action/commit/UpsertPartitioner.java#L254 getSmallFilesForPartitions() is parallelized over partitions. Try use 10-20 partitions may get this faster to <50s and make use of multiple executors. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Comment Edited] (HUDI-2576) flink do checkpoint error because parquet file is missing
[
https://issues.apache.org/jira/browse/HUDI-2576?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17430316#comment-17430316
]
liyuanzhao435 edited comment on HUDI-2576 at 10/19/21, 5:33 AM:
flink jobmanager deleted the file :
*2021-10-19 12:47:34,606 INFO org.apache.hudi.common.util.CommitUtils [] -
Creating metadata for null numWriteStats:1numReplaceFileIds:0*
*2021-10-19 12:47:34,607 INFO org.apache.hudi.client.AbstractHoodieWriteClient
[] - Committing 20211019124727 action deltacommit*
*2021-10-19 12:47:34,615 INFO org.apache.hudi.table.HoodieTable [] - Removing
duplicate data files created due to spark retries before committing.
Paths=[aa/c6eff439-d4e0-4deb-af43-f6906ab71d2b-0_0-1-0_20211019124727.parquet]*
*2021-10-19 12:47:34,617 INFO org.apache.hudi.table.HoodieTable [] -
{color:#de350b}Deleting invalid data
files{color}=[(hdfs://:/tmp/test_liyz2/aa,hdfs://:/tmp/test_liyz2/aa/c6eff439-d4e0-4deb-af43-f6906ab71d2b-0_0-1-0_20211019124727.parquet)]*
*2021-10-19 12:47:34,676 INFO
org.apache.hudi.common.table.timeline.HoodieActiveTimeline [] - Marking instant
complete [==>20211019124727__deltacommit__INFLIGHT]*
was (Author: liyuanzhao435):
flink jobmanager deleted the file :
*2021-10-19 12:47:34,606 INFO org.apache.hudi.common.util.CommitUtils [] -
Creating metadata for null numWriteStats:1numReplaceFileIds:0*
*2021-10-19 12:47:34,607 INFO org.apache.hudi.client.AbstractHoodieWriteClient
[] - Committing 20211019124727 action deltacommit*
*2021-10-19 12:47:34,615 INFO org.apache.hudi.table.HoodieTable [] - Removing
duplicate data files created due to spark retries before committing.
Paths=[aa/c6eff439-d4e0-4deb-af43-f6906ab71d2b-0_0-1-0_20211019124727.parquet]*
*2021-10-19 12:47:34,617 INFO org.apache.hudi.table.HoodieTable [] -
{color:#de350b}Deleting invalid data
files{color}=[(hdfs://:/tmp/test_liyz2/aa,hdfs://:/tmp/test_liyz2/aa/c6eff439-d4e0-4deb-af43-f6906ab71d2b-0_0-1-0_20211019124727.parquet)]*
*2021-10-19 12:47:34,676 INFO
org.apache.hudi.common.table.timeline.HoodieActiveTimeline [] - Marking instant
complete [==>20211019124727__deltacommit__INFLIGHT]*
*2021-10-19 12:47:34,677 INFO
org.apache.hudi.common.table.timeline.HoodieActiveTimeline [] - Checking for
file exists
?hdfs://26.6.4.165:8020/tmp/test_liyz2/.hoodie/20211019124727.deltacommit.inflight*
*2021-10-19 12:47:34,691 INFO
org.apache.hudi.common.table.timeline.HoodieActiveTimeline [] - Create new file
for toInstant
?hdfs://26.6.4.165:8020/tmp/test_liyz2/.hoodie/20211019124727.deltacommit*
*2021-10-19 12:47:34,691 INFO
org.apache.hudi.common.table.timeline.HoodieActiveTimeline [] - Completed
[==>20211019124727__deltacommit__INFLIGHT]*
*20*
> flink do checkpoint error because parquet file is missing
> --
>
> Key: HUDI-2576
> URL: https://issues.apache.org/jira/browse/HUDI-2576
> Project: Apache Hudi
> Issue Type: Bug
> Components: Flink Integration
>Affects Versions: 0.10.0
>Reporter: liyuanzhao435
>Priority: Major
> Labels: flink, hudi
> Fix For: 0.10.0
>
> Attachments: error.txt
>
> Original Estimate: 96h
> Remaining Estimate: 96h
>
> hudi:0.10.0, flink 1.13.1
> some times when flink do checkpoint , error occurs, the error shows a hudi
> parquet file is missing (says file not exists) :
> *2021-10-19 09:20:03,796 INFO
> org.apache.hudi.io.storage.row.HoodieRowDataCreateHandle [] - start close
> hoodie row data*
> *2021-10-19 09:20:03,800 WARN org.apache.hadoop.hdfs.DataStreamer [] -
> DataStreamer Exception*
> *java.io.FileNotFoundException: File does not exist:
> /tmp/test_liyz2/aa/2ff301cc-8db2-478e-b707-e8f2327ba38f-0_0-1-4_20211019091917.parquet
> (inode 32234795) Holder DFSClient_NONMAPREDUCE_633610786_99 does not have
> any open files.*
> *at
> org.apache.hadoop.hdfs.server.namenode.FSNamesystem.checkLease(FSNamesystem.java:2815)*
>
> detail see appendix
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Comment Edited] (HUDI-2576) flink do checkpoint error because parquet file is missing
[
https://issues.apache.org/jira/browse/HUDI-2576?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17430316#comment-17430316
]
liyuanzhao435 edited comment on HUDI-2576 at 10/19/21, 5:33 AM:
flink jobmanager deleted the file :
*2021-10-19 12:47:34,606 INFO org.apache.hudi.common.util.CommitUtils [] -
Creating metadata for null numWriteStats:1numReplaceFileIds:0*
*2021-10-19 12:47:34,607 INFO org.apache.hudi.client.AbstractHoodieWriteClient
[] - Committing 20211019124727 action deltacommit*
*2021-10-19 12:47:34,615 INFO org.apache.hudi.table.HoodieTable [] - Removing
duplicate data files created due to spark retries before committing.
Paths=[aa/c6eff439-d4e0-4deb-af43-f6906ab71d2b-0_0-1-0_20211019124727.parquet]*
*2021-10-19 12:47:34,617 INFO org.apache.hudi.table.HoodieTable [] -
{color:#de350b}Deleting invalid data
files{color}=[(hdfs://:/tmp/test_liyz2/aa,hdfs://:/tmp/test_liyz2/aa/c6eff439-d4e0-4deb-af43-f6906ab71d2b-0_0-1-0_20211019124727.parquet)]*
*2021-10-19 12:47:34,676 INFO
org.apache.hudi.common.table.timeline.HoodieActiveTimeline [] - Marking instant
complete [==>20211019124727__deltacommit__INFLIGHT]*
*2021-10-19 12:47:34,677 INFO
org.apache.hudi.common.table.timeline.HoodieActiveTimeline [] - Checking for
file exists
?hdfs://26.6.4.165:8020/tmp/test_liyz2/.hoodie/20211019124727.deltacommit.inflight*
*2021-10-19 12:47:34,691 INFO
org.apache.hudi.common.table.timeline.HoodieActiveTimeline [] - Create new file
for toInstant
?hdfs://26.6.4.165:8020/tmp/test_liyz2/.hoodie/20211019124727.deltacommit*
*2021-10-19 12:47:34,691 INFO
org.apache.hudi.common.table.timeline.HoodieActiveTimeline [] - Completed
[==>20211019124727__deltacommit__INFLIGHT]*
*20*
was (Author: liyuanzhao435):
flink jobmanager deleted the file :
*2021-10-19 12:47:34,606 INFO org.apache.hudi.common.util.CommitUtils [] -
Creating metadata for null numWriteStats:1numReplaceFileIds:0*
*2021-10-19 12:47:34,607 INFO org.apache.hudi.client.AbstractHoodieWriteClient
[] - Committing 20211019124727 action deltacommit*
*2021-10-19 12:47:34,615 INFO org.apache.hudi.table.HoodieTable [] - Removing
duplicate data files created due to spark retries before committing.
Paths=[aa/c6eff439-d4e0-4deb-af43-f6906ab71d2b-0_0-1-0_20211019124727.parquet]*
*2021-10-19 12:47:34,617 INFO org.apache.hudi.table.HoodieTable [] -
{color:#de350b}Deleting invalid data
files{color}=[(hdfs://:/tmp/test_liyz2/aa,hdfs://26.6.4.165:8020/tmp/test_liyz2/aa/c6eff439-d4e0-4deb-af43-f6906ab71d2b-0_0-1-0_20211019124727.parquet)]*
*2021-10-19 12:47:34,676 INFO
org.apache.hudi.common.table.timeline.HoodieActiveTimeline [] - Marking instant
complete [==>20211019124727__deltacommit__INFLIGHT]*
*2021-10-19 12:47:34,677 INFO
org.apache.hudi.common.table.timeline.HoodieActiveTimeline [] - Checking for
file exists
?hdfs://26.6.4.165:8020/tmp/test_liyz2/.hoodie/20211019124727.deltacommit.inflight*
*2021-10-19 12:47:34,691 INFO
org.apache.hudi.common.table.timeline.HoodieActiveTimeline [] - Create new file
for toInstant
?hdfs://26.6.4.165:8020/tmp/test_liyz2/.hoodie/20211019124727.deltacommit*
*2021-10-19 12:47:34,691 INFO
org.apache.hudi.common.table.timeline.HoodieActiveTimeline [] - Completed
[==>20211019124727__deltacommit__INFLIGHT]*
*20*
> flink do checkpoint error because parquet file is missing
> --
>
> Key: HUDI-2576
> URL: https://issues.apache.org/jira/browse/HUDI-2576
> Project: Apache Hudi
> Issue Type: Bug
> Components: Flink Integration
>Affects Versions: 0.10.0
>Reporter: liyuanzhao435
>Priority: Major
> Labels: flink, hudi
> Fix For: 0.10.0
>
> Attachments: error.txt
>
> Original Estimate: 96h
> Remaining Estimate: 96h
>
> hudi:0.10.0, flink 1.13.1
> some times when flink do checkpoint , error occurs, the error shows a hudi
> parquet file is missing (says file not exists) :
> *2021-10-19 09:20:03,796 INFO
> org.apache.hudi.io.storage.row.HoodieRowDataCreateHandle [] - start close
> hoodie row data*
> *2021-10-19 09:20:03,800 WARN org.apache.hadoop.hdfs.DataStreamer [] -
> DataStreamer Exception*
> *java.io.FileNotFoundException: File does not exist:
> /tmp/test_liyz2/aa/2ff301cc-8db2-478e-b707-e8f2327ba38f-0_0-1-4_20211019091917.parquet
> (inode 32234795) Holder DFSClient_NONMAPREDUCE_633610786_99 does not have
> any open files.*
> *at
> org.apache.hadoop.hdfs.server.namenode.FSNamesystem.checkLease(FSNamesystem.java:2815)*
>
> detail see appendix
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Commented] (HUDI-2576) flink do checkpoint error because parquet file is missing
[
https://issues.apache.org/jira/browse/HUDI-2576?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17430316#comment-17430316
]
liyuanzhao435 commented on HUDI-2576:
-
flink jobmanager deleted the file :
*2021-10-19 12:47:34,606 INFO org.apache.hudi.common.util.CommitUtils [] -
Creating metadata for null numWriteStats:1numReplaceFileIds:0*
*2021-10-19 12:47:34,607 INFO org.apache.hudi.client.AbstractHoodieWriteClient
[] - Committing 20211019124727 action deltacommit*
*2021-10-19 12:47:34,615 INFO org.apache.hudi.table.HoodieTable [] - Removing
duplicate data files created due to spark retries before committing.
Paths=[aa/c6eff439-d4e0-4deb-af43-f6906ab71d2b-0_0-1-0_20211019124727.parquet]*
*2021-10-19 12:47:34,617 INFO org.apache.hudi.table.HoodieTable [] -
{color:#de350b}Deleting invalid data
files{color}=[(hdfs://:/tmp/test_liyz2/aa,hdfs://26.6.4.165:8020/tmp/test_liyz2/aa/c6eff439-d4e0-4deb-af43-f6906ab71d2b-0_0-1-0_20211019124727.parquet)]*
*2021-10-19 12:47:34,676 INFO
org.apache.hudi.common.table.timeline.HoodieActiveTimeline [] - Marking instant
complete [==>20211019124727__deltacommit__INFLIGHT]*
*2021-10-19 12:47:34,677 INFO
org.apache.hudi.common.table.timeline.HoodieActiveTimeline [] - Checking for
file exists
?hdfs://26.6.4.165:8020/tmp/test_liyz2/.hoodie/20211019124727.deltacommit.inflight*
*2021-10-19 12:47:34,691 INFO
org.apache.hudi.common.table.timeline.HoodieActiveTimeline [] - Create new file
for toInstant
?hdfs://26.6.4.165:8020/tmp/test_liyz2/.hoodie/20211019124727.deltacommit*
*2021-10-19 12:47:34,691 INFO
org.apache.hudi.common.table.timeline.HoodieActiveTimeline [] - Completed
[==>20211019124727__deltacommit__INFLIGHT]*
*20*
> flink do checkpoint error because parquet file is missing
> --
>
> Key: HUDI-2576
> URL: https://issues.apache.org/jira/browse/HUDI-2576
> Project: Apache Hudi
> Issue Type: Bug
> Components: Flink Integration
>Affects Versions: 0.10.0
>Reporter: liyuanzhao435
>Priority: Major
> Labels: flink, hudi
> Fix For: 0.10.0
>
> Attachments: error.txt
>
> Original Estimate: 96h
> Remaining Estimate: 96h
>
> hudi:0.10.0, flink 1.13.1
> some times when flink do checkpoint , error occurs, the error shows a hudi
> parquet file is missing (says file not exists) :
> *2021-10-19 09:20:03,796 INFO
> org.apache.hudi.io.storage.row.HoodieRowDataCreateHandle [] - start close
> hoodie row data*
> *2021-10-19 09:20:03,800 WARN org.apache.hadoop.hdfs.DataStreamer [] -
> DataStreamer Exception*
> *java.io.FileNotFoundException: File does not exist:
> /tmp/test_liyz2/aa/2ff301cc-8db2-478e-b707-e8f2327ba38f-0_0-1-4_20211019091917.parquet
> (inode 32234795) Holder DFSClient_NONMAPREDUCE_633610786_99 does not have
> any open files.*
> *at
> org.apache.hadoop.hdfs.server.namenode.FSNamesystem.checkLease(FSNamesystem.java:2815)*
>
> detail see appendix
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Commented] (HUDI-2576) flink do checkpoint error because parquet file is missing
[ https://issues.apache.org/jira/browse/HUDI-2576?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17430311#comment-17430311 ] liyuanzhao435 commented on HUDI-2576: - I checked the hdfs audit log, the parquet file created and then deleted immediately, now I hive to fund the reason > flink do checkpoint error because parquet file is missing > -- > > Key: HUDI-2576 > URL: https://issues.apache.org/jira/browse/HUDI-2576 > Project: Apache Hudi > Issue Type: Bug > Components: Flink Integration >Affects Versions: 0.10.0 >Reporter: liyuanzhao435 >Priority: Major > Labels: flink, hudi > Fix For: 0.10.0 > > Attachments: error.txt > > Original Estimate: 96h > Remaining Estimate: 96h > > hudi:0.10.0, flink 1.13.1 > some times when flink do checkpoint , error occurs, the error shows a hudi > parquet file is missing (says file not exists) : > *2021-10-19 09:20:03,796 INFO > org.apache.hudi.io.storage.row.HoodieRowDataCreateHandle [] - start close > hoodie row data* > *2021-10-19 09:20:03,800 WARN org.apache.hadoop.hdfs.DataStreamer [] - > DataStreamer Exception* > *java.io.FileNotFoundException: File does not exist: > /tmp/test_liyz2/aa/2ff301cc-8db2-478e-b707-e8f2327ba38f-0_0-1-4_20211019091917.parquet > (inode 32234795) Holder DFSClient_NONMAPREDUCE_633610786_99 does not have > any open files.* > *at > org.apache.hadoop.hdfs.server.namenode.FSNamesystem.checkLease(FSNamesystem.java:2815)* > > detail see appendix -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [hudi] xushiyan closed issue #3728: [SUPPORT] Hudi Flink S3 Java Example
xushiyan closed issue #3728: URL: https://github.com/apache/hudi/issues/3728 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] nsivabalan commented on issue #2544: [SUPPORT]failed to read timestamp column in version 0.7.0 even when HIVE_SUPPORT_TIMESTAMP is enabled
nsivabalan commented on issue #2544: URL: https://github.com/apache/hudi/issues/2544#issuecomment-946369974 Closing due to inactivity and the issue is not reproducible anymore. thanks -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] nsivabalan closed issue #2544: [SUPPORT]failed to read timestamp column in version 0.7.0 even when HIVE_SUPPORT_TIMESTAMP is enabled
nsivabalan closed issue #2544: URL: https://github.com/apache/hudi/issues/2544 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] nsivabalan commented on issue #3603: [SUPPORT] delta streamer Failed to archive commits
nsivabalan commented on issue #3603: URL: https://github.com/apache/hudi/issues/3603#issuecomment-946369090 @fengjian428 : hey, can you give us any updates. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] nsivabalan commented on issue #3559: [SUPPORT] Failed to archive commits
nsivabalan commented on issue #3559: URL: https://github.com/apache/hudi/issues/3559#issuecomment-946367293 This was fixed in 090. closing it out. If you run into any issues, do reach out to us. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] nsivabalan closed issue #3559: [SUPPORT] Failed to archive commits
nsivabalan closed issue #3559: URL: https://github.com/apache/hudi/issues/3559 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] nsivabalan commented on issue #2802: Hive read issues when different partition have different schemas.
nsivabalan commented on issue #2802: URL: https://github.com/apache/hudi/issues/2802#issuecomment-946364855 @aditiwari01 : when you get a chance can you respond. Will close out in a week if we don't hear from you. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] nsivabalan commented on issue #3739: Hoodie clean is not deleting old files
nsivabalan commented on issue #3739: URL: https://github.com/apache/hudi/issues/3739#issuecomment-946363380 @codope : Can you create a ticket for adding ability via hudi-cli to clean up dangling data files. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (HUDI-2511) Aggressive archival configs compared to cleaner configs make cleaning moot
[ https://issues.apache.org/jira/browse/HUDI-2511?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] sivabalan narayanan updated HUDI-2511: -- Priority: Blocker (was: Major) > Aggressive archival configs compared to cleaner configs make cleaning moot > -- > > Key: HUDI-2511 > URL: https://issues.apache.org/jira/browse/HUDI-2511 > Project: Apache Hudi > Issue Type: Improvement >Reporter: sivabalan narayanan >Assignee: sivabalan narayanan >Priority: Blocker > Labels: sev:high, user-support-issues > > if hoodie.keep.max.commits <= hoodie.cleaner.commits.retained, then cleaner > will never kick in only. Bcoz, by then archival will kick in and will move > entries from active to archived. > We need to revisit this and either throw exception or make cleaner also look > into archived commits. > Related issue: [https://github.com/apache/hudi/issues/3739] > -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [hudi] nsivabalan closed issue #2564: Hoodie clean is not deleting old files
nsivabalan closed issue #2564: URL: https://github.com/apache/hudi/issues/2564 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] absognety edited a comment on issue #3758: [SUPPORT] Issues when writing dataframe to hudi format with hive syncing enabled for AWS Athena and Glue metadata persistence
absognety edited a comment on issue #3758: URL: https://github.com/apache/hudi/issues/3758#issuecomment-946311994 @nsivabalan I can confidently say that this is intermittently occurring issue, especially when we have concurrency in our code - doing concurrent writes to multiple tables in S3 (using threading or multiprocessing libraries). -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] absognety edited a comment on issue #3758: [SUPPORT] Issues when writing dataframe to hudi format with hive syncing enabled for AWS Athena and Glue metadata persistence
absognety edited a comment on issue #3758: URL: https://github.com/apache/hudi/issues/3758#issuecomment-946311994 @nsivabalan I can confidently say that this is intermittently occurring issue, especially when we have concurrency in our code - doing concurrent writes to different hudi partitions for multiple tables in S3 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot edited a comment on pull request #3519: [DO NOT MERGE] 0.9.0 release patch for flink
hudi-bot edited a comment on pull request #3519: URL: https://github.com/apache/hudi/pull/3519#issuecomment-903204631 ## CI report: * d108ef91b835ec89276863ac062bcc5cad6a2081 Azure: [CANCELED](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=2712) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run travis` re-run the last Travis build - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot edited a comment on pull request #3519: [DO NOT MERGE] 0.9.0 release patch for flink
hudi-bot edited a comment on pull request #3519: URL: https://github.com/apache/hudi/pull/3519#issuecomment-903204631 ## CI report: * c4ed928cfa949daca478608bee6046995b106c7d Azure: [CANCELED](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=2710) * d108ef91b835ec89276863ac062bcc5cad6a2081 UNKNOWN Bot commands @hudi-bot supports the following commands: - `@hudi-bot run travis` re-run the last Travis build - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] yanghua commented on pull request #3773: [HUDI-2507] Generate more dependency list file for other bundles
yanghua commented on pull request #3773: URL: https://github.com/apache/hudi/pull/3773#issuecomment-946329906 @vinothchandar Do you have any thoughts? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] yanghua commented on pull request #3773: [HUDI-2507] Generate more dependency list file for other bundles
yanghua commented on pull request #3773: URL: https://github.com/apache/hudi/pull/3773#issuecomment-946329594 > LGTM. Optional: maybe having a test PR to show what diffs people will get if changed/added a dependency can help understand the impact easily. sounds good, will try to write a guide and blog to explain how it works. Actually, I still did not figure out how to test it since the diff comes from the change of the dependencies. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot edited a comment on pull request #3519: [DO NOT MERGE] 0.9.0 release patch for flink
hudi-bot edited a comment on pull request #3519: URL: https://github.com/apache/hudi/pull/3519#issuecomment-903204631 ## CI report: * c4ed928cfa949daca478608bee6046995b106c7d Azure: [CANCELED](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=2710) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run travis` re-run the last Travis build - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot edited a comment on pull request #3519: [DO NOT MERGE] 0.9.0 release patch for flink
hudi-bot edited a comment on pull request #3519: URL: https://github.com/apache/hudi/pull/3519#issuecomment-903204631 ## CI report: * 0e29ebfbbc37cd342017bdd8290e34bf5336210d Azure: [SUCCESS](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=2702) * c4ed928cfa949daca478608bee6046995b106c7d UNKNOWN Bot commands @hudi-bot supports the following commands: - `@hudi-bot run travis` re-run the last Travis build - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Resolved] (HUDI-2572) Strength flink compaction rollback strategy
[ https://issues.apache.org/jira/browse/HUDI-2572?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Danny Chen resolved HUDI-2572. -- Resolution: Fixed Fixed via master branch: 3a78be9203a9c3cea33fa6120c89f7702275fc31 > Strength flink compaction rollback strategy > --- > > Key: HUDI-2572 > URL: https://issues.apache.org/jira/browse/HUDI-2572 > Project: Apache Hudi > Issue Type: Improvement > Components: Flink Integration >Reporter: Danny Chen >Assignee: Danny Chen >Priority: Major > Labels: pull-request-available > Fix For: 0.10.0 > > -- This message was sent by Atlassian Jira (v8.3.4#803005)
[hudi] branch master updated: [HUDI-2572] Strength flink compaction rollback strategy (#3819)
This is an automated email from the ASF dual-hosted git repository.
danny0405 pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/hudi.git
The following commit(s) were added to refs/heads/master by this push:
new 3a78be9 [HUDI-2572] Strength flink compaction rollback strategy
(#3819)
3a78be9 is described below
commit 3a78be9203a9c3cea33fa6120c89f7702275fc31
Author: Danny Chan
AuthorDate: Tue Oct 19 10:47:38 2021 +0800
[HUDI-2572] Strength flink compaction rollback strategy (#3819)
* make the events of commit task distinct by file id
* fix the existence check for inflight state file
* make the compaction task fail-safe
---
.../apache/hudi/sink/compact/CompactFunction.java | 2 +-
.../hudi/sink/compact/CompactionCommitEvent.java | 17 +++-
.../hudi/sink/compact/CompactionCommitSink.java| 47 +++---
.../hudi/sink/compact/CompactionPlanOperator.java | 27 +
4 files changed, 50 insertions(+), 43 deletions(-)
diff --git
a/hudi-flink/src/main/java/org/apache/hudi/sink/compact/CompactFunction.java
b/hudi-flink/src/main/java/org/apache/hudi/sink/compact/CompactFunction.java
index 5916244..57b79df 100644
--- a/hudi-flink/src/main/java/org/apache/hudi/sink/compact/CompactFunction.java
+++ b/hudi-flink/src/main/java/org/apache/hudi/sink/compact/CompactFunction.java
@@ -99,7 +99,7 @@ public class CompactFunction extends
ProcessFunction collector) throws
IOException {
List writeStatuses = FlinkCompactHelpers.compact(writeClient,
instantTime, compactionOperation);
-collector.collect(new CompactionCommitEvent(instantTime, writeStatuses,
taskID));
+collector.collect(new CompactionCommitEvent(instantTime,
compactionOperation.getFileId(), writeStatuses, taskID));
}
@VisibleForTesting
diff --git
a/hudi-flink/src/main/java/org/apache/hudi/sink/compact/CompactionCommitEvent.java
b/hudi-flink/src/main/java/org/apache/hudi/sink/compact/CompactionCommitEvent.java
index 52c0812..0444944 100644
---
a/hudi-flink/src/main/java/org/apache/hudi/sink/compact/CompactionCommitEvent.java
+++
b/hudi-flink/src/main/java/org/apache/hudi/sink/compact/CompactionCommitEvent.java
@@ -33,6 +33,12 @@ public class CompactionCommitEvent implements Serializable {
* The compaction commit instant time.
*/
private String instant;
+
+ /**
+ * The file ID.
+ */
+ private String fileId;
+
/**
* The write statuses.
*/
@@ -45,8 +51,9 @@ public class CompactionCommitEvent implements Serializable {
public CompactionCommitEvent() {
}
- public CompactionCommitEvent(String instant, List
writeStatuses, int taskID) {
+ public CompactionCommitEvent(String instant, String fileId,
List writeStatuses, int taskID) {
this.instant = instant;
+this.fileId = fileId;
this.writeStatuses = writeStatuses;
this.taskID = taskID;
}
@@ -55,6 +62,10 @@ public class CompactionCommitEvent implements Serializable {
this.instant = instant;
}
+ public void setFileId(String fileId) {
+this.fileId = fileId;
+ }
+
public void setWriteStatuses(List writeStatuses) {
this.writeStatuses = writeStatuses;
}
@@ -67,6 +78,10 @@ public class CompactionCommitEvent implements Serializable {
return instant;
}
+ public String getFileId() {
+return fileId;
+ }
+
public List getWriteStatuses() {
return writeStatuses;
}
diff --git
a/hudi-flink/src/main/java/org/apache/hudi/sink/compact/CompactionCommitSink.java
b/hudi-flink/src/main/java/org/apache/hudi/sink/compact/CompactionCommitSink.java
index e6c4ced..d90af2c 100644
---
a/hudi-flink/src/main/java/org/apache/hudi/sink/compact/CompactionCommitSink.java
+++
b/hudi-flink/src/main/java/org/apache/hudi/sink/compact/CompactionCommitSink.java
@@ -20,8 +20,6 @@ package org.apache.hudi.sink.compact;
import org.apache.hudi.avro.model.HoodieCompactionPlan;
import org.apache.hudi.client.WriteStatus;
-import org.apache.hudi.common.model.HoodieCommitMetadata;
-import org.apache.hudi.common.model.HoodieWriteStat;
import org.apache.hudi.common.util.CompactionUtils;
import org.apache.hudi.common.util.Option;
import org.apache.hudi.configuration.FlinkOptions;
@@ -33,7 +31,6 @@ import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.io.IOException;
-import java.util.ArrayList;
import java.util.Collection;
import java.util.HashMap;
import java.util.List;
@@ -61,9 +58,12 @@ public class CompactionCommitSink extends
CleanFunction {
/**
* Buffer to collect the event from each compact task {@code
CompactFunction}.
- * The key is the instant time.
+ *
+ * Stores the mapping of instant_time -> file_id -> event. Use a map to
collect the
+ * events because the rolling back of intermediate compaction tasks
generates corrupt
+ * events.
*/
- private transient Map> commitBuffer;
+ private transient Map>
commitBuffer;
public CompactionCommitSink(Configuration conf) {
[GitHub] [hudi] danny0405 merged pull request #3819: [HUDI-2572] Strength flink compaction rollback strategy
danny0405 merged pull request #3819: URL: https://github.com/apache/hudi/pull/3819 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (HUDI-2576) flink do checkpoint error because parquet file is missing
[ https://issues.apache.org/jira/browse/HUDI-2576?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17430282#comment-17430282 ] liyuanzhao435 commented on HUDI-2576: - the missing parquet file , either not created or deleted. according to the code, the file won't be deleted , so the reason is file not created but, there is no exception reported > flink do checkpoint error because parquet file is missing > -- > > Key: HUDI-2576 > URL: https://issues.apache.org/jira/browse/HUDI-2576 > Project: Apache Hudi > Issue Type: Bug > Components: Flink Integration >Affects Versions: 0.10.0 >Reporter: liyuanzhao435 >Priority: Major > Labels: flink, hudi > Fix For: 0.10.0 > > Attachments: error.txt > > Original Estimate: 96h > Remaining Estimate: 96h > > hudi:0.10.0, flink 1.13.1 > some times when flink do checkpoint , error occurs, the error shows a hudi > parquet file is missing (says file not exists) : > *2021-10-19 09:20:03,796 INFO > org.apache.hudi.io.storage.row.HoodieRowDataCreateHandle [] - start close > hoodie row data* > *2021-10-19 09:20:03,800 WARN org.apache.hadoop.hdfs.DataStreamer [] - > DataStreamer Exception* > *java.io.FileNotFoundException: File does not exist: > /tmp/test_liyz2/aa/2ff301cc-8db2-478e-b707-e8f2327ba38f-0_0-1-4_20211019091917.parquet > (inode 32234795) Holder DFSClient_NONMAPREDUCE_633610786_99 does not have > any open files.* > *at > org.apache.hadoop.hdfs.server.namenode.FSNamesystem.checkLease(FSNamesystem.java:2815)* > > detail see appendix -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [hudi] nsivabalan commented on pull request #3820: [BUGFIX] Merge commit state from previous commit instead of current
nsivabalan commented on pull request #3820: URL: https://github.com/apache/hudi/pull/3820#issuecomment-946312014 @davehagman let's proceed with the approach you suggested. If others have any thoughts, I can take it up in a follow up PR. but lets proceed with this for now. One more request: Do add a unit test for the changes in TransactionUtils. should be easy to add one. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] absognety commented on issue #3758: [SUPPORT] Issues when writing dataframe to hudi format with hive syncing enabled for AWS Athena and Glue metadata persistence
absognety commented on issue #3758: URL: https://github.com/apache/hudi/issues/3758#issuecomment-946311994 @nsivabalan I can confidently say that this is intermittently occurring issue, especially when we have concurrency in our code - doing concurrent writes to different hudi partitions in S3 . -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] rohit-m-99 opened a new issue #3821: [SUPPORT] Ingestion taking very long time getting small files from partitions/
rohit-m-99 opened a new issue #3821: URL: https://github.com/apache/hudi/issues/3821 **Describe the problem you faced** Currently running Hudi 0.9.0 in production without a specific partition field. We are running using 6 workers each with 7 cores and 28GB of RAM. The files are stored in S3. We run 50 `runs` each with about `4000` records. When then combine the runs into one dataframe, writing around 200k records at once using the `upsert` operation. Each record has around 280 columns. We see the majority of time being spent `GettingSmallFiles from partitions`. 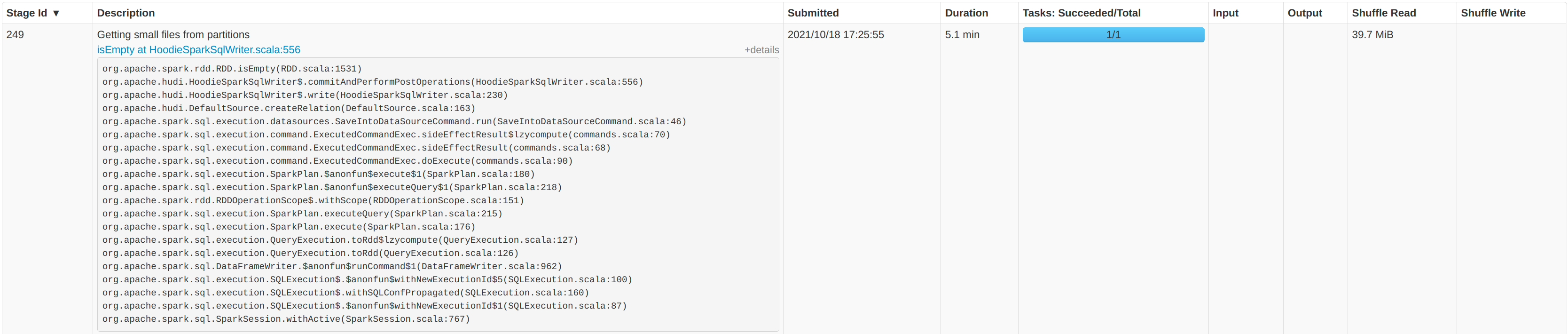 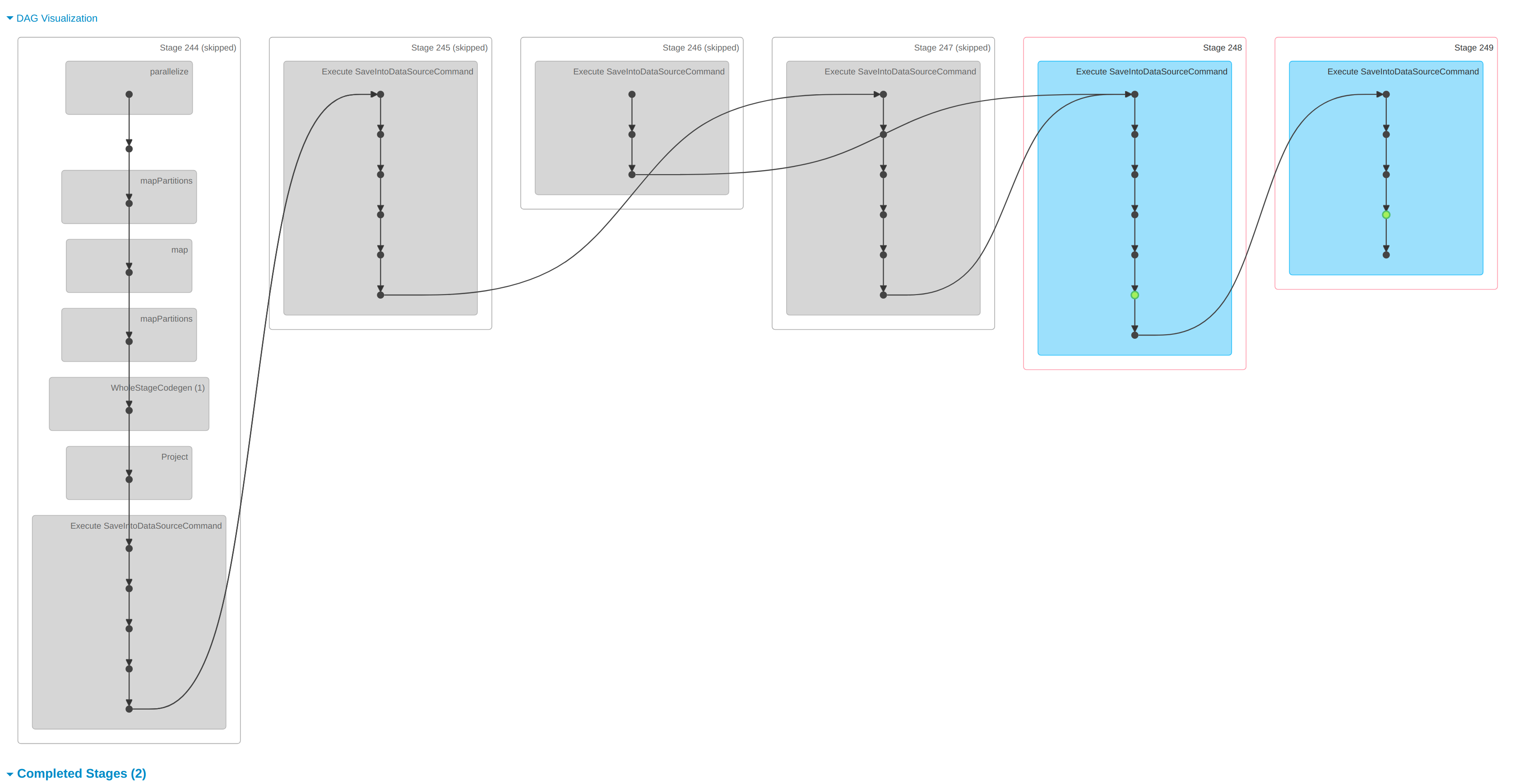  * Hudi version : spark_hudi_0.9.0-SNAPSHOT * Spark version : 3.0.3 * Hadoop version : 3.2.0 * Storage (HDFS/S3/GCS..) : S# * Running on Docker? (yes/no) : K8S -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (HUDI-2576) flink do checkpoint error because parquet file is missing
[ https://issues.apache.org/jira/browse/HUDI-2576?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] liyuanzhao435 updated HUDI-2576: Attachment: error.txt > flink do checkpoint error because parquet file is missing > -- > > Key: HUDI-2576 > URL: https://issues.apache.org/jira/browse/HUDI-2576 > Project: Apache Hudi > Issue Type: Bug > Components: Flink Integration >Affects Versions: 0.10.0 >Reporter: liyuanzhao435 >Priority: Major > Labels: flink, hudi > Fix For: 0.10.0 > > Attachments: error.txt > > Original Estimate: 96h > Remaining Estimate: 96h > > hudi:0.10.0, flink 1.13.1 > some times when flink do checkpoint , error occurs, the error shows a hudi > parquet file is missing (says file not exists) : > *2021-10-19 09:20:03,796 INFO > org.apache.hudi.io.storage.row.HoodieRowDataCreateHandle [] - start close > hoodie row data* > *2021-10-19 09:20:03,800 WARN org.apache.hadoop.hdfs.DataStreamer [] - > DataStreamer Exception* > *java.io.FileNotFoundException: File does not exist: > /tmp/test_liyz2/aa/2ff301cc-8db2-478e-b707-e8f2327ba38f-0_0-1-4_20211019091917.parquet > (inode 32234795) Holder DFSClient_NONMAPREDUCE_633610786_99 does not have > any open files.* > *at > org.apache.hadoop.hdfs.server.namenode.FSNamesystem.checkLease(FSNamesystem.java:2815)* > > detail see appendix -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Created] (HUDI-2576) flink do checkpoint error because parquet file is missing
liyuanzhao435 created HUDI-2576: --- Summary: flink do checkpoint error because parquet file is missing Key: HUDI-2576 URL: https://issues.apache.org/jira/browse/HUDI-2576 Project: Apache Hudi Issue Type: Bug Components: Flink Integration Affects Versions: 0.10.0 Reporter: liyuanzhao435 Fix For: 0.10.0 Attachments: error.txt hudi:0.10.0, flink 1.13.1 some times when flink do checkpoint , error occurs, the error shows a hudi parquet file is missing (says file not exists) : *2021-10-19 09:20:03,796 INFO org.apache.hudi.io.storage.row.HoodieRowDataCreateHandle [] - start close hoodie row data* *2021-10-19 09:20:03,800 WARN org.apache.hadoop.hdfs.DataStreamer [] - DataStreamer Exception* *java.io.FileNotFoundException: File does not exist: /tmp/test_liyz2/aa/2ff301cc-8db2-478e-b707-e8f2327ba38f-0_0-1-4_20211019091917.parquet (inode 32234795) Holder DFSClient_NONMAPREDUCE_633610786_99 does not have any open files.* *at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.checkLease(FSNamesystem.java:2815)* detail see appendix -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [hudi] nsivabalan commented on pull request #3820: [BUGFIX] Merge commit state from previous commit instead of current
nsivabalan commented on pull request #3820: URL: https://github.com/apache/hudi/pull/3820#issuecomment-946148718 yeah, the naming looks fine by me. btw, Can you please attach jira ticket to PR. prefix w/ ticket id. Especially for bugs, we need a tracking ticket. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[hudi] branch master updated (588a34a -> 335e80e)
This is an automated email from the ASF dual-hosted git repository. vinoth pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/hudi.git. from 588a34a [HUDI-2571] Remove include-flink-sql-connector-hive profile from flink bundle (#3818) add 335e80e [HUDI-2561] BitCaskDiskMap - avoiding hostname resolution when logging messages (#3811) No new revisions were added by this update. Summary of changes: .../java/org/apache/hudi/common/util/collection/BitCaskDiskMap.java | 5 + 1 file changed, 1 insertion(+), 4 deletions(-)
[GitHub] [hudi] davehagman commented on pull request #3820: [BUGFIX] Merge commit state from previous commit instead of current
davehagman commented on pull request #3820: URL: https://github.com/apache/hudi/pull/3820#issuecomment-946035803 I like that idea a lot. It reduces the chance of error as well. Here are some thoughts: > a new config called `hoodie.copy.over.deltastreamer.checkpoints` Since this is very specific to multi-writer/OCC what about putting it under the `concurrency` namespace? Something like `hoodie.write.concurrency.merge.deltastreamer.state`. This also removes the implementation detail of "checkpoint" in favor of a generalized "state" which will allow us to extend this to other keys in the future if necessary without needing more configs. > fetch value of "deltastreamer.checkpoint.key" from last committed transaction and copy to cur inflight commit extra metadata. Yea we can even re-use the existing code (still need my fix) that merges a key from the previous instant's metadata to the inflight (current) one. Now we will just make this access private and only expose a new method which is specific to copying over checkpoint state if the above config is set. Something like: `TransactionUtils.mergeCheckpointStateFromPreviousCommit(thisInstant, previousCommit)` this will ultimately just call the existing `overrideWithLatestCommitMetadata` (now private) specifically with the metadata key `deltastreamer.checkpoint.key`, successfully abstracting details and removing the need for users to know anything about the internal state of commits. Thoughts? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] nsivabalan edited a comment on pull request #3820: [BUGFIX] Merge commit state from previous commit instead of current
nsivabalan edited a comment on pull request #3820: URL: https://github.com/apache/hudi/pull/3820#issuecomment-946024720 thanks a lot for fixing this Dave. I would like to propose something here. I am wondering why do we need to retrofit copying over delta streamer checkpoint into logic meant for hoodie.write.meta.key.prefixes. to me, this new requirement is very simple and not really tied to `hoodie.write.meta.key.prefixes`. Let me propose something and see how that looks like. Introduce a new config called `hoodie.copy.over.deltastreamer.checkpoints`. we can brainstorm on actual naming later. When set to true, within TransactionUtils::overrideWithLatestCommitMetadata ``` fetch value of "deltastreamer.checkpoint.key" from last committed transaction and copy to cur inflight commit extra metadata. ``` This is very tight and not error prone. Users don't need to set two different config as below which is not very intuitive as to why they need to do this. ``` hoodie.write.meta.key.prefixes = 'deltastreamer.checkpoint.key' ``` and optionally ``` deltastreamer.checkpoint.key =. "" ``` All users have to do is, for all of their spark writers, they need to set `hoodie.copy.over.deltastreamer.checkpoints` to true. welcome thoughts @n3nash @vinothchandar @davehagman -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] nsivabalan edited a comment on pull request #3820: [BUGFIX] Merge commit state from previous commit instead of current
nsivabalan edited a comment on pull request #3820: URL: https://github.com/apache/hudi/pull/3820#issuecomment-946024720 thanks a lot for fixing this Dave. I would like to propose something here. I am wondering why do we need to retrofit copying over delta streamer checkpoint into hoodie.write.meta.key.prefixes. to me, this new requirement is very simple and not really tied to `hoodie.write.meta.key.prefixes`. Let me propose something and see how that looks like. Introduce a new config called `hoodie.copy.over.deltastreamer.checkpoints`. we can brainstorm on actual naming later. When set to true, within TransactionUtils::overrideWithLatestCommitMetadata ``` fetch value of "deltastreamer.checkpoint.key" from last committed transaction and copy to cur inflight commit extra metadata. ``` This is very tight and not error prone. Users don't need to set two different config as below which is not very intuitive as to why they need to do this. ``` hoodie.write.meta.key.prefixes = 'deltastreamer.checkpoint.key' ``` and optionally ``` deltastreamer.checkpoint.key =. "" ``` All users have to do is, for all of their spark writers, they need to set `hoodie.copy.over.deltastreamer.checkpoints` to true. welcome thoughts @n3nash @vinothchandar @davehagman -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] nsivabalan commented on pull request #3820: [BUGFIX] Merge commit state from previous commit instead of current
nsivabalan commented on pull request #3820: URL: https://github.com/apache/hudi/pull/3820#issuecomment-946024720 thanks a lot for fixing this Dave. I would like to propose something here. I am wondering why do we need to retrofit copying over delta streamer checkpoint into hoodie.write.meta.key.prefixes. to me, this new requirement is very simple and not really tied to `hoodie.write.meta.key.prefixes`. Let me propose something and see how that looks like. Introduce a new config called `hoodie.copy.over.deltastreamer.checkpoints`. we can brainstorm on actual naming later. When set to true, within TransactionUtils::overrideWithLatestCommitMetadata ``` fetch value of "deltastreamer.checkpoint.key" from last committed transaction and copy to cur inflight commit extra metadata. ``` This is very tight and not error prone. Users don't need to set two different config as below which is not very intuitive as to why they need to do this. ``` hoodie.write.meta.key.prefixes = 'deltastreamer.checkpoint.key' ``` and optionally ``` deltastreamer.checkpoint.key =. "" ``` All users have to do is, for all of their spark writers, they need to set `hoodie.copy.over.deltastreamer.checkpoints` to true. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot edited a comment on pull request #3820: [BUGFIX] Merge commit state from previous commit instead of current
hudi-bot edited a comment on pull request #3820: URL: https://github.com/apache/hudi/pull/3820#issuecomment-945958915 ## CI report: * 8de6afb8a205a41de2a4b214c8982488b2b8ec19 Azure: [SUCCESS](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=2708) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run travis` re-run the last Travis build - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] vinothchandar merged pull request #3811: [HUDI-2561] BitCaskDiskMap - avoiding hostname resolution when logging messages
vinothchandar merged pull request #3811: URL: https://github.com/apache/hudi/pull/3811 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] xushiyan commented on pull request #3781: [HUDI-2540] Fixed wrong validation for metadataTableEnabled in HoodieTable
xushiyan commented on pull request #3781: URL: https://github.com/apache/hudi/pull/3781#issuecomment-945974656 @RocMarshal for this PR's failure, it's most likely based on an impacted master build. you may want to rebase next time to stay on top of master. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (HUDI-2573) Deadlock w/ multi writer due to double locking
[ https://issues.apache.org/jira/browse/HUDI-2573?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] sivabalan narayanan updated HUDI-2573: -- Priority: Blocker (was: Major) > Deadlock w/ multi writer due to double locking > -- > > Key: HUDI-2573 > URL: https://issues.apache.org/jira/browse/HUDI-2573 > Project: Apache Hudi > Issue Type: Sub-task >Reporter: sivabalan narayanan >Assignee: sivabalan narayanan >Priority: Blocker > Labels: release-blocker, sev:critical > Fix For: 0.10.0 > > > With synchronous metadata patch, we added locking for cleaning and rollbacks. > but there are code paths, where we do double locking and hence it hangs or > fails after sometime. > > inline cleaning enabled. > > C1 acquires lock. > post commit -> triggers cleaning. > cleaning again tries to acquire lock when about to > commit and this is problematic. > > Also, when upgrade is needed, we take a lock and rollback failed writes. this > again will run into issues w/ double locking. > > > -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Updated] (HUDI-2559) Ensure unique timestamps are generated for commit times with concurrent writers
[
https://issues.apache.org/jira/browse/HUDI-2559?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
sivabalan narayanan updated HUDI-2559:
--
Priority: Blocker (was: Major)
> Ensure unique timestamps are generated for commit times with concurrent
> writers
> ---
>
> Key: HUDI-2559
> URL: https://issues.apache.org/jira/browse/HUDI-2559
> Project: Apache Hudi
> Issue Type: Sub-task
>Reporter: sivabalan narayanan
>Assignee: sivabalan narayanan
>Priority: Blocker
> Labels: release-blocker, sev:critical
>
> Ensure unique timestamps are generated for commit times with concurrent
> writers.
> this is the piece of code in HoodieActiveTimeline which creates a new commit
> time.
> {code:java}
> public static String createNewInstantTime(long milliseconds) {
> return lastInstantTime.updateAndGet((oldVal) -> {
> String newCommitTime;
> do {
> newCommitTime = HoodieActiveTimeline.COMMIT_FORMATTER.format(new
> Date(System.currentTimeMillis() + milliseconds));
> } while (HoodieTimeline.compareTimestamps(newCommitTime,
> LESSER_THAN_OR_EQUALS, oldVal));
> return newCommitTime;
> });
> }
> {code}
> There are chances that a deltastreamer and a concurrent spark ds writer gets
> same timestamp and one of them fails.
> Related issues and github jiras:
> [https://github.com/apache/hudi/issues/3782]
> https://issues.apache.org/jira/browse/HUDI-2549
>
>
>
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Updated] (HUDI-2573) Deadlock w/ multi writer due to double locking
[ https://issues.apache.org/jira/browse/HUDI-2573?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] sivabalan narayanan updated HUDI-2573: -- Parent: HUDI-1292 Issue Type: Sub-task (was: Bug) > Deadlock w/ multi writer due to double locking > -- > > Key: HUDI-2573 > URL: https://issues.apache.org/jira/browse/HUDI-2573 > Project: Apache Hudi > Issue Type: Sub-task >Reporter: sivabalan narayanan >Assignee: sivabalan narayanan >Priority: Major > Labels: release-blocker, sev:critical > Fix For: 0.10.0 > > > With synchronous metadata patch, we added locking for cleaning and rollbacks. > but there are code paths, where we do double locking and hence it hangs or > fails after sometime. > > inline cleaning enabled. > > C1 acquires lock. > post commit -> triggers cleaning. > cleaning again tries to acquire lock when about to > commit and this is problematic. > > Also, when upgrade is needed, we take a lock and rollback failed writes. this > again will run into issues w/ double locking. > > > -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Updated] (HUDI-2559) Ensure unique timestamps are generated for commit times with concurrent writers
[
https://issues.apache.org/jira/browse/HUDI-2559?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
sivabalan narayanan updated HUDI-2559:
--
Parent: HUDI-1292
Issue Type: Sub-task (was: Improvement)
> Ensure unique timestamps are generated for commit times with concurrent
> writers
> ---
>
> Key: HUDI-2559
> URL: https://issues.apache.org/jira/browse/HUDI-2559
> Project: Apache Hudi
> Issue Type: Sub-task
>Reporter: sivabalan narayanan
>Assignee: sivabalan narayanan
>Priority: Major
> Labels: release-blocker, sev:critical
>
> Ensure unique timestamps are generated for commit times with concurrent
> writers.
> this is the piece of code in HoodieActiveTimeline which creates a new commit
> time.
> {code:java}
> public static String createNewInstantTime(long milliseconds) {
> return lastInstantTime.updateAndGet((oldVal) -> {
> String newCommitTime;
> do {
> newCommitTime = HoodieActiveTimeline.COMMIT_FORMATTER.format(new
> Date(System.currentTimeMillis() + milliseconds));
> } while (HoodieTimeline.compareTimestamps(newCommitTime,
> LESSER_THAN_OR_EQUALS, oldVal));
> return newCommitTime;
> });
> }
> {code}
> There are chances that a deltastreamer and a concurrent spark ds writer gets
> same timestamp and one of them fails.
> Related issues and github jiras:
> [https://github.com/apache/hudi/issues/3782]
> https://issues.apache.org/jira/browse/HUDI-2549
>
>
>
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [hudi] hudi-bot edited a comment on pull request #3820: [BUGFIX] Merge commit state from previous commit instead of current
hudi-bot edited a comment on pull request #3820: URL: https://github.com/apache/hudi/pull/3820#issuecomment-945958915 ## CI report: * 8de6afb8a205a41de2a4b214c8982488b2b8ec19 Azure: [PENDING](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=2708) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run travis` re-run the last Travis build - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] davehagman commented on pull request #3820: [BUGFIX] Merge commit state from previous commit instead of current
davehagman commented on pull request #3820: URL: https://github.com/apache/hudi/pull/3820#issuecomment-945961702 I also noticed that there isn't any documentation around `hoodie.write.meta.key.prefixes` config in the multi-writer docs. We should add something about it since it is very important if you're multi-writer table includes a deltastreamer. Thoughts? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #3820: [BUGFIX] Merge commit state from previous commit instead of current
hudi-bot commented on pull request #3820: URL: https://github.com/apache/hudi/pull/3820#issuecomment-945958915 ## CI report: * 8de6afb8a205a41de2a4b214c8982488b2b8ec19 UNKNOWN Bot commands @hudi-bot supports the following commands: - `@hudi-bot run travis` re-run the last Travis build - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (HUDI-2573) Deadlock w/ multi writer due to double locking
[ https://issues.apache.org/jira/browse/HUDI-2573?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] sivabalan narayanan updated HUDI-2573: -- Labels: release-blocker sev:critical (was: ) > Deadlock w/ multi writer due to double locking > -- > > Key: HUDI-2573 > URL: https://issues.apache.org/jira/browse/HUDI-2573 > Project: Apache Hudi > Issue Type: Bug >Reporter: sivabalan narayanan >Assignee: sivabalan narayanan >Priority: Major > Labels: release-blocker, sev:critical > Fix For: 0.10.0 > > > With synchronous metadata patch, we added locking for cleaning and rollbacks. > but there are code paths, where we do double locking and hence it hangs or > fails after sometime. > > inline cleaning enabled. > > C1 acquires lock. > post commit -> triggers cleaning. > cleaning again tries to acquire lock when about to > commit and this is problematic. > > Also, when upgrade is needed, we take a lock and rollback failed writes. this > again will run into issues w/ double locking. > > > -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Updated] (HUDI-2559) Ensure unique timestamps are generated for commit times with concurrent writers
[
https://issues.apache.org/jira/browse/HUDI-2559?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
sivabalan narayanan updated HUDI-2559:
--
Labels: release-blocker sev:critical (was: )
> Ensure unique timestamps are generated for commit times with concurrent
> writers
> ---
>
> Key: HUDI-2559
> URL: https://issues.apache.org/jira/browse/HUDI-2559
> Project: Apache Hudi
> Issue Type: Improvement
>Reporter: sivabalan narayanan
>Assignee: sivabalan narayanan
>Priority: Major
> Labels: release-blocker, sev:critical
>
> Ensure unique timestamps are generated for commit times with concurrent
> writers.
> this is the piece of code in HoodieActiveTimeline which creates a new commit
> time.
> {code:java}
> public static String createNewInstantTime(long milliseconds) {
> return lastInstantTime.updateAndGet((oldVal) -> {
> String newCommitTime;
> do {
> newCommitTime = HoodieActiveTimeline.COMMIT_FORMATTER.format(new
> Date(System.currentTimeMillis() + milliseconds));
> } while (HoodieTimeline.compareTimestamps(newCommitTime,
> LESSER_THAN_OR_EQUALS, oldVal));
> return newCommitTime;
> });
> }
> {code}
> There are chances that a deltastreamer and a concurrent spark ds writer gets
> same timestamp and one of them fails.
> Related issues and github jiras:
> [https://github.com/apache/hudi/issues/3782]
> https://issues.apache.org/jira/browse/HUDI-2549
>
>
>
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Updated] (HUDI-1912) Presto defaults to GenericHiveRecordCursor for all Hudi tables
[
https://issues.apache.org/jira/browse/HUDI-1912?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Sagar Sumit updated HUDI-1912:
--
Status: Patch Available (was: In Progress)
> Presto defaults to GenericHiveRecordCursor for all Hudi tables
> --
>
> Key: HUDI-1912
> URL: https://issues.apache.org/jira/browse/HUDI-1912
> Project: Apache Hudi
> Issue Type: Sub-task
> Components: Presto Integration
>Affects Versions: 0.7.0
>Reporter: satish
>Assignee: Sagar Sumit
>Priority: Blocker
> Fix For: 0.10.0
>
>
> See code here
> https://github.com/prestodb/presto/blob/2ad67dcf000be86ebc5ff7732bbb9994c8e324a8/presto-hive/src/main/java/com/facebook/presto/hive/parquet/ParquetPageSourceFactory.java#L168
> Starting Hudi 0.7, HoodieInputFormat comes with
> UseRecordReaderFromInputFormat annotation. As a result, we are skipping all
> optimizations in parquet PageSource and using basic GenericHiveRecordCursor
> which has several limitations:
> 1) No support for timestamp
> 2) No support for synthesized columns
> 3) No support for vectorized reading?
> Example errors we saw:
> Error#1
> {code}
> java.lang.IllegalStateException: column type must be regular
> at
> com.google.common.base.Preconditions.checkState(Preconditions.java:507)
> at
> com.facebook.presto.hive.GenericHiveRecordCursor.(GenericHiveRecordCursor.java:167)
> at
> com.facebook.presto.hive.GenericHiveRecordCursorProvider.createRecordCursor(GenericHiveRecordCursorProvider.java:79)
> at
> com.facebook.presto.hive.HivePageSourceProvider.createHivePageSource(HivePageSourceProvider.java:449)
> at
> com.facebook.presto.hive.HivePageSourceProvider.createPageSource(HivePageSourceProvider.java:177)
> at
> com.facebook.presto.spi.connector.classloader.ClassLoaderSafeConnectorPageSourceProvider.createPageSource(ClassLoaderSafeConnectorPageSourceProvider.java:63)
> at
> com.facebook.presto.split.PageSourceManager.createPageSource(PageSourceManager.java:80)
> at
> com.facebook.presto.operator.ScanFilterAndProjectOperator.getOutput(ScanFilterAndProjectOperator.java:231)
> at com.facebook.presto.operator.Driver.processInternal(Driver.java:418)
> at
> com.facebook.presto.operator.Driver.lambda$processFor$9(Driver.java:301)
> at com.facebook.presto.operator.Driver.tryWithLock(Driver.java:722)
> at com.facebook.presto.operator.Driver.processFor(Driver.java:294)
> at
> com.facebook.presto.execution.SqlTaskExecution$DriverSplitRunner.processFor(SqlTaskExecution.java:1077)
> at
> com.facebook.presto.execution.executor.PrioritizedSplitRunner.process(PrioritizedSplitRunner.java:162)
> at
> com.facebook.presto.execution.executor.TaskExecutor$TaskRunner.run(TaskExecutor.java:545)
> at
> com.facebook.presto.$gen.Presto_0_247_17f857e20210506_210241_1.run(Unknown
> Source)
> at
> java.base/java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1128)
> at
> java.base/java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:628)
> at java.base/java.lang.Thread.run(Thread.java:834)
> {code}
> Error#2
> {code}
> java.lang.ClassCastException: class org.apache.hadoop.io.LongWritable cannot
> be cast to class org.apache.hadoop.hive.serde2.io.TimestampWritable
> (org.apache.hadoop.io.LongWritable and
> org.apache.hadoop.hive.serde2.io.TimestampWritable are in unnamed module of
> loader com.facebook.presto.server.PluginClassLoader @5c4e86e7)
> at
> org.apache.hadoop.hive.serde2.objectinspector.primitive.WritableTimestampObjectInspector.getPrimitiveJavaObject(WritableTimestampObjectInspector.java:39)
> at
> org.apache.hadoop.hive.serde2.objectinspector.primitive.WritableTimestampObjectInspector.getPrimitiveJavaObject(WritableTimestampObjectInspector.java:25)
> at
> com.facebook.presto.hive.GenericHiveRecordCursor.parseLongColumn(GenericHiveRecordCursor.java:286)
> at
> com.facebook.presto.hive.GenericHiveRecordCursor.parseColumn(GenericHiveRecordCursor.java:550)
> at
> com.facebook.presto.hive.GenericHiveRecordCursor.isNull(GenericHiveRecordCursor.java:508)
> at
> com.facebook.presto.hive.HiveRecordCursor.isNull(HiveRecordCursor.java:233)
> at
> com.facebook.presto.spi.RecordPageSource.getNextPage(RecordPageSource.java:112)
> at
> com.facebook.presto.operator.TableScanOperator.getOutput(TableScanOperator.java:251)
> at com.facebook.presto.operator.Driver.processInternal(Driver.java:418)
> at
> com.facebook.presto.operator.Driver.lambda$processFor$9(Driver.java:301)
> at com.facebook.presto.operator.Driver.tryWithLock(Driver.java:722)
> at com.facebook.presto.operator.Driver.processFor(Driver.java:294)
>
[jira] [Updated] (HUDI-1856) Upstream changes made in PrestoDB to eliminate file listing to Trino
[ https://issues.apache.org/jira/browse/HUDI-1856?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Sagar Sumit updated HUDI-1856: -- Status: Patch Available (was: In Progress) > Upstream changes made in PrestoDB to eliminate file listing to Trino > > > Key: HUDI-1856 > URL: https://issues.apache.org/jira/browse/HUDI-1856 > Project: Apache Hudi > Issue Type: Sub-task >Reporter: Nishith Agarwal >Assignee: Sagar Sumit >Priority: Blocker > Labels: sev:high, sev:triage > Fix For: 0.10.0 > > > inputFormat.getSplits() code was optimized for PrestoDB code base. This > change is not implemented / upstreamed in Trino. > > Additionally, there are other changes that need to be upstreamed in Trino. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Updated] (HUDI-1500) Support incrementally reading clustering commit via Spark Datasource/DeltaStreamer
[ https://issues.apache.org/jira/browse/HUDI-1500?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Sagar Sumit updated HUDI-1500: -- Status: Patch Available (was: In Progress) > Support incrementally reading clustering commit via Spark > Datasource/DeltaStreamer > --- > > Key: HUDI-1500 > URL: https://issues.apache.org/jira/browse/HUDI-1500 > Project: Apache Hudi > Issue Type: Sub-task > Components: DeltaStreamer, Spark Integration >Reporter: liwei >Assignee: Sagar Sumit >Priority: Blocker > Labels: pull-request-available > Fix For: 0.10.0 > > > now in DeltaSync.readFromSource() can not read last instant as replace > commit, such as clustering. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [hudi] davehagman commented on pull request #3820: [BUGFIX] Merge commit state from previous commit instead of current
davehagman commented on pull request #3820: URL: https://github.com/apache/hudi/pull/3820#issuecomment-945952200 Also worth noting that the config used to determine which keys are merged from the past commit into the current one is generic (`hoodie.write.meta.key.prefixes`). At the moment I know of only one use for this which is to copy over the checkpoint data from deltastreamer commits but with this fix we can copy over any data from the previous commit to the current one. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (HUDI-2287) Partition pruning not working on Hudi dataset
[
https://issues.apache.org/jira/browse/HUDI-2287?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
sivabalan narayanan updated HUDI-2287:
--
Remaining Estimate: 24h
Original Estimate: 24h
> Partition pruning not working on Hudi dataset
> -
>
> Key: HUDI-2287
> URL: https://issues.apache.org/jira/browse/HUDI-2287
> Project: Apache Hudi
> Issue Type: Sub-task
> Components: Performance
>Reporter: Rajkumar Gunasekaran
>Assignee: Raymond Xu
>Priority: Blocker
> Fix For: 0.10.0
>
> Original Estimate: 24h
> Remaining Estimate: 24h
>
> Hi, we have created a Hudi dataset which has two level partition like this
> {code:java}
> s3://somes3bucket/partition1=value/partition2=value
> {code}
> where _partition1_ and _partition2_ is of type string
> When running a simple count query using Hudi format in spark-shell, it takes
> almost 3 minutes to complete
>
> {code:scala}
> spark.read.format("hudi").load("s3://somes3bucket").
> where("partition1 = 'somevalue' and partition2 = 'somevalue'").
> count()
>
> res1: Long =
> attempt 1: 3.2 minutes
> attempt 2: 2.5 minutes
> {code}
> In the Spark UI ~9000 tasks (which is approximately equivalent to the total
> no of files in the ENTIRE dataset s3://somes3bucket) are used for
> computation. Seems like spark is reading the entire dataset instead of
> *partition pruning.*...and then filtering the dataset based on the where
> clause
> Whereas, if I use the parquet format to read the dataset, the query only
> takes ~30 seconds (vis-a-vis 3 minutes with Hudi format)
> {code:scala}
> spark.read.parquet("s3://somes3bucket").
> where("partition1 = 'somevalue' and partition2 = 'somevalue'").
> count()
> res2: Long =
> ~ 30 seconds
> {code}
> In the spark UI, only 1361 (ie 1361 tasks) files are scanned (vis-a-vis ~9000
> files in Hudi) and takes only 15 seconds
> Any idea why partition pruning is not working when using Hudi format?
> Wondering if I am missing any configuration during the creation of the
> dataset?
> PS: I ran this query in emr-6.3.0 which has Hudi version 0.7.0 and here is
> the configuration I have used for creating the dataset
> {code:scala}
> df.writeStream
> .trigger(Trigger.ProcessingTime(s"${param.triggerTimeInSeconds} seconds"))
> .partitionBy("partition1","partition2")
> .format("org.apache.hudi")
> .option(HoodieWriteConfig.TABLE_NAME, param.hiveNHudiTableName.get)
> //--
> .option(HoodieStorageConfig.PARQUET_COMPRESSION_CODEC, "snappy")
> .option(HoodieStorageConfig.PARQUET_FILE_MAX_BYTES,
> param.expectedFileSizeInBytes)
> .option(HoodieStorageConfig.PARQUET_BLOCK_SIZE_BYTES,
> HoodieStorageConfig.DEFAULT_PARQUET_BLOCK_SIZE_BYTES)
> //--
> .option(HoodieCompactionConfig.PARQUET_SMALL_FILE_LIMIT_BYTES,
> (param.expectedFileSizeInBytes / 100) * 80)
> .option(HoodieCompactionConfig.INLINE_COMPACT_PROP, "true")
> .option(HoodieCompactionConfig.INLINE_COMPACT_NUM_DELTA_COMMITS_PROP,
> param.runCompactionAfterNDeltaCommits.get)
> //--
> .option(DataSourceWriteOptions.TABLE_TYPE_OPT_KEY,
> DataSourceWriteOptions.MOR_TABLE_TYPE_OPT_VAL)
> .option(DataSourceWriteOptions.RECORDKEY_FIELD_OPT_KEY, "record_key_id")
> .option(DataSourceWriteOptions.KEYGENERATOR_CLASS_OPT_KEY,
> classOf[CustomKeyGenerator].getName)
> .option(DataSourceWriteOptions.PARTITIONPATH_FIELD_OPT_KEY,
> "partition1:SIMPLE,partition2:SIMPLE")
> .option(DataSourceWriteOptions.OPERATION_OPT_KEY,
> DataSourceWriteOptions.UPSERT_OPERATION_OPT_VAL)
> .option(DataSourceWriteOptions.PRECOMBINE_FIELD_OPT_KEY,
> hudiTablePrecombineKey)
> .option(DataSourceWriteOptions.HIVE_SYNC_ENABLED_OPT_KEY, "true")
> //.option(DataSourceWriteOptions.HIVE_USE_JDBC_OPT_KEY, "false")
> .option(DataSourceWriteOptions.HIVE_STYLE_PARTITIONING_OPT_KEY, "true")
> .option(DataSourceWriteOptions.HIVE_PARTITION_FIELDS_OPT_KEY,
> "partition1,partition2")
> .option(DataSourceWriteOptions.HIVE_DATABASE_OPT_KEY, param.hiveDb.get)
> .option(DataSourceWriteOptions.HIVE_TABLE_OPT_KEY,
> param.hiveNHudiTableName.get)
> .option(DataSourceWriteOptions.HIVE_PARTITION_EXTRACTOR_CLASS_OPT_KEY,
> classOf[MultiPartKeysValueExtractor].getName)
> .outputMode(OutputMode.Append())
> .queryName(s"${param.hiveDb}_${param.hiveNHudiTableName}_query"){code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [hudi] davehagman opened a new pull request #3820: [BUGFIX] Merge commit state from previous instant instead of current
davehagman opened a new pull request #3820: URL: https://github.com/apache/hudi/pull/3820 ## What is the purpose of the pull request In order to support multi-writer concurrency where one writer is the Deltastreamer, other writers must copy any checkpoint state from previous commits into their current one in order to prevent interleaved commits from crashing the deltastreamer. The code that does this did the following (before this change): * Get all the keys for the *current* inflight commit metadata * Filter out any keys that are not specified in the metadata config (a list of keys to replace) * For keys that exist in the current metadata, pull the data for that key from the *previous* commit and replace the current commit's metadata property value with that value This does not work because a non-deltastreamer writer (such as a spark datasource writer) will never have the checkpoint key specified in its commit metadata (`deltastreamer.checkpoint.key`) which results in a commit in the timeline that does not have checkpoint state. If the deltastreamer tries to start from that commit it will fail. This fixes that by changing the keyset that is filtered from the current commit to the previous commit. This fixes two issues: 1. Checkpoint state is copied over from a previous commit which was made by the deltastreamer 2. If the deltastreamer process fails or is stopped for a prolonged period of time, the non-deltastreamer writers will continue to carry over the checkpoint state which will allow the deltastreamer to correctly start from its last known position ## Brief change log *(for example:)* - *Modify `TransactionUtils::overrideWithLatestCommitMetadata` to pull the keys from the last commit instead of the current commit* ## Verify this pull request * Manually verified the change by running multiple writers against the same table * Writer One: Deltastreamer, kafka source * Writer Two: Spark datasource, event data from existing hudi table * Verified zero errors from deltastreamer over hundreds of interleaved commits * Shut down deltastreamer for a prolonged period, then verified that I could start it back up without losing its position in kafka (checkpoint state in tact on recent commits) ## Committer checklist - [x ] Has a corresponding JIRA in PR title & commit - [x] Commit message is descriptive of the change - [ ] CI is green - [ x] Necessary doc changes done or have another open PR -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (HUDI-2575) [UMBRELLA] Revamp CI bot
[
https://issues.apache.org/jira/browse/HUDI-2575?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17430073#comment-17430073
]
Raymond Xu commented on HUDI-2575:
--
from [~codope]
{quote}c) Apart from what you have already listed, may I also suggest a
[cc-bot|https://github.com/pytorch/pytorch/issues/24422] by which not just
PMC/committers but anyone in the community interested in following some story
gets tagged on the issue automatically.
PyTorch is a really big open source project. I found the following two posts a
good-read for maintaining such big projects in general.More on
principles/philosophy:
[https://soumith.ch/posts/2021/02/growing-opensource/]More on scaling
operationally: [http://blog.ezyang.com/2021/01/pytorch-open-source-process/]
{quote}
> [UMBRELLA] Revamp CI bot
> -
>
> Key: HUDI-2575
> URL: https://issues.apache.org/jira/browse/HUDI-2575
> Project: Apache Hudi
> Issue Type: New Feature
> Components: Testing
>Reporter: Raymond Xu
>Priority: Major
>
> Improvement ideas
> * it should periodically scan GH issues and auto close upon some condition
> (e.g. “block on user” and no response from last comment in 30 days)
> * it should help auto close or follow up on JIRAs upon some condition (yet
> to define)
> * PR test build is a pull model by periodic scanning PRs; better to use a
> push model to react to PR updates immediately like to trigger a build. Reduce
> a few min wait time
> * for every new commit, it should append a comment show new report
> “pending”; it should also update the same comment to show report results once
> build is done
> * a new commit or a force push should cancel previous build job and start a
> new job
> * users don’t need to use {{@hudi-bot run azure}}
> * it can also report back codecov reports once integrate with codecov in the
> mirror repo
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Updated] (HUDI-2575) [UMBRELLA] Revamp CI bot
[
https://issues.apache.org/jira/browse/HUDI-2575?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Raymond Xu updated HUDI-2575:
-
Component/s: Testing
> [UMBRELLA] Revamp CI bot
> -
>
> Key: HUDI-2575
> URL: https://issues.apache.org/jira/browse/HUDI-2575
> Project: Apache Hudi
> Issue Type: New Feature
> Components: Testing
>Reporter: Raymond Xu
>Priority: Major
>
> Improvement ideas
> * it should periodically scan GH issues and auto close upon some condition
> (e.g. “block on user” and no response from last comment in 30 days)
> * it should help auto close or follow up on JIRAs upon some condition (yet
> to define)
> * PR test build is a pull model by periodic scanning PRs; better to use a
> push model to react to PR updates immediately like to trigger a build. Reduce
> a few min wait time
> * for every new commit, it should append a comment show new report
> “pending”; it should also update the same comment to show report results once
> build is done
> * a new commit or a force push should cancel previous build job and start a
> new job
> * users don’t need to use {{@hudi-bot run azure}}
> * it can also report back codecov reports once integrate with codecov in the
> mirror repo
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Created] (HUDI-2575) [UMBRELLA] Revamp CI bot
Raymond Xu created HUDI-2575:
Summary: [UMBRELLA] Revamp CI bot
Key: HUDI-2575
URL: https://issues.apache.org/jira/browse/HUDI-2575
Project: Apache Hudi
Issue Type: New Feature
Reporter: Raymond Xu
Improvement ideas
* it should periodically scan GH issues and auto close upon some condition
(e.g. “block on user” and no response from last comment in 30 days)
* it should help auto close or follow up on JIRAs upon some condition (yet to
define)
* PR test build is a pull model by periodic scanning PRs; better to use a push
model to react to PR updates immediately like to trigger a build. Reduce a few
min wait time
* for every new commit, it should append a comment show new report “pending”;
it should also update the same comment to show report results once build is done
* a new commit or a force push should cancel previous build job and start a
new job
* users don’t need to use {{@hudi-bot run azure}}
* it can also report back codecov reports once integrate with codecov in the
mirror repo
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Updated] (HUDI-1183) PrestoDB dependency on Apache Hudi
[ https://issues.apache.org/jira/browse/HUDI-1183?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Sagar Sumit updated HUDI-1183: -- Parent: HUDI-2574 Issue Type: Sub-task (was: Improvement) > PrestoDB dependency on Apache Hudi > -- > > Key: HUDI-1183 > URL: https://issues.apache.org/jira/browse/HUDI-1183 > Project: Apache Hudi > Issue Type: Sub-task > Components: Presto Integration >Affects Versions: 0.9.0 >Reporter: Bhavani Sudha >Priority: Blocker > Fix For: 0.10.0 > > > Presto versions 0.232 and below depend on a bundle being dropped into the > presto plugin directories for integrating Hudi. From 0.233 we introduced > compile time dependency on `hudi-hadoop-mr`. The compile time dependency > works fine for snapshot queries and MOR queries on regular Hudi tables. For > due to some runtime issues that require shading of jars, we would rather > prefer the dependency on presto bundle instead. This Jira is to track this > gap and identify how we want to proceed forward. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Updated] (HUDI-1912) Presto defaults to GenericHiveRecordCursor for all Hudi tables
[
https://issues.apache.org/jira/browse/HUDI-1912?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Sagar Sumit updated HUDI-1912:
--
Parent: HUDI-2574
Issue Type: Sub-task (was: Bug)
> Presto defaults to GenericHiveRecordCursor for all Hudi tables
> --
>
> Key: HUDI-1912
> URL: https://issues.apache.org/jira/browse/HUDI-1912
> Project: Apache Hudi
> Issue Type: Sub-task
> Components: Presto Integration
>Affects Versions: 0.7.0
>Reporter: satish
>Assignee: Sagar Sumit
>Priority: Blocker
> Fix For: 0.10.0
>
>
> See code here
> https://github.com/prestodb/presto/blob/2ad67dcf000be86ebc5ff7732bbb9994c8e324a8/presto-hive/src/main/java/com/facebook/presto/hive/parquet/ParquetPageSourceFactory.java#L168
> Starting Hudi 0.7, HoodieInputFormat comes with
> UseRecordReaderFromInputFormat annotation. As a result, we are skipping all
> optimizations in parquet PageSource and using basic GenericHiveRecordCursor
> which has several limitations:
> 1) No support for timestamp
> 2) No support for synthesized columns
> 3) No support for vectorized reading?
> Example errors we saw:
> Error#1
> {code}
> java.lang.IllegalStateException: column type must be regular
> at
> com.google.common.base.Preconditions.checkState(Preconditions.java:507)
> at
> com.facebook.presto.hive.GenericHiveRecordCursor.(GenericHiveRecordCursor.java:167)
> at
> com.facebook.presto.hive.GenericHiveRecordCursorProvider.createRecordCursor(GenericHiveRecordCursorProvider.java:79)
> at
> com.facebook.presto.hive.HivePageSourceProvider.createHivePageSource(HivePageSourceProvider.java:449)
> at
> com.facebook.presto.hive.HivePageSourceProvider.createPageSource(HivePageSourceProvider.java:177)
> at
> com.facebook.presto.spi.connector.classloader.ClassLoaderSafeConnectorPageSourceProvider.createPageSource(ClassLoaderSafeConnectorPageSourceProvider.java:63)
> at
> com.facebook.presto.split.PageSourceManager.createPageSource(PageSourceManager.java:80)
> at
> com.facebook.presto.operator.ScanFilterAndProjectOperator.getOutput(ScanFilterAndProjectOperator.java:231)
> at com.facebook.presto.operator.Driver.processInternal(Driver.java:418)
> at
> com.facebook.presto.operator.Driver.lambda$processFor$9(Driver.java:301)
> at com.facebook.presto.operator.Driver.tryWithLock(Driver.java:722)
> at com.facebook.presto.operator.Driver.processFor(Driver.java:294)
> at
> com.facebook.presto.execution.SqlTaskExecution$DriverSplitRunner.processFor(SqlTaskExecution.java:1077)
> at
> com.facebook.presto.execution.executor.PrioritizedSplitRunner.process(PrioritizedSplitRunner.java:162)
> at
> com.facebook.presto.execution.executor.TaskExecutor$TaskRunner.run(TaskExecutor.java:545)
> at
> com.facebook.presto.$gen.Presto_0_247_17f857e20210506_210241_1.run(Unknown
> Source)
> at
> java.base/java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1128)
> at
> java.base/java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:628)
> at java.base/java.lang.Thread.run(Thread.java:834)
> {code}
> Error#2
> {code}
> java.lang.ClassCastException: class org.apache.hadoop.io.LongWritable cannot
> be cast to class org.apache.hadoop.hive.serde2.io.TimestampWritable
> (org.apache.hadoop.io.LongWritable and
> org.apache.hadoop.hive.serde2.io.TimestampWritable are in unnamed module of
> loader com.facebook.presto.server.PluginClassLoader @5c4e86e7)
> at
> org.apache.hadoop.hive.serde2.objectinspector.primitive.WritableTimestampObjectInspector.getPrimitiveJavaObject(WritableTimestampObjectInspector.java:39)
> at
> org.apache.hadoop.hive.serde2.objectinspector.primitive.WritableTimestampObjectInspector.getPrimitiveJavaObject(WritableTimestampObjectInspector.java:25)
> at
> com.facebook.presto.hive.GenericHiveRecordCursor.parseLongColumn(GenericHiveRecordCursor.java:286)
> at
> com.facebook.presto.hive.GenericHiveRecordCursor.parseColumn(GenericHiveRecordCursor.java:550)
> at
> com.facebook.presto.hive.GenericHiveRecordCursor.isNull(GenericHiveRecordCursor.java:508)
> at
> com.facebook.presto.hive.HiveRecordCursor.isNull(HiveRecordCursor.java:233)
> at
> com.facebook.presto.spi.RecordPageSource.getNextPage(RecordPageSource.java:112)
> at
> com.facebook.presto.operator.TableScanOperator.getOutput(TableScanOperator.java:251)
> at com.facebook.presto.operator.Driver.processInternal(Driver.java:418)
> at
> com.facebook.presto.operator.Driver.lambda$processFor$9(Driver.java:301)
> at com.facebook.presto.operator.Driver.tryWithLock(Driver.java:722)
> at com.facebook.presto.operator.Driver.processFor(Driver.jav
[jira] [Updated] (HUDI-2409) Using HBase shaded jars in Hudi presto bundle
[
https://issues.apache.org/jira/browse/HUDI-2409?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Sagar Sumit updated HUDI-2409:
--
Parent: HUDI-2574
Issue Type: Sub-task (was: Task)
> Using HBase shaded jars in Hudi presto bundle
> --
>
> Key: HUDI-2409
> URL: https://issues.apache.org/jira/browse/HUDI-2409
> Project: Apache Hudi
> Issue Type: Sub-task
>Reporter: Yue Zhang
>Priority: Blocker
> Labels: pull-request-available
> Fix For: 0.10.0
>
>
> Execute {{hbase-server}} and {{hbase-client}} dependency in
> Hudi-presto-bundle.
> Add {{hbase-shaded-client}} and {{hbase-shaded-server}} in Hudi-presto-bundle.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Updated] (HUDI-2409) Using HBase shaded jars in Hudi presto bundle
[
https://issues.apache.org/jira/browse/HUDI-2409?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Sagar Sumit updated HUDI-2409:
--
Status: In Progress (was: Open)
> Using HBase shaded jars in Hudi presto bundle
> --
>
> Key: HUDI-2409
> URL: https://issues.apache.org/jira/browse/HUDI-2409
> Project: Apache Hudi
> Issue Type: Sub-task
>Reporter: Yue Zhang
>Priority: Blocker
> Labels: pull-request-available
> Fix For: 0.10.0
>
>
> Execute {{hbase-server}} and {{hbase-client}} dependency in
> Hudi-presto-bundle.
> Add {{hbase-shaded-client}} and {{hbase-shaded-server}} in Hudi-presto-bundle.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Updated] (HUDI-1978) [UMBRELLA] Support for Hudi tables in trino-hive connector
[ https://issues.apache.org/jira/browse/HUDI-1978?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Sagar Sumit updated HUDI-1978: -- Summary: [UMBRELLA] Support for Hudi tables in trino-hive connector (was: [UMBRELLA] Support for Trino in Hive connector) > [UMBRELLA] Support for Hudi tables in trino-hive connector > -- > > Key: HUDI-1978 > URL: https://issues.apache.org/jira/browse/HUDI-1978 > Project: Apache Hudi > Issue Type: New Feature > Components: trino >Reporter: Vinoth Chandar >Assignee: Sagar Sumit >Priority: Major > Labels: hudi-umbrellas > -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Created] (HUDI-2574) [UMBRELLA] Support for Hudi tables in presto-hive connector
Sagar Sumit created HUDI-2574: - Summary: [UMBRELLA] Support for Hudi tables in presto-hive connector Key: HUDI-2574 URL: https://issues.apache.org/jira/browse/HUDI-2574 Project: Apache Hudi Issue Type: New Feature Reporter: Sagar Sumit Assignee: Sagar Sumit -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Updated] (HUDI-1978) [UMBRELLA] Support for Trino in Hive connector
[ https://issues.apache.org/jira/browse/HUDI-1978?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Sagar Sumit updated HUDI-1978: -- Summary: [UMBRELLA] Support for Trino in Hive connector (was: [UMBRELLA] Support for Trino) > [UMBRELLA] Support for Trino in Hive connector > -- > > Key: HUDI-1978 > URL: https://issues.apache.org/jira/browse/HUDI-1978 > Project: Apache Hudi > Issue Type: New Feature > Components: trino >Reporter: Vinoth Chandar >Assignee: Sagar Sumit >Priority: Major > Labels: hudi-umbrellas > -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (HUDI-2559) Ensure unique timestamps are generated for commit times with concurrent writers
[
https://issues.apache.org/jira/browse/HUDI-2559?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17430050#comment-17430050
]
Dave Hagman commented on HUDI-2559:
---
Testing approach 1 should be very easy given the way my branch is currently
setup so I can verify that it works (I see no reason why it wouldn't).
> Ensure unique timestamps are generated for commit times with concurrent
> writers
> ---
>
> Key: HUDI-2559
> URL: https://issues.apache.org/jira/browse/HUDI-2559
> Project: Apache Hudi
> Issue Type: Improvement
>Reporter: sivabalan narayanan
>Assignee: sivabalan narayanan
>Priority: Major
>
> Ensure unique timestamps are generated for commit times with concurrent
> writers.
> this is the piece of code in HoodieActiveTimeline which creates a new commit
> time.
> {code:java}
> public static String createNewInstantTime(long milliseconds) {
> return lastInstantTime.updateAndGet((oldVal) -> {
> String newCommitTime;
> do {
> newCommitTime = HoodieActiveTimeline.COMMIT_FORMATTER.format(new
> Date(System.currentTimeMillis() + milliseconds));
> } while (HoodieTimeline.compareTimestamps(newCommitTime,
> LESSER_THAN_OR_EQUALS, oldVal));
> return newCommitTime;
> });
> }
> {code}
> There are chances that a deltastreamer and a concurrent spark ds writer gets
> same timestamp and one of them fails.
> Related issues and github jiras:
> [https://github.com/apache/hudi/issues/3782]
> https://issues.apache.org/jira/browse/HUDI-2549
>
>
>
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Comment Edited] (HUDI-2559) Ensure unique timestamps are generated for commit times with concurrent writers
[
https://issues.apache.org/jira/browse/HUDI-2559?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17430048#comment-17430048
]
Dave Hagman edited comment on HUDI-2559 at 10/18/21, 2:40 PM:
--
I have been extensively testing approach #2 and so far it has worked very well.
I still need to fully test all the table services to ensure it doesn't break
anything.
With the experience I have behind approach 2, I don't see any reason why
approach 1 would not work however I do have a caution. Approach 2 guarantees
that two writers will never create conflicting commits (provided the user
ensures all writers have a unique ID) while approach 1 does not (it just make
it very unlikely). I have no worries about approach #1 but if we were to roll
forward with that, we would need to provide guidance around what to do if a
commit collision does occur. From my testing, simply restarting the failed
writer usually worked fine but we would need much more testing and verification
around this in order to ensure zero consistency/corruption issues (especially
with the new metadata table functionality).
was (Author: dave_hagman):
I have been extensively testing approach #2 and so far it has worked very well.
I still need to fully test all the table services to ensure it doesn't break
anything.
With the experience I have behind approach 2, I don't see any reason why
approach 1 would not work however I do have a caution. Approach 2 guarantees
that two writers will never create conflicting commits while approach 1 does
not (it just make it very unlikely). I have no worries about approach #1 but if
we were to roll forward with that, we would need to provide guidance around
what to do if a commit collision does occur. From my testing, simply restarting
the failed writer usually worked fine but we would need much more testing and
verification around this in order to ensure zero consistency/corruption issues
(especially with the new metadata table functionality).
> Ensure unique timestamps are generated for commit times with concurrent
> writers
> ---
>
> Key: HUDI-2559
> URL: https://issues.apache.org/jira/browse/HUDI-2559
> Project: Apache Hudi
> Issue Type: Improvement
>Reporter: sivabalan narayanan
>Assignee: sivabalan narayanan
>Priority: Major
>
> Ensure unique timestamps are generated for commit times with concurrent
> writers.
> this is the piece of code in HoodieActiveTimeline which creates a new commit
> time.
> {code:java}
> public static String createNewInstantTime(long milliseconds) {
> return lastInstantTime.updateAndGet((oldVal) -> {
> String newCommitTime;
> do {
> newCommitTime = HoodieActiveTimeline.COMMIT_FORMATTER.format(new
> Date(System.currentTimeMillis() + milliseconds));
> } while (HoodieTimeline.compareTimestamps(newCommitTime,
> LESSER_THAN_OR_EQUALS, oldVal));
> return newCommitTime;
> });
> }
> {code}
> There are chances that a deltastreamer and a concurrent spark ds writer gets
> same timestamp and one of them fails.
> Related issues and github jiras:
> [https://github.com/apache/hudi/issues/3782]
> https://issues.apache.org/jira/browse/HUDI-2549
>
>
>
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Commented] (HUDI-2559) Ensure unique timestamps are generated for commit times with concurrent writers
[
https://issues.apache.org/jira/browse/HUDI-2559?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17430048#comment-17430048
]
Dave Hagman commented on HUDI-2559:
---
I have been extensively testing approach #2 and so far it has worked very well.
I still need to fully test all the table services to ensure it doesn't break
anything.
With the experience I have behind approach 2, I don't see any reason why
approach 1 would not work however I do have a caution. Approach 2 guarantees
that two writers will never create conflicting commits while approach 1 does
not (it just make it very unlikely). I have no worries about approach #1 but if
we were to roll forward with that, we would need to provide guidance around
what to do if a commit collision does occur. From my testing, simply restarting
the failed writer usually worked fine but we would need much more testing and
verification around this in order to ensure zero consistency/corruption issues
(especially with the new metadata table functionality).
> Ensure unique timestamps are generated for commit times with concurrent
> writers
> ---
>
> Key: HUDI-2559
> URL: https://issues.apache.org/jira/browse/HUDI-2559
> Project: Apache Hudi
> Issue Type: Improvement
>Reporter: sivabalan narayanan
>Assignee: sivabalan narayanan
>Priority: Major
>
> Ensure unique timestamps are generated for commit times with concurrent
> writers.
> this is the piece of code in HoodieActiveTimeline which creates a new commit
> time.
> {code:java}
> public static String createNewInstantTime(long milliseconds) {
> return lastInstantTime.updateAndGet((oldVal) -> {
> String newCommitTime;
> do {
> newCommitTime = HoodieActiveTimeline.COMMIT_FORMATTER.format(new
> Date(System.currentTimeMillis() + milliseconds));
> } while (HoodieTimeline.compareTimestamps(newCommitTime,
> LESSER_THAN_OR_EQUALS, oldVal));
> return newCommitTime;
> });
> }
> {code}
> There are chances that a deltastreamer and a concurrent spark ds writer gets
> same timestamp and one of them fails.
> Related issues and github jiras:
> [https://github.com/apache/hudi/issues/3782]
> https://issues.apache.org/jira/browse/HUDI-2549
>
>
>
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Updated] (HUDI-2573) Deadlock w/ multi writer due to double locking
[ https://issues.apache.org/jira/browse/HUDI-2573?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] sivabalan narayanan updated HUDI-2573: -- Summary: Deadlock w/ multi writer due to double locking (was: Deadlock w/ multi writer ) > Deadlock w/ multi writer due to double locking > -- > > Key: HUDI-2573 > URL: https://issues.apache.org/jira/browse/HUDI-2573 > Project: Apache Hudi > Issue Type: Bug >Reporter: sivabalan narayanan >Assignee: sivabalan narayanan >Priority: Major > Fix For: 0.10.0 > > > With synchronous metadata patch, we added locking for cleaning and rollbacks. > but there are code paths, where we do double locking and hence it hangs or > fails after sometime. > > inline cleaning enabled. > > C1 acquires lock. > post commit -> triggers cleaning. > cleaning again tries to acquire lock when about to > commit and this is problematic. > > Also, when upgrade is needed, we take a lock and rollback failed writes. this > again will run into issues w/ double locking. > > > -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Updated] (HUDI-2573) Deadlock w/ multi writer
[ https://issues.apache.org/jira/browse/HUDI-2573?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] sivabalan narayanan updated HUDI-2573: -- Description: With synchronous metadata patch, we added locking for cleaning and rollbacks. but there are code paths, where we do double locking and hence it hangs or fails after sometime. inline cleaning enabled. C1 acquires lock. post commit -> triggers cleaning. cleaning again tries to acquire lock when about to commit and this is problematic. Also, when upgrade is needed, we take a lock and rollback failed writes. this again will run into issues w/ double locking. was: With synchronous metadata patch, we added locking for cleaning and rollbacks. but there are code paths, where we do double locking and hence it hangs or fails after sometime. inline cleaning enabled. ``` C1 acquires lock. post commit -> triggers cleaning. cleaning again tries to acquire lock when about to commit and this is problematic. ``` Also, when upgrade is needed, we take a lock and rollback failed writes. this again will run into issues w/ double locking. > Deadlock w/ multi writer > - > > Key: HUDI-2573 > URL: https://issues.apache.org/jira/browse/HUDI-2573 > Project: Apache Hudi > Issue Type: Bug >Reporter: sivabalan narayanan >Assignee: sivabalan narayanan >Priority: Major > Fix For: 0.10.0 > > > With synchronous metadata patch, we added locking for cleaning and rollbacks. > but there are code paths, where we do double locking and hence it hangs or > fails after sometime. > > inline cleaning enabled. > > C1 acquires lock. > post commit -> triggers cleaning. > cleaning again tries to acquire lock when about to > commit and this is problematic. > > Also, when upgrade is needed, we take a lock and rollback failed writes. this > again will run into issues w/ double locking. > > > -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Created] (HUDI-2573) Deadlock w/ multi writer
sivabalan narayanan created HUDI-2573: - Summary: Deadlock w/ multi writer Key: HUDI-2573 URL: https://issues.apache.org/jira/browse/HUDI-2573 Project: Apache Hudi Issue Type: Bug Reporter: sivabalan narayanan Assignee: sivabalan narayanan Fix For: 0.10.0 With synchronous metadata patch, we added locking for cleaning and rollbacks. but there are code paths, where we do double locking and hence it hangs or fails after sometime. inline cleaning enabled. ``` C1 acquires lock. post commit -> triggers cleaning. cleaning again tries to acquire lock when about to commit and this is problematic. ``` Also, when upgrade is needed, we take a lock and rollback failed writes. this again will run into issues w/ double locking. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [hudi] hudi-bot edited a comment on pull request #3819: [HUDI-2572] Strength flink compaction rollback strategy
hudi-bot edited a comment on pull request #3819: URL: https://github.com/apache/hudi/pull/3819#issuecomment-945644747 ## CI report: * 79056a50227330ba6965f7db5ca137fbdeff13ff UNKNOWN * 60ed0b24f27c773801db3228e5f53532ea3e0ae6 Azure: [SUCCESS](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=2707) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run travis` re-run the last Travis build - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (HUDI-2563) Refactor XScheduleCompactionActionExecutor and CompactionTriggerStrategy.
[ https://issues.apache.org/jira/browse/HUDI-2563?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17430028#comment-17430028 ] Yuepeng Pan commented on HUDI-2563: --- Hi, [~danny0405] Could you help me to review this pr ? Thank you. > Refactor XScheduleCompactionActionExecutor and CompactionTriggerStrategy. > - > > Key: HUDI-2563 > URL: https://issues.apache.org/jira/browse/HUDI-2563 > Project: Apache Hudi > Issue Type: Improvement > Components: CLI, Compaction, Writer Core >Reporter: Yuepeng Pan >Assignee: Yuepeng Pan >Priority: Minor > Labels: pull-request-available > > # Pull up some common methods from XXXScheduleCompactionActionExecutor to > BaseScheduleCompactionActionExecutor. > # Replace conditional in XXXScheduleCompactionActionExecutor with > polymorphsim of CompactionTriggerStrategy class. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [hudi] hudi-bot edited a comment on pull request #3819: [HUDI-2572] Strength flink compaction rollback strategy
hudi-bot edited a comment on pull request #3819: URL: https://github.com/apache/hudi/pull/3819#issuecomment-945644747 ## CI report: * 4c8a7378651c3911d30102d1c396fa59ef795c88 Azure: [SUCCESS](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=2706) * 79056a50227330ba6965f7db5ca137fbdeff13ff UNKNOWN * 60ed0b24f27c773801db3228e5f53532ea3e0ae6 Azure: [PENDING](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=2707) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run travis` re-run the last Travis build - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Comment Edited] (HUDI-2559) Ensure unique timestamps are generated for commit times with concurrent writers
[
https://issues.apache.org/jira/browse/HUDI-2559?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17430012#comment-17430012
]
sivabalan narayanan edited comment on HUDI-2559 at 10/18/21, 1:24 PM:
--
Here are the possible solutions:
# add millisec level granularity to commit timestamp.
[https://github.com/apache/hudi/pull/2701]
# Add a per writer config name writerUniqueId in config and user is expected
to set to unique string for every writer. Hudi does not depend on the actual
timestamp format and does string based comparison for commit timestamp for any
ordering in general. So, this should also work. for instance, as of today,
commit timestamps are as below
20211015191547
If we add a unique writer id as suffix to this,
20211015191547-writer1
And so, even if two writers happened to start a new write concurrently, and
even if same timestamp was generated, commit times will be as follows
20211015191547-writer1
20211015191547-writer2
Approach1:
Neat and elegant. very very unlikely, two writers will generate the same
timestamp as timestamp need to match at millisec granularity.
Approach2:
This also should work. If approach1 takes more time to develop or runs into any
issues, this solution should be straight forward. we can think about releasing
this as first version and go with approach1 later if need be.
was (Author: shivnarayan):
Here are the possible solutions:
# add millisec level granularity to commit timestamp.
[https://github.com/apache/hudi/pull/2701]
# Add a per writer config name writerUniqueId in config and user is expected
to set to unique string for every writer. Hudi does not depend on the actual
timestamp format and does string based comparison for commit timestamp for any
ordering in general. So, this should also work. for instance, as of today,
commit timestamps are as below
20211015191547
If we add a unique writer id as suffix to this,
20211015191547-writer1
And so, even if two writers happened to start a new write concurrently, and
even if same timestamp was generated, commit times will be as follows
20211015191547-writer1
20211015191547-writer2
Approach1:
Neat and elegant. very very unlikely, two writers will generate the same
timestamp as timestamp need to match at millisec granularity.
Approach2:
This also should work. If approach1 takes more time or runs into any issues,
this solution should be straight forward. we can think about releasing this as
first version and go with approach1 later if need be.
> Ensure unique timestamps are generated for commit times with concurrent
> writers
> ---
>
> Key: HUDI-2559
> URL: https://issues.apache.org/jira/browse/HUDI-2559
> Project: Apache Hudi
> Issue Type: Improvement
>Reporter: sivabalan narayanan
>Assignee: sivabalan narayanan
>Priority: Major
>
> Ensure unique timestamps are generated for commit times with concurrent
> writers.
> this is the piece of code in HoodieActiveTimeline which creates a new commit
> time.
> {code:java}
> public static String createNewInstantTime(long milliseconds) {
> return lastInstantTime.updateAndGet((oldVal) -> {
> String newCommitTime;
> do {
> newCommitTime = HoodieActiveTimeline.COMMIT_FORMATTER.format(new
> Date(System.currentTimeMillis() + milliseconds));
> } while (HoodieTimeline.compareTimestamps(newCommitTime,
> LESSER_THAN_OR_EQUALS, oldVal));
> return newCommitTime;
> });
> }
> {code}
> There are chances that a deltastreamer and a concurrent spark ds writer gets
> same timestamp and one of them fails.
> Related issues and github jiras:
> [https://github.com/apache/hudi/issues/3782]
> https://issues.apache.org/jira/browse/HUDI-2549
>
>
>
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Commented] (HUDI-2559) Ensure unique timestamps are generated for commit times with concurrent writers
[
https://issues.apache.org/jira/browse/HUDI-2559?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17430012#comment-17430012
]
sivabalan narayanan commented on HUDI-2559:
---
Here are the possible solutions:
# add millisec level granularity to commit timestamp.
[https://github.com/apache/hudi/pull/2701]
# Add a per writer config name writerUniqueId in config and user is expected
to set to unique string for every writer. Hudi does not depend on the actual
timestamp format and does string based comparison for commit timestamp for any
ordering in general. So, this should also work. for instance, as of today,
commit timestamps are as below
20211015191547
If we add a unique writer id as suffix to this,
20211015191547-writer1
And so, even if two writers happened to start a new write concurrently, and
even if same timestamp was generated, commit times will be as follows
20211015191547-writer1
20211015191547-writer2
Approach1:
Neat and elegant. very very unlikely, two writers will generate the same
timestamp as timestamp need to match at millisec granularity.
Approach2:
This also should work. If approach1 takes more time or runs into any issues,
this solution should be straight forward. we can think about releasing this as
first version and go with approach1 later if need be.
> Ensure unique timestamps are generated for commit times with concurrent
> writers
> ---
>
> Key: HUDI-2559
> URL: https://issues.apache.org/jira/browse/HUDI-2559
> Project: Apache Hudi
> Issue Type: Improvement
>Reporter: sivabalan narayanan
>Assignee: sivabalan narayanan
>Priority: Major
>
> Ensure unique timestamps are generated for commit times with concurrent
> writers.
> this is the piece of code in HoodieActiveTimeline which creates a new commit
> time.
> {code:java}
> public static String createNewInstantTime(long milliseconds) {
> return lastInstantTime.updateAndGet((oldVal) -> {
> String newCommitTime;
> do {
> newCommitTime = HoodieActiveTimeline.COMMIT_FORMATTER.format(new
> Date(System.currentTimeMillis() + milliseconds));
> } while (HoodieTimeline.compareTimestamps(newCommitTime,
> LESSER_THAN_OR_EQUALS, oldVal));
> return newCommitTime;
> });
> }
> {code}
> There are chances that a deltastreamer and a concurrent spark ds writer gets
> same timestamp and one of them fails.
> Related issues and github jiras:
> [https://github.com/apache/hudi/issues/3782]
> https://issues.apache.org/jira/browse/HUDI-2549
>
>
>
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Updated] (HUDI-2572) Strength flink compaction rollback strategy
[ https://issues.apache.org/jira/browse/HUDI-2572?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Danny Chen updated HUDI-2572: - Summary: Strength flink compaction rollback strategy (was: Make flink compaction commit fail-safe) > Strength flink compaction rollback strategy > --- > > Key: HUDI-2572 > URL: https://issues.apache.org/jira/browse/HUDI-2572 > Project: Apache Hudi > Issue Type: Improvement > Components: Flink Integration >Reporter: Danny Chen >Assignee: Danny Chen >Priority: Major > Labels: pull-request-available > Fix For: 0.10.0 > > -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [hudi] hudi-bot edited a comment on pull request #3819: [HUDI-2572] Strength flink compaction rollback strategy
hudi-bot edited a comment on pull request #3819: URL: https://github.com/apache/hudi/pull/3819#issuecomment-945644747 ## CI report: * 4c8a7378651c3911d30102d1c396fa59ef795c88 Azure: [SUCCESS](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=2706) * 79056a50227330ba6965f7db5ca137fbdeff13ff UNKNOWN * 60ed0b24f27c773801db3228e5f53532ea3e0ae6 UNKNOWN Bot commands @hudi-bot supports the following commands: - `@hudi-bot run travis` re-run the last Travis build - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot edited a comment on pull request #3819: [HUDI-2572] Strength flink compaction rollback strategy
hudi-bot edited a comment on pull request #3819: URL: https://github.com/apache/hudi/pull/3819#issuecomment-945644747 ## CI report: * 4c8a7378651c3911d30102d1c396fa59ef795c88 Azure: [SUCCESS](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=2706) * 79056a50227330ba6965f7db5ca137fbdeff13ff UNKNOWN Bot commands @hudi-bot supports the following commands: - `@hudi-bot run travis` re-run the last Travis build - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot edited a comment on pull request #3819: [HUDI-2572] Make flink compaction commit fail-safe
hudi-bot edited a comment on pull request #3819: URL: https://github.com/apache/hudi/pull/3819#issuecomment-945644747 ## CI report: * 8c27c74a4b89d2242f846e85c725fdfc09f8786a Azure: [SUCCESS](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=2705) * 4c8a7378651c3911d30102d1c396fa59ef795c88 Azure: [PENDING](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=2706) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run travis` re-run the last Travis build - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot edited a comment on pull request #3819: [HUDI-2572] Make flink compaction commit fail-safe
hudi-bot edited a comment on pull request #3819: URL: https://github.com/apache/hudi/pull/3819#issuecomment-945644747 ## CI report: * 8c27c74a4b89d2242f846e85c725fdfc09f8786a Azure: [SUCCESS](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=2705) * 4c8a7378651c3911d30102d1c396fa59ef795c88 UNKNOWN Bot commands @hudi-bot supports the following commands: - `@hudi-bot run travis` re-run the last Travis build - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot edited a comment on pull request #3819: [HUDI-2572] Make flink compaction commit fail-safe
hudi-bot edited a comment on pull request #3819: URL: https://github.com/apache/hudi/pull/3819#issuecomment-945644747 ## CI report: * 8c27c74a4b89d2242f846e85c725fdfc09f8786a Azure: [SUCCESS](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=2705) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run travis` re-run the last Travis build - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot edited a comment on pull request #3771: [HUDI-2402] Add Kerberos configuration options to Hive Sync
hudi-bot edited a comment on pull request #3771: URL: https://github.com/apache/hudi/pull/3771#issuecomment-939200284 ## CI report: * 9e64e88d819b6b6bf5ccc5811ea5f4714138fc9e UNKNOWN * e7e7f170612fcecc8b07839d296f2c06972f2f44 UNKNOWN * 86e65215ff5f069470d732f4dce80cd20426fb5c UNKNOWN * 15a0a763aae6dec5147f8081175d0c995d9a0e5d Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=2704) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run travis` re-run the last Travis build - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] novakov-alexey commented on pull request #3817: fix: HoodieDatasetBulkInsertHelper concurrently rowkey not found
novakov-alexey commented on pull request #3817: URL: https://github.com/apache/hudi/pull/3817#issuecomment-945682795 @Carl-Zhou-CN feel free to take it to your PR. Thanks -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot edited a comment on pull request #3819: [HUDI-2572] Make flink compaction commit fail-safe
hudi-bot edited a comment on pull request #3819: URL: https://github.com/apache/hudi/pull/3819#issuecomment-945644747 ## CI report: * 8c27c74a4b89d2242f846e85c725fdfc09f8786a Azure: [PENDING](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=2705) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run travis` re-run the last Travis build - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #3819: [HUDI-2572] Make flink compaction commit fail-safe
hudi-bot commented on pull request #3819: URL: https://github.com/apache/hudi/pull/3819#issuecomment-945644747 ## CI report: * 8c27c74a4b89d2242f846e85c725fdfc09f8786a UNKNOWN Bot commands @hudi-bot supports the following commands: - `@hudi-bot run travis` re-run the last Travis build - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org