[GitHub] [hudi] zhuanshenbsj1 commented on a diff in pull request #7159: [HUDI-5173] Skip if there is only one file in clusteringGroup
zhuanshenbsj1 commented on code in PR #7159:
URL: https://github.com/apache/hudi/pull/7159#discussion_r1025474961
##
hudi-client/hudi-spark-client/src/test/java/org/apache/hudi/table/action/cluster/strategy/TestSparkClusteringPlanPartitionFilter.java:
##
@@ -53,9 +53,9 @@ public void setUp() {
@Test
public void testFilterPartitionNoFilter() {
HoodieWriteConfig config =
hoodieWriteConfigBuilder.withClusteringConfig(HoodieClusteringConfig.newBuilder()
-
.withClusteringPlanPartitionFilterMode(ClusteringPlanPartitionFilterMode.NONE)
-.build())
-.build();
+
.withClusteringPlanPartitionFilterMode(ClusteringPlanPartitionFilterMode.NONE)
Review Comment:
done
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] zhuanshenbsj1 commented on a diff in pull request #7159: [HUDI-5173]Skip if there is only one file in clusteringGroup
zhuanshenbsj1 commented on code in PR #7159:
URL: https://github.com/apache/hudi/pull/7159#discussion_r1115286599
##
hudi-client/hudi-flink-client/src/main/java/org/apache/hudi/client/clustering/plan/strategy/FlinkSizeBasedClusteringPlanStrategy.java:
##
@@ -63,27 +63,41 @@ protected Stream
buildClusteringGroupsForPartition(String
List, Integer>> fileSliceGroups = new ArrayList<>();
List currentGroup = new ArrayList<>();
+
+// Sort fileSlices before dividing, which makes dividing more compact
+List sortedFileSlices = new ArrayList<>(fileSlices);
+sortedFileSlices.sort((o1, o2) -> (int)
+((o2.getBaseFile().isPresent() ? o2.getBaseFile().get().getFileSize()
: writeConfig.getParquetMaxFileSize())
+- (o1.getBaseFile().isPresent() ?
o1.getBaseFile().get().getFileSize() : writeConfig.getParquetMaxFileSize(;
+
long totalSizeSoFar = 0;
-for (FileSlice currentSlice : fileSlices) {
+for (FileSlice currentSlice : sortedFileSlices) {
+ long currentSize = currentSlice.getBaseFile().isPresent() ?
currentSlice.getBaseFile().get().getFileSize() :
writeConfig.getParquetMaxFileSize();
// check if max size is reached and create new group, if needed.
- // in now, every clustering group out put is 1 file group.
- if (totalSizeSoFar >= writeConfig.getClusteringTargetFileMaxBytes() &&
!currentGroup.isEmpty()) {
+ if (totalSizeSoFar + currentSize >
writeConfig.getClusteringMaxBytesInGroup() && !currentGroup.isEmpty()) {
+int numOutputGroups = getNumberOfOutputFileGroups(totalSizeSoFar,
writeConfig.getClusteringTargetFileMaxBytes());
LOG.info("Adding one clustering group " + totalSizeSoFar + " max
bytes: "
-+ writeConfig.getClusteringMaxBytesInGroup() + " num input slices:
" + currentGroup.size());
-fileSliceGroups.add(Pair.of(currentGroup, 1));
++ writeConfig.getClusteringMaxBytesInGroup() + " num input slices:
" + currentGroup.size() + " output groups: " + numOutputGroups);
+fileSliceGroups.add(Pair.of(currentGroup, numOutputGroups));
currentGroup = new ArrayList<>();
totalSizeSoFar = 0;
}
// Add to the current file-group
currentGroup.add(currentSlice);
// assume each file group size is ~= parquet.max.file.size
- totalSizeSoFar += currentSlice.getBaseFile().isPresent() ?
currentSlice.getBaseFile().get().getFileSize() :
writeConfig.getParquetMaxFileSize();
+ totalSizeSoFar += currentSize;
}
if (!currentGroup.isEmpty()) {
- fileSliceGroups.add(Pair.of(currentGroup, 1));
+ if (currentGroup.size() == 1 &&
!writeConfig.shouldClusteringSingleGroup()) {
+return Stream.empty();
+ }
Review Comment:
Resolved.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] zhuanshenbsj1 commented on a diff in pull request #7159: [HUDI-5173]Skip if there is only one file in clusteringGroup
zhuanshenbsj1 commented on code in PR #7159:
URL: https://github.com/apache/hudi/pull/7159#discussion_r1025485316
##
hudi-client/hudi-flink-client/src/main/java/org/apache/hudi/client/clustering/plan/strategy/FlinkSizeBasedClusteringPlanStrategy.java:
##
@@ -70,9 +70,11 @@ protected Stream
buildClusteringGroupsForPartition(String
// check if max size is reached and create new group, if needed.
// in now, every clustering group out put is 1 file group.
if (totalSizeSoFar >= writeConfig.getClusteringTargetFileMaxBytes() &&
!currentGroup.isEmpty()) {
-LOG.info("Adding one clustering group " + totalSizeSoFar + " max
bytes: "
-+ writeConfig.getClusteringMaxBytesInGroup() + " num input slices:
" + currentGroup.size());
-fileSliceGroups.add(Pair.of(currentGroup, 1));
+if (currentGroup.size() > 1 ||
(!StringUtils.isNullOrEmpty(writeConfig.getClusteringSortColumns()) &&
currentGroup.size() == 1)) {
Review Comment:
If the clustering instants was archived,can we recognize the file wheather
repalaced or not easily? I need to review the archive logic.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] zhuanshenbsj1 commented on a diff in pull request #7159: [HUDI-5173]Skip if there is only one file in clusteringGroup
zhuanshenbsj1 commented on code in PR #7159:
URL: https://github.com/apache/hudi/pull/7159#discussion_r1025380694
##
hudi-client/hudi-flink-client/src/main/java/org/apache/hudi/client/clustering/plan/strategy/FlinkSizeBasedClusteringPlanStrategy.java:
##
@@ -84,7 +86,9 @@ protected Stream
buildClusteringGroupsForPartition(String
}
if (!currentGroup.isEmpty()) {
Review Comment:
Good advice
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] zhuanshenbsj1 commented on a diff in pull request #7159: [HUDI-5173]Skip if there is only one file in clusteringGroup
zhuanshenbsj1 commented on code in PR #7159:
URL: https://github.com/apache/hudi/pull/7159#discussion_r1099707657
##
hudi-client/hudi-client-common/src/main/java/org/apache/hudi/config/HoodieClusteringConfig.java:
##
@@ -182,6 +182,12 @@ public class HoodieClusteringConfig extends HoodieConfig {
.sinceVersion("0.7.0")
.withDocumentation("Each group can produce 'N'
(CLUSTERING_MAX_GROUP_SIZE/CLUSTERING_TARGET_FILE_SIZE) output file groups");
+ public static final ConfigProperty PLAN_STRATEGY_FORCE =
ConfigProperty
+ .key(CLUSTERING_STRATEGY_PARAM_PREFIX + "force")
+ .defaultValue(true)
Review Comment:
IF the default value is false,too many ut need to modify to make it right.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] zhuanshenbsj1 commented on a diff in pull request #7159: [HUDI-5173]Skip if there is only one file in clusteringGroup
zhuanshenbsj1 commented on code in PR #7159:
URL: https://github.com/apache/hudi/pull/7159#discussion_r1099707657
##
hudi-client/hudi-client-common/src/main/java/org/apache/hudi/config/HoodieClusteringConfig.java:
##
@@ -182,6 +182,12 @@ public class HoodieClusteringConfig extends HoodieConfig {
.sinceVersion("0.7.0")
.withDocumentation("Each group can produce 'N'
(CLUSTERING_MAX_GROUP_SIZE/CLUSTERING_TARGET_FILE_SIZE) output file groups");
+ public static final ConfigProperty PLAN_STRATEGY_FORCE =
ConfigProperty
+ .key(CLUSTERING_STRATEGY_PARAM_PREFIX + "force")
+ .defaultValue(true)
Review Comment:
IF the default value is false,too many ut need to modify to make it right,
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] zhuanshenbsj1 commented on a diff in pull request #7159: [HUDI-5173]Skip if there is only one file in clusteringGroup
zhuanshenbsj1 commented on code in PR #7159:
URL: https://github.com/apache/hudi/pull/7159#discussion_r1099086012
##
hudi-client/hudi-spark-client/src/main/java/org/apache/hudi/client/clustering/plan/strategy/SparkSizeBasedClusteringPlanStrategy.java:
##
@@ -91,7 +93,7 @@ protected Stream
buildClusteringGroupsForPartition(String
totalSizeSoFar += currentSize;
}
-if (!currentGroup.isEmpty()) {
+if (currentGroup.size() > 1 || (writeConfig.isClusteringSortEnabled() &&
currentGroup.size() == 1)) {
Review Comment:
Adjust the judgment position.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] zhuanshenbsj1 commented on a diff in pull request #7159: [HUDI-5173]Skip if there is only one file in clusteringGroup
zhuanshenbsj1 commented on code in PR #7159:
URL: https://github.com/apache/hudi/pull/7159#discussion_r1092881634
##
hudi-client/hudi-flink-client/src/main/java/org/apache/hudi/client/clustering/plan/strategy/FlinkSizeBasedClusteringPlanStrategy.java:
##
@@ -70,9 +70,11 @@ protected Stream
buildClusteringGroupsForPartition(String
// check if max size is reached and create new group, if needed.
// in now, every clustering group out put is 1 file group.
if (totalSizeSoFar >= writeConfig.getClusteringTargetFileMaxBytes() &&
!currentGroup.isEmpty()) {
-LOG.info("Adding one clustering group " + totalSizeSoFar + " max
bytes: "
-+ writeConfig.getClusteringMaxBytesInGroup() + " num input slices:
" + currentGroup.size());
-fileSliceGroups.add(Pair.of(currentGroup, 1));
+if (currentGroup.size() > 1 || writeConfig.isClusteringSortEnabled()) {
+ LOG.info("Adding one clustering group " + totalSizeSoFar + " max
bytes: "
+ + writeConfig.getClusteringMaxBytesInGroup() + " num input
slices: " + currentGroup.size());
+ fileSliceGroups.add(Pair.of(currentGroup, 1));
Review Comment:
Like target size is 1G,4 file group input, these sizes are 256M, 256M,
256M, 512M, out put file group number should be 2(file1: 1G, file2: 256M). I
will modify this function according to spark case.
int numOutputGroups = getNumberOfOutputFileGroups(totalSizeSoFar,
writeConfig.getClusteringTargetFileMaxBytes());
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] zhuanshenbsj1 commented on a diff in pull request #7159: [HUDI-5173]Skip if there is only one file in clusteringGroup
zhuanshenbsj1 commented on code in PR #7159:
URL: https://github.com/apache/hudi/pull/7159#discussion_r1046889456
##
hudi-hadoop-mr/src/test/java/org/apache/hudi/hadoop/realtime/TestHoodieRealtimeRecordReader.java:
##
@@ -141,6 +141,7 @@ private void setHiveColumnNameProps(List
fields, JobConf jobConf,
jobConf.set(hive_metastoreConstants.META_TABLE_PARTITION_COLUMNS,
PARTITION_COLUMN);
}
jobConf.set(hive_metastoreConstants.META_TABLE_COLUMNS,
hiveOrderedColumnNames);
+jobConf.set("columns.types",
"string,string,string,string,string,string,string,string,bigint,string,string");
}
Review Comment:
> The NPE is caused by this change ?
No.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] zhuanshenbsj1 commented on a diff in pull request #7159: [HUDI-5173]Skip if there is only one file in clusteringGroup
zhuanshenbsj1 commented on code in PR #7159:
URL: https://github.com/apache/hudi/pull/7159#discussion_r1046699321
##
hudi-spark-datasource/hudi-spark/src/test/scala/org/apache/hudi/functional/cdc/TestCDCDataFrameSuite.scala:
##
@@ -118,6 +118,7 @@ class TestCDCDataFrameSuite extends HoodieCDCTestBase {
.option(DataSourceWriteOptions.OPERATION.key,
DataSourceWriteOptions.DELETE_OPERATION_OPT_VAL)
.option("hoodie.clustering.inline", "true")
.option("hoodie.clustering.inline.max.commits", "1")
+ .option("hoodie.clustering.plan.strategy.sort.columns", "_row_key")
.mode(SaveMode.Append)
Review Comment:
Without this change,after inputDF5 the timeline will be:
commit(instantC,cleaned)->clustering(instantD,cleaned)->commit(instantE)->clean(instantF)
and file belong to instantA will archived, it will case line-193 -> line
194:
allVisibleCDCData = cdcDataFrame((commitTime1.toLong - 1).toString)
assertCDCOpCnt(allVisibleCDCData, totalInsertedCnt, totalUpdatedCnt,
totalDeletedCnt)
can't get instantC file error.
With this change, after after inputDF5 the timeline will be:
clustering(instantD,cleaned)->clustering(instantE,cleaned)->commit(instantF)->clean(instantG),
it will fix this problem.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] zhuanshenbsj1 commented on a diff in pull request #7159: [HUDI-5173]Skip if there is only one file in clusteringGroup
zhuanshenbsj1 commented on code in PR #7159:
URL: https://github.com/apache/hudi/pull/7159#discussion_r1046731112
##
hudi-hadoop-mr/src/test/java/org/apache/hudi/hadoop/realtime/TestHoodieRealtimeRecordReader.java:
##
@@ -141,6 +141,7 @@ private void setHiveColumnNameProps(List
fields, JobConf jobConf,
jobConf.set(hive_metastoreConstants.META_TABLE_PARTITION_COLUMNS,
PARTITION_COLUMN);
}
jobConf.set(hive_metastoreConstants.META_TABLE_COLUMNS,
hiveOrderedColumnNames);
+jobConf.set("columns.types",
"string,string,string,string,string,string,string,string,bigint,string,string");
}
Review Comment:
This function (TestHoodieRealtimeRecordReader#testIncrementalWithOnlylog)
has a warn, and I should move this change to here.
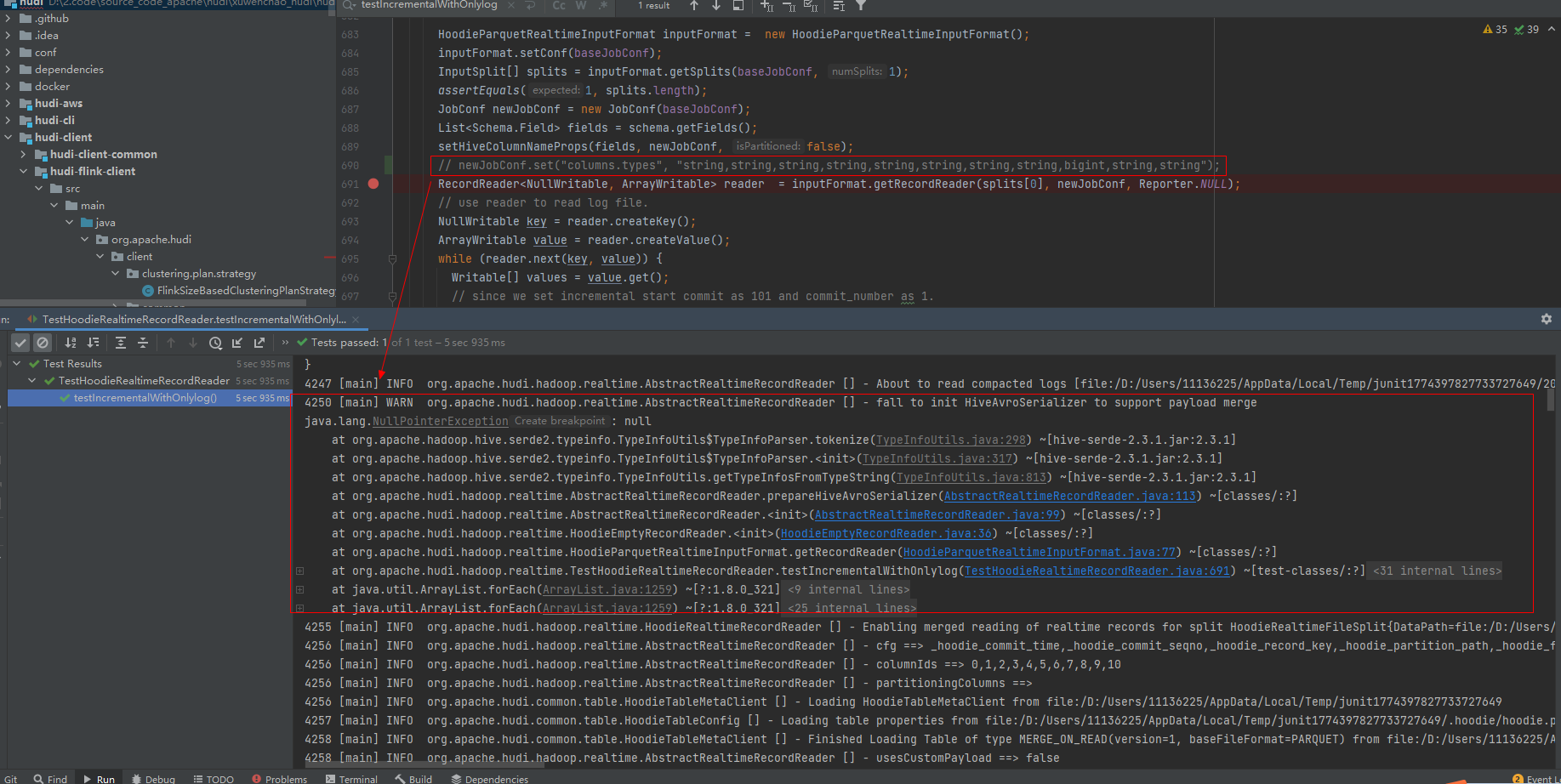
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] zhuanshenbsj1 commented on a diff in pull request #7159: [HUDI-5173]Skip if there is only one file in clusteringGroup
zhuanshenbsj1 commented on code in PR #7159:
URL: https://github.com/apache/hudi/pull/7159#discussion_r1046699321
##
hudi-spark-datasource/hudi-spark/src/test/scala/org/apache/hudi/functional/cdc/TestCDCDataFrameSuite.scala:
##
@@ -118,6 +118,7 @@ class TestCDCDataFrameSuite extends HoodieCDCTestBase {
.option(DataSourceWriteOptions.OPERATION.key,
DataSourceWriteOptions.DELETE_OPERATION_OPT_VAL)
.option("hoodie.clustering.inline", "true")
.option("hoodie.clustering.inline.max.commits", "1")
+ .option("hoodie.clustering.plan.strategy.sort.columns", "_row_key")
.mode(SaveMode.Append)
Review Comment:
Without this change,after inputDF5 the timeline will be:
commit(instantC,cleaned)->clustering(instantD,cleaned)->commit(instantE)->clean(instantF)
and file belong to instantA will archived, it will case line-193 -> line
194:
allVisibleCDCData = cdcDataFrame((commitTime1.toLong - 1).toString)
assertCDCOpCnt(allVisibleCDCData, totalInsertedCnt, totalUpdatedCnt,
totalDeletedCnt)
can't get instantA file error.
With this change, after after inputDF5 the timeline will be:
clustering(instantD,cleaned)->clustering(instantE,cleaned)->commit(instantF)->clean(instantG),
it will fix this problem.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] zhuanshenbsj1 commented on a diff in pull request #7159: [HUDI-5173]Skip if there is only one file in clusteringGroup
zhuanshenbsj1 commented on code in PR #7159:
URL: https://github.com/apache/hudi/pull/7159#discussion_r1046698488
##
hudi-spark-datasource/hudi-spark/src/test/scala/org/apache/hudi/functional/cdc/TestCDCDataFrameSuite.scala:
##
@@ -118,6 +118,7 @@ class TestCDCDataFrameSuite extends HoodieCDCTestBase {
.option(DataSourceWriteOptions.OPERATION.key,
DataSourceWriteOptions.DELETE_OPERATION_OPT_VAL)
.option("hoodie.clustering.inline", "true")
.option("hoodie.clustering.inline.max.commits", "1")
+ .option("hoodie.clustering.plan.strategy.sort.columns", "_row_key")
.mode(SaveMode.Append)
Review Comment:
Without this change,after inputDF5 the timeline will be:
commit(instantC,cleaned)->clustering(instantD,cleaned)->commit(instantE)->clean(instantF)
and file belong to instantA will archived, it will case line-193 -> line
194:
---
allVisibleCDCData = cdcDataFrame((commitTime1.toLong - 1).toString)
assertCDCOpCnt(allVisibleCDCData, totalInsertedCnt, totalUpdatedCnt,
totalDeletedCnt)
---
can't get instantA file error.
With this change, after after inputDF5 the timeline will be:
clustering(instantD,cleaned)->clustering(instantE,cleaned)->commit(instantF)->clean(instantG),
it will fix this problem.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] zhuanshenbsj1 commented on a diff in pull request #7159: [HUDI-5173]Skip if there is only one file in clusteringGroup
zhuanshenbsj1 commented on code in PR #7159:
URL: https://github.com/apache/hudi/pull/7159#discussion_r1046629024
##
hudi-hadoop-mr/src/test/java/org/apache/hudi/hadoop/realtime/TestHoodieRealtimeRecordReader.java:
##
@@ -141,6 +141,7 @@ private void setHiveColumnNameProps(List
fields, JobConf jobConf,
jobConf.set(hive_metastoreConstants.META_TABLE_PARTITION_COLUMNS,
PARTITION_COLUMN);
}
jobConf.set(hive_metastoreConstants.META_TABLE_COLUMNS,
hiveOrderedColumnNames);
+jobConf.set("columns.types",
"string,string,string,string,string,string,string,string,bigint,string,string");
}
Review Comment:
Without this change,after inputDF5 the timeline will be
commit(instantA)->clustering(instantB)->commit(instantC)->clean(instantD), and
instantA will archive by instantB, line-193:allVisibleCDCData =
cdcDataFrame((commitTime1.toLong - 1).toString)
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] zhuanshenbsj1 commented on a diff in pull request #7159: [HUDI-5173]Skip if there is only one file in clusteringGroup
zhuanshenbsj1 commented on code in PR #7159:
URL: https://github.com/apache/hudi/pull/7159#discussion_r1025485316
##
hudi-client/hudi-flink-client/src/main/java/org/apache/hudi/client/clustering/plan/strategy/FlinkSizeBasedClusteringPlanStrategy.java:
##
@@ -70,9 +70,11 @@ protected Stream
buildClusteringGroupsForPartition(String
// check if max size is reached and create new group, if needed.
// in now, every clustering group out put is 1 file group.
if (totalSizeSoFar >= writeConfig.getClusteringTargetFileMaxBytes() &&
!currentGroup.isEmpty()) {
-LOG.info("Adding one clustering group " + totalSizeSoFar + " max
bytes: "
-+ writeConfig.getClusteringMaxBytesInGroup() + " num input slices:
" + currentGroup.size());
-fileSliceGroups.add(Pair.of(currentGroup, 1));
+if (currentGroup.size() > 1 ||
(!StringUtils.isNullOrEmpty(writeConfig.getClusteringSortColumns()) &&
currentGroup.size() == 1)) {
Review Comment:
If the clustering instants was archived,can we recognize the file wheather
repalaced or not easily? I need to review the archive logic.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] zhuanshenbsj1 commented on a diff in pull request #7159: [HUDI-5173]Skip if there is only one file in clusteringGroup
zhuanshenbsj1 commented on code in PR #7159:
URL: https://github.com/apache/hudi/pull/7159#discussion_r1025474961
##
hudi-client/hudi-spark-client/src/test/java/org/apache/hudi/table/action/cluster/strategy/TestSparkClusteringPlanPartitionFilter.java:
##
@@ -53,9 +53,9 @@ public void setUp() {
@Test
public void testFilterPartitionNoFilter() {
HoodieWriteConfig config =
hoodieWriteConfigBuilder.withClusteringConfig(HoodieClusteringConfig.newBuilder()
-
.withClusteringPlanPartitionFilterMode(ClusteringPlanPartitionFilterMode.NONE)
-.build())
-.build();
+
.withClusteringPlanPartitionFilterMode(ClusteringPlanPartitionFilterMode.NONE)
Review Comment:
done
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] zhuanshenbsj1 commented on a diff in pull request #7159: [HUDI-5173]Skip if there is only one file in clusteringGroup
zhuanshenbsj1 commented on code in PR #7159:
URL: https://github.com/apache/hudi/pull/7159#discussion_r1025380694
##
hudi-client/hudi-flink-client/src/main/java/org/apache/hudi/client/clustering/plan/strategy/FlinkSizeBasedClusteringPlanStrategy.java:
##
@@ -84,7 +86,9 @@ protected Stream
buildClusteringGroupsForPartition(String
}
if (!currentGroup.isEmpty()) {
Review Comment:
Good advice
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] zhuanshenbsj1 commented on a diff in pull request #7159: [HUDI-5173]Skip if there is only one file in clusteringGroup
zhuanshenbsj1 commented on code in PR #7159:
URL: https://github.com/apache/hudi/pull/7159#discussion_r1025374617
##
hudi-client/hudi-flink-client/src/main/java/org/apache/hudi/client/clustering/plan/strategy/FlinkSizeBasedClusteringPlanStrategy.java:
##
@@ -84,7 +86,9 @@ protected Stream
buildClusteringGroupsForPartition(String
}
if (!currentGroup.isEmpty()) {
- fileSliceGroups.add(Pair.of(currentGroup, 1));
+ if (currentGroup.size() > 1) {
Review Comment:
Add UT & Fix SparkSizeBasedClusteringPlanStrategy same problem.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org