[spark] branch master updated (9107f77 -> 29b3e42)
This is an automated email from the ASF dual-hosted git repository. gurwls223 pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 9107f77 [SPARK-30843][SQL] Fix getting of time components before 1582 year add 29b3e42 [MINOR] Update the PR template for adding a link to the configuration naming guideline No new revisions were added by this update. Summary of changes: .github/PULL_REQUEST_TEMPLATE | 2 ++ 1 file changed, 2 insertions(+) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.0 updated: [SPARK-30843][SQL] Fix getting of time components before 1582 year
This is an automated email from the ASF dual-hosted git repository.
wenchen pushed a commit to branch branch-3.0
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.0 by this push:
new 518cc90 [SPARK-30843][SQL] Fix getting of time components before 1582
year
518cc90 is described below
commit 518cc90f434b08c553bc6a23d650decd3449db9d
Author: Maxim Gekk
AuthorDate: Mon Feb 17 13:59:21 2020 +0800
[SPARK-30843][SQL] Fix getting of time components before 1582 year
### What changes were proposed in this pull request?
1. Rewrite DateTimeUtils methods `getHours()`, `getMinutes()`,
`getSeconds()`, `getSecondsWithFraction()`, `getMilliseconds()` and
`getMicroseconds()` using Java 8 time APIs. This will automatically switch the
`Hour`, `Minute`, `Second` and `DatePart` expressions on Proleptic Gregorian
calendar.
2. Remove unused methods and constant of DateTimeUtils - `to2001`,
`YearZero `, `toYearZero` and `absoluteMicroSecond()`.
3. Remove unused value `timeZone` from `TimeZoneAwareExpression` since all
expressions have been migrated to Java 8 time API, and legacy instance of
`TimeZone` is not needed any more.
4. Change signatures of modified DateTimeUtils methods, and pass `ZoneId`
instead of `TimeZone`. This will allow to avoid unnecessary conversions
`TimeZone` -> `String` -> `ZoneId`.
5. Modify tests in `DateTimeUtilsSuite` and in `DateExpressionsSuite` to
pass `ZoneId` instead of `TimeZone`. Correct the tests, to pass tested zone id
instead of None.
### Why are the changes needed?
The changes fix the issue of wrong results returned by the `hour()`,
`minute()`, `second()`, `date_part('millisecond', ...)` and
`date_part('microsecond', )`, see example in
[SPARK-30843](https://issues.apache.org/jira/browse/SPARK-30843).
### Does this PR introduce any user-facing change?
Yes. After the changes, the results of examples from SPARK-30843:
```sql
spark-sql> select hour(timestamp '0010-01-01 00:00:00');
0
spark-sql> select minute(timestamp '0010-01-01 00:00:00');
0
spark-sql> select second(timestamp '0010-01-01 00:00:00');
0
spark-sql> select date_part('milliseconds', timestamp '0010-01-01
00:00:00');
0.000
spark-sql> select date_part('microseconds', timestamp '0010-01-01
00:00:00');
0
```
### How was this patch tested?
- By existing test suites `DateTimeUtilsSuite`, `DateExpressionsSuite` and
`DateFunctionsSuite`.
- Add new tests to `DateExpressionsSuite` and `DateTimeUtilsSuite` for 10
year, like:
```scala
input = date(10, 1, 1, 0, 0, 0, 0, zonePST)
assert(getHours(input, zonePST) === 0)
```
- Re-run `DateTimeBenchmark` using Amazon EC2.
| Item | Description |
| | |
| Region | us-west-2 (Oregon) |
| Instance | r3.xlarge |
| AMI | ami-06f2f779464715dc5
(ubuntu/images/hvm-ssd/ubuntu-bionic-18.04-amd64-server-20190722.1) |
| Java | OpenJDK8/11 |
Closes #27596 from MaxGekk/localtimestamp-greg-cal.
Lead-authored-by: Maxim Gekk
Co-authored-by: Max Gekk
Co-authored-by: Ubuntu
Signed-off-by: Wenchen Fan
(cherry picked from commit 9107f77f15cd0630dc981b6e8a9ca696b79e624f)
Signed-off-by: Wenchen Fan
---
.../catalyst/expressions/datetimeExpressions.scala | 37 ++-
.../spark/sql/catalyst/util/DateTimeUtils.scala| 44 +--
.../expressions/DateExpressionsSuite.scala | 39 ++-
.../sql/catalyst/util/DateTimeTestUtils.scala | 18 +-
.../sql/catalyst/util/DateTimeUtilsSuite.scala | 173 +--
.../benchmarks/DateTimeBenchmark-jdk11-results.txt | 326 ++---
sql/core/benchmarks/DateTimeBenchmark-results.txt | 326 ++---
7 files changed, 484 insertions(+), 479 deletions(-)
diff --git
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/datetimeExpressions.scala
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/datetimeExpressions.scala
index adf7251..05074d9 100644
---
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/datetimeExpressions.scala
+++
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/datetimeExpressions.scala
@@ -51,7 +51,6 @@ trait TimeZoneAwareExpression extends Expression {
/** Returns a copy of this expression with the specified timeZoneId. */
def withTimeZone(timeZoneId: String): TimeZoneAwareExpression
- @transient lazy val timeZone: TimeZone =
DateTimeUtils.getTimeZone(timeZoneId.get)
@transient lazy val zoneId: ZoneId = DateTimeUtils.getZoneId(timeZoneId.get)
}
@@ -229,13 +228,13 @@ case class Hour(child: Expression, timeZoneId:
Option[String] = None)
copy(timeZoneId = Option(timeZoneId))
override protected def nullSafeEval(timestamp: Any): Any = {
-DateTimeUtils.getHours(timestamp.asInstanceOf[Long],
[spark] branch master updated (619274e -> 9107f77)
This is an automated email from the ASF dual-hosted git repository. wenchen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 619274e [DOC] add config naming guideline add 9107f77 [SPARK-30843][SQL] Fix getting of time components before 1582 year No new revisions were added by this update. Summary of changes: .../catalyst/expressions/datetimeExpressions.scala | 37 ++- .../spark/sql/catalyst/util/DateTimeUtils.scala| 44 +-- .../expressions/DateExpressionsSuite.scala | 39 ++- .../sql/catalyst/util/DateTimeTestUtils.scala | 18 +- .../sql/catalyst/util/DateTimeUtilsSuite.scala | 173 +-- .../benchmarks/DateTimeBenchmark-jdk11-results.txt | 326 ++--- sql/core/benchmarks/DateTimeBenchmark-results.txt | 326 ++--- 7 files changed, 484 insertions(+), 479 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (619274e -> 9107f77)
This is an automated email from the ASF dual-hosted git repository. wenchen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 619274e [DOC] add config naming guideline add 9107f77 [SPARK-30843][SQL] Fix getting of time components before 1582 year No new revisions were added by this update. Summary of changes: .../catalyst/expressions/datetimeExpressions.scala | 37 ++- .../spark/sql/catalyst/util/DateTimeUtils.scala| 44 +-- .../expressions/DateExpressionsSuite.scala | 39 ++- .../sql/catalyst/util/DateTimeTestUtils.scala | 18 +- .../sql/catalyst/util/DateTimeUtilsSuite.scala | 173 +-- .../benchmarks/DateTimeBenchmark-jdk11-results.txt | 326 ++--- sql/core/benchmarks/DateTimeBenchmark-results.txt | 326 ++--- 7 files changed, 484 insertions(+), 479 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (ab07c63 -> 619274e)
This is an automated email from the ASF dual-hosted git repository. wenchen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from ab07c63 [SPARK-30799][SQL] "spark_catalog.t" should not be resolved to temp view add 619274e [DOC] add config naming guideline No new revisions were added by this update. Summary of changes: .../apache/spark/internal/config/ConfigEntry.scala | 29 ++ 1 file changed, 29 insertions(+) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (ab07c63 -> 619274e)
This is an automated email from the ASF dual-hosted git repository. wenchen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from ab07c63 [SPARK-30799][SQL] "spark_catalog.t" should not be resolved to temp view add 619274e [DOC] add config naming guideline No new revisions were added by this update. Summary of changes: .../apache/spark/internal/config/ConfigEntry.scala | 29 ++ 1 file changed, 29 insertions(+) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.0 updated: [SPARK-30799][SQL] "spark_catalog.t" should not be resolved to temp view
This is an automated email from the ASF dual-hosted git repository.
wenchen pushed a commit to branch branch-3.0
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.0 by this push:
new bda685d [SPARK-30799][SQL] "spark_catalog.t" should not be resolved
to temp view
bda685d is described below
commit bda685d9f9cdd745e0a8f842034ea5d843c3f836
Author: Wenchen Fan
AuthorDate: Mon Feb 17 12:07:46 2020 +0800
[SPARK-30799][SQL] "spark_catalog.t" should not be resolved to temp view
### What changes were proposed in this pull request?
No v2 command supports temp views and the
`ResolveCatalogs`/`ResolveSessionCatalog` framework is designed with this
assumption.
However, `ResolveSessionCatalog` needs to fallback to v1 commands, which do
support temp views (e.g. CACHE TABLE). To work around it, we add a hack in
`CatalogAndIdentifier`, which does not expand the given identifier with current
namespace if the catalog is session catalog.
This works fine in most cases, as temp views should take precedence over
tables during lookup. So if `CatalogAndIdentifier` returns a single name "t",
the v1 commands can still resolve it to temp views correctly, or resolve it to
table "default.t" if temp view doesn't exist.
However, if users write `spark_catalog.t`, it shouldn't be resolved to temp
views as temp views don't belong to any catalog. `CatalogAndIdentifier` can't
distinguish between `spark_catalog.t` and `t`, so the caller side may
mistakenly resolve `spark_catalog.t` to a temp view.
This PR proposes to fix this issue by
1. remove the hack in `CatalogAndIdentifier`, and clearly document that
this shouldn't be used to resolve temp views.
2. update `ResolveSessionCatalog` to explicitly look up temp views first
before calling `CatalogAndIdentifier`, for v1 commands that support temp views.
### Why are the changes needed?
To avoid releasing a behavior that we should not support.
Removing the hack also fixes the problem we hit in
https://github.com/apache/spark/pull/27532/files#diff-57b3d87be744b7d79a9beacf8e5e5eb2R937
### Does this PR introduce any user-facing change?
yes, now it's not allowed to refer to a temp view with `spark_catalog`
prefix.
### How was this patch tested?
new tests
Closes #27550 from cloud-fan/ns.
Authored-by: Wenchen Fan
Signed-off-by: Wenchen Fan
(cherry picked from commit ab07c6300c884e772f88694f4b718659c45dbb33)
Signed-off-by: Wenchen Fan
---
.../sql/catalyst/catalog/SessionCatalog.scala | 4 +
.../sql/connector/catalog/LookupCatalog.scala | 15 +-
.../sql/connector/catalog/LookupCatalogSuite.scala | 1 +
.../catalyst/analysis/ResolveSessionCatalog.scala | 180 +++--
.../sql/internal/BaseSessionStateBuilder.scala | 3 +-
.../resources/sql-tests/results/describe.sql.out | 12 +-
.../spark/sql/connector/DataSourceV2SQLSuite.scala | 32 +++-
.../execution/command/PlanResolutionSuite.scala| 3 +-
.../spark/sql/hive/HiveSessionStateBuilder.scala | 3 +-
9 files changed, 176 insertions(+), 77 deletions(-)
diff --git
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/catalog/SessionCatalog.scala
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/catalog/SessionCatalog.scala
index 12f9a61..c80d9d2 100644
---
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/catalog/SessionCatalog.scala
+++
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/catalog/SessionCatalog.scala
@@ -1344,6 +1344,10 @@ class SessionCatalog(
!hiveFunctions.contains(name.funcName.toLowerCase(Locale.ROOT))
}
+ def isTempFunction(name: String): Boolean = {
+isTemporaryFunction(FunctionIdentifier(name))
+ }
+
/**
* Return whether this function has been registered in the function registry
of the current
* session. If not existed, return false.
diff --git
a/sql/catalyst/src/main/scala/org/apache/spark/sql/connector/catalog/LookupCatalog.scala
b/sql/catalyst/src/main/scala/org/apache/spark/sql/connector/catalog/LookupCatalog.scala
index 080ddf1..b0b9d7b 100644
---
a/sql/catalyst/src/main/scala/org/apache/spark/sql/connector/catalog/LookupCatalog.scala
+++
b/sql/catalyst/src/main/scala/org/apache/spark/sql/connector/catalog/LookupCatalog.scala
@@ -94,6 +94,10 @@ private[sql] trait LookupCatalog extends Logging {
* Extract catalog and identifier from a multi-part name with the current
catalog if needed.
* Catalog name takes precedence over identifier, but for a single-part
name, identifier takes
* precedence over catalog name.
+ *
+ * Note that, this pattern is used to look up permanent catalog objects like
table, view,
+ * function, etc. If you need to look up temp objects like temp view, please
do it separately
+ * before calling this pattern, as
[spark] branch master updated (0353cbf -> ab07c63)
This is an automated email from the ASF dual-hosted git repository. wenchen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 0353cbf [MINOR][DOC] Fix 2 style issues in running-on-kubernetes doc add ab07c63 [SPARK-30799][SQL] "spark_catalog.t" should not be resolved to temp view No new revisions were added by this update. Summary of changes: .../sql/catalyst/catalog/SessionCatalog.scala | 4 + .../sql/connector/catalog/LookupCatalog.scala | 15 +- .../sql/connector/catalog/LookupCatalogSuite.scala | 1 + .../catalyst/analysis/ResolveSessionCatalog.scala | 180 +++-- .../sql/internal/BaseSessionStateBuilder.scala | 3 +- .../resources/sql-tests/results/describe.sql.out | 12 +- .../spark/sql/connector/DataSourceV2SQLSuite.scala | 32 +++- .../execution/command/PlanResolutionSuite.scala| 3 +- .../spark/sql/hive/HiveSessionStateBuilder.scala | 3 +- 9 files changed, 176 insertions(+), 77 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (0353cbf -> ab07c63)
This is an automated email from the ASF dual-hosted git repository. wenchen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 0353cbf [MINOR][DOC] Fix 2 style issues in running-on-kubernetes doc add ab07c63 [SPARK-30799][SQL] "spark_catalog.t" should not be resolved to temp view No new revisions were added by this update. Summary of changes: .../sql/catalyst/catalog/SessionCatalog.scala | 4 + .../sql/connector/catalog/LookupCatalog.scala | 15 +- .../sql/connector/catalog/LookupCatalogSuite.scala | 1 + .../catalyst/analysis/ResolveSessionCatalog.scala | 180 +++-- .../sql/internal/BaseSessionStateBuilder.scala | 3 +- .../resources/sql-tests/results/describe.sql.out | 12 +- .../spark/sql/connector/DataSourceV2SQLSuite.scala | 32 +++- .../execution/command/PlanResolutionSuite.scala| 3 +- .../spark/sql/hive/HiveSessionStateBuilder.scala | 3 +- 9 files changed, 176 insertions(+), 77 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.0 updated: [MINOR][DOC] Fix 2 style issues in running-on-kubernetes doc
This is an automated email from the ASF dual-hosted git repository.
gurwls223 pushed a commit to branch branch-3.0
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.0 by this push:
new 44e314e [MINOR][DOC] Fix 2 style issues in running-on-kubernetes doc
44e314e is described below
commit 44e314edb4b86ca3a8622124539073397dbe68de
Author: Kent Yao
AuthorDate: Mon Feb 17 12:06:25 2020 +0900
[MINOR][DOC] Fix 2 style issues in running-on-kubernetes doc
### What changes were proposed in this pull request?
fix style issue in the k8s document, please go to
http://spark.apache.org/docs/3.0.0-preview2/running-on-kubernetes.html and
search the keyword`spark.kubernetes.file.upload.path` to jump to the error
context
### Why are the changes needed?
doc correctness
### Does this PR introduce any user-facing change?
Nah
### How was this patch tested?
Nah
Closes #27582 from yaooqinn/k8s-doc.
Authored-by: Kent Yao
Signed-off-by: HyukjinKwon
(cherry picked from commit 0353cbf092e15a09e8979070ecd5b653062b2cb5)
Signed-off-by: HyukjinKwon
---
docs/running-on-kubernetes.md | 4 ++--
1 file changed, 2 insertions(+), 2 deletions(-)
diff --git a/docs/running-on-kubernetes.md b/docs/running-on-kubernetes.md
index 61d6154..53b883b 100644
--- a/docs/running-on-kubernetes.md
+++ b/docs/running-on-kubernetes.md
@@ -1120,7 +1120,7 @@ See the [configuration page](configuration.html) for
information on Spark config
(none)
Path to store files at the spark submit side in cluster mode. For example:
-spark.kubernetes.file.upload.path=s3a:///path
+spark.kubernetes.file.upload.path=s3a://s3-bucket/path
File should specified as file://path/to/file or absolute
path.
@@ -1247,7 +1247,7 @@ The following affect the driver and executor containers.
All other containers in
name
- See description.
+ See description
The container name will be assigned by spark ("spark-kubernetes-driver"
for the driver container, and
"executor" for each executor container) if not defined by the pod
template. If the container is defined by the
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (be3cb71 -> 0353cbf)
This is an automated email from the ASF dual-hosted git repository. gurwls223 pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from be3cb71 [SPARK-30834][DOCS][PYTHON] Add note for recommended pandas and pyarrow versions add 0353cbf [MINOR][DOC] Fix 2 style issues in running-on-kubernetes doc No new revisions were added by this update. Summary of changes: docs/running-on-kubernetes.md | 4 ++-- 1 file changed, 2 insertions(+), 2 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-2.4 updated: [SPARK-30834][DOCS][PYTHON][2.4] Add note for recommended pandas and pyarrow versions
This is an automated email from the ASF dual-hosted git repository. gurwls223 pushed a commit to branch branch-2.4 in repository https://gitbox.apache.org/repos/asf/spark.git The following commit(s) were added to refs/heads/branch-2.4 by this push: new c8f9ce8 [SPARK-30834][DOCS][PYTHON][2.4] Add note for recommended pandas and pyarrow versions c8f9ce8 is described below commit c8f9ce8c515baf8df3956f99246d52a0f4cb4413 Author: Bryan Cutler AuthorDate: Mon Feb 17 11:09:35 2020 +0900 [SPARK-30834][DOCS][PYTHON][2.4] Add note for recommended pandas and pyarrow versions ### What changes were proposed in this pull request? Add doc for recommended pandas and pyarrow versions. ### Why are the changes needed? The recommended versions are those that have been thoroughly tested by Spark CI. Other versions may be used at the discretion of the user. ### Does this PR introduce any user-facing change? No ### How was this patch tested? NA Closes #27586 from BryanCutler/python-doc-rec-pandas-pyarrow-SPARK-30834. Lead-authored-by: Bryan Cutler Co-authored-by: HyukjinKwon Signed-off-by: HyukjinKwon --- docs/sql-pyspark-pandas-with-arrow.md | 10 +- 1 file changed, 9 insertions(+), 1 deletion(-) diff --git a/docs/sql-pyspark-pandas-with-arrow.md b/docs/sql-pyspark-pandas-with-arrow.md index b11758b..08303c4 100644 --- a/docs/sql-pyspark-pandas-with-arrow.md +++ b/docs/sql-pyspark-pandas-with-arrow.md @@ -18,9 +18,11 @@ working with Arrow-enabled data. ### Ensure PyArrow Installed +To use Apache Arrow in PySpark, [the recommended version of PyArrow](#recommended-pandas-and-pyarrow-versions) +should be installed. If you install PySpark using pip, then PyArrow can be brought in as an extra dependency of the SQL module with the command `pip install pyspark[sql]`. Otherwise, you must ensure that PyArrow -is installed and available on all cluster nodes. The current supported version is 0.8.0. +is installed and available on all cluster nodes. You can install using pip or conda from the conda-forge channel. See PyArrow [installation](https://arrow.apache.org/docs/python/install.html) for details. @@ -166,6 +168,12 @@ different than a Pandas timestamp. It is recommended to use Pandas time series f working with timestamps in `pandas_udf`s to get the best performance, see [here](https://pandas.pydata.org/pandas-docs/stable/timeseries.html) for details. +### Recommended Pandas and PyArrow Versions + +For usage with pyspark.sql, the supported versions of Pandas is 0.19.2 and PyArrow is 0.8.0. Higher +versions may be used, however, compatibility and data correctness can not be guaranteed and should +be verified by the user. + ### Compatibiliy Setting for PyArrow >= 0.15.0 and Spark 2.3.x, 2.4.x Since Arrow 0.15.0, a change in the binary IPC format requires an environment variable to be - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.0 updated: [SPARK-30834][DOCS][PYTHON] Add note for recommended pandas and pyarrow versions
This is an automated email from the ASF dual-hosted git repository. gurwls223 pushed a commit to branch branch-3.0 in repository https://gitbox.apache.org/repos/asf/spark.git The following commit(s) were added to refs/heads/branch-3.0 by this push: new fb2e749 [SPARK-30834][DOCS][PYTHON] Add note for recommended pandas and pyarrow versions fb2e749 is described below commit fb2e7496006088bd6b98e9776ee51cedad1dfd6b Author: Bryan Cutler AuthorDate: Mon Feb 17 11:06:51 2020 +0900 [SPARK-30834][DOCS][PYTHON] Add note for recommended pandas and pyarrow versions ### What changes were proposed in this pull request? Add doc for recommended pandas and pyarrow versions. ### Why are the changes needed? The recommended versions are those that have been thoroughly tested by Spark CI. Other versions may be used at the discretion of the user. ### Does this PR introduce any user-facing change? No ### How was this patch tested? NA Closes #27587 from BryanCutler/python-doc-rec-pandas-pyarrow-SPARK-30834-3.0. Lead-authored-by: Bryan Cutler Co-authored-by: HyukjinKwon Signed-off-by: HyukjinKwon (cherry picked from commit be3cb71e9cb34ad9054325c3122745e66e6f1ede) Signed-off-by: HyukjinKwon --- docs/sql-pyspark-pandas-with-arrow.md | 10 +- 1 file changed, 9 insertions(+), 1 deletion(-) diff --git a/docs/sql-pyspark-pandas-with-arrow.md b/docs/sql-pyspark-pandas-with-arrow.md index 92a5157..63ba0ba 100644 --- a/docs/sql-pyspark-pandas-with-arrow.md +++ b/docs/sql-pyspark-pandas-with-arrow.md @@ -33,9 +33,11 @@ working with Arrow-enabled data. ### Ensure PyArrow Installed +To use Apache Arrow in PySpark, [the recommended version of PyArrow](#recommended-pandas-and-pyarrow-versions) +should be installed. If you install PySpark using pip, then PyArrow can be brought in as an extra dependency of the SQL module with the command `pip install pyspark[sql]`. Otherwise, you must ensure that PyArrow -is installed and available on all cluster nodes. The current supported version is 0.15.1+. +is installed and available on all cluster nodes. You can install using pip or conda from the conda-forge channel. See PyArrow [installation](https://arrow.apache.org/docs/python/install.html) for details. @@ -338,6 +340,12 @@ different than a Pandas timestamp. It is recommended to use Pandas time series f working with timestamps in `pandas_udf`s to get the best performance, see [here](https://pandas.pydata.org/pandas-docs/stable/timeseries.html) for details. +### Recommended Pandas and PyArrow Versions + +For usage with pyspark.sql, the supported versions of Pandas is 0.24.2 and PyArrow is 0.15.1. Higher +versions may be used, however, compatibility and data correctness can not be guaranteed and should +be verified by the user. + ### Compatibility Setting for PyArrow >= 0.15.0 and Spark 2.3.x, 2.4.x Since Arrow 0.15.0, a change in the binary IPC format requires an environment variable to be - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (da2ca85 -> be3cb71)
This is an automated email from the ASF dual-hosted git repository. gurwls223 pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from da2ca85 [SPARK-30703][SQL][DOCS][FOLLOWUP] Declare the ANSI SQL compliance options as experimental add be3cb71 [SPARK-30834][DOCS][PYTHON] Add note for recommended pandas and pyarrow versions No new revisions were added by this update. Summary of changes: docs/sql-pyspark-pandas-with-arrow.md | 10 +- 1 file changed, 9 insertions(+), 1 deletion(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.0 updated: [SPARK-30703][SQL][DOCS][FOLLOWUP] Declare the ANSI SQL compliance options as experimental
This is an automated email from the ASF dual-hosted git repository. gurwls223 pushed a commit to branch branch-3.0 in repository https://gitbox.apache.org/repos/asf/spark.git The following commit(s) were added to refs/heads/branch-3.0 by this push: new 39a9e41 [SPARK-30703][SQL][DOCS][FOLLOWUP] Declare the ANSI SQL compliance options as experimental 39a9e41 is described below commit 39a9e41753c6db606de501c53824b74d4927488f Author: Gengliang Wang AuthorDate: Mon Feb 17 09:54:00 2020 +0900 [SPARK-30703][SQL][DOCS][FOLLOWUP] Declare the ANSI SQL compliance options as experimental ### What changes were proposed in this pull request? This is a follow-up of https://github.com/apache/spark/pull/27489. It declares the ANSI SQL compliance options as experimental in the documentation. ### Why are the changes needed? The options are experimental. There can be new features/behaviors in future releases. ### Does this PR introduce any user-facing change? No ### How was this patch tested? Generating doc Closes #27590 from gengliangwang/ExperimentalAnsi. Authored-by: Gengliang Wang Signed-off-by: HyukjinKwon (cherry picked from commit da2ca85cee3960de7a86a21483de1d77767ca060) Signed-off-by: HyukjinKwon --- docs/sql-ref-ansi-compliance.md | 10 ++ 1 file changed, 6 insertions(+), 4 deletions(-) diff --git a/docs/sql-ref-ansi-compliance.md b/docs/sql-ref-ansi-compliance.md index d023835..267184a 100644 --- a/docs/sql-ref-ansi-compliance.md +++ b/docs/sql-ref-ansi-compliance.md @@ -19,11 +19,13 @@ license: | limitations under the License. --- -Spark SQL has two options to comply with the SQL standard: `spark.sql.ansi.enabled` and `spark.sql.storeAssignmentPolicy` (See a table below for details). +Since Spark 3.0, Spark SQL introduces two experimental options to comply with the SQL standard: `spark.sql.ansi.enabled` and `spark.sql.storeAssignmentPolicy` (See a table below for details). + When `spark.sql.ansi.enabled` is set to `true`, Spark SQL follows the standard in basic behaviours (e.g., arithmetic operations, type conversion, and SQL parsing). Moreover, Spark SQL has an independent option to control implicit casting behaviours when inserting rows in a table. The casting behaviours are defined as store assignment rules in the standard. -When `spark.sql.storeAssignmentPolicy` is set to `ANSI`, Spark SQL complies with the ANSI store assignment rules. + +When `spark.sql.storeAssignmentPolicy` is set to `ANSI`, Spark SQL complies with the ANSI store assignment rules. This is a separate configuration because its default value is `ANSI`, while the configuration `spark.sql.ansi.enabled` is disabled by default. Property NameDefaultMeaning @@ -31,7 +33,7 @@ When `spark.sql.storeAssignmentPolicy` is set to `ANSI`, Spark SQL complies with spark.sql.ansi.enabled false -When true, Spark tries to conform to the ANSI SQL specification: +(Experimental) When true, Spark tries to conform to the ANSI SQL specification: 1. Spark will throw a runtime exception if an overflow occurs in any operation on integral/decimal field. 2. Spark will forbid using the reserved keywords of ANSI SQL as identifiers in the SQL parser. @@ -40,7 +42,7 @@ When `spark.sql.storeAssignmentPolicy` is set to `ANSI`, Spark SQL complies with spark.sql.storeAssignmentPolicy ANSI -When inserting a value into a column with different data type, Spark will perform type coercion. +(Experimental) When inserting a value into a column with different data type, Spark will perform type coercion. Currently, we support 3 policies for the type coercion rules: ANSI, legacy and strict. With ANSI policy, Spark performs the type coercion as per ANSI SQL. In practice, the behavior is mostly the same as PostgreSQL. It disallows certain unreasonable type conversions such as converting string to int or double to boolean. - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (8ebbf85 -> da2ca85)
This is an automated email from the ASF dual-hosted git repository. gurwls223 pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 8ebbf85 [SPARK-30772][ML][SQL] avoid tuple assignment because it will circumvent the transient tag add da2ca85 [SPARK-30703][SQL][DOCS][FOLLOWUP] Declare the ANSI SQL compliance options as experimental No new revisions were added by this update. Summary of changes: docs/sql-ref-ansi-compliance.md | 10 ++ 1 file changed, 6 insertions(+), 4 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.0 updated: [SPARK-30703][SQL][DOCS][FOLLOWUP] Declare the ANSI SQL compliance options as experimental
This is an automated email from the ASF dual-hosted git repository. gurwls223 pushed a commit to branch branch-3.0 in repository https://gitbox.apache.org/repos/asf/spark.git The following commit(s) were added to refs/heads/branch-3.0 by this push: new 39a9e41 [SPARK-30703][SQL][DOCS][FOLLOWUP] Declare the ANSI SQL compliance options as experimental 39a9e41 is described below commit 39a9e41753c6db606de501c53824b74d4927488f Author: Gengliang Wang AuthorDate: Mon Feb 17 09:54:00 2020 +0900 [SPARK-30703][SQL][DOCS][FOLLOWUP] Declare the ANSI SQL compliance options as experimental ### What changes were proposed in this pull request? This is a follow-up of https://github.com/apache/spark/pull/27489. It declares the ANSI SQL compliance options as experimental in the documentation. ### Why are the changes needed? The options are experimental. There can be new features/behaviors in future releases. ### Does this PR introduce any user-facing change? No ### How was this patch tested? Generating doc Closes #27590 from gengliangwang/ExperimentalAnsi. Authored-by: Gengliang Wang Signed-off-by: HyukjinKwon (cherry picked from commit da2ca85cee3960de7a86a21483de1d77767ca060) Signed-off-by: HyukjinKwon --- docs/sql-ref-ansi-compliance.md | 10 ++ 1 file changed, 6 insertions(+), 4 deletions(-) diff --git a/docs/sql-ref-ansi-compliance.md b/docs/sql-ref-ansi-compliance.md index d023835..267184a 100644 --- a/docs/sql-ref-ansi-compliance.md +++ b/docs/sql-ref-ansi-compliance.md @@ -19,11 +19,13 @@ license: | limitations under the License. --- -Spark SQL has two options to comply with the SQL standard: `spark.sql.ansi.enabled` and `spark.sql.storeAssignmentPolicy` (See a table below for details). +Since Spark 3.0, Spark SQL introduces two experimental options to comply with the SQL standard: `spark.sql.ansi.enabled` and `spark.sql.storeAssignmentPolicy` (See a table below for details). + When `spark.sql.ansi.enabled` is set to `true`, Spark SQL follows the standard in basic behaviours (e.g., arithmetic operations, type conversion, and SQL parsing). Moreover, Spark SQL has an independent option to control implicit casting behaviours when inserting rows in a table. The casting behaviours are defined as store assignment rules in the standard. -When `spark.sql.storeAssignmentPolicy` is set to `ANSI`, Spark SQL complies with the ANSI store assignment rules. + +When `spark.sql.storeAssignmentPolicy` is set to `ANSI`, Spark SQL complies with the ANSI store assignment rules. This is a separate configuration because its default value is `ANSI`, while the configuration `spark.sql.ansi.enabled` is disabled by default. Property NameDefaultMeaning @@ -31,7 +33,7 @@ When `spark.sql.storeAssignmentPolicy` is set to `ANSI`, Spark SQL complies with spark.sql.ansi.enabled false -When true, Spark tries to conform to the ANSI SQL specification: +(Experimental) When true, Spark tries to conform to the ANSI SQL specification: 1. Spark will throw a runtime exception if an overflow occurs in any operation on integral/decimal field. 2. Spark will forbid using the reserved keywords of ANSI SQL as identifiers in the SQL parser. @@ -40,7 +42,7 @@ When `spark.sql.storeAssignmentPolicy` is set to `ANSI`, Spark SQL complies with spark.sql.storeAssignmentPolicy ANSI -When inserting a value into a column with different data type, Spark will perform type coercion. +(Experimental) When inserting a value into a column with different data type, Spark will perform type coercion. Currently, we support 3 policies for the type coercion rules: ANSI, legacy and strict. With ANSI policy, Spark performs the type coercion as per ANSI SQL. In practice, the behavior is mostly the same as PostgreSQL. It disallows certain unreasonable type conversions such as converting string to int or double to boolean. - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (01cc852 -> 8ebbf85)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 01cc852 [SPARK-30803][DOCS] Fix the home page link for Scala API document add 8ebbf85 [SPARK-30772][ML][SQL] avoid tuple assignment because it will circumvent the transient tag No new revisions were added by this update. Summary of changes: .../ml/stat/distribution/MultivariateGaussian.scala | 4 +++- .../org/apache/spark/ml/classification/NaiveBayes.scala | 16 .../mllib/stat/distribution/MultivariateGaussian.scala | 4 +++- 3 files changed, 18 insertions(+), 6 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (0a03e7e -> 01cc852)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 0a03e7e [SPARK-30691][SQL][DOC][FOLLOW-UP] Make link names exactly the same as the side bar names add 01cc852 [SPARK-30803][DOCS] Fix the home page link for Scala API document No new revisions were added by this update. Summary of changes: docs/_layouts/global.html | 2 +- docs/configuration.md | 8 +- docs/graphx-programming-guide.md | 68 docs/index.md | 2 +- docs/ml-advanced.md| 10 +-- docs/ml-classification-regression.md | 40 +- docs/ml-clustering.md | 10 +-- docs/ml-collaborative-filtering.md | 2 +- docs/ml-datasource.md | 4 +- docs/ml-features.md| 92 +++--- docs/ml-frequent-pattern-mining.md | 4 +- docs/ml-migration-guide.md | 36 - docs/ml-pipeline.md| 10 +-- docs/ml-statistics.md | 8 +- docs/ml-tuning.md | 18 ++--- docs/mllib-clustering.md | 26 +++--- docs/mllib-collaborative-filtering.md | 4 +- docs/mllib-data-types.md | 48 +-- docs/mllib-decision-tree.md| 10 +-- docs/mllib-dimensionality-reduction.md | 6 +- docs/mllib-ensembles.md| 10 +-- docs/mllib-evaluation-metrics.md | 8 +- docs/mllib-feature-extraction.md | 34 docs/mllib-frequent-pattern-mining.md | 14 ++-- docs/mllib-isotonic-regression.md | 2 +- docs/mllib-linear-methods.md | 22 +++--- docs/mllib-naive-bayes.md | 8 +- docs/mllib-optimization.md | 14 ++-- docs/mllib-pmml-model-export.md| 2 +- docs/mllib-statistics.md | 28 +++ docs/quick-start.md| 2 +- docs/rdd-programming-guide.md | 28 +++ docs/sql-data-sources-generic-options.md | 2 +- docs/sql-data-sources-jdbc.md | 2 +- docs/sql-data-sources-json.md | 2 +- docs/sql-getting-started.md| 16 ++-- docs/sql-migration-guide.md| 4 +- docs/sql-programming-guide.md | 2 +- docs/sql-ref-syntax-aux-analyze-table.md | 2 +- docs/sql-ref-syntax-aux-cache-refresh.md | 2 +- docs/sql-ref-syntax-aux-refresh-table.md | 2 +- docs/sql-ref-syntax-aux-resource-mgmt.md | 2 +- docs/sql-ref-syntax-aux-show-tables.md | 2 +- docs/sql-ref-syntax-aux-show.md| 2 +- docs/sql-ref-syntax-ddl-drop-database.md | 2 +- docs/sql-ref-syntax-ddl-drop-function.md | 2 +- ...f-syntax-dml-insert-overwrite-directory-hive.md | 2 +- ...ql-ref-syntax-dml-insert-overwrite-directory.md | 2 +- docs/sql-ref-syntax-dml.md | 2 +- docs/sql-ref-syntax-qry-select-clusterby.md| 2 +- docs/sql-ref-syntax-qry-select-distribute-by.md| 2 +- docs/sql-ref-syntax-qry-select-sortby.md | 2 +- docs/sql-ref-syntax-qry-select.md | 2 +- docs/streaming-custom-receivers.md | 2 +- docs/streaming-kafka-integration.md| 2 +- docs/streaming-kinesis-integration.md | 2 +- docs/streaming-programming-guide.md| 42 +- docs/structured-streaming-programming-guide.md | 22 +++--- docs/tuning.md | 2 +- 59 files changed, 355 insertions(+), 355 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.0 updated: [SPARK-30691][SQL][DOC][FOLLOW-UP] Make link names exactly the same as the side bar names
This is an automated email from the ASF dual-hosted git repository. srowen pushed a commit to branch branch-3.0 in repository https://gitbox.apache.org/repos/asf/spark.git The following commit(s) were added to refs/heads/branch-3.0 by this push: new 8ed8baa [SPARK-30691][SQL][DOC][FOLLOW-UP] Make link names exactly the same as the side bar names 8ed8baa is described below commit 8ed8baa74a6471d929fcc367bff282a87cead7a1 Author: Huaxin Gao AuthorDate: Sun Feb 16 09:53:12 2020 -0600 [SPARK-30691][SQL][DOC][FOLLOW-UP] Make link names exactly the same as the side bar names ### What changes were proposed in this pull request? Make link names exactly the same as the side bar names ### Why are the changes needed? Make doc look better ### Does this PR introduce any user-facing change? before:  after: 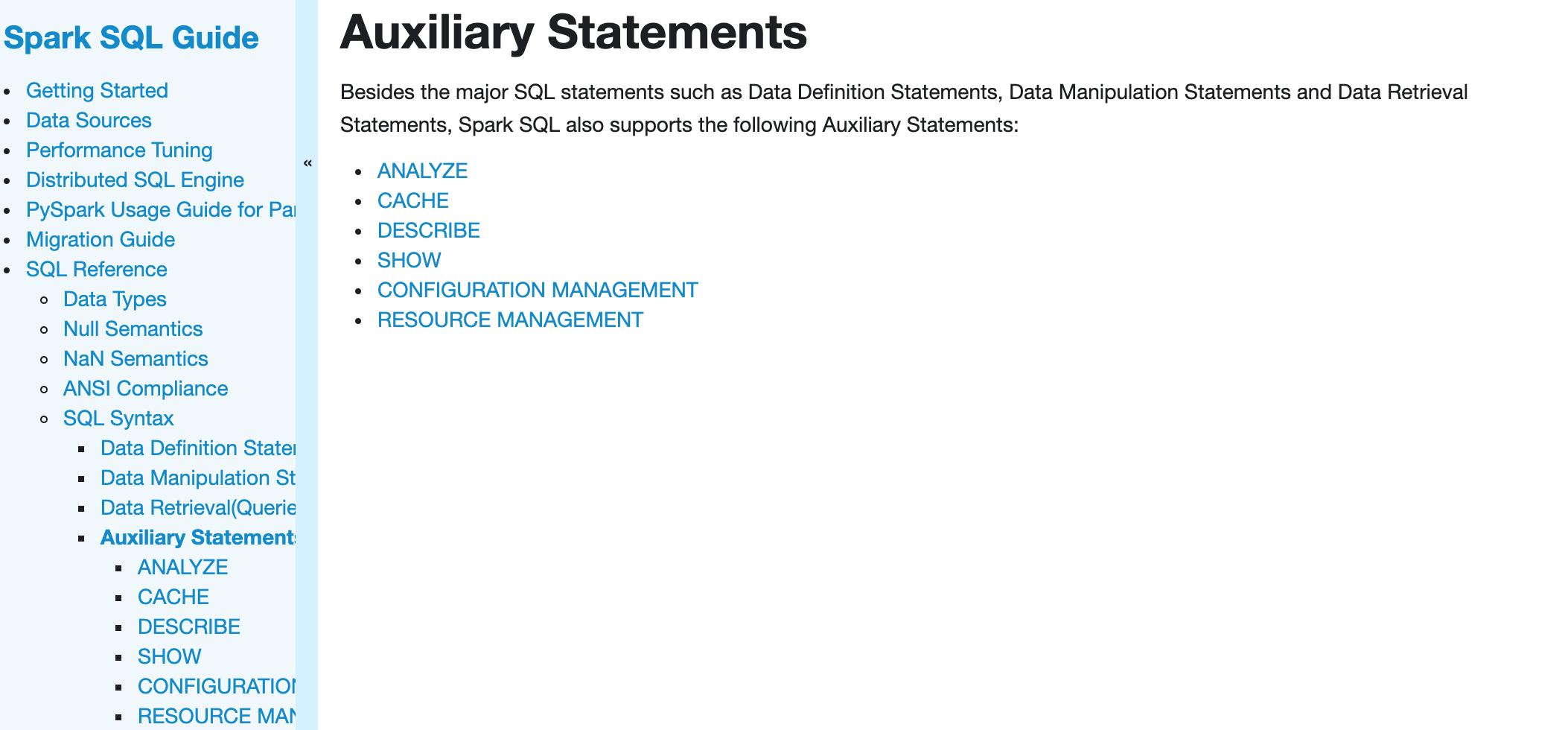 ### How was this patch tested? Manually build and check the docs Closes #27591 from huaxingao/spark-doc-followup. Authored-by: Huaxin Gao Signed-off-by: Sean Owen (cherry picked from commit 0a03e7e679771da8556fae72b35edf21ae71ac44) Signed-off-by: Sean Owen --- docs/_data/menu-sql.yaml | 12 ++-- 1 file changed, 6 insertions(+), 6 deletions(-) diff --git a/docs/_data/menu-sql.yaml b/docs/_data/menu-sql.yaml index 1e343f6..38a5cf6 100644 --- a/docs/_data/menu-sql.yaml +++ b/docs/_data/menu-sql.yaml @@ -157,12 +157,12 @@ - text: Auxiliary Statements url: sql-ref-syntax-aux.html subitems: -- text: Analyze statement +- text: ANALYZE url: sql-ref-syntax-aux-analyze.html subitems: - text: ANALYZE TABLE url: sql-ref-syntax-aux-analyze-table.html -- text: Caching statements +- text: CACHE url: sql-ref-syntax-aux-cache.html subitems: - text: CACHE TABLE @@ -175,7 +175,7 @@ url: sql-ref-syntax-aux-refresh-table.html - text: REFRESH url: sql-ref-syntax-aux-cache-refresh.md -- text: Describe Commands +- text: DESCRIBE url: sql-ref-syntax-aux-describe.html subitems: - text: DESCRIBE DATABASE @@ -186,7 +186,7 @@ url: sql-ref-syntax-aux-describe-function.html - text: DESCRIBE QUERY url: sql-ref-syntax-aux-describe-query.html -- text: Show commands +- text: SHOW url: sql-ref-syntax-aux-show.html subitems: - text: SHOW COLUMNS @@ -205,14 +205,14 @@ url: sql-ref-syntax-aux-show-partitions.html - text: SHOW CREATE TABLE url: sql-ref-syntax-aux-show-create-table.html -- text: Configuration Management Commands +- text: CONFIGURATION MANAGEMENT url: sql-ref-syntax-aux-conf-mgmt.html subitems: - text: SET url: sql-ref-syntax-aux-conf-mgmt-set.html - text: RESET url: sql-ref-syntax-aux-conf-mgmt-reset.html -- text: Resource Management Commands +- text: RESOURCE MANAGEMENT url: sql-ref-syntax-aux-resource-mgmt.html subitems: - text: ADD FILE - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (0a03e7e -> 01cc852)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 0a03e7e [SPARK-30691][SQL][DOC][FOLLOW-UP] Make link names exactly the same as the side bar names add 01cc852 [SPARK-30803][DOCS] Fix the home page link for Scala API document No new revisions were added by this update. Summary of changes: docs/_layouts/global.html | 2 +- docs/configuration.md | 8 +- docs/graphx-programming-guide.md | 68 docs/index.md | 2 +- docs/ml-advanced.md| 10 +-- docs/ml-classification-regression.md | 40 +- docs/ml-clustering.md | 10 +-- docs/ml-collaborative-filtering.md | 2 +- docs/ml-datasource.md | 4 +- docs/ml-features.md| 92 +++--- docs/ml-frequent-pattern-mining.md | 4 +- docs/ml-migration-guide.md | 36 - docs/ml-pipeline.md| 10 +-- docs/ml-statistics.md | 8 +- docs/ml-tuning.md | 18 ++--- docs/mllib-clustering.md | 26 +++--- docs/mllib-collaborative-filtering.md | 4 +- docs/mllib-data-types.md | 48 +-- docs/mllib-decision-tree.md| 10 +-- docs/mllib-dimensionality-reduction.md | 6 +- docs/mllib-ensembles.md| 10 +-- docs/mllib-evaluation-metrics.md | 8 +- docs/mllib-feature-extraction.md | 34 docs/mllib-frequent-pattern-mining.md | 14 ++-- docs/mllib-isotonic-regression.md | 2 +- docs/mllib-linear-methods.md | 22 +++--- docs/mllib-naive-bayes.md | 8 +- docs/mllib-optimization.md | 14 ++-- docs/mllib-pmml-model-export.md| 2 +- docs/mllib-statistics.md | 28 +++ docs/quick-start.md| 2 +- docs/rdd-programming-guide.md | 28 +++ docs/sql-data-sources-generic-options.md | 2 +- docs/sql-data-sources-jdbc.md | 2 +- docs/sql-data-sources-json.md | 2 +- docs/sql-getting-started.md| 16 ++-- docs/sql-migration-guide.md| 4 +- docs/sql-programming-guide.md | 2 +- docs/sql-ref-syntax-aux-analyze-table.md | 2 +- docs/sql-ref-syntax-aux-cache-refresh.md | 2 +- docs/sql-ref-syntax-aux-refresh-table.md | 2 +- docs/sql-ref-syntax-aux-resource-mgmt.md | 2 +- docs/sql-ref-syntax-aux-show-tables.md | 2 +- docs/sql-ref-syntax-aux-show.md| 2 +- docs/sql-ref-syntax-ddl-drop-database.md | 2 +- docs/sql-ref-syntax-ddl-drop-function.md | 2 +- ...f-syntax-dml-insert-overwrite-directory-hive.md | 2 +- ...ql-ref-syntax-dml-insert-overwrite-directory.md | 2 +- docs/sql-ref-syntax-dml.md | 2 +- docs/sql-ref-syntax-qry-select-clusterby.md| 2 +- docs/sql-ref-syntax-qry-select-distribute-by.md| 2 +- docs/sql-ref-syntax-qry-select-sortby.md | 2 +- docs/sql-ref-syntax-qry-select.md | 2 +- docs/streaming-custom-receivers.md | 2 +- docs/streaming-kafka-integration.md| 2 +- docs/streaming-kinesis-integration.md | 2 +- docs/streaming-programming-guide.md| 42 +- docs/structured-streaming-programming-guide.md | 22 +++--- docs/tuning.md | 2 +- 59 files changed, 355 insertions(+), 355 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.0 updated: [SPARK-30691][SQL][DOC][FOLLOW-UP] Make link names exactly the same as the side bar names
This is an automated email from the ASF dual-hosted git repository. srowen pushed a commit to branch branch-3.0 in repository https://gitbox.apache.org/repos/asf/spark.git The following commit(s) were added to refs/heads/branch-3.0 by this push: new 8ed8baa [SPARK-30691][SQL][DOC][FOLLOW-UP] Make link names exactly the same as the side bar names 8ed8baa is described below commit 8ed8baa74a6471d929fcc367bff282a87cead7a1 Author: Huaxin Gao AuthorDate: Sun Feb 16 09:53:12 2020 -0600 [SPARK-30691][SQL][DOC][FOLLOW-UP] Make link names exactly the same as the side bar names ### What changes were proposed in this pull request? Make link names exactly the same as the side bar names ### Why are the changes needed? Make doc look better ### Does this PR introduce any user-facing change? before:  after:  ### How was this patch tested? Manually build and check the docs Closes #27591 from huaxingao/spark-doc-followup. Authored-by: Huaxin Gao Signed-off-by: Sean Owen (cherry picked from commit 0a03e7e679771da8556fae72b35edf21ae71ac44) Signed-off-by: Sean Owen --- docs/_data/menu-sql.yaml | 12 ++-- 1 file changed, 6 insertions(+), 6 deletions(-) diff --git a/docs/_data/menu-sql.yaml b/docs/_data/menu-sql.yaml index 1e343f6..38a5cf6 100644 --- a/docs/_data/menu-sql.yaml +++ b/docs/_data/menu-sql.yaml @@ -157,12 +157,12 @@ - text: Auxiliary Statements url: sql-ref-syntax-aux.html subitems: -- text: Analyze statement +- text: ANALYZE url: sql-ref-syntax-aux-analyze.html subitems: - text: ANALYZE TABLE url: sql-ref-syntax-aux-analyze-table.html -- text: Caching statements +- text: CACHE url: sql-ref-syntax-aux-cache.html subitems: - text: CACHE TABLE @@ -175,7 +175,7 @@ url: sql-ref-syntax-aux-refresh-table.html - text: REFRESH url: sql-ref-syntax-aux-cache-refresh.md -- text: Describe Commands +- text: DESCRIBE url: sql-ref-syntax-aux-describe.html subitems: - text: DESCRIBE DATABASE @@ -186,7 +186,7 @@ url: sql-ref-syntax-aux-describe-function.html - text: DESCRIBE QUERY url: sql-ref-syntax-aux-describe-query.html -- text: Show commands +- text: SHOW url: sql-ref-syntax-aux-show.html subitems: - text: SHOW COLUMNS @@ -205,14 +205,14 @@ url: sql-ref-syntax-aux-show-partitions.html - text: SHOW CREATE TABLE url: sql-ref-syntax-aux-show-create-table.html -- text: Configuration Management Commands +- text: CONFIGURATION MANAGEMENT url: sql-ref-syntax-aux-conf-mgmt.html subitems: - text: SET url: sql-ref-syntax-aux-conf-mgmt-set.html - text: RESET url: sql-ref-syntax-aux-conf-mgmt-reset.html -- text: Resource Management Commands +- text: RESOURCE MANAGEMENT url: sql-ref-syntax-aux-resource-mgmt.html subitems: - text: ADD FILE - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (f5238ea -> 0a03e7e)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from f5238ea [GRAPHX][MINOR] Fix typo setRest => setDest add 0a03e7e [SPARK-30691][SQL][DOC][FOLLOW-UP] Make link names exactly the same as the side bar names No new revisions were added by this update. Summary of changes: docs/_data/menu-sql.yaml | 12 ++-- 1 file changed, 6 insertions(+), 6 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.0 updated: [SPARK-30691][SQL][DOC][FOLLOW-UP] Make link names exactly the same as the side bar names
This is an automated email from the ASF dual-hosted git repository. srowen pushed a commit to branch branch-3.0 in repository https://gitbox.apache.org/repos/asf/spark.git The following commit(s) were added to refs/heads/branch-3.0 by this push: new 8ed8baa [SPARK-30691][SQL][DOC][FOLLOW-UP] Make link names exactly the same as the side bar names 8ed8baa is described below commit 8ed8baa74a6471d929fcc367bff282a87cead7a1 Author: Huaxin Gao AuthorDate: Sun Feb 16 09:53:12 2020 -0600 [SPARK-30691][SQL][DOC][FOLLOW-UP] Make link names exactly the same as the side bar names ### What changes were proposed in this pull request? Make link names exactly the same as the side bar names ### Why are the changes needed? Make doc look better ### Does this PR introduce any user-facing change? before:  after:  ### How was this patch tested? Manually build and check the docs Closes #27591 from huaxingao/spark-doc-followup. Authored-by: Huaxin Gao Signed-off-by: Sean Owen (cherry picked from commit 0a03e7e679771da8556fae72b35edf21ae71ac44) Signed-off-by: Sean Owen --- docs/_data/menu-sql.yaml | 12 ++-- 1 file changed, 6 insertions(+), 6 deletions(-) diff --git a/docs/_data/menu-sql.yaml b/docs/_data/menu-sql.yaml index 1e343f6..38a5cf6 100644 --- a/docs/_data/menu-sql.yaml +++ b/docs/_data/menu-sql.yaml @@ -157,12 +157,12 @@ - text: Auxiliary Statements url: sql-ref-syntax-aux.html subitems: -- text: Analyze statement +- text: ANALYZE url: sql-ref-syntax-aux-analyze.html subitems: - text: ANALYZE TABLE url: sql-ref-syntax-aux-analyze-table.html -- text: Caching statements +- text: CACHE url: sql-ref-syntax-aux-cache.html subitems: - text: CACHE TABLE @@ -175,7 +175,7 @@ url: sql-ref-syntax-aux-refresh-table.html - text: REFRESH url: sql-ref-syntax-aux-cache-refresh.md -- text: Describe Commands +- text: DESCRIBE url: sql-ref-syntax-aux-describe.html subitems: - text: DESCRIBE DATABASE @@ -186,7 +186,7 @@ url: sql-ref-syntax-aux-describe-function.html - text: DESCRIBE QUERY url: sql-ref-syntax-aux-describe-query.html -- text: Show commands +- text: SHOW url: sql-ref-syntax-aux-show.html subitems: - text: SHOW COLUMNS @@ -205,14 +205,14 @@ url: sql-ref-syntax-aux-show-partitions.html - text: SHOW CREATE TABLE url: sql-ref-syntax-aux-show-create-table.html -- text: Configuration Management Commands +- text: CONFIGURATION MANAGEMENT url: sql-ref-syntax-aux-conf-mgmt.html subitems: - text: SET url: sql-ref-syntax-aux-conf-mgmt-set.html - text: RESET url: sql-ref-syntax-aux-conf-mgmt-reset.html -- text: Resource Management Commands +- text: RESOURCE MANAGEMENT url: sql-ref-syntax-aux-resource-mgmt.html subitems: - text: ADD FILE - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (f5238ea -> 0a03e7e)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from f5238ea [GRAPHX][MINOR] Fix typo setRest => setDest add 0a03e7e [SPARK-30691][SQL][DOC][FOLLOW-UP] Make link names exactly the same as the side bar names No new revisions were added by this update. Summary of changes: docs/_data/menu-sql.yaml | 12 ++-- 1 file changed, 6 insertions(+), 6 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (8b73b92 -> f5238ea)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 8b73b92 [SPARK-30826][SQL] Respect reference case in `StringStartsWith` pushed down to parquet add f5238ea [GRAPHX][MINOR] Fix typo setRest => setDest No new revisions were added by this update. Summary of changes: .../src/main/scala/org/apache/spark/graphx/impl/EdgePartition.scala | 4 ++-- 1 file changed, 2 insertions(+), 2 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (8b73b92 -> f5238ea)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 8b73b92 [SPARK-30826][SQL] Respect reference case in `StringStartsWith` pushed down to parquet add f5238ea [GRAPHX][MINOR] Fix typo setRest => setDest No new revisions were added by this update. Summary of changes: .../src/main/scala/org/apache/spark/graphx/impl/EdgePartition.scala | 4 ++-- 1 file changed, 2 insertions(+), 2 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org