[GitHub] [hudi] hudi-bot commented on pull request #8467: [HUDI-6084] Added FailOnFirstErrorWriteStatus for MDT to ensure that write operations fail fast on any error.
hudi-bot commented on PR #8467: URL: https://github.com/apache/hudi/pull/8467#issuecomment-1512476763 ## CI report: * d3e94f199a2afb0a19ae0129c93f18500e226c3b Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=16359) * e5912d810942cd3cace16cfab41ddfb16497bd3e UNKNOWN Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #8335: [HUDI-6009] Let the jetty server in TimelineService create daemon threads
hudi-bot commented on PR #8335: URL: https://github.com/apache/hudi/pull/8335#issuecomment-1512476342 ## CI report: * 81a556f91317143f4e869add5e140f08cf377587 Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=16394) Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=16410) * 22f3943f5074538dc39464bd2ab10832280402b6 Azure: [PENDING](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=16413) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #8385: [HUDI-6040]Stop writing and reading compaction plans from .aux folder
hudi-bot commented on PR #8385: URL: https://github.com/apache/hudi/pull/8385#issuecomment-1512468237 ## CI report: * 3874447e48c21cb336f28625e1682b8f229f623c UNKNOWN * 1cd0db680780d02ff786121f394dccfcd621d37d Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=16378) Azure: [SUCCESS](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=16409) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #8335: [HUDI-6009] Let the jetty server in TimelineService create daemon threads
hudi-bot commented on PR #8335: URL: https://github.com/apache/hudi/pull/8335#issuecomment-1512468066 ## CI report: * 81a556f91317143f4e869add5e140f08cf377587 Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=16394) Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=16410) * 22f3943f5074538dc39464bd2ab10832280402b6 UNKNOWN Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] prashantwason commented on a diff in pull request #8467: [HUDI-6084] Added FailOnFirstErrorWriteStatus for MDT to ensure that write operations fail fast on any error.
prashantwason commented on code in PR #8467: URL: https://github.com/apache/hudi/pull/8467#discussion_r1169505655 ## hudi-client/hudi-client-common/src/main/java/org/apache/hudi/metadata/HoodieBackedTableMetadataWriter.java: ## @@ -170,9 +171,12 @@ protected HoodieBackedTableMetadataWriter(Configu "Cleaning is controlled internally for Metadata table."); ValidationUtils.checkArgument(!this.metadataWriteConfig.inlineCompactionEnabled(), "Compaction is controlled internally for metadata table."); - // Metadata Table cannot have metadata listing turned on. (infinite loop, much?) + // Auto commit is required ValidationUtils.checkArgument(this.metadataWriteConfig.shouldAutoCommit(), "Auto commit is required for Metadata Table"); + ValidationUtils.checkArgument(this.metadataWriteConfig.getWriteStatusClassName().equals(FailOnFirstErrorWriteStatus.class.getName()), + "MDT should use " + FailOnFirstErrorWriteStatus.class.getName()); + // Metadata Table cannot have metadata listing turned on. (infinite loop, much?) Review Comment: Fixed (see the line added below). It was cherry pick merge issue. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] prashantwason commented on a diff in pull request #8467: [HUDI-6084] Added FailOnFirstErrorWriteStatus for MDT to ensure that write operations fail fast on any error.
prashantwason commented on code in PR #8467: URL: https://github.com/apache/hudi/pull/8467#discussion_r1169505655 ## hudi-client/hudi-client-common/src/main/java/org/apache/hudi/metadata/HoodieBackedTableMetadataWriter.java: ## @@ -170,9 +171,12 @@ protected HoodieBackedTableMetadataWriter(Configu "Cleaning is controlled internally for Metadata table."); ValidationUtils.checkArgument(!this.metadataWriteConfig.inlineCompactionEnabled(), "Compaction is controlled internally for metadata table."); - // Metadata Table cannot have metadata listing turned on. (infinite loop, much?) + // Auto commit is required ValidationUtils.checkArgument(this.metadataWriteConfig.shouldAutoCommit(), "Auto commit is required for Metadata Table"); + ValidationUtils.checkArgument(this.metadataWriteConfig.getWriteStatusClassName().equals(FailOnFirstErrorWriteStatus.class.getName()), + "MDT should use " + FailOnFirstErrorWriteStatus.class.getName()); + // Metadata Table cannot have metadata listing turned on. (infinite loop, much?) Review Comment: Fixed. It was cherry pick merge issue. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] aajisaka commented on issue #8160: [SUPPORT] Schema evolution wrt to datatype promotion isnt working. org.apache.avro.AvroRuntimeException: cannot support rewrite value for schema type
aajisaka commented on issue #8160: URL: https://github.com/apache/hudi/issues/8160#issuecomment-1512446866 > But this https://github.com/apache/hudi/issues/7283 issue states its fixed, which is not clear. Since we are using Glue 4 we dont know which Hudi version is used in the background. AWS Glue 4.0 uses Apache Hudi 0.12.1, which doesn't include the commit. Reference: https://docs.aws.amazon.com/glue/latest/dg/aws-glue-programming-etl-format-hudi.html -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Comment Edited] (HUDI-4459) Corrupt parquet file created when syncing huge table with 4000+ fields,using hudi cow table with bulk_insert type
[ https://issues.apache.org/jira/browse/HUDI-4459?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17713390#comment-17713390 ] StarBoy1005 edited comment on HUDI-4459 at 4/18/23 5:08 AM: Hi! I met a problem, I use flink 1.14.5 and hudi 1.13.0, read a csv file in hdfs and sink to hudi cow table. no matter streaming mode nor batch mode, if use bulk_insert, it can‘t finish the job, the instant always in flight state. this is my cow table ddl: create table web_returns_cow ( rid bigint PRIMARY KEY NOT ENFORCED, wr_returned_date_sk bigint, wr_returned_time_sk bigint, wr_item_sk bigint, wr_refunded_customer_sk bigint, wr_refunded_cdemo_sk bigint, wr_refunded_hdemo_sk bigint, wr_refunded_addr_sk bigint, wr_returning_customer_sk bigint, wr_returning_cdemo_sk bigint, wr_returning_hdemo_sk bigint, wr_returning_addr_sk bigint, wr_web_page_sk bigint, wr_reason_sk bigint, wr_order_number bigint, wr_return_quantity int, wr_return_amt float, wr_return_tax float, wr_return_amt_inc_tax float, wr_fee float, wr_return_ship_cost float, wr_refunded_cash float, wr_reversed_charge float, wr_account_credit float, wr_net_loss float ) PARTITIONED BY (`wr_returned_date_sk`) WITH ( 'connector'='hudi', 'path'='/tmp/data_gen/web_returns_cow', 'table.type'='COPY_ON_WRITE', 'read.start-commit'='earliest', 'read.streaming.enabled'='false', 'changelog.enabled'='true', 'write.precombine'='false', 'write.precombine.field'='no_precombine', 'write.operation'='bulk_insert', 'read.tasks'='5', 'write.tasks'='10', 'index.type'='BUCKET', 'metadata.enabled'='false', 'hoodie.bucket.index.hash.field'='rid', 'hoodie.bucket.index.num.buckets'='10', 'index.global.enabled'='false' ); was (Author: JIRAUSER289640): Hi! I met a problem, I use flink 1.14.5 and hudi 1.13.0, read a csv file in hdfs and sink to hudi cow table. no matter streaming mode nor batch mode, if use bulk_insert, it can‘t finish the job, the instant always in flight state. this is my cow table ddl: create table web_returns_cow ( rid bigint PRIMARY KEY NOT ENFORCED, wr_returned_date_sk bigint, wr_returned_time_sk bigint, wr_item_sk bigint, wr_refunded_customer_sk bigint, wr_refunded_cdemo_sk bigint, wr_refunded_hdemo_sk bigint, wr_refunded_addr_sk bigint, wr_returning_customer_sk bigint, wr_returning_cdemo_sk bigint, wr_returning_hdemo_sk bigint, wr_returning_addr_sk bigint, wr_web_page_sk bigint, wr_reason_sk bigint, wr_order_number bigint, wr_return_quantity int, wr_return_amt float, wr_return_tax float, wr_return_amt_inc_tax float, wr_fee float, wr_return_ship_cost float, wr_refunded_cash float, wr_reversed_charge float, wr_account_credit float, wr_net_loss float ) PARTITIONED BY (`wr_returned_date_sk`) WITH ( 'connector'='hudi', 'path'='/tmp/data_gen/web_returns_cow', 'table.type'='COPY_ON_WRITE', 'read.start-commit'='earliest', 'read.streaming.enabled'='false', 'changelog.enabled'='true', 'write.precombine'='false', 'write.precombine.field'='no_precombine', 'write.operation'='insert', 'read.tasks'='5', 'write.tasks'='10', 'index.type'='BUCKET', 'metadata.enabled'='false', 'hoodie.bucket.index.hash.field'='rid', 'hoodie.bucket.index.num.buckets'='10', 'index.global.enabled'='false' ); > Corrupt parquet file created when syncing huge table with 4000+ fields,using > hudi cow table with bulk_insert type > - > > Key: HUDI-4459 > URL: https://issues.apache.org/jira/browse/HUDI-4459 > Project: Apache Hudi > Issue Type: Bug >Reporter: Leo zhang >Assignee: Rajesh Mahindra >Priority: Major > Attachments: statements.sql, table.ddl > > > I am trying to sync a huge table with 4000+ fields into hudi, using cow table > with bulk_insert operate type. > The job can finished without any exception,but when I am trying to read data > from the table,I get empty result.The parquet file is corrupted, can't be > read correctly. > I had tried to trace the problem, and found it was caused by SortOperator. > After the record is serialized in the sorter, all the field get disorder and > is deserialized into one field.And finally the wrong record is written into > parquet file,and make the file unreadable. > Here's a few steps to reproduce the bug in the flink sql-client: > 1、execute the table ddl(provided in the table.ddl file in the attachments) > 2、execute the insert statement (provided in the statement.sql file in the > attachments) > 3、execute a select statement to query hudi table (provided in the > statement.sql file in the attachments) -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Commented] (HUDI-4459) Corrupt parquet file created when syncing huge table with 4000+ fields,using hudi cow table with bulk_insert type
[ https://issues.apache.org/jira/browse/HUDI-4459?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17713390#comment-17713390 ] StarBoy1005 commented on HUDI-4459: --- Hi! I met a problem, I use flink 1.14.5 and hudi 1.13.0, read a csv file in hdfs and sink to hudi cow table. no matter streaming mode nor batch mode, if use bulk_insert, it can‘t finish the job, the instant always in flight state. this is my cow table ddl: create table web_returns_cow ( rid bigint PRIMARY KEY NOT ENFORCED, wr_returned_date_sk bigint, wr_returned_time_sk bigint, wr_item_sk bigint, wr_refunded_customer_sk bigint, wr_refunded_cdemo_sk bigint, wr_refunded_hdemo_sk bigint, wr_refunded_addr_sk bigint, wr_returning_customer_sk bigint, wr_returning_cdemo_sk bigint, wr_returning_hdemo_sk bigint, wr_returning_addr_sk bigint, wr_web_page_sk bigint, wr_reason_sk bigint, wr_order_number bigint, wr_return_quantity int, wr_return_amt float, wr_return_tax float, wr_return_amt_inc_tax float, wr_fee float, wr_return_ship_cost float, wr_refunded_cash float, wr_reversed_charge float, wr_account_credit float, wr_net_loss float ) PARTITIONED BY (`wr_returned_date_sk`) WITH ( 'connector'='hudi', 'path'='/tmp/data_gen/web_returns_cow', 'table.type'='COPY_ON_WRITE', 'read.start-commit'='earliest', 'read.streaming.enabled'='false', 'changelog.enabled'='true', 'write.precombine'='false', 'write.precombine.field'='no_precombine', 'write.operation'='insert', 'read.tasks'='5', 'write.tasks'='10', 'index.type'='BUCKET', 'metadata.enabled'='false', 'hoodie.bucket.index.hash.field'='rid', 'hoodie.bucket.index.num.buckets'='10', 'index.global.enabled'='false' ); > Corrupt parquet file created when syncing huge table with 4000+ fields,using > hudi cow table with bulk_insert type > - > > Key: HUDI-4459 > URL: https://issues.apache.org/jira/browse/HUDI-4459 > Project: Apache Hudi > Issue Type: Bug >Reporter: Leo zhang >Assignee: Rajesh Mahindra >Priority: Major > Attachments: statements.sql, table.ddl > > > I am trying to sync a huge table with 4000+ fields into hudi, using cow table > with bulk_insert operate type. > The job can finished without any exception,but when I am trying to read data > from the table,I get empty result.The parquet file is corrupted, can't be > read correctly. > I had tried to trace the problem, and found it was caused by SortOperator. > After the record is serialized in the sorter, all the field get disorder and > is deserialized into one field.And finally the wrong record is written into > parquet file,and make the file unreadable. > Here's a few steps to reproduce the bug in the flink sql-client: > 1、execute the table ddl(provided in the table.ddl file in the attachments) > 2、execute the insert statement (provided in the statement.sql file in the > attachments) > 3、execute a select statement to query hudi table (provided in the > statement.sql file in the attachments) -- This message was sent by Atlassian Jira (v8.20.10#820010)
[GitHub] [hudi] hudi-bot commented on pull request #8477: [HUDI-6088] Do not set the optmistic concurrency mode when MDT is ena…
hudi-bot commented on PR #8477: URL: https://github.com/apache/hudi/pull/8477#issuecomment-1512424483 ## CI report: * 0b07745f2ea80c7a8facdd65b137c65d9bda21ab Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=16399) * d7b8c5746d29b2ca60997210add1d618fa70ae3c Azure: [PENDING](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=16412) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] codope commented on a diff in pull request #8402: [HUDI-6048] Check if partition exists before list partition by path prefix
codope commented on code in PR #8402:
URL: https://github.com/apache/hudi/pull/8402#discussion_r1169476798
##
hudi-spark-datasource/hudi-spark-common/src/main/scala/org/apache/hudi/SparkHoodieTableFileIndex.scala:
##
@@ -299,7 +299,9 @@ class SparkHoodieTableFileIndex(spark: SparkSession,
// prefix to try to reduce the scope of the required file-listing
val relativePartitionPathPrefix =
composeRelativePartitionPath(staticPartitionColumnNameValuePairs)
- if (staticPartitionColumnNameValuePairs.length ==
partitionColumnNames.length) {
+ if (!metaClient.getFs.exists(new Path(getBasePath,
relativePartitionPathPrefix))) {
Review Comment:
It does have getAllPartitionPaths but it is based in state of MDT and not
fs.exists. If i understand correctly, this PR is to fix the issue when metadata
is disabled and partitionPathPrefixAnalysis is enabled.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] ad1happy2go commented on issue #8447: [SUPPORT] Docker Demo Issue With Current master(0.14.0-SNAPSHOT)
ad1happy2go commented on issue #8447: URL: https://github.com/apache/hudi/issues/8447#issuecomment-1512417632 @agrawalreetika Were you able to run it using 0.13.0 ? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] bvaradar commented on a diff in pull request #8335: [HUDI-6009] Let the jetty server in TimelineService create daemon threads
bvaradar commented on code in PR #8335:
URL: https://github.com/apache/hudi/pull/8335#discussion_r1169474873
##
hudi-timeline-service/src/main/java/org/apache/hudi/timeline/service/TimelineService.java:
##
@@ -342,8 +341,13 @@ private int startServiceOnPort(int port) throws
IOException {
}
public int startService() throws IOException {
-final Server server = timelineServerConf.numThreads == DEFAULT_NUM_THREADS
? new JettyServer(new JavalinConfig()).server() :
-new Server(new QueuedThreadPool(timelineServerConf.numThreads));
+int maxThreads = timelineServerConf.numThreads > 0 ?
timelineServerConf.numThreads : 250;
Review Comment:
Can you update documentation in TimelineService.Config to reflect 250 as
default
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] Zouxxyy commented on a diff in pull request #8402: [HUDI-6048] Check if partition exists before list partition by path prefix
Zouxxyy commented on code in PR #8402:
URL: https://github.com/apache/hudi/pull/8402#discussion_r1165565949
##
hudi-spark-datasource/hudi-spark-common/src/main/scala/org/apache/hudi/SparkHoodieTableFileIndex.scala:
##
@@ -299,7 +299,9 @@ class SparkHoodieTableFileIndex(spark: SparkSession,
// prefix to try to reduce the scope of the required file-listing
val relativePartitionPathPrefix =
composeRelativePartitionPath(staticPartitionColumnNameValuePairs)
- if (staticPartitionColumnNameValuePairs.length ==
partitionColumnNames.length) {
+ if (!metaClient.getFs.exists(new Path(getBasePath,
relativePartitionPathPrefix))) {
Review Comment:
@codope Only when enable
`hoodie.datasource.read.file.index.listing.partition-path-prefix.analysis.enabled`
and partition predicates match partition prefix and only one partition, will
into this scenario, the cost should be small
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] wkhappy1 commented on issue #8483: [SUPPORT]hudi connector slower than hive connector
wkhappy1 commented on issue #8483: URL: https://github.com/apache/hudi/issues/8483#issuecomment-1512404390 i see hive connector seems like Parallel acquisition of partitions。 do i need update presto hudi connector with this path: Add asynchronous split generation in Hudi connector https://github.com/prestodb/presto/pull/18210/files -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #8477: [HUDI-6088] Do not set the optmistic concurrency mode when MDT is ena…
hudi-bot commented on PR #8477: URL: https://github.com/apache/hudi/pull/8477#issuecomment-1512398479 ## CI report: * 0b07745f2ea80c7a8facdd65b137c65d9bda21ab Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=16399) * d7b8c5746d29b2ca60997210add1d618fa70ae3c UNKNOWN Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #8449: [HUDI-6071] If the Flink Hive Catalog is used and the table type is B…
hudi-bot commented on PR #8449: URL: https://github.com/apache/hudi/pull/8449#issuecomment-1512394407 ## CI report: * 23304a278d00766d12b2e24f113b82e0f0580b6d Azure: [SUCCESS](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=16408) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Closed] (HUDI-6070) Files pruning for bucket index table pk filtering queries
[ https://issues.apache.org/jira/browse/HUDI-6070?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Danny Chen closed HUDI-6070. Resolution: Fixed Fixed via master branch: cc307d4899b184270c3059102dd02d405e0f5f6e > Files pruning for bucket index table pk filtering queries > - > > Key: HUDI-6070 > URL: https://issues.apache.org/jira/browse/HUDI-6070 > Project: Apache Hudi > Issue Type: Improvement > Components: flink >Reporter: Danny Chen >Priority: Major > Labels: pull-request-available > Fix For: 0.14.0 > > -- This message was sent by Atlassian Jira (v8.20.10#820010)
[hudi] branch master updated (5c278d46fb1 -> cc307d4899b)
This is an automated email from the ASF dual-hosted git repository. danny0405 pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/hudi.git from 5c278d46fb1 [HUDI-6082] Mark advanced Flink configs (#8463) add cc307d4899b [HUDI-6070] Files pruning for bucket index table pk filtering queries (#8461) No new revisions were added by this update. Summary of changes: .../apache/hudi/index/bucket/BucketIdentifier.java | 6 +- .../apache/hudi/configuration/OptionsResolver.java | 7 + .../sink/bucket/BucketStreamWriteFunction.java | 2 +- .../java/org/apache/hudi/sink/utils/Pipelines.java | 4 +- .../java/org/apache/hudi/source/FileIndex.java | 132 ++ .../apache/hudi/source/IncrementalInputSplits.java | 7 +- .../hudi/source/prune/PrimaryKeyPruners.java | 75 +++ .../org/apache/hudi/table/HoodieTableSource.java | 41 +- .../java/org/apache/hudi/util/ExpressionUtils.java | 69 ++ .../utils/BucketStreamWriteFunctionWrapper.java| 6 +- .../hudi/sink/utils/InsertFunctionWrapper.java | 5 + .../hudi/sink/utils/TestFunctionWrapper.java | 5 + .../org/apache/hudi/sink/utils/TestWriteBase.java | 8 +- .../java/org/apache/hudi/source/TestFileIndex.java | 6 +- .../apache/hudi/table/ITTestHoodieDataSource.java | 30 + .../apache/hudi/table/TestHoodieTableSource.java | 147 - .../org/apache/hudi/utils/TestConfigurations.java | 8 ++ .../test/java/org/apache/hudi/utils/TestData.java | 34 - 18 files changed, 537 insertions(+), 55 deletions(-) create mode 100644 hudi-flink-datasource/hudi-flink/src/main/java/org/apache/hudi/source/prune/PrimaryKeyPruners.java
[GitHub] [hudi] danny0405 merged pull request #8461: [HUDI-6070] Files pruning for bucket index table pk filtering queries
danny0405 merged PR #8461: URL: https://github.com/apache/hudi/pull/8461 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #8478: [HUDI-6086]. Improve HiveSchemaUtil#generateCreateDDL With ST.
hudi-bot commented on PR #8478: URL: https://github.com/apache/hudi/pull/8478#issuecomment-1512390559 ## CI report: * e16653effc2d7f7fb4fdceba7b5617cca682c880 Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=16407) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #8335: [HUDI-6009] Let the jetty server in TimelineService create daemon threads
hudi-bot commented on PR #8335: URL: https://github.com/apache/hudi/pull/8335#issuecomment-1512390209 ## CI report: * 81a556f91317143f4e869add5e140f08cf377587 Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=16394) Azure: [PENDING](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=16410) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (HUDI-6070) Files pruning for bucket index table pk filtering queries
[ https://issues.apache.org/jira/browse/HUDI-6070?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Danny Chen updated HUDI-6070: - Fix Version/s: 0.14.0 > Files pruning for bucket index table pk filtering queries > - > > Key: HUDI-6070 > URL: https://issues.apache.org/jira/browse/HUDI-6070 > Project: Apache Hudi > Issue Type: Improvement > Components: flink >Reporter: Danny Chen >Priority: Major > Labels: pull-request-available > Fix For: 0.14.0 > > -- This message was sent by Atlassian Jira (v8.20.10#820010)
[GitHub] [hudi] danny0405 commented on pull request #8472: [HUDI-5298] Optimize WriteStatus storing HoodieRecord
danny0405 commented on PR #8472: URL: https://github.com/apache/hudi/pull/8472#issuecomment-1512389020 It is great if we can have numbers to illustrate the gains after the patch, like the cost reduction for memory or something. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] danny0405 commented on a diff in pull request #8402: [HUDI-6048] Check if partition exists before list partition by path prefix
danny0405 commented on code in PR #8402:
URL: https://github.com/apache/hudi/pull/8402#discussion_r1169454449
##
hudi-spark-datasource/hudi-spark-common/src/main/scala/org/apache/hudi/SparkHoodieTableFileIndex.scala:
##
@@ -299,7 +299,9 @@ class SparkHoodieTableFileIndex(spark: SparkSession,
// prefix to try to reduce the scope of the required file-listing
val relativePartitionPathPrefix =
composeRelativePartitionPath(staticPartitionColumnNameValuePairs)
- if (staticPartitionColumnNameValuePairs.length ==
partitionColumnNames.length) {
+ if (!metaClient.getFs.exists(new Path(getBasePath,
relativePartitionPathPrefix))) {
Review Comment:
Does MDT has the interface to check whether a partition exists ? I don't
think so.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] danny0405 commented on a diff in pull request #8402: [HUDI-6048] Check if partition exists before list partition by path prefix
danny0405 commented on code in PR #8402:
URL: https://github.com/apache/hudi/pull/8402#discussion_r1169454449
##
hudi-spark-datasource/hudi-spark-common/src/main/scala/org/apache/hudi/SparkHoodieTableFileIndex.scala:
##
@@ -299,7 +299,9 @@ class SparkHoodieTableFileIndex(spark: SparkSession,
// prefix to try to reduce the scope of the required file-listing
val relativePartitionPathPrefix =
composeRelativePartitionPath(staticPartitionColumnNameValuePairs)
- if (staticPartitionColumnNameValuePairs.length ==
partitionColumnNames.length) {
+ if (!metaClient.getFs.exists(new Path(getBasePath,
relativePartitionPathPrefix))) {
Review Comment:
Does MDT have the interface to check whether a partition exists ? I don't
think so.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] danny0405 commented on a diff in pull request #8410: [HUDI-6050] Fix write helper deduplicate records lost origin data operation
danny0405 commented on code in PR #8410:
URL: https://github.com/apache/hudi/pull/8410#discussion_r1169453515
##
hudi-client/hudi-client-common/src/main/java/org/apache/hudi/table/action/commit/HoodieWriteHelper.java:
##
@@ -78,7 +79,8 @@ protected HoodieData> doDeduplicateRecords(
throw new HoodieException(String.format("Error to merge two records,
%s, %s", rec1, rec2), e);
}
HoodieKey reducedKey = rec1.getData().equals(reducedRecord.getData()) ?
rec1.getKey() : rec2.getKey();
- return reducedRecord.newInstance(reducedKey);
+ HoodieOperation operation =
rec1.getData().equals(reducedRecord.getData()) ? rec1.getOperation() :
rec2.getOperation();
+ return reducedRecord.newInstance(reducedKey, operation);
Review Comment:
> for partial update payload scenarios, new payload constructed will include
some values from old record and some from new incoming
Yeah, so new object is returns and the decision for `==` always returns
false, so this patch is kind of conservative and still keeps the `equals`
comparison for the payload, but for Flink, we just use the object `==` directly.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] danny0405 commented on a diff in pull request #8111: [HUDI-5887] Should not mark the concurrency mode as OCC by default when MDT is enabled
danny0405 commented on code in PR #8111:
URL: https://github.com/apache/hudi/pull/8111#discussion_r1169448529
##
hudi-client/hudi-client-common/src/main/java/org/apache/hudi/config/HoodieWriteConfig.java:
##
@@ -2971,13 +2977,10 @@ private void
autoAdjustConfigsForConcurrencyMode(boolean isLockProviderPropertyS
// This is targeted at Single writer with async table services
// If user does not set the lock provider, likely that the
concurrency mode is not set either
// Override the configs for metadata table
-writeConfig.setValue(WRITE_CONCURRENCY_MODE.key(),
-WriteConcurrencyMode.OPTIMISTIC_CONCURRENCY_CONTROL.value());
writeConfig.setValue(HoodieLockConfig.LOCK_PROVIDER_CLASS_NAME.key(),
InProcessLockProvider.class.getName());
-LOG.info(String.format("Automatically set %s=%s and %s=%s since
user has not set the "
+LOG.info(String.format("Automatically set %s=%s since user has not
set the "
Review Comment:
We still add lock provider for MDT, but it's not OCC because it is single
writer.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] cxzl25 commented on pull request #8335: [HUDI-6009] Let the jetty server in TimelineService create daemon threads
cxzl25 commented on PR #8335: URL: https://github.com/apache/hudi/pull/8335#issuecomment-1512379691 @hudi-bot run azure -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] xuzifu666 closed pull request #8255: [HUDI-5966] Fix arguments in CreateHoodieTableCommand::createHiveDataSourceTable
xuzifu666 closed pull request #8255: [HUDI-5966] Fix arguments in CreateHoodieTableCommand::createHiveDataSourceTable URL: https://github.com/apache/hudi/pull/8255 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] xuzifu666 closed pull request #8113: [Hotfix] refactor for PartialUpdateAvroPayload with delele constructor
xuzifu666 closed pull request #8113: [Hotfix] refactor for PartialUpdateAvroPayload with delele constructor URL: https://github.com/apache/hudi/pull/8113 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] xuzifu666 commented on pull request #8113: [Hotfix] refactor for PartialUpdateAvroPayload with delele constructor
xuzifu666 commented on PR #8113: URL: https://github.com/apache/hudi/pull/8113#issuecomment-1512371555 > @xuzifu666 : Can you kindly elaborate if this is a valid issue and why we removed natural ordering combining ? i would close the pr,thanks @bvaradar -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] bvaradar commented on a diff in pull request #8200: The hoodie.datasource.write.row.writer.enable should set to be true.
bvaradar commented on code in PR #8200:
URL: https://github.com/apache/hudi/pull/8200#discussion_r1169440451
##
hudi-client/hudi-spark-client/src/main/java/org/apache/hudi/client/clustering/run/strategy/MultipleSparkJobExecutionStrategy.java:
##
@@ -108,7 +108,7 @@ public HoodieWriteMetadata>
performClustering(final Hood
Stream> writeStatusesStream = FutureUtils.allOf(
clusteringPlan.getInputGroups().stream()
.map(inputGroup -> {
- if
(getWriteConfig().getBooleanOrDefault("hoodie.datasource.write.row.writer.enable",
false)) {
+ if
(getWriteConfig().getBooleanOrDefault("hoodie.datasource.write.row.writer.enable",
true)) {
Review Comment:
cc @nsivabalan .
Good catch. It looks like we cannot use the ConfigProperty directly due to
circular dependency. Can you comb the codebase to see if there are similar
cases ?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] Guanpx commented on issue #8475: [SUPPORT] ERROR HoodieMetadataException with spark clean
Guanpx commented on issue #8475: URL: https://github.com/apache/hudi/issues/8475#issuecomment-1512365925 > i use hudi-utilities-bundle_2.12-0.13.2.jar , no Exception but doesn't clean files -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] wkhappy1 opened a new issue, #8483: [SUPPORT]hudi connector slower than hive connector
wkhappy1 opened a new issue, #8483: URL: https://github.com/apache/hudi/issues/8483 vesion presto:0.275.1 hudi:0.11.1 hudi table type is copy on write。 when i execute sql like this: "select count(1) from table where Partition>=202301" Partition is Partition Fields. the above sql execute result is 933。 in hive connector,the above sql cost only 255ms。 in hudi connector,the above sql cost only 4.57s。 in presto ui,i find hudi connector planing time is 4s. and in Flame diagram ,i find hudi connector cost a lot time to getSplits 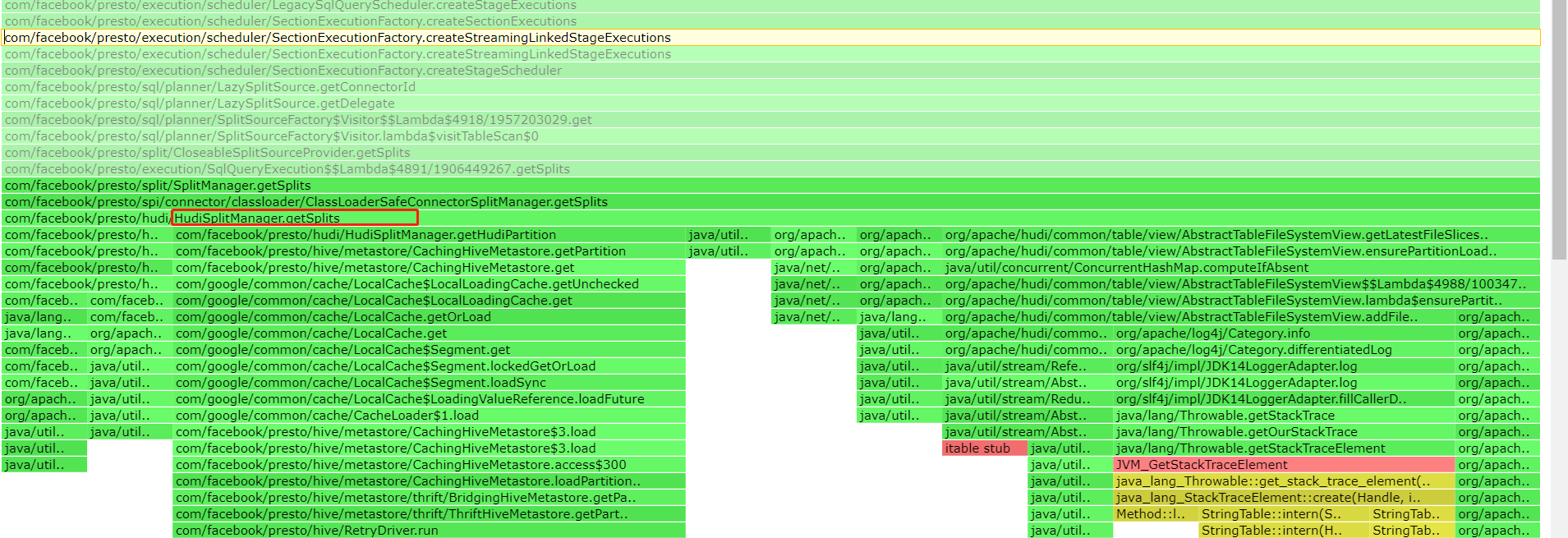 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #8449: [HUDI-6071] If the Flink Hive Catalog is used and the table type is B…
hudi-bot commented on PR #8449: URL: https://github.com/apache/hudi/pull/8449#issuecomment-1512354819 ## CI report: * 139aa8227f5b656e0b1a7e968984f89ccb1af98e Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=16395) * 23304a278d00766d12b2e24f113b82e0f0580b6d Azure: [PENDING](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=16408) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #8385: [HUDI-6040]Stop writing and reading compaction plans from .aux folder
hudi-bot commented on PR #8385: URL: https://github.com/apache/hudi/pull/8385#issuecomment-1512354643 ## CI report: * 3874447e48c21cb336f28625e1682b8f229f623c UNKNOWN * 1cd0db680780d02ff786121f394dccfcd621d37d Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=16378) Azure: [PENDING](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=16409) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] bvaradar commented on pull request #8113: [Hotfix] refactor for PartialUpdateAvroPayload with delele constructor
bvaradar commented on PR #8113: URL: https://github.com/apache/hudi/pull/8113#issuecomment-1512351797 @xuzifu666 : Can you kindly elaborate if this is a valid issue and why we removed natural ordering combining ? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] Mulavar commented on pull request #8385: [HUDI-6040]Stop writing and reading compaction plans from .aux folder
Mulavar commented on PR #8385: URL: https://github.com/apache/hudi/pull/8385#issuecomment-1512343133 @hudi-bot run azure -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] ksoullpwk opened a new issue, #8482: [SUPPORT] Build for Scala 2.13
ksoullpwk opened a new issue, #8482: URL: https://github.com/apache/hudi/issues/8482 My project depends on library that needs to use 2.13. Is there any plans to support this version? A clear and concise description of what you expected to happen. **Environment Description** * Hudi version : 0.12.2 * Spark version : 3.3.0 * Hive version : - * Hadoop version : - * Storage (HDFS/S3/GCS..) : GCS * Running on Docker? (yes/no) : no FYI (Out of this issue): [FAQs](https://hudi.apache.org/learn/faq/) link is broken. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] nsivabalan commented on a diff in pull request #8410: [HUDI-6050] Fix write helper deduplicate records lost origin data operation
nsivabalan commented on code in PR #8410:
URL: https://github.com/apache/hudi/pull/8410#discussion_r1169415773
##
hudi-client/hudi-client-common/src/main/java/org/apache/hudi/table/action/commit/HoodieWriteHelper.java:
##
@@ -78,7 +79,8 @@ protected HoodieData> doDeduplicateRecords(
throw new HoodieException(String.format("Error to merge two records,
%s, %s", rec1, rec2), e);
}
HoodieKey reducedKey = rec1.getData().equals(reducedRecord.getData()) ?
rec1.getKey() : rec2.getKey();
- return reducedRecord.newInstance(reducedKey);
+ HoodieOperation operation =
rec1.getData().equals(reducedRecord.getData()) ? rec1.getOperation() :
rec2.getOperation();
+ return reducedRecord.newInstance(reducedKey, operation);
Review Comment:
not sure this statement "the current contract of payload merging is either
one of the payload would be returned(no copying, no composition)" is true?
for partial update payload scenarios, new payload constructed will include
some values from old record and some from new incoming.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] nsivabalan commented on a diff in pull request #8402: [HUDI-6048] Check if partition exists before list partition by path prefix
nsivabalan commented on code in PR #8402:
URL: https://github.com/apache/hudi/pull/8402#discussion_r1169413988
##
hudi-spark-datasource/hudi-spark-common/src/main/scala/org/apache/hudi/SparkHoodieTableFileIndex.scala:
##
@@ -299,7 +299,9 @@ class SparkHoodieTableFileIndex(spark: SparkSession,
// prefix to try to reduce the scope of the required file-listing
val relativePartitionPathPrefix =
composeRelativePartitionPath(staticPartitionColumnNameValuePairs)
- if (staticPartitionColumnNameValuePairs.length ==
partitionColumnNames.length) {
+ if (!metaClient.getFs.exists(new Path(getBasePath,
relativePartitionPathPrefix))) {
Review Comment:
we should avoid fs.exists call. all direct fs calls should get routed to
BaseMetadataTable interface. if metadata is enabled, we fetch the value from
metadata table.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #8449: [HUDI-6071] If the Flink Hive Catalog is used and the table type is B…
hudi-bot commented on PR #8449: URL: https://github.com/apache/hudi/pull/8449#issuecomment-1512327300 ## CI report: * 139aa8227f5b656e0b1a7e968984f89ccb1af98e Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=16395) * 23304a278d00766d12b2e24f113b82e0f0580b6d UNKNOWN Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] ChestnutQiang commented on a diff in pull request #8449: [HUDI-6071] If the Flink Hive Catalog is used and the table type is B…
ChestnutQiang commented on code in PR #8449:
URL: https://github.com/apache/hudi/pull/8449#discussion_r1169409412
##
hudi-flink-datasource/hudi-flink/src/test/java/org/apache/hudi/util/TestExpressionUtils.java:
##
@@ -0,0 +1,166 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.hudi.util;
+
+import org.apache.flink.table.api.DataTypes;
+import org.apache.flink.table.expressions.CallExpression;
+import org.apache.flink.table.expressions.Expression;
+import org.apache.flink.table.expressions.FieldReferenceExpression;
+import org.apache.flink.table.expressions.ValueLiteralExpression;
+import org.apache.flink.table.functions.BuiltInFunctionDefinitions;
+import org.apache.flink.table.types.AtomicDataType;
+import org.apache.flink.table.types.DataType;
+import org.apache.flink.table.types.logical.BigIntType;
+import org.apache.flink.table.types.logical.BooleanType;
+import org.apache.flink.table.types.logical.DateType;
+import org.apache.flink.table.types.logical.DecimalType;
+import org.apache.flink.table.types.logical.DoubleType;
+import org.apache.flink.table.types.logical.FloatType;
+import org.apache.flink.table.types.logical.IntType;
+import org.apache.flink.table.types.logical.RowType;
+import org.apache.flink.table.types.logical.SmallIntType;
+import org.apache.flink.table.types.logical.TimeType;
+import org.apache.flink.table.types.logical.TimestampType;
+import org.apache.flink.table.types.logical.TinyIntType;
+import org.apache.flink.table.types.logical.VarBinaryType;
+import org.apache.flink.table.types.logical.VarCharType;
+import org.junit.jupiter.api.Test;
+
+import java.math.BigDecimal;
+import java.nio.charset.StandardCharsets;
+import java.time.LocalDate;
+import java.time.LocalDateTime;
+import java.time.LocalTime;
+import java.time.ZoneOffset;
+import java.time.temporal.ChronoField;
+import java.util.ArrayList;
+import java.util.Arrays;
+import java.util.List;
+
+import static org.junit.jupiter.api.Assertions.assertEquals;
+import static org.junit.jupiter.api.Assertions.assertTrue;
+
+class TestExpressionUtils {
+
+ private static final DataType ROW_DATA_TYPE = DataTypes.ROW(
+ DataTypes.FIELD("f_tinyint", DataTypes.TINYINT()),
+ DataTypes.FIELD("f_smallint", DataTypes.SMALLINT()),
+ DataTypes.FIELD("f_int", DataTypes.INT()),
+ DataTypes.FIELD("f_long", DataTypes.BIGINT()),
+ DataTypes.FIELD("f_float", DataTypes.FLOAT()),
+ DataTypes.FIELD("f_double", DataTypes.DOUBLE()),
+ DataTypes.FIELD("f_boolean", DataTypes.BOOLEAN()),
+ DataTypes.FIELD("f_decimal", DataTypes.DECIMAL(10, 2)),
+ DataTypes.FIELD("f_bytes", DataTypes.VARBINARY(10)),
+ DataTypes.FIELD("f_string", DataTypes.VARCHAR(10)),
+ DataTypes.FIELD("f_time", DataTypes.TIME(3)),
+ DataTypes.FIELD("f_date", DataTypes.DATE()),
+ DataTypes.FIELD("f_timestamp", DataTypes.TIMESTAMP(3))
+ ).notNull();
+
+
+ private static final DataType ROW_DATA_TYPE_FIELD_NON_NULL = DataTypes.ROW(
+ DataTypes.FIELD("f_tinyint", new AtomicDataType(new TinyIntType(false))),
Review Comment:
I've already fixed the DataType.notNull to construct the not nullable data
type.
@danny0405
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #8481: [DNM][HUDI-6091] Add Java 11 and 17 to bundle validation image
hudi-bot commented on PR #8481: URL: https://github.com/apache/hudi/pull/8481#issuecomment-1512317299 ## CI report: * b737cdef154f194c61b9d7283c9edd104af458f1 Azure: [SUCCESS](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=16405) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #8478: [HUDI-6086]. Improve HiveSchemaUtil#generateCreateDDL With ST.
hudi-bot commented on PR #8478: URL: https://github.com/apache/hudi/pull/8478#issuecomment-1512317254 ## CI report: * 48facb7f9d2adf5cf7e4931c2f63cd4cc2f4a810 Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=16400) * e16653effc2d7f7fb4fdceba7b5617cca682c880 Azure: [PENDING](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=16407) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] bvaradar commented on a diff in pull request #8384: [HUDI-6039] Fixing FS based listing for full cleaning in clean Planner
bvaradar commented on code in PR #8384:
URL: https://github.com/apache/hudi/pull/8384#discussion_r1169393529
##
hudi-spark-datasource/hudi-spark/src/test/scala/org/apache/spark/sql/hudi/TestAlterTableDropPartition.scala:
##
@@ -320,9 +364,26 @@ class TestAlterTableDropPartition extends
HoodieSparkSqlTestBase {
| )
|""".stripMargin)
+df.write.format("hudi")
+ .option(HoodieWriteConfig.TBL_NAME.key, tableName)
+ .option(TABLE_TYPE.key, COW_TABLE_TYPE_OPT_VAL)
+ .option(RECORDKEY_FIELD.key, "id")
+ .option(PRECOMBINE_FIELD.key, "ts")
+ .option(PARTITIONPATH_FIELD.key, "year,month,day")
+ .option(HIVE_STYLE_PARTITIONING.key, hiveStyle)
+ .option(KEYGENERATOR_CLASS_NAME.key,
classOf[ComplexKeyGenerator].getName)
+ .option(HoodieWriteConfig.INSERT_PARALLELISM_VALUE.key, "1")
+ .option(HoodieWriteConfig.UPSERT_PARALLELISM_VALUE.key, "1")
+ .mode(SaveMode.Append)
+ .save(tablePath)
+
// drop 2021-10-01 partition
spark.sql(s"alter table $tableName drop partition (year='2021',
month='10', day='01')")
+// trigger clean so that partition deletion kicks in.
+spark.sql(s"call run_clean(table => '$tableName', retain_commits =>
1)")
+ .collect()
+
Review Comment:
Should we expect the cleanup to delete non-zero files. If so, can we add
assertion ?
##
hudi-common/src/main/java/org/apache/hudi/metadata/HoodieTableMetadataUtil.java:
##
@@ -381,7 +376,7 @@ private static List
getPartitionsAdded(HoodieCommitMetadata commitMetada
}
private static List getPartitionsDeleted(HoodieCommitMetadata
commitMetadata) {
-if (commitMetadata instanceof HoodieReplaceCommitMetadata
+/*if (commitMetadata instanceof HoodieReplaceCommitMetadata
Review Comment:
Yes, Lets remove the function completely as it is returning just an empty
list.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] yihua commented on a diff in pull request #8342: [HUDI-5987] Fix clustering on bootstrap table with row writer disabled
yihua commented on code in PR #8342:
URL: https://github.com/apache/hudi/pull/8342#discussion_r1169386885
##
hudi-client/hudi-spark-client/src/main/java/org/apache/hudi/client/clustering/run/strategy/MultipleSparkJobExecutionStrategy.java:
##
@@ -327,21 +332,52 @@ private HoodieData>
readRecordsForGroupBaseFiles(JavaSparkContex
// NOTE: It's crucial to make sure that we don't capture whole "this"
object into the
// closure, as this might lead to issues attempting to serialize its
nested fields
+HoodieTableConfig tableConfig =
getHoodieTable().getMetaClient().getTableConfig();
+String bootstrapBasePath = tableConfig.getBootstrapBasePath().orElse(null);
+Option partitionFields = tableConfig.getPartitionFields();
+String timeZoneId = jsc.getConf().get("timeZone",
SQLConf.get().sessionLocalTimeZone());
+boolean shouldValidateColumns =
jsc.getConf().getBoolean("spark.sql.sources.validatePartitionColumns", true);
+
return HoodieJavaRDD.of(jsc.parallelize(clusteringOps,
clusteringOps.size())
.mapPartitions(clusteringOpsPartition -> {
List>> iteratorsForPartition = new
ArrayList<>();
clusteringOpsPartition.forEachRemaining(clusteringOp -> {
try {
Schema readerSchema = HoodieAvroUtils.addMetadataFields(new
Schema.Parser().parse(writeConfig.getSchema()));
HoodieFileReader baseFileReader =
HoodieFileReaderFactory.getReaderFactory(recordType).getFileReader(hadoopConf.get(),
new Path(clusteringOp.getDataFilePath()));
Review Comment:
We should skip this for bootstrap file group.
##
hudi-client/hudi-spark-client/src/main/java/org/apache/hudi/client/clustering/run/strategy/MultipleSparkJobExecutionStrategy.java:
##
@@ -327,21 +332,52 @@ private HoodieData>
readRecordsForGroupBaseFiles(JavaSparkContex
// NOTE: It's crucial to make sure that we don't capture whole "this"
object into the
// closure, as this might lead to issues attempting to serialize its
nested fields
+HoodieTableConfig tableConfig =
getHoodieTable().getMetaClient().getTableConfig();
+String bootstrapBasePath = tableConfig.getBootstrapBasePath().orElse(null);
+Option partitionFields = tableConfig.getPartitionFields();
+String timeZoneId = jsc.getConf().get("timeZone",
SQLConf.get().sessionLocalTimeZone());
+boolean shouldValidateColumns =
jsc.getConf().getBoolean("spark.sql.sources.validatePartitionColumns", true);
+
return HoodieJavaRDD.of(jsc.parallelize(clusteringOps,
clusteringOps.size())
.mapPartitions(clusteringOpsPartition -> {
List>> iteratorsForPartition = new
ArrayList<>();
clusteringOpsPartition.forEachRemaining(clusteringOp -> {
try {
Schema readerSchema = HoodieAvroUtils.addMetadataFields(new
Schema.Parser().parse(writeConfig.getSchema()));
HoodieFileReader baseFileReader =
HoodieFileReaderFactory.getReaderFactory(recordType).getFileReader(hadoopConf.get(),
new Path(clusteringOp.getDataFilePath()));
+ // handle bootstrap path
+ if (StringUtils.nonEmpty(clusteringOp.getBootstrapFilePath()) &&
StringUtils.nonEmpty(bootstrapBasePath)) {
Review Comment:
Do we need to provide the same fix for MOR table, in
`readRecordsForGroupWithLogs(jsc, clusteringOps, instantTime)`? E.g.,
clustering is applied to a bootstrap file group with bootstrap data file,
skeleton file, and log files.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #8478: [HUDI-6086]. Improve HiveSchemaUtil#generateCreateDDL With ST.
hudi-bot commented on PR #8478: URL: https://github.com/apache/hudi/pull/8478#issuecomment-1512291500 ## CI report: * 48facb7f9d2adf5cf7e4931c2f63cd4cc2f4a810 Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=16400) * e16653effc2d7f7fb4fdceba7b5617cca682c880 UNKNOWN Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] yihua commented on a diff in pull request #8342: [HUDI-5987] Fix clustering on bootstrap table with row writer disabled
yihua commented on code in PR #8342:
URL: https://github.com/apache/hudi/pull/8342#discussion_r1169374327
##
hudi-client/hudi-spark-client/src/main/java/org/apache/hudi/client/clustering/run/strategy/MultipleSparkJobExecutionStrategy.java:
##
@@ -368,6 +404,8 @@ private Dataset
readRecordsForGroupAsRow(JavaSparkContext jsc,
.stream()
.map(op -> {
ArrayList readPaths = new ArrayList<>();
+ // NOTE: for bootstrap tables, only need to handle data file path
(ehich is the skeleton file) because
Review Comment:
```suggestion
// NOTE: for bootstrap tables, only need to handle data file path
(which is the skeleton file) because
```
##
hudi-common/src/main/java/org/apache/hudi/io/storage/HoodieBootstrapFileReader.java:
##
@@ -0,0 +1,117 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.io.storage;
+
+import org.apache.hudi.avro.HoodieAvroUtils;
+import org.apache.hudi.common.bloom.BloomFilter;
+import org.apache.hudi.common.model.HoodieRecord;
+import org.apache.hudi.common.model.MetadataValues;
+import org.apache.hudi.common.util.Option;
+import org.apache.hudi.common.util.collection.ClosableIterator;
+
+import org.apache.avro.Schema;
+
+import java.io.IOException;
+import java.util.Set;
+
+public abstract class HoodieBootstrapFileReader implements
HoodieFileReader {
+
+ private final HoodieFileReader skeletonFileReader;
+ private final HoodieFileReader dataFileReader;
+
+ private final Option partitionFields;
+ private final Object[] partitionValues;
+
+ public HoodieBootstrapFileReader(HoodieFileReader skeletonFileReader,
HoodieFileReader dataFileReader, Option partitionFields, Object[]
partitionValues) {
+this.skeletonFileReader = skeletonFileReader;
+this.dataFileReader = dataFileReader;
+this.partitionFields = partitionFields;
+this.partitionValues = partitionValues;
+ }
+
+ @Override
+ public String[] readMinMaxRecordKeys() {
+return skeletonFileReader.readMinMaxRecordKeys();
+ }
+
+ @Override
+ public BloomFilter readBloomFilter() {
+return skeletonFileReader.readBloomFilter();
+ }
+
+ @Override
+ public Set filterRowKeys(Set candidateRowKeys) {
+return skeletonFileReader.filterRowKeys(candidateRowKeys);
+ }
+
+ @Override
+ public ClosableIterator> getRecordIterator(Schema
readerSchema, Schema requestedSchema) throws IOException {
+ClosableIterator> skeletonIterator =
skeletonFileReader.getRecordIterator(readerSchema, requestedSchema);
+ClosableIterator> dataFileIterator =
dataFileReader.getRecordIterator(HoodieAvroUtils.removeMetadataFields(readerSchema),
requestedSchema);
+return new ClosableIterator>() {
+ @Override
+ public void close() {
+skeletonIterator.close();
+dataFileIterator.close();
+ }
+
+ @Override
+ public boolean hasNext() {
+return skeletonIterator.hasNext() && dataFileIterator.hasNext();
+ }
+
+ @Override
+ public HoodieRecord next() {
+HoodieRecord dataRecord = dataFileIterator.next();
+HoodieRecord skeletonRecord = skeletonIterator.next();
+HoodieRecord ret = dataRecord.prependMetaFields(readerSchema,
readerSchema,
+new
MetadataValues().setCommitTime(skeletonRecord.getRecordKey(readerSchema,
HoodieRecord.COMMIT_TIME_METADATA_FIELD))
+.setCommitSeqno(skeletonRecord.getRecordKey(readerSchema,
HoodieRecord.COMMIT_SEQNO_METADATA_FIELD))
+.setRecordKey(skeletonRecord.getRecordKey(readerSchema,
HoodieRecord.RECORD_KEY_METADATA_FIELD))
+.setPartitionPath(skeletonRecord.getRecordKey(readerSchema,
HoodieRecord.PARTITION_PATH_METADATA_FIELD))
+.setFileName(skeletonRecord.getRecordKey(readerSchema,
HoodieRecord.FILENAME_METADATA_FIELD)), null);
+if (partitionFields.isPresent()) {
+ for (int i = 0; i < partitionValues.length; i++) {
+int position =
readerSchema.getField(partitionFields.get()[i]).pos();
+setPartitionField(position, partitionValues[i], ret.getData());
+ }
+}
+return ret;
+ }
+};
+ }
+
+
[GitHub] [hudi] hudi-bot commented on pull request #8480: [HUDI-6090] Optimise payload size for list of FileGroupDTO
hudi-bot commented on PR #8480: URL: https://github.com/apache/hudi/pull/8480#issuecomment-1512282911 ## CI report: * 7096396d3f2b6dc428fa05310054cc6294c9d580 Azure: [SUCCESS](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=16404) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[hudi] branch master updated (64bf871cfc3 -> 5c278d46fb1)
This is an automated email from the ASF dual-hosted git repository. yihua pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/hudi.git from 64bf871cfc3 [HUDI-6052] Standardise TIMESTAMP(6) format when writing to Parquet files (#8418) add 5c278d46fb1 [HUDI-6082] Mark advanced Flink configs (#8463) No new revisions were added by this update. Summary of changes: .../apache/hudi/common/config/AdvancedConfig.java | 14 ++- .../apache/hudi/configuration/FlinkOptions.java| 112 ++--- 2 files changed, 105 insertions(+), 21 deletions(-) copy hudi-spark-datasource/hudi-spark/src/test/java/org/apache/hudi/functional/SparkSQLCoreFlow.java => hudi-common/src/main/java/org/apache/hudi/common/config/AdvancedConfig.java (78%)
[GitHub] [hudi] yihua merged pull request #8463: [HUDI-6082] Mark advanced Flink configs
yihua merged PR #8463: URL: https://github.com/apache/hudi/pull/8463 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #8463: [HUDI-6082] Mark advanced Flink configs
hudi-bot commented on PR #8463: URL: https://github.com/apache/hudi/pull/8463#issuecomment-1512242567 ## CI report: * 2cc98f74450604a6fbeb35dd7dd625fd30c76a12 Azure: [SUCCESS](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=16355) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #8479: HUDI-6047: Consistent hash index metadata file related bug fix
hudi-bot commented on PR #8479: URL: https://github.com/apache/hudi/pull/8479#issuecomment-1512242634 ## CI report: * 4bc3d0240e9caf944f727db6e1772da630450597 Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=16403) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] nsivabalan commented on a diff in pull request #8111: [HUDI-5887] Should not mark the concurrency mode as OCC by default when MDT is enabled
nsivabalan commented on code in PR #8111:
URL: https://github.com/apache/hudi/pull/8111#discussion_r1169353294
##
hudi-client/hudi-client-common/src/main/java/org/apache/hudi/config/HoodieWriteConfig.java:
##
@@ -2971,13 +2977,10 @@ private void
autoAdjustConfigsForConcurrencyMode(boolean isLockProviderPropertyS
// This is targeted at Single writer with async table services
// If user does not set the lock provider, likely that the
concurrency mode is not set either
// Override the configs for metadata table
-writeConfig.setValue(WRITE_CONCURRENCY_MODE.key(),
-WriteConcurrencyMode.OPTIMISTIC_CONCURRENCY_CONTROL.value());
writeConfig.setValue(HoodieLockConfig.LOCK_PROVIDER_CLASS_NAME.key(),
InProcessLockProvider.class.getName());
-LOG.info(String.format("Automatically set %s=%s and %s=%s since
user has not set the "
+LOG.info(String.format("Automatically set %s=%s since user has not
set the "
Review Comment:
why removing concurrency mode ?
when metadata is enabled and if there any async tasble services, we want to
enable OCC (i.e. write concurrency mode, in process lock provider, lazy rollack
clean policy).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] AbhijeetSachdev1 commented on issue #8292: [SUPPORT] What all are the uses of hudi-archived files and consequences of deleting them manually.
AbhijeetSachdev1 commented on issue #8292: URL: https://github.com/apache/hudi/issues/8292#issuecomment-151922 @danny0405 Thanks for response, I am still not clear. Could you help me understand, what worst can happen if we DELETE archived files ? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #8472: [HUDI-5298] Optimize WriteStatus storing HoodieRecord
hudi-bot commented on PR #8472: URL: https://github.com/apache/hudi/pull/8472#issuecomment-1512189863 ## CI report: * 9da1c0da2753e7be3b6612568cc6750ba9944403 Azure: [SUCCESS](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=16402) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #8481: [DNM][HUDI-6091] Add Java 11 and 17 to bundle validation image
hudi-bot commented on PR #8481: URL: https://github.com/apache/hudi/pull/8481#issuecomment-1512131986 ## CI report: * b737cdef154f194c61b9d7283c9edd104af458f1 Azure: [PENDING](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=16405) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #8478: [HUDI-6086]. Improve HiveSchemaUtil#generateCreateDDL With ST.
hudi-bot commented on PR #8478: URL: https://github.com/apache/hudi/pull/8478#issuecomment-1512131928 ## CI report: * 48facb7f9d2adf5cf7e4931c2f63cd4cc2f4a810 Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=16400) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #8481: [DNM][HUDI-6091] Add Java 11 and 17 to bundle validation image
hudi-bot commented on PR #8481: URL: https://github.com/apache/hudi/pull/8481#issuecomment-1512125123 ## CI report: * b737cdef154f194c61b9d7283c9edd104af458f1 UNKNOWN Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (HUDI-6091) Add Java 11 and 17 to bundle validation image
[ https://issues.apache.org/jira/browse/HUDI-6091?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] ASF GitHub Bot updated HUDI-6091: - Labels: pull-request-available (was: ) > Add Java 11 and 17 to bundle validation image > - > > Key: HUDI-6091 > URL: https://issues.apache.org/jira/browse/HUDI-6091 > Project: Apache Hudi > Issue Type: New Feature >Reporter: Ethan Guo >Priority: Major > Labels: pull-request-available > -- This message was sent by Atlassian Jira (v8.20.10#820010)
[GitHub] [hudi] yihua opened a new pull request, #8481: [DNM][HUDI-6091] Add Java 11 and 17 to bundle validation image
yihua opened a new pull request, #8481: URL: https://github.com/apache/hudi/pull/8481 ### Change Logs _Describe context and summary for this change. Highlight if any code was copied._ ### Impact _Describe any public API or user-facing feature change or any performance impact._ ### Risk level (write none, low medium or high below) _If medium or high, explain what verification was done to mitigate the risks._ ### Documentation Update _Describe any necessary documentation update if there is any new feature, config, or user-facing change_ - _The config description must be updated if new configs are added or the default value of the configs are changed_ - _Any new feature or user-facing change requires updating the Hudi website. Please create a Jira ticket, attach the ticket number here and follow the [instruction](https://hudi.apache.org/contribute/developer-setup#website) to make changes to the website._ ### Contributor's checklist - [ ] Read through [contributor's guide](https://hudi.apache.org/contribute/how-to-contribute) - [ ] Change Logs and Impact were stated clearly - [ ] Adequate tests were added if applicable - [ ] CI passed -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Created] (HUDI-6091) Add Java 11 and 17 to bundle validation image
Ethan Guo created HUDI-6091: --- Summary: Add Java 11 and 17 to bundle validation image Key: HUDI-6091 URL: https://issues.apache.org/jira/browse/HUDI-6091 Project: Apache Hudi Issue Type: New Feature Reporter: Ethan Guo -- This message was sent by Atlassian Jira (v8.20.10#820010)
[GitHub] [hudi] hudi-bot commented on pull request #8477: [HUDI-6088] Do not set the optmistic concurrency mode when MDT is ena…
hudi-bot commented on PR #8477: URL: https://github.com/apache/hudi/pull/8477#issuecomment-1512057562 ## CI report: * 0b07745f2ea80c7a8facdd65b137c65d9bda21ab Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=16399) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #8476: [HUDI-6087] Fix Hudi-on-Flink stop-with-savepoint usecases
hudi-bot commented on PR #8476: URL: https://github.com/apache/hudi/pull/8476#issuecomment-1511980083 ## CI report: * fc432c7e02b22a7d0f58cbe0f913f6c76522f0af Azure: [SUCCESS](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=16398) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #8460: [HUDI-6079] Improve the code of HMSDDLExecutor, HiveQueryDDLExecutor.
hudi-bot commented on PR #8460: URL: https://github.com/apache/hudi/pull/8460#issuecomment-1511898256 ## CI report: * b3e968330154dad1e358399822c1558ebeb3c7ff Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=16396) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #8380: [HUDI-6033] Fix rounding exception when to decimal casting
hudi-bot commented on PR #8380: URL: https://github.com/apache/hudi/pull/8380#issuecomment-1511897752 ## CI report: * 4127079fc6162fee6b08501c700cf9b835a38d3c UNKNOWN * ddf99d1d66b9b98deeadc09136e07a0aaceb5c8a UNKNOWN * 27d656870879682bdabebbbf2c2b00a98d1fa579 UNKNOWN * 3bf8c8558ce88f9fe97efe290444a81a8f6a UNKNOWN * 07418ebae94ef7b69eb0aec3d9964548046be44c Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=16383) Azure: [SUCCESS](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=16397) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #8449: [HUDI-6071] If the Flink Hive Catalog is used and the table type is B…
hudi-bot commented on PR #8449: URL: https://github.com/apache/hudi/pull/8449#issuecomment-1511814095 ## CI report: * 139aa8227f5b656e0b1a7e968984f89ccb1af98e Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=16395) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #8480: [HUDI-6090] Optimise payload size for list of FileGroupDTO
hudi-bot commented on PR #8480: URL: https://github.com/apache/hudi/pull/8480#issuecomment-1511748474 ## CI report: * 7096396d3f2b6dc428fa05310054cc6294c9d580 Azure: [PENDING](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=16404) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #8470: [MINOR] Fix typos in hudi-utilities module
hudi-bot commented on PR #8470: URL: https://github.com/apache/hudi/pull/8470#issuecomment-1511736814 ## CI report: * a456a91c503846f33a396eef944c343c629cce16 Azure: [SUCCESS](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=16370) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #8480: [HUDI-6090] Optimise payload size for list of FileGroupDTO
hudi-bot commented on PR #8480: URL: https://github.com/apache/hudi/pull/8480#issuecomment-1511737192 ## CI report: * 7096396d3f2b6dc428fa05310054cc6294c9d580 UNKNOWN Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #8470: [MINOR] Fix typos in hudi-utilities module
hudi-bot commented on PR #8470: URL: https://github.com/apache/hudi/pull/8470#issuecomment-1511726263 ## CI report: * a456a91c503846f33a396eef944c343c629cce16 UNKNOWN Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #8335: [HUDI-6009] Let the jetty server in TimelineService create daemon threads
hudi-bot commented on PR #8335: URL: https://github.com/apache/hudi/pull/8335#issuecomment-1511724393 ## CI report: * 81a556f91317143f4e869add5e140f08cf377587 Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=16394) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] yihua commented on pull request #8470: [MINOR] Fix typos in hudi-utilities module
yihua commented on PR #8470: URL: https://github.com/apache/hudi/pull/8470#issuecomment-1511720105 CI is green. https://user-images.githubusercontent.com/2497195/232553372-53829012-e05c-4bac-b1eb-dc67f83a8b6b.png;> -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (HUDI-6090) Optimise payload size for list of FileGroupDTO
[ https://issues.apache.org/jira/browse/HUDI-6090?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] ASF GitHub Bot updated HUDI-6090: - Labels: pull-request-available (was: ) > Optimise payload size for list of FileGroupDTO > -- > > Key: HUDI-6090 > URL: https://issues.apache.org/jira/browse/HUDI-6090 > Project: Apache Hudi > Issue Type: Bug > Components: timeline-server >Reporter: Lokesh Jain >Assignee: Lokesh Jain >Priority: Major > Labels: pull-request-available > > FileGroupDTO has TimelineDTO as field. The timeline can be large and have > significant size. For a list of FileGroupDTOs, the same timeline is repeated > for every FileGroupDTO. The Jira aims to add an optimisation where for a list > of FileGroupDTOs, the timeline is sent only in the first FileGroupDTOs. On > the client side, FileGroup can be constructed using the TimelineDTO from the > first DTO. -- This message was sent by Atlassian Jira (v8.20.10#820010)
[GitHub] [hudi] lokeshj1703 opened a new pull request, #8480: [HUDI-6090] Optimise payload size for list of FileGroupDTO
lokeshj1703 opened a new pull request, #8480: URL: https://github.com/apache/hudi/pull/8480 ### Change Logs FileGroupDTO has TimelineDTO as field. The timeline can be large and have significant size. For a list of FileGroupDTOs, the same timeline is repeated for every FileGroupDTO. The Jira aims to add an optimisation where for a list of FileGroupDTOs, the timeline is sent only in the first FileGroupDTOs. On the client side, FileGroup can be constructed using the TimelineDTO from the first DTO. ### Impact NA ### Risk level (write none, low medium or high below) low ### Documentation Update NA ### Contributor's checklist - [ ] Read through [contributor's guide](https://hudi.apache.org/contribute/how-to-contribute) - [ ] Change Logs and Impact were stated clearly - [ ] Adequate tests were added if applicable - [ ] CI passed -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Created] (HUDI-6090) Optimise payload size for list of FileGroupDTO
Lokesh Jain created HUDI-6090: - Summary: Optimise payload size for list of FileGroupDTO Key: HUDI-6090 URL: https://issues.apache.org/jira/browse/HUDI-6090 Project: Apache Hudi Issue Type: Bug Components: timeline-server Reporter: Lokesh Jain Assignee: Lokesh Jain FileGroupDTO has TimelineDTO as field. The timeline can be large and have significant size. For a list of FileGroupDTOs, the same timeline is repeated for every FileGroupDTO. The Jira aims to add an optimisation where for a list of FileGroupDTOs, the timeline is sent only in the first FileGroupDTOs. On the client side, FileGroup can be constructed using the TimelineDTO from the first DTO. -- This message was sent by Atlassian Jira (v8.20.10#820010)
[GitHub] [hudi] hudi-bot commented on pull request #8463: [HUDI-6082] Mark advanced Flink configs
hudi-bot commented on PR #8463: URL: https://github.com/apache/hudi/pull/8463#issuecomment-1511655029 ## CI report: * 2cc98f74450604a6fbeb35dd7dd625fd30c76a12 Azure: [PENDING](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=16355) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #8463: [HUDI-6082] Mark advanced Flink configs
hudi-bot commented on PR #8463: URL: https://github.com/apache/hudi/pull/8463#issuecomment-1511637567 ## CI report: * 2cc98f74450604a6fbeb35dd7dd625fd30c76a12 UNKNOWN Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #7614: [HUDI-5509] check if dfs support atomic creation when using filesyste…
hudi-bot commented on PR #7614: URL: https://github.com/apache/hudi/pull/7614#issuecomment-1511621623 ## CI report: * 058ab2703bda207fc9f5861d5e4b865e83ee1b45 UNKNOWN * 9b853e4f449343ffae850eae895191fbdfb94b12 UNKNOWN * 60b50fe79f0e316d591dbecff68cbc3c2c5b4a4b Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=16193) Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=16393) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #8479: HUDI-6047: Consistent hash index metadata file related bug fix
hudi-bot commented on PR #8479: URL: https://github.com/apache/hudi/pull/8479#issuecomment-1511538937 ## CI report: * 4bc3d0240e9caf944f727db6e1772da630450597 Azure: [PENDING](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=16403) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #8479: HUDI-6047: Consistent hash index metadata file related bug fix
hudi-bot commented on PR #8479: URL: https://github.com/apache/hudi/pull/8479#issuecomment-1511522925 ## CI report: * 4bc3d0240e9caf944f727db6e1772da630450597 UNKNOWN Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (HUDI-6047) Clustering operation on consistent hashing resulting in duplicate data
[
https://issues.apache.org/jira/browse/HUDI-6047?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
ASF GitHub Bot updated HUDI-6047:
-
Labels: pull-request-available (was: )
> Clustering operation on consistent hashing resulting in duplicate data
> --
>
> Key: HUDI-6047
> URL: https://issues.apache.org/jira/browse/HUDI-6047
> Project: Apache Hudi
> Issue Type: Bug
>Reporter: Rohan
>Priority: Major
> Labels: pull-request-available
>
> Hudi chooses consistent hashing committed bucket metadata file on the basis
> of r{*}eplace commit logged on hudi active timeline{*}. but {*}once hudi
> archives timeline{*}, it falls back to *default consistent hashing bucket
> metadata* that is *00.hashing_meta* , which result in writing
> duplicate records in the table *.*
> above behaviour results in duplicate data in the hudi table and *failing in
> subsequent clustering operation as there is inconsistency between file groups
> on storage vs file groups in metadata files*
>
> Check the loadMetadata function of consistent hashing index implementation.
> [https://github.com/apache/hudi/blob/4da64686cfbcb6471b1967091401565f58c835c7/hudi-client/hudi-spark-client/src/main/java/org/apache/hudi/index/bucket/HoodieSparkConsistentBucketIndex.java#L190|http://example.com/]
>
> let me know if anything else is needed.
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[GitHub] [hudi] rohan-uptycs opened a new pull request, #8479: HUDI-6047: Consistent hash index metadata file related bug fix
rohan-uptycs opened a new pull request, #8479: URL: https://github.com/apache/hudi/pull/8479 ### Change Logs Following changes added 1. Hudi loads consistent hashing committed bucket metadata file on the basis of replace commit present on active timeline, but when replaced commit gets archived it falls back to default metadata file which result in data duplication. 2. Added patch for this bug https://issues.apache.org/jira/browse/HUDI-6047 ### Impact none ### Risk level (write none, low medium or high below) none ### Documentation Update none ### Contributor's checklist - [ ] Read through [contributor's guide](https://hudi.apache.org/contribute/how-to-contribute) - [ ] Change Logs and Impact were stated clearly - [ ] Adequate tests were added if applicable - [ ] CI passed -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] whight closed issue #8451: [SUPPORT] Insert write operation pre combined problem
whight closed issue #8451: [SUPPORT] Insert write operation pre combined problem URL: https://github.com/apache/hudi/issues/8451 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #8437: [HUDI-6066] HoodieTableSource supports parquet predicate push down
hudi-bot commented on PR #8437: URL: https://github.com/apache/hudi/pull/8437#issuecomment-1511419511 ## CI report: * 4fdb9dc536d97832f1dc16dd1c754ce7015b1bc6 UNKNOWN * 6af209c352d9665ad1f8a0243a27f50e0d26b43a Azure: [SUCCESS](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=16391) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #8472: [HUDI-5298] Optimize WriteStatus storing HoodieRecord
hudi-bot commented on PR #8472: URL: https://github.com/apache/hudi/pull/8472#issuecomment-1511403545 ## CI report: * 402e4a78e4f37f7e587a23855f9042363dd70368 Azure: [SUCCESS](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=16375) * 9da1c0da2753e7be3b6612568cc6750ba9944403 Azure: [PENDING](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=16402) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #8472: [HUDI-5298] Optimize WriteStatus storing HoodieRecord
hudi-bot commented on PR #8472: URL: https://github.com/apache/hudi/pull/8472#issuecomment-1511386394 ## CI report: * 402e4a78e4f37f7e587a23855f9042363dd70368 Azure: [SUCCESS](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=16375) * 9da1c0da2753e7be3b6612568cc6750ba9944403 UNKNOWN Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #8461: [HUDI-6070] Files pruning for bucket index table pk filtering queries
hudi-bot commented on PR #8461: URL: https://github.com/apache/hudi/pull/8461#issuecomment-1511367232 ## CI report: * 6f63e6704b12a56cbdcef44c34ba5595b163acfa Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=16364) Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=16390) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] pete91z commented on issue #8118: [SUPPORT] error in run_sync_tool.sh
pete91z commented on issue #8118: URL: https://github.com/apache/hudi/issues/8118#issuecomment-1511358660 Hi, my attention has been a bit diverted to other issues lately, but I should be able to re-test this week and update here. Thanks! -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] danny0405 commented on a diff in pull request #8449: [HUDI-6071] If the Flink Hive Catalog is used and the table type is B…
danny0405 commented on code in PR #8449:
URL: https://github.com/apache/hudi/pull/8449#discussion_r1168690800
##
hudi-flink-datasource/hudi-flink/src/test/java/org/apache/hudi/util/TestExpressionUtils.java:
##
@@ -0,0 +1,166 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.hudi.util;
+
+import org.apache.flink.table.api.DataTypes;
+import org.apache.flink.table.expressions.CallExpression;
+import org.apache.flink.table.expressions.Expression;
+import org.apache.flink.table.expressions.FieldReferenceExpression;
+import org.apache.flink.table.expressions.ValueLiteralExpression;
+import org.apache.flink.table.functions.BuiltInFunctionDefinitions;
+import org.apache.flink.table.types.AtomicDataType;
+import org.apache.flink.table.types.DataType;
+import org.apache.flink.table.types.logical.BigIntType;
+import org.apache.flink.table.types.logical.BooleanType;
+import org.apache.flink.table.types.logical.DateType;
+import org.apache.flink.table.types.logical.DecimalType;
+import org.apache.flink.table.types.logical.DoubleType;
+import org.apache.flink.table.types.logical.FloatType;
+import org.apache.flink.table.types.logical.IntType;
+import org.apache.flink.table.types.logical.RowType;
+import org.apache.flink.table.types.logical.SmallIntType;
+import org.apache.flink.table.types.logical.TimeType;
+import org.apache.flink.table.types.logical.TimestampType;
+import org.apache.flink.table.types.logical.TinyIntType;
+import org.apache.flink.table.types.logical.VarBinaryType;
+import org.apache.flink.table.types.logical.VarCharType;
+import org.junit.jupiter.api.Test;
+
+import java.math.BigDecimal;
+import java.nio.charset.StandardCharsets;
+import java.time.LocalDate;
+import java.time.LocalDateTime;
+import java.time.LocalTime;
+import java.time.ZoneOffset;
+import java.time.temporal.ChronoField;
+import java.util.ArrayList;
+import java.util.Arrays;
+import java.util.List;
+
+import static org.junit.jupiter.api.Assertions.assertEquals;
+import static org.junit.jupiter.api.Assertions.assertTrue;
+
+class TestExpressionUtils {
+
+ private static final DataType ROW_DATA_TYPE = DataTypes.ROW(
+ DataTypes.FIELD("f_tinyint", DataTypes.TINYINT()),
+ DataTypes.FIELD("f_smallint", DataTypes.SMALLINT()),
+ DataTypes.FIELD("f_int", DataTypes.INT()),
+ DataTypes.FIELD("f_long", DataTypes.BIGINT()),
+ DataTypes.FIELD("f_float", DataTypes.FLOAT()),
+ DataTypes.FIELD("f_double", DataTypes.DOUBLE()),
+ DataTypes.FIELD("f_boolean", DataTypes.BOOLEAN()),
+ DataTypes.FIELD("f_decimal", DataTypes.DECIMAL(10, 2)),
+ DataTypes.FIELD("f_bytes", DataTypes.VARBINARY(10)),
+ DataTypes.FIELD("f_string", DataTypes.VARCHAR(10)),
+ DataTypes.FIELD("f_time", DataTypes.TIME(3)),
+ DataTypes.FIELD("f_date", DataTypes.DATE()),
+ DataTypes.FIELD("f_timestamp", DataTypes.TIMESTAMP(3))
+ ).notNull();
+
+
+ private static final DataType ROW_DATA_TYPE_FIELD_NON_NULL = DataTypes.ROW(
+ DataTypes.FIELD("f_tinyint", new AtomicDataType(new TinyIntType(false))),
Review Comment:
Then uses the DataType.notNull to construct the not nullable data type.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] danny0405 commented on a diff in pull request #8394: [HUDI-6085] Eliminate cleaning tasks for flink mor table if async cleaning is disabled
danny0405 commented on code in PR #8394:
URL: https://github.com/apache/hudi/pull/8394#discussion_r1168688393
##
hudi-flink-datasource/hudi-flink/src/main/java/org/apache/hudi/table/HoodieTableSink.java:
##
@@ -103,6 +103,8 @@ public SinkRuntimeProvider getSinkRuntimeProvider(Context
context) {
conf.setBoolean(FlinkOptions.COMPACTION_ASYNC_ENABLED, false);
}
return Pipelines.compact(conf, pipeline);
+ } else if (OptionsResolver.isMorTable(conf)) {
+return Pipelines.dummySink(pipeline);
} else {
Review Comment:
The spark offline compaction Job does not take care of cleaning, could you
make it clrear how user can handle the cleaning when they use the flink
streaming ingestion and spark offline compaction.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[jira] [Closed] (HUDI-6052) Standardise TIMESTAMP(6) format when writing to Parquet files
[
https://issues.apache.org/jira/browse/HUDI-6052?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Danny Chen closed HUDI-6052.
Fix Version/s: 0.13.1
0.14.0
Resolution: Fixed
Fixed via master branch: 64bf871cfc3cfc08478cf04e02d2f7086f72548e
> Standardise TIMESTAMP(6) format when writing to Parquet files
> -
>
> Key: HUDI-6052
> URL: https://issues.apache.org/jira/browse/HUDI-6052
> Project: Apache Hudi
> Issue Type: Bug
>Reporter: voon
>Assignee: voon
>Priority: Major
> Labels: pull-request-available
> Fix For: 0.13.1, 0.14.0
>
>
> h1. APPEND-ONLY MODE
>
> When *TIMESTAMP(6)* is used for *APPEND-ONLY* pipelines with
> inline-clustering enabled, the error below will be thrown:
>
>
> {code:java}
> Caused by: org.apache.hudi.exception.HoodieException: unable to read next
> record from parquet file
> at
> org.apache.hudi.common.util.ParquetReaderIterator.hasNext(ParquetReaderIterator.java:53)
> at
> java.util.Spliterators$IteratorSpliterator.tryAdvance(Spliterators.java:1811)
> at
> java.util.stream.StreamSpliterators$WrappingSpliterator.lambda$initPartialTraversalState$0(StreamSpliterators.java:295)
> at
> java.util.stream.StreamSpliterators$AbstractWrappingSpliterator.fillBuffer(StreamSpliterators.java:207)
> at
> java.util.stream.StreamSpliterators$AbstractWrappingSpliterator.doAdvance(StreamSpliterators.java:162)
> at
> java.util.stream.StreamSpliterators$WrappingSpliterator.tryAdvance(StreamSpliterators.java:301)
> at java.util.Spliterators$1Adapter.hasNext(Spliterators.java:681)
> at
> org.apache.hudi.client.utils.ConcatenatingIterator.hasNext(ConcatenatingIterator.java:45)
> at
> org.apache.hudi.sink.clustering.ClusteringOperator.doClustering(ClusteringOperator.java:307)
> at
> org.apache.hudi.sink.clustering.ClusteringOperator.processElement(ClusteringOperator.java:240)
> at
> org.apache.flink.streaming.runtime.tasks.OneInputStreamTask$StreamTaskNetworkOutput.emitRecord(OneInputStreamTask.java:233)
> at
> org.apache.flink.streaming.runtime.io.AbstractStreamTaskNetworkInput.processElement(AbstractStreamTaskNetworkInput.java:134)
> at
> org.apache.flink.streaming.runtime.io.AbstractStreamTaskNetworkInput.emitNext(AbstractStreamTaskNetworkInput.java:105)
> at
> org.apache.flink.streaming.runtime.io.StreamOneInputProcessor.processInput(StreamOneInputProcessor.java:65)
> at
> org.apache.flink.streaming.runtime.tasks.StreamTask.processInput(StreamTask.java:524)
> at
> org.apache.flink.streaming.runtime.tasks.mailbox.MailboxProcessor.runMailboxLoop(MailboxProcessor.java:203)
> at
> org.apache.flink.streaming.runtime.tasks.StreamTask.runMailboxLoop(StreamTask.java:809)
> at
> org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:758)
> at
> org.apache.flink.runtime.taskmanager.Task.runWithSystemExitMonitoring(Task.java:951)
> at
> org.apache.flink.runtime.taskmanager.Task.restoreAndInvoke(Task.java:930)
> at org.apache.flink.runtime.taskmanager.Task.doRun(Task.java:744)
> at org.apache.flink.runtime.taskmanager.Task.run(Task.java:563)
> at java.lang.Thread.run(Thread.java:750)
> Caused by: org.apache.parquet.io.ParquetDecodingException: Can not read value
> at 1 in block 0 in file
> file:/var/folders/p_/09zfm5sx3v14w97hhk4vqrn8s817xt/T/junit5996224223926304717/par2/3cc78c96-2823-46fb-ab8c-7106edd55fc7-0_1-4-0_20230410162304415.parquet
> at
> org.apache.parquet.hadoop.InternalParquetRecordReader.nextKeyValue(InternalParquetRecordReader.java:254)
> at org.apache.parquet.hadoop.ParquetReader.read(ParquetReader.java:132)
> at org.apache.parquet.hadoop.ParquetReader.read(ParquetReader.java:136)
> at
> org.apache.hudi.common.util.ParquetReaderIterator.hasNext(ParquetReaderIterator.java:48)
> ... 22 more
> Caused by: java.lang.UnsupportedOperationException:
> org.apache.parquet.avro.AvroConverters$FieldLongConverter
> at
> org.apache.parquet.io.api.PrimitiveConverter.addBinary(PrimitiveConverter.java:70)
> at
> org.apache.parquet.column.impl.ColumnReaderBase$2$6.writeValue(ColumnReaderBase.java:390)
> at
> org.apache.parquet.column.impl.ColumnReaderBase.writeCurrentValueToConverter(ColumnReaderBase.java:440)
> at
> org.apache.parquet.column.impl.ColumnReaderImpl.writeCurrentValueToConverter(ColumnReaderImpl.java:30)
> at
> org.apache.parquet.io.RecordReaderImplementation.read(RecordReaderImplementation.java:406)
> at
> org.apache.parquet.hadoop.InternalParquetRecordReader.nextKeyValue(InternalParquetRecordReader.java:229)
> ... 25 more
> Process finished with exit code 255 {code}
>
>
> Sample code to trigger this:
>
> {code:java}
> CREATE TABLE
[hudi] branch master updated: [HUDI-6052] Standardise TIMESTAMP(6) format when writing to Parquet files (#8418)
This is an automated email from the ASF dual-hosted git repository.
danny0405 pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/hudi.git
The following commit(s) were added to refs/heads/master by this push:
new 64bf871cfc3 [HUDI-6052] Standardise TIMESTAMP(6) format when writing
to Parquet files (#8418)
64bf871cfc3 is described below
commit 64bf871cfc3cfc08478cf04e02d2f7086f72548e
Author: voonhous
AuthorDate: Mon Apr 17 21:12:06 2023 +0800
[HUDI-6052] Standardise TIMESTAMP(6) format when writing to Parquet files
(#8418)
Co-authored-by: hbgstc123
---
.../row/HoodieRowDataParquetWriteSupport.java | 2 +-
.../storage/row/parquet/ParquetRowDataWriter.java | 63 ++--
.../row/parquet/ParquetSchemaConverter.java| 10 +-
.../row/parquet/TestParquetSchemaConverter.java| 2 +-
.../org/apache/hudi/util/AvroSchemaConverter.java | 4 +-
.../apache/hudi/util/AvroToRowDataConverters.java | 2 +-
.../sink/cluster/ITTestHoodieFlinkClustering.java | 180 +
.../vector/reader/Int64TimestampColumnReader.java | 2 +-
.../vector/reader/Int64TimestampColumnReader.java | 2 +-
.../vector/reader/Int64TimestampColumnReader.java | 2 +-
.../vector/reader/Int64TimestampColumnReader.java | 2 +-
11 files changed, 244 insertions(+), 27 deletions(-)
diff --git
a/hudi-client/hudi-flink-client/src/main/java/org/apache/hudi/io/storage/row/HoodieRowDataParquetWriteSupport.java
b/hudi-client/hudi-flink-client/src/main/java/org/apache/hudi/io/storage/row/HoodieRowDataParquetWriteSupport.java
index b939498c3e2..4a3109db60a 100644
---
a/hudi-client/hudi-flink-client/src/main/java/org/apache/hudi/io/storage/row/HoodieRowDataParquetWriteSupport.java
+++
b/hudi-client/hudi-flink-client/src/main/java/org/apache/hudi/io/storage/row/HoodieRowDataParquetWriteSupport.java
@@ -20,11 +20,11 @@ package org.apache.hudi.io.storage.row;
import org.apache.hudi.avro.HoodieBloomFilterWriteSupport;
import org.apache.hudi.common.bloom.BloomFilter;
+import org.apache.hudi.common.util.Option;
import org.apache.flink.table.data.RowData;
import org.apache.flink.table.types.logical.RowType;
import org.apache.hadoop.conf.Configuration;
-import org.apache.hudi.common.util.Option;
import org.apache.parquet.hadoop.api.WriteSupport;
import java.nio.charset.StandardCharsets;
diff --git
a/hudi-client/hudi-flink-client/src/main/java/org/apache/hudi/io/storage/row/parquet/ParquetRowDataWriter.java
b/hudi-client/hudi-flink-client/src/main/java/org/apache/hudi/io/storage/row/parquet/ParquetRowDataWriter.java
index 3d9524eaa30..e5b9509d879 100644
---
a/hudi-client/hudi-flink-client/src/main/java/org/apache/hudi/io/storage/row/parquet/ParquetRowDataWriter.java
+++
b/hudi-client/hudi-flink-client/src/main/java/org/apache/hudi/io/storage/row/parquet/ParquetRowDataWriter.java
@@ -18,6 +18,8 @@
package org.apache.hudi.io.storage.row.parquet;
+import org.apache.hudi.common.util.ValidationUtils;
+
import org.apache.flink.table.data.ArrayData;
import org.apache.flink.table.data.DecimalDataUtils;
import org.apache.flink.table.data.MapData;
@@ -124,17 +126,19 @@ public class ParquetRowDataWriter {
return new DoubleWriter();
case TIMESTAMP_WITHOUT_TIME_ZONE:
TimestampType timestampType = (TimestampType) t;
-if (timestampType.getPrecision() == 3) {
- return new Timestamp64Writer();
+final int tsPrecision = timestampType.getPrecision();
+if (tsPrecision == 3 || tsPrecision == 6) {
+ return new Timestamp64Writer(tsPrecision);
} else {
- return new Timestamp96Writer(timestampType.getPrecision());
+ return new Timestamp96Writer(tsPrecision);
}
case TIMESTAMP_WITH_LOCAL_TIME_ZONE:
LocalZonedTimestampType localZonedTimestampType =
(LocalZonedTimestampType) t;
-if (localZonedTimestampType.getPrecision() == 3) {
- return new Timestamp64Writer();
+final int tsLtzPrecision = localZonedTimestampType.getPrecision();
+if (tsLtzPrecision == 3 || tsLtzPrecision == 6) {
+ return new Timestamp64Writer(tsLtzPrecision);
} else {
- return new Timestamp96Writer(localZonedTimestampType.getPrecision());
+ return new Timestamp96Writer(tsLtzPrecision);
}
case ARRAY:
ArrayType arrayType = (ArrayType) t;
@@ -284,33 +288,64 @@ public class ParquetRowDataWriter {
}
/**
- * Timestamp of INT96 bytes, julianDay(4) + nanosOfDay(8). See
+ * TIMESTAMP_MILLIS and TIMESTAMP_MICROS is the deprecated ConvertedType of
TIMESTAMP with the MILLIS and MICROS
+ * precision respectively. See
*
https://github.com/apache/parquet-format/blob/master/LogicalTypes.md#timestamp
- * TIMESTAMP_MILLIS and TIMESTAMP_MICROS are the deprecated ConvertedType.
*/
private class Timestamp64Writer implements FieldWriter {
-private Timestamp64Writer() {
+
[GitHub] [hudi] danny0405 merged pull request #8418: [HUDI-6052] Standardise TIMESTAMP(6) format when writing to Parquet f…
danny0405 merged PR #8418: URL: https://github.com/apache/hudi/pull/8418 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] danny0405 commented on pull request #8418: [HUDI-6052] Standardise TIMESTAMP(6) format when writing to Parquet f…
danny0405 commented on PR #8418: URL: https://github.com/apache/hudi/pull/8418#issuecomment-1511315828 The failed test cases in module `hudi-utilities` and `hudi-spark-client` have no relationship with this change, would merge it soon ~ -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] ad1happy2go commented on issue #8316: [SUPPORT] INSERT operation performance vs UPSERT operation
ad1happy2go commented on issue #8316: URL: https://github.com/apache/hudi/issues/8316#issuecomment-1511298675 @awk6873 Why are you not using Bulk insert? Insert operation also takes the similar write path as upsert so the performance can be similar although it doesn't do index lookup. Bulk insert should be very fast, and you can do separate clustering job to handle small files problem. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] clownxc commented on a diff in pull request #8472: [HUDI-5298] Optimize WriteStatus storing HoodieRecord
clownxc commented on code in PR #8472:
URL: https://github.com/apache/hudi/pull/8472#discussion_r1168657932
##
hudi-common/src/main/java/org/apache/hudi/common/model/HoodieRecordStatus.java:
##
@@ -0,0 +1,91 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.common.model;
+
+import org.apache.hudi.common.util.Option;
+
+import com.esotericsoftware.kryo.Kryo;
+import com.esotericsoftware.kryo.KryoSerializable;
+import com.esotericsoftware.kryo.io.Input;
+import com.esotericsoftware.kryo.io.Output;
+
+import java.io.Serializable;
+
+public class HoodieRecordStatus implements Serializable, KryoSerializable {
+
+
Review Comment:
> key + location are actually an index item, just rename it to `IndexItem` ?
Thank you very much for your review, I have modified the code, can you
re-review the code when you are free, and make some comments.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #2701: [HUDI 1623] New Hoodie Instant on disk format with end time and milliseconds granularity
hudi-bot commented on PR #2701: URL: https://github.com/apache/hudi/pull/2701#issuecomment-1511293218 ## CI report: * cf79ca863369d8d7326ade272da67ca63a42bad8 Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=359) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org