[spark] branch master updated (7d8a721 -> dc0fa1e)
This is an automated email from the ASF dual-hosted git repository. dongjoon pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 7d8a721 [SPARK-37569][SQL] Don't mark nested view fields as nullable add dc0fa1e [SPARK-37577][SQL] Fix ClassCastException: ArrayType cannot be cast to StructType for Generate Pruning No new revisions were added by this update. Summary of changes: .../catalyst/optimizer/NestedColumnAliasing.scala | 26 +- .../execution/datasources/SchemaPruningSuite.scala | 21 - 2 files changed, 40 insertions(+), 7 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (414771d -> 7d8a721)
This is an automated email from the ASF dual-hosted git repository. wenchen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 414771d [SPARK-37590][SQL][TEST] Unify v1 and v2 ALTER TABLE .. SET PROPERTIES tests add 7d8a721 [SPARK-37569][SQL] Don't mark nested view fields as nullable No new revisions were added by this update. Summary of changes: .../org/apache/spark/sql/catalyst/analysis/Analyzer.scala | 2 +- .../org/apache/spark/sql/execution/SQLViewTestSuite.scala | 10 ++ 2 files changed, 11 insertions(+), 1 deletion(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (1cc1459 -> 414771d)
This is an automated email from the ASF dual-hosted git repository.
wenchen pushed a change to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git.
from 1cc1459 [SPARK-36850][SQL][FOLLOWUP] Simplify exception code and fix
wrong condition for CTAS and RTAS
add 414771d [SPARK-37590][SQL][TEST] Unify v1 and v2 ALTER TABLE .. SET
PROPERTIES tests
No new revisions were added by this update.
Summary of changes:
.../sql/catalyst/catalog/InMemoryCatalog.scala | 6 +-
.../spark/sql/catalyst/parser/DDLParserSuite.scala | 32 --
.../spark/sql/connector/DataSourceV2SQLSuite.scala | 48 -
.../AlterNamespaceSetPropertiesParserSuite.scala | 49 +
.../AlterNamespaceSetPropertiesSuiteBase.scala | 117 +
.../sql/execution/command/DDLParserSuite.scala | 6 --
.../spark/sql/execution/command/DDLSuite.scala | 30 +-
...cala => AlterNamespaceSetPropertiesSuite.scala} | 18 ++--
...cala => AlterNamespaceSetPropertiesSuite.scala} | 8 +-
...cala => AlterNamespaceSetPropertiesSuite.scala} | 9 +-
10 files changed, 187 insertions(+), 136 deletions(-)
create mode 100644
sql/core/src/test/scala/org/apache/spark/sql/execution/command/AlterNamespaceSetPropertiesParserSuite.scala
create mode 100644
sql/core/src/test/scala/org/apache/spark/sql/execution/command/AlterNamespaceSetPropertiesSuiteBase.scala
copy
sql/core/src/test/scala/org/apache/spark/sql/execution/command/v1/{AlterNamespaceSetLocationSuite.scala
=> AlterNamespaceSetPropertiesSuite.scala} (76%)
copy
sql/core/src/test/scala/org/apache/spark/sql/execution/command/v2/{AlterNamespaceSetLocationSuite.scala
=> AlterNamespaceSetPropertiesSuite.scala} (81%)
copy
sql/hive/src/test/scala/org/apache/spark/sql/hive/execution/command/{AlterTableRecoverPartitionsSuite.scala
=> AlterNamespaceSetPropertiesSuite.scala} (75%)
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-36850][SQL][FOLLOWUP] Simplify exception code and fix wrong condition for CTAS and RTAS
This is an automated email from the ASF dual-hosted git repository.
wenchen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 1cc1459 [SPARK-36850][SQL][FOLLOWUP] Simplify exception code and fix
wrong condition for CTAS and RTAS
1cc1459 is described below
commit 1cc14598c7487887016793c0723624ceb4f13a8c
Author: Huaxin Gao
AuthorDate: Mon Dec 13 12:34:27 2021 +0800
[SPARK-36850][SQL][FOLLOWUP] Simplify exception code and fix wrong
condition for CTAS and RTAS
### What changes were proposed in this pull request?
fixed a few problems:
1. addressed this
[comment](https://github.com/apache/spark/pull/34060#discussion_r765992537)
2. combined several `xxxOnlySupportedWithV2TableError`
3. in CTAS and RTAS, the `if isSessionCatalog(catalog)` should not be on
the pattern, it should be `if (isSessionCatalog(catalog) &&
!isV2Provider(provider))`. Otherwise, `c.partitioning ++
c.tableSpec.bucketSpec.map(_.asTransform)` is not done for non SessionCatalog
case.
I tried this `c.partitioning ++ c.tableSpec.bucketSpec.map(_.asTransform)`
inside `AstBuilder` but it failed [here](
https://github.com/apache/spark/blob/master/sql/core/src/test/scala/org/apache/spark/sql/execution/command/DDLSuite.scala#L850)
so I kept this in `ResolveSessionCatalog`
### Why are the changes needed?
code cleaning up and bug fixing
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Existing tests
Closes #34857 from huaxingao/followup.
Lead-authored-by: Huaxin Gao
Co-authored-by: Huaxin Gao
Signed-off-by: Wenchen Fan
---
.../spark/sql/errors/QueryCompilationErrors.scala | 28 +
.../catalyst/analysis/ResolveSessionCatalog.scala | 73 --
.../spark/sql/streaming/DataStreamWriter.scala | 4 +-
.../spark/sql/connector/DataSourceV2SQLSuite.scala | 38 +++
4 files changed, 82 insertions(+), 61 deletions(-)
diff --git
a/sql/catalyst/src/main/scala/org/apache/spark/sql/errors/QueryCompilationErrors.scala
b/sql/catalyst/src/main/scala/org/apache/spark/sql/errors/QueryCompilationErrors.scala
index 920a748..4843051 100644
---
a/sql/catalyst/src/main/scala/org/apache/spark/sql/errors/QueryCompilationErrors.scala
+++
b/sql/catalyst/src/main/scala/org/apache/spark/sql/errors/QueryCompilationErrors.scala
@@ -479,48 +479,24 @@ object QueryCompilationErrors {
new AnalysisException("ADD COLUMN with v1 tables cannot specify NOT NULL.")
}
- def replaceColumnsOnlySupportedWithV2TableError(): Throwable = {
-new AnalysisException("REPLACE COLUMNS is only supported with v2 tables.")
- }
-
- def alterQualifiedColumnOnlySupportedWithV2TableError(): Throwable = {
-new AnalysisException("ALTER COLUMN with qualified column is only
supported with v2 tables.")
+ def operationOnlySupportedWithV2TableError(operation: String): Throwable = {
+new AnalysisException(s"$operation is only supported with v2 tables.")
}
def alterColumnWithV1TableCannotSpecifyNotNullError(): Throwable = {
new AnalysisException("ALTER COLUMN with v1 tables cannot specify NOT
NULL.")
}
- def alterOnlySupportedWithV2TableError(): Throwable = {
-new AnalysisException("ALTER COLUMN ... FIRST | ALTER is only supported
with v2 tables.")
- }
-
def alterColumnCannotFindColumnInV1TableError(colName: String, v1Table:
V1Table): Throwable = {
new AnalysisException(
s"ALTER COLUMN cannot find column $colName in v1 table. " +
s"Available: ${v1Table.schema.fieldNames.mkString(", ")}")
}
- def renameColumnOnlySupportedWithV2TableError(): Throwable = {
-new AnalysisException("RENAME COLUMN is only supported with v2 tables.")
- }
-
- def dropColumnOnlySupportedWithV2TableError(): Throwable = {
-new AnalysisException("DROP COLUMN is only supported with v2 tables.")
- }
-
def invalidDatabaseNameError(quoted: String): Throwable = {
new AnalysisException(s"The database name is not valid: $quoted")
}
- def replaceTableOnlySupportedWithV2TableError(): Throwable = {
-new AnalysisException("REPLACE TABLE is only supported with v2 tables.")
- }
-
- def replaceTableAsSelectOnlySupportedWithV2TableError(): Throwable = {
-new AnalysisException("REPLACE TABLE AS SELECT is only supported with v2
tables.")
- }
-
def cannotDropViewWithDropTableError(): Throwable = {
new AnalysisException("Cannot drop a view with DROP TABLE. Please use DROP
VIEW instead")
}
diff --git
a/sql/core/src/main/scala/org/apache/spark/sql/catalyst/analysis/ResolveSessionCatalog.scala
b/sql/core/src/main/scala/org/apache/spark/sql/catalyst/analysis/ResolveSessionCatalog.scala
index d5f99bf..15798e0 100644
---
a/sql/core/src/main/scala/org/apache/spark/sql/catalyst/analysis/ResolveSessionCatalog.scala
+++
[spark] branch master updated (5880df4 -> 7390eb0)
This is an automated email from the ASF dual-hosted git repository. wuyi pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 5880df4 [SPARK-37481][CORE][WEBUI] Fix disappearance of skipped stages after they retry add 7390eb0 [SPARK-37300][CORE] TaskSchedulerImpl should ignore task finished eve… No new revisions were added by this update. Summary of changes: .../apache/spark/scheduler/TaskSetManager.scala| 9 ++- .../spark/scheduler/TaskSchedulerImplSuite.scala | 94 +- 2 files changed, 101 insertions(+), 2 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.2 updated: [SPARK-37481][CORE][WEBUI] Fix disappearance of skipped stages after they retry
This is an automated email from the ASF dual-hosted git repository.
wuyi pushed a commit to branch branch-3.2
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.2 by this push:
new f20c408 [SPARK-37481][CORE][WEBUI] Fix disappearance of skipped
stages after they retry
f20c408 is described below
commit f20c408be0cd2f53815b4b26a88aa8c2e3545a5c
Author: Kent Yao
AuthorDate: Mon Dec 13 10:40:42 2021 +0800
[SPARK-37481][CORE][WEBUI] Fix disappearance of skipped stages after they
retry
### What changes were proposed in this pull request?
When skipped stages retry, their skipped info will be lost on the UI, and
then we may see a stage with 200 tasks indeed, shows that it only has 3 tasks
but its `retry 1` has 15 tasks and completely different inputs/outputs.
A simple way to reproduce,
```
bin/spark-sql --packages com.github.yaooqinn:itachi_2.12:0.3.0
```
and run
```
select * from (select v from (values (1), (2), (3) t(v))) t1 join (select
stage_id_with_retry(3) from (select v from values (1), (2), (3) t(v) group by
v)) t2;
```
Also, Detailed in the Gist here -
https://gist.github.com/yaooqinn/6acb7b74b343a6a6dffe8401f6b7b45c
In this PR, we increase the nextAttempIds of these skipped stages once they
get visited.
### Why are the changes needed?
fix problems when we have skipped stage retries.
### Does this PR introduce _any_ user-facing change?
Yes, the UI will keep the skipped stages info
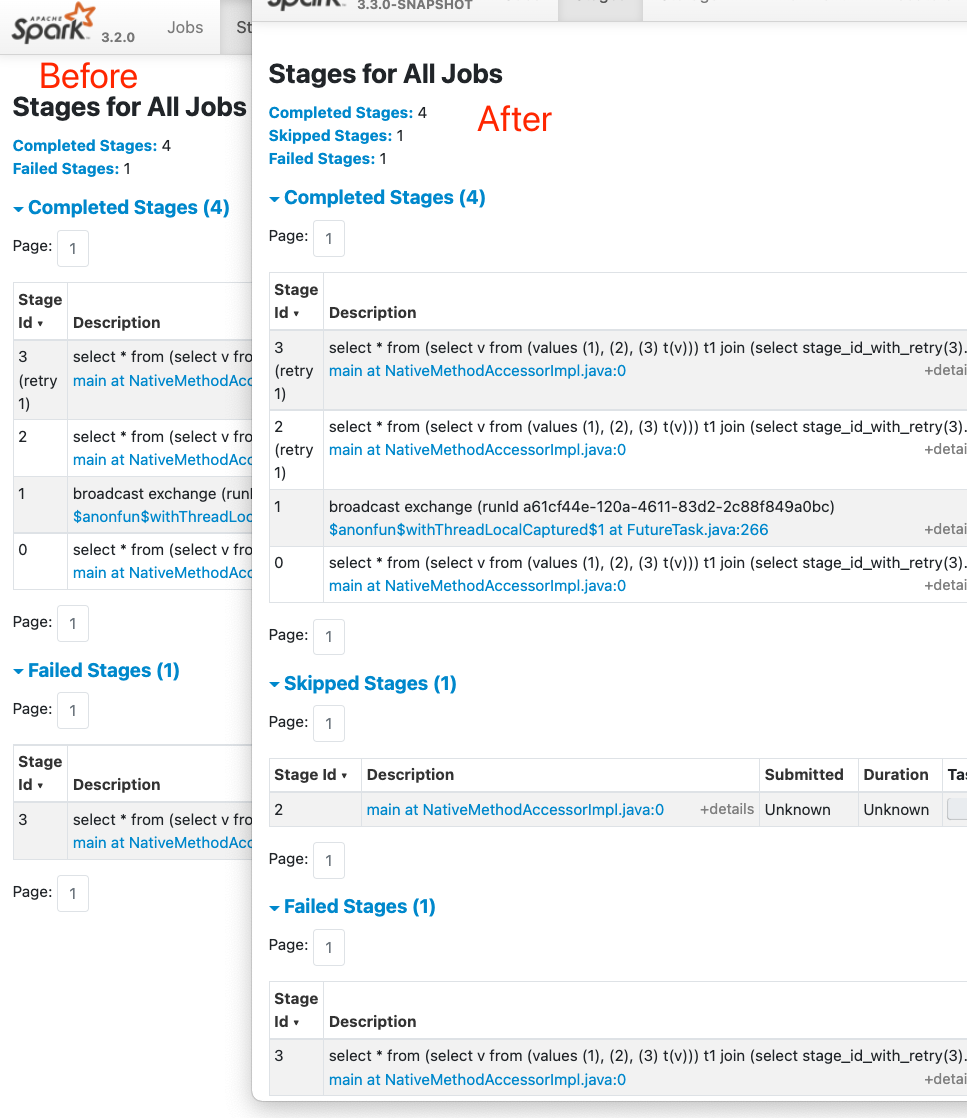
### How was this patch tested?
manually as recorded in
https://gist.github.com/yaooqinn/6acb7b74b343a6a6dffe8401f6b7b45c
existing tests
Closes #34735 from yaooqinn/SPARK-37481.
Authored-by: Kent Yao
Signed-off-by: yi.wu
(cherry picked from commit 5880df41f50210f2df44f25640437d99b8979d70)
Signed-off-by: yi.wu
---
core/src/main/scala/org/apache/spark/scheduler/DAGScheduler.scala | 6 ++
core/src/main/scala/org/apache/spark/scheduler/Stage.scala | 7 +++
.../test/scala/org/apache/spark/scheduler/DAGSchedulerSuite.scala | 6 +++---
3 files changed, 16 insertions(+), 3 deletions(-)
diff --git a/core/src/main/scala/org/apache/spark/scheduler/DAGScheduler.scala
b/core/src/main/scala/org/apache/spark/scheduler/DAGScheduler.scala
index bb77a58d..9a27d9c 100644
--- a/core/src/main/scala/org/apache/spark/scheduler/DAGScheduler.scala
+++ b/core/src/main/scala/org/apache/spark/scheduler/DAGScheduler.scala
@@ -716,6 +716,12 @@ private[spark] class DAGScheduler(
// read from merged output as the MergeStatuses are not
available.
if (!mapStage.isAvailable ||
!mapStage.shuffleDep.shuffleMergeFinalized) {
missing += mapStage
+} else {
+ // Forward the nextAttemptId if skipped and get visited for
the first time.
+ // Otherwise, once it gets retried,
+ // 1) the stuffs in stage info become distorting, e.g. task
num, input byte, e.t.c
+ // 2) the first attempt starts from 0-idx, it will not be
marked as a retry
+ mapStage.increaseAttemptIdOnFirstSkip()
}
case narrowDep: NarrowDependency[_] =>
waitingForVisit.prepend(narrowDep.rdd)
diff --git a/core/src/main/scala/org/apache/spark/scheduler/Stage.scala
b/core/src/main/scala/org/apache/spark/scheduler/Stage.scala
index ae7924d..9707211 100644
--- a/core/src/main/scala/org/apache/spark/scheduler/Stage.scala
+++ b/core/src/main/scala/org/apache/spark/scheduler/Stage.scala
@@ -107,6 +107,13 @@ private[scheduler] abstract class Stage(
nextAttemptId += 1
}
+ /** Forward the nextAttemptId if skipped and get visited for the first time.
*/
+ def increaseAttemptIdOnFirstSkip(): Unit = {
+if (nextAttemptId == 0) {
+ nextAttemptId = 1
+}
+ }
+
/** Returns the StageInfo for the most recent attempt for this stage. */
def latestInfo: StageInfo = _latestInfo
diff --git
a/core/src/test/scala/org/apache/spark/scheduler/DAGSchedulerSuite.scala
b/core/src/test/scala/org/apache/spark/scheduler/DAGSchedulerSuite.scala
index 4cb64ed..afea912 100644
--- a/core/src/test/scala/org/apache/spark/scheduler/DAGSchedulerSuite.scala
+++ b/core/src/test/scala/org/apache/spark/scheduler/DAGSchedulerSuite.scala
@@ -1622,7 +1622,7 @@ class DAGSchedulerSuite extends SparkFunSuite with
TempLocalSparkContext with Ti
// the shuffle map output is still available from stage 0); make sure
we've still got internal
// accumulators setup
assert(scheduler.stageIdToStage(2).latestInfo.taskMetrics != null)
-completeShuffleMapStageSuccessfully(2, 0, 2)
+
[spark] branch master updated (a30bec1 -> 5880df4)
This is an automated email from the ASF dual-hosted git repository. wuyi pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from a30bec1 [SPARK-37369][SQL] Avoid redundant ColumnarToRow transistion on InMemoryTableScan add 5880df4 [SPARK-37481][CORE][WEBUI] Fix disappearance of skipped stages after they retry No new revisions were added by this update. Summary of changes: core/src/main/scala/org/apache/spark/scheduler/DAGScheduler.scala | 6 ++ core/src/main/scala/org/apache/spark/scheduler/Stage.scala | 7 +++ .../test/scala/org/apache/spark/scheduler/DAGSchedulerSuite.scala | 6 +++--- 3 files changed, 16 insertions(+), 3 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-37369][SQL] Avoid redundant ColumnarToRow transistion on InMemoryTableScan
This is an automated email from the ASF dual-hosted git repository. viirya pushed a commit to branch master in repository https://gitbox.apache.org/repos/asf/spark.git The following commit(s) were added to refs/heads/master by this push: new a30bec1 [SPARK-37369][SQL] Avoid redundant ColumnarToRow transistion on InMemoryTableScan a30bec1 is described below commit a30bec17d6187ef6dfe276c67dbd4e023062b92b Author: Liang-Chi Hsieh AuthorDate: Sun Dec 12 17:49:58 2021 -0800 [SPARK-37369][SQL] Avoid redundant ColumnarToRow transistion on InMemoryTableScan ### What changes were proposed in this pull request? This patch proposes to let `InMemoryTableScanExec` produces row output directly, if its parent query plan only accepts rows instead of columnar output. In particular, this change adds a new method in `SparkPlan` called `supportsRowBased`, alongside with the existing `supportsColumnar`. ### Why are the changes needed? We currently have `supportsColumnar` indicating if a physical node can produce columnar output. The current columnar transition rule seems taking an assumption that one node can only produce columnar output but not row-based one if `supportsColumnar` returns true. But actually one node can possibly produce both format, i.e. columnar and row-based. For such node, if we require row-based output, the columnar transition rule will add additional columnar-to-row after it due to the wrong a [...] So this change introduces `supportsRowBased` which is used to indicates if the node can produce row-based output. The rule can check this method when deciding if a columnar-to-row transition is necessary or not. For example, `InMemoryTableScanExec` can produce columnar output. So if its parent plan isn't columnar, the rule adds a `ColumnarToRow` between them, e.g., ``` +- Union :- ColumnarToRow : +- InMemoryTableScan i#8, j#9 : +- InMemoryRelation i#8, j#9, StorageLevel(disk, memory, deserialized, 1 replicas) ``` But `InMemoryTableScanExec` is capable of row-based output too. After this change, for such case, we can simply ask `InMemoryTableScanExec` to produce row output instead of a redundant conversion. ``` Int In-memory OpenJDK 64-Bit Server VM 1.8.0_265-b01 on Mac OS X 10.16 Intel(R) Core(TM) i7-9750H CPU 2.60GHz Int In-Memory scan: Best Time(ms) Avg Time(ms) Stdev(ms)Rate(M/s) Per Row(ns) Relative -- columnar deserialization + columnar-to-row228245 15 4.4 227.7 1.0X row-based deserialization 179187 10 5.6 179.4 1.3X ``` ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Existing tests. Closes #34642 from viirya/SPARK-37369. Authored-by: Liang-Chi Hsieh Signed-off-by: Liang-Chi Hsieh --- .../InMemoryColumnarBenchmark-results.txt | 12 .../org/apache/spark/sql/execution/Columnar.scala | 4 +- .../org/apache/spark/sql/execution/SparkPlan.scala | 11 +++- .../sql/execution/columnar/InMemoryRelation.scala | 3 +- .../execution/columnar/InMemoryTableScanExec.scala | 2 + .../org/apache/spark/sql/CachedTableSuite.scala| 21 ++- .../spark/sql/DataFrameSetOperationsSuite.scala| 7 +-- .../sql/execution/WholeStageCodegenSuite.scala | 2 +- .../columnar/CachedBatchSerializerSuite.scala | 5 +- .../columnar/InMemoryColumnarBenchmark.scala | 66 ++ .../columnar/InMemoryColumnarQuerySuite.scala | 6 +- .../spark/sql/execution/debug/DebuggingSuite.scala | 5 +- .../sql/execution/metric/SQLMetricsSuite.scala | 6 +- 13 files changed, 128 insertions(+), 22 deletions(-) diff --git a/sql/core/benchmarks/InMemoryColumnarBenchmark-results.txt b/sql/core/benchmarks/InMemoryColumnarBenchmark-results.txt new file mode 100644 index 000..2998d8b --- /dev/null +++ b/sql/core/benchmarks/InMemoryColumnarBenchmark-results.txt @@ -0,0 +1,12 @@ + +Int In-memory + + +OpenJDK 64-Bit Server VM 1.8.0_312-b07 on Linux 5.11.0-1021-azure +Intel(R) Xeon(R) Platinum 8272CL CPU @ 2.60GHz +Int In-Memory scan: Best Time(ms) Avg Time(ms) Stdev(ms)Rate(M/s) Per Row(ns) Relative
[spark] branch master updated: [SPARK-36038][CORE] Speculation metrics summary at stage level
This is an automated email from the ASF dual-hosted git repository.
sarutak pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 4158d35 [SPARK-36038][CORE] Speculation metrics summary at stage level
4158d35 is described below
commit 4158d3544030058a23c7741d4283213a56ae7cc7
Author: Thejdeep Gudivada
AuthorDate: Mon Dec 13 09:58:27 2021 +0900
[SPARK-36038][CORE] Speculation metrics summary at stage level
### What changes were proposed in this pull request?
Currently there are no speculation metrics available for Spark either at
application/job/stage level. This PR is to add some basic speculation metrics
for a stage when speculation execution is enabled.
This is similar to the existing stage level metrics tracking numTotal
(total number of speculated tasks), numCompleted (total number of successful
speculated tasks), numFailed (total number of failed speculated tasks),
numKilled (total number of killed speculated tasks) etc.
With this new set of metrics, it helps further understanding speculative
execution feature in the context of the application and also helps in further
tuning the speculative execution config knobs.
### Why are the changes needed?
Additional metrics for speculative execution.
### Does this PR introduce _any_ user-facing change?
Yes, Stages Page in SHS UI will have an additional table for speculation
metrics, if present.
### How was this patch tested?
Unit tests added and also tested on our internal platform.
Absence of speculation metrics :
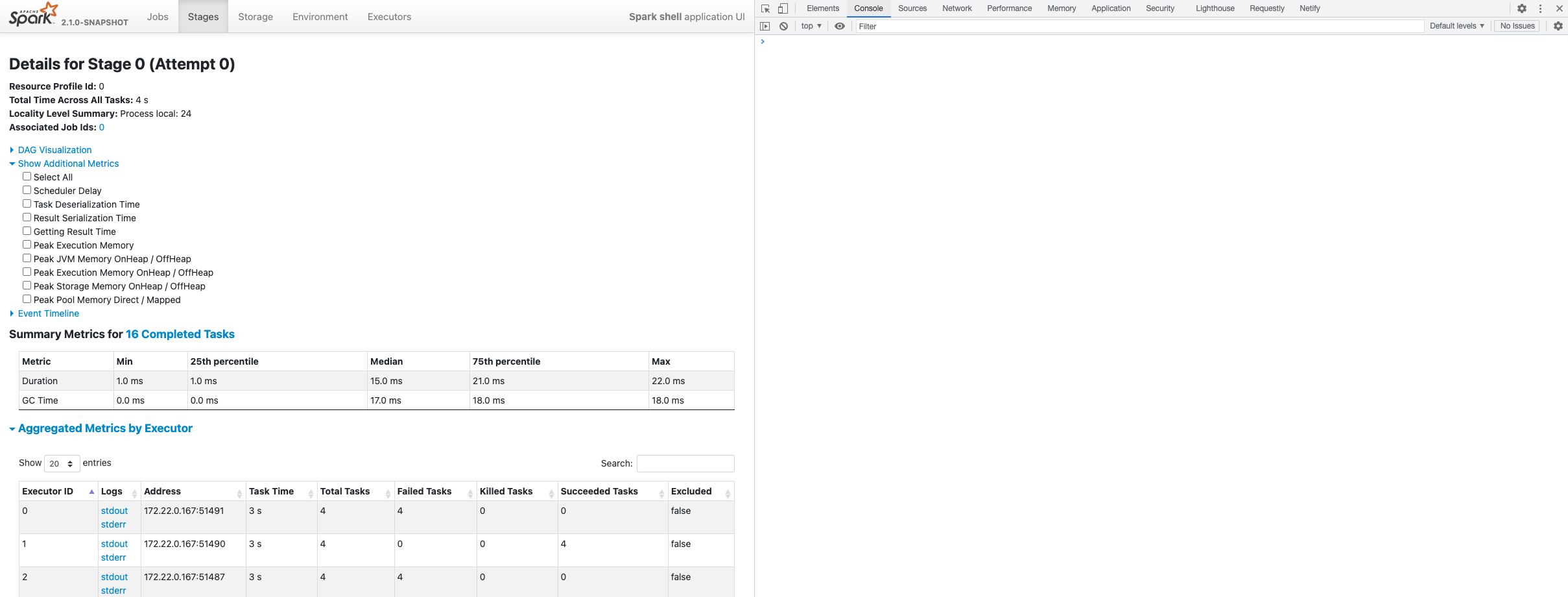
Presence of speculation metrics :

Closes #34607 from thejdeep/SPARK-36038.
Lead-authored-by: Thejdeep Gudivada
Co-authored-by: Ron Hu
Co-authored-by: Venkata krishnan Sowrirajan
Signed-off-by: Kousuke Saruta
---
.../org/apache/spark/ui/static/stagepage.js| 32 ++
.../spark/ui/static/stagespage-template.html | 15 +
.../resources/org/apache/spark/ui/static/webui.css | 10 +
.../apache/spark/status/AppStatusListener.scala| 14 +
.../org/apache/spark/status/AppStatusStore.scala | 11 +
.../scala/org/apache/spark/status/LiveEntity.scala | 26 ++
.../scala/org/apache/spark/status/api/v1/api.scala | 8 +
.../scala/org/apache/spark/status/storeTypes.scala | 12 +
.../scala/org/apache/spark/ui/jobs/JobPage.scala | 1 +
.../application_list_json_expectation.json | 15 +
.../completed_app_list_json_expectation.json | 15 +
.../limit_app_list_json_expectation.json | 30 +-
.../minDate_app_list_json_expectation.json | 15 +
.../minEndDate_app_list_json_expectation.json | 15 +
...stage_with_speculation_summary_expectation.json | 507 +
.../spark-events/application_1628109047826_1317105 | 52 +++
.../spark/deploy/history/HistoryServerSuite.scala | 5 +-
.../spark/status/AppStatusListenerSuite.scala | 10 +
.../apache/spark/status/AppStatusStoreSuite.scala | 51 ++-
.../scala/org/apache/spark/ui/StagePageSuite.scala | 1 +
dev/.rat-excludes | 3 +-
21 files changed, 830 insertions(+), 18 deletions(-)
diff --git a/core/src/main/resources/org/apache/spark/ui/static/stagepage.js
b/core/src/main/resources/org/apache/spark/ui/static/stagepage.js
index 584e1a7..a5955f3 100644
--- a/core/src/main/resources/org/apache/spark/ui/static/stagepage.js
+++ b/core/src/main/resources/org/apache/spark/ui/static/stagepage.js
@@ -652,6 +652,38 @@ $(document).ready(function () {
executorSummaryTableSelector.column(14).visible(dataToShow.showBytesSpilledData);
});
+// Prepare data for speculation metrics
+$("#speculationSummaryTitle").hide();
+$("#speculationSummary").hide();
+var speculationSummaryInfo = responseBody.speculationSummary;
+var speculationData;
+if(speculationSummaryInfo) {
+ speculationData = [[
+speculationSummaryInfo.numTasks,
+speculationSummaryInfo.numActiveTasks,
+speculationSummaryInfo.numCompletedTasks,
+speculationSummaryInfo.numFailedTasks,
+speculationSummaryInfo.numKilledTasks
+ ]];
+ if (speculationSummaryInfo.numTasks > 0) {
+// Show speculationSummary if there is atleast one speculated task
that ran
+$("#speculationSummaryTitle").show();
+$("#speculationSummary").show();
+ }
+}
+var speculationMetricsTableConf = {
+ "data":
[spark] branch master updated: [SPARK-37619][BUILD][TEST-MAVEN] Upgrade Maven to 3.8.4
This is an automated email from the ASF dual-hosted git repository.
gurwls223 pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 8477d82 [SPARK-37619][BUILD][TEST-MAVEN] Upgrade Maven to 3.8.4
8477d82 is described below
commit 8477d824d36b03222c310ebb2f1230e3e2466d08
Author: Dongjoon Hyun
AuthorDate: Mon Dec 13 09:53:28 2021 +0900
[SPARK-37619][BUILD][TEST-MAVEN] Upgrade Maven to 3.8.4
### What changes were proposed in this pull request?
This PR aims to upgrade Maven to 3.8.4 from 3.6.3.
### Why are the changes needed?
https://maven.apache.org/docs/3.8.4/release-notes.html
```
Upgrade to Jansi 2.4.0 which supports macOS on ARM natively
```
Note that MNG-6843 `Parallel build fails due to missing JAR artifacts in
compilePath` exists in both 3.6.3 and 3.8.4 because MNG-6843 was merged at
3.8.2 and reverted at 3.8.4.
https://issues.apache.org/jira/browse/MNG-6843
### Does this PR introduce _any_ user-facing change?
No. This is a dev-only change.
### How was this patch tested?
Pass the Jenkins with Maven. The current Jenkins run is triggered via
`Maven 3.8.4`
```
Building Spark
[info] Building Spark using Maven with these arguments: -Phadoop-3 -Pmesos
-Phadoop-cloud -Pdocker-integration-tests -Phive-thriftserver -Phive
-Pkubernetes -Pyarn -Pspark-ganglia-lgpl -Pkinesis-asl clean package -DskipTests
exec: curl --silent --show-error -L
https://downloads.lightbend.com/scala/2.12.15/scala-2.12.15.tgz
exec: curl --silent --show-error -L
https://www.apache.org/dyn/closer.lua/maven/maven-3/3.8.4/binaries/apache-maven-3.8.4-bin.tar.gz?action=download
exec: curl --silent --show-error -L
https://archive.apache.org/dist/maven/maven-3/3.8.4/binaries/apache-maven-3.8.4-bin.tar.gz.sha512
```
Closes #34873 from dongjoon-hyun/SPARK-37619.
Authored-by: Dongjoon Hyun
Signed-off-by: Hyukjin Kwon
---
dev/appveyor-install-dependencies.ps1 | 2 +-
docs/building-spark.md| 2 +-
pom.xml | 2 +-
3 files changed, 3 insertions(+), 3 deletions(-)
diff --git a/dev/appveyor-install-dependencies.ps1
b/dev/appveyor-install-dependencies.ps1
index fdc1e5e..5f239b2 100644
--- a/dev/appveyor-install-dependencies.ps1
+++ b/dev/appveyor-install-dependencies.ps1
@@ -81,7 +81,7 @@ if (!(Test-Path $tools)) {
# == Maven
# Push-Location $tools
#
-# $mavenVer = "3.6.3"
+# $mavenVer = "3.8.4"
# Start-FileDownload
"https://archive.apache.org/dist/maven/maven-3/$mavenVer/binaries/apache-maven-$mavenVer-bin.zip;
"maven.zip"
#
# # extract
diff --git a/docs/building-spark.md b/docs/building-spark.md
index 5428f77..4e77509 100644
--- a/docs/building-spark.md
+++ b/docs/building-spark.md
@@ -27,7 +27,7 @@ license: |
## Apache Maven
The Maven-based build is the build of reference for Apache Spark.
-Building Spark using Maven requires Maven 3.6.3 and Java 8.
+Building Spark using Maven requires Maven 3.8.4 and Java 8.
Spark requires Scala 2.12/2.13; support for Scala 2.11 was removed in Spark
3.0.0.
### Setting up Maven's Memory Usage
diff --git a/pom.xml b/pom.xml
index 4ea8b38..4c04c70 100644
--- a/pom.xml
+++ b/pom.xml
@@ -115,7 +115,7 @@
1.8
${java.version}
${java.version}
-3.6.3
+3.8.4
1.6.0
spark
1.7.30
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (01414e3 -> 79068fb)
This is an automated email from the ASF dual-hosted git repository. gurwls223 pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 01414e3 [SPARK-37152][PYTHON] Inline type hints for python/pyspark/context.py add 79068fb [SPARK-37598][PYTHON] Adding support for ShortWriables to pyspark's newAPIHadoopRDD method No new revisions were added by this update. Summary of changes: .../apache/spark/api/python/PythonHadoopUtil.scala | 4 ++ .../spark/api/python/PythonHadoopUtilSuite.scala | 80 ++ 2 files changed, 84 insertions(+) create mode 100644 core/src/test/scala/org/apache/spark/api/python/PythonHadoopUtilSuite.scala - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (7692773 -> 01414e3)
This is an automated email from the ASF dual-hosted git repository. zero323 pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 7692773 [SPARK-37615][BUILD][FOLLOWUP] Upgrade SBT to 1.5.6 in AppVeyor add 01414e3 [SPARK-37152][PYTHON] Inline type hints for python/pyspark/context.py No new revisions were added by this update. Summary of changes: python/pyspark/context.py | 375 ++--- python/pyspark/context.pyi | 195 --- python/pyspark/util.py | 4 + 3 files changed, 225 insertions(+), 349 deletions(-) delete mode 100644 python/pyspark/context.pyi - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org