[GitHub] [hudi] shengchiqu commented on issue #7229: [SUPPORT] flink connector sink Update the partition value, the old data is still there
shengchiqu commented on issue #7229: URL: https://github.com/apache/hudi/issues/7229#issuecomment-1384903763 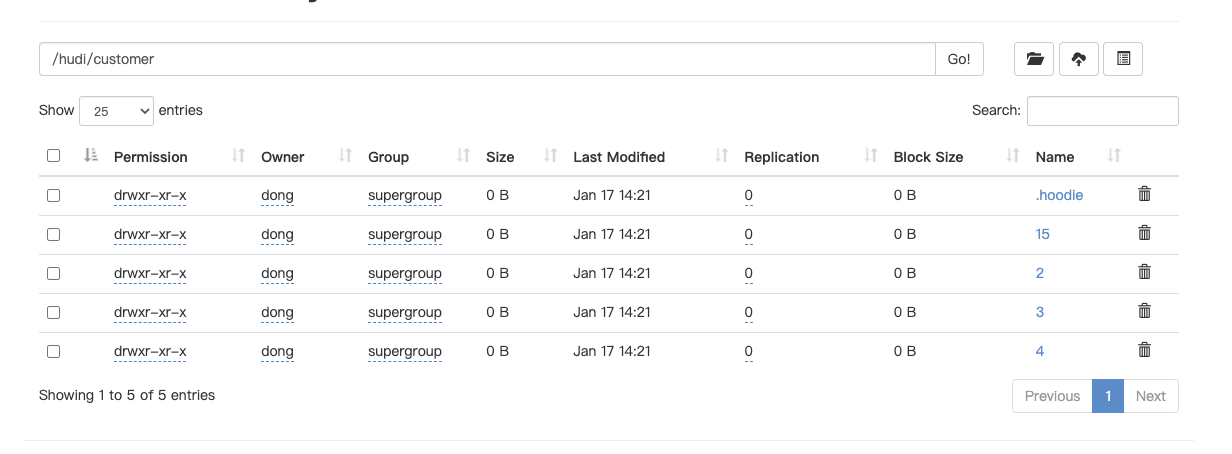 this is c_custkey=1, only 1 record update partition column, because change.enable=true and it will keep all change records, flink can not delete old data in old partition, so if use batch mode to read hudi with spark , it show deplicate data (different partition value in history), how to solve this problem? i want to buid data warehouse with flink and hudi. https://user-images.githubusercontent.com/118461079/212827501-45aa243b-7b9b-450a-b6b1-9ec9e5dd610e.png;> -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] shengchiqu commented on issue #7229: [SUPPORT] flink connector sink Update the partition value, the old data is still there
shengchiqu commented on issue #7229: URL: https://github.com/apache/hudi/issues/7229#issuecomment-1384901686 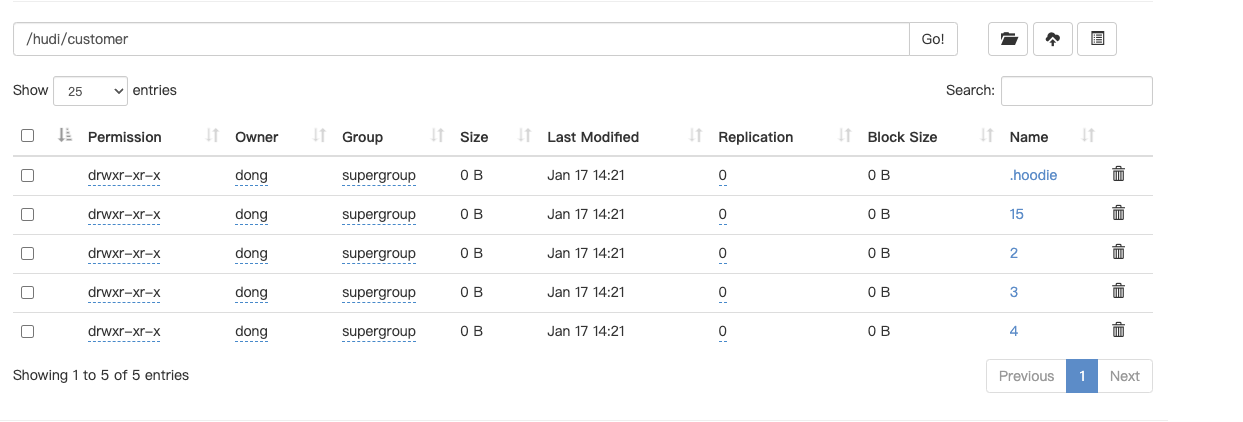 this is c_custkey=1, only 1 record update partition column, because change.enable=true and it will keep all change records, flink can not delete old data in old partition, so if use batch mode to read hudi with spark , it show deplicate data (different partition value in history), how to solve this problem? i want to buid data warehouse with flink and hudi.  -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] shengchiqu commented on issue #7229: [SUPPORT] flink connector sink Update the partition value, the old data is still there
shengchiqu commented on issue #7229: URL: https://github.com/apache/hudi/issues/7229#issuecomment-1384871989 @yihua thanks.My problem is that if changelog.enabled is true, flink incremental streaming reads are fine, but if spark/hive/flink is used to read the hudi directory table offline(batch read), there will be duplicates, all updates exist, and there is no de-duplication. Is it mutually exclusive if you want to use both incremental stream read and batch read? changelog.enabled=true => flink incr streaming shows the correct cdc; batch read is duplicate ```shell +-+++++---+++-+ | C_CUSTKEY | C_NAME | C_ADDRESS |C_NATIONKEY |C_PHONE | C_ACCTBAL | C_MKTSEGMENT | C_COMMENT | ts | +-+++++---+++-+ | 1 | Customer#1 | a | 1 |25-989-741-2988 | 711.56 | BUILDING | to the even, regular platel... | 2023-01-17 13:43:25.380 | | 1 | Customer#1 | a | 12 |25-989-741-2988 | 711.56 | BUILDING | to the even, regular platel... | 2023-01-17 13:43:31.383 | | 1 | Customer#1 | a | 2 |25-989-741-2988 | 711.56 | BUILDING | to the even, regular platel... | 2023-01-17 13:43:28.381 | | 1 | Customer#1 | a | 3 |25-989-741-2988 | 711.56 | BUILDING | to the even, regular platel... | 2023-01-17 13:43:31.383 | +-+++++---+++-+ ``` changelog.enabled=false => flink incr streaming is error; batch read is no-deplicate and the data is accurate ```shell Caused by: java.lang.IllegalStateException: Not expected to see delete records in this log-scan mode. Check Job Config at org.apache.hudi.common.table.log.HoodieUnMergedLogRecordScanner.processNextDeletedRecord(HoodieUnMergedLogRecordScanner.java:60) at java.util.Spliterators$ArraySpliterator.forEachRemaining(Spliterators.java:948) at java.util.stream.ReferencePipeline$Head.forEach(ReferencePipeline.java:647) at org.apache.hudi.common.table.log.AbstractHoodieLogRecordReader.processQueuedBlocksForInstant(AbstractHoodieLogRecordReader.java:473) at org.apache.hudi.common.table.log.AbstractHoodieLogRecordReader.scanInternal(AbstractHoodieLogRecordReader.java:343) ... 10 more ``` -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] shengchiqu commented on issue #7229: [SUPPORT] flink connector sink Update the partition value, the old data is still there
shengchiqu commented on issue #7229: URL: https://github.com/apache/hudi/issues/7229#issuecomment-1319602176 i try set changelog.enabled=false, the problem solved Is this because the changelog mode does not support global indexes? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org