[GitHub] [hudi] hudi-bot commented on pull request #6782: [HUDI-4911][HUDI-3301] Fixing `HoodieMetadataLogRecordReader` to avoid flushing cache for every lookup
hudi-bot commented on PR #6782: URL: https://github.com/apache/hudi/pull/6782#issuecomment-1370587477 ## CI report: * 182351f81d81cbfa9be87fa2e13d5d58a4d7bec4 Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=14090) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] yihua commented on a diff in pull request #7561: [HUDI-5477] Optimize timeline loading in Hudi sync client
yihua commented on code in PR #7561:
URL: https://github.com/apache/hudi/pull/7561#discussion_r1061210337
##
hudi-common/src/main/java/org/apache/hudi/common/table/timeline/TimelineUtils.java:
##
@@ -210,11 +210,30 @@ public static HoodieDefaultTimeline
getTimeline(HoodieTableMetaClient metaClient
return activeTimeline;
}
+ /**
+ * Returns a Hudi timeline with commits after the given instant time
(exclusive).
+ *
+ * @param metaClient{@link HoodieTableMetaClient} instance.
+ * @param exclusiveStartInstantTime Start instant time (exclusive).
+ * @return Hudi timeline.
+ */
+ public static HoodieTimeline getCommitsTimelineAfter(
+ HoodieTableMetaClient metaClient, String exclusiveStartInstantTime) {
+HoodieActiveTimeline activeTimeline = metaClient.getActiveTimeline();
+HoodieDefaultTimeline timeline =
+activeTimeline.isBeforeTimelineStarts(exclusiveStartInstantTime)
+? metaClient.getArchivedTimeline(exclusiveStartInstantTime)
+.mergeTimeline(activeTimeline)
+: activeTimeline;
+return timeline.getCommitsTimeline()
+.findInstantsAfter(exclusiveStartInstantTime, Integer.MAX_VALUE);
+ }
Review Comment:
I think I misunderstood your comment before. When
`activeTimeline.isBeforeTimelineStarts(exclusiveStartInstantTime)` is true,
`metaClient.getArchivedTimeline(exclusiveStartInstantTime)` is called to return
the archived timeline, which still contains the instant
exclusiveStartInstantTime (inclusive). So we still need `#findInstantsAfter`
as the last step to exclude that instant.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] voonhous commented on pull request #7159: [HUDI-5173]Skip if there is only one file in clusteringGroup
voonhous commented on PR #7159: URL: https://github.com/apache/hudi/pull/7159#issuecomment-1370582777 # Issue Issue at hand: Clustering will be performed for inputGroups with only 1 fileSlice, which may cause unnecessary file re-writes and write amplifications should there be no column sorting required. # Edge cases CMIIW, the changes here does not fully fix the cluster of inputGroups with only 1 fileSlice issue. I am not sure if I have missed out any scenarios, at the top of my head, I can only think of these 3 scenarios. 1. No sorting required 2. Sorting required; column has not been sorted (replacecommit/clustering not performed yet) 3. Sorting required; column has already been sorted (replacecommit/clustering has been performed) While this fix is able to fix the issue for case (1), it is not able to differentiate between the cases (2) and (3). As such, if a parquet file has the required columns that are already sorted, an unnecessary rewrite will be performed again. I am not sure if there are any way around this issue other than reading required replacecommit files (if they are not archived) to check if a sort operation has been performed. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] SabyasachiDasTR opened a new issue, #7600: Hoodie clean is not deleting old files for MOR table
SabyasachiDasTR opened a new issue, #7600: URL: https://github.com/apache/hudi/issues/7600 **Describe the problem you faced** We are incrementally upserting data into our Hudi table/s every 5 minutes. We have set CLEANER_POLICY as KEEP_LATEST_BY_HOURS with CLEANER_HOURS_RETAINED = 48. The old delta log files in our partition from 2 months back are still not cleaned and we can see in cli last cleanup happened 2 months back on November. I do not see any action being performed on cleaning the old log files. The only command we execute is Upsert and we have single writer and compaction runs every hour. We think this is causing out emr job to underperform and crash multiple times as very large number of delta log files are getting piled up in the partitions and compaction is trying to read them while processing the job.  **Options used during Upsert:**  **Writing to s3**  Partition structure: s3://bucket/table/partition/parquet and .log files **Expected behavior** As per my understanding the logs should be deleted beyond CLEANER_HOURS_RETAINED which is 2 days . **Environment Description** * Hudi version : 0.11.1 * Spark version : 3.2.1 * Hive version : Hive not install on EMR Cluster emr-6.7.0 * Hadoop version : 3.2.1 * Storage (HDFS/S3/GCS..) : s3 * Running on Docker? (yes/no) : No -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #7573: [HUDI-5484] Avoid using GenericRecord in ColumnStatMetadata
hudi-bot commented on PR #7573: URL: https://github.com/apache/hudi/pull/7573#issuecomment-1370533946 ## CI report: * 1ac267ba9af690ecd47f74f60c34851387aee9eb Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=14080) Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=14083) Azure: [SUCCESS](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=14089) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #7528: [HUDI-5443] Fixing exception trying to read MOR table after `NestedSchemaPruning` rule has been applied
hudi-bot commented on PR #7528: URL: https://github.com/apache/hudi/pull/7528#issuecomment-1370533874 ## CI report: * f3a439884f90500e29da0075f4d0ad7d73a484b3 UNKNOWN * 801223083980fed8f400a34588df98cca453e439 Azure: [SUCCESS](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=14088) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] danny0405 commented on pull request #7584: [HUDI-5205] Support Flink 1.16.0
danny0405 commented on PR #7584: URL: https://github.com/apache/hudi/pull/7584#issuecomment-1370531069 Thanks for the contribution, I have reviewed again and created another patch: [5205.patch.zip](https://github.com/apache/hudi/files/10341889/5205.patch.zip) The tests failed because the `JsonRowDataDeserializationSchema` is refactorted where the `#open` method must be called for some JSON infrustructures initialization. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] BruceKellan commented on pull request #7445: [HUDI-5380] Fixing change table path but table location in metastore …
BruceKellan commented on PR #7445: URL: https://github.com/apache/hudi/pull/7445#issuecomment-1370524442 The failure of CI seems to have flaky test. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Closed] (HUDI-5496) Prevent Hudi from generating clustering plans with filegroups consisting of only 1 fileSlice
[
https://issues.apache.org/jira/browse/HUDI-5496?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
voon closed HUDI-5496.
--
Resolution: Duplicate
> Prevent Hudi from generating clustering plans with filegroups consisting of
> only 1 fileSlice
>
>
> Key: HUDI-5496
> URL: https://issues.apache.org/jira/browse/HUDI-5496
> Project: Apache Hudi
> Issue Type: Bug
>Reporter: voon
>Assignee: voon
>Priority: Major
> Labels: pull-request-available
>
> Suppose a partition is no longer being written/updated, i.e. there will be no
> changes to the partition, therefore, size of parquet files will always be the
> same.
>
> If the parquet files in the partition (even after prior clustering) is
> smaller than {*}hoodie.clustering.plan.strategy.small.file.limit{*}, the
> fileSlice will always be returned as a candidate for
> {_}getFileSlicesEligibleForClustering(){_}.
>
> This may cause inputGroups with only 1 fileSlice to be selected as candidates
> for clustering. An of a clusteringPlan demonstrating such a case in JSON
> format is seen below.
>
>
> {code:java}
> {
> "inputGroups": [
> {
> "slices": [
> {
> "dataFilePath":
> "/path/clustering_test_table/dt=2023-01-03/cf2929a7-78dc-4e99-be0c-926e9487187d-0_0-2-0_20230104102201656.parquet",
> "deltaFilePaths": [],
> "fileId": "cf2929a7-78dc-4e99-be0c-926e9487187d-0",
> "partitionPath": "dt=2023-01-03",
> "bootstrapFilePath": "",
> "version": 1
> }
> ],
> "metrics": {
> "TOTAL_LOG_FILES": 0.0,
> "TOTAL_IO_MB": 260.0,
> "TOTAL_IO_READ_MB": 130.0,
> "TOTAL_LOG_FILES_SIZE": 0.0,
> "TOTAL_IO_WRITE_MB": 130.0
> },
> "numOutputFileGroups": 1,
> "extraMetadata": null,
> "version": 1
> },
> {
> "slices": [
> {
> "dataFilePath":
> "/path/clustering_test_table/dt=2023-01-04/b101162e-4813-4de6-9881-4ee0ff918f32-0_0-2-0_20230104103401458.parquet",
> "deltaFilePaths": [],
> "fileId": "b101162e-4813-4de6-9881-4ee0ff918f32-0",
> "partitionPath": "dt=2023-01-04",
> "bootstrapFilePath": "",
> "version": 1
> },
> {
> "dataFilePath":
> "/path/clustering_test_table/dt=2023-01-04/9b1c1494-2a58-43f1-890d-4b52070937b1-0_0-2-0_20230104102201656.parquet",
> "deltaFilePaths": [],
> "fileId": "9b1c1494-2a58-43f1-890d-4b52070937b1-0",
> "partitionPath": "dt=2023-01-04",
> "bootstrapFilePath": "",
> "version": 1
> }
> ],
> "metrics": {
> "TOTAL_LOG_FILES": 0.0,
> "TOTAL_IO_MB": 418.0,
> "TOTAL_IO_READ_MB": 209.0,
> "TOTAL_LOG_FILES_SIZE": 0.0,
> "TOTAL_IO_WRITE_MB": 209.0
> },
> "numOutputFileGroups": 1,
> "extraMetadata": null,
> "version": 1
> }
> ],
> "strategy": {
> "strategyClassName":
> "org.apache.hudi.client.clustering.run.strategy.SparkSortAndSizeExecutionStrategy",
> "strategyParams": {},
> "version": 1
> },
> "extraMetadata": {},
> "version": 1,
> "preserveHoodieMetadata": true
> }{code}
>
> Such a case will cause performance issues as a parquet file is re-written
> unnecessarily (write amplification).
>
> The fix is to only select inputGroups with more than 1 fileSlice as
> candidates for clustering.
>
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[jira] [Commented] (HUDI-5496) Prevent Hudi from generating clustering plans with filegroups consisting of only 1 fileSlice
[
https://issues.apache.org/jira/browse/HUDI-5496?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17654303#comment-17654303
]
voon commented on HUDI-5496:
Duplicate of HUDI-5173.
> Prevent Hudi from generating clustering plans with filegroups consisting of
> only 1 fileSlice
>
>
> Key: HUDI-5496
> URL: https://issues.apache.org/jira/browse/HUDI-5496
> Project: Apache Hudi
> Issue Type: Bug
>Reporter: voon
>Assignee: voon
>Priority: Major
> Labels: pull-request-available
>
> Suppose a partition is no longer being written/updated, i.e. there will be no
> changes to the partition, therefore, size of parquet files will always be the
> same.
>
> If the parquet files in the partition (even after prior clustering) is
> smaller than {*}hoodie.clustering.plan.strategy.small.file.limit{*}, the
> fileSlice will always be returned as a candidate for
> {_}getFileSlicesEligibleForClustering(){_}.
>
> This may cause inputGroups with only 1 fileSlice to be selected as candidates
> for clustering. An of a clusteringPlan demonstrating such a case in JSON
> format is seen below.
>
>
> {code:java}
> {
> "inputGroups": [
> {
> "slices": [
> {
> "dataFilePath":
> "/path/clustering_test_table/dt=2023-01-03/cf2929a7-78dc-4e99-be0c-926e9487187d-0_0-2-0_20230104102201656.parquet",
> "deltaFilePaths": [],
> "fileId": "cf2929a7-78dc-4e99-be0c-926e9487187d-0",
> "partitionPath": "dt=2023-01-03",
> "bootstrapFilePath": "",
> "version": 1
> }
> ],
> "metrics": {
> "TOTAL_LOG_FILES": 0.0,
> "TOTAL_IO_MB": 260.0,
> "TOTAL_IO_READ_MB": 130.0,
> "TOTAL_LOG_FILES_SIZE": 0.0,
> "TOTAL_IO_WRITE_MB": 130.0
> },
> "numOutputFileGroups": 1,
> "extraMetadata": null,
> "version": 1
> },
> {
> "slices": [
> {
> "dataFilePath":
> "/path/clustering_test_table/dt=2023-01-04/b101162e-4813-4de6-9881-4ee0ff918f32-0_0-2-0_20230104103401458.parquet",
> "deltaFilePaths": [],
> "fileId": "b101162e-4813-4de6-9881-4ee0ff918f32-0",
> "partitionPath": "dt=2023-01-04",
> "bootstrapFilePath": "",
> "version": 1
> },
> {
> "dataFilePath":
> "/path/clustering_test_table/dt=2023-01-04/9b1c1494-2a58-43f1-890d-4b52070937b1-0_0-2-0_20230104102201656.parquet",
> "deltaFilePaths": [],
> "fileId": "9b1c1494-2a58-43f1-890d-4b52070937b1-0",
> "partitionPath": "dt=2023-01-04",
> "bootstrapFilePath": "",
> "version": 1
> }
> ],
> "metrics": {
> "TOTAL_LOG_FILES": 0.0,
> "TOTAL_IO_MB": 418.0,
> "TOTAL_IO_READ_MB": 209.0,
> "TOTAL_LOG_FILES_SIZE": 0.0,
> "TOTAL_IO_WRITE_MB": 209.0
> },
> "numOutputFileGroups": 1,
> "extraMetadata": null,
> "version": 1
> }
> ],
> "strategy": {
> "strategyClassName":
> "org.apache.hudi.client.clustering.run.strategy.SparkSortAndSizeExecutionStrategy",
> "strategyParams": {},
> "version": 1
> },
> "extraMetadata": {},
> "version": 1,
> "preserveHoodieMetadata": true
> }{code}
>
> Such a case will cause performance issues as a parquet file is re-written
> unnecessarily (write amplification).
>
> The fix is to only select inputGroups with more than 1 fileSlice as
> candidates for clustering.
>
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[GitHub] [hudi] voonhous closed pull request #7599: [HUDI-5496] Prevent unnecessary rewrites when performing clustering
voonhous closed pull request #7599: [HUDI-5496] Prevent unnecessary rewrites when performing clustering URL: https://github.com/apache/hudi/pull/7599 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] voonhous commented on pull request #7599: [HUDI-5496] Prevent unnecessary rewrites when performing clustering
voonhous commented on PR #7599: URL: https://github.com/apache/hudi/pull/7599#issuecomment-1370517402 @SteNicholas great, I'll close my PR then. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] SteNicholas commented on pull request #7599: [HUDI-5496] Prevent unnecessary rewrites when performing clustering
SteNicholas commented on PR #7599: URL: https://github.com/apache/hudi/pull/7599#issuecomment-1370516264 @voonhous, you could take a look at the pull request: https://github.com/apache/hudi/pull/7159 . -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #7599: [HUDI-5496] Prevent unnecessary rewrites when performing clustering
hudi-bot commented on PR #7599: URL: https://github.com/apache/hudi/pull/7599#issuecomment-1370500287 ## CI report: * efb347ea9684ccafeb7208fb870c4ff19b300412 Azure: [PENDING](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=14093) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #7599: [HUDI-5496] Prevent unnecessary rewrites when performing clustering
hudi-bot commented on PR #7599: URL: https://github.com/apache/hudi/pull/7599#issuecomment-1370497402 ## CI report: * efb347ea9684ccafeb7208fb870c4ff19b300412 UNKNOWN Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #7445: [HUDI-5380] Fixing change table path but table location in metastore …
hudi-bot commented on PR #7445: URL: https://github.com/apache/hudi/pull/7445#issuecomment-1370493785 ## CI report: * 36bc81d1f49d09d22eb8ad87d280b0f1f61f4a44 Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=13998) Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=14025) Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=14031) Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=14087) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] maheshguptags commented on issue #7589: Keep only clustered file(all) after cleaning
maheshguptags commented on issue #7589: URL: https://github.com/apache/hudi/issues/7589#issuecomment-1370489489 Hi @yihua ,Thanks for looking into this. you are partially right but I want to preserve all the clustered file from 1 clustered file to till very end of the pipeline. let me give you the example. step 1 image : it contains the 3 commit of the file  step 2 image contain after the clustering file : 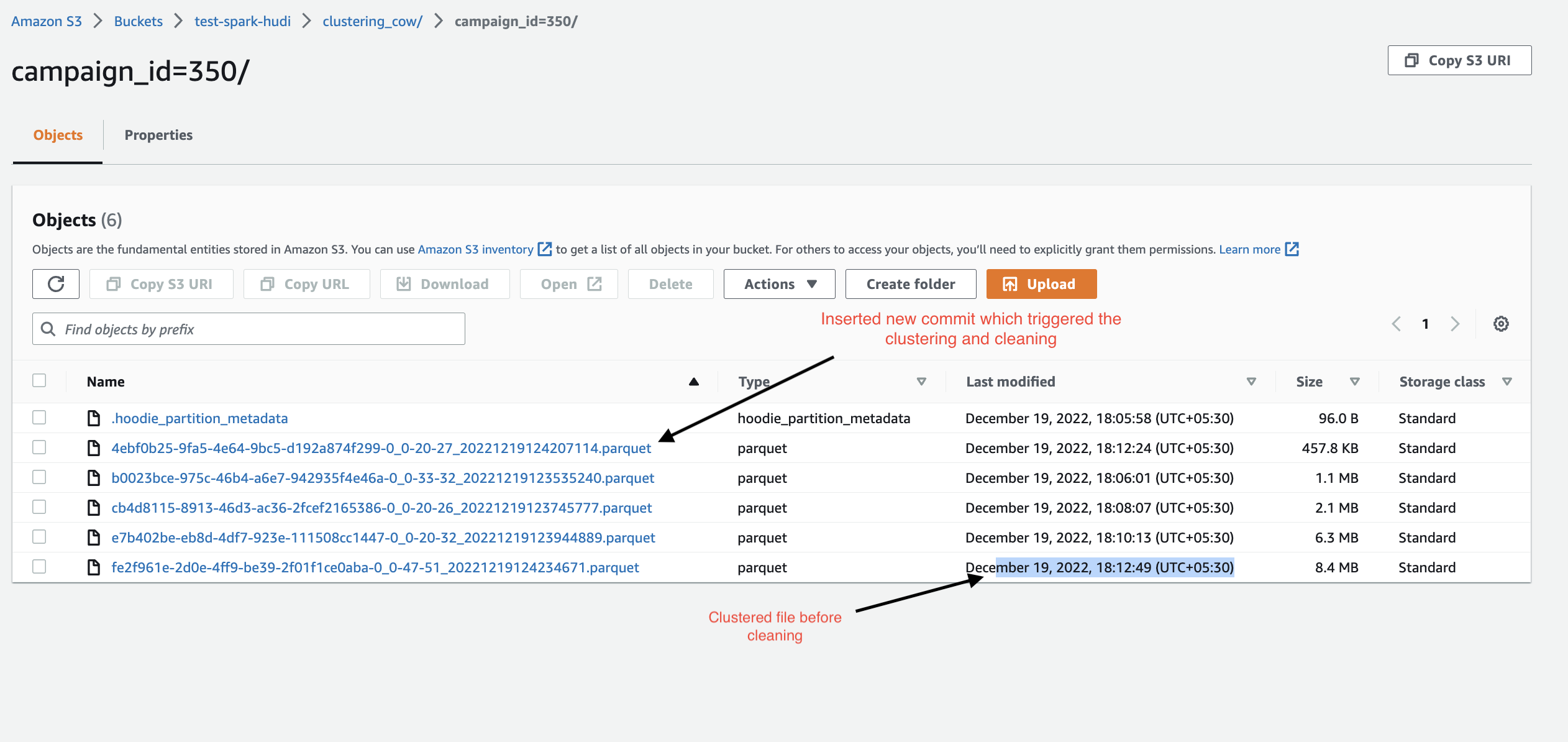 step 3 it contains only the clustered file and the latest commit files  step 4 image inserted few more commit then perform the clustering  Step 5 Image : Now this time clustering and cleaning will be triggered (4 commits completed) so it will clean the last cluster file (size exactly 8.4MB) and create new cluster file having all updated data. Whereas my wish is to preserve the old clustered file (8.4MB) file and create new clustered file. This way I will be able to maintain historical data of my process.  I hope I am able to explain the use case, If not we can quick catch up on call. Let me know your thought on this Thanks!! -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] BalaMahesh commented on issue #7595: [SUPPORT] Hudi Clean and Delta commits taking ~50 mins to finish frequently
BalaMahesh commented on issue #7595: URL: https://github.com/apache/hudi/issues/7595#issuecomment-1370487901 This is a non-partitioned table with minimum file size set to 1 MB and ~150 parquet files are created. Below are the screenshots from spark web ui. https://user-images.githubusercontent.com/25053668/210485678-01569009-8b3c-4b62-8d04-7d5149cbdb7b.png;> https://user-images.githubusercontent.com/25053668/210485684-b5314c87-a794-4242-889f-3a7a6623e395.png;> https://user-images.githubusercontent.com/25053668/210485691-d3112ff4-739e-429a-bca1-3abd44394ba6.png;> https://user-images.githubusercontent.com/25053668/210485699-26aeede3-24fa-46ec-9e4f-b07d87b842c9.png;> https://user-images.githubusercontent.com/25053668/210485707-bdd31536-0399-4a89-98b8-2816ed1fdff3.png;> I am adding the logs between 23/01/04 03:48:51 and 23/01/04 04:41:25 - which took longer duration for delta commit. [hudi_logs.txt](https://github.com/apache/hudi/files/10341543/hudi_logs.txt) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Assigned] (HUDI-5496) Prevent Hudi from generating clustering plans with filegroups consisting of only 1 fileSlice
[
https://issues.apache.org/jira/browse/HUDI-5496?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
voon reassigned HUDI-5496:
--
Assignee: voon
> Prevent Hudi from generating clustering plans with filegroups consisting of
> only 1 fileSlice
>
>
> Key: HUDI-5496
> URL: https://issues.apache.org/jira/browse/HUDI-5496
> Project: Apache Hudi
> Issue Type: Bug
>Reporter: voon
>Assignee: voon
>Priority: Major
> Labels: pull-request-available
>
> Suppose a partition is no longer being written/updated, i.e. there will be no
> changes to the partition, therefore, size of parquet files will always be the
> same.
>
> If the parquet files in the partition (even after prior clustering) is
> smaller than {*}hoodie.clustering.plan.strategy.small.file.limit{*}, the
> fileSlice will always be returned as a candidate for
> {_}getFileSlicesEligibleForClustering(){_}.
>
> This may cause inputGroups with only 1 fileSlice to be selected as candidates
> for clustering. An of a clusteringPlan demonstrating such a case in JSON
> format is seen below.
>
>
> {code:java}
> {
> "inputGroups": [
> {
> "slices": [
> {
> "dataFilePath":
> "/path/clustering_test_table/dt=2023-01-03/cf2929a7-78dc-4e99-be0c-926e9487187d-0_0-2-0_20230104102201656.parquet",
> "deltaFilePaths": [],
> "fileId": "cf2929a7-78dc-4e99-be0c-926e9487187d-0",
> "partitionPath": "dt=2023-01-03",
> "bootstrapFilePath": "",
> "version": 1
> }
> ],
> "metrics": {
> "TOTAL_LOG_FILES": 0.0,
> "TOTAL_IO_MB": 260.0,
> "TOTAL_IO_READ_MB": 130.0,
> "TOTAL_LOG_FILES_SIZE": 0.0,
> "TOTAL_IO_WRITE_MB": 130.0
> },
> "numOutputFileGroups": 1,
> "extraMetadata": null,
> "version": 1
> },
> {
> "slices": [
> {
> "dataFilePath":
> "/path/clustering_test_table/dt=2023-01-04/b101162e-4813-4de6-9881-4ee0ff918f32-0_0-2-0_20230104103401458.parquet",
> "deltaFilePaths": [],
> "fileId": "b101162e-4813-4de6-9881-4ee0ff918f32-0",
> "partitionPath": "dt=2023-01-04",
> "bootstrapFilePath": "",
> "version": 1
> },
> {
> "dataFilePath":
> "/path/clustering_test_table/dt=2023-01-04/9b1c1494-2a58-43f1-890d-4b52070937b1-0_0-2-0_20230104102201656.parquet",
> "deltaFilePaths": [],
> "fileId": "9b1c1494-2a58-43f1-890d-4b52070937b1-0",
> "partitionPath": "dt=2023-01-04",
> "bootstrapFilePath": "",
> "version": 1
> }
> ],
> "metrics": {
> "TOTAL_LOG_FILES": 0.0,
> "TOTAL_IO_MB": 418.0,
> "TOTAL_IO_READ_MB": 209.0,
> "TOTAL_LOG_FILES_SIZE": 0.0,
> "TOTAL_IO_WRITE_MB": 209.0
> },
> "numOutputFileGroups": 1,
> "extraMetadata": null,
> "version": 1
> }
> ],
> "strategy": {
> "strategyClassName":
> "org.apache.hudi.client.clustering.run.strategy.SparkSortAndSizeExecutionStrategy",
> "strategyParams": {},
> "version": 1
> },
> "extraMetadata": {},
> "version": 1,
> "preserveHoodieMetadata": true
> }{code}
>
> Such a case will cause performance issues as a parquet file is re-written
> unnecessarily (write amplification).
>
> The fix is to only select inputGroups with more than 1 fileSlice as
> candidates for clustering.
>
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[jira] [Updated] (HUDI-5496) Prevent Hudi from generating clustering plans with filegroups consisting of only 1 fileSlice
[
https://issues.apache.org/jira/browse/HUDI-5496?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
ASF GitHub Bot updated HUDI-5496:
-
Labels: pull-request-available (was: )
> Prevent Hudi from generating clustering plans with filegroups consisting of
> only 1 fileSlice
>
>
> Key: HUDI-5496
> URL: https://issues.apache.org/jira/browse/HUDI-5496
> Project: Apache Hudi
> Issue Type: Bug
>Reporter: voon
>Priority: Major
> Labels: pull-request-available
>
> Suppose a partition is no longer being written/updated, i.e. there will be no
> changes to the partition, therefore, size of parquet files will always be the
> same.
>
> If the parquet files in the partition (even after prior clustering) is
> smaller than {*}hoodie.clustering.plan.strategy.small.file.limit{*}, the
> fileSlice will always be returned as a candidate for
> {_}getFileSlicesEligibleForClustering(){_}.
>
> This may cause inputGroups with only 1 fileSlice to be selected as candidates
> for clustering. An of a clusteringPlan demonstrating such a case in JSON
> format is seen below.
>
>
> {code:java}
> {
> "inputGroups": [
> {
> "slices": [
> {
> "dataFilePath":
> "/path/clustering_test_table/dt=2023-01-03/cf2929a7-78dc-4e99-be0c-926e9487187d-0_0-2-0_20230104102201656.parquet",
> "deltaFilePaths": [],
> "fileId": "cf2929a7-78dc-4e99-be0c-926e9487187d-0",
> "partitionPath": "dt=2023-01-03",
> "bootstrapFilePath": "",
> "version": 1
> }
> ],
> "metrics": {
> "TOTAL_LOG_FILES": 0.0,
> "TOTAL_IO_MB": 260.0,
> "TOTAL_IO_READ_MB": 130.0,
> "TOTAL_LOG_FILES_SIZE": 0.0,
> "TOTAL_IO_WRITE_MB": 130.0
> },
> "numOutputFileGroups": 1,
> "extraMetadata": null,
> "version": 1
> },
> {
> "slices": [
> {
> "dataFilePath":
> "/path/clustering_test_table/dt=2023-01-04/b101162e-4813-4de6-9881-4ee0ff918f32-0_0-2-0_20230104103401458.parquet",
> "deltaFilePaths": [],
> "fileId": "b101162e-4813-4de6-9881-4ee0ff918f32-0",
> "partitionPath": "dt=2023-01-04",
> "bootstrapFilePath": "",
> "version": 1
> },
> {
> "dataFilePath":
> "/path/clustering_test_table/dt=2023-01-04/9b1c1494-2a58-43f1-890d-4b52070937b1-0_0-2-0_20230104102201656.parquet",
> "deltaFilePaths": [],
> "fileId": "9b1c1494-2a58-43f1-890d-4b52070937b1-0",
> "partitionPath": "dt=2023-01-04",
> "bootstrapFilePath": "",
> "version": 1
> }
> ],
> "metrics": {
> "TOTAL_LOG_FILES": 0.0,
> "TOTAL_IO_MB": 418.0,
> "TOTAL_IO_READ_MB": 209.0,
> "TOTAL_LOG_FILES_SIZE": 0.0,
> "TOTAL_IO_WRITE_MB": 209.0
> },
> "numOutputFileGroups": 1,
> "extraMetadata": null,
> "version": 1
> }
> ],
> "strategy": {
> "strategyClassName":
> "org.apache.hudi.client.clustering.run.strategy.SparkSortAndSizeExecutionStrategy",
> "strategyParams": {},
> "version": 1
> },
> "extraMetadata": {},
> "version": 1,
> "preserveHoodieMetadata": true
> }{code}
>
> Such a case will cause performance issues as a parquet file is re-written
> unnecessarily (write amplification).
>
> The fix is to only select inputGroups with more than 1 fileSlice as
> candidates for clustering.
>
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[GitHub] [hudi] voonhous opened a new pull request, #7599: [HUDI-5496] Prevent unnecessary rewrites when performing clustering
voonhous opened a new pull request, #7599: URL: https://github.com/apache/hudi/pull/7599 ### Change Logs Prevent unnecessary rewrites when performing clustering by only selecting _HoodieClusteringGroup_s with more than 1 fileSlice as candidates for clustering. ### Impact _Describe any public API or user-facing feature change or any performance impact._ None ### Risk level (write none, low medium or high below) None _If medium or high, explain what verification was done to mitigate the risks._ ### Documentation Update _Describe any necessary documentation update if there is any new feature, config, or user-facing change_ - _The config description must be updated if new configs are added or the default value of the configs are changed_ - _Any new feature or user-facing change requires updating the Hudi website. Please create a Jira ticket, attach the ticket number here and follow the [instruction](https://hudi.apache.org/contribute/developer-setup#website) to make changes to the website._ ### Contributor's checklist - [ ] Read through [contributor's guide](https://hudi.apache.org/contribute/how-to-contribute) - [ ] Change Logs and Impact were stated clearly - [ ] Adequate tests were added if applicable - [ ] CI passed -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (HUDI-5496) Prevent Hudi from generating clustering plans with filegroups consisting of only 1 fileSlice
[
https://issues.apache.org/jira/browse/HUDI-5496?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
voon updated HUDI-5496:
---
Description:
Suppose a partition is no longer being written/updated, i.e. there will be no
changes to the partition, therefore, size of parquet files will always be the
same.
If the parquet files in the partition (even after prior clustering) is smaller
than {*}hoodie.clustering.plan.strategy.small.file.limit{*}, the fileSlice will
always be returned as a candidate for
{_}getFileSlicesEligibleForClustering(){_}.
This may cause inputGroups with only 1 fileSlice to be selected as candidates
for clustering. An of a clusteringPlan demonstrating such a case in JSON format
is seen below.
{code:java}
{
"inputGroups": [
{
"slices": [
{
"dataFilePath":
"/path/clustering_test_table/dt=2023-01-03/cf2929a7-78dc-4e99-be0c-926e9487187d-0_0-2-0_20230104102201656.parquet",
"deltaFilePaths": [],
"fileId": "cf2929a7-78dc-4e99-be0c-926e9487187d-0",
"partitionPath": "dt=2023-01-03",
"bootstrapFilePath": "",
"version": 1
}
],
"metrics": {
"TOTAL_LOG_FILES": 0.0,
"TOTAL_IO_MB": 260.0,
"TOTAL_IO_READ_MB": 130.0,
"TOTAL_LOG_FILES_SIZE": 0.0,
"TOTAL_IO_WRITE_MB": 130.0
},
"numOutputFileGroups": 1,
"extraMetadata": null,
"version": 1
},
{
"slices": [
{
"dataFilePath":
"/path/clustering_test_table/dt=2023-01-04/b101162e-4813-4de6-9881-4ee0ff918f32-0_0-2-0_20230104103401458.parquet",
"deltaFilePaths": [],
"fileId": "b101162e-4813-4de6-9881-4ee0ff918f32-0",
"partitionPath": "dt=2023-01-04",
"bootstrapFilePath": "",
"version": 1
},
{
"dataFilePath":
"/path/clustering_test_table/dt=2023-01-04/9b1c1494-2a58-43f1-890d-4b52070937b1-0_0-2-0_20230104102201656.parquet",
"deltaFilePaths": [],
"fileId": "9b1c1494-2a58-43f1-890d-4b52070937b1-0",
"partitionPath": "dt=2023-01-04",
"bootstrapFilePath": "",
"version": 1
}
],
"metrics": {
"TOTAL_LOG_FILES": 0.0,
"TOTAL_IO_MB": 418.0,
"TOTAL_IO_READ_MB": 209.0,
"TOTAL_LOG_FILES_SIZE": 0.0,
"TOTAL_IO_WRITE_MB": 209.0
},
"numOutputFileGroups": 1,
"extraMetadata": null,
"version": 1
}
],
"strategy": {
"strategyClassName":
"org.apache.hudi.client.clustering.run.strategy.SparkSortAndSizeExecutionStrategy",
"strategyParams": {},
"version": 1
},
"extraMetadata": {},
"version": 1,
"preserveHoodieMetadata": true
}{code}
Such a case will cause performance issues as a parquet file is re-written
unnecessarily (write amplification).
The fix is to only select inputGroups with more than 1 fileSlice as candidates
for clustering.
was:
Suppose a partition is no longer being written/updated, i.e. there will be no
changes to the partition, therefore, size of parquet files will always be the
same.
If the parquet files in the partition (even after prior clustering) is smaller
than {*}hoodie.clustering.plan.strategy.small.file.limit{*}, ** the fileSlice
will always be returned as a candidate for
{_}getFileSlicesEligibleForClustering(){_}.
This may cause inputGroups with only 1 fileSlice to be selected as candidates
for clustering. An of a clusteringPlan demonstrating such a case in JSON format
is seen below.
{code:java}
{
"inputGroups": [
{
"slices": [
{
"dataFilePath":
"/path/clustering_test_table/dt=2023-01-03/cf2929a7-78dc-4e99-be0c-926e9487187d-0_0-2-0_20230104102201656.parquet",
"deltaFilePaths": [],
"fileId": "cf2929a7-78dc-4e99-be0c-926e9487187d-0",
"partitionPath": "dt=2023-01-03",
"bootstrapFilePath": "",
"version": 1
}
],
"metrics": {
"TOTAL_LOG_FILES": 0.0,
"TOTAL_IO_MB": 260.0,
"TOTAL_IO_READ_MB": 130.0,
"TOTAL_LOG_FILES_SIZE": 0.0,
"TOTAL_IO_WRITE_MB": 130.0
},
"numOutputFileGroups": 1,
"extraMetadata": null,
"version": 1
},
{
"slices": [
{
"dataFilePath":
"/path/clustering_test_table/dt=2023-01-04/b101162e-4813-4de6-9881-4ee0ff918f32-0_0-2-0_20230104103401458.parquet",
"deltaFilePaths": [],
"fileId": "b101162e-4813-4de6-9881-4ee0ff918f32-0",
"partitionPath": "dt=2023-01-04",
"bootstrapFilePath": "",
"version": 1
},
{
"dataFilePath":
"/path/clustering_test_table/dt=2023-01-04/9b1c1494-2a58-43f1-890d-4b52070937b1-0_0-2-0_20230104102201656.parquet",
"deltaFilePaths": [],
"fileId": "9b1c1494-2a58-43f1-890d-4b52070937b1-0",
"partitionPath":
[jira] [Created] (HUDI-5496) Prevent Hudi from generating clustering plans with filegroups consisting of only 1 fileSlice
voon created HUDI-5496:
--
Summary: Prevent Hudi from generating clustering plans with
filegroups consisting of only 1 fileSlice
Key: HUDI-5496
URL: https://issues.apache.org/jira/browse/HUDI-5496
Project: Apache Hudi
Issue Type: Bug
Reporter: voon
Suppose a partition is no longer being written/updated, i.e. there will be no
changes to the partition, therefore, size of parquet files will always be the
same.
If the parquet files in the partition (even after prior clustering) is smaller
than {*}hoodie.clustering.plan.strategy.small.file.limit{*}, ** the fileSlice
will always be returned as a candidate for
{_}getFileSlicesEligibleForClustering(){_}.
This may cause inputGroups with only 1 fileSlice to be selected as candidates
for clustering. An of a clusteringPlan demonstrating such a case in JSON format
is seen below.
{code:java}
{
"inputGroups": [
{
"slices": [
{
"dataFilePath":
"/path/clustering_test_table/dt=2023-01-03/cf2929a7-78dc-4e99-be0c-926e9487187d-0_0-2-0_20230104102201656.parquet",
"deltaFilePaths": [],
"fileId": "cf2929a7-78dc-4e99-be0c-926e9487187d-0",
"partitionPath": "dt=2023-01-03",
"bootstrapFilePath": "",
"version": 1
}
],
"metrics": {
"TOTAL_LOG_FILES": 0.0,
"TOTAL_IO_MB": 260.0,
"TOTAL_IO_READ_MB": 130.0,
"TOTAL_LOG_FILES_SIZE": 0.0,
"TOTAL_IO_WRITE_MB": 130.0
},
"numOutputFileGroups": 1,
"extraMetadata": null,
"version": 1
},
{
"slices": [
{
"dataFilePath":
"/path/clustering_test_table/dt=2023-01-04/b101162e-4813-4de6-9881-4ee0ff918f32-0_0-2-0_20230104103401458.parquet",
"deltaFilePaths": [],
"fileId": "b101162e-4813-4de6-9881-4ee0ff918f32-0",
"partitionPath": "dt=2023-01-04",
"bootstrapFilePath": "",
"version": 1
},
{
"dataFilePath":
"/path/clustering_test_table/dt=2023-01-04/9b1c1494-2a58-43f1-890d-4b52070937b1-0_0-2-0_20230104102201656.parquet",
"deltaFilePaths": [],
"fileId": "9b1c1494-2a58-43f1-890d-4b52070937b1-0",
"partitionPath": "dt=2023-01-04",
"bootstrapFilePath": "",
"version": 1
}
],
"metrics": {
"TOTAL_LOG_FILES": 0.0,
"TOTAL_IO_MB": 418.0,
"TOTAL_IO_READ_MB": 209.0,
"TOTAL_LOG_FILES_SIZE": 0.0,
"TOTAL_IO_WRITE_MB": 209.0
},
"numOutputFileGroups": 1,
"extraMetadata": null,
"version": 1
}
],
"strategy": {
"strategyClassName":
"org.apache.hudi.client.clustering.run.strategy.SparkSortAndSizeExecutionStrategy",
"strategyParams": {},
"version": 1
},
"extraMetadata": {},
"version": 1,
"preserveHoodieMetadata": true
}{code}
Such a case will cause performance issues as a parquet file is re-written
unnecessarily (write amplification).
The fix is to only select inputGroups with more than 1 fileSlice as candidates
for clustering.
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[GitHub] [hudi] hudi-bot commented on pull request #7598: [HUDI-5495] add some property to table config
hudi-bot commented on PR #7598: URL: https://github.com/apache/hudi/pull/7598#issuecomment-1370458184 ## CI report: * 2c35d032539bd064a57a1e25f062e5f93dceeccd Azure: [PENDING](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=14092) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #7593: [HUDI-5492] spark call command show_compaction doesn't return the com…
hudi-bot commented on PR #7593: URL: https://github.com/apache/hudi/pull/7593#issuecomment-1370458167 ## CI report: * 8dac276274844f65a48d2e877a3cb1ed1d4ec3e3 Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=14079) * eebec335595a73242a23d682c401b5b5c5d54284 Azure: [PENDING](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=14091) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #7528: [HUDI-5443] Fixing exception trying to read MOR table after `NestedSchemaPruning` rule has been applied
hudi-bot commented on PR #7528: URL: https://github.com/apache/hudi/pull/7528#issuecomment-1370458072 ## CI report: * f3a439884f90500e29da0075f4d0ad7d73a484b3 UNKNOWN * 636b3000094521146d90c541b8cfd3b4ee6e Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=13929) * 801223083980fed8f400a34588df98cca453e439 Azure: [PENDING](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=14088) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #6782: [HUDI-4911][HUDI-3301] Fixing `HoodieMetadataLogRecordReader` to avoid flushing cache for every lookup
hudi-bot commented on PR #6782: URL: https://github.com/apache/hudi/pull/6782#issuecomment-1370457674 ## CI report: * 0a57ee15196e2b6978dbf74efad95cd58f6e7f13 Azure: [CANCELED](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=13923) Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=13931) * 182351f81d81cbfa9be87fa2e13d5d58a4d7bec4 Azure: [PENDING](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=14090) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #7598: [HUDI-5495] add some property to table config
hudi-bot commented on PR #7598: URL: https://github.com/apache/hudi/pull/7598#issuecomment-1370455843 ## CI report: * 2c35d032539bd064a57a1e25f062e5f93dceeccd UNKNOWN Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #7593: [HUDI-5492] spark call command show_compaction doesn't return the com…
hudi-bot commented on PR #7593: URL: https://github.com/apache/hudi/pull/7593#issuecomment-1370455818 ## CI report: * 8dac276274844f65a48d2e877a3cb1ed1d4ec3e3 Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=14079) * eebec335595a73242a23d682c401b5b5c5d54284 UNKNOWN Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #7528: [HUDI-5443] Fixing exception trying to read MOR table after `NestedSchemaPruning` rule has been applied
hudi-bot commented on PR #7528: URL: https://github.com/apache/hudi/pull/7528#issuecomment-1370455694 ## CI report: * f3a439884f90500e29da0075f4d0ad7d73a484b3 UNKNOWN * 636b3000094521146d90c541b8cfd3b4ee6e Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=13929) * 801223083980fed8f400a34588df98cca453e439 UNKNOWN Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #6782: [HUDI-4911][HUDI-3301] Fixing `HoodieMetadataLogRecordReader` to avoid flushing cache for every lookup
hudi-bot commented on PR #6782: URL: https://github.com/apache/hudi/pull/6782#issuecomment-1370455241 ## CI report: * 0a57ee15196e2b6978dbf74efad95cd58f6e7f13 Azure: [CANCELED](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=13923) Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=13931) * 182351f81d81cbfa9be87fa2e13d5d58a4d7bec4 UNKNOWN Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #7573: [HUDI-5484] Avoid using GenericRecord in ColumnStatMetadata
hudi-bot commented on PR #7573: URL: https://github.com/apache/hudi/pull/7573#issuecomment-1370453158 ## CI report: * 1ac267ba9af690ecd47f74f60c34851387aee9eb Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=14080) Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=14083) Azure: [PENDING](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=14089) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[hudi] 41/45: fix read log not exist
This is an automated email from the ASF dual-hosted git repository.
forwardxu pushed a commit to branch release-0.12.1
in repository https://gitbox.apache.org/repos/asf/hudi.git
commit 4fe2aec44acefc7ec857836b54af69dce5f41bda
Author: XuQianJin-Stars
AuthorDate: Tue Dec 13 14:52:03 2022 +0800
fix read log not exist
---
.../org/apache/hudi/common/table/log/HoodieLogFormatReader.java | 8 ++--
1 file changed, 6 insertions(+), 2 deletions(-)
diff --git
a/hudi-common/src/main/java/org/apache/hudi/common/table/log/HoodieLogFormatReader.java
b/hudi-common/src/main/java/org/apache/hudi/common/table/log/HoodieLogFormatReader.java
index c48107e392..7f67c76870 100644
---
a/hudi-common/src/main/java/org/apache/hudi/common/table/log/HoodieLogFormatReader.java
+++
b/hudi-common/src/main/java/org/apache/hudi/common/table/log/HoodieLogFormatReader.java
@@ -67,8 +67,12 @@ public class HoodieLogFormatReader implements
HoodieLogFormat.Reader {
this.internalSchema = internalSchema == null ?
InternalSchema.getEmptyInternalSchema() : internalSchema;
if (logFiles.size() > 0) {
HoodieLogFile nextLogFile = logFiles.remove(0);
- this.currentReader = new HoodieLogFileReader(fs, nextLogFile,
readerSchema, bufferSize, readBlocksLazily, false,
- enableRecordLookups, recordKeyField, internalSchema);
+ if (fs.exists(nextLogFile.getPath())) {
+this.currentReader = new HoodieLogFileReader(fs, nextLogFile,
readerSchema, bufferSize, readBlocksLazily, false,
+enableRecordLookups, recordKeyField, internalSchema);
+ } else {
+LOG.warn("File does not exist: " + nextLogFile.getPath());
+ }
}
}
[hudi] 16/45: [HUDI-2624] Implement Non Index type for HUDI
This is an automated email from the ASF dual-hosted git repository.
forwardxu pushed a commit to branch release-0.12.1
in repository https://gitbox.apache.org/repos/asf/hudi.git
commit 8ba01dc70a718ddab3044b45f96a545f0aae4084
Author: XuQianJin-Stars
AuthorDate: Fri Oct 28 12:33:22 2022 +0800
[HUDI-2624] Implement Non Index type for HUDI
---
.../org/apache/hudi/config/HoodieIndexConfig.java | 43
.../org/apache/hudi/config/HoodieWriteConfig.java | 12 +
.../java/org/apache/hudi/index/HoodieIndex.java| 2 +-
.../java/org/apache/hudi/io/HoodieMergeHandle.java | 3 +-
.../apache/hudi/keygen/EmptyAvroKeyGenerator.java | 65 +
.../hudi/table/action/commit/BucketInfo.java | 4 +
.../hudi/table/action/commit/BucketType.java | 2 +-
.../apache/hudi/index/FlinkHoodieIndexFactory.java | 2 +
.../org/apache/hudi/index/FlinkHoodieNonIndex.java | 65 +
.../apache/hudi/index/SparkHoodieIndexFactory.java | 3 +
.../hudi/index/nonindex/SparkHoodieNonIndex.java | 73 ++
.../hudi/io/storage/row/HoodieRowCreateHandle.java | 5 +-
.../org/apache/hudi/keygen/EmptyKeyGenerator.java | 80 +++
.../commit/BaseSparkCommitActionExecutor.java | 17 ++
.../table/action/commit/UpsertPartitioner.java | 35 ++-
.../org/apache/hudi/common/model/FileSlice.java| 13 +
.../org/apache/hudi/common/model/HoodieKey.java| 2 +
.../table/log/HoodieMergedLogRecordScanner.java| 3 +-
.../apache/hudi/configuration/OptionsResolver.java | 4 +
.../org/apache/hudi/sink/StreamWriteFunction.java | 32 ++-
.../hudi/sink/StreamWriteOperatorCoordinator.java | 5 +
.../sink/nonindex/NonIndexStreamWriteFunction.java | 265 +
.../sink/nonindex/NonIndexStreamWriteOperator.java | 25 +-
.../java/org/apache/hudi/sink/utils/Pipelines.java | 7 +
.../org/apache/hudi/table/HoodieTableFactory.java | 12 +
.../org/apache/hudi/sink/TestWriteMergeOnRead.java | 54 +
.../hudi/sink/utils/InsertFunctionWrapper.java | 6 +
.../sink/utils/StreamWriteFunctionWrapper.java | 23 +-
.../hudi/sink/utils/TestFunctionWrapper.java | 6 +
.../org/apache/hudi/sink/utils/TestWriteBase.java | 48
.../test/java/org/apache/hudi/utils/TestData.java | 34 +++
.../test/scala/org/apache/hudi/TestNonIndex.scala | 110 +
32 files changed, 1030 insertions(+), 30 deletions(-)
diff --git
a/hudi-client/hudi-client-common/src/main/java/org/apache/hudi/config/HoodieIndexConfig.java
b/hudi-client/hudi-client-common/src/main/java/org/apache/hudi/config/HoodieIndexConfig.java
index ee5b83a43a..b5edaf4abc 100644
---
a/hudi-client/hudi-client-common/src/main/java/org/apache/hudi/config/HoodieIndexConfig.java
+++
b/hudi-client/hudi-client-common/src/main/java/org/apache/hudi/config/HoodieIndexConfig.java
@@ -270,6 +270,34 @@ public class HoodieIndexConfig extends HoodieConfig {
.withDocumentation("Index key. It is used to index the record and find
its file group. "
+ "If not set, use record key field as default");
+ /**
+ * public static final String
NON_INDEX_PARTITION_FILE_GROUP_CACHE_INTERVAL_MINUTE =
"hoodie.non.index.partition.file.group.cache.interval.minute"; //minutes
+ * public static final String
DEFAULT_NON_INDEX_PARTITION_FILE_GROUP_CACHE_INTERVAL_MINUTE = "1800";
+ *
+ * public static final String NON_INDEX_PARTITION_FILE_GROUP_STORAGE_TYPE
= "hoodie.non.index.partition.file.group.storage.type";
+ * public static final String
DEFAULT_NON_INDEX_PARTITION_FILE_GROUP_CACHE_STORAGE_TYPE = "IN_MEMORY";
+ *
+ * public static final String NON_INDEX_PARTITION_FILE_GROUP_CACHE_SIZE =
"hoodie.non.index.partition.file.group.cache.size"; //byte
+ * public static final String
DEFAULT_NON_INDEX_PARTITION_FILE_GROUP_CACHE_SIZE = String.valueOf(1048576000);
+ */
+ public static final ConfigProperty
NON_INDEX_PARTITION_FILE_GROUP_CACHE_INTERVAL_MINUTE = ConfigProperty
+ .key("hoodie.non.index.partition.file.group.cache.interval.minute")
+ .defaultValue(1800)
+ .withDocumentation("Only applies if index type is BUCKET. Determine the
number of buckets in the hudi table, "
+ + "and each partition is divided to N buckets.");
+
+ public static final ConfigProperty
NON_INDEX_PARTITION_FILE_GROUP_STORAGE_TYPE = ConfigProperty
+ .key("hoodie.non.index.partition.file.group.storage.type")
+ .defaultValue("IN_MEMORY")
+ .withDocumentation("Only applies if index type is BUCKET. Determine the
number of buckets in the hudi table, "
+ + "and each partition is divided to N buckets.");
+
+ public static final ConfigProperty
NON_INDEX_PARTITION_FILE_GROUP_CACHE_SIZE = ConfigProperty
+ .key("hoodie.non.index.partition.file.group.cache.size")
+ .defaultValue(1024 * 1024 * 1024L)
+ .withDocumentation("Only applies if index type is BUCKET. Determine the
number of buckets in the hudi table, "
+ + "and each partition is
[hudi] 22/45: [HUDI-4898] presto/hive respect payload during merge parquet file and logfile when reading mor table (#6741)
This is an automated email from the ASF dual-hosted git repository.
forwardxu pushed a commit to branch release-0.12.1
in repository https://gitbox.apache.org/repos/asf/hudi.git
commit 738e2cce8f437ed3a2f7fc474e4143bb42fbad22
Author: xiarixiaoyao
AuthorDate: Thu Nov 3 23:11:39 2022 +0800
[HUDI-4898] presto/hive respect payload during merge parquet file and
logfile when reading mor table (#6741)
* [HUDI-4898] presto/hive respect payload during merge parquet file and
logfile when reading mor table
* Update HiveAvroSerializer.java otherwise payload string type combine
field will cause cast exception
(cherry picked from commit cd314b8cfa58c32f731f7da2aa6377a09df4c6f9)
---
.../realtime/AbstractRealtimeRecordReader.java | 72 +++-
.../realtime/HoodieHFileRealtimeInputFormat.java | 2 +-
.../realtime/HoodieParquetRealtimeInputFormat.java | 14 +-
.../realtime/RealtimeCompactedRecordReader.java| 25 +-
.../hudi/hadoop/utils/HiveAvroSerializer.java | 409 +
.../utils/HoodieRealtimeInputFormatUtils.java | 19 +-
.../utils/HoodieRealtimeRecordReaderUtils.java | 5 +
.../hudi/hadoop/utils/TestHiveAvroSerializer.java | 148
8 files changed, 678 insertions(+), 16 deletions(-)
diff --git
a/hudi-hadoop-mr/src/main/java/org/apache/hudi/hadoop/realtime/AbstractRealtimeRecordReader.java
b/hudi-hadoop-mr/src/main/java/org/apache/hudi/hadoop/realtime/AbstractRealtimeRecordReader.java
index dfdda9dfc8..83b69812e1 100644
---
a/hudi-hadoop-mr/src/main/java/org/apache/hudi/hadoop/realtime/AbstractRealtimeRecordReader.java
+++
b/hudi-hadoop-mr/src/main/java/org/apache/hudi/hadoop/realtime/AbstractRealtimeRecordReader.java
@@ -18,26 +18,34 @@
package org.apache.hudi.hadoop.realtime;
-import org.apache.hudi.common.model.HoodieAvroPayload;
-import org.apache.hudi.common.model.HoodiePayloadProps;
-import org.apache.hudi.common.table.HoodieTableMetaClient;
-import org.apache.hudi.exception.HoodieException;
-import org.apache.hudi.common.table.TableSchemaResolver;
-import org.apache.hudi.hadoop.utils.HoodieRealtimeRecordReaderUtils;
-
import org.apache.avro.Schema;
import org.apache.avro.Schema.Field;
import org.apache.hadoop.hive.metastore.api.hive_metastoreConstants;
+import org.apache.hadoop.hive.ql.io.parquet.serde.ArrayWritableObjectInspector;
+import org.apache.hadoop.hive.serde.serdeConstants;
import org.apache.hadoop.hive.serde2.ColumnProjectionUtils;
+import org.apache.hadoop.hive.serde2.typeinfo.StructTypeInfo;
+import org.apache.hadoop.hive.serde2.typeinfo.TypeInfo;
+import org.apache.hadoop.hive.serde2.typeinfo.TypeInfoFactory;
+import org.apache.hadoop.hive.serde2.typeinfo.TypeInfoUtils;
import org.apache.hadoop.mapred.JobConf;
+import org.apache.hudi.common.model.HoodieAvroPayload;
+import org.apache.hudi.common.model.HoodiePayloadProps;
+import org.apache.hudi.common.table.HoodieTableMetaClient;
+import org.apache.hudi.common.table.TableSchemaResolver;
+import org.apache.hudi.exception.HoodieException;
+import org.apache.hudi.hadoop.utils.HiveAvroSerializer;
+import org.apache.hudi.hadoop.utils.HoodieRealtimeRecordReaderUtils;
import org.apache.log4j.LogManager;
import org.apache.log4j.Logger;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
+import java.util.Locale;
import java.util.Map;
import java.util.Properties;
+import java.util.Set;
import java.util.stream.Collectors;
/**
@@ -55,6 +63,10 @@ public abstract class AbstractRealtimeRecordReader {
private Schema writerSchema;
private Schema hiveSchema;
private HoodieTableMetaClient metaClient;
+ // support merge operation
+ protected boolean supportPayload = true;
+ // handle hive type to avro record
+ protected HiveAvroSerializer serializer;
public AbstractRealtimeRecordReader(RealtimeSplit split, JobConf job) {
this.split = split;
@@ -62,6 +74,7 @@ public abstract class AbstractRealtimeRecordReader {
LOG.info("cfg ==> " +
job.get(ColumnProjectionUtils.READ_COLUMN_NAMES_CONF_STR));
LOG.info("columnIds ==> " +
job.get(ColumnProjectionUtils.READ_COLUMN_IDS_CONF_STR));
LOG.info("partitioningColumns ==> " +
job.get(hive_metastoreConstants.META_TABLE_PARTITION_COLUMNS, ""));
+this.supportPayload =
Boolean.parseBoolean(job.get("hoodie.support.payload", "true"));
try {
metaClient =
HoodieTableMetaClient.builder().setConf(jobConf).setBasePath(split.getBasePath()).build();
if (metaClient.getTableConfig().getPreCombineField() != null) {
@@ -73,6 +86,7 @@ public abstract class AbstractRealtimeRecordReader {
} catch (Exception e) {
throw new HoodieException("Could not create HoodieRealtimeRecordReader
on path " + this.split.getPath(), e);
}
+prepareHiveAvroSerializer();
}
private boolean usesCustomPayload(HoodieTableMetaClient metaClient) {
@@ -80,6 +94,34 @@ public abstract class AbstractRealtimeRecordReader {
||
[hudi] 20/45: remove hudi-kafka-connect module
This is an automated email from the ASF dual-hosted git repository. forwardxu pushed a commit to branch release-0.12.1 in repository https://gitbox.apache.org/repos/asf/hudi.git commit 5f6d6ae42d4a4be1396c4cc585c503b1c23e9deb Author: XuQianJin-Stars AuthorDate: Wed Nov 2 14:44:30 2022 +0800 remove hudi-kafka-connect module --- pom.xml | 4 ++-- 1 file changed, 2 insertions(+), 2 deletions(-) diff --git a/pom.xml b/pom.xml index 0adb64838b..01be2c1f89 100644 --- a/pom.xml +++ b/pom.xml @@ -58,9 +58,9 @@ packaging/hudi-trino-bundle hudi-examples hudi-flink-datasource -hudi-kafka-connect + packaging/hudi-flink-bundle -packaging/hudi-kafka-connect-bundle + hudi-tests-common
[hudi] 06/45: [MINOR] fix Invalid value for YearOfEra
This is an automated email from the ASF dual-hosted git repository.
forwardxu pushed a commit to branch release-0.12.1
in repository https://gitbox.apache.org/repos/asf/hudi.git
commit c1ceb628e576dd50f9c3bdf1ab830dcf61f70296
Author: XuQianJin-Stars
AuthorDate: Sun Oct 23 17:35:58 2022 +0800
[MINOR] fix Invalid value for YearOfEra
---
.../apache/hudi/client/BaseHoodieWriteClient.java | 28 ++
.../apache/hudi/client/SparkRDDWriteClient.java| 22 +
.../table/timeline/HoodieActiveTimeline.java | 18 ++
3 files changed, 58 insertions(+), 10 deletions(-)
diff --git
a/hudi-client/hudi-client-common/src/main/java/org/apache/hudi/client/BaseHoodieWriteClient.java
b/hudi-client/hudi-client-common/src/main/java/org/apache/hudi/client/BaseHoodieWriteClient.java
index d9f260e633..ff500a617e 100644
---
a/hudi-client/hudi-client-common/src/main/java/org/apache/hudi/client/BaseHoodieWriteClient.java
+++
b/hudi-client/hudi-client-common/src/main/java/org/apache/hudi/client/BaseHoodieWriteClient.java
@@ -104,6 +104,7 @@ import org.apache.log4j.Logger;
import java.io.IOException;
import java.nio.charset.StandardCharsets;
+import java.text.ParseException;
import java.util.Collection;
import java.util.Collections;
import java.util.HashMap;
@@ -115,6 +116,7 @@ import java.util.stream.Collectors;
import java.util.stream.Stream;
import static org.apache.hudi.common.model.HoodieCommitMetadata.SCHEMA_KEY;
+import static org.apache.hudi.common.model.TableServiceType.CLEAN;
/**
* Abstract Write Client providing functionality for performing commit, index
updates and rollback
@@ -306,14 +308,20 @@ public abstract class BaseHoodieWriteClient createTable(HoodieWriteConfig
config, Configuration hadoopConf);
void emitCommitMetrics(String instantTime, HoodieCommitMetadata metadata,
String actionType) {
-if (writeTimer != null) {
- long durationInMs = metrics.getDurationInMs(writeTimer.stop());
- // instantTime could be a non-standard value, so use
`parseDateFromInstantTimeSafely`
- // e.g. INIT_INSTANT_TS, METADATA_BOOTSTRAP_INSTANT_TS and
FULL_BOOTSTRAP_INSTANT_TS in HoodieTimeline
-
HoodieActiveTimeline.parseDateFromInstantTimeSafely(instantTime).ifPresent(parsedInstant
->
- metrics.updateCommitMetrics(parsedInstant.getTime(), durationInMs,
metadata, actionType)
- );
- writeTimer = null;
+try {
+ if (writeTimer != null) {
+long durationInMs = metrics.getDurationInMs(writeTimer.stop());
+long commitEpochTimeInMs = 0;
+if (HoodieActiveTimeline.checkDateTime(instantTime)) {
+ commitEpochTimeInMs =
HoodieActiveTimeline.parseDateFromInstantTime(instantTime).getTime();
+}
+metrics.updateCommitMetrics(commitEpochTimeInMs, durationInMs,
+metadata, actionType);
+writeTimer = null;
+ }
+} catch (ParseException e) {
+ throw new HoodieCommitException("Failed to complete commit " +
config.getBasePath() + " at time " + instantTime
+ + "Instant time is not of valid format", e);
}
}
@@ -862,7 +870,7 @@ public abstract class BaseHoodieWriteClient> extraMetadata) throws HoodieIOException {
-return scheduleTableService(instantTime, extraMetadata,
TableServiceType.CLEAN).isPresent();
+return scheduleTableService(instantTime, extraMetadata, CLEAN).isPresent();
}
/**
diff --git
a/hudi-client/hudi-spark-client/src/main/java/org/apache/hudi/client/SparkRDDWriteClient.java
b/hudi-client/hudi-spark-client/src/main/java/org/apache/hudi/client/SparkRDDWriteClient.java
index 7110e26bb0..32c4a0a06d 100644
---
a/hudi-client/hudi-spark-client/src/main/java/org/apache/hudi/client/SparkRDDWriteClient.java
+++
b/hudi-client/hudi-spark-client/src/main/java/org/apache/hudi/client/SparkRDDWriteClient.java
@@ -45,6 +45,7 @@ import org.apache.hudi.common.util.collection.Pair;
import org.apache.hudi.config.HoodieWriteConfig;
import org.apache.hudi.data.HoodieJavaRDD;
import org.apache.hudi.exception.HoodieClusteringException;
+import org.apache.hudi.exception.HoodieCommitException;
import org.apache.hudi.exception.HoodieWriteConflictException;
import org.apache.hudi.index.HoodieIndex;
import org.apache.hudi.index.SparkHoodieIndexFactory;
@@ -68,6 +69,7 @@ import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import java.nio.charset.StandardCharsets;
+import java.text.ParseException;
import java.util.List;
import java.util.Map;
import java.util.stream.Collectors;
@@ -324,6 +326,16 @@ public class SparkRDDWriteClient extends
HoodieActiveTimeline.parseDateFromInstantTimeSafely(compactionCommitTime).ifPresent(parsedInstant
->
metrics.updateCommitMetrics(parsedInstant.getTime(), durationInMs,
metadata, HoodieActiveTimeline.COMPACTION_ACTION)
);
+ try {
+long commitEpochTimeInMs = 0;
+if
[hudi] 28/45: [HUDI-5095] Flink: Stores a special watermark(flag) to identify the current progress of writing data
This is an automated email from the ASF dual-hosted git repository.
forwardxu pushed a commit to branch release-0.12.1
in repository https://gitbox.apache.org/repos/asf/hudi.git
commit 005e913403824fc6d5494bbefe8a370712656782
Author: XuQianJin-Stars
AuthorDate: Thu Nov 24 13:17:21 2022 +0800
[HUDI-5095] Flink: Stores a special watermark(flag) to identify the current
progress of writing data
---
.../hudi/sink/StreamWriteOperatorCoordinator.java | 21 ++---
1 file changed, 10 insertions(+), 11 deletions(-)
diff --git
a/hudi-flink-datasource/hudi-flink/src/main/java/org/apache/hudi/sink/StreamWriteOperatorCoordinator.java
b/hudi-flink-datasource/hudi-flink/src/main/java/org/apache/hudi/sink/StreamWriteOperatorCoordinator.java
index 578bb10db5..4a3674ec29 100644
---
a/hudi-flink-datasource/hudi-flink/src/main/java/org/apache/hudi/sink/StreamWriteOperatorCoordinator.java
+++
b/hudi-flink-datasource/hudi-flink/src/main/java/org/apache/hudi/sink/StreamWriteOperatorCoordinator.java
@@ -511,28 +511,27 @@ public class StreamWriteOperatorCoordinator
}
setMinEventTime();
doCommit(instant, writeResults);
-resetMinEventTime();
return true;
}
public void setMinEventTime() {
if (commitEventTimeEnable) {
- LOG.info("[setMinEventTime] receive event time for current commit: {} ",
Arrays.stream(eventBuffer).map(WriteMetadataEvent::getMaxEventTime).map(String::valueOf)
- .collect(Collectors.joining(", ")));
- this.minEventTime = Arrays.stream(eventBuffer)
+ List eventTimes = Arrays.stream(eventBuffer)
.filter(Objects::nonNull)
- .filter(maxEventTime -> maxEventTime.getMaxEventTime() > 0)
.map(WriteMetadataEvent::getMaxEventTime)
- .min(Comparator.naturalOrder())
- .map(aLong -> Math.min(aLong,
this.minEventTime)).orElse(Long.MAX_VALUE);
+ .filter(maxEventTime -> maxEventTime > 0)
+ .collect(Collectors.toList());
+
+ if (!eventTimes.isEmpty()) {
+LOG.info("[setMinEventTime] receive event time for current commit: {}
",
+
eventTimes.stream().map(String::valueOf).collect(Collectors.joining(", ")));
+this.minEventTime = eventTimes.stream().min(Comparator.naturalOrder())
+.map(aLong -> Math.min(aLong,
this.minEventTime)).orElse(Long.MAX_VALUE);
+ }
LOG.info("[setMinEventTime] minEventTime: {} ", this.minEventTime);
}
}
- public void resetMinEventTime() {
-this.minEventTime = Long.MAX_VALUE;
- }
-
/**
* Performs the actual commit action.
*/
[hudi] 42/45: improve checkstyle
This is an automated email from the ASF dual-hosted git repository.
forwardxu pushed a commit to branch release-0.12.1
in repository https://gitbox.apache.org/repos/asf/hudi.git
commit 79abc24265debcd0ce4a57adbd1ca33e8591d1a4
Author: XuQianJin-Stars
AuthorDate: Thu Dec 15 16:45:05 2022 +0800
improve checkstyle
---
dev/tencent-install.sh | 5 +++--
dev/tencent-release.sh | 1 +
pom.xml| 10 ++
3 files changed, 14 insertions(+), 2 deletions(-)
diff --git a/dev/tencent-install.sh b/dev/tencent-install.sh
index 1e34f40440..173ca06671 100644
--- a/dev/tencent-install.sh
+++ b/dev/tencent-install.sh
@@ -40,6 +40,7 @@ echo "Preparing source for $tagrc"
# change version
echo "Change version for ${version}"
mvn versions:set -DnewVersion=${version} -DgenerateBackupPom=false -s
dev/settings.xml -U
+mvn -N versions:update-child-modules
mvn versions:commit -s dev/settings.xml -U
function git_push() {
@@ -118,9 +119,9 @@ function deploy_spark() {
FLINK_VERSION=$3
if [ ${release_repo} = "Y" ]; then
-COMMON_OPTIONS="-Dscala-${SCALA_VERSION} -Dspark${SPARK_VERSION}
-Dflink${FLINK_VERSION} -DskipTests -s dev/settings.xml
-DretryFailedDeploymentCount=30 -T 2.5C"
+COMMON_OPTIONS="-Dscala-${SCALA_VERSION} -Dspark${SPARK_VERSION}
-Dflink${FLINK_VERSION} -DskipTests -Dcheckstyle.skip=true
-Dscalastyle.skip=true -s dev/settings.xml -DretryFailedDeploymentCount=30 -T
2.5C"
else
-COMMON_OPTIONS="-Dscala-${SCALA_VERSION} -Dspark${SPARK_VERSION}
-Dflink${FLINK_VERSION} -DskipTests -s dev/settings.xml
-DretryFailedDeploymentCount=30 -T 2.5C"
+COMMON_OPTIONS="-Dscala-${SCALA_VERSION} -Dspark${SPARK_VERSION}
-Dflink${FLINK_VERSION} -DskipTests -Dcheckstyle.skip=true
-Dscalastyle.skip=true -s dev/settings.xml -DretryFailedDeploymentCount=30 -T
2.5C"
fi
# INSTALL_OPTIONS="-U -Drat.skip=true -Djacoco.skip=true
-Dscala-${SCALA_VERSION} -Dspark${SPARK_VERSION} -DskipTests -s
dev/settings.xml -T 2.5C"
diff --git a/dev/tencent-release.sh b/dev/tencent-release.sh
index b788d62dc7..54631f5c0f 100644
--- a/dev/tencent-release.sh
+++ b/dev/tencent-release.sh
@@ -40,6 +40,7 @@ echo "Preparing source for $tagrc"
# change version
echo "Change version for ${version}"
mvn versions:set -DnewVersion=${version} -DgenerateBackupPom=false -s
dev/settings.xml -U
+mvn -N versions:update-child-modules
mvn versions:commit -s dev/settings.xml -U
# create version.txt for this release
diff --git a/pom.xml b/pom.xml
index 01be2c1f89..230b338df6 100644
--- a/pom.xml
+++ b/pom.xml
@@ -583,6 +583,16 @@
+
+
+
+ org.codehaus.mojo
+ versions-maven-plugin
+ 2.7
+
+false
+
+
[hudi] 07/45: add 'backup_invalid_parquet' procedure
This is an automated email from the ASF dual-hosted git repository.
forwardxu pushed a commit to branch release-0.12.1
in repository https://gitbox.apache.org/repos/asf/hudi.git
commit 1d029e668bde07f764d3781d51b6c18c6fc025e1
Author: jiimmyzhan
AuthorDate: Wed Aug 24 22:27:11 2022 +0800
add 'backup_invalid_parquet' procedure
---
.../procedures/BackupInvalidParquetProcedure.scala | 89 ++
.../hudi/command/procedures/HoodieProcedures.scala | 1 +
.../TestBackupInvalidParquetProcedure.scala| 83
3 files changed, 173 insertions(+)
diff --git
a/hudi-spark-datasource/hudi-spark/src/main/scala/org/apache/spark/sql/hudi/command/procedures/BackupInvalidParquetProcedure.scala
b/hudi-spark-datasource/hudi-spark/src/main/scala/org/apache/spark/sql/hudi/command/procedures/BackupInvalidParquetProcedure.scala
new file mode 100644
index 00..fbbb1247fa
--- /dev/null
+++
b/hudi-spark-datasource/hudi-spark/src/main/scala/org/apache/spark/sql/hudi/command/procedures/BackupInvalidParquetProcedure.scala
@@ -0,0 +1,89 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.hudi.command.procedures
+
+import org.apache.hadoop.fs.Path
+import org.apache.hudi.client.common.HoodieSparkEngineContext
+import org.apache.hudi.common.config.SerializableConfiguration
+import org.apache.hudi.common.fs.FSUtils
+import
org.apache.parquet.format.converter.ParquetMetadataConverter.SKIP_ROW_GROUPS
+import org.apache.parquet.hadoop.ParquetFileReader
+import org.apache.spark.api.java.JavaRDD
+import org.apache.spark.sql.Row
+import org.apache.spark.sql.types.{DataTypes, Metadata, StructField,
StructType}
+
+import java.util.function.Supplier
+
+class BackupInvalidParquetProcedure extends BaseProcedure with
ProcedureBuilder {
+ private val PARAMETERS = Array[ProcedureParameter](
+ProcedureParameter.required(0, "path", DataTypes.StringType, None)
+ )
+
+ private val OUTPUT_TYPE = new StructType(Array[StructField](
+StructField("backup_path", DataTypes.StringType, nullable = true,
Metadata.empty),
+StructField("invalid_parquet_size", DataTypes.LongType, nullable = true,
Metadata.empty))
+ )
+
+ def parameters: Array[ProcedureParameter] = PARAMETERS
+
+ def outputType: StructType = OUTPUT_TYPE
+
+ override def call(args: ProcedureArgs): Seq[Row] = {
+super.checkArgs(PARAMETERS, args)
+
+val srcPath = getArgValueOrDefault(args,
PARAMETERS(0)).get.asInstanceOf[String]
+val backupPath = new Path(srcPath, ".backup").toString
+val fs = FSUtils.getFs(backupPath, jsc.hadoopConfiguration())
+fs.mkdirs(new Path(backupPath))
+
+val partitionPaths: java.util.List[String] =
FSUtils.getAllPartitionPaths(new HoodieSparkEngineContext(jsc), srcPath, false,
false)
+val javaRdd: JavaRDD[String] = jsc.parallelize(partitionPaths,
partitionPaths.size())
+val serHadoopConf = new
SerializableConfiguration(jsc.hadoopConfiguration())
+val invalidParquetCount = javaRdd.rdd.map(part => {
+ val fs = FSUtils.getFs(new Path(srcPath), serHadoopConf.get())
+ FSUtils.getAllDataFilesInPartition(fs, FSUtils.getPartitionPath(srcPath,
part))
+}).flatMap(_.toList)
+ .filter(status => {
+val filePath = status.getPath
+var isInvalid = false
+if (filePath.toString.endsWith(".parquet")) {
+ try ParquetFileReader.readFooter(serHadoopConf.get(), filePath,
SKIP_ROW_GROUPS).getFileMetaData catch {
+case e: Exception =>
+ isInvalid = e.getMessage.contains("is not a Parquet file")
+ filePath.getFileSystem(serHadoopConf.get()).rename(filePath, new
Path(backupPath, filePath.getName))
+ }
+}
+isInvalid
+ })
+ .count()
+Seq(Row(backupPath, invalidParquetCount))
+ }
+
+ override def build = new BackupInvalidParquetProcedure()
+}
+
+object BackupInvalidParquetProcedure {
+ val NAME = "backup_invalid_parquet"
+
+ def builder: Supplier[ProcedureBuilder] = new Supplier[ProcedureBuilder] {
+override def get(): ProcedureBuilder = new BackupInvalidParquetProcedure()
+ }
+}
+
+
+
diff --git
[hudi] 25/45: [HUDI-5095] Flink: Stores a special watermark(flag) to identify the current progress of writing data
This is an automated email from the ASF dual-hosted git repository.
forwardxu pushed a commit to branch release-0.12.1
in repository https://gitbox.apache.org/repos/asf/hudi.git
commit 9fbf3b920d24e3e9f517beca10a2f4d892ae2d06
Author: jerryyue
AuthorDate: Fri Oct 28 19:16:46 2022 +0800
[HUDI-5095] Flink: Stores a special watermark(flag) to identify the current
progress of writing data
---
.../java/org/apache/hudi/avro/HoodieAvroUtils.java | 28 +++
.../hudi/common/table/timeline/TimelineUtils.java | 2 +-
.../org/apache/hudi/common/util/DateTimeUtils.java | 8 +
.../apache/hudi/configuration/FlinkOptions.java| 7 +
.../org/apache/hudi/sink/StreamWriteFunction.java | 6 +
.../hudi/sink/StreamWriteOperatorCoordinator.java | 30 +++
.../hudi/sink/append/AppendWriteFunction.java | 2 +-
.../hudi/sink/bulk/BulkInsertWriteFunction.java| 10 +-
.../sink/common/AbstractStreamWriteFunction.java | 11 +-
.../hudi/sink/common/AbstractWriteFunction.java| 103 +
.../hudi/sink/common/AbstractWriteOperator.java| 9 +
.../apache/hudi/sink/event/WriteMetadataEvent.java | 31 ++-
.../java/org/apache/hudi/util/DataTypeUtils.java | 141 +
.../apache/hudi/sink/ITTestDataStreamWrite.java| 35
.../sink/TestWriteFunctionEventTimeExtract.java| 232 +
.../sink/utils/StreamWriteFunctionWrapper.java | 5 +-
.../apache/hudi/sink/utils/TestDataTypeUtils.java | 45
.../hudi/utils/source/ContinuousFileSource.java| 5 +
18 files changed, 692 insertions(+), 18 deletions(-)
diff --git
a/hudi-common/src/main/java/org/apache/hudi/avro/HoodieAvroUtils.java
b/hudi-common/src/main/java/org/apache/hudi/avro/HoodieAvroUtils.java
index a352e86b96..735940eea4 100644
--- a/hudi-common/src/main/java/org/apache/hudi/avro/HoodieAvroUtils.java
+++ b/hudi-common/src/main/java/org/apache/hudi/avro/HoodieAvroUtils.java
@@ -75,6 +75,7 @@ import java.util.List;
import java.util.Map;
import java.util.Deque;
import java.util.LinkedList;
+import java.util.Objects;
import java.util.Set;
import java.util.TimeZone;
import java.util.stream.Collectors;
@@ -657,6 +658,33 @@ public class HoodieAvroUtils {
return fieldValue;
}
+ public static Long getNestedFieldValAsLong(GenericRecord record, String
fieldName,boolean consistentLogicalTimestampEnabled, Long defaultValue) {
+GenericRecord valueNode = record;
+Object fieldValue = valueNode.get(fieldName);
+Schema fieldSchema = valueNode.getSchema().getField(fieldName).schema();
+if (fieldSchema.getLogicalType() == LogicalTypes.date()) {
+ return
LocalDate.ofEpochDay(Long.parseLong(fieldValue.toString())).toEpochDay();
+} else if (fieldSchema.getLogicalType() == LogicalTypes.timestampMillis()
&& consistentLogicalTimestampEnabled) {
+ return new Timestamp(Long.parseLong(fieldValue.toString())).getTime();
+} else if (fieldSchema.getLogicalType() == LogicalTypes.timestampMicros()
&& consistentLogicalTimestampEnabled) {
+ return new Timestamp(Long.parseLong(fieldValue.toString()) /
1000).getTime();
+} else if (fieldSchema.getLogicalType() instanceof LogicalTypes.Decimal) {
+ Decimal dc = (Decimal) fieldSchema.getLogicalType();
+ DecimalConversion decimalConversion = new DecimalConversion();
+ if (fieldSchema.getType() == Schema.Type.FIXED) {
+return decimalConversion.fromFixed((GenericFixed) fieldValue,
fieldSchema,
+ LogicalTypes.decimal(dc.getPrecision(), dc.getScale())).longValue();
+ } else if (fieldSchema.getType() == Schema.Type.BYTES) {
+ByteBuffer byteBuffer = (ByteBuffer) fieldValue;
+BigDecimal convertedValue = decimalConversion.fromBytes(byteBuffer,
fieldSchema,
+LogicalTypes.decimal(dc.getPrecision(), dc.getScale()));
+byteBuffer.rewind();
+return convertedValue.longValue();
+ }
+}
+return Objects.isNull(fieldValue) ? defaultValue :
Long.parseLong(fieldValue.toString());
+ }
+
public static Schema getNullSchema() {
return Schema.create(Schema.Type.NULL);
}
diff --git
a/hudi-common/src/main/java/org/apache/hudi/common/table/timeline/TimelineUtils.java
b/hudi-common/src/main/java/org/apache/hudi/common/table/timeline/TimelineUtils.java
index 75493e7b46..1b8450eecc 100644
---
a/hudi-common/src/main/java/org/apache/hudi/common/table/timeline/TimelineUtils.java
+++
b/hudi-common/src/main/java/org/apache/hudi/common/table/timeline/TimelineUtils.java
@@ -173,7 +173,7 @@ public class TimelineUtils {
HoodieInstant::getTimestamp, instant -> getMetadataValue(metaClient,
extraMetadataKey, instant)));
}
- private static Option getMetadataValue(HoodieTableMetaClient
metaClient, String extraMetadataKey, HoodieInstant instant) {
+ public static Option getMetadataValue(HoodieTableMetaClient
metaClient, String extraMetadataKey, HoodieInstant instant) {
try {
LOG.info("reading checkpoint info for:"
[hudi] 40/45: [HUDI-5314] add call help procedure (#7361)
This is an automated email from the ASF dual-hosted git repository.
forwardxu pushed a commit to branch release-0.12.1
in repository https://gitbox.apache.org/repos/asf/hudi.git
commit 5488c951e41446a02df0f3d1060b3ac985f19370
Author: 苏承祥
AuthorDate: Wed Dec 7 20:03:30 2022 +0800
[HUDI-5314] add call help procedure (#7361)
* add call help procedure
Co-authored-by: 苏承祥
(cherry picked from commit 7dfe960415f8ead645a1fbdb711a14110c3265f2)
---
.../hudi/spark/sql/parser/HoodieSqlCommon.g4 | 6 +-
.../hudi/command/procedures/HelpProcedure.scala| 125 +
.../hudi/command/procedures/HoodieProcedures.scala | 5 +
.../sql/parser/HoodieSqlCommonAstBuilder.scala | 21 ++--
.../sql/hudi/procedure/TestCommitsProcedure.scala | 2 +-
.../sql/hudi/procedure/TestHelpProcedure.scala | 84 ++
6 files changed, 231 insertions(+), 12 deletions(-)
diff --git
a/hudi-spark-datasource/hudi-spark/src/main/antlr4/org/apache/hudi/spark/sql/parser/HoodieSqlCommon.g4
b/hudi-spark-datasource/hudi-spark/src/main/antlr4/org/apache/hudi/spark/sql/parser/HoodieSqlCommon.g4
index 8643170f89..8a3106f7a5 100644
---
a/hudi-spark-datasource/hudi-spark/src/main/antlr4/org/apache/hudi/spark/sql/parser/HoodieSqlCommon.g4
+++
b/hudi-spark-datasource/hudi-spark/src/main/antlr4/org/apache/hudi/spark/sql/parser/HoodieSqlCommon.g4
@@ -47,7 +47,7 @@
statement
: compactionStatement
#compactionCommand
-| CALL multipartIdentifier '(' (callArgument (',' callArgument)*)? ')'
#call
+| CALL multipartIdentifier callArgumentList?#call
| CREATE INDEX (IF NOT EXISTS)? identifier ON TABLE?
tableIdentifier (USING indexType=identifier)?
LEFT_PAREN columns=multipartIdentifierPropertyList RIGHT_PAREN
@@ -69,6 +69,10 @@
: (db=IDENTIFIER '.')? table=IDENTIFIER
;
+ callArgumentList
+: '(' (callArgument (',' callArgument)*)? ')'
+;
+
callArgument
: expression#positionalArgument
| identifier '=>' expression#namedArgument
diff --git
a/hudi-spark-datasource/hudi-spark/src/main/scala/org/apache/spark/sql/hudi/command/procedures/HelpProcedure.scala
b/hudi-spark-datasource/hudi-spark/src/main/scala/org/apache/spark/sql/hudi/command/procedures/HelpProcedure.scala
new file mode 100644
index 00..b17d068e81
--- /dev/null
+++
b/hudi-spark-datasource/hudi-spark/src/main/scala/org/apache/spark/sql/hudi/command/procedures/HelpProcedure.scala
@@ -0,0 +1,125 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.hudi.command.procedures
+
+import org.apache.hudi.exception.HoodieException
+import org.apache.spark.internal.Logging
+import org.apache.spark.sql.Row
+import org.apache.spark.sql.types.{DataTypes, Metadata, StructField,
StructType}
+
+import java.util.function.Supplier
+
+class HelpProcedure extends BaseProcedure with ProcedureBuilder with Logging {
+
+ private val PARAMETERS = Array[ProcedureParameter](
+ProcedureParameter.optional(0, "cmd", DataTypes.StringType, None)
+ )
+
+ private val OUTPUT_TYPE = new StructType(Array[StructField](
+StructField("result", DataTypes.StringType, nullable = true,
Metadata.empty)
+ ))
+
+
+ /**
+ * Returns the description of this procedure.
+ */
+ override def description: String = s"The procedure help command allows you
to view all the commands currently provided, as well as their parameters and
output fields."
+
+ def parameters: Array[ProcedureParameter] = PARAMETERS
+
+ def outputType: StructType = OUTPUT_TYPE
+
+ override def call(args: ProcedureArgs): Seq[Row] = {
+super.checkArgs(PARAMETERS, args)
+val line = "\n"
+val tab = "\t"
+if (args.map.isEmpty) {
+ val procedures: Map[String, Supplier[ProcedureBuilder]] =
HoodieProcedures.procedures()
+ val result = new StringBuilder
+ result.append("synopsis").append(line)
+.append(tab).append("call
[command]([key1]=>[value1],[key2]=>[value2])").append(line)
+ result.append("commands and description").append(line)
+ procedures.keySet.foreach(name => {
+val
[hudi] branch release-0.12.1 updated (a5978cd230 -> 78fe5c73a4)
This is an automated email from the ASF dual-hosted git repository. forwardxu pushed a change to branch release-0.12.1 in repository https://gitbox.apache.org/repos/asf/hudi.git from a5978cd230 [MINOR] Update release version to reflect published version 0.12.1 new ac0d1d81a4 [MINOR] Adapt to tianqiong spark new 23412b2bee [MINOR] Add Zhiyan metrics reporter new d785b41f01 fix cherry pick err new ab5b4fa780 fix the bug, log file will not roll over to a new file new 553bb9eab4 [HUDI-4475] fix create table with not exists hoodie properties file new c1ceb628e5 [MINOR] fix Invalid value for YearOfEra new 1d029e668b add 'backup_invalid_parquet' procedure new 6dbe53e623 fix zhiyan reporter for metadata new f80900d91c [MINOR] Adapt to tianqiong spark new 9c94e388fe adapt tspark changes: backport 3.3 VectorizedParquetReader related code to 3.1 new e45564102b fix file not exists for getFileSize new 895f260983 opt procedure backup_invalid_parquet new 4e66857849 fix RowDataProjection with project and projectAsValues's NPE new 8d692f38c1 [HUDI-5041] Fix lock metric register confict error (#6968) new ee07cc6a3b Remove proxy new 8ba01dc70a [HUDI-2624] Implement Non Index type for HUDI new 97ce2b7f7b temp_view_support (#6990) new 90c09053da [HUDI-5105] Add Call show_commit_extra_metadata for spark sql (#7091) new ecd39e3ad7 add log to print scanInternal's logFilePath new 5f6d6ae42d remove hudi-kafka-connect module new 3c364bdf72 [MINOR] add integrity check of merged parquet file for HoodieMergeHandle. new 738e2cce8f [HUDI-4898] presto/hive respect payload during merge parquet file and logfile when reading mor table (#6741) new 7d6654c1d0 [HUDI-5178] Add Call show_table_properties for spark sql (#7161) new e95a9f56ae [HUDI-4526] Improve spillableMapBasePath when disk directory is full (#6284) new 9fbf3b920d [HUDI-5095] Flink: Stores a special watermark(flag) to identify the current progress of writing data new f02fef936b fix none index partition format new 005e913403 [HUDI-5095] Flink: Stores a special watermark(flag) to identify the current progress of writing data new 619b7504ca Reduce the scope and duration of holding checkpoint lock in stream read new f7fe437faf Fix tauth issue (merge request !102) new 00c3443cb4 optimize schema settings new ab5deef087 Merge branch 'optimize_schema_settings' into 'release-0.12.1' (merge request !108) new c070e0963a [HUDI-5095] Flink: Stores a special watermark(flag) to identify the current progress of writing data new b1f204fa55 Merge branch 'release-0.12.1' of https://git.woa.com/data-lake-technology/hudi into release-0.12.1 new f2256ec94c exclude hudi-kafka-connect & add some api to support FLIP-27 source new 0cf7d3dac8 fix database default error new bddf061a79 [HUDI-5223] Partial failover for flink (#7208) new adc8aa6ebd remove ZhiyanReporter's report print new 0d71705ec2 [MINOR] add integrity check of parquet file for HoodieRowDataParquetWriter. new e0faa0bbe1 [HUDI-5350] Fix oom cause compaction event lost problem (#7408) new 5488c951e4 [HUDI-5314] add call help procedure (#7361) new 4fe2aec44a fix read log not exist new 79abc24265 improve checkstyle new d0b3b36e96 check parquet file does not exist new 4f005ea5d4 improve DropHoodieTableCommand new 78fe5c73a4 [HUDI-3572] support DAY_ROLLING strategy in ClusteringPlanPartitionFilterMode (#4966) The 45 revisions listed above as "new" are entirely new to this repository and will be described in separate emails. The revisions listed as "add" were already present in the repository and have only been added to this reference. Summary of changes: dev/settings.xml | 247 + dev/tencent-install.sh | 158 dev/tencent-release.sh | 155 hudi-cli/pom.xml | 4 +- hudi-client/hudi-client-common/pom.xml | 7 + .../apache/hudi/async/AsyncPostEventService.java | 93 + .../apache/hudi/client/BaseHoodieWriteClient.java | 28 +- .../lock/metrics/HoodieLockMetrics.java| 19 +- .../org/apache/hudi/config/HoodieIndexConfig.java | 43 +++ .../org/apache/hudi/config/HoodieMemoryConfig.java | 9 +- .../org/apache/hudi/config/HoodieWriteConfig.java | 108 +- .../hudi/config/metrics/HoodieMetricsConfig.java | 23 +- .../config/metrics/HoodieMetricsZhiyanConfig.java | 143 +++ .../java/org/apache/hudi/index/HoodieIndex.java| 2 +- .../java/org/apache/hudi/io/HoodieMergeHandle.java | 23 +- .../src/main/java/org/apache/hudi/io/IOUtils.java | 14 + .../apache/hudi/keygen/EmptyAvroKeyGenerator.java | 70 .../keygen/TimestampBasedAvroKeyGenerator.java | 4 +-
[hudi] 33/45: Merge branch 'release-0.12.1' of https://git.woa.com/data-lake-technology/hudi into release-0.12.1
This is an automated email from the ASF dual-hosted git repository. forwardxu pushed a commit to branch release-0.12.1 in repository https://gitbox.apache.org/repos/asf/hudi.git commit b1f204fa5510bd02c758bb6403107232243150a9 Merge: 619b7504ca c070e0963a Author: XuQianJin-Stars AuthorDate: Wed Dec 7 13:16:44 2022 +0800 Merge branch 'release-0.12.1' of https://git.woa.com/data-lake-technology/hudi into release-0.12.1 .../src/main/java/org/apache/hudi/common/fs/FSUtils.java | 2 ++ .../hudi/metadata/FileSystemBackedTableMetadata.java | 2 ++ .../apache/hudi/sink/StreamWriteOperatorCoordinator.java | 5 + .../src/main/java/org/apache/hudi/util/HoodiePipeline.java | 14 ++ 4 files changed, 23 insertions(+)
[hudi] 30/45: Merge branch 'optimize_schema_settings' into 'release-0.12.1' (merge request !108)
This is an automated email from the ASF dual-hosted git repository. forwardxu pushed a commit to branch release-0.12.1 in repository https://gitbox.apache.org/repos/asf/hudi.git commit ab5deef087a4c23bf10106c4f8a3ff5474e8ea73 Merge: f7fe437faf 00c3443cb4 Author: forwardxu AuthorDate: Thu Nov 24 08:31:35 2022 + Merge branch 'optimize_schema_settings' into 'release-0.12.1' (merge request !108) Add schema settings with stream api 优化`stream api`的使用,无需用户对每个`field`都进行`.column()`,现只需`.schema()`即可。 .../src/main/java/org/apache/hudi/util/HoodiePipeline.java | 14 ++ 1 file changed, 14 insertions(+)
[hudi] 45/45: [HUDI-3572] support DAY_ROLLING strategy in ClusteringPlanPartitionFilterMode (#4966)
This is an automated email from the ASF dual-hosted git repository.
forwardxu pushed a commit to branch release-0.12.1
in repository https://gitbox.apache.org/repos/asf/hudi.git
commit 78fe5c73a4acaf5c4b8ff69c3c95fbd7d4c2dbaf
Author: 苏承祥 <1142819...@qq.com>
AuthorDate: Tue Jan 3 15:31:01 2023 +0800
[HUDI-3572] support DAY_ROLLING strategy in
ClusteringPlanPartitionFilterMode (#4966)
(cherry picked from commit 41bea2fec54ae6c2376f5c88bd5a524b60b74a11)
---
.../cluster/ClusteringPlanPartitionFilter.java | 23 +
.../cluster/ClusteringPlanPartitionFilterMode.java | 3 ++-
.../TestSparkClusteringPlanPartitionFilter.java| 29 ++
3 files changed, 54 insertions(+), 1 deletion(-)
diff --git
a/hudi-client/hudi-client-common/src/main/java/org/apache/hudi/table/action/cluster/ClusteringPlanPartitionFilter.java
b/hudi-client/hudi-client-common/src/main/java/org/apache/hudi/table/action/cluster/ClusteringPlanPartitionFilter.java
index 3a889de753..ecc3706f67 100644
---
a/hudi-client/hudi-client-common/src/main/java/org/apache/hudi/table/action/cluster/ClusteringPlanPartitionFilter.java
+++
b/hudi-client/hudi-client-common/src/main/java/org/apache/hudi/table/action/cluster/ClusteringPlanPartitionFilter.java
@@ -21,6 +21,9 @@ package org.apache.hudi.table.action.cluster;
import org.apache.hudi.config.HoodieWriteConfig;
import org.apache.hudi.exception.HoodieClusteringException;
+import org.joda.time.DateTime;
+
+import java.util.ArrayList;
import java.util.Comparator;
import java.util.List;
import java.util.stream.Collectors;
@@ -31,6 +34,11 @@ import java.util.stream.Stream;
* NONE: skip filter
* RECENT DAYS: output recent partition given skip num and days lookback
config
* SELECTED_PARTITIONS: output partition falls in the [start, end] condition
+ * DAY_ROLLING: Clustering all partitions once a day to avoid clustering data
of all partitions each time.
+ * sort partitions asc, choose which partition index % 24 = now_hour.
+ * tips: If hoodie.clustering.inline=true, try to reach the limit of
hoodie.clustering.inline.max.commits every hour.
+ *If hoodie.clustering.async.enabled=true, try to reach the limit of
hoodie.clustering.async.max.commits every hour.
+ *
*/
public class ClusteringPlanPartitionFilter {
@@ -43,11 +51,26 @@ public class ClusteringPlanPartitionFilter {
return recentDaysFilter(partitions, config);
case SELECTED_PARTITIONS:
return selectedPartitionsFilter(partitions, config);
+ case DAY_ROLLING:
+return dayRollingFilter(partitions, config);
default:
throw new HoodieClusteringException("Unknown partition filter, filter
mode: " + mode);
}
}
+ private static List dayRollingFilter(List partitions,
HoodieWriteConfig config) {
+int hour = DateTime.now().getHourOfDay();
+int len = partitions.size();
+List selectPt = new ArrayList<>();
+partitions.sort(String::compareTo);
+for (int i = 0; i < len; i++) {
+ if (i % 24 == hour) {
+selectPt.add(partitions.get(i));
+ }
+}
+return selectPt;
+ }
+
private static List recentDaysFilter(List partitions,
HoodieWriteConfig config) {
int targetPartitionsForClustering =
config.getTargetPartitionsForClustering();
int skipPartitionsFromLatestForClustering =
config.getSkipPartitionsFromLatestForClustering();
diff --git
a/hudi-client/hudi-client-common/src/main/java/org/apache/hudi/table/action/cluster/ClusteringPlanPartitionFilterMode.java
b/hudi-client/hudi-client-common/src/main/java/org/apache/hudi/table/action/cluster/ClusteringPlanPartitionFilterMode.java
index fbaf79797f..261c1874cc 100644
---
a/hudi-client/hudi-client-common/src/main/java/org/apache/hudi/table/action/cluster/ClusteringPlanPartitionFilterMode.java
+++
b/hudi-client/hudi-client-common/src/main/java/org/apache/hudi/table/action/cluster/ClusteringPlanPartitionFilterMode.java
@@ -24,5 +24,6 @@ package org.apache.hudi.table.action.cluster;
public enum ClusteringPlanPartitionFilterMode {
NONE,
RECENT_DAYS,
- SELECTED_PARTITIONS
+ SELECTED_PARTITIONS,
+ DAY_ROLLING
}
diff --git
a/hudi-client/hudi-spark-client/src/test/java/org/apache/hudi/table/action/cluster/strategy/TestSparkClusteringPlanPartitionFilter.java
b/hudi-client/hudi-spark-client/src/test/java/org/apache/hudi/table/action/cluster/strategy/TestSparkClusteringPlanPartitionFilter.java
index a68a9e3360..70643a327d 100644
---
a/hudi-client/hudi-spark-client/src/test/java/org/apache/hudi/table/action/cluster/strategy/TestSparkClusteringPlanPartitionFilter.java
+++
b/hudi-client/hudi-spark-client/src/test/java/org/apache/hudi/table/action/cluster/strategy/TestSparkClusteringPlanPartitionFilter.java
@@ -26,6 +26,7 @@ import org.apache.hudi.config.HoodieWriteConfig;
import org.apache.hudi.table.HoodieSparkCopyOnWriteTable;
import org.apache.hudi.table.action.cluster.ClusteringPlanPartitionFilterMode;
[hudi] 34/45: exclude hudi-kafka-connect & add some api to support FLIP-27 source
This is an automated email from the ASF dual-hosted git repository.
forwardxu pushed a commit to branch release-0.12.1
in repository https://gitbox.apache.org/repos/asf/hudi.git
commit f2256ec94ccf7c6fc68b49ddd351f5b2aaa8fc35
Author: shaoxiong.zhan
AuthorDate: Tue Dec 6 20:15:49 2022 +0800
exclude hudi-kafka-connect & add some api to support FLIP-27 source
---
.../apache/hudi/configuration/FlinkOptions.java| 6
.../org/apache/hudi/table/HoodieTableSource.java | 42 +-
.../table/format/mor/MergeOnReadInputFormat.java | 29 +++
.../table/format/mor/MergeOnReadInputSplit.java| 8 -
4 files changed, 68 insertions(+), 17 deletions(-)
diff --git
a/hudi-flink-datasource/hudi-flink/src/main/java/org/apache/hudi/configuration/FlinkOptions.java
b/hudi-flink-datasource/hudi-flink/src/main/java/org/apache/hudi/configuration/FlinkOptions.java
index aa1e3297bd..df2c96c8a9 100644
---
a/hudi-flink-datasource/hudi-flink/src/main/java/org/apache/hudi/configuration/FlinkOptions.java
+++
b/hudi-flink-datasource/hudi-flink/src/main/java/org/apache/hudi/configuration/FlinkOptions.java
@@ -200,6 +200,12 @@ public class FlinkOptions extends HoodieConfig {
.noDefaultValue()
.withDescription("Parallelism of tasks that do actual read, default is
the parallelism of the execution environment");
+ public static final ConfigOption NUM_RECORDS_PER_BATCH =
ConfigOptions
+ .key("num.records_per.batch")
+ .intType()
+ .defaultValue(1)
+ .withDescription("num records per batch in single split");
+
public static final ConfigOption SOURCE_AVRO_SCHEMA_PATH =
ConfigOptions
.key("source.avro-schema.path")
.stringType()
diff --git
a/hudi-flink-datasource/hudi-flink/src/main/java/org/apache/hudi/table/HoodieTableSource.java
b/hudi-flink-datasource/hudi-flink/src/main/java/org/apache/hudi/table/HoodieTableSource.java
index 6fac5e4b88..ab270f89b0 100644
---
a/hudi-flink-datasource/hudi-flink/src/main/java/org/apache/hudi/table/HoodieTableSource.java
+++
b/hudi-flink-datasource/hudi-flink/src/main/java/org/apache/hudi/table/HoodieTableSource.java
@@ -115,8 +115,9 @@ public class HoodieTableSource implements
private final transient HoodieTableMetaClient metaClient;
private final long maxCompactionMemoryInBytes;
- private final ResolvedSchema schema;
private final RowType tableRowType;
+ private final String[] schemaFieldNames;
+ private final DataType[] schemaTypes;
private final Path path;
private final List partitionKeys;
private final String defaultPartName;
@@ -135,34 +136,43 @@ public class HoodieTableSource implements
List partitionKeys,
String defaultPartName,
Configuration conf) {
-this(schema, path, partitionKeys, defaultPartName, conf, null, null, null,
null);
+
+this(schema.getColumnNames().toArray(new String[0]),
+schema.getColumnDataTypes().toArray(new DataType[0]),
+(RowType) schema.toPhysicalRowDataType().notNull().getLogicalType(),
+path, partitionKeys, defaultPartName, conf, null, null, null, null,
null);
}
public HoodieTableSource(
- ResolvedSchema schema,
+ String[] schemaFieldNames,
+ DataType[] schemaTypes,
+ RowType rowType,
Path path,
List partitionKeys,
String defaultPartName,
Configuration conf,
+ @Nullable FileIndex fileIndex,
@Nullable List> requiredPartitions,
@Nullable int[] requiredPos,
@Nullable Long limit,
- @Nullable List filters) {
-this.schema = schema;
-this.tableRowType = (RowType)
schema.toPhysicalRowDataType().notNull().getLogicalType();
+ @Nullable HoodieTableMetaClient metaClient) {
+this.schemaFieldNames = schemaFieldNames;
+this.schemaTypes = schemaTypes;
+this.tableRowType = rowType;
this.path = path;
this.partitionKeys = partitionKeys;
this.defaultPartName = defaultPartName;
this.conf = conf;
+this.fileIndex = fileIndex == null
+? FileIndex.instance(this.path, this.conf, this.tableRowType)
+: fileIndex;
this.requiredPartitions = requiredPartitions;
this.requiredPos = requiredPos == null
? IntStream.range(0, this.tableRowType.getFieldCount()).toArray()
: requiredPos;
this.limit = limit == null ? NO_LIMIT_CONSTANT : limit;
-this.filters = filters == null ? Collections.emptyList() : filters;
this.hadoopConf = HadoopConfigurations.getHadoopConf(conf);
-this.metaClient = StreamerUtil.metaClientForReader(conf, hadoopConf);
-this.fileIndex = FileIndex.instance(this.path, this.conf,
this.tableRowType);
+this.metaClient = metaClient == null ?
StreamerUtil.metaClientForReader(conf, hadoopConf) : metaClient;
this.maxCompactionMemoryInBytes =
StreamerUtil.getMaxCompactionMemoryInBytes(conf);
}
@@ -210,8 +220,8 @@ public class HoodieTableSource implements
@Override
public
[hudi] 44/45: improve DropHoodieTableCommand
This is an automated email from the ASF dual-hosted git repository.
forwardxu pushed a commit to branch release-0.12.1
in repository https://gitbox.apache.org/repos/asf/hudi.git
commit 4f005ea5d4532c6434548e0858b336fe6a30dd42
Author: XuQianJin-Stars
AuthorDate: Fri Dec 30 17:28:47 2022 +0800
improve DropHoodieTableCommand
---
.../spark/sql/hudi/command/DropHoodieTableCommand.scala | 13 +++--
1 file changed, 7 insertions(+), 6 deletions(-)
diff --git
a/hudi-spark-datasource/hudi-spark-common/src/main/scala/org/apache/spark/sql/hudi/command/DropHoodieTableCommand.scala
b/hudi-spark-datasource/hudi-spark-common/src/main/scala/org/apache/spark/sql/hudi/command/DropHoodieTableCommand.scala
index a0252861db..f9cae4369d 100644
---
a/hudi-spark-datasource/hudi-spark-common/src/main/scala/org/apache/spark/sql/hudi/command/DropHoodieTableCommand.scala
+++
b/hudi-spark-datasource/hudi-spark-common/src/main/scala/org/apache/spark/sql/hudi/command/DropHoodieTableCommand.scala
@@ -70,16 +70,17 @@ case class DropHoodieTableCommand(
val basePath = hoodieCatalogTable.tableLocation
val catalog = sparkSession.sessionState.catalog
+val hoodieTableExists = hoodieCatalogTable.hoodieTableExists
+val tableType = hoodieCatalogTable.tableType
// Drop table in the catalog
-if (hoodieCatalogTable.hoodieTableExists &&
-HoodieTableType.MERGE_ON_READ == hoodieCatalogTable.tableType &&
purge) {
+if (hoodieTableExists && HoodieTableType.MERGE_ON_READ == tableType &&
purge) {
val (rtTableOpt, roTableOpt) = getTableRTAndRO(catalog,
hoodieCatalogTable)
- rtTableOpt.foreach(table => catalog.dropTable(table.identifier, true,
false))
- roTableOpt.foreach(table => catalog.dropTable(table.identifier, true,
false))
- catalog.dropTable(table.identifier.copy(table =
hoodieCatalogTable.tableName), ifExists, purge)
+ rtTableOpt.foreach(table => catalog.dropTable(table.identifier,
ignoreIfNotExists = true, purge = false))
+ roTableOpt.foreach(table => catalog.dropTable(table.identifier,
ignoreIfNotExists = true, purge = false))
+ catalog.dropTable(table.identifier.copy(table =
hoodieCatalogTable.tableName), ignoreIfNotExists = true, purge = purge)
} else {
- catalog.dropTable(table.identifier, ifExists, purge)
+ catalog.dropTable(table.identifier, ignoreIfNotExists = true, purge =
purge)
}
// Recursively delete table directories
[hudi] 39/45: [HUDI-5350] Fix oom cause compaction event lost problem (#7408)
This is an automated email from the ASF dual-hosted git repository.
forwardxu pushed a commit to branch release-0.12.1
in repository https://gitbox.apache.org/repos/asf/hudi.git
commit e0faa0bbe1021204281e5dccc51fb99610326987
Author: Bingeng Huang <304979...@qq.com>
AuthorDate: Fri Dec 9 15:24:29 2022 +0800
[HUDI-5350] Fix oom cause compaction event lost problem (#7408)
Co-authored-by: hbg
(cherry picked from commit 115584c46e30998e0369b0e5550cc60eac8295ab)
---
.../main/java/org/apache/hudi/sink/utils/NonThrownExecutor.java | 8
1 file changed, 4 insertions(+), 4 deletions(-)
diff --git
a/hudi-flink-datasource/hudi-flink/src/main/java/org/apache/hudi/sink/utils/NonThrownExecutor.java
b/hudi-flink-datasource/hudi-flink/src/main/java/org/apache/hudi/sink/utils/NonThrownExecutor.java
index 4364d1d16d..4ed1716545 100644
---
a/hudi-flink-datasource/hudi-flink/src/main/java/org/apache/hudi/sink/utils/NonThrownExecutor.java
+++
b/hudi-flink-datasource/hudi-flink/src/main/java/org/apache/hudi/sink/utils/NonThrownExecutor.java
@@ -136,15 +136,15 @@ public class NonThrownExecutor implements AutoCloseable {
}
private void handleException(Throwable t, ExceptionHook hook,
Supplier actionString) {
-// if we have a JVM critical error, promote it immediately, there is a good
-// chance the
-// logging or job failing will not succeed any more
-ExceptionUtils.rethrowIfFatalErrorOrOOM(t);
final String errMsg = String.format("Executor executes action [%s] error",
actionString.get());
logger.error(errMsg, t);
if (hook != null) {
hook.apply(errMsg, t);
}
+// if we have a JVM critical error, promote it immediately, there is a good
+// chance the
+// logging or job failing will not succeed any more
+ExceptionUtils.rethrowIfFatalErrorOrOOM(t);
}
private Supplier getActionString(String actionName, Object...
actionParams) {
[hudi] 29/45: Fix tauth issue (merge request !102)
This is an automated email from the ASF dual-hosted git repository.
forwardxu pushed a commit to branch release-0.12.1
in repository https://gitbox.apache.org/repos/asf/hudi.git
commit f7fe437faf8f0d7ec358076973aec49a0d9e29ff
Author: superche
AuthorDate: Wed Nov 23 16:43:27 2022 +0800
Fix tauth issue (merge request !102)
Squash merge branch 'fix_tauth_issue' into 'release-0.12.1'
原因:`UserGroupInformation`在`presto work`节点中的用户信息改变为默认的`root`,导致Tauth认证失败;
解决:在获取`fileSystem`之前,都进行`UserGroupInformation.setConfiguration(hadoopConf.get());`
---
hudi-common/src/main/java/org/apache/hudi/common/fs/FSUtils.java| 2 ++
.../java/org/apache/hudi/metadata/FileSystemBackedTableMetadata.java| 2 ++
2 files changed, 4 insertions(+)
diff --git a/hudi-common/src/main/java/org/apache/hudi/common/fs/FSUtils.java
b/hudi-common/src/main/java/org/apache/hudi/common/fs/FSUtils.java
index 1350108a11..15a729a812 100644
--- a/hudi-common/src/main/java/org/apache/hudi/common/fs/FSUtils.java
+++ b/hudi-common/src/main/java/org/apache/hudi/common/fs/FSUtils.java
@@ -18,6 +18,7 @@
package org.apache.hudi.common.fs;
+import org.apache.hadoop.security.UserGroupInformation;
import org.apache.hudi.common.config.HoodieMetadataConfig;
import org.apache.hudi.common.config.SerializableConfiguration;
import org.apache.hudi.common.engine.HoodieEngineContext;
@@ -107,6 +108,7 @@ public class FSUtils {
FileSystem fs;
prepareHadoopConf(conf);
try {
+ UserGroupInformation.setConfiguration(conf);
fs = path.getFileSystem(conf);
} catch (IOException e) {
throw new HoodieIOException("Failed to get instance of " +
FileSystem.class.getName(), e);
diff --git
a/hudi-common/src/main/java/org/apache/hudi/metadata/FileSystemBackedTableMetadata.java
b/hudi-common/src/main/java/org/apache/hudi/metadata/FileSystemBackedTableMetadata.java
index bcfd891711..db1eeaed7e 100644
---
a/hudi-common/src/main/java/org/apache/hudi/metadata/FileSystemBackedTableMetadata.java
+++
b/hudi-common/src/main/java/org/apache/hudi/metadata/FileSystemBackedTableMetadata.java
@@ -18,6 +18,7 @@
package org.apache.hudi.metadata;
+import org.apache.hadoop.security.UserGroupInformation;
import org.apache.hudi.avro.model.HoodieMetadataColumnStats;
import org.apache.hudi.common.bloom.BloomFilter;
import org.apache.hudi.common.config.SerializableConfiguration;
@@ -96,6 +97,7 @@ public class FileSystemBackedTableMetadata implements
HoodieTableMetadata {
// result below holds a list of pair. first entry in the pair
optionally holds the deduced list of partitions.
// and second entry holds optionally a directory path to be processed
further.
List, Option>> result =
engineContext.map(dirToFileListing, fileStatus -> {
+ UserGroupInformation.setConfiguration(hadoopConf.get());
FileSystem fileSystem =
fileStatus.getPath().getFileSystem(hadoopConf.get());
if (fileStatus.isDirectory()) {
if (HoodiePartitionMetadata.hasPartitionMetadata(fileSystem,
fileStatus.getPath())) {
[hudi] 38/45: [MINOR] add integrity check of parquet file for HoodieRowDataParquetWriter.
This is an automated email from the ASF dual-hosted git repository.
forwardxu pushed a commit to branch release-0.12.1
in repository https://gitbox.apache.org/repos/asf/hudi.git
commit 0d71705ec2276f6524ab97e765563f6c902f35d9
Author: XuQianJin-Stars
AuthorDate: Fri Dec 9 12:39:39 2022 +0800
[MINOR] add integrity check of parquet file for HoodieRowDataParquetWriter.
---
.../java/org/apache/hudi/io/HoodieMergeHandle.java | 22 ++
.../src/main/java/org/apache/hudi/io/IOUtils.java | 14 ++
.../io/storage/row/HoodieRowDataParquetWriter.java | 2 ++
3 files changed, 22 insertions(+), 16 deletions(-)
diff --git
a/hudi-client/hudi-client-common/src/main/java/org/apache/hudi/io/HoodieMergeHandle.java
b/hudi-client/hudi-client-common/src/main/java/org/apache/hudi/io/HoodieMergeHandle.java
index 88db25bac4..c569acdda6 100644
---
a/hudi-client/hudi-client-common/src/main/java/org/apache/hudi/io/HoodieMergeHandle.java
+++
b/hudi-client/hudi-client-common/src/main/java/org/apache/hudi/io/HoodieMergeHandle.java
@@ -18,6 +18,10 @@
package org.apache.hudi.io;
+import org.apache.avro.Schema;
+import org.apache.avro.generic.GenericRecord;
+import org.apache.avro.generic.IndexedRecord;
+import org.apache.hadoop.fs.Path;
import org.apache.hudi.client.WriteStatus;
import org.apache.hudi.common.engine.TaskContextSupplier;
import org.apache.hudi.common.fs.FSUtils;
@@ -34,7 +38,6 @@ import org.apache.hudi.common.model.IOType;
import org.apache.hudi.common.util.DefaultSizeEstimator;
import org.apache.hudi.common.util.HoodieRecordSizeEstimator;
import org.apache.hudi.common.util.Option;
-import org.apache.hudi.common.util.ParquetUtils;
import org.apache.hudi.common.util.ValidationUtils;
import org.apache.hudi.common.util.collection.ExternalSpillableMap;
import org.apache.hudi.config.HoodieWriteConfig;
@@ -47,27 +50,19 @@ import org.apache.hudi.io.storage.HoodieFileWriter;
import org.apache.hudi.keygen.BaseKeyGenerator;
import org.apache.hudi.keygen.KeyGenUtils;
import org.apache.hudi.table.HoodieTable;
-
-import org.apache.avro.Schema;
-import org.apache.avro.generic.GenericRecord;
-import org.apache.avro.generic.IndexedRecord;
-import org.apache.hadoop.fs.Path;
import org.apache.log4j.LogManager;
import org.apache.log4j.Logger;
import javax.annotation.concurrent.NotThreadSafe;
-
import java.io.IOException;
import java.util.Collections;
import java.util.HashSet;
import java.util.Iterator;
import java.util.List;
-import java.util.NoSuchElementException;
import java.util.Map;
+import java.util.NoSuchElementException;
import java.util.Set;
-import static org.apache.hudi.common.model.HoodieFileFormat.PARQUET;
-
@SuppressWarnings("Duplicates")
/**
* Handle to merge incoming records to those in storage.
@@ -450,12 +445,7 @@ public class HoodieMergeHandle extends H
return;
}
-// Fast verify the integrity of the parquet file.
-// only check the readable of parquet metadata.
-final String extension = FSUtils.getFileExtension(newFilePath.toString());
-if (PARQUET.getFileExtension().equals(extension)) {
- new ParquetUtils().readMetadata(hoodieTable.getHadoopConf(),
newFilePath);
-}
+IOUtils.checkParquetFileVaid(hoodieTable.getHadoopConf(), newFilePath);
long oldNumWrites = 0;
try {
diff --git
a/hudi-client/hudi-client-common/src/main/java/org/apache/hudi/io/IOUtils.java
b/hudi-client/hudi-client-common/src/main/java/org/apache/hudi/io/IOUtils.java
index 7636384c3a..b231136ece 100644
---
a/hudi-client/hudi-client-common/src/main/java/org/apache/hudi/io/IOUtils.java
+++
b/hudi-client/hudi-client-common/src/main/java/org/apache/hudi/io/IOUtils.java
@@ -18,11 +18,16 @@
package org.apache.hudi.io;
+import org.apache.hadoop.conf.Configuration;
+import org.apache.hadoop.fs.Path;
import org.apache.hudi.common.config.HoodieConfig;
import org.apache.hudi.common.engine.EngineProperty;
import org.apache.hudi.common.engine.TaskContextSupplier;
+import org.apache.hudi.common.fs.FSUtils;
import org.apache.hudi.common.util.Option;
+import org.apache.hudi.common.util.ParquetUtils;
+import static org.apache.hudi.common.model.HoodieFileFormat.PARQUET;
import static
org.apache.hudi.config.HoodieMemoryConfig.DEFAULT_MAX_MEMORY_FOR_SPILLABLE_MAP_IN_BYTES;
import static
org.apache.hudi.config.HoodieMemoryConfig.DEFAULT_MIN_MEMORY_FOR_SPILLABLE_MAP_IN_BYTES;
import static
org.apache.hudi.config.HoodieMemoryConfig.MAX_MEMORY_FOR_COMPACTION;
@@ -72,4 +77,13 @@ public class IOUtils {
String fraction =
hoodieConfig.getStringOrDefault(MAX_MEMORY_FRACTION_FOR_COMPACTION);
return getMaxMemoryAllowedForMerge(context, fraction);
}
+
+ public static void checkParquetFileVaid(Configuration hadoopConf, Path
filePath) {
+// Fast verify the integrity of the parquet file.
+// only check the readable of parquet metadata.
+final String extension = FSUtils.getFileExtension(filePath.toString());
+
[hudi] 31/45: [HUDI-5095] Flink: Stores a special watermark(flag) to identify the current progress of writing data
This is an automated email from the ASF dual-hosted git repository.
forwardxu pushed a commit to branch release-0.12.1
in repository https://gitbox.apache.org/repos/asf/hudi.git
commit c070e0963a08264ace559333baa5b96780ddc8df
Author: XuQianJin-Stars
AuthorDate: Tue Nov 29 23:33:22 2022 +0800
[HUDI-5095] Flink: Stores a special watermark(flag) to identify the current
progress of writing data
---
.../java/org/apache/hudi/sink/StreamWriteOperatorCoordinator.java| 5 +
1 file changed, 5 insertions(+)
diff --git
a/hudi-flink-datasource/hudi-flink/src/main/java/org/apache/hudi/sink/StreamWriteOperatorCoordinator.java
b/hudi-flink-datasource/hudi-flink/src/main/java/org/apache/hudi/sink/StreamWriteOperatorCoordinator.java
index 4a3674ec29..f4acc2e83a 100644
---
a/hudi-flink-datasource/hudi-flink/src/main/java/org/apache/hudi/sink/StreamWriteOperatorCoordinator.java
+++
b/hudi-flink-datasource/hudi-flink/src/main/java/org/apache/hudi/sink/StreamWriteOperatorCoordinator.java
@@ -511,6 +511,7 @@ public class StreamWriteOperatorCoordinator
}
setMinEventTime();
doCommit(instant, writeResults);
+resetMinEventTime();
return true;
}
@@ -532,6 +533,10 @@ public class StreamWriteOperatorCoordinator
}
}
+ public void resetMinEventTime() {
+this.minEventTime = Long.MAX_VALUE;
+ }
+
/**
* Performs the actual commit action.
*/
[hudi] 36/45: [HUDI-5223] Partial failover for flink (#7208)
This is an automated email from the ASF dual-hosted git repository.
forwardxu pushed a commit to branch release-0.12.1
in repository https://gitbox.apache.org/repos/asf/hudi.git
commit bddf061a794df35936eb532ba7d747e7aa3fbb47
Author: Danny Chan
AuthorDate: Wed Nov 16 14:47:38 2022 +0800
[HUDI-5223] Partial failover for flink (#7208)
Before the patch, when there are partial failover within the write tasks,
the write task current instant was initialized as the latest inflight instant,
the write task then waits for a new instant to write with so hangs and failover
continuously.
For a task recovered from failover (with attempt number greater than 0),
the latest inflight instant can actually be reused, the intermediate data files
can be cleaned with MARGER files post commit.
(cherry picked from commit d3f957755abf76c64ff06fac6d857cba9bdbbacf)
---
.../src/main/java/org/apache/hudi/io/FlinkMergeHandle.java | 8 +---
.../apache/hudi/sink/common/AbstractStreamWriteFunction.java | 12 ++--
2 files changed, 11 insertions(+), 9 deletions(-)
diff --git
a/hudi-client/hudi-flink-client/src/main/java/org/apache/hudi/io/FlinkMergeHandle.java
b/hudi-client/hudi-flink-client/src/main/java/org/apache/hudi/io/FlinkMergeHandle.java
index 69121a9a04..a44783f99e 100644
---
a/hudi-client/hudi-flink-client/src/main/java/org/apache/hudi/io/FlinkMergeHandle.java
+++
b/hudi-client/hudi-flink-client/src/main/java/org/apache/hudi/io/FlinkMergeHandle.java
@@ -143,13 +143,7 @@ public class FlinkMergeHandle
break;
}
-// Override the old file name,
-// In rare cases, when a checkpoint was aborted and the instant time
-// is reused, the merge handle generates a new file name
-// with the reused instant time of last checkpoint, which is duplicate,
-// use the same name file as new base file in case data loss.
-oldFilePath = newFilePath;
-rolloverPaths.add(oldFilePath);
+rolloverPaths.add(newFilePath);
newFileName = newFileNameWithRollover(rollNumber++);
newFilePath = makeNewFilePath(partitionPath, newFileName);
LOG.warn("Duplicate write for MERGE bucket with path: " + oldFilePath
+ ", rolls over to new path: " + newFilePath);
diff --git
a/hudi-flink-datasource/hudi-flink/src/main/java/org/apache/hudi/sink/common/AbstractStreamWriteFunction.java
b/hudi-flink-datasource/hudi-flink/src/main/java/org/apache/hudi/sink/common/AbstractStreamWriteFunction.java
index b4569894a2..7642e9f28f 100644
---
a/hudi-flink-datasource/hudi-flink/src/main/java/org/apache/hudi/sink/common/AbstractStreamWriteFunction.java
+++
b/hudi-flink-datasource/hudi-flink/src/main/java/org/apache/hudi/sink/common/AbstractStreamWriteFunction.java
@@ -188,10 +188,9 @@ public abstract class AbstractStreamWriteFunction
// -
private void restoreWriteMetadata() throws Exception {
-String lastInflight = lastPendingInstant();
boolean eventSent = false;
for (WriteMetadataEvent event : this.writeMetadataState.get()) {
- if (Objects.equals(lastInflight, event.getInstantTime())) {
+ if (Objects.equals(this.currentInstant, event.getInstantTime())) {
// Reset taskID for event
event.setTaskID(taskID);
// The checkpoint succeed but the meta does not commit,
@@ -207,6 +206,15 @@ public abstract class AbstractStreamWriteFunction
}
private void sendBootstrapEvent() {
+int attemptId = getRuntimeContext().getAttemptNumber();
+if (attemptId > 0) {
+ // either a partial or global failover, reuses the current inflight
instant
+ if (this.currentInstant != null) {
+LOG.info("Recover task[{}] for instant [{}] with attemptId [{}]",
taskID, this.currentInstant, attemptId);
+this.currentInstant = null;
+ }
+ return;
+}
this.eventGateway.sendEventToCoordinator(WriteMetadataEvent.emptyBootstrap(taskID));
LOG.info("Send bootstrap write metadata event to coordinator, task[{}].",
taskID);
}
[hudi] 43/45: check parquet file does not exist
This is an automated email from the ASF dual-hosted git repository.
forwardxu pushed a commit to branch release-0.12.1
in repository https://gitbox.apache.org/repos/asf/hudi.git
commit d0b3b36e96d326d9f683f1d557527e4e50d92e78
Author: XuQianJin-Stars
AuthorDate: Wed Dec 28 10:06:17 2022 +0800
check parquet file does not exist
---
.../src/main/java/org/apache/hudi/io/HoodieMergeHandle.java | 8 +++-
.../apache/hudi/io/storage/row/HoodieRowDataParquetWriter.java| 4 +++-
2 files changed, 10 insertions(+), 2 deletions(-)
diff --git
a/hudi-client/hudi-client-common/src/main/java/org/apache/hudi/io/HoodieMergeHandle.java
b/hudi-client/hudi-client-common/src/main/java/org/apache/hudi/io/HoodieMergeHandle.java
index c569acdda6..17bbb2f7f0 100644
---
a/hudi-client/hudi-client-common/src/main/java/org/apache/hudi/io/HoodieMergeHandle.java
+++
b/hudi-client/hudi-client-common/src/main/java/org/apache/hudi/io/HoodieMergeHandle.java
@@ -445,7 +445,13 @@ public class HoodieMergeHandle extends H
return;
}
-IOUtils.checkParquetFileVaid(hoodieTable.getHadoopConf(), newFilePath);
+try {
+ if (fs.exists(newFilePath)) {
+IOUtils.checkParquetFileVaid(hoodieTable.getHadoopConf(), newFilePath);
+ }
+} catch (IOException e) {
+ throw new HoodieUpsertException("Failed to check for merge data
validation", e);
+}
long oldNumWrites = 0;
try {
diff --git
a/hudi-client/hudi-flink-client/src/main/java/org/apache/hudi/io/storage/row/HoodieRowDataParquetWriter.java
b/hudi-client/hudi-flink-client/src/main/java/org/apache/hudi/io/storage/row/HoodieRowDataParquetWriter.java
index fd1edaab84..66a830887a 100644
---
a/hudi-client/hudi-flink-client/src/main/java/org/apache/hudi/io/storage/row/HoodieRowDataParquetWriter.java
+++
b/hudi-client/hudi-flink-client/src/main/java/org/apache/hudi/io/storage/row/HoodieRowDataParquetWriter.java
@@ -75,6 +75,8 @@ public class HoodieRowDataParquetWriter extends
ParquetWriter
@Override
public void close() throws IOException {
super.close();
-IOUtils.checkParquetFileVaid(fs.getConf(), file);
+if (fs.exists(file)) {
+ IOUtils.checkParquetFileVaid(fs.getConf(), file);
+}
}
}
[hudi] 37/45: remove ZhiyanReporter's report print
This is an automated email from the ASF dual-hosted git repository.
forwardxu pushed a commit to branch release-0.12.1
in repository https://gitbox.apache.org/repos/asf/hudi.git
commit adc8aa6ebd082788e55519cefc54669c1ad68546
Author: XuQianJin-Stars
AuthorDate: Thu Dec 8 21:30:54 2022 +0800
remove ZhiyanReporter's report print
---
.../src/main/java/org/apache/hudi/metrics/zhiyan/ZhiyanReporter.java | 1 -
1 file changed, 1 deletion(-)
diff --git
a/hudi-client/hudi-client-common/src/main/java/org/apache/hudi/metrics/zhiyan/ZhiyanReporter.java
b/hudi-client/hudi-client-common/src/main/java/org/apache/hudi/metrics/zhiyan/ZhiyanReporter.java
index 4e5d416989..d0bea0705a 100644
---
a/hudi-client/hudi-client-common/src/main/java/org/apache/hudi/metrics/zhiyan/ZhiyanReporter.java
+++
b/hudi-client/hudi-client-common/src/main/java/org/apache/hudi/metrics/zhiyan/ZhiyanReporter.java
@@ -81,7 +81,6 @@ public class ZhiyanReporter extends ScheduledReporter {
String payload = builder.build();
-LOG.info("Payload is:" + payload);
try {
client.post(payload);
} catch (Exception e) {
[hudi] 12/45: opt procedure backup_invalid_parquet
This is an automated email from the ASF dual-hosted git repository.
forwardxu pushed a commit to branch release-0.12.1
in repository https://gitbox.apache.org/repos/asf/hudi.git
commit 895f260983f3f6875c862b1d8e62c04aed09ff17
Author: shaoxiong.zhan
AuthorDate: Thu Sep 22 20:18:37 2022 +0800
opt procedure backup_invalid_parquet
(cherry picked from commit 422f1e53)
903daba5 opt procedure backup_invalid_parquet
---
.../procedures/BackupInvalidParquetProcedure.scala| 15 ---
1 file changed, 12 insertions(+), 3 deletions(-)
diff --git
a/hudi-spark-datasource/hudi-spark/src/main/scala/org/apache/spark/sql/hudi/command/procedures/BackupInvalidParquetProcedure.scala
b/hudi-spark-datasource/hudi-spark/src/main/scala/org/apache/spark/sql/hudi/command/procedures/BackupInvalidParquetProcedure.scala
index fbbb1247fa..5c1234b7a2 100644
---
a/hudi-spark-datasource/hudi-spark/src/main/scala/org/apache/spark/sql/hudi/command/procedures/BackupInvalidParquetProcedure.scala
+++
b/hudi-spark-datasource/hudi-spark/src/main/scala/org/apache/spark/sql/hudi/command/procedures/BackupInvalidParquetProcedure.scala
@@ -21,15 +21,18 @@ import org.apache.hadoop.fs.Path
import org.apache.hudi.client.common.HoodieSparkEngineContext
import org.apache.hudi.common.config.SerializableConfiguration
import org.apache.hudi.common.fs.FSUtils
+import org.apache.hudi.common.model.HoodieFileFormat
+import org.apache.hudi.common.util.BaseFileUtils
import
org.apache.parquet.format.converter.ParquetMetadataConverter.SKIP_ROW_GROUPS
import org.apache.parquet.hadoop.ParquetFileReader
import org.apache.spark.api.java.JavaRDD
+import org.apache.spark.internal.Logging
import org.apache.spark.sql.Row
import org.apache.spark.sql.types.{DataTypes, Metadata, StructField,
StructType}
import java.util.function.Supplier
-class BackupInvalidParquetProcedure extends BaseProcedure with
ProcedureBuilder {
+class BackupInvalidParquetProcedure extends BaseProcedure with
ProcedureBuilder with Logging {
private val PARAMETERS = Array[ProcedureParameter](
ProcedureParameter.required(0, "path", DataTypes.StringType, None)
)
@@ -62,9 +65,15 @@ class BackupInvalidParquetProcedure extends BaseProcedure
with ProcedureBuilder
val filePath = status.getPath
var isInvalid = false
if (filePath.toString.endsWith(".parquet")) {
- try ParquetFileReader.readFooter(serHadoopConf.get(), filePath,
SKIP_ROW_GROUPS).getFileMetaData catch {
+ try {
+// check footer
+ParquetFileReader.readFooter(serHadoopConf.get(), filePath,
SKIP_ROW_GROUPS).getFileMetaData
+
+// check row group
+
BaseFileUtils.getInstance(HoodieFileFormat.PARQUET).readAvroRecords(serHadoopConf.get(),
filePath)
+ } catch {
case e: Exception =>
- isInvalid = e.getMessage.contains("is not a Parquet file")
+ isInvalid = true
filePath.getFileSystem(serHadoopConf.get()).rename(filePath, new
Path(backupPath, filePath.getName))
}
}
[hudi] 26/45: optimize schema settings
This is an automated email from the ASF dual-hosted git repository.
forwardxu pushed a commit to branch release-0.12.1
in repository https://gitbox.apache.org/repos/asf/hudi.git
commit 00c3443cb4112fbd94281d52465cccfbc00516c5
Author: superche
AuthorDate: Fri Nov 18 16:24:19 2022 +0800
optimize schema settings
---
.../src/main/java/org/apache/hudi/util/HoodiePipeline.java | 14 ++
1 file changed, 14 insertions(+)
diff --git
a/hudi-flink-datasource/hudi-flink/src/main/java/org/apache/hudi/util/HoodiePipeline.java
b/hudi-flink-datasource/hudi-flink/src/main/java/org/apache/hudi/util/HoodiePipeline.java
index f95367c836..0e7e262aeb 100644
---
a/hudi-flink-datasource/hudi-flink/src/main/java/org/apache/hudi/util/HoodiePipeline.java
+++
b/hudi-flink-datasource/hudi-flink/src/main/java/org/apache/hudi/util/HoodiePipeline.java
@@ -18,6 +18,8 @@
package org.apache.hudi.util;
+import org.apache.flink.table.api.Schema;
+import org.apache.flink.table.utils.EncodingUtils;
import org.apache.hudi.adapter.Utils;
import org.apache.hudi.exception.HoodieException;
import org.apache.hudi.table.HoodieTableFactory;
@@ -125,6 +127,18 @@ public class HoodiePipeline {
return this;
}
+public Builder schema(Schema schema) {
+ for (Schema.UnresolvedColumn column : schema.getColumns()) {
+column(column.toString());
+ }
+
+ if (schema.getPrimaryKey().isPresent()) {
+
pk(schema.getPrimaryKey().get().getColumnNames().stream().map(EncodingUtils::escapeIdentifier).collect(Collectors.joining(",
")));
+ }
+
+ return this;
+}
+
/**
* Add a config option.
*/
[hudi] 32/45: Reduce the scope and duration of holding checkpoint lock in stream read
This is an automated email from the ASF dual-hosted git repository.
forwardxu pushed a commit to branch release-0.12.1
in repository https://gitbox.apache.org/repos/asf/hudi.git
commit 619b7504ca10dffc517771c212adcb64a3c13f47
Author: XuQianJin-Stars
AuthorDate: Tue Aug 9 13:18:55 2022 +0800
Reduce the scope and duration of holding checkpoint lock in stream read
---
.../hudi/source/StreamReadMonitoringFunction.java | 33 --
1 file changed, 18 insertions(+), 15 deletions(-)
diff --git
a/hudi-flink-datasource/hudi-flink/src/main/java/org/apache/hudi/source/StreamReadMonitoringFunction.java
b/hudi-flink-datasource/hudi-flink/src/main/java/org/apache/hudi/source/StreamReadMonitoringFunction.java
index 3318cecf10..fde5130237 100644
---
a/hudi-flink-datasource/hudi-flink/src/main/java/org/apache/hudi/source/StreamReadMonitoringFunction.java
+++
b/hudi-flink-datasource/hudi-flink/src/main/java/org/apache/hudi/source/StreamReadMonitoringFunction.java
@@ -168,9 +168,7 @@ public class StreamReadMonitoringFunction
public void run(SourceFunction.SourceContext context)
throws Exception {
checkpointLock = context.getCheckpointLock();
while (isRunning) {
- synchronized (checkpointLock) {
-monitorDirAndForwardSplits(context);
- }
+ monitorDirAndForwardSplits(context);
TimeUnit.SECONDS.sleep(interval);
}
}
@@ -195,6 +193,8 @@ public class StreamReadMonitoringFunction
// table does not exist
return;
}
+
+long start = System.currentTimeMillis();
IncrementalInputSplits.Result result =
incrementalInputSplits.inputSplits(metaClient, this.hadoopConf,
this.issuedInstant);
if (result.isEmpty()) {
@@ -202,28 +202,31 @@ public class StreamReadMonitoringFunction
return;
}
-for (MergeOnReadInputSplit split : result.getInputSplits()) {
- context.collect(split);
+LOG.debug(
+"Discovered {} splits, time elapsed {}ms",
+result.getInputSplits().size(),
+System.currentTimeMillis() - start);
+
+// only need to hold the checkpoint lock when emitting the splits
+start = System.currentTimeMillis();
+synchronized (checkpointLock) {
+ for (MergeOnReadInputSplit split : result.getInputSplits()) {
+context.collect(split);
+ }
}
+
// update the issues instant time
this.issuedInstant = result.getEndInstant();
LOG.info("\n"
+ "\n"
-+ "-- consumed to instant: {}\n"
++ "-- consumed to instant: {}, time elapsed {}ms\n"
+ "",
-this.issuedInstant);
+this.issuedInstant, System.currentTimeMillis() - start);
}
@Override
public void close() throws Exception {
-super.close();
-
-if (checkpointLock != null) {
- synchronized (checkpointLock) {
-issuedInstant = null;
-isRunning = false;
- }
-}
+cancel();
if (LOG.isDebugEnabled()) {
LOG.debug("Closed File Monitoring Source for path: " + path + ".");
[hudi] 18/45: [HUDI-5105] Add Call show_commit_extra_metadata for spark sql (#7091)
This is an automated email from the ASF dual-hosted git repository.
forwardxu pushed a commit to branch release-0.12.1
in repository https://gitbox.apache.org/repos/asf/hudi.git
commit 90c09053da765e735fee90a19ede2d78dba62a2b
Author: ForwardXu
AuthorDate: Mon Oct 31 18:21:29 2022 +0800
[HUDI-5105] Add Call show_commit_extra_metadata for spark sql (#7091)
* [HUDI-5105] Add Call show_commit_extra_metadata for spark sql
(cherry picked from commit 79ad3571db62b51e8fe8cc9183c8c787e9ef57fe)
---
.../hudi/command/procedures/HoodieProcedures.scala | 1 +
.../ShowCommitExtraMetadataProcedure.scala | 138 +
.../sql/hudi/procedure/TestCommitsProcedure.scala | 54 +++-
3 files changed, 187 insertions(+), 6 deletions(-)
diff --git
a/hudi-spark-datasource/hudi-spark/src/main/scala/org/apache/spark/sql/hudi/command/procedures/HoodieProcedures.scala
b/hudi-spark-datasource/hudi-spark/src/main/scala/org/apache/spark/sql/hudi/command/procedures/HoodieProcedures.scala
index b308480c6d..fabfda9367 100644
---
a/hudi-spark-datasource/hudi-spark/src/main/scala/org/apache/spark/sql/hudi/command/procedures/HoodieProcedures.scala
+++
b/hudi-spark-datasource/hudi-spark/src/main/scala/org/apache/spark/sql/hudi/command/procedures/HoodieProcedures.scala
@@ -82,6 +82,7 @@ object HoodieProcedures {
,(HiveSyncProcedure.NAME, HiveSyncProcedure.builder)
,(BackupInvalidParquetProcedure.NAME,
BackupInvalidParquetProcedure.builder)
,(CopyToTempView.NAME, CopyToTempView.builder)
+ ,(ShowCommitExtraMetadataProcedure.NAME,
ShowCommitExtraMetadataProcedure.builder)
)
}
}
diff --git
a/hudi-spark-datasource/hudi-spark/src/main/scala/org/apache/spark/sql/hudi/command/procedures/ShowCommitExtraMetadataProcedure.scala
b/hudi-spark-datasource/hudi-spark/src/main/scala/org/apache/spark/sql/hudi/command/procedures/ShowCommitExtraMetadataProcedure.scala
new file mode 100644
index 00..1a8f4dd9e4
--- /dev/null
+++
b/hudi-spark-datasource/hudi-spark/src/main/scala/org/apache/spark/sql/hudi/command/procedures/ShowCommitExtraMetadataProcedure.scala
@@ -0,0 +1,138 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.hudi.command.procedures
+
+import org.apache.hudi.HoodieCLIUtils
+import org.apache.hudi.common.model.{HoodieCommitMetadata,
HoodieReplaceCommitMetadata}
+import org.apache.hudi.common.table.HoodieTableMetaClient
+import org.apache.hudi.common.table.timeline.{HoodieInstant, HoodieTimeline}
+import org.apache.hudi.exception.HoodieException
+import org.apache.spark.sql.Row
+import org.apache.spark.sql.types.{DataTypes, Metadata, StructField,
StructType}
+
+import java.util
+import java.util.function.Supplier
+import scala.collection.JavaConversions._
+
+class ShowCommitExtraMetadataProcedure() extends BaseProcedure with
ProcedureBuilder {
+ private val PARAMETERS = Array[ProcedureParameter](
+ProcedureParameter.required(0, "table", DataTypes.StringType, None),
+ProcedureParameter.optional(1, "limit", DataTypes.IntegerType, 100),
+ProcedureParameter.optional(2, "instant_time", DataTypes.StringType, None),
+ProcedureParameter.optional(3, "metadata_key", DataTypes.StringType, None)
+ )
+
+ private val OUTPUT_TYPE = new StructType(Array[StructField](
+StructField("instant_time", DataTypes.StringType, nullable = true,
Metadata.empty),
+StructField("action", DataTypes.StringType, nullable = true,
Metadata.empty),
+StructField("metadata_key", DataTypes.StringType, nullable = true,
Metadata.empty),
+StructField("metadata_value", DataTypes.StringType, nullable = true,
Metadata.empty)
+ ))
+
+ def parameters: Array[ProcedureParameter] = PARAMETERS
+
+ def outputType: StructType = OUTPUT_TYPE
+
+ override def call(args: ProcedureArgs): Seq[Row] = {
+super.checkArgs(PARAMETERS, args)
+
+val table = getArgValueOrDefault(args,
PARAMETERS(0)).get.asInstanceOf[String]
+val limit = getArgValueOrDefault(args, PARAMETERS(1)).get.asInstanceOf[Int]
+val instantTime = getArgValueOrDefault(args, PARAMETERS(2))
+val metadataKey = getArgValueOrDefault(args, PARAMETERS(3))
+
+val hoodieCatalogTable =
[hudi] 21/45: [MINOR] add integrity check of merged parquet file for HoodieMergeHandle.
This is an automated email from the ASF dual-hosted git repository.
forwardxu pushed a commit to branch release-0.12.1
in repository https://gitbox.apache.org/repos/asf/hudi.git
commit 3c364bdf721651ed20980c30ee9b521e3535286e
Author: xiarixiaoyao
AuthorDate: Wed Sep 28 15:05:26 2022 +0800
[MINOR] add integrity check of merged parquet file for HoodieMergeHandle.
---
.../src/main/java/org/apache/hudi/io/HoodieMergeHandle.java| 10 ++
1 file changed, 10 insertions(+)
diff --git
a/hudi-client/hudi-client-common/src/main/java/org/apache/hudi/io/HoodieMergeHandle.java
b/hudi-client/hudi-client-common/src/main/java/org/apache/hudi/io/HoodieMergeHandle.java
index e629c6a51e..88db25bac4 100644
---
a/hudi-client/hudi-client-common/src/main/java/org/apache/hudi/io/HoodieMergeHandle.java
+++
b/hudi-client/hudi-client-common/src/main/java/org/apache/hudi/io/HoodieMergeHandle.java
@@ -34,6 +34,7 @@ import org.apache.hudi.common.model.IOType;
import org.apache.hudi.common.util.DefaultSizeEstimator;
import org.apache.hudi.common.util.HoodieRecordSizeEstimator;
import org.apache.hudi.common.util.Option;
+import org.apache.hudi.common.util.ParquetUtils;
import org.apache.hudi.common.util.ValidationUtils;
import org.apache.hudi.common.util.collection.ExternalSpillableMap;
import org.apache.hudi.config.HoodieWriteConfig;
@@ -65,6 +66,8 @@ import java.util.NoSuchElementException;
import java.util.Map;
import java.util.Set;
+import static org.apache.hudi.common.model.HoodieFileFormat.PARQUET;
+
@SuppressWarnings("Duplicates")
/**
* Handle to merge incoming records to those in storage.
@@ -447,6 +450,13 @@ public class HoodieMergeHandle extends H
return;
}
+// Fast verify the integrity of the parquet file.
+// only check the readable of parquet metadata.
+final String extension = FSUtils.getFileExtension(newFilePath.toString());
+if (PARQUET.getFileExtension().equals(extension)) {
+ new ParquetUtils().readMetadata(hoodieTable.getHadoopConf(),
newFilePath);
+}
+
long oldNumWrites = 0;
try {
HoodieFileReader reader =
HoodieFileReaderFactory.getFileReader(hoodieTable.getHadoopConf(), oldFilePath);
[hudi] 24/45: [HUDI-4526] Improve spillableMapBasePath when disk directory is full (#6284)
This is an automated email from the ASF dual-hosted git repository.
forwardxu pushed a commit to branch release-0.12.1
in repository https://gitbox.apache.org/repos/asf/hudi.git
commit e95a9f56ae2703b566e9c21e58bacbd6379fa35e
Author: ForwardXu
AuthorDate: Wed Nov 9 13:07:55 2022 +0800
[HUDI-4526] Improve spillableMapBasePath when disk directory is full (#6284)
(cherry picked from commit 371296173a7c51c325e6f9c3a3ef2ba5f6a89f6e)
---
.../org/apache/hudi/config/HoodieMemoryConfig.java | 9 --
.../table/log/HoodieMergedLogRecordScanner.java| 9 +++---
.../org/apache/hudi/common/util/FileIOUtils.java | 36 ++
3 files changed, 47 insertions(+), 7 deletions(-)
diff --git
a/hudi-client/hudi-client-common/src/main/java/org/apache/hudi/config/HoodieMemoryConfig.java
b/hudi-client/hudi-client-common/src/main/java/org/apache/hudi/config/HoodieMemoryConfig.java
index 4e37796393..960ec61dc0 100644
---
a/hudi-client/hudi-client-common/src/main/java/org/apache/hudi/config/HoodieMemoryConfig.java
+++
b/hudi-client/hudi-client-common/src/main/java/org/apache/hudi/config/HoodieMemoryConfig.java
@@ -22,9 +22,10 @@ import org.apache.hudi.common.config.ConfigClassProperty;
import org.apache.hudi.common.config.ConfigGroups;
import org.apache.hudi.common.config.ConfigProperty;
import org.apache.hudi.common.config.HoodieConfig;
+import org.apache.hudi.common.util.FileIOUtils;
+import org.apache.hudi.common.util.Option;
import javax.annotation.concurrent.Immutable;
-
import java.io.File;
import java.io.FileReader;
import java.io.IOException;
@@ -80,7 +81,11 @@ public class HoodieMemoryConfig extends HoodieConfig {
public static final ConfigProperty SPILLABLE_MAP_BASE_PATH =
ConfigProperty
.key("hoodie.memory.spillable.map.path")
.defaultValue("/tmp/")
- .withDocumentation("Default file path prefix for spillable map");
+ .withInferFunction(cfg -> {
+String[] localDirs = FileIOUtils.getConfiguredLocalDirs();
+return (localDirs != null && localDirs.length > 0) ?
Option.of(localDirs[0]) : Option.empty();
+ })
+ .withDocumentation("Default file path for spillable map");
public static final ConfigProperty WRITESTATUS_FAILURE_FRACTION =
ConfigProperty
.key("hoodie.memory.writestatus.failure.fraction")
diff --git
a/hudi-common/src/main/java/org/apache/hudi/common/table/log/HoodieMergedLogRecordScanner.java
b/hudi-common/src/main/java/org/apache/hudi/common/table/log/HoodieMergedLogRecordScanner.java
index 5ef0a6821f..45975fbfde 100644
---
a/hudi-common/src/main/java/org/apache/hudi/common/table/log/HoodieMergedLogRecordScanner.java
+++
b/hudi-common/src/main/java/org/apache/hudi/common/table/log/HoodieMergedLogRecordScanner.java
@@ -18,6 +18,9 @@
package org.apache.hudi.common.table.log;
+import org.apache.avro.Schema;
+import org.apache.hadoop.fs.FileSystem;
+import org.apache.hadoop.fs.Path;
import org.apache.hudi.common.config.HoodieCommonConfig;
import org.apache.hudi.common.model.DeleteRecord;
import org.apache.hudi.common.model.HoodieAvroRecord;
@@ -34,12 +37,7 @@ import org.apache.hudi.common.util.ReflectionUtils;
import org.apache.hudi.common.util.SpillableMapUtils;
import org.apache.hudi.common.util.collection.ExternalSpillableMap;
import org.apache.hudi.exception.HoodieIOException;
-
-import org.apache.avro.Schema;
-import org.apache.hadoop.fs.FileSystem;
import org.apache.hudi.internal.schema.InternalSchema;
-
-import org.apache.hadoop.fs.Path;
import org.apache.log4j.LogManager;
import org.apache.log4j.Logger;
@@ -95,6 +93,7 @@ public class HoodieMergedLogRecordScanner extends
AbstractHoodieLogRecordReader
// Store merged records for all versions for this log file, set the
in-memory footprint to maxInMemoryMapSize
this.records = new ExternalSpillableMap<>(maxMemorySizeInBytes,
spillableMapBasePath, new DefaultSizeEstimator(),
new HoodieRecordSizeEstimator(readerSchema), diskMapType,
isBitCaskDiskMapCompressionEnabled);
+
this.maxMemorySizeInBytes = maxMemorySizeInBytes;
} catch (IOException e) {
throw new HoodieIOException("IOException when creating
ExternalSpillableMap at " + spillableMapBasePath, e);
diff --git
a/hudi-common/src/main/java/org/apache/hudi/common/util/FileIOUtils.java
b/hudi-common/src/main/java/org/apache/hudi/common/util/FileIOUtils.java
index 6a9e2e1b35..426a703503 100644
--- a/hudi-common/src/main/java/org/apache/hudi/common/util/FileIOUtils.java
+++ b/hudi-common/src/main/java/org/apache/hudi/common/util/FileIOUtils.java
@@ -204,4 +204,40 @@ public class FileIOUtils {
public static Option readDataFromPath(FileSystem fileSystem,
org.apache.hadoop.fs.Path detailPath) {
return readDataFromPath(fileSystem, detailPath, false);
}
+
+ /**
+ * Return the configured local directories where hudi can write files. This
+ * method does not create any directories on its own, it only encapsulates
the
[hudi] 35/45: fix database default error
This is an automated email from the ASF dual-hosted git repository.
forwardxu pushed a commit to branch release-0.12.1
in repository https://gitbox.apache.org/repos/asf/hudi.git
commit 0cf7d3dac8b5392e9357c386c4c90d49be2a5b0d
Author: XuQianJin-Stars
AuthorDate: Thu Dec 8 11:20:46 2022 +0800
fix database default error
---
.../src/main/java/org/apache/hudi/config/HoodieWriteConfig.java | 6 +++---
1 file changed, 3 insertions(+), 3 deletions(-)
diff --git
a/hudi-client/hudi-client-common/src/main/java/org/apache/hudi/config/HoodieWriteConfig.java
b/hudi-client/hudi-client-common/src/main/java/org/apache/hudi/config/HoodieWriteConfig.java
index 034519e64a..103123f980 100644
---
a/hudi-client/hudi-client-common/src/main/java/org/apache/hudi/config/HoodieWriteConfig.java
+++
b/hudi-client/hudi-client-common/src/main/java/org/apache/hudi/config/HoodieWriteConfig.java
@@ -46,7 +46,6 @@ import
org.apache.hudi.common.table.timeline.versioning.TimelineLayoutVersion;
import org.apache.hudi.common.table.view.FileSystemViewStorageConfig;
import org.apache.hudi.common.util.Option;
import org.apache.hudi.common.util.ReflectionUtils;
-import org.apache.hudi.common.util.StringUtils;
import org.apache.hudi.common.util.ValidationUtils;
import org.apache.hudi.config.metrics.HoodieMetricsCloudWatchConfig;
import org.apache.hudi.config.metrics.HoodieMetricsConfig;
@@ -92,6 +91,7 @@ import java.util.UUID;
import java.util.function.Supplier;
import java.util.stream.Collectors;
+import static org.apache.hudi.common.util.StringUtils.isNullOrEmpty;
import static org.apache.hudi.config.HoodieCleanConfig.CLEANER_POLICY;
/**
@@ -1710,7 +1710,7 @@ public class HoodieWriteConfig extends HoodieConfig {
public CompressionCodecName getParquetCompressionCodec() {
String codecName =
getString(HoodieStorageConfig.PARQUET_COMPRESSION_CODEC_NAME);
-return CompressionCodecName.fromConf(StringUtils.isNullOrEmpty(codecName)
? null : codecName);
+return CompressionCodecName.fromConf(isNullOrEmpty(codecName) ? null :
codecName);
}
public boolean parquetDictionaryEnabled() {
@@ -2308,7 +2308,7 @@ public class HoodieWriteConfig extends HoodieConfig {
}
public Builder withDatabaseName(String dbName) {
- writeConfig.setValue(DATABASE_NAME, dbName);
+ writeConfig.setValue(DATABASE_NAME, isNullOrEmpty(dbName) ? "default" :
dbName);
return this;
}
[hudi] 15/45: Remove proxy
This is an automated email from the ASF dual-hosted git repository. forwardxu pushed a commit to branch release-0.12.1 in repository https://gitbox.apache.org/repos/asf/hudi.git commit ee07cc6a3ba5287c11fb682faf40ee20975d4fb7 Author: simonssu AuthorDate: Thu Oct 20 14:17:43 2022 +0800 Remove proxy (cherry picked from commit b90d8a2e101b1cbc2bca85ee10eb8d6740caf5b6) --- dev/settings.xml | 19 --- 1 file changed, 19 deletions(-) diff --git a/dev/settings.xml b/dev/settings.xml index 5f5dfd4fa6..cad54797c9 100644 --- a/dev/settings.xml +++ b/dev/settings.xml @@ -1,23 +1,4 @@ - - -dev http -true -http -web-proxy.oa.com -8080 - mirrors.tencent.com|qq.com|localhost|127.0.0.1|*.oa.com|repo.maven.apache.org|packages.confluent.io - - -dev https -true -https -web-proxy.oa.com -8080 - mirrors.tencent.com|qq.com|localhost|127.0.0.1|*.oa.com|repo.maven.apache.org|packages.confluent.io - - - false
[hudi] 02/45: [MINOR] Add Zhiyan metrics reporter
This is an automated email from the ASF dual-hosted git repository.
forwardxu pushed a commit to branch release-0.12.1
in repository https://gitbox.apache.org/repos/asf/hudi.git
commit 23412b2bee1e05231f100f922fe3785c39f2891b
Author: simonssu
AuthorDate: Wed May 25 21:08:45 2022 +0800
[MINOR] Add Zhiyan metrics reporter
---
dev/tencent-release.sh | 4 +-
hudi-client/hudi-client-common/pom.xml | 7 +
.../apache/hudi/async/AsyncPostEventService.java | 93 +++
.../org/apache/hudi/config/HoodieWriteConfig.java | 84 ++
.../hudi/config/metrics/HoodieMetricsConfig.java | 23 ++-
.../config/metrics/HoodieMetricsZhiyanConfig.java | 143 +
.../org/apache/hudi/metrics/HoodieMetrics.java | 120 ++-
.../main/java/org/apache/hudi/metrics/Metrics.java | 1 +
.../hudi/metrics/MetricsReporterFactory.java | 4 +
.../apache/hudi/metrics/MetricsReporterType.java | 2 +-
.../hudi/metrics/zhiyan/ZhiyanHttpClient.java | 129
.../hudi/metrics/zhiyan/ZhiyanMetricsReporter.java | 66
.../apache/hudi/metrics/zhiyan/ZhiyanReporter.java | 170 +
.../java/org/apache/hudi/tdbank/TDBankClient.java | 103 +
.../java/org/apache/hudi/tdbank/TdbankConfig.java | 82 ++
.../hudi/tdbank/TdbankHoodieMetricsEvent.java | 110 +
.../apache/hudi/client/HoodieFlinkWriteClient.java | 6 +
.../hudi/common/table/HoodieTableConfig.java | 6 +-
.../apache/hudi/configuration/FlinkOptions.java| 40 +++--
.../apache/hudi/streamer/FlinkStreamerConfig.java | 4 +
.../apache/hudi/streamer/HoodieFlinkStreamer.java | 4 +-
.../org/apache/hudi/table/HoodieTableFactory.java | 2 +
.../main/java/org/apache/hudi/DataSourceUtils.java | 12 +-
.../scala/org/apache/hudi/HoodieCLIUtils.scala | 2 +-
.../org/apache/hudi/HoodieSparkSqlWriter.scala | 12 +-
.../AlterHoodieTableAddColumnsCommand.scala| 1 +
.../hudi/command/MergeIntoHoodieTableCommand.scala | 3 +-
.../java/org/apache/hudi/TestDataSourceUtils.java | 2 +-
.../org/apache/hudi/TestHoodieSparkSqlWriter.scala | 5 +-
.../org/apache/hudi/internal/DefaultSource.java| 1 +
.../apache/hudi/spark3/internal/DefaultSource.java | 4 +-
.../hudi/command/Spark31AlterTableCommand.scala| 2 +-
32 files changed, 1200 insertions(+), 47 deletions(-)
diff --git a/dev/tencent-release.sh b/dev/tencent-release.sh
index 944f497070..b788d62dc7 100644
--- a/dev/tencent-release.sh
+++ b/dev/tencent-release.sh
@@ -116,9 +116,9 @@ function deploy_spark(){
FLINK_VERSION=$3
if [ ${release_repo} = "Y" ]; then
-COMMON_OPTIONS="-Dscala-${SCALA_VERSION} -Dspark${SPARK_VERSION}
-Dflink${FLINK_VERSION} -DskipTests -s dev/settings.xml
-DretryFailedDeploymentCount=30"
+COMMON_OPTIONS="-Dscala-${SCALA_VERSION} -Dspark${SPARK_VERSION}
-Dflink${FLINK_VERSION} -DskipTests -s dev/settings.xml
-DretryFailedDeploymentCount=30 -T 2.5C"
else
-COMMON_OPTIONS="-Dscala-${SCALA_VERSION} -Dspark${SPARK_VERSION}
-Dflink${FLINK_VERSION} -DskipTests -s dev/settings.xml
-DretryFailedDeploymentCount=30"
+COMMON_OPTIONS="-Dscala-${SCALA_VERSION} -Dspark${SPARK_VERSION}
-Dflink${FLINK_VERSION} -DskipTests -s dev/settings.xml
-DretryFailedDeploymentCount=30 -T 2.5C"
fi
# INSTALL_OPTIONS="-U -Drat.skip=true -Djacoco.skip=true
-Dscala-${SCALA_VERSION} -Dspark${SPARK_VERSION} -DskipTests -s
dev/settings.xml -T 2.5C"
diff --git a/hudi-client/hudi-client-common/pom.xml
b/hudi-client/hudi-client-common/pom.xml
index 735b62957d..81bf645427 100644
--- a/hudi-client/hudi-client-common/pom.xml
+++ b/hudi-client/hudi-client-common/pom.xml
@@ -72,6 +72,13 @@
0.2.2
+
+
+ com.tencent.tdbank
+ TDBusSDK
+ 1.2.9
+
+
io.dropwizard.metrics
diff --git
a/hudi-client/hudi-client-common/src/main/java/org/apache/hudi/async/AsyncPostEventService.java
b/hudi-client/hudi-client-common/src/main/java/org/apache/hudi/async/AsyncPostEventService.java
new file mode 100644
index 00..84cf82c913
--- /dev/null
+++
b/hudi-client/hudi-client-common/src/main/java/org/apache/hudi/async/AsyncPostEventService.java
@@ -0,0 +1,93 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either
[hudi] 03/45: fix cherry pick err
This is an automated email from the ASF dual-hosted git repository.
forwardxu pushed a commit to branch release-0.12.1
in repository https://gitbox.apache.org/repos/asf/hudi.git
commit d785b41f01004897e0d9c2882a58f79827f5d9fe
Author: XuQianJin-Stars
AuthorDate: Sun Oct 23 17:09:49 2022 +0800
fix cherry pick err
---
.../hudi/metrics/zhiyan/ZhiyanMetricsReporter.java | 6 -
.../apache/hudi/configuration/FlinkOptions.java| 31 ++
.../main/java/org/apache/hudi/DataSourceUtils.java | 5
pom.xml| 12 -
4 files changed, 31 insertions(+), 23 deletions(-)
diff --git
a/hudi-client/hudi-client-common/src/main/java/org/apache/hudi/metrics/zhiyan/ZhiyanMetricsReporter.java
b/hudi-client/hudi-client-common/src/main/java/org/apache/hudi/metrics/zhiyan/ZhiyanMetricsReporter.java
index 323fe17106..6b820547a0 100644
---
a/hudi-client/hudi-client-common/src/main/java/org/apache/hudi/metrics/zhiyan/ZhiyanMetricsReporter.java
+++
b/hudi-client/hudi-client-common/src/main/java/org/apache/hudi/metrics/zhiyan/ZhiyanMetricsReporter.java
@@ -23,7 +23,6 @@ import com.codahale.metrics.MetricRegistry;
import org.apache.hudi.config.HoodieWriteConfig;
import org.apache.hudi.metrics.MetricsReporter;
-import java.io.Closeable;
import java.util.concurrent.TimeUnit;
public class ZhiyanMetricsReporter extends MetricsReporter {
@@ -54,11 +53,6 @@ public class ZhiyanMetricsReporter extends MetricsReporter {
reporter.report();
}
- @Override
- public Closeable getReporter() {
-return reporter;
- }
-
@Override
public void stop() {
reporter.stop();
diff --git
a/hudi-flink-datasource/hudi-flink/src/main/java/org/apache/hudi/configuration/FlinkOptions.java
b/hudi-flink-datasource/hudi-flink/src/main/java/org/apache/hudi/configuration/FlinkOptions.java
index 4a298839fb..31c8b554c0 100644
---
a/hudi-flink-datasource/hudi-flink/src/main/java/org/apache/hudi/configuration/FlinkOptions.java
+++
b/hudi-flink-datasource/hudi-flink/src/main/java/org/apache/hudi/configuration/FlinkOptions.java
@@ -416,7 +416,7 @@ public class FlinkOptions extends HoodieConfig {
.key("write.bucket_assign.tasks")
.intType()
.noDefaultValue()
- .withDescription("Parallelism of tasks that do bucket assign, default is
the parallelism of the execution environment");
+ .withDescription("Parallelism of tasks that do bucket assign, default
same as the write task parallelism");
public static final ConfigOption WRITE_TASKS = ConfigOptions
.key("write.tasks")
@@ -585,7 +585,7 @@ public class FlinkOptions extends HoodieConfig {
.stringType()
.defaultValue(HoodieCleaningPolicy.KEEP_LATEST_COMMITS.name())
.withDescription("Clean policy to manage the Hudi table. Available
option: KEEP_LATEST_COMMITS, KEEP_LATEST_FILE_VERSIONS, KEEP_LATEST_BY_HOURS."
- + "Default is KEEP_LATEST_COMMITS.");
+ + "Default is KEEP_LATEST_COMMITS.");
public static final ConfigOption CLEAN_RETAIN_COMMITS =
ConfigOptions
.key("clean.retain_commits")
@@ -594,6 +594,14 @@ public class FlinkOptions extends HoodieConfig {
.withDescription("Number of commits to retain. So data will be retained
for num_of_commits * time_between_commits (scheduled).\n"
+ "This also directly translates into how much you can incrementally
pull on this table, default 30");
+ public static final ConfigOption CLEAN_RETAIN_HOURS = ConfigOptions
+ .key("clean.retain_hours")
+ .intType()
+ .defaultValue(24)// default 24 hours
+ .withDescription("Number of hours for which commits need to be retained.
This config provides a more flexible option as"
+ + "compared to number of commits retained for cleaning service.
Setting this property ensures all the files, but the latest in a file group,"
+ + " corresponding to commits with commit times older than the
configured number of hours to be retained are cleaned.");
+
public static final ConfigOption CLEAN_RETAIN_FILE_VERSIONS =
ConfigOptions
.key("clean.retain_file_versions")
.intType()
@@ -657,7 +665,7 @@ public class FlinkOptions extends HoodieConfig {
public static final ConfigOption
CLUSTERING_PLAN_PARTITION_FILTER_MODE_NAME = ConfigOptions
.key("clustering.plan.partition.filter.mode")
.stringType()
- .defaultValue("NONE")
+ .defaultValue(ClusteringPlanPartitionFilterMode.NONE.name())
.withDescription("Partition filter mode used in the creation of
clustering plan. Available values are - "
+ "NONE: do not filter table partition and thus the clustering plan
will include all partitions that have clustering candidate."
+ "RECENT_DAYS: keep a continuous range of partitions, worked
together with configs '" + DAYBASED_LOOKBACK_PARTITIONS.key() + "' and '"
@@ -665,16 +673,16 @@ public class FlinkOptions extends HoodieConfig {
[hudi] 27/45: fix none index partition format
This is an automated email from the ASF dual-hosted git repository.
forwardxu pushed a commit to branch release-0.12.1
in repository https://gitbox.apache.org/repos/asf/hudi.git
commit f02fef936b7db27137229c4bd64397a7456b915c
Author: superche
AuthorDate: Thu Nov 17 16:02:31 2022 +0800
fix none index partition format
---
.../java/org/apache/hudi/keygen/EmptyAvroKeyGenerator.java| 11 ---
.../apache/hudi/keygen/TimestampBasedAvroKeyGenerator.java| 4 ++--
.../main/java/org/apache/hudi/keygen/EmptyKeyGenerator.java | 3 ++-
.../main/java/org/apache/hudi/table/HoodieTableFactory.java | 7 +++
4 files changed, 19 insertions(+), 6 deletions(-)
diff --git
a/hudi-client/hudi-client-common/src/main/java/org/apache/hudi/keygen/EmptyAvroKeyGenerator.java
b/hudi-client/hudi-client-common/src/main/java/org/apache/hudi/keygen/EmptyAvroKeyGenerator.java
index 01536f95e4..6759c3dc8e 100644
---
a/hudi-client/hudi-client-common/src/main/java/org/apache/hudi/keygen/EmptyAvroKeyGenerator.java
+++
b/hudi-client/hudi-client-common/src/main/java/org/apache/hudi/keygen/EmptyAvroKeyGenerator.java
@@ -18,6 +18,7 @@
package org.apache.hudi.keygen;
+import java.io.IOException;
import org.apache.avro.generic.GenericRecord;
import org.apache.hudi.common.model.HoodieKey;
@@ -36,13 +37,13 @@ import java.util.stream.Collectors;
/**
* Avro key generator for empty record key Hudi tables.
*/
-public class EmptyAvroKeyGenerator extends BaseKeyGenerator {
+public class EmptyAvroKeyGenerator extends TimestampBasedAvroKeyGenerator {
private static final Logger LOG =
LogManager.getLogger(EmptyAvroKeyGenerator.class);
public static final String EMPTY_RECORD_KEY = HoodieKey.EMPTY_RECORD_KEY;
private static final List EMPTY_RECORD_KEY_FIELD_LIST =
Collections.emptyList();
- public EmptyAvroKeyGenerator(TypedProperties props) {
+ public EmptyAvroKeyGenerator(TypedProperties props) throws IOException {
super(props);
if (config.containsKey(KeyGeneratorOptions.RECORDKEY_FIELD_NAME.key())) {
LOG.warn(KeyGeneratorOptions.RECORDKEY_FIELD_NAME.key() + " will be
ignored while using "
@@ -60,6 +61,10 @@ public class EmptyAvroKeyGenerator extends BaseKeyGenerator {
@Override
public String getPartitionPath(GenericRecord record) {
-return KeyGenUtils.getRecordPartitionPath(record,
getPartitionPathFields(), hiveStylePartitioning, encodePartitionPath,
isConsistentLogicalTimestampEnabled());
+if (this.timestampType == TimestampType.NO_TIMESTAMP) {
+ return KeyGenUtils.getRecordPartitionPath(record,
getPartitionPathFields(), hiveStylePartitioning, encodePartitionPath,
isConsistentLogicalTimestampEnabled());
+} else {
+ return super.getPartitionPath(record);
+}
}
}
diff --git
a/hudi-client/hudi-client-common/src/main/java/org/apache/hudi/keygen/TimestampBasedAvroKeyGenerator.java
b/hudi-client/hudi-client-common/src/main/java/org/apache/hudi/keygen/TimestampBasedAvroKeyGenerator.java
index 60ccc694f9..77863fd869 100644
---
a/hudi-client/hudi-client-common/src/main/java/org/apache/hudi/keygen/TimestampBasedAvroKeyGenerator.java
+++
b/hudi-client/hudi-client-common/src/main/java/org/apache/hudi/keygen/TimestampBasedAvroKeyGenerator.java
@@ -49,11 +49,11 @@ import static java.util.concurrent.TimeUnit.SECONDS;
*/
public class TimestampBasedAvroKeyGenerator extends SimpleAvroKeyGenerator {
public enum TimestampType implements Serializable {
-UNIX_TIMESTAMP, DATE_STRING, MIXED, EPOCHMILLISECONDS, SCALAR
+UNIX_TIMESTAMP, DATE_STRING, MIXED, EPOCHMILLISECONDS, SCALAR, NO_TIMESTAMP
}
private final TimeUnit timeUnit;
- private final TimestampType timestampType;
+ protected final TimestampType timestampType;
private final String outputDateFormat;
private transient Option inputFormatter;
private transient DateTimeFormatter partitionFormatter;
diff --git
a/hudi-client/hudi-spark-client/src/main/java/org/apache/hudi/keygen/EmptyKeyGenerator.java
b/hudi-client/hudi-spark-client/src/main/java/org/apache/hudi/keygen/EmptyKeyGenerator.java
index 9e4090a537..2ba0d5cf32 100644
---
a/hudi-client/hudi-spark-client/src/main/java/org/apache/hudi/keygen/EmptyKeyGenerator.java
+++
b/hudi-client/hudi-spark-client/src/main/java/org/apache/hudi/keygen/EmptyKeyGenerator.java
@@ -18,6 +18,7 @@
package org.apache.hudi.keygen;
+import java.io.IOException;
import org.apache.avro.generic.GenericRecord;
import org.apache.hudi.common.config.TypedProperties;
import org.apache.hudi.keygen.constant.KeyGeneratorOptions;
@@ -38,7 +39,7 @@ public class EmptyKeyGenerator extends BuiltinKeyGenerator {
private final EmptyAvroKeyGenerator emptyAvroKeyGenerator;
- public EmptyKeyGenerator(TypedProperties config) {
+ public EmptyKeyGenerator(TypedProperties config) throws IOException {
super(config);
this.emptyAvroKeyGenerator = new EmptyAvroKeyGenerator(config);
this.recordKeyFields =
[hudi] 08/45: fix zhiyan reporter for metadata
This is an automated email from the ASF dual-hosted git repository.
forwardxu pushed a commit to branch release-0.12.1
in repository https://gitbox.apache.org/repos/asf/hudi.git
commit 6dbe53e6232de8b85c7548fefda670d6f4359ec1
Author: XuQianJin-Stars
AuthorDate: Sun Jun 5 15:06:30 2022 +0800
fix zhiyan reporter for metadata
---
.../main/java/org/apache/hudi/config/HoodieWriteConfig.java | 8
.../apache/hudi/metadata/HoodieBackedTableMetadataWriter.java | 11 +++
2 files changed, 19 insertions(+)
diff --git
a/hudi-client/hudi-client-common/src/main/java/org/apache/hudi/config/HoodieWriteConfig.java
b/hudi-client/hudi-client-common/src/main/java/org/apache/hudi/config/HoodieWriteConfig.java
index 23bc0ee329..9610ad382b 100644
---
a/hudi-client/hudi-client-common/src/main/java/org/apache/hudi/config/HoodieWriteConfig.java
+++
b/hudi-client/hudi-client-common/src/main/java/org/apache/hudi/config/HoodieWriteConfig.java
@@ -2234,6 +2234,8 @@ public class HoodieWriteConfig extends HoodieConfig {
private boolean isPreCommitValidationConfigSet = false;
private boolean isMetricsJmxConfigSet = false;
private boolean isMetricsGraphiteConfigSet = false;
+
+private boolean isMetricsZhiyanConfig = false;
private boolean isLayoutConfigSet = false;
private boolean isTdbankConfigSet = false;
@@ -2429,6 +2431,12 @@ public class HoodieWriteConfig extends HoodieConfig {
return this;
}
+public Builder withMetricsZhiyanConfig(HoodieMetricsZhiyanConfig
metricsZhiyanConfig) {
+ writeConfig.getProps().putAll(metricsZhiyanConfig.getProps());
+ isMetricsZhiyanConfig = true;
+ return this;
+}
+
public Builder withPreCommitValidatorConfig(HoodiePreCommitValidatorConfig
validatorConfig) {
writeConfig.getProps().putAll(validatorConfig.getProps());
isPreCommitValidationConfigSet = true;
diff --git
a/hudi-client/hudi-client-common/src/main/java/org/apache/hudi/metadata/HoodieBackedTableMetadataWriter.java
b/hudi-client/hudi-client-common/src/main/java/org/apache/hudi/metadata/HoodieBackedTableMetadataWriter.java
index 962875fb92..405db43a51 100644
---
a/hudi-client/hudi-client-common/src/main/java/org/apache/hudi/metadata/HoodieBackedTableMetadataWriter.java
+++
b/hudi-client/hudi-client-common/src/main/java/org/apache/hudi/metadata/HoodieBackedTableMetadataWriter.java
@@ -65,6 +65,7 @@ import org.apache.hudi.config.HoodieWriteConfig;
import org.apache.hudi.config.metrics.HoodieMetricsConfig;
import org.apache.hudi.config.metrics.HoodieMetricsGraphiteConfig;
import org.apache.hudi.config.metrics.HoodieMetricsJmxConfig;
+import org.apache.hudi.config.metrics.HoodieMetricsZhiyanConfig;
import org.apache.hudi.exception.HoodieException;
import org.apache.hudi.exception.HoodieIndexException;
import org.apache.hudi.exception.HoodieMetadataException;
@@ -316,6 +317,16 @@ public abstract class HoodieBackedTableMetadataWriter
implements HoodieTableMeta
.toJmxHost(writeConfig.getJmxHost())
.build());
break;
+case ZHIYAN:
+
builder.withMetricsZhiyanConfig(HoodieMetricsZhiyanConfig.newBuilder()
+ .withReportServiceUrl(writeConfig.getZhiyanReportServiceURL())
+ .withApiTimeout(writeConfig.getZhiyanApiTimeoutSeconds())
+ .withAppMask(writeConfig.getZhiyanAppMask())
+
.withReportPeriodSeconds(writeConfig.getZhiyanReportPeriodSeconds())
+ .withSeclvlEnvName(writeConfig.getZhiyanSeclvlEnvName())
+ .withJobName(writeConfig.getZhiyanHoodieJobName())
+ .build());
+ break;
case DATADOG:
case PROMETHEUS:
case PROMETHEUS_PUSHGATEWAY:
[hudi] 13/45: fix RowDataProjection with project and projectAsValues's NPE
This is an automated email from the ASF dual-hosted git repository.
forwardxu pushed a commit to branch release-0.12.1
in repository https://gitbox.apache.org/repos/asf/hudi.git
commit 4e66857849d1ac793ad77d211d602295d08f827f
Author: XuQianJin-Stars
AuthorDate: Mon Aug 15 15:06:03 2022 +0800
fix RowDataProjection with project and projectAsValues's NPE
---
.../org/apache/hudi/util/RowDataProjection.java | 21 +++--
1 file changed, 19 insertions(+), 2 deletions(-)
diff --git
a/hudi-flink-datasource/hudi-flink/src/main/java/org/apache/hudi/util/RowDataProjection.java
b/hudi-flink-datasource/hudi-flink/src/main/java/org/apache/hudi/util/RowDataProjection.java
index 8076d982b9..51df29faae 100644
---
a/hudi-flink-datasource/hudi-flink/src/main/java/org/apache/hudi/util/RowDataProjection.java
+++
b/hudi-flink-datasource/hudi-flink/src/main/java/org/apache/hudi/util/RowDataProjection.java
@@ -24,6 +24,8 @@ import org.apache.flink.table.data.GenericRowData;
import org.apache.flink.table.data.RowData;
import org.apache.flink.table.types.logical.LogicalType;
import org.apache.flink.table.types.logical.RowType;
+import org.apache.log4j.LogManager;
+import org.apache.log4j.Logger;
import java.io.Serializable;
import java.util.Arrays;
@@ -33,14 +35,19 @@ import java.util.List;
* Utilities to project the row data with given positions.
*/
public class RowDataProjection implements Serializable {
+ private static final Logger LOG =
LogManager.getLogger(RowDataProjection.class);
+
private static final long serialVersionUID = 1L;
private final RowData.FieldGetter[] fieldGetters;
+ private final LogicalType[] types;
+
private RowDataProjection(LogicalType[] types, int[] positions) {
ValidationUtils.checkArgument(types.length == positions.length,
"types and positions should have the equal number");
this.fieldGetters = new RowData.FieldGetter[types.length];
+this.types = types;
for (int i = 0; i < types.length; i++) {
final LogicalType type = types[i];
final int pos = positions[i];
@@ -69,7 +76,12 @@ public class RowDataProjection implements Serializable {
public RowData project(RowData rowData) {
GenericRowData genericRowData = new
GenericRowData(this.fieldGetters.length);
for (int i = 0; i < this.fieldGetters.length; i++) {
- final Object val = this.fieldGetters[i].getFieldOrNull(rowData);
+ Object val = null;
+ try {
+val = rowData.isNullAt(i) ? null :
this.fieldGetters[i].getFieldOrNull(rowData);
+ } catch (Throwable e) {
+LOG.error(String.format("position=%s, fieldType=%s,\n data=%s", i,
types[i].toString(), rowData.toString()));
+ }
genericRowData.setField(i, val);
}
return genericRowData;
@@ -81,7 +93,12 @@ public class RowDataProjection implements Serializable {
public Object[] projectAsValues(RowData rowData) {
Object[] values = new Object[this.fieldGetters.length];
for (int i = 0; i < this.fieldGetters.length; i++) {
- final Object val = this.fieldGetters[i].getFieldOrNull(rowData);
+ Object val = null;
+ try {
+val = rowData.isNullAt(i) ? null :
this.fieldGetters[i].getFieldOrNull(rowData);
+ } catch (Throwable e) {
+LOG.error(String.format("position=%s, fieldType=%s,\n data=%s", i,
types[i].toString(), rowData.toString()));
+ }
values[i] = val;
}
return values;
[hudi] 11/45: fix file not exists for getFileSize
This is an automated email from the ASF dual-hosted git repository.
forwardxu pushed a commit to branch release-0.12.1
in repository https://gitbox.apache.org/repos/asf/hudi.git
commit e45564102b0d7e0d4ff35152262274de7737af0e
Author: XuQianJin-Stars
AuthorDate: Sun Oct 9 17:20:41 2022 +0800
fix file not exists for getFileSize
---
.../src/main/java/org/apache/hudi/common/fs/FSUtils.java | 14 --
1 file changed, 12 insertions(+), 2 deletions(-)
diff --git a/hudi-common/src/main/java/org/apache/hudi/common/fs/FSUtils.java
b/hudi-common/src/main/java/org/apache/hudi/common/fs/FSUtils.java
index 0257f8015b..1350108a11 100644
--- a/hudi-common/src/main/java/org/apache/hudi/common/fs/FSUtils.java
+++ b/hudi-common/src/main/java/org/apache/hudi/common/fs/FSUtils.java
@@ -191,8 +191,18 @@ public class FSUtils {
return fullFileName.split("_")[2].split("\\.")[0];
}
- public static long getFileSize(FileSystem fs, Path path) throws IOException {
-return fs.getFileStatus(path).getLen();
+ public static long getFileSize(FileSystem fs, Path path) {
+try {
+ if (fs.exists(path)) {
+return fs.getFileStatus(path).getLen();
+ } else {
+LOG.warn("getFileSize: " + path + " file not exists!");
+return 0L;
+ }
+} catch (IOException e) {
+ LOG.error("getFileSize: " + path + " error:", e);
+ return 0L;
+}
}
public static String getFileId(String fullFileName) {
[hudi] 10/45: adapt tspark changes: backport 3.3 VectorizedParquetReader related code to 3.1
This is an automated email from the ASF dual-hosted git repository.
forwardxu pushed a commit to branch release-0.12.1
in repository https://gitbox.apache.org/repos/asf/hudi.git
commit 9c94e388fecce8d02388a81f0da769d52fe5319c
Author: shaoxiong.zhan
AuthorDate: Fri Sep 16 11:00:33 2022 +0800
adapt tspark changes: backport 3.3 VectorizedParquetReader related code to
3.1
---
.../parquet/Spark31HoodieParquetFileFormat.scala | 20 +++-
1 file changed, 11 insertions(+), 9 deletions(-)
diff --git
a/hudi-spark-datasource/hudi-spark3.1.x/src/main/scala/org/apache/spark/sql/execution/datasources/parquet/Spark31HoodieParquetFileFormat.scala
b/hudi-spark-datasource/hudi-spark3.1.x/src/main/scala/org/apache/spark/sql/execution/datasources/parquet/Spark31HoodieParquetFileFormat.scala
index ca41490fc0..712c9c6d3e 100644
---
a/hudi-spark-datasource/hudi-spark3.1.x/src/main/scala/org/apache/spark/sql/execution/datasources/parquet/Spark31HoodieParquetFileFormat.scala
+++
b/hudi-spark-datasource/hudi-spark3.1.x/src/main/scala/org/apache/spark/sql/execution/datasources/parquet/Spark31HoodieParquetFileFormat.scala
@@ -19,6 +19,7 @@ package org.apache.spark.sql.execution.datasources.parquet
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.fs.Path
+import org.apache.hadoop.mapred.FileSplit
import org.apache.hadoop.mapreduce.task.TaskAttemptContextImpl
import org.apache.hadoop.mapreduce.{JobID, TaskAttemptID, TaskID, TaskType}
import org.apache.hudi.HoodieSparkUtils
@@ -135,14 +136,11 @@ class Spark31HoodieParquetFileFormat(private val
shouldAppendPartitionValues: Bo
assert(!shouldAppendPartitionValues || file.partitionValues.numFields ==
partitionSchema.size)
val filePath = new Path(new URI(file.filePath))
- val split =
-new org.apache.parquet.hadoop.ParquetInputSplit(
- filePath,
- file.start,
- file.start + file.length,
- file.length,
- Array.empty,
- null)
+ /**
+ * from https://github.com/apache/spark/pull/29542
+ * must use org.apache.hadoop.mapred.FileSplit
+ */
+ val split = new FileSplit(filePath, file.start, file.length,
Array.empty[String])
val sharedConf = broadcastedHadoopConf.value.value
@@ -170,7 +168,11 @@ class Spark31HoodieParquetFileFormat(private val
shouldAppendPartitionValues: Bo
// Try to push down filters when filter push-down is enabled.
val pushed = if (enableParquetFilterPushDown) {
val parquetSchema = footerFileMetaData.getSchema
-val parquetFilters = if (HoodieSparkUtils.gteqSpark3_1_3) {
+/**
+ * hard code for adaption, because tspark port 3.3 api to 3.1
+ */
+val ctor = classOf[ParquetFilters].getConstructors.head
+val parquetFilters = if (8.equals(ctor.getParameterCount) ||
HoodieSparkUtils.gteqSpark3_1_3) {
createParquetFilters(
parquetSchema,
pushDownDate,
[hudi] 23/45: [HUDI-5178] Add Call show_table_properties for spark sql (#7161)
This is an automated email from the ASF dual-hosted git repository.
forwardxu pushed a commit to branch release-0.12.1
in repository https://gitbox.apache.org/repos/asf/hudi.git
commit 7d6654c1d0ac00d01f322d4c9cd80fdfc5a03828
Author: ForwardXu
AuthorDate: Wed Nov 9 10:41:03 2022 +0800
[HUDI-5178] Add Call show_table_properties for spark sql (#7161)
(cherry picked from commit 1d1181a4410154ff0615f374cfee97630b425e88)
---
.../hudi/command/procedures/BaseProcedure.scala| 4 +-
.../hudi/command/procedures/HoodieProcedures.scala | 1 +
.../procedures/ShowTablePropertiesProcedure.scala | 71 ++
.../TestShowTablePropertiesProcedure.scala | 45 ++
4 files changed, 119 insertions(+), 2 deletions(-)
diff --git
a/hudi-spark-datasource/hudi-spark/src/main/scala/org/apache/spark/sql/hudi/command/procedures/BaseProcedure.scala
b/hudi-spark-datasource/hudi-spark/src/main/scala/org/apache/spark/sql/hudi/command/procedures/BaseProcedure.scala
index d0404664f4..67930cb3ed 100644
---
a/hudi-spark-datasource/hudi-spark/src/main/scala/org/apache/spark/sql/hudi/command/procedures/BaseProcedure.scala
+++
b/hudi-spark-datasource/hudi-spark/src/main/scala/org/apache/spark/sql/hudi/command/procedures/BaseProcedure.scala
@@ -22,7 +22,7 @@ import org.apache.hudi.client.SparkRDDWriteClient
import org.apache.hudi.client.common.HoodieSparkEngineContext
import org.apache.hudi.common.model.HoodieRecordPayload
import org.apache.hudi.config.{HoodieIndexConfig, HoodieWriteConfig}
-import org.apache.hudi.exception.HoodieClusteringException
+import org.apache.hudi.exception.HoodieException
import org.apache.hudi.index.HoodieIndex.IndexType
import org.apache.spark.api.java.JavaSparkContext
import org.apache.spark.sql.SparkSession
@@ -111,7 +111,7 @@ abstract class BaseProcedure extends Procedure {
t => HoodieCLIUtils.getHoodieCatalogTable(sparkSession,
t.asInstanceOf[String]).tableLocation)
.getOrElse(
tablePath.map(p => p.asInstanceOf[String]).getOrElse(
- throw new HoodieClusteringException("Table name or table path must
be given one"))
+ throw new HoodieException("Table name or table path must be given
one"))
)
}
diff --git
a/hudi-spark-datasource/hudi-spark/src/main/scala/org/apache/spark/sql/hudi/command/procedures/HoodieProcedures.scala
b/hudi-spark-datasource/hudi-spark/src/main/scala/org/apache/spark/sql/hudi/command/procedures/HoodieProcedures.scala
index fabfda9367..d6131353c5 100644
---
a/hudi-spark-datasource/hudi-spark/src/main/scala/org/apache/spark/sql/hudi/command/procedures/HoodieProcedures.scala
+++
b/hudi-spark-datasource/hudi-spark/src/main/scala/org/apache/spark/sql/hudi/command/procedures/HoodieProcedures.scala
@@ -83,6 +83,7 @@ object HoodieProcedures {
,(BackupInvalidParquetProcedure.NAME,
BackupInvalidParquetProcedure.builder)
,(CopyToTempView.NAME, CopyToTempView.builder)
,(ShowCommitExtraMetadataProcedure.NAME,
ShowCommitExtraMetadataProcedure.builder)
+ ,(ShowTablePropertiesProcedure.NAME,
ShowTablePropertiesProcedure.builder)
)
}
}
diff --git
a/hudi-spark-datasource/hudi-spark/src/main/scala/org/apache/spark/sql/hudi/command/procedures/ShowTablePropertiesProcedure.scala
b/hudi-spark-datasource/hudi-spark/src/main/scala/org/apache/spark/sql/hudi/command/procedures/ShowTablePropertiesProcedure.scala
new file mode 100644
index 00..d75df07fc9
--- /dev/null
+++
b/hudi-spark-datasource/hudi-spark/src/main/scala/org/apache/spark/sql/hudi/command/procedures/ShowTablePropertiesProcedure.scala
@@ -0,0 +1,71 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.hudi.command.procedures
+
+import org.apache.hudi.HoodieCLIUtils
+import org.apache.hudi.common.table.HoodieTableMetaClient
+import org.apache.spark.sql.Row
+import org.apache.spark.sql.types.{DataTypes, Metadata, StructField,
StructType}
+
+import java.util
+import java.util.function.Supplier
+import scala.collection.JavaConversions._
+
+class ShowTablePropertiesProcedure() extends BaseProcedure with
ProcedureBuilder {
+ private val PARAMETERS = Array[ProcedureParameter](
+
[hudi] 17/45: temp_view_support (#6990)
This is an automated email from the ASF dual-hosted git repository.
forwardxu pushed a commit to branch release-0.12.1
in repository https://gitbox.apache.org/repos/asf/hudi.git
commit 97ce2b7f7ba905337ea1d3b55e6febca1cf52833
Author: 苏承祥
AuthorDate: Wed Oct 26 13:11:15 2022 +0800
temp_view_support (#6990)
Co-authored-by: 苏承祥
(cherry picked from commit e13b2129dc144ca505e39c0d7fa479c47362bb56)
---
.../hudi/command/procedures/CopyToTempView.scala | 114 ++
.../hudi/command/procedures/HoodieProcedures.scala | 1 +
.../procedure/TestCopyToTempViewProcedure.scala| 168 +
3 files changed, 283 insertions(+)
diff --git
a/hudi-spark-datasource/hudi-spark/src/main/scala/org/apache/spark/sql/hudi/command/procedures/CopyToTempView.scala
b/hudi-spark-datasource/hudi-spark/src/main/scala/org/apache/spark/sql/hudi/command/procedures/CopyToTempView.scala
new file mode 100644
index 00..13259c4964
--- /dev/null
+++
b/hudi-spark-datasource/hudi-spark/src/main/scala/org/apache/spark/sql/hudi/command/procedures/CopyToTempView.scala
@@ -0,0 +1,114 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.hudi.command.procedures
+
+import org.apache.hudi.DataSourceReadOptions
+import org.apache.spark.internal.Logging
+import org.apache.spark.sql.Row
+import org.apache.spark.sql.types.{DataTypes, Metadata, StructField,
StructType}
+
+import java.util.function.Supplier
+
+class CopyToTempView extends BaseProcedure with ProcedureBuilder with Logging {
+
+ private val PARAMETERS = Array[ProcedureParameter](
+ProcedureParameter.required(0, "table", DataTypes.StringType, None),
+ProcedureParameter.optional(1, "query_type", DataTypes.StringType,
DataSourceReadOptions.QUERY_TYPE_SNAPSHOT_OPT_VAL),
+ProcedureParameter.required(2, "view_name", DataTypes.StringType, None),
+ProcedureParameter.optional(3, "begin_instance_time",
DataTypes.StringType, ""),
+ProcedureParameter.optional(4, "end_instance_time", DataTypes.StringType,
""),
+ProcedureParameter.optional(5, "as_of_instant", DataTypes.StringType, ""),
+ProcedureParameter.optional(6, "replace", DataTypes.BooleanType, false),
+ProcedureParameter.optional(7, "global", DataTypes.BooleanType, false)
+ )
+
+ private val OUTPUT_TYPE = new StructType(Array[StructField](
+StructField("status", DataTypes.IntegerType, nullable = true,
Metadata.empty))
+ )
+
+ def parameters: Array[ProcedureParameter] = PARAMETERS
+
+ def outputType: StructType = OUTPUT_TYPE
+
+ override def call(args: ProcedureArgs): Seq[Row] = {
+super.checkArgs(PARAMETERS, args)
+
+val tableName = getArgValueOrDefault(args, PARAMETERS(0))
+val queryType = getArgValueOrDefault(args,
PARAMETERS(1)).get.asInstanceOf[String]
+val viewName = getArgValueOrDefault(args,
PARAMETERS(2)).get.asInstanceOf[String]
+val beginInstance = getArgValueOrDefault(args,
PARAMETERS(3)).get.asInstanceOf[String]
+val endInstance = getArgValueOrDefault(args,
PARAMETERS(4)).get.asInstanceOf[String]
+val asOfInstant = getArgValueOrDefault(args,
PARAMETERS(5)).get.asInstanceOf[String]
+val replace = getArgValueOrDefault(args,
PARAMETERS(6)).get.asInstanceOf[Boolean]
+val global = getArgValueOrDefault(args,
PARAMETERS(7)).get.asInstanceOf[Boolean]
+
+val tablePath = getBasePath(tableName)
+
+val sourceDataFrame = queryType match {
+ case DataSourceReadOptions.QUERY_TYPE_SNAPSHOT_OPT_VAL => if
(asOfInstant.nonEmpty) {
+sparkSession.read
+ .format("org.apache.hudi")
+ .option(DataSourceReadOptions.QUERY_TYPE.key,
DataSourceReadOptions.QUERY_TYPE_SNAPSHOT_OPT_VAL)
+ .option(DataSourceReadOptions.TIME_TRAVEL_AS_OF_INSTANT.key,
asOfInstant)
+ .load(tablePath)
+ } else {
+sparkSession.read
+ .format("org.apache.hudi")
+ .option(DataSourceReadOptions.QUERY_TYPE.key,
DataSourceReadOptions.QUERY_TYPE_SNAPSHOT_OPT_VAL)
+ .load(tablePath)
+ }
+ case DataSourceReadOptions.QUERY_TYPE_INCREMENTAL_OPT_VAL =>
+assert(beginInstance.nonEmpty && endInstance.nonEmpty, "when the
query_type is incremental,
[hudi] 05/45: [HUDI-4475] fix create table with not exists hoodie properties file
This is an automated email from the ASF dual-hosted git repository.
forwardxu pushed a commit to branch release-0.12.1
in repository https://gitbox.apache.org/repos/asf/hudi.git
commit 553bb9eab475a05bb91e150ced3dc9c18df1cd7e
Author: XuQianJin-Stars
AuthorDate: Tue Aug 23 18:55:25 2022 +0800
[HUDI-4475] fix create table with not exists hoodie properties file
---
.../main/scala/org/apache/spark/sql/hudi/HoodieSqlCommonUtils.scala | 6 --
1 file changed, 4 insertions(+), 2 deletions(-)
diff --git
a/hudi-spark-datasource/hudi-spark-common/src/main/scala/org/apache/spark/sql/hudi/HoodieSqlCommonUtils.scala
b/hudi-spark-datasource/hudi-spark-common/src/main/scala/org/apache/spark/sql/hudi/HoodieSqlCommonUtils.scala
index 025a224373..775f90dae1 100644
---
a/hudi-spark-datasource/hudi-spark-common/src/main/scala/org/apache/spark/sql/hudi/HoodieSqlCommonUtils.scala
+++
b/hudi-spark-datasource/hudi-spark-common/src/main/scala/org/apache/spark/sql/hudi/HoodieSqlCommonUtils.scala
@@ -24,7 +24,7 @@ import
org.apache.hudi.common.config.{DFSPropertiesConfiguration, HoodieMetadata
import org.apache.hudi.common.fs.FSUtils
import org.apache.hudi.common.model.HoodieRecord
import org.apache.hudi.common.table.timeline.{HoodieActiveTimeline,
HoodieInstantTimeGenerator}
-import org.apache.hudi.common.table.{HoodieTableMetaClient,
TableSchemaResolver}
+import org.apache.hudi.common.table.{HoodieTableConfig, HoodieTableMetaClient,
TableSchemaResolver}
import org.apache.hudi.common.util.PartitionPathEncodeUtils
import org.apache.hudi.{AvroConversionUtils, DataSourceOptionsHelper,
DataSourceReadOptions, SparkAdapterSupport}
import org.apache.spark.api.java.JavaSparkContext
@@ -227,7 +227,9 @@ object HoodieSqlCommonUtils extends SparkAdapterSupport {
val basePath = new Path(tablePath)
val fs = basePath.getFileSystem(conf)
val metaPath = new Path(basePath, HoodieTableMetaClient.METAFOLDER_NAME)
-fs.exists(metaPath)
+val cfgPath = new Path(metaPath, HoodieTableConfig.HOODIE_PROPERTIES_FILE)
+val backupCfgPath = new Path(metaPath,
HoodieTableConfig.HOODIE_PROPERTIES_FILE_BACKUP)
+fs.exists(metaPath) && (fs.exists(cfgPath) || fs.exists(backupCfgPath))
}
/**
[hudi] 04/45: fix the bug, log file will not roll over to a new file
This is an automated email from the ASF dual-hosted git repository.
forwardxu pushed a commit to branch release-0.12.1
in repository https://gitbox.apache.org/repos/asf/hudi.git
commit ab5b4fa780c12b781509e44f88f7d849a5467e89
Author: XuQianJin-Stars
AuthorDate: Mon Jun 20 10:21:45 2022 +0800
fix the bug, log file will not roll over to a new file
---
.../org/apache/hudi/common/table/log/HoodieLogFormatWriter.java | 9 ++---
1 file changed, 6 insertions(+), 3 deletions(-)
diff --git
a/hudi-common/src/main/java/org/apache/hudi/common/table/log/HoodieLogFormatWriter.java
b/hudi-common/src/main/java/org/apache/hudi/common/table/log/HoodieLogFormatWriter.java
index 8dbe85efd1..60c124784a 100644
---
a/hudi-common/src/main/java/org/apache/hudi/common/table/log/HoodieLogFormatWriter.java
+++
b/hudi-common/src/main/java/org/apache/hudi/common/table/log/HoodieLogFormatWriter.java
@@ -94,7 +94,8 @@ public class HoodieLogFormatWriter implements
HoodieLogFormat.Writer {
Path path = logFile.getPath();
if (fs.exists(path)) {
boolean isAppendSupported =
StorageSchemes.isAppendSupported(fs.getScheme());
-if (isAppendSupported) {
+boolean needRollOverToNewFile = fs.getFileStatus(path).getLen() >
sizeThreshold;
+if (isAppendSupported && !needRollOverToNewFile) {
LOG.info(logFile + " exists. Appending to existing file");
try {
// open the path for append and record the offset
@@ -116,10 +117,12 @@ public class HoodieLogFormatWriter implements
HoodieLogFormat.Writer {
}
}
}
-if (!isAppendSupported) {
+if (!isAppendSupported || needRollOverToNewFile) {
rollOver();
createNewFile();
- LOG.info("Append not supported.. Rolling over to " + logFile);
+ if (isAppendSupported && needRollOverToNewFile) {
+LOG.info(String.format("current Log file size > %s roll over to a
new log file", sizeThreshold));
+ }
}
} else {
LOG.info(logFile + " does not exist. Create a new file");
[hudi] 09/45: [MINOR] Adapt to tianqiong spark
This is an automated email from the ASF dual-hosted git repository.
forwardxu pushed a commit to branch release-0.12.1
in repository https://gitbox.apache.org/repos/asf/hudi.git
commit f80900d91cd134cc2150d4e3ee6d85b8b00c2ad7
Author: XuQianJin-Stars
AuthorDate: Mon Oct 24 17:18:19 2022 +0800
[MINOR] Adapt to tianqiong spark
---
.../datasources/Spark31NestedSchemaPruning.scala | 24 ++
pom.xml| 10 -
2 files changed, 21 insertions(+), 13 deletions(-)
diff --git
a/hudi-spark-datasource/hudi-spark3.1.x/src/main/scala/org/apache/spark/sql/execution/datasources/Spark31NestedSchemaPruning.scala
b/hudi-spark-datasource/hudi-spark3.1.x/src/main/scala/org/apache/spark/sql/execution/datasources/Spark31NestedSchemaPruning.scala
index 1b29c428bb..76cdb443b4 100644
---
a/hudi-spark-datasource/hudi-spark3.1.x/src/main/scala/org/apache/spark/sql/execution/datasources/Spark31NestedSchemaPruning.scala
+++
b/hudi-spark-datasource/hudi-spark3.1.x/src/main/scala/org/apache/spark/sql/execution/datasources/Spark31NestedSchemaPruning.scala
@@ -17,15 +17,15 @@
package org.apache.spark.sql.execution.datasources
-import org.apache.hudi.{HoodieBaseRelation, SparkAdapterSupport}
-import org.apache.spark.sql.HoodieSpark3CatalystPlanUtils
-import org.apache.spark.sql.catalyst.expressions.{And, AttributeReference,
AttributeSet, Expression, NamedExpression, ProjectionOverSchema}
+import org.apache.hudi.HoodieBaseRelation
+import org.apache.spark.sql.catalyst.expressions.{Alias, And, Attribute,
AttributeReference, Expression, NamedExpression, ProjectionOverSchema}
import org.apache.spark.sql.catalyst.planning.PhysicalOperation
-import org.apache.spark.sql.catalyst.plans.logical.{Filter, LogicalPlan,
Project}
+import org.apache.spark.sql.catalyst.plans.logical.{Filter, LeafNode,
LogicalPlan, Project}
import org.apache.spark.sql.catalyst.rules.Rule
+import org.apache.spark.sql.execution.datasources.orc.OrcFileFormat
+import org.apache.spark.sql.execution.datasources.parquet.ParquetFileFormat
import org.apache.spark.sql.sources.BaseRelation
import org.apache.spark.sql.types.{ArrayType, DataType, MapType, StructType}
-import org.apache.spark.sql.util.SchemaUtils.restoreOriginalOutputNames
/**
* Prunes unnecessary physical columns given a [[PhysicalOperation]] over a
data source relation.
@@ -86,10 +86,8 @@ class Spark31NestedSchemaPruning extends Rule[LogicalPlan] {
// each schemata, assuming the fields in prunedDataSchema are a subset
of the fields
// in dataSchema.
if (countLeaves(dataSchema) > countLeaves(prunedDataSchema)) {
-val planUtils =
SparkAdapterSupport.sparkAdapter.getCatalystPlanUtils.asInstanceOf[HoodieSpark3CatalystPlanUtils]
-
val prunedRelation = outputRelationBuilder(prunedDataSchema)
-val projectionOverSchema =
planUtils.projectOverSchema(prunedDataSchema, AttributeSet(output))
+val projectionOverSchema = ProjectionOverSchema(prunedDataSchema)
Some(buildNewProjection(projects, normalizedProjects,
normalizedFilters,
prunedRelation, projectionOverSchema))
@@ -195,4 +193,14 @@ class Spark31NestedSchemaPruning extends Rule[LogicalPlan]
{
case _ => 1
}
}
+
+ def restoreOriginalOutputNames(
+ projectList: Seq[NamedExpression],
+ originalNames: Seq[String]):
Seq[NamedExpression] = {
+projectList.zip(originalNames).map {
+ case (attr: Attribute, name) => attr.withName(name)
+ case (alias: Alias, name) => alias
+ case (other, _) => other
+}
+ }
}
diff --git a/pom.xml b/pom.xml
index 60c13c8f07..0adb64838b 100644
--- a/pom.xml
+++ b/pom.xml
@@ -381,7 +381,7 @@
-ch.qos.logback:logback-classic
+
org.apache.hbase:hbase-common:*
@@ -389,7 +389,7 @@
org.apache.hbase:hbase-server:*
-org.slf4j:slf4j-simple:*:*:test
+
org.apache.hbase:hbase-common:${hbase.version}
org.apache.hbase:hbase-client:${hbase.version}
org.apache.hbase:hbase-server:${hbase.version}
@@ -1864,9 +1864,9 @@
-
-*:*_2.11
-
+
+
+
[hudi] 14/45: [HUDI-5041] Fix lock metric register confict error (#6968)
This is an automated email from the ASF dual-hosted git repository.
forwardxu pushed a commit to branch release-0.12.1
in repository https://gitbox.apache.org/repos/asf/hudi.git
commit 8d692f38c14f8d6e6fcb2f5fa1b159d0e5ade678
Author: Bingeng Huang <304979...@qq.com>
AuthorDate: Thu Oct 20 01:32:45 2022 +0800
[HUDI-5041] Fix lock metric register confict error (#6968)
Co-authored-by: hbg
(cherry picked from commit e6eb4e6f683ca9f66cdcca2d63eeb5a1a8d81241)
---
.../transaction/lock/metrics/HoodieLockMetrics.java | 19 +++
1 file changed, 11 insertions(+), 8 deletions(-)
diff --git
a/hudi-client/hudi-client-common/src/main/java/org/apache/hudi/client/transaction/lock/metrics/HoodieLockMetrics.java
b/hudi-client/hudi-client-common/src/main/java/org/apache/hudi/client/transaction/lock/metrics/HoodieLockMetrics.java
index 6ea7a1ae14..c33a86bfbe 100644
---
a/hudi-client/hudi-client-common/src/main/java/org/apache/hudi/client/transaction/lock/metrics/HoodieLockMetrics.java
+++
b/hudi-client/hudi-client-common/src/main/java/org/apache/hudi/client/transaction/lock/metrics/HoodieLockMetrics.java
@@ -18,15 +18,15 @@
package org.apache.hudi.client.transaction.lock.metrics;
-import org.apache.hudi.common.util.HoodieTimer;
-import org.apache.hudi.config.HoodieWriteConfig;
-import org.apache.hudi.metrics.Metrics;
-
import com.codahale.metrics.Counter;
import com.codahale.metrics.MetricRegistry;
import com.codahale.metrics.SlidingWindowReservoir;
import com.codahale.metrics.Timer;
+import org.apache.hudi.common.util.HoodieTimer;
+import org.apache.hudi.config.HoodieWriteConfig;
+import org.apache.hudi.metrics.Metrics;
+
import java.util.concurrent.TimeUnit;
public class HoodieLockMetrics {
@@ -46,6 +46,7 @@ public class HoodieLockMetrics {
private transient Counter failedLockAttempts;
private transient Timer lockDuration;
private transient Timer lockApiRequestDuration;
+ private static final Object REGISTRY_LOCK = new Object();
public HoodieLockMetrics(HoodieWriteConfig writeConfig) {
this.isMetricsEnabled = writeConfig.isLockingMetricsEnabled();
@@ -69,10 +70,12 @@ public class HoodieLockMetrics {
private Timer createTimerForMetrics(MetricRegistry registry, String metric) {
String metricName = getMetricsName(metric);
-if (registry.getMetrics().get(metricName) == null) {
- lockDuration = new Timer(new SlidingWindowReservoir(keepLastNtimes));
- registry.register(metricName, lockDuration);
- return lockDuration;
+synchronized (REGISTRY_LOCK) {
+ if (registry.getMetrics().get(metricName) == null) {
+lockDuration = new Timer(new SlidingWindowReservoir(keepLastNtimes));
+registry.register(metricName, lockDuration);
+return lockDuration;
+ }
}
return (Timer) registry.getMetrics().get(metricName);
}
[hudi] 19/45: add log to print scanInternal's logFilePath
This is an automated email from the ASF dual-hosted git repository.
forwardxu pushed a commit to branch release-0.12.1
in repository https://gitbox.apache.org/repos/asf/hudi.git
commit ecd39e3ad76b92a4f1dd0e18beed146736dc0592
Author: XuQianJin-Stars
AuthorDate: Wed Nov 2 12:26:49 2022 +0800
add log to print scanInternal's logFilePath
---
.../table/log/AbstractHoodieLogRecordReader.java | 41 --
1 file changed, 22 insertions(+), 19 deletions(-)
diff --git
a/hudi-common/src/main/java/org/apache/hudi/common/table/log/AbstractHoodieLogRecordReader.java
b/hudi-common/src/main/java/org/apache/hudi/common/table/log/AbstractHoodieLogRecordReader.java
index 4566b1f5cd..eaca33ddcf 100644
---
a/hudi-common/src/main/java/org/apache/hudi/common/table/log/AbstractHoodieLogRecordReader.java
+++
b/hudi-common/src/main/java/org/apache/hudi/common/table/log/AbstractHoodieLogRecordReader.java
@@ -72,7 +72,7 @@ import static
org.apache.hudi.common.table.log.block.HoodieLogBlock.HoodieLogBlo
/**
* Implements logic to scan log blocks and expose valid and deleted log
records to subclass implementation. Subclass is
* free to either apply merging or expose raw data back to the caller.
- *
+ *
* NOTE: If readBlockLazily is turned on, does not merge, instead keeps
reading log blocks and merges everything at once
* This is an optimization to avoid seek() back and forth to read new block
(forward seek()) and lazily read content of
* seen block (reverse and forward seek()) during merge | | Read Block 1
Metadata | | Read Block 1 Data | | | Read Block
@@ -208,6 +208,8 @@ public abstract class AbstractHoodieLogRecordReader {
HoodieTimeline commitsTimeline =
this.hoodieTableMetaClient.getCommitsTimeline();
HoodieTimeline completedInstantsTimeline =
commitsTimeline.filterCompletedInstants();
HoodieTimeline inflightInstantsTimeline =
commitsTimeline.filterInflights();
+HoodieLogFile logFile;
+Path logFilePath = null;
try {
// Get the key field based on populate meta fields config
// and the table type
@@ -216,12 +218,13 @@ public abstract class AbstractHoodieLogRecordReader {
// Iterate over the paths
boolean enableRecordLookups = !forceFullScan;
logFormatReaderWrapper = new HoodieLogFormatReader(fs,
- logFilePaths.stream().map(logFile -> new HoodieLogFile(new
Path(logFile))).collect(Collectors.toList()),
+ logFilePaths.stream().map(log -> new HoodieLogFile(new
Path(log))).collect(Collectors.toList()),
readerSchema, readBlocksLazily, reverseReader, bufferSize,
enableRecordLookups, keyField, internalSchema);
Set scannedLogFiles = new HashSet<>();
while (logFormatReaderWrapper.hasNext()) {
-HoodieLogFile logFile = logFormatReaderWrapper.getLogFile();
+logFile = logFormatReaderWrapper.getLogFile();
+logFilePath = logFile.getPath();
LOG.info("Scanning log file " + logFile);
scannedLogFiles.add(logFile);
totalLogFiles.set(scannedLogFiles.size());
@@ -250,7 +253,7 @@ public abstract class AbstractHoodieLogRecordReader {
case HFILE_DATA_BLOCK:
case AVRO_DATA_BLOCK:
case PARQUET_DATA_BLOCK:
-LOG.info("Reading a data block from file " + logFile.getPath() + "
at instant "
+LOG.info("Reading a data block from file " + logFilePath + " at
instant "
+ logBlock.getLogBlockHeader().get(INSTANT_TIME));
if (isNewInstantBlock(logBlock) && !readBlocksLazily) {
// If this is an avro data block belonging to a different
commit/instant,
@@ -261,7 +264,7 @@ public abstract class AbstractHoodieLogRecordReader {
currentInstantLogBlocks.push(logBlock);
break;
case DELETE_BLOCK:
-LOG.info("Reading a delete block from file " + logFile.getPath());
+LOG.info("Reading a delete block from file " + logFilePath);
if (isNewInstantBlock(logBlock) && !readBlocksLazily) {
// If this is a delete data block belonging to a different
commit/instant,
// then merge the last blocks and records into the main result
@@ -283,7 +286,7 @@ public abstract class AbstractHoodieLogRecordReader {
// written per ingestion batch for a file but in reality we need
to rollback (B1 & B2)
// The following code ensures the same rollback block (R1) is used
to rollback
// both B1 & B2
-LOG.info("Reading a command block from file " + logFile.getPath());
+LOG.info("Reading a command block from file " + logFilePath);
// This is a command block - take appropriate action based on the
command
HoodieCommandBlock commandBlock = (HoodieCommandBlock) logBlock;
String targetInstantForCommandBlock =
@@ -302,23 +305,23 @@ public abstract class AbstractHoodieLogRecordReader {
[hudi] 01/45: [MINOR] Adapt to tianqiong spark
This is an automated email from the ASF dual-hosted git repository. forwardxu pushed a commit to branch release-0.12.1 in repository https://gitbox.apache.org/repos/asf/hudi.git commit ac0d1d81a48d1ce558294757a5812487cd9b2cf0 Author: XuQianJin-Stars AuthorDate: Tue Aug 23 11:47:37 2022 +0800 [MINOR] Adapt to tianqiong spark --- dev/settings.xml | 266 + dev/tencent-install.sh | 157 dev/tencent-release.sh | 154 hudi-cli/pom.xml | 4 +- hudi-client/hudi-spark-client/pom.xml | 4 +- hudi-examples/hudi-examples-spark/pom.xml | 4 +- hudi-integ-test/pom.xml| 4 +- hudi-spark-datasource/hudi-spark-common/pom.xml| 12 +- hudi-spark-datasource/hudi-spark/pom.xml | 12 +- hudi-spark-datasource/hudi-spark2/pom.xml | 12 +- hudi-spark-datasource/hudi-spark3-common/pom.xml | 2 +- hudi-spark-datasource/hudi-spark3.1.x/pom.xml | 2 +- hudi-spark-datasource/hudi-spark3.2.x/pom.xml | 6 +- hudi-spark-datasource/hudi-spark3.3.x/pom.xml | 6 +- hudi-sync/hudi-hive-sync/pom.xml | 4 +- hudi-utilities/pom.xml | 10 +- .../org/apache/hudi/utilities/UtilHelpers.java | 38 ++- packaging/hudi-integ-test-bundle/pom.xml | 8 +- pom.xml| 94 +--- 19 files changed, 715 insertions(+), 84 deletions(-) diff --git a/dev/settings.xml b/dev/settings.xml new file mode 100644 index 00..5f5dfd4fa6 --- /dev/null +++ b/dev/settings.xml @@ -0,0 +1,266 @@ + + + +dev http +true +http +web-proxy.oa.com +8080 + mirrors.tencent.com|qq.com|localhost|127.0.0.1|*.oa.com|repo.maven.apache.org|packages.confluent.io + + +dev https +true +https +web-proxy.oa.com +8080 + mirrors.tencent.com|qq.com|localhost|127.0.0.1|*.oa.com|repo.maven.apache.org|packages.confluent.io + + + +false + + + +nexus + + +maven_public + https://mirrors.tencent.com/nexus/repository/maven-public/ + +true + + +false + + + +tencent_public + https://mirrors.tencent.com/repository/maven/tencent_public/ + +true + + +false + + + + +thirdparty + https://mirrors.tencent.com/repository/maven/thirdparty/ + +true + + +false + + + + +mqq + https://mirrors.tencent.com/repository/maven/mqq/ + +false + + +true + + + + +thirdparty-snapshots + https://mirrors.tencent.com/repository/maven/thirdparty-snapshots/ + +false + + +true + + + + + + +maven-public-plugin + https://mirrors.tencent.com/nexus/repository/maven-public/ + +true + + +false + + + +public-plugin + https://mirrors.tencent.com/repository/maven/tencent_public/ + +true + + +false + + + +thirdparty-plugin + https://mirrors.tencent.com/repository/maven/thirdparty/ + +true + + +false + + + + + + +tbds + + +tbds-maven-public +http://tbdsrepo.oa.com/repository/maven-public/ + +
[jira] [Updated] (HUDI-5495) add some property to table config
[ https://issues.apache.org/jira/browse/HUDI-5495?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] ASF GitHub Bot updated HUDI-5495: - Labels: pull-request-available (was: ) > add some property to table config > - > > Key: HUDI-5495 > URL: https://issues.apache.org/jira/browse/HUDI-5495 > Project: Apache Hudi > Issue Type: Improvement > Components: core >Reporter: Forward Xu >Assignee: Forward Xu >Priority: Major > Labels: pull-request-available > > add some property to table config > OperationField, > hoodie.index.type,hoodie.bucket.index.num.buckets,hoodie.bucket.index.hash.field -- This message was sent by Atlassian Jira (v8.20.10#820010)
[GitHub] [hudi] XuQianJin-Stars opened a new pull request, #7598: [HUDI-5495] add some property to table config
XuQianJin-Stars opened a new pull request, #7598: URL: https://github.com/apache/hudi/pull/7598 ### Change Logs add some property to table config `OperationField`, `hoodie.index.type`,`hoodie.bucket.index.num.buckets`,`hoodie.bucket.index.hash.field` ### Impact NA ### Risk level (write none, low medium or high below) None ### Documentation Update None ### Contributor's checklist - [ ] Read through [contributor's guide](https://hudi.apache.org/contribute/how-to-contribute) - [ ] Change Logs and Impact were stated clearly - [ ] Adequate tests were added if applicable - [ ] CI passed -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] boneanxs commented on a diff in pull request #7568: [HUDI-5341] CleanPlanner retains earliest commits must not be later than earliest pending commit
boneanxs commented on code in PR #7568:
URL: https://github.com/apache/hudi/pull/7568#discussion_r1061100539
##
hudi-common/src/main/java/org/apache/hudi/common/util/ClusteringUtils.java:
##
@@ -224,4 +225,37 @@ public static List
getPendingClusteringInstantTimes(HoodieTableMe
public static boolean isPendingClusteringInstant(HoodieTableMetaClient
metaClient, HoodieInstant instant) {
return getClusteringPlan(metaClient, instant).isPresent();
}
+
+ /**
+ * Checks whether the latest clustering instant has a subsequent cleaning
action. Returns
+ * the clustering instant if there is such cleaning action or empty.
+ *
+ * @param activeTimeline The active timeline
+ * @return the oldest instant to retain for clustering
+ */
+ public static Option
getOldestInstantToRetainForClustering(HoodieActiveTimeline activeTimeline)
+ throws IOException {
+HoodieTimeline replaceTimeline =
activeTimeline.getCompletedReplaceTimeline();
+if (!replaceTimeline.empty()) {
+ Option cleanInstantOpt =
+ activeTimeline.getCleanerTimeline().filter(instant ->
!instant.isCompleted()).firstInstant();
+ if (cleanInstantOpt.isPresent()) {
+// The first clustering instant of which timestamp is greater than or
equal to the earliest commit to retain of
+// the clean metadata.
+HoodieInstant cleanInstant = cleanInstantOpt.get();
+String earliestCommitToRetain =
Review Comment:
`earliestCommitToRetain` might be null if we use
`KEEP_LATEST_FILE_VERSIONS`, here we need to check it.
Also, if we use `KEEP_LATEST_FILE_VERSIONS`, not sure if this logic still is
valid.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] cxzl25 commented on pull request #7573: [HUDI-5484] Avoid using GenericRecord in ColumnStatMetadata
cxzl25 commented on PR #7573: URL: https://github.com/apache/hudi/pull/7573#issuecomment-1370432278 @hudi-bot run azure -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] fengjian428 commented on a diff in pull request #7440: [HUDI-5377] Write call stack information to lock file
fengjian428 commented on code in PR #7440:
URL: https://github.com/apache/hudi/pull/7440#discussion_r1061092800
##
hudi-client/hudi-client-common/src/main/java/org/apache/hudi/client/transaction/lock/FileSystemBasedLockProvider.java:
##
@@ -139,7 +152,32 @@ private boolean checkIfExpired() {
private void acquireLock() {
try {
- fs.create(this.lockFile, false).close();
+ if (!fs.exists(this.lockFile)) {
+FSDataOutputStream fos = fs.create(this.lockFile, false);
+initLockInfo();
+fos.writeBytes(lockInfo.toString());
Review Comment:
@nsivabalan I'm not sure about that since no S3 environment on my side. I
supposed there should be only one process to succeed, if not, we can write
InstantTime into file content and check the file content after obtaining the
lock as you said. I can add this logic, it should have no side effect
> May I know if you guys tested against both hdfs and S3.
>
> Atleast in S3, not sure if this works across all race conditions.
>
> what if two processes exactly checks fs.exists() concurrently and both
detects that file does not exist and goes ahead and creates the file. both
creation could succeed. So, how do we ensure only one of them succeed.
>
> Should we compare the file contents after creating. so that the current
writer which wrote the file will exactly know that it owns the lock if file
contents match.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[jira] [Updated] (HUDI-5485) Improve performance of savepoint with MDT
[ https://issues.apache.org/jira/browse/HUDI-5485?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Ethan Guo updated HUDI-5485: Epic Link: HUDI-1292 > Improve performance of savepoint with MDT > - > > Key: HUDI-5485 > URL: https://issues.apache.org/jira/browse/HUDI-5485 > Project: Apache Hudi > Issue Type: Improvement >Reporter: Ethan Guo >Assignee: Ethan Guo >Priority: Critical > Fix For: 0.13.0 > > > [https://github.com/apache/hudi/issues/7541] > When metadata table is enabled, the savepoint operation is slow for a large > number of partitions (e.g., 75k). The root cause is that for each partition, > the metadata table is scanned, which is unnecessary. -- This message was sent by Atlassian Jira (v8.20.10#820010)
[GitHub] [hudi] littleeleventhwolf commented on pull request #6524: [HUDI-4717] CompactionCommitEvent message corrupted when sent by compact_task
littleeleventhwolf commented on PR #6524: URL: https://github.com/apache/hudi/pull/6524#issuecomment-1370415430 > > > Does #7399 solve your problem here ? > > > > > > Yeah, we cherry-pick [#7399](https://github.com/apache/hudi/pull/7399). But if user enable latency-marker, there is still thread-safety problem. > > Does the Operator has any interface to handle the latency-marker yet ? Just like what we do to watermark. We can provide an empty method `processLatencyMarker(LatencyMarker latencyMarker)` to not propagate the latency-marker. But I don't think this is an elegant way, for two reasons: 1) if Flink generates a new `StreamElement` in future version, we also need to provide an empty method for compatibility; 2) if users want to use `Watermark` or `LatencyMarker` do some other work in Operator `Sink:compact_commit`, an empty method that does not propagate these events cannot support users' requirement. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Created] (HUDI-5495) add some property to table config
Forward Xu created HUDI-5495: Summary: add some property to table config Key: HUDI-5495 URL: https://issues.apache.org/jira/browse/HUDI-5495 Project: Apache Hudi Issue Type: Improvement Components: core Reporter: Forward Xu Assignee: Forward Xu add some property to table config OperationField, hoodie.index.type,hoodie.bucket.index.num.buckets,hoodie.bucket.index.hash.field -- This message was sent by Atlassian Jira (v8.20.10#820010)
[GitHub] [hudi] hudi-bot commented on pull request #7445: [HUDI-5380] Fixing change table path but table location in metastore …
hudi-bot commented on PR #7445: URL: https://github.com/apache/hudi/pull/7445#issuecomment-1370409959 ## CI report: * 36bc81d1f49d09d22eb8ad87d280b0f1f61f4a44 Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=13998) Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=14025) Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=14031) Azure: [PENDING](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=14087) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] BruceKellan commented on pull request #7445: [HUDI-5380] Fixing change table path but table location in metastore …
BruceKellan commented on PR #7445: URL: https://github.com/apache/hudi/pull/7445#issuecomment-1370408417 @hudi-bot run azure -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] BruceKellan commented on pull request #7445: [HUDI-5380] Fixing change table path but table location in metastore …
BruceKellan commented on PR #7445: URL: https://github.com/apache/hudi/pull/7445#issuecomment-1370407949 run azure -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] yanghua commented on a diff in pull request #7440: [HUDI-5377] Write call stack information to lock file
yanghua commented on code in PR #7440:
URL: https://github.com/apache/hudi/pull/7440#discussion_r1061082761
##
hudi-client/hudi-client-common/src/main/java/org/apache/hudi/client/transaction/lock/FileSystemBasedLockProvider.java:
##
@@ -139,7 +152,32 @@ private boolean checkIfExpired() {
private void acquireLock() {
try {
- fs.create(this.lockFile, false).close();
+ if (!fs.exists(this.lockFile)) {
+FSDataOutputStream fos = fs.create(this.lockFile, false);
+initLockInfo();
+fos.writeBytes(lockInfo.toString());
Review Comment:
>> May I know if you guys tested against both hdfs and S3.
I did not test on S3, just used this feature(on HDFS) only several times.
@fengjian428 Can you give it a try?
If it occurs race conditions on S3, we should find a way to fix it.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] yihua commented on issue #7472: [SUPPORT] Too many metadata timeline file caused by old rollback active timeline
yihua commented on issue #7472: URL: https://github.com/apache/hudi/issues/7472#issuecomment-1370396761 @yyar sounds good. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Created] (HUDI-5494) Make target file-size auto-tunable based on the target table's expected size
Alexey Kudinkin created HUDI-5494: - Summary: Make target file-size auto-tunable based on the target table's expected size Key: HUDI-5494 URL: https://issues.apache.org/jira/browse/HUDI-5494 Project: Apache Hudi Issue Type: Bug Reporter: Alexey Kudinkin Currently Hudi follows a model of having a static target file size configured by the user. We should consider a mode where Hudi will automatically configure the file-size based on the expected target table size, similar to what [Delta does|https://learn.microsoft.com/en-us/azure/databricks/delta/tune-file-size] for ex. -- This message was sent by Atlassian Jira (v8.20.10#820010)
[GitHub] [hudi] yihua commented on pull request #7568: [HUDI-5341] CleanPlanner retains earliest commits must not be later than earliest pending commit
yihua commented on PR #7568: URL: https://github.com/apache/hudi/pull/7568#issuecomment-1370393527 @SteNicholas could you check the CI failure? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] stayrascal commented on pull request #7584: [HUDI-5205] Support Flink 1.16.0
stayrascal commented on PR #7584: URL: https://github.com/apache/hudi/pull/7584#issuecomment-1370393070 > @stayrascal @danny0405 Thanks for making this change, just to confirm this is targeted for Hudi 0.13.0? Currently, this change is targeted to master branch(0.13.0), but in my case, I will apply this change in old version(0.11.1 or 0.12) once everything passed, is there any concern or blockers about apply this change to older version? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] stayrascal commented on pull request #7584: [HUDI-5205] Support Flink 1.16.0
stayrascal commented on PR #7584:
URL: https://github.com/apache/hudi/pull/7584#issuecomment-1370391345
> Thanks for the contribution, I have reviewed and applied a patch here:
[5205.zip](https://github.com/apache/hudi/files/10334376/5205.zip)
>
> You can apply the patch with cmd: `git apply ${patch_path}` Then force
push the branch with cmd: `git push ${branch_name} --force`.
Thanks a lot for reviewing this PR, will apply this patch.
BTW, there are some IT cases failed(NPE) about reading data from
`ContinousFileSource`, still need fix the issues later.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] stayrascal commented on a diff in pull request #7584: [HUDI-5205] Support Flink 1.16.0
stayrascal commented on code in PR #7584:
URL: https://github.com/apache/hudi/pull/7584#discussion_r1061072974
##
hudi-flink-datasource/hudi-flink1.13.x/src/main/java/org/apache/hudi/adapter/SortCodeGeneratorAdapter.java:
##
@@ -0,0 +1,15 @@
+package org.apache.hudi.adapter;
+
+import org.apache.flink.table.api.TableConfig;
+import org.apache.flink.table.planner.codegen.sort.SortCodeGenerator;
+import org.apache.flink.table.planner.plan.nodes.exec.spec.SortSpec;
+import org.apache.flink.table.types.logical.RowType;
+
+/**
+ * Bridge class for shaded guava clazz {@code SortCodeGenerator}.
+ */
Review Comment:
got it, thanks.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] stayrascal commented on a diff in pull request #7584: [HUDI-5205] Support Flink 1.16.0
stayrascal commented on code in PR #7584:
URL: https://github.com/apache/hudi/pull/7584#discussion_r1061072838
##
.github/workflows/bot.yml:
##
@@ -95,6 +96,8 @@ jobs:
strategy:
matrix:
include:
+ - flinkProfile: 'flink1.16'
+sparkProfile: 'spark3.3'
- flinkProfile: 'flink1.15'
sparkProfile: 'spark3.3'
Review Comment:
got it.
##
hudi-flink-datasource/hudi-flink1.13.x/src/main/java/org/apache/hudi/adapter/StreamWriteOperatorCoordinatorAdapter.java:
##
@@ -0,0 +1,9 @@
+package org.apache.hudi.adapter;
+
+import org.apache.flink.runtime.operators.coordination.OperatorCoordinator;
+
+/**
+ * Bridge class for shaded guava clazz {@code StreamWriteOperatorCoordinator}.
+ */
Review Comment:
got it.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] nsivabalan commented on a diff in pull request #6071: [HUDI-4065] Add FileBasedLockProvider
nsivabalan commented on code in PR #6071:
URL: https://github.com/apache/hudi/pull/6071#discussion_r1061068779
##
hudi-client/hudi-client-common/src/main/java/org/apache/hudi/client/transaction/lock/FileSystemBasedLockProvider.java:
##
@@ -0,0 +1,152 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.hudi.client.transaction.lock;
+
+import org.apache.hadoop.conf.Configuration;
+import org.apache.hadoop.fs.FileSystem;
+import org.apache.hadoop.fs.Path;
+import org.apache.hudi.common.config.LockConfiguration;
+import org.apache.hudi.common.fs.FSUtils;
+import org.apache.hudi.common.lock.LockProvider;
+import org.apache.hudi.common.lock.LockState;
+import org.apache.hudi.common.table.HoodieTableMetaClient;
+import org.apache.hudi.common.util.StringUtils;
+import org.apache.hudi.common.util.ValidationUtils;
+import org.apache.hudi.config.HoodieWriteConfig;
+import org.apache.hudi.exception.HoodieIOException;
+import org.apache.hudi.exception.HoodieLockException;
+import org.apache.log4j.LogManager;
+import org.apache.log4j.Logger;
+
+import java.io.IOException;
+import java.io.Serializable;
+import java.util.concurrent.TimeUnit;
+
+import static
org.apache.hudi.common.config.LockConfiguration.FILESYSTEM_LOCK_EXPIRE_PROP_KEY;
+import static
org.apache.hudi.common.config.LockConfiguration.FILESYSTEM_LOCK_PATH_PROP_KEY;
+
+/**
+ * A FileSystem based lock. This {@link LockProvider} implementation allows to
lock table operations
+ * using DFS. Users might need to manually clean the Locker's path if
writeClient crash and never run again.
+ * NOTE: This only works for DFS with atomic create/delete operation
+ */
+public class FileSystemBasedLockProvider implements LockProvider,
Serializable {
+
+ private static final Logger LOG =
LogManager.getLogger(FileSystemBasedLockProvider.class);
+
+ private static final String LOCK_FILE_NAME = "lock";
+
+ private final int lockTimeoutMinutes;
+ private transient FileSystem fs;
+ private transient Path lockFile;
+ protected LockConfiguration lockConfiguration;
+
+ public FileSystemBasedLockProvider(final LockConfiguration
lockConfiguration, final Configuration configuration) {
+checkRequiredProps(lockConfiguration);
+this.lockConfiguration = lockConfiguration;
+String lockDirectory =
lockConfiguration.getConfig().getString(FILESYSTEM_LOCK_PATH_PROP_KEY, null);
+if (StringUtils.isNullOrEmpty(lockDirectory)) {
+ lockDirectory =
lockConfiguration.getConfig().getString(HoodieWriteConfig.BASE_PATH.key())
++ Path.SEPARATOR + HoodieTableMetaClient.METAFOLDER_NAME;
+}
+this.lockTimeoutMinutes =
lockConfiguration.getConfig().getInteger(FILESYSTEM_LOCK_EXPIRE_PROP_KEY);
+this.lockFile = new Path(lockDirectory + Path.SEPARATOR + LOCK_FILE_NAME);
+this.fs = FSUtils.getFs(this.lockFile.toString(), configuration);
+ }
+
+ @Override
+ public void close() {
+synchronized (LOCK_FILE_NAME) {
+ try {
+fs.delete(this.lockFile, true);
+ } catch (IOException e) {
+throw new
HoodieLockException(generateLogStatement(LockState.FAILED_TO_RELEASE), e);
+ }
+}
+ }
+
+ @Override
+ public boolean tryLock(long time, TimeUnit unit) {
+try {
+ synchronized (LOCK_FILE_NAME) {
+// Check whether lock is already expired, if so try to delete lock file
+if (fs.exists(this.lockFile) && checkIfExpired()) {
+ fs.delete(this.lockFile, true);
+}
+acquireLock();
+return fs.exists(this.lockFile);
+ }
+} catch (IOException | HoodieIOException e) {
+ LOG.info(generateLogStatement(LockState.FAILED_TO_ACQUIRE), e);
+ return false;
+}
+ }
+
+ @Override
+ public void unlock() {
+synchronized (LOCK_FILE_NAME) {
+ try {
+if (fs.exists(this.lockFile)) {
+ fs.delete(this.lockFile, true);
+}
+ } catch (IOException io) {
+throw new
HoodieIOException(generateLogStatement(LockState.FAILED_TO_RELEASE), io);
+ }
+}
+ }
+
+ @Override
+ public String getLock() {
+return this.lockFile.toString();
+ }
+
+ private boolean checkIfExpired() {
+if (lockTimeoutMinutes == 0) {
+
[GitHub] [hudi] nsivabalan commented on a diff in pull request #7440: [HUDI-5377] Write call stack information to lock file
nsivabalan commented on code in PR #7440:
URL: https://github.com/apache/hudi/pull/7440#discussion_r1061068482
##
hudi-client/hudi-client-common/src/main/java/org/apache/hudi/client/transaction/lock/FileSystemBasedLockProvider.java:
##
@@ -139,7 +152,32 @@ private boolean checkIfExpired() {
private void acquireLock() {
try {
- fs.create(this.lockFile, false).close();
+ if (!fs.exists(this.lockFile)) {
+FSDataOutputStream fos = fs.create(this.lockFile, false);
+initLockInfo();
+fos.writeBytes(lockInfo.toString());
Review Comment:
May I know if you guys tested against both hdfs and S3.
Atleast in S3, not sure if this works across all race conditions.
what if two processes exactly checks fs.exists() concurrently and both
detects that file does not exist and goes ahead and creates the file. both
creation could succeed. So, how do we ensure only one of them succeed.
Should we compare the file contents after creating. so that the current
writer which wrote the file will exactly know that it owns the lock if file
contents match.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] nsivabalan commented on a diff in pull request #6071: [HUDI-4065] Add FileBasedLockProvider
nsivabalan commented on code in PR #6071:
URL: https://github.com/apache/hudi/pull/6071#discussion_r1061067820
##
hudi-client/hudi-client-common/src/main/java/org/apache/hudi/client/transaction/lock/FileSystemBasedLockProvider.java:
##
@@ -0,0 +1,152 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.hudi.client.transaction.lock;
+
+import org.apache.hadoop.conf.Configuration;
+import org.apache.hadoop.fs.FileSystem;
+import org.apache.hadoop.fs.Path;
+import org.apache.hudi.common.config.LockConfiguration;
+import org.apache.hudi.common.fs.FSUtils;
+import org.apache.hudi.common.lock.LockProvider;
+import org.apache.hudi.common.lock.LockState;
+import org.apache.hudi.common.table.HoodieTableMetaClient;
+import org.apache.hudi.common.util.StringUtils;
+import org.apache.hudi.common.util.ValidationUtils;
+import org.apache.hudi.config.HoodieWriteConfig;
+import org.apache.hudi.exception.HoodieIOException;
+import org.apache.hudi.exception.HoodieLockException;
+import org.apache.log4j.LogManager;
+import org.apache.log4j.Logger;
+
+import java.io.IOException;
+import java.io.Serializable;
+import java.util.concurrent.TimeUnit;
+
+import static
org.apache.hudi.common.config.LockConfiguration.FILESYSTEM_LOCK_EXPIRE_PROP_KEY;
+import static
org.apache.hudi.common.config.LockConfiguration.FILESYSTEM_LOCK_PATH_PROP_KEY;
+
+/**
+ * A FileSystem based lock. This {@link LockProvider} implementation allows to
lock table operations
+ * using DFS. Users might need to manually clean the Locker's path if
writeClient crash and never run again.
+ * NOTE: This only works for DFS with atomic create/delete operation
+ */
+public class FileSystemBasedLockProvider implements LockProvider,
Serializable {
+
+ private static final Logger LOG =
LogManager.getLogger(FileSystemBasedLockProvider.class);
+
+ private static final String LOCK_FILE_NAME = "lock";
+
+ private final int lockTimeoutMinutes;
+ private transient FileSystem fs;
+ private transient Path lockFile;
+ protected LockConfiguration lockConfiguration;
+
+ public FileSystemBasedLockProvider(final LockConfiguration
lockConfiguration, final Configuration configuration) {
+checkRequiredProps(lockConfiguration);
+this.lockConfiguration = lockConfiguration;
+String lockDirectory =
lockConfiguration.getConfig().getString(FILESYSTEM_LOCK_PATH_PROP_KEY, null);
+if (StringUtils.isNullOrEmpty(lockDirectory)) {
+ lockDirectory =
lockConfiguration.getConfig().getString(HoodieWriteConfig.BASE_PATH.key())
++ Path.SEPARATOR + HoodieTableMetaClient.METAFOLDER_NAME;
+}
+this.lockTimeoutMinutes =
lockConfiguration.getConfig().getInteger(FILESYSTEM_LOCK_EXPIRE_PROP_KEY);
+this.lockFile = new Path(lockDirectory + Path.SEPARATOR + LOCK_FILE_NAME);
+this.fs = FSUtils.getFs(this.lockFile.toString(), configuration);
+ }
+
+ @Override
+ public void close() {
+synchronized (LOCK_FILE_NAME) {
+ try {
+fs.delete(this.lockFile, true);
+ } catch (IOException e) {
+throw new
HoodieLockException(generateLogStatement(LockState.FAILED_TO_RELEASE), e);
+ }
+}
+ }
+
+ @Override
+ public boolean tryLock(long time, TimeUnit unit) {
+try {
+ synchronized (LOCK_FILE_NAME) {
+// Check whether lock is already expired, if so try to delete lock file
+if (fs.exists(this.lockFile) && checkIfExpired()) {
+ fs.delete(this.lockFile, true);
+}
+acquireLock();
+return fs.exists(this.lockFile);
+ }
+} catch (IOException | HoodieIOException e) {
+ LOG.info(generateLogStatement(LockState.FAILED_TO_ACQUIRE), e);
+ return false;
+}
+ }
+
+ @Override
+ public void unlock() {
+synchronized (LOCK_FILE_NAME) {
+ try {
+if (fs.exists(this.lockFile)) {
+ fs.delete(this.lockFile, true);
+}
+ } catch (IOException io) {
+throw new
HoodieIOException(generateLogStatement(LockState.FAILED_TO_RELEASE), io);
+ }
+}
+ }
+
+ @Override
+ public String getLock() {
+return this.lockFile.toString();
+ }
+
+ private boolean checkIfExpired() {
+if (lockTimeoutMinutes == 0) {
+