[GitHub] [hudi] hudi-bot commented on pull request #9278: [HUDI-6312] Rename enum values of `HollowCommitHandling`
hudi-bot commented on PR #9278: URL: https://github.com/apache/hudi/pull/9278#issuecomment-1649235024 ## CI report: * 52e1fa26d55c6b82562c802690dc4f42ace14783 Azure: [SUCCESS](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=18815) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] danny0405 commented on a diff in pull request #9182: fix duplicate fileId on TM exception partial-failover and recovery
danny0405 commented on code in PR #9182:
URL: https://github.com/apache/hudi/pull/9182#discussion_r1273084610
##
hudi-flink-datasource/hudi-flink/src/main/java/org/apache/hudi/sink/common/AbstractStreamWriteFunction.java:
##
@@ -220,7 +220,6 @@ private void sendBootstrapEvent() {
if (this.currentInstant != null) {
LOG.info("Recover task[{}] for instant [{}] with attemptId [{}]",
taskID, this.currentInstant, attemptId);
this.currentInstant = null;
-return;
}
Review Comment:
Can you elaborate a little more why the fix solves your problem ?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #8967: [HUDI-6378] allow to delete twice for an empty table
hudi-bot commented on PR #8967: URL: https://github.com/apache/hudi/pull/8967#issuecomment-1649234197 ## CI report: * 96b14a14446288bae5070db221f8d0ea04e98d8f UNKNOWN * 8de8962b2bebdf980a1c53b67e055747eb3c5a0e Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=18816) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] danny0405 commented on a diff in pull request #9229: [HUDI-6565] Spark offline compaction add failed retry mechanism
danny0405 commented on code in PR #9229:
URL: https://github.com/apache/hudi/pull/9229#discussion_r1273077993
##
hudi-utilities/src/main/java/org/apache/hudi/utilities/HoodieCompactor.java:
##
@@ -101,6 +104,12 @@ public static class Config implements Serializable {
public String runningMode = null;
@Parameter(names = {"--strategy", "-st"}, description = "Strategy Class",
required = false)
public String strategyClassName =
LogFileSizeBasedCompactionStrategy.class.getName();
+@Parameter(names = {"--job-max-processing-time-ms", "-mt"}, description =
"Take effect when using --mode/-m execute or scheduleAndExecute. "
++ "If maxProcessingTimeMs passed but compaction job is still
unfinished, hoodie would consider this job as failed and relaunch.")
+public long maxProcessingTimeMs = 0;
+@Parameter(names = {"--retry-last-failed-compaction-job", "-rc"},
description = "Take effect when using --mode/-m execute or scheduleAndExecute. "
Review Comment:
Got it, so do you still need this PR?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] SteNicholas commented on a diff in pull request #9212: [HUDI-6541] Multiple writers should create new and different instant time to avoid marker conflict of same instant
SteNicholas commented on code in PR #9212:
URL: https://github.com/apache/hudi/pull/9212#discussion_r1273049997
##
hudi-client/hudi-client-common/src/main/java/org/apache/hudi/client/BaseHoodieWriteClient.java:
##
@@ -862,11 +866,29 @@ public String startCommit(String actionType,
HoodieTableMetaClient metaClient) {
CleanerUtils.rollbackFailedWrites(config.getFailedWritesCleanPolicy(),
HoodieTimeline.COMMIT_ACTION, () ->
tableServiceClient.rollbackFailedWrites());
-String instantTime = HoodieActiveTimeline.createNewInstantTime();
+String instantTime = createCommit();
startCommit(instantTime, actionType, metaClient);
return instantTime;
}
+ /**
+ * Creates a new commit time for a write operation
(insert/update/delete/insert_overwrite/insert_overwrite_table).
+ *
+ * @return Instant time to be generated.
+ */
+ public String createCommit() {
+if
(config.getWriteConcurrencyMode().supportsOptimisticConcurrencyControl()) {
+ try {
+lockManager.lock();
+return HoodieActiveTimeline.createNewInstantTime();
Review Comment:
@KnightChess, I agree with this point. Table services have been updated to
use `BaseHoodieWriteClient#createNewInstantTime`.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] big-doudou commented on pull request #9182: fix duplicate fileId on TM exception partial-failover and recovery
big-doudou commented on PR #9182: URL: https://github.com/apache/hudi/pull/9182#issuecomment-1649187842 @danny0405 Can you help review this pr, this error can be reproduced 100%, please check for details https://github.com/apache/hudi/issues/8892#issuecomment-1632159235 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #9209: [HUDI-6539] New LSM tree style archived timeline
hudi-bot commented on PR #9209: URL: https://github.com/apache/hudi/pull/9209#issuecomment-1649184386 ## CI report: * 62001bbc6c5d9306f95d4bca3dd2bada3ca5c898 Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=18804) * 9889e40cdf17f6f24ddefff010a063d4dd2c58e7 Azure: [PENDING](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=18820) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] big-doudou commented on issue #8892: [SUPPORT] [BUG] Duplicate fileID ??? from bucket ?? of partition found during the BucketStreamWriteFunction index bootstrap.
big-doudou commented on issue #8892: URL: https://github.com/apache/hudi/issues/8892#issuecomment-1649180307 You must ensure that the amount of data received is large enough to pre-write the buffer file to disk before the checkpoint -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] big-doudou commented on issue #8892: [SUPPORT] [BUG] Duplicate fileID ??? from bucket ?? of partition found during the BucketStreamWriteFunction index bootstrap.
big-doudou commented on issue #8892: URL: https://github.com/apache/hudi/issues/8892#issuecomment-1649178251 > @big-doudou Apologies for the late reply. I was trying to reproduce this issue on our end, but was unable to do so. > > A little context on what we did: > > Using a datagen source, we'll sink the data into a hudi table. Before a checkpoint, we'll kill one of the TM's task. Upon doing so, a rollback will be triggered when all the TMs restart. I checked with a colleague of mine and they mentioned that when hudi is uperforming an upsert, there's a shuffle operation. The presence of a shuffle operation will trigger a "global failover". > > Here's the Flink-SQL that i used while attempting to reproduce your issue. > > ```sql > CREATE TEMPORARY TABLE buyer_info ( > id bigint, > dec_col decimal(25, 10), > country string, > age INT, > update_time STRING > ) WITH ( > 'connector' = 'datagen', > 'rows-per-second' = '10', > 'fields.age.min' = '0', > 'fields.age.max' = '7', > 'fields.country.length' = '1' > ); > > -- Hudi table to write to > CREATE TEMPORARY TABLE dim_buyer_info_test > ( > id bigint, > dec_col decimal(25, 10), > country string, > age INT, > update_time STRING > ) PARTITIONED BY (age) > WITH > ( > -- Hudi settings > 'connector' = 'hudi', > 'hoodie.datasource.write.recordkey.field' = 'id', > 'path' = '/path/to/hudi_table/duplicate_file_id_issue', > 'write.operation' = 'UPSERT', > 'table.type' = 'MERGE_ON_READ', > 'hoodie.compaction.payload.class' = 'org.apache.hudi.common.model.PartialUpdateAvroPayload', > 'hoodie.datasource.write.payload.class' = 'org.apache.hudi.common.model.PartialUpdateAvroPayload', > 'hoodie.table.keygenerator.class' = 'org.apache.hudi.keygen.ComplexAvroKeyGenerator', > 'write.precombine.field' = 'update_time', > 'index.type' = 'BUCKET', > 'hoodie.bucket.index.num.buckets' = '4', > 'write.tasks' = '8', > 'hoodie.bucket.index.hash.field' = 'id', > 'clean.retain_commits' = '5', > -- Hive sync settings > 'hive_sync.enable' = 'false' > ); > > -- Insert into Hudi sink > INSERT INTO dim_buyer_info_test > SELECT id, dec_col, country, age, update_time > FROM buyer_info; > ``` > > Might have butchered the explanation above... > > As such, we were unable to reproduce your issue where of a single TM restarting. > > Can you please share your job configurations and how you're doing your tests? Sorry, didn't see it in time My flink job runs on k8s, before checkpoint, after some log files are generated, kill the container -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #9209: [HUDI-6539] New LSM tree style archived timeline
hudi-bot commented on PR #9209: URL: https://github.com/apache/hudi/pull/9209#issuecomment-1649174677 ## CI report: * 62001bbc6c5d9306f95d4bca3dd2bada3ca5c898 Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=18804) * 9889e40cdf17f6f24ddefff010a063d4dd2c58e7 UNKNOWN Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] leesf commented on a diff in pull request #9199: [HUDI-6534]Support consistent hashing row writer
leesf commented on code in PR #9199:
URL: https://github.com/apache/hudi/pull/9199#discussion_r1273032213
##
hudi-client/hudi-spark-client/src/main/java/org/apache/hudi/execution/bulkinsert/ConsistentBucketIndexBulkInsertPartitionerWithRows.java:
##
@@ -0,0 +1,154 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.execution.bulkinsert;
+
+import org.apache.hudi.common.model.ConsistentHashingNode;
+import org.apache.hudi.common.model.HoodieConsistentHashingMetadata;
+import org.apache.hudi.common.model.HoodieTableType;
+import org.apache.hudi.common.util.Option;
+import org.apache.hudi.common.util.ValidationUtils;
+import org.apache.hudi.index.bucket.ConsistentBucketIdentifier;
+import org.apache.hudi.index.bucket.ConsistentBucketIndexUtils;
+import org.apache.hudi.index.bucket.HoodieSparkConsistentBucketIndex;
+import org.apache.hudi.keygen.BuiltinKeyGenerator;
+import org.apache.hudi.keygen.factory.HoodieSparkKeyGeneratorFactory;
+import org.apache.hudi.table.BulkInsertPartitioner;
+import org.apache.hudi.table.ConsistentHashingBucketInsertPartitioner;
+import org.apache.hudi.table.HoodieTable;
+
+import org.apache.spark.Partitioner;
+import org.apache.spark.api.java.JavaRDD;
+import org.apache.spark.sql.Dataset;
+import org.apache.spark.sql.Row;
+
+import java.util.ArrayList;
+import java.util.HashMap;
+import java.util.List;
+import java.util.Map;
+import java.util.stream.Collectors;
+
+import scala.Tuple2;
+
+/**
+ * Bulk_insert partitioner of Spark row using consistent hashing bucket index.
+ */
+public class ConsistentBucketIndexBulkInsertPartitionerWithRows
+implements BulkInsertPartitioner>,
ConsistentHashingBucketInsertPartitioner {
+
+ private final HoodieTable table;
+
+ private final String indexKeyFields;
+
+ private final List fileIdPfxList = new ArrayList<>();
+ private final Map> hashingChildrenNodes;
+
+ private Map partitionToIdentifier;
+
+ private final Option keyGeneratorOpt;
+
+ private Map> partitionToFileIdPfxIdxMap;
+
+ private final RowRecordKeyExtractor extractor;
+
+ public ConsistentBucketIndexBulkInsertPartitionerWithRows(HoodieTable table,
boolean populateMetaFields) {
+this.indexKeyFields = table.getConfig().getBucketIndexHashField();
+this.table = table;
+this.hashingChildrenNodes = new HashMap<>();
+if (!populateMetaFields) {
+ this.keyGeneratorOpt =
HoodieSparkKeyGeneratorFactory.getKeyGenerator(table.getConfig().getProps());
+} else {
+ this.keyGeneratorOpt = Option.empty();
+}
+this.extractor =
RowRecordKeyExtractor.getRowRecordKeyExtractor(populateMetaFields,
keyGeneratorOpt);
+
ValidationUtils.checkArgument(table.getMetaClient().getTableType().equals(HoodieTableType.MERGE_ON_READ),
Review Comment:
is the check by design for consistent hash index? if yes we could move the
check to the parent class?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[hudi] branch master updated: [HUDI-6438] Config parameter 'MAKE_NEW_COLUMNS_NULLABLE' to allow for marking a newly created column as nullable. (#9262)
This is an automated email from the ASF dual-hosted git repository.
sivabalan pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/hudi.git
The following commit(s) were added to refs/heads/master by this push:
new 42799c0956f [HUDI-6438] Config parameter 'MAKE_NEW_COLUMNS_NULLABLE'
to allow for marking a newly created column as nullable. (#9262)
42799c0956f is described below
commit 42799c0956f626bc47318ddd91c626b1e58a0fc8
Author: Amrish Lal
AuthorDate: Mon Jul 24 22:27:50 2023 -0700
[HUDI-6438] Config parameter 'MAKE_NEW_COLUMNS_NULLABLE' to allow for
marking a newly created column as nullable. (#9262)
- adds a config parameter 'hoodie.datasource.write.new.columns.nullable'
which when set to true will mark newly added column as nullable. By default
'hoodie.datasource.write.new.columns.nullable' is set to false to maintain
existing behavior.
---
.../hudi/common/config/HoodieCommonConfig.java | 8
.../schema/utils/AvroSchemaEvolutionUtils.java | 12 --
.../scala/org/apache/hudi/DataSourceOptions.scala | 2 +
.../org/apache/hudi/HoodieSparkSqlWriter.scala | 6 +--
.../scala/org/apache/hudi/HoodieWriterUtils.scala | 1 +
.../apache/hudi/functional/TestCOWDataSource.scala | 48 +-
6 files changed, 69 insertions(+), 8 deletions(-)
diff --git
a/hudi-common/src/main/java/org/apache/hudi/common/config/HoodieCommonConfig.java
b/hudi-common/src/main/java/org/apache/hudi/common/config/HoodieCommonConfig.java
index 4ff1b89ee9b..7c696b4c1d3 100644
---
a/hudi-common/src/main/java/org/apache/hudi/common/config/HoodieCommonConfig.java
+++
b/hudi-common/src/main/java/org/apache/hudi/common/config/HoodieCommonConfig.java
@@ -62,6 +62,14 @@ public class HoodieCommonConfig extends HoodieConfig {
+ "This enables us, to always extend the table's schema during
evolution and never lose the data (when, for "
+ "ex, existing column is being dropped in a new batch)");
+ public static final ConfigProperty MAKE_NEW_COLUMNS_NULLABLE =
ConfigProperty
+ .key("hoodie.datasource.write.new.columns.nullable")
+ .defaultValue(false)
+ .markAdvanced()
+ .withDocumentation("When a non-nullable column is added to datasource
during a write operation, the write "
+ + " operation will fail schema compatibility check. Set this option
to true will make the newly added "
+ + " column nullable to successfully complete the write operation.");
+
public static final ConfigProperty
SPILLABLE_DISK_MAP_TYPE = ConfigProperty
.key("hoodie.common.spillable.diskmap.type")
.defaultValue(ExternalSpillableMap.DiskMapType.BITCASK)
diff --git
a/hudi-common/src/main/java/org/apache/hudi/internal/schema/utils/AvroSchemaEvolutionUtils.java
b/hudi-common/src/main/java/org/apache/hudi/internal/schema/utils/AvroSchemaEvolutionUtils.java
index 2dab3d009b4..13c1f0e2277 100644
---
a/hudi-common/src/main/java/org/apache/hudi/internal/schema/utils/AvroSchemaEvolutionUtils.java
+++
b/hudi-common/src/main/java/org/apache/hudi/internal/schema/utils/AvroSchemaEvolutionUtils.java
@@ -23,9 +23,11 @@ import org.apache.hudi.internal.schema.InternalSchema;
import org.apache.hudi.internal.schema.action.TableChanges;
import java.util.List;
+import java.util.Map;
import java.util.TreeMap;
import java.util.stream.Collectors;
+import static
org.apache.hudi.common.config.HoodieCommonConfig.MAKE_NEW_COLUMNS_NULLABLE;
import static org.apache.hudi.common.util.CollectionUtils.reduce;
import static
org.apache.hudi.internal.schema.convert.AvroInternalSchemaConverter.convert;
@@ -116,9 +118,10 @@ public class AvroSchemaEvolutionUtils {
*
* @param sourceSchema source schema that needs reconciliation
* @param targetSchema target schema that source schema will be reconciled
against
+ * @param opts config options
* @return schema (based off {@code source} one) that has nullability
constraints reconciled
*/
- public static Schema reconcileNullability(Schema sourceSchema, Schema
targetSchema) {
+ public static Schema reconcileNullability(Schema sourceSchema, Schema
targetSchema, Map opts) {
if (sourceSchema.getFields().isEmpty() ||
targetSchema.getFields().isEmpty()) {
return sourceSchema;
}
@@ -129,9 +132,10 @@ public class AvroSchemaEvolutionUtils {
List colNamesSourceSchema =
sourceInternalSchema.getAllColsFullName();
List colNamesTargetSchema =
targetInternalSchema.getAllColsFullName();
List candidateUpdateCols = colNamesSourceSchema.stream()
-.filter(f -> colNamesTargetSchema.contains(f)
-&& sourceInternalSchema.findField(f).isOptional() !=
targetInternalSchema.findField(f).isOptional())
-.collect(Collectors.toList());
+.filter(f ->
(("true".equals(opts.get(MAKE_NEW_COLUMNS_NULLABLE.key())) &&
!colNamesTargetSchema.contains(f))
+|| colNamesTargetSchema.contains(f) &&
so
[GitHub] [hudi] nsivabalan merged pull request #9262: [HUDI-6438] Config parameter 'MAKE_NEW_COLUMNS_NULLABLE' to allow for marking a newly created column as nullable.
nsivabalan merged PR #9262: URL: https://github.com/apache/hudi/pull/9262 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #9274: [MINOR] fix millis append format error
hudi-bot commented on PR #9274: URL: https://github.com/apache/hudi/pull/9274#issuecomment-1649134459 ## CI report: * 94d9dbcb05d1505d4a1d5e82dca8a8ba946f47da Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=18806) Azure: [PENDING](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=18818) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] KnightChess commented on pull request #9274: [MINOR] fix millis append format error
KnightChess commented on PR #9274: URL: https://github.com/apache/hudi/pull/9274#issuecomment-1649131501 @hudi-bot run azure -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[hudi] branch master updated: [HUDI-3636] Disabling embedded timeline server with spark streaming sink (#9266)
This is an automated email from the ASF dual-hosted git repository.
yihua pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/hudi.git
The following commit(s) were added to refs/heads/master by this push:
new e466daf6f4b [HUDI-3636] Disabling embedded timeline server with spark
streaming sink (#9266)
e466daf6f4b is described below
commit e466daf6f4b57d5e2069a534b195434cca0e852f
Author: Sivabalan Narayanan
AuthorDate: Tue Jul 25 00:19:26 2023 -0400
[HUDI-3636] Disabling embedded timeline server with spark streaming sink
(#9266)
---
.../src/main/scala/org/apache/hudi/HoodieStreamingSink.scala | 5 +
1 file changed, 5 insertions(+)
diff --git
a/hudi-spark-datasource/hudi-spark-common/src/main/scala/org/apache/hudi/HoodieStreamingSink.scala
b/hudi-spark-datasource/hudi-spark-common/src/main/scala/org/apache/hudi/HoodieStreamingSink.scala
index 895e8fa5ab7..5667c8870d3 100644
---
a/hudi-spark-datasource/hudi-spark-common/src/main/scala/org/apache/hudi/HoodieStreamingSink.scala
+++
b/hudi-spark-datasource/hudi-spark-common/src/main/scala/org/apache/hudi/HoodieStreamingSink.scala
@@ -118,6 +118,11 @@ class HoodieStreamingSink(sqlContext: SQLContext,
// we need auto adjustment enabled for streaming sink since async table
services are feasible within the same JVM.
updatedOptions =
updatedOptions.updated(HoodieWriteConfig.AUTO_ADJUST_LOCK_CONFIGS.key, "true")
updatedOptions =
updatedOptions.updated(HoodieSparkSqlWriter.SPARK_STREAMING_BATCH_ID,
batchId.toString)
+if
(!options.containsKey(HoodieWriteConfig.EMBEDDED_TIMELINE_SERVER_ENABLE.key()))
{
+ // if user does not explicitly override, we are disabling timeline
server for streaming sink.
+ // refer to HUDI-3636 for more details
+ updatedOptions =
updatedOptions.updated(HoodieWriteConfig.EMBEDDED_TIMELINE_SERVER_ENABLE.key(),
" false")
+}
retry(retryCnt, retryIntervalMs)(
Try(
[GitHub] [hudi] yihua closed pull request #5269: [HUDI-3636] Create new write clients for async table services in DeltaStreamer and Spark streaming sink
yihua closed pull request #5269: [HUDI-3636] Create new write clients for async table services in DeltaStreamer and Spark streaming sink URL: https://github.com/apache/hudi/pull/5269 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] yihua merged pull request #9266: [HUDI-3636] Disabling embedded timeline server with spark streaming sink
yihua merged PR #9266: URL: https://github.com/apache/hudi/pull/9266 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #8967: [HUDI-6378] allow to delete twice for an empty table
hudi-bot commented on PR #8967: URL: https://github.com/apache/hudi/pull/8967#issuecomment-1649074473 ## CI report: * 96b14a14446288bae5070db221f8d0ea04e98d8f UNKNOWN * fdbbec8d0c523cbdce7cbb1f4d3c79f136a3f0e5 Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=18126) Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=18142) * 8de8962b2bebdf980a1c53b67e055747eb3c5a0e Azure: [PENDING](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=18816) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #8967: [HUDI-6378] allow to delete twice for an empty table
hudi-bot commented on PR #8967: URL: https://github.com/apache/hudi/pull/8967#issuecomment-1649060101 ## CI report: * 96b14a14446288bae5070db221f8d0ea04e98d8f UNKNOWN * fdbbec8d0c523cbdce7cbb1f4d3c79f136a3f0e5 Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=18126) Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=18142) * 8de8962b2bebdf980a1c53b67e055747eb3c5a0e UNKNOWN Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #9278: [HUDI-6312] Rename enum values of `HollowCommitHandling`
hudi-bot commented on PR #9278: URL: https://github.com/apache/hudi/pull/9278#issuecomment-1649047783 ## CI report: * 52e1fa26d55c6b82562c802690dc4f42ace14783 Azure: [PENDING](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=18815) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #9278: [HUDI-6312] Rename enum values of `HollowCommitHandling`
hudi-bot commented on PR #9278: URL: https://github.com/apache/hudi/pull/9278#issuecomment-1648966927 ## CI report: * 52e1fa26d55c6b82562c802690dc4f42ace14783 UNKNOWN Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Created] (HUDI-6587) Handle hollow commit for time travel query
Raymond Xu created HUDI-6587: Summary: Handle hollow commit for time travel query Key: HUDI-6587 URL: https://issues.apache.org/jira/browse/HUDI-6587 Project: Apache Hudi Issue Type: Improvement Components: reader-core Reporter: Raymond Xu -- This message was sent by Atlassian Jira (v8.20.10#820010)
[GitHub] [hudi] xushiyan opened a new pull request, #9278: [HUDI-6312] Rename enum values of `HollowCommitHandling`
xushiyan opened a new pull request, #9278: URL: https://github.com/apache/hudi/pull/9278 ### Change Logs - Rename `HollowCommitHandling#EXCEPTION` to `HollowCommitHandling#FAIL` - Rename `HollowCommitHandling#USE_STATE_TRANSITION_TIME` to `HollowCommitHandling#USE_TRANSITION_TIME` ### Impact User config change (no actual impact as this is newly added to not-yet-released 0.14.0) ### Risk level None. ### Documentation Update NA ### Contributor's checklist - [ ] Read through [contributor's guide](https://hudi.apache.org/contribute/how-to-contribute) - [ ] Change Logs and Impact were stated clearly - [ ] Adequate tests were added if applicable - [ ] CI passed -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] zhuanshenbsj1 commented on a diff in pull request #7159: [HUDI-5173] Skip if there is only one file in clusteringGroup
zhuanshenbsj1 commented on code in PR #7159:
URL: https://github.com/apache/hudi/pull/7159#discussion_r1025474961
##
hudi-client/hudi-spark-client/src/test/java/org/apache/hudi/table/action/cluster/strategy/TestSparkClusteringPlanPartitionFilter.java:
##
@@ -53,9 +53,9 @@ public void setUp() {
@Test
public void testFilterPartitionNoFilter() {
HoodieWriteConfig config =
hoodieWriteConfigBuilder.withClusteringConfig(HoodieClusteringConfig.newBuilder()
-
.withClusteringPlanPartitionFilterMode(ClusteringPlanPartitionFilterMode.NONE)
-.build())
-.build();
+
.withClusteringPlanPartitionFilterMode(ClusteringPlanPartitionFilterMode.NONE)
Review Comment:
done
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] nylqd commented on issue #9269: [SUPPORT] Hudi HMS Catalog hive_sync.conf.dir
nylqd commented on issue #9269: URL: https://github.com/apache/hudi/issues/9269#issuecomment-1648923651 > > hdfs path, since the code running on yarn and my hive-site.xml is in a local dir > > I guess you are right, the hive conf dir is only valid for the catalog itself, not the job, the catalog does not pass around all the hive related config options to the job. > > Maybe you can fire a fix for it, in the HoodieHiveCatalog, when generating a new catalog table, config the hive options through `hadoop.` prefix. > > Another way is to config the system variable: `HIVE_CONF_DIR`: > > 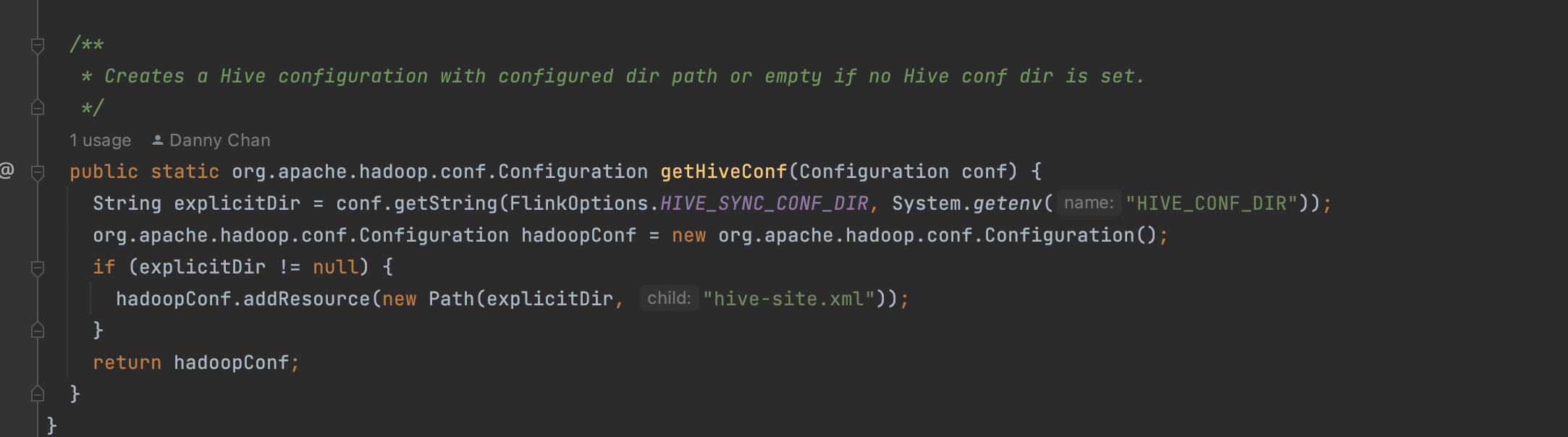 thx for ur clarification, after set hive tblproperties we finally sync schema successfully next step, we gonna try to set those properties in the HoodieHiveCatalog -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] ksmou commented on a diff in pull request #9229: [HUDI-6565] Spark offline compaction add failed retry mechanism
ksmou commented on code in PR #9229:
URL: https://github.com/apache/hudi/pull/9229#discussion_r1272927559
##
hudi-utilities/src/main/java/org/apache/hudi/utilities/HoodieCompactor.java:
##
@@ -101,6 +104,12 @@ public static class Config implements Serializable {
public String runningMode = null;
@Parameter(names = {"--strategy", "-st"}, description = "Strategy Class",
required = false)
public String strategyClassName =
LogFileSizeBasedCompactionStrategy.class.getName();
+@Parameter(names = {"--job-max-processing-time-ms", "-mt"}, description =
"Take effect when using --mode/-m execute or scheduleAndExecute. "
++ "If maxProcessingTimeMs passed but compaction job is still
unfinished, hoodie would consider this job as failed and relaunch.")
+public long maxProcessingTimeMs = 0;
+@Parameter(names = {"--retry-last-failed-compaction-job", "-rc"},
description = "Take effect when using --mode/-m execute or scheduleAndExecute. "
Review Comment:
Yes. We just only choose a failed compaction instant here. It will been
rolled back in subsequent executions `SparkRDDTableServiceClient#compact(String
compactionInstantTime, boolean shouldComplete)`
```java
// org/apache/hudi/client/SparkRDDTableServiceClient.java
protected HoodieWriteMetadata> compact(String
compactionInstantTime, boolean shouldComplete) {
HoodieSparkTable table = HoodieSparkTable.create(config, context);
HoodieTimeline pendingCompactionTimeline =
table.getActiveTimeline().filterPendingCompactionTimeline();
HoodieInstant inflightInstant =
HoodieTimeline.getCompactionInflightInstant(compactionInstantTime);
if (pendingCompactionTimeline.containsInstant(inflightInstant)) {
table.rollbackInflightCompaction(inflightInstant, commitToRollback ->
getPendingRollbackInfo(table.getMetaClient(), commitToRollback, false));
table.getMetaClient().reloadActiveTimeline();
}
compactionTimer = metrics.getCompactionCtx();
HoodieWriteMetadata> writeMetadata =
table.compact(context, compactionInstantTime);
HoodieWriteMetadata> compactionMetadata =
writeMetadata.clone(HoodieJavaRDD.getJavaRDD(writeMetadata.getWriteStatuses()));
if (shouldComplete &&
compactionMetadata.getCommitMetadata().isPresent()) {
completeTableService(TableServiceType.COMPACT,
compactionMetadata.getCommitMetadata().get(), table, compactionInstantTime,
Option.ofNullable(HoodieJavaRDD.of(compactionMetadata.getWriteStatuses(;
}
return compactionMetadata;
}
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] ksmou commented on a diff in pull request #9229: [HUDI-6565] Spark offline compaction add failed retry mechanism
ksmou commented on code in PR #9229:
URL: https://github.com/apache/hudi/pull/9229#discussion_r1272927559
##
hudi-utilities/src/main/java/org/apache/hudi/utilities/HoodieCompactor.java:
##
@@ -101,6 +104,12 @@ public static class Config implements Serializable {
public String runningMode = null;
@Parameter(names = {"--strategy", "-st"}, description = "Strategy Class",
required = false)
public String strategyClassName =
LogFileSizeBasedCompactionStrategy.class.getName();
+@Parameter(names = {"--job-max-processing-time-ms", "-mt"}, description =
"Take effect when using --mode/-m execute or scheduleAndExecute. "
++ "If maxProcessingTimeMs passed but compaction job is still
unfinished, hoodie would consider this job as failed and relaunch.")
+public long maxProcessingTimeMs = 0;
+@Parameter(names = {"--retry-last-failed-compaction-job", "-rc"},
description = "Take effect when using --mode/-m execute or scheduleAndExecute. "
Review Comment:
Yes. We just only choose a failed compaction instant here. It will been
rolled back in subsequent executions `SparkRDDTableServiceClient#compact(String
compactionInstantTime, boolean shouldComplete)`
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] weimingdiit commented on a diff in pull request #9252: [HUDI-6500] Fix bug when Using the RuntimeReplaceable function in the…
weimingdiit commented on code in PR #9252:
URL: https://github.com/apache/hudi/pull/9252#discussion_r1272924805
##
hudi-spark-datasource/hudi-spark/src/main/scala/org/apache/spark/sql/hudi/analysis/HoodieAnalysis.scala:
##
@@ -391,63 +392,65 @@ case class ResolveImplementationsEarly() extends
Rule[LogicalPlan] {
case class ResolveImplementations() extends Rule[LogicalPlan] {
override def apply(plan: LogicalPlan): LogicalPlan = {
-plan match {
- // Convert to MergeIntoHoodieTableCommand
- case mit@MatchMergeIntoTable(target@ResolvesToHudiTable(_), _, _) if
mit.resolved =>
-MergeIntoHoodieTableCommand(mit.asInstanceOf[MergeIntoTable])
-
- // Convert to UpdateHoodieTableCommand
- case ut@UpdateTable(plan@ResolvesToHudiTable(_), _, _) if ut.resolved =>
-UpdateHoodieTableCommand(ut)
-
- // Convert to DeleteHoodieTableCommand
- case dft@DeleteFromTable(plan@ResolvesToHudiTable(_), _) if dft.resolved
=>
-DeleteHoodieTableCommand(dft)
-
- // Convert to CompactionHoodieTableCommand
- case ct @ CompactionTable(plan @ ResolvesToHudiTable(table), operation,
options) if ct.resolved =>
-CompactionHoodieTableCommand(table, operation, options)
-
- // Convert to CompactionHoodiePathCommand
- case cp @ CompactionPath(path, operation, options) if cp.resolved =>
-CompactionHoodiePathCommand(path, operation, options)
-
- // Convert to CompactionShowOnTable
- case csot @ CompactionShowOnTable(plan @ ResolvesToHudiTable(table),
limit) if csot.resolved =>
-CompactionShowHoodieTableCommand(table, limit)
-
- // Convert to CompactionShowHoodiePathCommand
- case csop @ CompactionShowOnPath(path, limit) if csop.resolved =>
-CompactionShowHoodiePathCommand(path, limit)
-
- // Convert to HoodieCallProcedureCommand
- case c @ CallCommand(_, _) =>
-val procedure: Option[Procedure] = loadProcedure(c.name)
-val input = buildProcedureArgs(c.args)
-if (procedure.nonEmpty) {
- CallProcedureHoodieCommand(procedure.get, input)
-} else {
- c
-}
-
- // Convert to CreateIndexCommand
- case ci @ CreateIndex(plan @ ResolvesToHudiTable(table), indexName,
indexType, ignoreIfExists, columns, options, output) =>
-// TODO need to resolve columns
-CreateIndexCommand(table, indexName, indexType, ignoreIfExists,
columns, options, output)
-
- // Convert to DropIndexCommand
- case di @ DropIndex(plan @ ResolvesToHudiTable(table), indexName,
ignoreIfNotExists, output) if di.resolved =>
-DropIndexCommand(table, indexName, ignoreIfNotExists, output)
-
- // Convert to ShowIndexesCommand
- case si @ ShowIndexes(plan @ ResolvesToHudiTable(table), output) if
si.resolved =>
-ShowIndexesCommand(table, output)
-
- // Covert to RefreshCommand
- case ri @ RefreshIndex(plan @ ResolvesToHudiTable(table), indexName,
output) if ri.resolved =>
-RefreshIndexCommand(table, indexName, output)
-
- case _ => plan
+AnalysisHelper.allowInvokingTransformsInAnalyzer {
+ plan match {
+// Convert to MergeIntoHoodieTableCommand
Review Comment:
Calling sequence diagram:
ReplaceExpressions() ->
transformAllExpressionsWithPruning() ->
assertNotAnalysisRule()
In the assertNotAnalysisRule method, If do not call
AnalysisHelper.allowInvokingTransformsInAnalyzer(), Threadlocal
resolveOperatorDepth will be equal to 0, assertNotAnalysisRule will be throw
an exception in UT. So first call
AnalysisHelper.allowInvokingTransformsInAnalyzer(), and initialize
resolveOperatorDepth.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] danny0405 commented on a diff in pull request #9229: [HUDI-6565] Spark offline compaction add failed retry mechanism
danny0405 commented on code in PR #9229:
URL: https://github.com/apache/hudi/pull/9229#discussion_r1272922937
##
hudi-utilities/src/main/java/org/apache/hudi/utilities/HoodieCompactor.java:
##
@@ -101,6 +104,12 @@ public static class Config implements Serializable {
public String runningMode = null;
@Parameter(names = {"--strategy", "-st"}, description = "Strategy Class",
required = false)
public String strategyClassName =
LogFileSizeBasedCompactionStrategy.class.getName();
+@Parameter(names = {"--job-max-processing-time-ms", "-mt"}, description =
"Take effect when using --mode/-m execute or scheduleAndExecute. "
++ "If maxProcessingTimeMs passed but compaction job is still
unfinished, hoodie would consider this job as failed and relaunch.")
+public long maxProcessingTimeMs = 0;
+@Parameter(names = {"--retry-last-failed-compaction-job", "-rc"},
description = "Take effect when using --mode/-m execute or scheduleAndExecute. "
Review Comment:
So the failed compaction/clustering would finally got rolled back by the
subsequent executions?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] jlloh commented on issue #9256: [SUPPORT] How to do schema evolution for Flink Hudi table registered on Hive
jlloh commented on issue #9256: URL: https://github.com/apache/hudi/issues/9256#issuecomment-1648874648 Sure let me get back to you sometime later this week when I get some time to test your suggestions. Thanks for the quick support. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (HUDI-6582) Table create schema's name should be set accordingly
[
https://issues.apache.org/jira/browse/HUDI-6582?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Danny Chen updated HUDI-6582:
-
Fix Version/s: 0.14.0
> Table create schema's name should be set accordingly
>
>
> Key: HUDI-6582
> URL: https://issues.apache.org/jira/browse/HUDI-6582
> Project: Apache Hudi
> Issue Type: Bug
>Reporter: voon
>Assignee: voon
>Priority: Major
> Labels: pull-request-available
> Fix For: 0.14.0
>
>
> When recreating a hudi table with an existing hoodie.properties, the name of
> the hudi table will be changed to "topLevelRecord".
>
> This ticket is a followup for HUDI-6145 to ensure that the name/namespace of
> the table is standardised accordingly.
>
> {code:java}
> test("Test Create Hoodie Table with existing hoodie.properties") {
> withTempDir { tmp =>
> val tableName = generateTableName
> val tablePath = s"${tmp.getCanonicalPath}"
> spark.sql(
> s"""
> |create table $tableName (
> | id int,
> | name string,
> | price double,
> | ts long
> |) using hudi
> | location '$tablePath'
> | tblproperties (
> | primaryKey ='id',
> | type = 'cow',
> | preCombineField = 'ts'
> | )
> """.stripMargin)
> //
> hoodie.table.create.schema={"type":"record","name":"h0_record","namespace":"hoodie.h0","fields":[{"name":"id","type":["int","null"]},{"name":"name","type":["string","null"]},{"name":"price","type":["double","null"]},{"name":"ts","type":["long","null"]}]},
> but got
> {"type":"record","name":"topLevelRecord","fields":[{"name":"id","type":["int","null"]},{"name":"name","type":["string","null"]},{"name":"price","type":["double","null"]},{"name":"ts","type":["long","null"]}]}
> // drop the table without purging hdfs directory
> spark.sql(s"drop table $tableName".stripMargin)
> val tableSchemaAfterCreate1 = HoodieTableMetaClient.builder()
> .setConf(spark.sparkContext.hadoopConfiguration)
> .setBasePath(tablePath).build().getTableConfig.getTableCreateSchema
> // avro schema name and namespace should not change should not change
> spark.newSession().sql(
> s"""
> |create table $tableName (
> | id int,
> | name string,
> | price double,
> | ts long
> |) using hudi
> | location '$tablePath'
> | tblproperties (
> | primaryKey ='id',
> | type = 'cow',
> | preCombineField = 'ts'
> | )
> """.stripMargin)
> ///
> hoodie.table.create.schema={"type":"record","name":"topLevelRecord","fields":[{"name":"id","type":["int","null"]},{"name":"name","type":["string","null"]},{"name":"price","type":["double","null"]},{"name":"ts","type":["long","null"]}]}
> val tableSchemaAfterCreate2 = HoodieTableMetaClient.builder()
> .setConf(spark.sparkContext.hadoopConfiguration)
> .setBasePath(tablePath).build().getTableConfig.getTableCreateSchema
> assertResult(tableSchemaAfterCreate1.get)(tableSchemaAfterCreate2.get)
> } {code}
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[jira] [Closed] (HUDI-6582) Table create schema's name should be set accordingly
[
https://issues.apache.org/jira/browse/HUDI-6582?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Danny Chen closed HUDI-6582.
Resolution: Fixed
Fixed via master branch: f93028a90a53a1c31d44463c7eac4dc27daac599
> Table create schema's name should be set accordingly
>
>
> Key: HUDI-6582
> URL: https://issues.apache.org/jira/browse/HUDI-6582
> Project: Apache Hudi
> Issue Type: Bug
>Reporter: voon
>Assignee: voon
>Priority: Major
> Labels: pull-request-available
> Fix For: 0.14.0
>
>
> When recreating a hudi table with an existing hoodie.properties, the name of
> the hudi table will be changed to "topLevelRecord".
>
> This ticket is a followup for HUDI-6145 to ensure that the name/namespace of
> the table is standardised accordingly.
>
> {code:java}
> test("Test Create Hoodie Table with existing hoodie.properties") {
> withTempDir { tmp =>
> val tableName = generateTableName
> val tablePath = s"${tmp.getCanonicalPath}"
> spark.sql(
> s"""
> |create table $tableName (
> | id int,
> | name string,
> | price double,
> | ts long
> |) using hudi
> | location '$tablePath'
> | tblproperties (
> | primaryKey ='id',
> | type = 'cow',
> | preCombineField = 'ts'
> | )
> """.stripMargin)
> //
> hoodie.table.create.schema={"type":"record","name":"h0_record","namespace":"hoodie.h0","fields":[{"name":"id","type":["int","null"]},{"name":"name","type":["string","null"]},{"name":"price","type":["double","null"]},{"name":"ts","type":["long","null"]}]},
> but got
> {"type":"record","name":"topLevelRecord","fields":[{"name":"id","type":["int","null"]},{"name":"name","type":["string","null"]},{"name":"price","type":["double","null"]},{"name":"ts","type":["long","null"]}]}
> // drop the table without purging hdfs directory
> spark.sql(s"drop table $tableName".stripMargin)
> val tableSchemaAfterCreate1 = HoodieTableMetaClient.builder()
> .setConf(spark.sparkContext.hadoopConfiguration)
> .setBasePath(tablePath).build().getTableConfig.getTableCreateSchema
> // avro schema name and namespace should not change should not change
> spark.newSession().sql(
> s"""
> |create table $tableName (
> | id int,
> | name string,
> | price double,
> | ts long
> |) using hudi
> | location '$tablePath'
> | tblproperties (
> | primaryKey ='id',
> | type = 'cow',
> | preCombineField = 'ts'
> | )
> """.stripMargin)
> ///
> hoodie.table.create.schema={"type":"record","name":"topLevelRecord","fields":[{"name":"id","type":["int","null"]},{"name":"name","type":["string","null"]},{"name":"price","type":["double","null"]},{"name":"ts","type":["long","null"]}]}
> val tableSchemaAfterCreate2 = HoodieTableMetaClient.builder()
> .setConf(spark.sparkContext.hadoopConfiguration)
> .setBasePath(tablePath).build().getTableConfig.getTableCreateSchema
> assertResult(tableSchemaAfterCreate1.get)(tableSchemaAfterCreate2.get)
> } {code}
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[hudi] branch master updated (a32edd47c95 -> f93028a90a5)
This is an automated email from the ASF dual-hosted git repository. danny0405 pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/hudi.git from a32edd47c95 [MINOR] Optimize error display information (#9270) add f93028a90a5 [HUDI-6582] Fix the table schema for table recreation (#9272) No new revisions were added by this update. Summary of changes: .../sql/catalyst/catalog/HoodieCatalogTable.scala | 4 +- .../apache/spark/sql/hudi/TestCreateTable.scala| 52 ++ 2 files changed, 55 insertions(+), 1 deletion(-)
[GitHub] [hudi] danny0405 merged pull request #9272: [HUDI-6582] Ensure that default recordName/namespace is not used when…
danny0405 merged PR #9272: URL: https://github.com/apache/hudi/pull/9272 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #9277: [HUDI-6558] support SQL update for no-precombine field tables
hudi-bot commented on PR #9277: URL: https://github.com/apache/hudi/pull/9277#issuecomment-1648848964 ## CI report: * 4d363f192f951fb54799602270fb0ca16ce19d39 Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=18812) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] ksmou commented on a diff in pull request #9229: [HUDI-6565] Spark offline compaction add failed retry mechanism
ksmou commented on code in PR #9229:
URL: https://github.com/apache/hudi/pull/9229#discussion_r1272908002
##
hudi-utilities/src/main/java/org/apache/hudi/utilities/HoodieCompactor.java:
##
@@ -101,6 +104,12 @@ public static class Config implements Serializable {
public String runningMode = null;
@Parameter(names = {"--strategy", "-st"}, description = "Strategy Class",
required = false)
public String strategyClassName =
LogFileSizeBasedCompactionStrategy.class.getName();
+@Parameter(names = {"--job-max-processing-time-ms", "-mt"}, description =
"Take effect when using --mode/-m execute or scheduleAndExecute. "
++ "If maxProcessingTimeMs passed but compaction job is still
unfinished, hoodie would consider this job as failed and relaunch.")
+public long maxProcessingTimeMs = 0;
+@Parameter(names = {"--retry-last-failed-compaction-job", "-rc"},
description = "Take effect when using --mode/-m execute or scheduleAndExecute. "
Review Comment:
We choose a pending compaction instant which exceeds the compaction job
scheduling interval, this instant will be rollback in next call
`client.compact(cfg.compactionInstantTime)` internally. So I think there is no
need to rollback the previous pending compaction here.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[hudi] branch master updated (f5daa6d789d -> a32edd47c95)
This is an automated email from the ASF dual-hosted git repository. danny0405 pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/hudi.git from f5daa6d789d [MINOR] Fix CleanPlanActionExecutor logger print class (#9268) add a32edd47c95 [MINOR] Optimize error display information (#9270) No new revisions were added by this update. Summary of changes: .../src/main/scala/org/apache/hudi/DefaultSource.scala | 2 +- 1 file changed, 1 insertion(+), 1 deletion(-)
[GitHub] [hudi] danny0405 merged pull request #9270: [MINOR] Optimize error display information
danny0405 merged PR #9270: URL: https://github.com/apache/hudi/pull/9270 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[hudi] branch master updated: [MINOR] Fix CleanPlanActionExecutor logger print class (#9268)
This is an automated email from the ASF dual-hosted git repository.
danny0405 pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/hudi.git
The following commit(s) were added to refs/heads/master by this push:
new f5daa6d789d [MINOR] Fix CleanPlanActionExecutor logger print class
(#9268)
f5daa6d789d is described below
commit f5daa6d789dce6690a37b050fa0f57d385ccb78b
Author: cooper <1322849...@qq.com>
AuthorDate: Tue Jul 25 09:37:22 2023 +0800
[MINOR] Fix CleanPlanActionExecutor logger print class (#9268)
---
.../org/apache/hudi/table/action/clean/CleanPlanActionExecutor.java | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git
a/hudi-client/hudi-client-common/src/main/java/org/apache/hudi/table/action/clean/CleanPlanActionExecutor.java
b/hudi-client/hudi-client-common/src/main/java/org/apache/hudi/table/action/clean/CleanPlanActionExecutor.java
index 57b583f54b7..3b5d1233214 100644
---
a/hudi-client/hudi-client-common/src/main/java/org/apache/hudi/table/action/clean/CleanPlanActionExecutor.java
+++
b/hudi-client/hudi-client-common/src/main/java/org/apache/hudi/table/action/clean/CleanPlanActionExecutor.java
@@ -50,7 +50,7 @@ import static org.apache.hudi.common.util.MapUtils.nonEmpty;
public class CleanPlanActionExecutor extends BaseActionExecutor> {
- private static final Logger LOG =
LoggerFactory.getLogger(CleanPlanner.class);
+ private static final Logger LOG =
LoggerFactory.getLogger(CleanPlanActionExecutor.class);
private final Option> extraMetadata;
[GitHub] [hudi] danny0405 merged pull request #9268: [MINOR]fix the log print class
danny0405 merged PR #9268: URL: https://github.com/apache/hudi/pull/9268 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #9277: [HUDI-6558] support SQL update for no-precombine field tables
hudi-bot commented on PR #9277: URL: https://github.com/apache/hudi/pull/9277#issuecomment-1648742175 ## CI report: * 4d363f192f951fb54799602270fb0ca16ce19d39 Azure: [PENDING](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=18812) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Created] (HUDI-6586) Add Incremental scan support to dbt
Vinoth Govindarajan created HUDI-6586: - Summary: Add Incremental scan support to dbt Key: HUDI-6586 URL: https://issues.apache.org/jira/browse/HUDI-6586 Project: Apache Hudi Issue Type: Epic Components: connectors Reporter: Vinoth Govindarajan Assignee: Vinoth Govindarajan Fix For: 1.0.0 The current dbt support adds only the basic hudi primitives, but with deeper integration we could enable faster ETL queries using the incremental read primitive similar to the deltastreamer support. The goal of this epic is to enable incremental data processing for dbt. -- This message was sent by Atlassian Jira (v8.20.10#820010)
[GitHub] [hudi] hudi-bot commented on pull request #9277: [HUDI-6558] support SQL update for no-precombine field tables
hudi-bot commented on PR #9277: URL: https://github.com/apache/hudi/pull/9277#issuecomment-1648736039 ## CI report: * 4d363f192f951fb54799602270fb0ca16ce19d39 UNKNOWN Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (HUDI-6558) Support SQL Update for CoW when no precombine field is defined
[ https://issues.apache.org/jira/browse/HUDI-6558?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] kazdy updated HUDI-6558: Description: Support SQL updates without precombine field (for COW only) is already supported in MERGE INTO (was: Updates without precombine field (for COW only) is already supported in MERGE INTO) > Support SQL Update for CoW when no precombine field is defined > -- > > Key: HUDI-6558 > URL: https://issues.apache.org/jira/browse/HUDI-6558 > Project: Apache Hudi > Issue Type: Improvement >Reporter: kazdy >Assignee: kazdy >Priority: Major > Labels: pull-request-available > > Support SQL updates without precombine field (for COW only) is already > supported in MERGE INTO -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Updated] (HUDI-6558) Support SQL Update for CoW when no precombine field is defined
[ https://issues.apache.org/jira/browse/HUDI-6558?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] kazdy updated HUDI-6558: Description: Support SQL updates without precombine field (for COW only), is already supported in MERGE INTO (was: Support SQL updates without precombine field (for COW only) is already supported in MERGE INTO) > Support SQL Update for CoW when no precombine field is defined > -- > > Key: HUDI-6558 > URL: https://issues.apache.org/jira/browse/HUDI-6558 > Project: Apache Hudi > Issue Type: Improvement >Reporter: kazdy >Assignee: kazdy >Priority: Major > Labels: pull-request-available > > Support SQL updates without precombine field (for COW only), is already > supported in MERGE INTO -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Assigned] (HUDI-6558) Support SQL Update for CoW when no precombine field is defined
[ https://issues.apache.org/jira/browse/HUDI-6558?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] kazdy reassigned HUDI-6558: --- Assignee: kazdy > Support SQL Update for CoW when no precombine field is defined > -- > > Key: HUDI-6558 > URL: https://issues.apache.org/jira/browse/HUDI-6558 > Project: Apache Hudi > Issue Type: Improvement >Reporter: kazdy >Assignee: kazdy >Priority: Major > Labels: pull-request-available > > Updates without precombine field (for COW only) is already supported in MERGE > INTO -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Updated] (HUDI-6558) Support SQL Update for CoW when no precombine field is defined
[ https://issues.apache.org/jira/browse/HUDI-6558?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] kazdy updated HUDI-6558: Status: In Progress (was: Open) > Support SQL Update for CoW when no precombine field is defined > -- > > Key: HUDI-6558 > URL: https://issues.apache.org/jira/browse/HUDI-6558 > Project: Apache Hudi > Issue Type: Improvement >Reporter: kazdy >Priority: Major > Labels: pull-request-available > > Updates without precombine field (for COW only) is already supported in MERGE > INTO -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Updated] (HUDI-6558) Support SQL Update for CoW when no precombine field is defined
[ https://issues.apache.org/jira/browse/HUDI-6558?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] kazdy updated HUDI-6558: Status: Patch Available (was: In Progress) > Support SQL Update for CoW when no precombine field is defined > -- > > Key: HUDI-6558 > URL: https://issues.apache.org/jira/browse/HUDI-6558 > Project: Apache Hudi > Issue Type: Improvement >Reporter: kazdy >Priority: Major > Labels: pull-request-available > > Updates without precombine field (for COW only) is already supported in MERGE > INTO -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Updated] (HUDI-6558) Support SQL Update for CoW when no precombine field is defined
[ https://issues.apache.org/jira/browse/HUDI-6558?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] ASF GitHub Bot updated HUDI-6558: - Labels: pull-request-available (was: ) > Support SQL Update for CoW when no precombine field is defined > -- > > Key: HUDI-6558 > URL: https://issues.apache.org/jira/browse/HUDI-6558 > Project: Apache Hudi > Issue Type: Improvement >Reporter: kazdy >Priority: Major > Labels: pull-request-available > > Updates without precombine field (for COW only) is already supported in MERGE > INTO -- This message was sent by Atlassian Jira (v8.20.10#820010)
[GitHub] [hudi] kazdy opened a new pull request, #9277: [HUDI-6558] support SQL update for no-precombine field tables
kazdy opened a new pull request, #9277: URL: https://github.com/apache/hudi/pull/9277 ### Change Logs Support SQL update for no-precombine field tables, improves user experience and makes it easier to start with Hudi, this is now (current master, 0.14) supported in MERGE INTO and upsert can also skip to "combine" records, if user does not want to define pcf field, lets allow them to do sql updates out of the box, we do not expect duplicates here anyways. ### Impact Changes behaviour of SQL Update command in spark, now users can update records in tables where no precombine field is specified. For MOR tables with no precombine fields throws an error since MOR requires precombine field. ### Risk level (write none, low medium or high below) Low ### Documentation Update Need to update Spark quickstart, to note non-pcf sql updates are supported for CoW. ### Contributor's checklist - [ ] Read through [contributor's guide](https://hudi.apache.org/contribute/how-to-contribute) - [ ] Change Logs and Impact were stated clearly - [ ] Adequate tests were added if applicable - [ ] CI passed -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #9262: [HUDI-6438] Config parameter 'MAKE_NEW_COLUMNS_NULLABLE' to allow for marking a newly created column as nullable.
hudi-bot commented on PR #9262: URL: https://github.com/apache/hudi/pull/9262#issuecomment-1648677021 ## CI report: * 3558e69a749c890f7ddfe2d8e7719d17bea10a74 Azure: [SUCCESS](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=18811) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #9136: [HUDI-6509] Add GitHub CI for Java 17
hudi-bot commented on PR #9136: URL: https://github.com/apache/hudi/pull/9136#issuecomment-1648676701 ## CI report: * a0e7207fb19738237d56fa0060c91cb7865ae9c0 UNKNOWN * cda1e7724e6267ec471d8c318cd22703a2ecb69f UNKNOWN * 6b33d37bc57d2b5be3649590fee6767f34cccea3 Azure: [SUCCESS](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=18810) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] Armelabdelkbir commented on issue #9213: [SUPPORT] org.apache.hudi.exception.HoodieRollbackException: Failed to rollback
Armelabdelkbir commented on issue #9213: URL: https://github.com/apache/hudi/issues/9213#issuecomment-1648661942 @ad1happy2go i added some configuration to handle multiple writers, i have multiple micro batchs with spark structured streaming, and I have this issue only when my job crashes or restarts "hoodie.write.concurrency.mode"->"optimistic_concurrency_control", "hoodie.cleaner.policy.failed.writes" -> "LAZY", HoodieLockConfig.LOCK_PROVIDER_CLASS_NAME.key -> "org.apache.hudi.hive.HiveMetastoreBasedLockProvider", HoodieLockConfig.HIVE_TABLE_NAME.key -> (table.db_name + "." + table.table_name), HoodieLockConfig.HIVE_DATABASE_NAME.key -> table.db_name i also fixed kafka.group.id and reduce kafka.session.timeout.ms" to 1 I deploy my new release and wait if it reproduces -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #9136: [HUDI-6509] Add GitHub CI for Java 17
hudi-bot commented on PR #9136: URL: https://github.com/apache/hudi/pull/9136#issuecomment-1648519963 ## CI report: * a0e7207fb19738237d56fa0060c91cb7865ae9c0 UNKNOWN * cda1e7724e6267ec471d8c318cd22703a2ecb69f UNKNOWN * 91c5a055a0cc71d99aa6a3af513011667118f7b1 Azure: [CANCELED](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=18809) * 6b33d37bc57d2b5be3649590fee6767f34cccea3 Azure: [PENDING](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=18810) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #9275: [HUDI-6584] Abstract commit in CommitActionExecutor
hudi-bot commented on PR #9275: URL: https://github.com/apache/hudi/pull/9275#issuecomment-1648468317 ## CI report: * 5ff8958366e3b682552dc1a21f04bcf24333c84b Azure: [SUCCESS](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=18807) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #9262: [HUDI-6438] Config parameter 'MAKE_NEW_COLUMNS_NULLABLE' to allow for marking a newly created column as nullable.
hudi-bot commented on PR #9262: URL: https://github.com/apache/hudi/pull/9262#issuecomment-1648468178 ## CI report: * f66f9d88f825a896b5da3f081bd584dd1d0d9b96 Azure: [SUCCESS](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=18779) * 3558e69a749c890f7ddfe2d8e7719d17bea10a74 Azure: [PENDING](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=18811) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #9136: [HUDI-6509] Add GitHub CI for Java 17
hudi-bot commented on PR #9136: URL: https://github.com/apache/hudi/pull/9136#issuecomment-1648467682 ## CI report: * a0e7207fb19738237d56fa0060c91cb7865ae9c0 UNKNOWN * cda1e7724e6267ec471d8c318cd22703a2ecb69f UNKNOWN * 9bc507287e35e2c2005bcd6c72f50f73a8ae96cd Azure: [SUCCESS](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=18796) * 91c5a055a0cc71d99aa6a3af513011667118f7b1 Azure: [PENDING](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=18809) * 6b33d37bc57d2b5be3649590fee6767f34cccea3 UNKNOWN Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #9262: [HUDI-6438] Config parameter 'MAKE_NEW_COLUMNS_NULLABLE' to allow for marking a newly created column as nullable.
hudi-bot commented on PR #9262: URL: https://github.com/apache/hudi/pull/9262#issuecomment-1648457513 ## CI report: * f66f9d88f825a896b5da3f081bd584dd1d0d9b96 Azure: [SUCCESS](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=18779) * 3558e69a749c890f7ddfe2d8e7719d17bea10a74 UNKNOWN Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #9136: [HUDI-6509] Add GitHub CI for Java 17
hudi-bot commented on PR #9136: URL: https://github.com/apache/hudi/pull/9136#issuecomment-1648456986 ## CI report: * a0e7207fb19738237d56fa0060c91cb7865ae9c0 UNKNOWN * cda1e7724e6267ec471d8c318cd22703a2ecb69f UNKNOWN * 9bc507287e35e2c2005bcd6c72f50f73a8ae96cd Azure: [SUCCESS](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=18796) * 91c5a055a0cc71d99aa6a3af513011667118f7b1 Azure: [PENDING](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=18809) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] CTTY commented on a diff in pull request #9136: [HUDI-6509] Add GitHub CI for Java 17
CTTY commented on code in PR #9136:
URL: https://github.com/apache/hudi/pull/9136#discussion_r1272640363
##
hudi-common/pom.xml:
##
@@ -248,6 +248,13 @@
+
+ org.apache.spark
+
spark-streaming-kafka-0-10_${scala.binary.version}
+ test
+ ${spark.version}
+
Review Comment:
Removing this would cause test failures under Java 17 environment:
```
Caused by: java.lang.ClassNotFoundException:
org.apache.hadoop.shaded.com.ctc.wstx.io.InputBootstrapper
at
java.base/jdk.internal.loader.BuiltinClassLoader.loadClass(BuiltinClassLoader.java:641)
at
java.base/jdk.internal.loader.ClassLoaders$AppClassLoader.loadClass(ClassLoaders.java:188)
at java.base/java.lang.ClassLoader.loadClass(ClassLoader.java:520)
... 59 more
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #9274: [MINOR] fix millis append format error
hudi-bot commented on PR #9274: URL: https://github.com/apache/hudi/pull/9274#issuecomment-1648447286 ## CI report: * 94d9dbcb05d1505d4a1d5e82dca8a8ba946f47da Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=18806) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #9136: [HUDI-6509] Add GitHub CI for Java 17
hudi-bot commented on PR #9136: URL: https://github.com/apache/hudi/pull/9136#issuecomment-1648446789 ## CI report: * a0e7207fb19738237d56fa0060c91cb7865ae9c0 UNKNOWN * cda1e7724e6267ec471d8c318cd22703a2ecb69f UNKNOWN * 9bc507287e35e2c2005bcd6c72f50f73a8ae96cd Azure: [SUCCESS](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=18796) * 91c5a055a0cc71d99aa6a3af513011667118f7b1 UNKNOWN Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] amrishlal commented on a diff in pull request #9262: [HUDI-6438] Config parameter 'MAKE_NEW_COLUMNS_NULLABLE' to allow for marking a newly created column as nullable.
amrishlal commented on code in PR #9262:
URL: https://github.com/apache/hudi/pull/9262#discussion_r1272632308
##
hudi-spark-datasource/hudi-spark/src/test/scala/org/apache/hudi/functional/TestCOWDataSource.scala:
##
@@ -1538,7 +1539,52 @@ class TestCOWDataSource extends
HoodieSparkClientTestBase with ScalaAssertionSup
assertEquals(2, result.count())
assertEquals(0, result.filter(result("id") === 1).count())
}
+
+ /** Test case to verify MAKE_NEW_COLUMNS_NULLABLE config parameter. */
+ @Test
+ def testSchemaEvolutionWithNewColumn(): Unit = {
+val df1 = spark.sql("select '1' as event_id, '2' as ts, '3' as version,
'foo' as event_date")
+var hudiOptions = Map[String, String](
+ HoodieWriteConfig.TBL_NAME.key() -> "test_hudi_merger",
+ KeyGeneratorOptions.RECORDKEY_FIELD_NAME.key() -> "event_id",
+ KeyGeneratorOptions.PARTITIONPATH_FIELD_NAME.key() ->
"version,event_date",
Review Comment:
Fixed.
##
hudi-spark-datasource/hudi-spark/src/test/scala/org/apache/hudi/functional/TestCOWDataSource.scala:
##
@@ -1538,7 +1539,52 @@ class TestCOWDataSource extends
HoodieSparkClientTestBase with ScalaAssertionSup
assertEquals(2, result.count())
assertEquals(0, result.filter(result("id") === 1).count())
}
+
+ /** Test case to verify MAKE_NEW_COLUMNS_NULLABLE config parameter. */
+ @Test
+ def testSchemaEvolutionWithNewColumn(): Unit = {
+val df1 = spark.sql("select '1' as event_id, '2' as ts, '3' as version,
'foo' as event_date")
+var hudiOptions = Map[String, String](
+ HoodieWriteConfig.TBL_NAME.key() -> "test_hudi_merger",
+ KeyGeneratorOptions.RECORDKEY_FIELD_NAME.key() -> "event_id",
+ KeyGeneratorOptions.PARTITIONPATH_FIELD_NAME.key() ->
"version,event_date",
+ DataSourceWriteOptions.OPERATION.key() -> "insert",
+ HoodieWriteConfig.PRECOMBINE_FIELD_NAME.key() -> "ts",
+ HoodieWriteConfig.KEYGENERATOR_CLASS_NAME.key() ->
"org.apache.hudi.keygen.ComplexKeyGenerator",
+ KeyGeneratorOptions.HIVE_STYLE_PARTITIONING_ENABLE.key() -> "true",
+ HiveSyncConfigHolder.HIVE_SYNC_ENABLED.key() -> "false",
+ HoodieWriteConfig.RECORD_MERGER_IMPLS.key() ->
"org.apache.hudi.HoodieSparkRecordMerger"
+)
+
df1.write.format("org.apache.hudi").options(hudiOptions).mode(SaveMode.Append).save(basePath)
+
+// Try adding a string column. This operation is expected to throw 'schema
not compatible' exception since
+// 'MAKE_NEW_COLUMNS_NULLABLE' parameter is 'false' by default.
+val df2 = spark.sql("select '2' as event_id, '2' as ts, '3' as version,
'foo' as event_date, 'bar' as add_col")
+try {
+
(df2.write.format("org.apache.hudi").options(hudiOptions).mode("append").save(basePath))
Review Comment:
Fixed.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] ennox108 commented on issue #9070: [SUPPORT] Hudi Sink Connector shows broker disconnected
ennox108 commented on issue #9070: URL: https://github.com/apache/hudi/issues/9070#issuecomment-1648382447 @ad1happy2go the connector was able to create a folder. However, its still not writing any data to the folder. I am seeing the below error message  -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #9276: Mor perf spark33
hudi-bot commented on PR #9276: URL: https://github.com/apache/hudi/pull/9276#issuecomment-1648371876 ## CI report: * 37d3b9365a38e8f266c1c486e9d18c9ef34be2a0 Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=18808) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] nsivabalan commented on a diff in pull request #9262: [HUDI-6438] Config parameter 'MAKE_NEW_COLUMNS_NULLABLE' to allow for marking a newly created column as nullable.
nsivabalan commented on code in PR #9262:
URL: https://github.com/apache/hudi/pull/9262#discussion_r1272587654
##
hudi-spark-datasource/hudi-spark/src/test/scala/org/apache/hudi/functional/TestCOWDataSource.scala:
##
@@ -1538,7 +1539,52 @@ class TestCOWDataSource extends
HoodieSparkClientTestBase with ScalaAssertionSup
assertEquals(2, result.count())
assertEquals(0, result.filter(result("id") === 1).count())
}
+
+ /** Test case to verify MAKE_NEW_COLUMNS_NULLABLE config parameter. */
+ @Test
+ def testSchemaEvolutionWithNewColumn(): Unit = {
+val df1 = spark.sql("select '1' as event_id, '2' as ts, '3' as version,
'foo' as event_date")
+var hudiOptions = Map[String, String](
+ HoodieWriteConfig.TBL_NAME.key() -> "test_hudi_merger",
+ KeyGeneratorOptions.RECORDKEY_FIELD_NAME.key() -> "event_id",
+ KeyGeneratorOptions.PARTITIONPATH_FIELD_NAME.key() ->
"version,event_date",
+ DataSourceWriteOptions.OPERATION.key() -> "insert",
+ HoodieWriteConfig.PRECOMBINE_FIELD_NAME.key() -> "ts",
+ HoodieWriteConfig.KEYGENERATOR_CLASS_NAME.key() ->
"org.apache.hudi.keygen.ComplexKeyGenerator",
+ KeyGeneratorOptions.HIVE_STYLE_PARTITIONING_ENABLE.key() -> "true",
+ HiveSyncConfigHolder.HIVE_SYNC_ENABLED.key() -> "false",
+ HoodieWriteConfig.RECORD_MERGER_IMPLS.key() ->
"org.apache.hudi.HoodieSparkRecordMerger"
+)
+
df1.write.format("org.apache.hudi").options(hudiOptions).mode(SaveMode.Append).save(basePath)
+
+// Try adding a string column. This operation is expected to throw 'schema
not compatible' exception since
+// 'MAKE_NEW_COLUMNS_NULLABLE' parameter is 'false' by default.
+val df2 = spark.sql("select '2' as event_id, '2' as ts, '3' as version,
'foo' as event_date, 'bar' as add_col")
+try {
+
(df2.write.format("org.apache.hudi").options(hudiOptions).mode("append").save(basePath))
Review Comment:
minor
```
.format("hudi")
```
##
hudi-spark-datasource/hudi-spark/src/test/scala/org/apache/hudi/functional/TestCOWDataSource.scala:
##
@@ -1538,7 +1539,52 @@ class TestCOWDataSource extends
HoodieSparkClientTestBase with ScalaAssertionSup
assertEquals(2, result.count())
assertEquals(0, result.filter(result("id") === 1).count())
}
+
+ /** Test case to verify MAKE_NEW_COLUMNS_NULLABLE config parameter. */
+ @Test
+ def testSchemaEvolutionWithNewColumn(): Unit = {
+val df1 = spark.sql("select '1' as event_id, '2' as ts, '3' as version,
'foo' as event_date")
+var hudiOptions = Map[String, String](
+ HoodieWriteConfig.TBL_NAME.key() -> "test_hudi_merger",
+ KeyGeneratorOptions.RECORDKEY_FIELD_NAME.key() -> "event_id",
+ KeyGeneratorOptions.PARTITIONPATH_FIELD_NAME.key() ->
"version,event_date",
Review Comment:
partition path can be a simple field. "version" should suffice.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #9276: Mor perf spark33
hudi-bot commented on PR #9276: URL: https://github.com/apache/hudi/pull/9276#issuecomment-1648361875 ## CI report: * 37d3b9365a38e8f266c1c486e9d18c9ef34be2a0 UNKNOWN Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (HUDI-6438) Fix issue while inserting non-nullable array columns to nullable columns
[ https://issues.apache.org/jira/browse/HUDI-6438?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17746559#comment-17746559 ] Amrish Lal commented on HUDI-6438: -- This issue has been fixed. > Fix issue while inserting non-nullable array columns to nullable columns > > > Key: HUDI-6438 > URL: https://issues.apache.org/jira/browse/HUDI-6438 > Project: Apache Hudi > Issue Type: Bug > Components: writer-core >Reporter: Aditya Goenka >Priority: Critical > Labels: pull-request-available > Fix For: 0.14.0 > > > Github issue - [https://github.com/apache/hudi/issues/9042] -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Commented] (HUDI-6346) Allow duplicates by default for insert operation type
[ https://issues.apache.org/jira/browse/HUDI-6346?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17746556#comment-17746556 ] Amrish Lal commented on HUDI-6346: -- [~adityagoenka] I am wondering if you have a set of steps (or a link to github issue, etc) that can be used to reproduce this issue? > Allow duplicates by default for insert operation type > - > > Key: HUDI-6346 > URL: https://issues.apache.org/jira/browse/HUDI-6346 > Project: Apache Hudi > Issue Type: Improvement > Components: writer-core >Reporter: Aditya Goenka >Priority: Blocker > Labels: 0.14.0 > > Insert operation type by default results in some data inconsistency, as it > doesn't allow all duplicates and some of them are deduplicated when doing the > small file merging. -- This message was sent by Atlassian Jira (v8.20.10#820010)
[GitHub] [hudi] nsivabalan commented on a diff in pull request #9273: [HUDI-6320] Fix partition parsing in Spark file index for custom keygen
nsivabalan commented on code in PR #9273:
URL: https://github.com/apache/hudi/pull/9273#discussion_r1272554388
##
hudi-spark-datasource/hudi-spark-common/src/main/scala/org/apache/hudi/SparkHoodieTableFileIndex.scala:
##
@@ -115,14 +112,16 @@ class SparkHoodieTableFileIndex(spark: SparkSession,
// Note that key generator class name could be null
val keyGeneratorClassName = tableConfig.getKeyGeneratorClassName
if
(classOf[TimestampBasedKeyGenerator].getName.equalsIgnoreCase(keyGeneratorClassName)
-||
classOf[TimestampBasedAvroKeyGenerator].getName.equalsIgnoreCase(keyGeneratorClassName))
{
+||
classOf[TimestampBasedAvroKeyGenerator].getName.equalsIgnoreCase(keyGeneratorClassName)
+||
classOf[CustomKeyGenerator].getName.equalsIgnoreCase(keyGeneratorClassName)
+||
classOf[CustomAvroKeyGenerator].getName.equalsIgnoreCase(keyGeneratorClassName))
{
Review Comment:
we might need to consider one more thing here.
looks like for timestamp based partition field, we are harding the data type
to string.
so, within custom key gen, there could be more than 1 field. and so we need
to intercept the type of each field and only hard code the data type to string
if its of timestamp type.
##
hudi-spark-datasource/hudi-spark-common/src/main/scala/org/apache/hudi/HoodieFileIndex.scala:
##
@@ -342,6 +342,20 @@ object HoodieFileIndex extends Logging {
if (listingModeOverride != null) {
properties.setProperty(DataSourceReadOptions.FILE_INDEX_LISTING_MODE_OVERRIDE.key,
listingModeOverride)
}
+val tableConfig = metaClient.getTableConfig
+val partitionColumns = tableConfig.getPartitionFields
+if (partitionColumns.isPresent) {
+ val keyGeneratorClassName = tableConfig.getKeyGeneratorClassName
+ // NOTE: A custom key generator with multiple fields could have
non-encoded slashes in the partition columns'
+ // value. We might not be able to properly parse partition-values
from the listed partition-paths. Fallback
+ // to eager listing in this case.
+ val isCustomKeyGenerator =
(classOf[CustomKeyGenerator].getName.equalsIgnoreCase(keyGeneratorClassName)
+||
classOf[CustomAvroKeyGenerator].getName.equalsIgnoreCase(keyGeneratorClassName))
+ val hasMultiplePartitionFields = partitionColumns.get().length > 1
+ if (hasMultiplePartitionFields && isCustomKeyGenerator) {
+
properties.setProperty(DataSourceReadOptions.FILE_INDEX_LISTING_MODE_OVERRIDE.key,
DataSourceReadOptions.FILE_INDEX_LISTING_MODE_EAGER)
+ }
+}
Review Comment:
should we also consider complexKeyGen w/ multiple fields.
so all that matters here is, if there are more than 1 partitionColumns. we
don't really need to check for key gen class.
##
hudi-spark-datasource/hudi-spark-common/src/main/scala/org/apache/hudi/SparkHoodieTableFileIndex.scala:
##
@@ -115,14 +112,16 @@ class SparkHoodieTableFileIndex(spark: SparkSession,
// Note that key generator class name could be null
val keyGeneratorClassName = tableConfig.getKeyGeneratorClassName
if
(classOf[TimestampBasedKeyGenerator].getName.equalsIgnoreCase(keyGeneratorClassName)
-||
classOf[TimestampBasedAvroKeyGenerator].getName.equalsIgnoreCase(keyGeneratorClassName))
{
+||
classOf[TimestampBasedAvroKeyGenerator].getName.equalsIgnoreCase(keyGeneratorClassName)
+||
classOf[CustomKeyGenerator].getName.equalsIgnoreCase(keyGeneratorClassName)
+||
classOf[CustomAvroKeyGenerator].getName.equalsIgnoreCase(keyGeneratorClassName))
{
Review Comment:
we can take it as a follow up as well.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] SamarthRaval commented on issue #8925: Upsert taking too long to finish
SamarthRaval commented on issue #8925: URL: https://github.com/apache/hudi/issues/8925#issuecomment-1648317412 Hello guys, I got the chance to experiment with latest hudi 0.13.1 and enabled all metadata related config to enhance the performance. "hoodie.metadata.enable" "hoodie.meta.sync.metadata_file_listing" but still seeing the slow down, and spark server goes to idle state for more then an hour.  You can see the idle time in between stages which is weird and causing performance bottleneck. @ad1happy2go @yihua @parisni -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] jonvex opened a new pull request, #9276: Mor perf spark33
jonvex opened a new pull request, #9276: URL: https://github.com/apache/hudi/pull/9276 ### Change Logs _Describe context and summary for this change. Highlight if any code was copied._ ### Impact _Describe any public API or user-facing feature change or any performance impact._ ### Risk level (write none, low medium or high below) _If medium or high, explain what verification was done to mitigate the risks._ ### Documentation Update _Describe any necessary documentation update if there is any new feature, config, or user-facing change_ - _The config description must be updated if new configs are added or the default value of the configs are changed_ - _Any new feature or user-facing change requires updating the Hudi website. Please create a Jira ticket, attach the ticket number here and follow the [instruction](https://hudi.apache.org/contribute/developer-setup#website) to make changes to the website._ ### Contributor's checklist - [ ] Read through [contributor's guide](https://hudi.apache.org/contribute/how-to-contribute) - [ ] Change Logs and Impact were stated clearly - [ ] Adequate tests were added if applicable - [ ] CI passed -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #9273: [HUDI-6320] Fix partition parsing in Spark file index for custom keygen
hudi-bot commented on PR #9273: URL: https://github.com/apache/hudi/pull/9273#issuecomment-1648265809 ## CI report: * ccdc272f4c7c61263f15174d9b468301800b25c9 UNKNOWN * 7cd21f8fb35c94bd600cbcc75638ffdafe632625 Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=18805) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #9209: [HUDI-6539] New LSM tree style archived timeline
hudi-bot commented on PR #9209: URL: https://github.com/apache/hudi/pull/9209#issuecomment-1648265426 ## CI report: * 62001bbc6c5d9306f95d4bca3dd2bada3ca5c898 Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=18804) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Created] (HUDI-6585) Certify DedupeSparkJob for both table types
Sagar Sumit created HUDI-6585: - Summary: Certify DedupeSparkJob for both table types Key: HUDI-6585 URL: https://issues.apache.org/jira/browse/HUDI-6585 Project: Apache Hudi Issue Type: Task Reporter: Sagar Sumit Fix For: 1.0.0 Hudi has a utility `DedupeSparkJob` which can deduplicate data present in a partition. Need to check if it can dedupe across table for both table types. -- This message was sent by Atlassian Jira (v8.20.10#820010)
[GitHub] [hudi] yihua commented on a diff in pull request #9273: [HUDI-6320] Fix partition parsing in Spark file index for custom keygen
yihua commented on code in PR #9273:
URL: https://github.com/apache/hudi/pull/9273#discussion_r1272478660
##
hudi-spark-datasource/hudi-spark/src/test/scala/org/apache/hudi/functional/TestCOWDataSource.scala:
##
@@ -941,6 +942,70 @@ class TestCOWDataSource extends HoodieSparkClientTestBase
with ScalaAssertionSup
}
}
+ @ParameterizedTest
+ @EnumSource(value = classOf[HoodieRecordType], names = Array("AVRO",
"SPARK"))
+ def testSparkPartitionByWithCustomKeyGenerator(recordType:
HoodieRecordType): Unit = {
+val (writeOpts, readOpts) =
getWriterReaderOptsLessPartitionPath(recordType)
+// Specify fieldType as TIMESTAMP of type EPOCHMILLISECONDS and output
date format as /MM/dd
+var writer = getDataFrameWriter(classOf[CustomKeyGenerator].getName,
writeOpts)
+writer.partitionBy("current_ts:TIMESTAMP")
+ .option(TIMESTAMP_TYPE_FIELD.key, "EPOCHMILLISECONDS")
+ .option(TIMESTAMP_OUTPUT_DATE_FORMAT.key, "/MM/dd")
+ .mode(SaveMode.Overwrite)
+ .save(basePath)
+var recordsReadDF = spark.read.format("org.apache.hudi")
+ .options(readOpts)
+ .load(basePath)
+val udf_date_format = udf((data: Long) => new
DateTime(data).toString(DateTimeFormat.forPattern("/MM/dd")))
+
+assertEquals(0L, recordsReadDF.filter(col("_hoodie_partition_path") =!=
udf_date_format(col("current_ts"))).count())
+
+// Mixed fieldType with TIMESTAMP of type EPOCHMILLISECONDS and output
date format as /MM/dd
+writer = getDataFrameWriter(classOf[CustomKeyGenerator].getName, writeOpts)
+writer.partitionBy("driver", "rider:SIMPLE", "current_ts:TIMESTAMP")
+ .option(TIMESTAMP_TYPE_FIELD.key, "EPOCHMILLISECONDS")
+ .option(TIMESTAMP_OUTPUT_DATE_FORMAT.key, "/MM/dd")
+ .mode(SaveMode.Overwrite)
+ .save(basePath)
+recordsReadDF = spark.read.format("org.apache.hudi")
+ .options(readOpts)
+ .load(basePath)
+assertTrue(recordsReadDF.filter(col("_hoodie_partition_path") =!=
+ concat(col("driver"), lit("/"), col("rider"), lit("/"),
udf_date_format(col("current_ts".count() == 0)
+ }
+
+ @Test
+ def testPartitionPruningForTimestampBasedKeyGenerator(): Unit = {
+val (writeOpts, readOpts) =
getWriterReaderOptsLessPartitionPath(HoodieRecordType.AVRO, enableFileIndex =
true)
+val writer =
getDataFrameWriter(classOf[TimestampBasedKeyGenerator].getName, writeOpts)
+writer.partitionBy("current_ts")
+ .option(TIMESTAMP_TYPE_FIELD.key, "EPOCHMILLISECONDS")
+ .option(TIMESTAMP_OUTPUT_DATE_FORMAT.key, "/MM/dd")
+ .mode(SaveMode.Overwrite)
+ .save(basePath)
+
+val snapshotQueryRes = spark.read.format("hudi")
+ .options(readOpts)
+ .load(basePath)
+ .where("current_ts > '1970/01/16'")
+
assertTrue(checkPartitionFilters(snapshotQueryRes.queryExecution.executedPlan.toString,
"current_ts.* > 1970/01/16"))
Review Comment:
+1
##
hudi-spark-datasource/hudi-spark-common/src/main/scala/org/apache/hudi/HoodieFileIndex.scala:
##
@@ -342,6 +342,20 @@ object HoodieFileIndex extends Logging {
if (listingModeOverride != null) {
properties.setProperty(DataSourceReadOptions.FILE_INDEX_LISTING_MODE_OVERRIDE.key,
listingModeOverride)
}
+val tableConfig = metaClient.getTableConfig
+val partitionColumns = tableConfig.getPartitionFields
+if (partitionColumns.isPresent) {
+ val keyGeneratorClassName = tableConfig.getKeyGeneratorClassName
+ // NOTE: A custom key generator with multiple fields could have
non-encoded slashes in the partition columns'
+ // value. We might not be able to properly parse partition-values
from the listed partition-paths. Fallback
+ // to eager listing in this case.
+ val isCustomKeyGenerator =
(classOf[CustomKeyGenerator].getName.equalsIgnoreCase(keyGeneratorClassName)
+||
classOf[CustomAvroKeyGenerator].getName.equalsIgnoreCase(keyGeneratorClassName))
+ val hasMultiplePartitionFields = partitionColumns.get().length > 1
+ if (hasMultiplePartitionFields && isCustomKeyGenerator) {
+
properties.setProperty(DataSourceReadOptions.FILE_INDEX_LISTING_MODE_OVERRIDE.key,
DataSourceReadOptions.FILE_INDEX_LISTING_MODE_EAGER)
+ }
+}
Review Comment:
nit: only execute this part if `listingModeOverride` is lazy?
##
hudi-spark-datasource/hudi-spark/src/test/scala/org/apache/hudi/functional/TestCOWDataSource.scala:
##
@@ -941,6 +942,70 @@ class TestCOWDataSource extends HoodieSparkClientTestBase
with ScalaAssertionSup
}
}
+ @ParameterizedTest
+ @EnumSource(value = classOf[HoodieRecordType], names = Array("AVRO",
"SPARK"))
+ def testSparkPartitionByWithCustomKeyGenerator(recordType:
HoodieRecordType): Unit = {
+val (writeOpts, readOpts) =
getWriterReaderOptsLessPartitionPath(recordType)
+// Specify fieldType as TIMESTAMP of type EPOCHMILLISECONDS and output
date format as yy
[GitHub] [hudi] hudi-bot commented on pull request #9275: [HUDI-6584] Abstract commit in CommitActionExecutor
hudi-bot commented on PR #9275: URL: https://github.com/apache/hudi/pull/9275#issuecomment-1648204721 ## CI report: * 5ff8958366e3b682552dc1a21f04bcf24333c84b Azure: [PENDING](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=18807) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #9275: [HUDI-6584] Abstract commit in CommitActionExecutor
hudi-bot commented on PR #9275: URL: https://github.com/apache/hudi/pull/9275#issuecomment-1648189728 ## CI report: * 5ff8958366e3b682552dc1a21f04bcf24333c84b UNKNOWN Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #9274: [MINOR] fix millis append format error
hudi-bot commented on PR #9274: URL: https://github.com/apache/hudi/pull/9274#issuecomment-1648189672 ## CI report: * 94d9dbcb05d1505d4a1d5e82dca8a8ba946f47da Azure: [PENDING](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=18806) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #9274: [MINOR] fix millis append format error
hudi-bot commented on PR #9274: URL: https://github.com/apache/hudi/pull/9274#issuecomment-1648176390 ## CI report: * 94d9dbcb05d1505d4a1d5e82dca8a8ba946f47da UNKNOWN Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] Zouxxyy commented on a diff in pull request #9275: [HUDI-6584] Abstract commit in CommitActionExecutor
Zouxxyy commented on code in PR #9275:
URL: https://github.com/apache/hudi/pull/9275#discussion_r1272430983
##
hudi-client/hudi-spark-client/src/main/java/org/apache/hudi/table/action/bootstrap/SparkBootstrapCommitActionExecutor.java:
##
@@ -223,47 +221,11 @@ protected void commit(Option>
extraMetadata, HoodieWriteMeta
LOG.info("Finished writing bootstrap index for source " +
config.getBootstrapSourceBasePath() + " in table "
+ config.getBasePath());
}
-
-commit(extraMetadata, result, bootstrapSourceAndStats.values().stream()
+commit(result.getWriteStatuses(), result,
bootstrapSourceAndStats.values().stream()
.flatMap(f ->
f.stream().map(Pair::getValue)).collect(Collectors.toList()));
LOG.info("Committing metadata bootstrap !!");
}
- protected void commit(Option> extraMetadata,
HoodieWriteMetadata> result, List
stats) {
-String actionType = table.getMetaClient().getCommitActionType();
-LOG.info("Committing " + instantTime + ", action Type " + actionType);
-// Create a Hoodie table which encapsulated the commits and files visible
-HoodieSparkTable table = HoodieSparkTable.create(config, context);
-
-HoodieActiveTimeline activeTimeline = table.getActiveTimeline();
-HoodieCommitMetadata metadata = new HoodieCommitMetadata();
-
-result.setCommitted(true);
-stats.forEach(stat -> metadata.addWriteStat(stat.getPartitionPath(),
stat));
-result.setWriteStats(stats);
-
-// Finalize write
-finalizeWrite(instantTime, stats, result);
-// add in extra metadata
-if (extraMetadata.isPresent()) {
Review Comment:
For reviewer: `HoodieCommitMetadata` has been generated in
`result.setCommitMetadata`, which already contains `operation`, `metadata`,
`extrametadata`, `writestats` and so on
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] Zouxxyy opened a new pull request, #9275: [HUDI-6584] Abstract commit in CommitActionExecutor
Zouxxyy opened a new pull request, #9275: URL: https://github.com/apache/hudi/pull/9275 ### Change Logs Abstract commit in CommitActionExecutor ### Impact Abstract commit in CommitActionExecutor ### Risk level (write none, low medium or high below) low ### Documentation Update none ### Contributor's checklist - [ ] Read through [contributor's guide](https://hudi.apache.org/contribute/how-to-contribute) - [ ] Change Logs and Impact were stated clearly - [ ] Adequate tests were added if applicable - [ ] CI passed -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (HUDI-6584) Abstract commit in CommitActionExecutor
[ https://issues.apache.org/jira/browse/HUDI-6584?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] ASF GitHub Bot updated HUDI-6584: - Labels: pull-request-available (was: ) > Abstract commit in CommitActionExecutor > --- > > Key: HUDI-6584 > URL: https://issues.apache.org/jira/browse/HUDI-6584 > Project: Apache Hudi > Issue Type: Improvement >Reporter: zouxxyy >Priority: Major > Labels: pull-request-available > -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Created] (HUDI-6584) Abstract commit in CommitActionExecutor
zouxxyy created HUDI-6584: - Summary: Abstract commit in CommitActionExecutor Key: HUDI-6584 URL: https://issues.apache.org/jira/browse/HUDI-6584 Project: Apache Hudi Issue Type: Improvement Reporter: zouxxyy -- This message was sent by Atlassian Jira (v8.20.10#820010)
[GitHub] [hudi] hudi-bot commented on pull request #9273: [HUDI-6320] Fix partition parsing in Spark file index for custom keygen
hudi-bot commented on PR #9273: URL: https://github.com/apache/hudi/pull/9273#issuecomment-1648088921 ## CI report: * ccdc272f4c7c61263f15174d9b468301800b25c9 UNKNOWN * 7cd21f8fb35c94bd600cbcc75638ffdafe632625 Azure: [PENDING](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=18805) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] KnightChess opened a new pull request, #9274: [MINOR] fix millis append format error
KnightChess opened a new pull request, #9274: URL: https://github.com/apache/hudi/pull/9274 ### Change Logs MILLIS_GRANULARITY_DATE_FORMAT is `-MM-dd HH:mm:ss.SSS` ### Impact None ### Risk level (write none, low medium or high below) None ### Documentation Update None ### Contributor's checklist - [ ] Read through [contributor's guide](https://hudi.apache.org/contribute/how-to-contribute) - [ ] Change Logs and Impact were stated clearly - [ ] Adequate tests were added if applicable - [ ] CI passed -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #9273: [HUDI-6320] Fix partition parsing in Spark file index for custom keygen
hudi-bot commented on PR #9273: URL: https://github.com/apache/hudi/pull/9273#issuecomment-1648074941 ## CI report: * ccdc272f4c7c61263f15174d9b468301800b25c9 UNKNOWN * 7cd21f8fb35c94bd600cbcc75638ffdafe632625 UNKNOWN Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #9272: [HUDI-6582] Ensure that default recordName/namespace is not used when…
hudi-bot commented on PR #9272: URL: https://github.com/apache/hudi/pull/9272#issuecomment-1648074844 ## CI report: * 8aeaf2013c950b50e02c3820d5942ea52c84c1cc Azure: [SUCCESS](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=18802) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #9273: [HUDI-6320] Fix partition parsing in Spark file index for custom keygen
hudi-bot commented on PR #9273: URL: https://github.com/apache/hudi/pull/9273#issuecomment-1647999629 ## CI report: * ccdc272f4c7c61263f15174d9b468301800b25c9 UNKNOWN Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (HUDI-6320) Spark read inferring the data type incorrectly when partition path contains slash
[ https://issues.apache.org/jira/browse/HUDI-6320?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] ASF GitHub Bot updated HUDI-6320: - Labels: pull-request-available (was: ) > Spark read inferring the data type incorrectly when partition path contains > slash > - > > Key: HUDI-6320 > URL: https://issues.apache.org/jira/browse/HUDI-6320 > Project: Apache Hudi > Issue Type: Bug > Components: reader-core >Reporter: Aditya Goenka >Priority: Major > Labels: pull-request-available > Fix For: 0.14.0 > > > Github Issue - [https://github.com/apache/hudi/issues/8343] > When partition path contains slashes (eg - /MM/dd), spark is inferring > the partition column data type as long which is wrong. -- This message was sent by Atlassian Jira (v8.20.10#820010)
[GitHub] [hudi] codope opened a new pull request, #9273: [HUDI-6320] Fix partition parsing in Spark file index for custom keygen
codope opened a new pull request, #9273: URL: https://github.com/apache/hudi/pull/9273 ### Change Logs Whem using custom key generator with timestamp field with type `EPOCHMILLISECONDS` and output date format as `/MM/dd`, partition parsing fails because partition column is thought to be of LongType even though it is string. Another issue is that if there are multiple partition fields with cusotm keygen, then lazy listing fails due to parsing of partitions with non-encoded slashes. This PR fixes these issues. It also adds a test to check partition pruning kicks in for TimestampBasedKeyGenerator. ### Impact Fixes couple of bugs bug when using custom keygen with timestamp fields. ### Risk level (write none, low medium or high below) medium Eager listing in case of custom keygen with multiple fields can be costlier but functional. Before this patch, it wasn't even functional. ### Documentation Update _Describe any necessary documentation update if there is any new feature, config, or user-facing change_ - _The config description must be updated if new configs are added or the default value of the configs are changed_ - _Any new feature or user-facing change requires updating the Hudi website. Please create a Jira ticket, attach the ticket number here and follow the [instruction](https://hudi.apache.org/contribute/developer-setup#website) to make changes to the website._ ### Contributor's checklist - [ ] Read through [contributor's guide](https://hudi.apache.org/contribute/how-to-contribute) - [ ] Change Logs and Impact were stated clearly - [ ] Adequate tests were added if applicable - [ ] CI passed -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #9270: [MINOR] Optimize error display information
hudi-bot commented on PR #9270: URL: https://github.com/apache/hudi/pull/9270#issuecomment-1647966302 ## CI report: * c4188514ca4e4f80d4b8ad263f7cf329cd0480f7 Azure: [SUCCESS](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=18800) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] adityaverma1997 commented on issue #9257: [SUPPORT] Parquet files got cleaned up even when cleaning operation failed hence leading to subsequent failed clustering and cleaning
adityaverma1997 commented on issue #9257: URL: https://github.com/apache/hudi/issues/9257#issuecomment-1647925326 @danny0405 I haven't tried the other cleaning strategies, not even default one because I don't want to run cleaner after every commit. Also, in my case I want only last 2-3 commits to retain so thatswhy I changed following properties. ``` "hoodie.clean.max.commits": 10, "hoodie.cleaner.commits.retained": 2 ``` -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #9268: [MINOR]fix the log print class
hudi-bot commented on PR #9268: URL: https://github.com/apache/hudi/pull/9268#issuecomment-1647857893 ## CI report: * 8d99486574bd2cfb7bd0d2b6af3d24bfac0d2aaf Azure: [SUCCESS](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=18798) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #9209: [HUDI-6539] New LSM tree style archived timeline
hudi-bot commented on PR #9209: URL: https://github.com/apache/hudi/pull/9209#issuecomment-1647786249 ## CI report: * a71bc4b8c9eb8a9f0bf61d20934c62a9469c4fd1 Azure: [CANCELED](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=18799) * 62001bbc6c5d9306f95d4bca3dd2bada3ca5c898 Azure: [PENDING](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=18804) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #9209: [HUDI-6539] New LSM tree style archived timeline
hudi-bot commented on PR #9209: URL: https://github.com/apache/hudi/pull/9209#issuecomment-1647773627 ## CI report: * a71bc4b8c9eb8a9f0bf61d20934c62a9469c4fd1 Azure: [PENDING](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=18799) * 62001bbc6c5d9306f95d4bca3dd2bada3ca5c898 UNKNOWN Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #9255: [HUDI-6503] Make TableServiceClient's txnManager consistent with Writ…
hudi-bot commented on PR #9255: URL: https://github.com/apache/hudi/pull/9255#issuecomment-1647762907 ## CI report: * 257b18bc9faffdf7d063fb153e5ee1b53d57 Azure: [SUCCESS](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=18797) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] ad1happy2go commented on issue #9271: [SUPPORT] Duplicates upserting into large partitioned table with bloom index metadata enabled
ad1happy2go commented on issue #9271: URL: https://github.com/apache/hudi/issues/9271#issuecomment-1647758062 @jspaine When you were running insert, is your source containing duplicates? If yes, can you try using hoodie.datasource.write.operation as upsert only for the first case also. upsert deduplicates the records. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] danny0405 commented on issue #9269: [SUPPORT] Hudi HMS Catalog hive_sync.conf.dir
danny0405 commented on issue #9269: URL: https://github.com/apache/hudi/issues/9269#issuecomment-1647728384 > hdfs path, since the code running on yarn and my hive-site.xml is in a local dir I guess you are right, the hive conf dir is only valid for the catalog itself, not the job, the catalog does not pass around all the hive related config options to the job. Maybe you can fire a fix for it, in the HoodieHiveCatalog, when generating a new catalog table, config the hive options through `hadoop.` prefix. Another way is to config the system variable: `HIVE_CONF_DIR`:  -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org