[spark] branch master updated: [SPARK-26637][SQL] Makes GetArrayItem nullability more precise
This is an automated email from the ASF dual-hosted git repository.
wenchen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 1ed1b4d [SPARK-26637][SQL] Makes GetArrayItem nullability more precise
1ed1b4d is described below
commit 1ed1b4d8e1a5b9ca0ec8b15f36542d7a63eebf94
Author: Takeshi Yamamuro
AuthorDate: Wed Jan 23 15:33:02 2019 +0800
[SPARK-26637][SQL] Makes GetArrayItem nullability more precise
## What changes were proposed in this pull request?
In the master, GetArrayItem nullable is always true;
https://github.com/apache/spark/blob/cf133e611020ed178f90358464a1b88cdd9b7889/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/complexTypeExtractors.scala#L236
But, If input array size is constant and ordinal is foldable, we could make
GetArrayItem nullability more precise. This pr added code to make
`GetArrayItem` nullability more precise.
## How was this patch tested?
Added tests in `ComplexTypeSuite`.
Closes #23566 from maropu/GetArrayItemNullability.
Authored-by: Takeshi Yamamuro
Signed-off-by: Wenchen Fan
---
.../expressions/complexTypeExtractors.scala| 15 +-
.../catalyst/expressions/ComplexTypeSuite.scala| 33 ++
2 files changed, 47 insertions(+), 1 deletion(-)
diff --git
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/complexTypeExtractors.scala
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/complexTypeExtractors.scala
index 8994eef..104ad98 100644
---
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/complexTypeExtractors.scala
+++
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/complexTypeExtractors.scala
@@ -233,7 +233,20 @@ case class GetArrayItem(child: Expression, ordinal:
Expression)
override def right: Expression = ordinal
/** `Null` is returned for invalid ordinals. */
- override def nullable: Boolean = true
+ override def nullable: Boolean = if (ordinal.foldable && !ordinal.nullable) {
+val intOrdinal = ordinal.eval().asInstanceOf[Number].intValue()
+child match {
+ case CreateArray(ar) if intOrdinal < ar.length =>
+ar(intOrdinal).nullable
+ case GetArrayStructFields(CreateArray(elements), field, _, _, _)
+ if intOrdinal < elements.length =>
+elements(intOrdinal).nullable || field.nullable
+ case _ =>
+true
+}
+ } else {
+true
+ }
override def dataType: DataType =
child.dataType.asInstanceOf[ArrayType].elementType
diff --git
a/sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/expressions/ComplexTypeSuite.scala
b/sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/expressions/ComplexTypeSuite.scala
index dc60464..d8d6571 100644
---
a/sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/expressions/ComplexTypeSuite.scala
+++
b/sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/expressions/ComplexTypeSuite.scala
@@ -59,6 +59,39 @@ class ComplexTypeSuite extends SparkFunSuite with
ExpressionEvalHelper {
checkEvaluation(GetArrayItem(nestedArray, Literal(0)), Seq(1))
}
+ test("SPARK-26637 handles GetArrayItem nullability correctly when input
array size is constant") {
+// CreateArray case
+val a = AttributeReference("a", IntegerType, nullable = false)()
+val b = AttributeReference("b", IntegerType, nullable = true)()
+val array = CreateArray(a :: b :: Nil)
+assert(!GetArrayItem(array, Literal(0)).nullable)
+assert(GetArrayItem(array, Literal(1)).nullable)
+assert(!GetArrayItem(array, Subtract(Literal(2), Literal(2))).nullable)
+assert(GetArrayItem(array, AttributeReference("ordinal",
IntegerType)()).nullable)
+
+// GetArrayStructFields case
+val f1 = StructField("a", IntegerType, nullable = false)
+val f2 = StructField("b", IntegerType, nullable = true)
+val structType = StructType(f1 :: f2 :: Nil)
+val c = AttributeReference("c", structType, nullable = false)()
+val inputArray1 = CreateArray(c :: Nil)
+val inputArray1ContainsNull = c.nullable
+val stArray1 = GetArrayStructFields(inputArray1, f1, 0, 2,
inputArray1ContainsNull)
+assert(!GetArrayItem(stArray1, Literal(0)).nullable)
+val stArray2 = GetArrayStructFields(inputArray1, f2, 1, 2,
inputArray1ContainsNull)
+assert(GetArrayItem(stArray2, Literal(0)).nullable)
+
+val d = AttributeReference("d", structType, nullable = true)()
+val inputArray2 = CreateArray(c :: d :: Nil)
+val inputArray2ContainsNull = c.nullable || d.nullable
+val stArray3 = GetArrayStructFields(inputArray2, f1, 0, 2,
inputArray2ContainsNull)
+assert(!GetArrayItem(stArray3, Literal(0)).nullable)
+assert(GetArrayItem(stArray3, Literal(1)).nullable)
+val stArray4 = GetArrayStructFields(inpu
svn commit: r32100 - in /dev/spark/3.0.0-SNAPSHOT-2019_01_22_22_21-3da71f2-docs: ./ _site/ _site/api/ _site/api/R/ _site/api/java/ _site/api/java/lib/ _site/api/java/org/ _site/api/java/org/apache/ _s
Author: pwendell Date: Wed Jan 23 06:33:38 2019 New Revision: 32100 Log: Apache Spark 3.0.0-SNAPSHOT-2019_01_22_22_21-3da71f2 docs [This commit notification would consist of 1781 parts, which exceeds the limit of 50 ones, so it was shortened to the summary.] - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
svn commit: r32099 - in /dev/spark/2.4.1-SNAPSHOT-2019_01_22_20_11-f36d0c5-docs: ./ _site/ _site/api/ _site/api/R/ _site/api/java/ _site/api/java/lib/ _site/api/java/org/ _site/api/java/org/apache/ _s
Author: pwendell Date: Wed Jan 23 04:27:39 2019 New Revision: 32099 Log: Apache Spark 2.4.1-SNAPSHOT-2019_01_22_20_11-f36d0c5 docs [This commit notification would consist of 1476 parts, which exceeds the limit of 50 ones, so it was shortened to the summary.] - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
svn commit: r32098 - in /dev/spark/2.3.4-SNAPSHOT-2019_01_22_20_11-98d48c7-docs: ./ _site/ _site/api/ _site/api/R/ _site/api/java/ _site/api/java/lib/ _site/api/java/org/ _site/api/java/org/apache/ _s
Author: pwendell Date: Wed Jan 23 04:25:49 2019 New Revision: 32098 Log: Apache Spark 2.3.4-SNAPSHOT-2019_01_22_20_11-98d48c7 docs [This commit notification would consist of 1443 parts, which exceeds the limit of 50 ones, so it was shortened to the summary.] - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-22465][CORE][FOLLOWUP] Use existing partitioner when defaultNumPartitions is equal to maxPartitioner.numPartitions
This is an automated email from the ASF dual-hosted git repository.
wenchen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 3da71f2 [SPARK-22465][CORE][FOLLOWUP] Use existing partitioner when
defaultNumPartitions is equal to maxPartitioner.numPartitions
3da71f2 is described below
commit 3da71f2da192276af041024b73e85e0acaac66a4
Author: Ngone51
AuthorDate: Wed Jan 23 10:23:40 2019 +0800
[SPARK-22465][CORE][FOLLOWUP] Use existing partitioner when
defaultNumPartitions is equal to maxPartitioner.numPartitions
## What changes were proposed in this pull request?
Followup of #20091. We could also use existing partitioner when
defaultNumPartitions is equal to the maxPartitioner's numPartitions.
## How was this patch tested?
Existed.
Closes #23581 from
Ngone51/dev-use-existing-partitioner-when-defaultNumPartitions-equalTo-MaxPartitioner#-numPartitions.
Authored-by: Ngone51
Signed-off-by: Wenchen Fan
---
core/src/main/scala/org/apache/spark/Partitioner.scala | 8
1 file changed, 4 insertions(+), 4 deletions(-)
diff --git a/core/src/main/scala/org/apache/spark/Partitioner.scala
b/core/src/main/scala/org/apache/spark/Partitioner.scala
index 5152375..a0cba8a 100644
--- a/core/src/main/scala/org/apache/spark/Partitioner.scala
+++ b/core/src/main/scala/org/apache/spark/Partitioner.scala
@@ -51,8 +51,8 @@ object Partitioner {
*
* When available, we choose the partitioner from rdds with maximum number
of partitions. If this
* partitioner is eligible (number of partitions within an order of maximum
number of partitions
- * in rdds), or has partition number higher than default partitions number -
we use this
- * partitioner.
+ * in rdds), or has partition number higher than or equal to default
partitions number - we use
+ * this partitioner.
*
* Otherwise, we'll use a new HashPartitioner with the default partitions
number.
*
@@ -79,9 +79,9 @@ object Partitioner {
}
// If the existing max partitioner is an eligible one, or its partitions
number is larger
-// than the default number of partitions, use the existing partitioner.
+// than or equal to the default number of partitions, use the existing
partitioner.
if (hasMaxPartitioner.nonEmpty &&
(isEligiblePartitioner(hasMaxPartitioner.get, rdds) ||
-defaultNumPartitions < hasMaxPartitioner.get.getNumPartitions)) {
+defaultNumPartitions <= hasMaxPartitioner.get.getNumPartitions)) {
hasMaxPartitioner.get.partitioner.get
} else {
new HashPartitioner(defaultNumPartitions)
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
svn commit: r32096 - in /dev/spark/3.0.0-SNAPSHOT-2019_01_22_18_01-6dcad38-docs: ./ _site/ _site/api/ _site/api/R/ _site/api/java/ _site/api/java/lib/ _site/api/java/org/ _site/api/java/org/apache/ _s
Author: pwendell Date: Wed Jan 23 02:14:02 2019 New Revision: 32096 Log: Apache Spark 3.0.0-SNAPSHOT-2019_01_22_18_01-6dcad38 docs [This commit notification would consist of 1781 parts, which exceeds the limit of 50 ones, so it was shortened to the summary.] - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-2.3 updated: [SPARK-26228][MLLIB] OOM issue encountered when computing Gramian matrix
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch branch-2.3
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-2.3 by this push:
new 98d48c7 [SPARK-26228][MLLIB] OOM issue encountered when computing
Gramian matrix
98d48c7 is described below
commit 98d48c7ad2883a1dbaa81828184c3e1d76e3190a
Author: Sean Owen
AuthorDate: Tue Jan 22 19:22:06 2019 -0600
[SPARK-26228][MLLIB] OOM issue encountered when computing Gramian matrix
Avoid memory problems in closure cleaning when handling large Gramians (>=
16K rows/cols) by using null as zeroValue
Existing tests.
Note that it's hard to test the case that triggers this issue as it would
require a large amount of memory and run a while. I confirmed locally that a
16K x 16K Gramian failed with tons of driver memory before, and didn't fail
upfront after this change.
Closes #23600 from srowen/SPARK-26228.
Authored-by: Sean Owen
Signed-off-by: Sean Owen
(cherry picked from commit 6dcad38ba3393188084f378b7ff6dfc12b685b13)
Signed-off-by: Sean Owen
---
.../spark/mllib/linalg/distributed/RowMatrix.scala | 20 +---
1 file changed, 17 insertions(+), 3 deletions(-)
diff --git
a/mllib/src/main/scala/org/apache/spark/mllib/linalg/distributed/RowMatrix.scala
b/mllib/src/main/scala/org/apache/spark/mllib/linalg/distributed/RowMatrix.scala
index 78a8810..5109efb 100644
---
a/mllib/src/main/scala/org/apache/spark/mllib/linalg/distributed/RowMatrix.scala
+++
b/mllib/src/main/scala/org/apache/spark/mllib/linalg/distributed/RowMatrix.scala
@@ -119,11 +119,25 @@ class RowMatrix @Since("1.0.0") (
val nt = if (n % 2 == 0) ((n / 2) * (n + 1)) else (n * ((n + 1) / 2))
// Compute the upper triangular part of the gram matrix.
-val GU = rows.treeAggregate(new BDV[Double](nt))(
- seqOp = (U, v) => {
+val GU = rows.treeAggregate(null.asInstanceOf[BDV[Double]])(
+ seqOp = (maybeU, v) => {
+val U =
+ if (maybeU == null) {
+new BDV[Double](nt)
+ } else {
+maybeU
+ }
BLAS.spr(1.0, v, U.data)
U
- }, combOp = (U1, U2) => U1 += U2)
+ }, combOp = (U1, U2) =>
+if (U1 == null) {
+ U2
+} else if (U2 == null) {
+ U1
+} else {
+ U1 += U2
+}
+)
RowMatrix.triuToFull(n, GU.data)
}
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-2.4 updated: [SPARK-26228][MLLIB] OOM issue encountered when computing Gramian matrix
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch branch-2.4
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-2.4 by this push:
new f36d0c5 [SPARK-26228][MLLIB] OOM issue encountered when computing
Gramian matrix
f36d0c5 is described below
commit f36d0c56c256164f229b900778f593a0d8e4c7fc
Author: Sean Owen
AuthorDate: Tue Jan 22 19:22:06 2019 -0600
[SPARK-26228][MLLIB] OOM issue encountered when computing Gramian matrix
Avoid memory problems in closure cleaning when handling large Gramians (>=
16K rows/cols) by using null as zeroValue
Existing tests.
Note that it's hard to test the case that triggers this issue as it would
require a large amount of memory and run a while. I confirmed locally that a
16K x 16K Gramian failed with tons of driver memory before, and didn't fail
upfront after this change.
Closes #23600 from srowen/SPARK-26228.
Authored-by: Sean Owen
Signed-off-by: Sean Owen
(cherry picked from commit 6dcad38ba3393188084f378b7ff6dfc12b685b13)
Signed-off-by: Sean Owen
---
.../spark/mllib/linalg/distributed/RowMatrix.scala | 20 +---
1 file changed, 17 insertions(+), 3 deletions(-)
diff --git
a/mllib/src/main/scala/org/apache/spark/mllib/linalg/distributed/RowMatrix.scala
b/mllib/src/main/scala/org/apache/spark/mllib/linalg/distributed/RowMatrix.scala
index 78a8810..5109efb 100644
---
a/mllib/src/main/scala/org/apache/spark/mllib/linalg/distributed/RowMatrix.scala
+++
b/mllib/src/main/scala/org/apache/spark/mllib/linalg/distributed/RowMatrix.scala
@@ -119,11 +119,25 @@ class RowMatrix @Since("1.0.0") (
val nt = if (n % 2 == 0) ((n / 2) * (n + 1)) else (n * ((n + 1) / 2))
// Compute the upper triangular part of the gram matrix.
-val GU = rows.treeAggregate(new BDV[Double](nt))(
- seqOp = (U, v) => {
+val GU = rows.treeAggregate(null.asInstanceOf[BDV[Double]])(
+ seqOp = (maybeU, v) => {
+val U =
+ if (maybeU == null) {
+new BDV[Double](nt)
+ } else {
+maybeU
+ }
BLAS.spr(1.0, v, U.data)
U
- }, combOp = (U1, U2) => U1 += U2)
+ }, combOp = (U1, U2) =>
+if (U1 == null) {
+ U2
+} else if (U2 == null) {
+ U1
+} else {
+ U1 += U2
+}
+)
RowMatrix.triuToFull(n, GU.data)
}
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-26228][MLLIB] OOM issue encountered when computing Gramian matrix
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 6dcad38 [SPARK-26228][MLLIB] OOM issue encountered when computing
Gramian matrix
6dcad38 is described below
commit 6dcad38ba3393188084f378b7ff6dfc12b685b13
Author: Sean Owen
AuthorDate: Tue Jan 22 19:22:06 2019 -0600
[SPARK-26228][MLLIB] OOM issue encountered when computing Gramian matrix
## What changes were proposed in this pull request?
Avoid memory problems in closure cleaning when handling large Gramians (>=
16K rows/cols) by using null as zeroValue
## How was this patch tested?
Existing tests.
Note that it's hard to test the case that triggers this issue as it would
require a large amount of memory and run a while. I confirmed locally that a
16K x 16K Gramian failed with tons of driver memory before, and didn't fail
upfront after this change.
Closes #23600 from srowen/SPARK-26228.
Authored-by: Sean Owen
Signed-off-by: Sean Owen
---
.../spark/mllib/linalg/distributed/RowMatrix.scala | 40 ++
1 file changed, 34 insertions(+), 6 deletions(-)
diff --git
a/mllib/src/main/scala/org/apache/spark/mllib/linalg/distributed/RowMatrix.scala
b/mllib/src/main/scala/org/apache/spark/mllib/linalg/distributed/RowMatrix.scala
index ff02e5d..56caeac 100644
---
a/mllib/src/main/scala/org/apache/spark/mllib/linalg/distributed/RowMatrix.scala
+++
b/mllib/src/main/scala/org/apache/spark/mllib/linalg/distributed/RowMatrix.scala
@@ -119,11 +119,25 @@ class RowMatrix @Since("1.0.0") (
val nt = if (n % 2 == 0) ((n / 2) * (n + 1)) else (n * ((n + 1) / 2))
// Compute the upper triangular part of the gram matrix.
-val GU = rows.treeAggregate(new BDV[Double](nt))(
- seqOp = (U, v) => {
+val GU = rows.treeAggregate(null.asInstanceOf[BDV[Double]])(
+ seqOp = (maybeU, v) => {
+val U =
+ if (maybeU == null) {
+new BDV[Double](nt)
+ } else {
+maybeU
+ }
BLAS.spr(1.0, v, U.data)
U
- }, combOp = (U1, U2) => U1 += U2)
+ }, combOp = (U1, U2) =>
+if (U1 == null) {
+ U2
+} else if (U2 == null) {
+ U1
+} else {
+ U1 += U2
+}
+)
RowMatrix.triuToFull(n, GU.data)
}
@@ -136,8 +150,14 @@ class RowMatrix @Since("1.0.0") (
// This succeeds when n <= 65535, which is checked above
val nt = if (n % 2 == 0) ((n / 2) * (n + 1)) else (n * ((n + 1) / 2))
-val MU = rows.treeAggregate(new BDV[Double](nt))(
- seqOp = (U, v) => {
+val MU = rows.treeAggregate(null.asInstanceOf[BDV[Double]])(
+ seqOp = (maybeU, v) => {
+val U =
+ if (maybeU == null) {
+new BDV[Double](nt)
+ } else {
+maybeU
+ }
val n = v.size
val na = Array.ofDim[Double](n)
@@ -150,7 +170,15 @@ class RowMatrix @Since("1.0.0") (
BLAS.spr(1.0, new DenseVector(na), U.data)
U
- }, combOp = (U1, U2) => U1 += U2)
+ }, combOp = (U1, U2) =>
+if (U1 == null) {
+ U2
+} else if (U2 == null) {
+ U1
+} else {
+ U1 += U2
+}
+)
bc.destroy()
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-2.4 updated: [SPARK-26605][YARN] Update AM's credentials when creating tokens.
This is an automated email from the ASF dual-hosted git repository.
vanzin pushed a commit to branch branch-2.4
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-2.4 by this push:
new 10d7713 [SPARK-26605][YARN] Update AM's credentials when creating
tokens.
10d7713 is described below
commit 10d7713f1259d4ba49020bb880ded5218ece55fb
Author: Marcelo Vanzin
AuthorDate: Tue Jan 22 16:46:00 2019 -0800
[SPARK-26605][YARN] Update AM's credentials when creating tokens.
This ensures new executors in client mode also get the new tokens,
instead of being started with potentially expired tokens.
Closes #23523 from vanzin/SPARK-26605.
Authored-by: Marcelo Vanzin
Signed-off-by: Marcelo Vanzin
---
.../spark/deploy/yarn/security/AMCredentialRenewer.scala | 14 +++---
1 file changed, 11 insertions(+), 3 deletions(-)
diff --git
a/resource-managers/yarn/src/main/scala/org/apache/spark/deploy/yarn/security/AMCredentialRenewer.scala
b/resource-managers/yarn/src/main/scala/org/apache/spark/deploy/yarn/security/AMCredentialRenewer.scala
index bc8d47d..51ef7d3 100644
---
a/resource-managers/yarn/src/main/scala/org/apache/spark/deploy/yarn/security/AMCredentialRenewer.scala
+++
b/resource-managers/yarn/src/main/scala/org/apache/spark/deploy/yarn/security/AMCredentialRenewer.scala
@@ -86,6 +86,16 @@ private[yarn] class AMCredentialRenewer(
val originalCreds = UserGroupInformation.getCurrentUser().getCredentials()
val ugi = doLogin()
+ugi.doAs(new PrivilegedExceptionAction[Unit]() {
+ override def run(): Unit = {
+startInternal(ugi, originalCreds)
+ }
+})
+
+ugi
+ }
+
+ private def startInternal(ugi: UserGroupInformation, originalCreds:
Credentials): Unit = {
val tgtRenewalTask = new Runnable() {
override def run(): Unit = {
ugi.checkTGTAndReloginFromKeytab()
@@ -104,8 +114,6 @@ private[yarn] class AMCredentialRenewer(
val existing = ugi.getCredentials()
existing.mergeAll(originalCreds)
ugi.addCredentials(existing)
-
-ugi
}
def stop(): Unit = {
@@ -136,8 +144,8 @@ private[yarn] class AMCredentialRenewer(
// This shouldn't really happen, since the driver should register way
before tokens expire
// (or the AM should time out the application).
logWarning("Delegation tokens close to expiration but no driver has
registered yet.")
-SparkHadoopUtil.get.addDelegationTokens(tokens, sparkConf)
}
+ SparkHadoopUtil.get.addDelegationTokens(tokens, sparkConf)
} catch {
case e: Exception =>
val delay =
TimeUnit.SECONDS.toMillis(sparkConf.get(CREDENTIALS_RENEWAL_RETRY_WAIT))
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-24484][MLLIB] Power Iteration Clustering is giving incorrect clustering results when there are mutiple leading eigen values.
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 0d35f9e [SPARK-24484][MLLIB] Power Iteration Clustering is giving
incorrect clustering results when there are mutiple leading eigen values.
0d35f9e is described below
commit 0d35f9ea3a73efd858f9e1a70fd13813ffaa344d
Author: Shahid
AuthorDate: Tue Jan 22 18:29:18 2019 -0600
[SPARK-24484][MLLIB] Power Iteration Clustering is giving incorrect
clustering results when there are mutiple leading eigen values.
## What changes were proposed in this pull request?

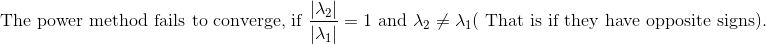
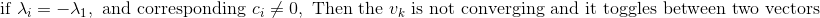
**Method to determine if the top eigen values has same magnitude but
opposite signs**
The vector is written as a linear combination of the eigen vectors at
iteration k.

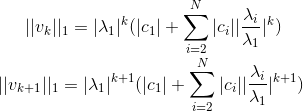



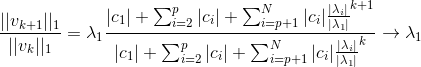


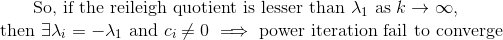

**So, we need to check if the reileigh coefficient at the convergence is
lesser than the norm of the estimated eigen vector before normalizing**
(Please fill in changes proposed in this fix)
Added a UT
Please review http://spark.apache.org/contributing.html before opening a
pull request.
Closes #21627 from shahidki31/picConvergence.
Authored-by: Shahid
Signed-off-by: Sean Owen
---
.../clustering/PowerIterationClustering.scala | 21 +++
.../clustering/PowerIterationClusteringSuite.scala | 68 ++
2 files changed, 89 insertions(+)
diff --git
a/mllib/src/main/scala/org/apache/spark/mllib/clustering/PowerIterationClustering.scala
b/mllib/src/main/scala/org/apache/spark/mllib/clustering/PowerIterationClustering.scala
index 9444f29..765f272 100644
---
a/mllib/src/main/scala/org/apache/spark/mllib/clustering/PowerIterationClustering.scala
+++
b/mllib/src/main/scala/org/apache/spark/mllib/clustering/PowerIterationClustering.scala
@@ -378,6 +378,27 @@ object PowerIterationClustering extends Logging {
logInfo(s"$msgPrefix: delta = $delta.")
diffDelta = math.abs(delta - prevDelta)
logInfo(s"$msgPrefix: diff(delta) = $diffDelta.")
+
+ if (math.abs(diffDelta) < tol) {
+/**
+ * Power Iteration fails to converge if absolute value of top 2 eigen
values are equal,
+ * but with opposite sign. The resultant vector flip-flops between two
vectors.
+ * We should give an exception, if we detect the failure of the
convergence of the
+ * power iteration
+ */
+
+// Rayleigh quotient = x^tAx / x^tx
+val xTAx = curG.joinVertices(v) {
+ case (_, x, y) => x * y
+}.vertices.values.sum()
+val xTx = curG.vertices.mapValues(x => x * x).values.sum()
+val rayleigh = xTAx / xTx
+
+if (math.abs(norm - math.abs(rayleigh)) > tol) {
+ logWarning(s"Power Iteration fail to converge. delta = ${delta}," +
+s" difference delta = ${diffDelta} and norm = ${norm}")
+}
+ }
// update v
curG = Graph(VertexRDD(v1), g.edges)
prevDelta = delta
diff --git
a/mllib/src/test/scala/org/apache/spark/ml/clustering/PowerIterationClusteringSuite.scala
b/mllib/src/test/scala/org/apache/spark/ml/clustering/PowerIterationClusteringSuite.scala
index 0ba3ffa..97269ee 100644
---
a/mllib/src/test/scala/org/apache/spark/ml/clustering/PowerIterationClusteringSuite.scala
+++
b/mllib/src/test/scala/org/apache/spark/ml/
[spark] branch master updated: [MINOR][DOC] Documentation on JVM options for SBT
This is an automated email from the ASF dual-hosted git repository. srowen pushed a commit to branch master in repository https://gitbox.apache.org/repos/asf/spark.git The following commit(s) were added to refs/heads/master by this push: new 9d2a115 [MINOR][DOC] Documentation on JVM options for SBT 9d2a115 is described below commit 9d2a11554b0b2ac27bd506e6941ef8d339756db2 Author: Darcy Shen AuthorDate: Tue Jan 22 18:27:24 2019 -0600 [MINOR][DOC] Documentation on JVM options for SBT ## What changes were proposed in this pull request? Documentation and .gitignore ## How was this patch tested? Manual test that SBT honors the settings in .jvmopts if present Closes #23615 from sadhen/impr/gitignore. Authored-by: Darcy Shen Signed-off-by: Sean Owen --- .gitignore | 3 +++ docs/building-spark.md | 8 2 files changed, 11 insertions(+) diff --git a/.gitignore b/.gitignore index e4c44d0..d5cf66d 100644 --- a/.gitignore +++ b/.gitignore @@ -94,3 +94,6 @@ spark-warehouse/ *.Rproj.* .Rproj.user + +# For SBT +.jvmopts diff --git a/docs/building-spark.md b/docs/building-spark.md index 55695f3..b16083f 100644 --- a/docs/building-spark.md +++ b/docs/building-spark.md @@ -138,6 +138,14 @@ To avoid the overhead of launching sbt each time you need to re-compile, you can in interactive mode by running `build/sbt`, and then run all build commands at the command prompt. +### Setting up SBT's Memory Usage +Configure the JVM options for SBT in `.jvmopts` at the project root, for example: + +-Xmx2g +-XX:ReservedCodeCacheSize=512m + +For the meanings of these two options, please carefully read the [Setting up Maven's Memory Usage section](http://spark.apache.org/docs/latest/building-spark.html#setting-up-mavens-memory-usage). + ## Speeding up Compilation Developers who compile Spark frequently may want to speed up compilation; e.g., by using Zinc - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-26661][SQL] Show actual class name of the writing command in CTAS explain
This is an automated email from the ASF dual-hosted git repository.
dongjoon pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 02d8ae3 [SPARK-26661][SQL] Show actual class name of the writing
command in CTAS explain
02d8ae3 is described below
commit 02d8ae3d598f201c8f614c8af5f0d94470e98e98
Author: Kris Mok
AuthorDate: Tue Jan 22 13:55:41 2019 -0800
[SPARK-26661][SQL] Show actual class name of the writing command in CTAS
explain
## What changes were proposed in this pull request?
The explain output of the Hive CTAS command, regardless of whether it's
actually writing via Hive's SerDe or converted into using Spark's data source,
would always show that it's using `InsertIntoHiveTable` because it's hardcoded.
e.g.
```
Execute OptimizedCreateHiveTableAsSelectCommand [Database:default,
TableName: foo, InsertIntoHiveTable]
```
This CTAS is converted into using Spark's data source, but it still says
`InsertIntoHiveTable` in the explain output.
It's better to show the actual class name of the writing command used. For
the example above, it'd be:
```
Execute OptimizedCreateHiveTableAsSelectCommand [Database:default,
TableName: foo, InsertIntoHadoopFsRelationCommand]
```
## How was this patch tested?
Added test case in `HiveExplainSuite`
Closes #23582 from rednaxelafx/fix-explain-1.
Authored-by: Kris Mok
Signed-off-by: Dongjoon Hyun
---
.../execution/CreateHiveTableAsSelectCommand.scala | 15 +++--
.../sql/hive/execution/HiveExplainSuite.scala | 25 ++
2 files changed, 38 insertions(+), 2 deletions(-)
diff --git
a/sql/hive/src/main/scala/org/apache/spark/sql/hive/execution/CreateHiveTableAsSelectCommand.scala
b/sql/hive/src/main/scala/org/apache/spark/sql/hive/execution/CreateHiveTableAsSelectCommand.scala
index 7249eac..9f79997 100644
---
a/sql/hive/src/main/scala/org/apache/spark/sql/hive/execution/CreateHiveTableAsSelectCommand.scala
+++
b/sql/hive/src/main/scala/org/apache/spark/sql/hive/execution/CreateHiveTableAsSelectCommand.scala
@@ -26,6 +26,7 @@ import org.apache.spark.sql.execution.SparkPlan
import org.apache.spark.sql.execution.command.{DataWritingCommand, DDLUtils}
import org.apache.spark.sql.execution.datasources.{HadoopFsRelation,
InsertIntoHadoopFsRelationCommand, LogicalRelation}
import org.apache.spark.sql.hive.HiveSessionCatalog
+import org.apache.spark.util.Utils
trait CreateHiveTableAsSelectBase extends DataWritingCommand {
val tableDesc: CatalogTable
@@ -83,10 +84,14 @@ trait CreateHiveTableAsSelectBase extends
DataWritingCommand {
tableDesc: CatalogTable,
tableExists: Boolean): DataWritingCommand
+ // A subclass should override this with the Class name of the concrete type
expected to be
+ // returned from `getWritingCommand`.
+ def writingCommandClassName: String
+
override def argString(maxFields: Int): String = {
-s"[Database:${tableDesc.database}, " +
+s"[Database: ${tableDesc.database}, " +
s"TableName: ${tableDesc.identifier.table}, " +
-s"InsertIntoHiveTable]"
+s"${writingCommandClassName}]"
}
}
@@ -118,6 +123,9 @@ case class CreateHiveTableAsSelectCommand(
ifPartitionNotExists = false,
outputColumnNames = outputColumnNames)
}
+
+ override def writingCommandClassName: String =
+Utils.getSimpleName(classOf[InsertIntoHiveTable])
}
/**
@@ -162,4 +170,7 @@ case class OptimizedCreateHiveTableAsSelectCommand(
Some(hadoopRelation.location),
query.output.map(_.name))
}
+
+ override def writingCommandClassName: String =
+Utils.getSimpleName(classOf[InsertIntoHadoopFsRelationCommand])
}
diff --git
a/sql/hive/src/test/scala/org/apache/spark/sql/hive/execution/HiveExplainSuite.scala
b/sql/hive/src/test/scala/org/apache/spark/sql/hive/execution/HiveExplainSuite.scala
index c349a32..d413dfb 100644
---
a/sql/hive/src/test/scala/org/apache/spark/sql/hive/execution/HiveExplainSuite.scala
+++
b/sql/hive/src/test/scala/org/apache/spark/sql/hive/execution/HiveExplainSuite.scala
@@ -20,9 +20,13 @@ package org.apache.spark.sql.hive.execution
import org.apache.spark.sql.QueryTest
import org.apache.spark.sql.catalyst.TableIdentifier
import org.apache.spark.sql.catalyst.parser.ParseException
+import
org.apache.spark.sql.execution.datasources.InsertIntoHadoopFsRelationCommand
+import org.apache.spark.sql.hive.HiveUtils
+import org.apache.spark.sql.hive.execution._
import org.apache.spark.sql.hive.test.TestHiveSingleton
import org.apache.spark.sql.internal.SQLConf
import org.apache.spark.sql.test.SQLTestUtils
+import org.apache.spark.util.Utils
/**
* A set of tests that validates support for Hive Explain command.
@@ -182,4 +186,25 @@ class HiveExplainSuite extends QueryTest with SQLTestUtils
with TestHiveSingle
svn commit: r32094 - in /dev/spark/3.0.0-SNAPSHOT-2019_01_22_13_39-dc2da72-docs: ./ _site/ _site/api/ _site/api/R/ _site/api/java/ _site/api/java/lib/ _site/api/java/org/ _site/api/java/org/apache/ _s
Author: pwendell Date: Tue Jan 22 21:51:47 2019 New Revision: 32094 Log: Apache Spark 3.0.0-SNAPSHOT-2019_01_22_13_39-dc2da72 docs [This commit notification would consist of 1781 parts, which exceeds the limit of 50 ones, so it was shortened to the summary.] - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
svn commit: r32093 - in /dev/spark/2.4.1-SNAPSHOT-2019_01_22_11_24-9814108-docs: ./ _site/ _site/api/ _site/api/R/ _site/api/java/ _site/api/java/lib/ _site/api/java/org/ _site/api/java/org/apache/ _s
Author: pwendell Date: Tue Jan 22 19:40:40 2019 New Revision: 32093 Log: Apache Spark 2.4.1-SNAPSHOT-2019_01_22_11_24-9814108 docs [This commit notification would consist of 1476 parts, which exceeds the limit of 50 ones, so it was shortened to the summary.] - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
svn commit: r32092 - in /dev/spark/2.3.4-SNAPSHOT-2019_01_22_11_24-b88067b-docs: ./ _site/ _site/api/ _site/api/R/ _site/api/java/ _site/api/java/lib/ _site/api/java/org/ _site/api/java/org/apache/ _s
Author: pwendell Date: Tue Jan 22 19:39:17 2019 New Revision: 32092 Log: Apache Spark 2.3.4-SNAPSHOT-2019_01_22_11_24-b88067b docs [This commit notification would consist of 1443 parts, which exceeds the limit of 50 ones, so it was shortened to the summary.] - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-26685][K8S] Correct placement of ARG declaration
This is an automated email from the ASF dual-hosted git repository.
vanzin pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new dc2da72 [SPARK-26685][K8S] Correct placement of ARG declaration
dc2da72 is described below
commit dc2da72100811988ee1b31190f219b620f88f8de
Author: Rob Vesse
AuthorDate: Tue Jan 22 10:31:17 2019 -0800
[SPARK-26685][K8S] Correct placement of ARG declaration
Latest Docker releases are stricter in their enforcement of build argument
scope. The location of the `ARG spark_uid` declaration in the Python and R
Dockerfiles means the variable is out of scope by the time it is used in a
`USER` declaration resulting in a container running as root rather than the
default/configured UID.
Also with some of the refactoring of the script that has happened since my
PR that introduced the configurable UID it turns out the `-u ` argument is
not being properly passed to the Python and R image builds when those are opted
into
## What changes were proposed in this pull request?
This commit moves the `ARG` declaration to just before the argument is used
such that it is in scope. It also ensures that Python and R image builds
receive the build arguments that include the `spark_uid` argument where relevant
## How was this patch tested?
Prior to the patch images are produced where the Python and R images ignore
the default/configured UID:
```
> docker run -it --entrypoint /bin/bash rvesse/spark-py:uid456
bash-4.4# whoami
root
bash-4.4# id -u
0
bash-4.4# exit
> docker run -it --entrypoint /bin/bash rvesse/spark:uid456
bash-4.4$ id -u
456
bash-4.4$ exit
```
Note that the Python image is still running as `root` having ignored the
configured UID of 456 while the base image has the correct UID because the
relevant `ARG` declaration is correctly in scope.
After the patch the correct UID is observed:
```
> docker run -it --entrypoint /bin/bash rvesse/spark-r:uid456
bash-4.4$ id -u
456
bash-4.4$ exit
exit
> docker run -it --entrypoint /bin/bash rvesse/spark-py:uid456
bash-4.4$ id -u
456
bash-4.4$ exit
exit
> docker run -it --entrypoint /bin/bash rvesse/spark:uid456
bash-4.4$ id -u
456
bash-4.4$ exit
```
Closes #23611 from rvesse/SPARK-26685.
Authored-by: Rob Vesse
Signed-off-by: Marcelo Vanzin
---
bin/docker-image-tool.sh | 3 ++-
.../kubernetes/docker/src/main/dockerfiles/spark/bindings/R/Dockerfile | 2 +-
.../docker/src/main/dockerfiles/spark/bindings/python/Dockerfile | 2 +-
3 files changed, 4 insertions(+), 3 deletions(-)
diff --git a/bin/docker-image-tool.sh b/bin/docker-image-tool.sh
index 4f66137..efaf09e 100755
--- a/bin/docker-image-tool.sh
+++ b/bin/docker-image-tool.sh
@@ -154,10 +154,11 @@ function build {
fi
local BINDING_BUILD_ARGS=(
-${BUILD_PARAMS}
+${BUILD_ARGS[@]}
--build-arg
base_img=$(image_ref spark)
)
+
local
BASEDOCKERFILE=${BASEDOCKERFILE:-"kubernetes/dockerfiles/spark/Dockerfile"}
local PYDOCKERFILE=${PYDOCKERFILE:-false}
local RDOCKERFILE=${RDOCKERFILE:-false}
diff --git
a/resource-managers/kubernetes/docker/src/main/dockerfiles/spark/bindings/R/Dockerfile
b/resource-managers/kubernetes/docker/src/main/dockerfiles/spark/bindings/R/Dockerfile
index 9ded57c..34d449c 100644
---
a/resource-managers/kubernetes/docker/src/main/dockerfiles/spark/bindings/R/Dockerfile
+++
b/resource-managers/kubernetes/docker/src/main/dockerfiles/spark/bindings/R/Dockerfile
@@ -16,7 +16,6 @@
#
ARG base_img
-ARG spark_uid=185
FROM $base_img
WORKDIR /
@@ -35,4 +34,5 @@ WORKDIR /opt/spark/work-dir
ENTRYPOINT [ "/opt/entrypoint.sh" ]
# Specify the User that the actual main process will run as
+ARG spark_uid=185
USER ${spark_uid}
diff --git
a/resource-managers/kubernetes/docker/src/main/dockerfiles/spark/bindings/python/Dockerfile
b/resource-managers/kubernetes/docker/src/main/dockerfiles/spark/bindings/python/Dockerfile
index 36b91eb..5044900 100644
---
a/resource-managers/kubernetes/docker/src/main/dockerfiles/spark/bindings/python/Dockerfile
+++
b/resource-managers/kubernetes/docker/src/main/dockerfiles/spark/bindings/python/Dockerfile
@@ -16,7 +16,6 @@
#
ARG base_img
-ARG spark_uid=185
FROM $base_img
WORKDIR /
@@ -46,4 +45,5 @@ WORKDIR /opt/spark/work-dir
ENTRYPOINT [ "/opt/entrypoint.sh" ]
# Specify the User that the actual main process will run as
+ARG spark_uid=185
USER ${spark_uid}
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-25887][K8S] Configurable K8S context support
This is an automated email from the ASF dual-hosted git repository. vanzin pushed a commit to branch master in repository https://gitbox.apache.org/repos/asf/spark.git The following commit(s) were added to refs/heads/master by this push: new c542c24 [SPARK-25887][K8S] Configurable K8S context support c542c24 is described below commit c542c247bbfe1214c0bf81076451718a9e8931dc Author: Rob Vesse AuthorDate: Tue Jan 22 10:17:40 2019 -0800 [SPARK-25887][K8S] Configurable K8S context support This enhancement allows for specifying the desired context to use for the initial K8S client auto-configuration. This allows users to more easily access alternative K8S contexts without having to first explicitly change their current context via kubectl. Explicitly set my K8S context to a context pointing to a non-existent cluster, then launched Spark jobs with explicitly specified contexts via the new `spark.kubernetes.context` configuration property. Example Output: ``` > kubectl config current-context minikube > minikube status minikube: Stopped cluster: kubectl: > ./spark-submit --master k8s://https://localhost:6443 --deploy-mode cluster --name spark-pi --class org.apache.spark.examples.SparkPi --conf spark.executor.instances=2 --conf spark.kubernetes.context=docker-for-desktop --conf spark.kubernetes.container.image=rvesse/spark:debian local:///opt/spark/examples/jars/spark-examples_2.11-3.0.0-SNAPSHOT.jar 4 18/10/31 11:57:51 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 18/10/31 11:57:51 INFO SparkKubernetesClientFactory: Auto-configuring K8S client using context docker-for-desktop from users K8S config file 18/10/31 11:57:52 INFO LoggingPodStatusWatcherImpl: State changed, new state: pod name: spark-pi-1540987071845-driver namespace: default labels: spark-app-selector -> spark-2c4abc226ed3415986eb602bd13f3582, spark-role -> driver pod uid: 32462cac-dd04-11e8-b6c6-0251 creation time: 2018-10-31T11:57:52Z service account name: default volumes: spark-local-dir-1, spark-conf-volume, default-token-glpfv node name: N/A start time: N/A phase: Pending container status: N/A 18/10/31 11:57:52 INFO LoggingPodStatusWatcherImpl: State changed, new state: pod name: spark-pi-1540987071845-driver namespace: default labels: spark-app-selector -> spark-2c4abc226ed3415986eb602bd13f3582, spark-role -> driver pod uid: 32462cac-dd04-11e8-b6c6-0251 creation time: 2018-10-31T11:57:52Z service account name: default volumes: spark-local-dir-1, spark-conf-volume, default-token-glpfv node name: docker-for-desktop start time: N/A phase: Pending container status: N/A ... 18/10/31 11:58:03 INFO LoggingPodStatusWatcherImpl: State changed, new state: pod name: spark-pi-1540987071845-driver namespace: default labels: spark-app-selector -> spark-2c4abc226ed3415986eb602bd13f3582, spark-role -> driver pod uid: 32462cac-dd04-11e8-b6c6-0251 creation time: 2018-10-31T11:57:52Z service account name: default volumes: spark-local-dir-1, spark-conf-volume, default-token-glpfv node name: docker-for-desktop start time: 2018-10-31T11:57:52Z phase: Succeeded container status: container name: spark-kubernetes-driver container image: rvesse/spark:debian container state: terminated container started at: 2018-10-31T11:57:54Z container finished at: 2018-10-31T11:58:02Z exit code: 0 termination reason: Completed ``` Without the `spark.kubernetes.context` setting this will fail because the current context - `minikube` - is pointing to a non-running cluster e.g. ``` > ./spark-submit --master k8s://https://localhost:6443 --deploy-mode cluster --name spark-pi --class org.apache.spark.examples.SparkPi --conf spark.executor.instances=2 --conf spark.kubernetes.container.image=rvesse/spark:debian local:///opt/spark/examples/jars/spark-examples_2.11-3.0.0-SNAPSHOT.jar 4 18/10/31 12:02:30 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 18/10/31 12:02:30 INFO SparkKubernetesClientFactory: Auto-configuring K8S client using current context from users K8S config file 18/10/31 12:02:31 WARN WatchConnectionManager: Exec Failure javax.net.ssl.SSLHandshakeException: sun.security.validator.ValidatorException: PKIX path building failed: sun.security.provider.certpath.SunCertPathBuilderException: unable to find valid certification pat
[spark] branch branch-2.3 updated: [SPARK-26665][CORE] Fix a bug that BlockTransferService.fetchBlockSync may hang forever
This is an automated email from the ASF dual-hosted git repository.
zsxwing pushed a commit to branch branch-2.3
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-2.3 by this push:
new b88067b [SPARK-26665][CORE] Fix a bug that
BlockTransferService.fetchBlockSync may hang forever
b88067b is described below
commit b88067bd0f7b9466a89ce6458cb7766a24283b13
Author: Shixiong Zhu
AuthorDate: Tue Jan 22 09:00:52 2019 -0800
[SPARK-26665][CORE] Fix a bug that BlockTransferService.fetchBlockSync may
hang forever
## What changes were proposed in this pull request?
`ByteBuffer.allocate` may throw `OutOfMemoryError` when the block is large
but no enough memory is available. However, when this happens, right now
BlockTransferService.fetchBlockSync will just hang forever as its
`BlockFetchingListener. onBlockFetchSuccess` doesn't complete `Promise`.
This PR catches `Throwable` and uses the error to complete `Promise`.
## How was this patch tested?
Added a unit test. Since I cannot make `ByteBuffer.allocate` throw
`OutOfMemoryError`, I passed a negative size to make `ByteBuffer.allocate`
fail. Although the error type is different, it should trigger the same code
path.
Closes #23590 from zsxwing/SPARK-26665.
Authored-by: Shixiong Zhu
Signed-off-by: Shixiong Zhu
---
.../spark/network/BlockTransferService.scala | 12 ++-
.../spark/network/BlockTransferServiceSuite.scala | 104 +
2 files changed, 112 insertions(+), 4 deletions(-)
diff --git
a/core/src/main/scala/org/apache/spark/network/BlockTransferService.scala
b/core/src/main/scala/org/apache/spark/network/BlockTransferService.scala
index eef8c31..875e4fc 100644
--- a/core/src/main/scala/org/apache/spark/network/BlockTransferService.scala
+++ b/core/src/main/scala/org/apache/spark/network/BlockTransferService.scala
@@ -105,10 +105,14 @@ abstract class BlockTransferService extends ShuffleClient
with Closeable with Lo
case f: FileSegmentManagedBuffer =>
result.success(f)
case _ =>
- val ret = ByteBuffer.allocate(data.size.toInt)
- ret.put(data.nioByteBuffer())
- ret.flip()
- result.success(new NioManagedBuffer(ret))
+ try {
+val ret = ByteBuffer.allocate(data.size.toInt)
+ret.put(data.nioByteBuffer())
+ret.flip()
+result.success(new NioManagedBuffer(ret))
+ } catch {
+case e: Throwable => result.failure(e)
+ }
}
}
}, tempFileManager)
diff --git
a/core/src/test/scala/org/apache/spark/network/BlockTransferServiceSuite.scala
b/core/src/test/scala/org/apache/spark/network/BlockTransferServiceSuite.scala
new file mode 100644
index 000..d7e4b91
--- /dev/null
+++
b/core/src/test/scala/org/apache/spark/network/BlockTransferServiceSuite.scala
@@ -0,0 +1,104 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.network
+
+import java.io.InputStream
+import java.nio.ByteBuffer
+
+import scala.concurrent.Future
+import scala.concurrent.duration._
+import scala.reflect.ClassTag
+
+import org.scalatest.concurrent._
+
+import org.apache.spark.{SparkException, SparkFunSuite}
+import org.apache.spark.network.buffer.ManagedBuffer
+import org.apache.spark.network.shuffle.{BlockFetchingListener,
DownloadFileManager}
+import org.apache.spark.storage.{BlockId, StorageLevel}
+
+class BlockTransferServiceSuite extends SparkFunSuite with TimeLimits {
+
+ implicit val defaultSignaler: Signaler = ThreadSignaler
+
+ test("fetchBlockSync should not hang when
BlockFetchingListener.onBlockFetchSuccess fails") {
+// Create a mocked `BlockTransferService` to call
`BlockFetchingListener.onBlockFetchSuccess`
+// with a bad `ManagedBuffer` which will trigger an exception in
`onBlockFetchSuccess`.
+val blockTransferService = new BlockTransferService {
+ override def init(blockDataManager: BlockDataManager): Unit = {}
+
+ override def close(): Unit = {}
+
+ override def p
svn commit: r32090 - in /dev/spark/3.0.0-SNAPSHOT-2019_01_22_09_07-66450bb-docs: ./ _site/ _site/api/ _site/api/R/ _site/api/java/ _site/api/java/lib/ _site/api/java/org/ _site/api/java/org/apache/ _s
Author: pwendell Date: Tue Jan 22 17:19:40 2019 New Revision: 32090 Log: Apache Spark 3.0.0-SNAPSHOT-2019_01_22_09_07-66450bb docs [This commit notification would consist of 1781 parts, which exceeds the limit of 50 ones, so it was shortened to the summary.] - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-2.4 updated: [SPARK-26665][CORE] Fix a bug that BlockTransferService.fetchBlockSync may hang forever
This is an automated email from the ASF dual-hosted git repository.
zsxwing pushed a commit to branch branch-2.4
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-2.4 by this push:
new 9814108 [SPARK-26665][CORE] Fix a bug that
BlockTransferService.fetchBlockSync may hang forever
9814108 is described below
commit 9814108a4f51aeb281f14a8421ac1d735c85
Author: Shixiong Zhu
AuthorDate: Tue Jan 22 09:00:52 2019 -0800
[SPARK-26665][CORE] Fix a bug that BlockTransferService.fetchBlockSync may
hang forever
## What changes were proposed in this pull request?
`ByteBuffer.allocate` may throw `OutOfMemoryError` when the block is large
but no enough memory is available. However, when this happens, right now
BlockTransferService.fetchBlockSync will just hang forever as its
`BlockFetchingListener. onBlockFetchSuccess` doesn't complete `Promise`.
This PR catches `Throwable` and uses the error to complete `Promise`.
## How was this patch tested?
Added a unit test. Since I cannot make `ByteBuffer.allocate` throw
`OutOfMemoryError`, I passed a negative size to make `ByteBuffer.allocate`
fail. Although the error type is different, it should trigger the same code
path.
Closes #23590 from zsxwing/SPARK-26665.
Authored-by: Shixiong Zhu
Signed-off-by: Shixiong Zhu
(cherry picked from commit 66450bbc1bb4397f06ca9a6ecba4d16c82d711fd)
Signed-off-by: Shixiong Zhu
---
.../spark/network/BlockTransferService.scala | 12 ++-
.../spark/network/BlockTransferServiceSuite.scala | 104 +
2 files changed, 112 insertions(+), 4 deletions(-)
diff --git
a/core/src/main/scala/org/apache/spark/network/BlockTransferService.scala
b/core/src/main/scala/org/apache/spark/network/BlockTransferService.scala
index a58c8fa..51ced69 100644
--- a/core/src/main/scala/org/apache/spark/network/BlockTransferService.scala
+++ b/core/src/main/scala/org/apache/spark/network/BlockTransferService.scala
@@ -107,10 +107,14 @@ abstract class BlockTransferService extends ShuffleClient
with Closeable with Lo
case e: EncryptedManagedBuffer =>
result.success(e)
case _ =>
- val ret = ByteBuffer.allocate(data.size.toInt)
- ret.put(data.nioByteBuffer())
- ret.flip()
- result.success(new NioManagedBuffer(ret))
+ try {
+val ret = ByteBuffer.allocate(data.size.toInt)
+ret.put(data.nioByteBuffer())
+ret.flip()
+result.success(new NioManagedBuffer(ret))
+ } catch {
+case e: Throwable => result.failure(e)
+ }
}
}
}, tempFileManager)
diff --git
a/core/src/test/scala/org/apache/spark/network/BlockTransferServiceSuite.scala
b/core/src/test/scala/org/apache/spark/network/BlockTransferServiceSuite.scala
new file mode 100644
index 000..d7e4b91
--- /dev/null
+++
b/core/src/test/scala/org/apache/spark/network/BlockTransferServiceSuite.scala
@@ -0,0 +1,104 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.network
+
+import java.io.InputStream
+import java.nio.ByteBuffer
+
+import scala.concurrent.Future
+import scala.concurrent.duration._
+import scala.reflect.ClassTag
+
+import org.scalatest.concurrent._
+
+import org.apache.spark.{SparkException, SparkFunSuite}
+import org.apache.spark.network.buffer.ManagedBuffer
+import org.apache.spark.network.shuffle.{BlockFetchingListener,
DownloadFileManager}
+import org.apache.spark.storage.{BlockId, StorageLevel}
+
+class BlockTransferServiceSuite extends SparkFunSuite with TimeLimits {
+
+ implicit val defaultSignaler: Signaler = ThreadSignaler
+
+ test("fetchBlockSync should not hang when
BlockFetchingListener.onBlockFetchSuccess fails") {
+// Create a mocked `BlockTransferService` to call
`BlockFetchingListener.onBlockFetchSuccess`
+// with a bad `ManagedBuffer` which will trigger an exception in
`onBlockFetchSuccess`.
+val blockTransferService = new BlockTransferService {
+ override def init(blockDa
[spark] branch master updated: [SPARK-26665][CORE] Fix a bug that BlockTransferService.fetchBlockSync may hang forever
This is an automated email from the ASF dual-hosted git repository.
zsxwing pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 66450bb [SPARK-26665][CORE] Fix a bug that
BlockTransferService.fetchBlockSync may hang forever
66450bb is described below
commit 66450bbc1bb4397f06ca9a6ecba4d16c82d711fd
Author: Shixiong Zhu
AuthorDate: Tue Jan 22 09:00:52 2019 -0800
[SPARK-26665][CORE] Fix a bug that BlockTransferService.fetchBlockSync may
hang forever
## What changes were proposed in this pull request?
`ByteBuffer.allocate` may throw `OutOfMemoryError` when the block is large
but no enough memory is available. However, when this happens, right now
BlockTransferService.fetchBlockSync will just hang forever as its
`BlockFetchingListener. onBlockFetchSuccess` doesn't complete `Promise`.
This PR catches `Throwable` and uses the error to complete `Promise`.
## How was this patch tested?
Added a unit test. Since I cannot make `ByteBuffer.allocate` throw
`OutOfMemoryError`, I passed a negative size to make `ByteBuffer.allocate`
fail. Although the error type is different, it should trigger the same code
path.
Closes #23590 from zsxwing/SPARK-26665.
Authored-by: Shixiong Zhu
Signed-off-by: Shixiong Zhu
---
.../spark/network/BlockTransferService.scala | 12 ++-
.../spark/network/BlockTransferServiceSuite.scala | 104 +
2 files changed, 112 insertions(+), 4 deletions(-)
diff --git
a/core/src/main/scala/org/apache/spark/network/BlockTransferService.scala
b/core/src/main/scala/org/apache/spark/network/BlockTransferService.scala
index a58c8fa..51ced69 100644
--- a/core/src/main/scala/org/apache/spark/network/BlockTransferService.scala
+++ b/core/src/main/scala/org/apache/spark/network/BlockTransferService.scala
@@ -107,10 +107,14 @@ abstract class BlockTransferService extends ShuffleClient
with Closeable with Lo
case e: EncryptedManagedBuffer =>
result.success(e)
case _ =>
- val ret = ByteBuffer.allocate(data.size.toInt)
- ret.put(data.nioByteBuffer())
- ret.flip()
- result.success(new NioManagedBuffer(ret))
+ try {
+val ret = ByteBuffer.allocate(data.size.toInt)
+ret.put(data.nioByteBuffer())
+ret.flip()
+result.success(new NioManagedBuffer(ret))
+ } catch {
+case e: Throwable => result.failure(e)
+ }
}
}
}, tempFileManager)
diff --git
a/core/src/test/scala/org/apache/spark/network/BlockTransferServiceSuite.scala
b/core/src/test/scala/org/apache/spark/network/BlockTransferServiceSuite.scala
new file mode 100644
index 000..d7e4b91
--- /dev/null
+++
b/core/src/test/scala/org/apache/spark/network/BlockTransferServiceSuite.scala
@@ -0,0 +1,104 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.network
+
+import java.io.InputStream
+import java.nio.ByteBuffer
+
+import scala.concurrent.Future
+import scala.concurrent.duration._
+import scala.reflect.ClassTag
+
+import org.scalatest.concurrent._
+
+import org.apache.spark.{SparkException, SparkFunSuite}
+import org.apache.spark.network.buffer.ManagedBuffer
+import org.apache.spark.network.shuffle.{BlockFetchingListener,
DownloadFileManager}
+import org.apache.spark.storage.{BlockId, StorageLevel}
+
+class BlockTransferServiceSuite extends SparkFunSuite with TimeLimits {
+
+ implicit val defaultSignaler: Signaler = ThreadSignaler
+
+ test("fetchBlockSync should not hang when
BlockFetchingListener.onBlockFetchSuccess fails") {
+// Create a mocked `BlockTransferService` to call
`BlockFetchingListener.onBlockFetchSuccess`
+// with a bad `ManagedBuffer` which will trigger an exception in
`onBlockFetchSuccess`.
+val blockTransferService = new BlockTransferService {
+ override def init(blockDataManager: BlockDataManager): Unit = {}
+
+ override def close(): Unit = {}
+
+ override def port: Int =
[spark] branch master updated: [SPARK-26657][SQL] Use Proleptic Gregorian calendar in DayWeek and in WeekOfYear
This is an automated email from the ASF dual-hosted git repository.
hvanhovell pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 64ce1c9 [SPARK-26657][SQL] Use Proleptic Gregorian calendar in
DayWeek and in WeekOfYear
64ce1c9 is described below
commit 64ce1c9f932b4acdf8f483265a628c124c9fd15d
Author: Maxim Gekk
AuthorDate: Tue Jan 22 17:33:29 2019 +0100
[SPARK-26657][SQL] Use Proleptic Gregorian calendar in DayWeek and in
WeekOfYear
## What changes were proposed in this pull request?
The expressions `DayWeek`, `DayOfWeek`, `WeekDay` and `WeekOfYear` are
changed to use Proleptic Gregorian calendar instead of the hybrid one
(Julian+Gregorian). This was achieved by using Java 8 API for date/timestamp
manipulation, in particular the `LocalDate` class.
Week of year calculation is performed according to ISO-8601. The first week
of a week-based-year is the first Monday-based week of the standard ISO year
that has at least 4 days in the new year (see
https://docs.oracle.com/javase/8/docs/api/java/time/temporal/IsoFields.html).
## How was this patch tested?
The changes were tested by `DateExpressionsSuite` and `DateFunctionsSuite`.
Closes #23594 from MaxGekk/dayweek-gregorian.
Lead-authored-by: Maxim Gekk
Co-authored-by: Maxim Gekk
Signed-off-by: Herman van Hovell
---
docs/sql-migration-guide-upgrade.md| 2 +
.../catalyst/expressions/datetimeExpressions.scala | 62 ++
.../expressions/DateExpressionsSuite.scala | 4 +-
3 files changed, 20 insertions(+), 48 deletions(-)
diff --git a/docs/sql-migration-guide-upgrade.md
b/docs/sql-migration-guide-upgrade.md
index 3d1b804..d442087 100644
--- a/docs/sql-migration-guide-upgrade.md
+++ b/docs/sql-migration-guide-upgrade.md
@@ -91,6 +91,8 @@ displayTitle: Spark SQL Upgrading Guide
- In Spark version 2.4 and earlier, if
`org.apache.spark.sql.functions.udf(Any, DataType)` gets a Scala closure with
primitive-type argument, the returned UDF will return null if the input values
is null. Since Spark 3.0, the UDF will return the default value of the Java
type if the input value is null. For example, `val f = udf((x: Int) => x,
IntegerType)`, `f($"x")` will return null in Spark 2.4 and earlier if column
`x` is null, and return 0 in Spark 3.0. This behavior change is int [...]
+ - Since Spark 3.0, the `weekofyear`, `weekday` and `dayofweek` functions use
java.time API for calculation week number of year and day number of week based
on Proleptic Gregorian calendar. In Spark version 2.4 and earlier, the hybrid
calendar (Julian + Gregorian) is used for the same purpose. Results of the
functions returned by Spark 3.0 and previous versions can be different for
dates before October 15, 1582 (Gregorian).
+
## Upgrading From Spark SQL 2.3 to 2.4
- In Spark version 2.3 and earlier, the second parameter to array_contains
function is implicitly promoted to the element type of first array type
parameter. This type promotion can be lossy and may cause `array_contains`
function to return wrong result. This problem has been addressed in 2.4 by
employing a safer type promotion mechanism. This can cause some change in
behavior and are illustrated in the table below.
diff --git
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/datetimeExpressions.scala
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/datetimeExpressions.scala
index e758362..ec59502 100644
---
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/datetimeExpressions.scala
+++
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/datetimeExpressions.scala
@@ -18,7 +18,9 @@
package org.apache.spark.sql.catalyst.expressions
import java.sql.Timestamp
-import java.util.{Calendar, Locale, TimeZone}
+import java.time.LocalDate
+import java.time.temporal.IsoFields
+import java.util.{Locale, TimeZone}
import scala.util.control.NonFatal
@@ -430,20 +432,14 @@ case class DayOfMonth(child: Expression) extends
UnaryExpression with ImplicitCa
case class DayOfWeek(child: Expression) extends DayWeek {
override protected def nullSafeEval(date: Any): Any = {
-cal.setTimeInMillis(date.asInstanceOf[Int] * 1000L * 3600L * 24L)
-cal.get(Calendar.DAY_OF_WEEK)
+val localDate = LocalDate.ofEpochDay(date.asInstanceOf[Int])
+localDate.getDayOfWeek.plus(1).getValue
}
override protected def doGenCode(ctx: CodegenContext, ev: ExprCode):
ExprCode = {
-nullSafeCodeGen(ctx, ev, time => {
- val cal = classOf[Calendar].getName
- val dtu = DateTimeUtils.getClass.getName.stripSuffix("$")
- val c = "calDayOfWeek"
- ctx.addImmutableStateIfNotExists(cal, c,
-v => s"""$v = $cal.getInstance($dtu.getTimeZone("UTC"));""")
+nullSafe
[spark] branch master updated: [SPARK-16838][PYTHON] Add PMML export for ML KMeans in PySpark
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 06792af [SPARK-16838][PYTHON] Add PMML export for ML KMeans in PySpark
06792af is described below
commit 06792afd4c9c719df4af34b0768a999271383330
Author: Huaxin Gao
AuthorDate: Tue Jan 22 09:34:59 2019 -0600
[SPARK-16838][PYTHON] Add PMML export for ML KMeans in PySpark
## What changes were proposed in this pull request?
Add PMML export support for ML KMeans to PySpark.
## How was this patch tested?
Add tests in ml.tests.PersistenceTest.
Closes #23592 from huaxingao/spark-16838.
Authored-by: Huaxin Gao
Signed-off-by: Sean Owen
---
python/pyspark/ml/clustering.py | 2 +-
python/pyspark/ml/tests/test_persistence.py | 37 +
2 files changed, 38 insertions(+), 1 deletion(-)
diff --git a/python/pyspark/ml/clustering.py b/python/pyspark/ml/clustering.py
index 5a776ae..b9c6bdf 100644
--- a/python/pyspark/ml/clustering.py
+++ b/python/pyspark/ml/clustering.py
@@ -323,7 +323,7 @@ class KMeansSummary(ClusteringSummary):
return self._call_java("trainingCost")
-class KMeansModel(JavaModel, JavaMLWritable, JavaMLReadable):
+class KMeansModel(JavaModel, GeneralJavaMLWritable, JavaMLReadable):
"""
Model fitted by KMeans.
diff --git a/python/pyspark/ml/tests/test_persistence.py
b/python/pyspark/ml/tests/test_persistence.py
index 34d6870..63b0594 100644
--- a/python/pyspark/ml/tests/test_persistence.py
+++ b/python/pyspark/ml/tests/test_persistence.py
@@ -23,6 +23,7 @@ import unittest
from pyspark.ml import Transformer
from pyspark.ml.classification import DecisionTreeClassifier,
LogisticRegression, OneVsRest, \
OneVsRestModel
+from pyspark.ml.clustering import KMeans
from pyspark.ml.feature import Binarizer, HashingTF, PCA
from pyspark.ml.linalg import Vectors
from pyspark.ml.param import Params
@@ -89,6 +90,42 @@ class PersistenceTest(SparkSessionTestCase):
except OSError:
pass
+def test_kmeans(self):
+kmeans = KMeans(k=2, seed=1)
+path = tempfile.mkdtemp()
+km_path = path + "/km"
+kmeans.save(km_path)
+kmeans2 = KMeans.load(km_path)
+self.assertEqual(kmeans.uid, kmeans2.uid)
+self.assertEqual(type(kmeans.uid), type(kmeans2.uid))
+self.assertEqual(kmeans2.uid, kmeans2.k.parent,
+ "Loaded KMeans instance uid (%s) did not match
Param's uid (%s)"
+ % (kmeans2.uid, kmeans2.k.parent))
+self.assertEqual(kmeans._defaultParamMap[kmeans.k],
kmeans2._defaultParamMap[kmeans2.k],
+ "Loaded KMeans instance default params did not match
" +
+ "original defaults")
+try:
+rmtree(path)
+except OSError:
+pass
+
+def test_kmean_pmml_basic(self):
+# Most of the validation is done in the Scala side, here we just check
+# that we output text rather than parquet (e.g. that the format flag
+# was respected).
+data = [(Vectors.dense([0.0, 0.0]),), (Vectors.dense([1.0, 1.0]),),
+(Vectors.dense([9.0, 8.0]),), (Vectors.dense([8.0, 9.0]),)]
+df = self.spark.createDataFrame(data, ["features"])
+kmeans = KMeans(k=2, seed=1)
+model = kmeans.fit(df)
+path = tempfile.mkdtemp()
+km_path = path + "/km-pmml"
+model.write().format("pmml").save(km_path)
+pmml_text_list = self.sc.textFile(km_path).collect()
+pmml_text = "\n".join(pmml_text_list)
+self.assertIn("Apache Spark", pmml_text)
+self.assertIn("PMML", pmml_text)
+
def _compare_params(self, m1, m2, param):
"""
Compare 2 ML Params instances for the given param, and assert both
have the same param value
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-24938][CORE] Prevent Netty from using onheap memory for headers without regard for configuration
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 055bf8e [SPARK-24938][CORE] Prevent Netty from using onheap memory
for headers without regard for configuration
055bf8e is described below
commit 055bf8ea1fe8dd4109772a282909ac3d69627f1b
Author: Nihar Sheth
AuthorDate: Tue Jan 22 08:41:42 2019 -0600
[SPARK-24938][CORE] Prevent Netty from using onheap memory for headers
without regard for configuration
## What changes were proposed in this pull request?
In MessageEncoder.java, the header would always be allocated on onheap
memory regardless of whether netty was configured to use/prefer onheap or
offheap. By default this made netty allocate 16mb of onheap memory for a tiny
header message. It would be more practical to use preallocated buffers.
Using a memory monitor tool on a simple spark application, the following
services currently allocate 16 mb of onheap memory:
netty-rpc-client
netty-blockTransfer-client
netty-external-shuffle-client
With this change, the memory monitor tool reports all three of these
services as using 0 b of onheap memory. The offheap memory allocation does not
increase, but more of the already-allocated space is used.
## How was this patch tested?
Manually tested change using spark-memory-tool
https://github.com/squito/spark-memory
Closes #22114 from NiharS/nettybuffer.
Lead-authored-by: Nihar Sheth
Co-authored-by: Nihar Sheth
Signed-off-by: Sean Owen
---
.../src/main/java/org/apache/spark/network/protocol/MessageEncoder.java | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git
a/common/network-common/src/main/java/org/apache/spark/network/protocol/MessageEncoder.java
b/common/network-common/src/main/java/org/apache/spark/network/protocol/MessageEncoder.java
index 997f74e..06dc447 100644
---
a/common/network-common/src/main/java/org/apache/spark/network/protocol/MessageEncoder.java
+++
b/common/network-common/src/main/java/org/apache/spark/network/protocol/MessageEncoder.java
@@ -79,7 +79,7 @@ public final class MessageEncoder extends
MessageToMessageEncoder {
// sent.
int headerLength = 8 + msgType.encodedLength() + in.encodedLength();
long frameLength = headerLength + (isBodyInFrame ? bodyLength : 0);
-ByteBuf header = ctx.alloc().heapBuffer(headerLength);
+ByteBuf header = ctx.alloc().buffer(headerLength);
header.writeLong(frameLength);
msgType.encode(header);
in.encode(header);
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-26463][CORE] Use ConfigEntry for hardcoded configs for scheduler categories.
This is an automated email from the ASF dual-hosted git repository. srowen pushed a commit to branch master in repository https://gitbox.apache.org/repos/asf/spark.git The following commit(s) were added to refs/heads/master by this push: new 7bf0794 [SPARK-26463][CORE] Use ConfigEntry for hardcoded configs for scheduler categories. 7bf0794 is described below commit 7bf0794651f4d11547325539ebf7131a57ee1ba2 Author: Kazuaki Ishizaki AuthorDate: Tue Jan 22 07:44:36 2019 -0600 [SPARK-26463][CORE] Use ConfigEntry for hardcoded configs for scheduler categories. ## What changes were proposed in this pull request? The PR makes hardcoded `spark.dynamicAllocation`, `spark.scheduler`, `spark.rpc`, `spark.task`, `spark.speculation`, and `spark.cleaner` configs to use `ConfigEntry`. ## How was this patch tested? Existing tests Closes #23416 from kiszk/SPARK-26463. Authored-by: Kazuaki Ishizaki Signed-off-by: Sean Owen --- .../scala/org/apache/spark/ContextCleaner.scala| 11 +- .../apache/spark/ExecutorAllocationManager.scala | 39 +++--- .../scala/org/apache/spark/HeartbeatReceiver.scala | 16 +-- .../scala/org/apache/spark/SecurityManager.scala | 2 +- .../main/scala/org/apache/spark/SparkConf.scala| 26 ++-- .../main/scala/org/apache/spark/SparkContext.scala | 3 +- .../src/main/scala/org/apache/spark/SparkEnv.scala | 4 +- .../scala/org/apache/spark/deploy/Client.scala | 5 +- .../apache/spark/deploy/SparkSubmitArguments.scala | 3 +- .../scala/org/apache/spark/executor/Executor.scala | 12 +- .../org/apache/spark/internal/config/Network.scala | 93 +++ .../org/apache/spark/internal/config/package.scala | 131 +++-- .../org/apache/spark/rdd/PairRDDFunctions.scala| 3 +- core/src/main/scala/org/apache/spark/rdd/RDD.scala | 5 +- .../spark/rdd/ReliableRDDCheckpointData.scala | 3 +- .../org/apache/spark/rpc/netty/Dispatcher.scala| 5 +- .../org/apache/spark/rpc/netty/NettyRpcEnv.scala | 7 +- .../scheduler/BarrierJobAllocationFailed.scala | 3 +- .../apache/spark/scheduler/BlacklistTracker.scala | 6 +- .../spark/scheduler/SchedulableBuilder.scala | 10 +- .../apache/spark/scheduler/TaskSchedulerImpl.scala | 13 +- .../apache/spark/scheduler/TaskSetManager.scala| 11 +- .../cluster/CoarseGrainedSchedulerBackend.scala| 12 +- .../apache/spark/status/AppStatusListener.scala| 7 +- .../org/apache/spark/storage/BlockManager.scala| 6 +- .../org/apache/spark/ui/UIWorkloadGenerator.scala | 5 +- .../org/apache/spark/ui/jobs/AllJobsPage.scala | 3 +- .../scala/org/apache/spark/ui/jobs/JobsTab.scala | 3 +- .../scala/org/apache/spark/ui/jobs/StagesTab.scala | 3 +- .../scala/org/apache/spark/util/RpcUtils.scala | 13 +- .../main/scala/org/apache/spark/util/Utils.scala | 4 +- .../spark/BarrierStageOnSubmittedSuite.scala | 30 ++--- .../org/apache/spark/ContextCleanerSuite.scala | 14 +-- .../spark/ExecutorAllocationManagerSuite.scala | 52 .../org/apache/spark/HeartbeatReceiverSuite.scala | 3 +- .../org/apache/spark/JobCancellationSuite.scala| 23 ++-- .../org/apache/spark/MapOutputTrackerSuite.scala | 13 +- .../scala/org/apache/spark/SparkConfSuite.scala| 17 +-- .../scala/org/apache/spark/SparkContextSuite.scala | 2 +- .../org/apache/spark/deploy/SparkSubmitSuite.scala | 4 +- .../deploy/StandaloneDynamicAllocationSuite.scala | 6 +- .../netty/NettyBlockTransferSecuritySuite.scala| 5 +- .../scala/org/apache/spark/rpc/RpcEnvSuite.scala | 13 +- .../scheduler/BlacklistIntegrationSuite.scala | 4 +- .../spark/scheduler/BlacklistTrackerSuite.scala| 8 +- .../CoarseGrainedSchedulerBackendSuite.scala | 8 +- .../org/apache/spark/scheduler/PoolSuite.scala | 12 +- .../scheduler/SchedulerIntegrationSuite.scala | 3 +- .../spark/scheduler/SparkListenerSuite.scala | 3 +- .../spark/scheduler/TaskResultGetterSuite.scala| 3 +- .../spark/scheduler/TaskSchedulerImplSuite.scala | 10 +- .../spark/scheduler/TaskSetManagerSuite.scala | 40 +++ .../KryoSerializerDistributedSuite.scala | 2 +- .../spark/status/AppStatusListenerSuite.scala | 2 +- .../scala/org/apache/spark/util/UtilsSuite.scala | 14 +-- .../mllib/util/LocalClusterSparkContext.scala | 3 +- .../k8s/KubernetesClusterSchedulerBackend.scala| 3 +- .../mesos/MesosCoarseGrainedSchedulerBackend.scala | 3 +- .../MesosCoarseGrainedSchedulerBackendSuite.scala | 6 +- .../scheduler/cluster/YarnSchedulerBackend.scala | 3 +- .../deploy/yarn/YarnShuffleIntegrationSuite.scala | 5 +- .../org/apache/spark/sql/RuntimeConfigSuite.scala | 2 +- .../streaming/state/StateStoreSuite.scala | 3 +- .../execution/ui/SQLAppStatusListenerSuite.scala | 2 +- .../sql/sources/v2/SimpleWritableD
[spark] branch master updated: [SPARK-26616][MLLIB] Expose document frequency in IDFModel
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new d2e86cb [SPARK-26616][MLLIB] Expose document frequency in IDFModel
d2e86cb is described below
commit d2e86cb3cd8aaf5a2db639bb7402e41bba16e9fe
Author: Jatin Puri
AuthorDate: Tue Jan 22 07:41:54 2019 -0600
[SPARK-26616][MLLIB] Expose document frequency in IDFModel
## What changes were proposed in this pull request?
This change exposes the `df` (document frequency) as a public val along
with the number of documents (`m`) as part of the IDF model.
* The document frequency is returned as an `Array[Long]`
* If the minimum document frequency is set, this is considered in the df
calculation. If the count is less than minDocFreq, the df is 0 for such terms
* numDocs is not very required. But it can be useful, if we plan to provide
a provision in future for user to give their own idf function, instead of using
a default (log((1+m)/(1+df))). In such cases, the user can provide a function
taking input of `m` and `df` and returning the idf value
* Pyspark changes
## How was this patch tested?
The existing test case was edited to also check for the document frequency
values.
I am not very good with python or pyspark. I have committed and run tests
based on my understanding. Kindly let me know if I have missed anything
Reviewer request: mengxr zjffdu yinxusen
Closes #23549 from purijatin/master.
Authored-by: Jatin Puri
Signed-off-by: Sean Owen
---
.../scala/org/apache/spark/ml/feature/IDF.scala| 31 +-
.../scala/org/apache/spark/mllib/feature/IDF.scala | 19 -
.../org/apache/spark/ml/feature/IDFSuite.scala | 7 +++--
.../org/apache/spark/mllib/feature/IDFSuite.scala | 12 ++---
project/MimaExcludes.scala | 6 -
python/pyspark/ml/feature.py | 20 ++
python/pyspark/ml/tests/test_feature.py| 2 ++
python/pyspark/mllib/feature.py| 14 ++
8 files changed, 91 insertions(+), 20 deletions(-)
diff --git a/mllib/src/main/scala/org/apache/spark/ml/feature/IDF.scala
b/mllib/src/main/scala/org/apache/spark/ml/feature/IDF.scala
index 58897cc..98a9674 100644
--- a/mllib/src/main/scala/org/apache/spark/ml/feature/IDF.scala
+++ b/mllib/src/main/scala/org/apache/spark/ml/feature/IDF.scala
@@ -32,6 +32,7 @@ import org.apache.spark.rdd.RDD
import org.apache.spark.sql._
import org.apache.spark.sql.functions._
import org.apache.spark.sql.types.StructType
+import org.apache.spark.util.VersionUtils.majorVersion
/**
* Params for [[IDF]] and [[IDFModel]].
@@ -151,6 +152,15 @@ class IDFModel private[ml] (
@Since("2.0.0")
def idf: Vector = idfModel.idf.asML
+ /** Returns the document frequency */
+ @Since("3.0.0")
+ def docFreq: Array[Long] = idfModel.docFreq
+
+ /** Returns number of documents evaluated to compute idf */
+ @Since("3.0.0")
+ def numDocs: Long = idfModel.numDocs
+
+
@Since("1.6.0")
override def write: MLWriter = new IDFModelWriter(this)
}
@@ -160,11 +170,11 @@ object IDFModel extends MLReadable[IDFModel] {
private[IDFModel] class IDFModelWriter(instance: IDFModel) extends MLWriter {
-private case class Data(idf: Vector)
+private case class Data(idf: Vector, docFreq: Array[Long], numDocs: Long)
override protected def saveImpl(path: String): Unit = {
DefaultParamsWriter.saveMetadata(instance, path, sc)
- val data = Data(instance.idf)
+ val data = Data(instance.idf, instance.docFreq, instance.numDocs)
val dataPath = new Path(path, "data").toString
sparkSession.createDataFrame(Seq(data)).repartition(1).write.parquet(dataPath)
}
@@ -178,10 +188,19 @@ object IDFModel extends MLReadable[IDFModel] {
val metadata = DefaultParamsReader.loadMetadata(path, sc, className)
val dataPath = new Path(path, "data").toString
val data = sparkSession.read.parquet(dataPath)
- val Row(idf: Vector) = MLUtils.convertVectorColumnsToML(data, "idf")
-.select("idf")
-.head()
- val model = new IDFModel(metadata.uid, new
feature.IDFModel(OldVectors.fromML(idf)))
+
+ val model = if (majorVersion(metadata.sparkVersion) >= 3) {
+val Row(idf: Vector, df: Seq[_], numDocs: Long) = data.select("idf",
"docFreq", "numDocs")
+ .head()
+new IDFModel(metadata.uid, new feature.IDFModel(OldVectors.fromML(idf),
+ df.asInstanceOf[Seq[Long]].toArray, numDocs))
+ } else {
+val Row(idf: Vector) = MLUtils.convertVectorColumnsToML(data, "idf")
+ .select("idf")
+ .head()
+new IDFModel(metadata.uid,
+ new feature.IDFModel(OldVectors.fromML(idf), new
Array[
[spark] tag v2.4.0 created (now 0a4c03f)
This is an automated email from the ASF dual-hosted git repository. wenchen pushed a change to tag v2.4.0 in repository https://gitbox.apache.org/repos/asf/spark.git. at 0a4c03f (commit) No new revisions were added by this update. - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] tag v2.4.0 deleted (was 075447b)
This is an automated email from the ASF dual-hosted git repository. wenchen pushed a change to tag v2.4.0 in repository https://gitbox.apache.org/repos/asf/spark.git. *** WARNING: tag v2.4.0 was deleted! *** was 075447b Preparing Spark release v2.4.0-rc5 The revisions that were on this tag are still contained in other references; therefore, this change does not discard any commits from the repository. - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org