[spark] branch master updated: [SPARK-37575][SQL][FOLLOWUP] Update migration guide for null values saving in CSV data source
This is an automated email from the ASF dual-hosted git repository. gurwls223 pushed a commit to branch master in repository https://gitbox.apache.org/repos/asf/spark.git The following commit(s) were added to refs/heads/master by this push: new 8630652 [SPARK-37575][SQL][FOLLOWUP] Update migration guide for null values saving in CSV data source 8630652 is described below commit 8630652f92dc02d5c27f64f81a7803d083817d4e Author: itholic AuthorDate: Wed Dec 15 15:58:24 2021 +0900 [SPARK-37575][SQL][FOLLOWUP] Update migration guide for null values saving in CSV data source ### What changes were proposed in this pull request? This is follow-up for https://github.com/apache/spark/pull/34853, to mention the behavior changes to migration guide, too. See also https://github.com/apache/spark/pull/34853#issuecomment-994266814 ### Why are the changes needed? We should mention the behavior change to the migration guide, although it's bug fix. ### Does this PR introduce _any_ user-facing change? The explanation is added to the migration guide as below: 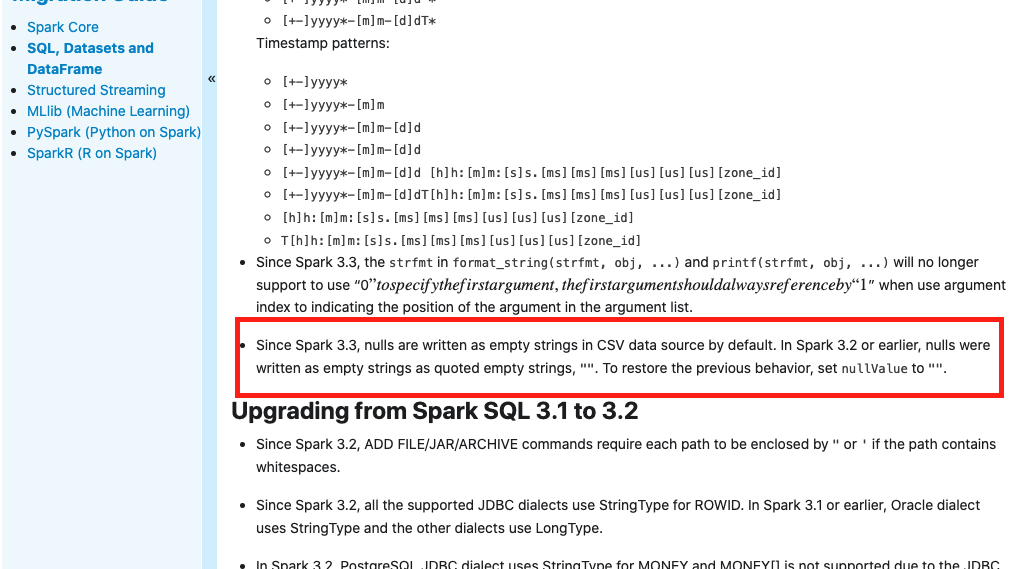 ### How was this patch tested? Manually built docs Closes #34905 from itholic/SPARK-37575-followup. Authored-by: itholic Signed-off-by: Hyukjin Kwon --- docs/sql-migration-guide.md | 2 ++ 1 file changed, 2 insertions(+) diff --git a/docs/sql-migration-guide.md b/docs/sql-migration-guide.md index c15f55d..51f3bd3 100644 --- a/docs/sql-migration-guide.md +++ b/docs/sql-migration-guide.md @@ -52,6 +52,8 @@ license: | - Since Spark 3.3, the `strfmt` in `format_string(strfmt, obj, ...)` and `printf(strfmt, obj, ...)` will no longer support to use "0$" to specify the first argument, the first argument should always reference by "1$" when use argument index to indicating the position of the argument in the argument list. + - Since Spark 3.3, nulls are written as empty strings in CSV data source by default. In Spark 3.2 or earlier, nulls were written as empty strings as quoted empty strings, `""`. To restore the previous behavior, set `nullValue` to `""`. + ## Upgrading from Spark SQL 3.1 to 3.2 - Since Spark 3.2, ADD FILE/JAR/ARCHIVE commands require each path to be enclosed by `"` or `'` if the path contains whitespaces. - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.2 updated: Revert "[SPARK-37575][SQL] null values should be saved as nothing rather than quoted empty Strings "" by default settings"
This is an automated email from the ASF dual-hosted git repository.
gurwls223 pushed a commit to branch branch-3.2
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.2 by this push:
new 50af717 Revert "[SPARK-37575][SQL] null values should be saved as
nothing rather than quoted empty Strings "" by default settings"
50af717 is described below
commit 50af71747be96b34f36b969e023237c7c5c0f31c
Author: Hyukjin Kwon
AuthorDate: Wed Dec 15 12:54:28 2021 +0900
Revert "[SPARK-37575][SQL] null values should be saved as nothing rather
than quoted empty Strings "" by default settings"
This reverts commit 62e4202b65d76b05f9f9a15819a631524c6e7985.
---
.../apache/spark/sql/catalyst/csv/UnivocityGenerator.scala | 2 ++
.../spark/sql/execution/datasources/csv/CSVSuite.scala | 13 +
2 files changed, 3 insertions(+), 12 deletions(-)
diff --git
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/csv/UnivocityGenerator.scala
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/csv/UnivocityGenerator.scala
index 8504877..2abf7bf 100644
---
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/csv/UnivocityGenerator.scala
+++
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/csv/UnivocityGenerator.scala
@@ -84,6 +84,8 @@ class UnivocityGenerator(
while (i < row.numFields) {
if (!row.isNullAt(i)) {
values(i) = valueConverters(i).apply(row, i)
+ } else {
+values(i) = options.nullValue
}
i += 1
}
diff --git
a/sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/csv/CSVSuite.scala
b/sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/csv/CSVSuite.scala
index a472221..7efdf7c 100644
---
a/sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/csv/CSVSuite.scala
+++
b/sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/csv/CSVSuite.scala
@@ -804,17 +804,6 @@ abstract class CSVSuite
}
}
- test("SPARK-37575: null values should be saved as nothing rather than " +
-"quoted empty Strings \"\" with default settings") {
-withTempPath { path =>
- Seq(("Tesla", null: String, ""))
-.toDF("make", "comment", "blank")
-.write
-.csv(path.getCanonicalPath)
- checkAnswer(spark.read.text(path.getCanonicalPath), Row("Tesla,,\"\""))
-}
- }
-
test("save csv with compression codec option") {
withTempDir { dir =>
val csvDir = new File(dir, "csv").getCanonicalPath
@@ -1585,7 +1574,7 @@ abstract class CSVSuite
(1, "John Doe"),
(2, "-"),
(3, "-"),
-(4, null)
+(4, "-")
).toDF("id", "name")
checkAnswer(computed, expected)
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (c75186c -> e21e0ec)
This is an automated email from the ASF dual-hosted git repository. gurwls223 pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from c75186c [SPARK-37563][PYTHON] Implement days, seconds, microseconds properties of TimedeltaIndex add e21e0ec [SPARK-37646][SQL] Avoid touching Scala reflection APIs in the lit function No new revisions were added by this update. Summary of changes: .../src/main/scala/org/apache/spark/sql/functions.scala | 15 ++- .../org/apache/spark/sql/ColumnExpressionSuite.scala | 12 2 files changed, 26 insertions(+), 1 deletion(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-37563][PYTHON] Implement days, seconds, microseconds properties of TimedeltaIndex
This is an automated email from the ASF dual-hosted git repository. gurwls223 pushed a commit to branch master in repository https://gitbox.apache.org/repos/asf/spark.git The following commit(s) were added to refs/heads/master by this push: new c75186c [SPARK-37563][PYTHON] Implement days, seconds, microseconds properties of TimedeltaIndex c75186c is described below commit c75186cd111b91d13e32159169334d562bdeb767 Author: Xinrong Meng AuthorDate: Wed Dec 15 11:47:42 2021 +0900 [SPARK-37563][PYTHON] Implement days, seconds, microseconds properties of TimedeltaIndex ### What changes were proposed in this pull request? Implement days, seconds, microseconds properties of TimedeltaIndex ### Why are the changes needed? To be consistent with pandas. ### Does this PR introduce _any_ user-facing change? Yes. ```py # Positive timedelta >>> psidx = ps.TimedeltaIndex( ... [ ... timedelta(days=1), ... timedelta(seconds=1), ... timedelta(microseconds=1), ... timedelta(milliseconds=1), ... timedelta(minutes=1), ... timedelta(hours=1), ... timedelta(weeks=1), ... ], ... name="x", ... ) >>> psidx.days Int64Index([1, 0, 0, 0, 0, 0, 7], dtype='int64', name='x') >>> psidx.seconds Int64Index([0, 1, 0, 0, 60, 3600, 0], dtype='int64', name='x') >>> psidx.microseconds Int64Index([0, 0, 1, 1000, 0, 0, 0], dtype='int64', name='x') # Negative timedelta >>> psidx = ps.TimedeltaIndex( ... [ ... timedelta(days=-1), ... timedelta(seconds=-1), ... timedelta(microseconds=-1), ... timedelta(milliseconds=-1), ... timedelta(minutes=-1), ... timedelta(hours=-1), ... timedelta(weeks=-1), ... ], ... name="x", ... ) >>> psidx.days Int64Index([-1, -1, -1, -1, -1, -1, -7], dtype='int64', name='x') >>> psidx.seconds Int64Index([0, 86399, 86399, 86399, 86340, 82800, 0], dtype='int64', name='x') >>> psidx.microseconds Int64Index([0, 0, 99, 999000, 0, 0, 0], dtype='int64', name='x') ``` ### How was this patch tested? Unit tests. Closes #34825 from xinrong-databricks/timedeltaProperties. Authored-by: Xinrong Meng Signed-off-by: Hyukjin Kwon --- dev/sparktestsupport/modules.py| 2 + .../source/reference/pyspark.pandas/indexing.rst | 23 -- python/pyspark/pandas/indexes/timedelta.py | 76 python/pyspark/pandas/missing/indexes.py | 3 - python/pyspark/pandas/spark/functions.py | 11 +++ .../pyspark/pandas/tests/indexes/test_timedelta.py | 84 ++ 6 files changed, 189 insertions(+), 10 deletions(-) diff --git a/dev/sparktestsupport/modules.py b/dev/sparktestsupport/modules.py index 5dd3ab6..297d2ea 100644 --- a/dev/sparktestsupport/modules.py +++ b/dev/sparktestsupport/modules.py @@ -614,6 +614,7 @@ pyspark_pandas = Module( "pyspark.pandas.indexes.base", "pyspark.pandas.indexes.category", "pyspark.pandas.indexes.datetimes", +"pyspark.pandas.indexes.timedelta", "pyspark.pandas.indexes.multi", "pyspark.pandas.indexes.numeric", "pyspark.pandas.spark.accessors", @@ -632,6 +633,7 @@ pyspark_pandas = Module( "pyspark.pandas.tests.data_type_ops.test_string_ops", "pyspark.pandas.tests.data_type_ops.test_udt_ops", "pyspark.pandas.tests.indexes.test_category", +"pyspark.pandas.tests.indexes.test_timedelta", "pyspark.pandas.tests.plot.test_frame_plot", "pyspark.pandas.tests.plot.test_frame_plot_matplotlib", "pyspark.pandas.tests.plot.test_frame_plot_plotly", diff --git a/python/docs/source/reference/pyspark.pandas/indexing.rst b/python/docs/source/reference/pyspark.pandas/indexing.rst index 0c94012..15539fa 100644 --- a/python/docs/source/reference/pyspark.pandas/indexing.rst +++ b/python/docs/source/reference/pyspark.pandas/indexing.rst @@ -336,13 +336,6 @@ DatatimeIndex DatetimeIndex -TimedeltaIndex --- -.. autosummary:: - :toctree: api/ - - TimedeltaIndex - Time/date components .. autosummary:: @@ -393,3 +386,19 @@ Time-specific operations DatetimeIndex.ceil DatetimeIndex.month_name DatetimeIndex.day_name + +TimedeltaIndex +-- +.. autosummary:: + :toctree: api/ + + TimedeltaIndex + +Components +~~ +.. autosummary:: + :toctree: api/ + + TimedeltaIndex.days + TimedeltaIndex.seconds + TimedeltaIndex.microseconds diff --git a/python/pyspark/pandas/indexes/timedelta.py b/python/pyspark/pand
[spark] branch master updated (c1d80bf -> 988381b)
This is an automated email from the ASF dual-hosted git repository. gurwls223 pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from c1d80bf [SPARK-37649][PYTHON] Switch default index to distributed-sequence by default in pandas API on Spark add 988381b [SPARK-37638][PYTHON] Use existing active Spark session instead of SparkSession.getOrCreate in pandas API on Spark No new revisions were added by this update. Summary of changes: python/pyspark/pandas/utils.py | 16 1 file changed, 4 insertions(+), 12 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (0a6be8c -> c1d80bf)
This is an automated email from the ASF dual-hosted git repository. gurwls223 pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 0a6be8c [SPARK-37629][SQL] Speed up Expression.canonicalized add c1d80bf [SPARK-37649][PYTHON] Switch default index to distributed-sequence by default in pandas API on Spark No new revisions were added by this update. Summary of changes: .../user_guide/pandas_on_spark/best_practices.rst | 2 +- .../source/user_guide/pandas_on_spark/options.rst | 128 ++--- python/pyspark/pandas/config.py| 15 +-- 3 files changed, 73 insertions(+), 72 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (b31f7bf -> 0a6be8c)
This is an automated email from the ASF dual-hosted git repository. gurwls223 pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from b31f7bf [SPARK-37146][PYTHON] Inline type hints for python/pyspark/__init__.py add 0a6be8c [SPARK-37629][SQL] Speed up Expression.canonicalized No new revisions were added by this update. Summary of changes: .../spark/sql/catalyst/analysis/unresolved.scala | 2 +- .../sql/catalyst/expressions/Canonicalize.scala| 67 +++--- .../spark/sql/catalyst/expressions/Cast.scala | 9 +++ .../sql/catalyst/expressions/DynamicPruning.scala | 6 +- .../sql/catalyst/expressions/Expression.scala | 35 +-- .../spark/sql/catalyst/expressions/PythonUDF.scala | 4 +- .../spark/sql/catalyst/expressions/ScalaUDF.scala | 4 +- .../expressions/aggregate/interfaces.scala | 6 +- .../expressions/complexTypeExtractors.scala| 4 ++ .../catalyst/expressions/decimalExpressions.scala | 2 +- .../expressions/higherOrderFunctions.scala | 6 +- .../catalyst/expressions/namedExpressions.scala| 4 ++ .../sql/catalyst/expressions/predicates.scala | 34 +++ .../spark/sql/catalyst/expressions/subquery.scala | 26 - .../catalyst/expressions/ExpressionSetSuite.scala | 40 ++--- .../org/apache/spark/sql/execution/subquery.scala | 6 +- 16 files changed, 136 insertions(+), 119 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-37146][PYTHON] Inline type hints for python/pyspark/__init__.py
This is an automated email from the ASF dual-hosted git repository.
zero323 pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new b31f7bf [SPARK-37146][PYTHON] Inline type hints for
python/pyspark/__init__.py
b31f7bf is described below
commit b31f7bf4c102368b63b08cfe3d36cc1d8d128738
Author: dch nguyen
AuthorDate: Tue Dec 14 23:10:02 2021 +0100
[SPARK-37146][PYTHON] Inline type hints for python/pyspark/__init__.py
### What changes were proposed in this pull request?
Inline type hints for python/pyspark/\_\_init\_\_.py
### Why are the changes needed?
We can take advantage of static type checking within the functions by
inlining the type hints.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Existing tests
Closes #34433 from dchvn/SPARK-37146.
Authored-by: dch nguyen
Signed-off-by: zero323
---
python/pyspark/__init__.py | 33 +-
python/pyspark/__init__.pyi | 77 -
python/pyspark/sql/conf.py | 5 +--
python/pyspark/sql/context.py | 3 +-
python/pyspark/sql/dataframe.py | 11 --
5 files changed, 38 insertions(+), 91 deletions(-)
diff --git a/python/pyspark/__init__.py b/python/pyspark/__init__.py
index aab95ad..e82817f 100644
--- a/python/pyspark/__init__.py
+++ b/python/pyspark/__init__.py
@@ -48,6 +48,7 @@ Public classes:
from functools import wraps
import types
+from typing import cast, Any, Callable, Optional, TypeVar, Union
from pyspark.conf import SparkConf
from pyspark.rdd import RDD, RDDBarrier
@@ -63,8 +64,11 @@ from pyspark.profiler import Profiler, BasicProfiler
from pyspark.version import __version__
from pyspark._globals import _NoValue # noqa: F401
+T = TypeVar("T")
+F = TypeVar("F", bound=Callable)
-def since(version):
+
+def since(version: Union[str, float]) -> Callable[[F], F]:
"""
A decorator that annotates a function to append the version of Spark the
function was added.
"""
@@ -72,7 +76,9 @@ def since(version):
indent_p = re.compile(r"\n( +)")
-def deco(f):
+def deco(f: F) -> F:
+assert f.__doc__ is not None
+
indents = indent_p.findall(f.__doc__)
indent = " " * (min(len(m) for m in indents) if indents else 0)
f.__doc__ = f.__doc__.rstrip() + "\n\n%s.. versionadded:: %s" %
(indent, version)
@@ -81,15 +87,26 @@ def since(version):
return deco
-def copy_func(f, name=None, sinceversion=None, doc=None):
+def copy_func(
+f: F,
+name: Optional[str] = None,
+sinceversion: Optional[Union[str, float]] = None,
+doc: Optional[str] = None,
+) -> F:
"""
Returns a function with same code, globals, defaults, closure, and
name (or provide a new name).
"""
# See
#
http://stackoverflow.com/questions/6527633/how-can-i-make-a-deepcopy-of-a-function-in-python
+assert isinstance(f, types.FunctionType)
+
fn = types.FunctionType(
-f.__code__, f.__globals__, name or f.__name__, f.__defaults__,
f.__closure__
+f.__code__,
+f.__globals__,
+name or f.__name__,
+f.__defaults__,
+f.__closure__,
)
# in case f was given attrs (note this dict is a shallow copy):
fn.__dict__.update(f.__dict__)
@@ -97,10 +114,10 @@ def copy_func(f, name=None, sinceversion=None, doc=None):
fn.__doc__ = doc
if sinceversion is not None:
fn = since(sinceversion)(fn)
-return fn
+return cast(F, fn)
-def keyword_only(func):
+def keyword_only(func: F) -> F:
"""
A decorator that forces keyword arguments in the wrapped method
and saves actual input keyword arguments in `_input_kwargs`.
@@ -111,13 +128,13 @@ def keyword_only(func):
"""
@wraps(func)
-def wrapper(self, *args, **kwargs):
+def wrapper(self: Any, *args: Any, **kwargs: Any) -> Any:
if len(args) > 0:
raise TypeError("Method %s forces keyword arguments." %
func.__name__)
self._input_kwargs = kwargs
return func(self, **kwargs)
-return wrapper
+return cast(F, wrapper)
# To avoid circular dependencies
diff --git a/python/pyspark/__init__.pyi b/python/pyspark/__init__.pyi
deleted file mode 100644
index fb045f2..000
--- a/python/pyspark/__init__.pyi
+++ /dev/null
@@ -1,77 +0,0 @@
-#
-# Licensed to the Apache Software Foundation (ASF) under one
-# or more contributor license agreements. See the NOTICE file
-# distributed with this work for additional information
-# regarding copyright ownership. The ASF licenses this file
-# to you under the Apache License, Version 2.0 (the
-# "License"); you may not use this file except in compliance
-# with the License. You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2
[spark] branch master updated (77b164a -> 51ee425)
This is an automated email from the ASF dual-hosted git repository. dongjoon pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 77b164a [SPARK-37592][SQL] Improve performance of `JoinSelection` add 51ee425 [SPARK-37645][K8S][TESTS] Rename a variable `labledConfigMaps` to `labeledConfigMaps` No new revisions were added by this update. Summary of changes: .../cluster/k8s/KubernetesClusterSchedulerBackendSuite.scala | 10 +- 1 file changed, 5 insertions(+), 5 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.2 updated: [SPARK-37217][SQL][3.2] The number of dynamic partitions should early check when writing to external tables
This is an automated email from the ASF dual-hosted git repository.
sunchao pushed a commit to branch branch-3.2
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.2 by this push:
new 9cd64f8 [SPARK-37217][SQL][3.2] The number of dynamic partitions
should early check when writing to external tables
9cd64f8 is described below
commit 9cd64f8fed396d38a4d2f64559ad00c261dad47e
Author: sychen
AuthorDate: Tue Dec 14 10:18:53 2021 -0800
[SPARK-37217][SQL][3.2] The number of dynamic partitions should early check
when writing to external tables
### What changes were proposed in this pull request?
SPARK-29295 introduces a mechanism that writes to external tables is a
dynamic partition method, and the data in the target partition will be deleted
first.
Assuming that 1001 partitions are written, the data of 10001 partitions
will be deleted first, but because `hive.exec.max.dynamic.partitions` is 1000
by default, loadDynamicPartitions will fail at this time, but the data of 1001
partitions has been deleted.
So we can check whether the number of dynamic partitions is greater than
`hive.exec.max.dynamic.partitions` before deleting, it should fail quickly at
this time.
### Why are the changes needed?
Avoid data that cannot be recovered when the job fails.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
add UT
Closes #34889 from cxzl25/SPARK-37217-3.2.
Authored-by: sychen
Signed-off-by: Chao Sun
---
.../spark/sql/errors/QueryExecutionErrors.scala| 11 +
.../sql/hive/execution/InsertIntoHiveTable.scala | 9 +++
.../spark/sql/hive/execution/SQLQuerySuite.scala | 28 ++
3 files changed, 48 insertions(+)
diff --git
a/sql/catalyst/src/main/scala/org/apache/spark/sql/errors/QueryExecutionErrors.scala
b/sql/catalyst/src/main/scala/org/apache/spark/sql/errors/QueryExecutionErrors.scala
index 7f77243..d4fbd38 100644
---
a/sql/catalyst/src/main/scala/org/apache/spark/sql/errors/QueryExecutionErrors.scala
+++
b/sql/catalyst/src/main/scala/org/apache/spark/sql/errors/QueryExecutionErrors.scala
@@ -1804,4 +1804,15 @@ object QueryExecutionErrors {
def pivotNotAfterGroupByUnsupportedError(): Throwable = {
new UnsupportedOperationException("pivot is only supported after a
groupBy")
}
+
+ def writePartitionExceedConfigSizeWhenDynamicPartitionError(
+ numWrittenParts: Int,
+ maxDynamicPartitions: Int,
+ maxDynamicPartitionsKey: String): Throwable = {
+new SparkException(
+ s"Number of dynamic partitions created is $numWrittenParts" +
+s", which is more than $maxDynamicPartitions" +
+s". To solve this try to set $maxDynamicPartitionsKey" +
+s" to at least $numWrittenParts.")
+ }
}
diff --git
a/sql/hive/src/main/scala/org/apache/spark/sql/hive/execution/InsertIntoHiveTable.scala
b/sql/hive/src/main/scala/org/apache/spark/sql/hive/execution/InsertIntoHiveTable.scala
index 108401c..4a678f7 100644
---
a/sql/hive/src/main/scala/org/apache/spark/sql/hive/execution/InsertIntoHiveTable.scala
+++
b/sql/hive/src/main/scala/org/apache/spark/sql/hive/execution/InsertIntoHiveTable.scala
@@ -21,6 +21,7 @@ import java.util.Locale
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.fs.Path
+import org.apache.hadoop.hive.conf.HiveConf
import org.apache.hadoop.hive.ql.ErrorMsg
import org.apache.hadoop.hive.ql.plan.TableDesc
@@ -212,6 +213,14 @@ case class InsertIntoHiveTable(
if (partition.nonEmpty) {
if (numDynamicPartitions > 0) {
if (overwrite && table.tableType == CatalogTableType.EXTERNAL) {
+ val numWrittenParts = writtenParts.size
+ val maxDynamicPartitionsKey =
HiveConf.ConfVars.DYNAMICPARTITIONMAXPARTS.varname
+ val maxDynamicPartitions = hadoopConf.getInt(maxDynamicPartitionsKey,
+HiveConf.ConfVars.DYNAMICPARTITIONMAXPARTS.defaultIntVal)
+ if (numWrittenParts > maxDynamicPartitions) {
+throw
QueryExecutionErrors.writePartitionExceedConfigSizeWhenDynamicPartitionError(
+ numWrittenParts, maxDynamicPartitions, maxDynamicPartitionsKey)
+ }
// SPARK-29295: When insert overwrite to a Hive external table
partition, if the
// partition does not exist, Hive will not check if the external
partition directory
// exists or not before copying files. So if users drop the
partition, and then do
diff --git
a/sql/hive/src/test/scala/org/apache/spark/sql/hive/execution/SQLQuerySuite.scala
b/sql/hive/src/test/scala/org/apache/spark/sql/hive/execution/SQLQuerySuite.scala
index 8d248bb..ba362d9 100644
---
a/sql/hive/src/test/scala/org/apache/spark/sql/hive/execution/SQLQuerySuite.scala
+++
b/sql/hive/src/test/scala/org/apache/spark/sql/hive/execution/SQLQuerySuite.sca
[spark] branch master updated (d270d40 -> 77b164a)
This is an automated email from the ASF dual-hosted git repository. wenchen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from d270d40 [SPARK-37635][SQL] SHOW TBLPROPERTIES should print the fully qualified table name add 77b164a [SPARK-37592][SQL] Improve performance of `JoinSelection` No new revisions were added by this update. Summary of changes: .../spark/sql/catalyst/plans/logical/hints.scala | 2 ++ .../org/apache/spark/sql/execution/Columnar.scala | 6 ++ .../spark/sql/execution/SparkStrategies.scala | 25 ++ 3 files changed, 20 insertions(+), 13 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (ae8940c -> d270d40)
This is an automated email from the ASF dual-hosted git repository. sarutak pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from ae8940c [SPARK-37310][SQL] Migrate ALTER NAMESPACE ... SET PROPERTIES to use V2 command by default add d270d40 [SPARK-37635][SQL] SHOW TBLPROPERTIES should print the fully qualified table name No new revisions were added by this update. Summary of changes: .../spark/sql/execution/datasources/v2/DataSourceV2Strategy.scala | 2 +- .../spark/sql/execution/datasources/v2/ShowTablePropertiesExec.scala | 3 ++- .../src/test/resources/sql-tests/results/show-tblproperties.sql.out| 2 +- 3 files changed, 4 insertions(+), 3 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (6a59fba -> ae8940c)
This is an automated email from the ASF dual-hosted git repository. sarutak pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 6a59fba [SPARK-37575][SQL] null values should be saved as nothing rather than quoted empty Strings "" by default settings add ae8940c [SPARK-37310][SQL] Migrate ALTER NAMESPACE ... SET PROPERTIES to use V2 command by default No new revisions were added by this update. Summary of changes: .../org/apache/spark/sql/catalyst/analysis/ResolveSessionCatalog.scala | 2 +- 1 file changed, 1 insertion(+), 1 deletion(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.2 updated: [SPARK-37575][SQL] null values should be saved as nothing rather than quoted empty Strings "" by default settings
This is an automated email from the ASF dual-hosted git repository.
maxgekk pushed a commit to branch branch-3.2
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.2 by this push:
new 62e4202 [SPARK-37575][SQL] null values should be saved as nothing
rather than quoted empty Strings "" by default settings
62e4202 is described below
commit 62e4202b65d76b05f9f9a15819a631524c6e7985
Author: wayneguow
AuthorDate: Tue Dec 14 11:26:34 2021 +0300
[SPARK-37575][SQL] null values should be saved as nothing rather than
quoted empty Strings "" by default settings
### What changes were proposed in this pull request?
Fix the bug that null values are saved as quoted empty strings "" (as the
same as empty strings) rather than nothing by default csv settings since Spark
2.4.
### Why are the changes needed?
This is an unexpected bug, if don't fix it, we still can't distinguish
null values and empty strings in saved csv files.
As mentioned in [spark sql migration
guide](https://spark.apache.org/docs/latest/sql-migration-guide.html#upgrading-from-spark-sql-23-to-24)(2.3=>2.4),
empty strings are saved as quoted empty string "", null values as saved as
nothing since Spark 2.4.
> Since Spark 2.4, empty strings are saved as quoted empty strings "". In
version 2.3 and earlier, empty strings are equal to null values and do not
reflect to any characters in saved CSV files. For example, the row of "a",
null, "", 1 was written as a,,,1. Since Spark 2.4, the same row is saved as
a,,"",1. To restore the previous behavior, set the CSV option emptyValue to
empty (not quoted) string.
But actually, we found that null values are also saved as quoted empty
strings "" as the same as empty strings.
For codes follows:
```scala
Seq(("Tesla", null.asInstanceOf[String], ""))
.toDF("make", "comment", "blank")
.coalesce(1)
.write.csv(path)
```
actual results:
>Tesla,"",""
expected results:
>Tesla,,""
### Does this PR introduce _any_ user-facing change?
Yes, if this bug has been fixed, the output of null values would been
changed to nothing rather than quoted empty strings "".
But, users can set nullValue to "\\"\\""(same as emptyValueInWrite's
default value) to restore the previous behavior since 2.4.
### How was this patch tested?
Adding a test case.
Closes #34853 from wayneguow/SPARK-37575.
Lead-authored-by: wayneguow
Co-authored-by: Wayne Guo
Signed-off-by: Max Gekk
(cherry picked from commit 6a59fba248359fb2614837fe8781dc63ac8fdc4c)
Signed-off-by: Max Gekk
---
.../apache/spark/sql/catalyst/csv/UnivocityGenerator.scala | 2 --
.../spark/sql/execution/datasources/csv/CSVSuite.scala | 13 -
2 files changed, 12 insertions(+), 3 deletions(-)
diff --git
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/csv/UnivocityGenerator.scala
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/csv/UnivocityGenerator.scala
index 2abf7bf..8504877 100644
---
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/csv/UnivocityGenerator.scala
+++
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/csv/UnivocityGenerator.scala
@@ -84,8 +84,6 @@ class UnivocityGenerator(
while (i < row.numFields) {
if (!row.isNullAt(i)) {
values(i) = valueConverters(i).apply(row, i)
- } else {
-values(i) = options.nullValue
}
i += 1
}
diff --git
a/sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/csv/CSVSuite.scala
b/sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/csv/CSVSuite.scala
index 7efdf7c..a472221 100644
---
a/sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/csv/CSVSuite.scala
+++
b/sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/csv/CSVSuite.scala
@@ -804,6 +804,17 @@ abstract class CSVSuite
}
}
+ test("SPARK-37575: null values should be saved as nothing rather than " +
+"quoted empty Strings \"\" with default settings") {
+withTempPath { path =>
+ Seq(("Tesla", null: String, ""))
+.toDF("make", "comment", "blank")
+.write
+.csv(path.getCanonicalPath)
+ checkAnswer(spark.read.text(path.getCanonicalPath), Row("Tesla,,\"\""))
+}
+ }
+
test("save csv with compression codec option") {
withTempDir { dir =>
val csvDir = new File(dir, "csv").getCanonicalPath
@@ -1574,7 +1585,7 @@ abstract class CSVSuite
(1, "John Doe"),
(2, "-"),
(3, "-"),
-(4, "-")
+(4, null)
).toDF("id", "name")
checkAnswer(computed, expected)
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail:
[spark] branch master updated: [SPARK-37575][SQL] null values should be saved as nothing rather than quoted empty Strings "" by default settings
This is an automated email from the ASF dual-hosted git repository.
maxgekk pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 6a59fba [SPARK-37575][SQL] null values should be saved as nothing
rather than quoted empty Strings "" by default settings
6a59fba is described below
commit 6a59fba248359fb2614837fe8781dc63ac8fdc4c
Author: wayneguow
AuthorDate: Tue Dec 14 11:26:34 2021 +0300
[SPARK-37575][SQL] null values should be saved as nothing rather than
quoted empty Strings "" by default settings
### What changes were proposed in this pull request?
Fix the bug that null values are saved as quoted empty strings "" (as the
same as empty strings) rather than nothing by default csv settings since Spark
2.4.
### Why are the changes needed?
This is an unexpected bug, if don't fix it, we still can't distinguish
null values and empty strings in saved csv files.
As mentioned in [spark sql migration
guide](https://spark.apache.org/docs/latest/sql-migration-guide.html#upgrading-from-spark-sql-23-to-24)(2.3=>2.4),
empty strings are saved as quoted empty string "", null values as saved as
nothing since Spark 2.4.
> Since Spark 2.4, empty strings are saved as quoted empty strings "". In
version 2.3 and earlier, empty strings are equal to null values and do not
reflect to any characters in saved CSV files. For example, the row of "a",
null, "", 1 was written as a,,,1. Since Spark 2.4, the same row is saved as
a,,"",1. To restore the previous behavior, set the CSV option emptyValue to
empty (not quoted) string.
But actually, we found that null values are also saved as quoted empty
strings "" as the same as empty strings.
For codes follows:
```scala
Seq(("Tesla", null.asInstanceOf[String], ""))
.toDF("make", "comment", "blank")
.coalesce(1)
.write.csv(path)
```
actual results:
>Tesla,"",""
expected results:
>Tesla,,""
### Does this PR introduce _any_ user-facing change?
Yes, if this bug has been fixed, the output of null values would been
changed to nothing rather than quoted empty strings "".
But, users can set nullValue to "\\"\\""(same as emptyValueInWrite's
default value) to restore the previous behavior since 2.4.
### How was this patch tested?
Adding a test case.
Closes #34853 from wayneguow/SPARK-37575.
Lead-authored-by: wayneguow
Co-authored-by: Wayne Guo
Signed-off-by: Max Gekk
---
.../apache/spark/sql/catalyst/csv/UnivocityGenerator.scala | 2 --
.../spark/sql/execution/datasources/csv/CSVSuite.scala | 13 -
2 files changed, 12 insertions(+), 3 deletions(-)
diff --git
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/csv/UnivocityGenerator.scala
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/csv/UnivocityGenerator.scala
index 10cccd5..9d65824 100644
---
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/csv/UnivocityGenerator.scala
+++
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/csv/UnivocityGenerator.scala
@@ -94,8 +94,6 @@ class UnivocityGenerator(
while (i < row.numFields) {
if (!row.isNullAt(i)) {
values(i) = valueConverters(i).apply(row, i)
- } else {
-values(i) = options.nullValue
}
i += 1
}
diff --git
a/sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/csv/CSVSuite.scala
b/sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/csv/CSVSuite.scala
index 8c8079f..c7328d9 100644
---
a/sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/csv/CSVSuite.scala
+++
b/sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/csv/CSVSuite.scala
@@ -805,6 +805,17 @@ abstract class CSVSuite
}
}
+ test("SPARK-37575: null values should be saved as nothing rather than " +
+"quoted empty Strings \"\" with default settings") {
+withTempPath { path =>
+ Seq(("Tesla", null: String, ""))
+.toDF("make", "comment", "blank")
+.write
+.csv(path.getCanonicalPath)
+ checkAnswer(spark.read.text(path.getCanonicalPath), Row("Tesla,,\"\""))
+}
+ }
+
test("save csv with compression codec option") {
withTempDir { dir =>
val csvDir = new File(dir, "csv").getCanonicalPath
@@ -1769,7 +1780,7 @@ abstract class CSVSuite
(1, "John Doe"),
(2, "-"),
(3, "-"),
-(4, "-")
+(4, null)
).toDF("id", "name")
checkAnswer(computed, expected)
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org