[GitHub] [hudi] TJX2014 commented on a diff in pull request #6567: [HUDI-4767] Fix non partition table in hudi-flink ignore KEYGEN_CLASS…
TJX2014 commented on code in PR #6567:
URL: https://github.com/apache/hudi/pull/6567#discussion_r962542029
##
hudi-flink-datasource/hudi-flink/src/main/java/org/apache/hudi/table/HoodieTableFactory.java:
##
@@ -217,31 +217,33 @@ private static void setupHoodieKeyOptions(Configuration
conf, CatalogTable table
}
}
-// tweak the key gen class if possible
-final String[] partitions =
conf.getString(FlinkOptions.PARTITION_PATH_FIELD).split(",");
-final String[] pks =
conf.getString(FlinkOptions.RECORD_KEY_FIELD).split(",");
-if (partitions.length == 1) {
- final String partitionField = partitions[0];
- if (partitionField.isEmpty()) {
-conf.setString(FlinkOptions.KEYGEN_CLASS_NAME,
NonpartitionedAvroKeyGenerator.class.getName());
-LOG.info("Table option [{}] is reset to {} because this is a
non-partitioned table",
-FlinkOptions.KEYGEN_CLASS_NAME.key(),
NonpartitionedAvroKeyGenerator.class.getName());
-return;
+if (StringUtils.isNullOrEmpty(conf.get(FlinkOptions.KEYGEN_CLASS_NAME))) {
+ // tweak the key gen class if possible
Review Comment:
Hudi configure keygen clazz auto is great, so the option should not exists,
once configured but not effect, is it strange?The code in spark has changed to
follow hudi-partition way, but in historical data, if the layout of
non-partitioned table with complex key by spark, the only chance for hudi-flink
it to configure keygen.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #6587: [HUDI-4775] Fixing incremental source for MOR table
hudi-bot commented on PR #6587: URL: https://github.com/apache/hudi/pull/6587#issuecomment-1236609160 ## CI report: * 9c996aa5881d2a9e341b5181ef635750a7f4c926 Azure: [SUCCESS](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=11142) * a8bbdf4475b8a9c204c2547071ecdb7ba26691ae UNKNOWN Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #6046: [HUDI-4363] Support Clustering row writer to improve performance
hudi-bot commented on PR #6046: URL: https://github.com/apache/hudi/pull/6046#issuecomment-1236608382 ## CI report: * 1c913457d2dd531fd1ecae6b0d60e600f59e261b Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=10760) * b8e848d0f8b32ff3c75762951e3af4c911419927 UNKNOWN Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #5478: [HUDI-3998] Fix getCommitsSinceLastCleaning failed when async cleaning
hudi-bot commented on PR #5478: URL: https://github.com/apache/hudi/pull/5478#issuecomment-1236607892 ## CI report: * 9b10ad3fb80db31e34e46abbd5d0b3ba9f179a8b Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=11140) * 9b0e2c00879a4b3b8fdfebb1a4ead10b1eed60eb UNKNOWN Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] TJX2014 commented on a diff in pull request #6567: [HUDI-4767] Fix non partition table in hudi-flink ignore KEYGEN_CLASS…
TJX2014 commented on code in PR #6567:
URL: https://github.com/apache/hudi/pull/6567#discussion_r962542972
##
hudi-flink-datasource/hudi-flink/src/main/java/org/apache/hudi/table/HoodieTableFactory.java:
##
@@ -217,31 +217,33 @@ private static void setupHoodieKeyOptions(Configuration
conf, CatalogTable table
}
}
-// tweak the key gen class if possible
-final String[] partitions =
conf.getString(FlinkOptions.PARTITION_PATH_FIELD).split(",");
-final String[] pks =
conf.getString(FlinkOptions.RECORD_KEY_FIELD).split(",");
-if (partitions.length == 1) {
- final String partitionField = partitions[0];
- if (partitionField.isEmpty()) {
-conf.setString(FlinkOptions.KEYGEN_CLASS_NAME,
NonpartitionedAvroKeyGenerator.class.getName());
-LOG.info("Table option [{}] is reset to {} because this is a
non-partitioned table",
-FlinkOptions.KEYGEN_CLASS_NAME.key(),
NonpartitionedAvroKeyGenerator.class.getName());
-return;
+if (StringUtils.isNullOrEmpty(conf.get(FlinkOptions.KEYGEN_CLASS_NAME))) {
+ // tweak the key gen class if possible
Review Comment:
Hudi configure keygen clazz auto is great, so the option should not exists,
once configured but not effect, is it strange?The code in spark has changed to
follow hudi-partition way, but in historical data, if the layout of
non-partitioned table with complex key by spark, the only chance for hudi-flink
is to configure keygen.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] TJX2014 commented on a diff in pull request #6567: [HUDI-4767] Fix non partition table in hudi-flink ignore KEYGEN_CLASS…
TJX2014 commented on code in PR #6567:
URL: https://github.com/apache/hudi/pull/6567#discussion_r962542972
##
hudi-flink-datasource/hudi-flink/src/main/java/org/apache/hudi/table/HoodieTableFactory.java:
##
@@ -217,31 +217,33 @@ private static void setupHoodieKeyOptions(Configuration
conf, CatalogTable table
}
}
-// tweak the key gen class if possible
-final String[] partitions =
conf.getString(FlinkOptions.PARTITION_PATH_FIELD).split(",");
-final String[] pks =
conf.getString(FlinkOptions.RECORD_KEY_FIELD).split(",");
-if (partitions.length == 1) {
- final String partitionField = partitions[0];
- if (partitionField.isEmpty()) {
-conf.setString(FlinkOptions.KEYGEN_CLASS_NAME,
NonpartitionedAvroKeyGenerator.class.getName());
-LOG.info("Table option [{}] is reset to {} because this is a
non-partitioned table",
-FlinkOptions.KEYGEN_CLASS_NAME.key(),
NonpartitionedAvroKeyGenerator.class.getName());
-return;
+if (StringUtils.isNullOrEmpty(conf.get(FlinkOptions.KEYGEN_CLASS_NAME))) {
+ // tweak the key gen class if possible
Review Comment:
Hudi configure keygen clazz auto is great, so the option should not exists,
once configured but not effect, is it strange?The code in spark has changed to
follow hudi-partition way, but in historical data, if the layout of
non-partitioned table with complex key by spark, the only chance for hudi-flink
it to configure keygen.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] TJX2014 commented on a diff in pull request #6567: [HUDI-4767] Fix non partition table in hudi-flink ignore KEYGEN_CLASS…
TJX2014 commented on code in PR #6567:
URL: https://github.com/apache/hudi/pull/6567#discussion_r962542029
##
hudi-flink-datasource/hudi-flink/src/main/java/org/apache/hudi/table/HoodieTableFactory.java:
##
@@ -217,31 +217,33 @@ private static void setupHoodieKeyOptions(Configuration
conf, CatalogTable table
}
}
-// tweak the key gen class if possible
-final String[] partitions =
conf.getString(FlinkOptions.PARTITION_PATH_FIELD).split(",");
-final String[] pks =
conf.getString(FlinkOptions.RECORD_KEY_FIELD).split(",");
-if (partitions.length == 1) {
- final String partitionField = partitions[0];
- if (partitionField.isEmpty()) {
-conf.setString(FlinkOptions.KEYGEN_CLASS_NAME,
NonpartitionedAvroKeyGenerator.class.getName());
-LOG.info("Table option [{}] is reset to {} because this is a
non-partitioned table",
-FlinkOptions.KEYGEN_CLASS_NAME.key(),
NonpartitionedAvroKeyGenerator.class.getName());
-return;
+if (StringUtils.isNullOrEmpty(conf.get(FlinkOptions.KEYGEN_CLASS_NAME))) {
+ // tweak the key gen class if possible
Review Comment:
Hudi configure keygen clazz auto is great, so the option should not exists,
once configured but not effect, is it strange?The code in spark has changed to
follow hudi-partition way, but in historical data, if the layout of
non-partitioned table with complex key by spark, the only chance for hudi-flink
it to configure keygen.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #6566: [HUDI-4766] Fix HoodieFlinkClusteringJob
hudi-bot commented on PR #6566: URL: https://github.com/apache/hudi/pull/6566#issuecomment-1236605102 ## CI report: * b10c9d062f03c2c2675866c6f4bf6346dc03ea49 UNKNOWN * a2dcd81f74603e88c4db895900d43eee6702a6da UNKNOWN * c404647afc6d26bc0e69a7a8ef93f378b397bb96 UNKNOWN * 1709f71ae9494da4d7ca6b9c62ac97cd11dd8046 Azure: [SUCCESS](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=11146) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] danny0405 commented on pull request #6582: [DOCS] Add Flink DataStream API demo in Flink Guide.
danny0405 commented on PR #6582: URL: https://github.com/apache/hudi/pull/6582#issuecomment-1236604028 Thanks, can we also add the doc for archived release 0.12.0 ? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] boneanxs commented on a diff in pull request #6046: [HUDI-4363] Support Clustering row writer to improve performance
boneanxs commented on code in PR #6046:
URL: https://github.com/apache/hudi/pull/6046#discussion_r962540143
##
hudi-client/hudi-spark-client/src/main/java/org/apache/hudi/execution/bulkinsert/RowSpatialCurveSortPartitioner.java:
##
@@ -0,0 +1,75 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.execution.bulkinsert;
+
+import org.apache.hudi.config.HoodieClusteringConfig;
+import org.apache.hudi.config.HoodieWriteConfig;
+import org.apache.hudi.sort.SpaceCurveSortingHelper;
+import org.apache.spark.sql.Dataset;
+import org.apache.spark.sql.Row;
+
+import java.util.Arrays;
+import java.util.List;
+
+public class RowSpatialCurveSortPartitioner extends
RowCustomColumnsSortPartitioner {
+
+ private final String[] orderByColumns;
+ private final HoodieClusteringConfig.LayoutOptimizationStrategy
layoutOptStrategy;
+ private final HoodieClusteringConfig.SpatialCurveCompositionStrategyType
curveCompositionStrategyType;
+
+ public RowSpatialCurveSortPartitioner(HoodieWriteConfig config) {
+super(config);
+this.layoutOptStrategy = config.getLayoutOptimizationStrategy();
+if (config.getClusteringSortColumns() != null) {
+ this.orderByColumns =
Arrays.stream(config.getClusteringSortColumns().split(","))
+ .map(String::trim).toArray(String[]::new);
+} else {
+ this.orderByColumns = getSortColumnNames();
+}
+this.curveCompositionStrategyType =
config.getLayoutOptimizationCurveBuildMethod();
+ }
+
+ @Override
+ public Dataset repartitionRecords(Dataset records, int
outputPartitions) {
+return reorder(records, outputPartitions);
Review Comment:
Looks When building clustering plan, we already consider this, only same
partition files will be combined to one `clusteringGroup`, so maybe we don't
need to handle it here?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] danny0405 commented on a diff in pull request #6385: [HUDI-4614] fix primary key extract of delete_record when complexKeyGen configured and ChangeLogDisabled
danny0405 commented on code in PR #6385:
URL: https://github.com/apache/hudi/pull/6385#discussion_r962539009
##
hudi-client/hudi-client-common/src/main/java/org/apache/hudi/keygen/KeyGenUtils.java:
##
@@ -73,21 +73,20 @@ public static String
getPartitionPathFromGenericRecord(GenericRecord genericReco
*/
public static String[] extractRecordKeys(String recordKey) {
String[] fieldKV = recordKey.split(",");
-if (fieldKV.length == 1) {
- return fieldKV;
-} else {
- // a complex key
- return Arrays.stream(fieldKV).map(kv -> {
-final String[] kvArray = kv.split(":");
-if (kvArray[1].equals(NULL_RECORDKEY_PLACEHOLDER)) {
- return null;
-} else if (kvArray[1].equals(EMPTY_RECORDKEY_PLACEHOLDER)) {
- return "";
-} else {
- return kvArray[1];
-}
- }).toArray(String[]::new);
-}
+
+return Arrays.stream(fieldKV).map(kv -> {
+ final String[] kvArray = kv.split(":");
Review Comment:
Thanks, we can rebase the PR and fix it.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] prasannarajaperumal commented on a diff in pull request #6476: [HUDI-3478] Support CDC for Spark in Hudi
prasannarajaperumal commented on code in PR #6476:
URL: https://github.com/apache/hudi/pull/6476#discussion_r962517070
##
hudi-common/src/main/java/org/apache/hudi/common/table/cdc/CDCExtractor.java:
##
@@ -0,0 +1,359 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.common.table.cdc;
+
+import org.apache.hadoop.fs.FileStatus;
+import org.apache.hadoop.fs.FileSystem;
+import org.apache.hadoop.fs.Path;
+
+import org.apache.hudi.common.fs.FSUtils;
+import org.apache.hudi.common.model.HoodieBaseFile;
+import org.apache.hudi.common.model.HoodieCommitMetadata;
+import org.apache.hudi.common.model.HoodieFileFormat;
+import org.apache.hudi.common.model.HoodieFileGroupId;
+import org.apache.hudi.common.model.HoodieLogFile;
+import org.apache.hudi.common.model.HoodieReplaceCommitMetadata;
+import org.apache.hudi.common.model.HoodieTableType;
+import org.apache.hudi.common.model.HoodieWriteStat;
+import org.apache.hudi.common.model.FileSlice;
+import org.apache.hudi.common.model.WriteOperationType;
+import org.apache.hudi.common.table.HoodieTableConfig;
+import org.apache.hudi.common.table.HoodieTableMetaClient;
+import org.apache.hudi.common.table.timeline.HoodieActiveTimeline;
+import org.apache.hudi.common.table.timeline.HoodieInstant;
+import org.apache.hudi.common.table.timeline.HoodieTimeline;
+import org.apache.hudi.common.table.view.HoodieTableFileSystemView;
+import org.apache.hudi.common.util.Option;
+import org.apache.hudi.common.util.StringUtils;
+import org.apache.hudi.common.util.collection.Pair;
+import org.apache.hudi.exception.HoodieException;
+import org.apache.hudi.exception.HoodieIOException;
+import org.apache.hudi.exception.HoodieNotSupportedException;
+
+import java.io.IOException;
+import java.util.ArrayList;
+import java.util.Arrays;
+import java.util.HashMap;
+import java.util.HashSet;
+import java.util.Locale;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+import java.util.stream.Collectors;
+
+import static
org.apache.hudi.common.table.cdc.HoodieCDCLogicalFileType.ADD_BASE_FILE;
+import static
org.apache.hudi.common.table.cdc.HoodieCDCLogicalFileType.CDC_LOG_FILE;
+import static
org.apache.hudi.common.table.cdc.HoodieCDCLogicalFileType.MOR_LOG_FILE;
+import static
org.apache.hudi.common.table.cdc.HoodieCDCLogicalFileType.REMOVE_BASE_FILE;
+import static
org.apache.hudi.common.table.cdc.HoodieCDCLogicalFileType.REPLACED_FILE_GROUP;
+import static
org.apache.hudi.common.table.timeline.HoodieTimeline.COMMIT_ACTION;
+import static
org.apache.hudi.common.table.timeline.HoodieTimeline.DELTA_COMMIT_ACTION;
+import static org.apache.hudi.common.table.timeline.HoodieTimeline.isInRange;
+import static
org.apache.hudi.common.table.timeline.HoodieTimeline.REPLACE_COMMIT_ACTION;
+
+public class CDCExtractor {
+
+ private final HoodieTableMetaClient metaClient;
+
+ private final Path basePath;
+
+ private final FileSystem fs;
+
+ private final String supplementalLoggingMode;
+
+ private final String startInstant;
+
+ private final String endInstant;
+
+ // TODO: this will be used when support the cdc query type of
'read_optimized'.
+ private final String cdcQueryType;
+
+ private Map commits;
+
+ private HoodieTableFileSystemView fsView;
+
+ public CDCExtractor(
+ HoodieTableMetaClient metaClient,
+ String startInstant,
+ String endInstant,
+ String cdcqueryType) {
+this.metaClient = metaClient;
+this.basePath = metaClient.getBasePathV2();
+this.fs = metaClient.getFs().getFileSystem();
+this.supplementalLoggingMode =
metaClient.getTableConfig().cdcSupplementalLoggingMode();
+this.startInstant = startInstant;
+this.endInstant = endInstant;
+if (HoodieTableType.MERGE_ON_READ == metaClient.getTableType()
+&& cdcqueryType.equals("read_optimized")) {
+ throw new HoodieNotSupportedException("The 'read_optimized' cdc query
type hasn't been supported for now.");
+}
+this.cdcQueryType = cdcqueryType;
+init();
+ }
+
+ private void init() {
+initInstantAndCommitMetadatas();
+initFSView();
+ }
+
+ /**
+ * At the granularity of a file group, trace the mapping between
+ * eac
[GitHub] [hudi] prasannarajaperumal commented on a diff in pull request #6476: [HUDI-3478] Support CDC for Spark in Hudi
prasannarajaperumal commented on code in PR #6476:
URL: https://github.com/apache/hudi/pull/6476#discussion_r962510356
##
hudi-common/src/main/java/org/apache/hudi/avro/SerializableRecord.java:
##
@@ -0,0 +1,42 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.avro;
+
+import org.apache.avro.generic.GenericData;
+
+import java.io.Serializable;
+
+/**
+ * In some cases like putting the [[GenericData.Record]] into
[[ExternalSpillableMap]],
+ * objects is asked to extend [[Serializable]].
+ *
+ * This class wraps [[GenericData.Record]].
+ */
+public class SerializableRecord implements Serializable {
Review Comment:
How does this work? GenericData.Record is not serializable so how would
storing this in SpillableMap actually serialize and de-serialize the data when
spilled.
1. We should write a test on the spillable property with CDC context.
2. If the serialization is not thought through - Create something similar to
HoodieAvroPayload (HoodieCDCPayload) and store the contents as byte[]
##
hudi-common/src/main/java/org/apache/hudi/common/table/cdc/CDCExtractor.java:
##
@@ -0,0 +1,359 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.common.table.cdc;
+
+import org.apache.hadoop.fs.FileStatus;
+import org.apache.hadoop.fs.FileSystem;
+import org.apache.hadoop.fs.Path;
+
+import org.apache.hudi.common.fs.FSUtils;
+import org.apache.hudi.common.model.HoodieBaseFile;
+import org.apache.hudi.common.model.HoodieCommitMetadata;
+import org.apache.hudi.common.model.HoodieFileFormat;
+import org.apache.hudi.common.model.HoodieFileGroupId;
+import org.apache.hudi.common.model.HoodieLogFile;
+import org.apache.hudi.common.model.HoodieReplaceCommitMetadata;
+import org.apache.hudi.common.model.HoodieTableType;
+import org.apache.hudi.common.model.HoodieWriteStat;
+import org.apache.hudi.common.model.FileSlice;
+import org.apache.hudi.common.model.WriteOperationType;
+import org.apache.hudi.common.table.HoodieTableConfig;
+import org.apache.hudi.common.table.HoodieTableMetaClient;
+import org.apache.hudi.common.table.timeline.HoodieActiveTimeline;
+import org.apache.hudi.common.table.timeline.HoodieInstant;
+import org.apache.hudi.common.table.timeline.HoodieTimeline;
+import org.apache.hudi.common.table.view.HoodieTableFileSystemView;
+import org.apache.hudi.common.util.Option;
+import org.apache.hudi.common.util.StringUtils;
+import org.apache.hudi.common.util.collection.Pair;
+import org.apache.hudi.exception.HoodieException;
+import org.apache.hudi.exception.HoodieIOException;
+import org.apache.hudi.exception.HoodieNotSupportedException;
+
+import java.io.IOException;
+import java.util.ArrayList;
+import java.util.Arrays;
+import java.util.HashMap;
+import java.util.HashSet;
+import java.util.Locale;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+import java.util.stream.Collectors;
+
+import static
org.apache.hudi.common.table.cdc.HoodieCDCLogicalFileType.ADD_BASE_FILE;
+import static
org.apache.hudi.common.table.cdc.HoodieCDCLogicalFileType.CDC_LOG_FILE;
+import static
org.apache.hudi.common.table.cdc.HoodieCDCLogicalFileType.MOR_LOG_FILE;
+import static
org.apache.hudi.common.table.cdc.HoodieCDCLogicalFileType.REMOVE_BASE_FILE;
+import static
org.apache.hudi.common.table.cdc.HoodieCDCLogicalFileType.REPLACED_FILE_GROUP;
+import static
org.apache.hudi.co
[GitHub] [hudi] nleena123 commented on issue #5540: [SUPPORT]HoodieException: Commit 20220509105215 failed and rolled-back ! at org.apache.hudi.utilities.deltastreamer.DeltaSync.writeToSink(DeltaSync.
nleena123 commented on issue #5540: URL: https://github.com/apache/hudi/issues/5540#issuecomment-1236584029 still i could see the same issue do i need to follow the below step to fix the issue ? --conf spark.driver.extraJavaOptions="-Dlog4j.configuration=file:/home/hadoop/log4j.properties" --conf spark.executor.extraJavaOptions="-Dlog4j.configuration=file:/home/hadoop/log4j.properties" but i am getting this issue while running data bricks job ? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] dik111 closed issue #6588: [SUPPORT]Caused by: java.lang.ClassNotFoundException: org.apache.hudi.org.apache.avro.util.Utf8
dik111 closed issue #6588: [SUPPORT]Caused by: java.lang.ClassNotFoundException: org.apache.hudi.org.apache.avro.util.Utf8 URL: https://github.com/apache/hudi/issues/6588 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] dik111 commented on issue #6588: [SUPPORT]Caused by: java.lang.ClassNotFoundException: org.apache.hudi.org.apache.avro.util.Utf8
dik111 commented on issue #6588: URL: https://github.com/apache/hudi/issues/6588#issuecomment-1236580669 I solved this problem by adding the following configuration in Packaging/Hudi-spark-bundle/pom.xml ``` ... org.apache.avro:avro ... ... org.apache.avro. org.apache.hudi.org.apache.avro. ... ... org.apache.avro avro 1.8.2 compile ... ``` -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] codope commented on a diff in pull request #6587: [HUDI-4775] Fixing incremental source for MOR table
codope commented on code in PR #6587:
URL: https://github.com/apache/hudi/pull/6587#discussion_r962515108
##
hudi-utilities/src/test/java/org/apache/hudi/utilities/sources/TestHoodieIncrSource.java:
##
@@ -55,20 +66,39 @@ public class TestHoodieIncrSource extends
SparkClientFunctionalTestHarness {
private HoodieTestDataGenerator dataGen;
private HoodieTableMetaClient metaClient;
+ private HoodieTableType tableType = COPY_ON_WRITE;
@BeforeEach
public void setUp() throws IOException {
dataGen = new HoodieTestDataGenerator();
-metaClient = getHoodieMetaClient(hadoopConf(), basePath());
}
- @Test
- public void testHoodieIncrSource() throws IOException {
+ @Override
+ public HoodieTableMetaClient getHoodieMetaClient(Configuration hadoopConf,
String basePath, Properties props) throws IOException {
+props = HoodieTableMetaClient.withPropertyBuilder()
+.setTableName(RAW_TRIPS_TEST_NAME)
+.setTableType(tableType)
+.setPayloadClass(HoodieAvroPayload.class)
+.fromProperties(props)
+.build();
+return HoodieTableMetaClient.initTableAndGetMetaClient(hadoopConf,
basePath, props);
+ }
+
+ private static Stream tableTypeParams() {
+return Arrays.stream(new HoodieTableType[][]
{{HoodieTableType.COPY_ON_WRITE},
{HoodieTableType.MERGE_ON_READ}}).map(Arguments::of);
+ }
+
+ @ParameterizedTest
+ @MethodSource("tableTypeParams")
+ public void testHoodieIncrSource(HoodieTableType tableType) throws
IOException {
+this.tableType = tableType;
+metaClient = getHoodieMetaClient(hadoopConf(), basePath());
HoodieWriteConfig writeConfig = getConfigBuilder(basePath(), metaClient)
.withArchivalConfig(HoodieArchivalConfig.newBuilder().archiveCommitsWith(2,
3).build())
.withCleanConfig(HoodieCleanConfig.newBuilder().retainCommits(1).build())
+
.withCompactionConfig(HoodieCompactionConfig.newBuilder().withInlineCompaction(true).withMaxNumDeltaCommitsBeforeCompaction(3).build())
.withMetadataConfig(HoodieMetadataConfig.newBuilder()
-.withMaxNumDeltaCommitsBeforeCompaction(1).build())
+.enable(false).build())
Review Comment:
got it
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[hudi] branch master updated (edbd7fd6cc -> d2c46fb62a)
This is an automated email from the ASF dual-hosted git repository. codope pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/hudi.git from edbd7fd6cc [HUDI-4528] Add diff tool to compare commit metadata (#6485) add d2c46fb62a [HUDI-4648] Support rename partition through CLI (#6569) No new revisions were added by this update. Summary of changes: .../apache/hudi/cli/commands/RepairsCommand.java | 32 +++- .../org/apache/hudi/cli/commands/SparkMain.java| 87 +- .../hudi/cli/commands/TestRepairsCommand.java | 48 3 files changed, 146 insertions(+), 21 deletions(-)
[GitHub] [hudi] codope merged pull request #6569: [HUDI-4648] Support rename partition through CLI
codope merged PR #6569: URL: https://github.com/apache/hudi/pull/6569 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[hudi] branch master updated (24dd00724c -> edbd7fd6cc)
This is an automated email from the ASF dual-hosted git repository. codope pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/hudi.git from 24dd00724c [HUDI-4739] Wrong value returned when key's length equals 1 (#6539) add edbd7fd6cc [HUDI-4528] Add diff tool to compare commit metadata (#6485) No new revisions were added by this update. Summary of changes: .../apache/hudi/cli/HoodieTableHeaderFields.java | 32 +++ .../apache/hudi/cli/commands/CommitsCommand.java | 229 - .../hudi/cli/commands/CompactionCommand.java | 52 ++--- .../org/apache/hudi/cli/commands/DiffCommand.java | 184 + .../cli/commands/HoodieSyncValidateCommand.java| 5 +- .../apache/hudi/cli/commands/RollbacksCommand.java | 34 +++ .../java/org/apache/hudi/cli/utils/CommitUtil.java | 4 +- .../hudi/cli/commands/TestCommitsCommand.java | 87 +--- .../hudi/cli/commands/TestCompactionCommand.java | 2 +- .../apache/hudi/cli/commands/TestDiffCommand.java | 147 + .../HoodieTestCommitMetadataGenerator.java | 32 ++- .../hudi/common/table/HoodieTableMetaClient.java | 7 +- .../table/timeline/HoodieArchivedTimeline.java | 2 +- .../table/timeline/HoodieDefaultTimeline.java | 15 ++ .../hudi/common/table/timeline/TimelineUtils.java | 10 +- 15 files changed, 630 insertions(+), 212 deletions(-) create mode 100644 hudi-cli/src/main/java/org/apache/hudi/cli/commands/DiffCommand.java create mode 100644 hudi-cli/src/test/java/org/apache/hudi/cli/commands/TestDiffCommand.java
[GitHub] [hudi] codope merged pull request #6485: [HUDI-4528] Add diff tool to compare commit metadata
codope merged PR #6485: URL: https://github.com/apache/hudi/pull/6485 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] nsivabalan commented on a diff in pull request #6587: [HUDI-4775] Fixing incremental source for MOR table
nsivabalan commented on code in PR #6587:
URL: https://github.com/apache/hudi/pull/6587#discussion_r962507509
##
hudi-utilities/src/test/java/org/apache/hudi/utilities/sources/TestHoodieIncrSource.java:
##
@@ -55,20 +66,39 @@ public class TestHoodieIncrSource extends
SparkClientFunctionalTestHarness {
private HoodieTestDataGenerator dataGen;
private HoodieTableMetaClient metaClient;
+ private HoodieTableType tableType = COPY_ON_WRITE;
@BeforeEach
public void setUp() throws IOException {
dataGen = new HoodieTestDataGenerator();
-metaClient = getHoodieMetaClient(hadoopConf(), basePath());
}
- @Test
- public void testHoodieIncrSource() throws IOException {
+ @Override
+ public HoodieTableMetaClient getHoodieMetaClient(Configuration hadoopConf,
String basePath, Properties props) throws IOException {
+props = HoodieTableMetaClient.withPropertyBuilder()
+.setTableName(RAW_TRIPS_TEST_NAME)
+.setTableType(tableType)
+.setPayloadClass(HoodieAvroPayload.class)
+.fromProperties(props)
+.build();
+return HoodieTableMetaClient.initTableAndGetMetaClient(hadoopConf,
basePath, props);
+ }
+
+ private static Stream tableTypeParams() {
+return Arrays.stream(new HoodieTableType[][]
{{HoodieTableType.COPY_ON_WRITE},
{HoodieTableType.MERGE_ON_READ}}).map(Arguments::of);
+ }
+
+ @ParameterizedTest
+ @MethodSource("tableTypeParams")
+ public void testHoodieIncrSource(HoodieTableType tableType) throws
IOException {
+this.tableType = tableType;
+metaClient = getHoodieMetaClient(hadoopConf(), basePath());
HoodieWriteConfig writeConfig = getConfigBuilder(basePath(), metaClient)
.withArchivalConfig(HoodieArchivalConfig.newBuilder().archiveCommitsWith(2,
3).build())
.withCleanConfig(HoodieCleanConfig.newBuilder().retainCommits(1).build())
+
.withCompactionConfig(HoodieCompactionConfig.newBuilder().withInlineCompaction(true).withMaxNumDeltaCommitsBeforeCompaction(3).build())
.withMetadataConfig(HoodieMetadataConfig.newBuilder()
-.withMaxNumDeltaCommitsBeforeCompaction(1).build())
+.enable(false).build())
Review Comment:
it messes w/ metadata compaction/archival. and so data table archival does
not kick in. I just want to simulate archival in datatable. also, in this test,
there is no real benefit w/ metadata enabled. we are just interested in the
timeline files.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] FredMkl opened a new issue, #6591: [SUPPORT]Duplicate records in MOR
FredMkl opened a new issue, #6591:
URL: https://github.com/apache/hudi/issues/6591
**Describe the problem you faced**
We use MOR table, we found that when updating an existing set of rows to
another partition will result in both a)generate a parquet file b)an update
written to a log file. This brings duplicate records
**To Reproduce**
```
//action1: spark-dataframe write
import org.apache.spark.sql.SaveMode._
import org.apache.hudi.DataSourceReadOptions._
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.spark.sql.{DataFrame, Row, SparkSession}
import scala.collection.mutable
val tableName = "f_schedule_test"
val basePath = "oss://nbadatalake-poc/fred/warehouse/dw/f_schedule_test"
val spark = SparkSession.builder.enableHiveSupport.getOrCreate
import spark.implicits._
// spark-shell
val df = Seq(
("1", "10001", "2022-08-30","2022-08-30 12:00:00.000","2022-08-30"),
("2", "10002", "2022-08-31","2022-08-30 12:00:00.000","2022-08-30"),
("3", "10003", "2022-08-31","2022-08-30 12:00:00.000","2022-08-30"),
("4", "10004", "2022-08-31","2022-08-30 12:00:00.000","2022-08-30"),
("5", "10005", "2022-08-31","2022-08-30 12:00:00.000","2022-08-30"),
("6", "10006", "2022-08-31","2022-08-30 12:00:00.000","2022-08-30")
).toDF("game_schedule_id", "game_id", "game_date_cn", "insert_date",
"dt")
// df.show()
val hudiOptions = mutable.Map(
"hoodie.datasource.write.table.type" -> "MERGE_ON_READ",
"hoodie.datasource.write.operation" -> "upsert",
"hoodie.datasource.write.recordkey.field" -> "game_schedule_id",
"hoodie.datasource.write.precombine.field" -> "insert_date",
"hoodie.datasource.write.partitionpath.field" -> "dt",
"hoodie.index.type" -> "GLOBAL_BLOOM",
"hoodie.compact.inline" -> "true",
"hoodie.datasource.write.keygenerator.class" ->
"org.apache.hudi.keygen.ComplexKeyGenerator"
)
//step1: insert --no issue
df.write.format("hudi").
options(hudiOptions).
mode(Append).
save(basePath)
//step2: move part data to another partition --no issue
val df1 = spark.sql("select * from dw.f_schedule_test where dt =
'2022-08-30'").withColumn("dt",lit("2022-08-31")).limit(3)
df1.write.format("hudi").
options(hudiOptions).
mode(Append).
save(basePath)
//step3: move back --duplicate occurs
//Updating an existing set of rows will result in either a) a companion
log/delta file for an existing base parquet file generated from a previous
compaction or b) an update written to a log/delta file in case no compaction
ever happened for it.
val df2 = spark.sql("select * from dw.f_schedule_test where dt =
'2022-08-31'").withColumn("dt",lit("2022-08-30")).limit(3)
df2.write.format("hudi").
options(hudiOptions).
mode(Append).
save(basePath)
```
**Checking scripts:**
```
select * from dw.f_schedule_test where game_schedule_id = 1;
select _hoodie_file_name,count(*) as co from dw.f_schedule_test group by
_hoodie_file_name;
```
**results:**


**Expected behavior**
Duplicate records should not occur
**Environment Description**
* Hudi version :0.10.1
* Spark version :3.2.1
* Hive version :3.1.2
* Hadoop version :3.2.1
* Storage (HDFS/S3/GCS..) :OSS
* Running on Docker? (yes/no) :no
[hoodie.zip](https://github.com/apache/hudi/files/9487065/hoodie.zip)
**Stacktrace**
```Pls check logs as attached
[hoodie.zip](https://github.com/apache/hudi/files/9487078/hoodie.zip)
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] Xiaohan-Shen opened a new issue, #6590: [SUPPORT] HoodieDeltaStreamer AWSDmsAvroPayload fails to handle deletes in MySQL
Xiaohan-Shen opened a new issue, #6590: URL: https://github.com/apache/hudi/issues/6590 **Describe the problem you faced** inspired by this [blog](https://cwiki.apache.org/confluence/display/HUDI/2020/01/20/Change+Capture+Using+AWS+Database+Migration+Service+and+Hudi), I am trying to set up Hudi Deltastreamer to continuously pick up changes in MySQL for a performance benchmark. My setup hosts MySQL on **AWS RDS**, captures changes in MySQL with **AWS DMS** as Parquet in S3, and runs HoodieDeltaStreamer with `--continuous` on **AWS EMR** to write the changes into a Hudi table on S3. It's working fine with updates and inserts but throws exceptions on deletes. The row deleted in MySQL is not deleted in the Hudi table. I am new to Hudi so it's possible I have something configured wrong. **To Reproduce** Steps to reproduce the behavior: 1. Follow the setup steps in the [blog](https://cwiki.apache.org/confluence/display/HUDI/2020/01/20/Change+Capture+Using+AWS+Database+Migration+Service+and+Hudi) 2. use this command for starting HoodieDeltaStreamer: ``` spark-submit --jars /usr/lib/spark/external/lib/spark-avro.jar,/usr/lib/hudi/hudi-spark-bundle.jar,/usr/lib/hudi/hudi-utilities-bundle.jar --class org.apache.hudi.utilities.deltastreamer.HoodieDeltaStreamer --packages org.apache.hudi:hudi-spark-bundle_2.12:0.11.0,org.apache.spark:spark-avro_2.12:3.2.1 --master yarn --deploy-mode client /usr/lib/hudi/hudi-utilities-bundle.jar --table-type COPY_ON_WRITE --source-ordering-field updated_at --source-class org.apache.hudi.utilities.sources.ParquetDFSSource --target-base-path s3://mysql-data-replication/hudi_orders --target-table hudi_orders --transformer-class org.apache.hudi.utilities.transform.AWSDmsTransformer --continuous --hoodie-conf hoodie.datasource.write.recordkey.field=order_id --hoodie-conf hoodie.datasource.write.partitionpath.field=customer_name --hoodie-conf hoodie.deltastreamer.source.dfs.root=s3://mysql-data-replication/hudi_dms/orders --payload-class org.apache.hudi.payload.AWSDmsAvroPayload ``` 3. Insert a few rows to the MySQL table 4. Delete a row **Expected behavior** Hudi should monitor and capture any changes (Inserts, updates, and deletes) in the MySQL table and writes them into the Hudi table. I specified `--payload-class org.apache.hudi.payload.AWSDmsAvroPayload`, which should tell Hudi the right way to handle a row with `Op = D`. I.e. when a row in MySQL is deleted, Hudi should capture the change and delete the corresponding row in the Hudi table. **Environment Description** * Hudi version : 0.11.0 * Spark version : 3.2.1 * Hive version : should be irrelevant, but 3.1.3 * Hadoop version : 3.2.1 * Storage (HDFS/S3/GCS..) : S3 * Running on Docker? (yes/no) : no **Additional context** The command I ran to start Hudi is slightly different from that provided in the blog. The original one didn't work for me out of the box. Please let me know if I passed in the wrong configs in the command that might've caused this issue. **Stacktrace** ``` Caused by: java.util.NoSuchElementException: No value present in Option at org.apache.hudi.common.util.Option.get(Option.java:89) at org.apache.hudi.payload.AWSDmsAvroPayload.getInsertValue(AWSDmsAvroPayload.java:74) at org.apache.hudi.io.HoodieMergeHandle.writeInsertRecord(HoodieMergeHandle.java:272) at org.apache.hudi.io.HoodieMergeHandle.writeIncomingRecords(HoodieMergeHandle.java:380) at org.apache.hudi.io.HoodieMergeHandle.close(HoodieMergeHandle.java:388) at org.apache.hudi.table.action.commit.HoodieMergeHelper.runMerge(HoodieMergeHelper.java:154) at org.apache.hudi.table.action.commit.BaseSparkCommitActionExecutor.handleUpdateInternal(BaseSparkCommitActionExecutor.java:358) at org.apache.hudi.table.action.commit.BaseSparkCommitActionExecutor.handleUpdate(BaseSparkCommitActionExecutor.java:349) at org.apache.hudi.table.action.commit.BaseSparkCommitActionExecutor.handleUpsertPartition(BaseSparkCommitActionExecutor.java:322) ... 28 more Driver stacktrace: at org.apache.hudi.utilities.deltastreamer.HoodieDeltaStreamer$DeltaSyncService.lambda$startService$0(HoodieDeltaStreamer.java:709) at java.util.concurrent.CompletableFuture$AsyncSupply.run(CompletableFuture.java:1604) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:750) Caused by: org.apache.spark.SparkException: Job aborted due to stage failure: Task 0 in stage 156.0 failed 4 times, most recent failure: Lost task 0.3 in stage 156.0 (TID 6494)
[GitHub] [hudi] hudi-bot commented on pull request #6574: Keep a clustering running at the same time.#6573
hudi-bot commented on PR #6574: URL: https://github.com/apache/hudi/pull/6574#issuecomment-1236562876 ## CI report: * bcc7396d9357eb792a0c7a61335910cb16746a62 Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=9) * 6dd530a55de90fe931c22597d453c92b56bb31c1 Azure: [PENDING](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=11148) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] ROOBALJINDAL commented on issue #5540: [SUPPORT]HoodieException: Commit 20220509105215 failed and rolled-back ! at org.apache.hudi.utilities.deltastreamer.DeltaSync.writeToSink(DeltaSy
ROOBALJINDAL commented on issue #5540: URL: https://github.com/apache/hudi/issues/5540#issuecomment-1236559491 @nsivabalan this was my issue which I have already closed. https://github.com/apache/hudi/issues/6348 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #6574: Keep a clustering running at the same time.#6573
hudi-bot commented on PR #6574: URL: https://github.com/apache/hudi/pull/6574#issuecomment-1236559694 ## CI report: * bcc7396d9357eb792a0c7a61335910cb16746a62 Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=9) * 6dd530a55de90fe931c22597d453c92b56bb31c1 UNKNOWN Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] flashJd commented on a diff in pull request #6385: [HUDI-4614] fix primary key extract of delete_record when complexKeyGen configured and ChangeLogDisabled
flashJd commented on code in PR #6385:
URL: https://github.com/apache/hudi/pull/6385#discussion_r962494062
##
hudi-client/hudi-client-common/src/main/java/org/apache/hudi/keygen/KeyGenUtils.java:
##
@@ -73,21 +73,20 @@ public static String
getPartitionPathFromGenericRecord(GenericRecord genericReco
*/
public static String[] extractRecordKeys(String recordKey) {
String[] fieldKV = recordKey.split(",");
-if (fieldKV.length == 1) {
- return fieldKV;
-} else {
- // a complex key
- return Arrays.stream(fieldKV).map(kv -> {
-final String[] kvArray = kv.split(":");
-if (kvArray[1].equals(NULL_RECORDKEY_PLACEHOLDER)) {
- return null;
-} else if (kvArray[1].equals(EMPTY_RECORDKEY_PLACEHOLDER)) {
- return "";
-} else {
- return kvArray[1];
-}
- }).toArray(String[]::new);
-}
+
+return Arrays.stream(fieldKV).map(kv -> {
+ final String[] kvArray = kv.split(":");
Review Comment:
> Yeah, i have merged #6539 , so this pr can be closed.
@danny0405 #6539 has little problem, if it's single pk and simple key
generator, we'll store 'danny' not 'id:danny', so kvArray[1] will be null point
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] CaesarWangX commented on issue #6543: [SUPPORT] Unable to load class of UserDefinedMetricsReporter in hudi0.11
CaesarWangX commented on issue #6543: URL: https://github.com/apache/hudi/issues/6543#issuecomment-1236558188 Hi @Zouxxyy Thanks for your suggestion. I tried your method, but I still got the same error spark-submit \ --master yarn \ --deploy-mode cluster \ --name \ --queue clustering \ --class com.test.MainClass \ --files test.conf \ --conf spark.driver.extraClassPath=my-jar-1.0.0-SNAPSHOT-jar-with-dependencies.jar \ --jars /usr/lib/hudi/hudi-spark-bundle.jar,/usr/lib/spark/external/lib/spark-avro.jar,/usr/lib/spark/external/lib/spark-sql-kafka-0-10.jar,/usr/lib/spark/external/lib/spark-streaming-kafka-0-10-assembly.jar,/usr/lib/spark/external/lib/spark-token-provider-kafka-0-10.jar \ my-jar-1.0.0-SNAPSHOT-jar-with-dependencies.jar -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #6489: [HUDI-4485] [cli] Bumped spring shell to 2.1.1. Updated the default …
hudi-bot commented on PR #6489: URL: https://github.com/apache/hudi/pull/6489#issuecomment-1236557079 ## CI report: * 47680402da599615de30c13a1f22f79f3573ee30 UNKNOWN * 5613f14b3d5f1c8aaf8de1730e2f21b78a657150 UNKNOWN * 61586bd9583dd4cb3fe6572d572911ca193faecf Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=11144) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] codope commented on a diff in pull request #6587: [HUDI-4775] Fixing incremental source for MOR table
codope commented on code in PR #6587:
URL: https://github.com/apache/hudi/pull/6587#discussion_r962489007
##
hudi-utilities/src/test/java/org/apache/hudi/utilities/sources/TestHoodieIncrSource.java:
##
@@ -55,20 +66,39 @@ public class TestHoodieIncrSource extends
SparkClientFunctionalTestHarness {
private HoodieTestDataGenerator dataGen;
private HoodieTableMetaClient metaClient;
+ private HoodieTableType tableType = COPY_ON_WRITE;
@BeforeEach
public void setUp() throws IOException {
dataGen = new HoodieTestDataGenerator();
-metaClient = getHoodieMetaClient(hadoopConf(), basePath());
}
- @Test
- public void testHoodieIncrSource() throws IOException {
+ @Override
+ public HoodieTableMetaClient getHoodieMetaClient(Configuration hadoopConf,
String basePath, Properties props) throws IOException {
+props = HoodieTableMetaClient.withPropertyBuilder()
+.setTableName(RAW_TRIPS_TEST_NAME)
+.setTableType(tableType)
+.setPayloadClass(HoodieAvroPayload.class)
+.fromProperties(props)
+.build();
+return HoodieTableMetaClient.initTableAndGetMetaClient(hadoopConf,
basePath, props);
+ }
+
+ private static Stream tableTypeParams() {
+return Arrays.stream(new HoodieTableType[][]
{{HoodieTableType.COPY_ON_WRITE},
{HoodieTableType.MERGE_ON_READ}}).map(Arguments::of);
+ }
+
+ @ParameterizedTest
+ @MethodSource("tableTypeParams")
+ public void testHoodieIncrSource(HoodieTableType tableType) throws
IOException {
+this.tableType = tableType;
+metaClient = getHoodieMetaClient(hadoopConf(), basePath());
HoodieWriteConfig writeConfig = getConfigBuilder(basePath(), metaClient)
.withArchivalConfig(HoodieArchivalConfig.newBuilder().archiveCommitsWith(2,
3).build())
.withCleanConfig(HoodieCleanConfig.newBuilder().retainCommits(1).build())
+
.withCompactionConfig(HoodieCompactionConfig.newBuilder().withInlineCompaction(true).withMaxNumDeltaCommitsBeforeCompaction(3).build())
.withMetadataConfig(HoodieMetadataConfig.newBuilder()
-.withMaxNumDeltaCommitsBeforeCompaction(1).build())
+.enable(false).build())
Review Comment:
Why false? Let's keep it default?
##
hudi-utilities/src/main/java/org/apache/hudi/utilities/sources/helpers/IncrSourceHelper.java:
##
@@ -73,7 +73,7 @@ public static Pair>
calculateBeginAndEndInstants(Ja
HoodieTableMetaClient srcMetaClient =
HoodieTableMetaClient.builder().setConf(jssc.hadoopConfiguration()).setBasePath(srcBasePath).setLoadActiveTimelineOnLoad(true).build();
final HoodieTimeline activeCommitTimeline =
-
srcMetaClient.getActiveTimeline().getCommitTimeline().filterCompletedInstants();
+
srcMetaClient.getCommitsAndCompactionTimeline().filterCompletedInstants();
Review Comment:
Eventually, we should replace this API. Simply use
`metaClient.getActiveTimeline().getWriteTimeline()` as much as possible. I
don't think this API brings any real benefit apart from filtering out certain
types (deltacommit and compaction) for COW table. Anyway, such commits won't be
there for COW table and active timeline has already been loaded by that time.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] hechao-ustc commented on pull request #6582: [DOCS] Add Flink DataStream API demo in Flink Guide.
hechao-ustc commented on PR #6582: URL: https://github.com/apache/hudi/pull/6582#issuecomment-1236542371 > Thanks for the contribution @hechao-ustc , i have left one small comment. @danny0405 hi danny,Thanks for your comment,I have updated the content: 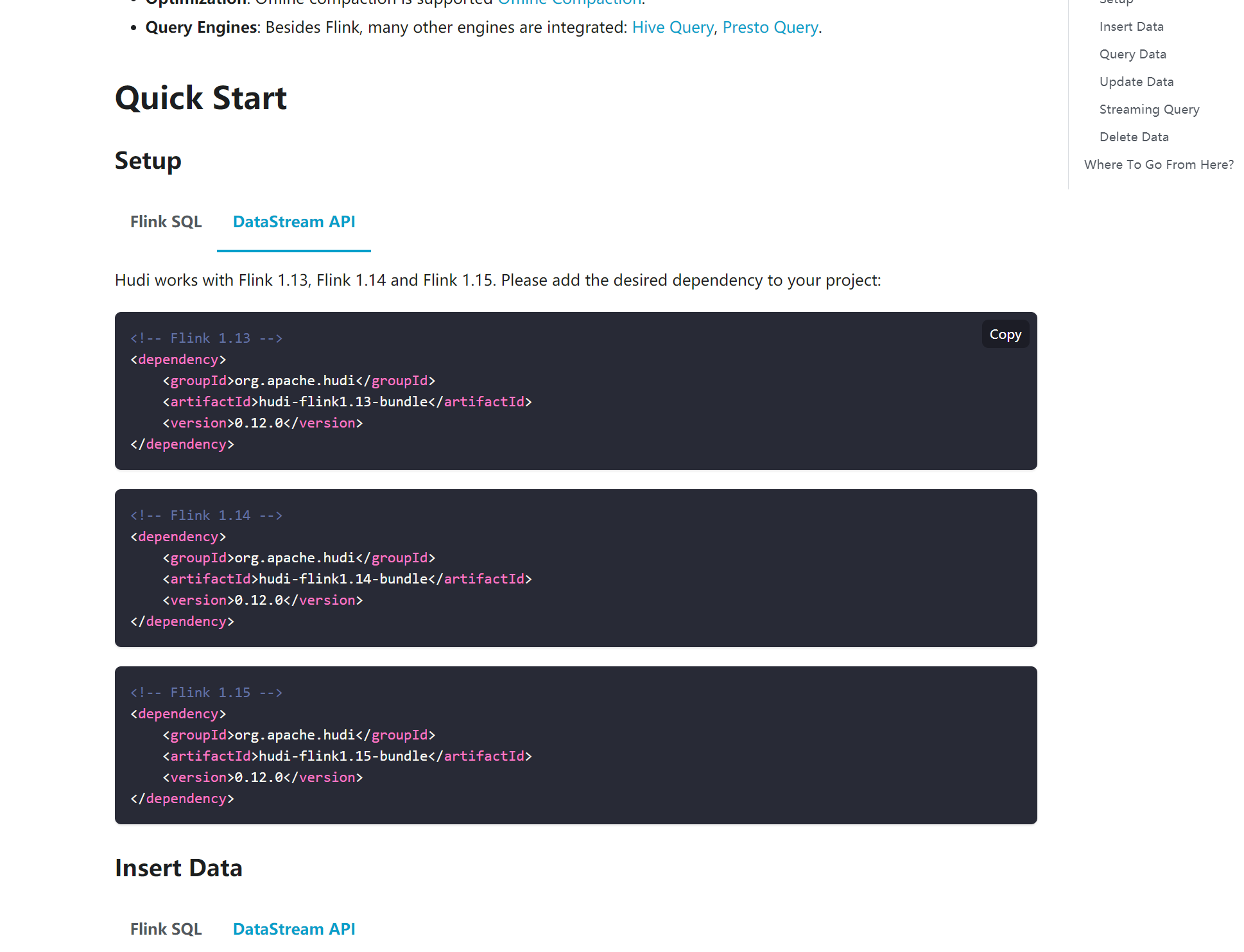 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #6589: [HUDI-4776] fix merge into use unresolved assignment
hudi-bot commented on PR #6589: URL: https://github.com/apache/hudi/pull/6589#issuecomment-1236532554 ## CI report: * 2779ca40748e4aa90ddecb01288c61fe478767a1 Azure: [PENDING](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=11147) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #6566: [HUDI-4766] Fix HoodieFlinkClusteringJob
hudi-bot commented on PR #6566: URL: https://github.com/apache/hudi/pull/6566#issuecomment-1236532503 ## CI report: * b10c9d062f03c2c2675866c6f4bf6346dc03ea49 UNKNOWN * a2dcd81f74603e88c4db895900d43eee6702a6da UNKNOWN * c404647afc6d26bc0e69a7a8ef93f378b397bb96 UNKNOWN * 257a2f2acf08448c082c89510cd731b4d8f1b877 Azure: [SUCCESS](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=11130) * 1709f71ae9494da4d7ca6b9c62ac97cd11dd8046 Azure: [PENDING](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=11146) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #6589: [HUDI-4776] fix merge into use unresolved assignment
hudi-bot commented on PR #6589: URL: https://github.com/apache/hudi/pull/6589#issuecomment-1236530342 ## CI report: * 2779ca40748e4aa90ddecb01288c61fe478767a1 UNKNOWN Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #6566: [HUDI-4766] Fix HoodieFlinkClusteringJob
hudi-bot commented on PR #6566: URL: https://github.com/apache/hudi/pull/6566#issuecomment-1236530294 ## CI report: * b10c9d062f03c2c2675866c6f4bf6346dc03ea49 UNKNOWN * a2dcd81f74603e88c4db895900d43eee6702a6da UNKNOWN * c404647afc6d26bc0e69a7a8ef93f378b397bb96 UNKNOWN * 257a2f2acf08448c082c89510cd731b4d8f1b877 Azure: [SUCCESS](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=11130) * 1709f71ae9494da4d7ca6b9c62ac97cd11dd8046 UNKNOWN Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] danny0405 commented on issue #6588: [SUPPORT]Caused by: java.lang.ClassNotFoundException: org.apache.hudi.org.apache.avro.util.Utf8
danny0405 commented on issue #6588: URL: https://github.com/apache/hudi/issues/6588#issuecomment-1236524891 what jar did you use for spark, you can open the spark jar with command: ```shell vim xxx.jar ``` and search about the missing clazz to see if the jar includes it. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] danny0405 commented on a diff in pull request #6385: [HUDI-4614] fix primary key extract of delete_record when complexKeyGen configured and ChangeLogDisabled
danny0405 commented on code in PR #6385:
URL: https://github.com/apache/hudi/pull/6385#discussion_r962462481
##
hudi-client/hudi-client-common/src/main/java/org/apache/hudi/keygen/KeyGenUtils.java:
##
@@ -73,21 +73,20 @@ public static String
getPartitionPathFromGenericRecord(GenericRecord genericReco
*/
public static String[] extractRecordKeys(String recordKey) {
String[] fieldKV = recordKey.split(",");
-if (fieldKV.length == 1) {
- return fieldKV;
-} else {
- // a complex key
- return Arrays.stream(fieldKV).map(kv -> {
-final String[] kvArray = kv.split(":");
-if (kvArray[1].equals(NULL_RECORDKEY_PLACEHOLDER)) {
- return null;
-} else if (kvArray[1].equals(EMPTY_RECORDKEY_PLACEHOLDER)) {
- return "";
-} else {
- return kvArray[1];
-}
- }).toArray(String[]::new);
-}
+
+return Arrays.stream(fieldKV).map(kv -> {
+ final String[] kvArray = kv.split(":");
Review Comment:
Yeah, i have merged #6539 , so this pr can be closed.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[jira] [Resolved] (HUDI-4739) Wrong value returned when length equals 1
[ https://issues.apache.org/jira/browse/HUDI-4739?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Danny Chen resolved HUDI-4739. -- > Wrong value returned when length equals 1 > - > > Key: HUDI-4739 > URL: https://issues.apache.org/jira/browse/HUDI-4739 > Project: Apache Hudi > Issue Type: Bug > Components: writer-core >Reporter: wuwenchi >Assignee: wuwenchi >Priority: Major > Labels: pull-request-available > Fix For: 0.12.1 > > > In "KeyGenUtils#extractRecordKeys" function, it will return the value > corresponding to the key, but when the length is equal to 1, the key and > value are returned. -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Commented] (HUDI-4739) Wrong value returned when length equals 1
[ https://issues.apache.org/jira/browse/HUDI-4739?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17600191#comment-17600191 ] Danny Chen commented on HUDI-4739: -- Fixed via master branch: 24dd00724cf8f49b8e2d5ad07afaa7756165e0a7 > Wrong value returned when length equals 1 > - > > Key: HUDI-4739 > URL: https://issues.apache.org/jira/browse/HUDI-4739 > Project: Apache Hudi > Issue Type: Bug > Components: writer-core >Reporter: wuwenchi >Assignee: wuwenchi >Priority: Major > Labels: pull-request-available > Fix For: 0.12.1 > > > In "KeyGenUtils#extractRecordKeys" function, it will return the value > corresponding to the key, but when the length is equal to 1, the key and > value are returned. -- This message was sent by Atlassian Jira (v8.20.10#820010)
[hudi] branch master updated: [HUDI-4739] Wrong value returned when key's length equals 1 (#6539)
This is an automated email from the ASF dual-hosted git repository.
danny0405 pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/hudi.git
The following commit(s) were added to refs/heads/master by this push:
new 24dd00724c [HUDI-4739] Wrong value returned when key's length equals 1
(#6539)
24dd00724c is described below
commit 24dd00724cf8f49b8e2d5ad07afaa7756165e0a7
Author: wuwenchi
AuthorDate: Mon Sep 5 12:10:13 2022 +0800
[HUDI-4739] Wrong value returned when key's length equals 1 (#6539)
* extracts key fields
Co-authored-by: 吴文池
---
.../java/org/apache/hudi/keygen/KeyGenUtils.java | 25 ++-
.../org/apache/hudi/keygen/TestKeyGenUtils.java| 37 ++
2 files changed, 47 insertions(+), 15 deletions(-)
diff --git
a/hudi-client/hudi-client-common/src/main/java/org/apache/hudi/keygen/KeyGenUtils.java
b/hudi-client/hudi-client-common/src/main/java/org/apache/hudi/keygen/KeyGenUtils.java
index 362ef208d4..1fd46d31e5 100644
---
a/hudi-client/hudi-client-common/src/main/java/org/apache/hudi/keygen/KeyGenUtils.java
+++
b/hudi-client/hudi-client-common/src/main/java/org/apache/hudi/keygen/KeyGenUtils.java
@@ -73,21 +73,16 @@ public class KeyGenUtils {
*/
public static String[] extractRecordKeys(String recordKey) {
String[] fieldKV = recordKey.split(",");
-if (fieldKV.length == 1) {
- return fieldKV;
-} else {
- // a complex key
- return Arrays.stream(fieldKV).map(kv -> {
-final String[] kvArray = kv.split(":");
-if (kvArray[1].equals(NULL_RECORDKEY_PLACEHOLDER)) {
- return null;
-} else if (kvArray[1].equals(EMPTY_RECORDKEY_PLACEHOLDER)) {
- return "";
-} else {
- return kvArray[1];
-}
- }).toArray(String[]::new);
-}
+return Arrays.stream(fieldKV).map(kv -> {
+ final String[] kvArray = kv.split(":");
+ if (kvArray[1].equals(NULL_RECORDKEY_PLACEHOLDER)) {
+return null;
+ } else if (kvArray[1].equals(EMPTY_RECORDKEY_PLACEHOLDER)) {
+return "";
+ } else {
+return kvArray[1];
+ }
+}).toArray(String[]::new);
}
public static String getRecordKey(GenericRecord record, List
recordKeyFields, boolean consistentLogicalTimestampEnabled) {
diff --git
a/hudi-client/hudi-client-common/src/test/java/org/apache/hudi/keygen/TestKeyGenUtils.java
b/hudi-client/hudi-client-common/src/test/java/org/apache/hudi/keygen/TestKeyGenUtils.java
new file mode 100644
index 00..06a6fcd7d7
--- /dev/null
+++
b/hudi-client/hudi-client-common/src/test/java/org/apache/hudi/keygen/TestKeyGenUtils.java
@@ -0,0 +1,37 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.keygen;
+
+import org.junit.jupiter.api.Assertions;
+import org.junit.jupiter.api.Test;
+
+public class TestKeyGenUtils {
+
+ @Test
+ public void testExtractRecordKeys() {
+String[] s1 = KeyGenUtils.extractRecordKeys("id:1");
+Assertions.assertArrayEquals(new String[]{"1"}, s1);
+
+String[] s2 = KeyGenUtils.extractRecordKeys("id:1,id:2");
+Assertions.assertArrayEquals(new String[]{"1", "2"}, s2);
+
+String[] s3 =
KeyGenUtils.extractRecordKeys("id:1,id2:__null__,id3:__empty__");
+Assertions.assertArrayEquals(new String[]{"1", null, ""}, s3);
+ }
+}
[GitHub] [hudi] danny0405 merged pull request #6539: [HUDI-4739] Wrong value returned when key's length equals 1
danny0405 merged PR #6539: URL: https://github.com/apache/hudi/pull/6539 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] danny0405 commented on a diff in pull request #6539: [HUDI-4739] Wrong value returned when key's length equals 1
danny0405 commented on code in PR #6539:
URL: https://github.com/apache/hudi/pull/6539#discussion_r962460133
##
hudi-client/hudi-client-common/src/main/java/org/apache/hudi/keygen/KeyGenUtils.java:
##
@@ -73,21 +73,16 @@ public static String
getPartitionPathFromGenericRecord(GenericRecord genericReco
*/
public static String[] extractRecordKeys(String recordKey) {
String[] fieldKV = recordKey.split(",");
-if (fieldKV.length == 1) {
- return fieldKV;
-} else {
- // a complex key
- return Arrays.stream(fieldKV).map(kv -> {
-final String[] kvArray = kv.split(":");
-if (kvArray[1].equals(NULL_RECORDKEY_PLACEHOLDER)) {
- return null;
-} else if (kvArray[1].equals(EMPTY_RECORDKEY_PLACEHOLDER)) {
- return "";
-} else {
- return kvArray[1];
-}
- }).toArray(String[]::new);
-}
+return Arrays.stream(fieldKV).map(kv -> {
+ final String[] kvArray = kv.split(":");
+ if (kvArray[1].equals(NULL_RECORDKEY_PLACEHOLDER)) {
+return null;
+ } else if (kvArray[1].equals(EMPTY_RECORDKEY_PLACEHOLDER)) {
+return "";
+ } else {
+return kvArray[1];
+ }
+}).toArray(String[]::new);
Review Comment:
Thanks, generally we should not use `Complex` key generators for single
field primary key, but the fix makes the logic more robust,
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] dik111 commented on issue #6588: [SUPPORT]Caused by: java.lang.ClassNotFoundException: org.apache.hudi.org.apache.avro.util.Utf8
dik111 commented on issue #6588: URL: https://github.com/apache/hudi/issues/6588#issuecomment-1236519071 > Seems that spark bundle jar does not contain the shaded avro clazz. What should I do about it ? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (HUDI-4776) missing specify value for the preCombineField when use merge into
[
https://issues.apache.org/jira/browse/HUDI-4776?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
ASF GitHub Bot updated HUDI-4776:
-
Labels: pull-request-available (was: )
> missing specify value for the preCombineField when use merge into
> -
>
> Key: HUDI-4776
> URL: https://issues.apache.org/jira/browse/HUDI-4776
> Project: Apache Hudi
> Issue Type: Bug
> Components: spark-sql
>Reporter: KnightChess
>Assignee: KnightChess
>Priority: Minor
> Labels: pull-request-available
>
>
> {code:java}
> org.apache.spark.sql.AnalysisException: Missing specify value for the
> preCombineField: ts in merge-into update action. You should add '... update
> set ts = xx' to the when-matched clause. at
> org.apache.spark.sql.hudi.analysis.HoodieResolveReferences$$anonfun$apply$1.$anonfun$applyOrElse$19(HoodieAnalysis.scala:387)
> at
> scala.collection.TraversableLike.$anonfun$map$1(TraversableLike.scala:238)
> at scala.collection.immutable.List.foreach(List.scala:392) at
> scala.collection.TraversableLike.map(TraversableLike.scala:238) at
> scala.collection.TraversableLike.map$(TraversableLike.scala:231) at
> scala.collection.immutable.List.map(List.scala:298) at
> org.apache.spark.sql.hudi.analysis.HoodieResolveReferences$$anonfun$apply$1.$anonfun$applyOrElse$14(HoodieAnalysis.scala:377)
> at
> scala.collection.TraversableLike.$anonfun$map$1(TraversableLike.scala:238)
> at scala.collection.mutable.ResizableArray.foreach(ResizableArray.scala:62)
> at scala.collection.mutable.ResizableArray.foreach$(ResizableArray.scala:55)
> {code}
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[GitHub] [hudi] KnightChess opened a new pull request, #6589: [HUDI-4776] fix merge into use unresolved assignment
KnightChess opened a new pull request, #6589: URL: https://github.com/apache/hudi/pull/6589 ### Change Logs fix merge into sql use unresolved attr cause use the wrong condition branch `resolve Star assignment` ### Impact _Describe any public API or user-facing feature change or any performance impact._ **Risk level: none | low | medium | high** _Choose one. If medium or high, explain what verification was done to mitigate the risks._ ### Contributor's checklist - [ ] Read through [contributor's guide](https://hudi.apache.org/contribute/how-to-contribute) - [ ] Change Logs and Impact were stated clearly - [ ] Adequate tests were added if applicable - [ ] CI passed -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] danny0405 commented on issue #6588: [SUPPORT]Caused by: java.lang.ClassNotFoundException: org.apache.hudi.org.apache.avro.util.Utf8
danny0405 commented on issue #6588: URL: https://github.com/apache/hudi/issues/6588#issuecomment-1236516899 Seems that spark bundle jar does not contain the shaded avro clazz. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] danny0405 commented on a diff in pull request #6567: [HUDI-4767] Fix non partition table in hudi-flink ignore KEYGEN_CLASS…
danny0405 commented on code in PR #6567:
URL: https://github.com/apache/hudi/pull/6567#discussion_r962456453
##
hudi-flink-datasource/hudi-flink/src/main/java/org/apache/hudi/table/HoodieTableFactory.java:
##
@@ -217,31 +217,33 @@ private static void setupHoodieKeyOptions(Configuration
conf, CatalogTable table
}
}
-// tweak the key gen class if possible
-final String[] partitions =
conf.getString(FlinkOptions.PARTITION_PATH_FIELD).split(",");
-final String[] pks =
conf.getString(FlinkOptions.RECORD_KEY_FIELD).split(",");
-if (partitions.length == 1) {
- final String partitionField = partitions[0];
- if (partitionField.isEmpty()) {
-conf.setString(FlinkOptions.KEYGEN_CLASS_NAME,
NonpartitionedAvroKeyGenerator.class.getName());
-LOG.info("Table option [{}] is reset to {} because this is a
non-partitioned table",
-FlinkOptions.KEYGEN_CLASS_NAME.key(),
NonpartitionedAvroKeyGenerator.class.getName());
-return;
+if (StringUtils.isNullOrEmpty(conf.get(FlinkOptions.KEYGEN_CLASS_NAME))) {
+ // tweak the key gen class if possible
Review Comment:
Generally that's true, but non-partitioned table is a special case and hudi
configure the keygen clazz transparently for user.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] voonhous commented on a diff in pull request #6566: [HUDI-4766] Fix HoodieFlinkClusteringJob
voonhous commented on code in PR #6566:
URL: https://github.com/apache/hudi/pull/6566#discussion_r962456335
##
hudi-flink-datasource/hudi-flink/src/main/java/org/apache/hudi/sink/clustering/HoodieFlinkClusteringJob.java:
##
@@ -259,15 +287,18 @@ private void cluster() throws Exception {
if (!clusteringPlanOption.isPresent()) {
// do nothing.
LOG.info("No clustering plan scheduled, turns on the clustering plan
schedule with --schedule option");
+executeDummyPipeline();
return;
}
+ clusteringInstant = clusteringPlanOption.get().getLeft();
HoodieClusteringPlan clusteringPlan =
clusteringPlanOption.get().getRight();
Review Comment:
No special reasons, I will remove it.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] danny0405 commented on pull request #6582: [DOCS] Add Flink DataStream API demo in Flink Guide.
danny0405 commented on PR #6582: URL: https://github.com/apache/hudi/pull/6582#issuecomment-1236515994 Thanks for the contribution @hechao-ustc , i have left one small comment. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] voonhous commented on a diff in pull request #6566: [HUDI-4766] Fix HoodieFlinkClusteringJob
voonhous commented on code in PR #6566:
URL: https://github.com/apache/hudi/pull/6566#discussion_r962455602
##
hudi-flink-datasource/hudi-flink/src/main/java/org/apache/hudi/sink/clustering/HoodieFlinkClusteringJob.java:
##
@@ -335,5 +391,17 @@ public void shutdownAsyncService(boolean error) {
public void shutDown() {
shutdownAsyncService(false);
}
+
+/**
+ * Execute a dummy pipeline to prevent "no execute() calls" exceptions
from being thrown if
+ * clustering is not performed.
+ */
Review Comment:
Hmmm, CMIIW, `execute()` is only triggered at the end of the `cluster()`
function.
```java
env.execute("flink_hudi_clustering_" + clusteringInstant.getTimestamp());
```
If `cluster()` function terminates before reaching the end, the `execute()`
function will not be called.
Hence, there will be a `no execute() exception` as shown in the image.
Jobs are submitted via Flink web portal using the hoodie flink bundle jar.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[jira] [Created] (HUDI-4776) missing specify value for the preCombineField when use merge into
KnightChess created HUDI-4776:
-
Summary: missing specify value for the preCombineField when use
merge into
Key: HUDI-4776
URL: https://issues.apache.org/jira/browse/HUDI-4776
Project: Apache Hudi
Issue Type: Bug
Components: spark-sql
Reporter: KnightChess
Assignee: KnightChess
{code:java}
org.apache.spark.sql.AnalysisException: Missing specify value for the
preCombineField: ts in merge-into update action. You should add '... update set
ts = xx' to the when-matched clause. at
org.apache.spark.sql.hudi.analysis.HoodieResolveReferences$$anonfun$apply$1.$anonfun$applyOrElse$19(HoodieAnalysis.scala:387)
at scala.collection.TraversableLike.$anonfun$map$1(TraversableLike.scala:238)
at scala.collection.immutable.List.foreach(List.scala:392) at
scala.collection.TraversableLike.map(TraversableLike.scala:238) at
scala.collection.TraversableLike.map$(TraversableLike.scala:231) at
scala.collection.immutable.List.map(List.scala:298) at
org.apache.spark.sql.hudi.analysis.HoodieResolveReferences$$anonfun$apply$1.$anonfun$applyOrElse$14(HoodieAnalysis.scala:377)
at scala.collection.TraversableLike.$anonfun$map$1(TraversableLike.scala:238)
at scala.collection.mutable.ResizableArray.foreach(ResizableArray.scala:62)
at scala.collection.mutable.ResizableArray.foreach$(ResizableArray.scala:55)
{code}
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[GitHub] [hudi] danny0405 commented on a diff in pull request #6582: [DOCS] Add Flink DataStream API demo in Flink Guide.
danny0405 commented on code in PR #6582: URL: https://github.com/apache/hudi/pull/6582#discussion_r962453282 ## website/versioned_docs/version-0.12.0/flink-quick-start-guide.md: ## @@ -74,9 +85,36 @@ export HADOOP_CLASSPATH=`$HADOOP_HOME/bin/hadoop classpath` Setup table name, base path and operate using SQL for this guide. The SQL CLI only executes the SQL line by line. + + + + +Please add the following dependency to your project: +```xml + +org.apache.hudi +hudi-flink1.13-bundle_2.11 +0.12.0 Review Comment: hudi-flink1.13-bundle ? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] eric9204 commented on pull request #6574: Keep a clustering running at the same time.#6573
eric9204 commented on PR #6574: URL: https://github.com/apache/hudi/pull/6574#issuecomment-1236512527 @danny0405 Actually, the clustering plan was scheduled for every successful commits. and there are too many inflight clustering job. I think need to make some change. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] TJX2014 commented on a diff in pull request #6567: [HUDI-4767] Fix non partition table in hudi-flink ignore KEYGEN_CLASS…
TJX2014 commented on code in PR #6567:
URL: https://github.com/apache/hudi/pull/6567#discussion_r962451609
##
hudi-flink-datasource/hudi-flink/src/main/java/org/apache/hudi/table/HoodieTableFactory.java:
##
@@ -217,31 +217,33 @@ private static void setupHoodieKeyOptions(Configuration
conf, CatalogTable table
}
}
-// tweak the key gen class if possible
-final String[] partitions =
conf.getString(FlinkOptions.PARTITION_PATH_FIELD).split(",");
-final String[] pks =
conf.getString(FlinkOptions.RECORD_KEY_FIELD).split(",");
-if (partitions.length == 1) {
- final String partitionField = partitions[0];
- if (partitionField.isEmpty()) {
-conf.setString(FlinkOptions.KEYGEN_CLASS_NAME,
NonpartitionedAvroKeyGenerator.class.getName());
-LOG.info("Table option [{}] is reset to {} because this is a
non-partitioned table",
-FlinkOptions.KEYGEN_CLASS_NAME.key(),
NonpartitionedAvroKeyGenerator.class.getName());
-return;
+if (StringUtils.isNullOrEmpty(conf.get(FlinkOptions.KEYGEN_CLASS_NAME))) {
+ // tweak the key gen class if possible
Review Comment:
But user cannot assign keygen_class seems not friendly.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] danny0405 commented on a diff in pull request #6566: [HUDI-4766] Fix HoodieFlinkClusteringJob
danny0405 commented on code in PR #6566:
URL: https://github.com/apache/hudi/pull/6566#discussion_r962450120
##
hudi-flink-datasource/hudi-flink/src/main/java/org/apache/hudi/sink/clustering/FlinkClusteringConfig.java:
##
@@ -69,13 +83,14 @@ public class FlinkClusteringConfig extends Configuration {
required = false)
public Integer archiveMaxCommits = 30;
- @Parameter(names = {"--schedule", "-sc"}, description = "Not recommended.
Schedule the clustering plan in this job.\n"
- + "There is a risk of losing data when scheduling clustering outside the
writer job.\n"
- + "Scheduling clustering in the writer job and only let this job do the
clustering execution is recommended.\n"
- + "Default is true", required = false)
- public Boolean schedule = true;
+ @Parameter(names = {"--schedule", "-sc"}, description = "Schedule the
clustering plan in this job.\n"
+ + "Default is false", required = false)
+ public Boolean schedule = false;
+
+ @Parameter(names = {"--instant-time", "-it"}, description = "Clustering
Instant time")
+ public String clusteringInstantTime = null;
Review Comment:
Fine, we can keep that if spark already name it like this.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] danny0405 commented on a diff in pull request #6566: [HUDI-4766] Fix HoodieFlinkClusteringJob
danny0405 commented on code in PR #6566:
URL: https://github.com/apache/hudi/pull/6566#discussion_r962449954
##
hudi-flink-datasource/hudi-flink/src/main/java/org/apache/hudi/sink/clustering/HoodieFlinkClusteringJob.java:
##
@@ -335,5 +391,17 @@ public void shutdownAsyncService(boolean error) {
public void shutDown() {
shutdownAsyncService(false);
}
+
+/**
+ * Execute a dummy pipeline to prevent "no execute() calls" exceptions
from being thrown if
+ * clustering is not performed.
+ */
Review Comment:
How do you submit the job, it weird what the no `execute()` exception throws
because we return early in the executor worker thread.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] danny0405 commented on a diff in pull request #6566: [HUDI-4766] Fix HoodieFlinkClusteringJob
danny0405 commented on code in PR #6566:
URL: https://github.com/apache/hudi/pull/6566#discussion_r962449324
##
hudi-flink-datasource/hudi-flink/src/main/java/org/apache/hudi/sink/clustering/HoodieFlinkClusteringJob.java:
##
@@ -259,15 +287,18 @@ private void cluster() throws Exception {
if (!clusteringPlanOption.isPresent()) {
// do nothing.
LOG.info("No clustering plan scheduled, turns on the clustering plan
schedule with --schedule option");
+executeDummyPipeline();
return;
}
+ clusteringInstant = clusteringPlanOption.get().getLeft();
HoodieClusteringPlan clusteringPlan =
clusteringPlanOption.get().getRight();
Review Comment:
Is there any special reason we need to overwrite the `clusteringInstant`
from the `clusteringPlanOption` ?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] dik111 opened a new issue, #6588: [SUPPORT]Caused by: java.lang.ClassNotFoundException: org.apache.hudi.org.apache.avro.util.Utf8
dik111 opened a new issue, #6588:
URL: https://github.com/apache/hudi/issues/6588
**_Tips before filing an issue_**
- Have you gone through our [FAQs](https://hudi.apache.org/learn/faq/)?
- Join the mailing list to engage in conversations and get faster support at
dev-subscr...@hudi.apache.org.
- If you have triaged this as a bug, then file an
[issue](https://issues.apache.org/jira/projects/HUDI/issues) directly.
**Describe the problem you faced**
I use spark to query hudi data, but it throws an exception Caused by:
java.lang.ClassNotFoundException: org.apache.hudi.org.apache.avro.util.Utf8
**To Reproduce**
Steps to reproduce the behavior:
1.use Flink to insert data
2.use spark to query data
**Expected behavior**
A clear and concise description of what you expected to happen.
**Environment Description**
* Hudi version : 0.12.0
* Spark version : 2.4.4
* Hive version : 3.0.0
* Hadoop version : 3.1.0
* Storage (HDFS/S3/GCS..) : HDFS
* Running on Docker? (yes/no) : no
**Additional context**
Here is my spark code
``` scala
System.setProperty("HADOOP_USER_NAME", "hdfs")
val spark:SparkSession = {
SparkSession.builder()
.appName(this.getClass.getSimpleName.stripSuffix("$"))
.master("local[2]")
.config("spark.serializer","org.apache.spark.serializer.KryoSerializer")
.getOrCreate()
}
val tablePath =
"hdfs://hdp03:8020/warehouse/tablespace/managed/hive/test.db/pt_sfy_sfy_oe_order_lines_all_hudi_0904"
val dataFrame = spark.read.format("org.apache.hudi").load(tablePath)
dataFrame.createOrReplaceTempView("pt_sfy_sfy_oe_order_lines_all_hudi_0904")
spark.sql("select * from pt_sfy_sfy_oe_order_lines_all_hudi_0904
").show()
spark.stop()
```
**Stacktrace**
```
00:34 WARN: [kryo] Unable to load class
org.apache.hudi.org.apache.avro.util.Utf8 with kryo's ClassLoader. Retrying
with current..
22/09/05 11:17:58 ERROR AbstractHoodieLogRecordReader: Got exception when
reading log file
com.esotericsoftware.kryo.KryoException: Unable to find class:
org.apache.hudi.org.apache.avro.util.Utf8
Serialization trace:
orderingVal (org.apache.hudi.common.model.DeleteRecord)
at
com.esotericsoftware.kryo.util.DefaultClassResolver.readName(DefaultClassResolver.java:160)
at
com.esotericsoftware.kryo.util.DefaultClassResolver.readClass(DefaultClassResolver.java:133)
at com.esotericsoftware.kryo.Kryo.readClass(Kryo.java:693)
at
com.esotericsoftware.kryo.serializers.ObjectField.read(ObjectField.java:118)
at
com.esotericsoftware.kryo.serializers.FieldSerializer.read(FieldSerializer.java:543)
at com.esotericsoftware.kryo.Kryo.readObject(Kryo.java:731)
at
com.esotericsoftware.kryo.serializers.DefaultArraySerializers$ObjectArraySerializer.read(DefaultArraySerializers.java:391)
at
com.esotericsoftware.kryo.serializers.DefaultArraySerializers$ObjectArraySerializer.read(DefaultArraySerializers.java:302)
at com.esotericsoftware.kryo.Kryo.readClassAndObject(Kryo.java:813)
at
org.apache.hudi.common.util.SerializationUtils$KryoSerializerInstance.deserialize(SerializationUtils.java:104)
at
org.apache.hudi.common.util.SerializationUtils.deserialize(SerializationUtils.java:78)
at
org.apache.hudi.common.table.log.block.HoodieDeleteBlock.deserialize(HoodieDeleteBlock.java:106)
at
org.apache.hudi.common.table.log.block.HoodieDeleteBlock.getRecordsToDelete(HoodieDeleteBlock.java:91)
at
org.apache.hudi.common.table.log.AbstractHoodieLogRecordReader.processQueuedBlocksForInstant(AbstractHoodieLogRecordReader.java:473)
at
org.apache.hudi.common.table.log.AbstractHoodieLogRecordReader.scanInternal(AbstractHoodieLogRecordReader.java:343)
at
org.apache.hudi.common.table.log.AbstractHoodieLogRecordReader.scan(AbstractHoodieLogRecordReader.java:192)
at
org.apache.hudi.common.table.log.HoodieMergedLogRecordScanner.performScan(HoodieMergedLogRecordScanner.java:110)
at
org.apache.hudi.common.table.log.HoodieMergedLogRecordScanner.(HoodieMergedLogRecordScanner.java:103)
at
org.apache.hudi.common.table.log.HoodieMergedLogRecordScanner$Builder.build(HoodieMergedLogRecordScanner.java:324)
at
org.apache.hudi.HoodieMergeOnReadRDD$.scanLog(HoodieMergeOnReadRDD.scala:402)
at
org.apache.hudi.HoodieMergeOnReadRDD$LogFileIterator.(HoodieMergeOnReadRDD.scala:196)
at
org.apache.hudi.HoodieMergeOnReadRDD.compute(HoodieMergeOnReadRDD.scala:124)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:324)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:288)
at
org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.
[GitHub] [hudi] danny0405 commented on pull request #6574: Keep a clustering running at the same time.#6573
danny0405 commented on PR #6574: URL: https://github.com/apache/hudi/pull/6574#issuecomment-1236507037 Don't think the change is necessary, we already have pluggable clustering strategies and by default a clustering plan is scheduled for 4 commits. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #6489: [HUDI-4485] [cli] Bumped spring shell to 2.1.1. Updated the default …
hudi-bot commented on PR #6489: URL: https://github.com/apache/hudi/pull/6489#issuecomment-1236505949 ## CI report: * 47680402da599615de30c13a1f22f79f3573ee30 UNKNOWN * 5613f14b3d5f1c8aaf8de1730e2f21b78a657150 UNKNOWN * 25282068fcb956637de49a5d06d9db2661a2d20b Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=11143) * 61586bd9583dd4cb3fe6572d572911ca193faecf Azure: [PENDING](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=11144) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #6489: [HUDI-4485] [cli] Bumped spring shell to 2.1.1. Updated the default …
hudi-bot commented on PR #6489: URL: https://github.com/apache/hudi/pull/6489#issuecomment-1236504333 ## CI report: * 47680402da599615de30c13a1f22f79f3573ee30 UNKNOWN * 5613f14b3d5f1c8aaf8de1730e2f21b78a657150 UNKNOWN * 00fdd9ced20c3dbbec946c86ebd9888249f13e0c Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=0) * 25282068fcb956637de49a5d06d9db2661a2d20b Azure: [PENDING](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=11143) * 61586bd9583dd4cb3fe6572d572911ca193faecf Azure: [PENDING](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=11144) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] flashJd commented on a diff in pull request #6385: [HUDI-4614] fix primary key extract of delete_record when complexKeyGen configured and ChangeLogDisabled
flashJd commented on code in PR #6385:
URL: https://github.com/apache/hudi/pull/6385#discussion_r962439646
##
hudi-client/hudi-client-common/src/main/java/org/apache/hudi/keygen/KeyGenUtils.java:
##
@@ -73,21 +73,20 @@ public static String
getPartitionPathFromGenericRecord(GenericRecord genericReco
*/
public static String[] extractRecordKeys(String recordKey) {
String[] fieldKV = recordKey.split(",");
-if (fieldKV.length == 1) {
- return fieldKV;
-} else {
- // a complex key
- return Arrays.stream(fieldKV).map(kv -> {
-final String[] kvArray = kv.split(":");
-if (kvArray[1].equals(NULL_RECORDKEY_PLACEHOLDER)) {
- return null;
-} else if (kvArray[1].equals(EMPTY_RECORDKEY_PLACEHOLDER)) {
- return "";
-} else {
- return kvArray[1];
-}
- }).toArray(String[]::new);
-}
+
+return Arrays.stream(fieldKV).map(kv -> {
+ final String[] kvArray = kv.split(":");
Review Comment:
@danny0405 can you review it, #6539 also reported it
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] paul8263 commented on pull request #6489: [HUDI-4485] [cli] Bumped spring shell to 2.1.1. Updated the default …
paul8263 commented on PR #6489: URL: https://github.com/apache/hudi/pull/6489#issuecomment-1236484951 > Hi community, > > After testing some compaction commands I found that there was a problem with SparkUtil::initLauncher. Spring shell 2.x requires Spring boot but the trick is, spring boot maven plugin repackage everything stored in src into /BOOT-INF/classes inside the jar, not in the root path of the jar. As a result SparkLauncher cannot find the main class. Currently I am working on how to solve this packaging problem. The hudi-cli packaging and SparkUtil issue has been fixed. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #6489: [HUDI-4485] [cli] Bumped spring shell to 2.1.1. Updated the default …
hudi-bot commented on PR #6489: URL: https://github.com/apache/hudi/pull/6489#issuecomment-1236482375 ## CI report: * 47680402da599615de30c13a1f22f79f3573ee30 UNKNOWN * 5613f14b3d5f1c8aaf8de1730e2f21b78a657150 UNKNOWN * 00fdd9ced20c3dbbec946c86ebd9888249f13e0c Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=0) * 25282068fcb956637de49a5d06d9db2661a2d20b Azure: [PENDING](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=11143) * 61586bd9583dd4cb3fe6572d572911ca193faecf UNKNOWN Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #6489: [HUDI-4485] [cli] Bumped spring shell to 2.1.1. Updated the default …
hudi-bot commented on PR #6489: URL: https://github.com/apache/hudi/pull/6489#issuecomment-1236479997 ## CI report: * 47680402da599615de30c13a1f22f79f3573ee30 UNKNOWN * 5613f14b3d5f1c8aaf8de1730e2f21b78a657150 UNKNOWN * 00fdd9ced20c3dbbec946c86ebd9888249f13e0c Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=0) * 25282068fcb956637de49a5d06d9db2661a2d20b Azure: [PENDING](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=11143) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #6489: [HUDI-4485] [cli] Bumped spring shell to 2.1.1. Updated the default …
hudi-bot commented on PR #6489: URL: https://github.com/apache/hudi/pull/6489#issuecomment-1236478361 ## CI report: * 47680402da599615de30c13a1f22f79f3573ee30 UNKNOWN * 5613f14b3d5f1c8aaf8de1730e2f21b78a657150 UNKNOWN * 00fdd9ced20c3dbbec946c86ebd9888249f13e0c Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=0) * 25282068fcb956637de49a5d06d9db2661a2d20b UNKNOWN Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] xiarixiaoyao commented on issue #6424: [SUPPORT] After schema evaluation, when time travel queries the historical data, the results show the latest schema instead of the historical sch
xiarixiaoyao commented on issue #6424: URL: https://github.com/apache/hudi/issues/6424#issuecomment-1236467962 close this issue, since We have solved this problem https://issues.apache.org/jira/browse/HUDI-4703 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] xiarixiaoyao closed issue #6424: [SUPPORT] After schema evaluation, when time travel queries the historical data, the results show the latest schema instead of the historical schema
xiarixiaoyao closed issue #6424: [SUPPORT] After schema evaluation, when time travel queries the historical data, the results show the latest schema instead of the historical schema URL: https://github.com/apache/hudi/issues/6424 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #6587: [HUDI-4775] Fixing incremental source for MOR table
hudi-bot commented on PR #6587: URL: https://github.com/apache/hudi/pull/6587#issuecomment-1236425951 ## CI report: * 9c996aa5881d2a9e341b5181ef635750a7f4c926 Azure: [SUCCESS](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=11142) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (HUDI-4526) improve spillableMapBasePath disk directory is full
[
https://issues.apache.org/jira/browse/HUDI-4526?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
sivabalan narayanan updated HUDI-4526:
--
Story Points: 2
> improve spillableMapBasePath disk directory is full
> ---
>
> Key: HUDI-4526
> URL: https://issues.apache.org/jira/browse/HUDI-4526
> Project: Apache Hudi
> Issue Type: Improvement
> Components: spark
>Reporter: Forward Xu
>Assignee: sivabalan narayanan
>Priority: Critical
> Labels: pull-request-available
> Fix For: 0.12.1
>
>
> {code:java}
> // code placeholder
> SLF4J: Class path contains multiple SLF4J bindings.
> SLF4J: Found binding in
> [jar:file:/data13/yarnenv/local/filecache/72005/spark-jars.zip/slf4j-log4j12-1.7.16.jar!/org/slf4j/impl/StaticLoggerBinder.class]
> SLF4J: Found binding in
> [jar:file:/data/gaiaadmin/gaiaenv/tdwgaia/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
> SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an
> explanation.
> SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
> 22/08/02 19:14:55 ERROR AbstractHoodieLogRecordReader: Got exception when
> reading log file
> org.apache.hudi.exception.HoodieIOException: Unable to create
> :/tmp/hudi-BITCASK-092a9065-a2b6-4a72-aff4-23a7072e8064
> at
> org.apache.hudi.common.util.collection.ExternalSpillableMap.getDiskBasedMap(ExternalSpillableMap.java:122)
> at
> org.apache.hudi.common.util.collection.ExternalSpillableMap.get(ExternalSpillableMap.java:197)
> at
> org.apache.hudi.common.table.log.HoodieMergedLogRecordScanner.processNextDeletedRecord(HoodieMergedLogRecordScanner.java:168)
> at
> java.util.Spliterators$ArraySpliterator.forEachRemaining(Spliterators.java:948)
> at
> java.util.stream.ReferencePipeline$Head.forEach(ReferencePipeline.java:647)
> at
> org.apache.hudi.common.table.log.AbstractHoodieLogRecordReader.processQueuedBlocksForInstant(AbstractHoodieLogRecordReader.java:473)
> at
> org.apache.hudi.common.table.log.AbstractHoodieLogRecordReader.scanInternal(AbstractHoodieLogRecordReader.java:343)
> at
> org.apache.hudi.common.table.log.AbstractHoodieLogRecordReader.scan(AbstractHoodieLogRecordReader.java:192)
> at
> org.apache.hudi.common.table.log.HoodieMergedLogRecordScanner.performScan(HoodieMergedLogRecordScanner.java:110)
> at
> org.apache.hudi.common.table.log.HoodieMergedLogRecordScanner.(HoodieMergedLogRecordScanner.java:103)
> at
> org.apache.hudi.common.table.log.HoodieMergedLogRecordScanner$Builder.build(HoodieMergedLogRecordScanner.java:324)
> at
> org.apache.hudi.HoodieMergeOnReadRDD$.scanLog(HoodieMergeOnReadRDD.scala:370)
> at
> org.apache.hudi.HoodieMergeOnReadRDD$LogFileIterator.(HoodieMergeOnReadRDD.scala:171)
> at
> org.apache.hudi.HoodieMergeOnReadRDD.compute(HoodieMergeOnReadRDD.scala:92)
> at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:346)
> at org.apache.spark.rdd.RDD.iterator(RDD.scala:310)
> at
> org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
> at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:346)
> at org.apache.spark.rdd.RDD.iterator(RDD.scala:310)
> at
> org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
> at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:346)
> at org.apache.spark.rdd.RDD.iterator(RDD.scala:310)
> at
> org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
> at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:346)
> at org.apache.spark.rdd.RDD.iterator(RDD.scala:310)
> at
> org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:99)
> at
> org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:55)
> at org.apache.spark.scheduler.Task.run(Task.scala:123)
> at
> org.apache.spark.executor.Executor$TaskRunner$$anonfun$10.apply(Executor.scala:408)
> at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1419)
> at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:414)
> at
> java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
> at
> java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
> at java.lang.Thread.run(Thread.java:748)
> Caused by: java.io.IOException: Unable to create
> :/tmp/hudi-BITCASK-092a9065-a2b6-4a72-aff4-23a7072e8064
> at org.apache.hudi.common.util.FileIOUtils.mkdir(FileIOUtils.java:70)
> at
> org.apache.hudi.common.util.collection.DiskMap.(DiskMap.java:55)
> at
> org.apache.hudi.common.util.collection.BitCaskDiskMap.(BitCa
[jira] [Updated] (HUDI-4256) Bulk insert of a large dataset with S3 fails w/ timeline server based markers
[
https://issues.apache.org/jira/browse/HUDI-4256?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
sivabalan narayanan updated HUDI-4256:
--
Story Points: 2
> Bulk insert of a large dataset with S3 fails w/ timeline server based markers
> -
>
> Key: HUDI-4256
> URL: https://issues.apache.org/jira/browse/HUDI-4256
> Project: Apache Hudi
> Issue Type: Bug
> Components: writer-core
>Reporter: sivabalan narayanan
>Assignee: Ethan Guo
>Priority: Critical
> Fix For: 0.12.1
>
>
> When timeline server based markers are used for very large table with
> bulk_insert row writer (1TB or more), we are running into null pointer
> exception.
>
> {code:java}
> 2022-06-14 13:27:13,135 WARN hudi.DataSourceUtils: Small Decimal Type found
> in current schema, auto set the value of
> hoodie.parquet.writelegacyformat.enabled to true
> 2022-06-14 13:27:13,562 WARN metadata.HoodieBackedTableMetadata: Metadata
> table was not found at path
> s3a://datasets-abcde/hudi/web_sales/.hoodie/metadata
> 2022-06-14 13:27:13,972 WARN metadata.HoodieBackedTableMetadata: Metadata
> table was not found at path
> s3a://datasets-abcde/hudi/web_sales/.hoodie/metadata
> Exception in thread "pool-37-thread-6" java.lang.NullPointerException200) /
> 200]
> at
> org.apache.hudi.timeline.service.handlers.marker.MarkerDirState.flushMarkersToFile(MarkerDirState.java:323)
> at
> org.apache.hudi.timeline.service.handlers.marker.MarkerDirState.processMarkerCreationRequests(MarkerDirState.java:219)
> at
> org.apache.hudi.timeline.service.handlers.marker.BatchedMarkerCreationRunnable.run(BatchedMarkerCreationRunnable.java:46)
> at
> java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
> at
> java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
> at java.lang.Thread.run(Thread.java:750)
> Exception in thread "pool-37-thread-8" java.lang.NullPointerException
> at
> org.apache.hudi.timeline.service.handlers.marker.MarkerDirState.flushMarkersToFile(MarkerDirState.java:323)
> at
> org.apache.hudi.timeline.service.handlers.marker.MarkerDirState.processMarkerCreationRequests(MarkerDirState.java:219)
> at
> org.apache.hudi.timeline.service.handlers.marker.BatchedMarkerCreationRunnable.run(BatchedMarkerCreationRunnable.java:46)
> at
> java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
> at
> java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
> at java.lang.Thread.run(Thread.java:750)
> 2022-06-14 13:31:30,483 WARN impl.BulkDeleteRetryHandler: Bulk delete
> operation interrupted: delete: com.amazonaws.SdkClientException: Failed to
> parse XML document with handler class
> com.amazonaws.services.s3.model.transform.XmlResponsesSaxParser$DeleteObjectsHandler:
> Failed to parse XML document with handler class
> com.amazonaws.services.s3.model.transform.XmlResponsesSaxParser$DeleteObjectsHandler
> Exception in thread "pool-37-thread-22" java.lang.NullPointerException
> at
> org.apache.hudi.timeline.service.handlers.marker.MarkerDirState.flushMarkersToFile(MarkerDirState.java:323)
> at
> org.apache.hudi.timeline.service.handlers.marker.MarkerDirState.processMarkerCreationRequests(MarkerDirState.java:219)
> at
> org.apache.hudi.timeline.service.handlers.marker.BatchedMarkerCreationRunnable.run(BatchedMarkerCreationRunnable.java:46)
> at
> java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
> at
> java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
> at java.lang.Thread.run(Thread.java:750)
> Exception in thread "pool-37-thread-10" java.lang.NullPointerException
> at
> org.apache.hudi.timeline.service.handlers.marker.MarkerDirState.flushMarkersToFile(MarkerDirState.java:323)
> at
> org.apache.hudi.timeline.service.handlers.marker.MarkerDirState.processMarkerCreationRequests(MarkerDirState.java:219)
> at
> org.apache.hudi.timeline.service.handlers.marker.BatchedMarkerCreationRunnable.run(BatchedMarkerCreationRunnable.java:46)
> at
> java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
> at
> java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
> at java.lang.Thread.run(Thread.java:750)
> Exception in thread "pool-37-thread-14" java.lang.NullPointerException
> at
> org.apache.hudi.timeline.service.handlers.marker.MarkerDirState.flushMarkersToFile(MarkerDirState.java:323)
> at
> org.apache.hudi.timeline.service.handlers.marker.MarkerDirState.processMarkerCreationRequests(MarkerDirState.java:219)
> at
> org.apache.
[jira] [Updated] (HUDI-4493) Fix handling of corrupt avro files properly
[ https://issues.apache.org/jira/browse/HUDI-4493?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] sivabalan narayanan updated HUDI-4493: -- Story Points: 0.5 > Fix handling of corrupt avro files properly > --- > > Key: HUDI-4493 > URL: https://issues.apache.org/jira/browse/HUDI-4493 > Project: Apache Hudi > Issue Type: Improvement > Components: archiving >Reporter: sivabalan narayanan >Assignee: sivabalan narayanan >Priority: Critical > Labels: pull-request-available > Fix For: 0.12.1 > > > We fixed handling of corupt files sometime back, but feedback was given that > we should catch only the required exception and stacktrace and not entire > "Exception" as it could mean other things as well. > > [https://github.com/apache/hudi/pull/5245/files#r927097078] > > > -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Updated] (HUDI-4201) Add tooling to delete empty non-completed instants from timeline
[ https://issues.apache.org/jira/browse/HUDI-4201?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] sivabalan narayanan updated HUDI-4201: -- Story Points: 2 > Add tooling to delete empty non-completed instants from timeline > > > Key: HUDI-4201 > URL: https://issues.apache.org/jira/browse/HUDI-4201 > Project: Apache Hudi > Issue Type: Improvement > Components: archiving, cli >Reporter: sivabalan narayanan >Assignee: Sagar Sumit >Priority: Critical > Fix For: 0.12.1 > > > If there are empty instants in timeline, older versions of hudi can run into > issues. We have put in a fix [here|https://github.com/apache/hudi/pull/5261] > for it. But would like to provider users in older versions w/ some tool to > assist deleting such empty instants if incase they are not completed. -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Updated] (HUDI-4282) Throws IOException in method HoodieLogFileReader.isBlockCorrupted()
[
https://issues.apache.org/jira/browse/HUDI-4282?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
sivabalan narayanan updated HUDI-4282:
--
Story Points: 1
> Throws IOException in method HoodieLogFileReader.isBlockCorrupted()
> ---
>
> Key: HUDI-4282
> URL: https://issues.apache.org/jira/browse/HUDI-4282
> Project: Apache Hudi
> Issue Type: Bug
> Components: compaction
>Reporter: sherhomhuang
>Assignee: sherhomhuang
>Priority: Critical
> Labels: pull-request-available
> Fix For: 0.12.1
>
>
> Not all dfs throw {_}*EOFException*{_}, when seek index out of the length of
> file, such as {*}chdfs{*}. So it is not suitable to use _*EOFException*_ to
> check whether "{_}*currentPos + blocksize - Long.BYTES*{_}" is out of the
> file length.
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[jira] [Updated] (HUDI-3994) HoodieDeltaStreamer - Spark master shouldn't have a default
[
https://issues.apache.org/jira/browse/HUDI-3994?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
sivabalan narayanan updated HUDI-3994:
--
Reviewers: Sagar Sumit (was: Raymond Xu)
Story Points: 0.5
> HoodieDeltaStreamer - Spark master shouldn't have a default
> ---
>
> Key: HUDI-3994
> URL: https://issues.apache.org/jira/browse/HUDI-3994
> Project: Apache Hudi
> Issue Type: Improvement
> Components: deltastreamer, spark
>Reporter: Angel Conde
>Assignee: Angel Conde
>Priority: Critical
> Labels: easyfix, pull-request-available
> Fix For: 0.12.1
>
> Original Estimate: 24h
> Remaining Estimate: 24h
>
> When trying to run HoodieDeltaStreamer on AWS Glue I found that the Spark
> master has no option to inherit from the environment as it defaults to
> {{{}local[2]{}}}. In these kind of Serverless environments where you do not
> have access to the master this configuration should be inherited
> This can be seen on line 329 on
> [HoodieDeltaStreamer|https://github.com/apache/hudi/blob/master/hudi-utilities/src/main/java/org/apache/hudi/utilities/deltastreamer/HoodieDeltaStreamer.java].
> {{public String sparkMaster = "local[2]";}}
> This should be changed for supporting this kind of scenarios, a
> JavaSparkContext option where no Spark master is defined should be there.
> *Expected behavior*
> The Spark master shouldn't have a default as there are some environments
> (usually serverless such as AWS Glue) where it will be inherited.
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[jira] [Updated] (HUDI-4199) Clean up row writer path for url encoding, consistent logical timestamp
[ https://issues.apache.org/jira/browse/HUDI-4199?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] sivabalan narayanan updated HUDI-4199: -- Story Points: 2 > Clean up row writer path for url encoding, consistent logical timestamp > --- > > Key: HUDI-4199 > URL: https://issues.apache.org/jira/browse/HUDI-4199 > Project: Apache Hudi > Issue Type: Bug > Components: spark >Reporter: sivabalan narayanan >Assignee: sivabalan narayanan >Priority: Critical > Fix For: 0.12.1 > > > SimpleKeyGen and other key gens have url encoding support and consistent > logical timestamp support. Row writer does not have these aligned. We need to > bring it to parity w/ non row wirter path. > -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Updated] (HUDI-3959) Rename class name for spark rdd reader
[ https://issues.apache.org/jira/browse/HUDI-3959?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] sivabalan narayanan updated HUDI-3959: -- Story Points: 0.5 > Rename class name for spark rdd reader > -- > > Key: HUDI-3959 > URL: https://issues.apache.org/jira/browse/HUDI-3959 > Project: Apache Hudi > Issue Type: Improvement > Components: spark >Reporter: Simon Su >Assignee: Raymond Xu >Priority: Critical > Labels: pull-request-available > Fix For: 0.12.1 > > Attachments: image-2022-04-24-10-51-46-595.png > > > !image-2022-04-24-10-51-46-595.png! > This class should rename to SparkRDDReadClient to avoid unclear meaning. -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Updated] (HUDI-3403) Manage immutable hudi Configurations
[ https://issues.apache.org/jira/browse/HUDI-3403?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] sivabalan narayanan updated HUDI-3403: -- Story Points: 2 > Manage immutable hudi Configurations > > > Key: HUDI-3403 > URL: https://issues.apache.org/jira/browse/HUDI-3403 > Project: Apache Hudi > Issue Type: Improvement > Components: core >Reporter: Yann Byron >Assignee: Sagar Sumit >Priority: Blocker > Fix For: 0.12.1 > > > https://github.com/apache/hudi/pull/4714#discussion_r798474157 -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Assigned] (HUDI-3403) Manage immutable hudi Configurations
[ https://issues.apache.org/jira/browse/HUDI-3403?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] sivabalan narayanan reassigned HUDI-3403: - Assignee: Sagar Sumit > Manage immutable hudi Configurations > > > Key: HUDI-3403 > URL: https://issues.apache.org/jira/browse/HUDI-3403 > Project: Apache Hudi > Issue Type: Improvement > Components: core >Reporter: Yann Byron >Assignee: Sagar Sumit >Priority: Blocker > Fix For: 0.12.1 > > > https://github.com/apache/hudi/pull/4714#discussion_r798474157 -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Updated] (HUDI-3796) Implement layout to filter out uncommitted log files without reading the log blocks
[ https://issues.apache.org/jira/browse/HUDI-3796?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] sivabalan narayanan updated HUDI-3796: -- Story Points: 1 > Implement layout to filter out uncommitted log files without reading the log > blocks > --- > > Key: HUDI-3796 > URL: https://issues.apache.org/jira/browse/HUDI-3796 > Project: Apache Hudi > Issue Type: Improvement > Components: writer-core >Reporter: Ethan Guo >Assignee: sivabalan narayanan >Priority: Critical > Fix For: 0.12.1 > > > Related: HUDI-3637 > At high level, getLatestFileSlices() is going to fetch the latest file slices > for committed base files and filter out any file slices with the uncommitted > base instant time. The uncommitted log files in the latest file slices may > be included, and they are skipped while doing log reading and merging, i.e., > the logic in "AbstractHoodieLogRecordReader". > We can use log instant time instead of base instant time for the log file > name so that it is able to filter out uncommitted log files without reading > the log blocks beforehand. -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Updated] (HUDI-3915) Error upserting bucketType UPDATE for partition :0
[ https://issues.apache.org/jira/browse/HUDI-3915?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] sivabalan narayanan updated HUDI-3915: -- Story Points: 2 > Error upserting bucketType UPDATE for partition :0 > -- > > Key: HUDI-3915 > URL: https://issues.apache.org/jira/browse/HUDI-3915 > Project: Apache Hudi > Issue Type: Bug > Components: deltastreamer >Reporter: Neetu Gupta >Assignee: Alexey Kudinkin >Priority: Critical > Fix For: 0.12.1 > > > I have updated the hudi column partition from 'year,month' to 'year. Then I > ran the process in overwrite mode. The process executed successfully and hudi > table got created. > However, when the process got triggered in 'append' mode, I started getting > the error mentioned below: > ' > Task 0 in stage 32.0 failed 4 times; aborting job java.lang.Exception: Job > aborted due to stage failure: Task 0 in stage 32.0 failed 4 times, most > recent failure: Lost task 0.3 in stage 32.0 (TID 1207, > ip-10-73-110-184.ec2.internal, executor 6): > org.apache.hudi.exception.HoodieUpsertException: Error upserting bucketType > UPDATE for partition :0 at > org.apache.hudi.table.action.commit.BaseSparkCommitActionExecutor.handleUpsertPartition(BaseSparkCommitActionExecutor.java:305) > ' > Then I reverted the partition columns back to 'year,month' but still got the > same error. But, when I am writing data in different folder in 'append' mode, > the script ran fine and I could see the Hudi table. > In short, the process is not working when I am trying to append the data in > the same path. Can you please look into this. This is critical to us because > the jobs are stuck. -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Updated] (HUDI-3055) Make sure that Compression Codec configuration is respected across the board
[ https://issues.apache.org/jira/browse/HUDI-3055?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] sivabalan narayanan updated HUDI-3055: -- Story Points: 2 > Make sure that Compression Codec configuration is respected across the board > > > Key: HUDI-3055 > URL: https://issues.apache.org/jira/browse/HUDI-3055 > Project: Apache Hudi > Issue Type: Bug > Components: storage-management >Reporter: Alexey Kudinkin >Assignee: Alexey Kudinkin >Priority: Major > Labels: new-to-hudi > Fix For: 0.12.1 > > > Currently there are quite a few places where we assume GZip as the > compression codec which is incorrect, given that this is configurable and > users might actually prefer to use different compression codec. > Examples: > [HoodieParquetDataBlock|https://github.com/apache/hudi/pull/4333/files#diff-798a773c6eef4011aef2da2b2fb71c25f753500548167b610021336ef6f14807] -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Updated] (HUDI-3954) Don't keep the last commit before the earliest commit to retain
[
https://issues.apache.org/jira/browse/HUDI-3954?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
sivabalan narayanan updated HUDI-3954:
--
Story Points: 0.5
> Don't keep the last commit before the earliest commit to retain
> ---
>
> Key: HUDI-3954
> URL: https://issues.apache.org/jira/browse/HUDI-3954
> Project: Apache Hudi
> Issue Type: Improvement
> Components: cleaning
>Reporter: 董可伦
>Assignee: sivabalan narayanan
>Priority: Critical
> Labels: pull-request-available
> Fix For: 0.12.1
>
>
> Don't keep the last commit before the earliest commit to retain
> According to the document of {{{}hoodie.cleaner.commits.retained{}}}:
> Number of commits to retain, without cleaning. This will be retained for
> num_of_commits * time_between_commits (scheduled). This also directly
> translates into how much data retention the table supports for incremental
> queries.
>
> We only need to keep the number of commit configured through parameters
> {{{}hoodie.cleaner.commits.retained{}}}.
> And the commit retained by clean is completed.This ensures that “This will be
> retained for num_of_commits * time_between_commits” in the document.
> So we don't need to keep the last commit before the earliest commit to
> retain,If we want to keep more versions, we can increase the parameters
> {{hoodie.cleaner.commits.retained}}
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[jira] [Updated] (HUDI-3775) Allow for offline compaction of MOR tables via spark streaming
[ https://issues.apache.org/jira/browse/HUDI-3775?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] sivabalan narayanan updated HUDI-3775: -- Story Points: 2 > Allow for offline compaction of MOR tables via spark streaming > -- > > Key: HUDI-3775 > URL: https://issues.apache.org/jira/browse/HUDI-3775 > Project: Apache Hudi > Issue Type: Improvement > Components: compaction, spark >Reporter: Rajesh >Assignee: sivabalan narayanan >Priority: Critical > Labels: easyfix > Fix For: 0.12.1 > > > Currently there is no way to avoid compaction taking up a lot of resources > when run inline or async for MOR tables via Spark Streaming. Delta Streamer > has ways to assign resources between ingestion and async compaction but Spark > Streaming does not have that option. > Introducing a flag to turn off automatic compaction and allowing users to run > compaction in a separate process will decouple both concerns. > This will also allow the users to size the cluster just for ingestion and > deal with compaction separate without blocking. We will need to look into > documenting best practices for running offline compaction. -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Updated] (HUDI-1885) Support Delete/Update Non-Pk Table
[
https://issues.apache.org/jira/browse/HUDI-1885?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
sivabalan narayanan updated HUDI-1885:
--
Story Points: 4
> Support Delete/Update Non-Pk Table
> --
>
> Key: HUDI-1885
> URL: https://issues.apache.org/jira/browse/HUDI-1885
> Project: Apache Hudi
> Issue Type: New Feature
> Components: spark, spark-sql
>Reporter: pengzhiwei
>Assignee: Yann Byron
>Priority: Critical
> Fix For: 0.12.1
>
>
> Allow to delete/update a non-pk table.
> {code:java}
> create table h0 (
> id int,
> name string,
> price double
> ) using hudi;
> delete from h0 where id = 10;
> update h0 set price = 10 where id = 12;
> {code}
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[jira] [Updated] (HUDI-3425) Clean up spill path created by Hudi during uneventful shutdown
[ https://issues.apache.org/jira/browse/HUDI-3425?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] sivabalan narayanan updated HUDI-3425: -- Story Points: 2 > Clean up spill path created by Hudi during uneventful shutdown > -- > > Key: HUDI-3425 > URL: https://issues.apache.org/jira/browse/HUDI-3425 > Project: Apache Hudi > Issue Type: Improvement > Components: compaction >Reporter: sivabalan narayanan >Assignee: sivabalan narayanan >Priority: Critical > Fix For: 0.12.1 > > > h1. Hudi spill path not getting cleared when containers getting killed > abruptly. > > When yarn kills the containers abruptly for any reason while hudi stage is in > progress then the spill path created by hudi on the disk is not cleaned and > as a result of which the nodes on the cluster start running out of space. We > need to clear the spill path manually to free out disk space. > > Ref issue: https://github.com/apache/hudi/issues/4771 -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Updated] (HUDI-4281) Using hudi to build a large number of tables in spark on hive causes OOM
[ https://issues.apache.org/jira/browse/HUDI-4281?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] sivabalan narayanan updated HUDI-4281: -- Sprint: 2022/09/19 (was: 2022/09/05) > Using hudi to build a large number of tables in spark on hive causes OOM > > > Key: HUDI-4281 > URL: https://issues.apache.org/jira/browse/HUDI-4281 > Project: Apache Hudi > Issue Type: Bug > Components: spark-sql >Affects Versions: 0.12.0 > Environment: spark on hive long running service > spark version: 3.2.1 > hive version: 2.3.x > hudi version: hudi-spark3.2-bundle_2.12-0.11.0 >Reporter: zhangrenhua >Assignee: zhangrenhua >Priority: Critical > Labels: pull-request-available > Fix For: 0.12.1 > > Original Estimate: 1h > Remaining Estimate: 1h > > On the long-running server of spark on hive, if a large number of tables are > created, OOM will occur because the IsolatedClientLoader object cannot be > released. > The Hive Client should adopt the singleton mode, which can avoid the oom > caused by the unreleased IsolatedClientLoader object. -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Updated] (HUDI-2786) Failed to connect to namenode in Docker Demo on Apple M1 chip
[
https://issues.apache.org/jira/browse/HUDI-2786?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
sivabalan narayanan updated HUDI-2786:
--
Story Points: 8
> Failed to connect to namenode in Docker Demo on Apple M1 chip
> -
>
> Key: HUDI-2786
> URL: https://issues.apache.org/jira/browse/HUDI-2786
> Project: Apache Hudi
> Issue Type: Bug
> Components: dependencies, dev-experience
>Reporter: Ethan Guo
>Priority: Critical
> Fix For: 0.12.1
>
>
> {code:java}
> > ./setup_demo.sh
> [+] Running 1/0
> ⠿ compose Warning: No resource found to remove
>
> 0.0s
> [+] Running 15/15
> ⠿ namenode Pulled
>
> 1.4s
> ⠿ kafka Pulled
>
> 1.3s
> ⠿ presto-worker-1 Pulled
>
> 1.3s
> ⠿ historyserver Pulled
>
> 1.4s
> ⠿ adhoc-2 Pulled
>
> 1.3s
> ⠿ adhoc-1 Pulled
>
> 1.4s
> ⠿ graphite Pulled
>
> 1.3s
> ⠿ sparkmaster Pulled
>
> 1.3s
> ⠿ hive-metastore-postgresql Pulled
>
> 1.3s
> ⠿ presto-coordinator-1 Pulled
>
> 1.3s
> ⠿ spark-worker-1 Pulled
>
> 1.4s
> ⠿ hiveserver Pulled
>
> 1.3s
> ⠿ hivemetastore Pulled
>
> 1.4s
> ⠿ zookeeper Pulled
>
> 1.3s
> ⠿ datanode1 Pulled
>
> 1.3s
> [+] Running 16/16
> ⠿ Network compose_default Created
>
> 0.0s
> ⠿ Container hive-metastore-postgresql Started
>
> 1.1s
> ⠿ Container kafkabroker Started
>
> 1.1s
> ⠿ Container zookeeper Started
>
>
[jira] [Updated] (HUDI-2786) Failed to connect to namenode in Docker Demo on Apple M1 chip
[
https://issues.apache.org/jira/browse/HUDI-2786?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
sivabalan narayanan updated HUDI-2786:
--
Story Points: 6 (was: 8)
> Failed to connect to namenode in Docker Demo on Apple M1 chip
> -
>
> Key: HUDI-2786
> URL: https://issues.apache.org/jira/browse/HUDI-2786
> Project: Apache Hudi
> Issue Type: Bug
> Components: dependencies, dev-experience
>Reporter: Ethan Guo
>Priority: Critical
> Fix For: 0.12.1
>
>
> {code:java}
> > ./setup_demo.sh
> [+] Running 1/0
> ⠿ compose Warning: No resource found to remove
>
> 0.0s
> [+] Running 15/15
> ⠿ namenode Pulled
>
> 1.4s
> ⠿ kafka Pulled
>
> 1.3s
> ⠿ presto-worker-1 Pulled
>
> 1.3s
> ⠿ historyserver Pulled
>
> 1.4s
> ⠿ adhoc-2 Pulled
>
> 1.3s
> ⠿ adhoc-1 Pulled
>
> 1.4s
> ⠿ graphite Pulled
>
> 1.3s
> ⠿ sparkmaster Pulled
>
> 1.3s
> ⠿ hive-metastore-postgresql Pulled
>
> 1.3s
> ⠿ presto-coordinator-1 Pulled
>
> 1.3s
> ⠿ spark-worker-1 Pulled
>
> 1.4s
> ⠿ hiveserver Pulled
>
> 1.3s
> ⠿ hivemetastore Pulled
>
> 1.4s
> ⠿ zookeeper Pulled
>
> 1.3s
> ⠿ datanode1 Pulled
>
> 1.3s
> [+] Running 16/16
> ⠿ Network compose_default Created
>
> 0.0s
> ⠿ Container hive-metastore-postgresql Started
>
> 1.1s
> ⠿ Container kafkabroker Started
>
> 1.1s
> ⠿ Container zookeeper Started
>
>
[jira] [Updated] (HUDI-3646) The Hudi update syntax should not modify the nullability attribute of a column
[
https://issues.apache.org/jira/browse/HUDI-3646?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
sivabalan narayanan updated HUDI-3646:
--
Story Points: 1.5
> The Hudi update syntax should not modify the nullability attribute of a column
> --
>
> Key: HUDI-3646
> URL: https://issues.apache.org/jira/browse/HUDI-3646
> Project: Apache Hudi
> Issue Type: Bug
> Components: spark-sql
>Affects Versions: 0.10.1
> Environment: spark3.1.2
>Reporter: Tao Meng
>Assignee: Alexey Kudinkin
>Priority: Minor
> Fix For: 0.12.1
>
>
> now, when we use sparksql to update hudi table, we find that hudi will
> change the nullability attribute of a column
> eg:
> {code:java}
> // code placeholder
> val tableName = generateTableName
> val tablePath = s"${new Path(tmp.getCanonicalPath,
> tableName).toUri.toString}"
> // create table
> spark.sql(
>s"""
> |create table $tableName (
> | id int,
> | name string,
> | price double,
> | ts long
> |) using hudi
> | location '$tablePath'
> | options (
> | type = '$tableType',
> | primaryKey = 'id',
> | preCombineField = 'ts'
> | )
> """.stripMargin)
> // insert data to table
> spark.sql(s"insert into $tableName select 1, 'a1', 10, 1000")
> spark.sql(s"select * from $tableName").printSchema()
> // update data
> spark.sql(s"update $tableName set price = 20 where id = 1")
> spark.sql(s"select * from $tableName").printSchema() {code}
>
> |-- _hoodie_commit_time: string (nullable = true)
> |-- _hoodie_commit_seqno: string (nullable = true)
> |-- _hoodie_record_key: string (nullable = true)
> |-- _hoodie_partition_path: string (nullable = true)
> |-- _hoodie_file_name: string (nullable = true)
> |-- id: integer (nullable = true)
> |-- name: string (nullable = true)
> *|-- price: double (nullable = true)*
> |-- ts: long (nullable = true)
>
> |-- _hoodie_commit_time: string (nullable = true)
> |-- _hoodie_commit_seqno: string (nullable = true)
> |-- _hoodie_record_key: string (nullable = true)
> |-- _hoodie_partition_path: string (nullable = true)
> |-- _hoodie_file_name: string (nullable = true)
> |-- id: integer (nullable = true)
> |-- name: string (nullable = true)
> *|-- price: double (nullable = false )*
> |-- ts: long (nullable = true)
>
> the nullable attribute of price has been changed to false, This is not the
> result we want
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[jira] [Updated] (HUDI-4620) No expected exception is thrown when create hudi table without primaryKey
[ https://issues.apache.org/jira/browse/HUDI-4620?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] sivabalan narayanan updated HUDI-4620: -- Reviewers: Ethan Guo > No expected exception is thrown when create hudi table without primaryKey > - > > Key: HUDI-4620 > URL: https://issues.apache.org/jira/browse/HUDI-4620 > Project: Apache Hudi > Issue Type: Bug >Affects Versions: 0.11.0 >Reporter: YangXuan >Priority: Major > Labels: pull-request-available > Fix For: 0.12.1 > > > Run the following SQL statement: > create table hudi_test (id int, comb int, par date) using hudi > partitioned by(par) options (type='cow', preCombineField='comb'); > The following exception is thrown: > “Can't find primaryKey `uuid` in root” > The expected exception is: > “java.lang.IllegalArgumentException: No `primaryKey` is specified." > > -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Assigned] (HUDI-4136) Run snapshot query in hive throw ' IOException: java.lang.IllegalArgumentException: HoodieRealtimeRecordReader can only work on RealtimeSplit and not with a empty file'.
[ https://issues.apache.org/jira/browse/HUDI-4136?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] sivabalan narayanan reassigned HUDI-4136: - Assignee: Sagar Sumit > Run snapshot query in hive throw ' IOException: > java.lang.IllegalArgumentException: HoodieRealtimeRecordReader can only work > on RealtimeSplit and not with a empty file'. When not execut compaction plan > --- > > Key: HUDI-4136 > URL: https://issues.apache.org/jira/browse/HUDI-4136 > Project: Apache Hudi > Issue Type: Bug > Components: compaction >Reporter: yuehanwang >Assignee: Sagar Sumit >Priority: Critical > Fix For: 0.12.1 > > > In Merge-On-Read table execut a snapshot query in -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Updated] (HUDI-3892) Add HoodieReadClient with java
[ https://issues.apache.org/jira/browse/HUDI-3892?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] sivabalan narayanan updated HUDI-3892: -- Sprint: 2022/09/19 (was: 2022/09/05) > Add HoodieReadClient with java > -- > > Key: HUDI-3892 > URL: https://issues.apache.org/jira/browse/HUDI-3892 > Project: Apache Hudi > Issue Type: Task > Components: reader-core >Reporter: sivabalan narayanan >Priority: Critical > Fix For: 0.12.1 > > > We might need a hoodie read client in java similar to the one we have for > spark. > [Apache Pulsar|https://github.com/apache/pulsar] is doing integration with > Hudi, and take Hudi as tiered storage to offload topic cold data into Hudi. > When consumers fetch cold data from topic, Pulsar broker will locate the > target data is stored in Pulsar or not. If the target data stored in tiered > storage (Hudi), Pulsar broker will fetch data from Hudi by Java API, and > package them into Pulsar format and dispatch to consumer side. > However, we found current Hudi implementation doesn't support read Hudi table > records by Java API, and we couldn't read the target data out from Hudi into > Pulsar Broker, which will block the Pulsar & Hudi integration. > h3. What we need > # We need Hudi to support reading records by Java API > # We need Hudi to support read records out which keep the writer order, or > support order by specific fields. -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Updated] (HUDI-4620) No expected exception is thrown when create hudi table without primaryKey
[ https://issues.apache.org/jira/browse/HUDI-4620?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] sivabalan narayanan updated HUDI-4620: -- Story Points: 0.5 > No expected exception is thrown when create hudi table without primaryKey > - > > Key: HUDI-4620 > URL: https://issues.apache.org/jira/browse/HUDI-4620 > Project: Apache Hudi > Issue Type: Bug >Affects Versions: 0.11.0 >Reporter: YangXuan >Priority: Major > Labels: pull-request-available > Fix For: 0.12.1 > > > Run the following SQL statement: > create table hudi_test (id int, comb int, par date) using hudi > partitioned by(par) options (type='cow', preCombineField='comb'); > The following exception is thrown: > “Can't find primaryKey `uuid` in root” > The expected exception is: > “java.lang.IllegalArgumentException: No `primaryKey` is specified." > > -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Updated] (HUDI-3067) "Table already exists" error with multiple writers and dynamodb
[
https://issues.apache.org/jira/browse/HUDI-3067?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
sivabalan narayanan updated HUDI-3067:
--
Story Points: 1
> "Table already exists" error with multiple writers and dynamodb
> ---
>
> Key: HUDI-3067
> URL: https://issues.apache.org/jira/browse/HUDI-3067
> Project: Apache Hudi
> Issue Type: Bug
>Reporter: Nikita Sheremet
>Assignee: Wenning Ding
>Priority: Critical
> Fix For: 0.12.1
>
>
> How reproduce:
> # Set up multiple writing
> [https://hudi.apache.org/docs/concurrency_control/] for dynamodb (do not
> forget to set _hoodie.write.lock.dynamodb.region_ and
> {_}hoodie.write.lock.dynamodb.billing_mode{_}). Do not create anty dynamodb
> table.
> # Run multiple writers to the table
> (Tested on aws EMR, so multiple writers is EMR steps)
> Expected result - all steps completed.
> Actual result: some steps failed with exception
> {code:java}
> Caused by: com.amazonaws.services.dynamodbv2.model.ResourceInUseException:
> Table already exists: truedata_detections (Service: AmazonDynamoDBv2; Status
> Code: 400; Error Code: ResourceInUseException; Request ID:; Proxy: null)
> at
> com.amazonaws.http.AmazonHttpClient$RequestExecutor.handleErrorResponse(AmazonHttpClient.java:1819)
> at
> com.amazonaws.http.AmazonHttpClient$RequestExecutor.handleServiceErrorResponse(AmazonHttpClient.java:1403)
> at
> com.amazonaws.http.AmazonHttpClient$RequestExecutor.executeOneRequest(AmazonHttpClient.java:1372)
> at
> com.amazonaws.http.AmazonHttpClient$RequestExecutor.executeHelper(AmazonHttpClient.java:1145)
> at
> com.amazonaws.http.AmazonHttpClient$RequestExecutor.doExecute(AmazonHttpClient.java:802)
> at
> com.amazonaws.http.AmazonHttpClient$RequestExecutor.executeWithTimer(AmazonHttpClient.java:770)
> at
> com.amazonaws.http.AmazonHttpClient$RequestExecutor.execute(AmazonHttpClient.java:744)
> at
> com.amazonaws.http.AmazonHttpClient$RequestExecutor.access$500(AmazonHttpClient.java:704)
> at
> com.amazonaws.http.AmazonHttpClient$RequestExecutionBuilderImpl.execute(AmazonHttpClient.java:686)
> at
> com.amazonaws.http.AmazonHttpClient.execute(AmazonHttpClient.java:550)
> at
> com.amazonaws.http.AmazonHttpClient.execute(AmazonHttpClient.java:530)
> at
> com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient.doInvoke(AmazonDynamoDBClient.java:6214)
> at
> com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient.invoke(AmazonDynamoDBClient.java:6181)
> at
> com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient.executeCreateTable(AmazonDynamoDBClient.java:1160)
> at
> com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient.createTable(AmazonDynamoDBClient.java:1124)
> at
> org.apache.hudi.aws.transaction.lock.DynamoDBBasedLockProvider.createLockTableInDynamoDB(DynamoDBBasedLockProvider.java:188)
> at
> org.apache.hudi.aws.transaction.lock.DynamoDBBasedLockProvider.(DynamoDBBasedLockProvider.java:99)
> at
> org.apache.hudi.aws.transaction.lock.DynamoDBBasedLockProvider.(DynamoDBBasedLockProvider.java:77)
> ... 54 more
> 21/12/19 13:42:06 INFO Yar {code}
> This happens because all steps tried to create table at the same time.
>
> Suggested solution:
> A catch statment for _Table already exists_ exception should be added into
> dynamodb table creation code. May be with delay and additional check that
> table is present.
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[jira] [Updated] (HUDI-3067) "Table already exists" error with multiple writers and dynamodb
[
https://issues.apache.org/jira/browse/HUDI-3067?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
sivabalan narayanan updated HUDI-3067:
--
Reviewers: sivabalan narayanan
> "Table already exists" error with multiple writers and dynamodb
> ---
>
> Key: HUDI-3067
> URL: https://issues.apache.org/jira/browse/HUDI-3067
> Project: Apache Hudi
> Issue Type: Bug
>Reporter: Nikita Sheremet
>Assignee: Wenning Ding
>Priority: Critical
> Fix For: 0.12.1
>
>
> How reproduce:
> # Set up multiple writing
> [https://hudi.apache.org/docs/concurrency_control/] for dynamodb (do not
> forget to set _hoodie.write.lock.dynamodb.region_ and
> {_}hoodie.write.lock.dynamodb.billing_mode{_}). Do not create anty dynamodb
> table.
> # Run multiple writers to the table
> (Tested on aws EMR, so multiple writers is EMR steps)
> Expected result - all steps completed.
> Actual result: some steps failed with exception
> {code:java}
> Caused by: com.amazonaws.services.dynamodbv2.model.ResourceInUseException:
> Table already exists: truedata_detections (Service: AmazonDynamoDBv2; Status
> Code: 400; Error Code: ResourceInUseException; Request ID:; Proxy: null)
> at
> com.amazonaws.http.AmazonHttpClient$RequestExecutor.handleErrorResponse(AmazonHttpClient.java:1819)
> at
> com.amazonaws.http.AmazonHttpClient$RequestExecutor.handleServiceErrorResponse(AmazonHttpClient.java:1403)
> at
> com.amazonaws.http.AmazonHttpClient$RequestExecutor.executeOneRequest(AmazonHttpClient.java:1372)
> at
> com.amazonaws.http.AmazonHttpClient$RequestExecutor.executeHelper(AmazonHttpClient.java:1145)
> at
> com.amazonaws.http.AmazonHttpClient$RequestExecutor.doExecute(AmazonHttpClient.java:802)
> at
> com.amazonaws.http.AmazonHttpClient$RequestExecutor.executeWithTimer(AmazonHttpClient.java:770)
> at
> com.amazonaws.http.AmazonHttpClient$RequestExecutor.execute(AmazonHttpClient.java:744)
> at
> com.amazonaws.http.AmazonHttpClient$RequestExecutor.access$500(AmazonHttpClient.java:704)
> at
> com.amazonaws.http.AmazonHttpClient$RequestExecutionBuilderImpl.execute(AmazonHttpClient.java:686)
> at
> com.amazonaws.http.AmazonHttpClient.execute(AmazonHttpClient.java:550)
> at
> com.amazonaws.http.AmazonHttpClient.execute(AmazonHttpClient.java:530)
> at
> com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient.doInvoke(AmazonDynamoDBClient.java:6214)
> at
> com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient.invoke(AmazonDynamoDBClient.java:6181)
> at
> com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient.executeCreateTable(AmazonDynamoDBClient.java:1160)
> at
> com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient.createTable(AmazonDynamoDBClient.java:1124)
> at
> org.apache.hudi.aws.transaction.lock.DynamoDBBasedLockProvider.createLockTableInDynamoDB(DynamoDBBasedLockProvider.java:188)
> at
> org.apache.hudi.aws.transaction.lock.DynamoDBBasedLockProvider.(DynamoDBBasedLockProvider.java:99)
> at
> org.apache.hudi.aws.transaction.lock.DynamoDBBasedLockProvider.(DynamoDBBasedLockProvider.java:77)
> ... 54 more
> 21/12/19 13:42:06 INFO Yar {code}
> This happens because all steps tried to create table at the same time.
>
> Suggested solution:
> A catch statment for _Table already exists_ exception should be added into
> dynamodb table creation code. May be with delay and additional check that
> table is present.
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[jira] [Updated] (HUDI-2369) Blog on bulk insert sort modes
[ https://issues.apache.org/jira/browse/HUDI-2369?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] sivabalan narayanan updated HUDI-2369: -- Story Points: 3 > Blog on bulk insert sort modes > -- > > Key: HUDI-2369 > URL: https://issues.apache.org/jira/browse/HUDI-2369 > Project: Apache Hudi > Issue Type: Task > Components: docs >Reporter: sivabalan narayanan >Assignee: sivabalan narayanan >Priority: Major > Labels: pull-request-available > Fix For: 0.12.1 > > > Blog on bulk insert sort modes -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Updated] (HUDI-4761) Test using spark listeners that guards any changes to DAG
[ https://issues.apache.org/jira/browse/HUDI-4761?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] sivabalan narayanan updated HUDI-4761: -- Fix Version/s: 0.12.1 > Test using spark listeners that guards any changes to DAG > - > > Key: HUDI-4761 > URL: https://issues.apache.org/jira/browse/HUDI-4761 > Project: Apache Hudi > Issue Type: Task >Reporter: Sagar Sumit >Assignee: sivabalan narayanan >Priority: Major > Fix For: 0.12.1 > > > For major write operations and table services, we should guard the DAG by > making use of spark listeners. Some basic things can be validated such as no. > of stages, tasks, executor runtime, records written. -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Assigned] (HUDI-4761) Test using spark listeners that guards any changes to DAG
[ https://issues.apache.org/jira/browse/HUDI-4761?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] sivabalan narayanan reassigned HUDI-4761: - Assignee: sivabalan narayanan > Test using spark listeners that guards any changes to DAG > - > > Key: HUDI-4761 > URL: https://issues.apache.org/jira/browse/HUDI-4761 > Project: Apache Hudi > Issue Type: Task >Reporter: Sagar Sumit >Assignee: sivabalan narayanan >Priority: Major > > For major write operations and table services, we should guard the DAG by > making use of spark listeners. Some basic things can be validated such as no. > of stages, tasks, executor runtime, records written. -- This message was sent by Atlassian Jira (v8.20.10#820010)