[GitHub] [hudi] codope commented on issue #6304: Hudi MultiTable Deltastreamer not updating glue catalog when new column added on Source
codope commented on issue #6304: URL: https://github.com/apache/hudi/issues/6304#issuecomment-1488046159 Closing due to inactivity. Have also tested the adding column scenario with glue sync for upcoming 0.12.3 release. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] codope closed issue #6304: Hudi MultiTable Deltastreamer not updating glue catalog when new column added on Source
codope closed issue #6304: Hudi MultiTable Deltastreamer not updating glue catalog when new column added on Source URL: https://github.com/apache/hudi/issues/6304 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] codope commented on issue #6283: [SUPPORT] No .marker files
codope commented on issue #6283: URL: https://github.com/apache/hudi/issues/6283#issuecomment-1488040027 Closing due to inactivity. Please reopen with steps to reproduce. The general flow works in master as well as 0.12.2 an d0.13.0. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] codope closed issue #6283: [SUPPORT] No .marker files
codope closed issue #6283: [SUPPORT] No .marker files URL: https://github.com/apache/hudi/issues/6283 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] voonhous commented on a diff in pull request #8307: [HUDI-5992] Fix (de)serialization for avro versions > 1.10.0
voonhous commented on code in PR #8307:
URL: https://github.com/apache/hudi/pull/8307#discussion_r1151467972
##
hudi-common/src/main/java/org/apache/hudi/avro/GenericAvroSerializer.java:
##
@@ -0,0 +1,148 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.avro;
+
+import com.esotericsoftware.kryo.Kryo;
+import com.esotericsoftware.kryo.Serializer;
+import com.esotericsoftware.kryo.io.Input;
+import com.esotericsoftware.kryo.io.Output;
+import org.apache.avro.Schema;
+import org.apache.avro.SchemaNormalization;
+import org.apache.avro.generic.GenericContainer;
+import org.apache.avro.generic.GenericDatumReader;
+import org.apache.avro.generic.GenericDatumWriter;
+import org.apache.avro.io.DatumReader;
+import org.apache.avro.io.DatumWriter;
+import org.apache.avro.io.Decoder;
+import org.apache.avro.io.DecoderFactory;
+import org.apache.avro.io.Encoder;
+import org.apache.avro.io.EncoderFactory;
+
+import java.io.IOException;
+import java.nio.charset.StandardCharsets;
+import java.util.HashMap;
+
+
+/**
+ * Custom serializer used for generic Avro containers.
+ *
+ * Heavily adapted from:
+ *
+ * https://github.com/apache/spark/blob/master/core/src/main/scala/org/apache/spark/serializer/GenericAvroSerializer.scala";>GenericAvroSerializer.scala
+ *
+ * As {@link org.apache.hudi.common.util.SerializationUtils} is not shared
between threads and does not concern any
+ * shuffling operations, compression and decompression cache is omitted as
network IO is not a concern.
+ *
+ * Unlike Spark's implementation, the class and constructor is not initialized
with a predefined map of avro schemas.
+ * This is the case as schemas to read and write are not known beforehand.
+ *
+ * @param the subtype of [[GenericContainer]] handled by this serializer
+ */
+public class GenericAvroSerializer extends
Serializer {
+
+ // reuses the same datum reader/writer since the same schema will be used
many times
+ private final HashMap> writerCache = new HashMap<>();
+ private final HashMap> readerCache = new HashMap<>();
+
+ // fingerprinting is very expensive so this alleviates most of the work
+ private final HashMap fingerprintCache = new HashMap<>();
+ private final HashMap schemaCache = new HashMap<>();
+
+ private Long getFingerprint(Schema schema) {
+if (fingerprintCache.containsKey(schema)) {
+ return fingerprintCache.get(schema);
+} else {
+ Long fingerprint = SchemaNormalization.parsingFingerprint64(schema);
+ fingerprintCache.put(schema, fingerprint);
+ return fingerprint;
+}
+ }
+
+ private Schema getSchema(Long fingerprint, byte[] schemaBytes) {
+if (schemaCache.containsKey(fingerprint)) {
+ return schemaCache.get(fingerprint);
+} else {
+ String schema = new String(schemaBytes, StandardCharsets.UTF_8);
+ Schema parsedSchema = new Schema.Parser().parse(schema);
+ schemaCache.put(fingerprint, parsedSchema);
+ return parsedSchema;
+}
+ }
+
+ private DatumWriter getDatumWriter(Schema schema) {
+DatumWriter writer;
+if (writerCache.containsKey(schema)) {
+ writer = writerCache.get(schema);
+} else {
+ writer = new GenericDatumWriter<>(schema);
+ writerCache.put(schema, writer);
+}
+return writer;
+ }
+
+ private DatumReader getDatumReader(Schema schema) {
+DatumReader reader;
+if (readerCache.containsKey(schema)) {
+ reader = readerCache.get(schema);
+} else {
+ reader = new GenericDatumReader<>(schema);
+ readerCache.put(schema, reader);
+}
+return reader;
+ }
+
+ private void serializeDatum(D datum, Output output) throws IOException {
+Encoder encoder = EncoderFactory.get().directBinaryEncoder(output, null);
+Schema schema = datum.getSchema();
+Long fingerprint = this.getFingerprint(schema);
+byte[] schemaBytes = schema.toString().getBytes(StandardCharsets.UTF_8);
Review Comment:
In that case, I'll change the cache as such?
```java
private final HashMap fingerprintCache = new HashMap<>();
private final HashMap schemaCache = new HashMap<>();
```
--
This is an automated message from the Apache Git Service.
To respond t
[jira] [Created] (HUDI-5997) Support DFS Schema Provider with S3/GCS EventsHoodieIncrSource
Sagar Sumit created HUDI-5997: - Summary: Support DFS Schema Provider with S3/GCS EventsHoodieIncrSource Key: HUDI-5997 URL: https://issues.apache.org/jira/browse/HUDI-5997 Project: Apache Hudi Issue Type: Improvement Components: deltastreamer Reporter: Sagar Sumit Fix For: 0.14.0 See for more details -- This message was sent by Atlassian Jira (v8.20.10#820010)
[GitHub] [hudi] codope commented on issue #8211: [SUPPORT] DFS Schema Provider not working with S3EventsHoodieIncrSource
codope commented on issue #8211: URL: https://github.com/apache/hudi/issues/8211#issuecomment-1488037163 The incremental source infers schema by simply loading the dataset from the source table. What you're proposing is a good enhancement. Would you like to take it up? HUDI-5997 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] voonhous commented on a diff in pull request #8307: [HUDI-5992] Fix (de)serialization for avro versions > 1.10.0
voonhous commented on code in PR #8307:
URL: https://github.com/apache/hudi/pull/8307#discussion_r1151467972
##
hudi-common/src/main/java/org/apache/hudi/avro/GenericAvroSerializer.java:
##
@@ -0,0 +1,148 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.avro;
+
+import com.esotericsoftware.kryo.Kryo;
+import com.esotericsoftware.kryo.Serializer;
+import com.esotericsoftware.kryo.io.Input;
+import com.esotericsoftware.kryo.io.Output;
+import org.apache.avro.Schema;
+import org.apache.avro.SchemaNormalization;
+import org.apache.avro.generic.GenericContainer;
+import org.apache.avro.generic.GenericDatumReader;
+import org.apache.avro.generic.GenericDatumWriter;
+import org.apache.avro.io.DatumReader;
+import org.apache.avro.io.DatumWriter;
+import org.apache.avro.io.Decoder;
+import org.apache.avro.io.DecoderFactory;
+import org.apache.avro.io.Encoder;
+import org.apache.avro.io.EncoderFactory;
+
+import java.io.IOException;
+import java.nio.charset.StandardCharsets;
+import java.util.HashMap;
+
+
+/**
+ * Custom serializer used for generic Avro containers.
+ *
+ * Heavily adapted from:
+ *
+ * https://github.com/apache/spark/blob/master/core/src/main/scala/org/apache/spark/serializer/GenericAvroSerializer.scala";>GenericAvroSerializer.scala
+ *
+ * As {@link org.apache.hudi.common.util.SerializationUtils} is not shared
between threads and does not concern any
+ * shuffling operations, compression and decompression cache is omitted as
network IO is not a concern.
+ *
+ * Unlike Spark's implementation, the class and constructor is not initialized
with a predefined map of avro schemas.
+ * This is the case as schemas to read and write are not known beforehand.
+ *
+ * @param the subtype of [[GenericContainer]] handled by this serializer
+ */
+public class GenericAvroSerializer extends
Serializer {
+
+ // reuses the same datum reader/writer since the same schema will be used
many times
+ private final HashMap> writerCache = new HashMap<>();
+ private final HashMap> readerCache = new HashMap<>();
+
+ // fingerprinting is very expensive so this alleviates most of the work
+ private final HashMap fingerprintCache = new HashMap<>();
+ private final HashMap schemaCache = new HashMap<>();
+
+ private Long getFingerprint(Schema schema) {
+if (fingerprintCache.containsKey(schema)) {
+ return fingerprintCache.get(schema);
+} else {
+ Long fingerprint = SchemaNormalization.parsingFingerprint64(schema);
+ fingerprintCache.put(schema, fingerprint);
+ return fingerprint;
+}
+ }
+
+ private Schema getSchema(Long fingerprint, byte[] schemaBytes) {
+if (schemaCache.containsKey(fingerprint)) {
+ return schemaCache.get(fingerprint);
+} else {
+ String schema = new String(schemaBytes, StandardCharsets.UTF_8);
+ Schema parsedSchema = new Schema.Parser().parse(schema);
+ schemaCache.put(fingerprint, parsedSchema);
+ return parsedSchema;
+}
+ }
+
+ private DatumWriter getDatumWriter(Schema schema) {
+DatumWriter writer;
+if (writerCache.containsKey(schema)) {
+ writer = writerCache.get(schema);
+} else {
+ writer = new GenericDatumWriter<>(schema);
+ writerCache.put(schema, writer);
+}
+return writer;
+ }
+
+ private DatumReader getDatumReader(Schema schema) {
+DatumReader reader;
+if (readerCache.containsKey(schema)) {
+ reader = readerCache.get(schema);
+} else {
+ reader = new GenericDatumReader<>(schema);
+ readerCache.put(schema, reader);
+}
+return reader;
+ }
+
+ private void serializeDatum(D datum, Output output) throws IOException {
+Encoder encoder = EncoderFactory.get().directBinaryEncoder(output, null);
+Schema schema = datum.getSchema();
+Long fingerprint = this.getFingerprint(schema);
+byte[] schemaBytes = schema.toString().getBytes(StandardCharsets.UTF_8);
Review Comment:
In that case, I'll change the cache as such?
```
private final HashMap fingerprintCache = new HashMap<>();
private final HashMap schemaCache = new HashMap<>();
```
--
This is an automated message from the Apache Git Service.
To respond to th
[GitHub] [hudi] danny0405 commented on issue #8087: [SUPPORT] split_reader don't checkpoint before consuming all splits
danny0405 commented on issue #8087: URL: https://github.com/apache/hudi/issues/8087#issuecomment-1488035083 > Can i create a pr then you review it Sure, but let's test the PR in production for at least one week, we also need to test the failover/restart for data completeness. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] danny0405 commented on issue #8267: [SUPPORT] Why some delta commit logs files are not converted to parquet ?
danny0405 commented on issue #8267: URL: https://github.com/apache/hudi/issues/8267#issuecomment-1488033858 > there is actually no filedId parquet file Confused by your words, can you re-organize it a little? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] codope commented on issue #8222: [SUPPORT] Incremental read with MOR does not work as COW
codope commented on issue #8222: URL: https://github.com/apache/hudi/issues/8222#issuecomment-1488033021 Maybe https://github.com/apache/hudi/pull/8299 fixes this issue @parisni -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] danny0405 commented on a diff in pull request #8307: [HUDI-5992] Fix (de)serialization for avro versions > 1.10.0
danny0405 commented on code in PR #8307:
URL: https://github.com/apache/hudi/pull/8307#discussion_r1151463202
##
hudi-common/src/main/java/org/apache/hudi/avro/GenericAvroSerializer.java:
##
@@ -0,0 +1,148 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.avro;
+
+import com.esotericsoftware.kryo.Kryo;
+import com.esotericsoftware.kryo.Serializer;
+import com.esotericsoftware.kryo.io.Input;
+import com.esotericsoftware.kryo.io.Output;
+import org.apache.avro.Schema;
+import org.apache.avro.SchemaNormalization;
+import org.apache.avro.generic.GenericContainer;
+import org.apache.avro.generic.GenericDatumReader;
+import org.apache.avro.generic.GenericDatumWriter;
+import org.apache.avro.io.DatumReader;
+import org.apache.avro.io.DatumWriter;
+import org.apache.avro.io.Decoder;
+import org.apache.avro.io.DecoderFactory;
+import org.apache.avro.io.Encoder;
+import org.apache.avro.io.EncoderFactory;
+
+import java.io.IOException;
+import java.nio.charset.StandardCharsets;
+import java.util.HashMap;
+
+
+/**
+ * Custom serializer used for generic Avro containers.
+ *
+ * Heavily adapted from:
+ *
+ * https://github.com/apache/spark/blob/master/core/src/main/scala/org/apache/spark/serializer/GenericAvroSerializer.scala";>GenericAvroSerializer.scala
+ *
+ * As {@link org.apache.hudi.common.util.SerializationUtils} is not shared
between threads and does not concern any
+ * shuffling operations, compression and decompression cache is omitted as
network IO is not a concern.
+ *
+ * Unlike Spark's implementation, the class and constructor is not initialized
with a predefined map of avro schemas.
+ * This is the case as schemas to read and write are not known beforehand.
+ *
+ * @param the subtype of [[GenericContainer]] handled by this serializer
+ */
+public class GenericAvroSerializer extends
Serializer {
+
+ // reuses the same datum reader/writer since the same schema will be used
many times
+ private final HashMap> writerCache = new HashMap<>();
+ private final HashMap> readerCache = new HashMap<>();
+
+ // fingerprinting is very expensive so this alleviates most of the work
+ private final HashMap fingerprintCache = new HashMap<>();
+ private final HashMap schemaCache = new HashMap<>();
+
+ private Long getFingerprint(Schema schema) {
+if (fingerprintCache.containsKey(schema)) {
+ return fingerprintCache.get(schema);
+} else {
+ Long fingerprint = SchemaNormalization.parsingFingerprint64(schema);
+ fingerprintCache.put(schema, fingerprint);
+ return fingerprint;
+}
+ }
+
+ private Schema getSchema(Long fingerprint, byte[] schemaBytes) {
+if (schemaCache.containsKey(fingerprint)) {
+ return schemaCache.get(fingerprint);
+} else {
+ String schema = new String(schemaBytes, StandardCharsets.UTF_8);
+ Schema parsedSchema = new Schema.Parser().parse(schema);
+ schemaCache.put(fingerprint, parsedSchema);
+ return parsedSchema;
+}
+ }
+
+ private DatumWriter getDatumWriter(Schema schema) {
+DatumWriter writer;
+if (writerCache.containsKey(schema)) {
+ writer = writerCache.get(schema);
+} else {
+ writer = new GenericDatumWriter<>(schema);
+ writerCache.put(schema, writer);
+}
+return writer;
+ }
+
+ private DatumReader getDatumReader(Schema schema) {
+DatumReader reader;
+if (readerCache.containsKey(schema)) {
+ reader = readerCache.get(schema);
+} else {
+ reader = new GenericDatumReader<>(schema);
+ readerCache.put(schema, reader);
+}
+return reader;
+ }
+
+ private void serializeDatum(D datum, Output output) throws IOException {
+Encoder encoder = EncoderFactory.get().directBinaryEncoder(output, null);
+Schema schema = datum.getSchema();
+Long fingerprint = this.getFingerprint(schema);
+byte[] schemaBytes = schema.toString().getBytes(StandardCharsets.UTF_8);
Review Comment:
You are right, we can use the schema bytes as the cache key. But be caution
of the `ByteBuffer` equals impls.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to th
[GitHub] [hudi] nsivabalan commented on a diff in pull request #8107: [HUDI-5514] Adding auto generation of record keys support to Hudi/Spark
nsivabalan commented on code in PR #8107:
URL: https://github.com/apache/hudi/pull/8107#discussion_r1151448306
##
hudi-common/src/main/java/org/apache/hudi/common/table/HoodieTableConfig.java:
##
@@ -260,6 +260,18 @@ public class HoodieTableConfig extends HoodieConfig {
.sinceVersion("0.13.0")
.withDocumentation("The metadata of secondary indexes");
+ public static final ConfigProperty AUTO_GENERATE_RECORD_KEYS =
ConfigProperty
+ .key("hoodie.table.auto.generate.record.keys")
+ .defaultValue("false")
+ .withDocumentation("Enables automatic generation of the record-keys in
cases when dataset bears "
Review Comment:
yes. @yihua had some tracking ticket for this. Ethan: I could not locate
one. can you share the jira link.
##
hudi-spark-datasource/hudi-spark-common/src/main/scala/org/apache/hudi/AutoRecordKeyGenerationUtils.scala:
##
@@ -0,0 +1,103 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.hudi
+
+import org.apache.avro.generic.GenericRecord
+import org.apache.hudi.DataSourceWriteOptions.INSERT_DROP_DUPS
+import org.apache.hudi.common.config.HoodieConfig
+import org.apache.hudi.common.model.{HoodieRecord, WriteOperationType}
+import org.apache.hudi.common.table.HoodieTableConfig
+import org.apache.hudi.config.HoodieWriteConfig
+import org.apache.hudi.exception.HoodieException
+import org.apache.spark.TaskContext
+
+object AutoRecordKeyGenerationUtils {
+
+ // supported operation types when auto generation of record keys is enabled.
+ val supportedOperations: Set[String] =
+Set(WriteOperationType.INSERT, WriteOperationType.BULK_INSERT,
WriteOperationType.DELETE,
+ WriteOperationType.INSERT_OVERWRITE,
WriteOperationType.INSERT_OVERWRITE_TABLE,
+ WriteOperationType.DELETE_PARTITION).map(_.name())
Review Comment:
yeah. we can't generate for an upsert. its only insert or bulk_insert for
spark-datasource writes. but w/ spark-sql, we might want to support MIT,
updates, deletes. so, will fix this accordingly.
##
hudi-client/hudi-client-common/src/main/java/org/apache/hudi/keygen/SimpleAvroKeyGenerator.java:
##
@@ -29,24 +31,29 @@
public class SimpleAvroKeyGenerator extends BaseKeyGenerator {
public SimpleAvroKeyGenerator(TypedProperties props) {
-this(props,
props.getString(KeyGeneratorOptions.RECORDKEY_FIELD_NAME.key()),
+this(props,
Option.ofNullable(props.getString(KeyGeneratorOptions.RECORDKEY_FIELD_NAME.key(),
null)),
props.getString(KeyGeneratorOptions.PARTITIONPATH_FIELD_NAME.key()));
}
SimpleAvroKeyGenerator(TypedProperties props, String partitionPathField) {
-this(props, null, partitionPathField);
+this(props, Option.empty(), partitionPathField);
}
- SimpleAvroKeyGenerator(TypedProperties props, String recordKeyField, String
partitionPathField) {
+ SimpleAvroKeyGenerator(TypedProperties props, Option recordKeyField,
String partitionPathField) {
Review Comment:
we are good. everywhere we use the constructor w/ just TypedProps
##
hudi-client/hudi-spark-client/src/main/scala/org/apache/hudi/HoodieDatasetBulkInsertHelper.scala:
##
@@ -82,9 +85,19 @@ object HoodieDatasetBulkInsertHelper
val keyGenerator =
ReflectionUtils.loadClass(keyGeneratorClassName, new
TypedProperties(config.getProps))
.asInstanceOf[SparkKeyGeneratorInterface]
+ val partitionId = TaskContext.getPartitionId()
Review Comment:
yeah. if entire source RDD is not re-computed, we should be ok.
##
hudi-spark-datasource/hudi-spark-common/src/main/scala/org/apache/hudi/AutoRecordKeyGenerationUtils.scala:
##
@@ -0,0 +1,103 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LI
[GitHub] [hudi] codope commented on issue #7452: [SUPPORT]SparkSQL can not read the latest data(snapshot mode) after write by flink
codope commented on issue #7452: URL: https://github.com/apache/hudi/issues/7452#issuecomment-1488030005 Closing it due to inactivity and not being a code issue. The workaround is mentioned above. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #8307: [HUDI-5992] Fix (de)serialization for avro versions > 1.10.0
hudi-bot commented on PR #8307: URL: https://github.com/apache/hudi/pull/8307#issuecomment-1488030487 ## CI report: * d8521565c1a8a4e215f779c525b7d123b44b94b3 Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15965) Azure: [PENDING](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15966) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] voonhous commented on pull request #8307: [HUDI-5992] Fix (de)serialization for avro versions > 1.10.0
voonhous commented on PR #8307: URL: https://github.com/apache/hudi/pull/8307#issuecomment-1488030287 @hudi-bot run azure -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] codope closed issue #7452: [SUPPORT]SparkSQL can not read the latest data(snapshot mode) after write by flink
codope closed issue #7452: [SUPPORT]SparkSQL can not read the latest data(snapshot mode) after write by flink URL: https://github.com/apache/hudi/issues/7452 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] 1032851561 commented on issue #8087: [SUPPORT] split_reader don't checkpoint before consuming all splits
1032851561 commented on issue #8087: URL: https://github.com/apache/hudi/issues/8087#issuecomment-1488028533 > Should be fine, we need to test it in practice about the performace and whether it resolves the problem that ckp takes too long time to be timedout. I have tested my case, and it looks good. Can i create a pr then you review it?  -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] codope commented on issue #7531: [SUPPORT] table comments not fully supported
codope commented on issue #7531: URL: https://github.com/apache/hudi/issues/7531#issuecomment-1488020421 Tracked in HUDI-5533 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #8307: [HUDI-5992] Fix (de)serialization for avro versions > 1.10.0
hudi-bot commented on PR #8307: URL: https://github.com/apache/hudi/pull/8307#issuecomment-1488016726 ## CI report: * d8521565c1a8a4e215f779c525b7d123b44b94b3 Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15965) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Resolved] (HUDI-5976) Add fs in the constructor of HoodieAvroHFileReader to avoid potential NPE
[ https://issues.apache.org/jira/browse/HUDI-5976?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Sagar Sumit resolved HUDI-5976. --- > Add fs in the constructor of HoodieAvroHFileReader to avoid potential NPE > - > > Key: HUDI-5976 > URL: https://issues.apache.org/jira/browse/HUDI-5976 > Project: Apache Hudi > Issue Type: Bug >Reporter: Sagar Sumit >Priority: Major > Labels: pull-request-available > > See https://github.com/apache/hudi/issues/8257 -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Updated] (HUDI-5976) Add fs in the constructor of HoodieAvroHFileReader to avoid potential NPE
[ https://issues.apache.org/jira/browse/HUDI-5976?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Sagar Sumit updated HUDI-5976: -- Fix Version/s: 0.14.0 > Add fs in the constructor of HoodieAvroHFileReader to avoid potential NPE > - > > Key: HUDI-5976 > URL: https://issues.apache.org/jira/browse/HUDI-5976 > Project: Apache Hudi > Issue Type: Bug >Reporter: Sagar Sumit >Priority: Major > Labels: pull-request-available > Fix For: 0.14.0 > > > See https://github.com/apache/hudi/issues/8257 -- This message was sent by Atlassian Jira (v8.20.10#820010)
[hudi] branch master updated (7243393c688 -> 21f83594a9c)
This is an automated email from the ASF dual-hosted git repository. codope pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/hudi.git from 7243393c688 [HUDI-5952] Fix NPE when use kafka callback (#8227) add 21f83594a9c [HUDI-5976] Add fs in the constructor of HoodieAvroHFileReader (#8277) No new revisions were added by this update. Summary of changes: .../src/main/java/org/apache/hudi/common/fs/FSUtils.java | 8 .../hudi/common/table/log/block/HoodieHFileDataBlock.java | 10 +- .../hudi/common/table/log/block/HoodieParquetDataBlock.java| 6 ++ 3 files changed, 15 insertions(+), 9 deletions(-)
[GitHub] [hudi] codope merged pull request #8277: [HUDI-5976] Add fs in the constructor of HoodieAvroHFileReader
codope merged PR #8277: URL: https://github.com/apache/hudi/pull/8277 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] nsivabalan commented on a diff in pull request #8107: [HUDI-5514] Adding auto generation of record keys support to Hudi/Spark
nsivabalan commented on code in PR #8107:
URL: https://github.com/apache/hudi/pull/8107#discussion_r1151439496
##
hudi-client/hudi-client-common/src/main/java/org/apache/hudi/keygen/SimpleAvroKeyGenerator.java:
##
@@ -29,24 +31,29 @@
public class SimpleAvroKeyGenerator extends BaseKeyGenerator {
public SimpleAvroKeyGenerator(TypedProperties props) {
-this(props,
props.getString(KeyGeneratorOptions.RECORDKEY_FIELD_NAME.key()),
+this(props,
Option.ofNullable(props.getString(KeyGeneratorOptions.RECORDKEY_FIELD_NAME.key(),
null)),
Review Comment:
we use TypedProperties and got getString, we call checkKey() which might
throw exception if key is not found
https://github.com/apache/hudi/blob/7243393c6881802803c0233cbac42daf1271afb3/hudi-common/src/main/java/org/apache/hudi/common/config/TypedProperties.java#L72
and hence.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[jira] [Created] (HUDI-5996) We should verify the consistency of bucket num at job startup.
HunterXHunter created HUDI-5996: --- Summary: We should verify the consistency of bucket num at job startup. Key: HUDI-5996 URL: https://issues.apache.org/jira/browse/HUDI-5996 Project: Apache Hudi Issue Type: Improvement Reporter: HunterXHunter Users may sometimes modify the bucket num, and the inconsistency of the bucket num will lead to data duplication and make it unavailability. Maybe there are some other parameters that should also be checked before the job starts -- This message was sent by Atlassian Jira (v8.20.10#820010)
[GitHub] [hudi] nsivabalan commented on a diff in pull request #8107: [HUDI-5514] Adding auto generation of record keys support to Hudi/Spark
nsivabalan commented on code in PR #8107:
URL: https://github.com/apache/hudi/pull/8107#discussion_r1151437700
##
hudi-client/hudi-client-common/src/main/java/org/apache/hudi/keygen/NonpartitionedAvroKeyGenerator.java:
##
@@ -36,8 +39,9 @@ public class NonpartitionedAvroKeyGenerator extends
BaseKeyGenerator {
public NonpartitionedAvroKeyGenerator(TypedProperties props) {
super(props);
-this.recordKeyFields =
Arrays.stream(props.getString(KeyGeneratorOptions.RECORDKEY_FIELD_NAME.key())
-.split(",")).map(String::trim).filter(s ->
!s.isEmpty()).collect(Collectors.toList());
+this.recordKeyFields = autoGenerateRecordKeys() ? Collections.emptyList() :
Review Comment:
we have 10+ classes to fix on this. wondering if we can make it in a
separate patch https://issues.apache.org/jira/browse/HUDI-5995
dont want to add more changes to this patch.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] codope closed issue #8261: [SUPPORT] How to reduce hoodie commit latency
codope closed issue #8261: [SUPPORT] How to reduce hoodie commit latency URL: https://github.com/apache/hudi/issues/8261 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Created] (HUDI-5995) Refactor key generators to set record keys in base class
sivabalan narayanan created HUDI-5995: - Summary: Refactor key generators to set record keys in base class Key: HUDI-5995 URL: https://issues.apache.org/jira/browse/HUDI-5995 Project: Apache Hudi Issue Type: Improvement Reporter: sivabalan narayanan Refactor key generators to set record keys in base class (BaseKeyGenerator) rather than in each individual sub classes. -- This message was sent by Atlassian Jira (v8.20.10#820010)
[GitHub] [hudi] DavidZ1 commented on issue #8267: [SUPPORT] Why some delta commit logs files are not converted to parquet ?
DavidZ1 commented on issue #8267: URL: https://github.com/apache/hudi/issues/8267#issuecomment-1487993254 Yes, we checked the Compaction archive file and found that the corresponding commit has completed the Compaction, but there is actually no filedId parquet file. 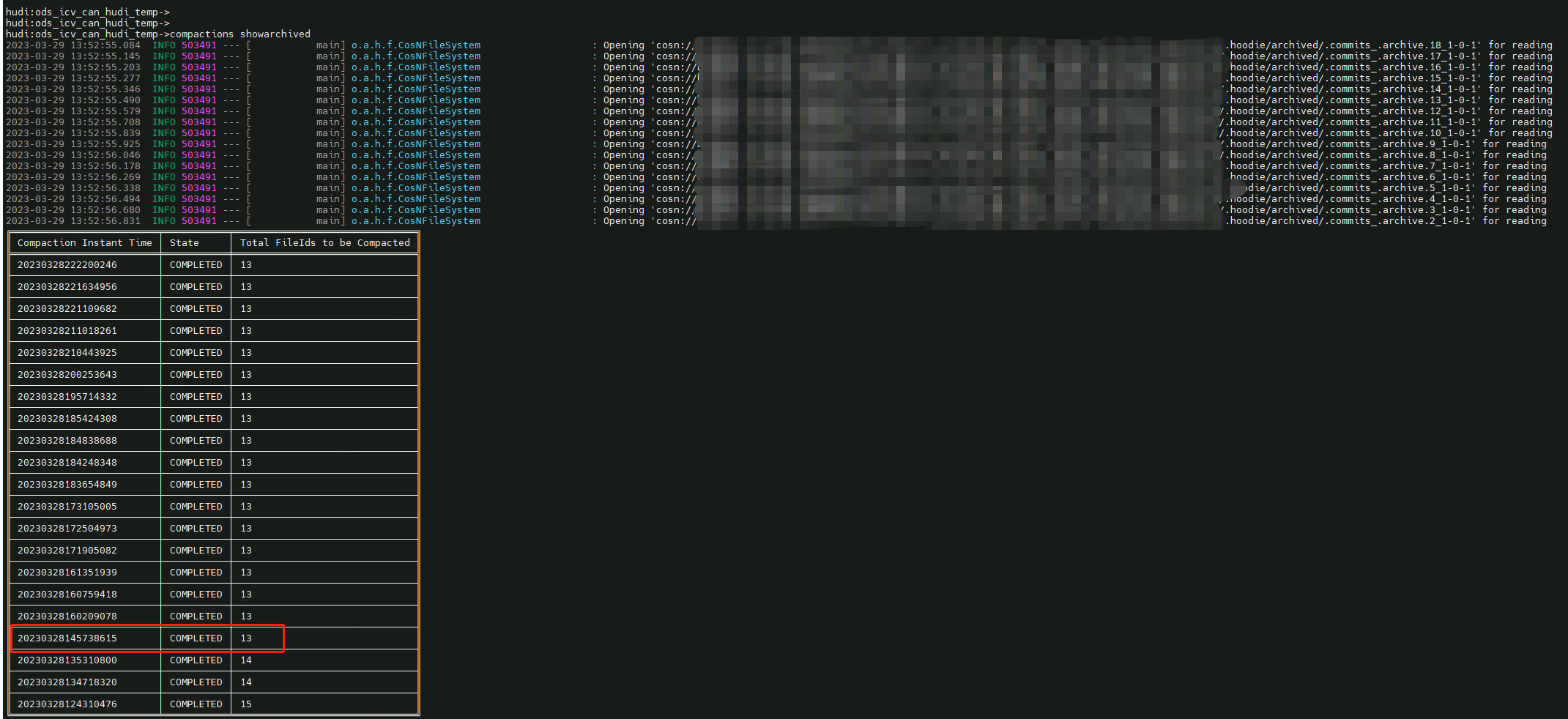 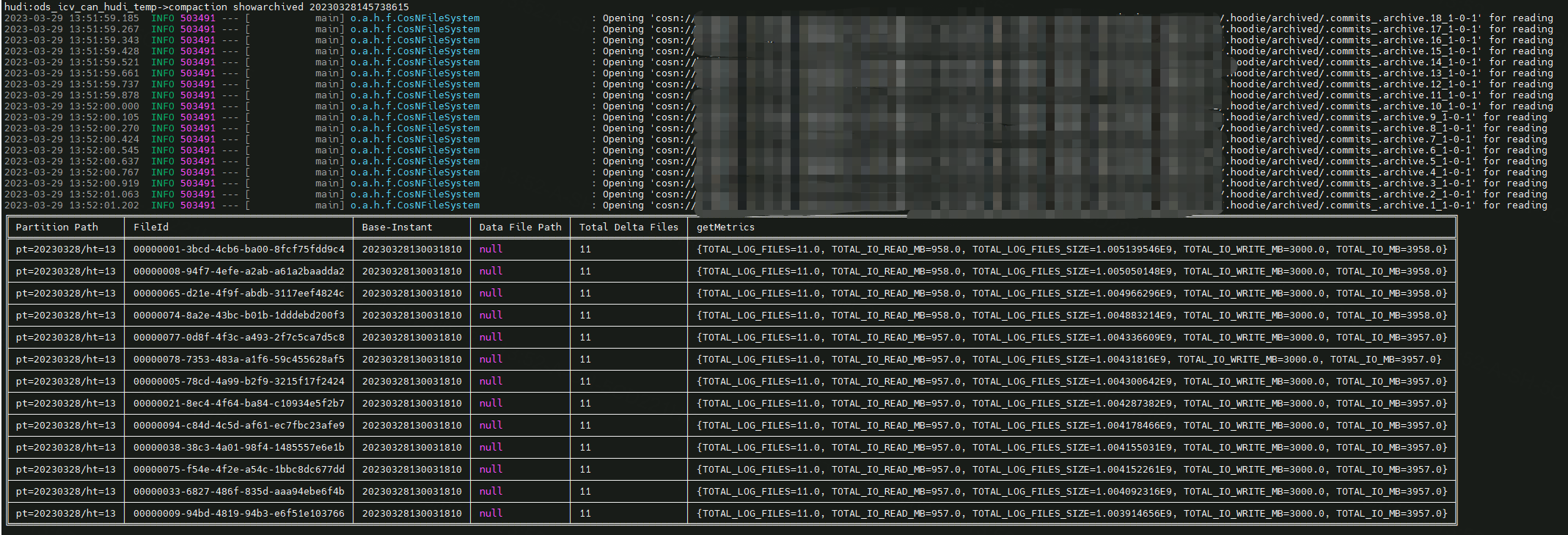 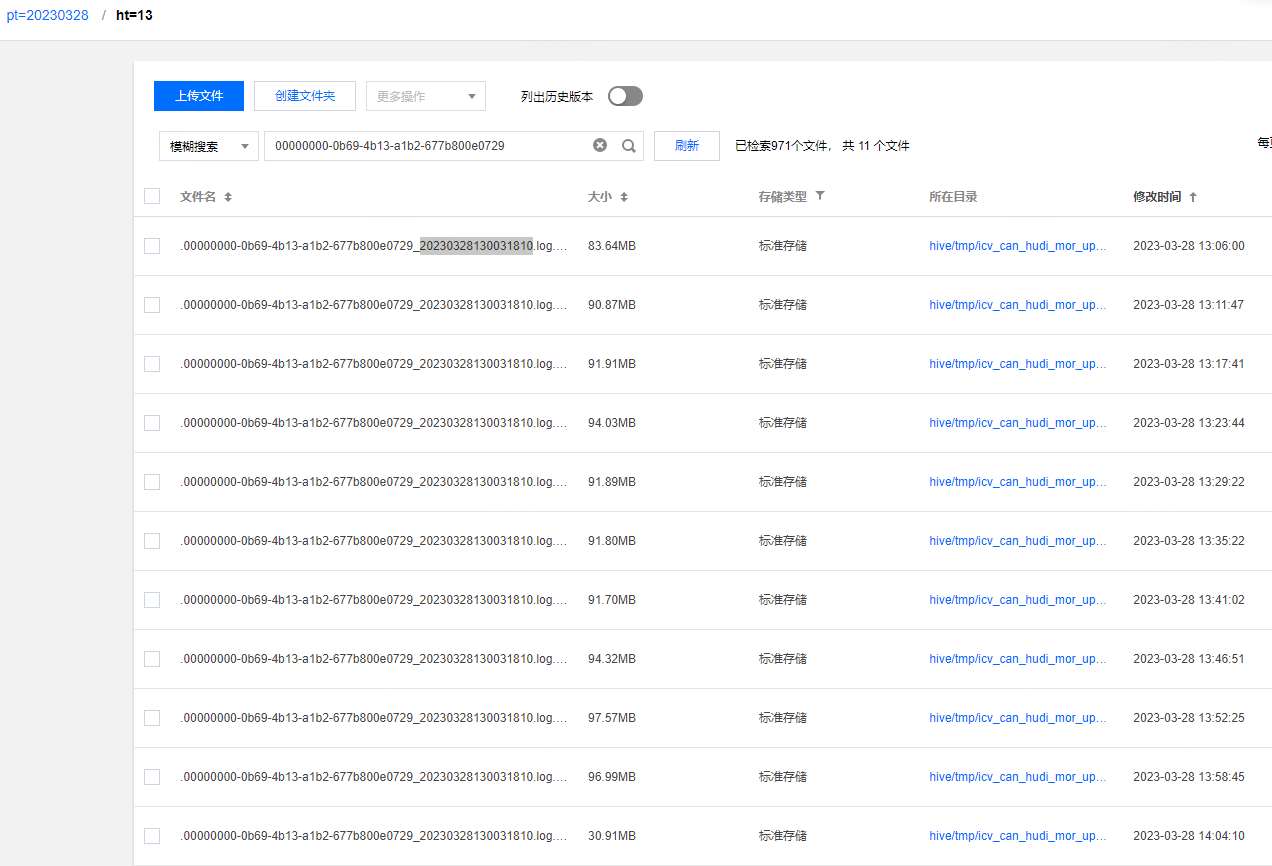 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] nsivabalan commented on a diff in pull request #8304: [HUDI-5993] Connection leak for lock provider
nsivabalan commented on code in PR #8304:
URL: https://github.com/apache/hudi/pull/8304#discussion_r1151428902
##
hudi-client/hudi-client-common/src/main/java/org/apache/hudi/client/transaction/lock/LockManager.java:
##
@@ -111,6 +111,7 @@ public void unlock() {
if
(writeConfig.getWriteConcurrencyMode().supportsOptimisticConcurrencyControl()) {
getLockProvider().unlock();
metrics.updateLockHeldTimerMetrics();
+ close();
Review Comment:
@vinothchandar : yes you are right. for streaming ingestion, we keep
re-using the same write client and hence.
##
hudi-client/hudi-client-common/src/test/java/org/apache/hudi/client/transaction/TestLockManager.java:
##
@@ -0,0 +1,119 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.client.transaction;
+
+import org.apache.hudi.client.transaction.lock.LockManager;
+import org.apache.hudi.client.transaction.lock.ZookeeperBasedLockProvider;
+import org.apache.hudi.common.model.HoodieFailedWritesCleaningPolicy;
+import org.apache.hudi.common.model.WriteConcurrencyMode;
+import org.apache.hudi.common.testutils.HoodieCommonTestHarness;
+import org.apache.hudi.config.HoodieCleanConfig;
+import org.apache.hudi.config.HoodieLockConfig;
+import org.apache.hudi.config.HoodieWriteConfig;
+
+import org.apache.curator.test.TestingServer;
+import org.apache.log4j.LogManager;
+import org.apache.log4j.Logger;
+import org.junit.jupiter.api.AfterAll;
+import org.junit.jupiter.api.BeforeAll;
+import org.junit.jupiter.api.BeforeEach;
+import org.junit.jupiter.api.Test;
+
+import java.io.IOException;
+import java.lang.reflect.Field;
+
+import static org.junit.jupiter.api.Assertions.assertDoesNotThrow;
+import static org.junit.jupiter.api.Assertions.assertNotNull;
+import static org.junit.jupiter.api.Assertions.assertNull;
+
+public class TestLockManager extends HoodieCommonTestHarness {
+
+ private static final Logger LOG =
LogManager.getLogger(TestLockManager.class);
+
+ private static TestingServer server;
+ private static String zk_basePath = "/hudi/test/lock";
+ private static String key = "table1";
+
+ HoodieWriteConfig writeConfig;
+ LockManager lockManager;
+
+ @BeforeAll
+ public static void setup() {
+while (server == null) {
+ try {
+server = new TestingServer();
+ } catch (Exception e) {
+LOG.error("Getting bind exception - retrying to allocate server");
+server = null;
+ }
+}
+ }
+
+ @AfterAll
+ public static void tearDown() throws IOException {
+if (server != null) {
+ server.close();
+}
+ }
+
+ private HoodieWriteConfig getWriteConfig() {
+return HoodieWriteConfig.newBuilder()
+.withPath(basePath)
+.withCleanConfig(HoodieCleanConfig.newBuilder()
+
.withFailedWritesCleaningPolicy(HoodieFailedWritesCleaningPolicy.LAZY)
+.build())
+
.withWriteConcurrencyMode(WriteConcurrencyMode.OPTIMISTIC_CONCURRENCY_CONTROL)
+.withLockConfig(HoodieLockConfig.newBuilder()
+.withLockProvider(ZookeeperBasedLockProvider.class)
+.withZkBasePath(zk_basePath)
+.withZkLockKey(key)
+.withZkQuorum(server.getConnectString())
+.build())
+.build();
+ }
+
+ @BeforeEach
+ private void init() throws IOException {
+initPath();
+initMetaClient();
+this.writeConfig = getWriteConfig();
+this.lockManager = new LockManager(this.writeConfig,
this.metaClient.getFs());
+ }
+
+ @Test
+ public void testLockAndUnlock() throws NoSuchFieldException,
IllegalAccessException{
+
+Field lockProvider =
lockManager.getClass().getDeclaredField("lockProvider");
+lockProvider.setAccessible(true);
+
+assertDoesNotThrow(() -> {
+ lockManager.lock();
+});
+
+assertNotNull(lockProvider.get(lockManager));
+
+assertDoesNotThrow(() -> {
+ lockManager.unlock();
Review Comment:
+1
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this
[GitHub] [hudi] nsivabalan commented on pull request #8304: [HUDI-5993] Connection leak for lock provider
nsivabalan commented on PR #8304: URL: https://github.com/apache/hudi/pull/8304#issuecomment-1487992098 LGTM. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] voonhous commented on a diff in pull request #8307: [HUDI-5992] Fix (de)serialization for avro versions > 1.10.0
voonhous commented on code in PR #8307:
URL: https://github.com/apache/hudi/pull/8307#discussion_r1151405975
##
hudi-common/src/main/java/org/apache/hudi/avro/GenericAvroSerializer.java:
##
@@ -0,0 +1,148 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.avro;
+
+import com.esotericsoftware.kryo.Kryo;
+import com.esotericsoftware.kryo.Serializer;
+import com.esotericsoftware.kryo.io.Input;
+import com.esotericsoftware.kryo.io.Output;
+import org.apache.avro.Schema;
+import org.apache.avro.SchemaNormalization;
+import org.apache.avro.generic.GenericContainer;
+import org.apache.avro.generic.GenericDatumReader;
+import org.apache.avro.generic.GenericDatumWriter;
+import org.apache.avro.io.DatumReader;
+import org.apache.avro.io.DatumWriter;
+import org.apache.avro.io.Decoder;
+import org.apache.avro.io.DecoderFactory;
+import org.apache.avro.io.Encoder;
+import org.apache.avro.io.EncoderFactory;
+
+import java.io.IOException;
+import java.nio.charset.StandardCharsets;
+import java.util.HashMap;
+
+
+/**
+ * Custom serializer used for generic Avro containers.
+ *
+ * Heavily adapted from:
+ *
+ * https://github.com/apache/spark/blob/master/core/src/main/scala/org/apache/spark/serializer/GenericAvroSerializer.scala";>GenericAvroSerializer.scala
+ *
+ * As {@link org.apache.hudi.common.util.SerializationUtils} is not shared
between threads and does not concern any
+ * shuffling operations, compression and decompression cache is omitted as
network IO is not a concern.
+ *
+ * Unlike Spark's implementation, the class and constructor is not initialized
with a predefined map of avro schemas.
+ * This is the case as schemas to read and write are not known beforehand.
+ *
+ * @param the subtype of [[GenericContainer]] handled by this serializer
+ */
+public class GenericAvroSerializer extends
Serializer {
+
+ // reuses the same datum reader/writer since the same schema will be used
many times
+ private final HashMap> writerCache = new HashMap<>();
+ private final HashMap> readerCache = new HashMap<>();
+
+ // fingerprinting is very expensive so this alleviates most of the work
+ private final HashMap fingerprintCache = new HashMap<>();
+ private final HashMap schemaCache = new HashMap<>();
+
+ private Long getFingerprint(Schema schema) {
+if (fingerprintCache.containsKey(schema)) {
+ return fingerprintCache.get(schema);
+} else {
+ Long fingerprint = SchemaNormalization.parsingFingerprint64(schema);
+ fingerprintCache.put(schema, fingerprint);
+ return fingerprint;
+}
+ }
+
+ private Schema getSchema(Long fingerprint, byte[] schemaBytes) {
+if (schemaCache.containsKey(fingerprint)) {
+ return schemaCache.get(fingerprint);
+} else {
+ String schema = new String(schemaBytes, StandardCharsets.UTF_8);
+ Schema parsedSchema = new Schema.Parser().parse(schema);
+ schemaCache.put(fingerprint, parsedSchema);
+ return parsedSchema;
+}
+ }
+
+ private DatumWriter getDatumWriter(Schema schema) {
+DatumWriter writer;
+if (writerCache.containsKey(schema)) {
+ writer = writerCache.get(schema);
+} else {
+ writer = new GenericDatumWriter<>(schema);
+ writerCache.put(schema, writer);
+}
+return writer;
+ }
+
+ private DatumReader getDatumReader(Schema schema) {
+DatumReader reader;
+if (readerCache.containsKey(schema)) {
+ reader = readerCache.get(schema);
+} else {
+ reader = new GenericDatumReader<>(schema);
+ readerCache.put(schema, reader);
+}
+return reader;
+ }
+
+ private void serializeDatum(D datum, Output output) throws IOException {
+Encoder encoder = EncoderFactory.get().directBinaryEncoder(output, null);
+Schema schema = datum.getSchema();
+Long fingerprint = this.getFingerprint(schema);
+byte[] schemaBytes = schema.toString().getBytes(StandardCharsets.UTF_8);
Review Comment:
> When fingleprint is disabled, the schema is decoded directly from the
compressee bytes.
Yeap. In this PR, our `schemaCache` serves the purpose of the
`decompressCache`, which is the cache used in the `decompress` function.
If you look at Spark
[GitHub] [hudi] voonhous commented on a diff in pull request #8307: [HUDI-5992] Fix (de)serialization for avro versions > 1.10.0
voonhous commented on code in PR #8307:
URL: https://github.com/apache/hudi/pull/8307#discussion_r1151405975
##
hudi-common/src/main/java/org/apache/hudi/avro/GenericAvroSerializer.java:
##
@@ -0,0 +1,148 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.avro;
+
+import com.esotericsoftware.kryo.Kryo;
+import com.esotericsoftware.kryo.Serializer;
+import com.esotericsoftware.kryo.io.Input;
+import com.esotericsoftware.kryo.io.Output;
+import org.apache.avro.Schema;
+import org.apache.avro.SchemaNormalization;
+import org.apache.avro.generic.GenericContainer;
+import org.apache.avro.generic.GenericDatumReader;
+import org.apache.avro.generic.GenericDatumWriter;
+import org.apache.avro.io.DatumReader;
+import org.apache.avro.io.DatumWriter;
+import org.apache.avro.io.Decoder;
+import org.apache.avro.io.DecoderFactory;
+import org.apache.avro.io.Encoder;
+import org.apache.avro.io.EncoderFactory;
+
+import java.io.IOException;
+import java.nio.charset.StandardCharsets;
+import java.util.HashMap;
+
+
+/**
+ * Custom serializer used for generic Avro containers.
+ *
+ * Heavily adapted from:
+ *
+ * https://github.com/apache/spark/blob/master/core/src/main/scala/org/apache/spark/serializer/GenericAvroSerializer.scala";>GenericAvroSerializer.scala
+ *
+ * As {@link org.apache.hudi.common.util.SerializationUtils} is not shared
between threads and does not concern any
+ * shuffling operations, compression and decompression cache is omitted as
network IO is not a concern.
+ *
+ * Unlike Spark's implementation, the class and constructor is not initialized
with a predefined map of avro schemas.
+ * This is the case as schemas to read and write are not known beforehand.
+ *
+ * @param the subtype of [[GenericContainer]] handled by this serializer
+ */
+public class GenericAvroSerializer extends
Serializer {
+
+ // reuses the same datum reader/writer since the same schema will be used
many times
+ private final HashMap> writerCache = new HashMap<>();
+ private final HashMap> readerCache = new HashMap<>();
+
+ // fingerprinting is very expensive so this alleviates most of the work
+ private final HashMap fingerprintCache = new HashMap<>();
+ private final HashMap schemaCache = new HashMap<>();
+
+ private Long getFingerprint(Schema schema) {
+if (fingerprintCache.containsKey(schema)) {
+ return fingerprintCache.get(schema);
+} else {
+ Long fingerprint = SchemaNormalization.parsingFingerprint64(schema);
+ fingerprintCache.put(schema, fingerprint);
+ return fingerprint;
+}
+ }
+
+ private Schema getSchema(Long fingerprint, byte[] schemaBytes) {
+if (schemaCache.containsKey(fingerprint)) {
+ return schemaCache.get(fingerprint);
+} else {
+ String schema = new String(schemaBytes, StandardCharsets.UTF_8);
+ Schema parsedSchema = new Schema.Parser().parse(schema);
+ schemaCache.put(fingerprint, parsedSchema);
+ return parsedSchema;
+}
+ }
+
+ private DatumWriter getDatumWriter(Schema schema) {
+DatumWriter writer;
+if (writerCache.containsKey(schema)) {
+ writer = writerCache.get(schema);
+} else {
+ writer = new GenericDatumWriter<>(schema);
+ writerCache.put(schema, writer);
+}
+return writer;
+ }
+
+ private DatumReader getDatumReader(Schema schema) {
+DatumReader reader;
+if (readerCache.containsKey(schema)) {
+ reader = readerCache.get(schema);
+} else {
+ reader = new GenericDatumReader<>(schema);
+ readerCache.put(schema, reader);
+}
+return reader;
+ }
+
+ private void serializeDatum(D datum, Output output) throws IOException {
+Encoder encoder = EncoderFactory.get().directBinaryEncoder(output, null);
+Schema schema = datum.getSchema();
+Long fingerprint = this.getFingerprint(schema);
+byte[] schemaBytes = schema.toString().getBytes(StandardCharsets.UTF_8);
Review Comment:
> When fingleprint is disabled, the schema is decoded directly from the
compressee bytes.
Yeap. In this PR, our `schemaCache` serves the purpose of the
`decompressCache`, which is the cache used in the `decompress` function.
If you look at Spark
[GitHub] [hudi] danny0405 commented on issue #8305: [SUPPORT] fluent-hc max connection restriction
danny0405 commented on issue #8305: URL: https://github.com/apache/hudi/issues/8305#issuecomment-1487936671 Nice catch, can you show me the code where the `org.apache.http.client.fluent.Executor` is used? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Closed] (HUDI-5952) NullPointerException when use kafka callback
[ https://issues.apache.org/jira/browse/HUDI-5952?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Danny Chen closed HUDI-5952. Fix Version/s: 0.14.0 Resolution: Fixed Fixed via master branch: 7243393c6881802803c0233cbac42daf1271afb3 > NullPointerException when use kafka callback > > > Key: HUDI-5952 > URL: https://issues.apache.org/jira/browse/HUDI-5952 > Project: Apache Hudi > Issue Type: Bug > Components: hudi-utilities >Reporter: wuzhenhua >Priority: Major > Labels: pull-request-available > Fix For: 0.14.0 > > Attachments: image-2023-03-18-11-41-35-135.png > > > hudi.conf: > hoodie.write.commit.callback.on true > hoodie.write.commit.callback.class > org.apache.hudi.utilities.callback.kafka.HoodieWriteCommitKafkaCallback > hoodie.write.commit.callback.kafka.bootstrap.servers localhost:9082 > hoodie.write.commit.callback.kafka.topic hudi-callback > hoodie.write.commit.callback.kafka.partition 1 > > !image-2023-03-18-11-41-35-135.png! -- This message was sent by Atlassian Jira (v8.20.10#820010)
[hudi] branch master updated (2023302ebee -> 7243393c688)
This is an automated email from the ASF dual-hosted git repository. danny0405 pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/hudi.git from 2023302ebee [HUDI-5986] Empty preCombineKey should never be stored in hoodie.properties (#8296) add 7243393c688 [HUDI-5952] Fix NPE when use kafka callback (#8227) No new revisions were added by this update. Summary of changes: .../kafka/HoodieWriteCommitKafkaCallback.java | 4 +- .../callback/TestKafkaCallbackProvider.java| 90 ++ 2 files changed, 92 insertions(+), 2 deletions(-) create mode 100644 hudi-utilities/src/test/java/org/apache/hudi/utilities/callback/TestKafkaCallbackProvider.java
[GitHub] [hudi] danny0405 merged pull request #8227: [HUDI-5952] Fix NPE when use kafka callback
danny0405 merged PR #8227: URL: https://github.com/apache/hudi/pull/8227 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Resolved] (HUDI-5986) empty preCombineKey should never be stored in hoodie.properties
[
https://issues.apache.org/jira/browse/HUDI-5986?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Danny Chen resolved HUDI-5986.
--
> empty preCombineKey should never be stored in hoodie.properties
> ---
>
> Key: HUDI-5986
> URL: https://issues.apache.org/jira/browse/HUDI-5986
> Project: Apache Hudi
> Issue Type: Bug
> Components: hudi-utilities
>Reporter: Wechar
>Priority: Major
> Labels: pull-request-available
>
> *Overview:*
> We found {{hoodie.properties}} will keep the empty preCombineKey if the table
> does not have preCombineKey. And the empty preCombineKey will cause the
> exception when insert data:
> {code:bash}
> Caused by: org.apache.hudi.exception.HoodieException: (Part -) field not
> found in record. Acceptable fields were :[id, name, price]
> at
> org.apache.hudi.avro.HoodieAvroUtils.getNestedFieldVal(HoodieAvroUtils.java:557)
> at
> org.apache.hudi.HoodieSparkSqlWriter$$anonfun$createHoodieRecordRdd$1$$anonfun$apply$5.apply(HoodieSparkSqlWriter.scala:1134)
> at
> org.apache.hudi.HoodieSparkSqlWriter$$anonfun$createHoodieRecordRdd$1$$anonfun$apply$5.apply(HoodieSparkSqlWriter.scala:1127)
> at scala.collection.Iterator$$anon$11.next(Iterator.scala:410)
> at scala.collection.Iterator$$anon$11.next(Iterator.scala:410)
> at
> org.apache.spark.util.collection.ExternalSorter.insertAll(ExternalSorter.scala:193)
> at
> org.apache.spark.shuffle.sort.SortShuffleWriter.write(SortShuffleWriter.scala:62)
> at
> org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:99)
> at
> org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:55)
> at org.apache.spark.scheduler.Task.run(Task.scala:123)
> at
> org.apache.spark.executor.Executor$TaskRunner$$anonfun$10.apply(Executor.scala:408)
> at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1360)
> at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:414)
> at
> java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
> at
> java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
> at java.lang.Thread.run(Thread.java:748)
> {code}
> *Steps to Reproduce:*
> {code:sql}
> -- 1. create a table without preCombineKey
> CREATE TABLE default.test_hudi_default_cm (
> uuid int,
> name string,
> price double
> ) USING hudi
> options (
> primaryKey='uuid');
> -- 2. config write operation to insert
> set hoodie.datasource.write.operation=insert;
> set hoodie.merge.allow.duplicate.on.inserts=true;
> -- 3. insert data
> insert into default.test_hudi_default_cm select 1, 'name1', 1.1;
> -- 4. insert overwrite
> insert overwrite table default.test_hudi_default_cm select 2, 'name3', 1.1;
> -- 5. insert data will occur exception
> insert into default.test_hudi_default_cm select 1, 'name3', 1.1;
> {code}
> *Root Cause:*
> Hudi re-construct the table when *insert overwrite table* in sql but the
> configured operation is not, then it stores the default empty preCombineKey
> in {{hoodie.properties}}.
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[jira] [Updated] (HUDI-5986) empty preCombineKey should never be stored in hoodie.properties
[
https://issues.apache.org/jira/browse/HUDI-5986?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Danny Chen updated HUDI-5986:
-
Fix Version/s: 0.14.0
> empty preCombineKey should never be stored in hoodie.properties
> ---
>
> Key: HUDI-5986
> URL: https://issues.apache.org/jira/browse/HUDI-5986
> Project: Apache Hudi
> Issue Type: Bug
> Components: hudi-utilities
>Reporter: Wechar
>Priority: Major
> Labels: pull-request-available
> Fix For: 0.14.0
>
>
> *Overview:*
> We found {{hoodie.properties}} will keep the empty preCombineKey if the table
> does not have preCombineKey. And the empty preCombineKey will cause the
> exception when insert data:
> {code:bash}
> Caused by: org.apache.hudi.exception.HoodieException: (Part -) field not
> found in record. Acceptable fields were :[id, name, price]
> at
> org.apache.hudi.avro.HoodieAvroUtils.getNestedFieldVal(HoodieAvroUtils.java:557)
> at
> org.apache.hudi.HoodieSparkSqlWriter$$anonfun$createHoodieRecordRdd$1$$anonfun$apply$5.apply(HoodieSparkSqlWriter.scala:1134)
> at
> org.apache.hudi.HoodieSparkSqlWriter$$anonfun$createHoodieRecordRdd$1$$anonfun$apply$5.apply(HoodieSparkSqlWriter.scala:1127)
> at scala.collection.Iterator$$anon$11.next(Iterator.scala:410)
> at scala.collection.Iterator$$anon$11.next(Iterator.scala:410)
> at
> org.apache.spark.util.collection.ExternalSorter.insertAll(ExternalSorter.scala:193)
> at
> org.apache.spark.shuffle.sort.SortShuffleWriter.write(SortShuffleWriter.scala:62)
> at
> org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:99)
> at
> org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:55)
> at org.apache.spark.scheduler.Task.run(Task.scala:123)
> at
> org.apache.spark.executor.Executor$TaskRunner$$anonfun$10.apply(Executor.scala:408)
> at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1360)
> at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:414)
> at
> java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
> at
> java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
> at java.lang.Thread.run(Thread.java:748)
> {code}
> *Steps to Reproduce:*
> {code:sql}
> -- 1. create a table without preCombineKey
> CREATE TABLE default.test_hudi_default_cm (
> uuid int,
> name string,
> price double
> ) USING hudi
> options (
> primaryKey='uuid');
> -- 2. config write operation to insert
> set hoodie.datasource.write.operation=insert;
> set hoodie.merge.allow.duplicate.on.inserts=true;
> -- 3. insert data
> insert into default.test_hudi_default_cm select 1, 'name1', 1.1;
> -- 4. insert overwrite
> insert overwrite table default.test_hudi_default_cm select 2, 'name3', 1.1;
> -- 5. insert data will occur exception
> insert into default.test_hudi_default_cm select 1, 'name3', 1.1;
> {code}
> *Root Cause:*
> Hudi re-construct the table when *insert overwrite table* in sql but the
> configured operation is not, then it stores the default empty preCombineKey
> in {{hoodie.properties}}.
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[jira] [Closed] (HUDI-5986) empty preCombineKey should never be stored in hoodie.properties
[
https://issues.apache.org/jira/browse/HUDI-5986?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Danny Chen closed HUDI-5986.
Resolution: Fixed
Fixed via master branch: 2023302ebeed728e632e43e2475c0045a9263067
> empty preCombineKey should never be stored in hoodie.properties
> ---
>
> Key: HUDI-5986
> URL: https://issues.apache.org/jira/browse/HUDI-5986
> Project: Apache Hudi
> Issue Type: Bug
> Components: hudi-utilities
>Reporter: Wechar
>Priority: Major
> Labels: pull-request-available
> Fix For: 0.14.0
>
>
> *Overview:*
> We found {{hoodie.properties}} will keep the empty preCombineKey if the table
> does not have preCombineKey. And the empty preCombineKey will cause the
> exception when insert data:
> {code:bash}
> Caused by: org.apache.hudi.exception.HoodieException: (Part -) field not
> found in record. Acceptable fields were :[id, name, price]
> at
> org.apache.hudi.avro.HoodieAvroUtils.getNestedFieldVal(HoodieAvroUtils.java:557)
> at
> org.apache.hudi.HoodieSparkSqlWriter$$anonfun$createHoodieRecordRdd$1$$anonfun$apply$5.apply(HoodieSparkSqlWriter.scala:1134)
> at
> org.apache.hudi.HoodieSparkSqlWriter$$anonfun$createHoodieRecordRdd$1$$anonfun$apply$5.apply(HoodieSparkSqlWriter.scala:1127)
> at scala.collection.Iterator$$anon$11.next(Iterator.scala:410)
> at scala.collection.Iterator$$anon$11.next(Iterator.scala:410)
> at
> org.apache.spark.util.collection.ExternalSorter.insertAll(ExternalSorter.scala:193)
> at
> org.apache.spark.shuffle.sort.SortShuffleWriter.write(SortShuffleWriter.scala:62)
> at
> org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:99)
> at
> org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:55)
> at org.apache.spark.scheduler.Task.run(Task.scala:123)
> at
> org.apache.spark.executor.Executor$TaskRunner$$anonfun$10.apply(Executor.scala:408)
> at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1360)
> at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:414)
> at
> java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
> at
> java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
> at java.lang.Thread.run(Thread.java:748)
> {code}
> *Steps to Reproduce:*
> {code:sql}
> -- 1. create a table without preCombineKey
> CREATE TABLE default.test_hudi_default_cm (
> uuid int,
> name string,
> price double
> ) USING hudi
> options (
> primaryKey='uuid');
> -- 2. config write operation to insert
> set hoodie.datasource.write.operation=insert;
> set hoodie.merge.allow.duplicate.on.inserts=true;
> -- 3. insert data
> insert into default.test_hudi_default_cm select 1, 'name1', 1.1;
> -- 4. insert overwrite
> insert overwrite table default.test_hudi_default_cm select 2, 'name3', 1.1;
> -- 5. insert data will occur exception
> insert into default.test_hudi_default_cm select 1, 'name3', 1.1;
> {code}
> *Root Cause:*
> Hudi re-construct the table when *insert overwrite table* in sql but the
> configured operation is not, then it stores the default empty preCombineKey
> in {{hoodie.properties}}.
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[GitHub] [hudi] danny0405 merged pull request #8296: [HUDI-5986] Empty preCombineKey should never be stored in hoodie.properties
danny0405 merged PR #8296: URL: https://github.com/apache/hudi/pull/8296 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[hudi] branch master updated (e1741ddc7d9 -> 2023302ebee)
This is an automated email from the ASF dual-hosted git repository. danny0405 pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/hudi.git from e1741ddc7d9 [MINOR] Fix typo for method in AvroSchemaConverter (#8306) add 2023302ebee [HUDI-5986] Empty preCombineKey should never be stored in hoodie.properties (#8296) No new revisions were added by this update. Summary of changes: .../hudi/common/table/HoodieTableMetaClient.java | 2 +- .../apache/spark/sql/hudi/TestInsertTable.scala| 34 ++ 2 files changed, 35 insertions(+), 1 deletion(-)
[GitHub] [hudi] hudi-bot commented on pull request #8307: [HUDI-5992] Fix (de)serialization for avro versions > 1.10.0
hudi-bot commented on PR #8307: URL: https://github.com/apache/hudi/pull/8307#issuecomment-1487931181 ## CI report: * 8aef9327c27d3f716a7f4c40f9a6d0ea6f370d3e Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15957) Azure: [SUCCESS](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15961) * d8521565c1a8a4e215f779c525b7d123b44b94b3 Azure: [PENDING](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15965) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] Zouxxyy commented on issue #8312: [SUPPORT] Metadata of hudi mor table (without ro/rt suffix) is not synchronized to HMS
Zouxxyy commented on issue #8312: URL: https://github.com/apache/hudi/issues/8312#issuecomment-1487927646 My idea is to remove `hoodie.datasource.hive_sync.skip_ro_suffix`, and control the metadata synchronization behavior only by `hoodie.datasource.hive_sync.table.strategy`: ALL: table (behavior is consistent with table_rt) table_ro table_rt RO table (behavior is consistent with table_rt) table_ro RT table (behavior is consistent with table_rt) table_rt But this change is a bit big, what do you think? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #8307: [HUDI-5992] Fix (de)serialization for avro versions > 1.10.0
hudi-bot commented on PR #8307: URL: https://github.com/apache/hudi/pull/8307#issuecomment-1487927175 ## CI report: * 8aef9327c27d3f716a7f4c40f9a6d0ea6f370d3e Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15957) Azure: [SUCCESS](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15961) * d8521565c1a8a4e215f779c525b7d123b44b94b3 UNKNOWN Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] Zouxxyy opened a new issue, #8312: [SUPPORT] Metadata of hudi mor table (without ro/rt suffix) is not synchronized to HMS
Zouxxyy opened a new issue, #8312:
URL: https://github.com/apache/hudi/issues/8312
**Describe the problem you faced**
When scan partitioned hudi mor table (without ro/rt suffix), we get nothing,
because metadata (especially partitions) is not synchronized to HMS. As follows
```java
protected void doSync() {
switch (syncClient.getTableType()) {
case COPY_ON_WRITE:
syncHoodieTable(snapshotTableName, false, false);
break;
case MERGE_ON_READ:
switch (HoodieSyncTableStrategy.valueOf(hiveSyncTableStrategy)) {
case RO :
// sync a RO table for MOR
syncHoodieTable(tableName, false, true);
break;
case RT :
// sync a RT table for MOR
syncHoodieTable(tableName, true, false);
break;
default:
// sync a RO table for MOR
syncHoodieTable(roTableName.get(), false, true);
// sync a RT table for MOR
syncHoodieTable(snapshotTableName, true, false);
}
break;
default:
LOG.error("Unknown table type " + syncClient.getTableType());
throw new InvalidTableException(syncClient.getBasePath());
}
}
```
In addition, there is a parameter,
`hoodie.datasource.hive_sync.skip_ro_suffix`, when set it to true, **will
register table without ro suffix as ro table**;
**This contradicts spark's behavior**, because the behavior of querying
table without suffix is **actually rt table**.
**To Reproduce**
Steps to reproduce the behavior:
```sql
-- spark
create table hudi_mor_test_tbl (
id bigint,
name string,
ts bigint,
dt string,
hh string
) using hudi
tblproperties (
type = 'mor',
primaryKey = 'id',
preCombineField = 'ts'
)
partitioned by (dt, hh);
insert into hudi_mor_test_tbl values (1, 'a1', 1001, '2021-12-09', '10');
-- hive
select * from hudi_mor_test_tbl;
```
**Expected behavior**
We should get query result
**Environment Description**
* Hudi version : 0.13.0
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] voonhous commented on a diff in pull request #8307: [HUDI-5992] Fix (de)serialization for avro versions > 1.10.0
voonhous commented on code in PR #8307:
URL: https://github.com/apache/hudi/pull/8307#discussion_r1151368487
##
hudi-common/src/main/java/org/apache/hudi/avro/GenericAvroSerializer.java:
##
@@ -0,0 +1,148 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.avro;
+
+import com.esotericsoftware.kryo.Kryo;
+import com.esotericsoftware.kryo.Serializer;
+import com.esotericsoftware.kryo.io.Input;
+import com.esotericsoftware.kryo.io.Output;
+import org.apache.avro.Schema;
+import org.apache.avro.SchemaNormalization;
+import org.apache.avro.generic.GenericContainer;
+import org.apache.avro.generic.GenericDatumReader;
+import org.apache.avro.generic.GenericDatumWriter;
+import org.apache.avro.io.DatumReader;
+import org.apache.avro.io.DatumWriter;
+import org.apache.avro.io.Decoder;
+import org.apache.avro.io.DecoderFactory;
+import org.apache.avro.io.Encoder;
+import org.apache.avro.io.EncoderFactory;
+
+import java.io.IOException;
+import java.nio.charset.StandardCharsets;
+import java.util.HashMap;
+
+
+/**
+ * Custom serializer used for generic Avro containers.
+ *
+ * Heavily adapted from:
+ *
+ * https://github.com/apache/spark/blob/master/core/src/main/scala/org/apache/spark/serializer/GenericAvroSerializer.scala";>GenericAvroSerializer.scala
+ *
+ * As {@link org.apache.hudi.common.util.SerializationUtils} is not shared
between threads and does not concern any
+ * shuffling operations, compression and decompression cache is omitted as
network IO is not a concern.
+ *
+ * Unlike Spark's implementation, the class and constructor is not initialized
with a predefined map of avro schemas.
+ * This is the case as schemas to read and write are not known beforehand.
+ *
+ * @param the subtype of [[GenericContainer]] handled by this serializer
+ */
+public class GenericAvroSerializer extends
Serializer {
+
+ // reuses the same datum reader/writer since the same schema will be used
many times
+ private final HashMap> writerCache = new HashMap<>();
+ private final HashMap> readerCache = new HashMap<>();
+
+ // fingerprinting is very expensive so this alleviates most of the work
+ private final HashMap fingerprintCache = new HashMap<>();
+ private final HashMap schemaCache = new HashMap<>();
+
+ private Long getFingerprint(Schema schema) {
+if (fingerprintCache.containsKey(schema)) {
+ return fingerprintCache.get(schema);
+} else {
+ Long fingerprint = SchemaNormalization.parsingFingerprint64(schema);
+ fingerprintCache.put(schema, fingerprint);
+ return fingerprint;
+}
+ }
+
+ private Schema getSchema(Long fingerprint, byte[] schemaBytes) {
+if (schemaCache.containsKey(fingerprint)) {
+ return schemaCache.get(fingerprint);
+} else {
+ String schema = new String(schemaBytes, StandardCharsets.UTF_8);
+ Schema parsedSchema = new Schema.Parser().parse(schema);
+ schemaCache.put(fingerprint, parsedSchema);
+ return parsedSchema;
+}
+ }
+
+ private DatumWriter getDatumWriter(Schema schema) {
+DatumWriter writer;
+if (writerCache.containsKey(schema)) {
+ writer = writerCache.get(schema);
+} else {
+ writer = new GenericDatumWriter<>(schema);
+ writerCache.put(schema, writer);
+}
+return writer;
+ }
+
+ private DatumReader getDatumReader(Schema schema) {
+DatumReader reader;
+if (readerCache.containsKey(schema)) {
+ reader = readerCache.get(schema);
+} else {
+ reader = new GenericDatumReader<>(schema);
+ readerCache.put(schema, reader);
+}
+return reader;
+ }
+
+ private void serializeDatum(D datum, Output output) throws IOException {
+Encoder encoder = EncoderFactory.get().directBinaryEncoder(output, null);
+Schema schema = datum.getSchema();
+Long fingerprint = this.getFingerprint(schema);
+byte[] schemaBytes = schema.toString().getBytes(StandardCharsets.UTF_8);
Review Comment:
However, compressBytes and decompressBytes are cached right?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commit
[GitHub] [hudi] danny0405 commented on issue #8087: [SUPPORT] split_reader don't checkpoint before consuming all splits
danny0405 commented on issue #8087: URL: https://github.com/apache/hudi/issues/8087#issuecomment-1487911609 Should be fine, we need to test it in practice about the performace and whether it resolves the problem that ckp takes too long time to be timedout. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] danny0405 commented on a diff in pull request #8307: [HUDI-5992] Fix (de)serialization for avro versions > 1.10.0
danny0405 commented on code in PR #8307:
URL: https://github.com/apache/hudi/pull/8307#discussion_r1151367039
##
hudi-common/src/main/java/org/apache/hudi/avro/GenericAvroSerializer.java:
##
@@ -0,0 +1,148 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.avro;
+
+import com.esotericsoftware.kryo.Kryo;
+import com.esotericsoftware.kryo.Serializer;
+import com.esotericsoftware.kryo.io.Input;
+import com.esotericsoftware.kryo.io.Output;
+import org.apache.avro.Schema;
+import org.apache.avro.SchemaNormalization;
+import org.apache.avro.generic.GenericContainer;
+import org.apache.avro.generic.GenericDatumReader;
+import org.apache.avro.generic.GenericDatumWriter;
+import org.apache.avro.io.DatumReader;
+import org.apache.avro.io.DatumWriter;
+import org.apache.avro.io.Decoder;
+import org.apache.avro.io.DecoderFactory;
+import org.apache.avro.io.Encoder;
+import org.apache.avro.io.EncoderFactory;
+
+import java.io.IOException;
+import java.nio.charset.StandardCharsets;
+import java.util.HashMap;
+
+
+/**
+ * Custom serializer used for generic Avro containers.
+ *
+ * Heavily adapted from:
+ *
+ * https://github.com/apache/spark/blob/master/core/src/main/scala/org/apache/spark/serializer/GenericAvroSerializer.scala";>GenericAvroSerializer.scala
+ *
+ * As {@link org.apache.hudi.common.util.SerializationUtils} is not shared
between threads and does not concern any
+ * shuffling operations, compression and decompression cache is omitted as
network IO is not a concern.
+ *
+ * Unlike Spark's implementation, the class and constructor is not initialized
with a predefined map of avro schemas.
+ * This is the case as schemas to read and write are not known beforehand.
+ *
+ * @param the subtype of [[GenericContainer]] handled by this serializer
+ */
+public class GenericAvroSerializer extends
Serializer {
+
+ // reuses the same datum reader/writer since the same schema will be used
many times
+ private final HashMap> writerCache = new HashMap<>();
+ private final HashMap> readerCache = new HashMap<>();
+
+ // fingerprinting is very expensive so this alleviates most of the work
+ private final HashMap fingerprintCache = new HashMap<>();
+ private final HashMap schemaCache = new HashMap<>();
+
+ private Long getFingerprint(Schema schema) {
+if (fingerprintCache.containsKey(schema)) {
+ return fingerprintCache.get(schema);
+} else {
+ Long fingerprint = SchemaNormalization.parsingFingerprint64(schema);
+ fingerprintCache.put(schema, fingerprint);
+ return fingerprint;
+}
+ }
+
+ private Schema getSchema(Long fingerprint, byte[] schemaBytes) {
+if (schemaCache.containsKey(fingerprint)) {
+ return schemaCache.get(fingerprint);
+} else {
+ String schema = new String(schemaBytes, StandardCharsets.UTF_8);
+ Schema parsedSchema = new Schema.Parser().parse(schema);
+ schemaCache.put(fingerprint, parsedSchema);
+ return parsedSchema;
+}
+ }
+
+ private DatumWriter getDatumWriter(Schema schema) {
+DatumWriter writer;
+if (writerCache.containsKey(schema)) {
+ writer = writerCache.get(schema);
+} else {
+ writer = new GenericDatumWriter<>(schema);
+ writerCache.put(schema, writer);
+}
+return writer;
+ }
+
+ private DatumReader getDatumReader(Schema schema) {
+DatumReader reader;
+if (readerCache.containsKey(schema)) {
+ reader = readerCache.get(schema);
+} else {
+ reader = new GenericDatumReader<>(schema);
+ readerCache.put(schema, reader);
+}
+return reader;
+ }
+
+ private void serializeDatum(D datum, Output output) throws IOException {
+Encoder encoder = EncoderFactory.get().directBinaryEncoder(output, null);
+Schema schema = datum.getSchema();
+Long fingerprint = this.getFingerprint(schema);
+byte[] schemaBytes = schema.toString().getBytes(StandardCharsets.UTF_8);
Review Comment:
The schema cache could be useless now, see the code in Spark:
```scala
def deserializeDatum(input: KryoInput): D = {
val schema = {
if (input.readBoolean()) {
val fingerprint = input.readLong()
schemaCache.ge
[GitHub] [hudi] danny0405 commented on a diff in pull request #8301: [HUDI-5988] Add a param, Implement a full partition sync operation wh…
danny0405 commented on code in PR #8301:
URL: https://github.com/apache/hudi/pull/8301#discussion_r1151366182
##
hudi-sync/hudi-sync-common/src/main/java/org/apache/hudi/sync/common/HoodieSyncConfig.java:
##
@@ -163,6 +163,11 @@ public class HoodieSyncConfig extends HoodieConfig {
.defaultValue("")
.withDocumentation("The spark version used when syncing with a
metastore.");
+ public static final ConfigProperty META_SYNC_PARTITION_FIXMODE =
ConfigProperty
+ .key("hoodie.datasource.hive_sync.partition_fixmode")
+ .defaultValue("false")
+ .withDocumentation("Implement a full partition sync operation when
partitions are lost.");
Review Comment:
`hoodie.datasource.hive_sync.partition_fixmode` ->
`hoodie.datasource.hive_sync.incremental` ? And by default, this option val is
true.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] voonhous commented on a diff in pull request #8307: [HUDI-5992] Fix (de)serialization for avro versions > 1.10.0
voonhous commented on code in PR #8307:
URL: https://github.com/apache/hudi/pull/8307#discussion_r1151365031
##
hudi-common/src/main/java/org/apache/hudi/avro/GenericAvroSerializer.java:
##
@@ -0,0 +1,148 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.avro;
+
+import com.esotericsoftware.kryo.Kryo;
+import com.esotericsoftware.kryo.Serializer;
+import com.esotericsoftware.kryo.io.Input;
+import com.esotericsoftware.kryo.io.Output;
+import org.apache.avro.Schema;
+import org.apache.avro.SchemaNormalization;
+import org.apache.avro.generic.GenericContainer;
+import org.apache.avro.generic.GenericDatumReader;
+import org.apache.avro.generic.GenericDatumWriter;
+import org.apache.avro.io.DatumReader;
+import org.apache.avro.io.DatumWriter;
+import org.apache.avro.io.Decoder;
+import org.apache.avro.io.DecoderFactory;
+import org.apache.avro.io.Encoder;
+import org.apache.avro.io.EncoderFactory;
+
+import java.io.IOException;
+import java.nio.charset.StandardCharsets;
+import java.util.HashMap;
+
+
+/**
+ * Custom serializer used for generic Avro containers.
+ *
+ * Heavily adapted from:
+ *
+ * https://github.com/apache/spark/blob/master/core/src/main/scala/org/apache/spark/serializer/GenericAvroSerializer.scala";>GenericAvroSerializer.scala
+ *
+ * As {@link org.apache.hudi.common.util.SerializationUtils} is not shared
between threads and does not concern any
+ * shuffling operations, compression and decompression cache is omitted as
network IO is not a concern.
+ *
+ * Unlike Spark's implementation, the class and constructor is not initialized
with a predefined map of avro schemas.
+ * This is the case as schemas to read and write are not known beforehand.
+ *
+ * @param the subtype of [[GenericContainer]] handled by this serializer
+ */
+public class GenericAvroSerializer extends
Serializer {
+
+ // reuses the same datum reader/writer since the same schema will be used
many times
+ private final HashMap> writerCache = new HashMap<>();
+ private final HashMap> readerCache = new HashMap<>();
+
+ // fingerprinting is very expensive so this alleviates most of the work
+ private final HashMap fingerprintCache = new HashMap<>();
+ private final HashMap schemaCache = new HashMap<>();
+
+ private Long getFingerprint(Schema schema) {
+if (fingerprintCache.containsKey(schema)) {
+ return fingerprintCache.get(schema);
+} else {
+ Long fingerprint = SchemaNormalization.parsingFingerprint64(schema);
+ fingerprintCache.put(schema, fingerprint);
+ return fingerprint;
+}
+ }
+
+ private Schema getSchema(Long fingerprint, byte[] schemaBytes) {
+if (schemaCache.containsKey(fingerprint)) {
+ return schemaCache.get(fingerprint);
+} else {
+ String schema = new String(schemaBytes, StandardCharsets.UTF_8);
+ Schema parsedSchema = new Schema.Parser().parse(schema);
+ schemaCache.put(fingerprint, parsedSchema);
+ return parsedSchema;
+}
+ }
+
+ private DatumWriter getDatumWriter(Schema schema) {
+DatumWriter writer;
+if (writerCache.containsKey(schema)) {
+ writer = writerCache.get(schema);
+} else {
+ writer = new GenericDatumWriter<>(schema);
+ writerCache.put(schema, writer);
+}
+return writer;
+ }
+
+ private DatumReader getDatumReader(Schema schema) {
+DatumReader reader;
+if (readerCache.containsKey(schema)) {
+ reader = readerCache.get(schema);
+} else {
+ reader = new GenericDatumReader<>(schema);
+ readerCache.put(schema, reader);
+}
+return reader;
+ }
+
+ private void serializeDatum(D datum, Output output) throws IOException {
+Encoder encoder = EncoderFactory.get().directBinaryEncoder(output, null);
+Schema schema = datum.getSchema();
+Long fingerprint = this.getFingerprint(schema);
+byte[] schemaBytes = schema.toString().getBytes(StandardCharsets.UTF_8);
Review Comment:
> Then at least there is no need to serialize the fingerprint right? Just
deserialize from the schema bytes directly should be fine.
So, `schemaCache` will be keyed by byte[]?
```java
private final HashMap schemaCache = new HashMap<>();
```
[GitHub] [hudi] voonhous commented on a diff in pull request #8307: [HUDI-5992] Fix (de)serialization for avro versions > 1.10.0
voonhous commented on code in PR #8307:
URL: https://github.com/apache/hudi/pull/8307#discussion_r1151363115
##
hudi-common/src/main/java/org/apache/hudi/avro/GenericAvroSerializer.java:
##
@@ -0,0 +1,148 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.avro;
+
+import com.esotericsoftware.kryo.Kryo;
+import com.esotericsoftware.kryo.Serializer;
+import com.esotericsoftware.kryo.io.Input;
+import com.esotericsoftware.kryo.io.Output;
+import org.apache.avro.Schema;
+import org.apache.avro.SchemaNormalization;
+import org.apache.avro.generic.GenericContainer;
+import org.apache.avro.generic.GenericDatumReader;
+import org.apache.avro.generic.GenericDatumWriter;
+import org.apache.avro.io.DatumReader;
+import org.apache.avro.io.DatumWriter;
+import org.apache.avro.io.Decoder;
+import org.apache.avro.io.DecoderFactory;
+import org.apache.avro.io.Encoder;
+import org.apache.avro.io.EncoderFactory;
+
+import java.io.IOException;
+import java.nio.charset.StandardCharsets;
+import java.util.HashMap;
+
+
+/**
+ * Custom serializer used for generic Avro containers.
+ *
+ * Heavily adapted from:
+ *
+ * https://github.com/apache/spark/blob/master/core/src/main/scala/org/apache/spark/serializer/GenericAvroSerializer.scala";>GenericAvroSerializer.scala
+ *
+ * As {@link org.apache.hudi.common.util.SerializationUtils} is not shared
between threads and does not concern any
+ * shuffling operations, compression and decompression cache is omitted as
network IO is not a concern.
+ *
+ * Unlike Spark's implementation, the class and constructor is not initialized
with a predefined map of avro schemas.
+ * This is the case as schemas to read and write are not known beforehand.
+ *
+ * @param the subtype of [[GenericContainer]] handled by this serializer
+ */
+public class GenericAvroSerializer extends
Serializer {
+
+ // reuses the same datum reader/writer since the same schema will be used
many times
+ private final HashMap> writerCache = new HashMap<>();
+ private final HashMap> readerCache = new HashMap<>();
+
+ // fingerprinting is very expensive so this alleviates most of the work
+ private final HashMap fingerprintCache = new HashMap<>();
+ private final HashMap schemaCache = new HashMap<>();
+
+ private Long getFingerprint(Schema schema) {
+if (fingerprintCache.containsKey(schema)) {
+ return fingerprintCache.get(schema);
+} else {
+ Long fingerprint = SchemaNormalization.parsingFingerprint64(schema);
+ fingerprintCache.put(schema, fingerprint);
+ return fingerprint;
+}
+ }
+
+ private Schema getSchema(Long fingerprint, byte[] schemaBytes) {
+if (schemaCache.containsKey(fingerprint)) {
+ return schemaCache.get(fingerprint);
+} else {
+ String schema = new String(schemaBytes, StandardCharsets.UTF_8);
+ Schema parsedSchema = new Schema.Parser().parse(schema);
+ schemaCache.put(fingerprint, parsedSchema);
+ return parsedSchema;
+}
+ }
+
+ private DatumWriter getDatumWriter(Schema schema) {
+DatumWriter writer;
+if (writerCache.containsKey(schema)) {
+ writer = writerCache.get(schema);
+} else {
+ writer = new GenericDatumWriter<>(schema);
+ writerCache.put(schema, writer);
+}
+return writer;
+ }
+
+ private DatumReader getDatumReader(Schema schema) {
+DatumReader reader;
+if (readerCache.containsKey(schema)) {
+ reader = readerCache.get(schema);
+} else {
+ reader = new GenericDatumReader<>(schema);
+ readerCache.put(schema, reader);
+}
+return reader;
+ }
+
+ private void serializeDatum(D datum, Output output) throws IOException {
+Encoder encoder = EncoderFactory.get().directBinaryEncoder(output, null);
+Schema schema = datum.getSchema();
+Long fingerprint = this.getFingerprint(schema);
+byte[] schemaBytes = schema.toString().getBytes(StandardCharsets.UTF_8);
Review Comment:
If you refer to the Spark's implementation, `schemaCache` is always a subset
of `schemas` (which is passed avro schemas registered by the session when
constructing the GenericAvroSerializer).
As such, if Spark's `GenericAvroSerializer` is given a schem
[GitHub] [hudi] danny0405 commented on a diff in pull request #8307: [HUDI-5992] Fix (de)serialization for avro versions > 1.10.0
danny0405 commented on code in PR #8307:
URL: https://github.com/apache/hudi/pull/8307#discussion_r1151364009
##
hudi-common/src/main/java/org/apache/hudi/avro/GenericAvroSerializer.java:
##
@@ -0,0 +1,148 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.avro;
+
+import com.esotericsoftware.kryo.Kryo;
+import com.esotericsoftware.kryo.Serializer;
+import com.esotericsoftware.kryo.io.Input;
+import com.esotericsoftware.kryo.io.Output;
+import org.apache.avro.Schema;
+import org.apache.avro.SchemaNormalization;
+import org.apache.avro.generic.GenericContainer;
+import org.apache.avro.generic.GenericDatumReader;
+import org.apache.avro.generic.GenericDatumWriter;
+import org.apache.avro.io.DatumReader;
+import org.apache.avro.io.DatumWriter;
+import org.apache.avro.io.Decoder;
+import org.apache.avro.io.DecoderFactory;
+import org.apache.avro.io.Encoder;
+import org.apache.avro.io.EncoderFactory;
+
+import java.io.IOException;
+import java.nio.charset.StandardCharsets;
+import java.util.HashMap;
+
+
+/**
+ * Custom serializer used for generic Avro containers.
+ *
+ * Heavily adapted from:
+ *
+ * https://github.com/apache/spark/blob/master/core/src/main/scala/org/apache/spark/serializer/GenericAvroSerializer.scala";>GenericAvroSerializer.scala
+ *
+ * As {@link org.apache.hudi.common.util.SerializationUtils} is not shared
between threads and does not concern any
+ * shuffling operations, compression and decompression cache is omitted as
network IO is not a concern.
+ *
+ * Unlike Spark's implementation, the class and constructor is not initialized
with a predefined map of avro schemas.
+ * This is the case as schemas to read and write are not known beforehand.
+ *
+ * @param the subtype of [[GenericContainer]] handled by this serializer
+ */
+public class GenericAvroSerializer extends
Serializer {
+
+ // reuses the same datum reader/writer since the same schema will be used
many times
+ private final HashMap> writerCache = new HashMap<>();
+ private final HashMap> readerCache = new HashMap<>();
+
+ // fingerprinting is very expensive so this alleviates most of the work
+ private final HashMap fingerprintCache = new HashMap<>();
+ private final HashMap schemaCache = new HashMap<>();
+
+ private Long getFingerprint(Schema schema) {
+if (fingerprintCache.containsKey(schema)) {
+ return fingerprintCache.get(schema);
+} else {
+ Long fingerprint = SchemaNormalization.parsingFingerprint64(schema);
+ fingerprintCache.put(schema, fingerprint);
+ return fingerprint;
+}
+ }
+
+ private Schema getSchema(Long fingerprint, byte[] schemaBytes) {
+if (schemaCache.containsKey(fingerprint)) {
+ return schemaCache.get(fingerprint);
+} else {
+ String schema = new String(schemaBytes, StandardCharsets.UTF_8);
+ Schema parsedSchema = new Schema.Parser().parse(schema);
+ schemaCache.put(fingerprint, parsedSchema);
+ return parsedSchema;
+}
+ }
+
+ private DatumWriter getDatumWriter(Schema schema) {
+DatumWriter writer;
+if (writerCache.containsKey(schema)) {
+ writer = writerCache.get(schema);
+} else {
+ writer = new GenericDatumWriter<>(schema);
+ writerCache.put(schema, writer);
+}
+return writer;
+ }
+
+ private DatumReader getDatumReader(Schema schema) {
+DatumReader reader;
+if (readerCache.containsKey(schema)) {
+ reader = readerCache.get(schema);
+} else {
+ reader = new GenericDatumReader<>(schema);
+ readerCache.put(schema, reader);
+}
+return reader;
+ }
+
+ private void serializeDatum(D datum, Output output) throws IOException {
+Encoder encoder = EncoderFactory.get().directBinaryEncoder(output, null);
+Schema schema = datum.getSchema();
+Long fingerprint = this.getFingerprint(schema);
+byte[] schemaBytes = schema.toString().getBytes(StandardCharsets.UTF_8);
Review Comment:
Then at least there is no need to serialize the fingerprint right? Just
deserialize from the schema bytes directly should be fine.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
[GitHub] [hudi] voonhous commented on a diff in pull request #8307: [HUDI-5992] Fix (de)serialization for avro versions > 1.10.0
voonhous commented on code in PR #8307:
URL: https://github.com/apache/hudi/pull/8307#discussion_r1151363115
##
hudi-common/src/main/java/org/apache/hudi/avro/GenericAvroSerializer.java:
##
@@ -0,0 +1,148 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.avro;
+
+import com.esotericsoftware.kryo.Kryo;
+import com.esotericsoftware.kryo.Serializer;
+import com.esotericsoftware.kryo.io.Input;
+import com.esotericsoftware.kryo.io.Output;
+import org.apache.avro.Schema;
+import org.apache.avro.SchemaNormalization;
+import org.apache.avro.generic.GenericContainer;
+import org.apache.avro.generic.GenericDatumReader;
+import org.apache.avro.generic.GenericDatumWriter;
+import org.apache.avro.io.DatumReader;
+import org.apache.avro.io.DatumWriter;
+import org.apache.avro.io.Decoder;
+import org.apache.avro.io.DecoderFactory;
+import org.apache.avro.io.Encoder;
+import org.apache.avro.io.EncoderFactory;
+
+import java.io.IOException;
+import java.nio.charset.StandardCharsets;
+import java.util.HashMap;
+
+
+/**
+ * Custom serializer used for generic Avro containers.
+ *
+ * Heavily adapted from:
+ *
+ * https://github.com/apache/spark/blob/master/core/src/main/scala/org/apache/spark/serializer/GenericAvroSerializer.scala";>GenericAvroSerializer.scala
+ *
+ * As {@link org.apache.hudi.common.util.SerializationUtils} is not shared
between threads and does not concern any
+ * shuffling operations, compression and decompression cache is omitted as
network IO is not a concern.
+ *
+ * Unlike Spark's implementation, the class and constructor is not initialized
with a predefined map of avro schemas.
+ * This is the case as schemas to read and write are not known beforehand.
+ *
+ * @param the subtype of [[GenericContainer]] handled by this serializer
+ */
+public class GenericAvroSerializer extends
Serializer {
+
+ // reuses the same datum reader/writer since the same schema will be used
many times
+ private final HashMap> writerCache = new HashMap<>();
+ private final HashMap> readerCache = new HashMap<>();
+
+ // fingerprinting is very expensive so this alleviates most of the work
+ private final HashMap fingerprintCache = new HashMap<>();
+ private final HashMap schemaCache = new HashMap<>();
+
+ private Long getFingerprint(Schema schema) {
+if (fingerprintCache.containsKey(schema)) {
+ return fingerprintCache.get(schema);
+} else {
+ Long fingerprint = SchemaNormalization.parsingFingerprint64(schema);
+ fingerprintCache.put(schema, fingerprint);
+ return fingerprint;
+}
+ }
+
+ private Schema getSchema(Long fingerprint, byte[] schemaBytes) {
+if (schemaCache.containsKey(fingerprint)) {
+ return schemaCache.get(fingerprint);
+} else {
+ String schema = new String(schemaBytes, StandardCharsets.UTF_8);
+ Schema parsedSchema = new Schema.Parser().parse(schema);
+ schemaCache.put(fingerprint, parsedSchema);
+ return parsedSchema;
+}
+ }
+
+ private DatumWriter getDatumWriter(Schema schema) {
+DatumWriter writer;
+if (writerCache.containsKey(schema)) {
+ writer = writerCache.get(schema);
+} else {
+ writer = new GenericDatumWriter<>(schema);
+ writerCache.put(schema, writer);
+}
+return writer;
+ }
+
+ private DatumReader getDatumReader(Schema schema) {
+DatumReader reader;
+if (readerCache.containsKey(schema)) {
+ reader = readerCache.get(schema);
+} else {
+ reader = new GenericDatumReader<>(schema);
+ readerCache.put(schema, reader);
+}
+return reader;
+ }
+
+ private void serializeDatum(D datum, Output output) throws IOException {
+Encoder encoder = EncoderFactory.get().directBinaryEncoder(output, null);
+Schema schema = datum.getSchema();
+Long fingerprint = this.getFingerprint(schema);
+byte[] schemaBytes = schema.toString().getBytes(StandardCharsets.UTF_8);
Review Comment:
If you refer to the Spark's implementation, `schemaCache` is always a subset
of `schemas` (which is passed avro schemas registered by the session when
constructing the GenericAvroSerializer).
As such, if Spark's `GenericAvroSerializer` is given a schem
[GitHub] [hudi] voonhous commented on a diff in pull request #8307: [HUDI-5992] Fix (de)serialization for avro versions > 1.10.0
voonhous commented on code in PR #8307:
URL: https://github.com/apache/hudi/pull/8307#discussion_r1151360834
##
hudi-common/src/main/java/org/apache/hudi/avro/GenericAvroSerializer.java:
##
@@ -0,0 +1,148 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.avro;
+
+import com.esotericsoftware.kryo.Kryo;
+import com.esotericsoftware.kryo.Serializer;
+import com.esotericsoftware.kryo.io.Input;
+import com.esotericsoftware.kryo.io.Output;
+import org.apache.avro.Schema;
+import org.apache.avro.SchemaNormalization;
+import org.apache.avro.generic.GenericContainer;
+import org.apache.avro.generic.GenericDatumReader;
+import org.apache.avro.generic.GenericDatumWriter;
+import org.apache.avro.io.DatumReader;
+import org.apache.avro.io.DatumWriter;
+import org.apache.avro.io.Decoder;
+import org.apache.avro.io.DecoderFactory;
+import org.apache.avro.io.Encoder;
+import org.apache.avro.io.EncoderFactory;
+
+import java.io.IOException;
+import java.nio.charset.StandardCharsets;
+import java.util.HashMap;
+
+
+/**
+ * Custom serializer used for generic Avro containers.
+ *
+ * Heavily adapted from:
+ *
+ * https://github.com/apache/spark/blob/master/core/src/main/scala/org/apache/spark/serializer/GenericAvroSerializer.scala";>GenericAvroSerializer.scala
+ *
+ * As {@link org.apache.hudi.common.util.SerializationUtils} is not shared
between threads and does not concern any
+ * shuffling operations, compression and decompression cache is omitted as
network IO is not a concern.
+ *
+ * Unlike Spark's implementation, the class and constructor is not initialized
with a predefined map of avro schemas.
+ * This is the case as schemas to read and write are not known beforehand.
+ *
+ * @param the subtype of [[GenericContainer]] handled by this serializer
+ */
+public class GenericAvroSerializer extends
Serializer {
+
+ // reuses the same datum reader/writer since the same schema will be used
many times
+ private final HashMap> writerCache = new HashMap<>();
+ private final HashMap> readerCache = new HashMap<>();
+
+ // fingerprinting is very expensive so this alleviates most of the work
+ private final HashMap fingerprintCache = new HashMap<>();
+ private final HashMap schemaCache = new HashMap<>();
+
+ private Long getFingerprint(Schema schema) {
+if (fingerprintCache.containsKey(schema)) {
+ return fingerprintCache.get(schema);
+} else {
+ Long fingerprint = SchemaNormalization.parsingFingerprint64(schema);
+ fingerprintCache.put(schema, fingerprint);
+ return fingerprint;
+}
+ }
+
+ private Schema getSchema(Long fingerprint, byte[] schemaBytes) {
+if (schemaCache.containsKey(fingerprint)) {
+ return schemaCache.get(fingerprint);
+} else {
+ String schema = new String(schemaBytes, StandardCharsets.UTF_8);
+ Schema parsedSchema = new Schema.Parser().parse(schema);
+ schemaCache.put(fingerprint, parsedSchema);
+ return parsedSchema;
+}
+ }
+
+ private DatumWriter getDatumWriter(Schema schema) {
+DatumWriter writer;
+if (writerCache.containsKey(schema)) {
+ writer = writerCache.get(schema);
+} else {
+ writer = new GenericDatumWriter<>(schema);
+ writerCache.put(schema, writer);
+}
+return writer;
+ }
+
+ private DatumReader getDatumReader(Schema schema) {
+DatumReader reader;
+if (readerCache.containsKey(schema)) {
+ reader = readerCache.get(schema);
+} else {
+ reader = new GenericDatumReader<>(schema);
+ readerCache.put(schema, reader);
+}
+return reader;
+ }
+
+ private void serializeDatum(D datum, Output output) throws IOException {
+Encoder encoder = EncoderFactory.get().directBinaryEncoder(output, null);
+Schema schema = datum.getSchema();
+Long fingerprint = this.getFingerprint(schema);
+byte[] schemaBytes = schema.toString().getBytes(StandardCharsets.UTF_8);
Review Comment:
Although the (schema) bytes are ALWAYS serialized, it may or may not be
parsed by:
```java
new Schema.Parser().parse(schema)
```
The fingerprint here is used as a key to check if parsing of the bytes ->
Schema is required, if it is not req
[GitHub] [hudi] voonhous commented on a diff in pull request #8307: [HUDI-5992] Fix (de)serialization for avro versions > 1.10.0
voonhous commented on code in PR #8307:
URL: https://github.com/apache/hudi/pull/8307#discussion_r1151360834
##
hudi-common/src/main/java/org/apache/hudi/avro/GenericAvroSerializer.java:
##
@@ -0,0 +1,148 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.avro;
+
+import com.esotericsoftware.kryo.Kryo;
+import com.esotericsoftware.kryo.Serializer;
+import com.esotericsoftware.kryo.io.Input;
+import com.esotericsoftware.kryo.io.Output;
+import org.apache.avro.Schema;
+import org.apache.avro.SchemaNormalization;
+import org.apache.avro.generic.GenericContainer;
+import org.apache.avro.generic.GenericDatumReader;
+import org.apache.avro.generic.GenericDatumWriter;
+import org.apache.avro.io.DatumReader;
+import org.apache.avro.io.DatumWriter;
+import org.apache.avro.io.Decoder;
+import org.apache.avro.io.DecoderFactory;
+import org.apache.avro.io.Encoder;
+import org.apache.avro.io.EncoderFactory;
+
+import java.io.IOException;
+import java.nio.charset.StandardCharsets;
+import java.util.HashMap;
+
+
+/**
+ * Custom serializer used for generic Avro containers.
+ *
+ * Heavily adapted from:
+ *
+ * https://github.com/apache/spark/blob/master/core/src/main/scala/org/apache/spark/serializer/GenericAvroSerializer.scala";>GenericAvroSerializer.scala
+ *
+ * As {@link org.apache.hudi.common.util.SerializationUtils} is not shared
between threads and does not concern any
+ * shuffling operations, compression and decompression cache is omitted as
network IO is not a concern.
+ *
+ * Unlike Spark's implementation, the class and constructor is not initialized
with a predefined map of avro schemas.
+ * This is the case as schemas to read and write are not known beforehand.
+ *
+ * @param the subtype of [[GenericContainer]] handled by this serializer
+ */
+public class GenericAvroSerializer extends
Serializer {
+
+ // reuses the same datum reader/writer since the same schema will be used
many times
+ private final HashMap> writerCache = new HashMap<>();
+ private final HashMap> readerCache = new HashMap<>();
+
+ // fingerprinting is very expensive so this alleviates most of the work
+ private final HashMap fingerprintCache = new HashMap<>();
+ private final HashMap schemaCache = new HashMap<>();
+
+ private Long getFingerprint(Schema schema) {
+if (fingerprintCache.containsKey(schema)) {
+ return fingerprintCache.get(schema);
+} else {
+ Long fingerprint = SchemaNormalization.parsingFingerprint64(schema);
+ fingerprintCache.put(schema, fingerprint);
+ return fingerprint;
+}
+ }
+
+ private Schema getSchema(Long fingerprint, byte[] schemaBytes) {
+if (schemaCache.containsKey(fingerprint)) {
+ return schemaCache.get(fingerprint);
+} else {
+ String schema = new String(schemaBytes, StandardCharsets.UTF_8);
+ Schema parsedSchema = new Schema.Parser().parse(schema);
+ schemaCache.put(fingerprint, parsedSchema);
+ return parsedSchema;
+}
+ }
+
+ private DatumWriter getDatumWriter(Schema schema) {
+DatumWriter writer;
+if (writerCache.containsKey(schema)) {
+ writer = writerCache.get(schema);
+} else {
+ writer = new GenericDatumWriter<>(schema);
+ writerCache.put(schema, writer);
+}
+return writer;
+ }
+
+ private DatumReader getDatumReader(Schema schema) {
+DatumReader reader;
+if (readerCache.containsKey(schema)) {
+ reader = readerCache.get(schema);
+} else {
+ reader = new GenericDatumReader<>(schema);
+ readerCache.put(schema, reader);
+}
+return reader;
+ }
+
+ private void serializeDatum(D datum, Output output) throws IOException {
+Encoder encoder = EncoderFactory.get().directBinaryEncoder(output, null);
+Schema schema = datum.getSchema();
+Long fingerprint = this.getFingerprint(schema);
+byte[] schemaBytes = schema.toString().getBytes(StandardCharsets.UTF_8);
Review Comment:
Although we are ALWAYS serializing the bytes, it may or may not be parsed by:
```java
new Schema.Parser().parse(schema)
```
The fingerprint here is used as a key to check if parsing of the bytes ->
Schema is required, if it is not required,
[GitHub] [hudi] danny0405 commented on a diff in pull request #8307: [HUDI-5992] Fix (de)serialization for avro versions > 1.10.0
danny0405 commented on code in PR #8307:
URL: https://github.com/apache/hudi/pull/8307#discussion_r1151359438
##
hudi-common/src/main/java/org/apache/hudi/avro/GenericAvroSerializer.java:
##
@@ -0,0 +1,148 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.avro;
+
+import com.esotericsoftware.kryo.Kryo;
+import com.esotericsoftware.kryo.Serializer;
+import com.esotericsoftware.kryo.io.Input;
+import com.esotericsoftware.kryo.io.Output;
+import org.apache.avro.Schema;
+import org.apache.avro.SchemaNormalization;
+import org.apache.avro.generic.GenericContainer;
+import org.apache.avro.generic.GenericDatumReader;
+import org.apache.avro.generic.GenericDatumWriter;
+import org.apache.avro.io.DatumReader;
+import org.apache.avro.io.DatumWriter;
+import org.apache.avro.io.Decoder;
+import org.apache.avro.io.DecoderFactory;
+import org.apache.avro.io.Encoder;
+import org.apache.avro.io.EncoderFactory;
+
+import java.io.IOException;
+import java.nio.charset.StandardCharsets;
+import java.util.HashMap;
+
+
+/**
+ * Custom serializer used for generic Avro containers.
+ *
+ * Heavily adapted from:
+ *
+ * https://github.com/apache/spark/blob/master/core/src/main/scala/org/apache/spark/serializer/GenericAvroSerializer.scala";>GenericAvroSerializer.scala
+ *
+ * As {@link org.apache.hudi.common.util.SerializationUtils} is not shared
between threads and does not concern any
+ * shuffling operations, compression and decompression cache is omitted as
network IO is not a concern.
+ *
+ * Unlike Spark's implementation, the class and constructor is not initialized
with a predefined map of avro schemas.
+ * This is the case as schemas to read and write are not known beforehand.
+ *
+ * @param the subtype of [[GenericContainer]] handled by this serializer
+ */
+public class GenericAvroSerializer extends
Serializer {
+
+ // reuses the same datum reader/writer since the same schema will be used
many times
+ private final HashMap> writerCache = new HashMap<>();
+ private final HashMap> readerCache = new HashMap<>();
+
+ // fingerprinting is very expensive so this alleviates most of the work
+ private final HashMap fingerprintCache = new HashMap<>();
+ private final HashMap schemaCache = new HashMap<>();
+
+ private Long getFingerprint(Schema schema) {
+if (fingerprintCache.containsKey(schema)) {
+ return fingerprintCache.get(schema);
+} else {
+ Long fingerprint = SchemaNormalization.parsingFingerprint64(schema);
+ fingerprintCache.put(schema, fingerprint);
+ return fingerprint;
+}
+ }
+
+ private Schema getSchema(Long fingerprint, byte[] schemaBytes) {
+if (schemaCache.containsKey(fingerprint)) {
+ return schemaCache.get(fingerprint);
+} else {
+ String schema = new String(schemaBytes, StandardCharsets.UTF_8);
+ Schema parsedSchema = new Schema.Parser().parse(schema);
+ schemaCache.put(fingerprint, parsedSchema);
+ return parsedSchema;
+}
+ }
+
+ private DatumWriter getDatumWriter(Schema schema) {
+DatumWriter writer;
+if (writerCache.containsKey(schema)) {
+ writer = writerCache.get(schema);
+} else {
+ writer = new GenericDatumWriter<>(schema);
+ writerCache.put(schema, writer);
+}
+return writer;
+ }
+
+ private DatumReader getDatumReader(Schema schema) {
+DatumReader reader;
+if (readerCache.containsKey(schema)) {
+ reader = readerCache.get(schema);
+} else {
+ reader = new GenericDatumReader<>(schema);
+ readerCache.put(schema, reader);
+}
+return reader;
+ }
+
+ private void serializeDatum(D datum, Output output) throws IOException {
+Encoder encoder = EncoderFactory.get().directBinaryEncoder(output, null);
+Schema schema = datum.getSchema();
+Long fingerprint = this.getFingerprint(schema);
+byte[] schemaBytes = schema.toString().getBytes(StandardCharsets.UTF_8);
Review Comment:
This is Spark impl for serializing:
```scala
def serializeDatum(datum: D, output: KryoOutput): Unit = {
val encoder = EncoderFactory.get.binaryEncoder(output, null)
val schema = datum.getSchema
val fingerprint = fingerprintCach
[GitHub] [hudi] danny0405 commented on a diff in pull request #8304: [HUDI-5993] Connection leak for lock provider
danny0405 commented on code in PR #8304:
URL: https://github.com/apache/hudi/pull/8304#discussion_r1151346499
##
hudi-client/hudi-client-common/src/test/java/org/apache/hudi/client/transaction/TestLockManager.java:
##
@@ -0,0 +1,119 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.client.transaction;
+
+import org.apache.hudi.client.transaction.lock.LockManager;
+import org.apache.hudi.client.transaction.lock.ZookeeperBasedLockProvider;
+import org.apache.hudi.common.model.HoodieFailedWritesCleaningPolicy;
+import org.apache.hudi.common.model.WriteConcurrencyMode;
+import org.apache.hudi.common.testutils.HoodieCommonTestHarness;
+import org.apache.hudi.config.HoodieCleanConfig;
+import org.apache.hudi.config.HoodieLockConfig;
+import org.apache.hudi.config.HoodieWriteConfig;
+
+import org.apache.curator.test.TestingServer;
+import org.apache.log4j.LogManager;
+import org.apache.log4j.Logger;
+import org.junit.jupiter.api.AfterAll;
+import org.junit.jupiter.api.BeforeAll;
+import org.junit.jupiter.api.BeforeEach;
+import org.junit.jupiter.api.Test;
+
+import java.io.IOException;
+import java.lang.reflect.Field;
+
+import static org.junit.jupiter.api.Assertions.assertDoesNotThrow;
+import static org.junit.jupiter.api.Assertions.assertNotNull;
+import static org.junit.jupiter.api.Assertions.assertNull;
+
+public class TestLockManager extends HoodieCommonTestHarness {
+
+ private static final Logger LOG =
LogManager.getLogger(TestLockManager.class);
+
+ private static TestingServer server;
+ private static String zk_basePath = "/hudi/test/lock";
+ private static String key = "table1";
+
+ HoodieWriteConfig writeConfig;
+ LockManager lockManager;
+
+ @BeforeAll
+ public static void setup() {
+while (server == null) {
+ try {
+server = new TestingServer();
+ } catch (Exception e) {
+LOG.error("Getting bind exception - retrying to allocate server");
+server = null;
+ }
+}
+ }
+
+ @AfterAll
+ public static void tearDown() throws IOException {
+if (server != null) {
+ server.close();
+}
+ }
+
+ private HoodieWriteConfig getWriteConfig() {
+return HoodieWriteConfig.newBuilder()
+.withPath(basePath)
+.withCleanConfig(HoodieCleanConfig.newBuilder()
+
.withFailedWritesCleaningPolicy(HoodieFailedWritesCleaningPolicy.LAZY)
+.build())
+
.withWriteConcurrencyMode(WriteConcurrencyMode.OPTIMISTIC_CONCURRENCY_CONTROL)
+.withLockConfig(HoodieLockConfig.newBuilder()
+.withLockProvider(ZookeeperBasedLockProvider.class)
+.withZkBasePath(zk_basePath)
+.withZkLockKey(key)
+.withZkQuorum(server.getConnectString())
+.build())
+.build();
+ }
+
+ @BeforeEach
+ private void init() throws IOException {
+initPath();
+initMetaClient();
+this.writeConfig = getWriteConfig();
+this.lockManager = new LockManager(this.writeConfig,
this.metaClient.getFs());
+ }
+
+ @Test
+ public void testLockAndUnlock() throws NoSuchFieldException,
IllegalAccessException{
+
+Field lockProvider =
lockManager.getClass().getDeclaredField("lockProvider");
+lockProvider.setAccessible(true);
+
+assertDoesNotThrow(() -> {
+ lockManager.lock();
+});
+
+assertNotNull(lockProvider.get(lockManager));
+
+assertDoesNotThrow(() -> {
+ lockManager.unlock();
Review Comment:
We can use the mokito to check the `#close` method invoke instead, take
`TestCloudWatchMetricsReporter` for an example.
##
hudi-client/hudi-client-common/src/test/java/org/apache/hudi/client/transaction/TestLockManager.java:
##
@@ -0,0 +1,119 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICEN
[GitHub] [hudi] danny0405 commented on issue #8310: [SUPPORT] We should verify the consistency of bucket num at job startup.
danny0405 commented on issue #8310: URL: https://github.com/apache/hudi/issues/8310#issuecomment-1487879170 Reasonable, can you fire a PR please? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] danny0405 commented on issue #8267: [SUPPORT] Why some delta commit logs files are not converted to parquet ?
danny0405 commented on issue #8267: URL: https://github.com/apache/hudi/issues/8267#issuecomment-1487874245 Had the partition been compacted already? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] danny0405 commented on pull request #8245: [HUDI-5944] Added the ability to fix partitiion missing in hudi synctool
danny0405 commented on PR #8245: URL: https://github.com/apache/hudi/pull/8245#issuecomment-1487872941 > Hi, > > We got the same issue before when syncing Hive partition if there are more then one writer. And we fix this issue by using @boneanxs 's solution in this PR: #7627 > > Further more, it can solve downstream pipeline stream reading issue. If there is a downstream Hudi reader reading data in stream mode, there will be the same issue as this ticket mentioned. @boneanxs 's solution can solve this problem fundamentally. > > May I ask if it is appropriate that we can add this feature (#7627) in Hudi timeline? Yes, adding the physical processing time instead of logical timestamp on timeline should be helpful in some senarios. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[hudi] branch master updated: [MINOR] Fix typo for method in AvroSchemaConverter (#8306)
This is an automated email from the ASF dual-hosted git repository.
danny0405 pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/hudi.git
The following commit(s) were added to refs/heads/master by this push:
new e1741ddc7d9 [MINOR] Fix typo for method in AvroSchemaConverter (#8306)
e1741ddc7d9 is described below
commit e1741ddc7d97989808f0f34f3f12e0feb91aae73
Author: Kunni
AuthorDate: Wed Mar 29 10:49:21 2023 +0800
[MINOR] Fix typo for method in AvroSchemaConverter (#8306)
---
.../src/main/java/org/apache/hudi/util/AvroSchemaConverter.java | 4 ++--
1 file changed, 2 insertions(+), 2 deletions(-)
diff --git
a/hudi-flink-datasource/hudi-flink/src/main/java/org/apache/hudi/util/AvroSchemaConverter.java
b/hudi-flink-datasource/hudi-flink/src/main/java/org/apache/hudi/util/AvroSchemaConverter.java
index 925819c871e..44253e37329 100644
---
a/hudi-flink-datasource/hudi-flink/src/main/java/org/apache/hudi/util/AvroSchemaConverter.java
+++
b/hudi-flink-datasource/hudi-flink/src/main/java/org/apache/hudi/util/AvroSchemaConverter.java
@@ -301,7 +301,7 @@ public class AvroSchemaConverter {
LogicalTypes.decimal(decimalType.getPrecision(),
decimalType.getScale())
.addToSchema(SchemaBuilder
.fixed(String.format("%s.fixed", rowName))
-
.size(computeMinBytesForDecimlPrecision(decimalType.getPrecision(;
+
.size(computeMinBytesForDecimalPrecision(decimalType.getPrecision(;
return nullable ? nullableSchema(decimal) : decimal;
case ROW:
RowType rowType = (RowType) logicalType;
@@ -377,7 +377,7 @@ public class AvroSchemaConverter {
: Schema.createUnion(SchemaBuilder.builder().nullType(), schema);
}
- private static int computeMinBytesForDecimlPrecision(int precision) {
+ private static int computeMinBytesForDecimalPrecision(int precision) {
int numBytes = 1;
while (Math.pow(2.0, 8 * numBytes - 1) < Math.pow(10.0, precision)) {
numBytes += 1;
[GitHub] [hudi] danny0405 merged pull request #8306: [MINOR] Fix typo for method in AvroSchemaConverter
danny0405 merged PR #8306: URL: https://github.com/apache/hudi/pull/8306 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] danny0405 commented on a diff in pull request #7627: [HUDI-5517] HoodieTimeline support filter instants by state transition time
danny0405 commented on code in PR #7627:
URL: https://github.com/apache/hudi/pull/7627#discussion_r1151337720
##
hudi-common/src/main/avro/HoodieArchivedMetaEntry.avsc:
##
@@ -128,6 +128,11 @@
"HoodieIndexCommitMetadata"
],
"default": null
+ },
+ {
+ "name":"stateTransitionTime",
+ "type":["null","string"],
+ "default": null
Review Comment:
This could cause backward compatibility issue, if the table is upgraded,
this field could be missing from the old table, we need to address this in
release note at least.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[jira] [Updated] (HUDI-5989) Fix the date conversion issue when lazy fetching partition path & file slice for HoodieFileIndex is used
[
https://issues.apache.org/jira/browse/HUDI-5989?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
voon updated HUDI-5989:
---
Summary: Fix the date conversion issue when lazy fetching partition path &
file slice for HoodieFileIndex is used (was: Fix the date convert issue when
lazy fetching partition path & file slice for HoodieFileIndex is used)
> Fix the date conversion issue when lazy fetching partition path & file slice
> for HoodieFileIndex is used
>
>
> Key: HUDI-5989
> URL: https://issues.apache.org/jira/browse/HUDI-5989
> Project: Apache Hudi
> Issue Type: Bug
>Reporter: voon
>Assignee: voon
>Priority: Major
> Labels: pull-request-available
>
> For partition filter like date column, spark internally will convert it to
> day numbers after timestamp 0, but hudi lazy fetching doesn't respect this
> behavior, this pr tries to fix it.
>
> {code:java}
> INFO DataSourceStrategy: Pruning directories with: isnotnull(country#80),
> isnotnull(par_date#81),(country#80 = ID),(par_date#81=19415)
> ...
> INFO AbstractTableFileSystemView: Building file system view for partition
> (country=ID/par_date=19415)
> {code}
>
> This will fix the partition pruning bug introduced in:
> [https://github.com/apache/hudi/pull/6680]
> h3.
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[GitHub] [hudi] danny0405 commented on a diff in pull request #7627: [HUDI-5517] HoodieTimeline support filter instants by state transition time
danny0405 commented on code in PR #7627:
URL: https://github.com/apache/hudi/pull/7627#discussion_r1151331104
##
hudi-common/src/main/java/org/apache/hudi/common/table/timeline/HoodieInstant.java:
##
@@ -46,14 +55,35 @@ public class HoodieInstant implements Serializable,
Comparable {
public static final Comparator COMPARATOR =
Comparator.comparing(HoodieInstant::getTimestamp)
.thenComparing(ACTION_COMPARATOR).thenComparing(HoodieInstant::getState);
+ public static final Comparator STATE_TRANSITION_COMPARATOR =
+ Comparator.comparing(HoodieInstant::getStateTransitionTime)
Review Comment:
We can just use `COMPARATOR` here.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] XuQianJin-Stars commented on a diff in pull request #8308: [HUDI-5994] Bucket index supports bulk insert mode.
XuQianJin-Stars commented on code in PR #8308:
URL: https://github.com/apache/hudi/pull/8308#discussion_r1151328221
##
hudi-spark-datasource/hudi-spark/src/test/scala/org/apache/spark/sql/hudi/TestInsertTable.scala:
##
@@ -1060,6 +1060,59 @@ class TestInsertTable extends HoodieSparkSqlTestBase {
}
}
+ test("Test Bulk Insert Into Bucket Index Table") {
+withSQLConf("hoodie.sql.bulk.insert.enable" -> "true") {
+ withTempDir { tmp =>
+val tableName = generateTableName
+// Create a partitioned table
+spark.sql(
+ s"""
+ |create table $tableName (
+ | id int,
+ | dt string,
+ | name string,
+ | price double,
+ | ts long
+ |) using hudi
+ | tblproperties (
+ | primaryKey = 'id,name',
+ | preCombineField = 'ts',
+ | hoodie.index.type = 'BUCKET',
+ | hoodie.bucket.index.hash.field = 'id,name')
+ | partitioned by (dt)
+ | location '${tmp.getCanonicalPath}'
+ """.stripMargin)
+
+// Note: Do not write the field alias, the partition field must be
placed last.
+spark.sql(
+ s"""
+ | insert into $tableName values
+ | (1, 'a1,1', 10, 1000, "2021-01-05"),
+ | (2, 'a2', 20, 2000, "2021-01-06"),
+ | (3, 'a3', 30, 3000, "2021-01-07")
+ """.stripMargin)
+
+checkAnswer(s"select id, name, price, ts, dt from $tableName")(
+ Seq(1, "a1,1", 10.0, 1000, "2021-01-05"),
+ Seq(2, "a2", 20.0, 2000, "2021-01-06"),
+ Seq(3, "a3", 30.0, 3000, "2021-01-07")
+)
+
+spark.sql(
+ s"""
+ | insert into $tableName values
+ | (1, 'a1,1', 10, 1000, "2021-01-05")
Review Comment:
Is this sql insertion to verify the update?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] XuQianJin-Stars commented on a diff in pull request #8308: [HUDI-5994] Bucket index supports bulk insert mode.
XuQianJin-Stars commented on code in PR #8308:
URL: https://github.com/apache/hudi/pull/8308#discussion_r1151327813
##
hudi-spark-datasource/hudi-spark/src/test/scala/org/apache/spark/sql/hudi/TestInsertTable.scala:
##
@@ -1060,6 +1060,59 @@ class TestInsertTable extends HoodieSparkSqlTestBase {
}
}
+ test("Test Bulk Insert Into Bucket Index Table") {
+withSQLConf("hoodie.sql.bulk.insert.enable" -> "true") {
+ withTempDir { tmp =>
+val tableName = generateTableName
+// Create a partitioned table
+spark.sql(
+ s"""
+ |create table $tableName (
+ | id int,
+ | dt string,
+ | name string,
+ | price double,
+ | ts long
+ |) using hudi
+ | tblproperties (
+ | primaryKey = 'id,name',
+ | preCombineField = 'ts',
+ | hoodie.index.type = 'BUCKET',
+ | hoodie.bucket.index.hash.field = 'id,name')
+ | partitioned by (dt)
+ | location '${tmp.getCanonicalPath}'
+ """.stripMargin)
+
+// Note: Do not write the field alias, the partition field must be
placed last.
+spark.sql(
+ s"""
+ | insert into $tableName values
+ | (1, 'a1,1', 10, 1000, "2021-01-05"),
Review Comment:
`a1,1` -> ` a1` ?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] XuQianJin-Stars commented on a diff in pull request #8308: [HUDI-5994] Bucket index supports bulk insert mode.
XuQianJin-Stars commented on code in PR #8308:
URL: https://github.com/apache/hudi/pull/8308#discussion_r1151324017
##
hudi-client/hudi-client-common/src/main/java/org/apache/hudi/index/bucket/BucketIdentifier.java:
##
@@ -91,6 +91,10 @@ public static String newBucketFileIdPrefix(int bucketId) {
return newBucketFileIdPrefix(bucketIdStr(bucketId));
}
+ public static String newBucketFileIdPrefix(String fileId, int bucketId) {
Review Comment:
This method is optimized with the other two methods
`newBucketFileIdPrefix(int bucketId)` and `newBucketFileIdPrefix(String
bucketId)`?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] 1032851561 commented on issue #8087: [SUPPORT] split_reader don't checkpoint before consuming all splits
1032851561 commented on issue #8087:
URL: https://github.com/apache/hudi/issues/8087#issuecomment-1487848948
> > processElement,snapshotState,processSplits are handle in same thread
>
> You are right, they are all executed in the task thread, how about we use
our own custom thread instead of the mailbox executor, the mailbox executor
does not really executes the task, instead it puts a new task mail into the
mailbox.
Yes, my first idea is to use a separate thread to process the splits, I am
trying to now. just like :
```
SplitProcessThread :
while (running) {
try {
processSplits();
} catch (IOException e) {
LOG.error("process splits wrong", e);
executor.execute(StreamReadOperator::splitProcessException,
"process splits wrong");
throw new RuntimeException(e);
}
}
StreamReadOperator:
splitProcessException(){
throw new Exception("split process thread exist.").
}
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] 1032851561 commented on issue #8087: [SUPPORT] split_reader don't checkpoint before consuming all splits
1032851561 commented on issue #8087: URL: https://github.com/apache/hudi/issues/8087#issuecomment-1487841746 > > processElement,snapshotState,processSplits are handle in same thread > > You are right, they are all executed in the task thread, how about we use our own custom thread instead of the mailbox executor, the mailbox executor does not really executes the task, instead it puts a new task mail into the mailbox. Yes, my first idea is to use a separate thread to process the splits, I am trying to now. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #7881: [HUDI-5723] Automate and standardize enum configs
hudi-bot commented on PR #7881: URL: https://github.com/apache/hudi/pull/7881#issuecomment-1487815586 ## CI report: * c378a74c177a2f1a924609a44f0978ee347d272a UNKNOWN * 8674a4b5d21a0b6254e02a4c36e69a9056e0f2e3 Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15964) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] yihua commented on issue #8186: upgrade from 0.5.0 to 0.13.0
yihua commented on issue #8186: URL: https://github.com/apache/hudi/issues/8186#issuecomment-1487789003 Hi @selvarajperiyasamy Thanks for your interest in 0.13.0 release. You may read the release notes, especially the migration guide, of each major release, particularly the releases that change the table version: - 0.6.0: https://hudi.apache.org/releases/older-releases#migration-guide-for-this-release-3 - 0.9.0: https://hudi.apache.org/releases/older-releases#migration-guide-for-this-release - 0.10.0: https://hudi.apache.org/releases/older-releases#migration-guide-3 - 0.11.0: https://hudi.apache.org/releases/older-releases#migration-guide-2 - 0.12.0: https://hudi.apache.org/releases/older-releases#migration-guide-1 - 0.13.0: https://hudi.apache.org/releases/release-0.13.0#migration-guide-overview You should be aware that there are known regressions in 0.13.0 (https://hudi.apache.org/releases/release-0.13.0#known-regressions) so if you'd like to upgrade to 0.13, it would be good to wait for 0.13.1 with more reliability. You may also consider upgrading to 0.10.1 release first. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] soumilshah1995 commented on issue #8309: [SUPPORT] Need Assistance with Hudi Delta Streamer for Community Video
soumilshah1995 commented on issue #8309: URL: https://github.com/apache/hudi/issues/8309#issuecomment-1487781478 @yihua @bvaradar i just fired job  As I was describing, even after 10 minutes, there are still only two files on S3 and no generated base files. I do, however, see the meta data folder that was created by hudi.  -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] yihua commented on issue #8278: [SUPPORT] Deltastreamer Fails with AWSDmsAvroPayload
yihua commented on issue #8278: URL: https://github.com/apache/hudi/issues/8278#issuecomment-1487779308 Hi @Hans-Raintree @stathismar Thanks for reporting the issue. We'll need to reproduce this and find the root cause. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #7359: [HUDI-3304] WIP - Allow selective partial update
hudi-bot commented on PR #7359: URL: https://github.com/apache/hudi/pull/7359#issuecomment-1487774930 ## CI report: * 527610d6fae8dee7c317d5ddf14ce1d0c6a4c2ea Azure: [SUCCESS](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15963) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] soumilshah1995 commented on issue #8309: [SUPPORT] Need Assistance with Hudi Delta Streamer for Community Video
soumilshah1995 commented on issue #8309: URL: https://github.com/apache/hudi/issues/8309#issuecomment-1487770185 Please correct me if I'm doing something incorrectly. I've attached base files for your reference. I see hudi folders being created, but I don't see any base files (Parquet files) being created. any idea why ? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] soumilshah1995 commented on issue #8309: [SUPPORT] Need Assistance with Hudi Delta Streamer for Community Video
soumilshah1995 commented on issue #8309: URL: https://github.com/apache/hudi/issues/8309#issuecomment-1487766708 does this looks okay to you @bvaradar | @yihua ``` spark-submit --master yarn --deploy-mode cluster --conf spark.serializer=org.apache.spark.serializer.KryoSerializer --conf spark.sql.extensions=org.apache.spark.sql.hudi.HoodieSparkSessionExtension --conf spark.sql.catalog.spark_catalog=org.apache.spark.sql.hudi.catalog.HoodieCatalog --class org.apache.hudi.utilities.deltastreamer.HoodieDeltaStreamer /usr/lib/hudi/hudi-utilities-bundle.jar --table-type COPY_ON_WRITE --source-ordering-field replicadmstimestamp --source-class org.apache.hudi.utilities.sources.ParquetDFSSource --target-base-path s3://sql-server-dms-demo/hudi/public/sales --target-table invoice --payload-class org.apache.hudi.common.model.AWSDmsAvroPayload --hoodie-conf hoodie.datasource.write.keygenerator.class=org.apache.hudi.keygen.SimpleKeyGenerator --hoodie-conf hoodie.datasource.write.recordkey.field=invoiceid --hoodie-conf hoodie.datasource.write.partitionpath.field=destinationstate --hoodie-conf hoodie.deltastreamer.source.dfs.root=s3://sql-server-dms-demo/raw/public/sales/ ``` -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] yihua commented on issue #8309: [SUPPORT] Need Assistance with Hudi Delta Streamer for Community Video
yihua commented on issue #8309: URL: https://github.com/apache/hudi/issues/8309#issuecomment-1487764451 Hi @soumilshah1995 The bottom exception complains that `Property hoodie.datasource.write.partitionpath.field not found`. You need to specify the partition path field with `--hoodie-conf hoodie.datasource.write.partitionpath.field=`. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] yihua commented on issue #8311: [SUPPORT] DeltaStreamer stops fetching changes after a SparkSQL Update query on its Hudi table
yihua commented on issue #8311: URL: https://github.com/apache/hudi/issues/8311#issuecomment-1487761250 Hi @stathismar Thanks for raising this. This seems to be unexpected. We'll need to reproduce this and find the root cause. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #7881: [HUDI-5723] Automate and standardize enum configs
hudi-bot commented on PR #7881: URL: https://github.com/apache/hudi/pull/7881#issuecomment-1487741365 ## CI report: * c378a74c177a2f1a924609a44f0978ee347d272a UNKNOWN * 2474b2fcb57e10a074fd118156e68f5a62af7cb2 Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15960) * 8674a4b5d21a0b6254e02a4c36e69a9056e0f2e3 Azure: [PENDING](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15964) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #7881: [HUDI-5723] Automate and standardize enum configs
hudi-bot commented on PR #7881: URL: https://github.com/apache/hudi/pull/7881#issuecomment-1487734115 ## CI report: * c378a74c177a2f1a924609a44f0978ee347d272a UNKNOWN * 2474b2fcb57e10a074fd118156e68f5a62af7cb2 Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15960) * 8674a4b5d21a0b6254e02a4c36e69a9056e0f2e3 UNKNOWN Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] soumilshah1995 commented on issue #8309: [SUPPORT] Need Assistance with Hudi Delta Streamer for YouTube Content for Community
soumilshah1995 commented on issue #8309: URL: https://github.com/apache/hudi/issues/8309#issuecomment-1487702678 @n3nash @bvaradar -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #8303: use hadoopfsrelation for bootstrap
hudi-bot commented on PR #8303: URL: https://github.com/apache/hudi/pull/8303#issuecomment-1487679360 ## CI report: * 7f9a12f98ef6555b75617aeee8eac57760c28c04 Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15962) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #7359: [HUDI-3304] WIP - Allow selective partial update
hudi-bot commented on PR #7359: URL: https://github.com/apache/hudi/pull/7359#issuecomment-1487627150 ## CI report: * 7f3578b831243a80ca4a2d79c9e4ff2ebd52e563 Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=14851) * 527610d6fae8dee7c317d5ddf14ce1d0c6a4c2ea Azure: [PENDING](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15963) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #7359: [HUDI-3304] WIP - Allow selective partial update
hudi-bot commented on PR #7359: URL: https://github.com/apache/hudi/pull/7359#issuecomment-1487619942 ## CI report: * 7f3578b831243a80ca4a2d79c9e4ff2ebd52e563 Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=14851) * 527610d6fae8dee7c317d5ddf14ce1d0c6a4c2ea UNKNOWN Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #8303: use hadoopfsrelation for bootstrap
hudi-bot commented on PR #8303: URL: https://github.com/apache/hudi/pull/8303#issuecomment-1487558217 ## CI report: * 221af924fdc9941787af0355360a5399c0386167 Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15948) * 7f9a12f98ef6555b75617aeee8eac57760c28c04 Azure: [PENDING](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15962) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #8303: use hadoopfsrelation for bootstrap
hudi-bot commented on PR #8303: URL: https://github.com/apache/hudi/pull/8303#issuecomment-1487549402 ## CI report: * 221af924fdc9941787af0355360a5399c0386167 Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15948) * 7f9a12f98ef6555b75617aeee8eac57760c28c04 UNKNOWN Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #8307: [HUDI-5992] Fix (de)serialization for avro versions > 1.10.0
hudi-bot commented on PR #8307: URL: https://github.com/apache/hudi/pull/8307#issuecomment-1487335083 ## CI report: * 8aef9327c27d3f716a7f4c40f9a6d0ea6f370d3e Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15957) Azure: [SUCCESS](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15961) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #7881: [HUDI-5723] Automate and standardize enum configs
hudi-bot commented on PR #7881: URL: https://github.com/apache/hudi/pull/7881#issuecomment-1487243188 ## CI report: * c378a74c177a2f1a924609a44f0978ee347d272a UNKNOWN * 2474b2fcb57e10a074fd118156e68f5a62af7cb2 Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15960) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #8308: [HUDI-5994] Bucket index supports bulk insert mode.
hudi-bot commented on PR #8308: URL: https://github.com/apache/hudi/pull/8308#issuecomment-1487231525 ## CI report: * 50ad5161dcdb9cd651e4ccf69f8a95b7c8a6ee6e Azure: [SUCCESS](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15959) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] Zouxxyy commented on pull request #8277: [HUDI-5976] Add fs in the constructor of HoodieAvroHFileReader
Zouxxyy commented on PR #8277: URL: https://github.com/apache/hudi/pull/8277#issuecomment-1487156207 @codope hi, CI is green -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] stathismar opened a new issue, #8311: [SUPPORT] DeltaStreamer stops fetching changes after a SparkSQL Update query on its Hudi table
stathismar opened a new issue, #8311: URL: https://github.com/apache/hudi/issues/8311 **_Tips before filing an issue_** - Have you gone through our [FAQs](https://hudi.apache.org/learn/faq/)? - Join the mailing list to engage in conversations and get faster support at dev-subscr...@hudi.apache.org. - If you have triaged this as a bug, then file an [issue](https://issues.apache.org/jira/projects/HUDI/issues) directly. **Describe the problem you faced** Hello! I have the following setup and a question: I have a Postgres Database -> DMS -> Hudi in order to implement a CDC Solution (Right now I'm experimenting with a simple example table called employee). Generally, this setup works fine. What I want to achieve to add a new column and add a default value to all old records. By default Hudi creates the new column and starts ingesting values for it. What I would like to achieve is to find a way to backfill this value for all old records. More specifically, I have created the following simple table in Postgres: ``` id |name |salary| ---+---+--+ 3004870|Employee 1 | 2000| 3004871|Employee 2 | 5000| ... 3004879|Employee 10| 2000| ``` If run `DeltaStreamer` in `BULK_INSRERT` mode and I can see the same data in the hudi table. Then I insert a new row ( i.e. 3004880|Employee 11| 1000| ) in the Postgres database and run DeltaStreamer in UPSERT mode it will continue working as expected: ``` 2023032809585829820230328095858298_0_0 3004872 salary=1000 ce6c1f0d-352b-440e-80d2-40a5dc989d3a-2_0-17-13_20230328100557913.parquet I 2023-03-28 09:57:04.729440 3004872 Employee 3 1000 2023032809585829820230328095858298_0_1 3004875 salary=1000 ce6c1f0d-352b-440e-80d2-40a5dc989d3a-2_0-17-13_20230328100557913.parquet I 2023-03-28 09:57:04.729453 3004875 Employee 6 1000 2023032809585829820230328095858298_0_2 3004878 salary=1000 ce6c1f0d-352b-440e-80d2-40a5dc989d3a-2_0-17-13_20230328100557913.parquet I 2023-03-28 09:57:04.729464 3004878 Employee 9 1000 2023032810055791320230328100557913_0_3 3004880 salary=1000 ce6c1f0d-352b-440e-80d2-40a5dc989d3a-2_0-17-13_20230328100557913.parquet I 2023-03-28 10:01:17.580412 3004880 Employee 11 1000 2023032809585829820230328095858298_0_0 3004870 salary=2000 ce6c1f0d-352b-440e-80d2-40a5dc989d3a-0_0-3-3_20230328095858298.parquet I 2023-03-28 09:57:04.729397 3004870 Employee 1 2000 2023032809585829820230328095858298_0_1 3004873 salary=2000 ce6c1f0d-352b-440e-80d2-40a5dc989d3a-0_0-3-3_20230328095858298.parquet I 2023-03-28 09:57:04.729445 3004873 Employee 4 2000 2023032809585829820230328095858298_0_2 3004876 salary=2000 ce6c1f0d-352b-440e-80d2-40a5dc989d3a-0_0-3-3_20230328095858298.parquet I 2023-03-28 09:57:04.729456 3004876 Employee 7 2000 2023032809585829820230328095858298_0_3 3004879 salary=2000 ce6c1f0d-352b-440e-80d2-40a5dc989d3a-0_0-3-3_20230328095858298.parquet I 2023-03-28 09:57:04.729470 3004879 Employee 10 2000 2023032809585829820230328095858298_0_0 3004871 salary=5000 ce6c1f0d-352b-440e-80d2-40a5dc989d3a-1_0-3-3_20230328095858298.parquet I 2023-03-28 09:57:04.729435 3004871 Employee 2 5000 2023032809585829820230328095858298_0_1 3004874 salary=5000 ce6c1f0d-352b-440e-80d2-40a5dc989d3a-1_0-3-3_20230328095858298.parquet I 2023-03-28 09:57:04.729449 3004874 Employee 5 5000 2023032809585829820230328095858298_0_2 3004877 salary=5000 ce6c1f0d-352b-440e-80d2-40a5dc989d3a-1_0-3-3_20230328095858298.parquet I 2023-03-28 09:57:04.729460 3004877 Employee 8 5000 ``` After this if I add a Column in the Postgres (with a Default value) e.g. (bonus field) ``` id |name |salary|bonus| ---+---+--+-+ 3004870|Employee 1 | 2000| 100| ... 3004880|Employee 11| 1000| 100| ``` and then add a single record(In the Postgres Database): ``` 3004881|Employee 12| 2000| 200| ``` and run `DeltaStreeamer` in `UPSERT` Mode, then in the hudi table I have the following: ``` 2023032809585829820230328095858298_0_0 3004870 salary=2000 ce6c1f0d-352b-440e-80d2-40a5dc989d3a-0_0-17-13_20230328101416065.parquet I 2023-03-28 09:57:04.729397 3004870 Employee 1 NULL2000 2023032809585829820230328095858298_0_1 3004873 salary=2000 ce6c1f0d-352b-440e-80d2-40a5dc989d3a-0_0-17-13_20230328101416065.parquet I 2023-03-28 09:57:04.729445 3004873 Employee 4 NULL2000 2023032809585829820230328095858298_0_2 3004876 salary=2000 ce6c1f0d-352b-440e-80d2-40a5dc989d3a-0_0-17-13_202
[GitHub] [hudi] LinMingQiang opened a new issue, #8310: [SUPPORT] We should verify the consistency of bucket num at job startup.
LinMingQiang opened a new issue, #8310: URL: https://github.com/apache/hudi/issues/8310 **_Tips before filing an issue_** Users may sometimes modify the bucket num, and the inconsistency of the bucket num will lead to data duplication and make it unavailability. Maybe there are some other parameters that should also be checked before the job starts - Have you gone through our [FAQs](https://hudi.apache.org/learn/faq/)? - Join the mailing list to engage in conversations and get faster support at dev-subscr...@hudi.apache.org. - If you have triaged this as a bug, then file an [issue](https://issues.apache.org/jira/projects/HUDI/issues) directly. **Describe the problem you faced** A clear and concise description of the problem. **To Reproduce** Steps to reproduce the behavior: 1. 2. 3. 4. **Expected behavior** A clear and concise description of what you expected to happen. **Environment Description** * Hudi version : * Spark version : * Hive version : * Hadoop version : * Storage (HDFS/S3/GCS..) : * Running on Docker? (yes/no) : **Additional context** Add any other context about the problem here. **Stacktrace** ```Add the stacktrace of the error.``` -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #7881: [HUDI-5723] Automate and standardize enum configs
hudi-bot commented on PR #7881: URL: https://github.com/apache/hudi/pull/7881#issuecomment-1487020845 ## CI report: * c378a74c177a2f1a924609a44f0978ee347d272a UNKNOWN * 4fd80c1f9dee94d53d213069c1ede42b1571858d Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15211) * 2474b2fcb57e10a074fd118156e68f5a62af7cb2 Azure: [PENDING](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15960) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #7881: [HUDI-5723] Automate and standardize enum configs
hudi-bot commented on PR #7881: URL: https://github.com/apache/hudi/pull/7881#issuecomment-1487006265 ## CI report: * c378a74c177a2f1a924609a44f0978ee347d272a UNKNOWN * 4fd80c1f9dee94d53d213069c1ede42b1571858d Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15211) * 2474b2fcb57e10a074fd118156e68f5a62af7cb2 UNKNOWN Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #8307: [HUDI-5992] Fix (de)serialization for avro versions > 1.10.0
hudi-bot commented on PR #8307: URL: https://github.com/apache/hudi/pull/8307#issuecomment-1486993617 ## CI report: * 8aef9327c27d3f716a7f4c40f9a6d0ea6f370d3e Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15957) Azure: [PENDING](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15961) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] voonhous commented on pull request #8307: [HUDI-5992] Fix (de)serialization for avro versions > 1.10.0
voonhous commented on PR #8307: URL: https://github.com/apache/hudi/pull/8307#issuecomment-1486933377 @hudi-bot run azure -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #8308: [HUDI-5994] Bucket index supports bulk insert mode.
hudi-bot commented on PR #8308: URL: https://github.com/apache/hudi/pull/8308#issuecomment-1486912920 ## CI report: * 50ad5161dcdb9cd651e4ccf69f8a95b7c8a6ee6e Azure: [PENDING](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15959) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org