spark git commit: [BUILD][MINOR] Fix java style check issues
Repository: spark
Updated Branches:
refs/heads/master 568055da9 -> 9c4b99861
[BUILD][MINOR] Fix java style check issues
## What changes were proposed in this pull request?
This patch fixes a few recently introduced java style check errors in master
and release branch.
As an aside, given that [java linting currently
fails](https://github.com/apache/spark/pull/10763
) on machines with a clean maven cache, it'd be great to find another
workaround to [re-enable the java style
checks](https://github.com/apache/spark/blob/3a07eff5af601511e97a05e6fea0e3d48f74c4f0/dev/run-tests.py#L577)
as part of Spark PRB.
/cc zsxwing JoshRosen srowen for any suggestions
## How was this patch tested?
Manual Check
Author: Sameer Agarwal
Closes #20323 from sameeragarwal/java.
Project: http://git-wip-us.apache.org/repos/asf/spark/repo
Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/9c4b9986
Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/9c4b9986
Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/9c4b9986
Branch: refs/heads/master
Commit: 9c4b99861cda3f9ec44ca8c1adc81a293508190c
Parents: 568055d
Author: Sameer Agarwal
Authored: Fri Jan 19 01:38:08 2018 -0800
Committer: Sameer Agarwal
Committed: Fri Jan 19 01:38:08 2018 -0800
--
.../apache/spark/sql/sources/v2/writer/DataSourceV2Writer.java | 6 --
.../org/apache/spark/sql/vectorized/ArrowColumnVector.java | 5 +++--
.../org/apache/spark/sql/sources/v2/JavaBatchDataSourceV2.java | 3 ++-
3 files changed, 9 insertions(+), 5 deletions(-)
--
http://git-wip-us.apache.org/repos/asf/spark/blob/9c4b9986/sql/core/src/main/java/org/apache/spark/sql/sources/v2/writer/DataSourceV2Writer.java
--
diff --git
a/sql/core/src/main/java/org/apache/spark/sql/sources/v2/writer/DataSourceV2Writer.java
b/sql/core/src/main/java/org/apache/spark/sql/sources/v2/writer/DataSourceV2Writer.java
index 317ac45..f1ef411 100644
---
a/sql/core/src/main/java/org/apache/spark/sql/sources/v2/writer/DataSourceV2Writer.java
+++
b/sql/core/src/main/java/org/apache/spark/sql/sources/v2/writer/DataSourceV2Writer.java
@@ -28,8 +28,10 @@ import org.apache.spark.sql.types.StructType;
/**
* A data source writer that is returned by
* {@link WriteSupport#createWriter(String, StructType, SaveMode,
DataSourceV2Options)}/
- * {@link
org.apache.spark.sql.sources.v2.streaming.MicroBatchWriteSupport#createMicroBatchWriter(String,
long, StructType, OutputMode, DataSourceV2Options)}/
- * {@link
org.apache.spark.sql.sources.v2.streaming.ContinuousWriteSupport#createContinuousWriter(String,
StructType, OutputMode, DataSourceV2Options)}.
+ * {@link
org.apache.spark.sql.sources.v2.streaming.MicroBatchWriteSupport#createMicroBatchWriter(
+ * String, long, StructType, OutputMode, DataSourceV2Options)}/
+ * {@link
org.apache.spark.sql.sources.v2.streaming.ContinuousWriteSupport#createContinuousWriter(
+ * String, StructType, OutputMode, DataSourceV2Options)}.
* It can mix in various writing optimization interfaces to speed up the data
saving. The actual
* writing logic is delegated to {@link DataWriter}.
*
http://git-wip-us.apache.org/repos/asf/spark/blob/9c4b9986/sql/core/src/main/java/org/apache/spark/sql/vectorized/ArrowColumnVector.java
--
diff --git
a/sql/core/src/main/java/org/apache/spark/sql/vectorized/ArrowColumnVector.java
b/sql/core/src/main/java/org/apache/spark/sql/vectorized/ArrowColumnVector.java
index eb69001..bfd1b4c 100644
---
a/sql/core/src/main/java/org/apache/spark/sql/vectorized/ArrowColumnVector.java
+++
b/sql/core/src/main/java/org/apache/spark/sql/vectorized/ArrowColumnVector.java
@@ -556,8 +556,9 @@ public final class ArrowColumnVector extends ColumnVector {
/**
* Any call to "get" method will throw UnsupportedOperationException.
*
- * Access struct values in a ArrowColumnVector doesn't use this accessor.
Instead, it uses getStruct() method defined
- * in the parent class. Any call to "get" method in this class is a bug in
the code.
+ * Access struct values in a ArrowColumnVector doesn't use this accessor.
Instead, it uses
+ * getStruct() method defined in the parent class. Any call to "get" method
in this class is a
+ * bug in the code.
*
*/
private static class StructAccessor extends ArrowVectorAccessor {
http://git-wip-us.apache.org/repos/asf/spark/blob/9c4b9986/sql/core/src/test/java/test/org/apache/spark/sql/sources/v2/JavaBatchDataSourceV2.java
--
diff --git
a/sql/core/src/test/java/test/org/apache/spark/sql/sources/v2/JavaBatchDataSourceV2.java
b/sql/core/src/test/java/test/org/apache/spark/sql/sources/v2/JavaBatchDataSourceV2.java
index 44e5146..98d6
spark git commit: [BUILD][MINOR] Fix java style check issues
Repository: spark
Updated Branches:
refs/heads/branch-2.3 541dbc00b -> 54c1fae12
[BUILD][MINOR] Fix java style check issues
## What changes were proposed in this pull request?
This patch fixes a few recently introduced java style check errors in master
and release branch.
As an aside, given that [java linting currently
fails](https://github.com/apache/spark/pull/10763
) on machines with a clean maven cache, it'd be great to find another
workaround to [re-enable the java style
checks](https://github.com/apache/spark/blob/3a07eff5af601511e97a05e6fea0e3d48f74c4f0/dev/run-tests.py#L577)
as part of Spark PRB.
/cc zsxwing JoshRosen srowen for any suggestions
## How was this patch tested?
Manual Check
Author: Sameer Agarwal
Closes #20323 from sameeragarwal/java.
(cherry picked from commit 9c4b99861cda3f9ec44ca8c1adc81a293508190c)
Signed-off-by: Sameer Agarwal
Project: http://git-wip-us.apache.org/repos/asf/spark/repo
Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/54c1fae1
Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/54c1fae1
Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/54c1fae1
Branch: refs/heads/branch-2.3
Commit: 54c1fae12df654c7713ac5e7eb4da7bb2f785401
Parents: 541dbc0
Author: Sameer Agarwal
Authored: Fri Jan 19 01:38:08 2018 -0800
Committer: Sameer Agarwal
Committed: Fri Jan 19 01:38:20 2018 -0800
--
.../apache/spark/sql/sources/v2/writer/DataSourceV2Writer.java | 6 --
.../org/apache/spark/sql/vectorized/ArrowColumnVector.java | 5 +++--
.../org/apache/spark/sql/sources/v2/JavaBatchDataSourceV2.java | 3 ++-
3 files changed, 9 insertions(+), 5 deletions(-)
--
http://git-wip-us.apache.org/repos/asf/spark/blob/54c1fae1/sql/core/src/main/java/org/apache/spark/sql/sources/v2/writer/DataSourceV2Writer.java
--
diff --git
a/sql/core/src/main/java/org/apache/spark/sql/sources/v2/writer/DataSourceV2Writer.java
b/sql/core/src/main/java/org/apache/spark/sql/sources/v2/writer/DataSourceV2Writer.java
index 317ac45..f1ef411 100644
---
a/sql/core/src/main/java/org/apache/spark/sql/sources/v2/writer/DataSourceV2Writer.java
+++
b/sql/core/src/main/java/org/apache/spark/sql/sources/v2/writer/DataSourceV2Writer.java
@@ -28,8 +28,10 @@ import org.apache.spark.sql.types.StructType;
/**
* A data source writer that is returned by
* {@link WriteSupport#createWriter(String, StructType, SaveMode,
DataSourceV2Options)}/
- * {@link
org.apache.spark.sql.sources.v2.streaming.MicroBatchWriteSupport#createMicroBatchWriter(String,
long, StructType, OutputMode, DataSourceV2Options)}/
- * {@link
org.apache.spark.sql.sources.v2.streaming.ContinuousWriteSupport#createContinuousWriter(String,
StructType, OutputMode, DataSourceV2Options)}.
+ * {@link
org.apache.spark.sql.sources.v2.streaming.MicroBatchWriteSupport#createMicroBatchWriter(
+ * String, long, StructType, OutputMode, DataSourceV2Options)}/
+ * {@link
org.apache.spark.sql.sources.v2.streaming.ContinuousWriteSupport#createContinuousWriter(
+ * String, StructType, OutputMode, DataSourceV2Options)}.
* It can mix in various writing optimization interfaces to speed up the data
saving. The actual
* writing logic is delegated to {@link DataWriter}.
*
http://git-wip-us.apache.org/repos/asf/spark/blob/54c1fae1/sql/core/src/main/java/org/apache/spark/sql/vectorized/ArrowColumnVector.java
--
diff --git
a/sql/core/src/main/java/org/apache/spark/sql/vectorized/ArrowColumnVector.java
b/sql/core/src/main/java/org/apache/spark/sql/vectorized/ArrowColumnVector.java
index eb69001..bfd1b4c 100644
---
a/sql/core/src/main/java/org/apache/spark/sql/vectorized/ArrowColumnVector.java
+++
b/sql/core/src/main/java/org/apache/spark/sql/vectorized/ArrowColumnVector.java
@@ -556,8 +556,9 @@ public final class ArrowColumnVector extends ColumnVector {
/**
* Any call to "get" method will throw UnsupportedOperationException.
*
- * Access struct values in a ArrowColumnVector doesn't use this accessor.
Instead, it uses getStruct() method defined
- * in the parent class. Any call to "get" method in this class is a bug in
the code.
+ * Access struct values in a ArrowColumnVector doesn't use this accessor.
Instead, it uses
+ * getStruct() method defined in the parent class. Any call to "get" method
in this class is a
+ * bug in the code.
*
*/
private static class StructAccessor extends ArrowVectorAccessor {
http://git-wip-us.apache.org/repos/asf/spark/blob/54c1fae1/sql/core/src/test/java/test/org/apache/spark/sql/sources/v2/JavaBatchDataSourceV2.java
--
diff --git
a/sql/core/src/test/java/test/org/apache/spark/sql/sources/v2/JavaBatchDataSourceV2.java
svn commit: r24312 - in /dev/spark/2.3.1-SNAPSHOT-2018_01_19_02_01-54c1fae-docs: ./ _site/ _site/api/ _site/api/R/ _site/api/java/ _site/api/java/lib/ _site/api/java/org/ _site/api/java/org/apache/ _s
Author: pwendell Date: Fri Jan 19 10:14:54 2018 New Revision: 24312 Log: Apache Spark 2.3.1-SNAPSHOT-2018_01_19_02_01-54c1fae docs [This commit notification would consist of 1441 parts, which exceeds the limit of 50 ones, so it was shortened to the summary.] - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
spark git commit: [SPARK-23127][DOC] Update FeatureHasher guide for categoricalCols parameter
Repository: spark Updated Branches: refs/heads/branch-2.3 54c1fae12 -> e58223171 [SPARK-23127][DOC] Update FeatureHasher guide for categoricalCols parameter Update user guide entry for `FeatureHasher` to match the Scala / Python doc, to describe the `categoricalCols` parameter. ## How was this patch tested? Doc only Author: Nick Pentreath Closes #20293 from MLnick/SPARK-23127-catCol-userguide. (cherry picked from commit 60203fca6a605ad158184e1e0ce5187e144a3ea7) Signed-off-by: Nick Pentreath Project: http://git-wip-us.apache.org/repos/asf/spark/repo Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/e5822317 Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/e5822317 Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/e5822317 Branch: refs/heads/branch-2.3 Commit: e58223171ecae6450482aadf4e7994c3b8d8a58d Parents: 54c1fae Author: Nick Pentreath Authored: Fri Jan 19 12:43:23 2018 +0200 Committer: Nick Pentreath Committed: Fri Jan 19 12:43:35 2018 +0200 -- docs/ml-features.md | 6 +++--- 1 file changed, 3 insertions(+), 3 deletions(-) -- http://git-wip-us.apache.org/repos/asf/spark/blob/e5822317/docs/ml-features.md -- diff --git a/docs/ml-features.md b/docs/ml-features.md index 7264313..10183c3 100644 --- a/docs/ml-features.md +++ b/docs/ml-features.md @@ -222,9 +222,9 @@ The `FeatureHasher` transformer operates on multiple columns. Each column may co numeric or categorical features. Behavior and handling of column data types is as follows: - Numeric columns: For numeric features, the hash value of the column name is used to map the -feature value to its index in the feature vector. Numeric features are never treated as -categorical, even when they are integers. You must explicitly convert numeric columns containing -categorical features to strings first. +feature value to its index in the feature vector. By default, numeric features are not treated +as categorical (even when they are integers). To treat them as categorical, specify the relevant +columns using the `categoricalCols` parameter. - String columns: For categorical features, the hash value of the string "column_name=value" is used to map to the vector index, with an indicator value of `1.0`. Thus, categorical features are "one-hot" encoded (similarly to using [OneHotEncoder](ml-features.html#onehotencoder) with - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
spark git commit: [SPARK-23127][DOC] Update FeatureHasher guide for categoricalCols parameter
Repository: spark Updated Branches: refs/heads/master 9c4b99861 -> 60203fca6 [SPARK-23127][DOC] Update FeatureHasher guide for categoricalCols parameter Update user guide entry for `FeatureHasher` to match the Scala / Python doc, to describe the `categoricalCols` parameter. ## How was this patch tested? Doc only Author: Nick Pentreath Closes #20293 from MLnick/SPARK-23127-catCol-userguide. Project: http://git-wip-us.apache.org/repos/asf/spark/repo Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/60203fca Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/60203fca Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/60203fca Branch: refs/heads/master Commit: 60203fca6a605ad158184e1e0ce5187e144a3ea7 Parents: 9c4b998 Author: Nick Pentreath Authored: Fri Jan 19 12:43:23 2018 +0200 Committer: Nick Pentreath Committed: Fri Jan 19 12:43:23 2018 +0200 -- docs/ml-features.md | 6 +++--- 1 file changed, 3 insertions(+), 3 deletions(-) -- http://git-wip-us.apache.org/repos/asf/spark/blob/60203fca/docs/ml-features.md -- diff --git a/docs/ml-features.md b/docs/ml-features.md index 7264313..10183c3 100644 --- a/docs/ml-features.md +++ b/docs/ml-features.md @@ -222,9 +222,9 @@ The `FeatureHasher` transformer operates on multiple columns. Each column may co numeric or categorical features. Behavior and handling of column data types is as follows: - Numeric columns: For numeric features, the hash value of the column name is used to map the -feature value to its index in the feature vector. Numeric features are never treated as -categorical, even when they are integers. You must explicitly convert numeric columns containing -categorical features to strings first. +feature value to its index in the feature vector. By default, numeric features are not treated +as categorical (even when they are integers). To treat them as categorical, specify the relevant +columns using the `categoricalCols` parameter. - String columns: For categorical features, the hash value of the string "column_name=value" is used to map to the vector index, with an indicator value of `1.0`. Thus, categorical features are "one-hot" encoded (similarly to using [OneHotEncoder](ml-features.html#onehotencoder) with - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
spark git commit: [SPARK-23048][ML] Add OneHotEncoderEstimator document and examples
Repository: spark
Updated Branches:
refs/heads/branch-2.3 e58223171 -> ef7989d55
[SPARK-23048][ML] Add OneHotEncoderEstimator document and examples
## What changes were proposed in this pull request?
We have `OneHotEncoderEstimator` now and `OneHotEncoder` will be deprecated
since 2.3.0. We should add `OneHotEncoderEstimator` into mllib document.
We also need to provide corresponding examples for `OneHotEncoderEstimator`
which are used in the document too.
## How was this patch tested?
Existing tests.
Author: Liang-Chi Hsieh
Closes #20257 from viirya/SPARK-23048.
(cherry picked from commit b74366481cc87490adf4e69d26389ec737548c15)
Signed-off-by: Nick Pentreath
Project: http://git-wip-us.apache.org/repos/asf/spark/repo
Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/ef7989d5
Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/ef7989d5
Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/ef7989d5
Branch: refs/heads/branch-2.3
Commit: ef7989d55b65f386ed1ab87535a44e9367029a52
Parents: e582231
Author: Liang-Chi Hsieh
Authored: Fri Jan 19 12:48:42 2018 +0200
Committer: Nick Pentreath
Committed: Fri Jan 19 12:48:55 2018 +0200
--
docs/ml-features.md | 28 ---
.../ml/JavaOneHotEncoderEstimatorExample.java | 74 ++
.../examples/ml/JavaOneHotEncoderExample.java | 79
.../ml/onehot_encoder_estimator_example.py | 49
.../main/python/ml/onehot_encoder_example.py| 50 -
.../ml/OneHotEncoderEstimatorExample.scala | 56 ++
.../examples/ml/OneHotEncoderExample.scala | 60 ---
7 files changed, 197 insertions(+), 199 deletions(-)
--
http://git-wip-us.apache.org/repos/asf/spark/blob/ef7989d5/docs/ml-features.md
--
diff --git a/docs/ml-features.md b/docs/ml-features.md
index 10183c3..466a8fb 100644
--- a/docs/ml-features.md
+++ b/docs/ml-features.md
@@ -775,35 +775,43 @@ for more details on the API.
-## OneHotEncoder
+## OneHotEncoder (Deprecated since 2.3.0)
-[One-hot encoding](http://en.wikipedia.org/wiki/One-hot) maps a column of
label indices to a column of binary vectors, with at most a single one-value.
This encoding allows algorithms which expect continuous features, such as
Logistic Regression, to use categorical features.
+Because this existing `OneHotEncoder` is a stateless transformer, it is not
usable on new data where the number of categories may differ from the training
data. In order to fix this, a new `OneHotEncoderEstimator` was created that
produces an `OneHotEncoderModel` when fitting. For more detail, please see
[SPARK-13030](https://issues.apache.org/jira/browse/SPARK-13030).
+
+`OneHotEncoder` has been deprecated in 2.3.0 and will be removed in 3.0.0.
Please use [OneHotEncoderEstimator](ml-features.html#onehotencoderestimator)
instead.
+
+## OneHotEncoderEstimator
+
+[One-hot encoding](http://en.wikipedia.org/wiki/One-hot) maps a categorical
feature, represented as a label index, to a binary vector with at most a single
one-value indicating the presence of a specific feature value from among the
set of all feature values. This encoding allows algorithms which expect
continuous features, such as Logistic Regression, to use categorical features.
For string type input data, it is common to encode categorical features using
[StringIndexer](ml-features.html#stringindexer) first.
+
+`OneHotEncoderEstimator` can transform multiple columns, returning an
one-hot-encoded output vector column for each input column. It is common to
merge these vectors into a single feature vector using
[VectorAssembler](ml-features.html#vectorassembler).
+
+`OneHotEncoderEstimator` supports the `handleInvalid` parameter to choose how
to handle invalid input during transforming data. Available options include
'keep' (any invalid inputs are assigned to an extra categorical index) and
'error' (throw an error).
**Examples**
-Refer to the [OneHotEncoder Scala
docs](api/scala/index.html#org.apache.spark.ml.feature.OneHotEncoder)
-for more details on the API.
+Refer to the [OneHotEncoderEstimator Scala
docs](api/scala/index.html#org.apache.spark.ml.feature.OneHotEncoderEstimator)
for more details on the API.
-{% include_example
scala/org/apache/spark/examples/ml/OneHotEncoderExample.scala %}
+{% include_example
scala/org/apache/spark/examples/ml/OneHotEncoderEstimatorExample.scala %}
-Refer to the [OneHotEncoder Java
docs](api/java/org/apache/spark/ml/feature/OneHotEncoder.html)
+Refer to the [OneHotEncoderEstimator Java
docs](api/java/org/apache/spark/ml/feature/OneHotEncoderEstimator.html)
for more details on the API.
-{% include_example
java/org/apache/spark/examples/ml/JavaOneHotEncoderExample.ja
spark git commit: [SPARK-23048][ML] Add OneHotEncoderEstimator document and examples
Repository: spark
Updated Branches:
refs/heads/master 60203fca6 -> b74366481
[SPARK-23048][ML] Add OneHotEncoderEstimator document and examples
## What changes were proposed in this pull request?
We have `OneHotEncoderEstimator` now and `OneHotEncoder` will be deprecated
since 2.3.0. We should add `OneHotEncoderEstimator` into mllib document.
We also need to provide corresponding examples for `OneHotEncoderEstimator`
which are used in the document too.
## How was this patch tested?
Existing tests.
Author: Liang-Chi Hsieh
Closes #20257 from viirya/SPARK-23048.
Project: http://git-wip-us.apache.org/repos/asf/spark/repo
Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/b7436648
Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/b7436648
Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/b7436648
Branch: refs/heads/master
Commit: b74366481cc87490adf4e69d26389ec737548c15
Parents: 60203fc
Author: Liang-Chi Hsieh
Authored: Fri Jan 19 12:48:42 2018 +0200
Committer: Nick Pentreath
Committed: Fri Jan 19 12:48:42 2018 +0200
--
docs/ml-features.md | 28 ---
.../ml/JavaOneHotEncoderEstimatorExample.java | 74 ++
.../examples/ml/JavaOneHotEncoderExample.java | 79
.../ml/onehot_encoder_estimator_example.py | 49
.../main/python/ml/onehot_encoder_example.py| 50 -
.../ml/OneHotEncoderEstimatorExample.scala | 56 ++
.../examples/ml/OneHotEncoderExample.scala | 60 ---
7 files changed, 197 insertions(+), 199 deletions(-)
--
http://git-wip-us.apache.org/repos/asf/spark/blob/b7436648/docs/ml-features.md
--
diff --git a/docs/ml-features.md b/docs/ml-features.md
index 10183c3..466a8fb 100644
--- a/docs/ml-features.md
+++ b/docs/ml-features.md
@@ -775,35 +775,43 @@ for more details on the API.
-## OneHotEncoder
+## OneHotEncoder (Deprecated since 2.3.0)
-[One-hot encoding](http://en.wikipedia.org/wiki/One-hot) maps a column of
label indices to a column of binary vectors, with at most a single one-value.
This encoding allows algorithms which expect continuous features, such as
Logistic Regression, to use categorical features.
+Because this existing `OneHotEncoder` is a stateless transformer, it is not
usable on new data where the number of categories may differ from the training
data. In order to fix this, a new `OneHotEncoderEstimator` was created that
produces an `OneHotEncoderModel` when fitting. For more detail, please see
[SPARK-13030](https://issues.apache.org/jira/browse/SPARK-13030).
+
+`OneHotEncoder` has been deprecated in 2.3.0 and will be removed in 3.0.0.
Please use [OneHotEncoderEstimator](ml-features.html#onehotencoderestimator)
instead.
+
+## OneHotEncoderEstimator
+
+[One-hot encoding](http://en.wikipedia.org/wiki/One-hot) maps a categorical
feature, represented as a label index, to a binary vector with at most a single
one-value indicating the presence of a specific feature value from among the
set of all feature values. This encoding allows algorithms which expect
continuous features, such as Logistic Regression, to use categorical features.
For string type input data, it is common to encode categorical features using
[StringIndexer](ml-features.html#stringindexer) first.
+
+`OneHotEncoderEstimator` can transform multiple columns, returning an
one-hot-encoded output vector column for each input column. It is common to
merge these vectors into a single feature vector using
[VectorAssembler](ml-features.html#vectorassembler).
+
+`OneHotEncoderEstimator` supports the `handleInvalid` parameter to choose how
to handle invalid input during transforming data. Available options include
'keep' (any invalid inputs are assigned to an extra categorical index) and
'error' (throw an error).
**Examples**
-Refer to the [OneHotEncoder Scala
docs](api/scala/index.html#org.apache.spark.ml.feature.OneHotEncoder)
-for more details on the API.
+Refer to the [OneHotEncoderEstimator Scala
docs](api/scala/index.html#org.apache.spark.ml.feature.OneHotEncoderEstimator)
for more details on the API.
-{% include_example
scala/org/apache/spark/examples/ml/OneHotEncoderExample.scala %}
+{% include_example
scala/org/apache/spark/examples/ml/OneHotEncoderEstimatorExample.scala %}
-Refer to the [OneHotEncoder Java
docs](api/java/org/apache/spark/ml/feature/OneHotEncoder.html)
+Refer to the [OneHotEncoderEstimator Java
docs](api/java/org/apache/spark/ml/feature/OneHotEncoderEstimator.html)
for more details on the API.
-{% include_example
java/org/apache/spark/examples/ml/JavaOneHotEncoderExample.java %}
+{% include_example
java/org/apache/spark/examples/ml/JavaOneHotEncoderEstimatorExample.java %}
spark git commit: [SPARK-23089][STS] Recreate session log directory if it doesn't exist
Repository: spark
Updated Branches:
refs/heads/master b74366481 -> e41400c3c
[SPARK-23089][STS] Recreate session log directory if it doesn't exist
## What changes were proposed in this pull request?
When creating a session directory, Thrift should create the parent directory
(i.e. /tmp/base_session_log_dir) if it is not present. It is common that many
tools delete empty directories, so the directory may be deleted. This can cause
the session log to be disabled.
This was fixed in HIVE-12262: this PR brings it in Spark too.
## How was this patch tested?
manual tests
Author: Marco Gaido
Closes #20281 from mgaido91/SPARK-23089.
Project: http://git-wip-us.apache.org/repos/asf/spark/repo
Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/e41400c3
Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/e41400c3
Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/e41400c3
Branch: refs/heads/master
Commit: e41400c3c8aace9eb72e6134173f222627fb0faf
Parents: b743664
Author: Marco Gaido
Authored: Fri Jan 19 19:46:48 2018 +0800
Committer: Wenchen Fan
Committed: Fri Jan 19 19:46:48 2018 +0800
--
.../hive/service/cli/session/HiveSessionImpl.java | 12
1 file changed, 12 insertions(+)
--
http://git-wip-us.apache.org/repos/asf/spark/blob/e41400c3/sql/hive-thriftserver/src/main/java/org/apache/hive/service/cli/session/HiveSessionImpl.java
--
diff --git
a/sql/hive-thriftserver/src/main/java/org/apache/hive/service/cli/session/HiveSessionImpl.java
b/sql/hive-thriftserver/src/main/java/org/apache/hive/service/cli/session/HiveSessionImpl.java
index 47bfaa8..108074c 100644
---
a/sql/hive-thriftserver/src/main/java/org/apache/hive/service/cli/session/HiveSessionImpl.java
+++
b/sql/hive-thriftserver/src/main/java/org/apache/hive/service/cli/session/HiveSessionImpl.java
@@ -223,6 +223,18 @@ public class HiveSessionImpl implements HiveSession {
@Override
public void setOperationLogSessionDir(File operationLogRootDir) {
+if (!operationLogRootDir.exists()) {
+ LOG.warn("The operation log root directory is removed, recreating: " +
+ operationLogRootDir.getAbsolutePath());
+ if (!operationLogRootDir.mkdirs()) {
+LOG.warn("Unable to create operation log root directory: " +
+operationLogRootDir.getAbsolutePath());
+ }
+}
+if (!operationLogRootDir.canWrite()) {
+ LOG.warn("The operation log root directory is not writable: " +
+ operationLogRootDir.getAbsolutePath());
+}
sessionLogDir = new File(operationLogRootDir,
sessionHandle.getHandleIdentifier().toString());
isOperationLogEnabled = true;
if (!sessionLogDir.exists()) {
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
spark git commit: [SPARK-23089][STS] Recreate session log directory if it doesn't exist
Repository: spark
Updated Branches:
refs/heads/branch-2.3 ef7989d55 -> b7a81999d
[SPARK-23089][STS] Recreate session log directory if it doesn't exist
## What changes were proposed in this pull request?
When creating a session directory, Thrift should create the parent directory
(i.e. /tmp/base_session_log_dir) if it is not present. It is common that many
tools delete empty directories, so the directory may be deleted. This can cause
the session log to be disabled.
This was fixed in HIVE-12262: this PR brings it in Spark too.
## How was this patch tested?
manual tests
Author: Marco Gaido
Closes #20281 from mgaido91/SPARK-23089.
(cherry picked from commit e41400c3c8aace9eb72e6134173f222627fb0faf)
Signed-off-by: Wenchen Fan
Project: http://git-wip-us.apache.org/repos/asf/spark/repo
Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/b7a81999
Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/b7a81999
Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/b7a81999
Branch: refs/heads/branch-2.3
Commit: b7a81999df8f43223403c77db9c1aedddb58370d
Parents: ef7989d
Author: Marco Gaido
Authored: Fri Jan 19 19:46:48 2018 +0800
Committer: Wenchen Fan
Committed: Fri Jan 19 19:47:15 2018 +0800
--
.../hive/service/cli/session/HiveSessionImpl.java | 12
1 file changed, 12 insertions(+)
--
http://git-wip-us.apache.org/repos/asf/spark/blob/b7a81999/sql/hive-thriftserver/src/main/java/org/apache/hive/service/cli/session/HiveSessionImpl.java
--
diff --git
a/sql/hive-thriftserver/src/main/java/org/apache/hive/service/cli/session/HiveSessionImpl.java
b/sql/hive-thriftserver/src/main/java/org/apache/hive/service/cli/session/HiveSessionImpl.java
index 47bfaa8..108074c 100644
---
a/sql/hive-thriftserver/src/main/java/org/apache/hive/service/cli/session/HiveSessionImpl.java
+++
b/sql/hive-thriftserver/src/main/java/org/apache/hive/service/cli/session/HiveSessionImpl.java
@@ -223,6 +223,18 @@ public class HiveSessionImpl implements HiveSession {
@Override
public void setOperationLogSessionDir(File operationLogRootDir) {
+if (!operationLogRootDir.exists()) {
+ LOG.warn("The operation log root directory is removed, recreating: " +
+ operationLogRootDir.getAbsolutePath());
+ if (!operationLogRootDir.mkdirs()) {
+LOG.warn("Unable to create operation log root directory: " +
+operationLogRootDir.getAbsolutePath());
+ }
+}
+if (!operationLogRootDir.canWrite()) {
+ LOG.warn("The operation log root directory is not writable: " +
+ operationLogRootDir.getAbsolutePath());
+}
sessionLogDir = new File(operationLogRootDir,
sessionHandle.getHandleIdentifier().toString());
isOperationLogEnabled = true;
if (!sessionLogDir.exists()) {
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
svn commit: r24315 - in /dev/spark/2.4.0-SNAPSHOT-2018_01_19_04_01-e41400c-docs: ./ _site/ _site/api/ _site/api/R/ _site/api/java/ _site/api/java/lib/ _site/api/java/org/ _site/api/java/org/apache/ _s
Author: pwendell Date: Fri Jan 19 12:19:02 2018 New Revision: 24315 Log: Apache Spark 2.4.0-SNAPSHOT-2018_01_19_04_01-e41400c docs [This commit notification would consist of 1441 parts, which exceeds the limit of 50 ones, so it was shortened to the summary.] - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
svn commit: r24322 - in /dev/spark/2.3.1-SNAPSHOT-2018_01_19_06_01-b7a8199-docs: ./ _site/ _site/api/ _site/api/R/ _site/api/java/ _site/api/java/lib/ _site/api/java/org/ _site/api/java/org/apache/ _s
Author: pwendell Date: Fri Jan 19 14:14:36 2018 New Revision: 24322 Log: Apache Spark 2.3.1-SNAPSHOT-2018_01_19_06_01-b7a8199 docs [This commit notification would consist of 1441 parts, which exceeds the limit of 50 ones, so it was shortened to the summary.] - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
spark git commit: [SPARK-23024][WEB-UI] Spark ui about the contents of the form need to have hidden and show features, when the table records very much.
Repository: spark
Updated Branches:
refs/heads/master e41400c3c -> e1c33b6cd
[SPARK-23024][WEB-UI] Spark ui about the contents of the form need to have
hidden and show features, when the table records very much.
## What changes were proposed in this pull request?
Spark ui about the contents of the form need to have hidden and show features,
when the table records very much. Because sometimes you do not care about the
record of the table, you just want to see the contents of the next table, but
you have to scroll the scroll bar for a long time to see the contents of the
next table.
Currently we have about 500 workers, but I just wanted to see the logs for the
running applications table. I had to scroll through the scroll bars for a long
time to see the logs for the running applications table.
In order to ensure functional consistency, I modified the Master Page, Worker
Page, Job Page, Stage Page, Task Page, Configuration Page, Storage Page, Pool
Page.
fix before:
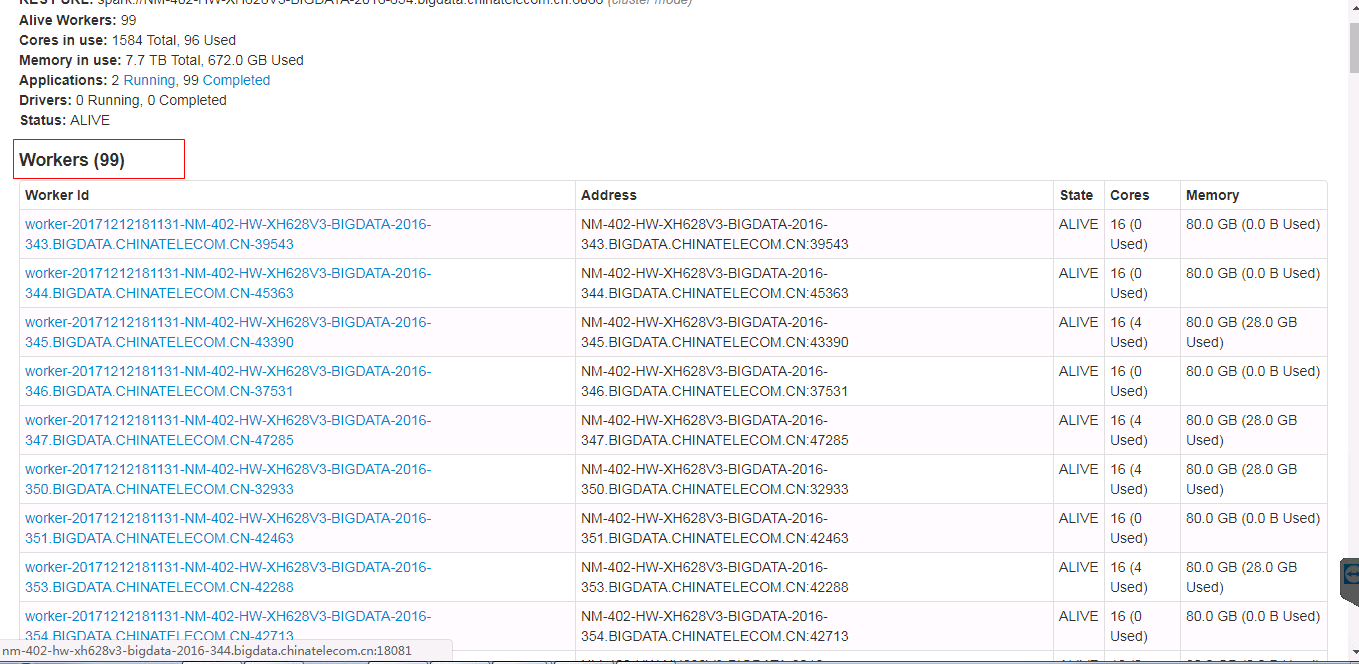
fix after:
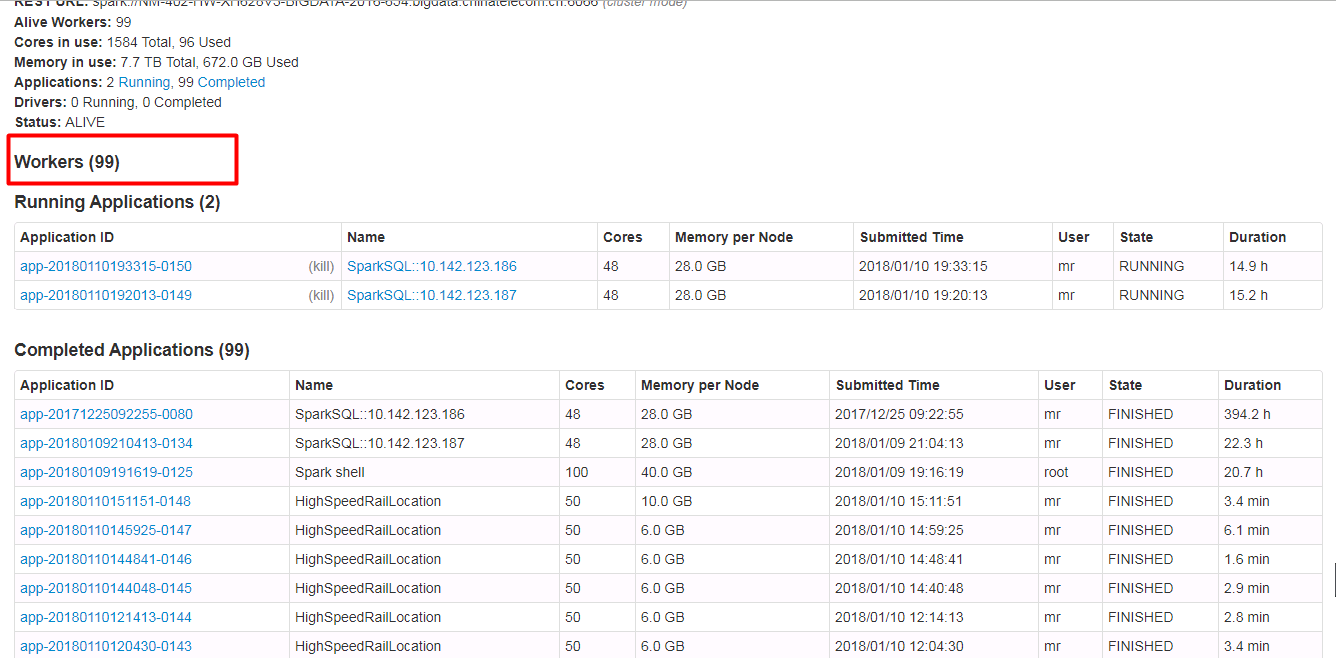
## How was this patch tested?
manual tests
Please review http://spark.apache.org/contributing.html before opening a pull
request.
Author: guoxiaolong
Closes #20216 from guoxiaolongzte/SPARK-23024.
Project: http://git-wip-us.apache.org/repos/asf/spark/repo
Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/e1c33b6c
Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/e1c33b6c
Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/e1c33b6c
Branch: refs/heads/master
Commit: e1c33b6cd14e4e1123814f4d040e3520db7d1ec9
Parents: e41400c
Author: guoxiaolong
Authored: Fri Jan 19 08:22:24 2018 -0600
Committer: Sean Owen
Committed: Fri Jan 19 08:22:24 2018 -0600
--
.../org/apache/spark/ui/static/webui.js | 30 +
.../deploy/master/ui/ApplicationPage.scala | 25 +--
.../spark/deploy/master/ui/MasterPage.scala | 63 +++---
.../spark/deploy/worker/ui/WorkerPage.scala | 52 ---
.../apache/spark/ui/env/EnvironmentPage.scala | 48 --
.../org/apache/spark/ui/jobs/AllJobsPage.scala | 39 +--
.../apache/spark/ui/jobs/AllStagesPage.scala| 67 ---
.../org/apache/spark/ui/jobs/JobPage.scala | 68 +---
.../org/apache/spark/ui/jobs/PoolPage.scala | 13 +++-
.../org/apache/spark/ui/jobs/StagePage.scala| 12 +++-
.../apache/spark/ui/storage/StoragePage.scala | 12 +++-
11 files changed, 373 insertions(+), 56 deletions(-)
--
http://git-wip-us.apache.org/repos/asf/spark/blob/e1c33b6c/core/src/main/resources/org/apache/spark/ui/static/webui.js
--
diff --git a/core/src/main/resources/org/apache/spark/ui/static/webui.js
b/core/src/main/resources/org/apache/spark/ui/static/webui.js
index 0fa1fcf..e575c4c 100644
--- a/core/src/main/resources/org/apache/spark/ui/static/webui.js
+++ b/core/src/main/resources/org/apache/spark/ui/static/webui.js
@@ -50,4 +50,34 @@ function collapseTable(thisName, table){
// to remember if it's collapsed on each page reload
$(function() {
collapseTablePageLoad('collapse-aggregated-metrics','aggregated-metrics');
+
collapseTablePageLoad('collapse-aggregated-executors','aggregated-executors');
+
collapseTablePageLoad('collapse-aggregated-removedExecutors','aggregated-removedExecutors');
+ collapseTablePageLoad('collapse-aggregated-workers','aggregated-workers');
+
collapseTablePageLoad('collapse-aggregated-activeApps','aggregated-activeApps');
+
collapseTablePageLoad('collapse-aggregated-activeDrivers','aggregated-activeDrivers');
+
collapseTablePageLoad('collapse-aggregated-completedApps','aggregated-completedApps');
+
collapseTablePageLoad('collapse-aggregated-completedDrivers','aggregated-completedDrivers');
+
collapseTablePageLoad('collapse-aggregated-runningExecutors','aggregated-runningExecutors');
+
collapseTablePageLoad('collapse-aggregated-runningDrivers','aggregated-runningDrivers');
+
collapseTablePageLoad('collapse-aggregated-finishedExecutors','aggregated-finishedExecutors');
+
collapseTablePageLoad('collapse-aggregated-finishedDrivers','aggregated-finishedDrivers');
+
collapseTablePageLoad('collapse-aggregated-runtimeInformation','aggregated-runtimeInformation');
+
collapseTablePageLoad('collapse-aggregated-sparkProperties','aggregated-sparkProperties');
+
collapseTablePageLoad('collapse-aggregated-systemProperties','aggregated-systemProperties');
+
collapseTablePageLoad('collapse-aggregated-classpathEntries','aggregated-classpathEntries');
+
collapseTablePageLoad('collapse-aggregated-activeJobs','aggregated-activ
[1/2] spark-website git commit: Add notice that site is licensed as AL2
Repository: spark-website Updated Branches: refs/heads/asf-site b3ecc858f -> 464ddc703 http://git-wip-us.apache.org/repos/asf/spark-website/blob/464ddc70/site/news/submit-talks-to-spark-summit-2014.html -- diff --git a/site/news/submit-talks-to-spark-summit-2014.html b/site/news/submit-talks-to-spark-summit-2014.html index f362e1e..16094ef 100644 --- a/site/news/submit-talks-to-spark-summit-2014.html +++ b/site/news/submit-talks-to-spark-summit-2014.html @@ -223,6 +223,8 @@ on Spark. Apache Spark, Spark, Apache, and the Spark logo are trademarks of https://www.apache.org";>The Apache Software Foundation. + Copyright © 2018 The Apache Software Foundation, Licensed under the + https://www.apache.org/licenses/LICENSE-2.0.html";>Apache License, Version 2.0. http://git-wip-us.apache.org/repos/asf/spark-website/blob/464ddc70/site/news/submit-talks-to-spark-summit-2016.html -- diff --git a/site/news/submit-talks-to-spark-summit-2016.html b/site/news/submit-talks-to-spark-summit-2016.html index 38182e4..0bc896b 100644 --- a/site/news/submit-talks-to-spark-summit-2016.html +++ b/site/news/submit-talks-to-spark-summit-2016.html @@ -215,6 +215,8 @@ Apache Spark, Spark, Apache, and the Spark logo are trademarks of https://www.apache.org";>The Apache Software Foundation. + Copyright © 2018 The Apache Software Foundation, Licensed under the + https://www.apache.org/licenses/LICENSE-2.0.html";>Apache License, Version 2.0. http://git-wip-us.apache.org/repos/asf/spark-website/blob/464ddc70/site/news/submit-talks-to-spark-summit-east-2016.html -- diff --git a/site/news/submit-talks-to-spark-summit-east-2016.html b/site/news/submit-talks-to-spark-summit-east-2016.html index 6f2df97..680c2d9 100644 --- a/site/news/submit-talks-to-spark-summit-east-2016.html +++ b/site/news/submit-talks-to-spark-summit-east-2016.html @@ -214,6 +214,8 @@ Apache Spark, Spark, Apache, and the Spark logo are trademarks of https://www.apache.org";>The Apache Software Foundation. + Copyright © 2018 The Apache Software Foundation, Licensed under the + https://www.apache.org/licenses/LICENSE-2.0.html";>Apache License, Version 2.0. http://git-wip-us.apache.org/repos/asf/spark-website/blob/464ddc70/site/news/submit-talks-to-spark-summit-eu-2016.html -- diff --git a/site/news/submit-talks-to-spark-summit-eu-2016.html b/site/news/submit-talks-to-spark-summit-eu-2016.html index 6bed86d..8e703cc 100644 --- a/site/news/submit-talks-to-spark-summit-eu-2016.html +++ b/site/news/submit-talks-to-spark-summit-eu-2016.html @@ -214,6 +214,8 @@ Apache Spark, Spark, Apache, and the Spark logo are trademarks of https://www.apache.org";>The Apache Software Foundation. + Copyright © 2018 The Apache Software Foundation, Licensed under the + https://www.apache.org/licenses/LICENSE-2.0.html";>Apache License, Version 2.0. http://git-wip-us.apache.org/repos/asf/spark-website/blob/464ddc70/site/news/two-weeks-to-spark-summit-2014.html -- diff --git a/site/news/two-weeks-to-spark-summit-2014.html b/site/news/two-weeks-to-spark-summit-2014.html index 6a15029..d051c0c 100644 --- a/site/news/two-weeks-to-spark-summit-2014.html +++ b/site/news/two-weeks-to-spark-summit-2014.html @@ -224,6 +224,8 @@ online to attend in person. Otherwise, the Summit will offer a free live video s Apache Spark, Spark, Apache, and the Spark logo are trademarks of https://www.apache.org";>The Apache Software Foundation. + Copyright © 2018 The Apache Software Foundation, Licensed under the + https://www.apache.org/licenses/LICENSE-2.0.html";>Apache License, Version 2.0. http://git-wip-us.apache.org/repos/asf/spark-website/blob/464ddc70/site/news/video-from-first-spark-development-meetup.html -- diff --git a/site/news/video-from-first-spark-development-meetup.html b/site/news/video-from-first-spark-development-meetup.html index 981a2b9..9571be8 100644 --- a/site/news/video-from-first-spark-development-meetup.html +++ b/site/news/video-from-first-spark-development-meetup.html @@ -214,6 +214,8 @@ Apache Spark, Spark, Apache, and the Spark logo are trademarks of https://www.apache.org";>The Apache Software Foundation. + Copyright © 2018 The Apache Software Foundation, Licensed under the + https://www.apache.org/licenses/LICENSE-2.0.html";>Apache License, Version 2.0. http://git-wip-us.apache.org/repos/asf/spark-website/blob/464ddc70/site/powered-by.html -- diff --git a/site/powered-by.html b/site/powered-by.html
[2/2] spark-website git commit: Add notice that site is licensed as AL2
Add notice that site is licensed as AL2 Project: http://git-wip-us.apache.org/repos/asf/spark-website/repo Commit: http://git-wip-us.apache.org/repos/asf/spark-website/commit/464ddc70 Tree: http://git-wip-us.apache.org/repos/asf/spark-website/tree/464ddc70 Diff: http://git-wip-us.apache.org/repos/asf/spark-website/diff/464ddc70 Branch: refs/heads/asf-site Commit: 464ddc70335231c0b1f995257ade31b5d3b51c14 Parents: b3ecc85 Author: Sean Owen Authored: Thu Jan 18 20:01:18 2018 -0600 Committer: Sean Owen Committed: Fri Jan 19 08:29:58 2018 -0600 -- LICENSE | 201 +++ _config.yml | 2 +- _layouts/global.html| 2 + site/committers.html| 2 + site/community.html | 2 + site/contributing.html | 2 + site/developer-tools.html | 2 + site/documentation.html | 2 + site/downloads.html | 2 + site/examples.html | 2 + site/faq.html | 2 + site/graphx/index.html | 2 + site/improvement-proposals.html | 2 + site/index.html | 2 + site/mailing-lists.html | 2 + site/mllib/index.html | 2 + site/news/amp-camp-2013-registration-ope.html | 2 + .../news/announcing-the-first-spark-summit.html | 2 + .../news/fourth-spark-screencast-published.html | 2 + site/news/index.html| 2 + site/news/nsdi-paper.html | 2 + site/news/one-month-to-spark-summit-2015.html | 2 + .../proposals-open-for-spark-summit-east.html | 2 + ...registration-open-for-spark-summit-east.html | 2 + .../news/run-spark-and-shark-on-amazon-emr.html | 2 + site/news/spark-0-6-1-and-0-5-2-released.html | 2 + site/news/spark-0-6-2-released.html | 2 + site/news/spark-0-7-0-released.html | 2 + site/news/spark-0-7-2-released.html | 2 + site/news/spark-0-7-3-released.html | 2 + site/news/spark-0-8-0-released.html | 2 + site/news/spark-0-8-1-released.html | 2 + site/news/spark-0-9-0-released.html | 2 + site/news/spark-0-9-1-released.html | 2 + site/news/spark-0-9-2-released.html | 2 + site/news/spark-1-0-0-released.html | 2 + site/news/spark-1-0-1-released.html | 2 + site/news/spark-1-0-2-released.html | 2 + site/news/spark-1-1-0-released.html | 2 + site/news/spark-1-1-1-released.html | 2 + site/news/spark-1-2-0-released.html | 2 + site/news/spark-1-2-1-released.html | 2 + site/news/spark-1-2-2-released.html | 2 + site/news/spark-1-3-0-released.html | 2 + site/news/spark-1-4-0-released.html | 2 + site/news/spark-1-4-1-released.html | 2 + site/news/spark-1-5-0-released.html | 2 + site/news/spark-1-5-1-released.html | 2 + site/news/spark-1-5-2-released.html | 2 + site/news/spark-1-6-0-released.html | 2 + site/news/spark-1-6-1-released.html | 2 + site/news/spark-1-6-2-released.html | 2 + site/news/spark-1-6-3-released.html | 2 + site/news/spark-2-0-0-released.html | 2 + site/news/spark-2-0-1-released.html | 2 + site/news/spark-2-0-2-released.html | 2 + site/news/spark-2-1-0-released.html | 2 + site/news/spark-2-1-1-released.html | 2 + site/news/spark-2-1-2-released.html | 2 + site/news/spark-2-2-0-released.html | 2 + site/news/spark-2-2-1-released.html | 2 + site/news/spark-2.0.0-preview.html | 2 + .../spark-accepted-into-apache-incubator.html | 2 + site/news/spark-and-shark-in-the-news.html | 2 + site/news/spark-becomes-tlp.html| 2 + site/news/spark-featured-in-wired.html | 2 + .../spark-mailing-lists-moving-to-apache.html | 2 + site/news/spark-meetups.html| 2 + site/news/spark-screencasts-published.html | 2 + site/news/spark-summit-2013-is-a-wrap.html | 2 + site/news/spark-summit-2014-videos-posted.html | 2 + site/news/spark-summit-2015-videos-posted.html | 2 + site/news/spark-summit-agenda-posted.html | 2 + .../spark-summit-east-2015-videos-posted.html | 2 + .../spark-summit-east-2016-cfp-closing.html | 2 + .../spark-summit-east-2017-agenda-posted.html | 2 + site/news/spark-summit-e
spark git commit: [SPARK-23000][TEST] Keep Derby DB Location Unchanged After Session Cloning
Repository: spark
Updated Branches:
refs/heads/master e1c33b6cd -> 6c39654ef
[SPARK-23000][TEST] Keep Derby DB Location Unchanged After Session Cloning
## What changes were proposed in this pull request?
After session cloning in `TestHive`, the conf of the singleton SparkContext for
derby DB location is changed to a new directory. The new directory is created
in `HiveUtils.newTemporaryConfiguration(useInMemoryDerby = false)`.
This PR is to keep the conf value of `ConfVars.METASTORECONNECTURLKEY.varname`
unchanged during the session clone.
## How was this patch tested?
The issue can be reproduced by the command:
> build/sbt -Phive "hive/test-only
> org.apache.spark.sql.hive.HiveSessionStateSuite
> org.apache.spark.sql.hive.DataSourceWithHiveMetastoreCatalogSuite"
Also added a test case.
Author: gatorsmile
Closes #20328 from gatorsmile/fixTestFailure.
Project: http://git-wip-us.apache.org/repos/asf/spark/repo
Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/6c39654e
Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/6c39654e
Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/6c39654e
Branch: refs/heads/master
Commit: 6c39654efcb2aa8cb4d082ab7277a6fa38fb48e4
Parents: e1c33b6
Author: gatorsmile
Authored: Fri Jan 19 22:47:18 2018 +0800
Committer: Wenchen Fan
Committed: Fri Jan 19 22:47:18 2018 +0800
--
.../org/apache/spark/sql/SessionStateSuite.scala| 5 +
.../org/apache/spark/sql/hive/test/TestHive.scala | 8 +++-
.../spark/sql/hive/HiveSessionStateSuite.scala | 16 +---
3 files changed, 21 insertions(+), 8 deletions(-)
--
http://git-wip-us.apache.org/repos/asf/spark/blob/6c39654e/sql/core/src/test/scala/org/apache/spark/sql/SessionStateSuite.scala
--
diff --git
a/sql/core/src/test/scala/org/apache/spark/sql/SessionStateSuite.scala
b/sql/core/src/test/scala/org/apache/spark/sql/SessionStateSuite.scala
index 5d75f58..4efae4c 100644
--- a/sql/core/src/test/scala/org/apache/spark/sql/SessionStateSuite.scala
+++ b/sql/core/src/test/scala/org/apache/spark/sql/SessionStateSuite.scala
@@ -17,8 +17,6 @@
package org.apache.spark.sql
-import org.scalatest.BeforeAndAfterAll
-import org.scalatest.BeforeAndAfterEach
import scala.collection.mutable.ArrayBuffer
import org.apache.spark.SparkFunSuite
@@ -28,8 +26,7 @@ import org.apache.spark.sql.catalyst.rules.Rule
import org.apache.spark.sql.execution.QueryExecution
import org.apache.spark.sql.util.QueryExecutionListener
-class SessionStateSuite extends SparkFunSuite
-with BeforeAndAfterEach with BeforeAndAfterAll {
+class SessionStateSuite extends SparkFunSuite {
/**
* A shared SparkSession for all tests in this suite. Make sure you reset
any changes to this
http://git-wip-us.apache.org/repos/asf/spark/blob/6c39654e/sql/hive/src/main/scala/org/apache/spark/sql/hive/test/TestHive.scala
--
diff --git
a/sql/hive/src/main/scala/org/apache/spark/sql/hive/test/TestHive.scala
b/sql/hive/src/main/scala/org/apache/spark/sql/hive/test/TestHive.scala
index b6be00d..c84131f 100644
--- a/sql/hive/src/main/scala/org/apache/spark/sql/hive/test/TestHive.scala
+++ b/sql/hive/src/main/scala/org/apache/spark/sql/hive/test/TestHive.scala
@@ -180,7 +180,13 @@ private[hive] class TestHiveSparkSession(
ConfVars.METASTORE_INTEGER_JDO_PUSHDOWN.varname -> "true",
// scratch directory used by Hive's metastore client
ConfVars.SCRATCHDIR.varname ->
TestHiveContext.makeScratchDir().toURI.toString,
- ConfVars.METASTORE_CLIENT_CONNECT_RETRY_DELAY.varname -> "1")
+ ConfVars.METASTORE_CLIENT_CONNECT_RETRY_DELAY.varname -> "1") ++
+ // After session cloning, the JDBC connect string for a JDBC metastore
should not be changed.
+ existingSharedState.map { state =>
+val connKey =
+
state.sparkContext.hadoopConfiguration.get(ConfVars.METASTORECONNECTURLKEY.varname)
+ConfVars.METASTORECONNECTURLKEY.varname -> connKey
+ }
metastoreTempConf.foreach { case (k, v) =>
sc.hadoopConfiguration.set(k, v)
http://git-wip-us.apache.org/repos/asf/spark/blob/6c39654e/sql/hive/src/test/scala/org/apache/spark/sql/hive/HiveSessionStateSuite.scala
--
diff --git
a/sql/hive/src/test/scala/org/apache/spark/sql/hive/HiveSessionStateSuite.scala
b/sql/hive/src/test/scala/org/apache/spark/sql/hive/HiveSessionStateSuite.scala
index f7da3c4..ecc09cd 100644
---
a/sql/hive/src/test/scala/org/apache/spark/sql/hive/HiveSessionStateSuite.scala
+++
b/sql/hive/src/test/scala/org/apache/spark/sql/hive/HiveSessionStateSuite.scala
@@ -17,7 +17,7 @@
package org.apache.spark.sql.hive
-import org.scalatest.BeforeAnd
spark git commit: [SPARK-23000][TEST] Keep Derby DB Location Unchanged After Session Cloning
Repository: spark
Updated Branches:
refs/heads/branch-2.3 b7a81999d -> 8d6845cf9
[SPARK-23000][TEST] Keep Derby DB Location Unchanged After Session Cloning
## What changes were proposed in this pull request?
After session cloning in `TestHive`, the conf of the singleton SparkContext for
derby DB location is changed to a new directory. The new directory is created
in `HiveUtils.newTemporaryConfiguration(useInMemoryDerby = false)`.
This PR is to keep the conf value of `ConfVars.METASTORECONNECTURLKEY.varname`
unchanged during the session clone.
## How was this patch tested?
The issue can be reproduced by the command:
> build/sbt -Phive "hive/test-only
> org.apache.spark.sql.hive.HiveSessionStateSuite
> org.apache.spark.sql.hive.DataSourceWithHiveMetastoreCatalogSuite"
Also added a test case.
Author: gatorsmile
Closes #20328 from gatorsmile/fixTestFailure.
(cherry picked from commit 6c39654efcb2aa8cb4d082ab7277a6fa38fb48e4)
Signed-off-by: Wenchen Fan
Project: http://git-wip-us.apache.org/repos/asf/spark/repo
Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/8d6845cf
Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/8d6845cf
Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/8d6845cf
Branch: refs/heads/branch-2.3
Commit: 8d6845cf926a14e21ca29a43f2cc9a3a9475afd5
Parents: b7a8199
Author: gatorsmile
Authored: Fri Jan 19 22:47:18 2018 +0800
Committer: Wenchen Fan
Committed: Fri Jan 19 22:47:36 2018 +0800
--
.../org/apache/spark/sql/SessionStateSuite.scala| 5 +
.../org/apache/spark/sql/hive/test/TestHive.scala | 8 +++-
.../spark/sql/hive/HiveSessionStateSuite.scala | 16 +---
3 files changed, 21 insertions(+), 8 deletions(-)
--
http://git-wip-us.apache.org/repos/asf/spark/blob/8d6845cf/sql/core/src/test/scala/org/apache/spark/sql/SessionStateSuite.scala
--
diff --git
a/sql/core/src/test/scala/org/apache/spark/sql/SessionStateSuite.scala
b/sql/core/src/test/scala/org/apache/spark/sql/SessionStateSuite.scala
index c016667..8386f32 100644
--- a/sql/core/src/test/scala/org/apache/spark/sql/SessionStateSuite.scala
+++ b/sql/core/src/test/scala/org/apache/spark/sql/SessionStateSuite.scala
@@ -17,8 +17,6 @@
package org.apache.spark.sql
-import org.scalatest.BeforeAndAfterAll
-import org.scalatest.BeforeAndAfterEach
import scala.collection.mutable.ArrayBuffer
import org.apache.spark.SparkFunSuite
@@ -28,8 +26,7 @@ import org.apache.spark.sql.catalyst.rules.Rule
import org.apache.spark.sql.execution.QueryExecution
import org.apache.spark.sql.util.QueryExecutionListener
-class SessionStateSuite extends SparkFunSuite
-with BeforeAndAfterEach with BeforeAndAfterAll {
+class SessionStateSuite extends SparkFunSuite {
/**
* A shared SparkSession for all tests in this suite. Make sure you reset
any changes to this
http://git-wip-us.apache.org/repos/asf/spark/blob/8d6845cf/sql/hive/src/main/scala/org/apache/spark/sql/hive/test/TestHive.scala
--
diff --git
a/sql/hive/src/main/scala/org/apache/spark/sql/hive/test/TestHive.scala
b/sql/hive/src/main/scala/org/apache/spark/sql/hive/test/TestHive.scala
index b6be00d..c84131f 100644
--- a/sql/hive/src/main/scala/org/apache/spark/sql/hive/test/TestHive.scala
+++ b/sql/hive/src/main/scala/org/apache/spark/sql/hive/test/TestHive.scala
@@ -180,7 +180,13 @@ private[hive] class TestHiveSparkSession(
ConfVars.METASTORE_INTEGER_JDO_PUSHDOWN.varname -> "true",
// scratch directory used by Hive's metastore client
ConfVars.SCRATCHDIR.varname ->
TestHiveContext.makeScratchDir().toURI.toString,
- ConfVars.METASTORE_CLIENT_CONNECT_RETRY_DELAY.varname -> "1")
+ ConfVars.METASTORE_CLIENT_CONNECT_RETRY_DELAY.varname -> "1") ++
+ // After session cloning, the JDBC connect string for a JDBC metastore
should not be changed.
+ existingSharedState.map { state =>
+val connKey =
+
state.sparkContext.hadoopConfiguration.get(ConfVars.METASTORECONNECTURLKEY.varname)
+ConfVars.METASTORECONNECTURLKEY.varname -> connKey
+ }
metastoreTempConf.foreach { case (k, v) =>
sc.hadoopConfiguration.set(k, v)
http://git-wip-us.apache.org/repos/asf/spark/blob/8d6845cf/sql/hive/src/test/scala/org/apache/spark/sql/hive/HiveSessionStateSuite.scala
--
diff --git
a/sql/hive/src/test/scala/org/apache/spark/sql/hive/HiveSessionStateSuite.scala
b/sql/hive/src/test/scala/org/apache/spark/sql/hive/HiveSessionStateSuite.scala
index 958ad3e..3d1a0b0 100644
---
a/sql/hive/src/test/scala/org/apache/spark/sql/hive/HiveSessionStateSuite.scala
+++
b/sql/hive/src/test/scala/org/apache/spark/sql/hive/HiveSessio
spark git commit: [SPARK-23085][ML] API parity for mllib.linalg.Vectors.sparse
Repository: spark
Updated Branches:
refs/heads/master 6c39654ef -> 606a7485f
[SPARK-23085][ML] API parity for mllib.linalg.Vectors.sparse
## What changes were proposed in this pull request?
`ML.Vectors#sparse(size: Int, elements: Seq[(Int, Double)])` support zero-length
## How was this patch tested?
existing tests
Author: Zheng RuiFeng
Closes #20275 from zhengruifeng/SparseVector_size.
Project: http://git-wip-us.apache.org/repos/asf/spark/repo
Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/606a7485
Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/606a7485
Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/606a7485
Branch: refs/heads/master
Commit: 606a7485f12c5d5377c50258006c353ba5e49c3f
Parents: 6c39654
Author: Zheng RuiFeng
Authored: Fri Jan 19 09:28:35 2018 -0600
Committer: Sean Owen
Committed: Fri Jan 19 09:28:35 2018 -0600
--
.../scala/org/apache/spark/ml/linalg/Vectors.scala| 2 +-
.../org/apache/spark/ml/linalg/VectorsSuite.scala | 14 ++
.../scala/org/apache/spark/mllib/linalg/Vectors.scala | 3 +--
.../org/apache/spark/mllib/linalg/VectorsSuite.scala | 14 ++
4 files changed, 30 insertions(+), 3 deletions(-)
--
http://git-wip-us.apache.org/repos/asf/spark/blob/606a7485/mllib-local/src/main/scala/org/apache/spark/ml/linalg/Vectors.scala
--
diff --git
a/mllib-local/src/main/scala/org/apache/spark/ml/linalg/Vectors.scala
b/mllib-local/src/main/scala/org/apache/spark/ml/linalg/Vectors.scala
index 941b6ec..5824e46 100644
--- a/mllib-local/src/main/scala/org/apache/spark/ml/linalg/Vectors.scala
+++ b/mllib-local/src/main/scala/org/apache/spark/ml/linalg/Vectors.scala
@@ -565,7 +565,7 @@ class SparseVector @Since("2.0.0") (
// validate the data
{
-require(size >= 0, "The size of the requested sparse vector must be
greater than 0.")
+require(size >= 0, "The size of the requested sparse vector must be no
less than 0.")
require(indices.length == values.length, "Sparse vectors require that the
dimension of the" +
s" indices match the dimension of the values. You provided
${indices.length} indices and " +
s" ${values.length} values.")
http://git-wip-us.apache.org/repos/asf/spark/blob/606a7485/mllib-local/src/test/scala/org/apache/spark/ml/linalg/VectorsSuite.scala
--
diff --git
a/mllib-local/src/test/scala/org/apache/spark/ml/linalg/VectorsSuite.scala
b/mllib-local/src/test/scala/org/apache/spark/ml/linalg/VectorsSuite.scala
index 79acef8..0a316f5 100644
--- a/mllib-local/src/test/scala/org/apache/spark/ml/linalg/VectorsSuite.scala
+++ b/mllib-local/src/test/scala/org/apache/spark/ml/linalg/VectorsSuite.scala
@@ -366,4 +366,18 @@ class VectorsSuite extends SparkMLFunSuite {
assert(v.slice(Array(2, 0)) === new SparseVector(2, Array(0), Array(2.2)))
assert(v.slice(Array(2, 0, 3, 4)) === new SparseVector(4, Array(0, 3),
Array(2.2, 4.4)))
}
+
+ test("sparse vector only support non-negative length") {
+val v1 = Vectors.sparse(0, Array.emptyIntArray, Array.emptyDoubleArray)
+val v2 = Vectors.sparse(0, Array.empty[(Int, Double)])
+assert(v1.size === 0)
+assert(v2.size === 0)
+
+intercept[IllegalArgumentException] {
+ Vectors.sparse(-1, Array(1), Array(2.0))
+}
+intercept[IllegalArgumentException] {
+ Vectors.sparse(-1, Array((1, 2.0)))
+}
+ }
}
http://git-wip-us.apache.org/repos/asf/spark/blob/606a7485/mllib/src/main/scala/org/apache/spark/mllib/linalg/Vectors.scala
--
diff --git a/mllib/src/main/scala/org/apache/spark/mllib/linalg/Vectors.scala
b/mllib/src/main/scala/org/apache/spark/mllib/linalg/Vectors.scala
index fd9605c..6e68d96 100644
--- a/mllib/src/main/scala/org/apache/spark/mllib/linalg/Vectors.scala
+++ b/mllib/src/main/scala/org/apache/spark/mllib/linalg/Vectors.scala
@@ -326,8 +326,6 @@ object Vectors {
*/
@Since("1.0.0")
def sparse(size: Int, elements: Seq[(Int, Double)]): Vector = {
-require(size > 0, "The size of the requested sparse vector must be greater
than 0.")
-
val (indices, values) = elements.sortBy(_._1).unzip
var prev = -1
indices.foreach { i =>
@@ -758,6 +756,7 @@ class SparseVector @Since("1.0.0") (
@Since("1.0.0") val indices: Array[Int],
@Since("1.0.0") val values: Array[Double]) extends Vector {
+ require(size >= 0, "The size of the requested sparse vector must be no less
than 0.")
require(indices.length == values.length, "Sparse vectors require that the
dimension of the" +
s" indices match the dimension of the values. You provided
${indices.length} indices and " +
s" ${values.length} values.")
http://git-wip-us.a
svn commit: r24325 - in /dev/spark/2.4.0-SNAPSHOT-2018_01_19_08_01-606a748-docs: ./ _site/ _site/api/ _site/api/R/ _site/api/java/ _site/api/java/lib/ _site/api/java/org/ _site/api/java/org/apache/ _s
Author: pwendell Date: Fri Jan 19 16:15:01 2018 New Revision: 24325 Log: Apache Spark 2.4.0-SNAPSHOT-2018_01_19_08_01-606a748 docs [This commit notification would consist of 1441 parts, which exceeds the limit of 50 ones, so it was shortened to the summary.] - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
spark git commit: [SPARK-23149][SQL] polish ColumnarBatch
Repository: spark
Updated Branches:
refs/heads/branch-2.3 8d6845cf9 -> 55efeffd7
[SPARK-23149][SQL] polish ColumnarBatch
## What changes were proposed in this pull request?
Several cleanups in `ColumnarBatch`
* remove `schema`. The `ColumnVector`s inside `ColumnarBatch` already have the
data type information, we don't need this `schema`.
* remove `capacity`. `ColumnarBatch` is just a wrapper of `ColumnVector`s, not
builders, it doesn't need a capacity property.
* remove `DEFAULT_BATCH_SIZE`. As a wrapper, `ColumnarBatch` can't decide the
batch size, it should be decided by the reader, e.g. parquet reader, orc
reader, cached table reader. The default batch size should also be defined by
the reader.
## How was this patch tested?
existing tests.
Author: Wenchen Fan
Closes #20316 from cloud-fan/columnar-batch.
(cherry picked from commit d8aaa771e249b3f54b57ce24763e53fd65a0dbf7)
Signed-off-by: gatorsmile
Project: http://git-wip-us.apache.org/repos/asf/spark/repo
Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/55efeffd
Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/55efeffd
Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/55efeffd
Branch: refs/heads/branch-2.3
Commit: 55efeffd774a776806f379df5b2209af05270cc4
Parents: 8d6845c
Author: Wenchen Fan
Authored: Fri Jan 19 08:58:21 2018 -0800
Committer: gatorsmile
Committed: Fri Jan 19 08:58:29 2018 -0800
--
.../datasources/orc/OrcColumnarBatchReader.java | 49 +++-
.../SpecificParquetRecordReaderBase.java| 12 ++---
.../parquet/VectorizedParquetRecordReader.java | 24 +-
.../execution/vectorized/ColumnVectorUtils.java | 18 +++
.../spark/sql/vectorized/ColumnarBatch.java | 20 +---
.../aggregate/VectorizedHashMapGenerator.scala | 2 +-
.../sql/execution/arrow/ArrowConverters.scala | 2 +-
.../columnar/InMemoryTableScanExec.scala| 5 +-
.../execution/python/ArrowEvalPythonExec.scala | 8 ++--
.../execution/python/ArrowPythonRunner.scala| 2 +-
.../sql/sources/v2/JavaBatchDataSourceV2.java | 3 +-
.../vectorized/ColumnarBatchSuite.scala | 7 ++-
.../sql/sources/v2/DataSourceV2Suite.scala | 3 +-
13 files changed, 61 insertions(+), 94 deletions(-)
--
http://git-wip-us.apache.org/repos/asf/spark/blob/55efeffd/sql/core/src/main/java/org/apache/spark/sql/execution/datasources/orc/OrcColumnarBatchReader.java
--
diff --git
a/sql/core/src/main/java/org/apache/spark/sql/execution/datasources/orc/OrcColumnarBatchReader.java
b/sql/core/src/main/java/org/apache/spark/sql/execution/datasources/orc/OrcColumnarBatchReader.java
index 36fdf2b..89bae43 100644
---
a/sql/core/src/main/java/org/apache/spark/sql/execution/datasources/orc/OrcColumnarBatchReader.java
+++
b/sql/core/src/main/java/org/apache/spark/sql/execution/datasources/orc/OrcColumnarBatchReader.java
@@ -49,18 +49,8 @@ import org.apache.spark.sql.vectorized.ColumnarBatch;
* After creating, `initialize` and `initBatch` should be called sequentially.
*/
public class OrcColumnarBatchReader extends RecordReader {
-
- /**
- * The default size of batch. We use this value for ORC reader to make it
consistent with Spark's
- * columnar batch, because their default batch sizes are different like the
following:
- *
- * - ORC's VectorizedRowBatch.DEFAULT_SIZE = 1024
- * - Spark's ColumnarBatch.DEFAULT_BATCH_SIZE = 4 * 1024
- */
- private static final int DEFAULT_SIZE = 4 * 1024;
-
- // ORC File Reader
- private Reader reader;
+ // TODO: make this configurable.
+ private static final int CAPACITY = 4 * 1024;
// Vectorized ORC Row Batch
private VectorizedRowBatch batch;
@@ -98,22 +88,22 @@ public class OrcColumnarBatchReader extends
RecordReader {
@Override
- public Void getCurrentKey() throws IOException, InterruptedException {
+ public Void getCurrentKey() {
return null;
}
@Override
- public ColumnarBatch getCurrentValue() throws IOException,
InterruptedException {
+ public ColumnarBatch getCurrentValue() {
return columnarBatch;
}
@Override
- public float getProgress() throws IOException, InterruptedException {
+ public float getProgress() throws IOException {
return recordReader.getProgress();
}
@Override
- public boolean nextKeyValue() throws IOException, InterruptedException {
+ public boolean nextKeyValue() throws IOException {
return nextBatch();
}
@@ -134,16 +124,15 @@ public class OrcColumnarBatchReader extends
RecordReader {
* Please note that `initBatch` is needed to be called after this.
*/
@Override
- public void initialize(InputSplit inputSplit, TaskAttemptContext
taskAttemptContext)
- throws IOException, InterruptedException {
+ public void initialize(
+ InputS
spark git commit: [SPARK-23149][SQL] polish ColumnarBatch
Repository: spark
Updated Branches:
refs/heads/master 606a7485f -> d8aaa771e
[SPARK-23149][SQL] polish ColumnarBatch
## What changes were proposed in this pull request?
Several cleanups in `ColumnarBatch`
* remove `schema`. The `ColumnVector`s inside `ColumnarBatch` already have the
data type information, we don't need this `schema`.
* remove `capacity`. `ColumnarBatch` is just a wrapper of `ColumnVector`s, not
builders, it doesn't need a capacity property.
* remove `DEFAULT_BATCH_SIZE`. As a wrapper, `ColumnarBatch` can't decide the
batch size, it should be decided by the reader, e.g. parquet reader, orc
reader, cached table reader. The default batch size should also be defined by
the reader.
## How was this patch tested?
existing tests.
Author: Wenchen Fan
Closes #20316 from cloud-fan/columnar-batch.
Project: http://git-wip-us.apache.org/repos/asf/spark/repo
Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/d8aaa771
Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/d8aaa771
Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/d8aaa771
Branch: refs/heads/master
Commit: d8aaa771e249b3f54b57ce24763e53fd65a0dbf7
Parents: 606a748
Author: Wenchen Fan
Authored: Fri Jan 19 08:58:21 2018 -0800
Committer: gatorsmile
Committed: Fri Jan 19 08:58:21 2018 -0800
--
.../datasources/orc/OrcColumnarBatchReader.java | 49 +++-
.../SpecificParquetRecordReaderBase.java| 12 ++---
.../parquet/VectorizedParquetRecordReader.java | 24 +-
.../execution/vectorized/ColumnVectorUtils.java | 18 +++
.../spark/sql/vectorized/ColumnarBatch.java | 20 +---
.../aggregate/VectorizedHashMapGenerator.scala | 2 +-
.../sql/execution/arrow/ArrowConverters.scala | 2 +-
.../columnar/InMemoryTableScanExec.scala| 5 +-
.../execution/python/ArrowEvalPythonExec.scala | 8 ++--
.../execution/python/ArrowPythonRunner.scala| 2 +-
.../sql/sources/v2/JavaBatchDataSourceV2.java | 3 +-
.../vectorized/ColumnarBatchSuite.scala | 7 ++-
.../sql/sources/v2/DataSourceV2Suite.scala | 3 +-
13 files changed, 61 insertions(+), 94 deletions(-)
--
http://git-wip-us.apache.org/repos/asf/spark/blob/d8aaa771/sql/core/src/main/java/org/apache/spark/sql/execution/datasources/orc/OrcColumnarBatchReader.java
--
diff --git
a/sql/core/src/main/java/org/apache/spark/sql/execution/datasources/orc/OrcColumnarBatchReader.java
b/sql/core/src/main/java/org/apache/spark/sql/execution/datasources/orc/OrcColumnarBatchReader.java
index 36fdf2b..89bae43 100644
---
a/sql/core/src/main/java/org/apache/spark/sql/execution/datasources/orc/OrcColumnarBatchReader.java
+++
b/sql/core/src/main/java/org/apache/spark/sql/execution/datasources/orc/OrcColumnarBatchReader.java
@@ -49,18 +49,8 @@ import org.apache.spark.sql.vectorized.ColumnarBatch;
* After creating, `initialize` and `initBatch` should be called sequentially.
*/
public class OrcColumnarBatchReader extends RecordReader {
-
- /**
- * The default size of batch. We use this value for ORC reader to make it
consistent with Spark's
- * columnar batch, because their default batch sizes are different like the
following:
- *
- * - ORC's VectorizedRowBatch.DEFAULT_SIZE = 1024
- * - Spark's ColumnarBatch.DEFAULT_BATCH_SIZE = 4 * 1024
- */
- private static final int DEFAULT_SIZE = 4 * 1024;
-
- // ORC File Reader
- private Reader reader;
+ // TODO: make this configurable.
+ private static final int CAPACITY = 4 * 1024;
// Vectorized ORC Row Batch
private VectorizedRowBatch batch;
@@ -98,22 +88,22 @@ public class OrcColumnarBatchReader extends
RecordReader {
@Override
- public Void getCurrentKey() throws IOException, InterruptedException {
+ public Void getCurrentKey() {
return null;
}
@Override
- public ColumnarBatch getCurrentValue() throws IOException,
InterruptedException {
+ public ColumnarBatch getCurrentValue() {
return columnarBatch;
}
@Override
- public float getProgress() throws IOException, InterruptedException {
+ public float getProgress() throws IOException {
return recordReader.getProgress();
}
@Override
- public boolean nextKeyValue() throws IOException, InterruptedException {
+ public boolean nextKeyValue() throws IOException {
return nextBatch();
}
@@ -134,16 +124,15 @@ public class OrcColumnarBatchReader extends
RecordReader {
* Please note that `initBatch` is needed to be called after this.
*/
@Override
- public void initialize(InputSplit inputSplit, TaskAttemptContext
taskAttemptContext)
- throws IOException, InterruptedException {
+ public void initialize(
+ InputSplit inputSplit, TaskAttemptContext taskAttemptContext) throws
IOException {
FileSplit fileSplit =
svn commit: r24327 - in /dev/spark/2.3.1-SNAPSHOT-2018_01_19_10_01-55efeff-docs: ./ _site/ _site/api/ _site/api/R/ _site/api/java/ _site/api/java/lib/ _site/api/java/org/ _site/api/java/org/apache/ _s
Author: pwendell Date: Fri Jan 19 18:15:05 2018 New Revision: 24327 Log: Apache Spark 2.3.1-SNAPSHOT-2018_01_19_10_01-55efeff docs [This commit notification would consist of 1441 parts, which exceeds the limit of 50 ones, so it was shortened to the summary.] - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
spark git commit: [SPARK-23104][K8S][DOCS] Changes to Kubernetes scheduler documentation
Repository: spark Updated Branches: refs/heads/master d8aaa771e -> 73d3b230f [SPARK-23104][K8S][DOCS] Changes to Kubernetes scheduler documentation ## What changes were proposed in this pull request? Docs changes: - Adding a warning that the backend is experimental. - Removing a defunct internal-only option from documentation - Clarifying that node selectors can be used right away, and other minor cosmetic changes ## How was this patch tested? Docs only change Author: foxish Closes #20314 from foxish/ambiguous-docs. Project: http://git-wip-us.apache.org/repos/asf/spark/repo Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/73d3b230 Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/73d3b230 Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/73d3b230 Branch: refs/heads/master Commit: 73d3b230f3816a854a181c0912d87b180e347271 Parents: d8aaa77 Author: foxish Authored: Fri Jan 19 10:23:13 2018 -0800 Committer: Marcelo Vanzin Committed: Fri Jan 19 10:23:13 2018 -0800 -- docs/cluster-overview.md | 4 ++-- docs/running-on-kubernetes.md | 43 ++ 2 files changed, 22 insertions(+), 25 deletions(-) -- http://git-wip-us.apache.org/repos/asf/spark/blob/73d3b230/docs/cluster-overview.md -- diff --git a/docs/cluster-overview.md b/docs/cluster-overview.md index 658e67f..7277e2f 100644 --- a/docs/cluster-overview.md +++ b/docs/cluster-overview.md @@ -52,8 +52,8 @@ The system currently supports three cluster managers: * [Apache Mesos](running-on-mesos.html) -- a general cluster manager that can also run Hadoop MapReduce and service applications. * [Hadoop YARN](running-on-yarn.html) -- the resource manager in Hadoop 2. -* [Kubernetes](running-on-kubernetes.html) -- [Kubernetes](https://kubernetes.io/docs/concepts/overview/what-is-kubernetes/) -is an open-source platform that provides container-centric infrastructure. +* [Kubernetes](running-on-kubernetes.html) -- an open-source system for automating deployment, scaling, + and management of containerized applications. A third-party project (not supported by the Spark project) exists to add support for [Nomad](https://github.com/hashicorp/nomad-spark) as a cluster manager. http://git-wip-us.apache.org/repos/asf/spark/blob/73d3b230/docs/running-on-kubernetes.md -- diff --git a/docs/running-on-kubernetes.md b/docs/running-on-kubernetes.md index d6b1735..3c7586e 100644 --- a/docs/running-on-kubernetes.md +++ b/docs/running-on-kubernetes.md @@ -8,6 +8,10 @@ title: Running Spark on Kubernetes Spark can run on clusters managed by [Kubernetes](https://kubernetes.io). This feature makes use of native Kubernetes scheduler that has been added to Spark. +**The Kubernetes scheduler is currently experimental. +In future versions, there may be behavioral changes around configuration, +container images and entrypoints.** + # Prerequisites * A runnable distribution of Spark 2.3 or above. @@ -41,11 +45,10 @@ logs and remains in "completed" state in the Kubernetes API until it's eventuall Note that in the completed state, the driver pod does *not* use any computational or memory resources. -The driver and executor pod scheduling is handled by Kubernetes. It will be possible to affect Kubernetes scheduling -decisions for driver and executor pods using advanced primitives like -[node selectors](https://kubernetes.io/docs/concepts/configuration/assign-pod-node/#nodeselector) -and [node/pod affinities](https://kubernetes.io/docs/concepts/configuration/assign-pod-node/#affinity-and-anti-affinity) -in a future release. +The driver and executor pod scheduling is handled by Kubernetes. It is possible to schedule the +driver and executor pods on a subset of available nodes through a [node selector](https://kubernetes.io/docs/concepts/configuration/assign-pod-node/#nodeselector) +using the configuration property for it. It will be possible to use more advanced +scheduling hints like [node/pod affinities](https://kubernetes.io/docs/concepts/configuration/assign-pod-node/#affinity-and-anti-affinity) in a future release. # Submitting Applications to Kubernetes @@ -62,8 +65,10 @@ use with the Kubernetes backend. Example usage is: -./bin/docker-image-tool.sh -r -t my-tag build -./bin/docker-image-tool.sh -r -t my-tag push +```bash +$ ./bin/docker-image-tool.sh -r -t my-tag build +$ ./bin/docker-image-tool.sh -r -t my-tag push +``` ## Cluster Mode @@ -94,7 +99,7 @@ must consist of lower case alphanumeric characters, `-`, and `.` and must start If you have a Kubernetes cluster setup, one way to discover the apiserver URL is by executing `kubectl cluster-info`. ```bash -kubectl cluster-info +
spark git commit: [SPARK-23104][K8S][DOCS] Changes to Kubernetes scheduler documentation
Repository: spark Updated Branches: refs/heads/branch-2.3 55efeffd7 -> ffe45913d [SPARK-23104][K8S][DOCS] Changes to Kubernetes scheduler documentation ## What changes were proposed in this pull request? Docs changes: - Adding a warning that the backend is experimental. - Removing a defunct internal-only option from documentation - Clarifying that node selectors can be used right away, and other minor cosmetic changes ## How was this patch tested? Docs only change Author: foxish Closes #20314 from foxish/ambiguous-docs. (cherry picked from commit 73d3b230f3816a854a181c0912d87b180e347271) Signed-off-by: Marcelo Vanzin Project: http://git-wip-us.apache.org/repos/asf/spark/repo Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/ffe45913 Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/ffe45913 Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/ffe45913 Branch: refs/heads/branch-2.3 Commit: ffe45913d0c666185f8c252be30b5e269a909c07 Parents: 55efeff Author: foxish Authored: Fri Jan 19 10:23:13 2018 -0800 Committer: Marcelo Vanzin Committed: Fri Jan 19 10:23:26 2018 -0800 -- docs/cluster-overview.md | 4 ++-- docs/running-on-kubernetes.md | 43 ++ 2 files changed, 22 insertions(+), 25 deletions(-) -- http://git-wip-us.apache.org/repos/asf/spark/blob/ffe45913/docs/cluster-overview.md -- diff --git a/docs/cluster-overview.md b/docs/cluster-overview.md index 658e67f..7277e2f 100644 --- a/docs/cluster-overview.md +++ b/docs/cluster-overview.md @@ -52,8 +52,8 @@ The system currently supports three cluster managers: * [Apache Mesos](running-on-mesos.html) -- a general cluster manager that can also run Hadoop MapReduce and service applications. * [Hadoop YARN](running-on-yarn.html) -- the resource manager in Hadoop 2. -* [Kubernetes](running-on-kubernetes.html) -- [Kubernetes](https://kubernetes.io/docs/concepts/overview/what-is-kubernetes/) -is an open-source platform that provides container-centric infrastructure. +* [Kubernetes](running-on-kubernetes.html) -- an open-source system for automating deployment, scaling, + and management of containerized applications. A third-party project (not supported by the Spark project) exists to add support for [Nomad](https://github.com/hashicorp/nomad-spark) as a cluster manager. http://git-wip-us.apache.org/repos/asf/spark/blob/ffe45913/docs/running-on-kubernetes.md -- diff --git a/docs/running-on-kubernetes.md b/docs/running-on-kubernetes.md index d6b1735..3c7586e 100644 --- a/docs/running-on-kubernetes.md +++ b/docs/running-on-kubernetes.md @@ -8,6 +8,10 @@ title: Running Spark on Kubernetes Spark can run on clusters managed by [Kubernetes](https://kubernetes.io). This feature makes use of native Kubernetes scheduler that has been added to Spark. +**The Kubernetes scheduler is currently experimental. +In future versions, there may be behavioral changes around configuration, +container images and entrypoints.** + # Prerequisites * A runnable distribution of Spark 2.3 or above. @@ -41,11 +45,10 @@ logs and remains in "completed" state in the Kubernetes API until it's eventuall Note that in the completed state, the driver pod does *not* use any computational or memory resources. -The driver and executor pod scheduling is handled by Kubernetes. It will be possible to affect Kubernetes scheduling -decisions for driver and executor pods using advanced primitives like -[node selectors](https://kubernetes.io/docs/concepts/configuration/assign-pod-node/#nodeselector) -and [node/pod affinities](https://kubernetes.io/docs/concepts/configuration/assign-pod-node/#affinity-and-anti-affinity) -in a future release. +The driver and executor pod scheduling is handled by Kubernetes. It is possible to schedule the +driver and executor pods on a subset of available nodes through a [node selector](https://kubernetes.io/docs/concepts/configuration/assign-pod-node/#nodeselector) +using the configuration property for it. It will be possible to use more advanced +scheduling hints like [node/pod affinities](https://kubernetes.io/docs/concepts/configuration/assign-pod-node/#affinity-and-anti-affinity) in a future release. # Submitting Applications to Kubernetes @@ -62,8 +65,10 @@ use with the Kubernetes backend. Example usage is: -./bin/docker-image-tool.sh -r -t my-tag build -./bin/docker-image-tool.sh -r -t my-tag push +```bash +$ ./bin/docker-image-tool.sh -r -t my-tag build +$ ./bin/docker-image-tool.sh -r -t my-tag push +``` ## Cluster Mode @@ -94,7 +99,7 @@ must consist of lower case alphanumeric characters, `-`, and `.` and must start If you have a Kubernetes cluster setup, one
spark git commit: [INFRA] Close stale PR.
Repository: spark Updated Branches: refs/heads/master 73d3b230f -> 07296a61c [INFRA] Close stale PR. Closes #20185. Project: http://git-wip-us.apache.org/repos/asf/spark/repo Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/07296a61 Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/07296a61 Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/07296a61 Branch: refs/heads/master Commit: 07296a61c29eb074553956b6c0f92810ecf7bab2 Parents: 73d3b23 Author: Marcelo Vanzin Authored: Fri Jan 19 10:25:18 2018 -0800 Committer: Marcelo Vanzin Committed: Fri Jan 19 10:25:18 2018 -0800 -- -- - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
spark git commit: [SPARK-20664][CORE] Delete stale application data from SHS.
Repository: spark
Updated Branches:
refs/heads/master 07296a61c -> fed2139f0
[SPARK-20664][CORE] Delete stale application data from SHS.
Detect the deletion of event log files from storage, and remove
data about the related application attempt in the SHS.
Also contains code to fix SPARK-21571 based on code by ericvandenbergfb.
Author: Marcelo Vanzin
Closes #20138 from vanzin/SPARK-20664.
Project: http://git-wip-us.apache.org/repos/asf/spark/repo
Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/fed2139f
Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/fed2139f
Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/fed2139f
Branch: refs/heads/master
Commit: fed2139f053fac4a9a6952ff0ab1cc2a5f657bd0
Parents: 07296a6
Author: Marcelo Vanzin
Authored: Fri Jan 19 13:26:37 2018 -0600
Committer: Imran Rashid
Committed: Fri Jan 19 13:26:37 2018 -0600
--
.../deploy/history/FsHistoryProvider.scala | 297 ---
.../deploy/history/FsHistoryProviderSuite.scala | 117 +++-
.../deploy/history/HistoryServerSuite.scala | 4 +-
3 files changed, 306 insertions(+), 112 deletions(-)
--
http://git-wip-us.apache.org/repos/asf/spark/blob/fed2139f/core/src/main/scala/org/apache/spark/deploy/history/FsHistoryProvider.scala
--
diff --git
a/core/src/main/scala/org/apache/spark/deploy/history/FsHistoryProvider.scala
b/core/src/main/scala/org/apache/spark/deploy/history/FsHistoryProvider.scala
index 94c80eb..f9d0b5e 100644
---
a/core/src/main/scala/org/apache/spark/deploy/history/FsHistoryProvider.scala
+++
b/core/src/main/scala/org/apache/spark/deploy/history/FsHistoryProvider.scala
@@ -19,7 +19,7 @@ package org.apache.spark.deploy.history
import java.io.{File, FileNotFoundException, IOException}
import java.util.{Date, ServiceLoader, UUID}
-import java.util.concurrent.{Executors, ExecutorService, Future, TimeUnit}
+import java.util.concurrent.{ExecutorService, TimeUnit}
import java.util.zip.{ZipEntry, ZipOutputStream}
import scala.collection.JavaConverters._
@@ -29,7 +29,7 @@ import scala.xml.Node
import com.fasterxml.jackson.annotation.JsonIgnore
import com.google.common.io.ByteStreams
-import com.google.common.util.concurrent.{MoreExecutors, ThreadFactoryBuilder}
+import com.google.common.util.concurrent.MoreExecutors
import org.apache.hadoop.fs.{FileStatus, Path}
import org.apache.hadoop.fs.permission.FsAction
import org.apache.hadoop.hdfs.DistributedFileSystem
@@ -116,8 +116,7 @@ private[history] class FsHistoryProvider(conf: SparkConf,
clock: Clock)
// Used by check event thread and clean log thread.
// Scheduled thread pool size must be one, otherwise it will have concurrent
issues about fs
// and applications between check task and clean task.
- private val pool = Executors.newScheduledThreadPool(1, new
ThreadFactoryBuilder()
-.setNameFormat("spark-history-task-%d").setDaemon(true).build())
+ private val pool =
ThreadUtils.newDaemonSingleThreadScheduledExecutor("spark-history-task-%d")
// The modification time of the newest log detected during the last scan.
Currently only
// used for logging msgs (logs are re-scanned based on file size, rather
than modtime)
@@ -174,7 +173,7 @@ private[history] class FsHistoryProvider(conf: SparkConf,
clock: Clock)
* Fixed size thread pool to fetch and parse log files.
*/
private val replayExecutor: ExecutorService = {
-if (!conf.contains("spark.testing")) {
+if (Utils.isTesting) {
ThreadUtils.newDaemonFixedThreadPool(NUM_PROCESSING_THREADS,
"log-replay-executor")
} else {
MoreExecutors.sameThreadExecutor()
@@ -275,7 +274,7 @@ private[history] class FsHistoryProvider(conf: SparkConf,
clock: Clock)
try {
Some(load(appId).toApplicationInfo())
} catch {
- case e: NoSuchElementException =>
+ case _: NoSuchElementException =>
None
}
}
@@ -405,49 +404,70 @@ private[history] class FsHistoryProvider(conf: SparkConf,
clock: Clock)
try {
val newLastScanTime = getNewLastScanTime()
logDebug(s"Scanning $logDir with lastScanTime==$lastScanTime")
- // scan for modified applications, replay and merge them
- val logInfos = Option(fs.listStatus(new
Path(logDir))).map(_.toSeq).getOrElse(Nil)
+
+ val updated = Option(fs.listStatus(new
Path(logDir))).map(_.toSeq).getOrElse(Nil)
.filter { entry =>
!entry.isDirectory() &&
// FsHistoryProvider generates a hidden file which can't be read.
Accidentally
// reading a garbage file is safe, but we would log an error which
can be scary to
// the end-user.
!entry.getPath().getName().startsWith(".") &&
-SparkHadoopUtil.get.checkAccessPermission(entry, FsAction
spark git commit: [SPARK-20664][CORE] Delete stale application data from SHS.
Repository: spark
Updated Branches:
refs/heads/branch-2.3 ffe45913d -> 4b79514c9
[SPARK-20664][CORE] Delete stale application data from SHS.
Detect the deletion of event log files from storage, and remove
data about the related application attempt in the SHS.
Also contains code to fix SPARK-21571 based on code by ericvandenbergfb.
Author: Marcelo Vanzin
Closes #20138 from vanzin/SPARK-20664.
(cherry picked from commit fed2139f053fac4a9a6952ff0ab1cc2a5f657bd0)
Signed-off-by: Imran Rashid
Project: http://git-wip-us.apache.org/repos/asf/spark/repo
Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/4b79514c
Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/4b79514c
Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/4b79514c
Branch: refs/heads/branch-2.3
Commit: 4b79514c90ca76674d17fd80d125e9dbfb0e845e
Parents: ffe4591
Author: Marcelo Vanzin
Authored: Fri Jan 19 13:26:37 2018 -0600
Committer: Imran Rashid
Committed: Fri Jan 19 13:27:02 2018 -0600
--
.../deploy/history/FsHistoryProvider.scala | 297 ---
.../deploy/history/FsHistoryProviderSuite.scala | 117 +++-
.../deploy/history/HistoryServerSuite.scala | 4 +-
3 files changed, 306 insertions(+), 112 deletions(-)
--
http://git-wip-us.apache.org/repos/asf/spark/blob/4b79514c/core/src/main/scala/org/apache/spark/deploy/history/FsHistoryProvider.scala
--
diff --git
a/core/src/main/scala/org/apache/spark/deploy/history/FsHistoryProvider.scala
b/core/src/main/scala/org/apache/spark/deploy/history/FsHistoryProvider.scala
index 94c80eb..f9d0b5e 100644
---
a/core/src/main/scala/org/apache/spark/deploy/history/FsHistoryProvider.scala
+++
b/core/src/main/scala/org/apache/spark/deploy/history/FsHistoryProvider.scala
@@ -19,7 +19,7 @@ package org.apache.spark.deploy.history
import java.io.{File, FileNotFoundException, IOException}
import java.util.{Date, ServiceLoader, UUID}
-import java.util.concurrent.{Executors, ExecutorService, Future, TimeUnit}
+import java.util.concurrent.{ExecutorService, TimeUnit}
import java.util.zip.{ZipEntry, ZipOutputStream}
import scala.collection.JavaConverters._
@@ -29,7 +29,7 @@ import scala.xml.Node
import com.fasterxml.jackson.annotation.JsonIgnore
import com.google.common.io.ByteStreams
-import com.google.common.util.concurrent.{MoreExecutors, ThreadFactoryBuilder}
+import com.google.common.util.concurrent.MoreExecutors
import org.apache.hadoop.fs.{FileStatus, Path}
import org.apache.hadoop.fs.permission.FsAction
import org.apache.hadoop.hdfs.DistributedFileSystem
@@ -116,8 +116,7 @@ private[history] class FsHistoryProvider(conf: SparkConf,
clock: Clock)
// Used by check event thread and clean log thread.
// Scheduled thread pool size must be one, otherwise it will have concurrent
issues about fs
// and applications between check task and clean task.
- private val pool = Executors.newScheduledThreadPool(1, new
ThreadFactoryBuilder()
-.setNameFormat("spark-history-task-%d").setDaemon(true).build())
+ private val pool =
ThreadUtils.newDaemonSingleThreadScheduledExecutor("spark-history-task-%d")
// The modification time of the newest log detected during the last scan.
Currently only
// used for logging msgs (logs are re-scanned based on file size, rather
than modtime)
@@ -174,7 +173,7 @@ private[history] class FsHistoryProvider(conf: SparkConf,
clock: Clock)
* Fixed size thread pool to fetch and parse log files.
*/
private val replayExecutor: ExecutorService = {
-if (!conf.contains("spark.testing")) {
+if (Utils.isTesting) {
ThreadUtils.newDaemonFixedThreadPool(NUM_PROCESSING_THREADS,
"log-replay-executor")
} else {
MoreExecutors.sameThreadExecutor()
@@ -275,7 +274,7 @@ private[history] class FsHistoryProvider(conf: SparkConf,
clock: Clock)
try {
Some(load(appId).toApplicationInfo())
} catch {
- case e: NoSuchElementException =>
+ case _: NoSuchElementException =>
None
}
}
@@ -405,49 +404,70 @@ private[history] class FsHistoryProvider(conf: SparkConf,
clock: Clock)
try {
val newLastScanTime = getNewLastScanTime()
logDebug(s"Scanning $logDir with lastScanTime==$lastScanTime")
- // scan for modified applications, replay and merge them
- val logInfos = Option(fs.listStatus(new
Path(logDir))).map(_.toSeq).getOrElse(Nil)
+
+ val updated = Option(fs.listStatus(new
Path(logDir))).map(_.toSeq).getOrElse(Nil)
.filter { entry =>
!entry.isDirectory() &&
// FsHistoryProvider generates a hidden file which can't be read.
Accidentally
// reading a garbage file is safe, but we would log an error which
can be scary to
// the end-user.
!entry.ge
spark git commit: [SPARK-23103][CORE] Ensure correct sort order for negative values in LevelDB.
Repository: spark
Updated Branches:
refs/heads/master fed2139f0 -> aa3a1276f
[SPARK-23103][CORE] Ensure correct sort order for negative values in LevelDB.
The code was sorting "0" as "less than" negative values, which is a little
wrong. Fix is simple, most of the changes are the added test and related
cleanup.
Author: Marcelo Vanzin
Closes #20284 from vanzin/SPARK-23103.
Project: http://git-wip-us.apache.org/repos/asf/spark/repo
Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/aa3a1276
Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/aa3a1276
Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/aa3a1276
Branch: refs/heads/master
Commit: aa3a1276f9e23ffbb093d00743e63cd4369f9f57
Parents: fed2139
Author: Marcelo Vanzin
Authored: Fri Jan 19 13:32:20 2018 -0600
Committer: Imran Rashid
Committed: Fri Jan 19 13:32:20 2018 -0600
--
.../spark/util/kvstore/LevelDBTypeInfo.java | 2 +-
.../spark/util/kvstore/DBIteratorSuite.java | 7 +-
.../apache/spark/util/kvstore/LevelDBSuite.java | 77 ++--
.../spark/status/AppStatusListenerSuite.scala | 8 +-
4 files changed, 52 insertions(+), 42 deletions(-)
--
http://git-wip-us.apache.org/repos/asf/spark/blob/aa3a1276/common/kvstore/src/main/java/org/apache/spark/util/kvstore/LevelDBTypeInfo.java
--
diff --git
a/common/kvstore/src/main/java/org/apache/spark/util/kvstore/LevelDBTypeInfo.java
b/common/kvstore/src/main/java/org/apache/spark/util/kvstore/LevelDBTypeInfo.java
index 232ee41..f4d3592 100644
---
a/common/kvstore/src/main/java/org/apache/spark/util/kvstore/LevelDBTypeInfo.java
+++
b/common/kvstore/src/main/java/org/apache/spark/util/kvstore/LevelDBTypeInfo.java
@@ -493,7 +493,7 @@ class LevelDBTypeInfo {
byte[] key = new byte[bytes * 2 + 2];
long longValue = ((Number) value).longValue();
key[0] = prefix;
-key[1] = longValue > 0 ? POSITIVE_MARKER : NEGATIVE_MARKER;
+key[1] = longValue >= 0 ? POSITIVE_MARKER : NEGATIVE_MARKER;
for (int i = 0; i < key.length - 2; i++) {
int masked = (int) ((longValue >>> (4 * i)) & 0xF);
http://git-wip-us.apache.org/repos/asf/spark/blob/aa3a1276/common/kvstore/src/test/java/org/apache/spark/util/kvstore/DBIteratorSuite.java
--
diff --git
a/common/kvstore/src/test/java/org/apache/spark/util/kvstore/DBIteratorSuite.java
b/common/kvstore/src/test/java/org/apache/spark/util/kvstore/DBIteratorSuite.java
index 9a81f86..1e06243 100644
---
a/common/kvstore/src/test/java/org/apache/spark/util/kvstore/DBIteratorSuite.java
+++
b/common/kvstore/src/test/java/org/apache/spark/util/kvstore/DBIteratorSuite.java
@@ -73,7 +73,9 @@ public abstract class DBIteratorSuite {
private static final BaseComparator NATURAL_ORDER = (t1, t2) ->
t1.key.compareTo(t2.key);
private static final BaseComparator REF_INDEX_ORDER = (t1, t2) ->
t1.id.compareTo(t2.id);
private static final BaseComparator COPY_INDEX_ORDER = (t1, t2) ->
t1.name.compareTo(t2.name);
- private static final BaseComparator NUMERIC_INDEX_ORDER = (t1, t2) -> t1.num
- t2.num;
+ private static final BaseComparator NUMERIC_INDEX_ORDER = (t1, t2) -> {
+return Integer.valueOf(t1.num).compareTo(t2.num);
+ };
private static final BaseComparator CHILD_INDEX_ORDER = (t1, t2) ->
t1.child.compareTo(t2.child);
/**
@@ -112,7 +114,8 @@ public abstract class DBIteratorSuite {
t.key = "key" + i;
t.id = "id" + i;
t.name = "name" + RND.nextInt(MAX_ENTRIES);
- t.num = RND.nextInt(MAX_ENTRIES);
+ // Force one item to have an integer value of zero to test the fix for
SPARK-23103.
+ t.num = (i != 0) ? (int) RND.nextLong() : 0;
t.child = "child" + (i % MIN_ENTRIES);
allEntries.add(t);
}
http://git-wip-us.apache.org/repos/asf/spark/blob/aa3a1276/common/kvstore/src/test/java/org/apache/spark/util/kvstore/LevelDBSuite.java
--
diff --git
a/common/kvstore/src/test/java/org/apache/spark/util/kvstore/LevelDBSuite.java
b/common/kvstore/src/test/java/org/apache/spark/util/kvstore/LevelDBSuite.java
index 2b07d24..b8123ac 100644
---
a/common/kvstore/src/test/java/org/apache/spark/util/kvstore/LevelDBSuite.java
+++
b/common/kvstore/src/test/java/org/apache/spark/util/kvstore/LevelDBSuite.java
@@ -21,6 +21,8 @@ import java.io.File;
import java.util.Arrays;
import java.util.List;
import java.util.NoSuchElementException;
+import java.util.stream.Collectors;
+import java.util.stream.StreamSupport;
import org.apache.commons.io.FileUtils;
import org.iq80.leveldb.DBIterator;
@@ -74,11 +76,7 @@ public class LevelDBSuite {
@Test
public void testObjectWriteReadDelete() t
spark git commit: [SPARK-23103][CORE] Ensure correct sort order for negative values in LevelDB.
Repository: spark
Updated Branches:
refs/heads/branch-2.3 4b79514c9 -> d0cb19873
[SPARK-23103][CORE] Ensure correct sort order for negative values in LevelDB.
The code was sorting "0" as "less than" negative values, which is a little
wrong. Fix is simple, most of the changes are the added test and related
cleanup.
Author: Marcelo Vanzin
Closes #20284 from vanzin/SPARK-23103.
(cherry picked from commit aa3a1276f9e23ffbb093d00743e63cd4369f9f57)
Signed-off-by: Imran Rashid
Project: http://git-wip-us.apache.org/repos/asf/spark/repo
Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/d0cb1987
Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/d0cb1987
Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/d0cb1987
Branch: refs/heads/branch-2.3
Commit: d0cb19873bb325be7e31de62b0ba117dd6b92619
Parents: 4b79514
Author: Marcelo Vanzin
Authored: Fri Jan 19 13:32:20 2018 -0600
Committer: Imran Rashid
Committed: Fri Jan 19 13:32:38 2018 -0600
--
.../spark/util/kvstore/LevelDBTypeInfo.java | 2 +-
.../spark/util/kvstore/DBIteratorSuite.java | 7 +-
.../apache/spark/util/kvstore/LevelDBSuite.java | 77 ++--
.../spark/status/AppStatusListenerSuite.scala | 8 +-
4 files changed, 52 insertions(+), 42 deletions(-)
--
http://git-wip-us.apache.org/repos/asf/spark/blob/d0cb1987/common/kvstore/src/main/java/org/apache/spark/util/kvstore/LevelDBTypeInfo.java
--
diff --git
a/common/kvstore/src/main/java/org/apache/spark/util/kvstore/LevelDBTypeInfo.java
b/common/kvstore/src/main/java/org/apache/spark/util/kvstore/LevelDBTypeInfo.java
index 232ee41..f4d3592 100644
---
a/common/kvstore/src/main/java/org/apache/spark/util/kvstore/LevelDBTypeInfo.java
+++
b/common/kvstore/src/main/java/org/apache/spark/util/kvstore/LevelDBTypeInfo.java
@@ -493,7 +493,7 @@ class LevelDBTypeInfo {
byte[] key = new byte[bytes * 2 + 2];
long longValue = ((Number) value).longValue();
key[0] = prefix;
-key[1] = longValue > 0 ? POSITIVE_MARKER : NEGATIVE_MARKER;
+key[1] = longValue >= 0 ? POSITIVE_MARKER : NEGATIVE_MARKER;
for (int i = 0; i < key.length - 2; i++) {
int masked = (int) ((longValue >>> (4 * i)) & 0xF);
http://git-wip-us.apache.org/repos/asf/spark/blob/d0cb1987/common/kvstore/src/test/java/org/apache/spark/util/kvstore/DBIteratorSuite.java
--
diff --git
a/common/kvstore/src/test/java/org/apache/spark/util/kvstore/DBIteratorSuite.java
b/common/kvstore/src/test/java/org/apache/spark/util/kvstore/DBIteratorSuite.java
index 9a81f86..1e06243 100644
---
a/common/kvstore/src/test/java/org/apache/spark/util/kvstore/DBIteratorSuite.java
+++
b/common/kvstore/src/test/java/org/apache/spark/util/kvstore/DBIteratorSuite.java
@@ -73,7 +73,9 @@ public abstract class DBIteratorSuite {
private static final BaseComparator NATURAL_ORDER = (t1, t2) ->
t1.key.compareTo(t2.key);
private static final BaseComparator REF_INDEX_ORDER = (t1, t2) ->
t1.id.compareTo(t2.id);
private static final BaseComparator COPY_INDEX_ORDER = (t1, t2) ->
t1.name.compareTo(t2.name);
- private static final BaseComparator NUMERIC_INDEX_ORDER = (t1, t2) -> t1.num
- t2.num;
+ private static final BaseComparator NUMERIC_INDEX_ORDER = (t1, t2) -> {
+return Integer.valueOf(t1.num).compareTo(t2.num);
+ };
private static final BaseComparator CHILD_INDEX_ORDER = (t1, t2) ->
t1.child.compareTo(t2.child);
/**
@@ -112,7 +114,8 @@ public abstract class DBIteratorSuite {
t.key = "key" + i;
t.id = "id" + i;
t.name = "name" + RND.nextInt(MAX_ENTRIES);
- t.num = RND.nextInt(MAX_ENTRIES);
+ // Force one item to have an integer value of zero to test the fix for
SPARK-23103.
+ t.num = (i != 0) ? (int) RND.nextLong() : 0;
t.child = "child" + (i % MIN_ENTRIES);
allEntries.add(t);
}
http://git-wip-us.apache.org/repos/asf/spark/blob/d0cb1987/common/kvstore/src/test/java/org/apache/spark/util/kvstore/LevelDBSuite.java
--
diff --git
a/common/kvstore/src/test/java/org/apache/spark/util/kvstore/LevelDBSuite.java
b/common/kvstore/src/test/java/org/apache/spark/util/kvstore/LevelDBSuite.java
index 2b07d24..b8123ac 100644
---
a/common/kvstore/src/test/java/org/apache/spark/util/kvstore/LevelDBSuite.java
+++
b/common/kvstore/src/test/java/org/apache/spark/util/kvstore/LevelDBSuite.java
@@ -21,6 +21,8 @@ import java.io.File;
import java.util.Arrays;
import java.util.List;
import java.util.NoSuchElementException;
+import java.util.stream.Collectors;
+import java.util.stream.StreamSupport;
import org.apache.commons.io.FileUtils;
import org.iq80.leveldb.DBItera
svn commit: r24328 - in /dev/spark/2.4.0-SNAPSHOT-2018_01_19_12_01-aa3a127-docs: ./ _site/ _site/api/ _site/api/R/ _site/api/java/ _site/api/java/lib/ _site/api/java/org/ _site/api/java/org/apache/ _s
Author: pwendell Date: Fri Jan 19 20:15:04 2018 New Revision: 24328 Log: Apache Spark 2.4.0-SNAPSHOT-2018_01_19_12_01-aa3a127 docs [This commit notification would consist of 1441 parts, which exceeds the limit of 50 ones, so it was shortened to the summary.] - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
spark git commit: [SPARK-23135][UI] Fix rendering of accumulators in the stage page.
Repository: spark
Updated Branches:
refs/heads/branch-2.3 d0cb19873 -> f9ad00a5a
[SPARK-23135][UI] Fix rendering of accumulators in the stage page.
This follows the behavior of 2.2: only named accumulators with a
value are rendered.
Screenshot:

Author: Marcelo Vanzin
Closes #20299 from vanzin/SPARK-23135.
(cherry picked from commit f6da41b0150725fe96ccb2ee3b48840b207f47eb)
Signed-off-by: Sameer Agarwal
Project: http://git-wip-us.apache.org/repos/asf/spark/repo
Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/f9ad00a5
Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/f9ad00a5
Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/f9ad00a5
Branch: refs/heads/branch-2.3
Commit: f9ad00a5aeeecf4b8d261a0dae6c8cb6be8daa67
Parents: d0cb198
Author: Marcelo Vanzin
Authored: Fri Jan 19 13:14:24 2018 -0800
Committer: Sameer Agarwal
Committed: Fri Jan 19 13:14:38 2018 -0800
--
.../org/apache/spark/ui/jobs/StagePage.scala| 20 +++-
1 file changed, 15 insertions(+), 5 deletions(-)
--
http://git-wip-us.apache.org/repos/asf/spark/blob/f9ad00a5/core/src/main/scala/org/apache/spark/ui/jobs/StagePage.scala
--
diff --git a/core/src/main/scala/org/apache/spark/ui/jobs/StagePage.scala
b/core/src/main/scala/org/apache/spark/ui/jobs/StagePage.scala
index af78373..38f7b35 100644
--- a/core/src/main/scala/org/apache/spark/ui/jobs/StagePage.scala
+++ b/core/src/main/scala/org/apache/spark/ui/jobs/StagePage.scala
@@ -260,7 +260,11 @@ private[ui] class StagePage(parent: StagesTab, store:
AppStatusStore) extends We
val accumulableHeaders: Seq[String] = Seq("Accumulable", "Value")
def accumulableRow(acc: AccumulableInfo): Seq[Node] = {
- {acc.name}{acc.value}
+ if (acc.name != null && acc.value != null) {
+{acc.name}{acc.value}
+ } else {
+Nil
+ }
}
val accumulableTable = UIUtils.listingTable(
accumulableHeaders,
@@ -856,7 +860,7 @@ private[ui] class TaskPagedTable(
{formatBytes(task.taskMetrics.map(_.peakExecutionMemory))}
{if (hasAccumulators(stage)) {
-accumulatorsInfo(task)
+{accumulatorsInfo(task)}
}}
{if (hasInput(stage)) {
metricInfo(task) { m =>
@@ -912,8 +916,12 @@ private[ui] class TaskPagedTable(
}
private def accumulatorsInfo(task: TaskData): Seq[Node] = {
-task.accumulatorUpdates.map { acc =>
- Unparsed(StringEscapeUtils.escapeHtml4(s"${acc.name}: ${acc.update}"))
+task.accumulatorUpdates.flatMap { acc =>
+ if (acc.name != null && acc.update.isDefined) {
+Unparsed(StringEscapeUtils.escapeHtml4(s"${acc.name}:
${acc.update.get}")) ++
+ } else {
+Nil
+ }
}
}
@@ -977,7 +985,9 @@ private object ApiHelper {
"Shuffle Spill (Disk)" -> TaskIndexNames.DISK_SPILL,
"Errors" -> TaskIndexNames.ERROR)
- def hasAccumulators(stageData: StageData): Boolean =
stageData.accumulatorUpdates.size > 0
+ def hasAccumulators(stageData: StageData): Boolean = {
+stageData.accumulatorUpdates.exists { acc => acc.name != null && acc.value
!= null }
+ }
def hasInput(stageData: StageData): Boolean = stageData.inputBytes > 0
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
spark git commit: [SPARK-23135][UI] Fix rendering of accumulators in the stage page.
Repository: spark
Updated Branches:
refs/heads/master aa3a1276f -> f6da41b01
[SPARK-23135][UI] Fix rendering of accumulators in the stage page.
This follows the behavior of 2.2: only named accumulators with a
value are rendered.
Screenshot:

Author: Marcelo Vanzin
Closes #20299 from vanzin/SPARK-23135.
Project: http://git-wip-us.apache.org/repos/asf/spark/repo
Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/f6da41b0
Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/f6da41b0
Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/f6da41b0
Branch: refs/heads/master
Commit: f6da41b0150725fe96ccb2ee3b48840b207f47eb
Parents: aa3a127
Author: Marcelo Vanzin
Authored: Fri Jan 19 13:14:24 2018 -0800
Committer: Sameer Agarwal
Committed: Fri Jan 19 13:14:24 2018 -0800
--
.../org/apache/spark/ui/jobs/StagePage.scala| 20 +++-
1 file changed, 15 insertions(+), 5 deletions(-)
--
http://git-wip-us.apache.org/repos/asf/spark/blob/f6da41b0/core/src/main/scala/org/apache/spark/ui/jobs/StagePage.scala
--
diff --git a/core/src/main/scala/org/apache/spark/ui/jobs/StagePage.scala
b/core/src/main/scala/org/apache/spark/ui/jobs/StagePage.scala
index 25bee33..0eb3190 100644
--- a/core/src/main/scala/org/apache/spark/ui/jobs/StagePage.scala
+++ b/core/src/main/scala/org/apache/spark/ui/jobs/StagePage.scala
@@ -260,7 +260,11 @@ private[ui] class StagePage(parent: StagesTab, store:
AppStatusStore) extends We
val accumulableHeaders: Seq[String] = Seq("Accumulable", "Value")
def accumulableRow(acc: AccumulableInfo): Seq[Node] = {
- {acc.name}{acc.value}
+ if (acc.name != null && acc.value != null) {
+{acc.name}{acc.value}
+ } else {
+Nil
+ }
}
val accumulableTable = UIUtils.listingTable(
accumulableHeaders,
@@ -864,7 +868,7 @@ private[ui] class TaskPagedTable(
{formatBytes(task.taskMetrics.map(_.peakExecutionMemory))}
{if (hasAccumulators(stage)) {
-accumulatorsInfo(task)
+{accumulatorsInfo(task)}
}}
{if (hasInput(stage)) {
metricInfo(task) { m =>
@@ -920,8 +924,12 @@ private[ui] class TaskPagedTable(
}
private def accumulatorsInfo(task: TaskData): Seq[Node] = {
-task.accumulatorUpdates.map { acc =>
- Unparsed(StringEscapeUtils.escapeHtml4(s"${acc.name}: ${acc.update}"))
+task.accumulatorUpdates.flatMap { acc =>
+ if (acc.name != null && acc.update.isDefined) {
+Unparsed(StringEscapeUtils.escapeHtml4(s"${acc.name}:
${acc.update.get}")) ++
+ } else {
+Nil
+ }
}
}
@@ -985,7 +993,9 @@ private object ApiHelper {
"Shuffle Spill (Disk)" -> TaskIndexNames.DISK_SPILL,
"Errors" -> TaskIndexNames.ERROR)
- def hasAccumulators(stageData: StageData): Boolean =
stageData.accumulatorUpdates.size > 0
+ def hasAccumulators(stageData: StageData): Boolean = {
+stageData.accumulatorUpdates.exists { acc => acc.name != null && acc.value
!= null }
+ }
def hasInput(stageData: StageData): Boolean = stageData.inputBytes > 0
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
svn commit: r24330 - in /dev/spark/2.3.1-SNAPSHOT-2018_01_19_14_01-f9ad00a-docs: ./ _site/ _site/api/ _site/api/R/ _site/api/java/ _site/api/java/lib/ _site/api/java/org/ _site/api/java/org/apache/ _s
Author: pwendell Date: Fri Jan 19 22:15:08 2018 New Revision: 24330 Log: Apache Spark 2.3.1-SNAPSHOT-2018_01_19_14_01-f9ad00a docs [This commit notification would consist of 1441 parts, which exceeds the limit of 50 ones, so it was shortened to the summary.] - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
spark git commit: [SPARK-21771][SQL] remove useless hive client in SparkSQLEnv
Repository: spark
Updated Branches:
refs/heads/branch-2.3 f9ad00a5a -> c647f918b
[SPARK-21771][SQL] remove useless hive client in SparkSQLEnv
## What changes were proposed in this pull request?
Once a meta hive client is created, it generates its SessionState which creates
a lot of session related directories, some deleteOnExit, some does not. if a
hive client is useless we may not create it at the very start.
## How was this patch tested?
N/A
cc hvanhovell cloud-fan
Author: Kent Yao <11215...@zju.edu.cn>
Closes #18983 from yaooqinn/patch-1.
(cherry picked from commit 793841c6b8b98b918dcf241e29f60ef125914db9)
Signed-off-by: gatorsmile
Project: http://git-wip-us.apache.org/repos/asf/spark/repo
Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/c647f918
Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/c647f918
Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/c647f918
Branch: refs/heads/branch-2.3
Commit: c647f918b1aee27d7a53852aca74629f03ad49f6
Parents: f9ad00a
Author: Kent Yao <11215...@zju.edu.cn>
Authored: Fri Jan 19 15:49:29 2018 -0800
Committer: gatorsmile
Committed: Fri Jan 19 15:49:37 2018 -0800
--
.../org/apache/spark/sql/hive/thriftserver/SparkSQLEnv.scala | 3 +--
1 file changed, 1 insertion(+), 2 deletions(-)
--
http://git-wip-us.apache.org/repos/asf/spark/blob/c647f918/sql/hive-thriftserver/src/main/scala/org/apache/spark/sql/hive/thriftserver/SparkSQLEnv.scala
--
diff --git
a/sql/hive-thriftserver/src/main/scala/org/apache/spark/sql/hive/thriftserver/SparkSQLEnv.scala
b/sql/hive-thriftserver/src/main/scala/org/apache/spark/sql/hive/thriftserver/SparkSQLEnv.scala
index 6b19f97..cbd75ad 100644
---
a/sql/hive-thriftserver/src/main/scala/org/apache/spark/sql/hive/thriftserver/SparkSQLEnv.scala
+++
b/sql/hive-thriftserver/src/main/scala/org/apache/spark/sql/hive/thriftserver/SparkSQLEnv.scala
@@ -50,8 +50,7 @@ private[hive] object SparkSQLEnv extends Logging {
sqlContext = sparkSession.sqlContext
val metadataHive = sparkSession
-.sharedState.externalCatalog.asInstanceOf[HiveExternalCatalog]
-.client.newSession()
+.sharedState.externalCatalog.asInstanceOf[HiveExternalCatalog].client
metadataHive.setOut(new PrintStream(System.out, true, "UTF-8"))
metadataHive.setInfo(new PrintStream(System.err, true, "UTF-8"))
metadataHive.setError(new PrintStream(System.err, true, "UTF-8"))
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
spark git commit: [SPARK-21771][SQL] remove useless hive client in SparkSQLEnv
Repository: spark
Updated Branches:
refs/heads/master f6da41b01 -> 793841c6b
[SPARK-21771][SQL] remove useless hive client in SparkSQLEnv
## What changes were proposed in this pull request?
Once a meta hive client is created, it generates its SessionState which creates
a lot of session related directories, some deleteOnExit, some does not. if a
hive client is useless we may not create it at the very start.
## How was this patch tested?
N/A
cc hvanhovell cloud-fan
Author: Kent Yao <11215...@zju.edu.cn>
Closes #18983 from yaooqinn/patch-1.
Project: http://git-wip-us.apache.org/repos/asf/spark/repo
Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/793841c6
Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/793841c6
Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/793841c6
Branch: refs/heads/master
Commit: 793841c6b8b98b918dcf241e29f60ef125914db9
Parents: f6da41b
Author: Kent Yao <11215...@zju.edu.cn>
Authored: Fri Jan 19 15:49:29 2018 -0800
Committer: gatorsmile
Committed: Fri Jan 19 15:49:29 2018 -0800
--
.../org/apache/spark/sql/hive/thriftserver/SparkSQLEnv.scala | 3 +--
1 file changed, 1 insertion(+), 2 deletions(-)
--
http://git-wip-us.apache.org/repos/asf/spark/blob/793841c6/sql/hive-thriftserver/src/main/scala/org/apache/spark/sql/hive/thriftserver/SparkSQLEnv.scala
--
diff --git
a/sql/hive-thriftserver/src/main/scala/org/apache/spark/sql/hive/thriftserver/SparkSQLEnv.scala
b/sql/hive-thriftserver/src/main/scala/org/apache/spark/sql/hive/thriftserver/SparkSQLEnv.scala
index 6b19f97..cbd75ad 100644
---
a/sql/hive-thriftserver/src/main/scala/org/apache/spark/sql/hive/thriftserver/SparkSQLEnv.scala
+++
b/sql/hive-thriftserver/src/main/scala/org/apache/spark/sql/hive/thriftserver/SparkSQLEnv.scala
@@ -50,8 +50,7 @@ private[hive] object SparkSQLEnv extends Logging {
sqlContext = sparkSession.sqlContext
val metadataHive = sparkSession
-.sharedState.externalCatalog.asInstanceOf[HiveExternalCatalog]
-.client.newSession()
+.sharedState.externalCatalog.asInstanceOf[HiveExternalCatalog].client
metadataHive.setOut(new PrintStream(System.out, true, "UTF-8"))
metadataHive.setInfo(new PrintStream(System.err, true, "UTF-8"))
metadataHive.setError(new PrintStream(System.err, true, "UTF-8"))
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
svn commit: r24331 - in /dev/spark/2.4.0-SNAPSHOT-2018_01_19_16_01-793841c-docs: ./ _site/ _site/api/ _site/api/R/ _site/api/java/ _site/api/java/lib/ _site/api/java/org/ _site/api/java/org/apache/ _s
Author: pwendell Date: Sat Jan 20 00:14:43 2018 New Revision: 24331 Log: Apache Spark 2.4.0-SNAPSHOT-2018_01_19_16_01-793841c docs [This commit notification would consist of 1441 parts, which exceeds the limit of 50 ones, so it was shortened to the summary.] - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
svn commit: r24332 - in /dev/spark/2.3.1-SNAPSHOT-2018_01_19_18_01-c647f91-docs: ./ _site/ _site/api/ _site/api/R/ _site/api/java/ _site/api/java/lib/ _site/api/java/org/ _site/api/java/org/apache/ _s
Author: pwendell Date: Sat Jan 20 02:15:17 2018 New Revision: 24332 Log: Apache Spark 2.3.1-SNAPSHOT-2018_01_19_18_01-c647f91 docs [This commit notification would consist of 1441 parts, which exceeds the limit of 50 ones, so it was shortened to the summary.] - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
spark git commit: [SPARK-23091][ML] Incorrect unit test for approxQuantile
Repository: spark
Updated Branches:
refs/heads/branch-2.3 c647f918b -> 0cde5212a
[SPARK-23091][ML] Incorrect unit test for approxQuantile
## What changes were proposed in this pull request?
Narrow bound on approx quantile test to epsilon from 2*epsilon to match paper
## How was this patch tested?
Existing tests.
Author: Sean Owen
Closes #20324 from srowen/SPARK-23091.
(cherry picked from commit 396cdfbea45232bacbc03bfaf8be4ea85d47d3fd)
Signed-off-by: gatorsmile
Project: http://git-wip-us.apache.org/repos/asf/spark/repo
Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/0cde5212
Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/0cde5212
Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/0cde5212
Branch: refs/heads/branch-2.3
Commit: 0cde5212a80b5572bfe53b06ed557e6c2ec8c903
Parents: c647f91
Author: Sean Owen
Authored: Fri Jan 19 22:46:34 2018 -0800
Committer: gatorsmile
Committed: Fri Jan 19 22:46:47 2018 -0800
--
.../apache/spark/sql/DataFrameStatSuite.scala | 24 ++--
1 file changed, 12 insertions(+), 12 deletions(-)
--
http://git-wip-us.apache.org/repos/asf/spark/blob/0cde5212/sql/core/src/test/scala/org/apache/spark/sql/DataFrameStatSuite.scala
--
diff --git
a/sql/core/src/test/scala/org/apache/spark/sql/DataFrameStatSuite.scala
b/sql/core/src/test/scala/org/apache/spark/sql/DataFrameStatSuite.scala
index 5169d2b..8eae353 100644
--- a/sql/core/src/test/scala/org/apache/spark/sql/DataFrameStatSuite.scala
+++ b/sql/core/src/test/scala/org/apache/spark/sql/DataFrameStatSuite.scala
@@ -154,24 +154,24 @@ class DataFrameStatSuite extends QueryTest with
SharedSQLContext {
val Array(d1, d2) = df.stat.approxQuantile("doubles", Array(q1, q2),
epsilon)
val Array(s1, s2) = df.stat.approxQuantile("singles", Array(q1, q2),
epsilon)
- val error_single = 2 * 1000 * epsilon
- val error_double = 2 * 2000 * epsilon
+ val errorSingle = 1000 * epsilon
+ val errorDouble = 2.0 * errorSingle
- assert(math.abs(single1 - q1 * n) < error_single)
- assert(math.abs(double2 - 2 * q2 * n) < error_double)
- assert(math.abs(s1 - q1 * n) < error_single)
- assert(math.abs(s2 - q2 * n) < error_single)
- assert(math.abs(d1 - 2 * q1 * n) < error_double)
- assert(math.abs(d2 - 2 * q2 * n) < error_double)
+ assert(math.abs(single1 - q1 * n) <= errorSingle)
+ assert(math.abs(double2 - 2 * q2 * n) <= errorDouble)
+ assert(math.abs(s1 - q1 * n) <= errorSingle)
+ assert(math.abs(s2 - q2 * n) <= errorSingle)
+ assert(math.abs(d1 - 2 * q1 * n) <= errorDouble)
+ assert(math.abs(d2 - 2 * q2 * n) <= errorDouble)
// Multiple columns
val Array(Array(ms1, ms2), Array(md1, md2)) =
df.stat.approxQuantile(Array("singles", "doubles"), Array(q1, q2),
epsilon)
- assert(math.abs(ms1 - q1 * n) < error_single)
- assert(math.abs(ms2 - q2 * n) < error_single)
- assert(math.abs(md1 - 2 * q1 * n) < error_double)
- assert(math.abs(md2 - 2 * q2 * n) < error_double)
+ assert(math.abs(ms1 - q1 * n) <= errorSingle)
+ assert(math.abs(ms2 - q2 * n) <= errorSingle)
+ assert(math.abs(md1 - 2 * q1 * n) <= errorDouble)
+ assert(math.abs(md2 - 2 * q2 * n) <= errorDouble)
}
// quantile should be in the range [0.0, 1.0]
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
spark git commit: [SPARK-23091][ML] Incorrect unit test for approxQuantile
Repository: spark
Updated Branches:
refs/heads/master 793841c6b -> 396cdfbea
[SPARK-23091][ML] Incorrect unit test for approxQuantile
## What changes were proposed in this pull request?
Narrow bound on approx quantile test to epsilon from 2*epsilon to match paper
## How was this patch tested?
Existing tests.
Author: Sean Owen
Closes #20324 from srowen/SPARK-23091.
Project: http://git-wip-us.apache.org/repos/asf/spark/repo
Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/396cdfbe
Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/396cdfbe
Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/396cdfbe
Branch: refs/heads/master
Commit: 396cdfbea45232bacbc03bfaf8be4ea85d47d3fd
Parents: 793841c
Author: Sean Owen
Authored: Fri Jan 19 22:46:34 2018 -0800
Committer: gatorsmile
Committed: Fri Jan 19 22:46:34 2018 -0800
--
.../apache/spark/sql/DataFrameStatSuite.scala | 24 ++--
1 file changed, 12 insertions(+), 12 deletions(-)
--
http://git-wip-us.apache.org/repos/asf/spark/blob/396cdfbe/sql/core/src/test/scala/org/apache/spark/sql/DataFrameStatSuite.scala
--
diff --git
a/sql/core/src/test/scala/org/apache/spark/sql/DataFrameStatSuite.scala
b/sql/core/src/test/scala/org/apache/spark/sql/DataFrameStatSuite.scala
index 5169d2b..8eae353 100644
--- a/sql/core/src/test/scala/org/apache/spark/sql/DataFrameStatSuite.scala
+++ b/sql/core/src/test/scala/org/apache/spark/sql/DataFrameStatSuite.scala
@@ -154,24 +154,24 @@ class DataFrameStatSuite extends QueryTest with
SharedSQLContext {
val Array(d1, d2) = df.stat.approxQuantile("doubles", Array(q1, q2),
epsilon)
val Array(s1, s2) = df.stat.approxQuantile("singles", Array(q1, q2),
epsilon)
- val error_single = 2 * 1000 * epsilon
- val error_double = 2 * 2000 * epsilon
+ val errorSingle = 1000 * epsilon
+ val errorDouble = 2.0 * errorSingle
- assert(math.abs(single1 - q1 * n) < error_single)
- assert(math.abs(double2 - 2 * q2 * n) < error_double)
- assert(math.abs(s1 - q1 * n) < error_single)
- assert(math.abs(s2 - q2 * n) < error_single)
- assert(math.abs(d1 - 2 * q1 * n) < error_double)
- assert(math.abs(d2 - 2 * q2 * n) < error_double)
+ assert(math.abs(single1 - q1 * n) <= errorSingle)
+ assert(math.abs(double2 - 2 * q2 * n) <= errorDouble)
+ assert(math.abs(s1 - q1 * n) <= errorSingle)
+ assert(math.abs(s2 - q2 * n) <= errorSingle)
+ assert(math.abs(d1 - 2 * q1 * n) <= errorDouble)
+ assert(math.abs(d2 - 2 * q2 * n) <= errorDouble)
// Multiple columns
val Array(Array(ms1, ms2), Array(md1, md2)) =
df.stat.approxQuantile(Array("singles", "doubles"), Array(q1, q2),
epsilon)
- assert(math.abs(ms1 - q1 * n) < error_single)
- assert(math.abs(ms2 - q2 * n) < error_single)
- assert(math.abs(md1 - 2 * q1 * n) < error_double)
- assert(math.abs(md2 - 2 * q2 * n) < error_double)
+ assert(math.abs(ms1 - q1 * n) <= errorSingle)
+ assert(math.abs(ms2 - q2 * n) <= errorSingle)
+ assert(math.abs(md1 - 2 * q1 * n) <= errorDouble)
+ assert(math.abs(md2 - 2 * q2 * n) <= errorDouble)
}
// quantile should be in the range [0.0, 1.0]
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org