[GitHub] [hudi] jenu9417 commented on issue #7991: Higher number of S3 HEAD requests, while writing data to S3.
jenu9417 commented on issue #7991: URL: https://github.com/apache/hudi/issues/7991#issuecomment-1465110980 @nsivabalan Thanks for the update. `/data/testfolder` is the basepath for the table. To clarify the below is the folder structure. ``` /data/testfolder/ /data/testfolder/.hoodie/ /data/testfolder/.hoodie/.aux/ /data/testfolder/.hoodie/.aux/.bootstrap/.fileids/ /data/testfolder/.hoodie/.aux/.bootstrap/.partitions/ /data/testfolder/.hoodie/.temp/ /data/testfolder/.hoodie/.temp/20230303104616/ /data/testfolder/.hoodie/archived/ /data/testfolder/.hoodie/hoodie.properties ``` There are no other non hudi folders present inside `/data/testfolder/` And I'm seeing a lot of HEAD operations happening for `/data/`and ` /data/testfolder/` Few Examples from S3 access logs. LIST `` "GET /?prefix=repo%2Fsms_data_1_newtable_ind_mor%2F&delimiter=%2F&max-keys=2&encoding-type=url HTTP/1.1" "GET /?prefix=repo%2Fsms_data_1_newtable_ind_mor%2F.hoodie%2F&delimiter=%2F&max-keys=2&encoding-type=url HTTP/1.1" "GET /?prefix=repo%2Fsms_data_1_newtable_ind_mor%2F.hoodie%2F.aux%2F.bootstrap%2F.partitions%2F&delimiter=%2F&max-keys=2&encoding-type=url HTTP/1.1" "GET /?prefix=repo%2Fsms_data_1_newtable_ind_mor%2F&delimiter=%2F&max-keys=2&encoding-type=url HTTP/1.1" ``` HEAD ``` "HEAD /repo HTTP/1.1" "HEAD /repo/sms_data_1_newtable_ind_mor HTTP/1.1" "HEAD /repo/sms_data_1_newtable_ind_mor/.hoodie HTTP/1.1" "HEAD /repo/sms_data_1_newtable_ind_mor HTTP/1.1" Such requests repeat through out the write operation. The major issue we face is the frequency of such API hits happening per write to 1 partition. We see around 100 LIST and 100 HEAD operations per write to 1 partition. Since LIST is costlier operation, the impact of such higher number of LIST API operations per write to 1 partition is making the overall approach costlier. If we could understand the correlation between various types of API hits (specifically LIST and HEAD) per write to 1 partition, it will be helpful for us to decide. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] XuQianJin-Stars commented on a diff in pull request #7680: [HUDI-5548] spark sql show | update hudi's table properties
XuQianJin-Stars commented on code in PR #7680:
URL: https://github.com/apache/hudi/pull/7680#discussion_r1133184491
##
hudi-spark-datasource/hudi-spark3.2plus-common/src/main/scala/org/apache/spark/sql/hudi/command/AlterTableCommand.scala:
##
@@ -179,37 +184,6 @@ case class AlterTableCommand(table: CatalogTable, changes:
Seq[TableChange], cha
logInfo("column update finished")
}
- // to do support unset default value to columns, and apply them to
internalSchema
Review Comment:
> Are we essentially moving this part in Spark 3.1 and 3.2 to
AlterHoodieTable[Un]Set class ? What are the side effects here ? Are we
disallowing existing mechanisms to set/unset props with this change ?
There are no side effects, which can simplify and unify the original code
logic.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #8102: [HUDI-5880] Support partition pruning for flink streaming source in runtime
hudi-bot commented on PR #8102: URL: https://github.com/apache/hudi/pull/8102#issuecomment-1465088667 ## CI report: * e2ceb307219b4e27b276ab986c47bf77a1ec2d25 Azure: [SUCCESS](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15678) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] nsivabalan commented on issue #8153: [SUPPORT] Async Clustering failing for MoR in 0.13.0
nsivabalan commented on issue #8153: URL: https://github.com/apache/hudi/issues/8153#issuecomment-1465088347 can you confirm you are have compile and run time spark versions matched? for eg, if you are using hudi-spark3.2-bundle, your run time spark should be spark3.2.* -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] nsivabalan commented on issue #8132: [SUPPORT] data loss in new base file after compaction
nsivabalan commented on issue #8132: URL: https://github.com/apache/hudi/issues/8132#issuecomment-1465088037 Do you know if there could be any unintentional multi-writer interplay? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] nsivabalan commented on issue #8132: [SUPPORT] data loss in new base file after compaction
nsivabalan commented on issue #8132: URL: https://github.com/apache/hudi/issues/8132#issuecomment-1465087986 I can't seem to find any reason why this could happen. but don't think 8079 is the issue. that would surface differently. anyways, 0.7.0 is very old. We have come a long way from 0.7.0. We have fixed issues w/ compaction and spark cache invalidation For eg https://github.com/apache/hudi/pull/4753 https://github.com/apache/hudi/pull/4856 but I could not exactly say if these are the issues. But from the timeline provided, I could not reason about why parquet size might reduce. infact number of records reduced by 50% from previous version, even though log file modified just 100 ish records :( -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] nsivabalan commented on issue #8132: [SUPPORT] data loss in new base file after compaction
nsivabalan commented on issue #8132: URL: https://github.com/apache/hudi/issues/8132#issuecomment-1465087152 I am not sure if this was related to https://github.com/apache/hudi/pull/8079 I am trying to analyze all details. will update if I have any findings. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] nsivabalan commented on issue #8130: Spark java.util.NoSuchElementException: FileID * partition path p_c=CN_1 does not exist.
nsivabalan commented on issue #8130: URL: https://github.com/apache/hudi/issues/8130#issuecomment-1465085889 how did you delete metadata table btw. can you post the contents of ".hoodie/hoodie.properties" -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] nsivabalan commented on issue #8129: [SUPPORT] hoodie.write.lock.dynamodb.partition_key not set automatically
nsivabalan commented on issue #8129:
URL: https://github.com/apache/hudi/issues/8129#issuecomment-1465085384
@Limess :
Are you setting "hoodie.table.name" in your write configs? this is our infer
fuction
```
public static final ConfigProperty DYNAMODB_LOCK_PARTITION_KEY =
ConfigProperty
.key(DYNAMODB_BASED_LOCK_PROPERTY_PREFIX + "partition_key")
.noDefaultValue()
.sinceVersion("0.10.0")
.withInferFunction(cfg -> {
if (cfg.contains(HoodieTableConfig.NAME)) {
return Option.of(cfg.getString(HoodieTableConfig.NAME));
}
return Option.empty();
})
.withDocumentation("For DynamoDB based lock provider, the partition
key for the DynamoDB lock table. "
+ "Each Hudi dataset should has it's unique key so
concurrent writers could refer to the same partition key."
+ " By default we use the Hudi table name specified
to be the partition key");
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] nsivabalan commented on issue #8121: [SUPPORT] MOR Table Duplicated Records Found
nsivabalan commented on issue #8121: URL: https://github.com/apache/hudi/issues/8121#issuecomment-1465084863 Could be couple of issues: 1. I see you are setting COMBINE_BEFORE_UPSERT.key() -> "false". this should be set to true. if not, duplicates records from incoming batch may not be deduped. 2. Could be due to https://github.com/apache/hudi/pull/8079 which we found recently. Can you try w/ latest master or apply above patch and give it a try. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] nsivabalan commented on issue #8100: [SUPPORT] Unstable Execution Time and Many RequestHandler WARN Logs
nsivabalan commented on issue #8100: URL: https://github.com/apache/hudi/issues/8100#issuecomment-1465084370 yes. if you enable inline compaction, once every N delta commits, compaction might kick in. and so, all other writes will see lesser write latency while the Nth delta commit will have higher latency since compaction also happens. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] nsivabalan closed issue #8085: [SUPPORT] deltacommit triggering criteria
nsivabalan closed issue #8085: [SUPPORT] deltacommit triggering criteria URL: https://github.com/apache/hudi/issues/8085 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] nsivabalan commented on issue #8085: [SUPPORT] deltacommit triggering criteria
nsivabalan commented on issue #8085: URL: https://github.com/apache/hudi/issues/8085#issuecomment-1465084173 yes, you are right. going ahead and closing out the github issue. Feel free to open a new one if you have any doubts or have more clarifications -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #8102: [HUDI-5880] Support partition pruning for flink streaming source in runtime
hudi-bot commented on PR #8102: URL: https://github.com/apache/hudi/pull/8102#issuecomment-1465074446 ## CI report: * 5b46e06d81e5680024cca39a94f00b2f18c179e0 Azure: [CANCELED](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15677) * e2ceb307219b4e27b276ab986c47bf77a1ec2d25 Azure: [PENDING](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15678) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #8102: [HUDI-5880] Support partition pruning for flink streaming source in runtime
hudi-bot commented on PR #8102: URL: https://github.com/apache/hudi/pull/8102#issuecomment-1465073621 ## CI report: * f500063efc2baefad6c6c53e77f25b730b0c0346 Azure: [SUCCESS](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15675) * 5b46e06d81e5680024cca39a94f00b2f18c179e0 Azure: [PENDING](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15677) * e2ceb307219b4e27b276ab986c47bf77a1ec2d25 UNKNOWN Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #8102: [HUDI-5880] Support partition pruning for flink streaming source in runtime
hudi-bot commented on PR #8102: URL: https://github.com/apache/hudi/pull/8102#issuecomment-1465065937 ## CI report: * f500063efc2baefad6c6c53e77f25b730b0c0346 Azure: [SUCCESS](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15675) * 5b46e06d81e5680024cca39a94f00b2f18c179e0 Azure: [PENDING](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15677) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #8102: [HUDI-5880] Support partition pruning for flink streaming source in runtime
hudi-bot commented on PR #8102: URL: https://github.com/apache/hudi/pull/8102#issuecomment-1465065055 ## CI report: * f500063efc2baefad6c6c53e77f25b730b0c0346 Azure: [SUCCESS](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15675) * 5b46e06d81e5680024cca39a94f00b2f18c179e0 UNKNOWN Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] bvaradar commented on pull request #7808: [MINOR] use ExecutorFactory in BootstrapHandler
bvaradar commented on PR #7808: URL: https://github.com/apache/hudi/pull/7808#issuecomment-1465061806 Just noting down: Existing tests cover the change. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] bvaradar commented on pull request #7129: [MINOR] Support column type evolution for Hive
bvaradar commented on PR #7129: URL: https://github.com/apache/hudi/pull/7129#issuecomment-1465059772 @fsilent : Thanks a lot for the PR. Can you fix the package dependencies and also add a jira ticket in the description. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] bvaradar commented on a diff in pull request #7129: [MINOR] Support column type evolution for Hive
bvaradar commented on code in PR #7129:
URL: https://github.com/apache/hudi/pull/7129#discussion_r1133166754
##
hudi-sync/hudi-hive-sync/pom.xml:
##
@@ -121,6 +121,17 @@
hive-common
${hive.version}
+
Review Comment:
Can you remove this dependency as the change is in hudi-hadoop-mr package
and hive-exec is already defined as dependency in hudi-hadoop-mr /pom.xml
##
hudi-spark-datasource/hudi-spark-common/pom.xml:
##
@@ -222,6 +222,20 @@
test
+
+
Review Comment:
This is still showing up. Can you remove this dependency as the change is in
hudi-hadoop-mr package and hive-exec is already defined as dependency in
hudi-hadoop-mr /pom.xml
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] bvaradar commented on a diff in pull request #7834: [HUDI-5690] Add simpleBucketPartitioner to support using the simple bucket index under bulkinsert
bvaradar commented on code in PR #7834:
URL: https://github.com/apache/hudi/pull/7834#discussion_r1133165678
##
hudi-client/hudi-client-common/src/main/java/org/apache/hudi/table/storage/HoodieSimpleBucketLayout.java:
##
@@ -34,6 +34,7 @@ public class HoodieSimpleBucketLayout extends
HoodieStorageLayout {
public static final Set SUPPORTED_OPERATIONS =
CollectionUtils.createImmutableSet(
WriteOperationType.INSERT,
WriteOperationType.INSERT_PREPPED,
+ WriteOperationType.BULK_INSERT,
Review Comment:
@wuwenchi @YuweiXiao : should HoodieBucketIndex.requiresTagging also return
True for Bulk_Index ?
##
hudi-client/hudi-spark-client/src/main/java/org/apache/hudi/execution/bulkinsert/RDDBucketIndexPartitioner.java:
##
@@ -18,15 +18,155 @@
package org.apache.hudi.execution.bulkinsert;
+import org.apache.avro.Schema;
+import org.apache.hudi.avro.HoodieAvroUtils;
+import org.apache.hudi.common.config.SerializableSchema;
+import org.apache.hudi.common.fs.FSUtils;
+import org.apache.hudi.common.model.HoodieKey;
import org.apache.hudi.common.model.HoodieRecord;
+import org.apache.hudi.common.model.HoodieTableType;
+import org.apache.hudi.common.util.Option;
+import org.apache.hudi.common.util.ValidationUtils;
+import org.apache.hudi.common.util.collection.FlatLists;
+import org.apache.hudi.io.AppendHandleFactory;
+import org.apache.hudi.io.SingleFileHandleCreateFactory;
+import org.apache.hudi.io.WriteHandleFactory;
import org.apache.hudi.table.BulkInsertPartitioner;
+import org.apache.hudi.table.HoodieTable;
+import org.apache.logging.log4j.LogManager;
+import org.apache.logging.log4j.Logger;
+import org.apache.spark.Partitioner;
import org.apache.spark.api.java.JavaRDD;
+import scala.Tuple2;
+
+import java.io.Serializable;
+import java.util.ArrayList;
+import java.util.Arrays;
+import java.util.Comparator;
+import java.util.List;
+
/**
* Abstract of bucket index bulk_insert partitioner
- * TODO implement partitioner for SIMPLE BUCKET INDEX
*/
public abstract class RDDBucketIndexPartitioner
implements BulkInsertPartitioner>> {
+
Review Comment:
HoodieBucketIndex is defined in Engine agnostic way (uses HoodieData and
HoodieEngineContext). Can we also define the base partitioner class using these
abstractions instead of directly using JavaRDD ?
##
hudi-client/hudi-spark-client/src/main/java/org/apache/hudi/execution/bulkinsert/RDDBucketIndexPartitioner.java:
##
@@ -18,15 +18,155 @@
package org.apache.hudi.execution.bulkinsert;
+import org.apache.avro.Schema;
+import org.apache.hudi.avro.HoodieAvroUtils;
+import org.apache.hudi.common.config.SerializableSchema;
+import org.apache.hudi.common.fs.FSUtils;
+import org.apache.hudi.common.model.HoodieKey;
import org.apache.hudi.common.model.HoodieRecord;
+import org.apache.hudi.common.model.HoodieTableType;
+import org.apache.hudi.common.util.Option;
+import org.apache.hudi.common.util.ValidationUtils;
+import org.apache.hudi.common.util.collection.FlatLists;
+import org.apache.hudi.io.AppendHandleFactory;
+import org.apache.hudi.io.SingleFileHandleCreateFactory;
+import org.apache.hudi.io.WriteHandleFactory;
import org.apache.hudi.table.BulkInsertPartitioner;
+import org.apache.hudi.table.HoodieTable;
+import org.apache.logging.log4j.LogManager;
+import org.apache.logging.log4j.Logger;
+import org.apache.spark.Partitioner;
import org.apache.spark.api.java.JavaRDD;
+import scala.Tuple2;
+
+import java.io.Serializable;
+import java.util.ArrayList;
+import java.util.Arrays;
+import java.util.Comparator;
+import java.util.List;
+
/**
* Abstract of bucket index bulk_insert partitioner
- * TODO implement partitioner for SIMPLE BUCKET INDEX
*/
public abstract class RDDBucketIndexPartitioner
implements BulkInsertPartitioner>> {
+
Review Comment:
HoodieBucketIndex is defined in Engine agnostic way (uses HoodieData and
HoodieEngineContext). Can we also define the base partitioner class using these
abstractions instead of directly using JavaRDD ?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] bvaradar commented on pull request #7922: [HUDI-5578] Upgrade base docker image for java 8
bvaradar commented on PR #7922: URL: https://github.com/apache/hudi/pull/7922#issuecomment-1465037484 @kazdy : Can you look at https://github.com/apache/hudi/tree/master/docker for details on how to setup locally ? Can you try locally removing all the pulled hudi images and try ? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] bvaradar commented on a diff in pull request #5965: [MINOR] Propagate cleaner exceptions
bvaradar commented on code in PR #5965:
URL: https://github.com/apache/hudi/pull/5965#discussion_r1133153557
##
hudi-utilities/src/main/java/org/apache/hudi/utilities/HoodieCleaner.java:
##
@@ -106,12 +106,7 @@ public static void main(String[] args) {
String dirName = new Path(cfg.basePath).getName();
JavaSparkContext jssc = UtilHelpers.buildSparkContext("hoodie-cleaner-" +
dirName, cfg.sparkMaster);
-try {
- new HoodieCleaner(cfg, jssc).run();
-} catch (Throwable throwable) {
- LOG.error("Fail to run cleaning for " + cfg.basePath, throwable);
-} finally {
- jssc.stop();
Review Comment:
@haggy : Can you make this change and update the PR ?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] bvaradar commented on pull request #7255: [HUDI-5250] use the estimate record size when estimation threshold is l…
bvaradar commented on PR #7255: URL: https://github.com/apache/hudi/pull/7255#issuecomment-1465030892 @honeyaya : Changes look good. Can you add a test-case where getRecordSizeEstimationThreshold < 0 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] bvaradar commented on a diff in pull request #7680: [HUDI-5548] spark sql show | update hudi's table properties
bvaradar commented on code in PR #7680:
URL: https://github.com/apache/hudi/pull/7680#discussion_r1133151769
##
hudi-spark-datasource/hudi-spark3.2plus-common/src/main/scala/org/apache/spark/sql/hudi/command/AlterTableCommand.scala:
##
@@ -179,37 +184,6 @@ case class AlterTableCommand(table: CatalogTable, changes:
Seq[TableChange], cha
logInfo("column update finished")
}
- // to do support unset default value to columns, and apply them to
internalSchema
Review Comment:
Are we essentially moving this part in Spark 3.1 and 3.2 to
AlterHoodieTable[Un]Set class ? What are the side effects here ? Are we
disallowing existing mechanisms to set/unset props with this change ?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #8102: [HUDI-5880] Support partition pruning for flink streaming source in runtime
hudi-bot commented on PR #8102: URL: https://github.com/apache/hudi/pull/8102#issuecomment-1464956060 ## CI report: * f500063efc2baefad6c6c53e77f25b730b0c0346 Azure: [SUCCESS](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15675) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] nsivabalan merged pull request #8156: [HUDI-5919] Fix the validation of partition listing in metadata table validator
nsivabalan merged PR #8156: URL: https://github.com/apache/hudi/pull/8156 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[hudi] branch master updated (9c44339e4bb -> b162330a1f3)
This is an automated email from the ASF dual-hosted git repository. sivabalan pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/hudi.git from 9c44339e4bb [HUDI-5909] Reuse hive client if possible (#8139) add b162330a1f3 [HUDI-5919] Fix the validation of partition listing in metadata table validator (#8156) No new revisions were added by this update. Summary of changes: .../hudi/utilities/HoodieMetadataTableValidator.java | 16 +++- 1 file changed, 15 insertions(+), 1 deletion(-)
[GitHub] [hudi] hudi-bot commented on pull request #8102: [HUDI-5880] Support partition pruning for flink streaming source in runtime
hudi-bot commented on PR #8102: URL: https://github.com/apache/hudi/pull/8102#issuecomment-1464923325 ## CI report: * 9fd31f69d5ae5a349a553cb207337833958c7099 Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15674) * f500063efc2baefad6c6c53e77f25b730b0c0346 Azure: [PENDING](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15675) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] soumilshah1995 commented on issue #8104: [AWS SUPPORT] Submiting Support Tickets so Amazon can update Hudi Version 0.13 in Glue 4.0
soumilshah1995 commented on issue #8104: URL: https://github.com/apache/hudi/issues/8104#issuecomment-1464922955 If everyone could submit a support ticket, AWS could do the upgrade more quickly since its requirement from most of users and company -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] soumilshah1995 commented on issue #8104: [AWS SUPPORT] Submiting Support Tickets so Amazon can update Hudi Version 0.13 in Glue 4.0
soumilshah1995 commented on issue #8104: URL: https://github.com/apache/hudi/issues/8104#issuecomment-1464922665 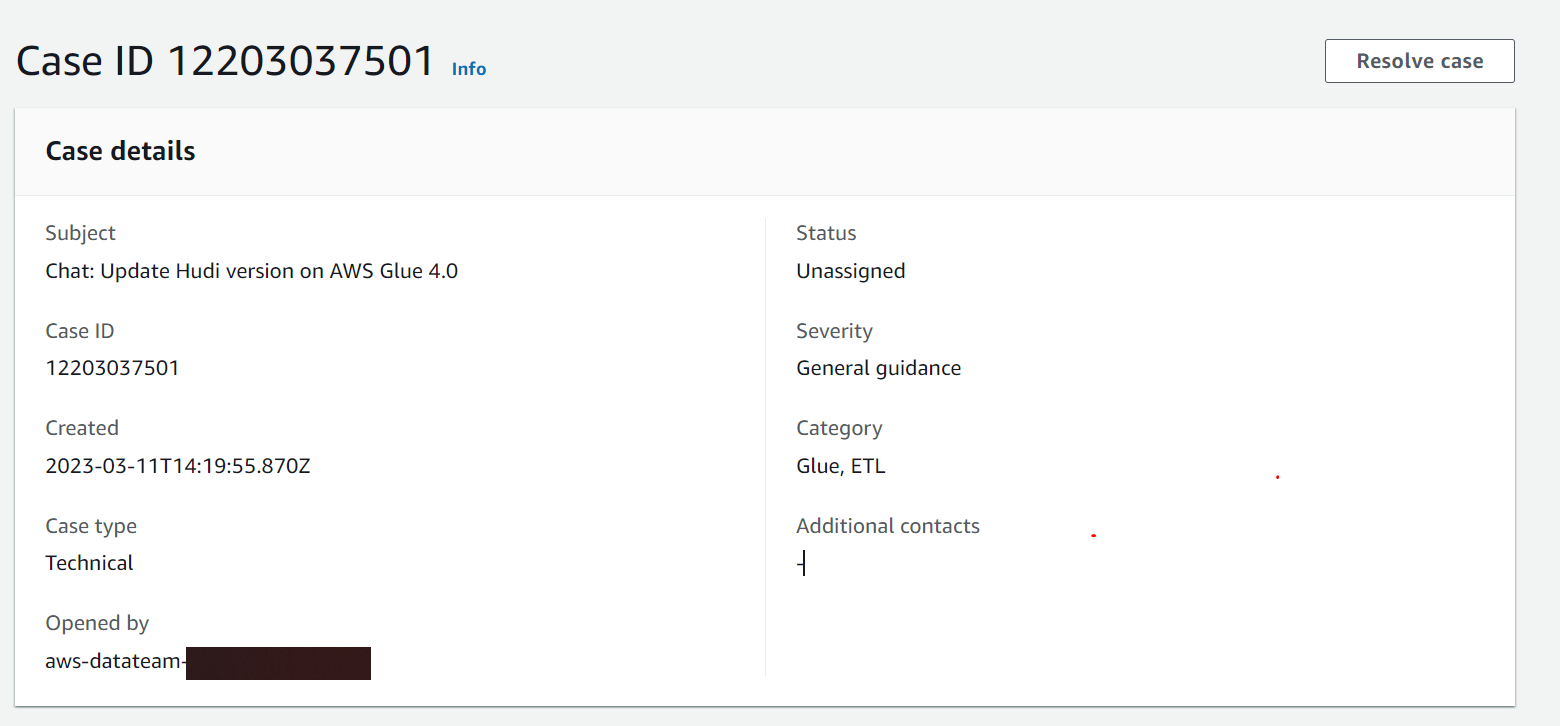 i will let you know if i hear back from support -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #8102: [HUDI-5880] Support partition pruning for flink streaming source in runtime
hudi-bot commented on PR #8102: URL: https://github.com/apache/hudi/pull/8102#issuecomment-1464922113 ## CI report: * 9fd31f69d5ae5a349a553cb207337833958c7099 Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15674) * f500063efc2baefad6c6c53e77f25b730b0c0346 UNKNOWN Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #8102: [HUDI-5880] Support partition pruning for flink streaming source in runtime
hudi-bot commented on PR #8102: URL: https://github.com/apache/hudi/pull/8102#issuecomment-1464899815 ## CI report: * 9fd31f69d5ae5a349a553cb207337833958c7099 Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15674) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #8156: [HUDI-5919] Fix the validation of partition listing in metadata table validator
hudi-bot commented on PR #8156: URL: https://github.com/apache/hudi/pull/8156#issuecomment-1464888401 ## CI report: * 6042ca5f4d6ce30b78b9c610de372fbf054a7aa1 Azure: [SUCCESS](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15673) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #8102: [HUDI-5880] Support partition pruning for flink streaming source in runtime
hudi-bot commented on PR #8102: URL: https://github.com/apache/hudi/pull/8102#issuecomment-1464880012 ## CI report: * 8958c445f7354ed113e8ff0a1aa9f56261bede34 Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15593) * 9fd31f69d5ae5a349a553cb207337833958c7099 Azure: [PENDING](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15674) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #8102: [HUDI-5880] Support partition pruning for flink streaming source in runtime
hudi-bot commented on PR #8102: URL: https://github.com/apache/hudi/pull/8102#issuecomment-1464878756 ## CI report: * 8958c445f7354ed113e8ff0a1aa9f56261bede34 Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15593) * 9fd31f69d5ae5a349a553cb207337833958c7099 UNKNOWN Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #8157: [HUDI-5920] Improve documentation of parallelism configs
hudi-bot commented on PR #8157: URL: https://github.com/apache/hudi/pull/8157#issuecomment-1464877673 ## CI report: * 5075feb0a984758ac4dc2999bf503d0df3b1dbd1 Azure: [SUCCESS](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15672) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Comment Edited] (HUDI-4542) Flink streaming query fails with ClassNotFoundException
[
https://issues.apache.org/jira/browse/HUDI-4542?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17699198#comment-17699198
]
Jarred Li edited comment on HUDI-4542 at 3/11/23 9:26 AM:
--
I have same issue. I copy hive-exec-2.3.1-core.jar into /usr/lib/flink/lib
was (Author: leejianwei):
I have same issue. Can I know what is the workaround? I copy hive-exec.jar into
/usr/lib/flink/lib, however there is class conflict.
> Flink streaming query fails with ClassNotFoundException
> ---
>
> Key: HUDI-4542
> URL: https://issues.apache.org/jira/browse/HUDI-4542
> Project: Apache Hudi
> Issue Type: Bug
> Components: flink-sql
>Reporter: Ethan Guo
>Priority: Critical
> Fix For: 0.13.1
>
> Attachments: Screen Shot 2022-08-04 at 17.17.42.png
>
>
> Environment: EMR 6.7.0 Flink 1.14.2
> Reproducible steps: Build Hudi Flink bundle from master
> {code:java}
> mvn clean package -DskipTests -pl :hudi-flink1.14-bundle -am {code}
> Copy to EMR master node /lib/flink/lib
> Launch Flink SQL client:
> {code:java}
> cd /lib/flink && ./bin/yarn-session.sh --detached
> ./bin/sql-client.sh {code}
> Write a Hudi table with a few commits with metadata table enabled (no column
> stats). Then, run the following for the streaming query
> {code:java}
> CREATE TABLE t2(
> uuid VARCHAR(20) PRIMARY KEY NOT ENFORCED,
> name VARCHAR(10),
> age INT,
> ts TIMESTAMP(3),
> `partition` VARCHAR(20)
> )
> PARTITIONED BY (`partition`)
> WITH (
> 'connector' = 'hudi',
> 'path' = 's3a://',
> 'table.type' = 'MERGE_ON_READ',
> 'read.streaming.enabled' = 'true', -- this option enable the streaming
> read
> 'read.start-commit' = '20220803165232362', -- specifies the start commit
> instant time
> 'read.streaming.check-interval' = '4' -- specifies the check interval for
> finding new source commits, default 60s.
> ); {code}
> {code:java}
> select * from t2; {code}
> {code:java}
> Flink SQL> select * from t2;
> 2022-08-05 00:12:43,635 INFO org.apache.hadoop.metrics2.impl.MetricsConfig
> [] - Loaded properties from hadoop-metrics2.properties
> 2022-08-05 00:12:43,650 INFO
> org.apache.hadoop.metrics2.impl.MetricsSystemImpl [] - Scheduled
> Metric snapshot period at 300 second(s).
> 2022-08-05 00:12:43,650 INFO
> org.apache.hadoop.metrics2.impl.MetricsSystemImpl [] -
> s3a-file-system metrics system started
> 2022-08-05 00:12:47,722 INFO org.apache.hadoop.fs.s3a.S3AInputStream
> [] - Switching to Random IO seek policy
> 2022-08-05 00:12:47,941 INFO org.apache.hadoop.yarn.client.RMProxy
> [] - Connecting to ResourceManager at
> ip-172-31-9-157.us-east-2.compute.internal/172.31.9.157:8032
> 2022-08-05 00:12:47,942 INFO org.apache.hadoop.yarn.client.AHSProxy
> [] - Connecting to Application History server at
> ip-172-31-9-157.us-east-2.compute.internal/172.31.9.157:10200
> 2022-08-05 00:12:47,942 INFO org.apache.flink.yarn.YarnClusterDescriptor
> [] - No path for the flink jar passed. Using the location of
> class org.apache.flink.yarn.YarnClusterDescriptor to locate the jar
> 2022-08-05 00:12:47,942 WARN org.apache.flink.yarn.YarnClusterDescriptor
> [] - Neither the HADOOP_CONF_DIR nor the YARN_CONF_DIR
> environment variable is set.The Flink YARN Client needs one of these to be
> set to properly load the Hadoop configuration for accessing YARN.
> 2022-08-05 00:12:47,959 INFO org.apache.flink.yarn.YarnClusterDescriptor
> [] - Found Web Interface
> ip-172-31-3-92.us-east-2.compute.internal:39605 of application
> 'application_1659656614768_0001'.
> [ERROR] Could not execute SQL statement. Reason:
> java.lang.ClassNotFoundException:
> org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat{code}
> {code:java}
> 2022-08-04 17:12:59
> org.apache.flink.runtime.JobException: Recovery is suppressed by
> NoRestartBackoffTimeStrategy
> at
> org.apache.flink.runtime.executiongraph.failover.flip1.ExecutionFailureHandler.handleFailure(ExecutionFailureHandler.java:138)
> at
> org.apache.flink.runtime.executiongraph.failover.flip1.ExecutionFailureHandler.getFailureHandlingResult(ExecutionFailureHandler.java:82)
> at
> org.apache.flink.runtime.scheduler.DefaultScheduler.handleTaskFailure(DefaultScheduler.java:228)
> at
> org.apache.flink.runtime.scheduler.DefaultScheduler.maybeHandleTaskFailure(DefaultScheduler.java:218)
> at
> org.apache.flink.runtime.scheduler.DefaultScheduler.updateTaskExecutionStateInternal(DefaultScheduler.java:209)
> at
> org.apache.flink.runtime.scheduler.SchedulerBase.updateTaskExecutionState(SchedulerBase.java:679)
> at
> org.apa
[jira] [Commented] (HUDI-4542) Flink streaming query fails with ClassNotFoundException
[
https://issues.apache.org/jira/browse/HUDI-4542?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17699198#comment-17699198
]
Jarred Li commented on HUDI-4542:
-
I have same issue. Can I know what is the workaround? I copy hive-exec.jar into
/usr/lib/flink/lib, however there is class conflict.
> Flink streaming query fails with ClassNotFoundException
> ---
>
> Key: HUDI-4542
> URL: https://issues.apache.org/jira/browse/HUDI-4542
> Project: Apache Hudi
> Issue Type: Bug
> Components: flink-sql
>Reporter: Ethan Guo
>Priority: Critical
> Fix For: 0.13.1
>
> Attachments: Screen Shot 2022-08-04 at 17.17.42.png
>
>
> Environment: EMR 6.7.0 Flink 1.14.2
> Reproducible steps: Build Hudi Flink bundle from master
> {code:java}
> mvn clean package -DskipTests -pl :hudi-flink1.14-bundle -am {code}
> Copy to EMR master node /lib/flink/lib
> Launch Flink SQL client:
> {code:java}
> cd /lib/flink && ./bin/yarn-session.sh --detached
> ./bin/sql-client.sh {code}
> Write a Hudi table with a few commits with metadata table enabled (no column
> stats). Then, run the following for the streaming query
> {code:java}
> CREATE TABLE t2(
> uuid VARCHAR(20) PRIMARY KEY NOT ENFORCED,
> name VARCHAR(10),
> age INT,
> ts TIMESTAMP(3),
> `partition` VARCHAR(20)
> )
> PARTITIONED BY (`partition`)
> WITH (
> 'connector' = 'hudi',
> 'path' = 's3a://',
> 'table.type' = 'MERGE_ON_READ',
> 'read.streaming.enabled' = 'true', -- this option enable the streaming
> read
> 'read.start-commit' = '20220803165232362', -- specifies the start commit
> instant time
> 'read.streaming.check-interval' = '4' -- specifies the check interval for
> finding new source commits, default 60s.
> ); {code}
> {code:java}
> select * from t2; {code}
> {code:java}
> Flink SQL> select * from t2;
> 2022-08-05 00:12:43,635 INFO org.apache.hadoop.metrics2.impl.MetricsConfig
> [] - Loaded properties from hadoop-metrics2.properties
> 2022-08-05 00:12:43,650 INFO
> org.apache.hadoop.metrics2.impl.MetricsSystemImpl [] - Scheduled
> Metric snapshot period at 300 second(s).
> 2022-08-05 00:12:43,650 INFO
> org.apache.hadoop.metrics2.impl.MetricsSystemImpl [] -
> s3a-file-system metrics system started
> 2022-08-05 00:12:47,722 INFO org.apache.hadoop.fs.s3a.S3AInputStream
> [] - Switching to Random IO seek policy
> 2022-08-05 00:12:47,941 INFO org.apache.hadoop.yarn.client.RMProxy
> [] - Connecting to ResourceManager at
> ip-172-31-9-157.us-east-2.compute.internal/172.31.9.157:8032
> 2022-08-05 00:12:47,942 INFO org.apache.hadoop.yarn.client.AHSProxy
> [] - Connecting to Application History server at
> ip-172-31-9-157.us-east-2.compute.internal/172.31.9.157:10200
> 2022-08-05 00:12:47,942 INFO org.apache.flink.yarn.YarnClusterDescriptor
> [] - No path for the flink jar passed. Using the location of
> class org.apache.flink.yarn.YarnClusterDescriptor to locate the jar
> 2022-08-05 00:12:47,942 WARN org.apache.flink.yarn.YarnClusterDescriptor
> [] - Neither the HADOOP_CONF_DIR nor the YARN_CONF_DIR
> environment variable is set.The Flink YARN Client needs one of these to be
> set to properly load the Hadoop configuration for accessing YARN.
> 2022-08-05 00:12:47,959 INFO org.apache.flink.yarn.YarnClusterDescriptor
> [] - Found Web Interface
> ip-172-31-3-92.us-east-2.compute.internal:39605 of application
> 'application_1659656614768_0001'.
> [ERROR] Could not execute SQL statement. Reason:
> java.lang.ClassNotFoundException:
> org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat{code}
> {code:java}
> 2022-08-04 17:12:59
> org.apache.flink.runtime.JobException: Recovery is suppressed by
> NoRestartBackoffTimeStrategy
> at
> org.apache.flink.runtime.executiongraph.failover.flip1.ExecutionFailureHandler.handleFailure(ExecutionFailureHandler.java:138)
> at
> org.apache.flink.runtime.executiongraph.failover.flip1.ExecutionFailureHandler.getFailureHandlingResult(ExecutionFailureHandler.java:82)
> at
> org.apache.flink.runtime.scheduler.DefaultScheduler.handleTaskFailure(DefaultScheduler.java:228)
> at
> org.apache.flink.runtime.scheduler.DefaultScheduler.maybeHandleTaskFailure(DefaultScheduler.java:218)
> at
> org.apache.flink.runtime.scheduler.DefaultScheduler.updateTaskExecutionStateInternal(DefaultScheduler.java:209)
> at
> org.apache.flink.runtime.scheduler.SchedulerBase.updateTaskExecutionState(SchedulerBase.java:679)
> at
> org.apache.flink.runtime.scheduler.SchedulerNG.updateTaskExecutionState(SchedulerNG.java:79)
> at
> org.apache.flink.runtime.jobmaster.JobMaster.updateTas
[GitHub] [hudi] hudi-bot commented on pull request #8156: [HUDI-5919] Fix the validation of partition listing in metadata table validator
hudi-bot commented on PR #8156: URL: https://github.com/apache/hudi/pull/8156#issuecomment-1464859692 ## CI report: * c2494f74ce709a29f512fc165dfe1b12b99aa244 Azure: [SUCCESS](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15668) * 6042ca5f4d6ce30b78b9c610de372fbf054a7aa1 Azure: [PENDING](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15673) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #8156: [HUDI-5919] Fix the validation of partition listing in metadata table validator
hudi-bot commented on PR #8156: URL: https://github.com/apache/hudi/pull/8156#issuecomment-1464858603 ## CI report: * c2494f74ce709a29f512fc165dfe1b12b99aa244 Azure: [SUCCESS](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15668) * 6042ca5f4d6ce30b78b9c610de372fbf054a7aa1 UNKNOWN Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org